혈관 분할을 위한 원샷 능동 학습
New AI learns from tiny, smart samples, saving time & resources for better disease insights.
배경 및 학문적 계보
의료 영상 분야에서 뇌혈관을 매핑하는 과정, 즉 혈관 분할(vessel segmentation)은 뇌 기능 이해와 뇌졸중과 같은 심각한 신경학적 질환 진단에 있어 핵심적인 단계이다. 역사적으로 이 작업에 딥러닝 모델이 표준으로 자리 잡으면서 거대한 병목 현상이 발생했는데, 이는 이러한 모델이 엄청난 양의 데이터를 필요로 한다는 점이다. 수천 개의 3D 뇌 스캔에 대해 의료 전문가가 세심하게 주석을 달아야 한다. 복잡하고 미세한 혈관망을 수동으로 추적하는 것은 지칠 뿐만 아니라 비용이 많이 들며, 단일 스캔당 전문가 인건비로 150달러 이상이 소요되기도 한다.
이를 완화하기 위해 해당 분야는 AI가 가장 유익한 레이블이 없는 샘플을 식별하고 인간 전문가에게 해당 샘플만 레이블링하도록 요청하는 패러다임인 Active Learning (AL)로 전환했다. 그러나 고전적인 AL은 매우 반복적이다. 모델을 훈련하고, 전문가에게 레이블을 요청하기 위해 일시 중지하고, 모델을 다시 훈련하고, 다시 요청하는 주기가 필요하다. 이러한 지속적인 상호 작용은 임상 전문가의 지속적인 가용성을 요구하며 막대한 계산 오버헤드를 발생시켜 실시간 임상 적용을 거의 불가능하게 만든다.
저자들이 이 논문을 작성하게 된 근본적인 한계는 다음 진화 단계인 One-Shot Active Learning (OSAL)의 결함에 있다. OSAL은 단일 패스에서 최소한의 샘플 세트를 선택하려고 시도하지만(상호 작용 제거), 이전 OSAL 모델은 본질적으로 "블랙 박스"였다. 이들은 일반적인 데이터 증강 또는 대조 학습에 의존했으며 뇌의 실제 해부학적 구조를 이해하기 위한 명시적인 메커니즘이 없었다. 특히, 혈관의 반복적이고 나무와 같은 구조를 완전히 무시했다. 이러한 이전 모델은 특정 데이터 포인트를 선택하는 이유를 해석할 수 없었기 때문에 대표성이 없는 샘플을 자주 선택했다. 이는 새롭고 보지 못한 환자 데이터에 대해 일반화되지 못하는 모델로 이어졌다. 저자들은 이를 수정하기 위해 뇌 혈관의 독특하고 반복적인 기하학 구조에 특화된 OSAL 프레임워크가 필요하다는 것을 깨달았다.
저자들이 이를 어떻게 해결했는지 직관적으로 이해할 수 있도록, 고도로 전문화된 도메인 용어를 일상적인 비유로 번역한 핵심 개념은 다음과 같다.
- One-Shot Active Learning (OSAL): 거대하고 복잡한 연회를 위해 식료품 쇼핑을 하는데, 단 한 번만 가게에 갈 수 있다고 상상해 보라. 누락된 재료를 발견할 때마다 가게로 다시 달려가는 대신(이는 반복적인 Active Learning이 작동하는 방식), 미리 레시피를 꼼꼼히 분석하고 한 번의 매우 효율적인 방문으로 완벽하게 다양한 최소한의 재료 세트를 구매한다.
- Dictionary Learning & Atoms: 마스터 빌더의 레고 세트와 같다고 생각하면 된다. AI는 이전에 만들어진 모든 장난감 성이나 우주선의 정확한 모양을 기억하려고 애쓰는 대신, "원자(atoms)"라고 불리는 소수의 기본 레고 블록 세트만 학습한다. 이러한 기본 블록을 다양한 방식으로 조합하여 AI는 마주치는 모든 복잡한 혈관 모양을 재구성할 수 있다.
- Latent Space: 책이 알파벳순이 아니라 줄거리의 유사성에 따라 정렬되는 거대하고 마법 같은 도서관을 상상해 보라. Latent space는 AI가 이미지 패치를 배치하는 수학적인 "방"이다. 유사한 혈관 패턴을 가진 패치는 서로 가까이 배치되고, 완전히 다른 패턴은 멀리 밀려나 데이터의 큰 그림을 쉽게 볼 수 있게 한다.
- Siamese Encoder: 같은 사건을 조사하는 쌍둥이 탐정을 떠올려 보라. 그들은 두 개의 다른 단서(이미지 패치)를 받는다. 단서가 같은 용의자(같은 혈관 패턴)에 속하면 탐정들은 짧은 끈으로 묶는다. 다른 용의자에게 속하면 서로 밀어낸다. 이 알고리즘은 Latent space가 완벽하게 구성되고 매우 변별력이 있도록 보장한다.
다음은 이 문제를 공식화하고 해결하는 데 사용된 주요 수학적 표기법에 대한 분석이다.
| 표기법 | 설명 |
|---|---|
| $\mathcal{I}$ | 이미지와 해당 전문가 주석을 포함하는 레이블이 지정된 데이터셋. |
| $\mathbf{I}$ | 데이터셋의 특정 3D 볼륨 이미지(예: MRI 뇌 스캔). |
| $\mathbf{L}$ | 이미지 $\mathbf{I}$와 관련된 Ground-truth 레이블 맵. |
| $H \times W \times S$ | 이미지의 차원(높이, 너비, 슬라이스 수). |
| $X_k, Y_k$ | 겹치지 않는 2D 이미지 패치와 해당 레이블 패치. |
| $\mathcal{Y}_{\mathcal{I}}$ | 데이터셋에서 추출된 이진 혈관 주석이 달린 패치 세트. |
| $\mathbf{B}$ | 나무와 같은 분기 패턴의 기본 구성 요소(원자)를 포함하는 과도한 사전(over-complete dictionary). |
| $\mathbf{z}$ | 표현 계수(어떤 원자가 활성화되는지 결정)를 포함하는 희소 벡터. |
| $\hat{\mathbf{B}}, \hat{\mathbf{Z}}$ | 최적화 후 얻어진 학습된 사전 및 학습된 희소 잠재 벡터. |
| $\lambda$ | 표현 벡터의 희소성을 제어하는 정규화 매개변수(모델이 가능한 한 적은 수의 원자를 사용하도록 강제). |
| $c_i$ | 특정 주석과 해당 이미지 패치에 할당된 k-평균 클러스터 레이블. |
| $\mathcal{E}_1, \mathcal{R}_1$ | 패치를 희소 잠재 벡터로 매핑하고 재구성하는 데 사용되는 선형 인코더 및 디코더. |
| $\mathcal{E}_s$ | MRI 패치에 대한 최종 유익한 잠재 공간을 생성하는 데 사용되는 Siamese 인코더 네트워크. |
| $\mathcal{I}^U$ | 모델이 샘플링해야 하는 레이블이 없는 이미지의 새 데이터셋. |
| $n$ | 인간 전문가에게 주석을 위해 보내도록 프레임워크에서 선택한 뇌 패치의 최소 부분 집합. |
| $\Phi$ | 새로 주석이 달린 패치를 사용하여 훈련된 최종 뇌 혈관 분할 모델. |
이러한 요소들을 결합하여 저자들은 혈관 패턴을 수학적으로 모델링하는 시스템인 V-DiSNet을 성공적으로 만들었다. $$ \mathbf{Y} = \mathbf{B}\mathbf{z} $$ 이 이해를 사용하여 인간이 레이블링할 절대적으로 최상의 $n$개 패치를 선택하며, 데이터의 30%만 레이블링해도 거의 전체 데이터셋 성능에 가까운 성능을 달성한다.
문제 정의 및 제약 조건
이 논문이 다루는 정확한 문제를 이해하기 위해서는 먼저 출발점과 도착점을 살펴볼 필요가 있다.
입력 (현재 상태): 우리는 방대한 양의 레이블이 없는 3D 뇌 스캔 데이터셋, 특히 자기공명혈관조영술(MRA) 이미지에서 시작한다. 수학적으로 이는 레이블이 없는 체적 이미지의 집합 $I^U = \{I_j\}_{j=1}^M \subset \mathbb{R}^{H \times W \times S}$이다.
출력 (목표 상태): 목표는 뇌의 복잡하고 나무와 같은 혈관을 정확하게 윤곽을 그리는(segmenting) 고도로 정확한 딥러닝 모델을 완전히 훈련시키는 것이다. 그러나 한 가지 조건이 있다. 원본 데이터의 극히 일부, 신중하게 선택된 부분(예: 30% 또는 그 이하)만을 의료 전문가가 수동으로 어노테이션하도록 하여 이를 달성하고자 한다.
누락된 연결고리: 입력과 목표 사이의 수학적 간극은 선택 메커니즘이다. 실제로 이미지 내부에 무엇이 있는지 알기 전에, 의사에게 레이블을 지정하도록 요청하는 소수의 이미지가 가장 유익한 이미지임을 수학적으로 어떻게 보장할 수 있는가? 저자들은 뇌 혈관이 반복적이고 계층적인 분기 패턴으로 구성되어 있다고 가정한다. 따라서 모든 혈관 트리 이미지 $\mathbf{Y}$는 기본 구성 요소(사전 $\mathbf{B}$)와 희소 계수($\mathbf{z}$)의 선형 조합으로 모델링될 수 있으며, $\mathbf{Y} = \mathbf{B}\mathbf{z}$이다. 이 논문이 연결하는 누락된 고리는 혈관 패턴의 숨겨진 사전을 학습하고 레이블이 없는 이미지를 수학적으로 가장 다양하고 대표적인 패치를 단일 패스로 샘플링할 수 있는 잠재 공간으로 매핑하는 방법을 알아내는 것이다.
이는 이전 연구자들이 겪었던 고통스러운 딜레마로 이어진다.
머신러닝 분야에서 인간 레이블의 필요성을 줄이는 것은 일반적으로 능동 학습(Active Learning, AL)에 의존한다. 전통적인 AL은 반복적인 프로세스이다. 모델은 몇 개의 이미지로 훈련하고, 가장 혼란스러워하는 부분을 파악한 다음, 인간 오라클에게 해당 특정 혼란스러운 이미지를 레이블링하도록 요청하고, 다시 훈련한다.
* 트레이드오프: 적은 레이블로 높은 정확도를 얻지만, 모델을 지속적으로 재훈련하는 데 따른 막대한 계산 비용이 발생한다. 더 나쁜 것은, 알고리즘의 질의에 응답하기 위해 의료 전문가가 지속적으로 대기해야 하는데, 이는 실제 임상 환경에서는 거의 불가능하다.
이를 해결하기 위해 연구자들은 반복적인 재훈련 루프를 제거하고, 한 번에 전체 유익한 샘플 배치를 선택하려고 시도하는 One-Shot Active Learning(OSAL)을 발명했다.
* 새로운 딜레마: 기존 OSAL 방법은 뇌의 실제 물리적 해부학적 구조에 완전히 눈먼 일반적인 "블랙박스" 수학(예: 대조 학습 또는 변분 오토인코더)에 의존한다. 이들은 혈관이 연속적이고 반복적인 관형 구조라는 것을 이해하지 못한다. 이러한 일반적인 방법을 사용하여 한 번에 샘플을 선택하면, 중요한 해부학적 변이를 완전히 놓치는 이미지 배치를 선택할 위험이 있다. 계산 효율성을 모델이 보지 못한 데이터에 대해 일반화하지 못하는 모델과 맞바꾸는 것이다. 왜냐하면 훈련 세트가 복잡한 혈관 트리를 진정으로 대표하지 못했기 때문이다.
이를 해결하기 위해 저자들은 몇 가지 가혹하고 현실적인 벽에 부딪혔다.
- 숨겨진 사전 제약: 뇌 혈관의 기본 구성 요소("원자")는 직접 관찰되지 않는다. 이를 찾기 위해 저자들은 재구성 오류를 최소화하면서 표현을 희소하게 만드는 고도로 제약된 최적화 문제를 해결해야 했다. 그들은 이를 수학적으로 다음과 같이 정의해야 했다.
$$ \hat{\mathbf{B}}, \hat{\mathbf{Z}} = \min_{\mathbf{B}, \mathbf{Z}} \|\mathcal{Y}_{\mathcal{I}} - \mathbf{B}\mathbf{Z}\|_2^2 $$
$\|\mathbf{Z}\|_1 < \lambda$라는 엄격한 희소성 제약 조건 하에서. 이를 해결하려면 학습된 반복 축소 임계값 알고리즘(LISTA)과 같은 특수하고 복잡한 알고리즘이 필요하다. - 극심한 데이터 희소성 및 복잡성: 혈관은 주변 뇌 조직에 비해 믿을 수 없을 정도로 얇고 복잡하며 희소하다. 이들의 연결성과 관형 모양을 포착하는 것은 표준 픽셀 단위 분석으로는 충분하지 않다는 것을 의미한다. 모델은 어떤 식으로든 분기 트리의 기하학적 구조를 이해해야 한다.
- 하드웨어 및 차원 제한: 3D 체적 뇌 스캔은 방대하다. 이러한 희소 사전을 학습하기 위해 전체 3D 패치를 처리하는 것은 메모리 집약적이다. 솔직히 말해서, 이것이 엄격하게 GPU 메모리 제한이었는지 아니면 수학적 복잡성 제한이었는지 완전히 확신할 수는 없지만, 저자들은 명백히 가혹한 절충을 인정했다. 그들은 사전을 학습 가능하게 만들기 위해 3D 볼륨을 2D 패치로 슬라이스해야 했다. 2D 패치에 대한 이러한 의존성은 혈관 트리의 일부 3D 공간 연결성을 잃을 위험을 의미한다. 이는 합리적인 계산 범위 내에서 수학이 작동하도록 하기 위해 받아들여야 했던 물리적 제약이다.
이 접근 방식은 왜
본 논문의 저자들은 기존의 최첨단(SOTA) One-Shot Active Learning (OSAL) 프레임워크가 인간 해부학에 근본적으로 맹목적이라는 사실을 깨달았을 때 결정적인 "아하!" 순간에 도달했다. 전통적인 방법은 일반적인 자기 지도 학습, Variational Autoencoders (VAEs), 또는 대조 학습에 크게 의존한다. 이러한 접근 방식은 표준 이미지 데이터셋에서 통계적 이상치를 찾는 데 뛰어나지만, 뇌 스캔을 일반적인 픽셀 분포로 취급한다. 이는 뇌 혈관의 반복적이고 나무와 같은 관형 구조를 전혀 고려하지 못한다.
이러한 해부학적 맹목성 때문에, 표준 딥러닝 모델은 선택된 샘플이 실제로 의미 있거나 전체 혈관 트리를 대표하는지 보장할 수 없었다. 저자들은 이를 해결하기 위해 계층적 분기를 본질적으로 이해하는 수학적 모델이 필요하다는 것을 인지했다. 이것이 바로 Dictionary Learning과 sparse coding의 결합이 유일하게 실행 가능한 해결책이었던 이유이다. 혈관 트리가 기본적인 구성 요소의 선형 조합으로 모델링될 수 있다는 이론적 기반에 따라, 그들은 혈관 패턴의 이러한 숨겨진 "원자"를 추출하는 문제로 공식화했다.
수학적으로, 그들은 다음 최적화 문제를 해결함으로써 이 추출을 정의했다:
$$ \hat{\mathbf{B}}, \hat{\mathbf{Z}} = \min_{\mathbf{B},\mathbf{Z}} \|\mathcal{Y}_{\mathcal{I}} - \mathbf{B}\mathbf{Z}\|_2^2 $$
희소성 제약 조건 $\|\mathbf{Z}\|_1 < \lambda$ 하에서. 여기서 $\mathcal{Y}_{\mathcal{I}}$는 관찰된 혈관 패치를 나타내고, $\mathbf{B}$는 혈관 패턴의 과도하게 완전한 사전(dictionary)이며, $\mathbf{Z}$는 희소 표현 계수를 포함한다. 학습된 Iterative Shrinkage Thresholding Algorithm (LISTA)를 사용함으로써, 그들은 이를 효율적으로 해결하여 네트워크가 고도로 압축되고 희소한 잠재 벡터를 학습하도록 강제했으며, 여기서 각 활성 요소는 혈관의 특정 물리적 특성(모양, 크기 또는 연결성과 같은)에 해당한다.
이 접근 방식을 이전의 금본위제(gold standards)와 비교하여 벤치마킹했을 때, V-DiSNet의 비교 우위는 Dice 점수와 같은 단순한 성능 지표를 훨씬 넘어선다. 진정한 구조적 이점은 해석 가능성(interpretability)과 효율성에 있다. 표준 OSAL 방법은 블랙박스이며, 왜 한 데이터 포인트가 다른 데이터 포인트보다 우선시되는지 설명할 수 없다. 대조적으로, V-DiSNet의 희소 잠재 공간은 완전히 투명하다. 잠재 벡터에서 특정 "원자"를 비활성화하면, 혈관의 특정 부분이 재구성에서 물리적으로 변형되거나 사라진다. 더 나아가, 고차원 볼륨 뇌 패치를 이 희소 잠재 공간으로 매핑하고 k-means 클러스터링을 적용함으로써, 모델은 검색 공간 복잡성을 극적으로 줄인다. 수백만 개의 고차원 패치 간의 거리를 무작위로 평가하는 대신, 시스템은 구조적 유사성에 따라 이를 그룹화하고 계층적 Farthest Point Sampling (FPS) 알고리즘을 사용하여 필요한 것을 정확히 선택함으로써, 전통적인 샘플링의 막대한 계산 오버헤드를 효과적으로 우회한다.
이 선택된 방법은 의료 분야의 엄격한 제약 조건과 완벽하게 일치한다. 임상 환경에서 의사와 전문가 주석가는 시간이 매우 제한적이다. Iterative Active Learning—인간이 몇 개의 이미지를 레이블링하고 모델이 재학습될 때까지 기다린 후 더 많은 이미지를 레이블링해야 하는 방식—은 지속적인 오버헤드 때문에 실질적으로 쓸모가 없다. 이 문제는 뇌 혈관의 방대한 다양성을 포착하면서도 "원샷" 솔루션(단일 레이블링 라운드)을 요구했다. 여기서의 "결합"은 아름답다: 반복적인 피드백이 전혀 없는 엄격한 제약 조건은 최소한의 패치 부분 집합이 혈관 트리의 모든 가능한 구조적 변이를 포함하도록 보장하는 Dictionary Learning의 고유한 능력으로 극복된다.
만약 저자들이 GANs 또는 표준 Diffusion 모델과 같은 다른 인기 있는 생성적 접근 방식을 사용하려고 시도했다면 실패했을 것이다. GAN은 매우 사실적인 합성 혈관을 생성할 수 있지만, 레이블이 지정되지 않은 데이터셋의 구조적 다양성을 측정하기 위한 명시적이고 해석 가능한 메커니즘을 제공하지 않는다. GAN과 Diffusion 모델은 데이터를 연속적이고 종종 얽힌 잠재 공간으로 매핑하며, 여기서 특정 "분기 패턴"을 분리하는 것은 매우 어렵다. 희소 Dictionary Learning을 선호하여 이러한 블랙박스 생성 모델을 거부함으로써, 저자들은 샘플링 전략이 불투명한 통계적 변동이 아닌 실제 검증 가능한 혈관 해부학에 의해 주도되도록 보장했다.
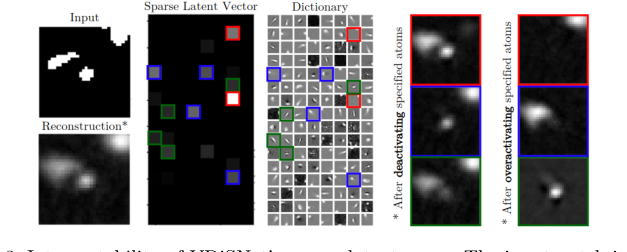 Figure 3. Interpretability of VDiSNet’s sparse latent space. The input patch is en- coded into a sparse representation using learned dictionary atoms. Deactivating or overactivating specific atoms alters specific vessel components, highlighting their role in the reconstruction
Figure 3. Interpretability of VDiSNet’s sparse latent space. The input patch is en- coded into a sparse representation using learned dictionary atoms. Deactivating or overactivating specific atoms alters specific vessel components, highlighting their role in the reconstruction
수학 및 논리 메커니즘
본 논문의 핵심에는 뇌 혈관의 혼란스럽고 분기하는 복잡성을 명확하고 관리 가능한 기본 형태의 어휘로 추출하기 위해 설계된 수학적 엔진이 있다. 이를 달성하기 위해 저자들은 희소 사전 학습(sparse dictionary learning)의 고전적인 공식을 활용하며, 이는 해석 가능한 잠재 공간(latent space)을 구축하기 위한 사전 과제(pretext task)로 적용된다.
프레임워크를 구동하는 마스터 방정식은 다음과 같다.
$$ \hat{\mathcal{B}}, \hat{\mathbf{Z}} = \min_{\mathcal{B}, \mathbf{Z}} \|\mathcal{Y}_{\mathcal{I}} - \mathcal{B}\mathbf{Z}\|_2^2 $$
제약 조건 하에서:
$$ \|\mathbf{Z}\|_1 < \lambda $$
이 방정식을 조각별로 분석하여 정확히 무엇을 하고 있는지 이해해 보자.
- $\hat{\mathcal{B}}, \hat{\mathbf{Z}}$: 이들은 엔진의 최종 최적화된 출력이다. $\hat{\mathcal{B}}$는 학습된 "사전(dictionary)"으로, 직선 튜브, 날카로운 곡선 또는 Y자형 분기점과 같은 근본적이고 반복적인 혈관 구성 요소의 카탈로그로 생각할 수 있다. $\hat{\mathbf{Z}}$는 희소 계수 행렬(sparse coefficient matrix)로, 각 이미지에 어떤 구성 요소를 사용할지를 알려주는 특정 레시피 역할을 한다.
- $\min_{\mathcal{B}, \mathbf{Z}}$: 이것은 최적화 지시어이다. 수학적 엔진에게 사전 $\mathcal{B}$와 레시피 $\mathbf{Z}$를 계속 조정하여 오른쪽의 표현식이 가능한 가장 낮은 값에 도달하도록 지시한다.
- $\mathcal{Y}_{\mathcal{I}}$: 입력 데이터 행렬이다. 물리적으로, 이는 데이터셋에서 추출된 뇌 혈관의 실제 관찰된 이진 이미지 패치이다.
- $-$ (뺄셈): 잔차(residual)를 계산하는 데 사용된다. 실제 혈관 패치와 이를 재현하려는 모델의 인공적인 시도 사이의 정확한 간격을 측정한다.
- $\mathcal{B}\mathbf{Z}$: 재구성된 데이터이다. 저자들은 행렬 곱셈이 선형 조합을 완벽하게 모델링하기 때문에 이를 사용한다. 행렬 곱셈은 $\mathbf{Z}$에 지정된 강도 가중치로 $\mathcal{B}$의 각 사전 원자(atom)를 스케일링한 다음 모두 더한다. 덧셈은 이러한 기본 형태를 서로 위에 쌓아 최종 복잡한 혈관 구조를 구축하는 데 사용된다.
- $\| \cdot \|_2^2$: 제곱 L2 노름(squared L2 norm)이다. 수학적으로, 실제 패치와 가짜 패치 간의 모든 픽셀의 제곱 차이를 합산한다. 물리적으로, 모델을 높은 충실도로 끌어당기는 고무줄 역할을 한다. 저자들은 절대 L1 노름 대신 제곱 L2 노름을 사용했는데, 이는 제곱이 큰 명백한 오류(두꺼운 혈관을 완전히 놓치는 것과 같은)를 크게 페널티화하여 모델이 전반적인 거시 구조를 정확하게 포착하도록 강제하기 때문이다.
- $\|\mathbf{Z}\|_1 < \lambda$: L1 노름을 사용한 희소성 제약 조건이다. 수학적으로, 레시피의 계수의 절대값을 합산한다. 물리적으로, 엄격한 예산 역할을 한다. 모델이 이미지를 재구성하기 위해 절대적으로 최소한의 사전 원자 수를 사용하도록 강제한다.
- $\lambda$: 정규화 매개변수(regularization parameter)이다. 희소성 예산이 얼마나 엄격한지를 결정하는 튜닝 노브이다. $\lambda$가 높을수록 더 희소한 표현을 강제하며, 이는 모델이 패치당 극소수의 원자만 선택할 수 있음을 의미한다.
단계별 흐름
간단한 레고 블록으로 복잡한 혈관 트리를 구축하기 위해 설계된 자동 조립 라인을 상상해 보자.
먼저, 뇌 혈관의 원시적인 레이블 없는 이미지 패치 $Y_i$가 공장으로 들어온다. 이것은 선형 인코더(스캐너 역할)에 공급된다. 이 스캐너는 복잡한 혈관을 보고 희소한 청사진 벡터 $\hat{z}_i$를 생성한다. 앞에서 논의한 엄격한 L1 예산 때문에 이 청사진은 대부분 0으로 구성되어 있으며, 소수의 필수 구성 요소만 활성화하도록 강제되어 매우 선택적이다.
다음으로, 이 청사진은 기본 혈관 부품을 저장하는 창고인 사전 $\mathcal{B}$로 전송된다. $\hat{z}_i$의 0이 아닌 값은 기계적 레버 역할을 한다. 청사진이 5번째 위치에 0.8의 값을 가지면, 창고에서 "원자 5"(특정 Y자형 분기점 모양일 수 있음)를 가져와 강도를 0.8로 스케일링한다.
마지막으로, 선택되고 스케일링된 부품들이 서로 위에 쌓여 최종 재구성된 패치 $\hat{Y}_i$를 구축한다. 그런 다음 시스템은 원본 패치와 이 새로운 구성 사이의 차이를 살펴보고 오류를 계산한 다음, 다음 라운드를 위해 스캐너와 창고 재고를 조정하기 위해 라인 시작 부분으로 신호를 보낸다.
최적화 역학
이 메커니즘은 실제로 어떻게 학습하고 수렴하는가? 여기서 최적화 풍경은 고전적인 줄다리기이다. L2 노름은 이미지를 완벽하게 재현하기를 원하며, 이는 일반적으로 사용 가능한 모든 도구를 사용하는 것을 의미한다(밀집된 $\mathbf{Z}$로 이어짐). 그러나 L1 제약 조건은 효율성을 요구하는 엄격한 관리자이며, $\mathbf{Z}$의 대부분을 0으로 강제한다.
이 비자명한 최적화 문제를 해결하기 위해 저자들은 표준 경사 하강법(gradient descent)만 사용하지 않는다. 그들은 LISTA(Learned Iterative Shrinkage Thresholding Algorithm)를 사용한다. LISTA는 전통적인 수학적 솔버를 가져와 반복 단계를 신경망의 계층으로 펼친다.
훈련 중에 손실 풍경은 부드러운 다차원 그릇(L2 노름에서 비롯됨)과 날카로운 다차원 다이아몬드(L1 노름에서 비롯됨)가 교차하는 모양을 띤다. 경사가 펼쳐진 LISTA 네트워크를 통해 역방향으로 흐르면서 "축소(shrinkage)" 연산은 가위 쌍과 같은 역할을 한다. 경사 업데이트를 살펴보고 작고 중요하지 않은 가중치를 정확히 0으로 잘라낸다.
시간이 지남에 따라 이러한 역학은 사전 $\mathcal{B}$가 쓸모없는 노이즈를 버리고 가장 보편적으로 적용 가능한 혈관 모양만 유지하도록 강제한다. 동시에 인코더는 이 다이아몬드 모양의 손실 풍경을 탐색하여 가장 효율적인 조합을 즉시 선택하도록 학습한다. 이 잠재 공간이 완전히 형성되고 클러스터링되면, 능동 학습 프레임워크는 다른 클러스터에서 쉽게 샘플링할 수 있어 인간 주석가가 레이블을 지정할 완벽하게 다양한 혈관 기하학 세트를 받을 수 있음을 보장한다.
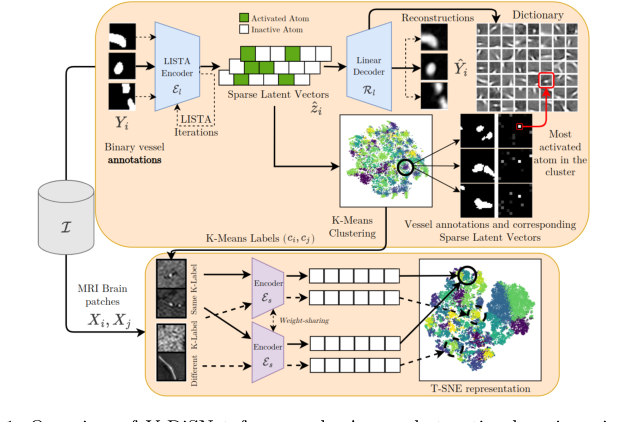 Figure 1. Overview of V-DiSNet framework: A one-shot active learning pipeline that leverages dictionary learning to capture intrinsic vessel patterns, constructs an informative latent space via a Siamese encoder, and applies diversity-based sampling to select a minimal yet representative set of vessel patches for efficient brain vessel segmentation
Figure 1. Overview of V-DiSNet framework: A one-shot active learning pipeline that leverages dictionary learning to capture intrinsic vessel patterns, constructs an informative latent space via a Siamese encoder, and applies diversity-based sampling to select a minimal yet representative set of vessel patches for efficient brain vessel segmentation
결과, 한계점 및 결론
거대하고 복잡한 도시의 배관 시스템을 지도화하는 임무를 맡았다고 상상해보자. 파이프를 직접 볼 수는 없고, 흐릿한 레이더 스캔만 가지고 있다. 정확한 지도를 만들기 위해서는 전문 배관공이 스캔을 보고 손으로 모든 파이프를 추적해야 한다. 이는 매우 비싸고(전문 의료 시간당 스캔당 약 500달러 소요) 고통스러울 정도로 느리다.
의료 영상 분야에서 이 "배관 시스템"은 인간 뇌의 혈관망이며, "레이더 스캔"은 자기공명혈관조영술(MRA) 이미지이다. 딥러닝 모델은 이러한 혈관을 매핑하는 데 뛰어나지만, 데이터 요구량이 매우 높다. 학습을 위해서는 완전히 레이블링된 데이터셋이 필요한데, 이는 인간 의사들이 3D 뇌 스캔을 복셀별로 수없이 많은 시간을 들여 주석을 달아야 함을 의미한다.
이 병목 현상을 우회하기 위해 과학자들은 Active Learning (AL)을 사용한다. 모든 것을 레이블링하는 대신, AI는 데이터를 보고 가장 혼란스럽거나 유익한 부분만 레이블링하도록 인간에게 요청한다. 그러나 전통적인 AL은 반복적이다. AI는 몇 개의 레이블을 요청하고, 스스로 학습한 다음, 더 많은 것이 필요하다는 것을 깨닫고 다시 요청한다. 이러한 끊임없는 상호작용은 바쁜 임상 환경에서 매우 비현실적이다. One-Shot Active Learning (OSAL)이 등장하는데, 여기서 AI는 한 번에 모두 레이블링될 최소한의 단일 데이터 배치를 선택한다.
이 논문의 저자들이 극복해야 했던 제약 조건은 기존 OSAL 방법이 본질적으로 해부학에 대해 눈이 멀었다는 것이다. 이들은 통계적 이상치나 픽셀 변동에 기반하여 데이터 포인트를 선택하며, 혈관이 연속적이고 나무 모양이며 관형 구조라는 근본적인 현실을 완전히 무시한다. 만약 OSAL 모델이 무작위로 "어려운" 패치를 선택한다면, 혈관 시스템을 정의하는 반복적인 분기 패턴을 놓칠 수 있으며, 이는 일반화에 실패하는 AI로 이어질 수 있다.
수학적 핵심: 해부학 해독
이를 해결하기 위해 저자들은 V-DiSNet (Vessel-Dictionary Selection Net)을 개발했다. 그들의 뛰어난 통찰력은 복잡한 혈관 트리를 무작위 픽셀 모음이 아닌, 직선 파이프, Y-접합, 곡선과 같은 기본적인 모양의 유한 알파벳으로 구성된 언어로 취급하는 것이었다.
수학적으로, 그들은 혈관 이미지 패치 $\mathcal{Y}$를 이러한 기본 빌딩 블록의 선형 조합으로 모델링했다. 그들은 과도하게 완전한 "사전" $\mathcal{B}$ (모양의 알파벳)와 희소 벡터 $\mathbf{Z}$ (어떤 모양을 사용하고 얼마나 강하게 가중치를 부여할지에 대한 특정 레시피)를 정의했다.
사전을 미리 알지 못했기 때문에 기존 레이블링된 데이터셋에서 학습해야 했다. 그들은 이를 최적화 문제로 구성했다.
$$ \hat{\mathcal{B}}, \hat{\mathbf{Z}} = \min_{\mathcal{B}, \mathbf{Z}} \|\mathcal{Y}_{\mathcal{I}} - \mathcal{B}\mathbf{Z}\|_2^2 $$
다음 제약 조건 하에:
$$ \|\mathbf{Z}\|_1 < \lambda $$
이것이 우아하게 의미하는 바는 다음과 같다. 알고리즘은 최적의 사전($\hat{\mathcal{B}}$)과 최적의 레시피($\hat{\mathbf{Z}}$)를 찾으려고 시도하여, 이 둘을 곱했을 때 재구성된 이미지와 실제 주석이 달린 이미지($\mathcal{Y}_{\mathcal{I}}$) 간의 차이가 가능한 한 0에 가깝도록 한다(제곱 L2 노름으로 최소화됨).
핵심 부분은 제약 조건 $\|\mathbf{Z}\|_1 < \lambda$이다. 이것은 희소성 제약이다. 이는 모델이 혈관을 재구성하기 위해 사전에서 절대적으로 최소한의 "재료"를 사용하도록 강제한다. 희소성을 강제함으로써 모델은 이미지를 단순히 암기할 수 없으며, 진정한, 근본적인, 반복되는 해부학적 패턴("원자")을 발견하도록 강제된다.
이러한 원자가 학습되면, 저자들은 Siamese 신경망 아키텍처를 사용하여 새로운, 레이블링되지 않은 MRI 패치를 잠재 공간(수학적 표현 공간)으로 매핑한다. 유사한 혈관 구조를 가진 패치는 서로 가깝게 끌어당겨지고, 다른 구조를 가진 패치는 서로 멀리 떨어뜨린다. 마지막으로, Farthest Point Sampling (FPS) 알고리즘을 사용하여 이 공간에 고르게 퍼져 있는 작고 매우 다양한 패치 세트를 선택한다. 이는 인간 전문가에게 뇌에 존재하는 모든 유형의 혈관 기하학의 완벽하게 대표적인 단면을 레이블링하도록 요청받도록 보장한다.
실험 아키텍처: 철저한 개념 증명
저자들은 단순히 모델을 데이터셋에 적용하고 약간의 정확도 향상만을 보고하지 않았다. 그들은 샘플링 메커니즘이 기존 패러다임보다 훨씬 우수함을 증명하기 위해 엄격한 스트레스 테스트를 설계했다.
그들의 "희생양"은 표준 Random Sampling (R-W)과 세 가지 최첨단 OSAL 기준선인 RA (Representative Annotation), CA (Contrastive Active Learning), AET (Active Learning via Epistemic and Aleatoric Uncertainty)였다. 그들은 결과가 특정 스캐너 유형의 우연이 아님을 보장하기 위해 세 가지 서로 다른 공개적으로 사용 가능한 3D MRA 데이터셋(OASIS-3, SMILE-UHURA, CAS)에 이 모델들을 배포했다.
V-DiSNet의 우수성에 대한 결정적인 증거는 극도로 적은 데이터 환경에서 발견되었다. 저자들은 모델에 0.1%, 1%, 5%, 10%의 레이블링된 데이터에만 접근하도록 하여 모델을 굶겼다. 이러한 극한 조건에서 V-DiSNet은 기준선들을 체계적으로 압도했다.
더욱이, 그들은 표준 픽셀 중첩(Dice score)만을 측정하지 않았다. 그들은 관형 구조의 위상학적 정확성과 연결성을 구체적으로 측정하는 clDice 메커니즘을 활용했다. 이는 V-DiSNet이 단순히 픽셀을 더 잘 추측하는 것이 아니라, 실제로 혈관의 연속적인 파이프와 같은 무결성을 보존하고 있음을 증명했다. 데이터에서 궁극적인 "마이크 드롭" 순간은 단 30%의 데이터셋만 레이블링되었음에도 불구하고, V-DiSNet이 100%의 완전한 주석이 달린 데이터로 학습된 모델과 거의 동일한 분할 성능을 달성했다는 것이다.
그들의 수학적 잠재 공간이 단순한 블랙박스가 아님을 증명하기 위해, 그들은 해석 가능성 실험을 수행했다. 학습된 사전 $\mathbf{Z}$의 특정 "원자"를 수동으로 비활성화함으로써, 재구성된 혈관의 특정 물리적 특징(예: 특정 분기 또는 곡선)이 사라짐을 보여주었다. 이는 그들의 수학이 인간 혈관의 물리적 기하학을 성공적으로 분리했음을 부인할 수 없게 증명했다.
향후 발전을 위한 논의 주제
이 논문의 심오한 함의를 바탕으로, 향후 탐구 및 비판적 사고를 위한 몇 가지 방향은 다음과 같다.
-
2D 패치에서 3D 전역 위상으로:
현재 프레임워크는 3D 볼륨에서 추출된 2D 패치에 대해 작동한다. 국소적으로는 효과적이지만, 혈관 트리의 전역 연속성(예: 여러 패치에 걸쳐 있는 긴 동맥)을 잃을 위험이 있다. 계산 비용이 폭발적으로 증가하지 않도록 3D 볼륨 그래프를 네이티브로 처리하도록 사전 학습 방정식을 어떻게 발전시킬 수 있을까? 샘플링 단계에서 전역 연결 제약 조건을 강제하기 위해 위상 데이터 분석(TDA)을 통합할 수 있을까? -
교차 양식 해부학적 전이성:
V-DiSNet은 MRA 스캔에서 사전을 학습한다. 그러나 혈관의 근본적인 모양은 MRA, CT 혈관조영술(CTA) 또는 초음파를 통해 보든 동일하게 유지된다. 보편적인 "혈관 사전"을 한 번 학습한 다음 완전히 다른 영상 양식에 걸쳐 전이시킬 수 있을까? 이를 통해 병원은 저렴하고 풍부한 MRA 데이터에서 학습된 사전을 사용하여 희귀하거나 비싸거나 새로운 영상 유형에 대해 One-Shot Active Learning을 수행할 수 있을 것이다. -
물리학 및 혈역학 통합:
현재 사전 원자는 순전히 정적 공간 기하학에서 학습된다. 그러나 혈관은 그 안을 흐르는 혈액의 유체 역학에 의해 형성된다. 만약 우리가 잠재 공간 생성에 물리학 기반 신경망(PINNs)을 주입한다면, Siamese 네트워크가 단순히 모양이 아닌 혈역학적 특성(예: 전단 응력 또는 유속)에 따라 혈관을 클러스터링하도록 강제할 수 있을까? 이는 동맥류 또는 뇌졸중 예측을 위한 데이터 샘플링 방식을 혁신할 수 있을 것이다.
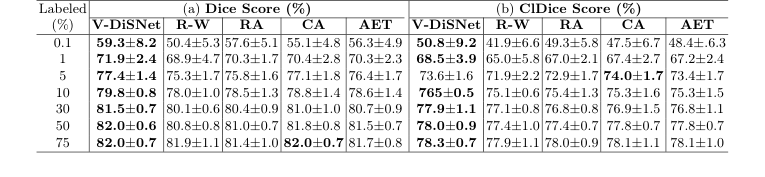 Table 1. Segmentation performance on 15 CAS dataset test patients at various labeling percentages. Eight experiments with distinct random seeds were run for each fraction and model. Results were averaged and standard deviations computed across test patients
Table 1. Segmentation performance on 15 CAS dataset test patients at various labeling percentages. Eight experiments with distinct random seeds were run for each fraction and model. Results were averaged and standard deviations computed across test patients
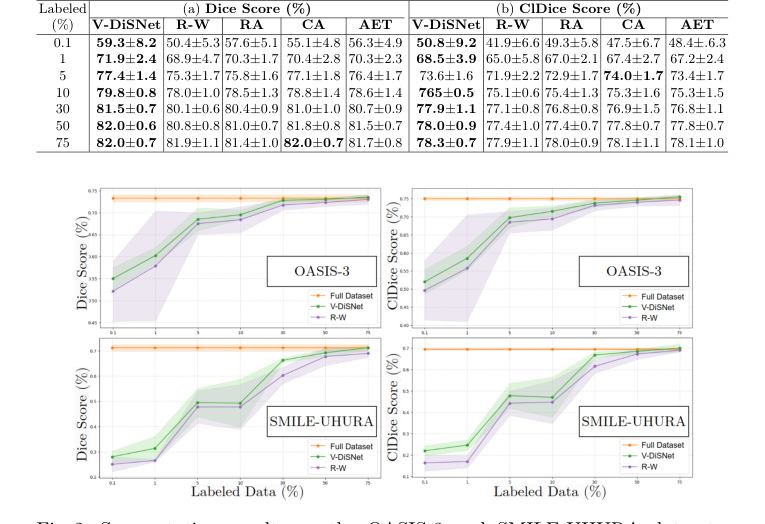 Figure 2. Segmentation results on the OASIS-3 and SMILE-UHURA datasets, showing Dice scores (left) and ClDice scores (right) for different percentages of sample and annotated patches
Figure 2. Segmentation results on the OASIS-3 and SMILE-UHURA datasets, showing Dice scores (left) and ClDice scores (right) for different percentages of sample and annotated patches
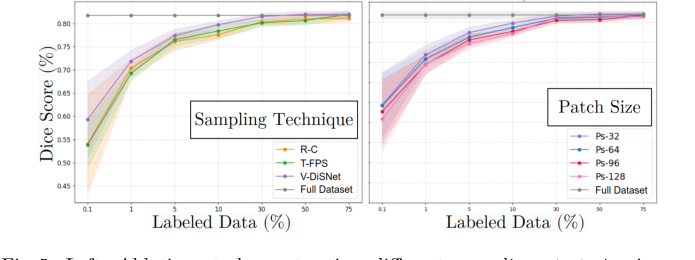 Figure 5. Left: Ablation study contrasting different sampling strategies in our learned latent space. Right: Evaluation of the impact of the patch size
Figure 5. Left: Ablation study contrasting different sampling strategies in our learned latent space. Right: Evaluation of the impact of the patch size