검색 기반 시각적 인컨텍스트 학습을 이용한 수술 전후 MRI 생성
New AI generates realistic post-op MRIs from pre-op scans, aiding brain tumor surgery.
배경 및 학문적 계보
뇌교종은 매우 공격적이고 빠르게 침윤하는 뇌종양이다. 신경외과 의사에게 이를 치료하는 것은 극도로 섬세한 균형 잡기 과정이다. 환자의 예후를 개선하기 위해 가능한 한 많은 종양을 제거해야 하지만, 심각한 수술 후 합병증을 최소화하기 위해 중요한 뇌 영역의 손상을 피해야만 한다. 역사적으로 외과 의사들은 환자의 뇌가 종양 제거 후 어떻게 보일지 추정하기 위해 과거 사례를 분석하며 자신의 공간적 직관과 정신적 시각화에 의존해야 했다. 인공지능이 의료 분야에 진입하면서 특정 문제가 대두되었다. 수술을 시작하기도 전에 수술 결과를 시각적으로 예측하고 치료 계획을 세우는 데 도움을 주기 위해, 수술 전 MRI로부터 수술 후 MRI를 자동으로 생성할 수 있을까?
저자들이 이 새로운 방법을 개발하도록 강제한 이전 접근 방식의 근본적인 한계는 기존의 생성 AI 모델이 주로 스타일 변환을 위해 설계되었다는 점이다. 표준 GAN이나 InstructPix2Pix와 같은 모델은 기본적인 구조를 유지하면서 이미지의 질감이나 색상을 변경하는 데 뛰어나다. 그러나 뇌 수술은 근본적으로 구조를 파괴하고 변경한다. 수술 후 MRI는 단순히 스타일이 다른 것이 아니라, 조직 손실(절제 부위), 빈 공간을 채우기 위해 이동하는 뇌 조직, 부기(부종), 출혈과 같은 거대한 물리적 변화를 특징으로 한다. 이전 모델들은 이러한 구조적 변화의 정도가 종양의 특정 위치와 모양에 전적으로 달려 있다는 것을 이해하지 못했기 때문에 여기서 처참하게 실패했다. 그들은 종종 현실적인 수술 부위 대신 흐릿하고 불분명한 덩어리를 생성했다.
이를 해결하기 위해 저자들은 몇 가지 고도로 전문화된 개념을 도입했다. 일상적인 용어로 그 의미는 다음과 같다.
- Visual In-Context Learning (시각적 인컨텍스트 학습): 뒷마당을 개조하기 위해 조경사를 고용했다고 상상해 보라. 단순히 서면 설명을 제공하는 대신, 레이아웃이 정확히 동일한 이웃의 마당에 대한 전후 사진을 보여준다. AI 모델도 마찬가지다. 처음부터 추측하는 대신 유사한 과거 수술의 시각적 "전후" 예시를 보고 수술 후 이미지를 생성하는 방법을 학습한다.
- Tumor-guided Retrieval (종양 안내 검색): 이것은 매우 구체적인 의료 매칭 서비스라고 생각하면 된다. 뇌가 어떻게 보일지 예측하기 위해 일반적인 수술 규칙을 적용하는 대신, 시스템은 과거 환자의 방대한 데이터베이스를 검색하여 현재 환자의 종양 크기, 모양, 위치가 거의 완벽하게 일치하는 환자를 찾는다. 그런 다음 해당 과거 환자의 실제 수술 결과를 안내 청사진으로 사용한다.
- Tumor-aware Prompt Adapter (종양 인식 프롬프트 어댑터): 이것을 마스터 청사진 생성기라고 생각하면 된다. 현재 환자의 뇌 해부학적 구조를 가져와 일치하는 과거 환자의 수술 구멍(절제 부위)을 디지털 방식으로 오버레이한다. 이 두 가지 정보를 하나의 명확한 수학적 지침 설명서로 혼합하여 AI가 생성된 이미지에서 어디를 "잘라야" 하는지 정확히 알 수 있도록 한다.
- Diffusion Model (확산 모델): 예술가가 무작위의 혼란스러운 회색 물감 얼룩(노이즈)으로 완전히 덮인 캔버스에서 시작한다고 상상해 보라. 천천히, 단계별로, 특정 얼룩을 조심스럽게 닦아내면 완벽하게 선명하고 매우 상세한 사진이 나타난다. 이것이 AI가 최종 MRI를 생성하는 방식이며, 정적에서 시작하여 의료 이미지로 정제한다.
저자들이 이 문제를 해결한 수학적 메커니즘을 이해하기 위해, 모델 구축에 사용된 주요 변수와 매개변수를 정의해야 한다.
| 표기 | 유형 | 설명 |
|---|---|---|
| $Q_{pre}$ | 변수 | 쿼리 수술 전 MRI (현재 환자의 수술 전 뇌 스캔). |
| $M^{Q}_{pre}$ | 변수 | 쿼리 수술 전 MRI의 분할 마스크 (종양이 정확히 어디에 있는지 강조하는 지도). |
| $I_{pre}$ | 변수 | 데이터베이스에서 검색된 수술 전 MRI ("이전" 이미지, 일치하는 과거 환자). |
| $I_{post}$ | 변수 | 데이터베이스에서 검색된 수술 후 MRI ("이후" 이미지, 일치하는 과거 환자). |
| $M^{I}_{pre}$ | 변수 | 검색된 수술 전 MRI의 분할 마스크. |
| $M^{Q}_{bbox}$ | 변수 | $M^{Q}_{pre}$에서 파생된 경계 상자 마스크, 종양 영역을 분리하는 데 사용됨. |
| $Q_{comp}$ | 변수 | 현재 환자의 해부학적 구조와 과거 환자의 수술 부위를 혼합한 복합 이미지. 다음과 같이 계산됨: $$Q_{comp} = M^{Q}_{bbox} \cdot I_{post} + (1 - M^{Q}_{bbox}) \cdot Q_{pre}$$ |
| $p_{comp}$ | 매개변수 | 복합 이미지 $Q_{comp}$에서 추출된 1024차원 잠재 표현. |
| $p_{seg}$ | 매개변수 | 수술 전 분할 마스크 $M^{Q}_{pre}$에서 추출된 1024차원 잠재 표현. |
| $p_{tumor}$ | 매개변수 | $p_{comp}$와 $p_{seg}$를 연결하여 생성된 최종 프롬프트 임베딩으로, 확산 모델을 안내함. |
| $\hat{Q}_{post}$ | 변수 | 최종 생성된 수술 후 MRI (AI의 수술 결과 예측). |
| $x_t$ | 변수 | 확산 과정 중 특정 시간 단계 $t$에서의 노이즈 이미지 표현. |
| $\epsilon$ | 변수 | 순방향 확산 과정 중 이미지에 추가된 실제 노이즈. |
| $\epsilon_\theta$ | 매개변수 | 노이즈를 추측하고 제거하려는 노이즈 예측 네트워크 (학습 가능한 매개변수 $\theta$ 포함). |
| $c$ | 변수 | 확산 모델의 조건 입력 (이 경우, $c = p_{tumor}$). |
| $L_{LDM}$ | 매개변수 | 확산 모델 학습에 사용되는 손실 함수. 다음과 같이 정의됨: $$L_{LDM} = \mathbb{E}_{x_0, \epsilon, t} \left[ \| \epsilon - \epsilon_\theta(x_t, t, c) \|^2 \right]$$ |
문제 정의 및 제약 조건
신경외과 의사가 복잡한 종양 제거 수술을 앞두고 환자의 뇌 스캔을 보고 있다고 상상해 보자. 그들은 가장 안전한 경로를 계획하기 위해 종양이 제거된 후 뇌가 어떻게 보일지 정확하게 시각화해야 한다. 본 논문은 바로 이러한 과제를 다룬다.
시작점과 목표
시작점(Input)은 교모세포종 환자의 수술 전 MRI 스캔과 종양의 정확한 경계를 수학적으로 정의하는 분할 마스크이다. 쿼리 수술 전 이미지를 $Q_{pre}$로, 해당 종양 마스크를 $M_{pre}^Q$로 표기한다. 원하는 종착점(Output)은 $\hat{Q}_{post}$로 표기되는 매우 사실적인 합성 수술 후 MRI이다. 이 생성된 이미지는 수술 후 뇌를 정확하게 묘사해야 하며, 종양이 있던 빈 공간과 자연스러운 수술 후 변화를 보여야 한다.
저자들이 해결하려는 정확한 수학적 간극은 매우 비선형적인 구조적 변환이다. 표준 이미지 생성 모델은 이미지의 "스타일"을 변경하는(예: 낮 사진을 밤 사진으로 바꾸는) 매핑 함수 $f(x) \rightarrow y$를 학습한다. 하지만 여기서는 이 함수가 가상 수술을 수행해야 한다. 즉, 특정 픽셀 영역을 삭제하고, 주변 뇌 조직의 물리적 붕괴 또는 이동을 모델링하며, $M_{pre}^Q$의 공간 좌표에 엄격하게 조건화된 새로운 수술 흔적을 도입해야 한다.
고통스러운 딜레마
이 문제를 해결하려 했던 이전 연구자들은 구조적 보존과 구조적 수정 간의 상충 관계라는 고전적인 생성 AI 딜레마에 빠져 있었다. 표준 이미지 대 이미지 변환 모델은 소스 이미지의 기본 기하학적 구조를 보존하도록 중점적으로 최적화된다.
엄격한 구조적 보존을 강제하면 모델은 뇌의 질감만 변경하고 종양은 그대로 남겨두어 작업을 완전히 실패하게 된다. 그러나 종양을 "제거"할 수 있도록 구조적 제약을 완화하면 네트워크는 공간적 앵커를 잃게 된다. 비현실적인 뇌 해부학을 환각하거나 정확한 수술 공동 대신 흐릿하고 불분명한 덩어리를 생성하기 시작한다. 건강한 조직의 고충실도 해부학적 보존과 종양 부위의 급격한 구조적 수정이라는 두 가지를 동시에 쉽게 달성할 수 없다.
가혹한 벽과 제약
설상가상으로 저자들은 이 문제를 극도로 어렵게 만드는 몇 가지 잔인하고 현실적인 벽에 부딪혔다.
- 극심한 데이터 희소성: 의료 데이터는 악명 높게 부족하다. 저자들은 71개의 수술 전후 MRI 스캔 쌍만 포함하는 LUMIERE 데이터셋을 사용하고 있다. 이렇게 작은 데이터셋에서 복잡한 공간 변형을 이해하도록 데이터에 굶주린 확산 모델을 훈련시키는 것은 엄청난 제약이다. 모델은 손실 함수 $\mathcal{L}_{LDM} = \mathbb{E}_{x_0, \epsilon, t} \left[ \| \epsilon - \epsilon_\theta(x_t, t, c) \|^2 \right]$를 사용하여 추가된 노이즈 $\epsilon$을 예측해야 하지만, 71명의 환자에게 과적합되지 않고 이를 수행하는 것은 매우 어렵다.
- 매우 가변적인 물리적 변형: 수술 후 MRI는 단순히 종양이 있던 "구멍"만 있는 것이 아니다. 뇌는 조직 이동(뇌가 빈 공간을 채우기 위해 물리적으로 이동), 부종(붓기), 출혈(출혈)을 포함한 복잡한 물리적 변화를 겪는다. 이러한 변화는 단순한 기하학적 자르기로 모델링할 수 없는 매우 가변적이고 환자 특유의 물리적 제약이다.
- 임상 맥락 의존성: 수술적 절제의 정도는 단순히 종양 마스크의 수학적 오프셋이 아니다. 이는 종양의 위치에 크게 좌우된다. 종양이 중요한 뇌 영역 근처에 있다면, 심각한 합병증을 예방하기 위해 외과의사는 더 많은 조직을 남겨둘 것이다. 모델은 명시적인 수술 규칙 없이 종양의 시각적 위치와 모양만으로 이러한 보이지 않는 임상 규칙을 추론해야 한다.
이러한 벽을 우회하기 위해 저자들은 표준 모델을 훈련시키는 것만으로는 충분하지 않았다. 그들은 데이터베이스에서 모양과 위치가 유사한 종양을 가진 과거 환자를 검색하는 "종양 안내 검색" 시스템을 발명해야 했고, 그런 다음 해당 과거 환자의 수술 전후 스캔을 시각적 프롬프트(Visual In-Context Learning)로 사용하여 확산 모델에 수술이 어떻게 보여야 하는지 정확하게 가르쳤다.
이 접근 방식은 왜
저자들이 이 특정 아키텍처를 구축한 이유를 이해하기 위해서는 먼저 전통적인 인공지능이 이미지 변환을 처리하는 방식의 근본적인 결함을 살펴봐야 한다. 저자들이 깨달음을 얻은 결정적인 순간은 기존의 최첨단(SOTA) 생성 모델, 즉 표준 생성적 적대 신경망(GAN)이나 기본적인 텍스트-이미지 확산 모델을 살펴보고 이러한 시스템이 스타일에 집착한다는 것을 깨달았을 때였다. 전통적인 이미지 변환 방법은 질감을 변경하면서 원본 이미지의 기본 구조를 보존하도록 설계되었다. 하지만 뇌 수술은 스타일 전이가 아니라 폭력적이고 물리적인 변형이다. 교모세포종이 제거될 때 뇌는 조직 이동, 부종(붓기) 형성, 출혈 발생과 같은 엄청난 구조적 변화를 겪는다.
저자들은 표준 합성곱 신경망(CNN)이나 기본적인 확산 모델에게 이러한 복잡한 물리적 변형을 단순히 "추측"하도록 요청하는 것이 불가능하다는 것을 깨달았다. 표준 모델은 뇌의 원래 모양을 그대로 유지하려고 시도하여 실제 조직 제거를 시뮬레이션하는 데 완전히 실패할 것이다. 더욱이, "수술 후 교모세포종 MRI"와 같은 텍스트 프롬프트는 모델에 정확히 어디에서 얼마나 많은 조직을 제거해야 하는지를 알려주는 데 필요한 조밀하고 고차원적인 공간 정보가 부족하기 때문에 텍스트 기반 확산 모델(InstructPix2Pix와 같은)은 여기서 실패한다. 이미지 전체에 균일한 효과를 적용하는 일반적인 150달러짜리 사진 편집 필터와 달리, 수술 결과는 환자마다 매우 다르며 종양의 고유한 위치와 모양에 전적으로 의존한다.
이러한 엄격한 제약 조건, 즉 매우 국소적이고 환자별 해부학적 변형을 예측해야 하는 필요성은 매우 독특한 해결책과의 "결합"을 강요했다: 종양 인식 시각적 인컨텍스트 학습(Tumor-aware Visual In-Context Learning)과 종양 안내 검색(Tumor-guided Retrieval)의 결합.
신경망이 뇌 수술의 물리학을 처음부터 암기하도록 강요하는 대신, 저자들은 예시를 통해 학습하는 시스템을 설계했다. 그들은 과거 환자 데이터베이스를 검색하여 현재 환자와 종양의 위치 및 모양이 매우 유사한 수술 전후 MRI 쌍을 찾는 검색 전략을 구축했다(분할 마스크의 IoU(Intersection over Union) 및 축 방향 정렬을 사용하여 측정).
하지만 진정한 구조적 이점, 즉 이 방법이 이전의 골드 스탠더드보다 압도적으로 우수한 이유는 검색된 지식을 현재 환자의 해부학과 수학적으로 융합하는 방식에 있다. 저자들은 모델이 절제 부위를 명시적으로 보도록 강제하는 "종양 인식 프롬프트 어댑터(Tumor-aware Prompt Adapter)"를 설계했다. 그들은 다음과 같은 훌륭한 합성 연산을 통해 이를 달성한다.
$$Q_{comp} = M_{bbox}^Q \cdot I_{post} + (1 - M_{bbox}^Q) \cdot Q_{pre}$$
이 방정식에서:
* $Q_{pre}$는 현재 환자의 수술 전 MRI이다.
* $I_{post}$는 검색된 과거 환자의 수술 후 MRI(시각적 지침)이다.
* $M_{bbox}^Q$는 종양 영역을 분리하는 경계 상자 마스크이다.
이 수학적 공식은 논문의 비밀 엔진이다. 이는 검색된 환자의 실제 수술 공동($I_{post}$)을 현재 환자의 뇌에 있는 정확한 종양 위치($M_{bbox}^Q$)에 비정상적으로 삽입하고, 현재 환자의 건강한 주변 해부학적 구조를 보존한다($(1 - M_{bbox}^Q) \cdot Q_{pre}$). 이 합성 이미지와 종양 분할 마스크는 잠재 표현($p_{tumor}$)으로 처리되어 교차 주의를 통해 Stable Diffusion 모델에 주입된다.
벤치마킹 논리는 이 접근 방식이 왜 질적으로 우수한지를 명확하게 증명한다. 저자들이 표준 확산 기반 편집 방법을 테스트했을 때, 해당 모델은 명시적인 공간 안내가 부족했기 때문에 종양 영역에서 흐릿하고 불분명한 덩어리를 생성했다. 다른 시각적 인컨텍스트 학습 방법(ImageBrush와 같은)조차도 실패했는데, 이는 수술 결과가 특정 종양 기하학에 전적으로 의존할 때 쓸모없는 무작위 시각적 지침을 사용했기 때문이다. 종양의 정확한 좌표에 시각적 지침을 명시적으로 맞춤으로써, 제안된 방법은 구조적 뇌 변화의 고차원적인 노이즈를 아름답게 처리하며, 우수한 정량적 지표(0.7001의 SSIM과 같은)를 달성하고, 전통적인 GAN 및 기본 트랜스포머로는 단순히 일치시킬 수 없는 선명하고 해부학적으로 현실적인 수술 후 스캔을 생성한다.
수학 및 논리 메커니즘
이 논문이 종양 수술 후 환자의 뇌가 어떻게 보일지 예측하는, 언뜻 불가능해 보이는 작업을 어떻게 달성하는지 이해하기 위해서는 시스템을 구동하는 수학적 논리를 살펴보아야 한다. 저자들은 본질적으로 의료 영상 분야의 타임머신을 구축했으며, 이는 두 개의 상호 연결된 수학적 엔진, 즉 공간 변환 논리와 확률론적 생성 목표에 의해 구동된다.
이 논문을 구동하는 핵심 방정식은 다음과 같다.
1. 종양 인지 합성 변환 (Tumor-Aware Compositing Transformation):
$$ \text{Q}_{\text{comp}} = \text{M}_{\text{bbox}}^{\text{Q}} \cdot \text{I}_{\text{post}} + (1 - \text{M}_{\text{bbox}}^{\text{Q}}) \cdot \text{Q}_{\text{pre}} $$
2. 잠재 확산 목표 함수 (Latent Diffusion Objective Function):
$$ \mathcal{L}_{LDM} = \mathbb{E}_{x_0, \epsilon, t} \left[ \| \epsilon - \epsilon_\theta(x_t, t, c) \|^2 \right] $$
기어들이 어떻게 돌아가는지 정확히 볼 수 있도록 이 방정식들을 하나씩 분해해 보자.
합성 변환의 분해
첫 번째 방정식은 공간적 청사진이다. 이는 과거 환자들의 수술 결과를 차용하여 미래 뇌의 "프랑켄슈타인과 같은" 초안을 생성한다.
- $\text{Q}_{\text{comp}}$: 결과 합성 이미지. 역할: 이는 원시 시각적 지침으로 작용한다. AI에게 "이것이 환자의 건강한 뇌이고, 종양으로 인한 구멍이 대략 이런 모습이다"라고 알려준다.
- $\text{M}_{\text{bbox}}^{\text{Q}}$: 현재 환자의 수술 전 MRI에서 파생된 이진 바운딩 박스 마스크. 역할: 이는 디지털 쿠키 커터 역할을 한다. 종양이 위치한 곳에서는 정확히 $1$이고, 다른 모든 곳에서는 $0$이다.
- $\cdot$ (곱셈): 역할: 이는 픽셀 단위 마스킹 연산자이다. 이미지에 이진 마스크를 곱하면 관심 영역 외부의 모든 것이 즉시 지워진다.
- $\text{I}_{\text{post}}$: 유사한 종양을 앓았던 다른 환자의 수술 후 MRI. 역할: 이는 수술 절제(구멍, 조직 이동 등)의 실제 시각적 질감을 제공한다.
- $+$ (덧셈): 역할: 이는 디지털 접착제 역할을 한다. 곱셈 대신 덧셈을 사용하는 이유는? $\text{M}_{\text{bbox}}^{\text{Q}}$와 $(1 - \text{M}_{\text{bbox}}^{\text{Q}})$라는 두 마스크는 상호 배타적이기 때문이다. 만약 이들을 곱하면 겹치는 영역이 0이 되어 검게 변할 것이다. 이들을 더함으로써 두 개의 서로 다른 이미지 영역을 고스팅이나 중첩 아티팩트 없이 완벽하게 이어 붙인다.
- $(1 - \text{M}_{\text{bbox}}^{\text{Q}})$: 역 마스크. 역할: 건강한 뇌 영역에서는 $1$이고, 종양이 있는 곳에서는 $0$이다. 이는 환자의 건강한 해부학적 구조가 검색된 이미지로 덮어쓰여지는 것을 방지한다.
- $\text{Q}_{\text{pre}}$: 현재 환자의 실제 수술 전 MRI. 역할: 개인화된 해부학적 배경을 제공한다.
확산 목표의 분해
합성 청사진이 만들어지면, 이는 잠재 벡터 $c$(논문에서는 $p_{tumor}$라고 구체적으로 명명됨)로 압축된다. 이 벡터는 생성 AI의 핵심인 두 번째 방정식을 조종한다.
- $\mathcal{L}_{LDM}$: 잠재 확산 모델 손실. 역할: 이는 모델이 최소화하려는 궁극적인 점수이다. 이는 이미지의 노이즈 제거 능력에서의 오류를 나타낸다.
- $\mathbb{E}_{x_0, \epsilon, t}$: 원본 이미지 $x_0$, 추가된 노이즈 $\epsilon$, 그리고 시간 단계 $t$에 대한 기댓값. 단순 합산 대신 기댓값(확률 분포에 대한 적분을 의미함)을 사용하는 이유는? 훈련 중에는 노이즈와 시간 단계가 무한 분포에서 연속적으로 샘플링되기 때문이다. 합산은 유한하고 이산적인 상태 집합을 의미할 것이다. 기댓값은 모델이 가능한 모든 노이즈 상태의 연속적인 지형 전체에 걸쳐 평균적으로 오류를 최소화하도록 강제한다.
- $\epsilon$: 이미지에 추가된 실제, Ground Truth 가우시안 노이즈. 역할: 목표. 이는 모델이 찾고 제거하려는 것이다.
- $\epsilon_\theta$: 학습 가능한 가중치 $\theta$로 매개변수화된 신경망(U-Net). 역할: 노이즈 예측기. 이는 정적(static)으로 채워진 이미지를 보고 정적이 어떤 모습인지 추측한다.
- $x_t$: 시간 단계 $t$에서의 노이즈가 포함된 이미지 표현. 역할: 손상된 캔버스.
- $t$: 현재 시간 단계. 역할: 이미지의 손상 과정이 얼마나 진행되었는지 네트워크에 알려준다.
- $c$: 조건 입력(우리의 $p_{tumor}$ 청사진). 역할: 조향 장치. 이는 네트워크가 단순히 무작위의 건강한 뇌를 생성하는 것이 아니라, 수술 청사진과 일치하는 방식으로 이미지의 노이즈를 제거하도록 강제한다.
- $\| \dots \|^2$: L2 노름(제곱 오차). 역할: 이는 수학적인 고무줄 역할을 한다. 큰 실수를 심하게 페널티한다. 네트워크가 노이즈를 잘못 예측하면, 이 항의 제곱 특성으로 인해 오류가 폭발하여 모델의 가중치를 올바른 예측으로 격렬하게 끌어당긴다.
단계별 흐름
하나의 추상적인 데이터 포인트, 즉 환자의 뇌 스캔이 이 기계적인 조립 라인을 통과하는 과정을 추적해 보자.
먼저, 환자의 수술 전 스캔($\text{Q}_{\text{pre}}$)이 시스템에 입력된다. 알고리즘은 데이터베이스를 검색하여 유사한 종양을 앓았던 과거 환자의 수술 후 스캔($\text{I}_{\text{post}}$)을 검색한다.
다음으로, 바운딩 박스 마스크($\text{M}_{\text{bbox}}^{\text{Q}}$)가 스탬프처럼 내려와 과거 환자의 스캔에서 수술 부위를 잘라낸다. 동시에, 역 마스크는 현재 환자의 스캔에서 종양이 있는 정확한 위치에 빈 구멍을 낸다. 덧셈 연산자는 이 두 조각을 레고 블록처럼 함께 붙여 합성 이미지($\text{Q}_{\text{comp}}$)를 생성한다.
이 합성 이미지는 이미지 인코더(MedSAM)를 통해 압축되어 2D 이미지에서 1024차원의 밀집된 수학적 벡터 $c$로 변환된다.
이제 확산 단계로 들어간다. 순수한 가우시안 노이즈로 이루어진 완전히 빈 격자($x_T$)가 생성된다. 단계 $t$에서 U-Net($\epsilon_\theta$)은 이 노이즈가 낀 격자를 본다. 또한 조향 벡터 $c$도 본다. $c$에 의해 안내되어, 네트워크는 정확히 어떤 픽셀이 "노이즈"인지 계산하고 이를 뺀다. 이 과정은 반복적으로 수행된다. 각 단계마다 정적이 사라지고 수술 후 뇌의 구조적 현실이 나타난다. 마지막으로, 단계 $t=0$에서 노이즈가 완전히 제거되어 깨끗하고 예측된 수술 후 MRI가 남는다.
최적화 동역학
이 메커니즘은 실제로 어떻게 수술을 예측하도록 학습하는가?
모델은 AdamW 옵티마이저를 사용하여 가중치 $\theta$를 업데이트한다. L2 노름에 의해 형성된 손실 지형은 거대한 다차원 그릇과 같다. 그릇의 바닥에는 완벽한 노이즈 예측이 있다. 기울기(이 그릇의 수학적 경사)는 신경망 가중치가 업데이트되는 속도와 방향을 결정한다.
모델이 $c$에 의해 조건화되기 때문에, 기울기는 모델이 수술 부위를 무시할 경우 특히 페널티를 부과한다. 만약 모델이 종양이 아직 온전한 뇌를 생성하려고 한다면, 오류 $\mathcal{L}_{LDM}$가 급증하고 기울기는 가중치를 절제 구역을 존중하도록 공격적으로 밀어붙인다.
더욱이, 저자들은 Classifier-Free Guidance라는 기법을 사용한다. 훈련 중에는 조건 벡터 $c$가 때때로 삭제된다(빈 벡터로 대체됨). 이는 모델이 수술 안내와 독립적으로 뇌 해부학의 기본 물리학을 학습하도록 강제한다. 추론 중에는 모델이 "조건화되지 않은" 뇌와 "조건화된" 뇌 간의 차이를 계산하고, 조건의 방향으로 크게 외삽한다. 이 동역학은 최종 생성 이미지가 종양 인지 프롬프트의 시각적 지시를 엄격하게 따르도록 하여, 매우 정확하고 환자별 수술 후 MRI를 생성한다.
결과, 한계점 및 결론
신경외과 의사가 공격성이 매우 높은 뇌종양인 교모세포종 수술을 앞두고 있다고 상상해 보자. 수술 전 MRI 영상이 있으며, 이는 종양이 포함된 환자의 뇌에 대한 3D 지도와 같다. 목표는 종양을 안전하게 제거하는 것이다. 하지만 절개를 한 후 뇌는 어떻게 보일까? 뇌는 단단한 플라스틱으로 만들어진 것이 아니다. 조직을 제거하면 주변 뇌 조직이 이동하고, 붓고(부종), 때로는 출혈이 발생한다. 수술이 시작되기 전에 매우 정확한 수술 후 MRI를 생성할 수 있다면, 수술 계획에 있어 엄청난 도약이 될 것이다. 기존의 계획 소프트웨어는 병원에 세션당 150달러 이상을 초과하는 비용을 발생시킬 수 있지만, 수술 후 상태를 정확하게 예측할 수 있는 AI는 고급 수술 예측 능력을 대중화할 수 있다.
하지만, 말 사진을 얼룩말 사진으로 바꾸는 것과 같은 표준 AI 이미지 변환은 여기서 매우 실패한다. 왜일까? 그러한 모델은 근본적인 구조적 기하학은 그대로 유지하면서 이미지의 "스타일"만 변경하기 때문이다. 수술은 근본적으로 기하학을 변경한다. AI는 종양이 정확히 어디에 있는지, 어떤 모양인지, 그리고 유사한 종양이 과거에 어떻게 제거되었는지 모두 엄격한 해부학적 제약을 준수하면서 이해해야 한다.
수학적 문제 및 해결책
저자들은 이를 조건부 이미지 생성 문제로 프레임화했다. 주어진 쿼리 수술 전 MRI $Q_{pre}$에 대해, 종양의 물리적 제거를 정확하게 반영하는 현실적인 수술 후 MRI $\hat{Q}_{post}$를 생성하는 것이 목표이다.
이를 해결하기 위해, 그들은 신경망에게 추측하라고만 요구하지 않았다. 그들은 영리한 검색 메커니즘으로 구동되는 "Visual In-Context Learning" 시스템을 구축했다. 수학적 및 논리적으로 해결한 방법은 다음과 같다.
-
종양 안내 검색: 그들은 과거 수술 데이터베이스를 검색하여 정확히 같은 위치와 모양의 종양을 가진 환자를 찾는다. 이를 위해 현재 환자의 분할 마스크 $M_{pre}^Q$와 과거 환자의 분할 마스크 간의 Intersection over Union (IoU)을 계산한다. 그들은 가장 잘 일치하는 세트, 즉 과거 수술 전 이미지 $I_{pre}$, 과거 수술 후 이미지 $I_{post}$, 그리고 그 마스크를 검색한다.
-
종양 인식 프롬프트 어댑터: 이것이 바로 핵심이다. 그들은 수학적으로 과거 환자의 수술 결과를 현재 환자의 뇌에 꿰매어 복합적인 힌트 $Q_{comp}$를 생성한다. 방정식은 다음과 같다.
$$Q_{comp} = M_{bbox}^Q \cdot I_{post} + (1 - M_{bbox}^Q) \cdot Q_{pre}$$
여기서 $M_{bbox}^Q$는 종양 주변의 바운딩 박스이다. 그들은 문자 그대로 $I_{post}$에서 수술로 남은 구멍을 가져와 쿼리 이미지 $Q_{pre}$에 붙여넣는다. 이 복합 이미지와 분할 마스크는 인코더(MedSAM)를 통해 잠재 표현 $p_{tumor}$을 생성한다. -
Visual In-Context Learning: 그들은 Stable Diffusion 모델을 사용한다. 그들은 $\{I_{pre}, I_{post}, Q_{pre}, B\}$를 포함하는 2x2 그리드를 모델에 입력하는데, 여기서 $B$는 빈 공간이다. 모델의 임무는 $B$를 채워 $\hat{Q}_{post}$를 생성하는 것이다. 모델은 손실 함수를 최소화하여 이미지를 노이즈 제거하는 방법을 학습한다.
$$L_{LDM} = \mathbb{E}_{x_0, \epsilon, t} \left[ \| \epsilon - \epsilon_\theta(x_t, t, c) \|^2 \right]$$
여기서 $c$는 조건부 프롬프트 $p_{tumor}$이다. 모델은 과거 쌍($I_{pre} \rightarrow I_{post}$)을 보고 $Q_{pre}$에 정확히 동일한 변환 논리를 적용한다.
실험 아키텍처 및 "희생양"
저자들은 단순히 "정확도 5% 향상"과 같은 지표를 나열하지 않았다. 그들은 기존의 최첨단 모델의 약점을 철저히 드러내기 위해 실험을 설계했다. 이 연구의 "희생양"은 확산 기반 이미지 편집 분야의 거물들이었다: DDPM, PBE, InstructPix2Pix, VISII, ImageBrush.
그들은 어떻게 자신들의 메커니즘이 작동함을 증명했을까? 그들은 실제 수술 공동을 살펴보았다. 기본 모델들은 조직이 제거되었다는 것을 전혀 이해하지 못했고, 종양이 있던 자리에 흐릿하고 불분명한 얼룩을 생성하여 본질적으로 수술 예측의 주요 목표를 달성하지 못했다.
결정적이고 부인할 수 없는 증거는 저자들의 ablation study에서 나왔다. 그들은 "종양 안내 검색"을 무작위 이미지 또는 일반적인 이미지 유사성 검색으로 대체했을 때, 모델의 성능이 붕괴되었다. 또한, 복합 이미지 $Q_{comp}$를 프롬프트 어댑터에서 제거했을 때, 모델은 절제 부위를 정확하게 그리는 능력을 잃었다. 이는 모델에 명시적으로 "과거 수술 구멍"을 제공하는 것이 성공의 부인할 수 없는 비결이었음을 증명했다. 솔직히 말해서, 검색된 바운딩 박스가 쿼리의 주변 조직과 완벽하게 잘못 정렬되는 극단적인 엣지 케이스를 모델이 어떻게 해결하는지는 완전히 확신할 수 없지만, 확산 과정은 이러한 아티팩트를 아름답게 완화하는 것으로 보인다.
향후 발전을 위한 논의 주제
이 훌륭한 기반을 바탕으로, 깊은 비판적 사고를 요구하는 몇 가지 향후 탐색 경로를 제시한다.
-
2D 슬라이스에서 3D 해부학적 일관성으로: 이 논문은 2D 축 방향 슬라이스를 다룬다. 그러나 인간의 뇌와 수술 절제는 본질적으로 3D이다. 이를 슬라이스별로 적용하면 수직적 연속성(예: 들쭉날쭉한 수술 공동)이 부족한 수술 후 볼륨을 생성할 위험이 있다. 치명적인 메모리 병목 현상 없이 3D 잠재 공간에서 작동하도록 이 시각적 인컨텍스트 학습을 어떻게 발전시킬 수 있을까? 3D 일관성을 강제하기 위해 직교 2D 투영을 사용할 수 있을까?
-
외과 의사의 의도 매개변수화: 현재 모델은 수술 결과가 종양의 위치와 모양의 함수라고 가정한다. 실제로는 절제 범위가 외과 의사의 전략(예: 운동 기능을 보존하기 위한 공격적인 전체 절제 대 보수적인 생검)에 크게 영향을 받는다. "외과 의사의 의도"를 조건부 벡터 $c$에 수학적으로 주입할 수 있을까? 목표 절제 마진을 나타내는 스칼라 또는 벡터를 도입할 수 있을까?
-
분포 외(OOD) 해부학 처리: 검색 메커니즘은 유사한 과거 사례를 찾는 데 의존한다. 환자가 매우 드문 종양 형태나 훈련 데이터베이스에 해당하는 것이 없는 거대한 정중선 이동을 보이는 경우에는 어떻게 될까? 우리는 확산 모델이 의료 영상에서 어떻게 안전하게 외삽할 수 있는지, 또는 환자에게 잘못 일치된 $I_{post}$를 강요하여 위험한 수술 계산 착오로 이어질 수 있는지에 대해 논의해야 한다.
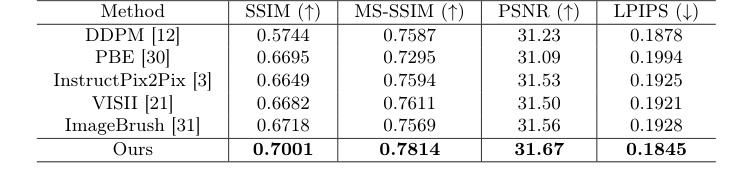 Table 1. Comparison of post-operative MRI generation results with state-of-the-art image editing methods
Table 1. Comparison of post-operative MRI generation results with state-of-the-art image editing methods
 Table 2. An ablation study on different retrieval strategies and the effectiveness of the two prompts in our tumor-aware prompt adapter. We evaluate three retrieval strategies: Random (random selection), Image-retrieval (retrieval based on cosine similarity in the image embedding space), and Ours (tumor-guided retrieval). Additionally, we assess the impact of two prompts: pseg (segmentation mask of the input pre-operative MRI) and pcomp (composite image)
Table 2. An ablation study on different retrieval strategies and the effectiveness of the two prompts in our tumor-aware prompt adapter. We evaluate three retrieval strategies: Random (random selection), Image-retrieval (retrieval based on cosine similarity in the image embedding space), and Ours (tumor-guided retrieval). Additionally, we assess the impact of two prompts: pseg (segmentation mask of the input pre-operative MRI) and pcomp (composite image)
다른 필드와의 동형 사상
본 논문의 핵심 구조 골격은 다음과 같이 정의될 수 있다: 역사적으로 유사한 상태 전이를 검색하고, 해당 국소화된 변환 규칙을 현재 시스템의 전역 구조와 혼합하여 공간적으로 복잡한 시스템의 미래 상태를 예측하는 메커니즘.
이러한 수학적 및 논리적 골격을 기반으로, 과학 및 공학의 완전히 다른 영역에서 이 문제의 놀라운 거울 이미지를 식별할 수 있다:
1. 도시 재난 예측 (토목 공학)
* 연결성: 국소화된 재난(예: 특정 지진 또는 홍수) 이후 도시의 모습과 그에 따른 파괴된 건물 철거를 예측하는 것은 수술 후 MRI 생성의 직접적인 거울 이미지이다. 이 시나리오에서 "수술 전 MRI"는 도시의 현재 위성 지도이다. "종양"은 국소화된 재난 지역이다. 저자들이 조직 절제를 이해하기 위해 과거의 유사한 수술을 검색하는 것처럼, 도시 계획가는 유사한 지리적 발자국을 가진 다른 도시의 역사적 재난을 검색할 수 있다. 이 모델은 대상 지역에 국소화된 파괴 및 제거(절제)를 적용하는 동시에 주변의 영향을 받지 않은 기반 시설(해부학적 구조)을 보존할 것이다.
2. 초신성 잔해 진화 (천체 물리학)
* 연결성: 은하 내 국소화된 항성 폭발의 구조적 여파를 예측하는 것은 본 논문의 논리와 완벽하게 일치한다. "수술 전" 상태는 초신성 이전의 은하이며, "종양"은 죽어가는 별의 위치와 질량이다. 우주의 다른 지역에서 역사적으로 유사한 초신성에 대한 데이터를 검색함으로써, 천체 물리학자들은 국소화된 공허와 충격파(절제 영역)를 모델링하는 동시에 더 넓고 영향을 받지 않은 은하 팔을 그대로 유지할 수 있다.
3. 기업 구조 조정 (거시 경제학)
* 연결성: 독성 자산 부서를 청산한 후 기업 네트워크의 건전성을 예측하는 것이다. "수술 전" 이미지는 회사의 현재 재정적 의존성의 복잡한 웹이다. "종양"은 제거해야 할 실패한 부서이다. 유사한 역사적 파산 또는 청산 사례를 검색함으로써, 경제학자들은 제거된 부서가 남긴 국소화된 구조적 격차를 예측하는 동시에 생존하는 기업 네트워크의 무결성을 유지할 수 있다.
급진적인 "만약" 시나리오
만약 기후 과학자가 내일 이 논문의 핵심 합성 방정식을 "훔친다면" 어떻게 될까?
$$Q_{comp} = M_{bbox}^Q \cdot I_{post} + (1 - M_{bbox}^Q) \cdot Q_{pre}$$
이 정확한 공식을 사용하여 특정 해안 격자에 영향을 미치는 카테고리 5 허리케인과 같은 국소화된 기후 사건의 지리적 흉터를 예측한다고 상상해 보라. 여기서 $Q_{pre}$는 현재 해안 지도이고, $M_{bbox}^Q$는 폭풍의 예상 영향 영역이며, $I_{post}$는 역사적으로 유사한 허리케인의 여파에 대한 검색된 위성 이미지이다. 연구자는 대륙 전체에 대한 계산적으로 방대한 유체 역학 및 구조 물리학 시뮬레이션을 실행하는 대신, 역사적인 국소화된 파괴를 현재 지도에 원활하게 이어 붙여 실시간으로 고충실도의 폭풍 후 위성 이미지를 생성할 수 있다. 이는 폭풍이 상륙하기도 전에 몇 초 안에 생성되는 실시간 시각적으로 정확한 대피 계획 및 피해 추정치가 될 것이다.
궁극적으로, 본 논문은 인간의 뇌에서 종양을 제거하든, 대도시에서 재난 지역을 정리하든, 또는 우주 폭발의 국소화된 여파를 예측하든, 국소화된 구조 변환의 수학적 청사진은 동일하게 유지된다는 것을 증명하며, 이는 구조의 보편적 라이브러리에 또 하나의 심오한 장을 추가한다.