Генерация МРТ до и после операции с помощью визуального обучения в контексте на основе поиска
Глиобластома — это крайне агрессивная и быстро инфильтрирующая опухоль головного мозга.
Предыстория и академическое происхождение
Глиобластома — это крайне агрессивная и быстро инфильтрирующая опухоль головного мозга. Для нейрохирургов лечение глиобластомы представляет собой чрезвычайно деликатный баланс: им необходимо удалить как можно большую часть опухоли для улучшения прогноза пациента, но при этом избежать повреждения критически важных областей мозга, чтобы минимизировать тяжелые послеоперационные осложнения. Исторически хирурги полагались на собственную пространственную интуицию и ментальную визуализацию, анализируя прошлые случаи для оценки того, как будет выглядеть мозг пациента после удаления опухоли. С появлением искусственного интеллекта в медицине возникла специфическая проблема: можем ли мы автоматически генерировать "послеоперационное" МРТ-изображение из " предоперационного" МРТ-изображения, чтобы помочь хирургам визуально предсказывать результаты операций и планировать лечение еще до первого разреза?
Фундаментальным ограничением предыдущих подходов, которое побудило авторов разработать новый метод, является то, что существующие генеративные модели ИИ были в первую очередь разработаны для стилевого перевода. Модели, такие как стандартные GAN или InstructPix2Pix, отлично справляются с изменением текстуры или цвета изображения при сохранении его базовой структуры. Однако нейрохирургия фундаментально разрушает и изменяет структуру. Послеоперационное МРТ-изображение отличается не только стилем; оно демонстрирует массивные физические изменения, такие как потеря тканей (резекционная полость), смещение тканей мозга для заполнения пустоты, отек (эдема) и кровоизлияние (геморрагия). Предыдущие модели потерпели полную неудачу в этом отношении, поскольку они не могли понять, что степень этих структурных изменений полностью зависит от конкретного местоположения и формы опухоли. Часто они генерировали размытые, нечеткие пятна вместо реалистичных хирургических полостей.
Для решения этой проблемы авторы предложили несколько высокоспециализированных концепций. Вот их значение в повседневных терминах:
- Визуальное обучение в контексте (Visual In-Context Learning): Представьте, что вы наняли ландшафтного дизайнера для реконструкции вашего заднего двора. Вместо того чтобы просто дать ему письменное описание, вы показываете ему фотографию "до" и "после" двора соседа, который имел точно такую же планировку. Модель ИИ делает то же самое: она учится генерировать послеоперационное изображение, просматривая визуальный пример "до" и "после" аналогичной прошлой операции, а не просто угадывая с нуля.
- Поиск на основе опухоли (Tumor-guided Retrieval): Думайте об этом как о высокоспециализированной службе медицинского подбора. Вместо применения общего хирургического правила для предсказания того, как будет выглядеть мозг, система ищет в огромной базе данных прошлых пациентов, чтобы найти того, чьи размер, форма и расположение опухоли почти идеально соответствуют текущему пациенту. Затем она использует фактический хирургический результат этого прошлого пациента в качестве ориентировочного шаблона.
- Адаптер подсказок, учитывающий опухоль (Tumor-aware Prompt Adapter): Рассматривайте это как генератор мастер-шаблона. Он берет анатомию мозга текущего пациента и накладывает на нее цифровую хирургическую полость (область резекции) от подобранного прошлого пациента. Он объединяет эту информацию в одно четкое математическое руководство, чтобы ИИ точно знал, где "резать" на генерируемом изображении.
- Диффузионная модель (Diffusion Model): Представьте художника, начинающего с холста, полностью покрытого случайными, хаотичными брызгами серой краски (шум). Медленно, шаг за шагом, он аккуратно удаляет определенные брызги, пока не появится совершенно четкая, высокодетализированная фотография. Именно так ИИ генерирует окончательное МРТ-изображение, начиная с шума и уточняя его до медицинского изображения.
Чтобы понять математические механизмы решения этой проблемы авторами, необходимо определить ключевые переменные и параметры, которые они использовали для построения своей модели.
| Обозначение | Тип | Описание |
|---|---|---|
| $Q_{pre}$ | Переменная | Запрос предоперационного МРТ (сканирование мозга текущего пациента до операции). |
| $M^{Q}_{pre}$ | Переменная | Маска сегментации предоперационного МРТ запроса (карта, выделяющая точное местоположение опухоли). |
| $I_{pre}$ | Переменная | Предоперационное МРТ, извлеченное из базы данных (изображение "до" подобранного прошлого пациента). |
| $I_{post}$ | Переменная | Послеоперационное МРТ, извлеченное из базы данных (изображение "после" подобранного прошлого пациента). |
| $M^{I}_{pre}$ | Переменная | Маска сегментации предоперационного МРТ, извлеченного из базы данных. |
| $M^{Q}_{bbox}$ | Переменная | Маска ограничивающей рамки, полученная из $M^{Q}_{pre}$, используемая для выделения области опухоли. |
| $Q_{comp}$ | Переменная | Композитное изображение, объединяющее анатомию текущего пациента с послеоперационной полостью прошлого пациента. Рассчитывается как: $$Q_{comp} = M^{Q}_{bbox} \cdot I_{post} + (1 - M^{Q}_{bbox}) \cdot Q_{pre}$$ |
| $p_{comp}$ | Параметр | Латентное представление размерностью 1024, извлеченное из композитного изображения $Q_{comp}$. |
| $p_{seg}$ | Параметр | Латентное представление размерностью 1024, извлеченное из маски сегментации предоперационного МРТ $M^{Q}_{pre}$. |
| $p_{tumor}$ | Параметр | Окончательное эмбеддинг подсказки, созданное путем конкатенации $p_{comp}$ и $p_{seg}$, которое направляет диффузионную модель. |
| $\hat{Q}_{post}$ | Переменная | Окончательное сгенерированное послеоперационное МРТ (предсказание ИИ исхода операции). |
| $x_t$ | Переменная | Зашумленное представление изображения в определенный момент времени $t$ в процессе диффузии. |
| $\epsilon$ | Переменная | Фактический шум, добавленный к изображению в процессе прямой диффузии. |
| $\epsilon_\theta$ | Параметр | Сеть предсказания шума (с обучаемыми параметрами $\theta$), которая пытается угадать и удалить шум. |
| $c$ | Переменная | Входные данные для кондиционирования диффузионной модели (в данном случае $c = p_{tumor}$). |
| $L_{LDM}$ | Параметр | Функция потерь, используемая для обучения диффузионной модели, определяемая как: $$L_{LDM} = \mathbb{E}_{x_0, \epsilon, t} \left[ \| \epsilon - \epsilon_\theta(x_t, t, c) \|^2 \right]$$ |
Определение проблемы и ограничения
Представьте себе нейрохирурга, изучающего снимок мозга пациента перед сложной операцией по удалению опухоли. Ему необходимо точно визуализировать, как будет выглядеть мозг после удаления опухоли, чтобы спланировать самый безопасный путь. Данная статья посвящена именно этой задаче.
Исходная точка и Цель
Исходной точкой (Input) является предоперационный МРТ-снимок пациента с глиобластомой, а также маска сегментации, математически определяющая точные границы опухоли. Обозначим запрос предоперационного изображения как $Q_{pre}$, а соответствующую маску опухоли как $M_{pre}^Q$. Желаемой конечной точкой (Output) является высокореалистичный синтезированный послеоперационный МРТ, обозначенный как $\hat{Q}_{post}$. Это сгенерированное изображение должно точно отображать мозг после операции, показывая пустую полость, где раньше находилась опухоль, а также естественные послеоперационные изменения.
Точный математический разрыв, который авторы пытаются преодолеть, представляет собой высоконелинейную структурную трансформацию. Стандартные модели генерации изображений обучают функцию отображения $f(x) \rightarrow y$, которая изменяет "стиль" изображения (например, превращает дневную фотографию в ночную). Но здесь функция должна выполнять виртуальную операцию: она должна удалять определенные пиксельные области, моделировать физический коллапс или смещение окружающих тканей мозга и вводить новые хирургические артефакты, причем все это строго обусловлено пространственными координатами $M_{pre}^Q$.
Мучительная дилемма
Предыдущие исследователи, пытавшиеся решить эту проблему, оказались в ловушке классической дилеммы генеративного ИИ: компромисс между сохранением структуры и модификацией структуры. Стандартные модели преобразования "изображение в изображение" сильно оптимизированы для сохранения базовой геометрии исходного изображения.
Если вы настаиваете на строгом сохранении структуры, модель просто изменяет текстуру мозга, но оставляет опухоль нетронутой — полностью проваливая задачу. Однако, если вы ослабляете структурные ограничения, чтобы позволить модели "удалить" опухоль, сеть теряет свою пространственную привязку. Она начинает генерировать нереалистичные анатомические структуры мозга или создавать размытые, нечеткие пятна вместо точной хирургической полости. Невозможно одновременно достичь высокой точности сохранения здоровых тканей и радикальной структурной модификации опухолевого участка.
Суровые стены и ограничения
Что еще хуже, авторы столкнулись с несколькими жестокими, реалистичными препятствиями, которые делают эту проблему невероятно сложной:
- Крайняя разреженность данных: Медицинские данные известны своей скудостью. Авторы работают с набором данных LUMIERE, который содержит всего 71 пару предоперационных и послеоперационных МРТ-снимков. Обучение "голодной" к данным диффузионной модели для понимания сложных пространственных деформаций на таком крошечном наборе данных является огромным ограничением. Модель должна предсказывать добавленный шум $\epsilon$ с использованием функции потерь $\mathcal{L}_{LDM} = \mathbb{E}_{x_0, \epsilon, t} \left[ \| \epsilon - \epsilon_\theta(x_t, t, c) \|^2 \right]$, но делать это без переобучения на 71 пациенте чрезвычайно сложно.
- Высокопеременные физические деформации: Послеоперационные МРТ не просто имеют "дыру" там, где была опухоль. Мозг претерпевает сложные физические изменения, включая смещение тканей (мозг физически смещается, чтобы заполнить пустоту), отек (отек) и кровоизлияние. Это высокопеременные, специфичные для пациента физические ограничения, которые нельзя смоделировать простым геометрическим обрезанием.
- Зависимость от клинического контекста: Степень хирургической резекции — это не просто математическое смещение маски опухоли. Она сильно зависит от расположения опухоли. Если опухоль находится рядом с критически важной областью мозга, хирург оставит больше тканей, чтобы предотвратить серьезные осложнения. Модель должна каким-то образом выводить эти невидимые клинические правила только на основе визуального расположения и формы опухоли, без явных хирургических протоколов.
Чтобы обойти эти препятствия, авторы не могли просто обучить стандартную модель. Им пришлось изобрести систему "направляемого опухолью поиска" (tumor-guided retrieval), которая ищет в базе данных прошлого пациента с опухолью схожей формы и расположения, а затем использует снимки "до" и "после" этого пациента в качестве визуального запроса (Visual In-Context Learning), чтобы научить диффузионную модель точному виду операции.
Почему этот подход
Чтобы понять, почему авторы разработали именно эту архитектуру, необходимо сначала рассмотреть фундаментальный недостаток традиционных методов искусственного интеллекта при работе с преобразованием изображений. Авторы осознали его, когда изучили существующие передовые (SOTA) генеративные модели — такие как стандартные генеративно-состязательные сети (GAN) или базовые диффузионные модели преобразования текста в изображение — и поняли, что эти системы одержимы стилем. Традиционные методы преобразования изображений предназначены для сохранения базовой структуры исходного изображения при изменении его текстуры. Однако нейрохирургия — это не перенос стиля; это насильственное физическое изменение. При удалении глиобластомы мозг претерпевает массивные структурные изменения: происходит смещение тканей, образуется отек (припухлость) и возникают кровоизлияния.
Авторы поняли, что просить стандартную сверточную нейронную сеть (CNN) или базовую диффузионную модель просто "угадать" эти сложные физические деформации невозможно. Стандартные модели попытались бы сохранить исходную форму мозга неизменной, полностью провалившись в симуляции фактического удаления ткани. Более того, диффузионные модели, управляемые текстом (например, InstructPix2Pix), здесь терпят неудачу, поскольку текстовый запрос, такой как "МРТ глиобластомы после операции", не содержит плотной, высокоразмерной пространственной информации, необходимой для того, чтобы точно указать модели, где и сколько ткани следует удалить. В отличие от универсального фильтра редактирования фотографий за 150 долларов, который применяет равномерный эффект ко всему изображению, результаты хирургических вмешательств строго индивидуальны для каждого пациента и полностью зависят от уникального расположения и формы опухоли.
Это жесткое ограничение — необходимость прогнозировать высоколокализованные, специфичные для пациента анатомические деформации — вынудило "союз" с весьма уникальным решением: визуальным обучением в контексте с учетом опухоли в сочетании с извлечением информации, управляемым опухолью.
Вместо того чтобы заставлять нейронную сеть с нуля запоминать физику нейрохирургии, авторы разработали систему, которая учится на примерах. Они создали стратегию извлечения, которая ищет в базе данных прошлых пациентов пару МРТ до и после операции, где расположение и форма опухоли максимально соответствуют текущему пациенту (измеряется с использованием Intersection over Union, или IoU, масок сегментации и выравнивания в аксиальной плоскости).
Но истинное структурное преимущество — причина, по которой этот метод подавляюще превосходит предыдущие золотые стандарты — заключается в том, как он математически объединяет извлеченные знания с анатомией текущего пациента. Авторы разработали "адаптер подсказок с учетом опухоли", который явно заставляет модель обращать внимание на область резекции. Они достигают этого посредством блестящей операции композитинга:
$$Q_{comp} = M_{bbox}^Q \cdot I_{post} + (1 - M_{bbox}^Q) \cdot Q_{pre}$$
В этом уравнении:
* $Q_{pre}$ — это предоперационная МРТ текущего пациента.
* $I_{post}$ — это послеоперационная МРТ извлеченного предыдущего пациента (визуальная инструкция).
* $M_{bbox}^Q$ — это маска ограничивающей рамки, изолирующая область опухоли.
Эта математическая формулировка является секретным двигателем статьи. Она берет фактическую хирургическую полость от извлеченного пациента ($I_{post}$) и бесшовно помещает ее в точное местоположение опухоли ($M_{bbox}^Q$) мозга текущего пациента, сохраняя при этом здоровую окружающую анатомию текущего пациента ($(1 - M_{bbox}^Q) \cdot Q_{pre}$). Это составное изображение вместе с маской сегментации опухоли обрабатывается в латентное представление ($p_{tumor}$) и вводится в модель Stable Diffusion посредством перекрестного внимания.
Логика бенчмаркинга наглядно демонстрирует, почему этот подход качественно превосходит другие. Когда авторы тестировали стандартные методы редактирования на основе диффузии, эти модели генерировали размытые, нечеткие пятна в области опухоли, поскольку им не хватало явного пространственного руководства. Даже другие методы визуального обучения в контексте (например, ImageBrush) потерпели неудачу, поскольку они использовали случайные визуальные инструкции, что бесполезно, когда результаты хирургического вмешательства полностью зависят от специфической геометрии опухоли. Явно адаптируя визуальную инструкцию к точным координатам опухоли, предложенный метод прекрасно справляется с высокоразмерным шумом структурных изменений мозга, достигая превосходных количественных показателей (таких как SSIM 0.7001) и генерируя четкие, анатомически реалистичные послеоперационные снимки, которые традиционные GAN и базовые трансформеры просто не могут обеспечить.
Математический и логический механизм
Чтобы понять, как данная статья достигает, казалось бы, невозможной задачи предсказания того, как будет выглядеть мозг пациента после операции по удалению опухоли, необходимо заглянуть под капот и рассмотреть математическую логику, управляющую системой. Авторы, по сути, создали машину времени для медицинской визуализации, работающую на двух взаимосвязанных математических движках: логике пространственной трансформации и вероятностной генеративной цели.
Вот основные уравнения, лежащие в основе этой статьи:
1. Трансформация композитинга с учетом опухоли:
$$ \text{Q}_{\text{comp}} = \text{M}_{\text{bbox}}^{\text{Q}} \cdot \text{I}_{\text{post}} + (1 - \text{M}_{\text{bbox}}^{\text{Q}}) \cdot \text{Q}_{\text{pre}} $$
2. Функция потерь латентной диффузии:
$$ \mathcal{L}_{LDM} = \mathbb{E}_{x_0, \epsilon, t} \left[ \| \epsilon - \epsilon_\theta(x_t, t, c) \|^2 \right] $$
Разберем эти уравнения по частям, чтобы вы могли точно увидеть, как работают механизмы.
Деконструкция трансформации композитинга
Первое уравнение представляет собой пространственный шаблон. Оно создает "франкенштейновский" черновик будущего мозга, заимствуя результаты операций у предыдущих пациентов.
- $\text{Q}_{\text{comp}}$: Результирующее составное изображение. Роль: Действует как необработанная визуальная инструкция. Сообщает ИИ: "Вот здоровый мозг пациента, и вот примерно как выглядит полость, оставшаяся после опухоли".
- $\text{M}_{\text{bbox}}^{\text{Q}}$: Бинарная маска ограничивающей рамки, полученная из запроса (текущего пациента) предоперационного МРТ. Роль: Действует как цифровая формочка для печенья. Она равна $1$ точно там, где расположена опухоль, и $0$ везде в другом месте.
- $\cdot$ (Умножение): Роль: Оператор поэлементного маскирования. Умножая изображение на бинарную маску, вы мгновенно стираете все за пределами интересующей области.
- $\text{I}_{\text{post}}$: Полученное послеоперационное МРТ от другого пациента с аналогичной опухолью. Роль: Предоставляет фактическую визуальную текстуру хирургической резекции (полость, смещение тканей и т. д.).
- $+$ (Сложение): Роль: Действует как цифровой клей. Почему сложение, а не умножение? Потому что две маски — $\text{M}_{\text{bbox}}^{\text{Q}}$ и $(1 - \text{M}_{\text{bbox}}^{\text{Q}})$ — взаимно исключают друг друга. Если бы вы их умножили, перекрывающиеся области обнулились бы и стали черными. Складывая их, вы идеально сшиваете две различные области изображения без каких-либо артефактов призрачного изображения или наложения.
- $(1 - \text{M}_{\text{bbox}}^{\text{Q}})$: Инверсная маска. Роль: Равна $1$ в областях здорового мозга и $0$ там, где находится опухоль. Она защищает здоровую анатомию пациента от перезаписи полученным изображением.
- $\text{Q}_{\text{pre}}$: Фактическое предоперационное МРТ текущего пациента. Роль: Предоставляет персонализированный анатомический фон.
Деконструкция диффузионной цели
После создания составного шаблона он сжимается в латентный вектор $c$ (в статье он конкретно называется $p_{tumor}$). Этот вектор управляет вторым уравнением, которое является мозгом генеративного ИИ.
- $\mathcal{L}_{LDM}$: Потери латентной диффузионной модели. Роль: Это конечная оценка, которую модель пытается минимизировать. Она представляет собой ошибку в способности модели удалять шум из изображения.
- $\mathbb{E}_{x_0, \epsilon, t}$: Математическое ожидание по исходному изображению $x_0$, добавленному шуму $\epsilon$ и временному шагу $t$. Почему математическое ожидание (что подразумевает интеграл по распределениям вероятностей), а не простое суммирование? Потому что во время обучения шум и временные шаги непрерывно выбираются из бесконечных распределений. Суммирование подразумевало бы конечное, дискретное множество состояний. Математическое ожидание заставляет модель минимизировать ошибку в среднем по всему непрерывному пространству возможных зашумленных состояний.
- $\epsilon$: Фактический, истинный Гауссовский шум, добавленный к изображению. Роль: Цель. Это то, что модель пытается найти и удалить.
- $\epsilon_\theta$: Нейронная сеть (U-Net) с параметрами, определяемыми обучаемыми весами $\theta$. Роль: Предсказатель шума. Она смотрит на зашумленное изображение и угадывает, что представляет собой этот шум.
- $x_t$: Зашумленное представление изображения на временном шаге $t$. Роль: Испорченный холст.
- $t$: Текущий временной шаг. Роль: Сообщает сети, насколько далеко продвинулся процесс искажения изображения.
- $c$: Условие (наш шаблон $p_{tumor}$). Роль: Руль. Он заставляет сеть удалять шум из изображения таким образом, чтобы он соответствовал хирургическому шаблону, а не просто генерировал случайный здоровый мозг.
- $\| \dots \|^2$: L2-норма (квадрат ошибки). Роль: Действует как математическая резинка. Сильно наказывает за большие ошибки. Если сеть неправильно предсказывает шум, квадратичная природа этого члена приводит к взрывному росту ошибки, резко возвращая веса модели к правильному предсказанию.
Пошаговый поток
Проследим за одной абстрактной точкой данных — сканом мозга пациента — по мере ее движения по этой механической сборочной линии.
Сначала в систему поступает предоперационный скан пациента ($\text{Q}_{\text{pre}}$). Алгоритм ищет в базе данных и извлекает послеоперационный скан ($\text{I}_{\text{post}}$) от предыдущего пациента с аналогичной опухолью.
Затем маска ограничивающей рамки ($\text{M}_{\text{bbox}}^{\text{Q}}$) опускается как штамп, вырезая хирургическую полость из скана предыдущего пациента. Одновременно инверсная маска вырезает пустую полость в скане текущего пациента точно там, где находилась его опухоль. Оператор сложения соединяет эти две части, как детали Lego, создавая составное изображение ($\text{Q}_{\text{comp}}$).
Затем это составное изображение сжимается через энкодер изображений (MedSAM), трансформируясь из 2D-изображения в плотный математический вектор размерностью 1024 $c$.
Теперь мы вступаем в фазу диффузии. Генерируется совершенно пустая сетка чистого Гауссовского шума ($x_T$). На шаге $t$ U-Net ($\epsilon_\theta$) смотрит на эту зашумленную сетку. Она также смотрит на вектор управления $c$. Руководствуясь $c$, сеть вычисляет, какие пиксели являются "шумом", и вычитает их. Этот процесс повторяется итеративно. С каждым шагом статика исчезает, и проявляется структурная реальность послеоперационного мозга. Наконец, на шаге $t=0$, шум полностью удален, оставляя чистое, предсказанное послеоперационное МРТ.
Динамика оптимизации
Как этот механизм на самом деле учится предсказывать результаты операции?
Модель обновляет свои веса $\theta$ с помощью оптимизатора AdamW. Ландшафт потерь, сформированный L2-нормой, подобен огромной многомерной чаше. На дне чаши находится идеальное предсказание шума. Градиенты (математические наклоны этой чаши) определяют скорость и направление, в которых обновляются веса сети.
Поскольку модель обусловлена $c$, градиенты специально наказывают модель, если она игнорирует хирургическую полость. Если модель пытается сгенерировать мозг, в котором опухоль все еще присутствует, ошибка $\mathcal{L}_{LDM}$ резко возрастает, и градиенты агрессивно подталкивают веса к соблюдению зоны резекции.
Кроме того, авторы используют технику, называемую условным свободным руководством (Classifier-Free Guidance). Во время обучения вектор условия $c$ периодически отбрасывается (заменяется пустым вектором). Это заставляет модель изучать фундаментальную физику анатомии мозга независимо от хирургического руководства. Во время инференса модель вычисляет разницу между "необусловленным" мозгом и "обусловленным" мозгом и сильно экстраполирует в направлении условия. Эта динамика заставляет окончательное сгенерированное изображение строго соответствовать визуальным инструкциям запроса с учетом опухоли, что приводит к высокоточному, специфичному для пациента послеоперационному МРТ.
Результаты, ограничения и заключение
Представьте, что вы нейрохирург, готовящийся к операции по удалению глиобластомы, крайне агрессивной опухоли головного мозга. У вас есть предоперационная МРТ, которая по сути является 3D-картой мозга пациента с опухолью. Ваша цель — безопасно удалить опухоль. Но как будет выглядеть мозг после разреза? Мозг не сделан из жесткого пластика; при удалении ткани окружающее вещество мозга смещается, отекает (отек) и иногда кровоточит. Если бы мы могли получить высокоточную послеоперационную МРТ до начала операции, это стало бы огромным шагом вперед в планировании хирургического вмешательства. В то время как традиционное программное обеспечение для планирования может стоить больнице более 150 долларов США за сеанс, ИИ, способный точно предсказывать послеоперационные состояния, мог бы демократизировать передовое хирургическое предвидение.
Однако стандартный перевод изображений с помощью ИИ (например, превращение фотографии лошади в зебру) здесь терпит полную неудачу. Почему? Потому что эти модели только меняют "стиль" изображения, сохраняя при этом неизменной базовую структурную геометрию. Хирургия фундаментально изменяет геометрию. ИИ должен точно понимать, где находится опухоль, какова ее форма и как подобные опухоли удалялись в прошлом, при этом соблюдая строгие анатомические ограничения.
Математическая задача и решение
Авторы сформулировали эту задачу как задачу условной генерации изображений. Учитывая запрос на предоперационную МРТ $Q_{pre}$, цель состоит в генерации реалистичной послеоперационной МРТ $\hat{Q}_{post}$, которая точно отражает физическое удаление опухоли.
Чтобы решить эту задачу, они не просто попросили нейронную сеть угадать. Они создали систему "визуального обучения в контексте" (Visual In-Context Learning), основанную на умном механизме поиска. Вот как они решили эту задачу математически и логически:
-
Поиск, управляемый опухолью: Они ищут в базе данных прошлых операций пациента с опухолью точно такого же расположения и формы. Они делают это, вычисляя Intersection over Union (IoU) между маской сегментации текущего пациента $M_{pre}^Q$ и прошлых пациентов. Они извлекают наилучший соответствующий набор: прошлое предоперационное изображение $I_{pre}$, прошлое послеоперационное изображение $I_{post}$ и его маску.
-
Адаптер подсказки, учитывающий опухоль: Это блестящая часть. Они математически "сшивают" результат операции прошлого пациента с мозгом текущего пациента, чтобы создать составную подсказку $Q_{comp}$. Уравнение выглядит так:
$$Q_{comp} = M_{bbox}^Q \cdot I_{post} + (1 - M_{bbox}^Q) \cdot Q_{pre}$$
Здесь $M_{bbox}^Q$ — это ограничивающая рамка вокруг опухоли. Они буквально берут полость, оставшуюся после операции на $I_{post}$, и вставляют ее в изображение запроса $Q_{pre}$. Это составное изображение вместе с маской сегментации передается через энкодер (MedSAM) для создания латентного представления $p_{tumor}$. -
Визуальное обучение в контексте: Они используют модель Stable Diffusion. Они подают модели сетку 2x2, содержащую $\{I_{pre}, I_{post}, Q_{pre}, B\}$, где $B$ — пустое пространство. Задача модели — заполнить $B$, чтобы создать $\hat{Q}_{post}$. Модель учится удалять шум из изображения, минимизируя функцию потерь:
$$L_{LDM} = \mathbb{E}_{x_0, \epsilon, t} \left[ \| \epsilon - \epsilon_\theta(x_t, t, c) \|^2 \right]$$
где $c$ — это условная подсказка $p_{tumor}$. Модель смотрит на прошлую пару ($I_{pre} \rightarrow I_{post}$) и применяет ту же логику преобразования к $Q_{pre}$.
Архитектура экспериментов и "жертвы"
Авторы не просто перечислили метрики, такие как "точность улучшилась на 5%". Они спроектировали свои эксперименты так, чтобы безжалостно выявить слабости существующих SOTA-моделей. "Жертвами" в этом исследовании стали тяжеловесы в области редактирования изображений на основе диффузии: DDPM, PBE, InstructPix2Pix, VISII и ImageBrush.
Как они доказали, что их механизм работает? Они посмотрели на фактические хирургические полости. Базовые модели полностью не смогли понять, что ткань была удалена; они генерировали размытые, нечеткие пятна там, где раньше была опухоль, по сути, не выполняя основную задачу прогнозирования хирургического вмешательства.
Окончательным, неоспоримым доказательством стало исследование абляции, проведенное авторами. Когда они заменили свой "поиск, управляемый опухолью" случайным изображением или поиском по общим признакам сходства изображений, производительность модели резко упала. Более того, когда они убрали составное изображение $Q_{comp}$ из адаптера подсказки, модель потеряла способность точно рисовать область резекции. Это доказало, что явное предоставление модели "прошлой хирургической полости" было неоспоримым секретом их успеха. Честно говоря, я не до конца уверен, как модель решает крайние случаи, когда извлеченная ограничивающая рамка идеально не совпадает с окружающими тканями запроса, но диффузионный процесс, похоже, прекрасно сглаживает эти артефакты.
Темы для обсуждения в контексте дальнейшего развития
Основываясь на этом блестящем фундаменте, вот несколько направлений для будущих исследований, требующих глубокого критического осмысления:
-
От 2D-срезов к 3D-анатомической согласованности: Данная работа оперирует 2D-аксиальными срезами. Однако человеческий мозг и хирургические резекции по своей природе являются трехмерными. Если применять это по срезам, мы рискуем получить послеоперационный объем, лишенный вертикальной непрерывности (например, зазубренную хирургическую полость). Как мы можем развить это визуальное обучение в контексте для работы в 3D-латентных пространствах, не сталкиваясь с катастрофическими узкими местами памяти? Можем ли мы использовать ортогональные 2D-проекции для обеспечения 3D-согласованности?
-
Параметризация хирургического намерения: Текущая модель предполагает, что хирургический результат является исключительно функцией расположения и формы опухоли. В действительности, степень резекции в значительной степени зависит от стратегии хирурга (например, агрессивная тотальная резекция против консервативной биопсии для сохранения моторной функции). Как мы можем математически внедрить "хирургическое намерение" в вектор условия $c$? Можем ли мы ввести скаляр или вектор, представляющий целевой край резекции?
-
Обработка выбросов (Out-of-Distribution, OOD) в анатомии: Механизм поиска основан на поиске схожего прошлого случая. Что происходит, когда пациент представляет собой крайне редкую морфологию опухоли или массивный сдвиг срединной линии, не имеющий аналогов в обучающей базе данных? Нам необходимо обсудить, как диффузионные модели могут безопасно экстраполировать в медицинской визуализации, вместо того чтобы принудительно применять плохо подобранное $I_{post}$ к пациенту, что может привести к опасным хирургическим просчетам.
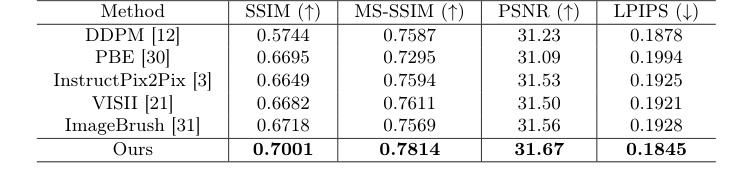 Table 1. Comparison of post-operative MRI generation results with state-of-the-art image editing methods
Table 1. Comparison of post-operative MRI generation results with state-of-the-art image editing methods
 Table 2. An ablation study on different retrieval strategies and the effectiveness of the two prompts in our tumor-aware prompt adapter. We evaluate three retrieval strategies: Random (random selection), Image-retrieval (retrieval based on cosine similarity in the image embedding space), and Ours (tumor-guided retrieval). Additionally, we assess the impact of two prompts: pseg (segmentation mask of the input pre-operative MRI) and pcomp (composite image)
Table 2. An ablation study on different retrieval strategies and the effectiveness of the two prompts in our tumor-aware prompt adapter. We evaluate three retrieval strategies: Random (random selection), Image-retrieval (retrieval based on cosine similarity in the image embedding space), and Ours (tumor-guided retrieval). Additionally, we assess the impact of two prompts: pseg (segmentation mask of the input pre-operative MRI) and pcomp (composite image)
Изоморфизмы с другими полями
В своей основе структурный каркас данной статьи можно определить как: механизм, предсказывающий будущее состояние пространственно сложной системы путем извлечения исторически аналогичного перехода состояния и смешивания его локализованных правил трансформации с глобальной структурой текущей системы.
Основываясь на этом математическом и логическом каркасе, мы можем выявить поразительные зеркальные отражения этой проблемы в совершенно различных областях науки и техники:
1. Прогнозирование стихийных бедствий в городах (Строительная инженерия)
* Связь: Прогнозирование того, как город будет выглядеть после локализованного бедствия (например, целенаправленного землетрясения или наводнения) и последующего сноса разрушенных зданий, является прямым зеркальным отражением генерации постоперационных МРТ. В этом сценарии "предоперационная МРТ" — это текущая спутниковая карта города. "Опухоль" — это зона локализованного бедствия. Подобно тому, как авторы извлекают данные о похожей прошлой операции для понимания резекции тканей, городской планировщик мог бы извлечь данные об историческом бедствии из другого города с аналогичным географическим охватом. Модель применила бы локализованное разрушение и расчистку (резекцию) к целевой зоне, сохраняя при этом окружающую неповрежденную инфраструктуру (анатомическую структуру).
2. Эволюция остатков сверхновых (Астрофизика)
* Связь: Прогнозирование структурных последствий локализованного звездного взрыва в галактике идеально отражает логику данной статьи. "Предоперационное" состояние — это галактика до сверхновой, а "опухоль" — это местоположение и масса умирающей звезды. Извлекая данные об исторически аналогичной сверхновой в другой части Вселенной, астрофизики могли бы смоделировать локализованную пустоту и ударную волну (область резекции), сохраняя при этом более широкие, неповрежденные галактические рукава.
3. Корпоративная реструктуризация (Макроэкономика)
* Связь: Прогнозирование состояния корпоративной сети после ликвидации токсичного актива. "Предоперационное" изображение — это сложная сеть текущих финансовых зависимостей компании. "Опухоль" — это терпящее крах подразделение, которое должно быть удалено. Извлекая данные о похожем историческом случае банкротства или ликвидации, экономисты могли бы предсказать локализованный структурный разрыв, оставленный удаленным подразделением, сохраняя при этом целостность оставшейся корпоративной сети.
Радикальный сценарий "Что если"
Что, если бы климатолог "украл" основное уравнение композитинга этой статьи завтра?
$$Q_{comp} = M_{bbox}^Q \cdot I_{post} + (1 - M_{bbox}^Q) \cdot Q_{pre}$$
Представьте себе применение этой точной формулы для прогнозирования географического шрамирования локализованного климатического события, такого как ураган 5-й категории, обрушивающийся на конкретную прибрежную сетку. Здесь $Q_{pre}$ — это текущая карта побережья, $M_{bbox}^Q$ — прогнозируемая зона воздействия шторма, а $I_{post}$ — извлеченное спутниковое изображение последствий исторически аналогичного урагана. Вместо выполнения вычислительно массивных симуляций гидродинамики и структурной физики для всего континента, исследователь мог бы мгновенно сгенерировать высокоточные спутниковые снимки после шторма, бесшовно вставляя исторические локализованные разрушения в текущую карту. Прорывом стало бы создание в реальном времени визуально точного плана эвакуации и оценки ущерба, генерируемого за секунды до того, как шторм вообще достигнет берега.
В конечном счете, данная статья доказывает, что независимо от того, удаляем ли мы опухоль из человеческого мозга, расчищаем зону бедствия в мегаполисе или прогнозируем локализованные последствия космического взрыва, математический план локализованной структурной трансформации остается идентичным, добавляя еще одну глубокую главу во Всеобщую Библиотеку Структур.