Видя за гранью поверхности: предсказание толщины сетчатки по цветным фундус-фотографиям для ведения диабетического макулярного отека
Проблема, рассматриваемая в данной статье, — предсказание карт толщины сетчатки (RTM) исключительно на основе цветных фундус фотографий (C FP) для ведения диабетического макулярного отека (DME), возникает из...
Предпосылки и академическая родословная
Истоки и академическая родословная
Проблема, рассматриваемая в данной статье, — предсказание карт толщины сетчатки (RTM) исключительно на основе цветных фундус-фотографий (C-FP) для ведения диабетического макулярного отека (DME), возникает из критической потребности в доступных и экономически эффективных диагностических инструментах в офтальмологии. Диабетический макулярный отек является ведущей причиной тяжелой потери зрения, особенно среди трудоспособного населения, что создает значительное бремя для глобального здравоохранения.
Исторически сложилось так, что оптическая когерентная томография (OCT) была золотым стандартом для оценки DME, поскольку она предоставляет подробные RTM, количественно определяющие патологии сетчатки с высокой точностью. Однако устройства OCT дороги и сложны в эксплуатации, что серьезно ограничивает их доступность, особенно в условиях ограниченных ресурсов или для рутинного домашнего мониторинга. Этот пробел в доступности часто приводит к недостаточному количеству визитов для последующего наблюдения и субоптимальным результатам лечения пациентов, проходящих терапию, такую как анти-фактор роста эндотелия сосудов (anti-VEGF).
Предыдущие попытки использовать C-FP, широко доступную и экономически эффективную 2D-технику визуализации (даже осуществимую с помощью смартфонов), столкнулись со значительными ограничениями. Ранние подходы полагались на суррогатные маркеры утолщения сетчатки, такие как липидные отложения, которым не хватало необходимого разрешения по глубине, что приводило к ограниченной специфичности и чувствительности для обнаружения DME. Например, предыдущие модели, пытавшиеся предсказать утолщение сетчатки по C-FP, часто не соответствовали клиническим стандартам, особенно при низком качестве изображений. Более поздние усилия были направлены на преодоление этого разрыва путем использования инфракрасной фундус-фотографии (IR-FP) в качестве промежуточного звена для извлечения информации о толщине. Хотя IR-FP используется в клинической практике для локализации при получении данных OCT, она все же требует дополнительного устройства, что ограничивает ее широкое применение. Кроме того, сама IR-FP имеет присущие ей недостатки, включая гиперрефлективные артефакты, ограниченный диапазон длин волн освещения, оптимизированный для подретинальных структур, и неадекватную визуализацию критических патологических маркеров, таких как твердые экссудаты и кровоизлияния.
Фундаментальная "болевая точка", которая заставила авторов написать эту статью, — это неспособность существующих методов предоставить комплексное, точное и доступное решение для оценки толщины сетчатки. OCT слишком дорога и сложна для широкого использования, в то время как предыдущие методы на основе C-FP и IR-FP были либо неточными, либо не имели информации о глубине, либо все еще требовали специализированного оборудования. Данная статья направлена на преодоление этих ограничений путем предложения первого подхода к предсказанию RTM исключительно на основе C-FP, тем самым превращая обычную фундус-визуализацию в комплексный и экономически эффективный диагностический инструмент для скрининга и мониторинга DME, особенно в условиях ограниченных ресурсов. Этот новый подход обещает улучшить результаты лечения пациентов за счет более своевременных и эффективных вмешательств.
Интуитивно понятные термины предметной области
Вот несколько специализированных терминов из статьи, объясненных с помощью повседневных аналогий для читателя с нулевой базой знаний:
- Диабетический макулярный отек (DME): Представьте себе небольшую, жизненно важную область в центре "сенсора камеры" вашего глаза (макулы), которая отекает и становится размытой из-за диабета. Это похоже на образование крошечной лужицы на линзе камеры, из-за чего все становится нечетким.
- Оптическая когерентная томография (OCT): Думайте об этом как о суперсовременном сонаре для вашего глаза. Вместо звуковых волн он использует световые волны для создания невероятно детальных поперечных снимков вашей сетчатки, показывая ее внутренние слои и толщину, подобно тому, как разрезают торт, чтобы увидеть все его слои.
- Карта толщины сетчатки (RTM): Это результат сканирования OCT, цветная "тепловая карта" вашей сетчатки. Области, которые толще нормы, могут быть окрашены в красный или желтый цвет, а более тонкие области — в синий, что дает врачам быстрый визуальный ориентир для проблемных участков, подобно карте погоды, показывающей изменения температуры.
- Цветная фундус-фотография (C-FP): Это просто стандартная, плоская 2D-фотография задней части вашего глаза, показывающая поверхностные структуры, такие как кровеносные сосуды и зрительный нерв. Это похоже на обычную фотографию пейзажа; вы видите деревья и горы, но не получаете представления об их высоте или глубине.
- Диффузионная модель: Это тип искусственного интеллекта, который учится создавать сложные изображения, начиная с чистого случайного шума и постепенно "устраняя шум" шаг за шагом, пока не получится четкое, желаемое изображение. Это похоже на скульптора, который начинает с бесформенного куска мрамора и медленно, итеративно вырезает, пока не появится детализированная статуя.
Таблица обозначений
| Обозначение | Описание
Определение проблемы и ограничения
Формулировка основной проблемы и дилемма
Основная проблема, рассматриваемая в данной статье, заключается в точном предсказании карт толщины сетчатки (RTM) исключительно на основе цветных фундус-фотографий (C-FP).
Входные данные/Текущее состояние:
Текущим золотым стандартом для ведения диабетического макулярного отека (DME) и оценки толщины сетчатки является оптическая когерентная томография (OCT). OCT предоставляет подробные RTM, которые являются количественными визуализациями структур и патологий сетчатки. В отличие от этого, цветная фундус-фотография (C-FP) является широко доступной, экономически эффективной и легкодоступной 2D-техникой визуализации, даже осуществимой с помощью смартфонов. Однако C-FP традиционно не обладает разрешением по глубине, необходимым для количественной оценки толщины сетчатки.
Желаемый конечный пункт/Целевое состояние:
Статья направлена на разработку системы, способной генерировать точные и комплексные RTM непосредственно из C-FP. Конечная цель состоит в том, чтобы эти RTM, полученные из C-FP, служили эффективным, доступным и экономически выгодным диагностическим и мониторинговым инструментом для DME, особенно в условиях ограниченных ресурсов. Это будет способствовать своевременному вмешательству, обоснованным решениям о лечении и улучшению визуальных исходов для пациентов, фактически превращая обычную фундус-визуализацию в мощный диагностический актив.
Отсутствующее звено или математический пробел:
Фундаментальным отсутствующим звеном является присущее 2D C-FP отсутствие разрешения по глубине. RTM представляют собой 3D-информацию о толщине, в то время как C-FP захватывает только 2D-проекцию. Предыдущие попытки преодолеть этот разрыв путем предсказания толщины по C-FP часто полагались на суррогатные маркеры (например, липидные отложения) с ограниченной специфичностью и чувствительностью, или на модели, которые просто не могли достичь необходимой клинической точности, особенно при различном качестве изображений. Математическая задача заключается в выводе непрерывного, количественного 3D-распределения толщины из 2D-изображения, где информация о глубине неявно закодирована в тонких визуальных подсказках, а не в явных измерениях.
Болезненный компромисс или дилемма:
Центральная дилемма заключается в компромиссе между доступностью/экономической эффективностью и количественной точностью/детализацией. OCT предоставляет RTM с высокой точностью, но является дорогостоящей, сложной в эксплуатации и имеет ограниченную доступность, что приводит к субоптимальному последующему наблюдению за пациентами во многих реальных сценариях. C-FP высокодоступна и недорога, но ее 2D-природа исторически мешала ей предоставлять точные количественные измерения толщины, необходимые для детального ведения DME. Исследователи оказались в ловушке, пытаясь извлечь достаточную количественную информацию из C-FP, не теряя ее присущих преимуществ доступности и низкой стоимости, или не вводя новых ограничений, полагаясь на промежуточные, менее доступные модальности, такие как IR-FP. Данная статья напрямую сталкивается с этой дилеммой, пытаясь достичь предсказания RTM уровня OCT исключительно на основе C-FP.
Ограничения и режимы отказа
Эта проблема чрезвычайно сложна из-за нескольких жестких, реалистичных ограничений:
- Присущая 2D-природа C-FP: Как упоминалось, C-FP не предоставляет прямой информации о глубине. Вывод 3D-толщины сетчатки из 2D-изображения является некорректно поставленной обратной задачей, требующей от модели изучения сложных, неочевидных взаимосвязей между поверхностными признаками и лежащей в основе толщиной.
- Тонкие патологические биомаркеры: Дезорганизация слоев сетчатки, вызванная DME, проявляется в виде "тонких вариаций текстуры и цвета" на C-FP. Эти тонкие подсказки трудно идентифицировать даже опытным клиницистам, не говоря уже об автоматизированной системе. Модель должна уметь обнаруживать эти незначительные изменения для точного предсказания толщины.
- Проблемы пространственного несоответствия и регистрации: Достижение точного попиксельного пространственного соответствия между C-FP (входные данные) и истинными значениями RTM (полученными из OCT, часто локализованными с помощью IR-FP) является серьезным препятствием. Различные модальности визуализации имеют разные поля зрения, разрешения и потенциальные искажения, что делает точную мультимодальную регистрацию сложным этапом предварительной обработки. В статье отмечается использование IR-FP в качестве промежуточного звена для регистрации, что подчеркивает эту трудность.
- Гетерогенность проявлений DME: DME проявляется широким спектром патологических поражений и нерегулярной анатомией сетчатки. Надежная модель должна обобщаться на эти разнообразные проявления, что требует захвата как глобальных контекстуальных признаков (например, сосудистых сетей), так и детальных локальных деталей (изменения в макулярной области).
- Вычислительные затраты на генерацию с высокой точностью: Генерация высокоразрешающих, точных RTM с использованием передовых генеративных моделей, таких как диффузионные модели, может быть вычислительно затратной, особенно на этапе вывода (сэмплирования). Необходимость "ускорить сэмплирование при сохранении высокой точности" (как решается с помощью DDIM) подчеркивает это вычислительное ограничение.
- Строгие требования к клинической точности: Предыдущие модели предсказания на основе C-FP "не соответствовали клиническим стандартам". Это устанавливает высокую планку для требуемой точности, специфичности и чувствительности любого нового решения, чтобы оно было клинически жизнеспособным. Предсказания модели должны быть достаточно надежными для принятия критически важных медицинских решений.
- Доступность данных и качество аннотаций: Обучение такой модели требует больших наборов данных точно сопряженных изображений C-FP, IR-FP и OCT с экспертными аннотациями для RTM и диагностики DME. Получение и курирование таких высококачественных мультимодальных наборов данных является трудоемким и ресурсоемким процессом.
- Потеря периферического контекста против детализации макулы: Хотя макулярная область имеет решающее значение для оценки толщины, важные глобальные структуры сетчатки и патологические биомаркеры (например, диск зрительного нерва, сосудистые сети) присутствуют в более широком изображении глазного дна. Фокусировка только на макуле рискует потерять этот важный "периферический контекст", что требует двухпоточного подхода для интеграции как глобальных, так и локальных признаков.
Почему такой подход
Неизбежность выбора
Авторы оказались в ситуации, когда традиционные "SOTA" (State-of-the-Art) методы, включая стандартные CNN, базовые диффузионные модели или Трансформеры, просто не справлялись с конкретной, нюансированной задачей предсказания карт толщины сетчатки (RTM) непосредственно из цветных фундус-фотографий (C-FP). Основное осознание вытекало из критической клинической потребности: хотя оптическая когерентная томография (OCT) является золотым стандартом для диагностики и ведения диабетического макулярного отека (DME), ее высокая стоимость и ограниченная доступность в условиях ограниченных ресурсов делают ее непрактичной для широкомасштабного скрининга и частого мониторинга. Это создало срочную потребность в более доступной альтернативе.
Цветная фундус-фотография (C-FP) стала наиболее жизнеспособным, экономически эффективным инструментом скрининга, будучи широко доступной и даже осуществимой с помощью смартфонов. Однако C-FP представляет собой фундаментальную проблему: это 2D-техника визуализации, которой по своей сути не хватает разрешения по глубине, необходимого для количественной оценки слоев сетчатки. Предыдущие попытки предсказать толщину сетчатки по C-FP полагались на суррогатные маркеры, такие как липидные отложения, которые демонстрировали ограниченную специфичность и чувствительность. Даже более продвинутые модели глубокого обучения, такие как модель Arcadu et al. [3], не смогли соответствовать клиническим стандартам точности предсказания, особенно при плохом качестве изображений.
Авторы также рассматривали инфракрасную фундус-фотографию (IR-FP) в качестве промежуточного звена, которую использовали некоторые SOTA-методы, такие как DeepRT [15] и M²FRT [26]. Однако IR-FP все еще требует дополнительного устройства, что ограничивает ее клиническое применение. Более того, сама IR-FP имеет присущие ей ограничения, такие как гиперрефлективные артефакты и неадекватная визуализация критических патологических маркеров, таких как кровоизлияния. C-FP, напротив, предлагает превосходное пространственное разрешение, более широкий спектральный диапазон и более широкое поле зрения. Она фиксирует критические глобальные структуры сетчатки, такие как сосудистые сети и диски зрительного нерва, которые являются ключевыми патологическими биомаркерами. Точный момент осознания необходимости нового подхода, вероятно, наступил, когда стало ясно, что существующие методы либо не могут обеспечить достаточную точность при выводе 2D-в-3D, либо полагаются на модальности визуализации, которые не соответствуют требованиям доступности и экономической эффективности. Тонкие вариации текстуры и цвета на C-FP, указывающие на дезорганизацию слоев сетчатки, вызванную DME, требовали модели, способной извлекать как надежные высокоуровневые семантические признаки, так и точные локальные детали макулы, что является возможностью, которую стандартные SOTA-методы с трудом достигали одновременно и с достаточной точностью.
Сравнительное превосходство
Глобально-локальная условная диффузионная модель для предсказания толщины сетчатки (GLD-RT) демонстрирует подавляющее качественное превосходство, выходящее за рамки простых метрик производительности. Ее структурное преимущество заключается в уникальной двухпотоковой, гибридной архитектуре условной диффузии CNN-трансформер, которая специально разработана для решения присущих сложностей данных C-FP для генерации RTM.
Во-первых, способность GLD-RT интегрировать как глобальные контекстуальные признаки, так и детальные локальные детали является значительным структурным преимуществом. Глобальный энкодер полного глазного дна ($E_g$), использующий предварительно обученную модель RETFound, фиксирует надежные анатомические и патологические закономерности со всего изображения C-FP. Одновременно локальный энкодер макулы ($E_m$), построенный на Swin-Transformer, извлекает сложные, детальные признаки из макулярной области. Этот двухпоточный подход гарантирует, что модель не упускает более широкий контекст, одновременно фокусируясь на тонких, но клинически важных локальных вариациях в макуле, которые часто указывают на DME. Это крайне важно, поскольку DME влияет как на характеристики крупных сосудов, так и на целостность мельчайших слоев сетчатки.
Во-вторых, использование условного диффузионного декодера качественно превосходит эту генеративную задачу. В отличие от традиционных дискриминативных моделей или даже более простых генеративно-состязательных сетей (GAN), диффузионные модели преуспевают в генерации высокоточных, разнообразных и анатомически согласованных результатов путем постепенного устранения шума из входных данных. Это особенно выгодно для предсказания RTM, где выходные данные представляют собой сложную, непрерывную карту толщины, которая должна точно отражать как физиологическую, так и патологическую морфологию. Процесс диффузии, управляемый богатыми глобальными и локальными признаками, позволяет более тонко и точно изображать тонкую и нерегулярную анатомию сетчатки, особенно в сложной центральной макуле (область G1), что подтверждается качественными результатами на рис. 2 и аблюционным исследованием. Принятие Denoising Diffusion Implicit Model (DDIM) также позволяет значительно сократить количество шагов сэмплирования, повышая практическую эффективность без ущерба для точности.
Эта структурная конструкция позволяет GLD-RT лучше справляться с высоким уровнем шума и вариативности, присущих изображениям C-FP, по сравнению с предыдущими методами. Она не просто предсказывает карту; она генерирует правдоподобную, детализированную RTM, которая соответствует сложной лежащей в основе структуре сетчатки, задачу, в которой более простые модели часто терпят неудачу в поддержании анатомической согласованности и мелких деталей.
Соответствие ограничениям
Выбранный метод GLD-RT идеально соответствует жестким требованиям задачи, образуя "брак" между клинической необходимостью и инновационным дизайном решения.
-
Ограничение: Ограниченная доступность OCT и высокая стоимость.
- Соответствие: GLD-RT — первая модель, предсказывающая RTM исключительно на основе C-FP. C-FP широко доступна, экономически эффективна и может быть получена даже с помощью смартфонов. Это напрямую отвечает потребности в доступном и недорогом диагностическом инструменте, превращая обычную фундус-визуализацию в комплексное решение для скрининга и мониторинга в условиях ограниченных ресурсов.
-
Ограничение: 2D-природа C-FP не имеет разрешения по глубине для количественной оценки.
- Соответствие: Условная диффузионная модель по своей сути является генеративной моделью, способной синтезировать сложные, многомерные выходные данные из условных входных данных. Изучая сложную карту из 2D-признаков C-FP в 3D-распределения толщины сетчатки, GLD-RT эффективно выводит информацию о глубине, которая явно отсутствует во входном изображении. Эта генеративная способность является ключом к преодолению 2D-ограничения.
-
Ограничение: Необходимость точных, детализированных и клинически значимых RTM.
- Соответствие: Двухпоточная архитектура (глобально-локальные энкодеры) гарантирует, что захватывается как широкий анатомический контекст, так и детальные макулярные детали. Глобальный энкодер (RETFound) предоставляет надежные высокоуровневые семантические признаки, в то время как локальный энкодер (Swin-Transformer) извлекает точные локальные детали. Затем они объединяются и подаются в иерархический диффузионный декодер, который обеспечивает "глобально-локальную анатомическую согласованность". Эта конструкция имеет решающее значение для точного изображения как физиологической, так и патологической морфологии сетчатки, что имеет первостепенное значение для клинической полезности и детального изучения структур сетчатки. Аблюционное исследование подтверждает, что диффузионный процесс успешно захватывает структуру макулы с мелкими деталями, особенно в сложной центральной макуле (G1).
-
Ограничение: Практичность для условий ограниченных ресурсов (эффективность).
- Соответствие: Хотя диффузионные модели могут быть вычислительно затратными, использование DDIM для сэмплирования значительно сокращает количество шагов, необходимых для вывода, делая процесс более эффективным и практичным для реального клинического применения. Общая цель — предоставить "эффективный диагностический инструмент для своевременного вмешательства".
Отклонение альтернатив
Статья неявно и явно отклоняет несколько альтернативных подходов, подчеркивая их ограничения в контексте предсказания RTM по C-FP.
Во-первых, традиционные методы, основанные на суррогатных маркерах (например, липидные отложения, лазерные рубцы), были признаны недостаточными. Авторы заявляют, что эти подходы демонстрировали "ограниченную специфичность и чувствительность для обнаружения DME" [28, 29]. Это явное отклонение не-машинного обучения или более простых методов, основанных на правилах, которые не могут уловить сложные, тонкие проявления DME.
Во-вторых, более ранние модели глубокого обучения для предсказания RTM на основе C-FP оказались недостаточными. В статье упоминается, что модель Arcadu et al. [3] "не соответствовала клиническим стандартам" по точности предсказания, особенно при плохом качестве изображений. Это предполагает, что более простые архитектуры на основе CNN или менее сложные генеративные модели (которые были распространены в то время) не могли извлечь необходимую информацию из C-FP для получения клинически приемлемых RTM. Вероятно, они испытывали трудности с выводом 2D-в-3D и тонкими вариациями на C-FP, указывающими на DME.
В-третьих, методы, основанные на инфракрасной фундус-фотографии (IR-FP), такие как DeepRT [15] и M²FRT [26], были отклонены как единственное жизнеспособное решение из-за практических и присущих им ограничений визуализации. Хотя эти методы показали улучшения, они все же требовали "дополнительного устройства для получения IR-FP", что ограничивает их клиническое применение в условиях ограниченных ресурсов. Более того, сама IR-FP страдает от "гиперрефлективных артефактов, ограниченного диапазона длин волн освещения, оптимизированного для подретинальных структур, и неадекватной визуализации критических патологических маркеров" [1]. Это делает C-FP более желательным входным сигналом, несмотря на ее проблемы.
Наконец, аблюционное исследование статьи предоставляет убедительные доказательства отклонения более простых механизмов декодирования и необходимости диффузионного процесса. Результаты показывают, что предложенный диффузионный декодер ($D_d$) "заметно улучшил производительность модели, особенно в центральной макуле (G1)" по сравнению с декодером без диффузии ($D_{nd}$). Это означает, что стандартные подходы к декодированию, которые могут использоваться в генеративных моделях, отличных от диффузионных, или в моделях прямой регрессии, были недостаточны для захвата тонких структурных деталей и анатомической согласованности, требуемых в этой сложной области. Утверждение о том, что "глобально-локальное условное кодирование превосходит стандартные подходы к декодированию", далее подтверждает, что более простые, неиерархические или некондиционные генеративные фреймворки были бы менее эффективны в использовании богатой, многомасштабной информации из C-FP. Хотя GAN явно не названы, акцент на высокоточную генерацию, анатомическую согласованность и способность захватывать тонкие детали убедительно свидетельствует о том, что диффузионные модели были выбраны вместо других генеративных парадигм из-за их превосходной производительности в этих аспектах для синтеза медицинских изображений.
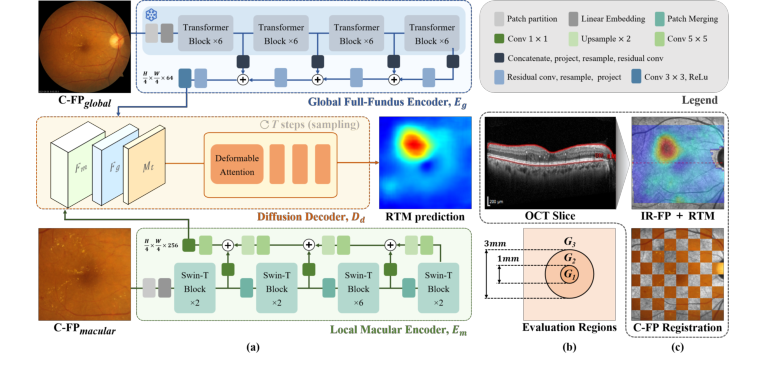 Figure 1. (a) GLD-RT leverages a dual-stream diffusion framework to integrate global contextual features with fine-grained details. (b) Evaluation regions for RTM predic- tion. (c)IR-FP, the localizer in OCT imaging that generates RTM, is used to register C-FPglobal with RTM, generating C-FPmacular
Figure 1. (a) GLD-RT leverages a dual-stream diffusion framework to integrate global contextual features with fine-grained details. (b) Evaluation regions for RTM predic- tion. (c)IR-FP, the localizer in OCT imaging that generates RTM, is used to register C-FPglobal with RTM, generating C-FPmacular
Математический и логический механизм
Основное уравнение
Абсолютным ядром механизма обучения GLD-RT является его целевая функция оптимизации, которая представляет собой функцию потерь среднеквадратичной ошибки (MSE). Это уравнение направляет модель в обучении точному предсказанию карт толщины сетчатки (RTM) из цветных фундус-фотографий (C-FP), минимизируя разницу между ее предсказаниями и истинными значениями.
Основное уравнение представлено как:
$$ \mathcal{L} = \mathbb{E}_{M,t,F_m,F_g} [||M – D_d(M_t, t, F_m, F_g) ||^2] $$
Пословный разбор
Давайте разберем это уравнение, чтобы понять роль каждого компонента:
-
$\mathcal{L}$:
- Математическое определение: Этот символ обозначает общую функцию потерь, в частности, функцию потерь среднеквадратичной ошибки (MSE).
- Физическая/логическая роль: Это количественная оценка расхождения между предсказанной моделью RTM и фактической истинной RTM. Основная цель во время обучения модели — минимизировать это значение, тем самым побуждая модель делать более точные предсказания.
- Почему используется: MSE является стандартной и эффективной функцией потерь для задач регрессии. Ее операция возведения в квадрат наказывает большие ошибки сильнее, чем меньшие, побуждая модель уменьшать существенные отклонения.
-
$\mathbb{E}_{M,t,F_m,F_g}$:
- Математическое определение: Это обозначает оператор математического ожидания, означающий среднее значение по случайным переменным $M$, $t$, $F_m$ и $F_g$.
- Физическая/логическая роль: На практике, во время обучения, это математическое ожидание аппроксимируется усреднением квадратов разностей по пакету обучающих выборок. Каждая выборка включает истинную RTM ($M$), конкретный временной шаг шума ($t$), локальные признаки макулы ($F_m$) и глобальные признаки полного глазного дна ($F_g$). Это усреднение гарантирует, что модель хорошо обобщается на разнообразный набор входных данных и условий шума.
- Почему используется: Усреднение потерь по пакету выборок обеспечивает более стабильный и репрезентативный градиент для обновления параметров модели по сравнению с вычислением потерь для одной выборки, которая может быть зашумленной.
-
$M$:
- Математическое определение: Это истинная карта толщины сетчатки (RTM). Это 2D-матрица действительных значений, обычно с размерами $H \times W$, где $H$ и $W$ — высота и ширина карты.
- Физическая/логическая роль: Это "правильный ответ" или целевой вывод, который модель GLD-RT стремится предсказать. Он служит эталоном, по которому сравниваются предсказания модели.
- Почему используется: Это необходимый эталон для расчета ошибки и оценки производительности модели.
-
$D_d(\cdot)$:
- Математическое определение: Это диффузионный декодер, представляющий собой сложную нейронную сеть. Он принимает на вход зашумленную RTM, временной шаг и условные признаки, и его цель — предсказать исходную, не зашумленную RTM.
- Физическая/логическая роль: Это генеративный механизм модели. Во время обучения он учится "устранять шум" из зашумленной RTM, чтобы восстановить исходную $M$, руководствуясь извлеченными признаками C-FP. Во время вывода он итеративно преобразует чистый шум в предсказанную RTM, снова используя признаки C-FP в качестве руководства.
- Почему используется: Фреймворк диффузионной модели выбран из-за его доказанной способности генерировать высокоточные изображения и моделировать сложные распределения данных, что критически важно для сложных деталей RTM. Условный аспект позволяет управлять процессом генерации входными признаками C-FP.
-
$M_t$:
- Математическое определение: Это зашумленная версия истинной RTM, $M$, на определенном временном шаге диффузии $t$. Она создается путем добавления запланированного гауссовского шума к $M$.
- Физическая/логическая роль: Это входные данные для диффузионного декодера во время обучения. Задача декодера — научиться эффективно удалять шум из $M_t$ для восстановления исходной $M$. Этот процесс имитирует обращение прямого процесса диффузии, в котором постепенно вводится шум.
- Почему используется: Диффузионные модели работают, обучаясь обращать предопределенный прямой процесс добавления шума. Обучая модель на $M_t$ при различных временных шагах, она развивает способность устранять шум в широком спектре уровней шума.
-
$t$:
- Математическое определение: Это временной шаг диффузии, целочисленное значение, указывающее количество шума, добавленного к $M$ для получения $M_t$. Обычно он варьируется от малого значения (минимальный шум) до большого значения (максимальный шум).
- Физическая/логическая роль: Он предоставляет критически важную информацию диффузионному декодеру об текущем уровне шума, присутствующем в $M_t$. Знание $t$ позволяет декодеру применять соответствующую операцию шумоподавления для данной интенсивности шума.
- Почему используется: Временной шаг является фундаментальным для диффузионных моделей, поскольку стратегия шумоподавления сильно зависит от количества шума. Различные временные шаги требуют различных подходов к шумоподавлению.
-
$F_m$:
- Математическое определение: Это детальные локальные признаки макулы, извлеченные локальным энкодером макулы ($E_m$) из обрезанной макулярной области изображения C-FP ($C\text{-}FP_{macular}$). Эти признаки имеют размеры $R^{\frac{H}{4} \times \frac{W}{4} \times 256}$.
- Физическая/логическая роль: Эти признаки предоставляют очень детальную информацию о макулярной области, которая необходима для точного предсказания толщины в этой клинически важной области. Они действуют как локальное условие, направляя процесс диффузии детальным анатомическим контекстом.
- Почему используется: Макулярная область — это место, где патологии диабетического макулярного отека (DME) наиболее очевидны и требуют тщательного анализа. Энкодер $E_m$, использующий Swin-Transformer и сеть пирамиды признаков, разработан для захвата этих иерархических и детальных признаков.
-
$F_g$:
- Математическое определение: Это глобальные признаки полного глазного дна, извлеченные глобальным энкодером полного глазного дна ($E_g$) из всего изображения C-FP ($C\text{-}FP_{global}$). Эти признаки имеют размеры $R^{\frac{H}{16} \times \frac{W}{16} \times 64}$.
- Физическая/логическая роль: Эти признаки предоставляют высокоуровневый семантический контекст и информацию об общей структуре сетчатки. Они компенсируют любой периферический контекст, потерянный при фокусировке исключительно на макулярной области, действуя как глобальное условие для процесса диффузии.
- Почему используется: Глобальный контекст помогает обеспечить анатомическую согласованность по всей сетчатке и предоставляет более широкие патологические маркеры (например, сосудистые сети), которые могут влиять на толщину макулы. Энкодер $E_g$ использует предварительно обученный Vision Transformer RETFound для этой цели.
-
$|| \cdot ||^2$:
- Математическое определение: Это обозначает квадрат нормы L2, который вычисляет сумму квадратов всех элементов вектора или матрицы. Для матрицы $A$, $||A||^2 = \sum_{i,j} A_{i,j}^2$.
- Физическая/логическая роль: Он вычисляет квадрат разницы между истинной RTM и RTM, предсказанной диффузионным декодером. Возведение разницы в квадрат гарантирует, что как положительные, так и отрицательные ошибки одинаково учитываются в потерях, и что большие ошибки наказываются сильнее.
- Почему используется: Квадрат нормы L2 является фундаментальным компонентом функции потерь среднеквадратичной ошибки (MSE), которая широко используется для задач регрессии благодаря своей дифференцируемости и выпуклости, что упрощает процесс оптимизации.
-
$M - D_d(\dots)$:
- Математическое определение: Это обозначает поэлементную разницу между истинной RTM и предсказанной RTM.
- Физическая/логическая роль: Это ошибка или остаток, который модель стремится минимизировать. Это прямое сравнение желаемого вывода и фактического вывода модели.
- Почему используется: Это прямое вычитание составляет основу для количественной оценки ошибки, которую модель должна научиться уменьшать.
Пошаговый поток
Давайте проследим путь одного абстрактного элемента данных через механизм GLD-RT, от входных данных до расчета потерь:
-
Начальный ввод данных: Процесс начинается с одного изображения цветной фундус-фотографии (C-FP) и соответствующей истинной карты толщины сетчатки (RTM), $M$, полученной в результате сканирования оптической когерентной томографии (OCT).
-
Мультимодальная регистрация и обрезка: Изображение C-FP проходит точный процесс регистрации для выравнивания пиксель за пикселем с пространственными координатами RTM. Это включает использование промежуточного изображения инфракрасной фундус-фотографии (IR-FP) в качестве эталона. Ключевые шаги включают сегментацию сосудов сетчатки, обнаружение ключевых точек (например, с помощью AKAZE), вычисление матриц гомографии (например, с помощью RANSAC) и нежесткую регистрацию полного C-FP ($C\text{-}FP_{global}$) к IR-FP. Из этого генерируется обрезанная версия, $C\text{-}FP_{macular}$, фокусирующаяся конкретно на макулярной области, соответствующей RTM.
-
Параллельное извлечение признаков:
- Поток глобального контекста: Полное изображение $C\text{-}FP_{global}$ подается в глобальный энкодер полного глазного дна ($E_g$). Этот энкодер, использующий предварительно обученный Vision Transformer RETFound, обрабатывает изображение для извлечения высокоуровневых семантических признаков, $F_g$. Эти признаки инкапсулируют общую структуру сетчатки и более широкий контекст.
- Поток локальных деталей: Одновременно обрезанное изображение $C\text{-}FP_{macular}$ поступает в локальный энкодер макулы ($E_m$). Этот энкодер, построенный на Swin-Transformer и сети пирамиды признаков, извлекает детальные, иерархические признаки, $F_m$, предоставляя детальную информацию, специфичную для макулярной области.
-
Введение шума (только на этапе обучения): Если модель находится в фазе обучения, выбирается случайный временной шаг $t$. Затем к истинной RTM, $M$, добавляется гауссовский шум, масштабированный в соответствии с этим временным шагом, что приводит к зашумленной RTM, $M_t$.
-
Условное шумоподавление диффузионным декодером: Зашумленная RTM, $M_t$, наряду с выбранным временным шагом $t$ и извлеченными условными признаками ($F_m$ и $F_g$), передаются в диффузионный декодер ($D_d$). Основная задача декодера — научиться "устранять шум" из $M_t$, чтобы восстановить исходную, чистую RTM, $M$. Этот процесс шумоподавления критически направляется богатой контекстуальной информацией, предоставляемой $F_m$ (локальные детали) и $F_g$ (глобальный контекст).
-
Предсказание RTM: Декодер выводит свою лучшую оценку исходной RTM, которую мы можем обозначить как $D_d(M_t, t, F_m, F_g)$.
-
Расчет потерь: Предсказанная RTM затем напрямую сравнивается с исходной истинной RTM, $M$. Вычисляется квадрат нормы L2 их поэлементной разницы, $||M – D_d(M_t, t, F_m, F_g) ||^2$. Это значение представляет собой ошибку для данной конкретной точки данных.
-
Усреднение по пакету: Эта индивидуальная квадратичная ошибка затем усредняется по всем выборкам в текущем обучающем пакете (каждая со своей комбинацией $M$, $t$, $F_m$, $F_g$), чтобы получить окончательные потери $\mathcal{L}$ для данной итерации.
-
Вывод (фаза генерации): Во время вывода процесс для диффузионного декодера изменяется. Вместо того чтобы начинать с зашумленной версии истинной RTM, декодер начинает с чистого случайного шума. Затем он итеративно применяет шаги шумоподавления, руководствуясь признаками $F_m$ и $F_g$, извлеченными из нового входного сигнала C-FP. Этот итеративный процесс, часто использующий немарковское детерминированное сэмплирование, такое как DDIM, постепенно преобразует начальный шум в связную и детализированную предсказанную RTM за значительно меньшее количество шагов (например, 5 шагов).
Динамика оптимизации
Механизм GLD-RT обучается, обновляется и сходится путем итеративной минимизации функции потерь среднеквадратичной ошибки (MSE), $\mathcal{L}$, посредством процесса оптимизации на основе градиента.
-
Ландшафт потерь: Обучение модели происходит в сложном ландшафте потерь. Этот ландшафт формируется сложной взаимосвязью между истинными RTM, различными уровнями шума, вводимого на разных временных шагах, и богатыми, многомасштабными условными признаками, извлеченными из изображений C-FP. Конечная цель — перемещаться по этому ландшафту, чтобы найти набор параметров модели (весов и смещений в энкодерах $E_m$, $E_g$ и диффузионном декодере $D_d$), которые соответствуют "долине", где предсказанные RTM последовательно близки к истинным значениям. Хотя общий ландшафт глубоких нейронных сетей по своей сути невыпуклый, цель MSE предоставляет четкий, дифференцируемый сигнал для оптимизации. Внутренняя структура диффузионного процесса, который включает обучение шумоподавлению в спектре уровней шума, действует как мощный регуляризатор, потенциально приводя к более гладкому и надежному ландшафту потерь по сравнению с более простыми моделями прямой регрессии.
-
Расчет градиента: В каждой итерации обучения, после вычисления потерь $\mathcal{L}$ для данного пакета данных, инициируется процесс обратного распространения ошибки. Этот алгоритм эффективно вычисляет градиенты потерь по отношению к каждому обучаемому параметру в энкодерах ($E_m$, $E_g$) и диффузионном декодере ($D_d$). Эти градиенты имеют решающее значение; они указывают точное направление и величину, в которой каждый параметр должен быть скорректирован для уменьшения рассчитанных потерь.
-
Обновление параметров: В статье указано, что для обновления параметров модели используется оптимизатор Adam [16]. Adam — это сложный адаптивный алгоритм оптимизации скорости обучения. Он динамически вычисляет индивидуальные скорости обучения для различных параметров, поддерживая экспоненциально взвешенные средние прошлых градиентов (первый момент) и прошлых квадратов градиентов (второй момент).
- Конкретные гиперпараметры для Adam установлены как $\beta_1 = 0.9$ и $\beta_2 = 0.999$, что является широко принятыми значениями по умолчанию.
- Для эффективного управления скоростью обучения используется стратегия косинусного затухания. Этот график применяется после начального 16-эпохового фазы "разогрева", в течение которой скорость обучения постепенно увеличивается от очень малого значения ($1 \times 10^{-8}$) до немного большего ($6 \times 10^{-5}$). После этого разогрева скорость обучения медленно затухает в соответствии с косинусной функцией в течение 300 эпох. Эта стратегия позволяет модели сначала осторожно исследовать ландшафт потерь, затем ускорить сходимость и, наконец, тонко настроить параметры, уменьшая скорость обучения, предотвращая перескок оптимального минимума.
- Кроме того, применяется фиксированное затухание весов $1 \times 10^{-2}$. Затухание весов, также известное как L2-регуляризация, помогает предотвратить переобучение, наказывая большие значения параметров. Это побуждает модель изучать более обобщенные и менее сложные признаки, улучшая ее производительность на невидимых данных.
-
Итеративное уточнение и сходимость: Этот цикл вычисления потерь, расчета градиентов и обновления параметров повторяется итеративно в течение многих эпох обучения (в данном исследовании 300 эпох). По мере прогресса обучения параметры модели постоянно уточняются для минимизации $\mathcal{L}$. Диффузионный декодер постепенно учится точно обращать процесс шума, становясь все более искусным в предсказании $M$ из $M_t$ при условии $F_m$ и $F_g$. Модель считается сошедшейся, когда потери как на обучающем, так и на валидационном наборах данных стабилизируются или достигают минимума. Это указывает на то, что модель успешно научилась генерировать RTM, которые точно соответствуют истинным значениям, демонстрируя свою способность захватывать лежащие в основе распределения толщины сетчатки. Принятие Denoising Diffusion Implicit Model (DDIM) для сэмплирования во время вывода, немарковского и детерминированного процесса, далее способствует практической сходимости, обеспечивая более быстрое и стабильное генерирование RTM со значительно меньшим количеством шагов (например, 5 шагов), что делает механизм более эффективным для реального применения.
Результаты, ограничения и заключение
Экспериментальный дизайн и базовые модели
Модель GLD-RT была разработана и тщательно проверена с использованием комплексного набора данных. Для основной задачи предсказания RTM исследователи использовали 2918 триплетов данных, каждый из которых включал соответствующие изображения оптической когерентной томографии (OCT), инфракрасной фундус-фотографии (IR-FP) и цветной фундус-фотографии (C-FP). Эти триплеты были получены от 1418 пациентов с диабетическим макулярным отеком (DME), проходящих терапию anti-VEGF в больнице Kangbuk Samsung. Когорта демонстрировала среднюю толщину сетчатки $296.99 \pm 30.67 \text{ мкм}$ и центральную толщину макулы $292.46 \pm 75.00 \text{ мкм}$, что указывает на значительную распространенность макулярного отека. IR-FP и 31 B-скан OCT были получены с помощью устройств Heidelberg, которые автоматически предоставляют сегментации мембран. Опытные офтальмологи тщательно исключали сканы с плохой фиксацией или ошибками сегментации для обеспечения качества данных.
Для критически важной задачи диагностики DME использовался набор данных Mobile Brazilian Retinal Dataset (mBRSET). Этот набор данных состоит из 5164 изображений C-FP от 1291 пациента с диабетом из Итабуны, Баия, Бразилия, все из которых были тщательно аннотированы диагнозом DME и метками качества изображений.
Предварительная обработка данных включала несколько шагов для обеспечения согласованности и выравнивания. Изображения IR-FP были центрально обрезаны до $544 \times 544$ пикселей, что соответствует области сканирования OCT. Изображения C-FPglobal были уменьшены с $3608 \times 3608$ до $544 \times 544$ для соответствия разрешению IR-FP. Карты толщины сетчатки (RTM) были вычислены из 31 B-скана и линейно интерполированы для соответствия разрешению IR-FP. Для сохранения структурной целостности при одновременном уменьшении артефактов RTM подвергались последовательному сглаживанию с помощью гауссовской фильтрации ($\sigma = 3$), за которым следовало шумоподавление методом нелокальных средних. Для диагностики DME изображения C-FP были обрезаны до $800 \times 800$ на основе положения фовеа, а затем уменьшены до $544 \times 544$.
Набор данных был разделен на уровне пациентов для надежной оценки: 2043 обучающих, 292 валидационных и 583 тестовых триплета для разработки GLD-RT. mBRSET был аналогично разделен на 2409 обучающих, 345 валидационных и 688 тестовых изображений для диагностики DME. Модель GLD-RT была оптимизирована с использованием оптимизатора Adam [16] со стандартными параметрами $(\beta_1, \beta_2) = (0.9, 0.999)$, косинусной схемой затухания скорости обучения после 16-эпохового разогрева и фиксированным затуханием весов $1 \times 10^{-2}$. Диффузионный процесс использовал 20 временных шагов для обучения и 5 для вывода. Все эксперименты проводились на GPU NVIDIA GeForce RTX 3090, включая аугментацию данных путем случайного отражения и вращения.
Чтобы безжалостно доказать свои математические утверждения, авторы противопоставили GLD-RT нескольким установленным и передовым (SOTA) моделям. Для предсказания RTM "жертвами" стали общие модели плотного предсказания медицинских изображений, такие как UNet [23], Trans-UNet [5] и Swin-Unetr [12], а также специализированные фреймворки предсказания RTM, такие как DeepRT [15] и M²FRT [26]. Эти базовые модели оценивались с различными конфигурациями входных данных (IR-FP, C-FP или оба) для обеспечения всестороннего сравнения. Для диагностики DME подход с использованием GLD-RT сравнивался с базовой моделью только на C-FP с использованием классификатора ResNet50 [13].
Что доказывают доказательства
Экспериментальные данные однозначно доказывают, что предложенная глобально-локальная условная диффузионная модель для предсказания толщины сетчатки (GLD-RT) значительно превосходит существующие методы в предсказании RTM по цветным фундус-фотографиям (C-FP) и предлагает существенные преимущества для диагностики DME.
Для предсказания RTM GLD-RT достигла превосходной производительности во всех областях сетчатки (G1, G2, G3, соответствующие сетке ETDRS) при оценке с использованием средней абсолютной ошибки (MAE) в микрометрах ($\mu$m) и пикового отношения сигнал/шум (PSNR) в децибелах (dB). В частности, GLD-RT, используя только C-FP в качестве входных данных, показала общую MAE 20.08 $\mu$m и PSNR 30.91 dB. Это было заметным улучшением по сравнению с предыдущим SOTA, M²FRT [26], который достиг общей MAE 23.21 $\mu$m и PSNR 29.34 dB при входных данных C-FP. Статистическая значимость этих улучшений была подтверждена p-значениями менее 0.01, что указывает на то, что производительность GLD-RT не была случайной.
Наиболее убедительным доказательством того, что основной механизм GLD-RT работает на практике, является его производительность в фовеальной области (G1). Эта область клинически важна из-за ее сложной слоистой структуры и прямого влияния на центральное зрение. Здесь GLD-RT достигла MAE 31.97 $\mu$m и PSNR 30.18 dB, демонстрируя существенное улучшение по сравнению с MAE M²FRT 36.25 $\mu$m и PSNR 28.31 dB при входных данных C-FP. Это указывает на то, что двухпоточная архитектура GLD-RT, интегрирующая глобальный контекст с детальными локальными признаками через иерархический диффузионный декодер, эффективно захватывает тонкую и нерегулярную анатомию сетчатки, критически важную для точной количественной оценки толщины в этой сложной области.
Качественные результаты, как показано на рисунке 2, далее подчеркивают эти улучшения. GLD-RT надежно обнаруживала вариации толщины, связанные с различными патологическими поражениями, такими как друзы, макулярный отек и окклюзия ветви вены, предоставляя более точные представления анатомии сетчатки по сравнению с M²FRT. Карты разностей (предсказание минус истинное значение) последовательно показывали меньшие ошибки для GLD-RT, визуально подтверждая ее превосходную точность.
Аблюционное исследование предоставило убедительные доказательства вклада каждого архитектурного компонента. Базовая модель (Em, Dnd, т.е. локальный энкодер макулы с декодером без диффузии) уже превосходила M²FRT, подтверждая эффективность улучшенного извлечения локальных признаков. Добавление диффузионного декодера (Dd) значительно улучшило производительность, особенно в G1, доказывая способность диффузионного процесса захватывать тонкие детали макулы. Кроме того, включение глобального энкодера полного глазного дна (Eg) с предварительным обучением RETFound еще больше повысило производительность, подчеркивая критическую роль предметно-ориентированного предварительного обучения и глобальной анатомической согласованности. Полная модель GLD-RT, объединяющая Eg (RETFound), Em, Dd, последовательно давала наилучшие результаты.
Помимо предсказания RTM, сгенерированные GLD-RT RTM оказались бесценными для диагностики DME. При конкатенации с C-FP в качестве двойного входа для классификатора ResNet50 этот подход последовательно превосходил базовую модель только на C-FP. Модель с двойным входом достигла точности 93.44% (против 92.21%), полноты 79.49% (против 64.41%), F1-оценки 85.90% (против 75.84%) и AUC 0.919 (против 0.855). Эти неоспоримые доказательства демонстрируют, что RTM, сгенерированные C-FP, предоставляют дополнительные диагностические сведения, соответствующие клиническим протоколам, которые часто требуют как OCT, так и C-FP обследований. Это делает GLD-RT перспективным, экономически эффективным диагностическим инструментом, особенно для условий ограниченных ресурсов.
Ограничения и будущие направления
Хотя GLD-RT представляет собой значительный шаг вперед в предсказании толщины сетчатки по C-FP и помощи в диагностике DME, важно признать ее текущие ограничения и рассмотреть направления для будущего развития.
Одним из присущих ограничений, хотя и решаемым целью модели, является то, что C-FP, будучи 2D-техникой визуализации, по своей сути не имеет разрешения по глубине, как OCT. Хотя GLD-RT эффективно выводит толщину, истинные RTM получены из высокоразрешающих сканов OCT. Сама статья указывает на "включение OCT с более высоким разрешением для детального предсказания RTM" как на будущее направление, предполагая, что даже с достижениями GLD-RT может существовать предел детализации, достижимой исключительно на основе C-FP без дальнейшей интеграции технологий или более точных истинных значений. Текущая модель, хотя и надежна, все еще является предсказанием на основе 2D-входа, и ее способность захватывать каждую мельчайшую деталь сложных 3D-структур сетчатки может быть ограничена.
Другим аспектом, который следует учитывать, является обобщаемость результатов. Модель была обучена на наборах данных из конкретных больниц и регионов (Kangbuk Samsung Hospital и mBRSET). Хотя это существенные наборы данных, реальная клиническая практика включает огромное разнообразие демографических данных пациентов, тяжести заболеваний и устройств визуализации от различных производителей. Производительность GLD-RT на внешних, невидимых наборах данных из разных популяций или с различными протоколами получения изображений потребует дальнейшей проспективной клинической валидации. В статье упоминается "проспективная клиническая валидация" как будущее направление, что косвенно признает эту потребность в более широком тестировании.
Более того, хотя модель предоставляет RTM, необходимо установить клинический рабочий процесс для интерпретации этих сгенерированных ИИ карт наряду с традиционными изображениями C-FP. Клиницисты привыкли к RTM, полученным с помощью OCT, и переход к RTM, сгенерированным C-FP, потребует четких руководств и обучения для обеспечения точной интерпретации и интеграции в решения о лечении. Предложение статьи об "интеграции в существующие рабочие процессы здравоохранения" подчеркивает эту практическую проблему.
Заглядывая вперед, из этой работы вытекает несколько захватывающих тем для обсуждения:
- Улучшенная клиническая интеграция и поддержка принятия решений: Как GLD-RT может быть интегрирована в существующие системы электронных медицинских карт для предоставления прогнозов RTM в реальном времени во время рутинных скринингов C-FP? Может ли модель быть расширена не только для предсказания толщины, но и для автоматического выделения областей, вызывающих беспокойство, или предложения последующих действий, тем самым выступая в качестве более комплексного инструмента поддержки принятия решений для врачей первичного звена или даже пациентов в условиях домашнего мониторинга? Каковы регуляторные пути и этические соображения для развертывания такого автономного диагностического помощника?
- Предсказание множественных заболеваний и открытие биомаркеров: Учитывая успех GLD-RT в использовании C-FP для DME, может ли этот фреймворк быть адаптирован или расширен для предсказания других патологий сетчатки или биомаркеров, которые в настоящее время зависят от более дорогостоящей или инвазивной визуализации? Например, может ли он предсказывать ранние признаки глаукомы (например, истончение слоя нервных волокон сетчатки) или возрастной макулярной дегенерации (например, объем друзов) по C-FP? Это могло бы превратить C-FP в действительно многоцелевой инструмент скрининга.
- Надежность к качеству изображений и артефактам: Реальные изображения C-FP часто страдают от различного качества из-за сотрудничества пациента, помутнения сред или неоптимальных настроек камеры. Хотя текущее исследование отфильтровывало сканы низкого качества, будущая работа могла бы сосредоточиться на повышении надежности GLD-RT к этим несовершенствам, возможно, путем включения модулей оценки качества изображений или обучения с более широким спектром деградированных изображений. Как модель может поддерживать свою высокую точность даже при представлении неидеальных входных данных?
- Вычислительная эффективность и развертывание на периферии: Текущая модель работает на NVIDIA GeForce RTX 3090. Для широкого внедрения в условиях ограниченных ресурсов или для портативных устройств оптимизация модели для меньших вычислительных ресурсов и более быстрого времени вывода будет иметь решающее значение. Могут ли методы дистилляции знаний или квантования моделей применяться для создания более легкой версии, подходящей для периферийных вычислений, потенциально позволяя генерировать RTM в реальном времени на фундус-камере, подключенной к смартфону?
- Продольный мониторинг и реакция на лечение: Может ли GLD-RT использоваться для продольного мониторинга пациентов с DME, отслеживая изменения толщины сетчатки с течением времени для оценки реакции на лечение или прогрессирования заболевания? Это потребует проверки согласованности и чувствительности модели к незначительным изменениям в течение длительных периодов. Как предсказания модели могут информировать персонализированные стратегии лечения, оптимизируя графики инъекций anti-VEGF или другие вмешательства?
- Объяснимость и доверие: По мере того как модели ИИ все больше интегрируются в клиническую практику, понимание того, почему модель делает определенное предсказание, имеет жизненно важное значение для построения доверия среди клиницистов. Будущие исследования могли бы изучить методы повышения объяснимости предсказаний RTM GLD-RT, возможно, путем визуализации признаков, на которые модель обращает внимание на изображении C-FP, тем самым предоставляя клиницистам большее понимание и уверенность в ее результатах.
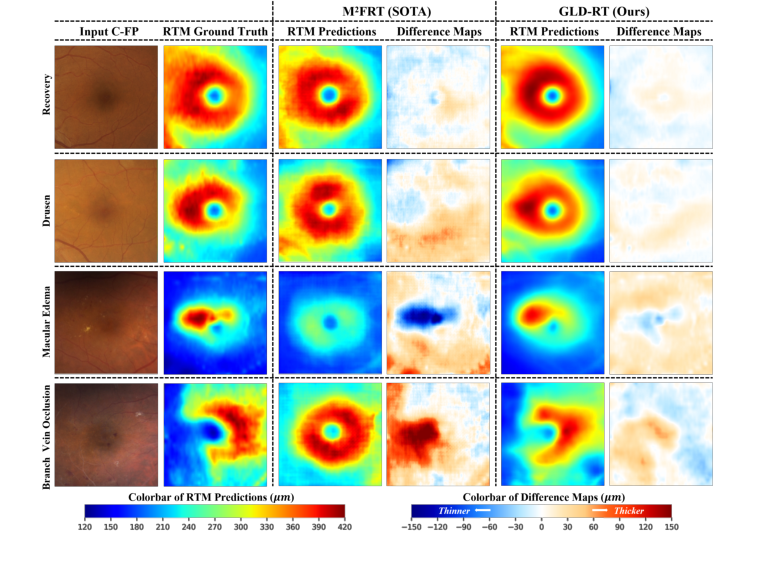 Figure 2. Qualitative results of our model and M2FRT. GLD-RT robustly detects diverse pathological lesions and accurately depicts subtle and irregular retinal anatomy. Dif- ference maps (prediction minus ground truth) further underscore these gains
Figure 2. Qualitative results of our model and M2FRT. GLD-RT robustly detects diverse pathological lesions and accurately depicts subtle and irregular retinal anatomy. Dif- ference maps (prediction minus ground truth) further underscore these gains
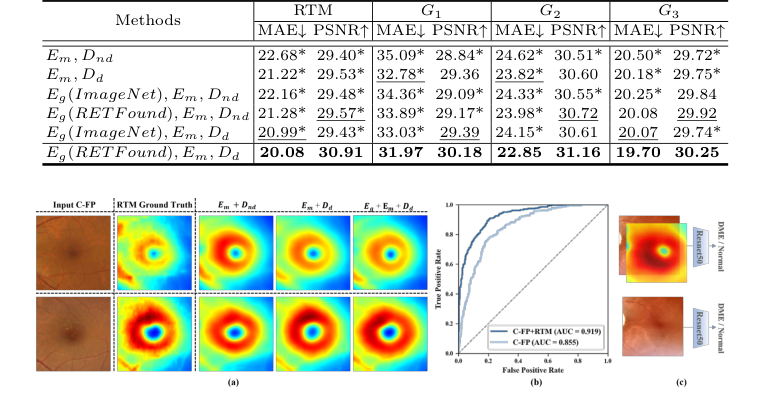 Figure 3. (a) Qualitative results of ablation study on GLD-RT. The proposed Dd sig- nificantly enhanced fine macular structural details, while Eg further enforced global anatomical consistency. (b) Receiver operating characteristic curve of DME diagnosis. (c)Experiment design of DME diagnosis
Figure 3. (a) Qualitative results of ablation study on GLD-RT. The proposed Dd sig- nificantly enhanced fine macular structural details, while Eg further enforced global anatomical consistency. (b) Receiver operating characteristic curve of DME diagnosis. (c)Experiment design of DME diagnosis
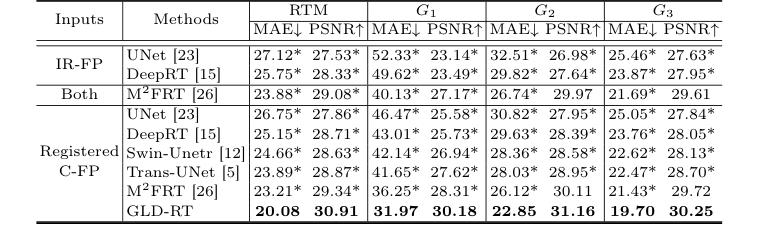 Table 1. Quantitative comparison of different methods for RTM prediction, with MAE (µm) and PSNR (dB). * indicates GLD-RT outperforms baselines with p-values<0.01
Table 1. Quantitative comparison of different methods for RTM prediction, with MAE (µm) and PSNR (dB). * indicates GLD-RT outperforms baselines with p-values<0.01
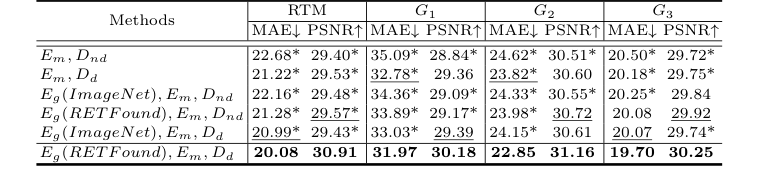 Table 2. Ablation study of RTM prediction, with MAE (µm) and PSNR (dB). * indicates GLD-RT outperforms baselines with p-values<0.01
Table 2. Ablation study of RTM prediction, with MAE (µm) and PSNR (dB). * indicates GLD-RT outperforms baselines with p-values<0.01