单次主动学习用于血管分割
New AI learns from tiny, smart samples, saving time & resources for better disease insights.
背景与学术传承
在医学影像领域,绘制大脑血管图谱(即血管分割)是理解脑部功能和诊断中风等严重神经系统疾病的关键步骤。历史上,随着深度学习模型成为该任务的黄金标准,出现了一个巨大的瓶颈:这些模型极其“饥渴”,需要数千张三维脑部扫描图由医学专家进行细致标注。手动追踪错综复杂、微观的血管网络不仅耗时耗力,而且成本高昂,单张扫描图的专家劳动成本有时就高达150美元或更多。
为了缓解这一问题,该领域转向了主动学习(Active Learning, AL)范式,即人工智能识别最具信息量的未标记样本,并要求人类专家仅标注这些样本。然而,传统的AL高度迭代,需要一个训练模型、暂停以请求专家标注、重新训练模型、再次请求的循环。这种持续的来回交互要求临床专家持续可用,并产生巨大的计算开销,使得实时临床应用几乎不可能实现。
迫使作者撰写本文的根本性局限性在于下一演进步骤——单次主动学习(One-Shot Active Learning, OSAL)的缺陷。尽管OSAL试图在单次遍历中选择最少量的样本(消除了来回交互),但之前的OSAL模型本质上是“黑箱”。它们依赖于通用的数据增强或对比学习,而没有任何明确的机制来理解大脑的实际解剖结构。具体来说,它们完全忽略了血管的重复性、树状结构。由于这些旧模型无法解释为何它们选择某些数据点,因此它们经常选择不具代表性的样本。这导致模型无法泛化到新的、未见过患者的数据。作者意识到,要解决这个问题,他们需要一个专门针对大脑血管独特、重复几何形状定制的OSAL框架。
为了帮助您直观地理解作者是如何解决这个问题的,以下是将高度专业化的领域术语转化为日常类比的核心概念:
- 单次主动学习(One-Shot Active Learning, OSAL): 想象您要去为一场盛大而复杂的宴会采购食材,但您只能去商店一次。与每次意识到缺少某种配料时都要跑回商店(这是迭代式主动学习的工作方式)不同,您会提前仔细分析您的食谱,并在一次高效的行程中购买一套完美多样、数量最少的食材。
- 字典学习与原子(Dictionary Learning & Atoms): 这就像一位大师建筑师的乐高积木套装。人工智能不是试图记住曾经建造过的每一个玩具城堡或宇宙飞船的确切形状,而是只学习一小组基本的乐高积木(称为“原子”)。通过以不同的方式组合这些基本积木,人工智能可以重构它遇到的任何复杂的血管形状。
- 潜在空间(Latent Space): 想象一个庞大而神奇的图书馆,书籍不是按字母顺序排列,而是根据情节的相似性进行排序。潜在空间是一个数学“房间”,人工智能将图像块放置在其中。具有相似血管模式的图像块会放置在一起,而完全不同的模式则被推开,从而可以轻松地看到数据的全貌。
- 孪生编码器(Siamese Encoder): 想象两名孪生侦探在调查同一案件。他们会收到两份不同的线索(图像块)。如果线索属于同一个嫌疑人(相同的血管模式),侦探们就会用一根短绳将它们联系起来。如果它们属于不同的嫌疑人,他们就会将它们分开。这个算法确保了潜在空间的完美组织和高度区分性。
以下是用于构建和解决此问题的关键数学符号的分解:
| 符号 | 描述 |
|---|---|
| $\mathcal{I}$ | 包含图像及其对应专家标注的已标记数据集。 |
| $\mathbf{I}$ | 数据集中的特定三维体积图像(例如,MRI脑部扫描)。 |
| $\mathbf{L}$ | 与图像 $\mathbf{I}$ 相关的真实标签图。 |
| $H \times W \times S$ | 图像的尺寸(高度、宽度和切片数)。 |
| $X_k, Y_k$ | 非重叠的二维图像块及其对应的标签块。 |
| $\mathcal{Y}_{\mathcal{I}}$ | 从数据集中提取的二值血管标注块的集合。 |
| $\mathbf{B}$ | 一个过完备字典,包含树状分支模式的基本构建块(原子)。 |
| $\mathbf{z}$ | 一个稀疏向量,包含表示系数(确定哪些原子被激活)。 |
| $\hat{\mathbf{B}}, \hat{\mathbf{Z}}$ | 经过优化后学习到的字典和学习到的稀疏潜在向量。 |
| $\lambda$ | 一个正则化参数,控制表示向量的稀疏性(迫使模型使用尽可能少的原子)。 |
| $c_i$ | 分配给特定标注及其对应图像块的k-means聚类标签。 |
| $\mathcal{E}_1, \mathcal{R}_1$ | 用于将图像块映射到稀疏潜在向量并进行重构的线性编码器和解码器。 |
| $\mathcal{E}_s$ | 用于生成MRI图像块最终信息潜在空间的孪生编码器网络。 |
| $\mathcal{I}^U$ | 模型需要从中采样的新未标记图像数据集。 |
| $n$ | 由框架选择的、需要发送给人类专家进行标注的最少脑部图像块子集。 |
| $\Phi$ | 使用新标注的图像块训练的最终脑血管分割模型。 |
通过结合这些元素,作者成功创建了V-DiSNet,一个数学模型将血管的重复模式建模为 $$ \mathbf{Y} = \mathbf{B}\mathbf{z} $$,并利用这种理解来挑选人类需要标注的最佳 $n$ 个图像块,仅用30%的数据标注就实现了接近全数据集的性能。
问题定义与约束
为了理解本文所要解决的具体问题,我们首先需要审视其起点和终点。
输入(当前状态): 我们从一个海量的、未标记的 3D 脑部扫描数据集开始,具体来说是磁共振血管造影(MRA)图像。在数学上,这是一组无标签的体积图像 $I^U = \{I_j\}_{j=1}^M \subset \mathbb{R}^{H \times W \times S}$。
输出(目标状态): 目标是训练出一个高度精确的深度学习模型,该模型能够分割(精确勾勒)大脑中错综复杂、呈树状分支的血管。然而,这里有一个挑战:我们希望通过人工标注原始数据中一小部分、经过精心挑选的样本(例如,仅 30% 甚至更少)来实现这一目标,而这些标注由医学专家手动完成。
缺失的环节: 输入和目标之间的数学鸿沟在于选择机制。在实际知道图像内容之前,如何从数学上保证你要求医生标注的那一小部分图像是最具信息量的?作者假设脑血管是由可重复出现的、分层的分支模式构成的。因此,任何血管树图像 $\mathbf{Y}$ 都可以被建模为基本构成单元(一个字典 $\mathbf{B}$)和稀疏系数($\mathbf{z}$)的线性组合,即 $\mathbf{Y} = \mathbf{B}\mathbf{z}$。本文弥合的缺失环节在于如何学习这种隐藏的血管模式字典,并将未标记的图像映射到一个潜在空间,在这个空间中我们可以通过数学方法一次性采样到最多样化、最具代表性的图像块。
这引出了困扰先前研究人员的棘手困境。
在机器学习领域,减少对人工标签的需求通常依赖于主动学习(Active Learning, AL)。传统的主动学习是一个迭代过程:模型在少量图像上进行训练,找出它最困惑的部分,然后请求人类“神谕”标注这些特定的困惑图像,再进行重新训练。
* 权衡: 你可以用少量标签获得高精度,但需要承担模型不断重新训练带来的巨大计算成本。更糟糕的是,这需要医学专家持续待命,以回应算法的查询,这在实际临床环境中几乎是不可能实现的。
为了解决这个问题,研究人员发明了单次主动学习(One-Shot Active Learning, OSAL),它试图一次性选择所有信息量大的样本,从而消除了迭代重训练的循环。
* 新的困境: 现有的 OSAL 方法依赖于通用的“黑箱”数学方法(如对比学习或变分自编码器),这些方法完全忽视了大脑的实际物理解剖结构。它们不理解血管是连续的、可重复的管状结构。如果使用这些通用方法一次性选择样本,就有可能选择到一组完全忽略了关键解剖学变异的图像。你牺牲了计算效率,换来的是一个无法泛化到未见数据的模型,因为其训练集并未真正代表复杂的血管树。
为了解决这个问题,作者们遇到了几个严峻的现实挑战:
- 隐藏字典约束: 脑血管的基本构成单元(“原子”)无法直接观测。为了找到它们,作者们必须解决一个高度约束的优化问题,以最小化重构误差,同时强制表示具有稀疏性。他们必须在数学上将其定义为:
$$ \hat{\mathbf{B}}, \hat{\mathbf{Z}} = \min_{\mathbf{B}, \mathbf{Z}} \|\mathcal{Y}_{\mathcal{I}} - \mathbf{B}\mathbf{Z}\|_2^2 $$
并受到严格的稀疏性约束 $\|\mathbf{Z}\|_1 < \lambda$。解决这个问题需要专门的复杂算法,例如学习型迭代收缩阈值算法(LISTA)。 - 极端数据稀疏性和复杂性: 与周围的脑组织相比,血管极其细小、错综复杂且稀疏。捕捉它们的连通性和管状形状意味着标准的逐像素分析不足以胜任;模型必须以某种方式理解分叉树的几何结构。
- 硬件和维度限制: 3D 体积脑部扫描数据量巨大。处理完整的 3D 图像块来学习这些稀疏字典需要极大的内存。坦白说,我并不完全确定这是否严格是 GPU 内存限制还是数学复杂度限制,但作者们明确承认了一个严峻的妥协:他们不得不将 3D 体积切片成 2D 图像块,以使字典学习变得可行。这种对 2D 图像块的依赖意味着他们冒着丢失血管树某些全局 3D 空间连通性的风险——这是一个为了在合理计算范围内实现数学上的可行性而不得不接受的物理约束。
为何采用此方法
本文作者在意识到现有的最先进(SOTA)的单次主动学习(OSAL)框架在根本上忽视了人体解剖结构时,达到了一个关键的“顿悟”时刻。传统方法严重依赖于通用的自监督学习、变分自编码器(VAEs)或对比学习。尽管这些方法在标准图像数据集中寻找统计异常值方面表现出色,但它们将脑部扫描视为通用的像素分布。它们完全未能考虑到脑血管反复出现的、树状的、管状结构。
由于这种解剖学上的盲点,标准的深度学习模型无法保证所选样本确实是有意义的或能代表整个血管树。作者认识到,要解决这个问题,他们需要一个能够内在理解分层分支的数学模型。这就是为什么字典学习结合稀疏编码是唯一可行的解决方案。基于血管树可以被建模为基本构建块的线性组合的理论基础,他们将问题构建为提取这些隐藏的血管模式“原子”。
在数学上,他们通过求解以下优化问题来定义这种提取:
$$ \hat{\mathbf{B}}, \hat{\mathbf{Z}} = \min_{\mathbf{B},\mathbf{Z}} \|\mathcal{Y}_{\mathcal{I}} - \mathbf{B}\mathbf{Z}\|_2^2 $$
受限于稀疏约束 $\|\mathbf{Z}\|_1 < \lambda$。其中,$\mathcal{Y}_{\mathcal{I}}$ 代表观测到的血管块,$\mathbf{B}$ 是血管模式的过完备字典,$\mathbf{Z}$ 包含稀疏表示系数。通过使用学习到的迭代收缩阈值算法(LISTA),他们能够高效地解决这个问题,迫使网络学习一个高度压缩、稀疏的潜在向量,其中每个激活元素对应于血管的特定物理特征(如其形状、大小或连通性)。
在将此方法与先前的黄金标准进行基准测试时,V-DiSNet 的比较优势远远超出了简单的性能指标,如 Dice 分数。真正的结构优势在于其可解释性和效率。标准的 OSAL 方法是黑箱;它们无法解释为什么一个数据点比另一个数据点更受重视。相比之下,V-DiSNet 的稀疏潜在空间是完全透明的。如果禁用潜在向量中的特定“原子”,血管的特定部分在重建中会物理地改变或消失。此外,通过将高维体积脑部块映射到这个稀疏潜在空间并应用 k-means 聚类,该模型极大地降低了搜索空间的复杂性。系统不再盲目地评估数百万个高维块之间的距离,而是按结构相似性对它们进行分组,并使用分层的最远点采样(FPS)算法来精确选择所需内容,从而有效地绕过了传统采样带来的巨大计算开销。
这种选择的方法完美地契合了医学领域的严苛约束。在临床环境中,医生和专家标注员的时间非常有限。迭代主动学习——需要人类标注少量图像,等待模型重新训练,然后再次标注——由于其持续的开销,实际上是无效的。这个问题需要一个“单次”解决方案(一次标注轮次),同时仍能捕捉到脑血管的巨大多样性。这里的“结合”非常巧妙:字典学习独特的能力保证了发送给预言机的最小块子集涵盖了血管树所有可能的结构变异,从而克服了零迭代反馈的严苛约束。
如果作者试图使用其他流行的生成方法,如 GANs 或标准的扩散模型,他们将会失败。虽然 GANs 可以生成高度逼真的合成血管,但它不提供明确、可解释的机制来衡量未标记数据集的结构多样性。GANs 和扩散模型将数据映射到连续的、通常是纠缠的潜在空间,从中分离出特定的“分支模式”非常困难。通过拒绝这些黑箱生成模型,转而采用稀疏字典学习,作者确保了他们的采样策略是由实际的、可验证的血管解剖结构驱动的,而不是由不透明的统计方差驱动的。
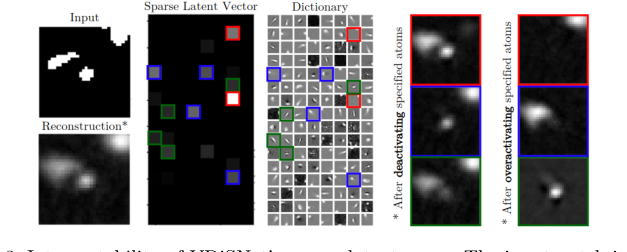 Figure 3. Interpretability of VDiSNet’s sparse latent space. The input patch is en- coded into a sparse representation using learned dictionary atoms. Deactivating or overactivating specific atoms alters specific vessel components, highlighting their role in the reconstruction
Figure 3. Interpretability of VDiSNet’s sparse latent space. The input patch is en- coded into a sparse representation using learned dictionary atoms. Deactivating or overactivating specific atoms alters specific vessel components, highlighting their role in the reconstruction
数学与逻辑机制
本文的核心在于一个数学引擎,该引擎旨在将大脑血管的混乱、分支状复杂性提炼成一套清晰、易于管理的基元形状词汇。为此,作者借鉴了稀疏字典学习的经典公式,并将其改编为一个预训练任务,以构建一个可解释的潜在空间。
驱动该框架的正是这个主方程:
$$ \hat{\mathcal{B}}, \hat{\mathbf{Z}} = \min_{\mathcal{B}, \mathbf{Z}} \|\mathcal{Y}_{\mathcal{I}} - \mathcal{B}\mathbf{Z}\|_2^2 $$
受限于:
$$ \|\mathbf{Z}\|_1 < \lambda $$
让我们逐一剖析这个方程,以准确理解其工作原理:
- $\hat{\mathcal{B}}, \hat{\mathbf{Z}}$: 这是引擎的最终优化输出。$\hat{\mathcal{B}}$ 是学习到的“字典”,可以将其视为基元、重复出现的血管构件(如直线管、急转弯或 Y 形分叉)的目录。$\hat{\mathbf{Z}}$ 是稀疏系数矩阵,它充当了具体的“配方”,指示系统为每个图像使用哪些构件。
- $\min_{\mathcal{B}, \mathbf{Z}}$: 这是优化指令。它指示数学引擎不断调整字典 $\mathcal{B}$ 和配方 $\mathbf{Z}$,直到其右侧的表达式达到最低可能值。
- $\mathcal{Y}_{\mathcal{I}}$: 输入数据矩阵。在物理上,这是从数据集中提取的实际观察到的、二值的脑血管图像块。
- $-$ (减法): 此处用于计算残差。它衡量真实血管块与模型人工重构尝试之间的确切差距。
- $\mathcal{B}\mathbf{Z}$: 重构数据。作者在此处使用矩阵乘法,因为它完美地模拟了线性组合。矩阵乘法将 $\mathcal{B}$ 中的每个字典原子与其在 $\mathbf{Z}$ 中指定的强度权重相乘,然后将它们全部相加。加法用于将这些基元形状叠加在一起,以构建最终复杂的血管结构。
- $\| \cdot \|_2^2$: 2-范数的平方。在数学上,它对真实块和伪造块之间所有像素的平方差求和。在物理上,它就像一个橡皮筋,将模型拉向高保真度。作者在此处使用 2-范数的平方而非绝对值 1-范数,是因为平方会严重惩罚大的、明显的错误(例如完全遗漏粗血管),迫使模型准确捕捉整体宏观结构。
- $\|\mathbf{Z}\|_1 < \lambda$: 使用 1-范数的稀疏性约束。在数学上,它对配方中系数的绝对值求和。在物理上,它充当严格的预算。它迫使模型使用最少数量的字典原子来重构图像。
- $\lambda$: 正则化参数。它是决定稀疏性预算严格程度的调谐旋钮。较高的 $\lambda$ 会强制更稀疏的表示,这意味着模型每个图像块只能选择极少数原子。
分步流程
想象一个自动化装配线,旨在用简单的乐高积木构建复杂的血管树。
首先,一个原始的、未标记的脑血管图像块 $Y_i$ 进入工厂。它被送入一个线性编码器(充当扫描仪)。该扫描仪观察复杂的血管,并生成一个稀疏的蓝图向量 $\hat{z}_i$。由于我们讨论的严格的 1-范数预算,这个蓝图大部分是零——它被迫高度选择性,只激活少数关键组件。
接下来,这个蓝图被发送到字典 $\mathcal{B}$,这是存储基本血管部件的仓库。$\hat{z}_i$ 中的非零值充当机械杠杆。如果蓝图在第 5 位有一个值为 $0.8$,它就会从仓库中提取“原子 5”(可能是一个特定的 Y 形分叉形状),并将其强度缩放到 $0.8$。
最后,将这些选定的、缩放后的部件堆叠在一起,构建最终的重构图像块 $\hat{Y}_i$。然后,系统会查看原始图像块与这个新构建图像块之间的差异,计算误差,并将信号发送回生产线起点,以便在下一轮调整扫描仪和仓库库存。
优化动力学
这个机制究竟是如何学习和收敛的?这里的优化景观是一个经典的拔河比赛。2-范数希望完美地重构图像,这通常意味着使用所有可用的工具(导致 $\mathbf{Z}$ 密集)。但 1-范数约束是一个严格的管理者,要求效率,迫使 $\mathbf{Z}$ 的大部分变为零。
为了解决这个非平凡的优化问题,作者们不仅仅使用了标准的梯度下降。他们采用了 LISTA(学习迭代收缩阈值算法)。LISTA 将传统的数学求解器展开其迭代步骤,并将其转化为神经网络的层。
在训练过程中,损失景观的形状就像一个光滑的多维碗(来自 2-范数)与一个尖锐的多维钻石(来自 1-范数)相交。当梯度通过展开的 LISTA 网络反向流动时,“收缩”操作就像一把剪刀。它会查看梯度更新,并将小的、不重要的权重精确地裁剪为零。
随着时间的推移,这种动力学迫使字典 $\mathcal{B}$ 丢弃无用的噪声,只保留最普遍适用的血管形状。同时,编码器学会导航这个菱形损失景观,以即时选择最有效的组合。一旦这个潜在空间完全形成并聚类,主动学习框架就可以轻松地从不同的簇中采样,从而保证人类标注者能够获得一套具有完美多样性的血管几何形状进行标记。
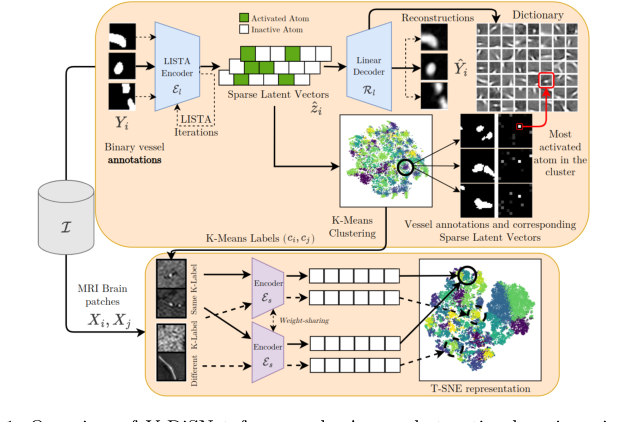 Figure 1. Overview of V-DiSNet framework: A one-shot active learning pipeline that leverages dictionary learning to capture intrinsic vessel patterns, constructs an informative latent space via a Siamese encoder, and applies diversity-based sampling to select a minimal yet representative set of vessel patches for efficient brain vessel segmentation
Figure 1. Overview of V-DiSNet framework: A one-shot active learning pipeline that leverages dictionary learning to capture intrinsic vessel patterns, constructs an informative latent space via a Siamese encoder, and applies diversity-based sampling to select a minimal yet representative set of vessel patches for efficient brain vessel segmentation
结果、局限性与结论
想象一下,你被赋予了绘制一座庞大复杂城市的错综复杂的管道系统的任务。你无法直接看到管道,只能获得模糊的雷达扫描。为了绘制一张精确的地图,你需要一位专业的管道工仔细查看扫描图并手工描绘每一根管道。这成本极其高昂——可能每张扫描图需要花费 500 美元的专家医疗时间——而且过程极其缓慢。
在医学影像领域,这个“管道系统”就是人脑的血管网络,“雷达扫描”则是磁共振血管造影(MRA)图像。深度学习模型在绘制这些血管方面表现出色,但它们极其“饥渴”于数据。它们需要完全标注的数据集来学习,这意味着人类医生必须花费无数小时逐个体素地标注 3D 脑部扫描。
为了绕过这个瓶颈,科学家们使用了 主动学习(Active Learning, AL)。与其标注所有内容,不如让 AI 查看数据并要求人类只标注最令人困惑或信息量最大的部分。然而,传统的主动学习是迭代的:AI 请求少量标注,自行训练,意识到需要更多,然后再次请求。这种持续的来回交互在繁忙的临床环境中非常不切实际。于是,单次主动学习(One-Shot Active Learning, OSAL) 应运而生,在这种方法中,AI 选择一个单一的、最小的数据批次进行一次性标注。
本文作者必须克服的限制是,现有的 OSAL 方法在本质上对解剖结构是“盲目”的。它们根据统计异常或像素方差来选择数据点,完全忽略了血管是连续的、树状的、管状结构的根本现实。如果一个 OSAL 模型只是随机选择“困难”的图像块,它可能会错过定义血管系统的重复分叉模式,导致 AI 无法泛化。
数学核心:解码解剖结构
为了解决这个问题,作者们创建了 V-DiSNet(Vessel-Dictionary Selection Net)。他们巧妙的见解是将复杂的血管树视为一种由有限的、基本的形状字母表构建的语言,而不是随机的像素集合——例如直线管道、Y 型分支和曲线。
在数学上,他们将血管图像块 $\mathcal{Y}$ 建模为这些基本构建块的线性组合。他们定义了一个过完备的“字典” $\mathcal{B}$(形状的字母表)和一个稀疏向量 $\mathbf{Z}$(使用哪些形状以及如何加权它们的具体配方)。
由于他们事先不知道字典,因此必须从现有的标注数据集中学习它。他们将此视为一个优化问题:
$$ \hat{\mathcal{B}}, \hat{\mathbf{Z}} = \min_{\mathcal{B}, \mathbf{Z}} \|\mathcal{Y}_{\mathcal{I}} - \mathcal{B}\mathbf{Z}\|_2^2 $$
受限于:
$$ \|\mathbf{Z}\|_1 < \lambda $$
这优雅地意味着:算法试图找到最优字典 ($\hat{\mathcal{B}}$) 和最优配方 ($\hat{\mathbf{Z}}$),以便当它们相乘时,重构图像与真实标注图像 ($\mathcal{Y}_{\mathcal{I}}$) 之间的差异尽可能接近于零(通过平方 L2 范数最小化)。
关键部分是约束 $\|\mathbf{Z}\|_1 < \lambda$。这是一个稀疏性约束。它迫使模型使用字典中最少量的“成分”来重构血管。通过强制稀疏性,模型无法仅仅记忆图像;它被迫发现真正潜在的、重复出现的解剖模式(“原子”)。
一旦这些原子被学习,作者们就使用 Siamese 神经网络架构将新的、未标注的 MRI 图像块映射到一个 latent space(数学表示空间)。具有相似血管结构的图像块会被拉近,而具有不同结构的图像块会被推开。最后,他们使用 Farthest Point Sampling (FPS) 算法来选择一小组高度多样化的图像块,这些图像块均匀地分布在这个空间中。这保证了人类专家被要求标注大脑中存在的每种血管几何形状的完美代表性横截面。
实验架构:严苛的概念验证
作者们并没有仅仅将他们的模型应用于一个数据集并报告微小的准确性提升。他们设计了一个严格的压力测试,以证明他们的采样机制远优于现有的范式。
他们的“受试者”是标准的随机采样(Random Sampling, R-W)和三个最先进的 OSAL 基线:RA(Representative Annotation)、CA(Contrastive Active Learning)和 AET(Active Learning via Epistemic and Aleatoric Uncertainty)。他们将这些模型部署在三个不同的、公开可用的 3D MRA 数据集(OASIS-3、SMILE-UHURA 和 CAS)上,以确保结果不是由某个特定扫描仪类型造成的偶然现象。
在极低数据量的情况下,发现了 V-DiSNet 优越性的决定性证据。作者们“饿”了模型,只允许它们访问 0.1%、1%、5% 和 10% 的标注数据。在这些极端条件下,V-DiSNet 系统性地击败了基线模型。
此外,他们不仅仅测量了标准的像素重叠(Dice score)。他们使用了 clDice 指标,该指标专门衡量管状结构的拓扑正确性和连通性。这证明了 V-DiSNet 不仅仅是更好地猜测像素;它实际上保留了血管的连续、管道状的完整性。他们数据中最具决定性的时刻是,仅使用了 30% 的数据集进行标注,V-DiSNet 就达到了与在 100% 完全标注数据上训练的模型几乎相同的分割性能。
为了证明他们的数学 latent space 不仅仅是一个黑箱,他们进行了一项可解释性实验。通过手动禁用其学习字典 $\mathbf{Z}$ 中的特定“原子”,他们表明重构血管的特定物理特征(如特定的分支或曲线)会消失。这无可辩驳地证明了他们的数学成功地分离了人类血管系统的物理几何形状。
未来演进的讨论话题
基于本文的深刻启示,以下是未来探索和批判性思考的几个方向:
-
从 2D 图像块到 3D 全局拓扑:
当前框架在从 3D 体积中提取的 2D 图像块上运行。虽然在局部有效,但这有丢失血管树全局连续性的风险(例如,一条跨越多个图像块的长动脉)。我们如何才能改进字典学习方程,使其能够原生处理 3D 体积图,而不会导致计算成本爆炸?我们能否在采样阶段整合拓扑数据分析(TDA)来强制执行全局连通性约束? -
跨模态解剖可迁移性:
V-DiSNet 从 MRA 扫描中学习其字典。然而,无论通过 MRA、CT 血管造影(CTA)还是超声波观察,血血管的基本形状都是相同的。能否一次性训练一个通用的“血管字典”,然后将其迁移到完全不同的成像模态?这将允许医院使用从廉价、丰富的 MRA 数据中学到的字典,对稀有、昂贵或新型成像类型执行单次主动学习。 -
整合物理学和血流动力学:
目前,字典原子仅从静态空间几何中学习。但是,血管的形状受到流经它们的血液的流体动力学的影响。如果我们能将物理信息神经网络(PINNs)注入 latent space 生成过程,能否迫使 Siamese 网络不仅根据形状对血管进行聚类,还根据它们的血流动力学特性(例如,剪切应力或流速)进行聚类?这可能彻底改变我们为预测动脉瘤或中风而采样数据的方式。
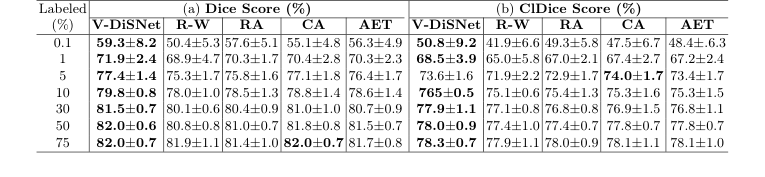 Table 1. Segmentation performance on 15 CAS dataset test patients at various labeling percentages. Eight experiments with distinct random seeds were run for each fraction and model. Results were averaged and standard deviations computed across test patients
Table 1. Segmentation performance on 15 CAS dataset test patients at various labeling percentages. Eight experiments with distinct random seeds were run for each fraction and model. Results were averaged and standard deviations computed across test patients
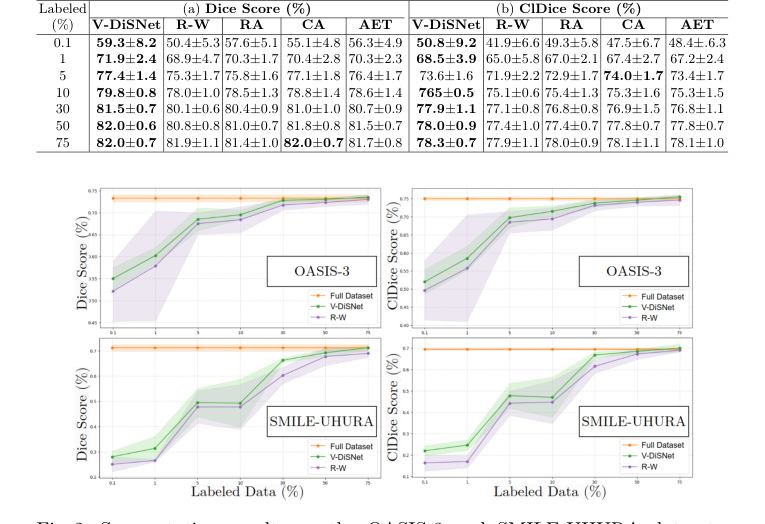 Figure 2. Segmentation results on the OASIS-3 and SMILE-UHURA datasets, showing Dice scores (left) and ClDice scores (right) for different percentages of sample and annotated patches
Figure 2. Segmentation results on the OASIS-3 and SMILE-UHURA datasets, showing Dice scores (left) and ClDice scores (right) for different percentages of sample and annotated patches
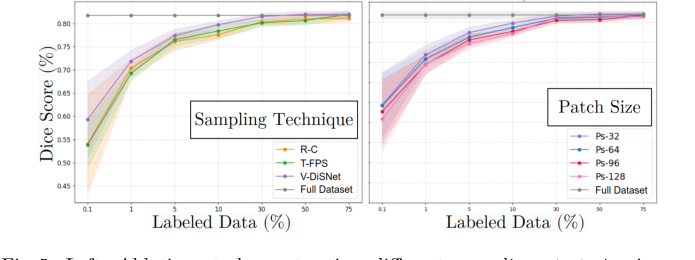 Figure 5. Left: Ablation study contrasting different sampling strategies in our learned latent space. Right: Evaluation of the impact of the patch size
Figure 5. Left: Ablation study contrasting different sampling strategies in our learned latent space. Right: Evaluation of the impact of the patch size