단일 이미지 테스트 시간 적응을 위한 다중 뷰 공동 학습
Test-time adaptation enables a trained model to adjust to a new domain during inference, making it particularly valuable in clinical settings where such on-the-fly adaptation is required.
배경 및 학문적 계보
의료 영상 AI는 오랫동안 좌절스러운 현실에 직면해 왔다. 즉, 병원 A에서 종양을 탐지하도록 훈련된 딥러닝 모델이 병원 B에 배포될 때 자주 실패한다는 것이다. 이는 병원마다 다른 MRI 스캐너(예: GE 대 Siemens), 다양한 자기장 강도, 그리고 고유한 소프트웨어 프로토콜을 사용하기 때문이다. 컴퓨터 비전 및 의료 영상 분석의 학술 분야에서 이러한 불일치는 "도메인 시프트(domain shift)"로 알려져 있다.
역사적으로 연구자들은 새로운 병원에서 대규모 데이터셋을 수집하여 모델을 재훈련하거나 fine-tuning함으로써 이 문제를 해결하려고 시도했다. 그러나 실제 임상 환경에서는 의사들이 방금 병원에 도착한 단일 환자에 대해 즉각적이고 on-the-fly 분석을 필요로 한다. 환자에게 병원이 소프트웨어를 업데이트하기 위해 천 개 이상의 스캔을 추가로 수집하는 동안 몇 주를 기다리라고 말할 수는 없다. 이러한 긴급한 필요성은 Test-Time Adaptation (TTA)이라는 하위 분야를 탄생시켰으며, 여기서 모델은 추론 시점에 정확하게 새로운 데이터에 스스로를 조정하려고 시도한다.
TTA의 가능성에도 불구하고, 이전 접근 방식들은 심각한 근본적인 한계에 시달렸다. 첫째, 대부분의 기존 TTA 방법은 통계적 조정(특히 Batch Normalization 통계)을 계산하기 위해 대규모 "배치(batch)"의 입력 이미지를 필요로 한다. 병원에서 단 한 명의 환자만 스캔해야 한다면, 이러한 배치 의존적인 방법은 완전히 실패한다. 둘째, 이전 모델들은 종종 무거운 아키텍처 수정이 필요하거나 실제 종양의 높은 해부학적 변동성에 견디지 못하는 엄격한 형태 사전 정보(shape priors)에 의존했다. 마지막으로, 대부분의 현재 방법은 의료 스캔을 평평한 2D 슬라이스로 처리하며, 데이터의 풍부한 3D 볼륨 컨텍스트를 완전히 무시한다. 고해상도 3D 의료 볼륨을 처리하려면 막대한 GPU 메모리가 필요하며, 이는 대규모 배치 처리를 단일 환자에 대해 수학적으로 잘못되었을 뿐만 아니라 계산적으로도 너무 비싸게 만든다. 이는 병원이 표준 150달러 하드웨어 업그레이드만 예산으로 책정했을 때 거대한 서버 팜을 구매하도록 강요하는 것과 같다. 저자들은 단일 3D 이미지만을 사용하여 치명적인 메모리 비용이나 성능 저하 없이 실시간으로 모델을 조정할 수 있는 기존 방법이 없었기 때문에 이 논문을 작성해야 했다.
저자들이 이 문제를 어떻게 해결했는지 이해를 돕기 위해, 몇 가지 매우 전문적인 도메인 용어를 직관적인 개념으로 분해해 보자.
- 도메인 시프트 (Domain Shift): AI가 실제 세계에서 보는 데이터가 훈련된 데이터와 다를 때 AI의 성능이 저하되는 현상.
- 비유: 조용하고, 맑고, 예측 가능한 교외에서 운전하는 법을 배우는 것(훈련 데이터)을 상상해 보라. 만약 당신이 갑자기 출퇴근 시간 동안 혼란스럽고 눈이 오는 도심에 던져진다면(테스트 데이터), 당신의 운전 기술은 급격히 떨어질 것이다. 이러한 풍경의 변화가 도메인 시프트이다.
- Test-Time Adaptation (TTA): AI 모델이 재훈련을 위해 오프라인으로 전환될 필요 없이, 활발하게 사용되는 동안 스스로를 업데이트하고 개선하는 능력.
- 비유: 콘서트홀의 음향이 약간 좋지 않다는 것을 깨닫는 라이브 무대 음악가를 생각해 보라. 쇼를 멈추고 리허설 스튜디오로 돌아가는 대신, 그들은 음표 사이의 무대 위에서 미묘하게 악기를 조율한다.
- 의사 레이블링 (Pseudolabeling): AI가 주석이 없는 데이터에 대해 최선의 추측을 하고, 그 추측을 "절대적인 진실"로 취급하여 스스로를 더 훈련시키는 기법.
- 비유: 학생이 답안지 없이 연습 문제를 푸는 것을 상상해 보라. 그들은 자신이 매우 확신하는 문제에 답하고, 그 답이 맞다고 가정하며, 어려운 문제에 대한 패턴을 파악하는 데 사용한다.
- 다중 뷰 공동 훈련 (Multi-View Co-Training): AI가 3D 데이터를 보는 각도나 관점(예: 위, 앞, 또는 옆에서 보는 것)에 관계없이 예측이 일관되게 유지되도록 훈련하는 것.
- 비유: 어두운 방에서 신비한 물체를 검사하고 있다면, 당신은 그것을 앞에서만 보지 않을 것이다. 당신은 그것 주위를 돌아다니며 위와 옆에서 볼 것이다. 만약 당신의 뇌가 앞에서 볼 때 그것이 의자라고 결론 내리고, 옆에서 볼 때 탁자라고 결론 내린다면, 무언가 잘못된 것이다. 다중 뷰 공동 훈련은 AI의 결론이 모든 각도에서 일치하도록 강제한다.
저자들이 해결한 문제를 정확히 수학적으로 해석하고 단일 이미지 적응을 어떻게 구성했는지 이해하려면, 그들이 사용한 핵심 변수와 매개변수를 정의해야 한다. 아래는 다중 뷰 일관성 프레임워크의 기초를 나타낼 표기법 테이블이다.
| 표기법 | 설명 |
|---|---|
| $M(\theta_s)$ | 소스 도메인에서 학습된 가중치 $\theta_s$로 매개변수화된 사전 훈련된 신경망 모델. |
| $X_s, Y_s$ | 소스 도메인 3D 이미지 텐서 및 해당 밀집 레이블이 지정된 복셀 단위의 Ground Truth 마스크. |
| $X_t, Y_t$ | 타겟 도메인 3D 이미지 텐서 및 해당 Ground Truth 마스크 (테스트 시간 적응 중에는 사용할 수 없음). |
| $x_t$ | 테스트 시간 동안 발생하는 단일 3D 타겟 이미지로, 모델이 적응해야 한다. |
| $\mu_s, \sigma_s$ | 모델의 사전 훈련 단계 동안 얻어진 원래의 평균 및 분산 통계. |
| $\gamma, \beta$ | 전체 배치 새 이미지 없이 테스트 시간 동안 네트워크를 조절하는 데 사용되는 학습 가능한 아핀 변환 매개변수. |
| $x_{t_{p_i}}$ | 단일 타겟 테스트 이미지 $x_t$에서 추출된 $i$-번째 중첩 3D 패치. |
| $\pi_1, \pi_2$ | 패치를 대체 해부학적 뷰(예: 축 방향에서 시상 또는 관상 방향)로 회전하거나 변환하는 데 사용되는 뷰별 순열 함수. |
| $v$ | 원본 패치와 변환된 버전으로 구성된 뷰 집합, $v \in \{x_{t_{p_i}}, x'_{t_{p_i}}, x''_{t_{p_i}}\}$로 정의됨. |
| $H(z)$ | 모델의 예측 확률 $z$에서 계산된 픽셀당 엔트로피. 모델의 불확실성을 측정한다. |
| $\tau$ | 경험적으로 설정된 엔트로피 임계값. 이 임계값보다 낮은 불확실성을 가진 예측은 확신 있는 것으로 받아들여진다. |
| $\hat{y}_{t_{p_i}}$ | 특정 패치에 대해 생성된 엔트로피 기반 의사 레이블로, 자체 훈련을 위한 임시 Ground Truth로 사용된다. |
| $\mathcal{L}_{sl}$ | Dice Loss와 Cross-Entropy Loss를 결합하여 모델을 자체 의사 레이블로 훈련시키는 자체 학습 손실 함수. |
| $\mathcal{L}_{consistency}$ | 모델이 어떤 뷰($x'_{t_{p_i}}$ 또는 $x''_{t_{p_i}}$)를 처리하든 동일한 분할을 출력하도록 강제하는 일관성 손실 함수. |
| $\mathcal{L}_{cosine}$ | 의사 레이블과 독립적으로 다른 뷰의 딥 피처 임베딩이 정렬되도록 보장하는 코사인 유사도 손실. |
역사적인 배치 통계($\mu_s, \sigma_s$)를 고정하고 경량 매개변수($\gamma, \beta$)만 결합 손실 함수 $$\mathcal{L}_{total} = \lambda_1\mathcal{L}_{sl} + \lambda_2\mathcal{L}_{consistency} + \lambda_3\mathcal{L}_{cosine}$$를 사용하여 업데이트함으로써, 저자들은 단일 이미지만을 사용하여 새로운 병원의 MRI 스캐너에 적응하는 방법을 성공적으로 개발했으며, 이는 이전 접근 방식들을 좌절시켰던 대규모 데이터 및 메모리 병목 현상을 완전히 우회했다.
문제 정의 및 제약 조건
시작점, 목표점, 그리고 임상적 함정
본 논문의 획기적인 성과를 진정으로 이해하기 위해서는, 먼저 수학적 및 실질적 시작점, 원하는 최종 목표, 그리고 병원 환경에 인공지능을 배포할 때 마주하는 냉혹한 현실을 파악해야 한다.
시작점 (입력 상태):
우리는 소스 데이터셋에 대해 사전 학습되어 $f: X_s \rightarrow Y_s$라는 매핑 함수를 학습한 딥러닝 모델 $M(\theta_s)$로 시작한다. 여기서 $X_s$는 특정 병원의 3D 의료 영상 텐서(예: 유방 MRI)를 나타내며, $Y_s$는 종양의 정확한 경계를 나타내는 밀집 레이블이 지정된 복셀 단위 3D 분할 마스크를 나타낸다.
테스트 시점에 모델은 새로운 병원에 배포된다. 이때 타겟 도메인 $t$에서 온 단일의 레이블 없는 3D 영상 텐서 $x_t \in X_t$가 주어진다. 이 새로운 영상은 다른 MRI 스캐너에서 촬영되었기 때문에 대비, 해상도 또는 노이즈 프로필이 다를 수 있다. 우리는 원본 소스 데이터 $s$에 전혀 접근할 수 없으며, 이 새로운 환자에 대한 Ground Truth 레이블도 가지고 있지 않다.
목표 상태 (출력):
목표는 모델 파라미터 $\theta_s$를 새로운 타겟 도메인에 즉시 적응시켜, 이 특정 환자에 대한 3D 분할 마스크 $Y_t$를 정확하게 출력하는 새로운 함수 $k: X_t \rightarrow Y_t$를 학습하는 것이다. 결정적으로, 모델은 제공된 단일 영상 $x_t$만을 사용하여 즉석에서 이를 수행해야 한다.
수학적 간극:
누락된 연결 고리는 비지도 최적화 브릿지이다. 타겟 $Y_t$와 비교할 대상이 없고, 새로운 통계적 분포를 추정하기에 타겟 도메인 $X_t$의 데이터 포인트가 충분하지 않을 때, 어떻게 손실 기울기를 계산하여 $\theta_s$를 업데이트할 수 있는가?
통계적 안정성 대 임상 지연: 고통스러운 딜레마
Test-Time Adaptation (TTA) 분야에서 연구자들은 통계적 안정성과 임상 지연 사이의 악순환적인 절충안에 갇혀 있었다.
대부분의 기존 TTA 방법은 Batch Normalization (BN) 레이어 업데이트에 크게 의존한다. 모델을 새로운 도메인에 적응시키기 위해, 이러한 방법들은 새로운 타겟 분포의 평균 $\mu$와 분산 $\sigma^2$을 재계산한다. 그러나 분포에 대한 안정적인 수학적 추정치를 얻으려면 대규모 데이터 배치(batch)가 필요하다.
여기 딜레마가 있다: BN 통계치를 안정화하기 위해 대규모 환자 스캔 배치를 수집할 때까지 기다린다면, 임상 진료의 실시간, 온디맨드 특성을 파괴하게 된다. 의사는 앞에 앉아 있는 환자를 AI가 진단하기 전에 30명의 환자가 더 스캔되기를 기다릴 수 없다. 반대로, 배치 크기를 정확히 1(단일 환자)을 사용하여 BN 통계치를 적응시키려고 하면, 통계적 추정치가 극심하게 변동하여 모델의 예측이 붕괴된다. 모델의 정확성을 깨뜨리거나 병원의 워크플로우를 깨뜨리는 것 중 하나를 선택해야 한다.
의료 영상 적응의 가혹한 장벽
저자들은 이 특정 문제를 해결하기 매우 어렵게 만드는 몇 가지 냉혹하고 현실적인 제약에 직면했다.
- 데이터의 극심한 희소성 (단일 영상의 벽):
모델은 $N=1$개의 샘플을 사용하여 적응해야 한다. 테스트 시점에는 학습할 데이터셋이 없고, 단지 단일 인스턴스만 존재한다. 단일 지점에서 분포를 매핑할 수 없기 때문에, 전통적인 비지도 도메인 적응 기법에 의존하는 것은 수학적으로 불가능하다. - 하드웨어 메모리 제한 (VRAM의 벽):
2D 사진과 달리, 의료 영상은 고해상도 3D 볼륨 데이터를 사용한다. 3D 텐서를 처리하려면 막대한 양의 GPU 메모리(VRAM)가 필요하다. 병원에서 알고리즘을 안정화하기 위해 대규모 배치 크기를 사용하고 싶더라도, 표준 병원 하드웨어는 한 번에 대규모 3D MRI 배치를 메모리에 담을 수 없다. - 소스 없는 제약 (개인 정보 보호의 벽):
엄격한 환자 개인 정보 보호법과 막대한 저장 공간 요구 사항으로 인해, 원본 소스 학습 데이터 $X_s$는 모델과 함께 제공될 수 없다. 적응은 완전히 "소스 없는(source-free)" 방식으로 이루어져야 하며, 이는 모델이 새로운 스캐너에 적응하는 동안 종양이 어떻게 보여야 하는지 기억하기 위해 이전 데이터를 다시 볼 수 없음을 의미한다. - 다중 스캐너 설정의 움직이는 목표:
병원에서 추론을 지연시키고 들어오는 환자 배치를 기다리기로 결정하더라도, 해당 환자들이 단일 타겟 분포를 공유한다는 보장은 없다. 다중 스캐너 병원에서는 환자 A가 GE 장비에서, 환자 B가 Siemens 장비에서 스캔될 수 있다. 공유 타겟 분포를 계산하기 위해 이들을 배치로 그룹화하는 것은 수학적으로 결함이 있어, 전통적인 배치 기반 적응 기법을 완전히 비효율적으로 만든다.
이 접근 방식은 왜
이 논문의 탁월함을 이해하기 위해서는 먼저 병원에서 인공지능을 배포할 때 마주하는 혹독한 현실을 파악해야 한다. 병원 A의 MRI 스캔을 사용하여 유방 종양을 탐지하도록 훈련된 딥러닝 모델을 상상해보자. 이 모델은 해당 병원에서는 완벽하게 작동한다. 하지만 다른 MRI 스캐너, 다른 자기장 강도, 다른 영상 프로토콜을 사용하는 병원 B에 배포하면 모델은 갑자기 실패한다. 이를 "도메인 시프트(domain shift)"라고 한다.
전통적으로 엔지니어들은 병원 B에서 수천 장의 이미지를 수집하여 모델을 재훈련하는 방식으로 이 문제를 해결한다. 그러나 실제 임상 환경에서는 의사들이 환자의 스캔을 즉시 분석해야 한다. 그들은 방대한 데이터셋을 수집하기 위해 몇 달을 기다릴 수 없다. 모델은 해당 환자의 단일 스캔만을 사용하여 즉석에서 적응해야 한다. 이것이 바로 단일 이미지 테스트 시간 적응(Single Image Test-Time Adaptation, TTA)의 근본적인 과제이다.
"아하!" 순간: SOTA 방법론이 실패한 이유
저자들은 결정적인 깨달음을 얻었다. 현재 컴퓨터 비전 분야의 최첨단(State-of-the-Art, SOTA) 방법론들은 3D 의료 영상의 물리적, 임상적 제약 조건과 근본적으로 양립할 수 없다는 것이다.
Tent, PTN, BNAdapt와 같은 인기 있는 TTA 방법론들을 살펴보면서 저자들은 치명적인 결함을 발견했다. 이러한 방법론들은 배치 정규화(Batch Normalization, BN)에 크게 의존한다. 새로운 도메인에 적응하기 위해, 이들은 네트워크를 업데이트하기 위해 대규모 배치의 수신 테스트 이미지들의 통계적 평균과 분산을 계산한다. 그러나 병원에서는 한 번에 한 명의 환자를 평가한다. 더욱이, 의료 영상은 평평한 2D 이미지가 아니라 거대하고 고해상도의 3D 볼륨이다. 3D MRI의 대규모 배치를 처리하려면 막대한 GPU 메모리(VRAM)가 필요하며, 이는 표준 병원 하드웨어에서는 계산적으로 불가능하다.
단 하나의 이미지에 대해서만 BN 통계를 계산하려고 하면 수학적으로 무너지고 모델의 성능은 실제로 악화된다. 저자들은 표준 CNN 적응 기법, 심지어 최신 트랜스포머 기반 배치 방법론들조차 이 특정 문제에 대해 완전히 불충분하다는 것을 깨달았다.
솔직히 말해서, 저자들이 이 정확한 단일 이미지 설정에 대해 GAN이나 Diffusion 모델과 같은 무거운 생성 모델을 명시적으로 테스트했는지 완전히 확신할 수는 없지만, 이 논문은 왜 실패할 것인지를 강력하게 시사한다. 이러한 모델들은 방대한 대상 데이터셋과 광범위한 재훈련 시간을 요구하며, 이는 임상 환경에서 요구되는 "실시간, 환자별" 제약 조건을 완전히 위반한다. 더욱이, 저자들은 "프로토타입 기반(Prototype-based)" 적응 방법론들을 명시적으로 거부했다. 왜냐하면 프로토타입 방법론은 일관된 모양(shape priors)에 의존하는데, 유방 종양은 해부학적 변동성이 극도로 높기 때문이다. 예측 가능한 모양을 따르지 않는다.
벤치마킹 논리: 구조적 우수성
전통적인 방법론들이 실패했기 때문에, 저자들은 질적으로 우수한 접근 방식을 발명해야 했다: 패치 기반 다중 뷰 공동 훈련(Patch-Based Multi-View Co-Training, MuVi).
MuVi는 새로운 도메인을 파악하기 위해 다른 환자들의 대규모 배치에 의존하는 대신, 단일 환자의 MRI에서 겹치는 3D 패치를 추출하고 세 가지 다른 직교 각도(축 방향, 시상 방향, 관상 방향)에서 이를 살펴본다.
이는 막대한 구조적 이점을 제공한다. 모델이 동일한 3D 조직을 다른 관점에서 보도록 강제함으로써, 단일 이미지에서 충분히 "다양한" 데이터를 인위적으로 생성하여 네트워크를 적응시킨다. 이는 대규모 배치 크기의 필요성을 완전히 우회하며, 메모리 및 데이터 요구량을 $N$명의 환자에서 $1$명으로 효과적으로 줄인다.
수학적으로, 그들은 정규화 과정을 분할함으로써 배치 정규화 위기를 해결했다. 소스 통계를 대체하는 대신, 훈련 중에 학습된 원래 평균 $\mu_s$와 분산 $\sigma_s$를 고정하고 정규화된 입력을 다음과 같이 계산한다.
$$ \hat{x} = \frac{x - \mu_s}{\sqrt{\sigma_s^2 + \epsilon}} $$
그런 다음, 경사 하강법을 통해 경량의 아핀 변환 매개변수($\gamma$ 및 $\beta$)만 업데이트하도록 허용한다.
$$ y = \gamma \hat{x} + \beta $$
이는 모델이 단일 이미지의 고차원 노이즈에 직면했을 때 붕괴되는 것을 방지하는 동시에 새로운 스캐너의 대비 및 강도에 적응할 수 있도록 한다.
제약 조건과 해결책의 완벽한 조화
이 논문의 진정한 우아함은 수학적 해결책이 혹독한 임상 제약 조건과 얼마나 완벽하게 일치하는지에 있다.
새로운 환자에 대한 정답 레이블이 없기 때문에 모델은 스스로 학습해야 한다(self-training). 그러나 자기 훈련은 레이블 노이즈에 매우 민감하다. 모델이 잘못 추측하면 자신의 실수로부터 학습하여 통제 불능 상태에 빠질 수 있다.
이를 극복하기 위해 저자들은 엔트로피 기반 자기 훈련(Entropy-guided Self-Training)을 도입했다. 그들은 픽셀별 섀넌 엔트로피를 계산하여 모델이 예측에 대해 얼마나 "불확실한지"를 측정한다.
$$ H(z) = -z \log_2(z) - (1-z) \log_2(1-z) $$
여기서 $z \in [0, 1]$는 종양에 대한 예측 확률이다. 모델은 엔트로피가 엄격한 임계값 $\tau$보다 낮은 경우에만 예측을 수락한다(모델이 매우 확신함을 의미).
그런 다음 세 가지 다른 뷰에서 이러한 높은 확신도를 가진 예측을 결합하여 신뢰할 수 있는 "의사 레이블(pseudolabel)"을 생성한다. 마지막으로, 모든 뷰에 걸쳐 일관성을 강제하는 결합 손실 함수를 사용하여 네트워크를 업데이트한다.
$$ \mathcal{L}_{total} = \lambda_1 \mathcal{L}_{sl} + \lambda_2 \mathcal{L}_{consistency} + \lambda_3 \mathcal{L}_{cosine} $$
이것은 완벽한 조화이다.
1. 제약 조건: 단 하나의 이미지만 사용 가능. 해결책: 해당 단일 3D 볼륨에서 여러 뷰를 생성한다.
2. 제약 조건: 레이블 없음. 해결책: 엔트로피 수학을 사용하여 노이즈를 필터링하고 높은 확신도를 가진 의사 레이블을 생성한다.
3. 제약 조건: 제한된 GPU 메모리. 해결책: 무거운 배치 통계를 고정하고 작은 3D 패치에 대해서만 경량 매개변수를 업데이트한다.
이러한 고유한 속성을 일치시킴으로써, 저자들은 단 한 명의 추가 환자 스캔 없이 기존의 모든 SOTA 방법론들을 능가하며 Dice 유사도 계수(Dice Similarity Coefficient)에서 5.57%의 개선을 달성했다.
수학 및 논리 메커니즘
병원 A의 수천 건의 MRI 스캔을 통해 유방 종양을 식별하도록 훈련된 뛰어난 의사를 상상해 보십시오. 만약 이 의사를 갑자기 병원 B로 옮긴다면 어려움을 겪을 수 있습니다. 병원 B는 자기장의 세기, 조영제, 노이즈 프로파일이 다른 다양한 MRI 장비를 사용합니다. 인공지능 분야에서는 이를 "도메인 시프트(domain shift)"라고 부릅니다.
일반적으로 이를 해결하기 위해 데이터 과학자들은 병원 B에서 수천 개의 새로운 이미지를 수집하여 AI를 재훈련시킬 것입니다. 하지만 실제 임상 환경에서는 이는 불가능합니다. 의사는 지금 당장 앞에 앉아 있는 단일 환자에 대한 정확한 분할(segmentation)이 필요합니다. 방대한 데이터셋이 컴파일될 때까지 기다릴 수 없습니다. 더욱이, 의료 영상은 풍부한 3D 볼륨 데이터이지만, 대부분의 기존 적응 방법은 이를 평평한 2D 사진처럼 취급하여 공간적 깊이를 무시합니다.
이 논문의 저자들은 매우 제약적인 문제를 해결했습니다. 사전 훈련된 3D 의료 AI가 원래 훈련 데이터를 다시 전혀 보지 않고, 단일 이미지만을 사용하여 완전히 새롭고 보지 못한 환경에 어떻게 적응하도록 강제할 수 있을까요?
이를 달성하기 위해 저자들은 다중 뷰 공동 훈련(Multi-View Co-Training) 엔진을 구축했습니다. 이것을 가능하게 하는 수학을 분석해 봅시다.
핵심 수학 엔진
이 시스템은 2단계 메커니즘으로 구동됩니다. 첫째, 단일 이미지로부터 높은 신뢰도의 "가짜 정답(fake ground truth)" (의사 레이블, pseudolabel)을 생성합니다. 둘째, 서로 다른 3D 기하학적 뷰에 걸쳐 복합 손실 함수를 최소화함으로써 네트워크가 스스로 업데이트되도록 강제합니다.
이러한 적응을 주도하는 마스터 방정식은 다음과 같습니다.
1. 의사 레이블 생성 (엔트로피 기반 합집합, Entropy-Guided Union):
$$ \hat{y} = \bigcup_{v \in \{x_t, x'_t, x''_t\}} \{j \mid H(\sigma(f(v(j)))) < \tau_v\} $$
2. 자기 학습 목표 (Self-Learning Objective):
$$ \mathcal{L}_{sl} = \sum_{v \in \{x_{t_{p_i}}, x'_{t_{p_i}}, x''_{t_{p_i}}\}} \left[ \mathcal{L}_{DICE}(f(v), \hat{y}_{t_{p_i}}) + \mathcal{L}_{CE}(f(v), \hat{y}_{t_{p_i}}) \right] $$
3. 특징 일관성 목표 (Feature Consistency Objective):
$$ \mathcal{L}_{cosine} = 1 - \cos(g(x_{t_{p_i}}), g(x'_{t_{p_i}})) + 1 - \cos(g(x_{t_{p_i}}), g(x''_{t_{p_i}})) $$
4. 총 최적화 지형 (Total Optimization Landscape):
$$ \mathcal{L}_{total} = \lambda_1 \mathcal{L}_{sl} + \lambda_2 \mathcal{L}_{consistency} + \lambda_3 \mathcal{L}_{cosine} $$
방정식을 분해하다
이 수학적 기계 장치의 모든 기어와 스프링을 분해해 봅시다.
의사 레이블 방정식 ($\hat{y}$)에서:
* $\hat{y}$: 마스터 의사 레이블입니다. 이것은 종양이 어디에 있는지에 대한 모델의 가장 자신감 있는 추측이며, 다음 훈련 단계에서 "정답(ground truth)" 역할을 할 것입니다.
* $v \in \{x_t, x'_t, x''_t\}$: 대상 이미지의 세 가지 서로 다른 3D 뷰 (축 방향, 관상 방향, 시상 방향 평면)입니다.
* $j$: MRI 스캔의 특정 복셀(voxel, 3D 픽셀)입니다.
* $f(v(j))$: 해당 복셀에 대한 신경망의 원시 예측입니다.
* $\sigma(\cdot)$: 시그모이드 활성화 함수입니다. 원시 예측을 0과 1 사이의 확률로 압축합니다.
* $H(\cdot)$: 섀넌 엔트로피 함수로, $H(z) = -z \log_2(z) - (1-z) \log_2(1-z)$로 정의됩니다. 논리적으로 이것은 엄격한 문지기 역할을 합니다. 모델이 확신하지 못하면(예: 종양 확률 50%), 엔트로피가 높습니다. 매우 확신하면(예: 99% 또는 1%), 엔트로피가 낮습니다.
* $\tau_v$: 신뢰도 임계값입니다. 엔트로피가 이 숫자보다 낮으면 예측이 수락됩니다.
* $\bigcup$: 합집합 연산자입니다. 교집합 대신 합집합을 사용하는 이유는 무엇일까요? 서로 다른 3D 뷰는 서로 다른 해부학적 경계를 포착하기 때문입니다. 교집합은 세 뷰 모두가 동의하는 복셀만 유지하여 심각하게 축소되고 보수적인 종양 마스크를 생성할 것입니다. 합집합은 모든 관점에서 높은 신뢰도의 발견을 집계하여 포괄적인 3D 맵을 구축합니다.
자기 학습 방정식 ($\mathcal{L}_{sl}$)에서:
* $\sum$: 세 뷰에 대한 합계입니다. 곱셈 대신 덧셈을 사용하는 이유는 무엇일까요? 모든 관점에서 누적된 오류를 원합니다. 곱셈을 사용하면 한 뷰에서의 거의 0에 가까운 오류가 다른 뷰에서의 엄청난 오류를 상쇄할 수 있으며, 이는 의료 영상에서 위험합니다.
* $\mathcal{L}_{DICE}$: 다이스 손실(Dice Loss)입니다. 예측과 의사 레이블 간의 공간적 중첩을 측정합니다. 이것은 예측된 종양의 전체 모양을 의사 레이블에 맞추도록 잡아당기는 고무줄 역할을 하며, 종양이 배경에 비해 매우 작아 불균형한 의료 영상에서 중요합니다.
* $\mathcal{L}_{CE}$: 교차 엔트로피 손실(Cross-Entropy Loss)입니다. 복셀별 분류 정확도를 평가합니다. DICE와 CE를 함께 더하는 이유는 무엇일까요? DICE는 전체 모양에 탁월하지만 경사 하강 중에 수학적으로 불안정할 수 있습니다. CE는 매우 안정적이지만 전체 구조를 무시합니다. 이를 더하면 완벽하게 균형 잡히고 안정적인 경사를 제공합니다.
특징 일관성 방정식 ($\mathcal{L}_{cosine}$)에서:
* $g(\cdot)$: 특징 추출기 (신경망의 깊은 내부 계층, 최종 분류 이전)입니다.
* $\cos(\cdot, \cdot)$: 코사인 유사도(Cosine similarity)입니다.
* $1 - \cos(\cdot, \cdot)$: 코사인 거리(Cosine distance)입니다. 표준 L2 (유클리드) 거리 대신 코사인 거리를 사용하는 이유는 무엇일까요? 깊고 고차원적인 신경망에서 특징 벡터의 방향은 의미론적 의미(예: "이 질감은 종양이다")를 가지는 반면, 크기는 해당 특징의 강도를 나타낼 뿐입니다. 코사인 거리는 벡터 간의 각도를 엄격하게 측정하여, 뷰 각도에 관계없이 종양의 의미론적 의미를 정렬하도록 네트워크를 강제합니다.
총 손실 ($\mathcal{L}_{total}$)에서:
* $\lambda_1, \lambda_2, \lambda_3$: 자기 학습, 예측 일관성, 특징 일관성의 중요도를 보정하는 스칼라 가중치입니다. 저자들은 균형을 맞추기 위해 이를 동일하게 설정했습니다.
단계별 흐름: 조립 라인
단일 추상 데이터 포인트, 즉 환자의 3D MRI 스캔을 이 엔진을 통해 추적해 봅시다.
- 관점 분할: 3D 스캔 $x_t$가 시스템에 들어가 즉시 세 가지 서로 다른 기하학적 방향, 즉 축 방향, 관상 방향, 시상 방향으로 순열됩니다.
- 신뢰도 필터: 고정된 모델이 세 가지 뷰를 모두 살펴보고 예비 종양 마스크를 생성합니다. 엔트로피 함수 $H$가 모든 복셀을 스캔합니다. 모델이 망설이거나 약한 확률을 출력하면 해당 복셀은 즉시 폐기됩니다.
- 마스터 키 제작: 세 뷰 모두에서 살아남은 높은 신뢰도의 복셀들이 합집합 연산자 $\bigcup$을 통해 융합되어 골든 의사 레이블 $\hat{y}$을 생성합니다.
- 패치 추출: 3D 의료 영상은 매우 크고 GPU 메모리를 초과할 수 있으므로, 이미지를 더 작은 3D 블록(패치) $x_{t_{p_i}}$으로 분할합니다.
- 이중 보정 루프: 각 패치가 네트워크를 통과합니다. 네트워크의 최종 출력은 DICE + CE 손실을 사용하여 골든 의사 레이블과 비교됩니다. 동시에 패치의 깊은 내부 표현 $g(x)$가 추출됩니다. 코사인 손실은 서로 다른 뷰의 특징 벡터를 가져와 고차원 공간에서 물리적으로 회전시켜 정확히 같은 방향을 가리키도록 합니다.
최적화 역학: 실제 학습 방식
여기서 저자들은 뛰어난 최적화 전략을 선보입니다. 단일 이미지에서 모델을 훈련하면서 즉시 과적합되어 붕괴되지 않도록 어떻게 할까요?
모델은 단일 에포크(epoch)에서 업데이트됩니다. 또한, 저자들은 전체 네트워크를 업데이트하지 않습니다. 거의 모든 것을 고정하고 그래디언트가 정규화 계층의 아핀 매개변수($\gamma$ 및 $\beta$)만 업데이트하도록 허용합니다.
왜 그럴까요? 표준 배치 정규화(Batch Normalization)에서 네트워크는 대규모 이미지 배치(batch)의 평균($\mu$) 및 분산($\sigma$)에 의존합니다. 하지만 여기서는 이미지가 하나뿐입니다. 단일 이미지는 전체 데이터셋의 분포를 재정의할 만큼 충분한 통계적 힘을 갖지 못합니다. 따라서 저자들은 원래 소스 도메인의 $\mu$ 및 $\sigma$를 고정합니다.
그래디언트가 $\mathcal{L}_{total}$에서 역방향으로 흐르면서, $\gamma$(스케일)와 $\beta$(이동)만 조정합니다. 이것은 경량 보정 노브 역할을 합니다. 모델이 원래 학습한 기본적인 종양 탐지 로직을 파괴하지 않으면서 새로운 병원의 MRI 대비 및 밝기에 적응하도록 특징 맵을 충분히 이동하고 스케일링합니다.
여기서 손실 지형은 다중 뷰 일관성에 의해 크게 제약됩니다. 서로 다른 기하학적 변환에 걸쳐 모델이 스스로 동의하도록 강제함으로써, $\mathcal{L}_{cosine}$ 및 $\mathcal{L}_{consistency}$ 항은 거대한 정규화기 역할을 합니다. 이것들은 수렴을 위한 가파르고 좁은 경로를 깎아내어, 모델이 단일 노이즈가 있는 이미지에 기반하여 무분별한 예측을 환각하는 것을 방지합니다. 네트워크는 이전 훈련 데이터와 새롭고 보지 못한 환자 간의 격차를 완벽하게 연결하는 지역 최소값으로 빠르게 수렴합니다.
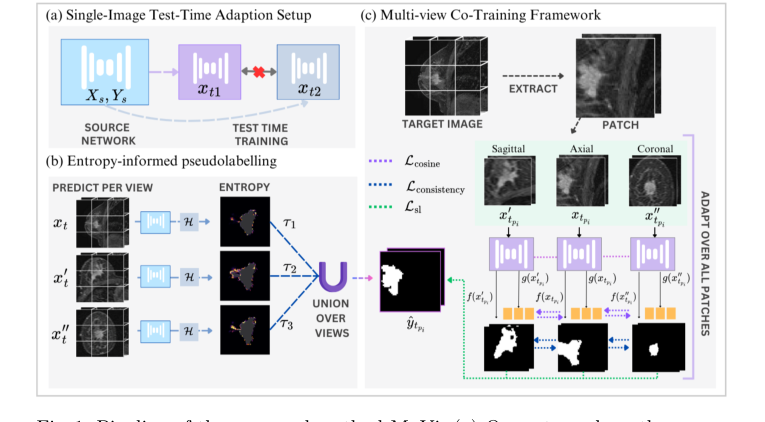 Figure 1. Pipeline of the proposed method MuVi. (a) Our setup where the source network is adapted independently for each target sample xt, (b) computing pseu- dolabel through entropy-threshold union of prediction from each view, (c) Adap- tation via patch-based training through our multi-view consistency framework
Figure 1. Pipeline of the proposed method MuVi. (a) Our setup where the source network is adapted independently for each target sample xt, (b) computing pseu- dolabel through entropy-threshold union of prediction from each view, (c) Adap- tation via patch-based training through our multi-view consistency framework
결과, 한계점 및 결론
운전면허를 조용하고 햇볕이 잘 드는 교외 마을에서 배웠다고 상상해보자. 도로, 표지판, 교통 흐름을 모두 익혔다. 그런데 갑자기 혼란스럽고 눈보라가 몰아치는 대도시 한복판에 던져져 운전하라는 지시를 받는다. 기본적인 운전 기술은 그대로지만, 도메인이 너무나 극적으로 바뀌었기 때문에 실수를 할 수밖에 없다.
의료 영상 분야에서 딥러닝 모델은 이와 정확히 동일한 악몽에 직면한다. 한 병원의 MRI 스캐너 영상으로 학습된 모델은 다른 병원의 스캐너 영상 분석 시 종종 치명적인 실패를 겪는다. 자기장 강도, 재구성 소프트웨어, 영상 프로토콜은 "도메인 시프트"를 야기한다.
이를 해결하기 위해 연구자들은 Test-Time Adaptation (TTA)을 사용한다. 모델 전체를 처음부터 다시 학습시키는 것—이는 병원을 바꿀 때마다 15만 달러 상당의 새 의료 기기를 구매하는 것만큼이나 비용이 많이 든다— 대신, TTA는 모델이 예측을 하는 바로 그 순간에 모델을 약간 조정한다. 그러나 기존 TTA 방법에는 치명적인 결함이 있다. 새로운 환경을 이해하기 위해 대규모 이미지 배치를 요구한다는 것이다. 실제 임상 환경에서 의사들은 배치를 사용하지 않는다. 그들은 진단을 기다리는 단일 환자의 단일 3D 스캔만을 가지고 있다. 더 나아가, 기존 방법들은 종종 3D 의료 영상을 평평한 2D 사진의 스택처럼 취급하여 인간 해부학의 풍부하고 입체적인 현실을 완전히 무시한다.
본 논문은 획기적인 소스-프리 솔루션인 Patch-Based Multi-View Co-Training (MuVi)를 소개한다. 이들이 단일 이미지 3D 적응 문제를 어떻게 해결했는지 자세히 살펴보자.
문제와 해결책의 수학적 핵심
문제:
소스 데이터셋 $s$에서 이미 학습된 매핑 함수 $f: X_s \rightarrow Y_s$를 갖는 파라미터 $\theta_s$의 모델 $M(\theta_s)$가 주어졌다고 가정하자. 우리의 목표는 이 모델을 새로운 타겟 도메인 $t$에 적응시켜 새로운 함수 $k: X_t \rightarrow Y_t$를 학습하는 것이다. 여기서의 엄청난 제약은 원본 소스 데이터에 접근할 수 없고, 타겟 데이터의 Ground Truth 레이블에 접근할 수 없으며, 단일 타겟 이미지 $x_t \in X_t$만을 사용하여 이를 수행해야 한다는 것이다.
해결책:
저자들은 영리한 통계 보존과 기하학적 일관성의 조합을 통해 이 문제를 해결한다.
-
소스 통계 보존:
표준 Batch Normalization (BN)은 데이터 배치의 평균 $\mu$와 분산 $\sigma$에 의존한다. 단일 이미지에서 $\mu$와 $\sigma$를 계산하려고 하면 수학적으로 노이즈가 많은 혼돈으로 분해된다. 따라서 저자들은 원본 소스 통계 $\mu_s$와 $\sigma_s$를 고정한다. 그들은 테스트 시점에 학습 가능한 아핀 변환 파라미터 $\gamma$와 $\beta$만 업데이트하도록 허용하며, 여기서 정규화된 출력은 $y = \gamma \hat{x} + \beta$이다. -
Multi-View Co-Training & Entropy-Guided Self-Training:
단일 3D 이미지만 가지고 있기 때문에, 겹치는 3D 패치 $\{x_{t_{p_1}}, x_{t_{p_2}}, \dots, x_{t_{p_n}}\}$를 추출한다. 각 패치에 대해, 축 방향, 시상 방향, 관상 방향의 세 가지 다른 해부학적 평면에서 보기 위해 수학적으로 축을 순열한다. 이 세 가지 뷰를 $v \in \{x_{t_{p_i}}, x'_{t_{p_i}}, x''_{t_{p_i}}\}$로 정의하자.인간 레이블 없이 모델을 학습시키기 위해, 모델이 자체 "의사 레이블(pseudolabel)"을 생성하도록 강제한다. 모델의 불확실성을 측정하기 위해 픽셀 단위 섀넌 엔트로피를 계산한다:
$$H(z) = -z \log_2(z) - (1-z) \log_2(1-z)$$
여기서 $z \in [0, 1]$는 종양의 예측 확률이다. 엔트로피 $H(z)$가 엄격한 임계값 $\tau$보다 낮은 예측만 수락한다. 최종 의사 레이블 $\hat{y}$는 세 가지 뷰에 걸친 확신 있는 예측들의 합집합이다. -
최적화 목표:
모델은 단일 에포크 동안 삼중 손실 함수를 최소화함으로써 적응된다:
$$\mathcal{L}_{total} = \lambda_1 \mathcal{L}_{sl} + \lambda_2 \mathcal{L}_{consistency} + \lambda_3 \mathcal{L}_{cosine}$$
여기서 $\mathcal{L}_{sl}$은 Dice 및 Cross-Entropy 손실을 사용하여 모델의 예측이 고신뢰도 의사 레이블과 일치하도록 강제한다. $\mathcal{L}_{consistency}$는 세 가지 다른 뷰의 예측이 서로 일치하도록 강제한다. 마지막으로 $\mathcal{L}_{cosine}$은 신경망 깊숙한 곳에서 작동하며, 코사인 유사도를 사용하여 특징 추출기 $g(\cdot)$가 다른 뷰의 깊은 임베딩을 정렬하도록 강제한다:
$$\mathcal{L}_{cosine} = 1 - \cos(g(x_{t_{p_i}}), g(x'_{t_{p_i}})) + 1 - \cos(g(x_{t_{p_i}}), g(x''_{t_{p_i}}))$$
실험 아키텍처와 "희생양"
저자들은 자신들의 수학이 작동한다고 주장하는 데 그치지 않고, 이를 증명하기 위해 가혹한 실험 아키텍처를 설계했다. 그들은 대규모 데이터셋(Duke-Breast-Cancer-MRI)으로 기준선 3D UNet을 학습시킨 후, 서로 다른 스캐너(GE, Siemens, Philips)와 다른 획득 평면을 특징으로 하는 완전히 보지 못한 두 개의 데이터셋(TCGA-BRCA 및 ISPY1)으로 이를 기습 공격했다.
이 실험의 "희생양"은 최첨단 TTA 방법인 PTN, Tent, BNAdapt, InTent, MEMO였다.
MuVi의 우월성을 보여주는 결정적인 증거는 명확했다. 단일 이미지 기반으로 배치 통계를 업데이트하려는 Tent 및 PTN과 같은 방법은 실제로 기준선 모델의 성능을 저하시켰다. 그들은 단일 이미지 통계 노이즈의 함정에 빠졌다. 증강을 사용하는 MEMO는 거의 변화를 주지 못했다. 그러나 MuVi는 Dice 유사도 계수를 기준선 대비 최대 5.57% 향상시키며 엄청난 도약을 달성했다.
결정적인 증거는 그들의 ablation study였다. 다중 뷰 일관성 제약을 제거하거나 소스 BN 통계를 폐기했을 때, 모델의 성능은 급격히 하락했다. 이는 3D 모델이 해부학적 평면 전반에 걸쳐 자체적으로 일치하도록 강제하는 특정 메커니즘이 소스 통계에 의해 고정될 때 실제로 성공하는 이유임을 부인할 수 없이 증명했다. 흥미롭게도, Batch Normalization을 Instance Normalization으로 교체했을 때, 그들의 비지도 학습 방법은 타겟 데이터에 완전히 지도 학습된 모델보다 더 낮은 거리 오차 지표를 달성했다. 솔직히 말해서, 비지도 적응이 특정 지표에서 지도 학습 상한선을 어떻게 능가하는지는 완전히 확신할 수 없지만, Instance Normalization이 단일 환자 스타일 변형을 처리하는 데 훨씬 뛰어나다는 것을 강력하게 시사한다.
미래 발전을 위한 논의 주제
이러한 훌륭한 연구 결과를 바탕으로, 비판적 사고를 자극하기 위한 몇 가지 미래 탐구 방향은 다음과 같다.
- 단일 인스턴스 적응의 한계: 단일 이미지에 적응하는 것이 임상적으로 이상적이지만, 이것이 본질적으로 "군중의 지혜"를 희생시키는가? 모델이 한 환자의 고유한 해부학에 과도하게 적응하면, 인구 수준의 통계적 관점이 무시했을 양성 이상에서 환각 종양을 일으킬 위험이 있는가? 단일 환자 개인화와 전역 해부학적 사전 지식을 어떻게 균형 맞출 수 있는가?
- 불확실성 정량화를 위한 엔트로피 너머: 저자들은 모델 신뢰도의 대리 지표로 섀넌 엔트로피를 사용한다. 그러나 딥 신경망은 악명 높게 과신하여, 완전히 틀렸을 때도 종종 낮은 엔트로피를 생성한다. 수학적으로 엄격한 불확실성 경계를 생성하기 위해 베이지안 신경망 또는 증거 딥러닝을 통합하여 훨씬 더 안전하고 정확한 의사 레이블을 만들 수 있는가?
- 교차 모달리티 기하학적 일관성: 본 논문은 다중 뷰 일관성이 다른 MRI 스캐너 간의 전환 시 작동함을 증명한다. 그러나 도메인 시프트가 완전히 다른 물리적 모달리티 간에 발생하는 경우는 어떠한가? 예를 들어 MRI로 학습된 모델을 CT 스캔에 적응시키는 경우이다. 장기의 근본적인 3D 기하학은 동일하지만, 픽셀 강도의 물리 법칙은 완전히 다르다. 픽셀 수준의 유사성에 의존하지 않고 모달리티 간의 구조적 특징을 정렬하기 위해 $\mathcal{L}_{cosine}$을 발전시킬 수 있는가?
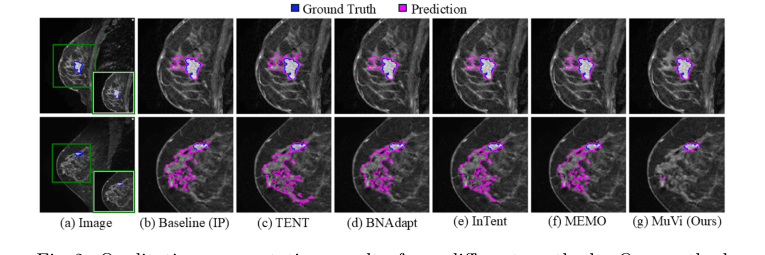 Figure 2. Qualitative segmentation results from different methods. Our method localizes the tumor precisely while removing the misidentified breast tissue
Figure 2. Qualitative segmentation results from different methods. Our method localizes the tumor precisely while removing the misidentified breast tissue