표면 너머를 보다: DME 관리를 위한 컬러 안저 사진으로부터의 망막 두께 예측
New model turns basic eye scans into detailed maps, boosting DME diagnosis in low-resource areas.
배경 및 학술적 계보
기원 및 학술적 계보
당면한 문제, 즉 당뇨병성 황반부종(Diabetic Macular Edema, DME) 관리를 위해 컬러 안저 사진(Color Fundus Photography, C-FP)만으로 망막 두께 지도(Retinal Thickness Maps, RTMs)를 예측하는 것은 안과 분야에서 접근 가능하고 비용 효율적인 진단 도구에 대한 절실한 필요성에서 비롯된다. 당뇨병성 황반부종은 심각한 시력 저하의 주요 원인이며, 특히 경제 활동 인구에서 상당한 전 세계적 의료 부담을 야기한다.
역사적으로 광간섭단층촬영(Optical Coherence Tomography, OCT)은 DME 평가의 황금 표준으로 사용되어 왔으며, 이는 망막 병변을 높은 정확도로 정량화하는 상세한 RTM을 제공한다. 그러나 OCT 장비는 고가이며 작동이 복잡하여, 특히 자원이 제한된 환경이나 일상적인 가정 모니터링에서 접근성을 심각하게 제한한다. 이러한 접근성 격차는 종종 불충분한 추적 방문과 항혈관내피성장인자(anti-Vascular Endothelial Growth Factor, anti-VEGF)와 같은 치료를 받는 환자들의 최적화되지 않은 치료 결과로 이어진다.
널리 사용 가능하고 비용 효율적인 2D 영상 기법(스마트폰으로도 가능한)인 C-FP를 활용하려는 이전 시도들은 상당한 한계에 직면했다. 초기 접근 방식은 망막 두께의 대리 표지자(surrogate markers)에 의존했는데, 이는 필요한 깊이 해상도가 부족하여 DME 탐지의 특이도와 민감도가 제한적이었다. 예를 들어, C-FP로부터 망막 두께를 예측하려는 이전 모델들은 종종 임상 표준을 충족시키지 못했으며, 특히 낮은 이미지 품질에서 그러했다. 최근의 노력은 깊이 정보를 추출하기 위해 적외선 안저 사진(Infrared Fundus Photography, IR-FP)을 중개자로 사용하여 이 격차를 해소하려고 시도했다. IR-FP는 임상 실습에서 OCT 획득을 위한 국소화기로 사용되지만, 여전히 추가 장치가 필요하여 광범위한 적용을 제한한다. 더욱이 IR-FP 자체는 과반사 인공물(hyperreflective artifacts), 망막하 구조에 최적화된 제한된 조명 파장, 그리고 경성 삼출물(hard exudates) 및 출혈과 같은 중요한 병리학적 표지자의 부적절한 시각화와 같은 고유한 단점을 가지고 있다.
저자들이 이 논문을 작성하게 된 근본적인 "고충점(pain point)"은 기존 방법들이 망막 두께 평가를 위한 포괄적이고 정확하며 접근 가능한 솔루션을 제공하지 못한다는 점이다. OCT는 광범위한 사용에 비해 너무 비싸고 복잡하며, 이전의 C-FP 및 IR-FP 기반 방법들은 부정확하거나, 깊이 정보가 부족하거나, 여전히 전문 장비가 필요했다. 본 논문은 C-FP만으로 RTM을 예측하는 최초의 접근 방식을 제안함으로써 이러한 한계를 극복하는 것을 목표로 하며, 이를 통해 기존 안저 영상 촬영을 DME 선별 및 모니터링을 위한 포괄적이고 비용 효율적인 진단 도구로 변환하여, 특히 자원이 제한된 환경에서 환자 결과를 개선하기 위한 시기적절하고 효과적인 개입을 약속한다.
직관적인 도메인 용어
이 논문에서 사용된 몇 가지 전문 용어를 제로베이스 독자를 위한 일상적인 비유와 함께 설명한다.
- 당뇨병성 황반부종 (DME): 당뇨병으로 인해 눈의 "카메라 센서"(황반) 중앙에 있는 작고 중요한 영역이 붓고 흐릿해지는 것을 상상해 보라. 마치 카메라 렌즈 위에 작은 물웅덩이가 생겨 모든 것이 흐릿해지는 것과 같다.
- 광간섭단층촬영 (OCT): 이것을 눈을 위한 초고성능 소나라고 생각하라. 음파 대신 빛 파동을 사용하여 망막의 내부 층과 두께를 보여주는 매우 상세한 단면 사진을 생성하며, 마치 케이크를 잘라 모든 층을 보는 것과 같다.
- 망막 두께 지도 (RTM): 이것은 OCT 스캔의 결과물로, 망막의 다채로운 "열 지도"이다. 정상보다 두꺼운 영역은 빨간색이나 노란색으로 표시되고, 얇은 영역은 파란색으로 표시되어 의사에게 문제 부위에 대한 빠른 시각적 안내를 제공한다. 마치 날씨 지도에서 온도 변화를 보여주는 것과 같다.
- 컬러 안저 사진 (C-FP): 이것은 단순히 눈 뒤쪽의 표준적인 평면 2D 사진으로, 혈관과 시신경과 같은 표면 특징을 보여준다. 마치 풍경의 일반적인 사진을 찍는 것과 같아서, 나무와 산은 보이지만 높이나 깊이에 대한 감각은 얻지 못한다.
- 확산 모델 (Diffusion Model): 이것은 순수한 무작위 노이즈로 시작하여 점진적으로 단계별로 "노이즈를 제거"하여 명확하고 원하는 이미지를 형성함으로써 복잡한 이미지를 생성하는 방법을 학습하는 인공지능의 한 유형이다. 마치 조각가가 형태 없는 대리석 덩어리에서 시작하여 점진적으로 조각해 나가 상세한 조각상이 나타나는 것과 유사하다.
표기법 표
| 표기법 | 설명 |
|---|---|
문제 정의 및 제약 조건
핵심 문제 공식화 및 딜레마
이 논문에서 다루는 핵심 문제는 컬러 안저 사진(C-FP)만으로 망막 두께 지도(RTMs)를 정확하게 예측하는 것이다.
입력/현재 상태:
당뇨병성 황반부종(DME) 관리 및 망막 두께 평가를 위한 현재 황금 표준은 광간섭단층촬영(OCT)을 포함한다. OCT는 망막 구조 및 병변의 정량적 시각화인 상세한 RTM을 제공한다. 대조적으로, 컬러 안저 사진(C-FP)은 스마트폰으로도 가능한, 널리 사용 가능하고 비용 효율적이며 쉽게 접근 가능한 2D 영상 기법이다. 그러나 C-FP는 전통적으로 정량적 망막 두께 평가에 필요한 깊이 정보가 부족하다.
원하는 최종 상태/목표 상태:
본 논문은 C-FP에서 직접 정확하고 포괄적인 RTM을 생성할 수 있는 시스템을 개발하는 것을 목표로 한다. 궁극적인 목표는 이러한 C-FP에서 파생된 RTM이 DME를 위한 효율적이고 접근 가능하며 비용 효율적인 진단 및 모니터링 도구 역할을 하여, 특히 자원이 제한된 환경에서 시기적절한 개입, 정보에 입각한 치료 결정 및 환자의 시각 결과 개선을 촉진하는 것이다. 이는 기존 안저 영상 촬영을 강력한 진단 자산으로 변환할 것이다.
누락된 연결 또는 수학적 격차:
근본적인 누락된 연결은 2D C-FP 이미지의 본질적인 깊이 해상도 부족이다. RTM은 3D 두께 정보를 나타내는 반면, C-FP는 2D 투영만 캡처한다. C-FP로부터 두께를 예측하여 이 격차를 해소하려는 이전 시도들은 종종 특이도와 민감도가 제한적인 대리 표지자(예: 지질 침착물)에 의존하거나, 특히 다양한 이미지 품질에서 필요한 임상 정확도를 달성하지 못한 모델에 의존했다. 수학적 과제는 깊이 정보가 명시적인 측정보다는 미묘한 시각적 단서에 암묵적으로 인코딩된 2D 이미지에서 연속적이고 정량적인 3D 두께 분포를 추론하는 것이다.
고통스러운 절충 또는 딜레마:
중심 딜레마는 접근성/비용 효율성과 정량적 정확도/세부 정보 간의 절충이다. OCT는 고충실도 RTM을 제공하지만 비싸고 작동이 복잡하며 접근성이 제한되어 많은 실제 시나리오에서 최적화되지 않은 환자 추적 관찰로 이어진다. C-FP는 매우 접근 가능하고 저렴하지만, 그 2D 특성은 역사적으로 상세한 DME 관리에 필요한 정확한 정량적 두께 측정을 제공하는 것을 방해해 왔다. 연구자들은 C-FP의 고유한 접근성 및 저비용 이점을 잃지 않으면서도, IR-FP와 같이 덜 접근 가능한 중간 양상을 이용하여 충분한 정량적 정보를 추출하려고 노력해 왔다. 본 논문은 C-FP만으로 OCT 수준의 RTM 예측을 달성하려고 시도함으로써 이 딜레마에 직접적으로 맞선다.
제약 조건 및 실패 모드
이 문제는 몇 가지 가혹하고 현실적인 제약 조건으로 인해 믿을 수 없을 정도로 어렵다.
- C-FP의 본질적인 2D 특성: 언급했듯이 C-FP는 직접적인 깊이 정보를 제공하지 않는다. 2D 이미지에서 3D 망막 두께를 추론하는 것은 잘 정의되지 않은 역문제(ill-posed inverse problem)이며, 모델이 표면 특징과 내부 두께 간의 복잡하고 명확하지 않은 관계를 학습해야 한다.
- 미묘한 병리학적 생체 표지자: DME로 인한 망막 층의 비정상적인 구조는 C-FP에서 "미묘한 질감 및 색상 변화"로 나타난다. 이러한 미묘한 단서는 숙련된 임상의조차도 식별하기 어렵기 때문에 자동화된 시스템은 말할 것도 없다. 모델은 두께를 정확하게 예측하기 위해 이러한 미세한 변화를 감지할 수 있어야 한다.
- 공간적 불일치 및 등록 문제: C-FP(입력)와 RTM 기준 진실(OCT에서 파생, 종종 IR-FP로 국소화됨) 간의 정확한 픽셀 단위 공간 대응을 달성하는 것은 상당한 장애물이다. 다른 영상 양상은 다양한 시야, 해상도 및 잠재적 왜곡을 가지므로 정확한 다중 양상 등록은 복잡한 전처리 단계이다. 본 논문은 이 어려움을 강조하며 등록을 위한 중개자로 IR-FP를 사용하는 것을 언급한다.
- DME 발현의 이질성: DME는 광범위한 병리학적 병변과 불규칙한 망막 해부학적 구조를 나타낸다. 강력한 모델은 이러한 다양한 발현에 대해 일반화해야 하며, 이는 전역적 맥락 특징(예: 혈관 네트워크)과 미세한 국소 세부 정보(황반 영역 변화)를 모두 포착해야 한다.
- 고충실도 생성을 위한 계산 요구 사항: 확산 모델과 같은 고급 생성 모델을 사용하여 고해상도이고 정확한 RTM을 생성하는 것은 특히 추론(샘플링) 단계에서 계산 집약적일 수 있다. "높은 충실도를 유지하면서 샘플링을 신속하게 처리"할 필요성(DDIM에서 다루는)은 이 계산 제약 조건을 강조한다.
- 엄격한 임상 정확도 요구 사항: 이전의 C-FP 기반 예측 모델은 "임상 표준을 충족시키지 못했다." 이는 임상적으로 실행 가능하기 위해 필요한 새로운 솔루션의 정확도, 특이도 및 민감도에 대한 높은 기준을 설정한다. 모델의 예측은 중요한 의료 결정에 정보를 제공할 만큼 신뢰할 수 있어야 한다.
- 데이터 가용성 및 주석 품질: 이러한 모델을 훈련하려면 RTM 및 DME 진단에 대한 전문가 주석과 함께 정확하게 쌍을 이룬 C-FP, IR-FP 및 OCT 이미지의 대규모 데이터 세트가 필요하다. 이러한 고품질의 다중 양상 데이터 세트를 획득하고 큐레이션하는 것은 시간과 자원이 많이 소요되는 과정이다.
- 주변 맥락 손실 대 황반 세부 정보: 황반 영역은 두께 평가에 중요하지만, 중요한 전역 망막 구조 및 병리학적 생체 표지자(예: 시신경 유두, 혈관 네트워크)는 더 넓은 안저 이미지에 존재한다. 황반에만 집중하면 이 중요한 "주변 맥락"을 잃을 위험이 있어 전역 및 국소 특징을 모두 통합하는 이중 스트림 접근 방식이 필요하다.
왜 이 접근 방식인가
선택의 불가피성
저자들은 기존의 "SOTA"(State-of-the-Art) 방법들, 즉 표준 CNN, 기본 확산 모델 또는 트랜스포머들이 컬러 안저 사진(C-FP)으로부터 망막 두께 지도(RTMs)를 직접 예측하는 특정하고 미묘한 문제에 대해 단순히 충분하지 않다는 상황에 놓였다. 핵심적인 깨달음은 중요한 임상적 필요성에서 비롯되었다. 광간섭단층촬영(OCT)은 당뇨병성 황반부종(DME)을 진단하고 관리하는 황금 표준이지만, 높은 비용과 자원이 제한된 환경에서의 제한된 접근성은 광범위한 선별 검사 및 빈번한 모니터링에 비실용적이다. 이는 더 접근 가능한 대안에 대한 긴급한 수요를 창출했다.
컬러 안저 사진(C-FP)은 스마트폰으로도 가능한, 널리 사용 가능하고 비용 효율적인 선별 검사 도구로서 가장 실행 가능한 선택으로 부상했다. 그러나 C-FP는 근본적인 문제를 제시한다. 그것은 2D 영상 기법이며, 본질적으로 정량적 망막 층 평가에 필요한 깊이 해상도가 부족하다. C-FP로부터 망막 두께를 예측하려는 이전 시도들은 특이도와 민감도가 제한적인 지질 침착물과 같은 대리 표지자에 의존했다. Arcadu 등 [3]의 모델과 같은 더 발전된 딥러닝 모델조차도, 특히 낮은 이미지 품질에서 예측 정확도에 대한 임상 표준을 충족시키지 못했다.
저자들은 또한 일부 SOTA 방법들인 DeepRT [15] 및 M²FRT [26]와 같이 중개자로 적외선 안저 사진(IR-FP)을 사용한 방법들을 고려했다. 그러나 IR-FP는 여전히 추가 장치가 필요하여 임상 적용을 제한한다. 더욱이 IR-FP 자체는 과반사 인공물, 제한된 조명 파장, 그리고 출혈과 같은 중요한 병리학적 표지자의 부적절한 시각화와 같은 고유한 한계를 가지고 있다. 대조적으로 C-FP는 우수한 공간 해상도, 더 넓은 스펙트럼 범위 및 더 넓은 시야를 제공한다. 그것은 혈관 네트워크 및 시신경 유두와 같은 중요한 전역 망막 구조를 캡처하며, 이는 주요 병리학적 생체 표지자이다. 새로운 접근 방식이 필요하다는 정확한 순간은 기존 방법들이 2D에서 3D로의 추론을 충분히 정확하게 처리하지 못하거나, 접근성 및 비용 효율성 요구 사항을 충족하지 못하는 영상 양상에 의존한다는 것이 명확해졌을 때 발생했을 가능성이 높다. DME로 인한 망막 층의 비정상적인 구조를 나타내는 C-FP의 미묘한 질감 및 색상 변화는 강력한 고수준 의미론적 특징과 정확한 국소 황반 세부 정보를 모두 추출할 수 있는 모델을 요구했으며, 이는 표준 SOTA 방법들이 동시에 충분한 충실도로 달성하는 데 어려움을 겪었던 기능이다.
비교 우위
망막 두께 예측을 위한 전역-국소 조건부 확산 모델(Global-to-Local conditional Diffusion model for Retinal Thickness prediction, GLD-RT)은 단순한 성능 지표를 넘어 압도적인 질적 우수성을 보여준다. 그 구조적 이점은 C-FP 데이터의 고유한 복잡성을 RTM 생성에 맞게 특별히 설계된 독특한 이중 스트림, 하이브리드 CNN-트랜스포머 조건부 확산 아키텍처에 있다.
첫째, GLD-RT의 전역 맥락 특징과 미세한 국소 세부 정보를 모두 통합하는 능력은 중요한 구조적 이점이다. 사전 훈련된 RETFound 모델을 활용하는 전역 전체 안저 인코더($E_g$)는 전체 C-FP 이미지에서 강력한 해부학적 및 병리학적 패턴을 캡처한다. 동시에 Swin-Transformer로 구축된 국소 황반 인코더($E_m$)는 황반 영역에서 복잡하고 미세한 특징을 추출한다. 이 이중 스트림 접근 방식은 모델이 광범위한 맥락을 놓치지 않으면서도 DME를 나타내는 황반의 미묘하지만 임상적으로 중요한 국소 변화에 집중하도록 보장한다. 이는 DME가 대규모 혈관 특성과 미세한 망막 층 무결성에 모두 영향을 미치기 때문에 중요하다.
둘째, 조건부 확산 디코더의 사용은 이 생성 작업에 질적으로 우수하다. 전통적인 판별 모델이나 더 간단한 생성적 적대 신경망(GAN)과 달리, 확산 모델은 노이즈가 많은 입력에서 점진적으로 노이즈를 제거함으로써 고충실도, 다양하고 해부학적으로 일관된 출력을 생성하는 데 탁월하다. 이는 RTM 예측에 특히 유리한데, 여기서 출력은 생리학적 및 병리학적 형태를 모두 정확하게 반영해야 하는 복잡하고 연속적인 두께 지도이다. 풍부한 전역 및 국소 특징에 의해 안내되는 확산 과정은 Fig. 2의 질적 결과와 무작위 연구에서 입증된 바와 같이, 특히 어려운 중앙 황반(G1 영역)에서 미묘하고 불규칙한 망막 해부학적 구조를 더 미묘하고 정확하게 묘사할 수 있게 한다. Denoising Diffusion Implicit Model (DDIM)의 채택은 또한 샘플링 단계를 상당히 줄여 충실도를 희생하지 않고 실용적인 효율성을 향상시킨다.
이 구조적 설계는 GLD-RT가 이전 방법보다 C-FP 이미지에 내재된 고차원 노이즈 및 변동성을 더 잘 처리할 수 있도록 한다. 단순히 지도를 예측하는 것이 아니라, 복잡한 내부 망막 구조와 일치하는 가능하고 상세한 RTM을 생성하며, 이는 단순한 모델이 해부학적 일관성과 미세한 세부 정보를 유지하는 데 종종 부족한 작업이다.
제약 조건과의 일치
선택된 GLD-RT 방법은 문제의 가혹한 요구 사항과 완벽하게 일치하며, "임상적 필요성과 혁신적인 솔루션 설계 간의 결혼"을 형성한다.
-
제약 조건: 제한된 OCT 접근성 및 높은 비용.
- 일치: GLD-RT는 C-FP만으로 RTM을 예측하는 최초의 모델이다. C-FP는 널리 사용 가능하고 비용 효율적이며 스마트폰으로도 캡처할 수 있다. 이는 접근 가능하고 저렴한 진단 도구에 대한 요구를 직접적으로 해결하며, 기존 안저 영상 촬영을 자원이 제한된 환경을 위한 포괄적인 선별 및 모니터링 솔루션으로 변환한다.
-
제약 조건: C-FP의 2D 특성은 정량적 평가를 위한 깊이 해상도가 부족하다.
- 일치: 조건부 확산 모델은 본질적으로 조건부 입력에서 복잡한 고차원 출력을 합성할 수 있는 생성 모델이다. GLD-RT는 2D C-FP 특징에서 3D 망막 두께 분포로의 복잡한 매핑을 학습함으로써, 입력 이미지에 명시적으로 존재하지 않는 깊이 정보를 효과적으로 추론한다. 이 생성 능력은 2D 제약을 극복하는 핵심이다.
-
제약 조건: 정확하고 상세하며 임상적으로 관련성 있는 RTM의 필요성.
- 일치: 이중 스트림 아키텍처(전역-국소 인코더)는 광범위한 해부학적 맥락과 미세한 황반 세부 정보가 모두 캡처되도록 보장한다. 전역 인코더(RETFound)는 강력한 고수준 의미론적 특징을 제공하며, 국소 인코더(Swin-Transformer)는 정확한 국소 세부 정보를 추출한다. 이들은 융합되어 "전역-국소 해부학적 일관성"을 보장하는 계층적 확산 디코더에 공급된다. 이 설계는 생리학적 및 병리학적 망막 형태를 정확하게 묘사하는 데 중요하며, 이는 임상적 유용성과 망막 구조의 상세한 검사에 필수적이다. 무작위 연구는 확산 과정이 특히 복잡한 중앙 황반(G1)에서 황반 구조를 미세한 세부 정보로 성공적으로 포착했음을 확인한다.
-
제약 조건: 자원이 제한된 환경을 위한 실용성(효율성).
- 일치: 확산 모델은 계산 집약적일 수 있지만, 샘플링을 위해 DDIM을 사용하면 추론에 필요한 단계 수가 크게 줄어들어 실제 임상 적용에 더 효율적이고 실용적이다. 전반적인 목표는 "시기적절한 개입을 위한 효율적인 진단 도구"를 제공하는 것이다.
대안의 기각
본 논문은 C-FP로부터 RTM 예측이라는 맥락에서 여러 대안적 접근 방식의 한계를 강조함으로써 이를 암묵적으로 그리고 명시적으로 기각한다.
첫째, 대리 표지자에 의존하는 전통적인 방법 (예: 지질 침착물, 레이저 흉터)은 불충분한 것으로 간주되었다. 저자들은 이러한 접근 방식이 "DME 탐지의 특이도와 민감도가 제한적"이라고 언급했다 [28, 29]. 이것은 DME의 복잡하고 미묘한 발현을 포착할 수 없는 비기계 학습 또는 더 간단한 규칙 기반 방법의 명확한 기각이다.
둘째, C-FP 기반 RTM 예측을 위한 초기 딥러닝 모델은 부족한 것으로 밝혀졌다. 본 논문은 Arcadu 등 [3]의 모델이 "임상 표준을 충족시키지 못했다"고 언급했으며, 특히 낮은 이미지 품질에서 예측 정확도에 대한 것이다. 이는 더 간단한 CNN 기반 아키텍처 또는 덜 정교한 생성 모델(당시 일반적이었던)이 임상적으로 허용 가능한 RTM을 생성하기 위해 C-FP에서 필요한 정보를 추출할 수 없었음을 시사한다. 그들은 아마도 2D에서 3D로의 추론과 DME를 나타내는 C-FP의 미묘한 변화를 처리하는 데 어려움을 겪었을 것이다.
셋째, DeepRT [15] 및 M²FRT [26]와 같은 적외선 안저 사진(IR-FP)에 의존하는 방법은 실용적 및 고유한 영상 제한으로 인해 유일한 실행 가능한 솔루션으로 기각되었다. 이러한 방법들은 개선을 보였지만, 여전히 "IR-FP를 캡처하기 위한 추가 장치가 필요했다"는 점은 자원이 제한된 환경에서의 임상 적용을 제한한다. 더욱이 IR-FP 자체는 "과반사 인공물, 망막하 구조에 최적화된 제한된 조명 파장, 그리고 중요한 병리학적 표지자의 부적절한 시각화"와 같은 단점을 가지고 있다 [1]. 이는 C-FP를 더 바람직한 입력으로 만들지만, 그 어려움에도 불구하고 그렇다.
마지막으로, 본 논문의 무작위 연구는 더 간단한 디코딩 메커니즘의 기각과 확산 과정의 필요성에 대한 결정적인 증거를 제공한다. 결과는 제안된 확산 디코더($D_d$)가 확산이 없는 디코더($D_{nd}$)보다 "특히 중앙 황반(G1)에서 모델 성능을 현저히 향상시켰다"는 것을 보여준다. 이는 GAN과 같은 표준 디코딩 접근 방식이 이 복잡한 영역에서 요구되는 미세 구조 세부 정보 및 해부학적 일관성을 포착하는 데 불충분했음을 시사한다. "전역-국소 특징 조건화가 표준 디코딩 접근 방식을 능가했다"는 진술은 계층적이지 않거나 비계층적인 생성 프레임워크가 C-FP에서 오는 풍부한 다중 스케일 정보를 활용하는 데 덜 효과적이었을 것임을 더욱 강화한다. GAN을 명시적으로 명명하지는 않았지만, 고충실도 생성, 해부학적 일관성 및 미묘한 세부 정보를 포착하는 능력에 대한 강조는 확산 모델이 이러한 측면에서 더 나은 성능을 보였기 때문에 다른 생성 패러다임보다 선택되었음을 강력하게 시사한다.
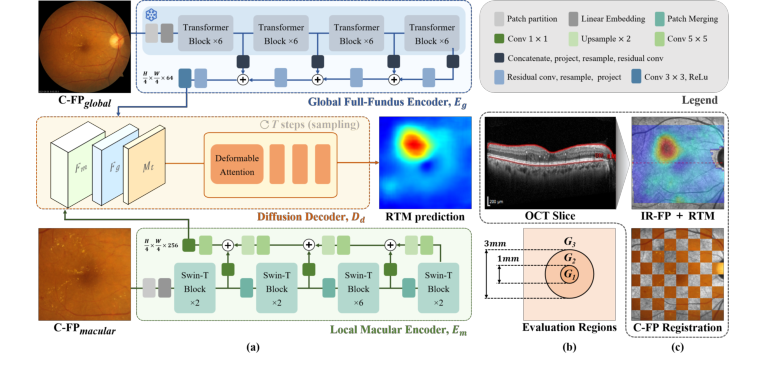 Figure 1. (a) GLD-RT leverages a dual-stream diffusion framework to integrate global contextual features with fine-grained details. (b) Evaluation regions for RTM predic- tion. (c)IR-FP, the localizer in OCT imaging that generates RTM, is used to register C-FPglobal with RTM, generating C-FPmacular
Figure 1. (a) GLD-RT leverages a dual-stream diffusion framework to integrate global contextual features with fine-grained details. (b) Evaluation regions for RTM predic- tion. (c)IR-FP, the localizer in OCT imaging that generates RTM, is used to register C-FPglobal with RTM, generating C-FPmacular
수학적 및 논리적 메커니즘
마스터 방정식
GLD-RT 프레임워크의 학습 메커니즘의 절대적인 핵심은 평균 제곱 오차(Mean Squared Error, MSE) 손실 함수인 최적화 목표이다. 이 방정식은 모델이 컬러 안저 사진(C-FP)으로부터 망막 두께 지도(RTMs)를 정확하게 예측하도록 안내하며, 예측과 기준 진실 간의 차이를 최소화한다.
마스터 방정식은 다음과 같이 제시된다.
$$ \mathcal{L} = \mathbb{E}_{M,t,F_m,F_g} [||M – D_d(M_t, t, F_m, F_g) ||^2] $$
항별 분석
이 방정식을 분해하여 각 구성 요소의 역할을 이해해 보자.
-
$\mathcal{L}$:
- 수학적 정의: 이 기호는 전체 손실 함수, 특히 평균 제곱 오차(MSE) 손실을 나타낸다.
- 물리적/논리적 역할: 모델의 예측과 실제 기준 진실 RTM 간의 불일치를 정량화한다. 모델 훈련의 주요 목표는 이 값을 최소화하여 모델이 더 정확한 예측을 하도록 유도하는 것이다.
- 사용 이유: MSE는 회귀 작업에 표준적이고 효과적인 손실 함수이다. 제곱 연산은 더 큰 오류를 더 많이 페널티를 주어 모델이 상당한 편차를 줄이도록 장려한다.
-
$\mathbb{E}_{M,t,F_m,F_g}$:
- 수학적 정의: 이것은 기대값 연산자를 나타내며, 확률 변수 $M$, $t$, $F_m$, $F_g$에 대한 평균을 의미한다.
- 물리적/논리적 역할: 실제 훈련 중에는 이 기대값이 훈련 샘플 배치에 대한 제곱 차이의 평균으로 근사된다. 각 샘플은 기준 진실 RTM($M$), 특정 노이즈 타임스텝($t$), 국소 황반 특징($F_m$), 그리고 전역 전체 안저 특징($F_g$)을 포함한다. 이 평균화는 모델이 다양한 입력 및 노이즈 조건에 대해 잘 일반화되도록 학습하도록 보장한다.
- 사용 이유: 샘플 배치에 대한 손실을 평균화하면 단일 샘플에 대한 손실을 계산하는 것보다 더 안정적이고 대표적인 기울기를 제공하여 모델 매개변수를 업데이트할 수 있다.
-
$M$:
- 수학적 정의: 이것은 기준 진실 망막 두께 지도(RTM)를 나타낸다. 일반적으로 높이와 너비가 $H \times W$인 2D 행렬이며, 여기서 $H$와 $W$는 지도의 높이와 너비이다.
- 물리적/논리적 역할: 이것은 GLD-RT 모델이 예측하려고 하는 "정답" 또는 목표 출력이다. 모델의 예측과 비교되는 기준점 역할을 한다.
- 사용 이유: 오류를 계산하고 모델 성능을 평가하는 데 필수적인 벤치마크이다.
-
$D_d(\cdot)$:
- 수학적 정의: 이것은 확산 디코더를 나타내며, 복잡한 신경망이다. 노이즈가 많은 RTM, 타임스텝 및 조건부 특징을 입력으로 받아 원래의 노이즈 없는 RTM을 예측하는 것을 목표로 한다.
- 물리적/논리적 역할: 이것은 모델의 생성 엔진이다. 훈련 중에는 C-FP 특징에서 추출된 정보를 바탕으로 노이즈가 많은 RTM을 원래의 RTM으로 "노이즈 제거"하는 방법을 학습한다. 추론 중에는 C-FP 특징을 안내로 사용하여 순수한 노이즈를 예측된 RTM으로 반복적으로 변환한다.
- 사용 이유: 확산 모델 프레임워크는 고충실도 이미지를 생성하고 복잡한 데이터 분포를 모델링하는 입증된 능력을 위해 선택되었으며, 이는 RTM의 복잡한 세부 정보에 중요하다. 조건부 측면은 생성 프로세스를 입력 C-FP 특징으로 안내할 수 있게 한다.
-
$M_t$:
- 수학적 정의: 이것은 특정 확산 타임스텝 $t$에서 기준 진실 RTM, $M$의 노이즈가 많은 버전이다. $M$에 예약된 가우시안 노이즈를 추가하여 생성된다.
- 물리적/논리적 역할: 이것은 훈련 중 확산 디코더의 입력으로 사용된다. 디코더의 작업은 $M_t$에서 노이즈를 효과적으로 제거하여 원래의 $M$을 재구성하는 방법을 학습하는 것이다. 이 과정은 점진적으로 노이즈가 추가되는 순방향 확산 프로세스의 역전을 모방한다.
- 사용 이유: 확산 모델은 미리 정의된 노이즈 추가 프로세스를 역전시키는 방법을 학습함으로써 작동한다. 다양한 타임스텝에서 $M_t$에 대해 모델을 훈련함으로써, 광범위한 노이즈 수준에 걸쳐 노이즈를 제거하는 능력을 개발한다.
-
$t$:
- 수학적 정의: 이것은 확산 타임스텝으로, $M$에 추가된 노이즈의 양을 나타내는 정수 값이다. 일반적으로 작은 값(최소 노이즈)에서 큰 값(최대 노이즈)까지 범위를 갖는다.
- 물리적/논리적 역할: 확산 디코더에게 $M_t$에 존재하는 현재 노이즈 수준에 대한 중요한 정보를 제공한다. $t$를 알면 디코더가 해당 특정 노이즈 강도에 대해 적절한 노이즈 제거 작업을 적용할 수 있다.
- 사용 이유: 타임스텝은 확산 모델에 기본적이며, 노이즈 제거 전략은 노이즈 양에 따라 크게 달라진다. 다른 타임스텝은 다른 노이즈 제거 접근 방식을 필요로 한다.
-
$F_m$:
- 수학적 정의: 이것은 C-FP 이미지의 잘린 황반 영역($C\text{-}FP_{macular}$)에서 국소 황반 인코더($E_m$)에 의해 추출된 미세한 국소 황반 특징이다. 이 특징들은 $\frac{H}{4} \times \frac{W}{4} \times 256$의 차원을 갖는다.
- 물리적/논리적 역할: 이 특징들은 이 임상적으로 중요한 영역에서 정확한 두께 예측에 필수적인 황반 영역에 대한 매우 상세한 정보를 제공한다. 그것들은 미세한 해부학적 맥락으로 확산 프로세스를 안내하는 국소 조건 역할을 한다.
- 사용 이유: 황반 영역은 당뇨병성 황반부종(DME) 병변이 가장 명확하게 나타나고 세심한 분석이 필요한 곳이다. Swin-Transformer와 Feature Pyramid Network를 사용하는 $E_m$ 인코더는 이러한 계층적이고 상세한 특징을 포착하도록 설계되었다.
-
$F_g$:
- 수학적 정의: 이것은 전체 C-FP 이미지($C\text{-}FP_{global}$)에서 전역 전체 안저 인코더($E_g$)에 의해 추출된 전역 전체 안저 특징이다. 이 특징들은 $\frac{H}{16} \times \frac{W}{16} \times 64$의 차원을 갖는다.
- 물리적/논리적 역할: 이 특징들은 높은 수준의 의미론적 맥락과 전체 망막 구조에 대한 정보를 제공한다. 그것들은 황반 영역에만 집중할 때 손실될 수 있는 주변 맥락을 보상하며, 확산 프로세스에 대한 전역 조건 역할을 한다.
- 사용 이유: 전역 맥락은 전체 망막에 걸쳐 해부학적 일관성을 보장하고 황반 두께에 영향을 미칠 수 있는 더 넓은 병리학적 표지자(예: 혈관 네트워크)를 제공한다. $E_g$ 인코더는 이를 위해 사전 훈련된 RETFound Vision Transformer를 활용한다.
-
$|| \cdot ||^2$:
- 수학적 정의: 이것은 L2 노름의 제곱을 나타내며, 벡터 또는 행렬의 모든 요소의 제곱 합을 계산한다. 행렬 $A$에 대해 $||A||^2 = \sum_{i,j} A_{i,j}^2$이다.
- 물리적/논리적 역할: 기준 진실 RTM과 확산 디코더가 예측한 RTM 간의 제곱 차이를 계산한다. 차이를 제곱하면 양수 및 음수 오류가 모두 동일하게 손실에 기여하고 더 큰 오류에 더 큰 페널티를 부과한다.
- 사용 이유: 제곱 L2 노름은 평균 제곱 오차(MSE) 손실의 기본 구성 요소이며, 회귀 작업에 널리 채택된다. 이는 미분 가능하고 볼록한 특성으로 최적화 프로세스를 단순화한다.
-
$M - D_d(\dots)$:
- 수학적 정의: 이것은 기준 진실 RTM과 예측된 RTM 간의 요소별 차이를 나타낸다.
- 물리적/논리적 역할: 이것은 모델이 최소화하려고 노력하는 오류 또는 잔차이다. 원하는 출력과 모델의 실제 출력 간의 직접적인 비교이다.
- 사용 이유: 이 직접적인 빼기는 모델이 줄여야 할 오류를 정량화하는 기초를 형성한다.
단계별 흐름
데이터 포인트 하나가 GLD-RT 메커니즘을 통해 입력에서 손실 계산까지 어떻게 진행되는지 추적해 보자.
-
초기 데이터 입력: 프로세스는 컬러 안저 사진(C-FP) 이미지와 해당 기준 진실 망막 두께 지도(RTM), 즉 광간섭단층촬영(OCT) 스캔에서 얻은 $M$으로 시작된다.
-
다중 양상 등록 및 자르기: C-FP 이미지는 RTM의 공간 좌표와 픽셀 단위로 정렬하기 위해 정확한 등록 프로세스를 거친다. 여기에는 중간 적외선 안저 사진(IR-FP) 이미지를 참조로 사용하는 것이 포함된다. 주요 단계에는 망막 혈관 분할, 주요 지점 감지(예: AKAZE 사용), 호모그래피 행렬 계산(예: RANSAC 사용), 그리고 전체 C-FP($C\text{-}FP_{global}$)를 IR-FP에 비선형적으로 등록하는 것이 포함된다. 이를 통해 RTM에 해당하는 황반 영역에만 초점을 맞춘 잘린 버전 $C\text{-}FP_{macular}$가 생성된다.
-
병렬 특징 추출:
- 전역 맥락 스트림: 전체 $C\text{-}FP_{global}$ 이미지가 전역 전체 안저 인코더($E_g$)에 공급된다. 사전 훈련된 RETFound Vision Transformer를 활용하는 이 인코더는 이미지를 처리하여 전역 망막 구조와 더 넓은 맥락 정보를 포함하는 고수준 의미론적 특징 $F_g$를 추출한다.
- 국소 세부 정보 스트림: 동시에 잘린 $C\text{-}FP_{macular}$ 이미지가 국소 황반 인코더($E_m$)에 들어간다. Swin-Transformer와 Feature Pyramid Network로 구축된 이 인코더는 황반 영역에 특정한 상세 정보를 제공하는 미세한 계층적 특징 $F_m$을 추출한다.
-
노이즈 주입 (훈련 단계만 해당): 모델이 훈련 단계에 있다면, 임의의 타임스텝 $t$가 미리 정의된 노이즈 스케줄에서 선택된다. 이 타임스텝에 따라 스케일링된 가우시안 노이즈가 기준 진실 RTM $M$에 추가되어 노이즈가 많은 RTM $M_t$가 생성된다.
-
확산 디코더에 의한 조건부 노이즈 제거: 노이즈가 많은 RTM $M_t$, 선택된 타임스텝 $t$, 그리고 추출된 조건부 특징($F_m$ 및 $F_g$)이 모두 확산 디코더($D_d$)에 전달된다. 디코더의 주요 작업은 $M_t$를 노이즈 제거하여 원래의 깨끗한 RTM $M$으로 되돌리는 방법을 학습하는 것이다. 이 노이즈 제거 과정은 $F_m$(국소 세부 정보) 및 $F_g$(전역 맥락)에서 제공하는 풍부한 맥락 정보에 의해 중요하게 안내된다.
-
RTM 예측: 디코더는 원래 RTM에 대한 최상의 추정치를 출력하며, 이를 $D_d(M_t, t, F_m, F_g)$로 표시할 수 있다.
-
손실 계산: 예측된 RTM은 원래 기준 진실 RTM $M$과 직접 비교된다. 요소별 차이의 제곱 L2 노름, $||M – D_d(M_t, t, F_m, F_g) ||^2$이 계산된다. 이 값은 이 특정 데이터 포인트에 대한 오류를 나타낸다.
-
배치 평균화: 이 개별 제곱 오류는 현재 훈련 배치 내의 모든 샘플에 대한 평균으로 계산되어(각각 자체 $M$, $t$, $F_m$, $F_g$ 조합 포함) 해당 반복에 대한 최종 손실 $\mathcal{L}$을 생성한다.
-
추론 (생성 단계): 추론 중에는 확산 디코더에 대한 프로세스가 변경된다. 기준 진실 RTM의 노이즈가 많은 버전으로 시작하는 대신, 디코더는 순수한 무작위 노이즈로 시작한다. 그런 다음 C-FP 입력에서 추출된 $F_m$ 및 $F_g$ 특징에 의해 안내되는 노이즈 제거 단계를 반복적으로 적용한다. DDIM과 같은 비마르코프 결정적 샘플링 접근 방식을 사용하는 이 반복 프로세스는 훨씬 적은 단계 수(예: 5단계)에 걸쳐 일관되고 상세한 RTM 예측으로 초기 노이즈를 점진적으로 변환한다.
최적화 역학
GLD-RT 메커니즘은 기울기 기반 최적화 프로세스를 통해 평균 제곱 오차(MSE) 손실 함수 $\mathcal{L}$을 반복적으로 최소화함으로써 학습, 업데이트 및 수렴한다.
-
손실 지형: 모델의 학습은 복잡한 손실 지형 내에서 발생한다. 이 지형은 기준 진실 RTM, 다양한 타임스텝에서 도입된 노이즈 수준, 그리고 C-FP 이미지에서 추출된 풍부한 다중 스케일 조건부 특징 간의 복잡한 관계에 의해 형성된다. 궁극적인 목표는 예측된 RTM이 기준 진실과 일관되게 일치하는 "계곡"에 해당하는 모델 매개변수(인코더 $E_m$, $E_g$, 및 확산 디코더 $D_d$ 내의 가중치 및 편향) 세트를 찾는 것이다. 신경망의 전체 지형은 본질적으로 비볼록하지만, MSE 목표는 최적화를 단순화하는 명확하고 미분 가능한 신호를 제공한다. 다양한 노이즈 수준에 걸쳐 노이즈를 제거하는 방법을 학습하는 확산 프로세스의 고유한 구조는 더 간단한 직접 회귀 모델에 비해 더 부드럽고 강력한 손실 지형으로 이어질 수 있는 강력한 정규화기 역할을 한다.
-
기울기 계산: 각 훈련 반복에서 배치 데이터에 대한 손실 $\mathcal{L}$이 계산된 후, 역전파 알고리즘이 시작된다. 이 알고리즘은 손실의 기울기를 인코더($E_m$, $E_g$) 및 확산 디코더($D_d$) 내의 모든 학습 가능한 매개변수에 대해 효율적으로 계산한다. 이러한 기울기는 각 매개변수가 계산된 손실을 줄이기 위해 조정되어야 하는 정확한 방향과 크기를 나타내므로 매우 중요하다.
-
매개변수 업데이트: 본 논문에서는 Adam 옵티마이저 [16]를 사용하여 모델의 매개변수를 업데이트한다고 명시한다. Adam은 과거 기울기(첫 번째 모멘트) 및 과거 제곱 기울기(두 번째 모멘트)의 지수 가중 평균을 유지함으로써 다양한 매개변수에 대해 개별 학습률을 동적으로 계산하는 정교한 적응형 학습률 최적화 알고리즘이다.
- Adam의 특정 하이퍼파라미터는 $\beta_1 = 0.9$ 및 $\beta_2 = 0.999$로 설정되며, 이는 널리 받아들여지는 기본값이다.
- 학습률을 효과적으로 관리하기 위해 16에포크 "웜업" 단계 이후 코사인 감쇠 스케줄링 전략이 사용된다. 이 스케줄은 학습률이 매우 작은 값($1 \times 10^{-8}$)에서 약간 더 큰 값($6 \times 10^{-5}$)으로 점진적으로 증가하는 동안 적용된다. 이 웜업 후, 학습률은 300에포크에 걸쳐 코사인 함수에 따라 느리게 감소한다. 이 전략은 모델이 처음에 손실 지형을 신중하게 탐색하고, 그런 다음 수렴을 가속화하고, 마지막으로 학습률을 줄여 최적의 최소값을 초과하는 것을 방지하여 매개변수를 미세 조정할 수 있도록 한다.
- 또한 고정된 가중치 감쇠 $1 \times 10^{-2}$가 적용된다. L2 정규화라고도 알려진 가중치 감쇠는 큰 매개변수 값을 페널티를 주어 과적합을 방지한다. 이는 모델이 더 일반화되고 덜 복잡한 특징을 학습하도록 장려하여 보지 못한 데이터에 대한 성능을 향상시킨다.
-
반복적 개선 및 수렴: 손실 $\mathcal{L}$을 계산하고, 기울기를 계산하고, 매개변수를 업데이트하는 이 주기(300에포크 동안)는 많은 훈련 에포크에 걸쳐 반복적으로 반복된다. 훈련이 진행됨에 따라 모델의 매개변수는 $\mathcal{L}$을 최소화하기 위해 지속적으로 개선된다. 확산 디코더는 점진적으로 노이즈 프로세스를 정확하게 역전시키는 방법을 학습하여, $F_m$ 및 $F_g$에 의해 조건화될 때 $M$을 예측하는 데 점점 더 능숙해진다. 모델은 훈련 및 검증 데이터 세트의 손실이 안정화되거나 최소값에 도달할 때 수렴한 것으로 간주된다. 이는 모델이 기준 진실과 밀접하게 일치하는 RTM을 생성하는 데 성공적으로 학습했음을 나타내며, 이는 망막 두께 분포의 근본적인 것을 포착하는 능력을 보여준다. 추론 중 샘플링을 위해 Denoising Diffusion Implicit Model (DDIM)을 채택한 것(비마르코프적이고 결정적인 프로세스)은 훨씬 적은 단계 수(예: 5단계)로 더 빠르고 안정적인 RTM 생성을 가능하게 하여 메커니즘을 실제 적용에 더 효율적으로 만들어 실용적인 수렴에 더욱 기여한다.
결과, 한계 및 결론
실험 설계 및 기준선
GLD-RT 모델은 포괄적인 데이터 세트를 사용하여 개발되고 엄격하게 검증되었다. 핵심 RTM 예측 작업을 위해 연구자들은 각각 해당 광간섭단층촬영(OCT), 적외선 안저 사진(IR-FP), 컬러 안저 사진(C-FP) 이미지를 포함하는 2,918개의 데이터 삼중항을 사용했다. 이 삼중항은 항혈관내피성장인자(anti-VEGF) 치료를 받는 당뇨병성 황반부종(DME) 환자 1,418명으로부터 강북삼성병원에서 채취되었다. 코호트는 평균 망막 두께 $296.99 \pm 30.67 \text{ µm}$ 및 중심 황반 두께 $292.46 \pm 75.00 \text{ µm}$를 보여 황반부종의 상당한 유병률을 나타냈다. IR-FP 및 31개의 OCT B-스캔은 Heidelberg 장비를 사용하여 획득되었으며, 이는 자동으로 막 분할을 제공한다. 숙련된 안과 의사들은 데이터 품질을 보장하기 위해 고정 불량 또는 분할 오류가 있는 스캔을 신중하게 제외했다.
DME 진단의 중요한 작업을 위해 Mobile Brazilian Retinal Dataset (mBRSET)이 사용되었다. 이 데이터 세트는 브라질 이타부나의 당뇨병 환자 1,291명으로부터 5,164개의 C-FP 이미지로 구성되며, 모두 DME 진단 및 이미지 품질 레이블로 세심하게 주석이 달렸다.
데이터 전처리는 일관성과 정렬을 보장하기 위해 여러 단계를 포함했다. IR-FP 이미지는 OCT 스캔 영역과 일치하도록 $544 \times 544$ 픽셀로 중앙에서 잘렸다. C-FPglobal 이미지는 IR-FP 해상도와 일치하도록 $3608 \times 3608$에서 $544 \times 544$로 다운샘플링되었다. 망막 두께 지도(RTM)는 31개의 B-스캔 라인에서 계산되어 IR-FP 해상도와 일치하도록 선형적으로 보간되었다. 구조적 무결성을 유지하면서 인공물을 줄이기 위해 RTM은 가우시안 필터링($\sigma = 3$) 후 비국소 평균 노이즈 제거를 사용하여 순차적으로 평활화되었다. DME 진단을 위해 C-FP 이미지는 황반 위치를 기준으로 $800 \times 800$으로 잘린 후 $544 \times 544$로 다운샘플링되었다.
데이터 세트는 환자 수준에서 분할되어 강력한 평가를 수행했다. GLD-RT 개발을 위해 훈련용 2043개, 검증용 292개, 테스트용 583개의 삼중항이 사용되었다. mBRSET은 DME 진단을 위해 2409개의 훈련, 345개의 검증, 688개의 테스트 이미지로 유사하게 분할되었다. GLD-RT 모델은 표준 매개변수 $(\beta_1, \beta_2) = (0.9, 0.999)$를 가진 Adam 옵티마이저 [16]를 사용하여 최적화되었으며, 16에포크 웜업 후 코사인 감쇠 학습률 스케줄과 $1 \times 10^{-2}$의 고정 가중치 감쇠를 사용했다. 확산 프로세스는 훈련에 20개의 타임스텝, 추론에 5개의 타임스텝을 사용했다. 모든 실험은 NVIDIA GeForce RTX 3090 GPU에서 수행되었으며, 무작위 뒤집기 및 회전을 통한 데이터 증강을 포함했다.
수학적 주장을 무자비하게 증명하기 위해 저자들은 GLD-RT를 여러 확립된 최신(SOTA) 모델과 비교했다. RTM 예측을 위해 "희생자"에는 UNet [23], Trans-UNet [5], Swin-Unetr [12]와 같은 일반적인 의료 영상 밀집 예측 모델뿐만 아니라 DeepRT [15] 및 M²FRT [26]와 같은 특수 RTM 예측 프레임워크가 포함되었다. 이러한 기준선은 포괄적인 비교를 제공하기 위해 다양한 입력 구성(IR-FP, C-FP 또는 둘 다)으로 평가되었다. DME 진단을 위해 GLD-RT 보조 접근 방식은 ResNet50 [13] 분류기를 사용한 C-FP 전용 기준선과 비교되었다.
증거가 증명하는 것
실험 증거는 제안된 전역-국소 조건부 확산 모델(GLD-RT)이 컬러 안저 사진(C-FP)으로부터 RTM을 예측하는 데 있어 기존 방법들을 훨씬 능가하며, DME 진단에 상당한 이점을 제공한다는 것을 확실하게 증명한다.
RTM 예측의 경우, GLD-RT는 마이크로미터($\mu$m) 단위의 평균 절대 오차(MAE)와 데시벨(dB) 단위의 피크 신호 대 잡음비(PSNR)를 사용하여 모든 망막 영역(G1, G2, G3, ETDRS 그리드에 해당)에서 우수한 성능을 달성했다. 구체적으로, GLD-RT는 C-FP만 입력으로 사용하여 전체 MAE 20.08 $\mu$m와 PSNR 30.91 dB를 기록했다. 이는 C-FP 입력으로 전체 MAE 23.21 $\mu$m와 PSNR 29.34 dB를 달성한 이전 SOTA인 M²FRT [26]에 비해 상당한 개선이었다. 이러한 이득의 통계적 유의성은 p-값 0.01 미만으로 확인되었으며, 이는 GLD-RT의 성능이 우연에 의한 것이 아님을 나타낸다.
실제에서 GLD-RT의 핵심 메커니즘이 작동한다는 가장 설득력 있는 증거는 시각 영역(G1)에서의 성능에 있다. 이 영역은 복잡한 층 구조와 중심 시력에 대한 직접적인 영향으로 인해 임상적으로 중요한다. 여기서 GLD-RT는 MAE 31.97 $\mu$m와 PSNR 30.18 dB를 달성했으며, 이는 C-FP 입력에 대한 M²FRT의 36.25 $\mu$m MAE 및 28.31 dB PSNR보다 상당한 개선을 보여준다. 이는 GLD-RT의 전역 맥락과 미세한 국소 특징을 계층적 확산 디코더를 통해 통합하는 이중 스트림 아키텍처가 이 어려운 영역에서 정확한 두께 정량화에 중요한 미묘하고 불규칙한 망막 해부학적 구조를 효과적으로 포착한다는 것을 시사한다.
그림 2에 묘사된 질적 결과는 이러한 이득을 더욱 강조한다. GLD-RT는 건성 황반변성(Drusen), 황반부종(Macular Edema), 분지정맥폐쇄(Branch Vein Occlusion)와 같은 다양한 병리학적 병변과 관련된 두께 변화를 강력하게 감지하여 M²FRT보다 더 정확한 망막 해부학적 구조를 제공했다. 차이 지도(예측 빼기 기준 진실)는 일관되게 GLD-RT에 대해 더 작은 오류를 보여주어 우수한 충실도를 시각적으로 확인했다.
무작위 연구는 각 아키텍처 구성 요소의 기여에 대한 결정적인 증거를 제공했다. 백본(Em, Dnd, 즉 확산이 없는 디코더를 가진 국소 황반 인코더)은 이미 M²FRT를 능가하여 향상된 국소 특징 추출의 효과를 검증했다. 확산 디코더(Dd)의 추가는 특히 G1에서 성능을 크게 향상시켜 확산 프로세스의 미세 황반 세부 정보를 포착하는 능력을 입증했다. 또한 RETFound 사전 훈련을 포함한 전역 전체 안저 인코더(Eg)는 성능을 더욱 향상시켜 도메인별 사전 훈련 및 전역 해부학적 일관성의 중요한 역할을 강조했다. Eg (RETFound), Em, Dd를 결합한 전체 GLD-RT 모델은 일관되게 최고의 결과를 산출했다.
RTM 예측을 넘어, GLD-RT 생성 RTM은 DME 진단에 매우 유용했다. C-FP와 이중 입력으로 연결되어 ResNet50 분류기에 사용될 때, 이 접근 방식은 C-FP 전용 기준선을 일관되게 능가했다. 이중 입력 모델은 93.44%의 정확도(92.21% 대비), 79.49%의 재현율(64.41% 대비), 85.90%의 F1-점수(75.84% 대비), 그리고 0.919의 AUC(0.855 대비)를 달성했다. 이 부인할 수 없는 증거는 C-FP에서 생성된 RTM이 보완적인 진단 통찰력을 제공하며, 종종 OCT 및 C-FP 검사를 모두 요구하는 임상 프로토콜과 일치한다는 것을 보여준다. 이는 GLD-RT를 특히 자원이 제한된 환경에서 유망하고 비용 효율적인 진단 도구로 만든다.
한계 및 향후 방향
GLD-RT는 C-FP로부터 망막 두께를 예측하고 DME 진단을 지원하는 데 있어 상당한 발전을 보여주지만, 현재의 한계를 인정하고 향후 개발을 고려하는 것이 중요하다.
하나의 본질적인 한계는 모델의 목적과는 별개로, C-FP는 2D 영상 기법이기 때문에 본질적으로 OCT의 깊이 해상도가 부족하다는 점이다. GLD-RT는 두께를 효과적으로 추론하지만, 기준 진실 RTM은 고해상도 OCT 스캔에서 파생된다. 논문 자체는 "상세한 RTM 예측을 위해 더 높은 해상도의 OCT 통합"을 향후 방향으로 언급하며, GLD-RT의 발전에도 불구하고 추가적인 기술 통합이나 더 높은 충실도의 기준 진실 없이는 C-FP만으로 달성할 수 있는 세부 정보의 상한선이 있을 수 있음을 시사한다. 현재 모델은 강력하지만 여전히 2D 입력에 기반한 예측이며, 복잡한 3D 망막 구조의 모든 미세한 세부 정보를 포착하는 능력은 제한될 수 있다.
또 다른 고려 사항은 결과의 일반화 가능성이다. 모델은 특정 병원 및 지역(강북삼성병원 및 mBRSET)의 데이터 세트에서 훈련되었다. 이들은 상당한 데이터 세트이지만, 실제 임상 실습에는 다양한 환자 인구 통계, 질병 심각도 및 다양한 제조업체의 영상 장치가 포함된다. 다른 인구 또는 다양한 이미지 획득 프로토콜을 가진 외부, 보지 못한 데이터 세트에서 GLD-RT의 성능은 추가적인 전향적 임상 검증을 필요로 할 것이다. 본 논문은 "전향적 임상 검증"을 향후 방향으로 언급하며, 이는 이러한 광범위한 테스트의 필요성을 암묵적으로 인정한다.
또한, 모델이 RTM을 제공하지만, 전통적인 C-FP 이미지와 함께 이러한 AI 생성 지도를 해석하기 위한 임상 워크플로우를 수립해야 한다. 임상의들은 OCT에서 파생된 RTM에 익숙하며, C-FP에서 생성된 RTM으로의 전환은 정확한 해석과 치료 결정으로의 통합을 보장하기 위해 명확한 지침과 교육이 필요할 것이다. 본 논문에서 "기존 의료 워크플로우로의 통합"을 제안하는 것은 이러한 실용적인 과제를 강조한다.
앞으로 나아가면서 이 연구에서 몇 가지 흥미로운 논의 주제가 나온다.
- 향상된 임상 통합 및 의사 결정 지원: GLD-RT를 기존 전자 건강 기록 시스템에 통합하여 일상적인 C-FP 선별 검사 중에 실시간 RTM 예측을 제공할 수 있는 방법은 무엇인가? 모델을 확장하여 단순히 두께를 예측하는 것뿐만 아니라 우려되는 영역을 자동으로 강조하거나 후속 조치를 제안하여, 1차 진료 의사 또는 가정 모니터링 환자를 위한 더 포괄적인 의사 결정 지원 도구 역할을 할 수 있는가? 이러한 자율 진단 보조 장치를 배포하기 위한 규제 경로 및 윤리적 고려 사항은 무엇인가?
- 다중 질병 예측 및 생체 표지자 발견: DME에 C-FP를 활용하는 GLD-RT의 성공을 고려할 때, 이 프레임워크를 다른 망막 병변 또는 현재 더 비싸거나 침습적인 영상 촬영에 의존하는 생체 표지자를 예측하도록 조정하거나 확장할 수 있는가? 예를 들어, C-FP로부터 녹내장(예: 망막 신경 섬유층 얇아짐) 또는 노인성 황반 변성(예: 건성 황반변성 침착물 부피)의 초기 징후를 예측할 수 있는가? 이는 C-FP를 진정한 다목적 선별 도구로 변환할 수 있다.
- 이미지 품질 및 인공물에 대한 견고성: 실제 C-FP 이미지는 환자 협조, 매체 혼탁 또는 최적화되지 않은 카메라 설정으로 인해 종종 다양한 품질로 고통받는다. 현재 연구에서는 저품질 스캔을 필터링했지만, 향후 작업은 이미지 품질 평가 모듈을 통합하거나 다양한 저하된 이미지로 훈련함으로써 이러한 불완전성에 대해 GLD-RT를 더 견고하게 만드는 데 초점을 맞출 수 있다. 모델이 이상적이지 않은 입력으로도 높은 정확도를 유지할 수 있는 방법은 무엇인가?
- 계산 효율성 및 엣지 배포: 현재 모델은 NVIDIA GeForce RTX 3090에서 실행된다. 자원이 제한된 환경이나 휴대용 장치에서 광범위하게 채택하려면 모델을 더 낮은 계산 발자국과 더 빠른 추론 시간을 위해 최적화하는 것이 중요할 것이다. 스마트폰에 부착된 안저 카메라에서 실시간 RTM 생성을 가능하게 하는 엣지 컴퓨팅에 적합한 더 가벼운 버전을 만들기 위해 지식 증류 또는 모델 양자화 기술을 적용할 수 있는가?
- 종단 모니터링 및 치료 반응: GLD-RT를 DME 환자의 종단 모니터링에 사용하여 망막 두께 변화를 추적하여 치료 반응 또는 질병 진행을 평가할 수 있는가? 이를 위해서는 장기간에 걸친 모델의 일관성과 미묘한 변화에 대한 민감도를 검증해야 한다. 모델의 예측이 개인화된 치료 전략을 어떻게 알릴 수 있으며, 항혈관내피성장인자 주사 일정 또는 기타 개입을 최적화할 수 있는가?
- 설명 가능성 및 신뢰: AI 모델이 임상 실습에 더 통합됨에 따라 모델이 특정 예측을 하는 이유를 이해하는 것은 임상의들 사이에서 신뢰를 구축하는 데 필수적이다. 향후 연구는 GLD-RT의 RTM 예측에 대한 설명 가능성을 향상시키는 방법을 탐색할 수 있으며, 아마도 모델이 C-FP 이미지에서 주의를 기울이는 특징을 시각화함으로써 임상의들에게 그 출력에 대한 더 큰 통찰력과 자신감을 제공할 수 있다.
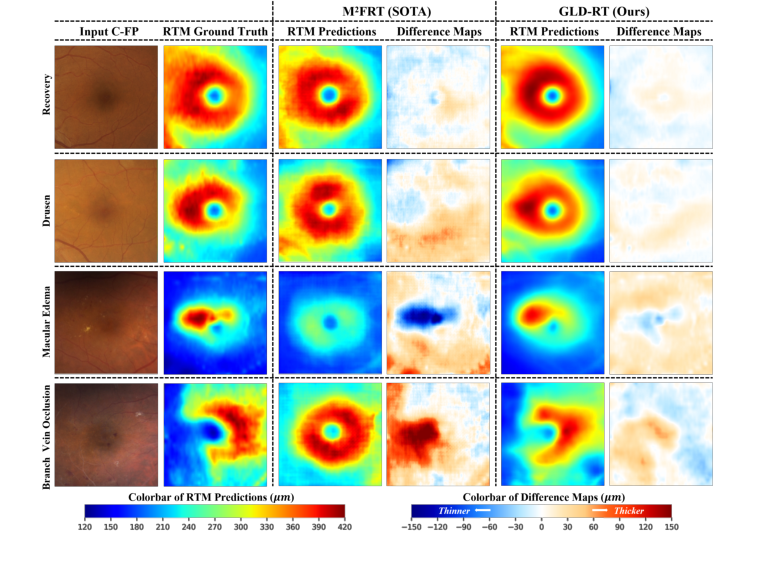 Figure 2. Qualitative results of our model and M2FRT. GLD-RT robustly detects diverse pathological lesions and accurately depicts subtle and irregular retinal anatomy. Dif- ference maps (prediction minus ground truth) further underscore these gains
Figure 2. Qualitative results of our model and M2FRT. GLD-RT robustly detects diverse pathological lesions and accurately depicts subtle and irregular retinal anatomy. Dif- ference maps (prediction minus ground truth) further underscore these gains
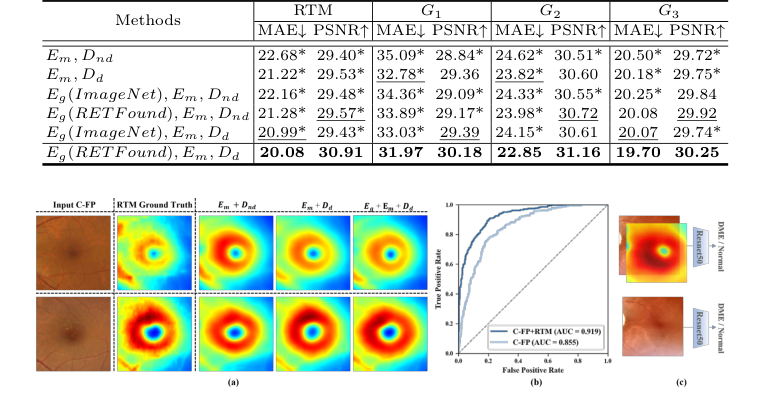 Figure 3. (a) Qualitative results of ablation study on GLD-RT. The proposed Dd sig- nificantly enhanced fine macular structural details, while Eg further enforced global anatomical consistency. (b) Receiver operating characteristic curve of DME diagnosis. (c)Experiment design of DME diagnosis
Figure 3. (a) Qualitative results of ablation study on GLD-RT. The proposed Dd sig- nificantly enhanced fine macular structural details, while Eg further enforced global anatomical consistency. (b) Receiver operating characteristic curve of DME diagnosis. (c)Experiment design of DME diagnosis
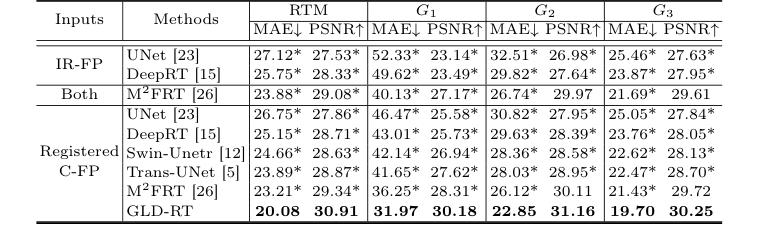 Table 1. Quantitative comparison of different methods for RTM prediction, with MAE (µm) and PSNR (dB). * indicates GLD-RT outperforms baselines with p-values<0.01
Table 1. Quantitative comparison of different methods for RTM prediction, with MAE (µm) and PSNR (dB). * indicates GLD-RT outperforms baselines with p-values<0.01
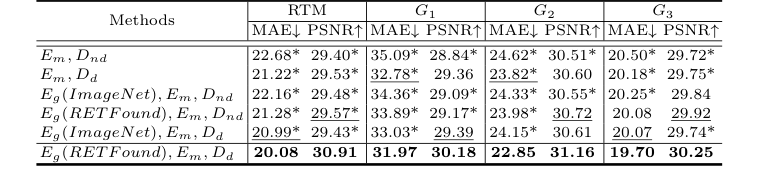 Table 2. Ablation study of RTM prediction, with MAE (µm) and PSNR (dB). * indicates GLD-RT outperforms baselines with p-values<0.01
Table 2. Ablation study of RTM prediction, with MAE (µm) and PSNR (dB). * indicates GLD-RT outperforms baselines with p-values<0.01