पुनर्प्राप्ति-आधारित विज़ुअल इन-कॉन्टेक्स्ट लर्निंग के साथ प्री-टू-पोस्ट ऑपरेटिव एमआरआई जनरेशन
ग्लियोब्लास्टोमा एक अत्यंत आक्रामक और तेजी से फैलने वाला मस्तिष्क ट्यूमर है। न्यूरोसर्जन के लिए, इसका उपचार एक अविश्वसनीय रूप से नाजुक संतुलनकारी कार्य है: उन्हें रोगी के पूर्वानुमान को बेहतर बनाने के लिए यथासंभव अधिक...
पृष्ठभूमि और अकादमिक वंश
ग्लियोब्लास्टोमा एक अत्यंत आक्रामक और तेजी से फैलने वाला मस्तिष्क ट्यूमर है। न्यूरोसर्जन के लिए, इसका उपचार एक अविश्वसनीय रूप से नाजुक संतुलनकारी कार्य है: उन्हें रोगी के पूर्वानुमान को बेहतर बनाने के लिए यथासंभव अधिक से अधिक ट्यूमर को हटाना होता है, लेकिन गंभीर पोस्ट-ऑपरेटिव जटिलताओं को कम करने के लिए महत्वपूर्ण मस्तिष्क क्षेत्रों को नुकसान पहुँचाने से भी बचना होता है। ऐतिहासिक रूप से, सर्जनों को अपनी स्थानिक अंतर्ज्ञान और मानसिक विज़ुअलाइज़ेशन पर निर्भर रहना पड़ता था, यह अनुमान लगाने के लिए कि ट्यूमर हटाए जाने के बाद रोगी का मस्तिष्क कैसा दिखेगा, पिछले मामलों का विश्लेषण करके। जैसे-जैसे कृत्रिम बुद्धिमत्ता (AI) चिकित्सा क्षेत्र में प्रवेश कर गई, एक विशिष्ट समस्या उत्पन्न हुई: क्या हम सर्जनों को चीरा लगाने से पहले ही सर्जिकल परिणामों का दृश्य रूप से अनुमान लगाने और अपने उपचारों की योजना बनाने में मदद करने के लिए "प्री-ऑपरेटिव" एमआरआई से स्वचालित रूप से "पोस्ट-ऑपरेटिव" एमआरआई उत्पन्न कर सकते हैं?
पिछले दृष्टिकोणों की मौलिक सीमा—जिसने लेखकों को इस नई विधि को विकसित करने के लिए मजबूर किया—यह है कि मौजूदा जनरेटिव AI मॉडल मुख्य रूप से शैली अनुवाद के लिए डिज़ाइन किए गए थे। मानक GANs या InstructPix2Pix जैसे मॉडल अंतर्निहित संरचना को बनाए रखते हुए किसी छवि की बनावट या रंग बदलने में उत्कृष्ट होते हैं। हालांकि, मस्तिष्क सर्जरी मौलिक रूप से संरचना को नष्ट और परिवर्तित करती है। एक पोस्ट-ऑपरेटिव एमआरआई केवल शैली में भिन्न नहीं दिखता है; इसमें ऊतक का गायब होना (रिसेक्शन कैविटी), खाली जगह को भरने के लिए मस्तिष्क ऊतक का खिसकना, सूजन (एडिमा), और रक्तस्राव (हेमरेज) जैसे बड़े पैमाने पर भौतिक परिवर्तन होते हैं। पिछले मॉडल यहाँ बुरी तरह विफल रहे क्योंकि वे यह नहीं समझ सके कि इन संरचनात्मक परिवर्तनों की सीमा पूरी तरह से ट्यूमर के विशिष्ट स्थान और आकार पर निर्भर करती है। वे अक्सर यथार्थवादी सर्जिकल कैविटी के बजाय धुंधले, अस्पष्ट धब्बे उत्पन्न करते थे।
इसे हल करने के लिए, लेखकों ने कई अत्यधिक विशिष्ट अवधारणाएँ प्रस्तुत कीं। यहाँ उनका रोजमर्रा की भाषा में अर्थ दिया गया है:
- विज़ुअल इन-कॉन्टेक्स्ट लर्निंग (Visual In-Context Learning): कल्पना कीजिए कि आप अपने पिछवाड़े को फिर से मॉडल करने के लिए एक भूदृश्यकार को नियुक्त करते हैं। उन्हें केवल एक लिखित विवरण देने के बजाय, आप उन्हें एक पड़ोसी के यार्ड की "पहले और बाद" की तस्वीर दिखाते हैं जिसका लेआउट बिल्कुल वैसा ही था। AI मॉडल भी यही करता है: यह केवल खरोंच से अनुमान लगाने के बजाय, एक समान पिछली सर्जरी के दृश्य "पहले और बाद" उदाहरण को देखकर पोस्ट-सर्जरी छवि उत्पन्न करना सीखता है।
- ट्यूमर-गाइडेड रिट्रीवल (Tumor-guided Retrieval): इसे एक अत्यधिक विशिष्ट चिकित्सा मैचमेकिंग सेवा के रूप में सोचें। मस्तिष्क कैसा दिखेगा, इसका अनुमान लगाने के लिए एक सामान्य सर्जिकल नियम लागू करने के बजाय, सिस्टम पिछले रोगियों के एक विशाल डेटाबेस में खोज करता है ताकि उस रोगी को ढूंढा जा सके जिसका ट्यूमर का आकार, आकृति और स्थान वर्तमान रोगी से लगभग पूरी तरह मेल खाता है। फिर यह उस पिछले रोगी के वास्तविक सर्जिकल परिणाम को एक मार्गदर्शक ब्लूप्रिंट के रूप में उपयोग करता है।
- ट्यूमर-अवेयर प्रॉम्प्ट एडॉप्टर (Tumor-aware Prompt Adapter): इसे एक मास्टर ब्लूप्रिंट जनरेटर के रूप में मानें। यह वर्तमान रोगी की मस्तिष्क की शारीरिक रचना लेता है और मिलान किए गए पिछले रोगी से सर्जिकल छेद (रिसेक्शन क्षेत्र) को डिजिटल रूप से ओवरले करता है। यह इन दो सूचनाओं को एक स्पष्ट, गणितीय निर्देश पुस्तिका में मिश्रित करता है ताकि AI को उत्पन्न छवि में ठीक-ठीक पता चल सके कि कहाँ "काटना" है।
- डिफ्यूजन मॉडल (Diffusion Model): कल्पना कीजिए कि एक कलाकार एक कैनवास से शुरुआत करता है जो पूरी तरह से यादृच्छिक, अराजक भूरे रंग के पेंट के छींटों (शोर) से ढका हुआ है। धीरे-धीरे, कदम दर कदम, वे सावधानीपूर्वक विशिष्ट छींटों को पोंछते हैं जब तक कि एक पूरी तरह से स्पष्ट, अत्यधिक विस्तृत तस्वीर उभर न जाए। AI इसी तरह अंतिम एमआरआई उत्पन्न करता है, जो स्थैतिक से शुरू होकर इसे एक चिकित्सा छवि में परिष्कृत करता है।
यह समझने के लिए कि लेखकों ने इस समस्या को गणितीय रूप से कैसे हल किया, हमें उनके मॉडल के निर्माण के लिए उपयोग किए गए प्रमुख चर और मापदंडों को परिभाषित करने की आवश्यकता है।
| संकेतन (Notation) | प्रकार (Type) | विवरण (Description) |
|---|---|---|
| $Q_{pre}$ | चर (Variable) | क्वेरी प्री-ऑपरेटिव एमआरआई (सर्जरी से पहले वर्तमान रोगी का मस्तिष्क स्कैन)। |
| $M^{Q}_{pre}$ | चर (Variable) | क्वेरी प्री-ऑपरेटिव एमआरआई का सेगमेंटेशन मास्क (एक नक्शा जो ठीक से उजागर करता है कि ट्यूमर कहाँ है)। |
| $I_{pre}$ | चर (Variable) | डेटाबेस से प्राप्त प्री-ऑपरेटिव एमआरआई (मिलान किए गए पिछले रोगी की "पहले" छवि)। |
| $I_{post}$ | चर (Variable) | डेटाबेस से प्राप्त पोस्ट-ऑपरेटिव एमआरआई (मिलान किए गए पिछले रोगी की "बाद" छवि)। |
| $M^{I}_{pre}$ | चर (Variable) | प्राप्त प्री-ऑपरेटिव एमआरआई का सेगमेंटेशन मास्क। |
| $M^{Q}_{bbox}$ | चर (Variable) | $M^{Q}_{pre}$ से प्राप्त एक बाउंडिंग बॉक्स मास्क, जिसका उपयोग ट्यूमर क्षेत्र को अलग करने के लिए किया जाता है। |
| $Q_{comp}$ | चर (Variable) | वर्तमान रोगी की शारीरिक रचना को पिछले रोगी की सर्जिकल कैविटी के साथ मिश्रित करने वाली कंपोजिट छवि। इसकी गणना इस प्रकार की जाती है: $$Q_{comp} = M^{Q}_{bbox} \cdot I_{post} + (1 - M^{Q}_{bbox}) \cdot Q_{pre}$$ |
| $p_{comp}$ | पैरामीटर (Parameter) | कंपोजिट छवि $Q_{comp}$ से निकाला गया 1024-आयामी लेटेंट प्रतिनिधित्व। |
| $p_{seg}$ | पैरामीटर (Parameter) | प्री-ऑपरेटिव सेगमेंटेशन मास्क $M^{Q}_{pre}$ से निकाला गया 1024-आयामी लेटेंट प्रतिनिधित्व। |
| $p_{tumor}$ | पैरामीटर (Parameter) | अंतिम प्रॉम्प्ट एम्बेडिंग, जिसे $p_{comp}$ और $p_{seg}$ को जोड़कर बनाया गया है, जो डिफ्यूजन मॉडल को निर्देशित करता है। |
| $\hat{Q}_{post}$ | चर (Variable) | अंतिम उत्पन्न पोस्ट-ऑपरेटिव एमआरआई (सर्जरी परिणाम की AI की भविष्यवाणी)। |
| $x_t$ | चर (Variable) | डिफ्यूजन प्रक्रिया के दौरान एक विशिष्ट समय चरण $t$ पर शोर वाली छवि का प्रतिनिधित्व। |
| $\epsilon$ | चर (Variable) | फॉरवर्ड डिफ्यूजन प्रक्रिया के दौरान छवि में जोड़ा गया वास्तविक शोर। |
| $\epsilon_\theta$ | पैरामीटर (Parameter) | शोर भविष्यवाणी नेटवर्क (सीखने योग्य मापदंडों $\theta$ के साथ) जो शोर का अनुमान लगाने और उसे हटाने का प्रयास करता है। |
| $c$ | चर (Variable) | डिफ्यूजन मॉडल के लिए कंडीशनिंग इनपुट (इस मामले में, $c = p_{tumor}$)। |
| $L_{LDM}$ | पैरामीटर (Parameter) | डिफ्यूजन मॉडल को प्रशिक्षित करने के लिए उपयोग किया जाने वाला लॉस फ़ंक्शन, जिसे इस प्रकार परिभाषित किया गया है: $$L_{LDM} = \mathbb{E}_{x_0, \epsilon, t} \left[ \| \epsilon - \epsilon_\theta(x_t, t, c) \|^2 \right]$$ |
समस्या परिभाषा और बाधाएं
एक न्यूरोसर्जन की कल्पना करें जो एक जटिल ट्यूमर हटाने की सर्जरी से पहले रोगी के मस्तिष्क के स्कैन को देख रहा है। उन्हें यह कल्पना करने की आवश्यकता है कि सबसे सुरक्षित मार्ग की योजना बनाने के लिए ट्यूमर को काटने के बाद मस्तिष्क कैसा दिखेगा। यह पेपर ठीक उसी चुनौती से निपटता है।
प्रारंभिक बिंदु और लक्ष्य
प्रारंभिक बिंदु (इनपुट) ग्लियोब्लास्टोमा वाले रोगी का प्री-ऑपरेटिव एमआरआई स्कैन है, साथ ही एक सेगमेंटेशन मास्क भी है जो गणितीय रूप से ट्यूमर की सटीक सीमाओं को परिभाषित करता है। आइए क्वेरी प्री-ऑपरेटिव छवि को $Q_{pre}$ और उसके संबंधित ट्यूमर मास्क को $M_{pre}^Q$ के रूप में निरूपित करें। वांछित अंतिम बिंदु (आउटपुट) एक अत्यधिक यथार्थवादी, संश्लेषित पोस्ट-ऑपरेटिव एमआरआई है, जिसे $\hat{Q}_{post}$ के रूप में निरूपित किया गया है। इस उत्पन्न छवि को सर्जरी के बाद मस्तिष्क को सटीक रूप से चित्रित करना चाहिए, जिसमें उस खाली गुहा को दिखाया गया हो जहाँ ट्यूमर हुआ करता था, साथ ही प्राकृतिक पोस्ट-सर्जिकल परिवर्तन भी हों।
लेखक जिस सटीक गणितीय अंतर को पाटने की कोशिश कर रहे हैं, वह एक अत्यधिक अरैखिक संरचनात्मक परिवर्तन है। मानक छवि निर्माण मॉडल एक मैपिंग फ़ंक्शन $f(x) \rightarrow y$ सीखते हैं जो एक छवि की "शैली" को बदलता है (जैसे दिन की तस्वीर को रात की तस्वीर में बदलना)। लेकिन यहाँ, फ़ंक्शन को आभासी सर्जरी करनी चाहिए: इसे विशिष्ट पिक्सेल क्षेत्रों को हटाना चाहिए, आसपास के मस्तिष्क ऊतक के भौतिक पतन या बदलाव को मॉडल करना चाहिए, और नए सर्जिकल कलाकृतियों को पेश करना चाहिए, यह सब $M_{pre}^Q$ के स्थानिक निर्देशांकों पर सख्ती से निर्भर करता है।
कष्टदायक दुविधा
इस समस्या को हल करने की कोशिश करने वाले पिछले शोधकर्ताओं को एक क्लासिक जनरेटिव एआई दुविधा में फंसा दिया गया था: संरचनात्मक संरक्षण और संरचनात्मक संशोधन के बीच संतुलन। मानक छवि-से-छवि अनुवाद मॉडल स्रोत छवि की अंतर्निहित ज्यामिति को संरक्षित करने के लिए भारी रूप से अनुकूलित होते हैं।
यदि आप सख्त संरचनात्मक संरक्षण को लागू करते हैं, तो मॉडल केवल मस्तिष्क की बनावट को बदलता है लेकिन ट्यूमर को बरकरार रखता है - कार्य को पूरी तरह से विफल करता है। हालाँकि, यदि आप मॉडल को ट्यूमर को "हटाने" की अनुमति देने के लिए संरचनात्मक बाधाओं को शिथिल करते हैं, तो नेटवर्क अपना स्थानिक लंगर खो देता है। यह अवास्तविक मस्तिष्क एनाटॉमी को मतिभ्रम करना शुरू कर देता है या एक सटीक सर्जिकल गुहा के बजाय धुंधले, अस्पष्ट धब्बे उत्पन्न करता है। आप स्वस्थ ऊतक के उच्च-निष्ठा शारीरिक संरक्षण और ट्यूमर साइट के कट्टरपंथी संरचनात्मक संशोधन को एक साथ आसानी से प्राप्त नहीं कर सकते हैं।
कठोर दीवारें और बाधाएँ
मामलों को बदतर बनाने के लिए, लेखकों को कई क्रूर, यथार्थवादी दीवारों का सामना करना पड़ा, जो इस समस्या को अविश्वसनीय रूप से कठिन बनाती हैं:
- चरम डेटा विरलता: चिकित्सा डेटा कुख्यात रूप से दुर्लभ है। लेखक LUMIERE डेटासेट के साथ काम कर रहे हैं, जिसमें केवल 71 युग्मित प्री- और पोस्ट-ऑपरेटिव एमआरआई स्कैन शामिल हैं। इतने छोटे डेटासेट से जटिल स्थानिक विकृतियों को समझने के लिए डेटा-भूखे प्रसार मॉडल को प्रशिक्षित करना एक बहुत बड़ी बाधा है। मॉडल को एक हानि फ़ंक्शन $\mathcal{L}_{LDM} = \mathbb{E}_{x_0, \epsilon, t} \left[ \| \epsilon - \epsilon_\theta(x_t, t, c) \|^2 \right]$ का उपयोग करके जोड़े गए शोर $\epsilon$ की भविष्यवाणी करनी चाहिए, लेकिन 71 रोगियों पर ओवरफिटिंग के बिना ऐसा करना अविश्वसनीय रूप से कठिन है।
- अत्यधिक परिवर्तनशील भौतिक विकृतियाँ: पोस्ट-ऑपरेटिव एमआरआई में सिर्फ ट्यूमर की जगह एक "छेद" नहीं होता है। मस्तिष्क जटिल भौतिक परिवर्तनों से गुजरता है जिसमें ऊतक शिफ्ट (मस्तिष्क खाली जगह को भरने के लिए भौतिक रूप से चलता है), एडिमा (सूजन), और रक्तस्राव (रक्तस्राव) शामिल हैं। ये अत्यधिक परिवर्तनशील, रोगी-विशिष्ट भौतिक बाधाएँ हैं जिन्हें सरल ज्यामितीय क्रॉपिंग के साथ मॉडल नहीं किया जा सकता है।
- नैदानिक संदर्भ निर्भरता: सर्जिकल रिसेक्शन की सीमा केवल ट्यूमर मास्क का एक गणितीय ऑफसेट नहीं है। यह ट्यूमर के स्थान पर बहुत अधिक निर्भर करता है। यदि कोई ट्यूमर किसी महत्वपूर्ण मस्तिष्क क्षेत्र के पास है, तो सर्जन गंभीर जटिलताओं को रोकने के लिए अधिक ऊतक छोड़ देगा। मॉडल को स्पष्ट सर्जिकल नियमपुस्तिकाओं के बिना, केवल ट्यूमर के दृश्य स्थान और आकार से इन अदृश्य नैदानिक नियमों का अनुमान लगाना चाहिए।
इन दीवारों को बायपास करने के लिए, लेखक केवल एक मानक मॉडल को प्रशिक्षित नहीं कर सके। उन्हें एक "ट्यूमर-निर्देशित पुनर्प्राप्ति" प्रणाली का आविष्कार करना पड़ा जो एक डेटाबेस में समान आकार और स्थान वाले ट्यूमर वाले पिछले रोगी की खोज करती है, और फिर उस पिछले रोगी के पहले और बाद के स्कैन का उपयोग विज़ुअल प्रॉम्प्ट (विज़ुअल इन-कॉन्टेक्स्ट लर्निंग) के रूप में प्रसार मॉडल को सिखाने के लिए करती है कि सर्जरी कैसी दिखनी चाहिए।
यह तरीका क्यों
यह समझने के लिए कि लेखकों ने यह विशिष्ट आर्किटेक्चर क्यों बनाया, हमें पहले पारंपरिक कृत्रिम बुद्धिमत्ता द्वारा छवि अनुवाद को संभालने के मूलभूत दोष को देखना होगा। लेखकों को जिस क्षण अहसास हुआ, वह तब हुआ जब उन्होंने मौजूदा अत्याधुनिक (SOTA) जनरेटिव मॉडल—जैसे मानक जनरेटिव एडवरसैरियल नेटवर्क (GANs) या बेसिक टेक्स्ट-टू-इमेज डिफ्यूजन मॉडल—को देखा और महसूस किया कि ये सिस्टम शैली के प्रति जुनूनी थे। पारंपरिक छवि अनुवाद विधियों को स्रोत छवि की अंतर्निहित संरचना को बनाए रखते हुए उसकी बनावट को बदलने के लिए डिज़ाइन किया गया है। लेकिन मस्तिष्क सर्जरी कोई शैली हस्तांतरण नहीं है; यह एक हिंसक, भौतिक परिवर्तन है। जब एक ग्लियोब्लास्टोमा को हटाया जाता है, तो मस्तिष्क में बड़े पैमाने पर संरचनात्मक परिवर्तन होते हैं: ऊतक शिफ्ट होते हैं, एडिमा (सूजन) बनती है, और रक्तस्राव होता है।
लेखकों ने महसूस किया कि एक मानक कनवल्शनल न्यूरल नेटवर्क (CNN) या एक बेसिक डिफ्यूजन मॉडल से इन जटिल भौतिक विकृतियों का "अनुमान" लगाने के लिए कहना असंभव था। मानक मॉडल मस्तिष्क के मूल आकार को बरकरार रखने की कोशिश करेंगे, ऊतक को हटाने के वास्तविक अनुकरण में पूरी तरह से विफल रहेंगे। इसके अलावा, टेक्स्ट-गाइडेड डिफ्यूजन मॉडल (जैसे InstructPix2Pix) यहां विफल हो जाते हैं क्योंकि "ऑपरेशन के बाद ग्लियोब्लास्टोमा एमआरआई" जैसा टेक्स्ट प्रॉम्प्ट मॉडल को ठीक कहां और कितना ऊतक हटाना है, यह बताने के लिए आवश्यक घनी, उच्च-आयामी स्थानिक जानकारी का अभाव है। $150 के सामान्य फोटो संपादन फ़िल्टर के विपरीत जो पूरे चित्र पर एक समान प्रभाव लागू करता है, सर्जिकल परिणाम अत्यधिक रोगी-विशिष्ट होते हैं और पूरी तरह से ट्यूमर के अद्वितीय स्थान और आकार पर निर्भर करते हैं।
यह कठोर बाधा—अत्यधिक स्थानीयकृत, रोगी-विशिष्ट शारीरिक विकृतियों की भविष्यवाणी करने की आवश्यकता—ने एक अत्यधिक अद्वितीय समाधान के साथ "विवाह" को मजबूर किया: ट्यूमर-अवेयर विजुअल इन-कॉन्टेक्स्ट लर्निंग को ट्यूमर-गाइडेड रिट्रीवल के साथ जोड़ा गया।
न्यूरल नेटवर्क को शुरू से ही मस्तिष्क सर्जरी के भौतिकी को याद रखने के लिए मजबूर करने के बजाय, लेखकों ने एक ऐसी प्रणाली डिज़ाइन की जो उदाहरणों से सीखती है। उन्होंने एक रिट्रीवल रणनीति बनाई जो पिछले रोगियों के डेटाबेस में खोज करती है ताकि प्री- और पोस्ट-ऑपरेटिव एमआरआई जोड़ी मिल सके जहां ट्यूमर का स्थान और आकार वर्तमान रोगी से निकटता से मेल खाता हो (सेगमेंटेशन मास्क के इंटरसेक्शन ओवर यूनियन, या IoU, और एक्सियल प्लेन संरेखण का उपयोग करके मापा जाता है)।
लेकिन वास्तविक संरचनात्मक लाभ—वह कारण जिससे यह विधि पिछले स्वर्ण मानकों से अत्यधिक बेहतर है—इस बात में निहित है कि यह गणितीय रूप से इस प्राप्त ज्ञान को वर्तमान रोगी की शारीरिक रचना के साथ कैसे जोड़ती है। लेखकों ने एक "ट्यूमर-अवेयर प्रॉम्प्ट अडैप्टर" डिज़ाइन किया जो स्पष्ट रूप से मॉडल को रिसेक्शन क्षेत्र को देखने के लिए मजबूर करता है। वे इसे एक शानदार कंपोजिटिंग ऑपरेशन के माध्यम से प्राप्त करते हैं:
$$Q_{comp} = M_{bbox}^Q \cdot I_{post} + (1 - M_{bbox}^Q) \cdot Q_{pre}$$
इस समीकरण में:
* $Q_{pre}$ वर्तमान रोगी का प्री-ऑपरेटिव एमआरआई है।
* $I_{post}$ प्राप्त पिछले रोगी का पोस्ट-ऑपरेटिव एमआरआई है (विजुअल इंस्ट्रक्शन)।
* $M_{bbox}^Q$ ट्यूमर क्षेत्र को अलग करने वाला बाउंडिंग बॉक्स मास्क है।
यह गणितीय सूत्रीकरण पेपर का गुप्त इंजन है। यह प्राप्त रोगी ($I_{post}$) से वास्तविक सर्जिकल कैविटी लेता है और इसे वर्तमान रोगी के मस्तिष्क के सटीक ट्यूमर स्थान ($M_{bbox}^Q$) में निर्बाध रूप से डालता है, जबकि वर्तमान रोगी की स्वस्थ आसपास की शारीरिक रचना ($(1 - M_{bbox}^Q) \cdot Q_{pre}$) को संरक्षित करता है। यह कंपोजिट छवि, ट्यूमर सेगमेंटेशन मास्क के साथ, एक लेटेंट प्रतिनिधित्व ($p_{tumor}$) में संसाधित की जाती है और क्रॉस-अटेंशन के माध्यम से एक स्टेबल डिफ्यूजन मॉडल में इंजेक्ट की जाती है।
बेंचमार्किंग लॉजिक स्पष्ट रूप से साबित करता है कि यह दृष्टिकोण गुणात्मक रूप से बेहतर क्यों है। जब लेखकों ने मानक डिफ्यूजन-आधारित संपादन विधियों का परीक्षण किया, तो उन मॉडलों ने ट्यूमर क्षेत्र में धुंधले, अस्पष्ट धब्बे उत्पन्न किए क्योंकि उनमें स्पष्ट स्थानिक मार्गदर्शन की कमी थी। यहां तक कि अन्य विजुअल इन-कॉन्टेक्स्ट लर्निंग विधियां (जैसे ImageBrush) भी विफल रहीं क्योंकि उन्होंने यादृच्छिक विजुअल निर्देशों का उपयोग किया, जो तब बेकार है जब सर्जिकल परिणाम पूरी तरह से विशिष्ट ट्यूमर ज्यामिति पर निर्भर करते हैं। ट्यूमर के सटीक निर्देशांकों के लिए विजुअल निर्देश को स्पष्ट रूप से तैयार करके, प्रस्तावित विधि संरचनात्मक मस्तिष्क परिवर्तनों के उच्च-आयामी शोर को खूबसूरती से संभालती है, बेहतर मात्रात्मक मेट्रिक्स (जैसे 0.7001 का SSIM) प्राप्त करती है, और कुरकुरी, शारीरिक रूप से यथार्थवादी पोस्ट-ऑपरेटिव स्कैन उत्पन्न करती है जिन्हें पारंपरिक GANs और बेसिक ट्रांसफॉर्मर बस मेल नहीं खा सकते।
गणितीय और तार्किक तंत्र
यह समझने के लिए कि यह पेपर उस प्रतीत होने वाले असंभव कार्य को कैसे प्राप्त करता है, जो एक रोगी के मस्तिष्क का ट्यूमर सर्जरी के बाद कैसा दिखेगा, इसकी भविष्यवाणी करता है, हमें सिस्टम को चलाने वाले गणितीय तर्क को देखना होगा। लेखकों ने अनिवार्य रूप से चिकित्सा इमेजिंग के लिए एक टाइम मशीन बनाई है, और यह दो परस्पर जुड़े गणितीय इंजनों द्वारा संचालित है: एक स्थानिक परिवर्तन तर्क (spatial transformation logic) और एक संभाव्य जनरेटिव उद्देश्य (probabilistic generative objective)।
यहां वे पूर्ण मुख्य समीकरण दिए गए हैं जो इस पेपर को शक्ति प्रदान करते हैं:
1. ट्यूमर-जागरूक कंपोजिटिंग ट्रांसफॉर्मेशन (Tumor-Aware Compositing Transformation):
$$ \text{Q}_{\text{comp}} = \text{M}_{\text{bbox}}^{\text{Q}} \cdot \text{I}_{\text{post}} + (1 - \text{M}_{\text{bbox}}^{\text{Q}}) \cdot \text{Q}_{\text{pre}} $$
2. लेटेंट डिफ्यूजन ऑब्जेक्टिव फंक्शन (Latent Diffusion Objective Function):
$$ \mathcal{L}_{LDM} = \mathbb{E}_{x_0, \epsilon, t} \left[ \| \epsilon - \epsilon_\theta(x_t, t, c) \|^2 \right] $$
आइए इन समीकरणों को एक-एक करके तोड़ें ताकि आप देख सकें कि गियर ठीक कैसे घूमते हैं।
कंपोजिटिंग ट्रांसफॉर्मेशन का विच्छेदन
यह पहला समीकरण एक स्थानिक खाका है। यह पिछले रोगियों के सर्जिकल परिणामों को उधार लेकर भविष्य के मस्तिष्क का "फ्रैंकनस्टीन-जैसा" मसौदा बनाता है।
- $\text{Q}_{\text{comp}}$: परिणामी कंपोजिट छवि। भूमिका: यह कच्ची दृश्य निर्देश के रूप में कार्य करती है। यह AI को बताती है, "यह रोगी का स्वस्थ मस्तिष्क है, और यह मोटे तौर पर दिखता है कि ट्यूमर से बची हुई जगह कैसी दिखती है।"
- $\text{M}_{\text{bbox}}^{\text{Q}}$: क्वेरी (वर्तमान रोगी के) प्री-ऑपरेटिव एमआरआई से प्राप्त एक बाइनरी बाउंडिंग बॉक्स मास्क। भूमिका: यह एक डिजिटल कुकी कटर के रूप में कार्य करता है। यह ठीक वहीं $1$ के बराबर होता है जहां ट्यूमर स्थित है और बाकी सब जगह $0$ होता है।
- $\cdot$ (गुणा): भूमिका: यह एक पिक्सेल-वार मास्किंग ऑपरेटर है। किसी छवि को बाइनरी मास्क से गुणा करके, आप रुचि के क्षेत्र के बाहर की हर चीज को तुरंत मिटा देते हैं।
- $\text{I}_{\text{post}}$: एक अलग रोगी से प्राप्त पोस्ट-ऑपरेटिव एमआरआई जिसने समान ट्यूमर था। भूमिका: यह सर्जिकल रिसेक्शन (गुहा, ऊतक शिफ्ट, आदि) का वास्तविक दृश्य बनावट प्रदान करता है।
- $+$ (जोड़): भूमिका: यह डिजिटल गोंद के रूप में कार्य करता है। गुणा के बजाय जोड़ क्यों? क्योंकि दो मास्क—$\text{M}_{\text{bbox}}^{\text{Q}}$ और $(1 - \text{M}_{\text{bbox}}^{\text{Q}})$—आपस में विशिष्ट हैं। यदि आप उन्हें गुणा करते, तो ओवरलैपिंग क्षेत्र शून्य हो जाते और काले हो जाते। उन्हें जोड़कर, आप बिना किसी भूतियापन या ओवरलैपिंग कलाकृतियों के दो अलग-अलग छवि क्षेत्रों को पूरी तरह से एक साथ सिल देते हैं।
- $(1 - \text{M}_{\text{bbox}}^{\text{Q}})$: व्युत्क्रम मास्क। भूमिका: यह स्वस्थ मस्तिष्क क्षेत्रों में $1$ के बराबर होता है और जहां ट्यूमर है वहां $0$ होता है। यह रोगी की स्वस्थ शारीरिक रचना को प्राप्त छवि द्वारा अधिलेखित होने से बचाता है।
- $\text{Q}_{\text{pre}}$: वर्तमान रोगी का वास्तविक प्री-ऑपरेटिव एमआरआई। भूमिका: व्यक्तिगत शारीरिक पृष्ठभूमि प्रदान करता है।
डिफ्यूजन ऑब्जेक्टिव का विच्छेदन
एक बार कंपोजिट खाका बन जाने के बाद, इसे एक लेटेंट वेक्टर $c$ (पेपर में विशेष रूप से $p_{tumor}$ कहा जाता है) में संपीड़ित किया जाता है। यह वेक्टर दूसरे समीकरण को निर्देशित करता है, जो जनरेटिव AI का मस्तिष्क है।
- $\mathcal{L}_{LDM}$: लेटेंट डिफ्यूजन मॉडल लॉस। भूमिका: यह अंतिम स्कोर है जिसे मॉडल कम करने का प्रयास करता है। यह किसी छवि को डीनोइज़ करने की मॉडल की क्षमता में त्रुटि का प्रतिनिधित्व करता है।
- $\mathbb{E}_{x_0, \epsilon, t}$: मूल छवि $x_0$, जोड़ी गई शोर $\epsilon$, और समय चरण $t$ पर अपेक्षित मान। सरल योग के बजाय अपेक्षा (जो संभाव्यता वितरण पर एकीकरण का अर्थ है) क्यों? क्योंकि प्रशिक्षण के दौरान, शोर और समय चरण अनंत वितरण से लगातार नमूना लिए जाते हैं। योग में सीमित, असतत अवस्थाओं का एक सेट शामिल होगा। अपेक्षा मॉडल को औसतन सभी संभावित शोर वाले राज्यों के निरंतर परिदृश्य में त्रुटि को कम करने के लिए मजबूर करती है।
- $\epsilon$: छवि में जोड़ी गई वास्तविक, ग्राउंड-ट्रुथ गॉसियन शोर। भूमिका: लक्ष्य। यह वह है जिसे मॉडल खोजने और हटाने की कोशिश कर रहा है।
- $\epsilon_\theta$: न्यूरल नेटवर्क (एक U-Net) जो सीखने योग्य भार $\theta$ द्वारा पैरामीट्रिज्ड है। भूमिका: शोर-भविष्यवक्ता। यह एक स्थिर-भरी हुई छवि को देखता है और अनुमान लगाता है कि स्थिर कैसा दिखता है।
- $x_t$: समय चरण $t$ पर शोर वाली छवि प्रतिनिधित्व। भूमिका: दूषित कैनवास।
- $t$: वर्तमान समय चरण। भूमिका: नेटवर्क को बताता है कि छवि संदूषण प्रक्रिया में कितनी दूर है।
- $c$: कंडीशनिंग इनपुट (हमारा $p_{tumor}$ खाका)। भूमिका: स्टीयरिंग व्हील। यह नेटवर्क को छवि को डीनोइज़ करने के लिए मजबूर करता है ताकि वह सर्जिकल खाके से मेल खा सके, न कि केवल एक यादृच्छिक स्वस्थ मस्तिष्क उत्पन्न कर सके।
- $\| \dots \|^2$: L2 नॉर्म (वर्ग त्रुटि)। भूमिका: यह एक गणितीय रबर बैंड के रूप में कार्य करता है। यह बड़ी गलतियों को भारी दंडित करता है। यदि नेटवर्क शोर का गलत अनुमान लगाता है, तो इस शब्द की वर्गाकार प्रकृति त्रुटि को बढ़ा देती है, जिससे मॉडल के भार सही भविष्यवाणी की ओर हिंसक रूप से खिंच जाते हैं।
चरण-दर-चरण प्रवाह
आइए एक एकल अमूर्त डेटा बिंदु—एक रोगी के मस्तिष्क का स्कैन—का पता लगाएं क्योंकि यह इस यांत्रिक असेंबली लाइन से गुजरता है।
सबसे पहले, रोगी का प्री-ऑपरेटिव स्कैन ($\text{Q}_{\text{pre}}$) सिस्टम में प्रवेश करता है। एल्गोरिथम एक डेटाबेस खोजता है और समान ट्यूमर वाले पिछले रोगी से सर्जरी के बाद का स्कैन ($\text{I}_{\text{post}}$) प्राप्त करता है।
इसके बाद, बाउंडिंग बॉक्स मास्क ($\text{M}_{\text{bbox}}^{\text{Q}}$) एक स्टाम्प की तरह नीचे गिरता है, जो पिछले रोगी की स्कैन से सर्जिकल गुहा को काटता है। साथ ही, व्युत्क्रम मास्क वर्तमान रोगी के स्कैन में ठीक उसी जगह एक खाली छेद बनाता है जहां उनका ट्यूमर है। जोड़ ऑपरेटर इन दो टुकड़ों को लेगो ईंटों की तरह एक साथ स्नैप करता है, जिससे कंपोजिट छवि ($\text{Q}_{\text{comp}}$) बनती है।
इस कंपोजिट छवि को फिर एक छवि एन्कोडर (MedSAM) के माध्यम से निचोड़ा जाता है, जो 2D चित्र से एक सघन, 1024-आयामी गणितीय वेक्टर $c$ में परिवर्तित हो जाता है।
अब, हम डिफ्यूजन चरण में प्रवेश करते हैं। शुद्ध गॉसियन शोर ($x_T$) का एक पूरी तरह से खाली ग्रिड उत्पन्न होता है। चरण $t$ पर, U-Net ($\epsilon_\theta$) इस शोर वाले ग्रिड को देखता है। यह स्टीयरिंग वेक्टर $c$ को भी देखता है। $c$ द्वारा निर्देशित, नेटवर्क ठीक गणना करता है कि कौन से पिक्सेल "शोर" हैं और उन्हें घटाता है। यह प्रक्रिया पुनरावृत्त रूप से दोहराई जाती है। प्रत्येक चरण के साथ, स्थैतिक fades, और एक पोस्ट-ऑपरेटिव मस्तिष्क की संरचनात्मक वास्तविकता उभरती है। अंत में, चरण $t=0$ पर, शोर पूरी तरह से हटा दिया जाता है, जिससे एक प्राचीन, अनुमानित पोस्ट-ऑपरेटिव एमआरआई बच जाता है।
अनुकूलन गतिशीलता (Optimization Dynamics)
यह तंत्र वास्तव में सर्जरी की भविष्यवाणी करना कैसे सीखता है?
मॉडल एडमडब्ल्यू ऑप्टिमाइज़र (AdamW optimizer) का उपयोग करके अपने भार $\theta$ को अपडेट करता है। L2 नॉर्म द्वारा आकारित लॉस लैंडस्केप एक विशाल, बहु-आयामी कटोरे की तरह है। कटोरे के नीचे शोर की उत्तम भविष्यवाणी है। ग्रेडिएंट (इस कटोरे के गणितीय ढलान) नेटवर्क के भार को अपडेट करने की गति और दिशा निर्धारित करते हैं।
चूंकि मॉडल को $c$ पर कंडीशन किया गया है, ग्रेडिएंट विशेष रूप से मॉडल को दंडित करते हैं यदि वह सर्जिकल गुहा को अनदेखा करता है। यदि मॉडल एक ऐसा मस्तिष्क उत्पन्न करने की कोशिश करता है जहां ट्यूमर अभी भी बरकरार है, तो त्रुटि $\mathcal{L}_{LDM}$ बढ़ जाती है, और ग्रेडिएंट आक्रामक रूप से भार को रिसेक्शन ज़ोन का सम्मान करने के लिए धकेलते हैं।
इसके अलावा, लेखक क्लासिफायर-फ्री गाइडेंस (Classifier-Free Guidance) नामक एक तकनीक का उपयोग करते हैं। प्रशिक्षण के दौरान, कंडीशनिंग वेक्टर $c$ को कभी-कभी छोड़ दिया जाता है (एक खाली वेक्टर से बदल दिया जाता है)। यह मॉडल को सर्जिकल मार्गदर्शन से स्वतंत्र रूप से मस्तिष्क की शारीरिक रचना के अंतर्निहित भौतिकी को सीखने के लिए मजबूर करता है। अनुमान के दौरान, मॉडल "अनकंडीशन्ड" मस्तिष्क और "कंडीशन्ड" मस्तिष्क के बीच के अंतर की गणना करता है, और कंडीशन की दिशा में भारी विस्तार करता है। यह गति अंतिम उत्पन्न छवि को ट्यूमर-जागरूक प्रॉम्प्ट के दृश्य निर्देशों का सख्ती से पालन करने के लिए धकेलती है, जिसके परिणामस्वरूप एक अत्यधिक सटीक, रोगी-विशिष्ट पोस्ट-ऑपरेटिव एमआरआई होता है।
परिणाम, सीमाएँ और निष्कर्ष
कल्पना कीजिए कि आप एक न्यूरोसर्जन हैं जो एक ग्लियोब्लास्टोमा, एक अत्यंत आक्रामक मस्तिष्क ट्यूमर का ऑपरेशन करने वाले हैं। आपके पास एक प्री-ऑपरेटिव एमआरआई है, जो अनिवार्य रूप से ट्यूमर के अंदर रोगी के मस्तिष्क का एक 3डी मानचित्र है। आपका लक्ष्य ट्यूमर को सुरक्षित रूप से हटाना है। लेकिन कट लगाने के बाद मस्तिष्क कैसा दिखेगा? मस्तिष्क कठोर प्लास्टिक से नहीं बना है; जब आप ऊतक हटाते हैं, तो आसपास का मस्तिष्क पदार्थ खिसकता है, सूज जाता है (एडिमा), और कभी-कभी रक्तस्राव होता है। यदि हम सर्जरी शुरू होने से पहले ही एक अत्यधिक सटीक पोस्ट-ऑपरेटिव एमआरआई उत्पन्न कर सकें, तो यह सर्जिकल योजना के लिए एक बड़ा कदम होगा। जबकि पारंपरिक योजना सॉफ्टवेयर की लागत एक अस्पताल को प्रति सत्र 150 अमेरिकी डॉलर से अधिक हो सकती है, एक एआई जो पोस्ट-ऑप स्थितियों का सटीक अनुमान लगा सकता है, उन्नत सर्जिकल दूरदर्शिता को लोकतांत्रित कर सकता है।
हालांकि, मानक एआई छवि अनुवाद (जैसे घोड़े की तस्वीर को ज़ेबरा में बदलना) यहां बुरी तरह विफल हो जाता है। क्यों? क्योंकि वे मॉडल केवल एक छवि की "शैली" बदलते हैं जबकि अंतर्निहित संरचनात्मक ज्यामिति को बिल्कुल समान रखते हैं। सर्जरी मौलिक रूप से ज्यामिति को बदल देती है। एआई को ठीक से समझना चाहिए कि ट्यूमर कहां है, उसका आकार कैसा है, और ऐतिहासिक रूप से समान ट्यूमर कैसे हटाए गए हैं, यह सब सख्त शारीरिक बाधाओं का पालन करते हुए।
गणितीय समस्या और समाधान
लेखकों ने इसे एक सशर्त छवि निर्माण समस्या के रूप में तैयार किया। एक क्वेरी प्री-ऑपरेटिव एमआरआई $Q_{pre}$ को देखते हुए, लक्ष्य एक यथार्थवादी पोस्ट-ऑपरेटिव एमआरआई $\hat{Q}_{post}$ उत्पन्न करना है जो ट्यूमर को भौतिक रूप से हटाने को सटीक रूप से दर्शाता है।
इसे हल करने के लिए, उन्होंने केवल एक तंत्रिका नेटवर्क से अनुमान लगाने के लिए नहीं कहा। उन्होंने एक "विज़ुअल इन-कॉन्टेक्स्ट लर्निंग" प्रणाली का निर्माण किया जो एक चतुर पुनर्प्राप्ति तंत्र द्वारा संचालित थी। यहाँ उन्होंने इसे गणितीय और तार्किक रूप से कैसे हल किया:
-
ट्यूमर-निर्देशित पुनर्प्राप्ति: वे पिछले सर्जरी के डेटाबेस में एक ऐसे रोगी को खोजने के लिए खोज करते हैं जिसका ट्यूमर बिल्कुल उसी स्थान और आकार में हो। वे वर्तमान रोगी $M_{pre}^Q$ और पिछले रोगियों के बीच इंटरसेक्शन ओवर यूनियन (IoU) की गणना करके ऐसा करते हैं। वे सर्वोत्तम मिलान सेट पुनर्प्राप्त करते हैं: एक पिछला प्री-ऑप छवि $I_{pre}$, एक पिछला पोस्ट-ऑप छवि $I_{post}$, और उसका मास्क।
-
ट्यूमर-जागरूक प्रॉम्प्ट अडैप्टर: यह शानदार हिस्सा है। वे गणितीय रूप से पिछले रोगी के सर्जिकल परिणाम को वर्तमान रोगी के मस्तिष्क में जोड़ते हैं ताकि एक मिश्रित संकेत, $Q_{comp}$ बनाया जा सके। समीकरण है:
$$Q_{comp} = M_{bbox}^Q \cdot I_{post} + (1 - M_{bbox}^Q) \cdot Q_{pre}$$
यहां, $M_{bbox}^Q$ ट्यूमर के चारों ओर एक बाउंडिंग बॉक्स है। वे सचमुच $I_{post}$ में सर्जरी से बचे छेद को ले रहे हैं और इसे क्वेरी छवि $Q_{pre}$ में चिपका रहे हैं। यह मिश्रित छवि, सेगमेंटेशन मास्क के साथ, एक एनकोडर (MedSAM) के माध्यम से पारित की जाती है ताकि एक अव्यक्त प्रतिनिधित्व $p_{tumor}$ बनाया जा सके। -
विज़ुअल इन-कॉन्टेक्स्ट लर्निंग: वे एक स्टेबल डिफ्यूजन मॉडल का उपयोग करते हैं। वे मॉडल को $\{I_{pre}, I_{post}, Q_{pre}, B\}$ युक्त 2x2 ग्रिड फीड करते हैं, जहां $B$ एक खाली स्थान है। मॉडल का काम $B$ को $\hat{Q}_{post}$ बनाने के लिए भरना है। मॉडल हानि फ़ंक्शन को कम करके छवि को डीनोइज़ करना सीखता है:
$$L_{LDM} = \mathbb{E}_{x_0, \epsilon, t} \left[ \| \epsilon - \epsilon_\theta(x_t, t, c) \|^2 \right]$$
जहां $c$ कंडीशनिंग प्रॉम्प्ट $p_{tumor}$ है। मॉडल पिछले जोड़े ($I_{pre} \rightarrow I_{post}$) को देखता है और $Q_{pre}$ पर उसी परिवर्तन तर्क को लागू करता है।
प्रयोग वास्तुकला और "पीड़ित"
लेखकों ने केवल "सटीकता 5% बढ़ी" जैसे मेट्रिक्स सूचीबद्ध नहीं किए। उन्होंने मौजूदा अत्याधुनिक मॉडलों की कमजोरियों को निर्ममता से उजागर करने के लिए अपने प्रयोगों को आर्किटेक्ट किया। इस अध्ययन में "पीड़ित" डिफ्यूजन-आधारित छवि संपादन में भारी थे: DDPM, PBE, InstructPix2Pix, VISII, और ImageBrush।
उन्होंने कैसे साबित किया कि उनका तंत्र काम करता है? उन्होंने वास्तविक सर्जिकल गुहाओं को देखा। बेसलाइन मॉडल पूरी तरह से यह समझने में विफल रहे कि ऊतक हटा दिया गया था; उन्होंने उस स्थान पर धुंधले, अस्पष्ट धब्बे उत्पन्न किए जहां ट्यूमर हुआ करता था, अनिवार्य रूप से सर्जिकल भविष्यवाणी के प्राथमिक उद्देश्य में विफल रहे।
निश्चित, निर्विवाद प्रमाण लेखकों के एब्लेशन अध्ययन से आया। जब उन्होंने अपने "ट्यूमर-गाइडेड रिट्रीवल" को एक यादृच्छिक छवि या एक सामान्य छवि-समानता खोज के साथ बदल दिया, तो मॉडल का प्रदर्शन ध्वस्त हो गया। इसके अलावा, जब उन्होंने प्रॉम्प्ट अडैप्टर से मिश्रित छवि $Q_{comp}$ को हटा दिया, तो मॉडल ने पुनर्वसन क्षेत्र को सटीक रूप से चित्रित करने की अपनी क्षमता खो दी। इसने साबित कर दिया कि मॉडल को स्पष्ट रूप से एक "पिछला सर्जिकल छेद" खिलाना उनकी सफलता का निर्विवाद रहस्य था। ईमानदारी से कहूं तो, मुझे पूरी तरह से यकीन नहीं है कि मॉडल चरम एज मामलों को कैसे हल करता है जहां पुनर्प्राप्त बाउंडिंग बॉक्स क्वेरी के आसपास के ऊतक के साथ पूरी तरह से बेमेल हो जाता है, लेकिन डिफ्यूजन प्रक्रिया इन कलाकृतियों को खूबसूरती से सुचारू बनाती है।
भविष्य के विकास के लिए चर्चा विषय
इस शानदार नींव के आधार पर, भविष्य के अन्वेषण के लिए यहां कई रास्ते दिए गए हैं जिनके लिए गहन आलोचनात्मक सोच की आवश्यकता है:
-
2डी स्लाइस से 3डी शारीरिक स्थिरता तक: यह पेपर 2डी अक्षीय स्लाइस पर संचालित होता है। हालांकि, मानव मस्तिष्क और सर्जिकल पुनर्वसन स्वाभाविक रूप से 3डी हैं। यदि हम इसे स्लाइस-दर-स्लाइस लागू करते हैं, तो हम एक पोस्ट-ऑपरेटिव वॉल्यूम उत्पन्न करने का जोखिम उठाते हैं जिसमें ऊर्ध्वाधर निरंतरता की कमी होती है (जैसे, एक दांतेदार सर्जिकल गुहा)। हम 3डी अव्यक्त स्थानों पर संचालित करने के लिए इस विज़ुअल इन-कॉन्टेक्स्ट लर्निंग को कैसे विकसित कर सकते हैं, बिना विनाशकारी मेमोरी बॉटलनेक का सामना किए? क्या हम 3डी स्थिरता को लागू करने के लिए ऑर्थोगोनल 2डी अनुमानों का उपयोग कर सकते हैं?
-
सर्जन के इरादे का पैरामीटराइजेशन: वर्तमान मॉडल मानता है कि सर्जिकल परिणाम विशुद्ध रूप से ट्यूमर के स्थान और आकार का एक कार्य है। वास्तविकता में, पुनर्वसन की सीमा सर्जन की रणनीति से बहुत प्रभावित होती है (जैसे, मोटर फ़ंक्शन को संरक्षित करने के लिए आक्रामक कुल पुनर्वसन बनाम रूढ़िवादी बायोप्सी)। हम कंडीशनिंग वेक्टर $c$ में "सर्जन के इरादे" को गणितीय रूप से कैसे इंजेक्ट कर सकते हैं? क्या हम लक्षित पुनर्वसन मार्जिन का प्रतिनिधित्व करने वाला एक स्केलर या वेक्टर पेश कर सकते हैं?
-
आउट-ऑफ-डिस्ट्रीब्यूशन (OOD) एनाटॉमी को संभालना: पुनर्प्राप्ति तंत्र एक समान पिछले मामले को खोजने पर निर्भर करता है। जब कोई रोगी अत्यधिक दुर्लभ ट्यूमर आकारिकी या एक बड़े मध्य रेखा शिफ्ट के साथ प्रस्तुत करता है जिसका प्रशिक्षण डेटाबेस में कोई समकक्ष नहीं है तो क्या होता है? हमें चर्चा करने की आवश्यकता है कि डिफ्यूजन मॉडल चिकित्सा इमेजिंग में सुरक्षित रूप से कैसे एक्सट्रपलेशन कर सकते हैं बजाय इसके कि रोगी पर खराब मिलान वाले $I_{post}$ को मजबूर किया जाए, जिससे खतरनाक सर्जिकल गलत गणना हो सकती है।
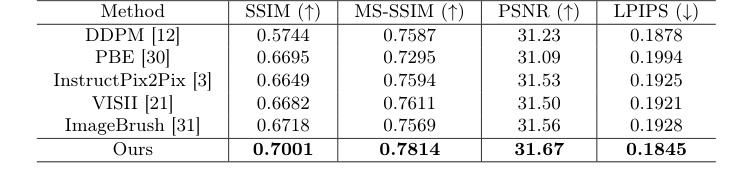 Table 1. Comparison of post-operative MRI generation results with state-of-the-art image editing methods
Table 1. Comparison of post-operative MRI generation results with state-of-the-art image editing methods
 Table 2. An ablation study on different retrieval strategies and the effectiveness of the two prompts in our tumor-aware prompt adapter. We evaluate three retrieval strategies: Random (random selection), Image-retrieval (retrieval based on cosine similarity in the image embedding space), and Ours (tumor-guided retrieval). Additionally, we assess the impact of two prompts: pseg (segmentation mask of the input pre-operative MRI) and pcomp (composite image)
Table 2. An ablation study on different retrieval strategies and the effectiveness of the two prompts in our tumor-aware prompt adapter. We evaluate three retrieval strategies: Random (random selection), Image-retrieval (retrieval based on cosine similarity in the image embedding space), and Ours (tumor-guided retrieval). Additionally, we assess the impact of two prompts: pseg (segmentation mask of the input pre-operative MRI) and pcomp (composite image)