सतह से परे देखना: डीएमई प्रबंधन के लिए रंगीन फंडस फोटोग्राफी से रेटिनल मोटाई का अनुमान
सतह से परे देखना: डीएमई प्रबंधन के लिए रंगीन फंडस फोटोग्राफी से रेटिनल मोटाई का अनुमान
पृष्ठभूमि और अकादमिक वंश
उत्पत्ति और अकादमिक वंश
मधुमेह मैक्यूलर एडिमा (DME) प्रबंधन के लिए केवल रंगीन फंडस फोटोग्राफी (C-FP) से रेटिनल मोटाई मानचित्र (RTMs) की भविष्यवाणी करने की समस्या, नेत्र विज्ञान में सुलभ और लागत प्रभावी नैदानिक उपकरणों की महत्वपूर्ण आवश्यकता से उत्पन्न होती है। डायबिटिक मैक्यूलर एडिमा गंभीर दृष्टि हानि का एक प्रमुख कारण है, विशेष रूप से कामकाजी उम्र की आबादी में, जो एक महत्वपूर्ण वैश्विक स्वास्थ्य बोझ डालता है।
ऐतिहासिक रूप से, ऑप्टिकल कोहेरेंस टोमोग्राफी (OCT) DME के मूल्यांकन के लिए स्वर्ण मानक रहा है, क्योंकि यह विस्तृत RTMs प्रदान करता है जो उच्च सटीकता के साथ रेटिनल विकृति को मापता है। हालांकि, OCT उपकरण महंगे और संचालित करने में जटिल होते हैं, जिससे उनकी पहुंच गंभीर रूप से सीमित हो जाती है, विशेष रूप से संसाधन-बाधित सेटिंग्स में या नियमित घरेलू निगरानी के लिए। यह पहुंच अंतर अक्सर अपर्याप्त फॉलो-अप विज़िट और एंटी-वैस्कुलर एंडोथेलियल ग्रोथ फैक्टर (anti-VEGF) जैसी थेरेपी से गुजर रहे रोगियों के लिए उप-इष्टतम उपचार परिणामों की ओर ले जाता है।
C-FP का लाभ उठाने के पिछले प्रयास, जो एक व्यापक रूप से उपलब्ध और लागत प्रभावी 2D इमेजिंग तकनीक है (स्मार्टफोन के साथ भी संभव है), महत्वपूर्ण सीमाओं का सामना करना पड़ा। शुरुआती दृष्टिकोण रेटिनल मोटा होने के प्रॉक्सी मार्करों पर निर्भर थे, जैसे कि लिपिड जमाव, जिनमें आवश्यक गहराई रिज़ॉल्यूशन की कमी थी और DME का पता लगाने के लिए सीमित विशिष्टता और संवेदनशीलता के परिणामस्वरूप। उदाहरण के लिए, C-FP से रेटिनल मोटा होने की भविष्यवाणी करने का प्रयास करने वाले पूर्व मॉडल अक्सर नैदानिक मानकों को पूरा करने में विफल रहे, विशेष रूप से निम्न छवि गुणवत्ता के साथ। हाल के प्रयासों ने मोटाई की जानकारी निकालने के लिए एक मध्यस्थ के रूप में इन्फ्रारेड फंडस फोटोग्राफी (IR-FP) का उपयोग करके इस अंतर को पाटने की कोशिश की। जबकि IR-FP का उपयोग नैदानिक अभ्यास में OCT अधिग्रहण के लिए एक स्थानीयकरणकर्ता के रूप में किया जाता है, इसके लिए अभी भी एक अतिरिक्त उपकरण की आवश्यकता होती है, जो इसके व्यापक अनुप्रयोग को सीमित करता है। इसके अलावा, IR-FP में स्वयं अंतर्निहित कमियां हैं, जिनमें हाइपररिफ्लेक्टिव आर्टिफैक्ट्स, सबरेटिनल संरचनाओं के लिए अनुकूलित एक प्रतिबंधित रोशनी तरंग दैर्ध्य, और हार्ड एक्सयूडेट्स और हेमोरेज जैसे महत्वपूर्ण पैथोलॉजिकल मार्करों का अपर्याप्त विज़ुअलाइज़ेशन शामिल है।
लेखकों को इस पत्र को लिखने के लिए मजबूर करने वाला मौलिक "दर्द बिंदु" रेटिनल मोटाई मूल्यांकन के लिए एक व्यापक, सटीक और सुलभ समाधान प्रदान करने में मौजूदा तरीकों की अक्षमता है। OCT व्यापक उपयोग के लिए बहुत महंगा और जटिल है, जबकि पिछले C-FP और IR-FP आधारित तरीके या तो गलत थे, गहराई की जानकारी का अभाव था, या फिर भी विशेष उपकरण की आवश्यकता थी। यह पत्र C-FP से विशेष रूप से RTMs की भविष्यवाणी करने के लिए पहला दृष्टिकोण प्रस्तावित करके इन सीमाओं को दूर करने का लक्ष्य रखता है, जिससे पारंपरिक फंडस इमेजिंग को DME स्क्रीनिंग और निगरानी के लिए एक व्यापक और लागत प्रभावी नैदानिक उपकरण में बदल दिया जा सके, विशेष रूप से संसाधन-सीमित वातावरण में। यह उपन्यास दृष्टिकोण अधिक समय पर और प्रभावी हस्तक्षेपों के माध्यम से रोगी के परिणामों में सुधार करने का वादा करता है।
सहज डोमेन शब्द
यहां पेपर से कुछ विशेष शब्द दिए गए हैं, जिन्हें शून्य-आधारित पाठक के लिए रोजमर्रा की सादृश्यों के साथ समझाया गया है:
- डायबिटिक मैक्यूलर एडिमा (DME): कल्पना करें कि आपके आंख के "कैमरा सेंसर" (मैक्यूला) के केंद्र में एक छोटा, महत्वपूर्ण क्षेत्र मधुमेह के कारण सूज जाता है और धुंधला हो जाता है। यह कैमरे के लेंस पर एक छोटी सी पोखर बनने जैसा है, जिससे सब कुछ धुंधला हो जाता है।
- ऑप्टिकल कोहेरेंस टोमोग्राफी (OCT): इसे अपनी आंख के लिए एक सुपर-एडवांस्ड सोनार के रूप में सोचें। ध्वनि तरंगों के बजाय, यह आपकी रेटिना की अविश्वसनीय रूप से विस्तृत क्रॉस-सेक्शनल तस्वीरें बनाने के लिए प्रकाश तरंगों का उपयोग करता है, जो इसकी आंतरिक परतों और मोटाई को दिखाता है, ठीक उसी तरह जैसे केक को उसकी सभी परतों को देखने के लिए काटना।
- रेटिनल मोटाई मानचित्र (RTM): यह OCT स्कैन का आउटपुट है, आपकी रेटिना का एक रंगीन "हीट मैप"। सामान्य से अधिक मोटे क्षेत्र लाल या पीले रंग के हो सकते हैं, जबकि पतले क्षेत्र नीले होते हैं, जिससे डॉक्टरों को समस्या वाले स्थानों का एक त्वरित दृश्य मार्गदर्शक मिलता है, जैसे कि तापमान भिन्नता दिखाने वाला मौसम मानचित्र।
- कलर फंडस फोटोग्राफी (C-FP): यह बस आपकी आंख के पीछे की एक मानक, सपाट, 2D तस्वीर है, जो रक्त वाहिकाओं और ऑप्टिक तंत्रिका जैसी सतह की विशेषताओं को दिखाती है। यह एक परिदृश्य की नियमित तस्वीर लेने जैसा है; आप पेड़ और पहाड़ देखते हैं, लेकिन आपको उनकी ऊंचाई या गहराई का अंदाजा नहीं होता है।
- डिफ्यूजन मॉडल: यह कृत्रिम बुद्धिमत्ता का एक प्रकार है जो शुद्ध यादृच्छिक शोर के साथ शुरू करके और धीरे-धीरे इसे चरण-दर-चरण "डीनोइज़" करके जटिल चित्र बनाना सीखता है जब तक कि यह एक स्पष्ट, वांछित छवि नहीं बन जाता। यह एक मूर्तिकार के समान है जो एक आकारहीन संगमरमर के ब्लॉक से शुरू करता है और धीरे-धीरे, पुनरावृत्त रूप से तब तक तराशता है जब तक कि एक विस्तृत मूर्ति उभर न जाए।
संकेतन तालिका
| संकेतन | विवरण |
|---|---|
समस्या परिभाषा और बाधाएँ
मुख्य समस्या सूत्रीकरण और दुविधा
इस पत्र द्वारा संबोधित मुख्य समस्या केवल रंगीन फंडस फोटोग्राफी (C-FP) से रेटिनल मोटाई मानचित्र (RTMs) की सटीक भविष्यवाणी करना है।
इनपुट/वर्तमान स्थिति:
डायबिटिक मैक्यूलर एडिमा (DME) के प्रबंधन और रेटिनल मोटाई के मूल्यांकन के लिए वर्तमान स्वर्ण मानक में ऑप्टिकल कोहेरेंस टोमोग्राफी (OCT) शामिल है। OCT विस्तृत RTMs प्रदान करता है, जो रेटिनल संरचनाओं और विकृति के मात्रात्मक विज़ुअलाइज़ेशन हैं। इसके विपरीत, कलर फंडस फोटोग्राफी (C-FP) एक व्यापक रूप से उपलब्ध, लागत प्रभावी और आसानी से सुलभ 2D इमेजिंग तकनीक है, जो स्मार्टफोन के साथ भी संभव है। हालांकि, C-FP में पारंपरिक रूप से मात्रात्मक रेटिनल मोटाई मूल्यांकन के लिए आवश्यक गहराई की जानकारी का अभाव है।
वांछित अंतिम बिंदु/लक्ष्य स्थिति:
पत्र का उद्देश्य एक ऐसी प्रणाली विकसित करना है जो सीधे C-FP से सटीक और व्यापक RTMs उत्पन्न कर सके। अंतिम लक्ष्य इन C-FP-व्युत्पन्न RTMs को DME के लिए एक कुशल, सुलभ और लागत प्रभावी नैदानिक और निगरानी उपकरण के रूप में काम करना है, विशेष रूप से संसाधन-सीमित सेटिंग्स में। यह समय पर हस्तक्षेप, सूचित उपचार निर्णय और बेहतर रोगी दृश्य परिणामों की सुविधा प्रदान करेगा, प्रभावी ढंग से पारंपरिक फंडस इमेजिंग को एक शक्तिशाली नैदानिक संपत्ति में बदल देगा।
लुप्त कड़ी या गणितीय अंतर:
मौलिक लुप्त कड़ी 2D C-FP छवियों में गहराई रिज़ॉल्यूशन की अंतर्निहित कमी है। RTMs 3D मोटाई जानकारी का प्रतिनिधित्व करते हैं, जबकि C-FP केवल एक 2D प्रक्षेपण को कैप्चर करता है। C-FP से मोटाई की भविष्यवाणी करने के लिए इस अंतर को पाटने के पिछले प्रयास अक्सर प्रॉक्सी मार्करों (जैसे लिपिड जमाव) पर निर्भर करते थे जिनमें सीमित विशिष्टता और संवेदनशीलता थी, या ऐसे मॉडल जो बस आवश्यक नैदानिक सटीकता प्राप्त नहीं कर सके, विशेष रूप से विभिन्न छवि गुणवत्ता के साथ। गणितीय चुनौती एक 2D छवि से एक सतत, मात्रात्मक 3D मोटाई वितरण का अनुमान लगाना है जहां गहराई की जानकारी स्पष्ट माप के बजाय सूक्ष्म दृश्य संकेतों में निहित रूप से एन्कोड की जाती है।
दर्दनाक समझौता या दुविधा:
केंद्रीय दुविधा पहुंच/लागत-प्रभावशीलता और मात्रात्मक सटीकता/विवरण के बीच समझौता है। OCT उच्च-निष्ठा RTMs प्रदान करता है लेकिन यह महंगा, संचालित करने में जटिल और सीमित पहुंच वाला है, जिससे कई वास्तविक दुनिया के परिदृश्यों में उप-इष्टतम रोगी अनुवर्ती कार्रवाई होती है। C-FP अत्यधिक सुलभ और सस्ता है, लेकिन इसकी 2D प्रकृति ने ऐतिहासिक रूप से इसे विस्तृत DME प्रबंधन के लिए आवश्यक सटीक मात्रात्मक मोटाई माप प्रदान करने से रोका है। शोधकर्ता C-FP से पर्याप्त मात्रात्मक जानकारी निकालने के लिए फंस गए हैं, इसके अंतर्निहित पहुंच और कम लागत के लाभों को खोए बिना, या मध्यवर्ती, कम सुलभ तौर-तरीकों जैसे IR-FP पर भरोसा करके नई सीमाएं पेश किए बिना। यह पत्र सीधे इस दुविधा का सामना करता है, जो C-FP से विशेष रूप से OCT-स्तर RTM भविष्यवाणी प्राप्त करने का प्रयास करता है।
बाधाएँ और विफलता मोड
यह समस्या कई कठोर, यथार्थवादी बाधाओं के कारण अविश्वसनीय रूप से कठिन है:
- C-FP की अंतर्निहित 2D प्रकृति: जैसा कि उल्लेख किया गया है, C-FP कोई प्रत्यक्ष गहराई जानकारी प्रदान नहीं करता है। 2D छवि से 3D रेटिनल मोटाई का अनुमान लगाना एक ill-posed व्युत्क्रम समस्या है, जिसके लिए मॉडल को सतह सुविधाओं और अंतर्निहित मोटाई के बीच जटिल, गैर-स्पष्ट संबंधों को सीखने की आवश्यकता होती है।
- सूक्ष्म पैथोलॉजिकल बायोमार्कर: DME-प्रेरित रेटिनल परत अव्यवस्था C-FP में "सूक्ष्म बनावट और रंग भिन्नता" के रूप में प्रकट होती है। ये सूक्ष्म संकेत अनुभवी चिकित्सकों के लिए भी पहचानना चुनौतीपूर्ण हैं, स्वचालित प्रणाली के लिए तो छोड़ ही दें। मोटाई की सटीक भविष्यवाणी करने के लिए मॉडल को इन सूक्ष्म परिवर्तनों का पता लगाने में सक्षम होना चाहिए।
- स्थानिक मिसलिग्न्मेंट और पंजीकरण चुनौतियाँ: C-FP (इनपुट) और RTM ग्राउंड ट्रुथ (OCT से प्राप्त, अक्सर IR-FP द्वारा स्थानीयकृत) के बीच सटीक पिक्सेल-वार स्थानिक पत्राचार प्राप्त करना एक महत्वपूर्ण बाधा है। विभिन्न इमेजिंग तौर-तरीकों में अलग-अलग दृश्य क्षेत्र, रिज़ॉल्यूशन और संभावित विकृतियां होती हैं, जिससे सटीक मल्टी-मोडल पंजीकरण एक जटिल प्री-प्रोसेसिंग कदम बन जाता है। पत्र पंजीकरण के लिए एक मध्यस्थ के रूप में IR-FP के उपयोग का उल्लेख करता है, इस कठिनाई को उजागर करता है।
- DME अभिव्यक्तियों की विषमता: DME पैथोलॉजिकल घावों और अनियमित रेटिनल एनाटॉमी की एक विस्तृत श्रृंखला के साथ प्रस्तुत करता है। एक मजबूत मॉडल को इन विविध अभिव्यक्तियों में सामान्यीकृत करने की आवश्यकता है, जिसके लिए वैश्विक प्रासंगिक सुविधाओं (जैसे संवहनी नेटवर्क) और महीन-दानेदार स्थानीय विवरण (मैक्यूलर क्षेत्र परिवर्तन) दोनों को कैप्चर करने की आवश्यकता होती है।
- उच्च-निष्ठा पीढ़ी के लिए कम्प्यूटेशनल मांगें: प्रसार मॉडल जैसे उन्नत जनरेटिव मॉडल का उपयोग करके उच्च-रिज़ॉल्यूशन, सटीक RTMs उत्पन्न करना कम्प्यूटेशनल रूप से गहन हो सकता है, विशेष रूप से अनुमान (नमूनाकरण) चरण के दौरान। "उच्च निष्ठा बनाए रखते हुए नमूनाकरण में तेजी लाने" की आवश्यकता (जैसा कि DDIM द्वारा संबोधित किया गया है) इस कम्प्यूटेशनल बाधा को रेखांकित करती है।
- सख्त नैदानिक सटीकता आवश्यकताएँ: पिछले C-FP-आधारित भविष्यवाणी मॉडल "नैदानिक मानकों को पूरा करने में विफल रहे।" यह किसी भी नए समाधान की आवश्यक सटीकता, विशिष्टता और संवेदनशीलता के लिए एक उच्च बार निर्धारित करता है ताकि वह चिकित्सकीय रूप से व्यवहार्य हो सके। मॉडल की भविष्यवाणियों को महत्वपूर्ण चिकित्सा निर्णयों को सूचित करने के लिए विश्वसनीय होना चाहिए।
- डेटा उपलब्धता और एनोटेशन गुणवत्ता: ऐसे मॉडल को प्रशिक्षित करने के लिए RTMs और DME निदान के लिए विशेषज्ञ एनोटेशन के साथ सटीक रूप से युग्मित C-FP, IR-FP और OCT छवियों के बड़े डेटासेट की आवश्यकता होती है। ऐसे उच्च-गुणवत्ता, मल्टी-मोडल डेटासेट का अधिग्रहण और क्यूरेट करना एक समय लेने वाली और संसाधन-गहन प्रक्रिया है।
- मैक्यूलर विवरण बनाम परिधीय संदर्भ हानि: जबकि मैक्यूलर क्षेत्र मोटाई मूल्यांकन के लिए महत्वपूर्ण है, महत्वपूर्ण वैश्विक रेटिनल संरचनाएं और पैथोलॉजिकल बायोमार्कर (जैसे, ऑप्टिक तंत्रिका सिर, संवहनी नेटवर्क) व्यापक फंडस छवि में मौजूद हैं। केवल मैक्यूला पर ध्यान केंद्रित करने से इस महत्वपूर्ण "परिधीय संदर्भ" को खोने का जोखिम होता है, जिसके लिए वैश्विक और स्थानीय दोनों सुविधाओं को एकीकृत करने के लिए एक दोहरी-धारा दृष्टिकोण की आवश्यकता होती है।
यह दृष्टिकोण क्यों
चुनाव की अनिवार्यता
लेखकों ने खुद को एक ऐसी स्थिति में पाया जहां पारंपरिक "SOTA" (State-of-the-Art) विधियां, जिनमें मानक CNNs, बुनियादी प्रसार मॉडल, या ट्रांसफॉर्मर शामिल हैं, कलर फंडस फोटोग्राफी (C-FP) से विशेष, सूक्ष्म समस्या रेटिनल मोटाई मानचित्र (RTMs) की भविष्यवाणी के लिए पर्याप्त नहीं थे। मुख्य अहसास एक महत्वपूर्ण नैदानिक आवश्यकता से उपजा है: जबकि ऑप्टिकल कोहेरेंस टोमोग्राफी (OCT) डायबिटिक मैक्यूलर एडिमा (DME) के निदान और प्रबंधन के लिए स्वर्ण मानक है, इसकी उच्च लागत और संसाधन-सीमित सेटिंग्स में सीमित पहुंच इसे व्यापक स्क्रीनिंग और लगातार निगरानी के लिए अव्यावहारिक बनाती है। इसने अधिक सुलभ विकल्प की तत्काल मांग पैदा की।
कलर फंडस फोटोग्राफी (C-FP) सबसे व्यवहार्य, लागत प्रभावी स्क्रीनिंग टूल के रूप में उभरी, जो व्यापक रूप से उपलब्ध है और स्मार्टफोन के साथ भी संभव है। हालांकि, C-FP एक मौलिक चुनौती प्रस्तुत करता है: यह एक 2D इमेजिंग तकनीक है, जिसमें मात्रात्मक रेटिनल परत मूल्यांकन के लिए आवश्यक गहराई रिज़ॉल्यूशन का अभाव है। C-FP से रेटिनल मोटाई की भविष्यवाणी करने के पिछले प्रयासों ने प्रॉक्सी मार्करों जैसे लिपिड जमाव पर भरोसा किया, जिन्होंने सीमित विशिष्टता और संवेदनशीलता दिखाई। यहां तक कि अधिक उन्नत डीप लर्निंग मॉडल, जैसे कि Arcadu et al. [3] द्वारा, खराब छवि गुणवत्ता के साथ विशेष रूप से भविष्यवाणी सटीकता के लिए नैदानिक मानकों को पूरा करने में विफल रहे।
लेखकों ने इन्फ्रारेड फंडस फोटोग्राफी (IR-FP) को एक मध्यस्थ के रूप में भी माना, जिसका उपयोग कुछ SOTA विधियों जैसे DeepRT [15] और M²FRT [26] ने किया था। हालांकि, IR-FP के लिए अभी भी एक अतिरिक्त उपकरण की आवश्यकता होती है, जो इसके नैदानिक अनुप्रयोग को सीमित करता है। इसके अलावा, IR-FP में स्वयं अंतर्निहित सीमाएं हैं, जैसे हाइपररिफ्लेक्टिव आर्टिफैक्ट्स और महत्वपूर्ण पैथोलॉजिकल मार्करों जैसे हेमोरेज का अपर्याप्त विज़ुअलाइज़ेशन। इसके विपरीत, C-FP बेहतर स्थानिक रिज़ॉल्यूशन, एक व्यापक स्पेक्ट्रल रेंज और एक व्यापक दृश्य क्षेत्र प्रदान करता है। यह महत्वपूर्ण वैश्विक रेटिनल संरचनाओं, जैसे संवहनी नेटवर्क और ऑप्टिक तंत्रिका सिर को कैप्चर करता है, जो प्रमुख पैथोलॉजिकल बायोमार्कर हैं। जिस क्षण यह अहसास हुआ कि एक उपन्यास दृष्टिकोण की आवश्यकता थी, वह तब हुआ जब यह स्पष्ट हो गया कि मौजूदा विधियां या तो 2D-से-3D अनुमान को पर्याप्त रूप से सटीक रूप से संभाल नहीं सकती थीं, या वे इमेजिंग तौर-तरीकों पर निर्भर थीं जो पहुंच और लागत-प्रभावशीलता आवश्यकताओं को पूरा नहीं करती थीं। C-FP में सूक्ष्म बनावट और रंग भिन्नताएं, जो DME-प्रेरित रेटिनल परत अव्यवस्था का संकेत देती हैं, एक ऐसे मॉडल की मांग करती हैं जो मजबूत उच्च-स्तरीय सिमेंटिक सुविधाओं और सटीक स्थानीय मैक्यूलर विवरण दोनों को निकालने में सक्षम हो, एक ऐसी क्षमता जिसे मानक SOTA विधियों ने एक साथ और पर्याप्त निष्ठा के साथ प्राप्त करने के लिए संघर्ष किया।
तुलनात्मक श्रेष्ठता
रेटिनल मोटाई भविष्यवाणी के लिए ग्लोबल-टू-लोकल कंडीशनल डिफ्यूजन मॉडल (GLD-RT) केवल प्रदर्शन मेट्रिक्स से परे भारी गुणात्मक श्रेष्ठता प्रदर्शित करता है। इसका संरचनात्मक लाभ इसके अद्वितीय दोहरी-धारा, हाइब्रिड CNN-ट्रांसफार्मर कंडीशनल डिफ्यूजन आर्किटेक्चर में निहित है, जिसे विशेष रूप से RTM पीढ़ी के लिए C-FP डेटा की अंतर्निहित जटिलताओं को संबोधित करने के लिए डिज़ाइन किया गया है।
सबसे पहले, वैश्विक प्रासंगिक सुविधाओं और महीन-दानेदार स्थानीय विवरणों दोनों को एकीकृत करने की GLD-RT की क्षमता एक महत्वपूर्ण संरचनात्मक लाभ है। वैश्विक पूर्ण-फंडस एनकोडर ($E_g$), एक पूर्व-प्रशिक्षित RETFound मॉडल का लाभ उठाते हुए, पूरे C-FP छवि से मजबूत शारीरिक और पैथोलॉजिकल पैटर्न को कैप्चर करता है। साथ ही, स्थानीय मैक्यूलर एनकोडर ($E_m$), एक Swin-Transformer के साथ निर्मित, मैक्यूलर क्षेत्र से जटिल, महीन-दानेदार सुविधाओं को निकालता है। यह दोहरी-धारा दृष्टिकोण सुनिश्चित करता है कि मॉडल व्यापक संदर्भ को याद नहीं करता है, जबकि मैक्यूला में सूक्ष्म, फिर भी चिकित्सकीय रूप से महत्वपूर्ण, स्थानीय विविधताओं पर भी ध्यान केंद्रित करता है, जो अक्सर DME का संकेत देते हैं। यह महत्वपूर्ण है क्योंकि DME बड़े पैमाने पर वाहिका विशेषताओं और मिनट रेटिनल परत अखंडता दोनों को प्रभावित करता है।
दूसरे, कंडीशनल डिफ्यूजन डिकोडर का उपयोग इस जनरेटिव कार्य के लिए गुणात्मक रूप से श्रेष्ठ है। पारंपरिक विभेदक मॉडल या यहां तक कि सरल जनरेटिव एडवरसैरियल नेटवर्क (GANs) के विपरीत, डिफ्यूजन मॉडल धीरे-धीरे शोर को डीनोइज़ करके उच्च-निष्ठा, विविध और शारीरिक रूप से सुसंगत आउटपुट उत्पन्न करने में उत्कृष्ट हैं। यह RTM भविष्यवाणी के लिए विशेष रूप से फायदेमंद है, जहां आउटपुट एक जटिल, सतत मोटाई मानचित्र है जिसे शारीरिक और पैथोलॉजिकल दोनों आकारिकी को सटीक रूप से प्रतिबिंबित करना चाहिए। समृद्ध वैश्विक और स्थानीय सुविधाओं द्वारा निर्देशित डिफ्यूजन प्रक्रिया, विशेष रूप से चुनौतीपूर्ण केंद्रीय मैक्यूला (G1 क्षेत्र) में सूक्ष्म और अनियमित रेटिनल एनाटॉमी के अधिक सूक्ष्म और सटीक चित्रण की अनुमति देती है, जैसा कि fig. 2 में गुणात्मक परिणामों और ablation अध्ययन द्वारा प्रमाणित किया गया है। Denoising Diffusion Implicit Model (DDIM) को अपनाने से निष्ठा से समझौता किए बिना नमूनाकरण चरणों की संख्या में काफी कमी आती है।
यह संरचनात्मक डिजाइन GLD-RT को पिछले तरीकों की तुलना में C-FP छवियों में अंतर्निहित उच्च-आयामी शोर और परिवर्तनशीलता को बेहतर ढंग से संभालने में सक्षम बनाता है। यह केवल एक मानचित्र की भविष्यवाणी नहीं करता है; यह एक संभावित, विस्तृत RTM उत्पन्न करता है जो जटिल अंतर्निहित रेटिनल संरचना के साथ संरेखित होता है, एक ऐसा कार्य जहां सरल मॉडल अक्सर शारीरिक स्थिरता और महीन विवरण बनाए रखने में विफल रहते हैं।
बाधाओं के साथ संरेखण
चुना गया GLD-RT विधि समस्या की कठोर आवश्यकताओं के साथ पूरी तरह से संरेखित होती है, जो नैदानिक आवश्यकता और नवीन समाधान डिजाइन के बीच एक "विवाह" बनाती है।
-
बाधा: सीमित OCT पहुंच और उच्च लागत।
- संरेखण: GLD-RT RTMs की भविष्यवाणी करने वाला पहला मॉडल है विशेष रूप से C-FP से। C-FP व्यापक रूप से उपलब्ध, लागत प्रभावी है, और स्मार्टफोन के साथ भी कैप्चर किया जा सकता है। यह सीधे एक सुलभ और किफायती नैदानिक उपकरण की आवश्यकता को संबोधित करता है, संसाधन-सीमित सेटिंग्स के लिए एक व्यापक स्क्रीनिंग और निगरानी समाधान में पारंपरिक फंडस इमेजिंग को बदल देता है।
-
बाधा: C-FP की 2D प्रकृति में मात्रात्मक मूल्यांकन के लिए गहराई रिज़ॉल्यूशन का अभाव है।
- संरेखण: कंडीशनल डिफ्यूजन मॉडल स्वाभाविक रूप से एक जनरेटिव मॉडल है जो कंडीशनल इनपुट से जटिल, उच्च-आयामी आउटपुट को संश्लेषित करने में सक्षम है। 2D C-FP सुविधाओं से 3D रेटिनल मोटाई वितरण तक जटिल मैपिंग सीखकर, GLD-RT प्रभावी ढंग से गहराई की जानकारी का अनुमान लगाता है जो इनपुट छवि में स्पष्ट रूप से मौजूद नहीं है। यह जनरेटिव क्षमता 2D सीमा को दूर करने की कुंजी है।
-
बाधा: सटीक, विस्तृत और चिकित्सकीय रूप से प्रासंगिक RTMs की आवश्यकता।
- संरेखण: दोहरी-धारा वास्तुकला (वैश्विक-से-स्थानीय एनकोडर) सुनिश्चित करती है कि व्यापक शारीरिक संदर्भ और महीन-दानेदार मैक्यूलर विवरण दोनों कैप्चर किए गए हैं। वैश्विक एनकोडर (RETFound) मजबूत उच्च-स्तरीय सिमेंटिक सुविधाएँ प्रदान करता है, जबकि स्थानीय एनकोडर (Swin-Transformer) सटीक स्थानीय विवरण निकालता है। इन्हें फिर फ्यूज किया जाता है और एक पदानुक्रमित डिफ्यूजन डिकोडर में फीड किया जाता है जो "वैश्विक-से-स्थानीय शारीरिक स्थिरता" सुनिश्चित करता है। यह डिजाइन शारीरिक और पैथोलॉजिकल दोनों रेटिनल आकारिकी के सटीक चित्रण के लिए महत्वपूर्ण है, जो नैदानिक उपयोगिता और रेटिनल संरचनाओं की विस्तृत परीक्षा के लिए सर्वोपरि है। ablation अध्ययन पुष्टि करता है कि डिफ्यूजन प्रक्रिया मैक्यूलर संरचना को महीन विवरणों के साथ सफलतापूर्वक कैप्चर करती है, विशेष रूप से जटिल केंद्रीय मैक्यूला (G1) में।
-
बाधा: संसाधन-सीमित सेटिंग्स (दक्षता) के लिए व्यावहारिकता।
- संरेखण: जबकि डिफ्यूजन मॉडल कम्प्यूटेशनल रूप से गहन हो सकते हैं, नमूनाकरण के लिए DDIM का उपयोग अनुमान के लिए आवश्यक चरणों की संख्या को काफी कम कर देता है, जिससे प्रक्रिया वास्तविक दुनिया के नैदानिक अनुप्रयोग के लिए अधिक कुशल और व्यावहारिक हो जाती है। समग्र लक्ष्य "समय पर हस्तक्षेप के लिए एक कुशल नैदानिक उपकरण" प्रदान करना है।
विकल्पों का अस्वीकरण
यह पत्र स्पष्ट रूप से और अंतर्निहित रूप से कई वैकल्पिक दृष्टिकोणों को अस्वीकार करता है, C-FP से RTM भविष्यवाणी के संदर्भ में उनकी सीमाओं को उजागर करके।
सबसे पहले, प्रॉक्सी मार्करों पर निर्भर पारंपरिक विधियों (जैसे, लिपिड जमाव, लेजर निशान) को अपर्याप्त माना गया। लेखकों का कहना है कि इन दृष्टिकोणों ने "DME का पता लगाने के लिए सीमित विशिष्टता और संवेदनशीलता" दिखाई [28, 29]। यह गैर-मशीन लर्निंग या सरल नियम-आधारित विधियों का एक स्पष्ट अस्वीकरण है जो DME की जटिल, सूक्ष्म अभिव्यक्तियों को कैप्चर नहीं कर सकते हैं।
दूसरे, C-FP-आधारित RTM भविष्यवाणी के लिए पहले के डीप लर्निंग मॉडल को कमी पाया गया। पत्र में उल्लेख किया गया है कि Arcadu et al. [3] द्वारा एक मॉडल ने खराब छवि गुणवत्ता के साथ विशेष रूप से भविष्यवाणी सटीकता के लिए "नैदानिक मानकों को पूरा करने में विफल" रहा। यह बताता है कि सरल CNN-आधारित आर्किटेक्चर या कम परिष्कृत जनरेटिव मॉडल (जो उस समय आम थे) C-FP से आवश्यक जानकारी निकालने में असमर्थ थे ताकि चिकित्सकीय रूप से स्वीकार्य RTMs उत्पन्न हो सकें। वे संभवतः 2D-से-3D अनुमान और C-FP में सूक्ष्म विविधताओं से जूझ रहे थे जो DME का संकेत देते हैं।
तीसरे, इन्फ्रारेड फंडस फोटोग्राफी (IR-FP) पर निर्भर विधियों, जैसे DeepRT [15] और M²FRT [26], को व्यावहारिक और अंतर्निहित इमेजिंग सीमाओं के कारण एकमात्र व्यवहार्य समाधान के रूप में अस्वीकार कर दिया गया था। जबकि इन विधियों ने सुधार दिखाया, उन्हें अभी भी "IR-FP को कैप्चर करने के लिए एक अतिरिक्त उपकरण की आवश्यकता थी," जो संसाधन-सीमित सेटिंग्स में उनके नैदानिक अनुप्रयोग को सीमित करता है। इसके अलावा, IR-FP स्वयं "हाइपररिफ्लेक्टिव आर्टिफैक्ट्स, सबरेटिनल संरचनाओं के लिए अनुकूलित प्रतिबंधित रोशनी तरंग दैर्ध्य, और महत्वपूर्ण पैथोलॉजिकल मार्करों के अपर्याप्त विज़ुअलाइज़ेशन" से ग्रस्त है [1]। यह C-FP को एक अधिक वांछनीय इनपुट बनाता है, इसकी चुनौतियों के बावजूद।
अंत में, ablation अध्ययन सरल डिकोडिंग तंत्र की अस्वीकृति और डिफ्यूजन प्रक्रिया की आवश्यकता के लिए निर्णायक सबूत प्रदान करता है। परिणाम बताते हैं कि प्रस्तावित डिफ्यूजन डिकोडर ($D_d$) ने डिफ्यूजन के बिना डिकोडर ($D_{nd}$) की तुलना में "मॉडल के प्रदर्शन में उल्लेखनीय रूप से सुधार किया, विशेष रूप से केंद्रीय मैक्यूला (G1) में"। इसका तात्पर्य है कि मानक डिकोडिंग दृष्टिकोण, जिनका उपयोग गैर-डिफ्यूजन जनरेटिव मॉडल या प्रत्यक्ष प्रतिगमन मॉडल में किया जा सकता है, इस जटिल क्षेत्र में आवश्यक महीन संरचनात्मक विवरण और शारीरिक स्थिरता को कैप्चर करने के लिए अपर्याप्त थे। यह कथन कि "ग्लोबल-टू-लोकल फीचर कंडीशनिंग ने मानक डिकोडिंग दृष्टिकोणों को बेहतर प्रदर्शन किया" आगे इस बात को पुष्ट करता है कि सरल, गैर-पदानुक्रमित या गैर-कंडीशनल जनरेटिव फ्रेमवर्क C-FP से बहु-स्तरीय जानकारी का लाभ उठाने में कम प्रभावी रहे होंगे। हालांकि स्पष्ट रूप से GANs का नाम नहीं लिया गया है, उच्च-निष्ठा पीढ़ी, शारीरिक स्थिरता और महीन विवरणों को कैप्चर करने की क्षमता पर जोर दृढ़ता से बताता है कि डिफ्यूजन मॉडल को इन पहलुओं में उनके बेहतर प्रदर्शन के कारण अन्य जनरेटिव प्रतिमानों पर चुना गया था।
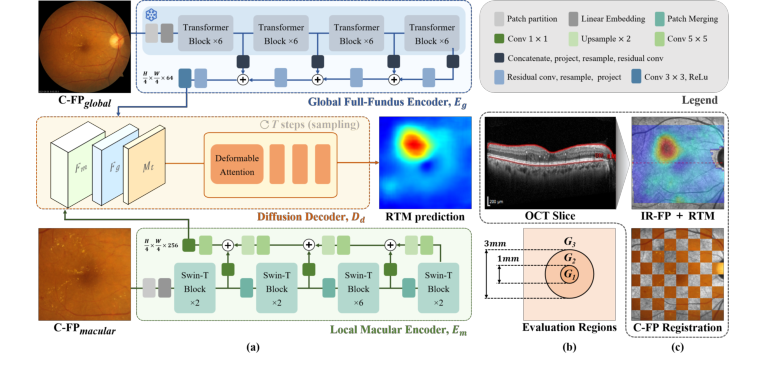 Figure 1. (a) GLD-RT leverages a dual-stream diffusion framework to integrate global contextual features with fine-grained details. (b) Evaluation regions for RTM predic- tion. (c)IR-FP, the localizer in OCT imaging that generates RTM, is used to register C-FPglobal with RTM, generating C-FPmacular
Figure 1. (a) GLD-RT leverages a dual-stream diffusion framework to integrate global contextual features with fine-grained details. (b) Evaluation regions for RTM predic- tion. (c)IR-FP, the localizer in OCT imaging that generates RTM, is used to register C-FPglobal with RTM, generating C-FPmacular
गणितीय और तार्किक तंत्र
मास्टर समीकरण
GLD-RT फ्रेमवर्क के सीखने के तंत्र का पूर्ण मूल इसका अनुकूलन उद्देश्य है, जो एक माध्य वर्ग त्रुटि (MSE) हानि फ़ंक्शन है। यह समीकरण मॉडल को इसके भविष्यवाणियों और ग्राउंड ट्रुथ के बीच अंतर को कम करके कलर फंडस फोटोग्राफी (C-FP) से रेटिनल मोटाई मानचित्र (RTMs) की सटीक भविष्यवाणी करने के लिए मार्गदर्शन करता है।
मास्टर समीकरण प्रस्तुत किया गया है:
$$ \mathcal{L} = \mathbb{E}_{M,t,F_m,F_g} [||M – D_d(M_t, t, F_m, F_g) ||^2] $$
पद-दर-पद ऑटोप्सी
आइए प्रत्येक घटक की भूमिका को समझने के लिए इस समीकरण का विश्लेषण करें:
-
$\mathcal{L}$:
- गणितीय परिभाषा: यह प्रतीक समग्र हानि फ़ंक्शन का प्रतिनिधित्व करता है, विशेष रूप से माध्य वर्ग त्रुटि (MSE) हानि।
- भौतिक/तार्किक भूमिका: यह मॉडल की अनुमानित RTM और वास्तविक ग्राउंड ट्रुथ RTM के बीच विसंगति को मापता है। मॉडल के प्रशिक्षण के दौरान प्राथमिक उद्देश्य इस मान को कम करना है, जिससे मॉडल को अधिक सटीक भविष्यवाणियां करने के लिए प्रेरित किया जा सके।
- क्यों उपयोग किया जाता है: MSE प्रतिगमन कार्यों के लिए एक मानक और प्रभावी हानि फ़ंक्शन है। इसका वर्ग संचालन बड़े त्रुटियों को छोटी त्रुटियों की तुलना में अधिक दंडित करता है, जिससे मॉडल को महत्वपूर्ण विचलन को कम करने के लिए प्रोत्साहित किया जाता है।
-
$\mathbb{E}_{M,t,F_m,F_g}$:
- गणितीय परिभाषा: यह अपेक्षा ऑपरेटर को दर्शाता है, जो यादृच्छिक चर $M$, $t$, $F_m$, और $F_g$ पर एक औसत का संकेत देता है।
- भौतिक/तार्किक भूमिका: व्यवहार में, प्रशिक्षण के दौरान, इस अपेक्षा का अनुमान प्रशिक्षण नमूनों के एक बैच पर वर्ग अंतरों का औसत करके लगाया जाता है। प्रत्येक नमूना में एक ग्राउंड ट्रुथ RTM ($M$), एक विशिष्ट शोर टाइमस्टेप ($t$), स्थानीय मैक्यूलर सुविधाएँ ($F_m$), और वैश्विक पूर्ण-फंडस सुविधाएँ ($F_g$) शामिल हैं। यह औसत सुनिश्चित करता है कि मॉडल इनपुट और शोर की स्थितियों की एक विविध श्रृंखला में अच्छी तरह से सामान्यीकृत करना सीखता है।
- क्यों उपयोग किया जाता है: नमूनों के एक बैच पर हानि का औसत करना, एक एकल नमूने के लिए हानि की गणना की तुलना में मॉडल मापदंडों को अद्यतन करने के लिए एक अधिक स्थिर और प्रतिनिधि ग्रेडिएंट प्रदान करता है, जो शोरगुल वाला हो सकता है।
-
$M$:
- गणितीय परिभाषा: यह ग्राउंड ट्रुथ रेटिनल मोटाई मानचित्र (RTM) का प्रतिनिधित्व करता है। यह वास्तविक मानों का एक 2D मैट्रिक्स है, जिसमें आमतौर पर $H \times W$ आयाम होते हैं, जहां $H$ और $W$ मानचित्र की ऊंचाई और चौड़ाई हैं।
- भौतिक/तार्किक भूमिका: यह "सही उत्तर" या लक्ष्य आउटपुट है जिसकी GLD-RT मॉडल भविष्यवाणी करने का लक्ष्य रखता है। यह मॉडल की भविष्यवाणियों की तुलना करने के लिए संदर्भ के रूप में कार्य करता है।
- क्यों उपयोग किया जाता है: यह त्रुटि की गणना करने और मॉडल के प्रदर्शन का मूल्यांकन करने के लिए आवश्यक बेंचमार्क है।
-
$D_d(\cdot)$:
- गणितीय परिभाषा: यह डिफ्यूजन डिकोडर का प्रतिनिधित्व करता है, जो एक जटिल तंत्रिका नेटवर्क है। यह एक शोरगुल RTM, एक टाइमस्टेप और कंडीशनल सुविधाओं को इनपुट के रूप में लेता है, और इसका लक्ष्य मूल, अन-शोरगुल RTM की भविष्यवाणी करना है।
- भौतिक/तार्किक भूमिका: यह मॉडल का जनरेटिव इंजन है। प्रशिक्षण के दौरान, यह C-FP सुविधाओं से निकाले गए मार्गदर्शन से, एक दूषित RTM को उसके मूल स्थिति में "डीनोइज़" करना सीखता है। अनुमान के दौरान, यह C-FP सुविधाओं को मार्गदर्शन के रूप में उपयोग करते हुए, शुद्ध शोर को एक अनुमानित RTM में पुनरावृत्त रूप से परिवर्तित करता है।
- क्यों उपयोग किया जाता है: डिफ्यूजन मॉडल फ्रेमवर्क को उच्च-निष्ठा चित्र उत्पन्न करने और जटिल डेटा वितरणों को मॉडल करने की इसकी सिद्ध क्षमता के लिए चुना गया है, जो RTMs के जटिल विवरणों के लिए महत्वपूर्ण है। कंडीशनल पहलू जनरेशन प्रक्रिया को इनपुट C-FP सुविधाओं द्वारा निर्देशित करने की अनुमति देता है।
-
$M_t$:
- गणितीय परिभाषा: यह एक विशिष्ट डिफ्यूजन टाइमस्टेप $t$ पर ग्राउंड ट्रुथ RTM, $M$, का एक शोरगुल संस्करण है। इसे $M$ में निर्धारित गॉसियन शोर जोड़कर बनाया गया है।
- भौतिक/तार्किक भूमिका: यह प्रशिक्षण के दौरान डिफ्यूजन डिकोडर के लिए इनपुट के रूप में कार्य करता है। डिकोडर का कार्य $M_t$ से शोर को प्रभावी ढंग से हटाकर मूल $M$ को पुनर्निर्मित करना सीखना है। यह प्रक्रिया धीरे-धीरे शोर पेश करने वाली एक फॉरवर्ड डिफ्यूजन प्रक्रिया के उलटने की नकल करती है।
- क्यों उपयोग किया जाता है: डिफ्यूजन मॉडल शोर जोड़ने की एक पूर्वनिर्धारित प्रक्रिया को उलटने के लिए सीखने से संचालित होते हैं। विभिन्न टाइमस्टेप्स पर $M_t$ पर मॉडल को प्रशिक्षित करके, यह शोर के एक विस्तृत स्पेक्ट्रम में डीनोइज़ करने की क्षमता विकसित करता है।
-
$t$:
- गणितीय परिभाषा: यह डिफ्यूजन टाइमस्टेप है, एक पूर्णांक मान जो $M$ में जोड़े गए शोर की मात्रा को इंगित करता है ताकि $M_t$ का उत्पादन हो सके। यह आमतौर पर एक छोटी सी मान (न्यूनतम शोर) से एक बड़ी सी मान (अधिकतम शोर) तक होता है।
- भौतिक/तार्किक भूमिका: यह डिफ्यूजन डिकोडर को $M_t$ में मौजूद वर्तमान शोर स्तर के बारे में महत्वपूर्ण जानकारी प्रदान करता है। $t$ जानने से डिकोडर उस विशिष्ट शोर तीव्रता के लिए उपयुक्त डीनोइज़िंग ऑपरेशन लागू कर सकता है।
- क्यों उपयोग किया जाता है: टाइमस्टेप डिफ्यूजन मॉडल के लिए मौलिक है, क्योंकि डीनोइज़िंग रणनीति शोर की मात्रा पर अत्यधिक निर्भर है। विभिन्न टाइमस्टेप्स के लिए अलग-अलग डीनोइज़िंग दृष्टिकोणों की आवश्यकता होती है।
-
$F_m$:
- गणितीय परिभाषा: ये स्थानीय मैक्यूलर एनकोडर ($E_m$) द्वारा C-FP छवि ($C\text{-}FP_{macular}$) के क्रॉप किए गए मैक्यूलर क्षेत्र से निकाले गए महीन-दानेदार स्थानीय मैक्यूलर सुविधाएँ हैं। इन सुविधाओं के आयाम $R^{\frac{H}{4} \times \frac{W}{4} \times 256}$ हैं।
- भौतिक/तार्किक भूमिका: ये सुविधाएँ मैक्यूलर क्षेत्र के बारे में अत्यधिक विस्तृत जानकारी प्रदान करती हैं, जो इस चिकित्सकीय रूप से महत्वपूर्ण क्षेत्र में सटीक मोटाई भविष्यवाणी के लिए आवश्यक है। वे एक स्थानीय स्थिति के रूप में कार्य करते हैं, डिफ्यूजन प्रक्रिया को महीन-दानेदार शारीरिक संदर्भ के साथ निर्देशित करते हैं।
- क्यों उपयोग किया जाता है: मैक्यूलर क्षेत्र वह स्थान है जहाँ डायबिटिक मैक्यूलर एडिमा (DME) विकृति सबसे अधिक स्पष्ट होती है और इसके लिए सावधानीपूर्वक विश्लेषण की आवश्यकता होती है। $E_m$ एनकोडर, एक Swin-Transformer और फीचर पिरामिड नेटवर्क का उपयोग करते हुए, इन पदानुक्रमित और विस्तृत सुविधाओं को कैप्चर करने के लिए डिज़ाइन किया गया है।
-
$F_g$:
- गणितीय परिभाषा: ये वैश्विक पूर्ण-फंडस एनकोडर ($E_g$) द्वारा पूरे C-FP छवि ($C\text{-}FP_{global}$) से निकाले गए वैश्विक पूर्ण-फंडस सुविधाएँ हैं। इन सुविधाओं के आयाम $R^{\frac{H}{16} \times \frac{W}{16} \times 64}$ हैं।
- भौतिक/तार्किक भूमिका: ये सुविधाएँ उच्च-स्तरीय सिमेंटिक संदर्भ और समग्र रेटिनल संरचना के बारे में जानकारी प्रदान करती हैं। वे मैक्यूलर क्षेत्र पर ध्यान केंद्रित करते समय खोए हुए किसी भी परिधीय संदर्भ की भरपाई करते हैं, डिफ्यूजन प्रक्रिया के लिए एक वैश्विक स्थिति के रूप में कार्य करते हैं।
- क्यों उपयोग किया जाता है: वैश्विक संदर्भ पूरे रेटिना में शारीरिक स्थिरता सुनिश्चित करने में मदद करता है और व्यापक पैथोलॉजिकल मार्कर (जैसे संवहनी नेटवर्क) प्रदान करता है जो मैक्यूलर मोटाई को प्रभावित कर सकते हैं। $E_g$ एनकोडर इस उद्देश्य के लिए एक पूर्व-प्रशिक्षित RETFound विजन ट्रांसफार्मर का लाभ उठाता है।
-
$|| \cdot ||^2$:
- गणितीय परिभाषा: यह वर्ग L2 नॉर्म को दर्शाता है, जो एक वेक्टर या मैट्रिक्स में सभी तत्वों के वर्गों का योग करता है। एक मैट्रिक्स $A$ के लिए, $||A||^2 = \sum_{i,j} A_{i,j}^2$।
- भौतिक/तार्किक भूमिका: यह ग्राउंड ट्रुथ RTM और डिफ्यूजन डिकोडर द्वारा अनुमानित RTM के बीच वर्ग अंतर की गणना करता है। अंतर को वर्ग करने से यह सुनिश्चित होता है कि सकारात्मक और नकारात्मक दोनों त्रुटियां समान रूप से हानि में योगदान करती हैं और बड़ी त्रुटियों को अधिक भारी दंडित किया जाता है।
- क्यों उपयोग किया जाता है: वर्ग L2 नॉर्म माध्य वर्ग त्रुटि (MSE) हानि का मौलिक घटक है, जिसे इसके अवकलनीयता और उत्तल प्रकृति के कारण प्रतिगमन कार्यों के लिए व्यापक रूप से अपनाया जाता है, जिससे अनुकूलन प्रक्रिया सरल हो जाती है।
-
$M - D_d(\dots)$:
- गणितीय परिभाषा: यह ग्राउंड ट्रुथ RTM और अनुमानित RTM के बीच तत्व-वार अंतर का प्रतिनिधित्व करता है।
- भौतिक/तार्किक भूमिका: यह वह त्रुटि या अवशिष्ट है जिसे मॉडल कम करने का प्रयास करता है। यह वांछित आउटपुट और मॉडल के वास्तविक आउटपुट के बीच सीधा तुलना है।
- क्यों उपयोग किया जाता है: यह सीधा घटाव उस त्रुटि को मापने का आधार बनता है जिसे मॉडल को कम करना सीखना चाहिए।
चरण-दर-चरण प्रवाह
आइए GLD-RT तंत्र के माध्यम से एक एकल अमूर्त डेटा बिंदु की यात्रा का पता लगाएं, इनपुट से हानि गणना तक:
-
प्रारंभिक डेटा इनपुट: प्रक्रिया एक कलर फंडस फोटोग्राफी (C-FP) छवि और ऑप्टिकल कोहेरेंस टोमोग्राफी (OCT) स्कैन से प्राप्त इसके संबंधित ग्राउंड ट्रुथ रेटिनल मोटाई मानचित्र (RTM), $M$ के साथ शुरू होती है।
-
मल्टी-मोडल पंजीकरण और क्रॉपिंग: C-FP छवि को RTM के स्थानिक निर्देशांक के साथ पिक्सेल-वार संरेखित करने के लिए एक सटीक पंजीकरण प्रक्रिया से गुजरना पड़ता है। इसमें संदर्भ के रूप में एक मध्यवर्ती इन्फ्रारेड फंडस फोटोग्राफी (IR-FP) छवि का उपयोग शामिल है। प्रमुख चरणों में रेटिनल वाहिकाओं का विभाजन, प्रमुख बिंदुओं का पता लगाना (जैसे, AKAZE का उपयोग करके), होमोग्राफी मैट्रिक्स की गणना (जैसे, RANSAC के साथ), और पूर्ण C-FP ($C\text{-}FP_{global}$) का IR-FP के लिए गैर-कठोर पंजीकरण शामिल है। इससे, एक क्रॉप किया गया संस्करण, $C\text{-}FP_{macular}$, उत्पन्न होता है, जो विशेष रूप से RTM के अनुरूप मैक्यूलर क्षेत्र पर केंद्रित होता है।
-
समानांतर सुविधा निष्कर्षण:
- वैश्विक संदर्भ धारा: पूर्ण $C\text{-}FP_{global}$ छवि को ग्लोबल फुल-फंडस एनकोडर ($E_g$) में फीड किया जाता है। यह एनकोडर, जो एक पूर्व-प्रशिक्षित RETFound विजन ट्रांसफार्मर का लाभ उठाता है, समग्र रेटिनल संरचना और व्यापक प्रासंगिक जानकारी को समाहित करते हुए, उच्च-स्तरीय सिमेंटिक सुविधाओं, $F_g$ को निकालने के लिए छवि को संसाधित करता है।
- स्थानीय विवरण धारा: साथ ही, क्रॉप की गई $C\text{-}FP_{macular}$ छवि स्थानीय मैक्यूलर एनकोडर ($E_m$) में प्रवेश करती है। यह एनकोडर, एक Swin-Transformer और फीचर पिरामिड नेटवर्क के साथ निर्मित, महीन-दानेदार, पदानुक्रमित सुविधाओं, $F_m$ को निकालता है, जो मैक्यूलर क्षेत्र के लिए विशिष्ट विस्तृत जानकारी प्रदान करता है।
-
शोर इंजेक्शन (केवल प्रशिक्षण चरण): यदि मॉडल अपने प्रशिक्षण चरण में है, तो एक यादृच्छिक टाइमस्टेप $t$ एक पूर्वनिर्धारित शोर अनुसूची से चुना जाता है। इस टाइमस्टेप के अनुसार स्केल किया गया गॉसियन शोर, फिर ग्राउंड ट्रुथ RTM, $M$ में जोड़ा जाता है, जिसके परिणामस्वरूप एक शोरगुल RTM, $M_t$ होता है।
-
डिफ्यूजन डिकोडर द्वारा कंडीशनल डीनोइज़िंग: शोरगुल RTM, $M_t$, चुने गए टाइमस्टेप $t$, और निकाले गए कंडीशनल सुविधाओं ($F_m$ और $F_g$) के साथ, सभी डिफ्यूजन डिकोडर ($D_d$) में पास किए जाते हैं। डिकोडर का प्राथमिक कार्य $M_t$ को मूल, स्वच्छ RTM, $M$ की ओर "डीनोइज़" करना सीखना है। यह डीनोइज़िंग प्रक्रिया $F_m$ (स्थानीय विवरण) और $F_g$ (वैश्विक संदर्भ) द्वारा प्रदान की गई समृद्ध प्रासंगिक जानकारी द्वारा महत्वपूर्ण रूप से निर्देशित होती है।
-
RTM भविष्यवाणी: डिकोडर मूल RTM के अपने सर्वोत्तम अनुमान को आउटपुट करता है, जिसे हम $D_d(M_t, t, F_m, F_g)$ के रूप में दर्शा सकते हैं।
-
हानि गणना: अनुमानित RTM की फिर सीधे मूल ग्राउंड ट्रुथ RTM, $M$ से तुलना की जाती है। उनके तत्व-वार अंतर के वर्ग L2 नॉर्म, $||M – D_d(M_t, t, F_m, F_g) ||^2$, की गणना की जाती है। यह मान इस विशिष्ट डेटा बिंदु के लिए त्रुटि का प्रतिनिधित्व करता है।
-
बैच औसत: इस व्यक्तिगत वर्ग त्रुटि को फिर वर्तमान प्रशिक्षण बैच में सभी नमूनों (प्रत्येक अपने स्वयं के $M$, $t$, $F_m$, $F_g$ संयोजन के साथ) पर औसत किया जाता है ताकि उस पुनरावृति के लिए अंतिम हानि $\mathcal{L}$ प्राप्त हो सके।
-
अनुमान (जनरेशन चरण): अनुमान के दौरान, डिफ्यूजन डिकोडर के लिए प्रक्रिया बदल जाती है। ग्राउंड ट्रुथ RTM के शोरगुल संस्करण के साथ शुरू करने के बजाय, डिकोडर शुद्ध यादृच्छिक शोर के साथ शुरू होता है। यह फिर $F_m$ और $F_g$ सुविधाओं से निर्देशित, पुनरावृत्त रूप से डीनोइज़िंग चरणों को लागू करता है जो एक नए C-FP इनपुट से निकाले गए हैं। यह पुनरावृत्त प्रक्रिया, अक्सर एक गैर-मार्कोवियन नियतात्मक नमूनाकरण दृष्टिकोण जैसे DDIM का उपयोग करके, प्रारंभिक शोर को एक सुसंगत और विस्तृत RTM भविष्यवाणी में धीरे-धीरे बदल देती है, जो काफी कम चरणों (जैसे, 5 चरण) में होती है।
अनुकूलन गतिशीलता
GLD-RT तंत्र माध्य वर्ग त्रुटि (MSE) हानि फ़ंक्शन, $\mathcal{L}$ को पुनरावृत्त रूप से कम करके ग्रेडिएंट-आधारित अनुकूलन की प्रक्रिया के माध्यम से सीखता है, अद्यतन करता है और अभिसरण करता है।
-
हानि परिदृश्य: मॉडल का सीखना एक जटिल हानि परिदृश्य के भीतर होता है। यह परिदृश्य ग्राउंड ट्रुथ RTMs, विभिन्न टाइमस्टेप्स पर पेश किए गए शोर के विभिन्न स्तरों, और C-FP छवियों से निकाले गए बहु-स्तरीय कंडीशनल सुविधाओं के बीच जटिल संबंध से आकार लेता है। अंतिम लक्ष्य मॉडल मापदंडों (एनकोडर $E_m$, $E_g$, और डिफ्यूजन डिकोडर $D_d$ के भीतर वजन और पूर्वाग्रह) के एक सेट को खोजना है जो अनुमानित RTMs लगातार ग्राउंड ट्रुथ के साथ निकटता से संरेखित होते हैं, जो एक "घाटी" के अनुरूप है। जबकि डीप न्यूरल नेटवर्क के समग्र परिदृश्य स्वाभाविक रूप से गैर-उत्तल हैं, MSE उद्देश्य अनुकूलन के लिए एक स्पष्ट, अवकलनीय संकेत प्रदान करता है। डिफ्यूजन प्रक्रिया की अंतर्निहित संरचना, जिसमें शोर के स्पेक्ट्रम में डीनोइज़िंग सीखना शामिल है, एक शक्तिशाली नियमितीकरण के रूप में कार्य करता है, संभावित रूप से सरल प्रत्यक्ष प्रतिगमन मॉडल की तुलना में एक चिकना और अधिक मजबूत हानि परिदृश्य की ओर ले जाता है।
-
ग्रेडिएंट गणना: प्रत्येक प्रशिक्षण पुनरावृति में, जब डेटा के एक बैच के लिए हानि $\mathcal{L}$ की गणना की जाती है, तो बैकप्रॉपैगेशन की प्रक्रिया शुरू की जाती है। यह एल्गोरिथम एनकोडर ($E_m$, $E_g$) और डिफ्यूजन डिकोडर ($D_d$) के भीतर प्रत्येक प्रशिक्षण योग्य पैरामीटर के संबंध में ग्रेडिएंट की कुशलतापूर्वक गणना करता है। ये ग्रेडिएंट महत्वपूर्ण हैं; वे सटीक दिशा और परिमाण को इंगित करते हैं जिससे प्रत्येक पैरामीटर को गणना की गई हानि को कम करने के लिए समायोजित करने की आवश्यकता होती है।
-
पैरामीटर अद्यतन: पत्र निर्दिष्ट करता है कि मॉडल के मापदंडों को अद्यतन करने के लिए Adam ऑप्टिमाइज़र [16] का उपयोग किया जाता है। Adam एक परिष्कृत अनुकूली सीखने की दर अनुकूलन एल्गोरिथम है। यह पिछले ग्रेडिएंट्स (पहले क्षण) और पिछले वर्ग ग्रेडिएंट्स (दूसरे क्षण) के घातीय रूप से भारित औसत को बनाए रखकर विभिन्न मापदंडों के लिए व्यक्तिगत सीखने की दरों की गतिशील रूप से गणना करता है।
- Adam के लिए विशिष्ट हाइपरपैरामीटर $\beta_1 = 0.9$ और $\beta_2 = 0.999$ पर सेट किए गए हैं, जो व्यापक रूप से स्वीकृत डिफ़ॉल्ट मान हैं।
- सीखने की दर को प्रभावी ढंग से प्रबंधित करने के लिए, 16-एपॉक "वार्म-अप" चरण के बाद एक कोसाइन क्षय शेड्यूलिंग रणनीति नियोजित की जाती है, जिसके दौरान सीखने की दर धीरे-धीरे बहुत छोटे मान ($1 \times 10^{-8}$) से थोड़े बड़े मान ($6 \times 10^{-5}$) तक बढ़ जाती है। इस वार्म-अप के बाद, सीखने की दर 300 एपॉक पर एक कोसाइन फ़ंक्शन के अनुसार धीरे-धीरे घट जाती है। यह रणनीति मॉडल को शुरू में सावधानीपूर्वक हानि परिदृश्य का पता लगाने, फिर अभिसरण को तेज करने और अंत में सीखने की दर को कम करके मापदंडों को ठीक करने की अनुमति देती है, जिससे ओवरशूटिंग इष्टतम न्यूनतम को रोका जा सके।
- इसके अतिरिक्त, $1 \times 10^{-2}$ का एक निश्चित वजन क्षय लागू किया जाता है। वजन क्षय, जिसे L2 नियमितीकरण के रूप में भी जाना जाता है, बड़े पैरामीटर मानों को दंडित करके ओवरफिटिंग को रोकने में मदद करता है। यह मॉडल को अधिक सामान्यीकृत और कम जटिल सुविधाओं को सीखने के लिए प्रोत्साहित करता है, जिससे अनदेखे डेटा पर इसके प्रदर्शन में सुधार होता है।
-
पुनरावृत्त शोधन और अभिसरण: हानि की गणना, ग्रेडिएंट्स की गणना और मापदंडों को अद्यतन करने के इस चक्र को कई प्रशिक्षण एपॉक (इस अध्ययन में 300 एपॉक) पर पुनरावृत्त रूप से दोहराया जाता है। जैसे-जैसे प्रशिक्षण आगे बढ़ता है, मॉडल के मापदंडों को $\mathcal{L}$ को कम करने के लिए लगातार परिष्कृत किया जाता है। डिफ्यूजन डिकोडर धीरे-धीरे शोर प्रक्रिया को उलटने में सटीक होने के लिए सीखता है, $F_m$ और $F_g$ पर सशर्त होने पर $M$ की भविष्यवाणी करने में तेजी से कुशल हो जाता है। मॉडल को अभिसरण माना जाता है जब प्रशिक्षण और सत्यापन डेटासेट दोनों पर हानि स्थिर हो जाती है या न्यूनतम तक पहुंच जाती है। यह इंगित करता है कि मॉडल ने सफलतापूर्वक RTMs उत्पन्न करना सीख लिया है जो ग्राउंड ट्रुथ से निकटता से मेल खाते हैं, अंतर्निहित रेटिनल मोटाई वितरण को कैप्चर करने की अपनी क्षमता का प्रदर्शन करते हैं। अनुमान के दौरान नमूनाकरण के लिए Denoising Diffusion Implicit Model (DDIM) को अपनाने, एक गैर-मार्कोवियन और नियतात्मक प्रक्रिया, काफी कम चरणों (जैसे, 5 चरण) के साथ RTMs के तेज और अधिक स्थिर पीढ़ी को सक्षम करके व्यावहारिक अभिसरण में और योगदान देता है, जिससे तंत्र वास्तविक दुनिया के अनुप्रयोग के लिए अधिक कुशल हो जाता है।
परिणाम, सीमाएँ और निष्कर्ष
प्रयोगात्मक डिजाइन और बेसलाइन
GLD-RT मॉडल को एक व्यापक डेटासेट का उपयोग करके विकसित और कठोरता से मान्य किया गया था। मुख्य RTM भविष्यवाणी कार्य के लिए, शोधकर्ताओं ने 2,918 डेटा ट्रिपलेट्स का उपयोग किया, जिनमें से प्रत्येक में संबंधित ऑप्टिकल कोहेरेंस टोमोग्राफी (OCT), इन्फ्रारेड फंडस फोटोग्राफी (IR-FP), और कलर फंडस फोटोग्राफी (C-FP) छवियां शामिल थीं। ये ट्रिपलेट्स कांगबुक सैमसंग अस्पताल में एंटी-VEGF थेरेपी से गुजर रहे 1,418 डायबिटिक मैक्यूलर एडिमा (DME) रोगियों से प्राप्त किए गए थे। कोहोर्ट ने $296.99 \pm 30.67 \text{ µm}$ की औसत रेटिनल मोटाई और $292.46 \pm 75.00 \text{ µm}$ की केंद्रीय मैक्यूलर मोटाई प्रदर्शित की, जो मैक्यूलर एडिमा की महत्वपूर्ण व्यापकता का संकेत देती है। Heidelberg उपकरणों का उपयोग करके IR-FP और 31 OCT B-स्कैन प्राप्त किए गए थे, जो स्वचालित रूप से झिल्ली सेगमेंटेशन प्रदान करते हैं। अनुभवी नेत्र रोग विशेषज्ञों ने डेटा गुणवत्ता सुनिश्चित करने के लिए खराब फिक्सेशन या सेगमेंटेशन त्रुटियों वाले स्कैन को सावधानीपूर्वक बाहर रखा।
DME निदान के महत्वपूर्ण कार्य के लिए, मोबाइल ब्राजीलियाई रेटिनल डेटासेट (mBRSET) को नियोजित किया गया था। इस डेटासेट में इटबुना, बाहिया, ब्राजील के 1,291 मधुमेह रोगियों से 5,164 C-FP छवियां शामिल हैं, सभी को DME निदान और छवि गुणवत्ता लेबल के साथ सावधानीपूर्वक एनोटेट किया गया है।
डेटा प्री-प्रोसेसिंग में स्थिरता और संरेखण सुनिश्चित करने के लिए कई कदम शामिल थे। IR-FP छवियों को $544 \times 544$ पिक्सेल तक केंद्रीय रूप से क्रॉप किया गया था, जो OCT स्कैनिंग क्षेत्र से मेल खाता है। C-FPglobal छवियों को IR-FP रिज़ॉल्यूशन से मेल खाने के लिए $3608 \times 3608$ से $544 \times 544$ तक डाउनसैंपल किया गया था। रेटिनल मोटाई मानचित्र (RTMs) को 31 B-स्कैन लाइनों से गणना की गई और IR-FP रिज़ॉल्यूशन से मेल खाने के लिए रैखिक रूप से इंटरपोलेट किया गया। संरचनात्मक अखंडता को बनाए रखने के साथ-साथ कलाकृतियों को कम करने के लिए, RTMs को गॉसियन फ़िल्टरिंग ($\sigma = 3$) के बाद नॉन-लोकल मीन्स डीनोइज़िंग का उपयोग करके क्रमिक रूप से स्मूथ किया गया था। DME निदान के लिए, fovea स्थान के आधार पर C-FP छवियों को $800 \times 800$ तक क्रॉप किया गया और फिर $544 \times 544$ तक डाउनसैंपल किया गया।
डेटा को रोगी स्तर पर मजबूत मूल्यांकन के लिए विभाजित किया गया था: GLD-RT विकास के लिए 2043 प्रशिक्षण, 292 सत्यापन और 583 परीक्षण ट्रिपलेट्स। mBRSET को DME निदान के लिए 2409 प्रशिक्षण, 345 सत्यापन और 688 परीक्षण छवियों में इसी तरह विभाजित किया गया था। GLD-RT मॉडल को Adam ऑप्टिमाइज़र [16] का उपयोग करके मानक मापदंडों $(\beta_1, \beta_2) = (0.9, 0.999)$ के साथ अनुकूलित किया गया था, 16-एपॉक वार्म-अप के बाद एक कोसाइन क्षय सीखने की दर अनुसूची, और $1 \times 10^{-2}$ का एक निश्चित वजन क्षय। डिफ्यूजन प्रक्रिया ने प्रशिक्षण के लिए 20 टाइमस्टेप्स और अनुमान के लिए 5 का उपयोग किया। सभी प्रयोग NVIDIA GeForce RTX 3090 GPUs पर किए गए थे, जिसमें यादृच्छिक फ़्लिपिंग और रोटेशन के माध्यम से डेटा वृद्धि शामिल थी।
अपने गणितीय दावों को क्रूरतापूर्वक साबित करने के लिए, लेखकों ने GLD-RT को कई स्थापित और अत्याधुनिक (SOTA) मॉडलों के खिलाफ खड़ा किया। RTM भविष्यवाणी के लिए, "पीड़ितों" में UNet [23], Trans-UNet [5], और Swin-Unetr [12] जैसे सामान्य चिकित्सा छवि सघन भविष्यवाणी मॉडल, साथ ही DeepRT [15] और M²FRT [26] जैसे विशेष RTM भविष्यवाणी फ्रेमवर्क शामिल थे। इन बेसलाइन का मूल्यांकन विभिन्न इनपुट कॉन्फ़िगरेशन (IR-FP, C-FP, या दोनों) के साथ एक व्यापक तुलना प्रदान करने के लिए किया गया था। DME निदान के लिए, GLD-RT-सहायता प्राप्त दृष्टिकोण की तुलना ResNet50 [13] क्लासिफायर का उपयोग करके C-FP-केवल बेसलाइन से की गई थी।
साक्ष्य क्या साबित करता है
प्रायोगिक साक्ष्य निश्चित रूप से साबित करते हैं कि कलर फंडस फोटोग्राफी (C-FP) से RTMs की भविष्यवाणी करने और DME निदान में सहायता करने में रेटिनल मोटाई भविष्यवाणी के लिए ग्लोबल-टू-लोकल कंडीशनल डिफ्यूजन मॉडल (GLD-RT) मौजूदा तरीकों से काफी बेहतर प्रदर्शन करता है और महत्वपूर्ण लाभ प्रदान करता है।
RTM भविष्यवाणी के लिए, GLD-RT ने सभी रेटिनल क्षेत्रों (G1, G2, G3, ETDRS ग्रिड के अनुरूप) में बेहतर प्रदर्शन हासिल किया, जब माइक्रोमीटर ($\mu$m) में माध्य निरपेक्ष त्रुटि (MAE) और डेसिबल (dB) में पीक सिग्नल-टू-नॉइज़ अनुपात (PSNR) का उपयोग करके मूल्यांकन किया गया था। विशेष रूप से, GLD-RT, केवल C-FP को इनपुट के रूप में उपयोग करते हुए, 20.08 $\mu$m का समग्र MAE और 30.91 dB का PSNR दर्ज किया। यह पिछले SOTA, M²FRT [26] की तुलना में एक चिह्नित सुधार था, जिसने C-FP इनपुट के साथ 23.21 $\mu$m MAE और 29.34 dB PSNR हासिल किया। इन लाभों की सांख्यिकीय सार्थकता को p-मान 0.01 से कम के साथ पुष्टि की गई थी, जो इंगित करता है कि GLD-RT का प्रदर्शन संयोग के कारण नहीं था।
वास्तविकता में GLD-RT के मुख्य तंत्र के काम करने के सबसे सम्मोहक प्रमाण G1 क्षेत्र में इसके प्रदर्शन में निहित हैं। यह क्षेत्र अपनी जटिल स्तरित संरचना और केंद्रीय दृष्टि पर प्रत्यक्ष प्रभाव के कारण चिकित्सकीय रूप से महत्वपूर्ण है। यहां, GLD-RT ने 31.97 $\mu$m MAE और 30.18 dB PSNR हासिल किया, जो C-FP इनपुट के लिए M²FRT के 36.25 $\mu$m MAE और 28.31 dB PSNR पर एक महत्वपूर्ण सुधार प्रदर्शित करता है। यह इंगित करता है कि GLD-RT का दोहरी-धारा वास्तुकला, वैश्विक संदर्भ को महीन-दानेदार स्थानीय सुविधाओं के साथ एकीकृत करते हुए, पदानुक्रमित डिफ्यूजन डिकोडर के माध्यम से, इस चुनौतीपूर्ण क्षेत्र में सटीक मोटाई मात्रा के लिए महत्वपूर्ण सूक्ष्म और अनियमित रेटिनल एनाटॉमी को प्रभावी ढंग से कैप्चर करता है।
चित्र 2 में दर्शाए गए गुणात्मक परिणाम, इन लाभों को और रेखांकित करते हैं। GLD-RT ने ड्रूसन, मैक्यूलर एडिमा और ब्रांच वेन ऑक्लूजन जैसे विभिन्न पैथोलॉजिकल घावों से जुड़े मोटाई विविधताओं का मजबूती से पता लगाया, जिससे M²FRT की तुलना में रेटिनल एनाटॉमी का अधिक सटीक प्रतिनिधित्व हुआ। अंतर मानचित्र (भविष्यवाणी माइनस ग्राउंड ट्रुथ) ने लगातार GLD-RT के लिए छोटे त्रुटियों को दिखाया, जो इसकी बेहतर निष्ठा की दृश्य पुष्टि करता है।
ablation अध्ययन ने प्रत्येक वास्तुकला घटक के योगदान के लिए निर्णायक सबूत प्रदान किए। बैकबोन (Em, Dnd, यानी डिफ्यूजन के बिना डिकोडर के साथ स्थानीय मैक्यूलर एनकोडर) ने पहले ही M²FRT को बेहतर प्रदर्शन किया, जो बेहतर स्थानीय सुविधा निष्कर्षण की प्रभावशीलता को मान्य करता है। डिफ्यूजन डिकोडर (Dd) का जोड़ प्रदर्शन में काफी सुधार हुआ, विशेष रूप से G1 में, जो महीन मैक्यूलर विवरणों को कैप्चर करने में डिफ्यूजन प्रक्रिया की क्षमता को साबित करता है। इसके अलावा, ग्लोबल फुल-फंडस एनकोडर (Eg) को RETFound प्री-ट्रेनिंग के साथ शामिल करने से प्रदर्शन और भी बढ़ गया, जो डोमेन-विशिष्ट प्री-ट्रेनिंग और वैश्विक शारीरिक स्थिरता की महत्वपूर्ण भूमिका को उजागर करता है। पूर्ण GLD-RT मॉडल, Eg (RETFound), Em, Dd को मिलाकर, लगातार सर्वोत्तम परिणाम देता है।
RTM भविष्यवाणी से परे, GLD-RT-जनित RTMs DME निदान के लिए अमूल्य साबित हुए। जब C-FP के साथ एक ResNet50 क्लासिफायरियर के लिए दोहरे इनपुट के रूप में जोड़ा गया, तो इस दृष्टिकोण ने लगातार C-FP-केवल बेसलाइन को बेहतर प्रदर्शन किया। दोहरे-इनपुट मॉडल ने 93.44% (बनाम 92.21%) की सटीकता, 79.49% (बनाम 64.41%) की रिकॉल, 85.90% (बनाम 75.84%) का F1-स्कोर और 0.919 (बनाम 0.855) का AUC हासिल किया। यह निर्विवाद साक्ष्य प्रदर्शित करता है कि C-FP-जनित RTMs पूरक नैदानिक अंतर्दृष्टि प्रदान करते हैं, जो नैदानिक प्रोटोकॉल के साथ संरेखित होते हैं जिनके लिए अक्सर OCT और C-FP दोनों परीक्षाओं की आवश्यकता होती है। यह GLD-RT को एक आशाजनक, लागत प्रभावी नैदानिक उपकरण बनाता है, विशेष रूप से संसाधन-सीमित सेटिंग्स के लिए।
सीमाएँ और भविष्य की दिशाएँ
जबकि GLD-RT C-FP से रेटिनल मोटाई की भविष्यवाणी करने और DME निदान में सहायता करने में एक महत्वपूर्ण छलांग प्रस्तुत करता है, इसकी वर्तमान सीमाओं को स्वीकार करना और भविष्य के विकास पर विचार करना महत्वपूर्ण है।
एक अंतर्निहित सीमा, हालांकि मॉडल के उद्देश्य से संबोधित की गई है, यह है कि C-FP, एक 2D इमेजिंग तकनीक होने के नाते, मौलिक रूप से OCT की गहराई रिज़ॉल्यूशन का अभाव है। जबकि GLD-RT प्रभावी ढंग से मोटाई का अनुमान लगाता है, ग्राउंड ट्रुथ RTMs उच्च-रिज़ॉल्यूशन OCT स्कैन से प्राप्त होते हैं। पत्र स्वयं "विस्तृत RTM भविष्यवाणी के लिए उच्च-रिज़ॉल्यूशन OCT को शामिल करने" को भविष्य की दिशा के रूप में इंगित करता है, यह सुझाव देता है कि GLD-RT की प्रगति के साथ भी, केवल C-FP से प्राप्त विवरण की एक सीमा हो सकती है जिसे आगे के तकनीकी एकीकरण या उच्च-निष्ठा ग्राउंड ट्रुथ के बिना प्राप्त किया जा सकता है। वर्तमान मॉडल, हालांकि मजबूत है, अभी भी 2D इनपुट पर आधारित एक भविष्यवाणी है, और जटिल 3D रेटिनल संरचनाओं के हर सूक्ष्म विवरण को कैप्चर करने की इसकी क्षमता प्रतिबंधित हो सकती है।
एक अन्य पहलू पर विचार करना निष्कर्षों की सामान्यता है। मॉडल को विशिष्ट अस्पतालों और क्षेत्रों (कांगबुक सैमसंग अस्पताल और mBRSET) के डेटासेट पर प्रशिक्षित किया गया था। जबकि ये पर्याप्त डेटासेट हैं, वास्तविक दुनिया के नैदानिक अभ्यास में रोगी जनसांख्यिकी, रोग की गंभीरता और विभिन्न निर्माताओं से इमेजिंग उपकरणों की एक विशाल विविधता शामिल है। विभिन्न आबादी या विभिन्न छवि अधिग्रहण प्रोटोकॉल से बाहरी, अनदेखे डेटासेट पर GLD-RT के प्रदर्शन के लिए आगे की संभावित नैदानिक सत्यापन की आवश्यकता होगी। पत्र "संभावित नैदानिक सत्यापन" का उल्लेख करता है क्योंकि भविष्य की दिशा, जो अंतर्निहित रूप से इस व्यापक परीक्षण की आवश्यकता को स्वीकार करती है।
इसके अलावा, जबकि मॉडल RTMs प्रदान करता है, पारंपरिक C-FP छवियों के साथ इन AI-जनित मानचित्रों की व्याख्या के लिए नैदानिक कार्यप्रवाह स्थापित करने की आवश्यकता है। चिकित्सक OCT-व्युत्पन्न RTMs के आदी हैं, और C-FP-जनित RTMs में संक्रमण के लिए सटीक व्याख्या और उपचार निर्णयों में एकीकरण सुनिश्चित करने के लिए स्पष्ट दिशानिर्देशों और प्रशिक्षण की आवश्यकता होगी। पेपर के "मौजूदा स्वास्थ्य सेवा वर्कफ़्लो में एकीकरण" के सुझाव इस व्यावहारिक चुनौती को उजागर करते हैं।
आगे देखते हुए, इस कार्य से कई रोमांचक चर्चा विषय उभरते हैं:
- उन्नत नैदानिक एकीकरण और निर्णय समर्थन: नियमित C-FP स्क्रीनिंग के दौरान वास्तविक समय RTM भविष्यवाणियों को प्रदान करने के लिए GLD-RT को मौजूदा इलेक्ट्रॉनिक स्वास्थ्य रिकॉर्ड सिस्टम में कैसे एकीकृत किया जा सकता है? क्या मॉडल को केवल मोटाई की भविष्यवाणी करने के बजाय चिंता के क्षेत्रों को स्वचालित रूप से हाइलाइट करने या अनुवर्ती कार्रवाई का सुझाव देने के लिए बढ़ाया जा सकता है, इस प्रकार प्राथमिक देखभाल चिकित्सकों या यहां तक कि घर की निगरानी सेटिंग्स में रोगियों के लिए एक अधिक व्यापक निर्णय-समर्थन उपकरण के रूप में कार्य कर सकता है? ऐसे स्वायत्त नैदानिक सहायता को तैनात करने के लिए नियामक मार्ग और नैतिक विचार क्या हैं?
- बहु-रोग भविष्यवाणी और बायोमार्कर खोज: DME के लिए C-FP का लाभ उठाने में GLD-RT की सफलता को देखते हुए, क्या इस ढांचे को अन्य रेटिनल विकृति या बायोमार्कर की भविष्यवाणी करने के लिए अनुकूलित या बढ़ाया जा सकता है जो वर्तमान में अधिक महंगे या आक्रामक इमेजिंग पर निर्भर हैं? उदाहरण के लिए, क्या यह C-FP से ग्लूकोमा (जैसे, रेटिनल तंत्रिका फाइबर परत पतली होना) या उम्र से संबंधित मैक्यूलर डिजनरेशन (जैसे, ड्रूसन मात्रा) के शुरुआती लक्षणों की भविष्यवाणी कर सकता है? यह C-FP को एक वास्तविक बहुउद्देश्यीय स्क्रीनिंग टूल में बदल सकता है।
- छवि गुणवत्ता और कलाकृतियों के प्रति मजबूती: रोगी सहयोग, मीडिया अपारदर्शिता, या उप-इष्टतम कैमरा सेटिंग्स के कारण वास्तविक दुनिया C-FP छवियों में अक्सर विभिन्न गुणवत्ता से पीड़ित होते हैं। जबकि वर्तमान अध्ययन ने खराब गुणवत्ता वाले स्कैन को फ़िल्टर किया, भविष्य के काम में इन खामियों के प्रति GLD-RT को अधिक मजबूत बनाने पर ध्यान केंद्रित किया जा सकता है, शायद छवि गुणवत्ता मूल्यांकन मॉड्यूल को शामिल करके या खराब छवियों की एक विस्तृत श्रृंखला के साथ प्रशिक्षण करके। मॉडल अपनी उच्च सटीकता को खराब इनपुट के साथ भी कैसे बनाए रख सकता है?
- कम्प्यूटेशनल दक्षता और एज परिनियोजन: वर्तमान मॉडल NVIDIA GeForce RTX 3090 पर चलता है। संसाधन-सीमित सेटिंग्स या पोर्टेबल उपकरणों में व्यापक रूप से अपनाने के लिए, कम कम्प्यूटेशनल पदचिह्न और तेज अनुमान समय के लिए मॉडल को अनुकूलित करना महत्वपूर्ण होगा। क्या एज कंप्यूटिंग के लिए उपयुक्त एक हल्का संस्करण बनाने के लिए ज्ञान आसवन या मॉडल मात्राकरण तकनीकों को लागू किया जा सकता है, संभावित रूप से स्मार्टफोन-संलग्न फंडस कैमरे पर वास्तविक समय RTM पीढ़ी को सक्षम किया जा सकता है?
- अनुदैर्ध्य निगरानी और उपचार प्रतिक्रिया: क्या GLD-RT का उपयोग DME रोगियों की अनुदैर्ध्य निगरानी के लिए किया जा सकता है, उपचार प्रतिक्रिया या रोग प्रगति का आकलन करने के लिए समय के साथ रेटिनल मोटाई में परिवर्तन को ट्रैक किया जा सकता है? इसके लिए विस्तारित अवधि में मॉडल की स्थिरता और सूक्ष्म परिवर्तनों के प्रति संवेदनशीलता को मान्य करने की आवश्यकता होगी। मॉडल की भविष्यवाणियां व्यक्तिगत उपचार रणनीतियों को कैसे सूचित कर सकती हैं, एंटी-VEGF इंजेक्शन शेड्यूल या अन्य हस्तक्षेपों को अनुकूलित कर सकती हैं?
- व्याख्यात्मकता और विश्वास: जैसे-जैसे AI मॉडल नैदानिक अभ्यास में अधिक एकीकृत होते जाते हैं, यह समझना महत्वपूर्ण है कि एक मॉडल एक निश्चित भविष्यवाणी क्यों करता है, चिकित्सकों के बीच विश्वास बनाने के लिए महत्वपूर्ण है। भविष्य के शोध GLD-RT की RTM भविष्यवाणियों की व्याख्यात्मकता को बढ़ाने के तरीकों का पता लगा सकते हैं, शायद उन सुविधाओं को देखकर जिन पर मॉडल C-FP छवि में ध्यान केंद्रित करता है, इस प्रकार चिकित्सकों को इसके आउटपुट में अधिक अंतर्दृष्टि और आत्मविश्वास प्रदान करता है।
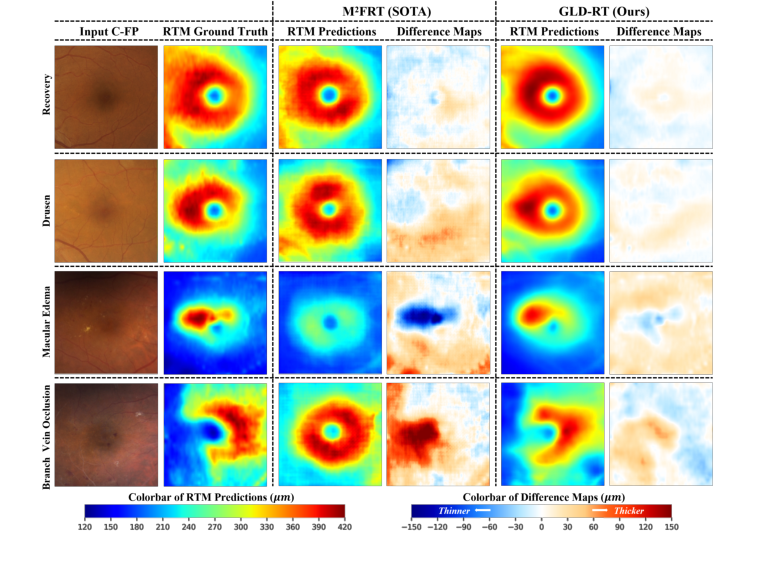 Figure 2. Qualitative results of our model and M2FRT. GLD-RT robustly detects diverse pathological lesions and accurately depicts subtle and irregular retinal anatomy. Dif- ference maps (prediction minus ground truth) further underscore these gains
Figure 2. Qualitative results of our model and M2FRT. GLD-RT robustly detects diverse pathological lesions and accurately depicts subtle and irregular retinal anatomy. Dif- ference maps (prediction minus ground truth) further underscore these gains
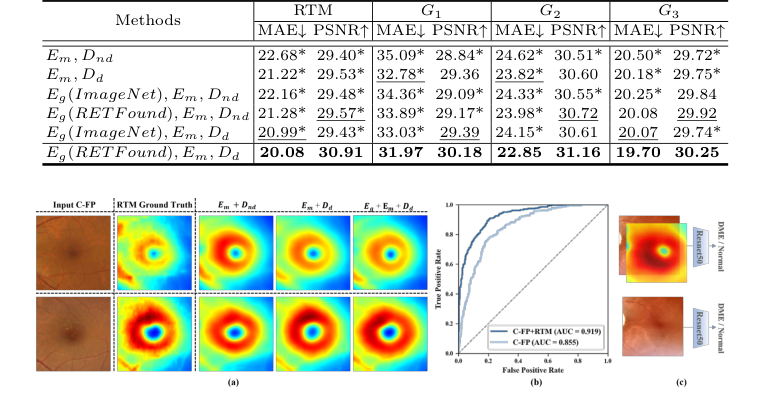 Figure 3. (a) Qualitative results of ablation study on GLD-RT. The proposed Dd sig- nificantly enhanced fine macular structural details, while Eg further enforced global anatomical consistency. (b) Receiver operating characteristic curve of DME diagnosis. (c)Experiment design of DME diagnosis
Figure 3. (a) Qualitative results of ablation study on GLD-RT. The proposed Dd sig- nificantly enhanced fine macular structural details, while Eg further enforced global anatomical consistency. (b) Receiver operating characteristic curve of DME diagnosis. (c)Experiment design of DME diagnosis
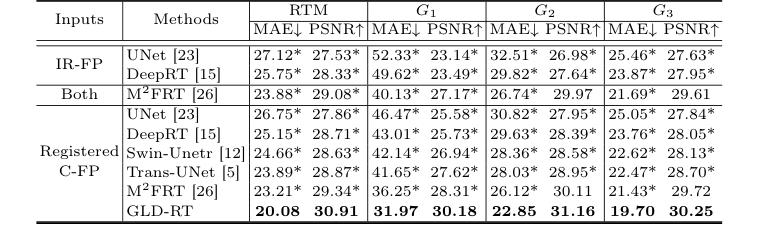 Table 1. Quantitative comparison of different methods for RTM prediction, with MAE (µm) and PSNR (dB). * indicates GLD-RT outperforms baselines with p-values<0.01
Table 1. Quantitative comparison of different methods for RTM prediction, with MAE (µm) and PSNR (dB). * indicates GLD-RT outperforms baselines with p-values<0.01
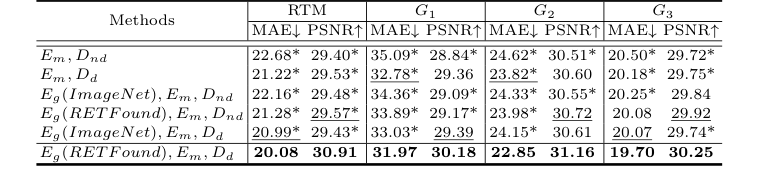 Table 2. Ablation study of RTM prediction, with MAE (µm) and PSNR (dB). * indicates GLD-RT outperforms baselines with p-values<0.01
Table 2. Ablation study of RTM prediction, with MAE (µm) and PSNR (dB). * indicates GLD-RT outperforms baselines with p-values<0.01