基于检索的视觉上下文学习的术前术后MRI生成
New AI generates realistic post-op MRIs from pre-op scans, aiding brain tumor surgery.
背景与学术传承
胶质母细胞瘤是一种高度侵袭性且快速浸润的脑部肿瘤。对于神经外科医生而言,治疗它是一项极其精细的平衡工作:他们必须尽可能多地切除肿瘤以改善患者的预后,但同时也要避免损伤关键脑区,以最大程度地减少术后严重并发症。历史上,外科医生不得不依赖于自身的空间直觉和心智可视化,分析既往病例来估计肿瘤切除后患者大脑的形态。随着人工智能进入医疗领域,一个具体的问题浮现出来:我们能否从术前 MRI 自动生成术后 MRI,以帮助外科医生在进行任何切口之前,直观地预测手术结果并规划治疗方案?
以往方法的根本局限性——促使作者开发此新方法——在于现有的生成式 AI 模型主要为风格迁移而设计。像标准的 GAN 或 InstructPix2Pix 模型擅长在保持底层结构的同时,改变图像的纹理或颜色。然而,脑部手术从根本上会破坏和改变结构。术后 MRI 不仅仅是风格上的差异;它呈现出巨大的物理变化,如组织缺失(切除腔)、脑组织移位以填补空隙、肿胀(水肿)和出血(血肿)。以往的模型在此方面表现拙劣,因为它们无法理解这些结构性变化的程度完全取决于肿瘤的具体位置和形状。它们常常生成模糊不清的团块,而非逼真的手术腔。
为解决此问题,作者引入了几个高度专业化的概念。以下是它们在日常语境中的含义:
- 视觉上下文学习 (Visual In-Context Learning): 想象一下,您雇佣一位景观设计师来改造您的后院。您没有仅仅给他们一个书面描述,而是给他们看了一张邻居院子的前后对比照片,该院子与您的院子布局完全相同。AI 模型也做同样的事情:它通过查看类似既往手术的视觉“前后对比”示例来学习如何生成术后图像,而不是凭空猜测。
- 肿瘤引导检索 (Tumor-guided Retrieval): 可以将其视为一个高度特定的医疗匹配服务。系统不是应用通用的手术规则来预测大脑的形态,而是搜索一个庞大的既往患者数据库,找到其肿瘤大小、形状和位置与当前患者几乎完全匹配的患者。然后,它将该既往患者的实际手术结果作为指导蓝图。
- 肿瘤感知提示适配器 (Tumor-aware Prompt Adapter): 可以将其视为一个主蓝图生成器。它获取当前患者的大脑解剖结构,并将匹配到的既往患者的手术腔(切除区域)进行数字叠加。它将这两种信息融合为一个清晰的数学指令手册,以便 AI 确切知道在生成的图像中“切割”何处。
- 扩散模型 (Diffusion Model): 想象一位艺术家从一个完全覆盖着随机、混乱的灰色颜料飞溅(噪声)的画布开始。然后,他们一步一步地小心擦掉特定的飞溅,直到出现一张清晰、高度精细的照片。AI 生成最终 MRI 的过程就是如此,它从静态噪声开始,并将其精炼成医学图像。
为了理解作者解决此问题的数学机制,我们需要定义他们用于构建模型的关键变量和参数。
| 符号 | 类型 | 描述 |
|---|---|---|
| $Q_{pre}$ | 变量 | 查询的术前 MRI(当前患者手术前的脑部扫描)。 |
| $M^{Q}_{pre}$ | 变量 | 查询术前 MRI 的分割掩码(突出显示肿瘤确切位置的图)。 |
| $I_{pre}$ | 变量 | 从数据库检索到的术前 MRI(匹配到的既往患者的“之前”图像)。 |
| $I_{post}$ | 变量 | 从数据库检索到的术后 MRI(匹配到的既往患者的“之后”图像)。 |
| $M^{I}_{pre}$ | 变量 | 检索到的术前 MRI 的分割掩码。 |
| $M^{Q}_{bbox}$ | 变量 | 从 $M^{Q}_{pre}$ 派生的边界框掩码,用于隔离肿瘤区域。 |
| $Q_{comp}$ | 变量 | 将当前患者的解剖结构与既往患者的手术腔融合的复合图像。计算公式为: $$Q_{comp} = M^{Q}_{bbox} \cdot I_{post} + (1 - M^{Q}_{bbox}) \cdot Q_{pre}$$ |
| $p_{comp}$ | 参数 | 从复合图像 $Q_{comp}$ 中提取的 1024 维潜在表示。 |
| $p_{seg}$ | 参数 | 从术前分割掩码 $M^{Q}_{pre}$ 中提取的 1024 维潜在表示。 |
| $p_{tumor}$ | 参数 | 最终的提示嵌入,通过连接 $p_{comp}$ 和 $p_{seg}$ 创建,用于指导扩散模型。 |
| $\hat{Q}_{post}$ | 变量 | 最终生成的术后 MRI(AI 对手术结果的预测)。 |
| $x_t$ | 变量 | 在扩散过程的特定时间步 $t$ 下的噪声图像表示。 |
| $\epsilon$ | 变量 | 在前向扩散过程中添加到图像中的实际噪声。 |
| $\epsilon_\theta$ | 参数 | 噪声预测网络(具有可学习参数 $\theta$),尝试猜测并移除噪声。 |
| $c$ | 变量 | 扩散模型的条件输入(在此情况下,$c = p_{tumor}$)。 |
| $L_{LDM}$ | 参数 | 用于训练扩散模型的损失函数,定义为: $$L_{LDM} = \mathbb{E}_{x_0, \epsilon, t} \left[ \| \epsilon - \epsilon_\theta(x_t, t, c) \|^2 \right]$$ |
问题定义与约束
设想一位神经外科医生在进行复杂肿瘤切除手术前,正在查看患者的脑部扫描图像。他们需要精确地可视化肿瘤被切除后大脑的形态,以便规划最安全的手术路径。本文正是致力于解决这一挑战。
起点与目标
起点(输入)是患者胶质母细胞瘤术前 MRI 扫描图像,以及一个数学上定义肿瘤精确边界的分割掩码。我们将查询的术前图像表示为 $Q_{pre}$,其对应的肿瘤掩码表示为 $M_{pre}^Q$。期望的终点(输出)是一张高度逼真、合成的术后 MRI 图像,表示为 $\hat{Q}_{post}$。这张生成的图像必须准确地描绘手术后的脑部,显示肿瘤原先所在位置的空腔,以及自然的术后变化。
作者试图弥合的精确数学鸿沟是一种高度非线性的结构变换。标准的图像生成模型学习一个映射函数 $f(x) \rightarrow y$,该函数改变图像的“风格”(例如,将白天照片转换为夜晚照片)。但在这里,该函数必须执行虚拟手术:它必须删除特定的像素区域,模拟周围脑组织的物理塌陷或移位,并引入新的手术伪影,所有这些都严格以 $M_{pre}^Q$ 的空间坐标为条件。
痛苦的困境
先前试图解决此问题的研究人员陷入了生成式 AI 的经典困境:结构保留与结构修改之间的权衡。标准的图像到图像翻译模型经过高度优化,以保留源图像的底层几何结构。
如果强制严格的结构保留,模型只会改变大脑的纹理,而保留肿瘤——完全无法完成任务。然而,如果放宽结构约束以允许模型“移除”肿瘤,网络就会失去其空间锚点。它开始产生不切实际的脑解剖结构幻觉,或者生成模糊不清的团块,而不是精确的手术腔。同时实现健康组织的保真解剖保留和肿瘤部位的激进结构修改并非易事。
严酷的壁垒与约束
更糟糕的是,作者遇到了几个严峻的现实壁垒,使得这个问题异常困难:
- 极端的数据稀疏性: 医学数据出了名的稀缺。作者使用的是 LUMIERE 数据集,其中仅包含 71 对术前和术后 MRI 扫描。从如此小的数据集中训练一个数据饥渴的扩散模型来理解复杂空间变形是一项巨大的约束。模型需要使用损失函数 $\mathcal{L}_{LDM} = \mathbb{E}_{x_0, \epsilon, t} \left[ \| \epsilon - \epsilon_\theta(x_t, t, c) \|^2 \right]$ 来预测添加的噪声 $\epsilon$,但在 71 名患者上做到这一点而不发生过拟合是极其困难的。
- 高度可变的物理变形: 术后 MRI 不仅仅是在肿瘤所在位置有一个“洞”。大脑会经历复杂的物理变化,包括组织移位(大脑物理移动以填补空隙)、水肿(肿胀)和出血。这些是高度可变、患者特异性的物理约束,无法通过简单的几何裁剪来建模。
- 临床情境依赖性: 手术切除的程度不仅仅是肿瘤掩码的数学偏移。它在很大程度上取决于肿瘤的位置。如果肿瘤靠近关键脑区,外科医生会保留更多组织以防止严重并发症。模型必须仅凭肿瘤的视觉位置和形状,在没有明确手术规则手册的情况下,推断出这些看不见的临床规则。
为了绕过这些壁垒,作者不能仅仅训练一个标准模型。他们不得不发明一个“肿瘤引导检索”系统,该系统在一个数据库中搜索过去具有相似形状和位置肿瘤的患者,然后使用该过去患者的术前和术后扫描作为视觉提示(Visual In-Context Learning),来教会扩散模型手术应该是什么样子。
为何采用此方法
为了理解作者为何构建此特定架构,我们首先需要审视传统人工智能处理图像转换的根本缺陷。作者们顿悟的时刻源于审视现有的 SOTA (state-of-the-art) 生成模型——例如标准的生成对抗网络 (GANs) 或基础的文本到图像扩散模型 (Diffusion models)——并意识到这些系统过度关注“风格”。传统的图像转换方法旨在在改变纹理的同时保留源图像的底层结构。然而,脑部手术并非风格迁移,而是一种剧烈、物理性的改变。当胶质母细胞瘤被切除时,大脑会发生巨大的结构性变化:组织移位、水肿(肿胀)形成以及出血。
作者们意识到,要求标准的卷积神经网络 (CNN) 或基础的扩散模型仅仅“猜测”这些复杂的物理形变是不可能的。标准模型会试图保持大脑原始形状的完整性,从而完全无法模拟实际的组织切除。此外,文本引导的扩散模型(如 InstructPix2Pix)在此类任务中会失败,因为诸如“术后胶质母细胞瘤 MRI”之类的文本提示缺乏模型所需的密集、高维空间信息,无法精确告知模型确切切除组织的位置和数量。与应用于整个图像的通用、统一效果的 \$150 照片编辑滤镜不同,手术结果高度个体化,完全取决于肿瘤的独特位置和形状。
这种严苛的约束——预测高度局部化、个体化解剖形变的需求——迫使该研究与一种高度独特的解决方案“联姻”:肿瘤感知视觉上下文学习 (Tumor-aware Visual In-Context Learning) 结合 肿瘤引导检索 (Tumor-guided Retrieval)。
作者们没有强迫神经网络从头开始记忆脑部手术的物理过程,而是设计了一个通过示例学习的系统。他们构建了一种检索策略,该策略搜索过去患者的数据库,以查找术前和术后 MRI 对,其中肿瘤的位置和形状与当前患者高度匹配(通过分割掩码的交并比 (IoU) 和轴向对齐进行衡量)。
然而,真正的结构优势——该方法压倒性优于先前黄金标准的原因——在于它如何将检索到的知识与当前患者的解剖结构进行数学融合。作者们设计了一个“肿瘤感知提示适配器 (Tumor-aware Prompt Adapter)”,该适配器明确强制模型关注切除区域。他们通过一个巧妙的复合操作实现了这一点:
$$Q_{comp} = M_{bbox}^Q \cdot I_{post} + (1 - M_{bbox}^Q) \cdot Q_{pre}$$
在此方程中:
* $Q_{pre}$ 是当前患者的术前 MRI。
* $I_{post}$ 是检索到的过去患者的术后 MRI(视觉指令)。
* $M_{bbox}^Q$ 是隔离肿瘤区域的边界框掩码。
这种数学表述是本文的秘密引擎。它将检索到的患者的实际手术腔 ($I_{post}$) 无缝地置于当前患者大脑的确切肿瘤位置 ($M_{bbox}^Q$) 中,同时保留当前患者健康的周围解剖结构 ($(1 - M_{bbox}^Q) \cdot Q_{pre}$)。这个复合图像与肿瘤分割掩码一起,被处理成一个潜在表示 ($p_{tumor}$),并通过交叉注意力注入到 Stable Diffusion 模型中。
基准测试逻辑清楚地证明了该方法在质量上的优越性。当作者们测试标准的基于扩散的编辑方法时,这些模型在肿瘤区域生成了模糊不清的团块,因为它们缺乏明确的空间指导。即使是其他视觉上下文学习方法(如 ImageBrush)也失败了,因为它们使用了随机的视觉指令,而当手术结果完全依赖于特定的肿瘤几何形状时,这毫无用处。通过明确地将视觉指令定制到肿瘤的确切坐标,所提出的方法能够出色地处理结构性脑部变化的高维噪声,实现了卓越的定量指标(如 0.7001 的 SSIM),并生成了传统 GAN 和基础 Transformer 无法比拟的清晰、解剖学上逼真的术后扫描。
数学与逻辑机制
为了理解本文如何实现预测患者术后大脑外观这一看似不可能的任务,我们必须深入探究驱动该系统的数学逻辑。作者们本质上为医学影像构建了一台时间机器,其动力来源于两个相互关联的数学引擎:空间变换逻辑和概率生成目标函数。
以下是驱动本文的核心方程:
1. 肿瘤感知复合变换:
$$ \text{Q}_{\text{comp}} = \text{M}_{\text{bbox}}^{\text{Q}} \cdot \text{I}_{\text{post}} + (1 - \text{M}_{\text{bbox}}^{\text{Q}}) \cdot \text{Q}_{\text{pre}} $$
2. 潜在扩散目标函数:
$$ \mathcal{L}_{LDM} = \mathbb{E}_{x_0, \epsilon, t} \left[ \| \epsilon - \epsilon_\theta(x_t, t, c) \|^2 \right] $$
让我们逐一解析这些方程,以便您能清晰地了解其工作机制。
解析复合变换
第一个方程是一个空间蓝图。它通过借鉴过去患者的手术结果,构建了一个未来大脑的“弗兰肯斯坦式”草图。
- $\text{Q}_{\text{comp}}$:最终的复合图像。作用: 它充当原始视觉指令。它告诉人工智能:“这是患者的健康大脑,这是肿瘤留下的空腔大致的样子。”
- $\text{M}_{\text{bbox}}^{\text{Q}}$:从查询(当前患者)的术前 MRI 中提取的二值边界框掩码。作用: 它充当数字饼干模具。在肿瘤所在位置为 $1$,其他地方为 $0$。
- $\cdot$(乘法):作用: 这是一个像素级掩码算子。通过将图像与二值掩码相乘,可以立即擦除感兴趣区域之外的所有内容。
- $\text{I}_{\text{post}}$:从另一位患有类似肿瘤的患者那里检索到的术后 MRI。作用: 它提供了手术切除(空腔、组织移位等)的实际视觉纹理。
- $+$(加法):作用: 它充当数字胶水。为何使用加法而非乘法? 因为两个掩码—$\text{M}_{\text{bbox}}^{\text{Q}}$ 和 $(1 - \text{M}_{\text{bbox}}^{\text{Q})}$—是互斥的。如果将它们相乘,重叠区域将变为零并变成黑色。通过将它们相加,可以在不产生任何鬼影或重叠伪影的情况下,完美地将两个不同的图像区域缝合在一起。
- $(1 - \text{M}_{\text{bbox}}^{\text{Q}})$:逆掩码。作用: 在健康大脑区域为 $1$,在肿瘤区域为 $0$。它保护患者的健康解剖结构不被检索图像覆盖。
- $\text{Q}_{\text{pre}}$:当前患者的实际术前 MRI。作用: 提供个性化的解剖背景。
解析扩散目标函数
一旦复合蓝图生成,它就会被压缩成一个潜在向量 $c$(在论文中特称为 $p_{tumor}$)。该向量指导第二个方程,即生成式 AI 的核心。
- $\mathcal{L}_{LDM}$:潜在扩散模型损失。作用: 这是模型试图最小化的最终分数。它代表了模型去噪图像能力中的误差。
- $\mathbb{E}_{x_0, \epsilon, t}$:关于原始图像 $x_0$、添加的噪声 $\epsilon$ 和时间步 $t$ 的期望值。为何使用期望值(暗示对概率分布进行积分)而非简单的求和? 因为在训练过程中,噪声和时间步是从无限分布中连续采样的。求和将暗示有限的、离散的状态集。期望值迫使模型在所有可能的噪声状态的整个连续景观上平均最小化误差。
- $\epsilon$:添加到图像中的实际、Ground Truth 高斯噪声。作用: 目标。这是模型试图找到并移除的内容。
- $\epsilon_\theta$:由可学习权重 $\theta$ 参数化的神经网络(U-Net)。作用: 噪声预测器。它查看充满静态的图像,并猜测静态是什么样的。
- $x_t$:时间步 $t$ 下的噪声图像表示。作用: 损坏的画布。
- $t$:当前时间步。作用: 告知网络图像在腐蚀过程中的进展程度。
- $c$:条件输入(我们的 $p_{tumor}$ 蓝图)。作用: 转向器。它迫使网络以与手术蓝图匹配的方式去噪图像,而不是仅仅生成一个随机的健康大脑。
- $\| \dots \|^2$:L2 范数(平方误差)。作用: 它充当数学橡皮筋。它会严重惩罚大的错误。如果网络错误地预测了噪声,该项的平方性质会导致误差爆炸,从而将模型的权重猛烈地拉回到正确的预测方向。
逐步流程
让我们追踪一个抽象数据点—患者的大脑扫描—在这一机械流水线上移动的过程。
首先,患者的术前扫描 ($\text{Q}_{\text{pre}}$) 进入系统。算法搜索数据库,并检索一位患有类似肿瘤的过去患者的术后扫描 ($\text{I}_{\text{post}}$)。
接下来,边界框掩码 ($\text{M}_{\text{bbox}}^{\text{Q}}$) 像邮票一样落下,从过去患者的扫描中切割出手术腔。同时,逆掩码在当前患者扫描中精确地在其肿瘤所在位置挖出一个空洞。加法算子像乐高积木一样将这两部分拼接在一起,创建复合图像 ($\text{Q}_{\text{comp}}$)。
然后,该复合图像通过图像编码器(MedSAM)进行压缩,从二维图片转换为一个密集、1024 维的数学向量 $c$。
现在,我们进入扩散阶段。生成一个完全空白的纯高斯噪声网格 ($x_T$)。在时间步 $t$,U-Net ($\epsilon_\theta$) 查看这个噪声网格。它还查看转向向量 $c$。在 $c$ 的指导下,网络计算出哪些像素是“噪声”并将其减去。这个过程会迭代重复。每一步,静态都会消退,术后大脑的结构现实逐渐显现。最后,在时间步 $t=0$ 时,噪声被完全去除,留下一个清晰、预测的术后 MRI。
优化动力学
这个机制是如何学会预测手术的?
模型使用 AdamW 优化器更新其权重 $\theta$。由 L2 范数塑造的损失景观就像一个巨大的、多维的碗。碗的底部是完美的噪声预测。梯度(这个碗的数学斜率)决定了网络权重更新的速度和方向。
由于模型以 $c$ 为条件,梯度会特别惩罚模型忽略手术腔的行为。如果模型试图生成一个肿瘤仍然完好的大脑,损失 $\mathcal{L}_{LDM}$ 会飙升,梯度会积极地推动权重以尊重切除区域。
此外,作者们使用了一种称为“无分类器引导”(Classifier-Free Guidance)的技术。在训练期间,条件向量 $c$ 会被偶尔丢弃(替换为空向量)。这迫使模型独立于手术指导来学习大脑解剖学的基本物理原理。在推理时,模型计算“无条件”大脑和“有条件”大脑之间的差异,并在条件的指导方向上进行大量外推。这种动态使最终生成的图像严格遵循肿瘤感知提示的视觉指令,从而产生高度准确、患者特异性的术后 MRI。
结果、局限性与结论
想象一下,您是一位即将为胶质母细胞瘤(一种高度侵袭性脑肿瘤)进行手术的神经外科医生。您有一张术前核磁共振成像(MRI),它本质上是患者大脑的三维地图,其中包含肿瘤。您的目标是安全地切除肿瘤。但是,在您下刀之后,大脑会是什么样子呢?大脑并非由坚硬的塑料制成;当您移除组织时,周围的脑组织会移位、肿胀(水肿),有时还会出血。如果我们能在手术开始前生成一张高度精确的术后 MRI,这将是手术规划的巨大飞跃。虽然传统的规划软件可能让医院每次会话花费高达 150 美元,但一个能够准确预测术后状态的人工智能可以普及先进的外科预判能力。
然而,标准的人工智能图像翻译(例如将马的照片变成斑马)在这里会惨败。为什么?因为那些模型只改变图像的“风格”,而保持底层结构几何形状完全不变。手术会从根本上改变几何形状。人工智能必须准确理解肿瘤的位置、形状,以及历史上如何切除类似肿瘤,同时还要遵守严格的解剖学限制。
数学问题与解决方案
作者将此问题构建为一个条件图像生成问题。给定一个查询的术前 MRI $Q_{pre}$,目标是生成一个逼真的术后 MRI $\hat{Q}_{post}$,该 MRI 能够准确反映肿瘤的物理切除情况。
为了解决这个问题,他们并没有仅仅让神经网络进行猜测。他们构建了一个由巧妙的检索机制驱动的“视觉上下文学习”系统。以下是他们从数学和逻辑上解决此问题的方法:
-
肿瘤引导检索: 他们搜索一个包含过去手术的数据库,以找到一个肿瘤位置和形状与当前患者完全相同的病例。他们通过计算当前患者分割掩码 $M_{pre}^Q$ 与过去患者分割掩码之间的交并比(IoU)来实现这一点。他们检索最佳匹配集:一个过去的术前图像 $I_{pre}$、一个过去的术后图像 $I_{post}$ 及其掩码。
-
肿瘤感知提示适配器: 这是最巧妙的部分。他们将过去患者的手术结果在数学上缝合到当前患者的大脑上,以创建一个复合提示 $Q_{comp}$。公式如下:
$$Q_{comp} = M_{bbox}^Q \cdot I_{post} + (1 - M_{bbox}^Q) \cdot Q_{pre}$$
其中,$M_{bbox}^Q$ 是肿瘤的边界框。他们实际上是将 $I_{post}$ 中手术留下的空腔粘贴到查询图像 $Q_{pre}$ 中。这个复合图像与分割掩码一起,通过一个编码器(MedSAM)生成一个潜在表示 $p_{tumor}$。 -
视觉上下文学习: 他们使用了一个 Stable Diffusion 模型。他们向模型输入一个包含 $\{I_{pre}, I_{post}, Q_{pre}, B\}$ 的 2x2 网格,其中 $B$ 是一个空白区域。模型的任务是填充 $B$ 以创建 $\hat{Q}_{post}$。模型通过最小化损失函数来学习对图像进行去噪:
$$L_{LDM} = \mathbb{E}_{x_0, \epsilon, t} \left[ \| \epsilon - \epsilon_\theta(x_t, t, c) \|^2 \right]$$
其中 $c$ 是条件提示 $p_{tumor}$。模型会查看过去的配对($I_{pre} \rightarrow I_{post}$),并将完全相同的转换逻辑应用于 $Q_{pre}$。
实验架构与“牺牲品”
作者们并没有仅仅列出“准确率提高了 5%”之类的指标。他们精心设计了实验,以无情地揭示现有 SOTA 模型(state-of-the-art models)的弱点。本研究中的“牺牲品”是基于扩散的图像编辑领域的重量级模型:DDPM、PBE、InstructPix2Pix、VISII 和 ImageBrush。
他们是如何证明他们的机制有效的?他们查看了实际的手术腔。基线模型完全未能理解组织已被移除;它们在肿瘤原先所在的位置生成了模糊不清的斑点,基本上未能达到手术预测的主要目标。
作者的消融研究提供了决定性的、不容置疑的证据。当他们将“肿瘤引导检索”替换为随机图像或通用图像相似性搜索时,模型的性能急剧下降。此外,当他们从提示适配器中移除复合图像 $Q_{comp}$ 时,模型就失去了准确绘制切除区域的能力。这证明了明确地向模型提供“过去的手术空腔”是他们成功的无可辩驳的秘诀。坦白说,我并不完全确定模型如何解决检索到的边界框与查询周围组织完全错位的极端边缘情况,但扩散过程似乎能很好地平滑这些伪影。
未来演进的讨论话题
基于这个出色的基础,以下是需要深入批判性思考的几个未来探索方向:
-
从二维切片到三维解剖一致性: 本文在二维轴向切片上进行操作。然而,人脑和手术切除本质上是三维的。如果我们逐一切片应用,我们可能会生成一个缺乏垂直连续性的术后体积(例如,一个锯齿状的手术腔)。我们如何才能在不遇到灾难性的内存瓶颈的情况下,将这种视觉上下文学习演进到在三维潜在空间中操作?我们可以使用正交二维投影来强制执行三维一致性吗?
-
参数化外科医生意图: 当前模型假设手术结果仅仅是肿瘤位置和形状的函数。实际上,切除范围很大程度上受到外科医生策略的影响(例如,积极的根治性切除与保守活检以保留运动功能)。我们如何将“外科医生意图”在数学上注入到条件向量 $c$ 中?我们可以引入一个标量或向量来表示目标切除边缘吗?
-
处理分布外(OOD)解剖结构: 检索机制依赖于找到相似的过去病例。当患者出现高度罕见的肿瘤形态或与训练数据库中没有任何对应关系的大幅度中线移位时,会发生什么?我们需要讨论扩散模型如何在医学成像中安全地进行外推,而不是强行将一个匹配度差的 $I_{post}$ 应用于患者,这可能导致危险的手术计算错误。
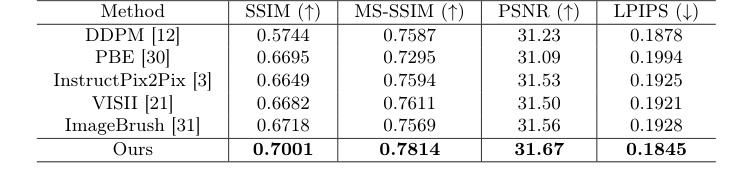 Table 1. Comparison of post-operative MRI generation results with state-of-the-art image editing methods
Table 1. Comparison of post-operative MRI generation results with state-of-the-art image editing methods
 Table 2. An ablation study on different retrieval strategies and the effectiveness of the two prompts in our tumor-aware prompt adapter. We evaluate three retrieval strategies: Random (random selection), Image-retrieval (retrieval based on cosine similarity in the image embedding space), and Ours (tumor-guided retrieval). Additionally, we assess the impact of two prompts: pseg (segmentation mask of the input pre-operative MRI) and pcomp (composite image)
Table 2. An ablation study on different retrieval strategies and the effectiveness of the two prompts in our tumor-aware prompt adapter. We evaluate three retrieval strategies: Random (random selection), Image-retrieval (retrieval based on cosine similarity in the image embedding space), and Ours (tumor-guided retrieval). Additionally, we assess the impact of two prompts: pseg (segmentation mask of the input pre-operative MRI) and pcomp (composite image)
与其他域的同构
本文的核心结构骨架可定义为:通过检索历史上相似的状态跃迁,并将该跃迁的局部变换规则与当前系统的全局结构相结合,来预测空间复杂系统未来状态的机制。
基于这一数学和逻辑骨架,我们可以在完全不同的科学和工程领域中,识别出该问题的鲜明镜像:
1. 城市灾害预测(土木工程)
* 联系: 预测城市在局部灾害(如定向地震或洪水)发生后以及随后被毁建筑拆除后的样貌,与术后 MRI 生成是直接的镜像。在此场景下,“术前 MRI”是城市当前的卫星地图。“肿瘤”是局部灾害区域。正如作者通过检索相似的既往手术来理解组织切除一样,城市规划者可以检索另一个具有相似地理足迹的城市发生的历史灾害。该模型将局部破坏和清理(即切除)应用于目标区域,同时保留周围未受影响的基础设施(即解剖结构)。
2. 超新星遗迹演化(天体物理学)
* 联系: 预测星系内局部恒星爆炸的结构性后果,与本文的逻辑完美契合。“术前”状态是超新星爆发前的星系,“肿瘤”是垂死恒星的位置和质量。通过检索宇宙其他地方历史上相似的超新星数据,天体物理学家可以模拟局部空洞和冲击波(即切除区域),同时保持更广泛、未受影响的旋臂的完整性。
3. 企业重组(宏观经济学)
* 联系: 预测公司网络在清算有毒资产部门后的健康状况。“术前”图像是公司当前复杂的财务依赖关系网络。“肿瘤”是必须被切除的亏损部门。通过检索类似的既往破产或清算案例,经济学家可以预测被移除部门留下的局部结构性缺口,同时保持幸存公司网络的完整性。
激进的“假设”场景
如果一位气候科学家明天“窃取”了本文的核心合成方程呢?
$$Q_{comp} = M_{bbox}^Q \cdot I_{post} + (1 - M_{bbox}^Q) \cdot Q_{pre}$$
想象一下将这个精确的公式应用于预测局部气候事件(如 5 级飓风袭击特定沿海网格)造成的地理创伤。在这里,$Q_{pre}$ 是当前沿海地图,$M_{bbox}^Q$ 是风暴的预期影响区域,$I_{post}$ 是历史上相似飓风灾后卫星图像的检索。研究人员无需对整个大陆运行计算量巨大的流体动力学和结构物理学模拟,而是可以通过将历史上的局部破坏无缝地叠加到当前地图上,即时生成高保真度的风暴后卫星图像。这将是革命性的,能够在风暴登陆前几秒钟内生成实时、视觉上准确的疏散计划和损害评估。
最终,本文证明了,无论我们是从人脑中切除肿瘤、清理大都市的灾区,还是预测宇宙爆炸的局部后果,局部结构变换的数学蓝图都保持不变,为“万物结构通用图书馆”增添了又一个深刻的篇章。