洞悉表面之下:从彩色眼底照片预测黄斑水肿的视网膜厚度图,助力DME管理
New model turns basic eye scans into detailed maps, boosting DME diagnosis in low-resource areas.
背景与学术渊源
起源与学术渊源
本文旨在解决的问题,即仅从彩色眼底摄影(C-FP)预测视网膜厚度图(RTMs),以用于糖尿病性黄斑水肿(DME)的管理,源于眼科领域对可及且经济高效的诊断工具的迫切需求。糖尿病性黄斑水肿是导致严重视力丧失的主要原因,尤其是在劳动年龄人口中,给全球医疗系统带来了沉重的负担。
历史上,光学相干断层扫描(OCT)一直是评估DME的黄金标准,因为它能提供详细的RTMs,以高精度量化视网膜病变。然而,OCT设备价格昂贵且操作复杂,严重限制了其可及性,尤其是在资源匮乏的环境或用于日常家庭监测时。这种可及性差距常常导致患者接受抗血管内皮生长因子(anti-VEGF)等治疗时,随访次数不足,治疗效果不佳。
以往利用C-FP(一种广泛可用且经济高效的2D成像技术,甚至可以通过智能手机实现)的尝试面临着显著的局限性。早期方法依赖于视网膜增厚的替代标志物,如脂质沉积,但这些标志物缺乏必要的深度分辨率,导致DME检测的特异性和敏感性有限。例如,先前试图从C-FP预测视网膜增厚的研究模型,尤其是在图像质量较低的情况下,往往未能达到临床标准。近期的一些努力试图通过使用红外眼底摄影(IR-FP)作为提取厚度信息的中间媒介来弥合这一差距。尽管IR-FP在临床实践中被用作OCT采集的定位器,但它仍需要额外的设备,限制了其广泛应用。此外,IR-FP本身也存在固有的缺点,包括高反射伪影、针对视网膜下结构优化的受限照明波长,以及对硬性渗出物和出血等关键病理标志物可视化不足。
迫使作者撰写本文的根本“痛点”在于,现有方法无法提供全面、准确且可及的视网膜厚度评估解决方案。OCT过于昂贵且复杂,不适合广泛使用;而先前基于C-FP和IR-FP的方法要么不准确,要么缺乏深度信息,要么仍需要专用设备。本文旨在克服这些局限性,提出首个仅从C-FP预测RTMs的方法,从而将传统的眼底成像转化为一种全面且经济高效的DME筛查和监测诊断工具,尤其是在资源有限的环境中。这种新颖的方法有望通过更及时有效的干预来改善患者的治疗效果。
直观的领域术语
以下是论文中的一些专业术语,用日常类比为零基础读者进行解释:
- 糖尿病性黄斑水肿(DME): 想象一下您眼睛“相机传感器”(黄斑)中心的一个微小、关键区域,由于糖尿病而变得肿胀和模糊。这就像相机镜头上形成了一个微小的水坑,导致一切都变得模糊不清。
- 光学相干断层扫描(OCT): 将其视为眼睛的超高级声纳。它不使用声波,而是使用光波来创建视网膜极其详细的横截面图像,显示其内部层和厚度,就像切开蛋糕以查看所有层一样。
- 视网膜厚度图(RTM): 这是OCT扫描的输出,一张彩色的视网膜“热图”。比正常厚度大的区域可能显示为红色或黄色,而较薄的区域显示为蓝色,为医生提供快速的视觉问题点指南,类似于显示温度变化的地图。
- 彩色眼底摄影(C-FP): 这仅仅是眼睛后部的一张标准、平面的2D照片,显示了血管和视神经等表面特征。这就像拍摄一张普通风景照片;您可以看到树木和山脉,但无法感知它们的高度或深度。
- 扩散模型(Diffusion Model): 这是一种人工智能,它通过从纯粹的随机噪声开始,然后逐步“去噪”直到形成清晰、期望的图像来学习创建复杂图像。这类似于雕塑家从一块无形的石头开始,然后缓慢、迭代地进行雕刻,直到出现精美的雕像。
符号表
| 符号 | 描述
问题定义与约束
核心问题表述与困境
本文的核心问题是如何仅从彩色眼底摄影(C-FP)中准确预测视网膜厚度图(RTMs)。
输入/当前状态:
目前,管理糖尿病性黄斑水肿(DME)和评估视网膜厚度的黄金标准是光学相干断层扫描(OCT)。OCT提供详细的RTMs,这些是视网膜结构和病变的定量可视化。相比之下,彩色眼底摄影(C-FP)是一种广泛可用、经济高效且易于获取的2D成像技术,甚至可以通过智能手机实现。然而,C-FP传统上缺乏定量评估视网膜厚度所需的深度信息。
期望终点/目标状态:
本文旨在开发一个系统,能够直接从C-FP生成精确且全面的RTMs。最终目标是使这些源自C-FP的RTMs能够作为DME的有效、可及且经济高效的诊断和监测工具,尤其是在资源有限的环境中。这将有助于及时干预、知情的治疗决策以及改善患者的视觉预后,从而有效地将传统的眼底成像转化为强大的诊断资产。
缺失环节或数学鸿沟:
根本的缺失环节是2D C-FP图像固有的深度分辨率不足。RTMs代表3D厚度信息,而C-FP仅捕获2D投影。先前试图通过从C-FP预测厚度来弥合这一差距的方法,通常依赖于特异性和敏感性有限的替代标志物(如脂质沉积),或者模型根本无法达到必要的临床精度,尤其是在图像质量变化的情况下。数学挑战在于,从一个深度信息隐式编码在细微视觉线索而非显式测量中的2D图像中,推断出连续的、定量的3D厚度分布。
痛苦的权衡或困境:
核心困境在于可及性/成本效益与定量精度/细节之间的权衡。OCT提供高保真度的RTMs,但价格昂贵、操作复杂且可及性有限,导致在许多实际场景中患者随访不理想。C-FP高度可及且价格低廉,但其2D特性历来阻碍了其提供详细DME管理所需的精确定量厚度测量。研究人员一直被困在尝试从C-FP提取足够的定量信息,同时又不损失其固有的可及性和低成本优势,或者不引入新的局限性(例如依赖于中间的、可及性较低的模式如IR-FP)。本文通过尝试仅从C-FP实现OCT级别的RTM预测,直接应对了这一困境。
约束与失效模式
由于存在以下严苛的现实约束,这个问题极其困难:
- C-FP固有的2D性质: 如前所述,C-FP不提供直接的深度信息。从2D图像推断3D视网膜厚度是一个病态逆问题,需要模型学习表面特征与底层厚度之间复杂、不明显的关联。
- 细微的病理生物标志物: DME引起的视网膜层紊乱在C-FP中表现为“细微的纹理和颜色变化”。这些细微线索即使对经验丰富的临床医生来说也很难识别,更不用说自动化系统了。模型必须能够检测到这些微小的变化,才能准确预测厚度。
- 空间错位和配准挑战: 实现C-FP(输入)与RTM地面真实值(来自OCT,通常由IR-FP定位)之间的精确像素级空间对应是一个重大障碍。不同的成像模态具有不同的视场、分辨率和潜在的失真,使得准确的多模态配准成为一个复杂的预处理步骤。本文提到了使用IR-FP作为配准的中间媒介,突显了这一难度。
- DME表现的异质性: DME表现出各种各样的病理病灶和不规则的视网膜解剖结构。一个鲁棒的模型必须能够泛化到这些多样的表现,这需要同时捕捉全局上下文特征(如血管网络)和细粒度的局部细节(黄斑区域变化)。
- 高保真度生成所需的计算需求: 使用扩散模型等先进的生成模型生成高分辨率、准确的RTMs可能计算量巨大,尤其是在推理(采样)阶段。需要“在保持高保真的同时加快采样速度”(如DDIM所解决的)这一需求,凸显了这一计算约束。
- 严格的临床精度要求: 先前的C-FP预测模型“未能达到临床标准”。这为新解决方案所需的精度、特异性和敏感性设定了高标准,才能在临床上可行。模型预测必须足够可靠,才能为关键的医疗决策提供依据。
- 数据可用性和标注质量: 训练这样的模型需要大量精确配对的C-FP、IR-FP和OCT图像,以及用于RTMs和DME诊断的专家标注。获取和整理如此高质量的多模态数据集是一个耗时且资源密集的过程。
- 周边上下文丢失与黄斑细节的权衡: 尽管黄斑区域对于厚度评估至关重要,但重要的全局视网膜结构和病理生物标志物(如视盘、血管网络)存在于更广阔的眼底图像中。仅关注黄斑可能导致丢失关键的“周边上下文”,因此需要一种双流方法来整合全局和局部特征。
为什么选择这种方法
选择的必然性
作者发现,传统的“SOTA”(State-of-the-Art)方法,包括标准的CNN、基础扩散模型或Transformer,对于仅从彩色眼底摄影(C-FP)预测视网膜厚度图(RTMs)这一特定、细微的问题,根本无法胜任。核心认识源于一个关键的临床需求:尽管光学相干断层扫描(OCT)是诊断和管理糖尿病性黄斑水肿(DME)的黄金标准,但其高昂的成本和在资源匮乏环境中的可及性有限,使其不适合广泛筛查和频繁监测。这产生了对更易于获取的替代方案的迫切需求。
彩色眼底摄影(C-FP)作为最可行、最具成本效益的筛查工具脱颖而出,它广泛可用,甚至可以通过智能手机实现。然而,C-FP提出了一个根本性的挑战:它是一种2D成像技术,本质上缺乏定量视网膜层评估所需的深度分辨率。先前从C-FP预测视网膜厚度的尝试依赖于脂质沉积等替代标志物,其特异性和敏感性有限。即使是像Arcadu等人[3]那样更先进的深度学习模型,在预测精度方面,尤其是在图像质量较差的情况下,也未能达到临床标准。
作者还考虑了红外眼底摄影(IR-FP)作为中间媒介,一些SOTA方法如DeepRT [15]和M²FRT [26]也使用了它。然而,IR-FP仍然需要额外的设备,限制了其临床应用。此外,IR-FP本身也存在固有的局限性,如高反射伪影和对关键病理标志物(如出血)可视化不足。相比之下,C-FP提供了卓越的空间分辨率、更宽的光谱范围和更广的视场。它捕获了关键的全局视网膜结构,如血管网络和视盘,这些都是关键的病理生物标志物。需要新方法的明确时刻很可能发生在认识到现有方法要么无法足够准确地处理2D到3D的推理,要么它们依赖于不符合可及性和成本效益要求的成像模式时。C-FP中指示DME引起的视网膜层紊乱的细微纹理和颜色变化,要求模型能够同时提取强大的高级语义特征和精确的局部黄斑细节,而标准SOTA方法在同时实现这一目标并保持足够保真度方面存在困难。
比较优势
用于视网膜厚度预测的全局到局部条件扩散模型(GLD-RT)在定性优势上远远超越了单纯的性能指标。其结构优势在于其独特的双流、混合CNN-Transformer条件扩散架构,该架构专门设计用于解决C-FP数据在RTM生成方面的固有复杂性。
首先,GLD-RT整合全局上下文特征和细粒度局部细节的能力是一个显著的结构优势。全局全眼底编码器($E_g$),利用预训练的RETFound模型,从整个C-FP图像中捕获强大的解剖学和病理学模式。同时,局部黄斑编码器($E_m$),基于Swin-Transformer构建,提取黄斑区域的精细、细粒度特征。这种双流方法确保了模型在关注黄斑中细微但临床重要的局部变化的同时,不会忽略更广泛的上下文,而这些变化通常是DME的指示。这至关重要,因为DME同时影响大范围的血管特征和微小的视网膜层完整性。
其次,使用条件扩散解码器对于这项生成任务在定性上具有优势。与传统的判别模型甚至更简单的生成对抗网络(GANs)不同,扩散模型通过逐步去噪输入来生成高保真度、多样化且解剖学上一致的输出,在这方面表现出色。这对于RTM预测尤其有利,因为输出是一个复杂的、连续的厚度图,必须准确反映生理和病理形态。由丰富的全局和局部特征引导的扩散过程,能够更细致、更准确地描绘视网膜解剖结构,尤其是在具有挑战性的中央黄斑(G1区域),这在图2的定性结果和消融研究中得到了证明。采用Denoising Diffusion Implicit Model(DDIM)也允许显著减少采样步数,在不牺牲保真度的情况下提高了实际效率。
这种结构设计使得GLD-RT比先前的方法更能更好地处理C-FP图像中固有的高维噪声和变异性。它不仅仅是预测一个图,而是生成一个合理的、详细的RTM,该RTM与底层复杂的视网膜结构一致,这是简单模型常常在保持解剖学一致性和精细细节方面失败的任务。
与约束的对齐
所选的GLD-RT方法完美地符合问题的严苛要求,形成了“临床需求与创新解决方案设计”的“联姻”。
-
约束:OCT可及性有限且成本高昂。
- 对齐: GLD-RT是第一个仅从C-FP预测RTMs的模型。C-FP广泛可用、成本效益高,甚至可以通过智能手机捕获。这直接满足了对可及且负担得起的诊断工具的需求,将传统的眼底成像转化为资源有限环境中的全面筛查和监测解决方案。
-
约束:C-FP的2D性质缺乏用于定量评估的深度分辨率。
- 对齐: 条件扩散模型本质上是一种生成模型,能够从条件输入合成复杂的高维输出。通过学习从2D C-FP特征到3D视网膜厚度分布的复杂映射,GLD-RT有效地推断了输入图像中不存在的深度信息。这种生成能力是克服2D局限性的关键。
-
约束:需要准确、详细且具有临床意义的RTMs。
- 对齐: 双流架构(全局到局部编码器)确保了全局解剖上下文和细粒度的黄斑细节都被捕获。全局编码器(RETFound)提供强大的高级语义特征,而局部编码器(Swin-Transformer)提取精确的局部细节。这些特征随后被融合并馈送到一个分层扩散解码器,该解码器确保了“全局到局部的解剖学一致性”。这种设计对于准确描绘生理和病理视网膜形态至关重要,这对于临床效用和视网膜结构的详细检查是至关重要的。消融研究证实,扩散过程成功地捕捉了黄斑结构及其精细细节,尤其是在复杂的中央黄斑(G1)区域。
-
约束:资源有限环境的实用性(效率)。
- 对齐: 尽管扩散模型可能计算量巨大,但使用DDIM进行采样显著减少了推理所需的步数,使得该过程对于实际临床应用更加高效和实用。总体目标是提供一个“有效的诊断工具,以实现及时干预”。
替代方案的拒绝
本文通过强调其在C-FP预测RTMs方面的局限性,隐式和显式地拒绝了几种替代方法。
首先,依赖替代标志物的传统方法(例如,脂质沉积、激光疤痕)被认为不足。作者指出,这些方法显示出“对DME检测的特异性和敏感性有限”[28, 29]。这明确拒绝了非机器学习或更简单的基于规则的方法,这些方法无法捕捉DME的复杂、细微的表现。
其次,早期用于C-FP RTM预测的深度学习模型被发现不足。本文提到,Arcadu等人[3]的模型“未能达到临床标准”的预测精度,尤其是在图像质量较差的情况下。这表明更简单的基于CNN的架构或不太复杂的生成模型(当时很常见)无法从C-FP中提取必要的信息来产生临床上可接受的RTMs。它们可能难以处理2D到3D的推理以及指示DME的C-FP中的细微变化。
第三,依赖红外眼底摄影(IR-FP)的方法,如DeepRT [15]和M²FRT [26],由于实际和固有的成像限制而被拒绝作为唯一可行的解决方案。尽管这些方法有所改进,但它们仍然需要“额外的设备来捕获IR-FP”,这限制了它们在资源有限环境中的临床应用。此外,IR-FP本身也存在“高反射伪影、针对视网膜下结构优化的受限照明波长,以及对关键病理标志物可视化不足”[1]等缺点。这使得C-FP成为一个更理想的输入,尽管它存在挑战。
最后,本文的消融研究为拒绝更简单的解码机制和扩散过程的必要性提供了确凿证据。结果表明,提出的扩散解码器($D_d$)“显著提高了模型性能,尤其是在中央黄斑(G1)区域”,与没有扩散的解码器($D_{nd}$)相比。这表明标准解码方法(可能用于非扩散生成模型或直接回归模型)不足以捕捉这种复杂区域所需的精细结构细节和解剖学一致性。“全局到局部特征条件化优于标准解码方法”的说法进一步证实,更简单、非分层或非条件生成框架在利用C-FP的多尺度信息方面效果较差。尽管没有明确命名GANs,但对高保真度生成、解剖学一致性以及捕捉细微细节的能力的强调,强烈暗示了扩散模型因其在这些方面的优越性能而被选择用于医学图像合成,而不是其他生成范式。
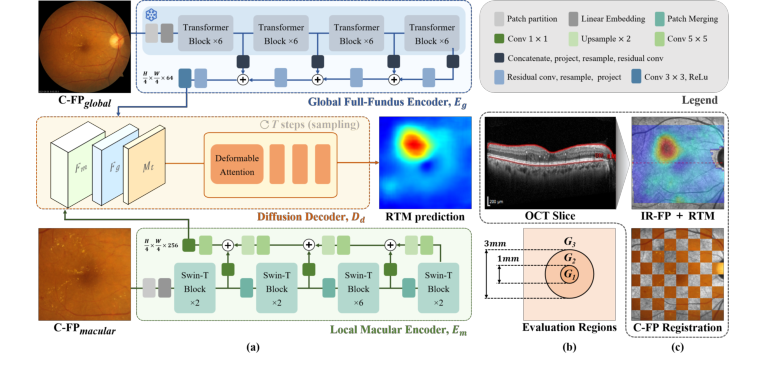 Figure 1. (a) GLD-RT leverages a dual-stream diffusion framework to integrate global contextual features with fine-grained details. (b) Evaluation regions for RTM predic- tion. (c)IR-FP, the localizer in OCT imaging that generates RTM, is used to register C-FPglobal with RTM, generating C-FPmacular
Figure 1. (a) GLD-RT leverages a dual-stream diffusion framework to integrate global contextual features with fine-grained details. (b) Evaluation regions for RTM predic- tion. (c)IR-FP, the localizer in OCT imaging that generates RTM, is used to register C-FPglobal with RTM, generating C-FPmacular
数学与逻辑机制
核心方程
GLD-RT框架学习机制的绝对核心是其优化目标,即均方误差(MSE)损失函数。该方程通过最小化其预测与地面真实值之间的差异,指导模型学习仅从彩色眼底摄影(C-FP)准确预测视网膜厚度图(RTMs)。
核心方程表示为:
$$ \mathcal{L} = \mathbb{E}_{M,t,F_m,F_g} [||M – D_d(M_t, t, F_m, F_g) ||^2] $$
各项剖析
让我们剖析这个方程,以理解每个组件的作用:
-
$\mathcal{L}$:
- 数学定义: 该符号代表整体损失函数,特别是均方误差(MSE)损失。
- 物理/逻辑作用: 它量化了模型预测的RTM与实际地面真实RTM之间的差异。模型训练的主要目标是最小化此值,从而驱动模型做出更准确的预测。
- 为何使用: MSE是回归任务的标准且有效的损失函数。其平方运算对较大误差的惩罚比对较小误差更重,鼓励模型减少显著偏差。
-
$\mathbb{E}_{M,t,F_m,F_g}$:
- 数学定义: 这表示期望算子,意味着对随机变量$M$、$t$、$F_m$和$F_g$取平均值。
- 物理/逻辑作用: 在实践中,训练期间,此期望值通过对训练样本批次取平均值来近似。每个样本包含一个地面真实RTM($M$)、一个特定的噪声时间步长($t$)、局部黄斑特征($F_m$)和全局全眼底特征($F_g$)。这种平均确保模型能够很好地泛化到各种输入和噪声条件。
- 为何使用: 对样本批次损失取平均值,比计算单个样本的损失(可能存在噪声)提供更稳定、更具代表性的梯度来更新模型参数。
-
$M$:
- 数学定义: 这代表地面真实视网膜厚度图(RTM)。它是一个实值2D矩阵,通常尺寸为$H \times W$,其中$H$和$W$是图的高度和宽度。
- 物理/逻辑作用: 这是GLD-RT模型旨在预测的“正确答案”或目标输出。它作为模型预测进行比较的基准。
- 为何使用: 它是计算误差和评估模型性能的必要基准。
-
$D_d(\cdot)$:
- 数学定义: 这代表扩散解码器,它是一个复杂的神经网络。它接收一个带噪声的RTM、一个时间步长和条件特征作为输入,其目标是预测原始的、无噪声的RTM。
- 物理/逻辑作用: 这是模型中的生成引擎。在训练期间,它学习在C-FP特征的引导下,有效地去除$M_t$中的噪声以重建原始的$M$。在推理期间,它迭代地将纯噪声转化为预测的RTM,同样使用C-FP特征作为指导。
- 为何使用: 选择扩散模型框架是因为它在生成高保真图像和建模复杂数据分布方面具有公认的能力,这对于RTMs的复杂细节至关重要。条件方面允许生成过程由输入的C-FP特征引导。
-
$M_t$:
- 数学定义: 这是地面真实RTM,$M$,在特定扩散时间步长$t$下的带噪声版本。它通过向$M$添加预定的高斯噪声来创建。
- 物理/逻辑作用: 在训练期间,它作为扩散解码器的输入。解码器的任务是学习如何有效地从$M_t$中去除噪声以重建原始的$M$。这个过程模仿了噪声逐渐引入的前向扩散过程的反转。
- 为何使用: 扩散模型通过学习反转预定的噪声添加过程来运行。通过在各种噪声水平下对$M_t$进行训练,模型开发了跨广泛噪声水平进行去噪的能力。
-
$t$:
- 数学定义: 这是扩散时间步长,一个整数值,表示添加到$M$以产生$M_t$的噪声量。它通常从一个小值(最小噪声)到一个大值(最大噪声)不等。
- 物理/逻辑作用: 它向扩散解码器提供了关于$M_t$中当前噪声水平的关键信息。知道$t$允许解码器应用适合该特定噪声强度的去噪操作。
- 为何使用: 时间步长是扩散模型的基础,因为去噪策略高度依赖于噪声的数量。不同的时间步长需要不同的去噪方法。
-
$F_m$:
- 数学定义: 这些是由局部黄斑编码器($E_m$)从C-FP图像的黄斑区域裁剪部分($C\text{-}FP_{macular}$)提取的精细局部黄斑特征。这些特征的尺寸为$R^{\frac{H}{4} \times \frac{W}{4} \times 256}$。
- 物理/逻辑作用: 这些特征提供了关于黄斑区域的高度详细信息,这对于该临床关键区域的精确厚度预测至关重要。它们充当局部条件,用细粒度的解剖上下文指导扩散过程。
- 为何使用: 黄斑区域是糖尿病性黄斑水肿(DME)病变最明显且需要仔细分析的地方。$E_m$编码器利用Swin-Transformer和特征金字塔网络,旨在捕获这些分层和详细的特征。
-
$F_g$:
- 数学定义: 这些是由全局全眼底编码器($E_g$)从整个C-FP图像($C\text{-}FP_{global}$)提取的全局全眼底特征。这些特征的尺寸为$R^{\frac{H}{16} \times \frac{W}{16} \times 64}$。
- 物理/逻辑作用: 这些特征提供了高级语义上下文和整体视网膜结构的信息。它们补偿了在仅关注黄斑区域时可能丢失的周边上下文,充当扩散过程的全局条件。
- 为何使用: 全局上下文有助于确保整个视网膜的解剖学一致性,并提供可能影响黄斑厚度的更广泛病理标志物(如血管网络)。$E_g$编码器利用预训练的RETFound Vision Transformer来实现此目的。
-
$|| \cdot ||^2$:
- 数学定义: 这表示平方L2范数,它计算向量或矩阵中所有元素的平方和。对于矩阵$A$, $||A||^2 = \sum_{i,j} A_{i,j}^2$。
- 物理/逻辑作用: 它计算地面真实RTM与扩散解码器预测的RTM之间的平方差。平方差确保正负误差都同等地计入损失,并且较大误差受到更重的惩罚。
- 为何使用: 平方L2范数是均方误差(MSE)损失的基本组成部分,由于其可微分性和凸性,MSE在回归任务中被广泛采用,从而简化了优化过程。
-
$M - D_d(\dots)$:
- 数学定义: 这表示地面真实RTM与预测RTM之间的逐元素差值。
- 物理/逻辑作用: 这是模型力求最小化的误差或残差。它是期望输出与模型实际输出之间的直接比较。
- 为何使用: 这种直接减法构成了量化模型需要学习减少的误差的基础。
分步流程
让我们追踪一个抽象数据点通过GLD-RT机制的历程,从输入到损失计算:
-
初始数据输入: 过程始于一张彩色眼底摄影(C-FP)图像及其对应的地面真实视网膜厚度图(RTM),$M$,该图来自光学相干断层扫描(OCT)扫描。
-
多模态配准与裁剪: C-FP图像经过精确配准过程,以像素级将其与RTM的空间坐标对齐。这包括使用中间的红外眼底摄影(IR-FP)图像作为参考。关键步骤包括分割视网膜血管,检测关键点(例如,使用AKAZE),计算同态矩阵(例如,使用RANSAC),以及对全眼底C-FP($C\text{-}FP_{global}$)进行非刚性配准以匹配IR-FP。由此生成一个裁剪版本$C\text{-}FP_{macular}$,专门聚焦于对应于RTM的黄斑区域。
-
并行特征提取:
- 全局上下文流: 全局$C\text{-}FP_{global}$图像被馈送到全局全眼底编码器($E_g$)。该编码器利用预训练的RETFound Vision Transformer,处理图像以提取高级语义特征$F_g$。这些特征封装了整体视网膜结构和更广泛的上下文信息。
- 局部细节流: 同时,裁剪的$C\text{-}FP_{macular}$图像进入局部黄斑编码器($E_m$)。该编码器基于Swin-Transformer和特征金字塔网络构建,提取精细、分层的特征$F_m$,提供特定于黄斑区域的详细信息。
-
噪声注入(仅训练阶段): 如果模型处于训练阶段,则会从预定的噪声调度中选择一个随机时间步长$t$。然后,根据此时间步长缩放的高斯噪声被添加到地面真实RTM,$M$中,得到一个带噪声的RTM,$M_t$。
-
扩散解码器的条件去噪: 带噪声的RTM,$M_t$,以及选择的时间步长$t$,和提取的条件特征($F_m$和$F_g$),都被输入到扩散解码器($D_d$)中。解码器的主要任务是学习如何有效地将$M_t$“去噪”回原始的、干净的RTM,$M$。这个去噪过程受到$F_m$(局部细节)和$F_g$(全局上下文)提供的丰富上下文信息的关键指导。
-
RTM预测: 解码器输出其对原始RTM的最佳估计,我们可以将其表示为$D_d(M_t, t, F_m, F_g)$。
-
损失计算: 然后将预测的RTM与原始地面真实RTM,$M$进行直接比较。计算其逐元素差值的平方L2范数,$||M – D_d(M_t, t, F_m, F_g) ||^2$。该值代表此特定数据点的误差。
-
批次平均: 然后将此单个平方误差在当前训练批次的所有样本(每个样本都有其自己的$M$、$t$、$F_m$、$F_g$组合)上取平均值,以得到该迭代的最终损失$\mathcal{L}$。
-
推理(生成阶段): 在推理期间,扩散解码器的过程发生变化。与从地面真实RTM的带噪声版本开始不同,解码器从纯粹的随机噪声开始。然后,在$F_m$和$F_g$特征的指导下,它迭代地应用去噪步骤,这些特征是从新的C-FP输入中提取的。这个迭代过程,通常使用非马尔可夫确定性采样方法如DDIM,在显著更少的步数(例如,5步)中逐渐将初始噪声转化为连贯且详细的RTM预测。
优化动力学
GLD-RT机制通过梯度优化过程,迭代地最小化均方误差(MSE)损失函数$\mathcal{L}$来学习、更新和收敛。
-
损失景观: 模型的学习发生在复杂的损失景观中。这个景观由地面真实RTMs、不同时间步长引入的噪声水平以及从C-FP图像中提取的丰富多尺度条件特征之间的复杂关系所塑造。最终目标是导航这个景观,找到一组模型参数(编码器$E_m$、$E_g$和扩散解码器$D_d$中的权重和偏差),这些参数对应于一个“谷”,其中预测的RTMs持续地与地面真实值紧密对齐。尽管深度神经网络的整体景观本质上是非凸的,但MSE目标提供了清晰、可微分的优化信号。扩散过程的固有结构,涉及学习跨越噪声水平的去噪,作为一种强大的正则化器,可能比简单的直接回归模型产生更平滑、更鲁棒的损失景观。
-
梯度计算: 在每个训练迭代中,在计算出给定数据批次的损失$\mathcal{L}$后,将启动反向传播过程。该算法有效地计算损失相对于编码器($E_m$、$E_g$)和扩散解码器($D_d$)中每个可训练参数的梯度。这些梯度至关重要;它们指示了每个参数需要调整以减少计算损失的确切方向和幅度。
-
参数更新: 文中明确指出,使用Adam优化器[16]来更新模型的参数。Adam是一种先进的自适应学习率优化算法。它通过维护过去梯度的一阶指数加权平均值(一阶矩)和过去平方梯度的一阶指数加权平均值(二阶矩)来动态计算不同参数的个体学习率。
- Adam的特定超参数设置为$\beta_1 = 0.9$和$\beta_2 = 0.999$,这些是广泛接受的默认值。
- 为了有效地管理学习率,在最初的16个epoch的“预热”阶段之后,采用余弦衰减调度策略。在此阶段,学习率从一个非常小的值($1 \times 10^{-8}$)逐渐增加到一个稍大的值($6 \times 10^{-5}$)。在此预热之后,学习率在300个epoch内根据余弦函数缓慢衰减。这种策略允许模型最初谨慎地探索损失景观,然后加速收敛,最后通过减小学习率来微调参数,防止过冲最优最小值。
- 此外,还应用了固定的$1 \times 10^{-2}$的权重衰减。权重衰减,也称为L2正则化,通过惩罚大的参数值来帮助防止过拟合。这鼓励模型学习更通用、更不复杂的特征,从而提高其在未见数据上的性能。
-
迭代精炼与收敛: 这个计算损失、计算梯度和更新参数的循环在许多训练epoch(本研究中为300个epoch)中反复进行。随着训练的进行,模型的参数不断被精炼以最小化$\mathcal{L}$。扩散解码器逐渐学会准确地逆转噪声过程,在给定$F_m$和$F_g$的条件下,从$M_t$预测$M$的能力越来越强。当训练集和验证集上的损失稳定或达到最小值时,模型被认为已收敛。这表明模型已成功学会生成与地面真实值高度匹配的RTMs,证明了其捕捉底层视网膜厚度分布的能力。在推理期间采用Denoising Diffusion Implicit Model(DDIM)进行采样,这是一种非马尔可夫确定性过程,通过显著减少步数(例如,5步)实现更快、更稳定的RTM生成,进一步为该机制在实际应用中的效率做出了贡献。
结果、局限性与结论
实验设计与基线
GLD-RT模型是使用一个全面的数据集开发并经过严格验证的。对于核心的RTM预测任务,研究人员使用了2,918个数据三元组,每个三元组包含来自1,418名接受抗VEGF治疗的糖尿病性黄斑水肿(DME)患者的相应光学相干断层扫描(OCT)、红外眼底摄影(IR-FP)和彩色眼底摄影(C-FP)图像。这些患者来自Kangbuk Samsung医院。该队列表现出平均视网膜厚度为$296.99 \pm 30.67 \text{ µm}$,中央黄斑厚度为$292.46 \pm 75.00 \text{ µm}$,表明黄斑水肿患病率很高。IR-FP和31条OCT B扫描均使用Heidelberg设备采集,该设备自动提供膜分割。经验丰富的眼科医生仔细排除了固定不良或分割错误的扫描,以确保数据质量。
对于关键的DME诊断任务,采用了Mobile Brazilian Retinal Dataset(mBRSET)。该数据集包含来自巴西伊塔布纳巴伊亚州1,291名糖尿病患者的5,164张C-FP图像,所有图像都经过细致的DME诊断和图像质量标签标注。
数据预处理涉及多个步骤,以确保一致性和对齐。IR-FP图像被裁剪为$544 \times 544$像素,与OCT扫描区域匹配。C-FPglobal图像从$3608 \times 3608$降采样至$544 \times 544$,以匹配IR-FP分辨率。视网膜厚度图(RTMs)从31条B扫描线计算得出,并进行线性插值以匹配IR-FP分辨率。为了在减少伪影的同时保持结构完整性,RTMs经过了高斯滤波($\sigma = 3$)和非局部均值去噪的顺序平滑处理。对于DME诊断,C-FP图像根据黄斑位置裁剪为$800 \times 800$,然后降采样至$544 \times 544$。
数据集在患者级别进行分割,以进行稳健的评估:GLD-RT开发使用2043个训练、292个验证和583个测试三元组。mBRSET也类似地分割为2409个训练、345个验证和688个测试图像用于DME诊断。GLD-RT模型使用Adam优化器[16]进行优化,其标准参数为$(\beta_1, \beta_2) = (0.9, 0.999)$,在16个epoch的预热后采用余弦衰减学习率调度,以及固定的$1 \times 10^{-2}$权重衰减。扩散过程在训练中使用20个时间步长,在推理中使用5个时间步长。所有实验均在NVIDIA GeForce RTX 3090 GPU上进行,并结合了随机翻转和旋转的数据增强。
为了无情地证明其数学主张,作者将GLD-RT与几种已建立的和最先进的(SOTA)模型进行了比较。对于RTM预测,“受害者”包括通用的医学图像密集预测模型,如UNet [23]、Trans-UNet [5]和Swin-Unetr [12],以及专门的RTM预测框架,如DeepRT [15]和M²FRT [26]。这些基线模型使用了不同的输入配置(仅IR-FP、仅C-FP或两者兼有)进行评估,以提供全面的比较。对于DME诊断,GLD-RT辅助方法与仅使用C-FP的ResNet50 [13]分类器基线进行了比较。
证据证明的内容
实验证据明确证明,提出的用于视网膜厚度预测的全局到局部条件扩散模型(GLD-RT)在从彩色眼底摄影(C-FP)预测RTMs方面显著优于现有方法,并为DME诊断提供了实质性优势。
在RTM预测方面,GLD-RT在所有视网膜区域(G1、G2、G3,对应于ETDRS网格)上均取得了优越的性能,使用微米($\mu$m)的平均绝对误差(MAE)和分贝(dB)的峰值信噪比(PSNR)进行评估。具体而言,GLD-RT仅使用C-FP作为输入,记录了20.08 $\mu$m的总体MAE和30.91 dB的PSNR。这比先前SOTA方法M²FRT [26]有了显著改进,后者使用C-FP输入时,总体MAE为23.21 $\mu$m,PSNR为29.34 dB。这些增益的统计显著性通过p值小于0.01得到证实,表明GLD-RT的性能并非偶然。
GLD-RT核心机制在现实中奏效的最令人信服的证据在于其在黄斑区域(G1)的表现。该区域因其复杂的层状结构和对中心视力的直接影响而具有临床关键性。在此,GLD-RT实现了31.97 $\mu$m的MAE和30.18 dB的PSNR,与M²FRT在C-FP输入下的36.25 $\mu$m MAE和28.31 dB PSNR相比,有了显著改进。这表明GLD-RT的双流架构,通过分层扩散解码器整合全局上下文和细粒度局部特征,有效地捕捉了该挑战区域精确厚度量化所需的细微且不规则的视网膜解剖结构。
图2所示的定性结果进一步强调了这些收益。GLD-RT能够稳健地检测与各种病理病灶相关的厚度变化,如玻璃体黄斑前膜、黄斑水肿和视网膜分支静脉阻塞,与M²FRT相比,提供了更准确的视网膜解剖结构表示。差异图(预测减去地面真实值)一致显示GLD-RT的误差较小,直观地证实了其卓越的保真度。
消融研究为每个架构组件的贡献提供了确凿证据。骨干网络(Em, Dnd,即带有无扩散解码器的局部黄斑编码器)已经优于M²FRT,验证了增强局部特征提取的有效性。扩散解码器(Dd)的加入显著提高了性能,尤其是在G1区域,证明了扩散过程捕捉黄斑精细细节的能力。此外,整合全局全眼底编码器(Eg)并进行RETFound预训练进一步提升了性能,突显了领域特定预训练和全局解剖学一致性的关键作用。完整的GLD-RT模型,结合了Eg (RETFound), Em, Dd,始终产生了最佳结果。
除了RTM预测,GLD-RT生成的RTMs在DME诊断方面也证明了其价值。当与C-FP连接作为ResNet50分类器的双输入时,这种方法始终优于仅使用C-FP的基线。双输入模型实现了93.44%的准确率(对比92.21%)、79.49%的召回率(对比64.41%)、85.90%的F1分数(对比75.84%)和0.919的AUC(对比0.855)。这些无可辩驳的证据表明,C-FP生成的RTMs提供了互补的诊断见解,这与通常需要OCT和C-FP检查的临床方案一致。这使得GLD-RT成为一种有前景的、经济高效的诊断工具,尤其适用于资源有限的环境。
局限性与未来方向
尽管GLD-RT在从C-FP预测视网膜厚度并辅助DME诊断方面取得了重大进展,但认识到其当前局限性并考虑未来发展方向至关重要。
一个固有的局限性,尽管是模型目的的一部分,是C-FP作为一种2D成像技术,从根本上缺乏OCT的深度分辨率。虽然GLD-RT有效地推断了厚度,但地面真实RTMs是从高分辨率OCT扫描中获得的。本文本身就指出“整合更高分辨率的OCT以进行详细的RTM预测”作为未来方向,这表明即使GLD-RT取得了进步,仅从C-FP获得的细节也可能受到限制,除非进一步的技术整合或更高保真度的地面真实值。当前模型虽然鲁棒,但仍然是基于2D输入的预测,其捕捉复杂3D视网膜结构的所有细微细节的能力可能受到限制。
另一个需要考虑的方面是研究结果的泛化能力。该模型是在特定医院和地区(Kangbuk Samsung Hospital和mBRSET)的数据集上训练的。尽管这些是大量数据集,但现实世界的临床实践涉及各种患者人口、疾病严重程度以及来自不同制造商的成像设备。GLD-RT在外部、未见过的不同人群或具有不同图像采集协议的数据集上的性能,需要进一步的前瞻性临床验证。本文将“前瞻性临床验证”作为未来方向,这隐含地承认了对更广泛测试的需求。
此外,尽管模型提供了RTMs,但解释这些AI生成的图谱与传统C-FP图像相结合的临床工作流程仍需建立。临床医生习惯于OCT衍生的RTMs,向C-FP生成的RTMs的过渡将需要明确的指南和培训,以确保准确的解释并整合到治疗决策中。本文提出的“整合到现有医疗保健工作流程中”强调了这一实际挑战。
展望未来,这项工作带来了几个令人兴奋的讨论话题:
- 增强的临床整合与决策支持: 如何将GLD-RT整合到现有的电子健康记录系统中,以便在常规C-FP筛查期间提供实时的RTM预测?能否将模型扩展到不仅预测厚度,还能自动突出显示关注区域或建议后续行动,从而成为全科医生甚至家庭监测患者的更全面的决策支持工具?部署此类自主诊断辅助工具的监管途径和伦理考量是什么?
- 多疾病预测与生物标志物发现: 鉴于GLD-RT在利用C-FP进行DME方面的成功,能否将其框架改编或扩展以预测其他目前依赖于更昂贵或侵入性成像的视网膜疾病或生物标志物?例如,它能否从C-FP预测青光眼(如视网膜神经纤维层变薄)或年龄相关性黄斑变性(如玻璃体黄斑前膜体积)的早期迹象?这可以将C-FP转变为一个真正多功能的筛查工具。
- 对图像质量和伪影的鲁棒性: 由于患者配合度、介质混浊或相机设置不佳,现实世界的C-FP图像经常受到不同质量的影响。尽管当前研究过滤掉了低质量扫描,但未来的工作可以专注于使GLD-RT对这些缺陷更加鲁棒,或许通过整合图像质量评估模块或使用更广泛的退化图像进行训练。模型如何在接收到不理想的输入时仍保持其高精度?
- 计算效率与边缘部署: 当前模型在NVIDIA GeForce RTX 3090上运行。为了在资源有限的环境或便携式设备中广泛采用,优化模型以降低计算足迹和加快推理速度至关重要。是否可以应用知识蒸馏或模型量化技术来创建适合边缘计算的更轻量级版本,从而可能在智能手机连接的眼底相机上实现实时RTM生成?
- 纵向监测与治疗反应: GLD-RT能否用于DME患者的纵向监测,跟踪视网膜厚度的随时间变化以评估治疗反应或疾病进展?这将需要验证模型在长时间内的稳定性和对细微变化的敏感性。模型的预测如何指导个性化治疗策略,优化抗VEGF注射计划或其他干预措施?
- 可解释性与信任: 随着人工智能模型越来越多地融入临床实践,理解模型为何做出特定预测对于建立临床医生之间的信任至关重要。未来的研究可以探索增强GLD-RT RTM预测可解释性的方法,例如通过可视化模型在C-FP图像中关注的特征,从而为临床医生提供对其输出的更大洞察力和信心。
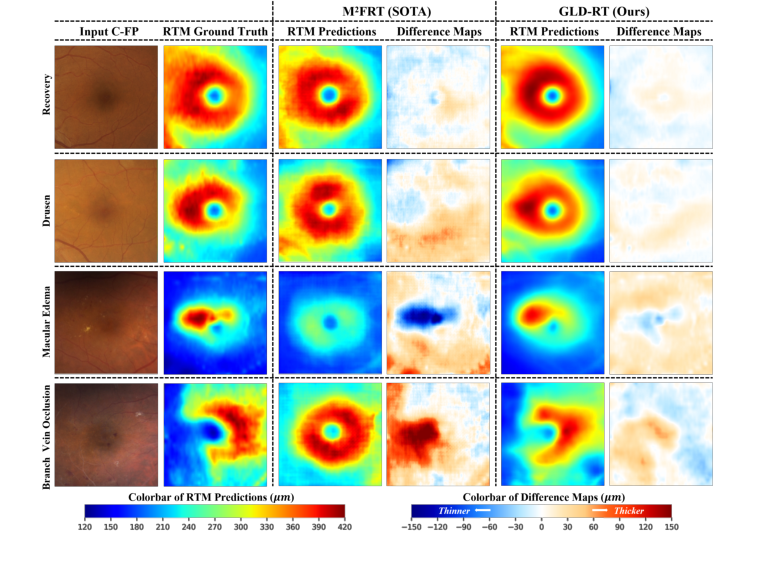 Figure 2. Qualitative results of our model and M2FRT. GLD-RT robustly detects diverse pathological lesions and accurately depicts subtle and irregular retinal anatomy. Dif- ference maps (prediction minus ground truth) further underscore these gains
Figure 2. Qualitative results of our model and M2FRT. GLD-RT robustly detects diverse pathological lesions and accurately depicts subtle and irregular retinal anatomy. Dif- ference maps (prediction minus ground truth) further underscore these gains
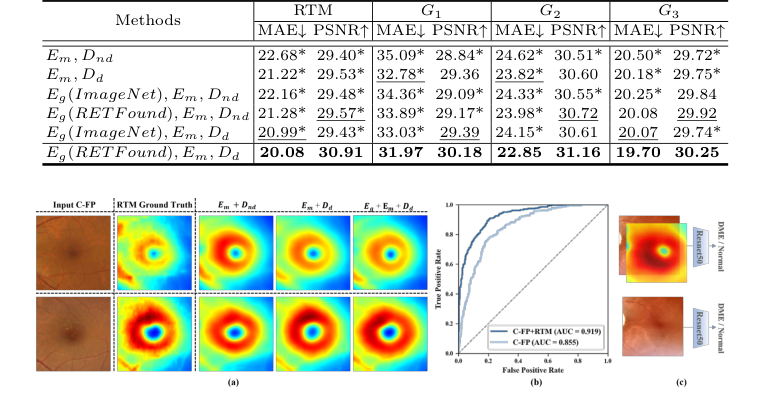 Figure 3. (a) Qualitative results of ablation study on GLD-RT. The proposed Dd sig- nificantly enhanced fine macular structural details, while Eg further enforced global anatomical consistency. (b) Receiver operating characteristic curve of DME diagnosis. (c)Experiment design of DME diagnosis
Figure 3. (a) Qualitative results of ablation study on GLD-RT. The proposed Dd sig- nificantly enhanced fine macular structural details, while Eg further enforced global anatomical consistency. (b) Receiver operating characteristic curve of DME diagnosis. (c)Experiment design of DME diagnosis
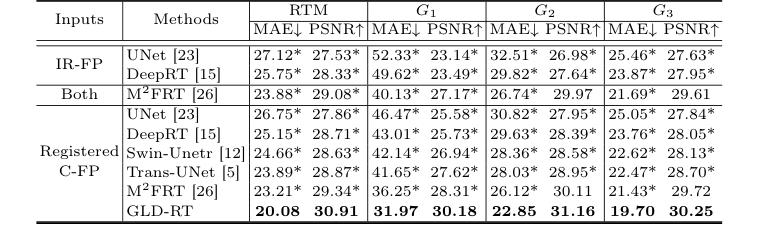 Table 1. Quantitative comparison of different methods for RTM prediction, with MAE (µm) and PSNR (dB). * indicates GLD-RT outperforms baselines with p-values<0.01
Table 1. Quantitative comparison of different methods for RTM prediction, with MAE (µm) and PSNR (dB). * indicates GLD-RT outperforms baselines with p-values<0.01
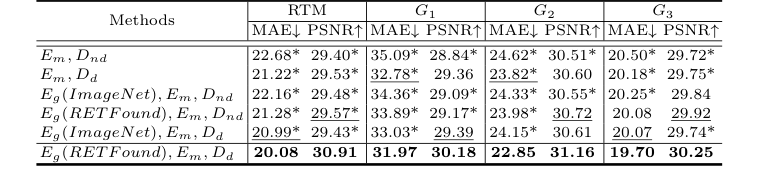 Table 2. Ablation study of RTM prediction, with MAE (µm) and PSNR (dB). * indicates GLD-RT outperforms baselines with p-values<0.01
Table 2. Ablation study of RTM prediction, with MAE (µm) and PSNR (dB). * indicates GLD-RT outperforms baselines with p-values<0.01
与其他领域的同构性
结构骨架
本文的核心数学与逻辑机制是一个生成模型,它通过条件扩散过程,将2D输入图像的多尺度特征映射到一个定量的2D输出图。