検索ベースのビジュアルインコンテキスト学習による術前・術後MRI生成
New AI generates realistic post-op MRIs from pre-op scans, aiding brain tumor surgery.
背景と学術的系譜
Glioblastoma は、非常に攻撃的で急速に浸潤する脳腫瘍である。神経外科医にとって、その治療は極めて繊細なバランス調整を伴う。患者の予後を改善するために腫瘍を可能な限り多く摘出しなければならない一方で、重篤な術後合併症を最小限に抑えるために重要な脳領域の損傷を避けなければならない。歴史的に、外科医は自身の空間的直感と精神的視覚化に頼り、過去の症例を分析して、腫瘍摘出後の患者の脳がどのようになるかを推定する必要があった。人工知能が医療分野に進出するにつれて、特定の課題が生じた。外科医が切開を加える前に、手術結果を視覚的に予測し、治療計画を立てるのを助けるために、「術前」MRI から「術後」MRI を自動生成することは可能だろうか?
著者らがこの新しい手法を開発するに至った、以前のアプローチの根本的な限界は、既存の生成AIモデルが主に スタイル変換 のために設計されていたことである。標準的な GAN や InstructPix2Pix のようなモデルは、基盤となる構造を維持しながら、画像のテクスチャや色を変更することに優れている。しかし、脳外科手術は根本的に構造を破壊し、変化させる。術後MRIは単にスタイルが異なるだけでなく、組織の欠損(摘出腔)、空隙を埋めるための脳組織の移動、腫れ(浮腫)、出血(血腫)といった大規模な物理的変化を特徴とする。以前のモデルは、これらの構造的変化の程度が腫瘍の特定の位置と形状に完全に依存することを理解できなかったため、この点で著しく失敗した。それらはしばしば、現実的な手術腔ではなく、ぼやけた不明瞭な塊を生成した。
これを解決するために、著者はいくつかの高度に専門化された概念を導入した。以下にそれらを日常的な言葉で説明する。
- Visual In-Context Learning (視覚的コンテキスト内学習): あなたが裏庭の改築のために造園業者を雇ったと想像してほしい。単に書面での説明を与えるのではなく、全く同じ間取りの隣人の庭の、改築前と改築後の写真を見せる。AIモデルも同様のことを行う。それは、ゼロから推測するのではなく、類似した過去の手術の視覚的な「前後の」例を見ることで、術後の画像を生成する方法を学習する。
- Tumor-guided Retrieval (腫瘍誘導型検索): これは、非常に特異的な医療マッチングサービスと考えることができる。脳がどのようになるかを予測するために一般的な手術規則を適用する代わりに、システムは過去の患者の巨大なデータベースを検索し、現在の患者と腫瘍のサイズ、形状、位置がほぼ完全に一致する患者を見つける。そして、その過去の患者の実際の外科手術の結果を、ガイドとなる設計図として使用する。
- Tumor-aware Prompt Adapter (腫瘍認識プロンプトアダプター): これはマスター設計図ジェネレーターと考えることができる。現在の患者の脳の解剖学的構造を取り込み、一致した過去の患者の手術による穴(摘出領域)をデジタル的に重ね合わせる。これらの2つの情報を1つの明確な数学的な指示マニュアルにブレンドすることで、AIは生成画像でどこを「切断」すべきかを正確に把握する。
- Diffusion Model (拡散モデル): アーティストが、ランダムで混沌とした灰色の絵の具の飛沫(ノイズ)で完全に覆われたキャンバスから始めると想像してほしい。ゆっくりと、一歩一歩、特定の飛沫を注意深く拭い去り、完全に鮮明で詳細な写真が現れる。AIが最終的なMRIを生成する方法はこれであり、静止画から始めて医療画像へと洗練させていく。
著者がこの問題をどのように解決したかの数学的なメカニズムを理解するためには、モデル構築に使用された主要な変数とパラメータを定義する必要がある。
| Notations | Type | Description |
|---|---|---|
| $Q_{pre}$ | Variable | クエリの術前MRI(手術前の現在の患者の脳スキャン)。 |
| $M^{Q}_{pre}$ | Variable | クエリの術前MRIのセグメンテーションマスク(腫瘍がどこにあるかを正確に強調するマップ)。 |
| $I_{pre}$ | Variable | データベースから検索された術前MRI(一致した過去の患者の「前」の画像)。 |
| $I_{post}$ | Variable | データベースから検索された術後MRI(一致した過去の患者の「後」の画像)。 |
| $M^{I}_{pre}$ | Variable | 検索された術前MRIのセグメンテーションマスク。 |
| $M^{Q}_{bbox}$ | Variable | $M^{Q}_{pre}$ から導出されたバウンディングボックスマスク。腫瘍領域を分離するために使用される。 |
| $Q_{comp}$ | Variable | 現在の患者の解剖学的構造と過去の患者の手術腔をブレンドした複合画像。次のように計算される: $$Q_{comp} = M^{Q}_{bbox} \cdot I_{post} + (1 - M^{Q}_{bbox}) \cdot Q_{pre}$$ |
| $p_{comp}$ | Parameter | 複合画像 $Q_{comp}$ から抽出された1024次元の潜在表現。 |
| $p_{seg}$ | Parameter | 術前セグメンテーションマスク $M^{Q}_{pre}$ から抽出された1024次元の潜在表現。 |
| $p_{tumor}$ | Parameter | $p_{comp}$ と $p_{seg}$ を連結して作成された最終的なプロンプト埋め込み。拡散モデルをガイドする。 |
| $\hat{Q}_{post}$ | Variable | 最終的に生成された術後MRI(AIによる手術結果の予測)。 |
| $x_t$ | Variable | 拡散プロセス中の特定のタイムステップ $t$ におけるノイズ画像表現。 |
| $\epsilon$ | Variable | フォワード拡散プロセス中に画像に追加される実際のノイズ。 |
| $\epsilon_\theta$ | Parameter | ノイズを推測して除去しようとするノイズ予測ネットワーク(学習可能なパラメータ $\theta$ を持つ)。 |
| $c$ | Variable | 拡散モデルの条件付け入力(この場合、$c = p_{tumor}$)。 |
| $L_{LDM}$ | Parameter | 拡散モデルのトレーニングに使用される損失関数。次のように定義される: $$L_{LDM} = \mathbb{E}_{x_0, \epsilon, t} \left[ \| \epsilon - \epsilon_\theta(x_t, t, c) \|^2 \right]$$ |
問題定義と制約
術前の複雑な腫瘍切除手術を控えた患者の脳スキャンを観察する神経外科医を想像してほしい。彼らは、腫瘍を切除した後の脳がどのように見えるかを正確に視覚化し、最も安全な経路を計画する必要がある。本稿は、まさにその課題に取り組むものである。
出発点と目標
出発点(入力)は、神経膠芽腫を患う患者の術前MRIスキャンと、腫瘍の正確な境界を数学的に定義するセグメンテーションマスクである。クエリとなる術前画像を $Q_{pre}$、対応する腫瘍マスクを $M_{pre}^Q$ と表記する。望ましい終着点(出力)は、$\hat{Q}_{post}$ と表記される、非常にリアルな合成術後MRIである。この生成された画像は、手術後の脳を正確に描写し、腫瘍があった空洞、および自然な術後変化を示す必要がある。
著者らが橋渡ししようとしている正確な数学的なギャップは、高度に非線形な構造変換である。標準的な画像生成モデルは、画像の「スタイル」を変更する(昼間の写真を夜の写真に変えるような)マッピング関数 $f(x) \rightarrow y$ を学習する。しかしここでは、その関数は仮想手術を実行しなければならない。それは、特定のピクセル領域を削除し、周囲の脳組織の物理的な崩壊または移動をモデル化し、新しい手術痕を導入する必要がある。これらすべては、$M_{pre}^Q$ の空間座標に厳密に条件付けられる。
苦悩のジレンマ
この問題を解決しようとした過去の研究者たちは、構造的保存と構造的変更のトレードオフという、生成AIにおける古典的なジレンマに陥っていた。標準的な画像間翻訳モデルは、ソース画像の基盤となる幾何学的構造を保存するように高度に最適化されている。
厳密な構造的保存を強制すると、モデルは脳のテクスチャを変更するだけで腫瘍はそのまま残ってしまう—タスクの遂行には完全に失敗する。しかし、モデルが腫瘍を「除去」できるように構造的制約を緩和すると、ネットワークはその空間的アンカーを失う。非現実的な脳解剖を幻視し始めたり、正確な手術腔ではなく、ぼやけた不明瞭な塊を生成したりするようになる。健康な組織の高い忠実度での解剖学的保存と、腫瘍部位の抜本的な構造的変更を同時に容易に達成することはできない。
過酷な壁と制約
さらに悪いことに、著者らはこの問題を非常に困難にする、いくつかの過酷で現実的な壁に直面した。
- 極端なデータ疎性: 医療データは著しく不足していることで知られている。著者らは、術前・術後のMRIスキャンがペアで71例しか含まれていないLUMIEREデータセットを使用している。このようなわずかなデータセットから複雑な空間変形を理解するために、データ hungry な拡散モデルをトレーニングすることは、大きな制約である。モデルは、損失関数 $\mathcal{L}_{LDM} = \mathbb{E}_{x_0, \epsilon, t} \left[ \| \epsilon - \epsilon_\theta(x_t, t, c) \|^2 \right]$ を使用して追加されたノイズ $\epsilon$ を予測する必要があるが、71人の患者で過学習することなくこれを実行することは非常に困難である。
- 高度に変動する物理的変形: 術後MRIには、腫瘍があった場所に単なる「穴」があるだけではない。脳は、組織の移動(空隙を埋めるために脳が物理的に移動する)、浮腫(腫れ)、および出血(出血)を含む複雑な物理的変化を起こす。これらは高度に変動し、患者固有の物理的制約であり、単純な幾何学的クロッピングではモデル化できない。
- 臨床的文脈依存性: 外科的切除の範囲は、腫瘍マスクの単なる数学的なオフセットではない。それは腫瘍の位置に大きく依存する。腫瘍が重要な脳領域の近くにある場合、外科医は重篤な合併症を防ぐために、より多くの組織を残すことになる。モデルは、明示的な手術規則なしに、腫瘍の視覚的な位置と形状からのみ、これらの目に見えない臨床的規則を推測する必要がある。
これらの壁を回避するために、著者らは標準的なモデルをトレーニングするだけでは済まなかった。彼らは、「腫瘍誘導検索」システムを発明しなければならなかった。これは、データベースを検索して、同様の形状と位置の腫瘍を持つ過去の患者を見つけ、その過去の患者の術前・術後スキャンを視覚的なプロンプト(Visual In-Context Learning)として使用して、拡散モデルに手術がどのように見えるべきかを正確に教えるものである。
このアプローチの理由
著者らがこの特定のアーキテクチャを構築した理由を理解するためには、まず従来の人工知能が画像変換をどのように扱うかにおける根本的な欠陥に目を向ける必要がある。著者らがその realization に至ったのは、既存の state-of-the-art (SOTA) 生成モデル、例えば標準的な Generative Adversarial Networks (GANs) や基本的な text-to-image Diffusion モデルを見たときであり、これらのシステムが スタイル に執着していることに気づいたのである。従来の画像変換手法は、ソース画像の基盤となる構造を維持しつつ、そのテクスチャを変更するように設計されている。しかし、脳外科手術はスタイル転送ではなく、激しく物理的な変化である。神経膠芽腫が除去されると、脳は大規模な構造的変化を被る:組織の移動、浮腫(腫れ)の形成、および出血が発生する。
著者らは、標準的な Convolutional Neural Network (CNN) や基本的な Diffusion モデルに、これらの複雑な物理的変形を単に「推測」させることは不可能であると悟った。標準モデルは脳の元の形状をそのまま維持しようとし、組織除去の実際のシミュレーションに完全に失敗するだろう。さらに、テキスト誘導型拡散モデル(InstructPix2Pixなど)は、ここで失敗する。なぜなら、「術後の神経膠芽腫MRI」のようなテキストプロンプトは、モデルに 正確に どのくらいの組織をどこから除去すべきかを伝えるために必要な、高次元の密な空間情報を欠いているからである。画像全体に均一な効果を適用する一般的な150ドルの写真編集フィルターとは異なり、手術の結果は患者固有であり、腫瘍のユニークな位置と形状に完全に依存する。
この厳しい制約、すなわち、高度に局所化された患者固有の解剖学的変形を予測する必要性は、「Tumor-aware Visual In-Context Learning」と「Tumor-guided Retrieval」との「結婚」を強いた。
著者らは、ニューラルネットワークに脳外科手術の物理学を一から記憶させるのではなく、例によって学習するシステムを設計した。彼らは、過去の患者のデータベースを検索し、現在の患者と腫瘍の位置および形状が近い術前・術後MRIのペアを見つける検索戦略を構築した(これは、セグメンテーションマスクの Intersection over Union (IoU) および軸方向アライメントを用いて測定される)。
しかし、真の構造的利点、すなわちこの手法が以前のゴールドスタンダードよりも圧倒的に優れている理由は、この検索された知識を現在の患者の解剖学的構造と数学的に融合させる方法にある。著者らは、「Tumor-aware Prompt Adapter」を設計し、モデルに切除領域を明示的に見させるように強制した。彼らはこれを、見事な合成操作によって達成する:
$$Q_{comp} = M_{bbox}^Q \cdot I_{post} + (1 - M_{bbox}^Q) \cdot Q_{pre}$$
この方程式において:
* $Q_{pre}$ は現在の患者の術前MRIである。
* $I_{post}$ は検索された過去の患者の術後MRI(視覚的指示)である。
* $M_{bbox}^Q$ は腫瘍領域を分離するバウンディングボックスマスクである。
この数学的定式化が、この論文の秘密のエンジンである。それは、検索された患者の実際の外科的空洞 ($I_{post}$) を取得し、それを現在の患者の脳の正確な腫瘍位置 ($M_{bbox}^Q$) にシームレスにドロップインさせ、同時に現在の患者の健康な周囲の解剖学的構造を維持する ($(1 - M_{bbox}^Q) \cdot Q_{pre}$)。この合成画像は、腫瘍セグメンテーションマスクとともに、潜在表現 ($p_{tumor}$) に処理され、クロスアテンションを介してStable Diffusionモデルに注入される。
ベンチマーキングロジックは、このアプローチが質的に優れている理由を明確に証明している。著者らが標準的な拡散ベースの編集手法をテストしたとき、それらのモデルは腫瘍領域にぼやけた不明瞭な塊を生成した。なぜなら、それらは明示的な空間ガイダンスを欠いていたからである。他の視覚的in-context学習手法(ImageBrushなど)でさえ失敗した。なぜなら、それらはランダムな視覚的指示を使用していたからであり、これは手術の結果が特定の腫瘍形状に完全に依存する場合には無用である。腫瘍の正確な座標に視覚的指示を明示的に適合させることにより、提案手法は構造的な脳の変化による高次元ノイズを美しく処理し、優れた定量的指標(SSIM 0.7001など)を達成し、従来のGANや基本的なTransformerでは単に一致できない、鮮明で解剖学的に現実的な術後スキャンを生成する。
数学的・論理的メカニズム
この論文が、患者の腫瘍手術後の脳の様子を予測するという、一見不可能に見えるタスクをどのように達成しているのかを理解するためには、システムを駆動する数学的論理の内部を覗く必要がある。著者らは実質的に医療画像のためのタイムマシンを構築し、それは2つの相互接続された数学的エンジン、すなわち空間変換論理と確率的生成目的関数によって駆動されている。
この論文を駆動する絶対的なコア方程式は以下の通りである。
1. 腫瘍認識型コンポジット変換:
$$ \text{Q}_{\text{comp}} = \text{M}_{\text{bbox}}^{\text{Q}} \cdot \text{I}_{\text{post}} + (1 - \text{M}_{\text{bbox}}^{\text{Q}}) \cdot \text{Q}_{\text{pre}} $$
2. ラテント拡散目的関数:
$$ \mathcal{L}_{LDM} = \mathbb{E}_{x_0, \epsilon, t} \left[ \| \epsilon - \epsilon_\theta(x_t, t, c) \|^2 \right] $$
これらの数式を一つずつ分解し、歯車がどのように回るのかを正確に見ていこう。
コンポジット変換の分解
最初の数式は空間的な設計図である。これは、過去の患者の外科的結果を借りて、未来の脳の「フランケンシュタイン風」の下書きを作成する。
- $\text{Q}_{\text{comp}}$: 結果として得られる合成画像。役割: これは生の視覚的指示として機能する。AIに「ここに患者の健康な脳があり、ここに腫瘍が残した穴のおおよその様子がある」と伝える。
- $\text{M}_{\text{bbox}}^{\text{Q}}$: クエリ(現在の患者)の術前MRIから派生した二値バウンディングボックスマスク。役割: デジタルクッキーカッターとして機能する。腫瘍が存在する場所では正確に $1$ となり、それ以外の場所では $0$ となる。
- $\cdot$ (乗算): 役割: これはピクセル単位のマスキング演算子である。画像を二値マスクで乗算することにより、関心領域の外側にあるものを即座に消去する。
- $\text{I}_{\text{post}}$: 同様の腫瘍を持っていた別の患者から取得された術後MRI。役割: 外科的切除の実際の視覚的テクスチャ(空洞、組織のずれなど)を提供する。
- $+$ (加算): 役割: デジタル接着剤として機能する。なぜ乗算ではなく加算なのか? $\text{M}_{\text{bbox}}^{\text{Q}}$ と $(1 - \text{M}_{\text{bbox}}^{\text{Q}})$ という2つのマスクは相互に排他的であるためである。これらを乗算すると、重なり合う領域はゼロになり黒くなる。加算することにより、ゴーストや重なり合うアーティファクトなしに、2つの異なる画像領域を完全に縫い合わせる。
- $(1 - \text{M}_{\text{bbox}}^{\text{Q}})$: 逆マスク。役割: 健康な脳領域では $1$ となり、腫瘍がある場所では $0$ となる。取得された画像によって患者の健康な解剖学的構造が上書きされるのを防ぐ。
- $\text{Q}_{\text{pre}}$: 現在の患者の実際の術前MRI。役割: 個別化された解剖学的背景を提供する。
拡散目的関数の分解
合成設計図が作成されると、それはラテントベクトル $c$(論文では具体的に $p_{tumor}$ と呼ばれる)に圧縮される。このベクトルが、生成AIの頭脳である2番目の数式を誘導する。
- $\mathcal{L}_{LDM}$: ラテント拡散モデルの損失。役割: モデルが最小化しようとする究極のスコアである。画像のノイズ除去能力における誤差を表す。
- $\mathbb{E}_{x_0, \epsilon, t}$: 元の画像 $x_0$、追加されたノイズ $\epsilon$、およびタイムステップ $t$ に対する期待値。単純な総和ではなく、なぜ期待値(確率分布に対する積分を意味する)なのか? トレーニング中、ノイズとタイムステップは無限の分布から連続的にサンプリングされるためである。総和は有限で離散的な状態のセットを意味するだろう。期待値は、モデルが可能なノイズ状態の全連続的な風景にわたって平均的に誤差を最小化することを強制する。
- $\epsilon$: 画像に追加された実際のグラウンドトゥルースのガウスノイズ。役割: ターゲット。これはモデルが探し出して除去しようとしているものである。
- $\epsilon_\theta$: 学習可能な重み $\theta$ によってパラメータ化されたニューラルネットワーク(U-Net)。役割: ノイズ予測器。静止画で満たされた画像を見て、その静止画がどのようなものかを推測する。
- $x_t$: タイムステップ $t$ におけるノイズ画像表現。役割: 破損したキャンバス。
- $t$: 現在のタイムステップ。役割: 画像が破損プロセスのどの段階にあるかをネットワークに伝える。
- $c$: 条件付け入力(我々の $p_{tumor}$ 設計図)。役割: ハンドル。ランダムな健康な脳を生成するだけでなく、外科的設計図に一致するように画像をノイズ除去するようにネットワークを強制する。
- $\| \dots \|^2$: L2ノルム(二乗誤差)。役割: 数学的な輪ゴムとして機能する。大きな間違いを強く罰する。ネットワークがノイズを誤って推測した場合、この項の二乗性質により誤差が爆発し、モデルの重みを正しい予測に向かって激しく引き戻す。
ステップバイステップのフロー
抽象的なデータポイント(患者の脳スキャン)が、この機械的な組み立てラインをどのように通過するかを追ってみよう。
まず、患者の術前スキャン($\text{Q}_{\text{pre}}$)がシステムに入力される。アルゴリズムはデータベースを検索し、同様の腫瘍を持つ過去の患者の術後スキャン($\text{I}_{\text{post}}$)を取得する。
次に、バウンディングボックスマスク($\text{M}_{\text{bbox}}^{\text{Q}}$)がスタンプのように降りてきて、過去の患者のスキャンから外科的空洞を切り出す。同時に、逆マスクは現在の患者のスキャン上の腫瘍の位置に正確に空の穴をくり抜く。加算演算子は、これらの2つの部分をレゴブロックのようにカチッとはめ込み、合成画像($\text{Q}_{\text{comp}}$)を作成する。
この合成画像は、画像エンコーダー(MedSAM)を通して圧縮され、2D画像から密な1024次元の数学的ベクトル $c$ に変換される。
次に、拡散フェーズに入る。純粋なガウスノイズの完全に空白なグリッド($x_T$)が生成される。ステップ $t$ で、U-Net($\epsilon_\theta$)はこのノイズグリッドを見る。また、ステアリングベクトル $c$ も見る。$c$ によって誘導され、ネットワークはどのピクセルが「ノイズ」であるかを正確に計算し、それらを減算する。このプロセスは反復的に繰り返される。各ステップで、静止画は薄れ、術後脳の構造的な現実が現れる。最終的に、ステップ $t=0$ で、ノイズは完全に削り取られ、完璧な予測術後MRIが残る。
最適化ダイナミクス
このメカニズムは、実際に手術を予測することをどのように学習するのだろうか?
モデルはAdamWオプティマイザを使用して重み $\theta$ を更新する。L2ノルムによって形成される損失ランドスケープは、巨大な多次元ボウルに似ている。ボウルの底には、ノイズの完璧な予測がある。勾配(このボウルの数学的な傾斜)は、ネットワークの重みが更新される速度と方向を決定する。
モデルは $c$ によって条件付けられているため、勾配は、モデルが外科的空洞を無視した場合に特にペナルティを与える。モデルが腫瘍がまだ残っている脳を生成しようとした場合、誤差 $\mathcal{L}_{LDM}$ が急増し、勾配は切除領域を尊重するように重みを積極的にプッシュする。
さらに、著者らはClassifier-Free Guidanceと呼ばれる技術を使用している。トレーニング中、条件付けベクトル $c$ は時折ドロップされる(空のベクトルに置き換えられる)。これにより、モデルは外科的ガイダンスに依存せずに脳解剖学の基本的な物理学を学習することを強制される。推論中、モデルは「無条件」の脳と「条件付き」の脳の差を計算し、条件の方向に大きく外挿する。このダイナミクスにより、最終的な生成画像は腫瘍認識型プロンプトの視覚的指示に厳密に従うようになり、非常に正確で患者固有の術後MRIが得られる。
結果、限界と結論
神経外科医が膠芽腫、すなわち非常に悪性度の高い脳腫瘍の手術を行う場面を想像してほしい。手術前には、腫瘍を含む患者の脳の3Dマップである術前MRIが存在する。目標は腫瘍を安全に摘出することである。しかし、切開を加えた後の脳はどのように見えるだろうか?脳は硬いプラスチックでできているわけではない。組織を除去すると、周囲の脳組織はずれ、腫れ(浮腫)、時には出血も起こる。もし手術が始まる前に、術後のMRIを高精度に生成できれば、手術計画において飛躍的な進歩となるだろう。従来の計画ソフトウェアは病院にセッションあたり150米ドル以上かかる場合があるが、術後状態を正確に予測できるAIは、高度な手術予測を民主化できる可能性がある。
しかし、標準的なAI画像変換(馬の写真をシマウマに変えるようなもの)は、この問題には全く通用しない。なぜか?それらのモデルは、画像の下にある構造的な幾何学的形状を全く変えずに、画像の「スタイル」だけを変更するからである。手術は根本的に幾何学的形状を変化させる。AIは、腫瘍がどこにあり、どのような形状をしており、過去に類似の腫瘍がどのように摘出されたかを正確に理解する必要がある。同時に、厳格な解剖学的制約を遵守しなければならない。
数学的問題と解決策
著者らはこれを条件付き画像生成問題として定式化した。クエリとなる術前MRI $Q_{pre}$ が与えられたとき、腫瘍の物理的な摘出を正確に反映した、現実的な術後MRI $\hat{Q}_{post}$ を生成することが目標である。
これを解決するために、著者らはニューラルネットワークに推測させるだけではなかった。巧妙な検索メカニズムに支えられた「Visual In-Context Learning」システムを構築した。以下に、著者らが数学的かつ論理的にこれを解決した方法を示す。
-
腫瘍誘導検索 (Tumor-guided Retrieval): 過去の手術データベースを検索し、全く同じ位置と形状の腫瘍を持つ患者を見つける。これは、現在の患者のセグメンテーションマスク $M_{pre}^Q$ と過去の患者のマスクとの間のIntersection over Union (IoU) を計算することによって行われる。最も一致するセット(過去の術前画像 $I_{pre}$、過去の術後画像 $I_{post}$、およびそのマスク)を取得する。
-
腫瘍認識プロンプトアダプター (Tumor-aware Prompt Adapter): これが素晴らしい部分である。著者らは数学的に過去の患者の手術結果を現在の患者の脳に縫合し、複合的なヒント $Q_{comp}$ を作成する。その式は以下の通りである。
$$Q_{comp} = M_{bbox}^Q \cdot I_{post} + (1 - M_{bbox}^Q) \cdot Q_{pre}$$
ここで、$M_{bbox}^Q$ は腫瘍のバウンディングボックスである。彼らは文字通り $I_{post}$ における手術によって残された「穴」を取り出し、それをクエリ画像 $Q_{pre}$ に貼り付けている。この複合画像は、セグメンテーションマスクとともにエンコーダー(MedSAM)を通して潜在表現 $p_{tumor}$ を生成する。 -
Visual In-Context Learning: Stable Diffusionモデルを使用する。モデルには、$\{I_{pre}, I_{post}, Q_{pre}, B\}$ を含む2x2のグリッドを入力する。ここで $B$ は空白の領域である。モデルの仕事は、$B$ を埋めて $\hat{Q}_{post}$ を作成することである。モデルは、損失関数を最小化することによって画像のノイズ除去を学習する。
$$L_{LDM} = \mathbb{E}_{x_0, \epsilon, t} \left[ \| \epsilon - \epsilon_\theta(x_t, t, c) \|^2 \right]$$
ここで $c$ は条件付けプロンプト $p_{tumor}$ である。モデルは過去のペア ($I_{pre} \rightarrow I_{post}$) を参照し、その全く同じ変換ロジックを $Q_{pre}$ に適用する。
実験アーキテクチャと「犠牲者」
著者らは単に「精度が5%向上した」といった指標を列挙したわけではない。彼らは、既存の最先端モデルの弱点を徹底的に暴くように実験を設計した。この研究における「犠牲者」は、拡散ベースの画像編集における有力モデルであるDDPM、PBE、InstructPix2Pix、VISII、ImageBrushであった。
彼らはどのようにしてメカニズムが機能したことを証明したのか?彼らは実際の外科的腔を見た。ベースラインモデルは、組織が除去されたことを全く理解できず、腫瘍があった場所にぼやけた不明瞭な染みを作り出し、本質的に手術予測の主要な目的を達成できなかった。
決定的で否定できない証拠は、著者らのアブレーションスタディから得られた。彼らが「腫瘍誘導検索」をランダムな画像や一般的な画像類似性検索に置き換えたとき、モデルの性能は崩壊した。さらに、プロンプトアダプターから複合画像 $Q_{comp}$ を削除すると、モデルは切除領域を正確に描画する能力を失った。これは、モデルに明示的に「過去の手術の穴」を供給することが、彼らの成功の否定できない秘密であったことを証明した。正直なところ、検索されたバウンディングボックスがクエリの周囲組織と完全にずれている極端なエッジケースをモデルがどのように解決するのか完全には確信が持てないが、拡散プロセスはこのアーティファクトを美しく平滑化しているように見える。
将来的な進化のための議論トピック
この素晴らしい基盤に基づき、深い批判的思考を必要とする将来的な探求のいくつかの方向性を以下に示す。
-
2Dスライスから3D解剖学的整合性へ: この論文は2D軸断面スライスで動作する。しかし、人間の脳と外科的切除は本質的に3Dである。これをスライスごとに適用すると、垂直方向の連続性(例えば、ギザギザの手術腔)を欠く術後ボリュームを生成するリスクがある。このVisual In-Context Learningを、壊滅的なメモリボトルネックに遭遇することなく、3D潜在空間で動作するように進化させるにはどうすればよいか?3D整合性を強制するために直交2D投影を使用できるだろうか?
-
外科医の意図のパラメータ化: 現在のモデルは、手術結果が腫瘍の位置と形状のみの関数であると仮定している。実際には、切除の範囲は外科医の戦略(例えば、運動機能を温存するための積極的な全摘出対保存的生検)に大きく影響される。どうすれば数学的に「外科医の意図」を条件付けベクトル $c$ に注入できるだろうか?目標切除マージンを表すスカラーまたはベクトルを導入できるだろうか?
-
分布外 (OOD) 解剖学的構造の処理: 検索メカニズムは、類似の過去の症例を見つけることに依存している。患者が非常にまれな腫瘍形態や、トレーニングデータベースに相当するものがない大規模な正中シフトを呈する場合、どうなるだろうか?不適切な $I_{post}$ を患者に無理に適用すると危険な手術計算ミスにつながる可能性があるため、拡散モデルが医療画像で安全に外挿する方法について議論する必要がある。
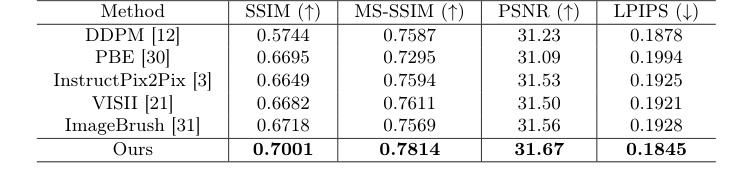 Table 1. Comparison of post-operative MRI generation results with state-of-the-art image editing methods
Table 1. Comparison of post-operative MRI generation results with state-of-the-art image editing methods
 Table 2. An ablation study on different retrieval strategies and the effectiveness of the two prompts in our tumor-aware prompt adapter. We evaluate three retrieval strategies: Random (random selection), Image-retrieval (retrieval based on cosine similarity in the image embedding space), and Ours (tumor-guided retrieval). Additionally, we assess the impact of two prompts: pseg (segmentation mask of the input pre-operative MRI) and pcomp (composite image)
Table 2. An ablation study on different retrieval strategies and the effectiveness of the two prompts in our tumor-aware prompt adapter. We evaluate three retrieval strategies: Random (random selection), Image-retrieval (retrieval based on cosine similarity in the image embedding space), and Ours (tumor-guided retrieval). Additionally, we assess the impact of two prompts: pseg (segmentation mask of the input pre-operative MRI) and pcomp (composite image)
他の体との同型
本稿の構造的骨子は、以下のように定義できる。すなわち、歴史的に類似した状態遷移を検索し、その局所的な変換規則を現在のシステムのグローバル構造とブレンドすることにより、空間的に複雑なシステムの将来の状態を予測するメカニズムである。
この数学的および論理的な骨子に基づき、科学および工学の全く異なる領域において、この問題の顕著な鏡像を特定することができる。
1. 都市災害予測(土木工学)
* 関連性: 局所的な災害(標的型地震や洪水など)とその後の破壊された建物の解体後の都市の姿を予測することは、術後のMRI生成の直接的な鏡像である。このシナリオでは、「術前のMRI」は都市の現在の衛星地図である。「腫瘍」は局所的な災害地域である。著者らが組織切除を理解するために過去の類似手術を検索するのと同様に、都市計画者は類似した地理的フットプリントを持つ別の都市の歴史的な災害を検索することができる。このモデルは、標的地域に局所的な破壊と除去(切除)を適用しつつ、周囲の被害を受けていないインフラ(解剖学的構造)を維持する。
2. 超新星残骸の進化(天体物理学)
* 関連性: 銀河内における局所的な恒星爆発の構造的後遺症を予測することは、本稿の論理と完全に鏡像関係にある。「術前」の状態は超新星前の銀河であり、「腫瘍」は死にゆく星の位置と質量である。宇宙の別の場所での歴史的に類似した超新星のデータを検索することにより、天体物理学者は局所的な空洞と衝撃波(切除領域)をモデル化しつつ、より広範で影響を受けていない銀河の腕を維持することができる。
3. 企業再編(マクロ経済学)
* 関連性: 有毒資産部門を清算した後の企業ネットワークの健全性を予測する。「術前」の画像は、企業の現在の複雑な財務依存関係の網である。「腫瘍」は、切除されなければならない失敗した部門である。類似した歴史的な破産または清算事例を検索することにより、経済学者は除去された部門によって残された局所的な構造的ギャップを予測しつつ、生き残った企業ネットワークの整合性を維持することができる。
ラディカルな「もしも」シナリオ
もし気候科学者が明日、本稿のコアコンポジット方程式を「盗んだ」らどうなるだろうか?
$$Q_{comp} = M_{bbox}^Q \cdot I_{post} + (1 - M_{bbox}^Q) \cdot Q_{pre}$$
この正確な公式を、特定の沿岸グリッドを襲うカテゴリー5のハリケーンのような局所的な気候イベントによる地理的傷跡を予測するために適用することを想像してほしい。ここでは、$Q_{pre}$は現在の沿岸地図、$M_{bbox}^Q$は嵐の影響を受ける予測ゾーン、$I_{post}$は歴史的に類似したハリケーンの余波の検索された衛星画像である。研究者は、大陸全体に対して計算負荷の高い流体力学および構造物理学シミュレーションを実行する代わりに、歴史的な局所的破壊を現在の地図にシームレスにステッチすることにより、即座に高忠実度の、嵐後の衛星画像を生成できるだろう。ブレークスルーは、嵐が上陸する前に数秒で生成されるリアルタイムで視覚的に正確な避難計画と被害推定となるだろう。
最終的に、本稿は、人間の脳から腫瘍を切除する場合であれ、大都市の災害地域を浄化する場合であれ、あるいは宇宙爆発の局所的な余波を予測する場合であれ、局所的な構造変換の数学的青写真は同一であり、構造の普遍的ライブラリにさらに深遠な章を加えることを証明している。