बहु-दृश्य सह-प्रशिक्षण द्वारा एकल-छवि परीक्षण-समय अनुकूलन
चिकित्सा इमेजिंग AI लंबे समय से एक निराशाजनक वास्तविकता से जूझ रहा है: हॉस्पिटल A में ट्यूमर का पता लगाने के लिए प्रशिक्षित एक डीप लर्निंग मॉडल अक्सर हॉस्पिटल B में तैनात होने पर विफल हो जाता है। ऐसा इसलिए होता है...
पृष्ठभूमि और शैक्षणिक वंश
चिकित्सा इमेजिंग AI लंबे समय से एक निराशाजनक वास्तविकता से जूझ रहा है: हॉस्पिटल A में ट्यूमर का पता लगाने के लिए प्रशिक्षित एक डीप लर्निंग मॉडल अक्सर हॉस्पिटल B में तैनात होने पर विफल हो जाता है। ऐसा इसलिए होता है क्योंकि विभिन्न अस्पताल विभिन्न एमआरआई स्कैनर (जैसे, GE बनाम सीमेंस), भिन्न चुंबकीय क्षेत्र की ताकत और विशिष्ट सॉफ्टवेयर प्रोटोकॉल का उपयोग करते हैं। कंप्यूटर विजन और मेडिकल इमेज एनालिसिस के अकादमिक क्षेत्र में, इस विसंगति को "डोमेन शिफ्ट" के रूप में जाना जाता है।
ऐतिहासिक रूप से, शोधकर्ताओं ने नए अस्पताल से बड़े डेटासेट एकत्र करके मॉडल को फिर से प्रशिक्षित या फाइन-ट्यून करके इसे हल करने का प्रयास किया। हालांकि, वास्तविक दुनिया के नैदानिक वातावरण में, डॉक्टरों को एक ऐसे एकल रोगी के लिए तत्काल, ऑन-द-फ्लाई विश्लेषण की आवश्यकता होती है जो अभी-अभी क्लिनिक में आया है। आप किसी रोगी को यह नहीं कह सकते कि वह सॉफ्टवेयर को अपडेट करने के लिए अस्पताल द्वारा एक हजार और स्कैन एकत्र किए जाने तक हफ्तों तक प्रतीक्षा करे। इस तत्काल आवश्यकता ने टेस्ट-टाइम एडैप्टेशन (TTA) के उप-क्षेत्र को जन्म दिया, जहां एक मॉडल अनुमान के सटीक क्षण में नए डेटा के अनुकूल होने का प्रयास करता है।
TTA के वादे के बावजूद, पिछले दृष्टिकोण गंभीर मौलिक सीमाओं से ग्रस्त थे। पहला, अधिकांश मौजूदा TTA विधियों को सांख्यिकीय समायोजन (विशेष रूप से, बैच नॉर्मलाइजेशन आँकड़े) की गणना के लिए आने वाली छवियों के एक बड़े "बैच" की आवश्यकता होती है। यदि किसी अस्पताल को केवल एक रोगी को स्कैन करने की आवश्यकता है, तो ये बैच-निर्भर विधियाँ पूरी तरह से विफल हो जाती हैं। दूसरा, पिछले मॉडल को अक्सर भारी आर्किटेक्चरल संशोधनों की आवश्यकता होती थी या वे कठोर आकार के पूर्व-निर्धारितों पर निर्भर करते थे जो वास्तविक ट्यूमर की उच्च शारीरिक परिवर्तनशीलता के खिलाफ टिके नहीं रहते थे। अंत में, अधिकांश वर्तमान विधियाँ मेडिकल स्कैन को फ्लैट 2D स्लाइस के रूप में संसाधित करती हैं, डेटा के समृद्ध 3D वॉल्यूमेट्रिक संदर्भ को पूरी तरह से अनदेखा करती हैं। उच्च-रिज़ॉल्यूशन 3D मेडिकल वॉल्यूम को संसाधित करने के लिए भारी GPU मेमोरी की आवश्यकता होती है, जिससे बड़े-बैच प्रसंस्करण न केवल एकल रोगियों के लिए गणितीय रूप से त्रुटिपूर्ण हो जाता है, बल्कि कम्प्यूटेशनल रूप से बहुत महंगा भी हो जाता है - यह एक क्लिनिक को एक विशाल सर्वर फार्म खरीदने के लिए मजबूर करने जैसा है जब उन्होंने केवल एक मानक USD 150 हार्डवेयर अपग्रेड के लिए बजट बनाया था। लेखकों को यह पेपर लिखने के लिए मजबूर होना पड़ा क्योंकि कोई भी मौजूदा विधि बिना विनाशकारी मेमोरी लागत या प्रदर्शन में गिरावट के, वास्तविक समय में केवल एक एकल 3D छवि का उपयोग करके एक मॉडल को अनुकूलित नहीं कर सकती थी।
यह समझने में आपकी सहायता के लिए कि लेखकों ने इसे कैसे हल किया, आइए कुछ अत्यधिक विशिष्ट डोमेन शब्दों को सहज अवधारणाओं में तोड़ें:
- डोमेन शिफ्ट (Domain Shift): जब AI द्वारा देखी जाने वाली वास्तविक दुनिया का डेटा उस डेटा से भिन्न होता है जिस पर उसे प्रशिक्षित किया गया था, तो AI के प्रदर्शन में गिरावट।
- सादृश्य: एक शांत, धूप वाले और अनुमानित उपनगर (प्रशिक्षण डेटा) में ड्राइविंग सीखने की कल्पना करें। यदि आपको अचानक भीड़-भाड़ वाले समय के दौरान एक अराजक, बर्फीले शहर के केंद्र में डाल दिया जाता है (परीक्षण डेटा), तो आपके ड्राइविंग कौशल में भारी गिरावट आएगी। उस दृश्य में परिवर्तन एक डोमेन शिफ्ट है।
- टेस्ट-टाइम एडैप्टेशन (Test-Time Adaptation - TTA): एक AI मॉडल की क्षमता जो पुनः प्रशिक्षण के लिए ऑफ़लाइन होने की आवश्यकता के बजाय, सक्रिय रूप से उपयोग किए जाने पर ऑन-द-फ्लाई खुद को अपडेट और बेहतर बनाने में सक्षम है।
- सादृश्य: एक लाइव स्टेज संगीतकार के बारे में सोचें जो महसूस करता है कि कॉन्सर्ट हॉल की ध्वनिकी थोड़ी ऑफ है। शो को रोकने और रिहर्सल स्टूडियो में वापस जाने के बजाय, वे नोट्स के बीच मंच पर ही अपने वाद्य यंत्र को सूक्ष्मता से ट्यून करते हैं।
- स्यूडोलेबलिंग (Pseudolabeling): एक ऐसी तकनीक जहाँ AI बिना एनोटेट किए गए डेटा पर अपना सर्वश्रेष्ठ अनुमान लगाता है और फिर उस अनुमान को स्वयं को और प्रशिक्षित करने के लिए "पूर्ण सत्य" के रूप में मानता है।
- सादृश्य: एक छात्र की कल्पना करें जो उत्तर कुंजी के बिना एक अभ्यास परीक्षा दे रहा है। वे उन प्रश्नों के उत्तर देते हैं जिनके बारे में वे बहुत आश्वस्त हैं, मानते हैं कि वे उत्तर सही हैं, और कठिन प्रश्नों के पैटर्न का पता लगाने के लिए उनका उपयोग करते हैं।
- मल्टी-व्यू को-ट्रेनिंग (Multi-View Co-Training): एक AI को प्रशिक्षित करना ताकि यह सुनिश्चित हो सके कि 3D डेटा को देखने वाले कोण या परिप्रेक्ष्य (जैसे, ऊपर, सामने, या किनारे से देखना) से कोई फर्क नहीं पड़ता, उसकी भविष्यवाणियां सुसंगत बनी रहें।
- सादृश्य: यदि आप एक अंधेरे कमरे में एक रहस्यमय वस्तु का निरीक्षण कर रहे हैं, तो आप उसे केवल सामने से नहीं देखेंगे। आप उसके चारों ओर घूमेंगे और ऊपर और किनारों से देखेंगे। यदि आपका मस्तिष्क सामने से इसे कुर्सी के रूप में, लेकिन किनारे से मेज के रूप में निष्कर्ष निकालता है, तो कुछ गलत है। मल्टी-व्यू को-ट्रेनिंग AI के निष्कर्षों को सभी कोणों से संरेखित करने के लिए मजबूर करती है।
लेखकों ने गणितीय रूप से ठीक उसी समस्या को हल किया है जिसे उन्होंने हल किया है और उन्होंने अपने एकल-छवि अनुकूलन को कैसे संरचित किया है, इसे समझने के लिए, हमें उन मुख्य चर और मापदंडों को परिभाषित करना होगा जिनका उन्होंने उपयोग किया था। नीचे संकेतन तालिका दी गई है जो उनके मल्टी-व्यू स्थिरता ढांचे की नींव का प्रतिनिधित्व करेगी।
| संकेतन | विवरण |
|---|---|
| $M(\theta_s)$ | पूर्व-प्रशिक्षित तंत्रिका नेटवर्क मॉडल, स्रोत डोमेन से सीखे गए भार $\theta_s$ द्वारा पैरामीट्रिज्ड। |
| $X_s, Y_s$ | स्रोत डोमेन 3D छवि टेंसर और उसका संबंधित सघन रूप से लेबल किया गया वोक्सेल-वार ग्राउंड ट्रुथ मास्क। |
| $X_t, Y_t$ | लक्ष्य डोमेन 3D छवि टेंसर और उसका ग्राउंड ट्रुथ मास्क (जो टेस्ट-टाइम एडैप्टेशन के दौरान अनुपलब्ध है)। |
| $x_t$ | टेस्ट टाइम के दौरान सामना की जाने वाली एक एकल 3D लक्ष्य छवि जिसे मॉडल को अनुकूलित करना चाहिए। |
| $\mu_s, \sigma_s$ | मॉडल के पूर्व-प्रशिक्षण चरण के दौरान प्राप्त मूल माध्य और विचरण आँकड़े। |
| $\gamma, \beta$ | सीखने योग्य एफाइन परिवर्तन पैरामीटर जिनका उपयोग पूर्ण बैच नई छवियों की आवश्यकता के बिना टेस्ट टाइम के दौरान नेटवर्क को संशोधित करने के लिए किया जाता है। |
| $x_{t_{p_i}}$ | एकल लक्ष्य परीक्षण छवि $x_t$ से निकाला गया $i$-वां ओवरलैपिंग 3D पैच। |
| $\pi_1, \pi_2$ | व्यू-विशिष्ट क्रमपरिवर्तन फ़ंक्शन जिनका उपयोग पैच को वैकल्पिक शारीरिक दृश्यों (जैसे, एक्सियल से सैजिटल या कोरोनल) में घुमाने या बदलने के लिए किया जाता है। |
| $v$ | मूल पैच और उसके रूपांतरित संस्करणों का प्रतिनिधित्व करने वाले दृश्यों का एक सेट, जिसे $v \in \{x_{t_{p_i}}, x'_{t_{p_i}}, x''_{t_{p_i}}\}$ के रूप में परिभाषित किया गया है। |
| $H(z)$ | मॉडल की अनुमानित संभाव्यता $z$ से गणना की गई प्रति-पिक्सेल एन्ट्रॉपी। यह मॉडल की अनिश्चितता को मापता है। |
| $\tau$ | अनुभवजन्य रूप से निर्धारित एन्ट्रॉपी थ्रेशोल्ड। इस थ्रेशोल्ड से कम अनिश्चितता वाली भविष्यवाणियों को आत्मविश्वासी के रूप में स्वीकार किया जाता है। |
| $\hat{y}_{t_{p_i}}$ | एक विशिष्ट पैच के लिए उत्पन्न एन्ट्रॉपी-आधारित स्यूडोलेबल, जिसे सेल्फ-ट्रेनिंग के लिए अस्थायी ग्राउंड ट्रुथ के रूप में उपयोग किया जाता है। |
| $\mathcal{L}_{sl}$ | सेल्फ-लर्निंग लॉस फ़ंक्शन, जो मॉडल को उसके अपने स्यूडोलेबल पर प्रशिक्षित करने के लिए डाइस लॉस और क्रॉस-एंट्रॉपी लॉस को जोड़ता है। |
| $\mathcal{L}_{consistency}$ | स्थिरता लॉस फ़ंक्शन जो मॉडल को यह सुनिश्चित करने के लिए मजबूर करता है कि वह किसी भी दृश्य ($x'_{t_{p_i}}$ या $x''_{t_{p_i}}$) को संसाधित कर रहा है, इससे कोई फर्क नहीं पड़ता कि वह समान सेगमेंटेशन आउटपुट करता है। |
| $\mathcal{L}_{cosine}$ | एक कोसाइन समानता लॉस जो यह सुनिश्चित करता है कि विभिन्न दृश्यों के डीप फीचर एम्बेडिंग, स्यूडोलेबल से स्वतंत्र, संरेखित रहें। |
ऐतिहासिक बैच आँकड़ों ($\mu_s, \sigma_s$) को फ्रीज करके और केवल हल्के मापदंडों ($\gamma, \beta$) को एक संयुक्त लॉस फ़ंक्शन $$\mathcal{L}_{total} = \lambda_1\mathcal{L}_{sl} + \lambda_2\mathcal{L}_{consistency} + \lambda_3\mathcal{L}_{cosine}$$ का उपयोग करके अपडेट करके, लेखकों ने सफलतापूर्वक एक ऐसी विधि बनाई जो केवल एक एकल छवि का उपयोग करके एक बिल्कुल नए अस्पताल के एमआरआई स्कैनर के अनुकूल हो जाती है, जिससे बड़े डेटा और मेमोरी बाधाओं को पूरी तरह से दरकिनार कर दिया जाता है जिन्होंने पिछले दृष्टिकोणों को पंगु बना दिया था।
समस्या परिभाषा और बाधाएँ
प्रारंभिक बिंदु, लक्ष्य और नैदानिक जाल
इस पत्र में हुई अभूतपूर्व प्रगति के महत्व को वास्तव में समझने के लिए, हमें पहले सटीक गणितीय और व्यावहारिक प्रारंभिक बिंदु, वांछित अंतिम लक्ष्य और अस्पताल के वातावरण में कृत्रिम बुद्धिमत्ता को तैनात करने की क्रूर वास्तविकता को समझना होगा।
प्रारंभिक बिंदु (इनपुट स्थिति):
हम एक डीप लर्निंग मॉडल, जिसे $M(\theta_s)$ से दर्शाया गया है, से शुरुआत करते हैं, जिसे स्रोत डेटासेट पर पूर्व-प्रशिक्षित किया गया है ताकि एक मैपिंग फ़ंक्शन $f: X_s \rightarrow Y_s$ सीखा जा सके। यहाँ, $X_s$ एक विशिष्ट अस्पताल से 3D मेडिकल इमेज टेंसर (जैसे स्तन एमआरआई) का प्रतिनिधित्व करता है, और $Y_s$ सघन रूप से लेबल किए गए वोक्सेल-वार 3D सेगमेंटेशन मास्क (एक ट्यूमर की सटीक सीमाएं) का प्रतिनिधित्व करता है।
परीक्षण के समय, मॉडल को एक नए अस्पताल में तैनात किया जाता है। इसे लक्ष्य डोमेन $t$ से एक एकल, बिना लेबल वाला 3D इमेज टेंसर $x_t \in X_t$ सौंपा जाता है। यह नई छवि अलग कंट्रास्ट, रिज़ॉल्यूशन या शोर प्रोफाइल वाली हो सकती है क्योंकि इसे एक अलग एमआरआई स्कैनर पर लिया गया था। हमारे पास मूल स्रोत डेटा $s$ तक बिल्कुल भी पहुंच नहीं है, न ही हमारे पास इस नए रोगी के लिए ग्राउंड ट्रुथ लेबल है।
लक्ष्य स्थिति (आउटपुट):
उद्देश्य मॉडल मापदंडों $\theta_s$ को नए लक्ष्य डोमेन के लिए तुरंत अनुकूलित करना है, एक नया फ़ंक्शन $k: X_t \rightarrow Y_t$ सीखना है जो इस विशिष्ट रोगी के लिए सटीक रूप से 3D सेगमेंटेशन मास्क $Y_t$ आउटपुट करता है। महत्वपूर्ण रूप से, मॉडल को इसे ऑन-द-फ्लाई करना होगा, केवल प्रदान की गई एकल छवि $x_t$ का उपयोग करके।
गणितीय अंतर:
लुप्त कड़ी एक अनसुपरवाइज्ड ऑप्टिमाइज़ेशन ब्रिज है। आप $\theta_s$ को अपडेट करने के लिए लॉस ग्रेडिएंट की गणना कैसे करते हैं जब आपके पास तुलना करने के लिए कोई लक्ष्य $Y_t$ नहीं होता है, और आपके पास नए सांख्यिकीय वितरण का अनुमान लगाने के लिए लक्ष्य डोमेन $X_t$ में पर्याप्त डेटा पॉइंट नहीं होते हैं?
सांख्यिकीय स्थिरता बनाम नैदानिक वास्तविकता का दर्दनाक दुविधा
टेस्ट-टाइम एडैप्टेशन (TTA) के क्षेत्र में, शोधकर्ता सांख्यिकीय स्थिरता और नैदानिक विलंबता के बीच एक दुष्चक्र में फंस गए हैं।
अधिकांश मौजूदा TTA विधियाँ बैच नॉर्मलाइज़ेशन (BN) परतों को अपडेट करने पर बहुत अधिक निर्भर करती हैं। एक मॉडल को नए डोमेन के अनुकूल बनाने के लिए, ये विधियाँ नए लक्ष्य वितरण के माध्य $\mu$ और विचरण $\sigma^2$ की पुनर्गणना करती हैं। हालांकि, एक वितरण का एक स्थिर गणितीय अनुमान प्राप्त करने के लिए, आपको डेटा के एक बड़े बैच की आवश्यकता होती है।
यहाँ दुविधा है: यदि आप अपने BN आँकड़ों को स्थिर करने के लिए रोगी स्कैन के एक बड़े बैच को इकट्ठा करने की प्रतीक्षा करते हैं, तो आप नैदानिक देखभाल की वास्तविक समय, ऑन-डिमांड प्रकृति को नष्ट कर देते हैं। एक डॉक्टर को AI द्वारा उनके सामने बैठे रोगी का निदान करने से पहले 30 और रोगियों के स्कैन होने का इंतजार नहीं करना पड़ सकता है। इसके विपरीत, यदि आप ठीक एक (एकल रोगी) के बैच आकार का उपयोग करके BN आँकड़ों को अनुकूलित करने का प्रयास करते हैं, तो सांख्यिकीय अनुमान बेतहाशा उतार-चढ़ाव करते हैं, जिससे मॉडल की भविष्यवाणियां ध्वस्त हो जाती हैं। आपको मॉडल की सटीकता को तोड़ने या अस्पताल के वर्कफ़्लो को तोड़ने के बीच चयन करने के लिए मजबूर किया जाता है।
मेडिकल इमेज एडैप्टेशन की कठोर दीवारें
लेखकों ने कई क्रूर, यथार्थवादी बाधाओं का सामना किया है जो इस विशिष्ट समस्या को हल करना बेहद मुश्किल बनाती हैं:
- डेटा की अत्यधिक विरलता (एकल-छवि दीवार):
मॉडल को $N=1$ नमूनों का उपयोग करके अनुकूलित होना चाहिए। परीक्षण के समय सीखने के लिए कोई डेटासेट नहीं है, केवल एक एकल उदाहरण है। पारंपरिक अनसुपरवाइज्ड डोमेन एडैप्टेशन तकनीकों पर निर्भर रहना यहाँ गणितीय रूप से असंभव है क्योंकि आप एक एकल बिंदु से वितरण का मानचित्रण नहीं कर सकते। - हार्डवेयर मेमोरी सीमा (VRAM दीवार):
2D तस्वीरों के विपरीत, मेडिकल इमेजिंग उच्च-रिज़ॉल्यूशन 3D वॉल्यूमेट्रिक डेटा पर निर्भर करती है। 3D टेंसर को संसाधित करने के लिए भारी मात्रा में GPU मेमोरी (VRAM) की आवश्यकता होती है। भले ही कोई क्लिनिक अपने एल्गोरिदम को स्थिर करने के लिए एक बड़े बैच आकार का उपयोग करना चाहता हो, मानक अस्पताल हार्डवेयर एक बार में 3D एमआरआई के एक बड़े बैच को मेमोरी में रखने में शारीरिक रूप से सक्षम नहीं है। - स्रोत-मुक्त बाधा (गोपनीयता दीवार):
सख्त रोगी गोपनीयता कानूनों और भारी भंडारण आवश्यकताओं के कारण, मूल स्रोत प्रशिक्षण डेटा $X_s$ को मॉडल के साथ नहीं भेजा जा सकता है। अनुकूलन पूरी तरह से "स्रोत-मुक्त" होना चाहिए, जिसका अर्थ है कि मॉडल नए स्कैनर के अनुकूल होने के दौरान यह याद रखने के लिए पुराने डेटा को वापस नहीं देख सकता है कि एक ट्यूमर कैसा दिखना चाहिए। - बहु-स्कैनर सेटअप का चलता-फिरता लक्ष्य:
भले ही किसी अस्पताल ने अनुमान में देरी करने और आने वाले रोगियों के बैच की प्रतीक्षा करने का फैसला किया हो, इस बात की कोई गारंटी नहीं है कि वे रोगी एक ही लक्ष्य वितरण साझा करते हैं। एक बहु-स्कैनर अस्पताल में, रोगी ए को जीई मशीन पर स्कैन किया जा सकता है, और रोगी बी को सीमेंस मशीन पर। एक साझा लक्ष्य वितरण की गणना करने के लिए उन्हें एक बैच में समूहित करना गणितीय रूप से त्रुटिपूर्ण है, जिससे पारंपरिक बैच-आधारित अनुकूलन तकनीकों को पूरी तरह से अप्रभावी बना दिया जाता है।
यह तरीका क्यों
इस पत्र की उत्कृष्टता को समझने के लिए, हमें पहले अस्पतालों में कृत्रिम बुद्धिमत्ता (artificial intelligence) को तैनात करने की कठोर वास्तविकता को समझना होगा। कल्पना कीजिए कि एक डीप लर्निंग मॉडल को हॉस्पिटल A से एमआरआई स्कैन का उपयोग करके स्तन ट्यूमर का पता लगाने के लिए प्रशिक्षित किया गया है। यह वहां पूरी तरह से काम करता है। लेकिन जब आप इसे हॉस्पिटल B में तैनात करते हैं, जो विभिन्न एमआरआई स्कैनर, विभिन्न चुंबकीय क्षेत्र की ताकत और विभिन्न इमेजिंग प्रोटोकॉल का उपयोग करता है, तो मॉडल अचानक विफल हो जाता है। इसे "डोमेन शिफ्ट" (domain shift) कहा जाता है।
परंपरागत रूप से, इंजीनियर हॉस्पिटल B से हजारों छवियां एकत्र करके और मॉडल को पुनः प्रशिक्षित करके इस समस्या का समाधान करते हैं। लेकिन एक वास्तविक नैदानिक वातावरण में, डॉक्टरों को किसी रोगी के स्कैन का विश्लेषण तुरंत करने की आवश्यकता होती है। वे एक विशाल डेटासेट एकत्र करने के लिए महीनों इंतजार नहीं कर सकते। मॉडल को केवल उस एकल रोगी के स्कैन का उपयोग करके, ऑन-द-फ्लाई (on-the-fly) अनुकूलित होना चाहिए। यह सिंगल इमेज टेस्ट-टाइम एडैप्टेशन (Single Image Test-Time Adaptation - TTA) की मौलिक चुनौती है।
"आहा!" क्षण: SOTA विधियाँ क्यों विफल हुईं
लेखकों को एक महत्वपूर्ण अहसास हुआ: कंप्यूटर विज़न में वर्तमान स्टेट-ऑफ-द-आर्ट (State-of-the-Art - SOTA) विधियाँ 3D मेडिकल इमेजिंग की भौतिक और नैदानिक बाधाओं के साथ मौलिक रूप से असंगत थीं।
लोकप्रिय TTA विधियों (जैसे Tent, PTN, या BNAdapt) को देखते हुए, लेखकों ने एक घातक दोष देखा। ये विधियाँ बैच नॉर्मलाइज़ेशन (Batch Normalization - BN) पर बहुत अधिक निर्भर करती हैं। एक नए डोमेन के अनुकूल होने के लिए, वे नेटवर्क को अपडेट करने के लिए आने वाली परीक्षण छवियों के बड़े बैच के सांख्यिकीय माध्य (mean) और प्रसरण (variance) की गणना करते हैं। लेकिन एक अस्पताल में, आप एक समय में एक रोगी का मूल्यांकन कर रहे होते हैं। इसके अलावा, मेडिकल छवियां सपाट 2D चित्र नहीं हैं; वे विशाल, उच्च-रिज़ॉल्यूशन 3D वॉल्यूम हैं। 3D एमआरआई के एक बड़े बैच को संसाधित करने के लिए अत्यधिक GPU मेमोरी (VRAM) की आवश्यकता होती है, जिससे यह मानक अस्पताल हार्डवेयर के लिए कम्प्यूटेशनल रूप से असंभव हो जाता है।
यदि आप केवल एकल छवि पर BN आँकड़ों की गणना करने का प्रयास करते हैं, तो गणित ढह जाता है, और मॉडल का प्रदर्शन वास्तव में खराब हो जाता है। लेखकों ने महसूस किया कि मानक CNN एडैप्टेशन तकनीकें, और यहां तक कि आधुनिक ट्रांसफार्मर-आधारित बैच विधियाँ भी, इस विशिष्ट समस्या के लिए पूरी तरह से अपर्याप्त थीं।
ईमानदारी से कहूं तो, मुझे पूरी तरह से यकीन नहीं है कि लेखकों ने इस सटीक एकल-छवि सेटअप के लिए GANs या डिफ्यूज़न मॉडल जैसे भारी जनरेटिव मॉडल का स्पष्ट रूप से परीक्षण किया है या नहीं, लेकिन यह पत्र दृढ़ता से बताता है कि वे क्यों विफल होंगे: उन मॉडलों को विशाल लक्ष्य डेटासेट और व्यापक पुनः प्रशिक्षण समय की आवश्यकता होती है, जो नैदानिक सेटिंग्स में आवश्यक "वास्तविक समय, प्रति-रोगी" बाधा का पूरी तरह से उल्लंघन करते हैं। इसके अलावा, लेखकों ने स्पष्ट रूप से "प्रोटोटाइप-आधारित" एडैप्टेशन विधियों को अस्वीकार कर दिया। क्यों? क्योंकि प्रोटोटाइप विधियाँ सुसंगत आकृतियों (shape priors) पर निर्भर करती हैं, और स्तन ट्यूमर में अत्यधिक उच्च शारीरिक परिवर्तनशीलता होती है। वे एक पूर्वानुमानित आकार का पालन नहीं करते हैं।
बेंचमार्किंग तर्क: संरचनात्मक श्रेष्ठता
चूंकि पारंपरिक विधियाँ विफल रहीं, लेखकों को गुणात्मक रूप से श्रेष्ठ दृष्टिकोण का आविष्कार करना पड़ा: पैच-आधारित मल्टी-व्यू को-ट्रेनिंग (Patch-Based Multi-View Co-Training - MuVi)।
विभिन्न रोगियों के बड़े बैचों पर नए डोमेन का पता लगाने के लिए निर्भर रहने के बजाय, MuVi एकल रोगी के एमआरआई से ओवरलैपिंग 3D पैच निकालता है और उन्हें तीन अलग-अलग ऑर्थोगोनल कोणों (axial, sagittal, और coronal views) से देखता है।
यह एक विशाल संरचनात्मक लाभ प्रदान करता है। मॉडल को एक ही 3D ऊतक को विभिन्न दृष्टिकोणों से देखने के लिए मजबूर करके, वे कृत्रिम रूप से नेटवर्क को अनुकूलित करने के लिए एक छवि से पर्याप्त "विविध" डेटा बनाते हैं। यह बड़े बैच आकार की आवश्यकता को पूरी तरह से बायपास करता है, प्रभावी रूप से मेमोरी और डेटा आवश्यकता को $N$ रोगियों से घटाकर $1$ कर देता है।
गणितीय रूप से, उन्होंने नॉर्मलाइज़ेशन प्रक्रिया को विभाजित करके बैच नॉर्मलाइज़ेशन संकट को हल किया। स्रोत आँकड़ों को बदलने के बजाय, वे प्रशिक्षण के दौरान सीखे गए मूल माध्य $\mu_s$ और प्रसरण $\sigma_s$ को फ्रीज़ करते हैं, और नॉर्मलाइज़्ड इनपुट की गणना इस प्रकार करते हैं:
$$ \hat{x} = \frac{x - \mu_s}{\sqrt{\sigma_s^2 + \epsilon}} $$
फिर, वे केवल ग्रेडिएंट डिसेंट (gradient descent) के माध्यम से हल्के एफाइन ट्रांसफॉर्मेशन पैरामीटर ($\gamma$ और $\beta$) को अपडेट करने की अनुमति देते हैं:
$$ y = \gamma \hat{x} + \beta $$
यह मॉडल को एकल छवि के उच्च-आयामी शोर का सामना करने पर ढहने से रोकता है, जबकि अभी भी इसे नए स्कैनर के कंट्रास्ट और तीव्रता के अनुकूल होने की अनुमति देता है।
बाधाओं और समाधान का उत्तम संयोजन
इस पत्र की वास्तविक सुंदरता इस बात में निहित है कि गणितीय समाधान कठोर नैदानिक बाधाओं के साथ कितनी पूरी तरह से संरेखित होता है।
चूंकि उनके पास नए रोगी के लिए कोई ग्राउंड-ट्रुथ लेबल नहीं हैं, मॉडल को स्वयं को सिखाना होगा (सेल्फ-ट्रेनिंग)। हालांकि, सेल्फ-ट्रेनिंग लेबल शोर के प्रति कुख्यात रूप से संवेदनशील है; यदि मॉडल गलत अनुमान लगाता है, तो वह अपनी गलतियों से सीखेगा और नियंत्रण से बाहर हो जाएगा।
इसे दूर करने के लिए, लेखकों ने एंट्रॉपी-गाइडेड सेल्फ-ट्रेनिंग (Entropy-guided Self-Training) पेश की। वे अपने अनुमान के बारे में मॉडल कितना "अनिश्चित" है, इसे मापने के लिए प्रति-पिक्सेल शैनन एंट्रॉपी (Shannon entropy) की गणना करते हैं:
$$ H(z) = -z \log_2(z) - (1-z) \log_2(1-z) $$
जहां $z \in [0, 1]$ एक ट्यूमर की अनुमानित संभावना है। मॉडल केवल उन भविष्यवाणियों को स्वीकार करता है जहां एंट्रॉपी एक सख्त सीमा $\tau$ से नीचे होती है (जिसका अर्थ है कि मॉडल अत्यधिक आत्मविश्वासी है)।
फिर वे एक विश्वसनीय "स्यूडोलेबल" बनाने के लिए तीन अलग-अलग दृश्यों से इन अत्यधिक आत्मविश्वासी भविष्यवाणियों को जोड़ते हैं। अंत में, वे एक संयुक्त लॉस फ़ंक्शन का उपयोग करके नेटवर्क को अपडेट करते हैं जो सभी दृश्यों में स्थिरता को लागू करता है:
$$ \mathcal{L}_{total} = \lambda_1 \mathcal{L}_{sl} + \lambda_2 \mathcal{L}_{consistency} + \lambda_3 \mathcal{L}_{cosine} $$
यह उत्तम संयोजन है:
1. बाधा: केवल एक छवि उपलब्ध है। समाधान: उस एकल 3D वॉल्यूम से कई दृश्य उत्पन्न करें।
2. बाधा: कोई लेबल उपलब्ध नहीं है। समाधान: शोर को फ़िल्टर करने और अत्यधिक आत्मविश्वासी स्यूडोलेबल उत्पन्न करने के लिए एंट्रॉपी गणित का उपयोग करें।
3. बाधा: सीमित GPU मेमोरी। समाधान: भारी बैच आँकड़ों को फ्रीज़ करें और केवल छोटे 3D पैच पर हल्के पैरामीटर अपडेट करें।
इन अद्वितीय गुणों को संरेखित करके, लेखकों ने किसी भी अतिरिक्त रोगी स्कैन की आवश्यकता के बिना, मौजूदा सभी SOTA विधियों को बेहतर प्रदर्शन करते हुए, डाइस सिमिलरिटी कोएफ़िशिएंट (Dice Similarity Coefficient) में 5.57% सुधार हासिल किया।
गणितीय और तार्किक तंत्र
कल्पना कीजिए कि आपने अस्पताल A से हजारों एमआरआई स्कैन का उपयोग करके स्तन ट्यूमर की पहचान करने के लिए एक प्रतिभाशाली डॉक्टर को प्रशिक्षित किया है। यदि आप अचानक इस डॉक्टर को अस्पताल B में स्थानांतरित करते हैं, तो उन्हें कठिनाई हो सकती है। अस्पताल B विभिन्न चुंबकीय शक्ति, कंट्रास्ट एजेंट और शोर प्रोफाइल वाली विभिन्न एमआरआई मशीनों का उपयोग करता है। कृत्रिम बुद्धिमत्ता की दुनिया में, हम इसे "डोमेन शिफ्ट" कहते हैं।
सामान्य तौर पर, इसे ठीक करने के लिए, डेटा वैज्ञानिक अस्पताल B से हजारों नई छवियां एकत्र करेंगे और एआई को फिर से प्रशिक्षित करेंगे। लेकिन एक वास्तविक नैदानिक सेटिंग में, यह असंभव है। एक डॉक्टर को अभी उनके सामने बैठे एकल रोगी के लिए एक सटीक विभाजन की आवश्यकता होती है। वे एक बड़े डेटासेट के संकलित होने की प्रतीक्षा नहीं कर सकते। इसके अलावा, चिकित्सा छवियां समृद्ध, 3डी वॉल्यूमेट्रिक डेटा होती हैं, लेकिन अधिकांश मौजूदा अनुकूलन विधियां उन्हें सपाट 2डी तस्वीरों की तरह मानती हैं, जो स्थानिक गहराई को अनदेखा करती हैं।
इस पेपर के लेखकों ने एक अत्यधिक प्रतिबंधित समस्या का समाधान किया: आप एक पूर्व-प्रशिक्षित 3डी मेडिकल एआई को केवल एकल छवि का उपयोग करके, वास्तविक समय में, अपने मूल प्रशिक्षण डेटा को फिर से देखे बिना, पूरी तरह से नए, अनदेखे वातावरण के अनुकूल होने के लिए कैसे मजबूर करते हैं?
इसे प्राप्त करने के लिए, उन्होंने एक मल्टी-व्यू को-ट्रेनिंग इंजन बनाया। आइए उन गणितीय सिद्धांतों को समझें जो इसे संभव बनाते हैं।
मुख्य गणितीय इंजन
यह प्रणाली दो-चरणीय तंत्र द्वारा संचालित होती है: पहला, यह एकल छवि से एक अत्यधिक आत्मविश्वासी "नकली ग्राउंड ट्रुथ" (एक छद्म-लेबल) उत्पन्न करती है। फिर, यह विभिन्न 3डी ज्यामितीय दृश्यों में एक समग्र हानि फ़ंक्शन को कम करके नेटवर्क को स्वयं को अपडेट करने के लिए मजबूर करती है।
यहां अनुकूलन को चलाने वाले मुख्य समीकरण दिए गए हैं:
1. छद्म-लेबल निर्माण (एंट्रॉपी-निर्देशित यूनियन):
$$ \hat{y} = \bigcup_{v \in \{x_t, x'_t, x''_t\}} \{j \mid H(\sigma(f(v(j)))) < \tau_v\} $$
2. स्व-शिक्षण उद्देश्य:
$$ \mathcal{L}_{sl} = \sum_{v \in \{x_{t_{p_i}}, x'_{t_{p_i}}, x''_{t_{p_i}}\}} \left[ \mathcal{L}_{DICE}(f(v), \hat{y}_{t_{p_i}}) + \mathcal{L}_{CE}(f(v), \hat{y}_{t_{p_i}}) \right] $$
3. फ़ीचर स्थिरता उद्देश्य:
$$ \mathcal{L}_{cosine} = 1 - \cos(g(x_{t_{p_i}}), g(x'_{t_{p_i}})) + 1 - \cos(g(x_{t_{p_i}}), g(x''_{t_{p_i}})) $$
4. कुल अनुकूलन परिदृश्य:
$$ \mathcal{L}_{total} = \lambda_1 \mathcal{L}_{sl} + \lambda_2 \mathcal{L}_{consistency} + \lambda_3 \mathcal{L}_{cosine} $$
समीकरणों को अलग करना
आइए इस गणितीय मशीनरी में हर गियर और स्प्रिंग को तोड़ें।
छद्म-लेबल समीकरण ($\hat{y}$) में:
* $\hat{y}$: मास्टर छद्म-लेबल। यह मॉडल का सबसे अच्छा, सबसे आत्मविश्वासी अनुमान है कि ट्यूमर कहाँ है, जो आगामी प्रशिक्षण चरण के लिए "ग्राउंड ट्रुथ" के रूप में कार्य करेगा।
* $v \in \{x_t, x'_t, x''_t\}$: लक्ष्य छवि के तीन अलग-अलग 3डी दृश्य (अक्षीय, कोरोनल और सेजिटल प्लेन)।
* $j$: एमआरआई स्कैन में एक विशिष्ट वोक्सेल (एक 3डी पिक्सेल)।
* $f(v(j))$: उस विशिष्ट वोक्सेल के लिए न्यूरल नेटवर्क की कच्ची भविष्यवाणी।
* $\sigma(\cdot)$: सिग्मॉइड सक्रियण फ़ंक्शन। यह कच्चे भविष्यवाणी को 0 और 1 के बीच की संभावना में संपीड़ित करता है।
* $H(\cdot)$: शैनन एंट्रॉपी फ़ंक्शन, जिसे $H(z) = -z \log_2(z) - (1-z) \log_2(1-z)$ के रूप में परिभाषित किया गया है। तार्किक रूप से, यह एक सख्त बाउंसर के रूप में कार्य करता है। यदि मॉडल अनिश्चित है (जैसे, ट्यूमर की 50% संभावना की भविष्यवाणी करना), तो एंट्रॉपी अधिक होती है। यदि यह अत्यधिक आत्मविश्वासी है (जैसे, 99% या 1%), तो एंट्रॉपी कम होती है।
* $\tau_v$: आत्मविश्वास सीमा। यदि एंट्रॉपी इस संख्या से कम है, तो भविष्यवाणी स्वीकार की जाती है।
* $\bigcup$: यूनियन ऑपरेटर। इंटरसेक्शन के बजाय यूनियन का उपयोग क्यों करें? क्योंकि विभिन्न 3डी दृश्य विभिन्न शारीरिक सीमाओं को कैप्चर करते हैं। एक इंटरसेक्शन केवल उन वोक्सेल को रखेगा जिन पर तीनों दृश्य सहमत हैं, जिसके परिणामस्वरूप एक गंभीर रूप से सिकुड़ा हुआ, रूढ़िवादी ट्यूमर मास्क होगा। एक यूनियन सभी दृष्टिकोणों से अत्यधिक आत्मविश्वासी खोजों को एकत्रित करता है, एक व्यापक 3डी मानचित्र बनाता है।
स्व-शिक्षण समीकरण ($\mathcal{L}_{sl}$) में:
* $\sum$: तीन दृश्यों पर योग। गुणा के बजाय जोड़ का उपयोग क्यों करें? हम चाहते हैं कि कुल दंड सभी दृष्टिकोणों से संचित त्रुटियों का योग हो। यदि हम उन्हें गुणा करते हैं, तो एक दृश्य में लगभग शून्य त्रुटि दूसरे में भारी त्रुटियों को रद्द कर सकती है, जो चिकित्सा इमेजिंग में खतरनाक है।
* $\mathcal{L}_{DICE}$: डाइस लॉस। यह भविष्यवाणी और छद्म-लेबल के बीच स्थानिक ओवरलैप को मापता है। यह एक रबर बैंड के रूप में कार्य करता है, जो भविष्यवाणी किए गए ट्यूमर के वैश्विक आकार को छद्म-लेबल से मेल खाने के लिए खींचता है, जो अत्यधिक असंतुलित चिकित्सा छवियों के लिए महत्वपूर्ण है जहां ट्यूमर पृष्ठभूमि की तुलना में बहुत छोटा होता है।
* $\mathcal{L}_{CE}$: क्रॉस-एंट्रॉपी लॉस। यह वोक्सेल-दर-वोक्सेल वर्गीकरण सटीकता का मूल्यांकन करता है। DICE और CE को एक साथ क्यों जोड़ें? DICE वैश्विक आकार के लिए उत्कृष्ट है लेकिन ग्रेडिएंट डिसेंट के दौरान गणितीय रूप से अस्थिर हो सकता है। CE अत्यधिक स्थिर है लेकिन वैश्विक संरचना को अनदेखा करता है। उन्हें जोड़ने से एक पूरी तरह से संतुलित, स्थिर ग्रेडिएंट मिलता है।
फ़ीचर स्थिरता समीकरण ($\mathcal{L}_{cosine}$) में:
* $g(\cdot)$: फ़ीचर एक्सट्रैक्टर (न्यूरल नेटवर्क की गहरी आंतरिक परतें, अंतिम वर्गीकरण से पहले)।
* $\cos(\cdot, \cdot)$: कोसाइन समानता।
* $1 - \cos(\cdot, \cdot)$: कोसाइन दूरी। मानक L2 (यूक्लिडियन) दूरी के बजाय कोसाइन दूरी का उपयोग क्यों करें? गहरी, उच्च-आयामी न्यूरल नेटवर्क में, एक फ़ीचर वेक्टर की दिशा अर्थपूर्ण अर्थ रखती है (जैसे, "यह बनावट एक ट्यूमर है"), जबकि परिमाण केवल उस फ़ीचर की तीव्रता का प्रतिनिधित्व करता है। कोसाइन दूरी सख्ती से वैक्टर के बीच के कोण को मापती है, जिससे नेटवर्क को देखने के कोण की परवाह किए बिना ट्यूमर के अर्थपूर्ण अर्थ को संरेखित करने के लिए मजबूर किया जाता है।
कुल हानि ($\mathcal{L}_{total}$) में:
* $\lambda_1, \lambda_2, \lambda_3$: स्केलर भार जो स्व-शिक्षण, भविष्यवाणी स्थिरता और फ़ीचर स्थिरता के महत्व को कैलिब्रेट करते हैं। लेखकों ने संतुलन बलों के लिए इन्हें समान रूप से निर्धारित किया।
चरण-दर-चरण प्रवाह: असेंबली लाइन
आइए इस इंजन के माध्यम से एक एकल अमूर्त डेटा बिंदु - एक रोगी के 3डी एमआरआई स्कैन - का पता लगाएं।
- दृष्टिकोणों को स्लाइस करना: 3डी स्कैन $x_t$ सिस्टम में प्रवेश करता है और तुरंत तीन अलग-अलग ज्यामितीय अभिविन्यासों में क्रमबद्ध हो जाता है: अक्षीय, कोरोनल और सेजिटल।
- आत्मविश्वास फ़िल्टर: जमे हुए मॉडल सभी तीन दृश्यों को देखता है और प्रारंभिक ट्यूमर मास्क उत्पन्न करता है। एंट्रॉपी फ़ंक्शन $H$ हर एकल वोक्सेल को स्कैन करता है। यदि मॉडल हिचकिचाता है या कमजोर संभावना आउटपुट करता है, तो उस वोक्सेल को तुरंत हटा दिया जाता है।
- मास्टर कुंजी बनाना: सभी तीन दृश्यों से बचे हुए, अत्यधिक आत्मविश्वासी वोक्सेल को गोल्डन छद्म-लेबल $\hat{y}$ बनाने के लिए यूनियन ऑपरेटर $\bigcup$ के माध्यम से फ्यूज किया जाता है।
- पैच निष्कर्षण: क्योंकि 3डी चिकित्सा छवियां विशाल होती हैं और जीपीयू मेमोरी को क्रैश कर देंगी, छवि को छोटे 3डी ब्लॉक (पैच) $x_{t_{p_i}}$ में काटा जाता है।
- दोहरी-सुधार लूप: प्रत्येक पैच नेटवर्क से गुजरता है। नेटवर्क के अंतिम आउटपुट की तुलना DICE + CE हानि का उपयोग करके गोल्डन छद्म-लेबल से की जाती है। साथ ही, पैच $g(x)$ का गहरा आंतरिक प्रतिनिधित्व निकाला जाता है। कोसाइन हानि विभिन्न दृश्यों से फ़ीचर वैक्टर को पकड़ती है और उन्हें उच्च-आयामी स्थान में भौतिक रूप से घुमाती है जब तक कि वे बिल्कुल एक ही दिशा में इंगित न करें।
अनुकूलन गतिशीलता: यह वास्तव में कैसे सीखता है
यहीं पर लेखक एक शानदार अनुकूलन रणनीति निकालते हैं। आप एक एकल छवि पर एक मॉडल को कैसे प्रशिक्षित करते हैं, बिना वह तुरंत ओवरफिट हो जाए और ढह जाए?
मॉडल एकल युग में अपडेट होता है। इसके अलावा, लेखकों ने पूरे नेटवर्क को अपडेट नहीं किया। उन्होंने लगभग सब कुछ जमा दिया और केवल सामान्यीकरण परतों के एफाइन मापदंडों ($\gamma$ और $\beta$) को अपडेट करने के लिए ग्रेडिएंट्स की अनुमति दी।
क्यों? मानक बैच सामान्यीकरण में, नेटवर्क छवियों के एक बड़े बैच के माध्य ($\mu$) और विचरण ($\sigma$) पर निर्भर करता है। लेकिन यहां, हमारे पास केवल एक छवि है। एक एकल छवि में पूरे डेटासेट के वितरण को फिर से परिभाषित करने के लिए पर्याप्त सांख्यिकीय शक्ति नहीं होती है। इसलिए, लेखकों ने मूल स्रोत डोमेन के $\mu$ और $\sigma$ को जगह पर बंद कर दिया।
जैसे ही ग्रेडिएंट्स $\mathcal{L}_{total}$ से पीछे की ओर प्रवाहित होते हैं, वे केवल $\gamma$ (स्केल) और $\beta$ (शिफ्ट) को ठीक करते हैं। यह एक हल्के कैलिब्रेशन नॉब के रूप में कार्य करता है। यह फ़ीचर मैप्स को नए अस्पताल के एमआरआई कंट्रास्ट और चमक के अनुकूल होने के लिए पर्याप्त रूप से शिफ्ट और स्केल करता है, बिना मॉडल द्वारा मूल रूप से सीखी गई मौलिक ट्यूमर-पहचान तर्क को नष्ट किए।
यहां हानि परिदृश्य बहु-दृश्य स्थिरता द्वारा भारी रूप से प्रतिबंधित है। मॉडल को विभिन्न ज्यामितीय परिवर्तनों में स्वयं से सहमत होने के लिए मजबूर करके, $\mathcal{L}_{cosine}$ और $\mathcal{L}_{consistency}$ पद बड़े नियमितीकरण के रूप में कार्य करते हैं। वे अभिसरण के लिए एक खड़ी, संकीर्ण पथ बनाते हैं, जिससे मॉडल को एक एकल शोर वाली छवि के आधार पर जंगली भविष्यवाणियों की कल्पना करने से रोका जा सके। नेटवर्क तेजी से एक स्थानीय न्यूनतम में बस जाता है जो पुराने प्रशिक्षण डेटा और नए, अनदेखे रोगी के बीच के अंतर को पूरी तरह से पाट देता है।
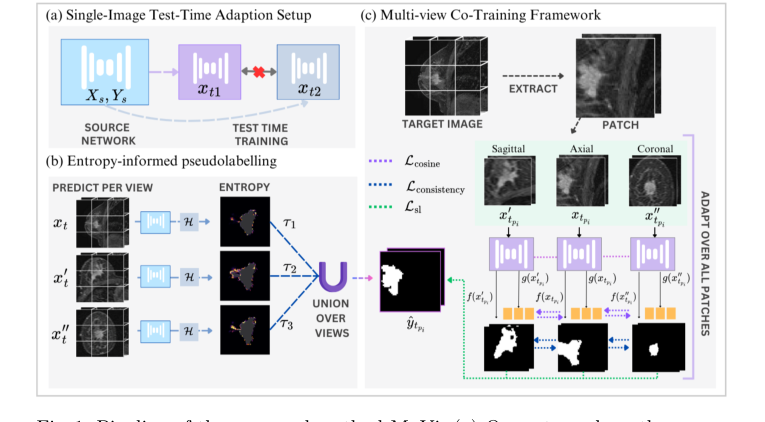 Figure 1. Pipeline of the proposed method MuVi. (a) Our setup where the source network is adapted independently for each target sample xt, (b) computing pseu- dolabel through entropy-threshold union of prediction from each view, (c) Adap- tation via patch-based training through our multi-view consistency framework
Figure 1. Pipeline of the proposed method MuVi. (a) Our setup where the source network is adapted independently for each target sample xt, (b) computing pseu- dolabel through entropy-threshold union of prediction from each view, (c) Adap- tation via patch-based training through our multi-view consistency framework
परिणाम, सीमाएँ और निष्कर्ष
कल्पना कीजिए कि आप एक शांत, धूप वाले उपनगरीय शहर में गाड़ी चलाना सीखते हैं। आप सड़कों, संकेतों और यातायात के प्रवाह में महारत हासिल करते हैं। अब, अचानक, आपको एक अराजक, बर्फीले महानगर के बीच में छोड़ दिया जाता है और गाड़ी चलाने के लिए कहा जाता है। आपके मौलिक ड्राइविंग कौशल बरकरार हैं, लेकिन डोमेन इतना नाटकीय रूप से बदल गया है कि आपसे गलतियाँ होने की संभावना है।
मेडिकल इमेजिंग की दुनिया में, डीप लर्निंग मॉडल इसी तरह के दुःस्वप्न का सामना करते हैं। एक अस्पताल के एमआरआई स्कैनर की छवियों पर प्रशिक्षित मॉडल अक्सर दूसरे अस्पताल के स्कैनर की छवियों का विश्लेषण करते समय विनाशकारी रूप से विफल हो जाता है। चुंबकीय क्षेत्र की शक्ति, पुनर्निर्माण सॉफ्टवेयर और इमेजिंग प्रोटोकॉल "डोमेन शिफ्ट" बनाते हैं।
इसे ठीक करने के लिए, शोधकर्ता टेस्ट-टाइम एडैप्टेशन (TTA) का उपयोग करते हैं। पूरे मॉडल को खरोंच से फिर से प्रशिक्षित करने के बजाय - जो हर बार अस्पताल बदलने पर \$150,000 का नया मेडिकल उपकरण खरीदने जितना महंगा है - TTA भविष्यवाणी करते समय ठीक उसी क्षण मॉडल को थोड़ा सा समायोजित करता है। हालांकि, मौजूदा TTA विधियों में एक घातक खामी है: उन्हें नए वातावरण को समझने के लिए बड़ी संख्या में छवियों की आवश्यकता होती है। एक वास्तविक नैदानिक सेटिंग में, डॉक्टरों के पास बैच नहीं होते हैं; उनके पास निदान की प्रतीक्षा कर रहे एक एकल रोगी का एक एकल 3डी स्कैन होता है। इसके अलावा, मौजूदा विधियाँ अक्सर 3डी मेडिकल छवियों को सपाट 2डी तस्वीरों के ढेर की तरह मानती हैं, जो मानव शरीर रचना की समृद्ध, वॉल्यूमेट्रिक वास्तविकता को पूरी तरह से नजरअंदाज करती हैं।
यह पेपर एक शानदार, स्रोत-मुक्त समाधान प्रस्तुत करता है: पैच-आधारित मल्टी-व्यू को-ट्रेनिंग (MuVi)। आइए विस्तार से देखें कि उन्होंने इस एकल-छवि 3डी एडैप्टेशन समस्या को कैसे हल किया।
समस्या और समाधान का गणितीय मूल
समस्या:
हमें पैरामीटर $\theta_s$ के साथ एक मॉडल $M(\theta_s)$ दिया गया है जिसने पहले ही स्रोत डेटासेट $s$ पर एक मैपिंग फ़ंक्शन $f: X_s \rightarrow Y_s$ सीखा है। हमारा लक्ष्य इस मॉडल को एक नए लक्ष्य डोमेन $t$ के अनुकूल बनाना है ताकि एक नया फ़ंक्शन $k: X_t \rightarrow Y_t$ सीखा जा सके। यहाँ सबसे बड़ी बाधा यह है कि हमारे पास मूल स्रोत डेटा तक पहुँच नहीं है, लक्ष्य डेटा के ग्राउंड ट्रुथ लेबल तक पहुँच नहीं है, और हमें यह केवल एक एकल लक्ष्य छवि $x_t \in X_t$ का उपयोग करके करना होगा।
समाधान:
लेखकों ने चतुर सांख्यिकीय संरक्षण और ज्यामितीय स्थिरता के संयोजन के माध्यम से इसे संबोधित किया है।
-
स्रोत सांख्यिकी का संरक्षण:
मानक बैच नॉर्मलाइजेशन (BN) डेटा के बैच के माध्य $\mu$ और विचरण $\sigma$ पर निर्भर करता है। यदि आप एक एकल छवि से $\mu$ और $\sigma$ की गणना करने का प्रयास करते हैं, तो गणित शोरगुल वाले अराजकता में टूट जाता है। इसलिए, लेखक मूल स्रोत सांख्यिकी $\mu_s$ और $\sigma_s$ को फ्रीज करते हैं। वे परीक्षण समय के दौरान केवल सीखने योग्य एफाइन परिवर्तन पैरामीटर $\gamma$ और $\beta$ को अपडेट करने की अनुमति देते हैं, जहां सामान्यीकृत आउटपुट $y = \gamma \hat{x} + \beta$ होता है। -
मल्टी-व्यू को-ट्रेनिंग और एन्ट्रॉपी-गाइडेड सेल्फ-ट्रेनिंग:
चूंकि उनके पास केवल एक 3डी छवि है, वे ओवरलैपिंग 3डी पैच $\{x_{t_{p_1}}, x_{t_{p_2}}, \dots, x_{t_{p_n}}\}$ निकालते हैं। प्रत्येक पैच के लिए, वे इसे तीन अलग-अलग शारीरिक विमानों: अक्षीय, सग्जिट्टल और कोरोनल से देखने के लिए गणितीय रूप से अक्षों को क्रमबद्ध करते हैं। आइए इन तीन दृश्यों को $v \in \{x_{t_{p_i}}, x'_{t_{p_i}}, x''_{t_{p_i}}\}$ के रूप में परिभाषित करें।मानव लेबल के बिना मॉडल को प्रशिक्षित करने के लिए, वे मॉडल को अपने स्वयं के "छद्म लेबल" उत्पन्न करने के लिए मजबूर करते हैं। वे मॉडल की अनिश्चितता को मापने के लिए पिक्सेल-वार शैनन एन्ट्रॉपी की गणना करते हैं:
$$H(z) = -z \log_2(z) - (1-z) \log_2(1-z)$$
जहां $z \in [0, 1]$ एक ट्यूमर की अनुमानित संभावना है। वे केवल उन भविष्यवाणियों को स्वीकार करते हैं जहां एन्ट्रॉपी $H(z)$ एक सख्त सीमा $\tau$ से नीचे है। अंतिम छद्म लेबल $\hat{y}$ तीनों दृश्यों में आत्मविश्वास से की गई भविष्यवाणियों का संघ है। -
अनुकूलन उद्देश्य:
फिर मॉडल को केवल एक युग के लिए एक त्रिपक्षीय हानि फ़ंक्शन को कम करके अनुकूलित किया जाता है:
$$\mathcal{L}_{total} = \lambda_1 \mathcal{L}_{sl} + \lambda_2 \mathcal{L}_{consistency} + \lambda_3 \mathcal{L}_{cosine}$$
यहां, $\mathcal{L}_{sl}$ मॉडल की भविष्यवाणियों को डाइस और क्रॉस-एंट्रॉपी हानि का उपयोग करके उच्च-आत्मविश्वास वाले छद्म लेबल से मेल खाने के लिए मजबूर करता है। $\mathcal{L}_{consistency}$ तीन अलग-अलग दृश्यों से भविष्यवाणियों को एक-दूसरे से सहमत होने के लिए मजबूर करता है। अंत में, $\mathcal{L}_{cosine}$ न्यूरल नेटवर्क के गहरे अंदर काम करता है, फीचर एक्सट्रैक्टर $g(\cdot)$ को कोसाइन समानता का उपयोग करके विभिन्न दृश्यों के गहरे एम्बेडिंग को संरेखित करने के लिए मजबूर करता है:
$$\mathcal{L}_{cosine} = 1 - \cos(g(x_{t_{p_i}}), g(x'_{t_{p_i}})) + 1 - \cos(g(x_{t_{p_i}}), g(x''_{t_{p_i}}))$$
प्रयोगात्मक वास्तुकला और "पीड़ित"
लेखकों ने केवल यह दावा नहीं किया कि उनका गणित काम करता है; उन्होंने इसे साबित करने के लिए एक क्रूर प्रयोगात्मक वास्तुकला तैयार की। उन्होंने एक विशाल डेटासेट (Duke-Breast-Cancer-MRI) पर एक बेसलाइन 3डी UNet को प्रशिक्षित किया और फिर इसे दो पूरी तरह से अनदेखे डेटासेट (TCGA-BRCA और ISPY1) के साथ घात लगाकर हमला किया, जिसमें विभिन्न स्कैनर (GE, सीमेंस, फिलिप्स) और विभिन्न अधिग्रहण विमान थे।
इस प्रयोग में "पीड़ित" अत्याधुनिक TTA विधियाँ थीं: PTN, Tent, BNAdapt, InTent, और MEMO।
MuVi की श्रेष्ठता का निर्णायक प्रमाण स्पष्ट था। Tent और PTN जैसी विधियाँ, जो एक एकल छवि के आधार पर बैच सांख्यिकी को अपडेट करने का प्रयास करती हैं, वास्तव में बेसलाइन मॉडल के प्रदर्शन को खराब करती हैं। वे एकल-छवि सांख्यिकीय शोर के जाल में फंस गए। MEMO, जो संवर्द्धन का उपयोग करता है, ने सुई को मुश्किल से हिलाया। हालांकि, MuVi ने एक बड़ा उछाल हासिल किया, बेसलाइन की तुलना में डाइस सिमिलैरिटी कोएफ़िशिएंट में 5.57% तक सुधार किया।
धूम्रपान बंदूक उनका एब्लेशन अध्ययन था। जब उन्होंने मल्टी-व्यू स्थिरता बाधा को हटा दिया, या जब उन्होंने स्रोत BN सांख्यिकी को छोड़ दिया, तो मॉडल का प्रदर्शन ढह गया। इसने निर्विवाद रूप से साबित कर दिया कि उनका विशिष्ट तंत्र - एक 3डी मॉडल को विभिन्न शारीरिक विमानों में स्वयं से सहमत होने के लिए मजबूर करना, जबकि स्रोत सांख्यिकी द्वारा लंगर डाला गया - वास्तव में वह कारण था कि यह वास्तविकता में सफल हुआ। दिलचस्प बात यह है कि जब उन्होंने बैच नॉर्मलाइजेशन को इंस्टेंस नॉर्मलाइजेशन से बदला, तो उनकी अनसुपरवाइज्ड विधि ने लक्ष्य डेटा पर पूरी तरह से सुपरवाइज्ड मॉडल की तुलना में भी कम दूरी त्रुटि मेट्रिक्स हासिल किए। ईमानदारी से कहूं तो, मुझे पूरी तरह से यकीन नहीं है कि एक अनसुपरवाइज्ड एडैप्टेशन उस विशिष्ट मीट्रिक में एक सुपरवाइज्ड अपर बाउंड को कैसे हरा सकता है, लेकिन यह दृढ़ता से सुझाव देता है कि इंस्टेंस नॉर्मलाइजेशन एकल-रोगी शैली भिन्नताओं को संभालने में काफी बेहतर है।
भविष्य के विकास के लिए चर्चा विषय
इन शानदार निष्कर्षों के आधार पर, महत्वपूर्ण सोच को प्रोत्साहित करने के लिए भविष्य के अन्वेषण के कई रास्ते यहां दिए गए हैं:
- एकल-इंस्टेंस एडैप्टेशन की सीमाएँ: जबकि एकल छवि के अनुकूलन नैदानिक रूप से आदर्श है, क्या यह स्वाभाविक रूप से "भीड़ की बुद्धिमत्ता" का त्याग करता है? यदि कोई मॉडल किसी रोगी की अनूठी शरीर रचना के लिए हाइपर-एडैप्ट करता है, तो क्या यह सौम्य विसंगतियों से ट्यूमर का मतिभ्रम करने का जोखिम उठाता है जिसे जनसंख्या-स्तरीय सांख्यिकीय दृश्य ने अनदेखा कर दिया होगा? हम एकल-रोगी वैयक्तिकरण को वैश्विक शारीरिक पूर्वजों के साथ कैसे संतुलित कर सकते हैं?
- अनिश्चितता मात्राकरण के लिए एन्ट्रॉपी से परे: लेखकों ने मॉडल के आत्मविश्वास के प्रॉक्सी के रूप में शैनन एन्ट्रॉपी का उपयोग किया है। हालांकि, डीप न्यूरल नेटवर्क कुख्यात रूप से अति-आत्मविश्वासी होते हैं, अक्सर तब भी कम एन्ट्रॉपी देते हैं जब वे पूरी तरह से गलत होते हैं। क्या हम बहुत सुरक्षित और अधिक सटीक छद्म लेबल बनाने के लिए गणितीय रूप से कठोर अनिश्चितता बाउंड उत्पन्न करने के लिए बायेसियन न्यूरल नेटवर्क या एविडेंशियल डीप लर्निंग को एकीकृत कर सकते हैं?
- क्रॉस-मोडेलिटी ज्यामितीय स्थिरता: यह पेपर साबित करता है कि मल्टी-व्यू स्थिरता विभिन्न एमआरआई स्कैनर के बीच स्थानांतरण करते समय काम करती है। लेकिन क्या होगा यदि डोमेन शिफ्ट पूरी तरह से अलग भौतिक तौर-तरीकों के पार हो, जैसे कि सीटी स्कैन के लिए एमआरआई-प्रशिक्षित मॉडल को अनुकूलित करना? अंगों की अंतर्निहित 3डी ज्यामिति समान रहती है, लेकिन पिक्सेल तीव्रता भौतिकी पूरी तरह से भिन्न होती है। क्या $\mathcal{L}_{cosine}$ को पिक्सेल-स्तरीय समानताओं पर निर्भर किए बिना तौर-तरीकों के पार संरचनात्मक विशेषताओं को संरेखित करने के लिए विकसित किया जा सकता है?
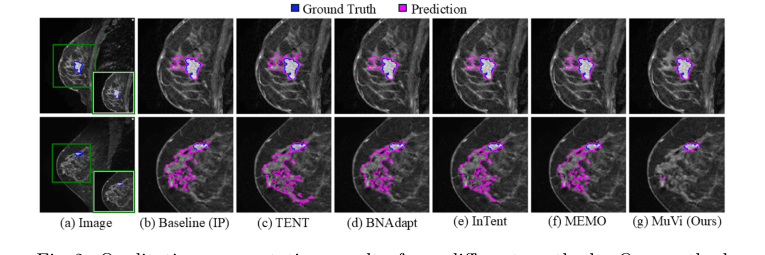 Figure 2. Qualitative segmentation results from different methods. Our method localizes the tumor precisely while removing the misidentified breast tissue
Figure 2. Qualitative segmentation results from different methods. Our method localizes the tumor precisely while removing the misidentified breast tissue