表面を超えて見る:DME管理のためのカラー眼底写真からの網膜厚予測
New model turns basic eye scans into detailed maps, boosting DME diagnosis in low-resource areas.
背景と学術的系譜
起源と学術的系譜
糖尿病黄斑浮腫(Diabetic Macular Edema; DME)管理のために、カラー眼底写真(Color Fundus Photography; C-FP)のみから網膜厚マップ(Retinal Thickness Maps; RTMs)を予測するという本論文で取り組む問題は、眼科領域におけるアクセス可能で費用対効果の高い診断ツールの喫緊の必要性から生じている。糖尿病黄斑浮腫は重度の視力低下の主要な原因であり、特に生産年齢人口において、世界的な医療負担を著しく増大させている。
歴史的に、光干渉断層計(Optical Coherence Tomography; OCT)はDME評価のゴールドスタンダードとされてきた。なぜなら、OCTは網膜病変を高い精度で定量化する詳細なRTMを提供するからである。しかし、OCT装置は高価で操作が複雑であり、特にリソースが限られた環境や日常的な自宅モニタリングにおけるアクセス性を著しく制限している。このアクセシビリティのギャップは、しばしば不十分なフォローアップ受診や、抗血管内皮増殖因子(anti-Vascular Endothelial Growth Factor; anti-VEGF)療法を受けている患者における最適ではない治療結果につながる。
広く利用可能で費用対効果の高い2D画像技術であるC-FP(スマートフォンでも実現可能)を活用しようとする過去の試みは、著しい限界に直面していた。初期のアプローチは、網膜肥厚の代理マーカーである脂質沈着などに依存していたが、必要な深度分解能を欠いており、DME検出の特異度と感度が限定的であった。例えば、C-FPから網膜肥厚を予測しようとする以前のモデルは、特に画像品質が低い場合に、臨床基準を満たせないことが多かった。より最近の取り組みでは、赤外線眼底写真(Infrared Fundus Photography; IR-FP)を中間媒体として使用し、厚み情報を抽出することでこのギャップを埋めようとした。IR-FPは臨床現場でOCT取得のローカライザーとして使用されるが、追加のデバイスが必要であり、その広範な応用を制限している。さらに、IR-FP自体も、高反射性アーチファクト、網膜下構造に最適化された限定的な照明波長、および硬性白斑や出血などの重要な病理学的マーカーの不十分な可視化といった固有の欠点を有している。
著者らが本論文の執筆を余儀なくされた根本的な「ペインポイント」は、網膜厚評価のための包括的で正確、かつアクセス可能なソリューションを提供する既存手法の能力不足である。OCTは広範な使用には高価すぎ、複雑すぎる。一方、以前のC-FPおよびIR-FPベースの手法は、不正確であったり、深度情報が欠如していたり、あるいは依然として特殊な機器を必要としていた。本論文は、C-FPのみからRTMを予測する最初の試みとして、これらの限界を克服することを目指しており、従来の眼底画像診断を、特にリソースが限られた環境におけるDMEスクリーニングおよびモニタリングのための包括的で費用対効果の高い診断ツールへと変革する。この新しいアプローチは、よりタイムリーで効果的な介入を通じて、患者の転帰を改善することが期待される。
直感的なドメイン用語
本論文の専門用語をいくつか、ゼロベースの読者向けに日常的なアナロジーで説明する。
- 糖尿病黄斑浮腫(DME): 糖尿病が原因で、目の「カメラセンサー」(黄斑)の中心にある小さく重要な領域が腫れてぼやけていると想像してほしい。カメラのレンズの上に小さな水たまりができ、すべてがぼやけているようなものである。
- 光干渉断層計(OCT): これは目のための超高度なソナーだと考えてほしい。音波の代わりに光波を使用し、網膜の内部層とその厚さを詳細に示す、信じられないほど詳細な断層画像を作成する。これは、ケーキを切ってすべての層を見るようなものである。
- 網膜厚マップ(RTM): これはOCTスキャンの出力であり、網膜のカラフルな「ヒートマップ」である。正常より厚い領域は赤や黄色で色付けされ、薄い領域は青で色付けされ、医師に問題箇所を素早く視覚的にガイドする。これは気温の変動を示す天気図のようなものである。
- カラー眼底写真(C-FP): これは単に目の裏側の標準的な平坦な2D写真であり、血管や視神経などの表面の特徴を示す。これは風景の通常の写真を撮るようなもので、木や山は見えますが、その高さや深さはわかりません。
- 拡散モデル(Diffusion Model): これは、純粋なランダムノイズから始まり、段階的に「ノイズ除去」していくことで複雑な画像を生成することを学習する人工知能の一種である。これは、形のない大理石の塊から始まり、ゆっくりと繰り返し彫り進んで詳細な彫像が現れる彫刻家に似ている。
記法表
| 記法 | 説明 |
|---|---|
問題定義と制約
中核問題の定式化とジレンマ
本論文で取り組む中核問題は、カラー眼底写真(C-FP)のみから網膜厚マップ(RTMs)を正確に予測することである。
入力/現状:
糖尿病黄斑浮腫(DME)の管理と網膜厚の評価における現在のゴールドスタンダードは、光干渉断層計(OCT)である。OCTは詳細なRTMを提供し、これは網膜構造と病変の定量的可視化である。対照的に、カラー眼底写真(C-FP)は、広く利用可能で費用対効果が高く、アクセスしやすい2D画像技術であり、スマートフォンでも実現可能である。しかし、C-FPは伝統的に、定量的な網膜厚評価に必要な深度情報を欠いている。
望ましい終点/目標状態:
本論文は、C-FPから直接、正確で包括的なRTMを生成できるシステムを開発することを目指している。最終的な目標は、これらのC-FP由来RTMが、特にリソースが限られた環境において、DMEの効率的でアクセス可能、かつ費用対効果の高い診断およびモニタリングツールとして機能することである。これにより、タイムリーな介入、情報に基づいた治療決定、および患者の視覚転帰の改善が促進され、従来の眼底画像診断を強力な診断資産へと効果的に変革する。
欠落リンクまたは数学的ギャップ:
根本的な欠落リンクは、2D C-FP画像における深度分解能の固有の欠如である。RTMは3D厚み情報を表すが、C-FPは2D投影しかキャプチャしない。C-FPから厚みを予測することでこのギャップを埋めようとする以前の試みは、しばしば特異度と感度が限定的な代理マーカー(脂質沈着など)に依存していたり、あるいは単純に、特に画像品質が変動する場合に、必要な臨床精度を達成できなかったモデルに依存していたりした。数学的な課題は、深度情報が明示的な測定ではなく、微妙な視覚的手がかりに暗黙的にエンコードされている2D画像から、連続的で定量的な3D厚み分布を推論することである。
痛みを伴うトレードオフまたはジレンマ:
中心的なジレンマは、「アクセス可能性/費用対効果」と「定量的精度/詳細度」の間のトレードオフである。OCTは高忠実度のRTMを提供するが、高価で操作が複雑で、アクセス性が限られており、多くの実世界シナリオで最適ではない患者フォローアップにつながる。C-FPは非常にアクセスしやすく安価であるが、その2D性質は、詳細なDME管理に必要な正確な定量的厚み測定を提供することを歴史的に妨げてきた。研究者は、C-FPの固有の利点であるアクセス性と低コストを失うことなく、あるいはIR-FPのような中間的でアクセス性の低いモダリティに依存することなく、C-FPから十分な定量的情報を抽出することに苦慮してきた。本論文は、C-FPのみからOCTレベルのRTM予測を達成しようとすることで、このジレンマに直接立ち向かう。
制約と失敗モード
この問題は、いくつかの厳しい現実的な制約により、信じられないほど困難である。
- C-FPの固有の2D性質: 前述の通り、C-FPは直接的な深度情報を提供しない。2D画像から3D網膜厚を推論することは、モデルに表面特徴と基盤となる厚みの間の複雑で明白でない関係を学習させる必要がある、不良設定の逆問題である。
- 微妙な病理学的バイオマーカー: DMEによって誘発される網膜層の再編成は、C-FPにおける「微妙なテクスチャと色の変化」として現れる。これらの微妙な手がかりは、経験豊富な臨床家にとっても識別が困難であり、自動システムにとってはなおさらである。モデルは、厚みを正確に予測するために、これらの微細な変化を検出できる必要がある。
- 空間的な不整合とレジストレーションの課題: C-FP(入力)とRTMグラウンドトゥルース(OCTから派生し、しばしばIR-FPによってローカライズされる)との間の正確なピクセルごとの空間的対応を達成することは、大きなハードルである。異なる画像モダリティは、異なる視野、解像度、および潜在的な歪みを有しており、正確なマルチモーダルレジストレーションを複雑な前処理ステップとしている。本論文は、レジストレーションの中間媒体としてIR-FPの使用に言及し、この困難さを強調している。
- DME発現の異質性: DMEは、広範囲の病理学的病変と不規則な網膜解剖学的構造を示す。堅牢なモデルは、これらの多様な発現を一般化する必要があり、グローバルな文脈特徴(血管ネットワークなど)と微細な局所詳細(黄斑領域の変化)の両方を捉える必要がある。
- 高忠実度生成のための計算需要: 拡散モデルのような高度な生成モデルを使用した高解像度で正確なRTMの生成は、特に推論(サンプリング)段階で計算集約的になる可能性がある。高忠実度を維持しながらサンプリングを迅速化する必要性(DDIMによって対処される)は、この計算制約を強調している。
- 厳格な臨床精度要件: 以前のC-FPベースの予測モデルは、「臨床基準を満たせなかった」。これは、臨床的に実行可能であるためには、新しいソリューションに必要な精度、特異度、および感度に対して高い基準を設定する。モデルの予測は、重要な医療決定を情報化するのに十分信頼できる必要がある。
- データ可用性とアノテーション品質: このようなモデルをトレーニングするには、正確にペアリングされたC-FP、IR-FP、およびOCT画像と、RTMおよびDME診断のための専門家アノテーションの大規模なデータセットが必要である。このような高品質なマルチモーダルデータセットの取得とキュレーションは、時間とリソースを大量に消費するプロセスである。
- 周辺文脈の損失対黄斑の詳細: 黄斑領域は厚み評価に重要であるが、重要な網膜全体の構造と病理学的バイオマーカー(視神経乳頭、血管ネットワークなど)は、より広い眼底画像に存在する。黄斑のみに焦点を当てることは、この重要な「周辺文脈」を失うリスクがあり、グローバルとローカルの両方の特徴を統合するためのデュアルストリームアプローチが必要となる。
なぜこのアプローチなのか
選択の必然性
著者らは、網膜厚マップ(RTMs)をカラー眼底写真(C-FP)から直接予測するという、特定の微妙な問題に対して、標準的な「SOTA」(State-of-the-Art)手法、すなわち標準的なCNN、基本的な拡散モデル、またはTransformerでは不十分である状況に陥った。根本的な認識は、臨床上の重要な必要性から生じた。光干渉断層計(OCT)は糖尿病黄斑浮腫(DME)の診断と管理のゴールドスタンダードであるが、その高コストとリソースが限られた環境でのアクセス性の低さは、広範なスクリーニングと頻繁なモニタリングには非現実的である。これにより、よりアクセスしやすい代替手段への緊急の需要が生じた。
カラー眼底写真(C-FP)は、最も実行可能な、費用対効果の高いスクリーニングツールとして浮上した。これは広く利用可能であり、スマートフォンでも実現可能である。しかし、C-FPは根本的な課題を提示している。それは、定量的な網膜層評価に必要な深度分解能を固有に欠く2D画像技術であることだ。C-FPから網膜厚を予測しようとする以前の試みは、脂質沈着のような代理マーカーに依存していたが、特異度と感度が限定的であった。Arcaduら[3]によるモデルのような、より高度な深層学習モデルでさえ、特に画像品質が低い場合に、予測精度の臨床基準を満たせなかった。
著者らはまた、DeepRT [15]やM²FRT [26]のような一部のSOTA手法が使用した中間媒体として、赤外線眼底写真(IR-FP)も検討した。しかし、IR-FPは依然として追加のデバイスを必要とし、その臨床応用を制限している。さらに、IR-FP自体も、高反射性アーチファクトや、硬性白斑や出血のような重要な病理学的マーカーの不十分な可視化といった固有の限界を有している。対照的に、C-FPは優れた空間解像度、より広いスペクトル範囲、およびより広い視野を提供する。それは、DMEの重要な病理学的バイオマーカーである血管ネットワークや視神経乳頭といった、重要な網膜全体の構造を捉える。新しいアプローチが必要であるという認識の正確な瞬間は、既存の手法が2Dから3Dへの推論を十分に正確に処理できなかったか、あるいはアクセス性と費用対効果の要件を満たさない画像モダリティに依存していたことが明らかになったときに起こった可能性が高い。C-FPにおける網膜層の再編成を示す微妙なテクスチャと色の変化は、高レベルのセマンティック特徴と正確な局所黄斑詳細の両方を抽出できるモデルを必要とした。これは、標準的なSOTA手法が同時に、かつ十分な忠実度で達成するのに苦労していた能力である。
比較優位性
網膜厚予測のためのグローバル・ツー・ローカル条件付き拡散モデル(GLD-RT)は、単なるパフォーマンス指標を超えた圧倒的な質的優位性を示す。その構造的利点は、C-FPデータからRTM生成への固有の複雑性に対処するために特別に設計された、独自のデュアルストリーム、ハイブリッドCNN-Transformer条件付き拡散アーキテクチャにある。
第一に、GLD-RTがグローバルな文脈特徴と微細な局所詳細の両方を統合できる能力は、重要な構造的利点である。グローバルなフル眼底エンコーダー($E_g$)は、事前学習済みのRETFoundモデルを活用し、C-FP画像全体から堅牢な解剖学的および病理学的パターンを捉える。同時に、Swin-Transformerで構築されたローカル黄斑エンコーダー($E_m$)は、黄斑領域から複雑で微細な特徴を抽出する。このデュアルストリームアプローチにより、モデルは広範な文脈を見逃すことなく、DMEを示す微妙でありながら臨床的に重要な局所的な変化にも焦点を当てることができる。これは、DMEが大規模な血管特性と微細な網膜層の完全性の両方に影響を与えるため、重要である。
第二に、条件付き拡散デコーダーの使用は、この生成タスクにおいて質的に優れている。従来の識別モデルや、より単純な敵対的生成ネットワーク(GAN)とは異なり、拡散モデルは、ノイズ入力を段階的にノイズ除去することにより、高忠実度で多様で解剖学的に一貫した出力を生成することに優れている。これは、RTM予測に特に有利である。RTM予測では、出力は生理学的および病理学的形態の両方を正確に反映する必要がある複雑で連続的な厚みマップである。グローバルおよびローカル特徴の豊富な情報によって導かれる拡散プロセスは、特に困難な中心黄斑(G1領域)における微妙で不規則な網膜解剖学的構造の、より微妙で正確な描写を可能にする。これは、図2の質的結果とアブレーションスタディによって証明されている。Denoising Diffusion Implicit Model(DDIM)の採用も、忠実度を犠牲にすることなく、サンプリングステップを大幅に削減することを可能にし、実用的な効率を向上させる。
この構造設計により、GLD-RTは、以前の手法よりもC-FP画像に固有の高次元ノイズと変動性をより良く処理できる。単にマップを予測するだけでなく、解剖学的に一貫した詳細なRTMを生成する。これは、単純なモデルが解剖学的一貫性と微細な詳細の維持においてしばしば失敗するタスクである。
制約との整合性
選択されたGLD-RT手法は、問題の厳しい要件と完全に整合しており、「臨床的必要性」と「革新的なソリューション設計」の「結婚」を形成している。
-
制約:OCTのアクセス性の制限と高コスト。
- 整合性: GLD-RTは、C-FPのみからRTMを予測する最初のモデルである。C-FPは広く利用可能で費用対効果が高く、スマートフォンでもキャプチャできる。これは、アクセス可能で手頃な価格の診断ツールの必要性を直接満たし、従来の眼底画像診断をリソースが限られた環境における包括的なスクリーニングおよびモニタリングソリューションへと変革する。
-
制約:C-FPの2D性質は、定量的評価のための深度分解能を欠く。
- 整合性: 条件付き拡散モデルは、本質的に、条件付き入力から複雑な高次元出力を合成できる生成モデルである。GLD-RTは、2D C-FP特徴から3D網膜厚分布への複雑なマッピングを学習することにより、入力画像に明示的に存在しない深度情報を効果的に推論する。この生成能力は、2Dの限界を克服する鍵である。
-
制約:正確で詳細で臨床的に関連性のあるRTMの必要性。
- 整合性: デュアルストリームアーキテクチャ(グローバル・ツー・ローカルエンコーダー)は、広範な解剖学的文脈と微細な黄斑詳細の両方が捉えられることを保証する。グローバルエンコーダー(RETFound)は堅牢な高レベルセマンティック特徴を提供し、ローカルエンコーダー(Swin-Transformer)は正確な局所詳細を抽出する。これらは融合され、階層的な拡散デコーダーに供給され、「グローバル・ツー・ローカル解剖学的一貫性」を保証する。この設計は、生理学的および病理学的網膜形態の両方を正確に描写するために不可欠であり、臨床的有用性と網膜構造の詳細な検査にとって極めて重要である。アブレーションスタディは、拡散プロセスが特に複雑な中心黄斑(G1)において、黄斑構造を微細な詳細で捉えることに成功したことを確認している。
-
制約:リソースが限られた環境での実用性(効率性)。
- 整合性: 拡散モデルは計算集約的になる可能性があるが、サンプリングのためのDDIMの使用は、推論に必要なステップ数を大幅に削減し、実際の臨床応用にとってプロセスをより効率的かつ実用的にする。全体的な目標は、「タイムリーな介入のための効率的な診断ツール」を提供することである。
代替案の却下
本論文は、C-FPからのRTM予測の文脈におけるそれらの限界を強調することによって、いくつかの代替アプローチを暗黙的かつ明示的に却下している。
第一に、代理マーカーに依存する従来のモデル(例:脂質沈着、レーザースカー)は不十分と見なされた。著者らは、これらのアプローチが「DME検出の特異度と感度が限定的」であったと述べている[28, 29]。これは、DMEの複雑で微妙な発現を捉えることができない、機械学習を使用しない、またはより単純なルールベースのモデルの明確な却下である。
第二に、C-FPベースのRTM予測のための以前の深層学習モデルは不十分であることが判明した。本論文は、Arcaduら[3]によるモデルが、特に画像品質が低い場合に、予測精度に関して「臨床基準を満たせなかった」と述べている。これは、より単純なCNNベースのアーキテクチャや、より洗練されていない生成モデル(当時一般的であった)が、臨床的に許容可能なRTMを生成するためにC-FPから必要な情報を抽出できなかったことを示唆している。それらは、2Dから3Dへの推論や、DMEを示すC-FPの微妙な変化を捉えるのに苦労した可能性が高い。
第三に、赤外線眼底写真(IR-FP)に依存する手法、例えばDeepRT [15]やM²FRT [26]は、実用的および固有の画像化の限界のために、唯一の実行可能なソリューションとして却下された。これらの手法は改善を示したが、リソースが限られた環境での臨床応用を制限する「IR-FPをキャプチャするための追加デバイス」を依然として必要とした。さらに、IR-FP自体は、「高反射性アーチファクト、網膜下構造に最適化された照明波長の制限、および重要な病理学的マーカーの不十分な可視化」といった欠点を有している[1]。これにより、その課題にもかかわらず、C-FPはより望ましい入力となる。
最後に、本論文のアブレーションスタディは、より単純なデコーディングメカニズムの却下と拡散プロセスの必要性の決定的な証拠を提供する。結果は、提案された拡散デコーダー($D_d$)が、拡散のないデコーダー($D_{nd}$)と比較して、「モデルパフォーマンスを著しく向上させ、特に中心黄斑(G1)において」ことを示している。これは、非拡散生成モデルや直接回帰モデルで使用される可能性のある標準的なデコーディングアプローチが、この複雑な領域で必要とされる構造的詳細と解剖学的整合性を捉えるのに不十分であったことを意味する。 「グローバル・ツー・ローカル特徴条件付けが標準的なデコーディングアプローチを上回った」という記述は、階層的でない、または非階層的な生成フレームワークが、C-FPからの豊富なマルチスケール情報を活用する上で効果が低かったであろうことをさらに強化する。GANが明示的に名前が挙げられていないとしても、高忠実度生成、解剖学的整合性、および微妙な詳細を捉える能力への重点は、拡散モデルがこれらの側面においてより優れたパフォーマンスを発揮するため、他の生成パラダイムよりも選択されたことを強く示唆している。
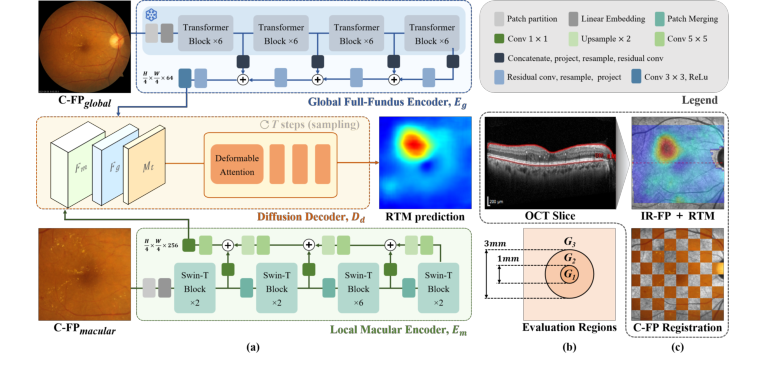 Figure 1. (a) GLD-RT leverages a dual-stream diffusion framework to integrate global contextual features with fine-grained details. (b) Evaluation regions for RTM predic- tion. (c)IR-FP, the localizer in OCT imaging that generates RTM, is used to register C-FPglobal with RTM, generating C-FPmacular
Figure 1. (a) GLD-RT leverages a dual-stream diffusion framework to integrate global contextual features with fine-grained details. (b) Evaluation regions for RTM predic- tion. (c)IR-FP, the localizer in OCT imaging that generates RTM, is used to register C-FPglobal with RTM, generating C-FPmacular
数学的・論理的メカニズム
マスター方程式
GLD-RTフレームワークの学習メカニズムの絶対的な核心は、その最適化目標であり、これは平均二乗誤差(Mean Squared Error; MSE)損失関数である。この方程式は、モデルがカラー眼底写真(C-FP)から網膜厚マップ(RTMs)を正確に予測することを学習するように導き、その予測とグラウンドトゥルースとの差を最小化する。
マスター方程式は次のように提示される。
$$ \mathcal{L} = \mathbb{E}_{M,t,F_m,F_g} [||M – D_d(M_t, t, F_m, F_g) ||^2] $$
用語ごとの解剖
この方程式の各コンポーネントの役割を理解するために分解してみよう。
-
$\mathcal{L}$:
- 数学的定義: この記号は、全体的な損失関数、特に平均二乗誤差(MSE)損失を表す。
- 物理的/論理的役割: モデルの予測RTMと実際のグラウンドトゥルースRTMとの間の不一致を定量化する。モデルのトレーニング中の主な目的は、この値を最小化し、それによってモデルに、より正確な予測を行わせることである。
- 使用理由: MSEは、回帰タスクのための標準的で効果的な損失関数である。その二乗演算は、より大きな誤差をより小さく誤差よりも大きく罰し、モデルに大幅な偏差を減らすことを奨励する。
-
$\mathbb{E}_{M,t,F_m,F_g}$:
- 数学的定義: これは期待値演算子を意味し、$M$、$t$、$F_m$、$F_g$の確率変数に対する平均を意味する。
- 物理的/論理的役割: 実際には、トレーニング中、この期待値は、トレーニングサンプルのバッチに対する二乗差の平均によって近似される。各サンプルは、グラウンドトゥルースRTM($M$)、特定のノイズタイムステップ($t$)、ローカル黄斑特徴($F_m$)、およびグローバルフル眼底特徴($F_g$)で構成される。この平均化により、モデルが多様な入力とノイズ条件全体でうまく一般化することを学習することが保証される。
- 使用理由: サンプルバッチ全体で損失を平均化することは、単一サンプルの損失(ノイズが多い可能性がある)を計算するよりも、モデルパラメータを更新するための、より安定した代表的な勾配を提供する。
-
$M$:
- 数学的定義: これはグラウンドトゥルース網膜厚マップ(RTM)を表す。これは、高さと幅がマップの高さと幅である$H \times W$の次元を持つ実数値の2D行列である。
- 物理的/論理的役割: これは、GLD-RTモデルが予測しようとする「正解」またはターゲット出力である。モデルの予測が比較される参照として機能する。
- 使用理由: エラーを計算し、モデルのパフォーマンスを評価するための不可欠なベンチマークである。
-
$D_d(\cdot)$:
- 数学的定義: これは拡散デコーダーを表し、複雑なニューラルネットワークである。ノイズのあるRTM、タイムステップ、および条件付き特徴を入力として受け取り、元のノイズのないRTMを予測することを目的とする。
- 物理的/論理的役割: これはモデルの生成エンジンである。トレーニング中、それは抽出されたC-FP特徴によって導かれ、ノイズのあるRTMをノイズ除去して元のRTMを再構築することを学習する。推論中、それはC-FP特徴をガイドとして使用して、純粋なノイズを反復的に予測RTMに変換する。
- 使用理由: 拡散モデルフレームワークは、高忠実度の画像を生成し、複雑なデータ分布をモデル化する能力で証明されているため、RTMの複雑な詳細に不可欠である。条件付き側面により、生成プロセスを入力C-FP特徴によって誘導できる。
-
$M_t$:
- 数学的定義: これは、特定の拡散タイムステップ$t$におけるグラウンドトゥルースRTM、$M$のノイズのあるバージョンである。これは、$M$にスケジュールされたガウスノイズを追加することによって作成される。
- 物理的/論理的役割: これはトレーニング中の拡散デコーダーへの入力として機能する。デコーダーのタスクは、$M_t$からノイズを効果的に除去して元の$M$を再構築する方法を学習することである。このプロセスは、ノイズが段階的に導入される前方拡散プロセスの逆転を模倣する。
- 使用理由: 拡散モデルは、ノイズ付加の定義済み前方プロセスを逆転させることを学習することによって動作する。モデルを様々なノイズレベルのタイムステップでトレーニングすることにより、広範囲のノイズレベルをノイズ除去する能力を開発する。
-
$t$:
- 数学的定義: これは拡散タイムステップであり、$M_t$を生成するために$M$に追加されたノイズの量を示す整数値である。通常、小さい値(最小ノイズ)から大きい値(最大ノイズ)の範囲である。
- 物理的/論理的役割: $M_t$に存在する現在のノイズレベルについて、拡散デコーダーに重要な情報を提供する。$t$を知ることで、デコーダーはその特定のノイズ強度に対して適切なノイズ除去操作を適用できる。
- 使用理由: ノイズ除去戦略はノイズ量に大きく依存するため、タイムステップは拡散モデルの基本である。異なるタイムステップは、異なるノイズ除去アプローチを必要とする。
-
$F_m$:
- 数学的定義: これらは、C-FP画像の黄斑領域のクロップ($C\text{-}FP_{macular}$)からローカル黄斑エンコーダー($E_m$)によって抽出された微細な局所黄斑特徴である。これらの特徴は、$R^{\frac{H}{4} \times \frac{W}{4} \times 256}$の次元を持つ。
- 物理的/論理的役割: これらの特徴は、この臨床的に重要な領域における正確な厚み予測に不可欠な、非常に詳細な情報を提供する。それらは、微細な解剖学的文脈で拡散プロセスをガイドするローカル条件として機能する。
- 使用理由: 黄斑領域は、糖尿病黄斑浮腫(DME)の病変が最も顕著であり、細心の分析を必要とする場所である。Swin-TransformerとFeature Pyramid Networkを利用した$E_m$エンコーダーは、これらの階層的で詳細な特徴を捉えるように設計されている。
-
$F_g$:
- 数学的定義: これらは、C-FP画像全体($C\text{-}FP_{global}$)からグローバルフル眼底エンコーダー($E_g$)によって抽出されたグローバルフル眼底特徴である。これらの特徴は、$R^{\frac{H}{16} \times \frac{W}{16} \times 64}$の次元を持つ。
- 物理的/論理的役割: これらの特徴は、高レベルのセマンティック文脈と網膜全体の構造に関する情報を提供する。それらは、黄斑領域のみに焦点を当てる際に失われる可能性のある周辺文脈を補償し、拡散プロセスに対するグローバル条件として機能する。
- 使用理由: グローバル文脈は、網膜全体の解剖学的整合性を確保するのに役立ち、黄斑厚に影響を与える可能性のあるより広範な病理学的マーカー(血管ネットワークなど)を提供する。$E_g$エンコーダーは、この目的のために事前学習済みのRETFound Vision Transformerを活用する。
-
$|| \cdot ||^2$:
- 数学的定義: これは二乗L2ノルムを表し、ベクトルまたは行列のすべての要素の二乗の合計を計算する。行列$A$に対して、$||A||^2 = \sum_{i,j} A_{i,j}^2$である。
- 物理的/論理的役割: グラウンドトゥルースRTMと拡散デコーダー($D_d(\cdot)$)によって予測されたRTMとの間の要素ごとの差の二乗を計算する。差を二乗することで、正と負のエラーの両方が損失に等しく寄与し、より大きなエラーがより重く罰せられることが保証される。
- 使用理由: 二乗L2ノルムは、平均二乗誤差(MSE)損失の基本的な構成要素であり、微分可能で凸状であるため、回帰タスクで広く採用されており、最適化プロセスを簡素化する。
-
$M - D_d(\dots)$:
- 数学的定義: これは、グラウンドトゥルースRTMと予測RTMとの間の要素ごとの差を表す。
- 物理的/論理的役割: これは、モデルが最小化しようと努めるエラーまたは残差である。これは、望ましい出力とモデルの実際の出力との直接的な比較である。
- 使用理由: この直接的な減算は、モデルが削減することを学習する必要があるエラーを定量化するための基礎を形成する。
ステップバイステップフロー
GLD-RTメカニズムを、入力から損失計算までの単一の抽象データポイントの旅を追ってみよう。
-
初期データ入力: プロセスは、単一のカラー眼底写真(C-FP)画像とその対応するグラウンドトゥルース網膜厚マップ(RTM)、すなわち光干渉断層計(OCT)スキャンから得られた$M$から始まる。
-
マルチモーダルレジストレーションとクロッピング: C-FP画像は、RTMの空間座標にピクセルごとに整列させるために、正確なレジストレーションプロセスを受ける。これには、中間赤外線眼底写真(IR-FP)画像を基準として使用することが含まれる。主要なステップには、網膜血管のセグメンテーション、キーポイント(例:AKAZEを使用)の検出、ホモグラフィ行列(例:RANSACを使用)の計算、およびフルC-FP($C\text{-}FP_{global}$)をIR-FPに非剛体レジストレーションすることが含まれる。これから、RTMに対応する黄斑領域に特に焦点を当てたクロップされたバージョン、$C\text{-}FP_{macular}$が生成される。
-
並列特徴抽出:
- グローバル文脈ストリーム: フル$C\text{-}FP_{global}$画像は、グローバルフル眼底エンコーダー($E_g$)に供給される。事前学習済みのRETFound Vision Transformerを活用するこのエンコーダーは、画像を処理して高レベルのセマンティック特徴、$F_g$を抽出する。これらの特徴は、網膜全体の構造とより広範な文脈情報をカプセル化する。
- ローカル詳細ストリーム: 同時に、クロップされた$C\text{-}FP_{macular}$画像は、ローカル黄斑エンコーダー($E_m$)に入る。Swin-TransformerとFeature Pyramid Networkで構築されたこのエンコーダーは、微細な階層的特徴、$F_m$を抽出し、黄斑領域に特化した詳細情報を提供する。
-
ノイズ注入(トレーニングフェーズのみ): モデルがトレーニングフェーズにある場合、ランダムなタイムステップ$t$が定義済みのノイズスケジュールから選択される。このタイムステップに応じてスケーリングされたガウスノイズが、グラウンドトゥルースRTM、$M$に追加され、ノイズのあるRTM、$M_t$が生成される。
-
拡散デコーダーによる条件付きノイズ除去: ノイズのあるRTM、$M_t$、選択されたタイムステップ$t$、および抽出された条件付き特徴($F_m$と$F_g$)はすべて、拡散デコーダー($D_d$)に渡される。デコーダーの主なタスクは、$M_t$をノイズ除去して元のクリーンなRTM、$M$に戻す方法を学習することである。このノイズ除去プロセスは、$F_m$(局所詳細)と$F_g$(グローバル文脈)によって提供される豊富な文脈情報によって、決定的にガイドされる。
-
RTM予測: デコーダーは、元のRTMの最良の推定値を出力する。これは$D_d(M_t, t, F_m, F_g)$と表すことができる。
-
損失計算: 予測されたRTMは、元のグラウンドトゥルースRTM、$M$と比較される。それらの要素ごとの差の二乗L2ノルム、$||M – D_d(M_t, t, F_m, F_g) ||^2$が計算される。この値は、この特定のデータポイントのエラーを表す。
-
バッチ平均化: この個々の二乗エラーは、すべてのサンプル(それぞれが$M$、$t$、$F_m$、$F_g$の組み合わせを持つ)にわたって平均化され、その反復の最終的な損失$\mathcal{L}$が得られる。
-
推論(生成フェーズ): 推論中、拡散デコーダーのプロセスは変化する。グラウンドトゥルースRTMのノイズのあるバージョンから始まる代わりに、デコーダーは純粋なランダムノイズから始まる。次に、新しいC-FP入力から抽出された$F_m$と$F_g$特徴によってガイドされるノイズ除去ステップを反復的に適用する。この反復プロセスは、しばしば非マルコフ決定論的サンプリングアプローチであるDDIMを使用して、大幅に少ないステップ数(例:5ステップ)で、一貫した詳細なRTM予測に初期ノイズを徐々に変換する。
最適化ダイナミクス
GLD-RTメカニズムは、勾配ベースの最適化プロセスを通じて、平均二乗誤差(MSE)損失関数$\mathcal{L}$を反復的に最小化することによって学習、更新、および収束する。
-
損失ランドスケープ: モデルの学習は、複雑な損失ランドスケープ内で発生する。このランドスケープは、グラウンドトゥルースRTM、様々なタイムステップで導入されるノイズのレベル、およびC-FP画像から抽出される豊富でマルチスケールの条件付き特徴との間の複雑な関係によって形成される。最終的な目標は、予測RTMが常にグラウンドトゥルースに密接に一致する「谷」に対応するモデルパラメータ(エンコーダー$E_m$、$E_g$および拡散デコーダー$D_d$内の重みとバイアス)のセットを見つけるために、このランドスケープをナビゲートすることである。深層ニューラルネットワークの全体的なランドスケープは本質的に非凸であるが、MSE目標は最適化のための明確で微分可能な信号を提供する。拡散プロセスの固有の構造(ノイズレベルのスペクトル全体にわたるノイズ除去を学習することを含む)は、単純な直接回帰モデルと比較して、より滑らかで堅牢な損失ランドスケープにつながる可能性のある強力な正則化器として機能する。
-
勾配計算: 各トレーニング反復で、バッチデータに対する損失$\mathcal{L}$が計算された後、逆伝播アルゴリズムが開始される。このアルゴリズムは、エンコーダー($E_m$、$E_g$)および拡散デコーダー($D_d$)内のすべての学習可能パラメータに対する損失の勾配を効率的に計算する。これらの勾配は非常に重要である。それらは、計算された損失を削減するために各パラメータを調整する必要がある正確な方向と大きさを指示する。
-
パラメータ更新: 本論文では、Adamオプティマイザー[16]を使用してモデルのパラメータを更新することを指定している。Adamは洗練された適応学習率最適化アルゴリズムである。過去の勾配(一次モーメント)と過去の二乗勾配(二次モーメント)の指数加重平均を維持することによって、異なるパラメータに対して個別の学習率を動的に計算する。
- Adamの特定のハイパーパラメータは、$\beta_1 = 0.9$および$\beta_2 = 0.999$に設定されており、これらは広く受け入れられているデフォルト値である。
- 学習率を効果的に管理するために、16エポックの「ウォームアップ」期間の後、コサイン減衰スケジューリング戦略が採用される。このスケジュールでは、学習率は非常に小さい値($1 \times 10^{-8}$)からわずかに大きい値($6 \times 10^{-5}$)まで徐々にランプアップされる。このウォームアップの後、学習率は300エポックにわたってコサイン関数に従ってゆっくりと減衰する。この戦略により、モデルは最初に損失ランドスケープを慎重に探索し、次に収束を加速し、最後に学習率を減らすことによってパラメータを微調整し、過剰な最小値へのオーバーシュートを防ぐことができる。
- さらに、固定の重み減衰$1 \times 10^{-2}$が適用される。重み減衰は、L2正則化としても知られ、大きなパラメータ値を罰することによって過学習を防ぐのに役立つ。これは、モデルがより一般的で複雑でない特徴を学習することを奨励し、未知のデータに対するパフォーマンスを向上させる。
-
反復的な改善と収束: 損失の計算、勾配の計算、およびパラメータの更新というこのサイクルは、多くのトレーニングエポック(この研究では300エポック)にわたって反復的に繰り返される。トレーニングが進むにつれて、モデルのパラメータは$\mathcal{L}$を最小化するように継続的に洗練される。拡散デコーダーは、ノイズプロセスを正確に逆転させることを徐々に学習し、$F_m$と$F_g$で条件付けられた場合に$M$を予測する能力がますます向上する。モデルは、トレーニングデータセットと検証データセットの両方の損失が安定するか、最小値に達すると、収束したと見なされる。これは、モデルがRTMをグラウンドトゥルースに密接に一致するように生成することに成功したことを示し、基盤となる網膜厚分布を捉える能力を実証する。推論中のサンプリングのためのDenoising Diffusion Implicit Model(DDIM)の採用は、非マルコフ決定論的プロセスであり、より少ないステップ数(例:5ステップ)でRTMのより高速で安定した生成を可能にすることにより、メカニズムを実世界での応用により効率的にすることにより、実用的な収束にさらに貢献する。
結果、限界、および結論
実験デザインとベースライン
GLD-RTモデルは、包括的なデータセットを使用して開発され、厳密に検証された。中核となるRTM予測タスクのために、研究者らは、光干渉断層計(OCT)、赤外線眼底写真(IR-FP)、およびカラー眼底写真(C-FP)の対応する画像からなる各トリプレットである2,918のデータトリプレットを使用した。これらのトリプレットは、抗VEGF療法を受けている1,418人の糖尿病黄斑浮腫(DME)患者から、Kangbuk Samsung Hospitalから収集された。コホートは、平均網膜厚$296.99 \pm 30.67 \text{ µm}$および中心黄斑厚$292.46 \pm 75.00 \text{ µm}$を示し、黄斑浮腫の有意な有病率を示唆している。IR-FPと31のOCT BスキャンはHeidelbergデバイスを使用して取得され、膜セグメンテーションが自動的に提供された。経験豊富な眼科医は、固定不良またはセグメンテーションエラーのあるスキャンを慎重に除外し、データ品質を確保した。
DME診断の重要なタスクのために、Mobile Brazilian Retinal Dataset(mBRSET)が採用された。このデータセットは、ブラジル、バイーア州イタプナの1,291人の糖尿病患者からの5,164枚のC-FP画像で構成されており、DME診断と画像品質ラベルがすべて細心の注意を払ってアノテーションされている。
データ前処理には、一貫性と整合性を確保するためにいくつかのステップが含まれた。IR-FP画像は、OCTスキャン領域に一致するように、$544 \times 544$ピクセルに中央クロップされた。C-FPglobal画像は、IR-FP解像度に一致するように、$3608 \times 3608$から$544 \times 544$にダウンサンプリングされた。網膜厚マップ(RTMs)は、31本のBスキャンラインから計算され、IR-FP解像度に一致するように線形補間された。構造的完全性を維持しつつアーチファクトを低減するために、RTMはガウスフィルタリング($\sigma = 3$)による連続平滑化と、それに続く非局所平均ノイズ除去を受けた。DME診断のために、C-FP画像は、フォビアの位置に基づいて$800 \times 800$にクロップされ、その後$544 \times 544$にダウンサンプリングされた。
データセットは、堅牢な評価のために患者レベルで分割された:GLD-RT開発のための2043のトレーニング、292の検証、および583のテストトリプレット。mBRSETも同様に、DME診断のための2409のトレーニング、345の検証、および688のテスト画像に分割された。GLD-RTモデルは、標準パラメータ($\beta_1, \beta_2) = (0.9, 0.999)$、16エポックのウォームアップ後のコサイン減衰学習率スケジュール、および固定重み減衰$1 \times 10^{-2}$を備えたAdamオプティマイザー[16]を使用して最適化された。拡散プロセスは、トレーニングに20タイムステップ、推論に5タイムステップを使用した。すべての実験は、NVIDIA GeForce RTX 3090 GPUで実施され、ランダムフリッピングと回転によるデータ拡張が組み込まれた。
数学的主張を徹底的に証明するために、著者らはGLD-RTをいくつかの確立された最先端(SOTA)モデルと対比させた。RTM予測のために、「犠牲者」には、UNet [23]、Trans-UNet [5]、およびSwin-Unetr [12]のような一般的な医療画像密な予測モデル、ならびにDeepRT [15]およびM²FRT [26]のような専門的なRTM予測フレームワークが含まれた。これらのベースラインは、包括的な比較を提供するために、様々な入力構成(IR-FP、C-FP、またはその両方)で評価された。DME診断のために、GLD-RT支援アプローチは、ResNet50 [13]分類器を使用したC-FPのみのベースラインと比較された。
証拠が証明すること
実験的証拠は、提案されたグローバル・ツー・ローカル条件付き拡散モデル(GLD-RT)が、カラー眼底写真(C-FP)からのRTM予測において既存の手法を大幅に上回り、DME診断に実質的な利点を提供することを明確に証明している。
RTM予測に関して、GLD-RTは、平均絶対誤差(MAE)(マイクロメートル; $\mu$m)およびピーク信号対雑音比(PSNR)(デシベル; dB)で評価された場合、すべての網膜領域(G1、G2、G3、ETDRSグリッドに対応)で優れたパフォーマンスを達成した。具体的には、GLD-RTは、C-FPのみを入力として使用し、全体的なMAEが20.08 $\mu$m、PSNRが30.91 dBを記録した。これは、C-FP入力で全体的なMAE 23.21 $\mu$m、PSNR 29.34 dBを達成した以前のSOTAであるM²FRT [26]よりも顕著な改善であった。これらの増加の統計的有意性は、p値が0.01未満で確認され、GLD-RTのパフォーマンスが偶然によるものではないことを示唆している。
現実世界におけるGLD-RTのコアメカニズムの有効性の最も説得力のある証拠は、網膜中心部(G1)におけるパフォーマンスに lies。この領域は、その複雑な層構造と中心視力への直接的な影響により、臨床的に重要である。ここでは、GLD-RTはMAE 31.97 $\mu$m、PSNR 30.18 dBを達成し、C-FP入力に対するM²FRTの36.25 $\mu$m MAEと28.31 dB PSNRを大幅に上回った。これは、グローバル文脈と微細な局所特徴を階層的拡散デコーダーを介して統合するGLD-RTのデュアルストリームアーキテクチャが、この困難な領域における正確な厚み定量化に不可欠な、微妙で不規則な網膜解剖学的構造を効果的に捉えていることを示している。
図2に示す質的結果は、これらの増加をさらに強調している。GLD-RTは、網膜腫瘍、黄斑浮腫、および網膜静脈分枝閉塞などの多様な病理学的病変に関連する厚みの変化を堅牢に検出し、M²FRTよりも網膜解剖学的構造のより正確な表現を提供した。差分マップ(予測マイナスグラウンドトゥルース)は、一貫してGLD-RTの誤差が小さく、その優れた忠実度を視覚的に確認した。
アブレーションスタディは、各アーキテクチャコンポーネントの貢献の決定的な証拠を提供した。バックボーン(Em, Dnd、すなわち拡散のないデコーダーを備えたローカル黄斑エンコーダー)は、すでにM²FRTを上回っており、強化された局所特徴抽出の有効性を検証している。拡散デコーダー(Dd)の追加は、特にG1においてパフォーマンスを大幅に向上させ、拡散プロセスが黄斑の微細な詳細を捉える能力を証明した。さらに、グローバルフル眼底エンコーダー(Eg)をRETFound事前学習で組み込むことは、パフォーマンスをさらに向上させ、ドメイン固有の事前学習とグローバル解剖学的整合性の重要な役割を強調した。完全なGLD-RTモデル(Eg (RETFound), Em, Ddを組み合わせたもの)は、一貫して最良の結果をもたらした。
RTM予測を超えて、GLD-RT生成RTMはDME診断に非常に価値があることが証明された。ResNet50分類器のデュアル入力としてC-FPと連結された場合、このアプローチはC-FPのみのベースラインを一貫して上回った。デュアル入力モデルは、精度93.44%(対92.21%)、リコール79.49%(対64.41%)、F1スコア85.90%(対75.84%)、およびAUC 0.919(対0.855)を達成した。この否定できない証拠は、C-FP生成RTMが補完的な診断洞察を提供することを示しており、しばしばOCTおよびC-FP検査の両方を必要とする臨床プロトコルと一致している。これにより、GLD-RTは、特にリソースが限られた環境において、有望な費用対効果の高い診断ツールとなる。
限界と将来の方向性
GLD-RTは、C-FPからの網膜厚予測とDME診断支援において大きな進歩を示すが、現在の限界を認識し、将来の開発の方向性を考慮することが重要である。
1つの固有の限界は、モデルの目的ではあるが、C-FPは2D画像技術であるため、本質的にOCTの深度分解能を欠いていることである。GLD-RTは厚みを効果的に推論するが、グラウンドトゥルースRTMは高解像度OCTスキャンから派生している。本論文自体が、「詳細なRTM予測のための高解像度OCTの組み込み」を将来の方向性として示唆しており、GLD-RTの進歩をもってしても、さらなる技術統合や高忠実度のグラウンドトゥルースなしでは、C-FPのみから達成可能な詳細度には上限がある可能性があることを示唆している。現在のモデルは堅牢であるが、依然として2D入力に基づく予測であり、複雑な3D網膜構造のあらゆる微細な詳細を捉える能力は制約される可能性がある。
考慮すべきもう1つの側面は、発見の一般化可能性である。モデルは、特定の病院と地域(Kangbuk Samsung HospitalおよびmBRSET)のデータセットでトレーニングされた。これらは大規模なデータセットであるが、実際の臨床実践には、患者の人口統計、疾患の重症度、および様々なメーカーの画像デバイスの広範な多様性が含まれる。異なる集団または異なる画像取得プロトコルからの外部の未知のデータセットに対するGLD-RTのパフォーマンスは、さらなる前向き臨床検証を必要とするだろう。本論文は、「前向き臨床検証」を将来の方向性として言及しており、これはこの必要性を暗黙的に認識している。
さらに、モデルはRTMを提供するが、従来のC-FP画像とともにこれらのAI生成マップを解釈するための臨床ワークフローを確立する必要がある。臨床家はOCT由来RTMに慣れており、C-FP生成RTMへの移行には、正確な解釈と治療決定への統合を確実にするために、明確なガイドラインとトレーニングが必要となるだろう。「既存のヘルスケアワークフローへの統合」という本論文の提案は、この実践的な課題を強調している。
今後、この研究からいくつかのエキサイティングな議論のトピックが生まれる。
- 強化された臨床統合と意思決定支援: GLD-RTを既存の電子カルテシステムに統合して、日常的なC-FPスクリーニング中にリアルタイムRTM予測を提供するにはどうすればよいか?モデルを拡張して、厚みを予測するだけでなく、懸念領域を自動的に強調したり、フォローアップアクションを提案したりして、一次ケア医師や自宅モニタリング設定の患者のためのより包括的な意思決定支援ツールとして機能させることができるか?このような自律診断支援を展開するための規制経路と倫理的考慮事項は何であるか?
- 多疾患予測とバイオマーカー発見: DMEに対するC-FPの活用におけるGLD-RTの成功を考えると、このフレームワークを、より高価または侵襲的な画像診断に依存している他の網膜病変またはバイオマーカーを予測するために適応または拡張できるか?例えば、緑内障の初期兆候(例:網膜神経線維層の菲薄化)または加齢黄斑変性(例:ドルーゼン量)の兆候をC-FPから予測できるか?これは、C-FPを真に多目的スクリーニングツールへと変革する可能性がある。
- 画像品質とアーチファクトに対する堅牢性: 実際のC-FP画像は、患者の協力、メディアの混濁、または最適でないカメラ設定による様々な品質の問題をしばしば抱えている。現在の研究では低品質のスキャンを除外したが、将来の研究では、画像品質評価モジュールを組み込んだり、より広範な劣化画像でトレーニングしたりすることによって、これらの不完全性に対するGLD-RTの堅牢性を高めることに焦点を当てるべきである。モデルは、理想的でない入力であっても、その高い精度を維持するにはどうすればよいか?
- 計算効率とエッジ展開: 現在のモデルはNVIDIA GeForce RTX 3090で動作する。リソースが限られた環境またはポータブルデバイスでの広範な採用のためには、モデルをより低い計算フットプリントとより高速な推論時間に合わせて最適化することが重要になるだろう。知識蒸留またはモデル量子化技術を適用して、スマートフォンに接続された眼底カメラでリアルタイムRTM生成を可能にするエッジコンピューティングに適した軽量バージョンを作成できるか?
- 縦断的モニタリングと治療応答: GLD-RTをDME患者の縦断的モニタリングに使用し、網膜厚の変化を時間とともに追跡して治療応答または疾患進行を評価できるか?これには、モデルの一貫性と、長期間にわたる微妙な変化に対する感度を検証する必要がある。モデルの予測は、パーソナライズされた治療戦略、抗VEGF注射スケジュールの最適化、またはその他の介入をどのように情報化できるか?
- 説明可能性と信頼: AIモデルが臨床実践にますます統合されるにつれて、モデルが特定の予測を行う理由を理解することは、臨床家間の信頼を築く上で不可欠である。将来の研究では、GLD-RTのRTM予測の説明可能性を高める方法を模索する可能性がある。例えば、モデルがC-FP画像で注意を払う特徴を視覚化することによって、臨床家にその出力に対するより深い洞察と信頼を提供する可能性がある。
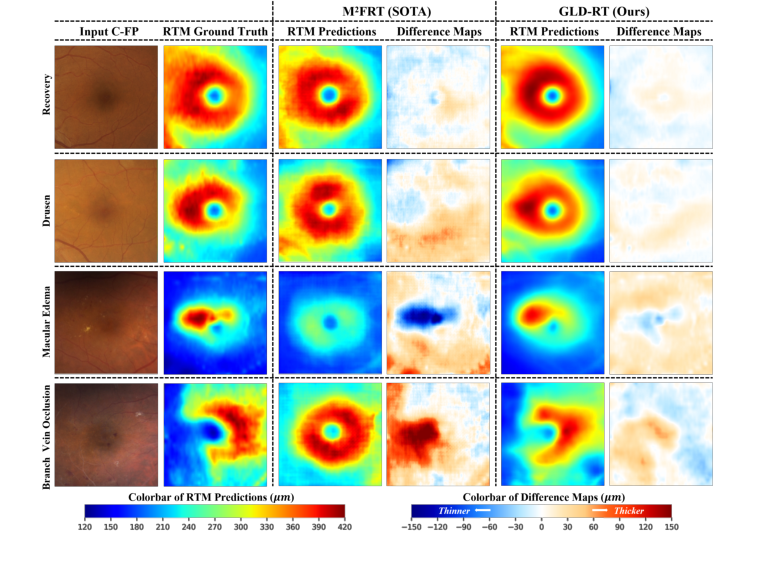 Figure 2. Qualitative results of our model and M2FRT. GLD-RT robustly detects diverse pathological lesions and accurately depicts subtle and irregular retinal anatomy. Dif- ference maps (prediction minus ground truth) further underscore these gains
Figure 2. Qualitative results of our model and M2FRT. GLD-RT robustly detects diverse pathological lesions and accurately depicts subtle and irregular retinal anatomy. Dif- ference maps (prediction minus ground truth) further underscore these gains
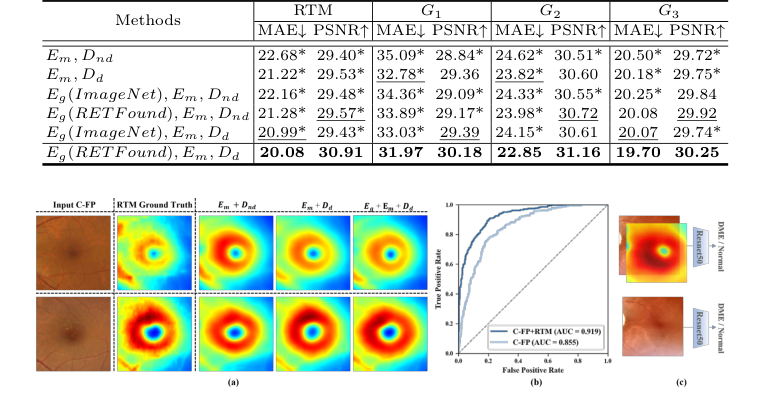 Figure 3. (a) Qualitative results of ablation study on GLD-RT. The proposed Dd sig- nificantly enhanced fine macular structural details, while Eg further enforced global anatomical consistency. (b) Receiver operating characteristic curve of DME diagnosis. (c)Experiment design of DME diagnosis
Figure 3. (a) Qualitative results of ablation study on GLD-RT. The proposed Dd sig- nificantly enhanced fine macular structural details, while Eg further enforced global anatomical consistency. (b) Receiver operating characteristic curve of DME diagnosis. (c)Experiment design of DME diagnosis
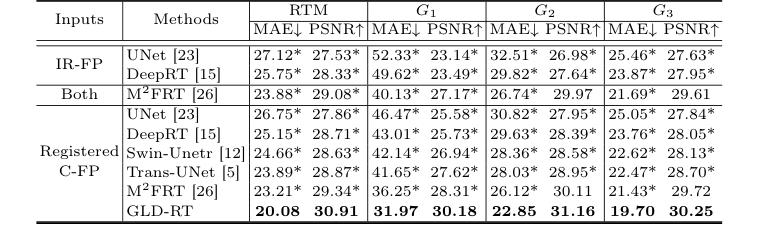 Table 1. Quantitative comparison of different methods for RTM prediction, with MAE (µm) and PSNR (dB). * indicates GLD-RT outperforms baselines with p-values<0.01
Table 1. Quantitative comparison of different methods for RTM prediction, with MAE (µm) and PSNR (dB). * indicates GLD-RT outperforms baselines with p-values<0.01
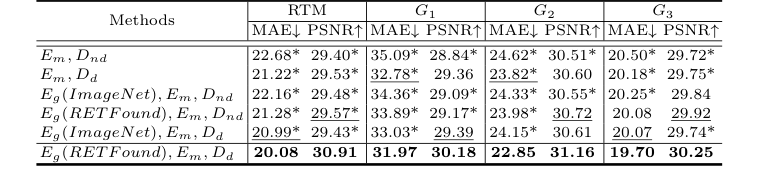 Table 2. Ablation study of RTM prediction, with MAE (µm) and PSNR (dB). * indicates GLD-RT outperforms baselines with p-values<0.01
Table 2. Ablation study of RTM prediction, with MAE (µm) and PSNR (dB). * indicates GLD-RT outperforms baselines with p-values<0.01