单张图像测试时自适应的多视角协同训练
Test-time adaptation enables a trained model to adjust to a new domain during inference, making it particularly valuable in clinical settings where such on-the-fly adaptation is required.
背景与学术传承
医学影像AI长期以来一直面临一个令人沮丧的现实:在A医院训练的用于检测肿瘤的深度学习模型,在部署到B医院时常常会失效。这是因为不同医院使用不同的MRI扫描仪(例如,GE与西门子)、不同的磁场强度以及不同的软件协议。在计算机视觉和医学图像分析的学术领域,这种差异被称为“域偏移”(domain shift)。
传统上,研究人员试图通过收集新医院的大量数据集来重新训练或微调模型来解决这个问题。然而,在真实的临床环境中,医生需要对刚刚走进诊所的单个患者进行即时、实时的分析。你不能让患者等待数周,而医院则需要收集数千张额外的扫描图像来更新其软件。这种迫切的需求催生了测试时域自适应(Test-Time Adaptation, TTA)这一子领域,即模型在推理的精确时刻尝试调整自身以适应新数据。
尽管TTA前景广阔,但以往的方法却受到严重的根本性限制。首先,大多数现有的TTA方法需要大量的输入图像“批次”来计算统计调整(特别是Batch Normalization统计)。如果医院只需要扫描一名患者,这些依赖批次的 方法就会完全失效。其次,以往的模型通常需要大量的架构修改,或者依赖于刚性的形状先验,而这些先验在面对真实肿瘤高变异的解剖结构时并不可靠。最后,大多数当前方法将医学扫描视为平面的2D切片进行处理,完全忽略了数据的丰富3D体积上下文。处理高分辨率3D医学体积需要巨大的GPU内存,这使得大批量处理不仅在数学上对单患者不适用,而且在计算上也过于昂贵——这就像强迫一家诊所购买一个巨大的服务器集群,而他们预算的只是标准的150美元硬件升级。作者之所以被迫撰写本文,是因为没有现有方法能够仅使用一张3D图像在实时情况下适应模型,而不会导致灾难性的内存成本或性能下降。
为了帮助您理解作者是如何解决这个问题的,让我们将几个高度专业化的领域术语分解为直观的概念:
- 域偏移(Domain Shift): 当AI在现实世界中看到的数据与其训练数据不同时,AI性能的下降。
- 类比: 想象一下在一个安静、阳光明媚、可预测的郊区学习驾驶(训练数据)。如果你突然被置于一个混乱、下雪的市中心高峰时段(测试数据),你的驾驶技能将急剧下降。这种场景的变化就是域偏移。
- 测试时域自适应(Test-Time Adaptation, TTA): AI模型在实际使用过程中能够实时更新和改进自身的能力,而无需离线重新训练。
- 类比: 想象一位现场音乐家意识到音乐厅的声学效果略有偏差。他们不会停止演出回到排练室,而是在演奏的音符之间在舞台上巧妙地调整乐器。
- 伪标签(Pseudolabeling): 一种技术,AI对未标注数据做出最佳猜测,然后将该猜测视为“绝对真理”来进一步训练自身。
- 类比: 想象一个学生在没有答案密钥的情况下进行模拟测试。他们回答那些他们非常有信心的题目,假设这些答案是正确的,并利用它们来找出更难题目的模式。
- 多视图协同训练(Multi-View Co-Training): 训练AI以确保其预测无论从哪个角度或视角观察3D数据(例如,从顶部、正面或侧面观察)都保持一致。
- 类比: 如果你在一个黑暗的房间里检查一个神秘的物体,你不会只从正面看它。你会绕着它走,从顶部和侧面观察。如果你的大脑从正面得出它是椅子的结论,但从侧面得出它是桌子的结论,那说明有问题。多视图协同训练迫使AI的结论从所有角度都保持一致。
为了数学上精确地解释作者解决了什么问题以及他们如何构建单图像自适应,我们必须定义他们使用的核心变量和参数。下表是代表他们多视图一致性框架基础的符号表。
| 符号 | 描述 |
|---|---|
| $M(\theta_s)$ | 预训练的神经网络模型,由从源域学习到的权重 $\theta_s$ 参数化。 |
| $X_s, Y_s$ | 源域3D图像张量及其对应的密集标注的体素级真实标签掩码。 |
| $X_t, Y_t$ | 目标域3D图像张量及其真实标签掩码(在测试时域自适应期间不可用)。 |
| $x_t$ | 在测试时遇到的单个3D目标图像,模型必须对其进行自适应。 |
| $\mu_s, \sigma_s$ | 模型预训练阶段获得的原始均值和方差统计量。 |
| $\gamma, \beta$ | 可学习的仿射变换参数,用于在测试时调制网络,而无需新的图像批次。 |
| $x_{t_{p_i}}$ | 从单个目标测试图像 $x_t$ 中提取的第 $i$ 个重叠3D块。 |
| $\pi_1, \pi_2$ | 视图特定的排列函数,用于将块旋转或变换到其他解剖视图(例如,轴向到矢状面或冠状面)。 |
| $v$ | 一组视图,表示原始块及其变换版本,定义为 $v \in \{x_{t_{p_i}}, x'_{t_{p_i}}, x''_{t_{p_i}}\}$。 |
| $H(z)$ | 从模型预测概率 $z$ 计算的每像素熵。它衡量模型的不确定性。 |
| $\tau$ | 经验设定的熵阈值。不确定性低于此阈值的预测被接受为置信度高。 |
| $\hat{y}_{t_{p_i}}$ | 为特定块生成的基于熵的伪标签,用作自训练的临时真实标签。 |
| $\mathcal{L}_{sl}$ | 自学习损失函数,结合Dice Loss和Cross-Entropy Loss,在模型的伪标签上训练模型。 |
| $\mathcal{L}_{consistency}$ | 一致性损失函数,迫使模型输出相同的分割结果,无论它处理的是哪个视图($x'_{t_{p_i}}$ 或 $x''_{t_{p_i}}$)。 |
| $\mathcal{L}_{cosine}$ | 余弦相似度损失,确保不同视图的深度特征嵌入保持对齐,独立于伪标签。 |
通过冻结历史批次统计量($\mu_s, \sigma_s$)并仅使用组合损失函数 $$\mathcal{L}_{total} = \lambda_1\mathcal{L}_{sl} + \lambda_2\mathcal{L}_{consistency} + \lambda_3\mathcal{L}_{cosine}$$ 更新轻量级参数($\gamma, \beta$),作者成功创建了一种方法,该方法仅使用一张图像即可适应全新的医院的MRI扫描仪,完全绕过了阻碍先前方法的巨大数据和内存瓶颈。
问题定义与约束
起点、终点与临床陷阱
要真正领会本文突破的意义,我们首先需要理解其精确的数学和实践起点、期望的终点,以及将人工智能部署到医院环境中的残酷现实。
起点(输入状态):
我们从一个深度学习模型 $M(\theta_s)$ 开始,该模型已在源数据集上进行了预训练,学习了一个映射函数 $f: X_s \rightarrow Y_s$。其中,$X_s$ 代表来自特定医院的 3D 医学图像张量(如乳腺 MRI),$Y_s$ 代表密集标记的体素级 3D 分割掩码(肿瘤的确切边界)。
在测试时,该模型被部署到一家新医院。它接收来自目标域 $t$ 的一个单一、未标记的 3D 图像张量 $x_t \in X_t$。这张新图像可能具有不同的对比度、分辨率或噪声特征,因为它是在不同的 MRI 扫描仪上拍摄的。我们完全无法访问原始源数据 $s$,也无法获得这张新患者的 ground truth 标签。
终点(输出状态):
目标是在新目标域上即时调整模型参数 $\theta_s$,学习一个新的函数 $k: X_t \rightarrow Y_t$,该函数能够为该特定患者准确地输出 3D 分割掩码 $Y_t$。至关重要的是,模型必须仅使用提供的单一图像 $x_t$ 来实时完成此任务。
数学鸿沟:
缺失的环节是一个无监督优化桥梁。当没有目标 $Y_t$ 可供比较,并且目标域 $X_t$ 中的数据点不足以估计新的统计分布时,如何计算损失梯度来更新 $\theta_s$?
统计稳定性与临床延迟的痛苦困境
在 Test-Time Adaptation (TTA) 的领域,研究人员一直被困在统计稳定性与临床延迟之间的恶性权衡中。
大多数现有的 TTA 方法严重依赖于更新 Batch Normalization (BN) 层。为了使模型适应新域,这些方法会重新计算新目标分布的均值 $\mu$ 和方差 $\sigma^2$。然而,要获得对分布的稳定数学估计,需要大量数据批次。
这里存在一个困境:如果您等待收集大量患者扫描数据来稳定 BN 统计量,您就破坏了临床护理的实时、按需特性。医生不能等待另外 30 名患者扫描完毕,然后 AI 才能诊断面前的患者。反之,如果您尝试使用批量大小为一(单个患者)来调整 BN 统计量,统计估计就会剧烈波动,导致模型的预测崩溃。您被迫在破坏模型准确性或破坏医院工作流程之间做出选择。
医学图像适应的严酷壁垒
作者们遇到了几个严酷且现实的约束,使得这个问题极其难以解决:
- 数据的极端稀疏性(单图像壁垒):
模型必须使用 $N=1$ 个样本进行适应。测试时没有数据集可供学习,只有一个单独的实例。依赖传统的无监督域适应技术在这里在数学上是不可能的,因为您无法从单个点映射一个分布。 - 硬件内存限制(VRAM 壁垒):
与 2D 照片不同,医学成像依赖于高分辨率的 3D 体积数据。处理 3D 张量需要大量的 GPU 内存(VRAM)。即使诊所愿意使用大批量大小来稳定其算法,标准的医院硬件也无法一次性在内存中容纳大量 3D MRI。 - 无源约束(隐私壁垒):
由于严格的患者隐私法和巨大的存储需求,原始源训练数据 $X_s$ 不能随模型一起传输。适应必须是完全“无源”的,这意味着模型在适应新扫描仪时,不能回顾旧数据来回忆肿瘤应该是什么样子。 - 多扫描仪设置的移动目标:
即使医院决定延迟推理并等待一批入站患者,也不能保证这些患者共享一个单一的目标分布。在多扫描仪医院中,患者 A 可能在 GE 机器上扫描,患者 B 可能在西门子机器上扫描。将他们分组到一个批次来计算共享的目标分布在数学上是错误的,这使得传统的基于批次的适应技术完全无效。
为何采用此方法
要理解这篇论文的精妙之处,我们首先需要认识到在医院部署人工智能所面临的严峻现实。设想一个深度学习模型,它通过医院A的MRI扫描训练,用于检测乳腺肿瘤。在该医院,该模型表现完美。但当将其部署到医院B时,由于医院B使用了不同的MRI扫描仪、不同的磁场强度和不同的成像协议,该模型突然失效。这就是所谓的“域偏移”(domain shift)。
传统上,工程师会收集医院B的数千张图像并重新训练模型来解决这个问题。但在真实的临床环境中,医生需要立即分析患者的扫描图像。他们无法等待数月来收集海量数据集。模型必须利用仅有的单张患者扫描图像进行即时适应。这就是单张图像测试时域适应(Single Image Test-Time Adaptation, TTA)所面临的根本挑战。
“灵光一闪”的时刻:为何SOTA方法失效
作者们有一个关键的认识:当前计算机视觉领域最先进(State-of-the-Art, SOTA)的方法在根本上与3D医学成像的物理和临床约束不兼容。
在审视流行的TTA方法(如Tent、PTN或BNAdapt)时,作者们注意到一个致命的缺陷。这些方法严重依赖于批量归一化(Batch Normalization, BN)。为了适应新域,它们会计算大批量输入测试图像的统计均值和方差来更新网络。但在医院,一次只评估一名患者。此外,医学图像并非平面的2D图像,而是庞大、高分辨率的3D体积。处理大批量3D MRI需要巨大的GPU内存(VRAM),这使得标准医院硬件在计算上不可行。
如果尝试仅对单张图像计算BN统计量,数学上就会崩溃,模型的性能反而会下降。作者们意识到,标准的CNN适应技术,甚至现代基于Transformer的批量方法,对于这个特定问题都完全不足。
坦白说,我并不完全确定作者们是否明确测试了像GANs或Diffusion模型这样的重度生成模型用于这种精确的单张图像设置,但论文强烈暗示了它们为何会失败:这些模型需要海量的目标数据集和广泛的再训练时间,这完全违背了临床环境中所需的“实时、每位患者”的约束。此外,作者们明确排除了“基于原型”(Prototype-based)的适应方法。原因何在?因为原型方法依赖于一致的形状(shape priors),而乳腺肿瘤具有极高的解剖学变异性。它们的形状不遵循可预测的模式。
基准测试逻辑:结构上的优越性
由于传统方法失效,作者们不得不发明一种在质量上更优越的方法:基于块的多视图协同训练(Patch-Based Multi-View Co-Training, MuVi)。
MuVi不依赖于不同患者的大批量数据来理解新域,而是从单张患者的MRI中提取重叠的3D块(patches),并从三个不同的正交视角(轴向、矢状和冠状视图)进行观察。
这提供了巨大的结构优势。通过迫使模型从不同视角观察同一3D组织,它们人为地从单张图像中创造了足够“多样化”的数据来适应网络。这完全绕过了对大批量大小的需求,有效地将内存和数据需求从$N$位患者降低到1位。
在数学上,他们通过拆分归一化过程解决了批量归一化危机。他们不替换源统计量,而是冻结训练期间学习到的原始均值 $\mu_s$ 和方差 $\sigma_s$,计算归一化输入:
$$ \hat{x} = \frac{x - \mu_s}{\sqrt{\sigma_s^2 + \epsilon}} $$
然后,他们仅允许网络通过梯度下降更新轻量级的仿射变换参数($\gamma$ 和 $\beta$):
$$ y = \gamma \hat{x} + \beta $$
这可以防止模型在面对单张图像的高维噪声时崩溃,同时仍允许其适应新扫描仪的对比度和强度。
约束与解决方案的完美结合
这篇论文的真正精妙之处在于其数学解决方案与严峻临床约束的完美契合。
由于没有新患者的Ground Truth标签,模型必须进行自我学习(self-training)。然而,自我学习对标签噪声非常敏感;如果模型猜测错误,它将从自己的错误中学习并失控。
为了克服这一点,作者们引入了熵引导的自我训练(Entropy-guided Self-Training)。他们计算每像素的香农熵(Shannon entropy)来衡量模型对其预测的“不确定性”:
$$ H(z) = -z \log_2(z) - (1-z) \log_2(1-z) $$
其中 $z \in [0, 1]$ 是肿瘤的预测概率。模型仅接受熵低于严格阈值 $\tau$ 的预测(意味着模型高度置信)。
然后,他们将来自三个不同视图的高度置信预测结合起来,生成一个可靠的“伪标签”(pseudolabel)。最后,他们使用一个组合损失函数来更新网络,该函数强制所有视图之间的一致性:
$$ \mathcal{L}_{total} = \lambda_1 \mathcal{L}_{sl} + \lambda_2 \mathcal{L}_{consistency} + \lambda_3 \mathcal{L}_{cosine} $$
这是完美的结合:
1. 约束: 仅有一张图像可用。解决方案: 从该单张3D体积生成多个视图。
2. 约束: 没有标签可用。解决方案: 使用熵数学来过滤噪声并生成高度置信的伪标签。
3. 约束: GPU内存有限。解决方案: 冻结重度批量统计量,仅在小3D块上更新轻量级参数。
通过对这些独特属性的协调,作者们在Dice相似系数(Dice Similarity Coefficient)上取得了比基线高出5.57%的改进,在无需额外患者扫描的情况下,超越了所有现有的SOTA方法。
数学与逻辑机制
想象一下,您已经训练了一位才华横溢的医生,使其能够利用医院A提供的数千张核磁共振成像(MRI)扫描图像来识别乳腺肿瘤。如果突然将这位医生调往医院B,她可能会遇到困难。医院B使用的MRI设备具有不同的磁场强度、造影剂和噪声特征。在人工智能领域,我们将这种情况称为“域偏移”(domain shift)。
通常情况下,为了解决这个问题,数据科学家会收集医院B的数千张新图像并重新训练AI模型。但在实际临床环境中,这是不可能的。医生需要为眼前单一位患者提供准确的分割结果。她不能等待一个庞大的数据集被编译。此外,医学图像是丰富的3D体数据,但大多数现有的适应方法将其视为平面的2D照片,忽略了空间深度。
本文的作者解决了一个高度受限的问题:如何在不重新查看原始训练数据的情况下,仅使用一张图像,实时地迫使一个预训练的3D医学AI模型适应一个全新、未见过环境?
为了实现这一目标,他们构建了一个多视图协同训练(Multi-View Co-Training)引擎。让我们来剖析一下实现这一目标背后的数学原理。
核心数学引擎
该系统由一个两阶段机制驱动:首先,它从单张图像生成一个高度置信的“伪真实标签”(pseudolabel)。然后,它通过最小化不同3D几何视图上的复合损失函数来迫使网络自我更新。
以下是驱动这种适应性的主方程:
1. 伪标签生成(熵导向并集):
$$ \hat{y} = \bigcup_{v \in \{x_t, x'_t, x''_t\}} \{j \mid H(\sigma(f(v(j)))) < \tau_v\} $$
2. 自学习目标:
$$ \mathcal{L}_{sl} = \sum_{v \in \{x_{t_{p_i}}, x'_{t_{p_i}}, x''_{t_{p_i}}\}} \left[ \mathcal{L}_{DICE}(f(v), \hat{y}_{t_{p_i}}) + \mathcal{L}_{CE}(f(v), \hat{y}_{t_{p_i}}) \right] $$
3. 特征一致性目标:
$$ \mathcal{L}_{cosine} = 1 - \cos(g(x_{t_{p_i}}), g(x'_{t_{p_i}})) + 1 - \cos(g(x_{t_{p_i}}), g(x''_{t_{p_i}})) $$
4. 总优化景观:
$$ \mathcal{L}_{total} = \lambda_1 \mathcal{L}_{sl} + \lambda_2 \mathcal{L}_{consistency} + \lambda_3 \mathcal{L}_{cosine} $$
剖析方程
让我们来分解这个数学机器中的每一个齿轮和弹簧。
在伪标签方程($\hat{y}$)中:
* $\hat{y}$:主伪标签。这是模型对肿瘤位置的最佳、最自信的猜测,它将作为即将进行的训练阶段的“真实标签”。
* $v \in \{x_t, x'_t, x''_t\}$:目标图像的三个不同3D视图(轴向、冠状和矢状切面)。
* $j$:MRI扫描中的一个特定体素(3D像素)。
* $f(v(j))$:神经网络对该特定体素的原始预测。
* $\sigma(\cdot)$:Sigmoid激活函数。它将原始预测压缩到0到1之间的概率。
* $H(\cdot)$:香农熵函数,定义为 $H(z) = -z \log_2(z) - (1-z) \log_2(1-z)$。从逻辑上讲,它充当一个严格的“门卫”。如果模型不确定(例如,预测肿瘤的概率为50%),熵就会很高。如果模型高度自信(例如,99%或1%),熵就会很低。
* $\tau_v$:置信度阈值。如果熵低于此数值,则接受该预测。
* $\bigcup$:并集运算符。为什么使用并集而不是交集? 因为不同的3D视图捕捉了不同的解剖边界。交集只会保留所有三个视图都同意的体素,从而导致一个严重缩小、保守的肿瘤掩码。并集则聚合了所有视角下高度置信的发现,构建了一个全面的3D地图。
在自学习方程($\mathcal{L}_{sl}$)中:
* $\sum$:对三个视图求和。为什么使用加法而不是乘法? 我们希望总惩罚是所有视角下累积的误差。如果我们将它们相乘,一个视图中的近乎零的误差会抵消另一个视图中的巨大误差,这在医学成像中是危险的。
* $\mathcal{L}_{DICE}$:Dice损失。它衡量预测与伪标签之间的空间重叠。它充当橡皮筋,将预测肿瘤的整体形状拉向匹配伪标签,这对于肿瘤相对于背景非常小的、高度不平衡的医学图像至关重要。
* $\mathcal{L}_{CE}$:交叉熵损失。它评估逐体素的分类准确性。为什么将DICE和CE加在一起? DICE在整体形状方面表现出色,但在梯度下降过程中可能不稳定。CE非常稳定但忽略了整体结构。将它们相加提供了一个完美平衡、稳定的梯度。
在特征一致性方程($\mathcal{L}_{cosine}$)中:
* $g(\cdot)$:特征提取器(神经网络的深层内部层,在最终分类之前)。
* $\cos(\cdot, \cdot)$:余弦相似度。
* $1 - \cos(\cdot, \cdot)$:余弦距离。为什么使用余弦距离而不是标准的L2(欧几里得)距离? 在深度、高维神经网络中,特征向量的方向承载着语义信息(例如,“这种纹理是肿瘤”),而幅度仅表示该特征的强度。余弦距离严格测量向量之间的角度,迫使网络对肿瘤的语义意义进行对齐,而不考虑观察角度。
在总损失($\mathcal{L}_{total}$)中:
* $\lambda_1, \lambda_2, \lambda_3$:标量权重,用于校准自学习、预测一致性和特征一致性的重要性。作者将它们设置为相等,以平衡这些力。
分步流程:组装线
让我们追踪一个抽象数据点——患者的3D MRI扫描——通过这个引擎。
- 切分视角: 3D扫描 $x_t$ 进入系统,并立即被置换成三种不同的几何方向:轴向、冠状和矢状。
- 置信度过滤器: 冻结的模型查看所有三个视图并生成初步的肿瘤掩码。熵函数 $H$ 扫描每一个体素。如果模型犹豫或输出弱概率,该体素将被立即丢弃。
- 锻造主密钥: 来自所有三个视图的、幸存下来的高度置信的体素通过并集运算符 $\bigcup$ 融合在一起,创建黄金伪标签 $\hat{y}$。
- 块提取: 由于3D医学图像非常庞大,会耗尽GPU内存,因此将图像切分成更小的3D块(patches)$x_{t_{p_i}}$。
- 双重校正循环: 每个块通过网络。使用DICE + CE损失将网络的最终输出与黄金伪标签进行比较。同时,提取块的深层内部表示 $g(x)$。余弦损失获取来自不同视图的特征向量,并在高维空间中对其进行物理旋转,直到它们指向完全相同的方向。
优化动力学:它如何实际学习
这就是作者们巧妙的优化策略所在。如何在不让模型立即过拟合并崩溃的情况下,仅在一张图像上训练模型?
模型在一个epoch内更新。此外,作者们不更新整个网络。他们几乎冻结了所有层,只允许梯度更新归一化层(Normalization layers)的仿射参数($\gamma$和$\beta$)。
为什么?在标准的批量归一化(Batch Normalization)中,网络依赖于大量图像批次的均值($\mu$)和方差($\sigma$)。但在这里,我们只有一张图像。单张图像没有足够的统计能力来重新定义整个数据集的分布。因此,作者们锁定了原始源域的 $\mu$ 和 $\sigma$。
当梯度从 $\mathcal{L}_{total}$ 反向传播时,它们只调整 $\gamma$(尺度)和 $\beta$(偏移)。这充当了一个轻量级的校准旋钮。它对特征图进行适度的移位和缩放,以适应新医院的MRI对比度和亮度,而不会破坏模型最初学到的基本肿瘤检测逻辑。
这里的损失景观受到多视图一致性的强烈约束。通过迫使模型在不同的几何变换下与自身保持一致,$\mathcal{L}_{cosine}$ 和 $\mathcal{L}_{consistency}$ 项充当了巨大的正则化器。它们开辟了一条陡峭而狭窄的收敛路径,防止模型基于单张噪声图像产生幻觉式的预测。网络迅速收敛到一个局部最小值,完美地弥合了旧训练数据与新、未见过患者之间的差距。
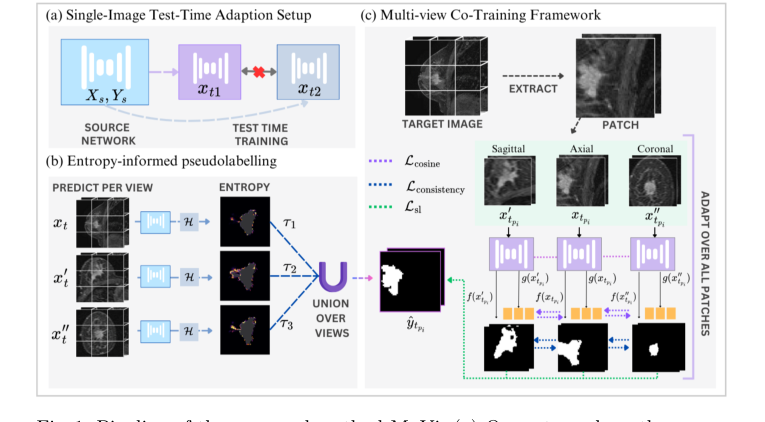 Figure 1. Pipeline of the proposed method MuVi. (a) Our setup where the source network is adapted independently for each target sample xt, (b) computing pseu- dolabel through entropy-threshold union of prediction from each view, (c) Adap- tation via patch-based training through our multi-view consistency framework
Figure 1. Pipeline of the proposed method MuVi. (a) Our setup where the source network is adapted independently for each target sample xt, (b) computing pseu- dolabel through entropy-threshold union of prediction from each view, (c) Adap- tation via patch-based training through our multi-view consistency framework
结果、局限性与结论
想象一下,你在一个宁静、阳光明媚的郊区小镇学会了开车。你熟练掌握了道路、标志和交通流。现在,你突然被置于一个混乱、暴风雪肆虐的大都市中心,并被告知要开车。你基本的驾驶技能完好无损,但领域发生了剧烈变化,你注定会犯错误。
在医学影像领域,深度学习模型正面临着这种噩梦。一个在一家医院的 MRI 扫描仪图像上训练的模型,在分析来自另一家医院扫描仪的图像时,通常会灾难性地失败。磁场强度、重建软件和成像协议造成了“领域偏移”。
为了解决这个问题,研究人员使用了测试时自适应(Test-Time Adaptation, TTA)。TTA 不是从头开始重新训练整个模型——这就像每次更换医院都要购买一台价值 15 万美元的新医疗设备一样昂贵——而是在模型做出预测的那一刻对其进行微调。然而,现有的 TTA 方法存在一个致命缺陷:它们需要大量的图像批次来理解新环境。在真实的临床环境中,医生没有批次;他们只有一个患者的单个 3D 扫描等待诊断。此外,现有方法通常将 3D 医学图像视为一叠扁平的 2D 照片,完全忽略了人体解剖学的丰富、体积现实。
本文介绍了一种出色的、无源的解决方案:基于块的多视角协同训练(Patch-Based Multi-View Co-Training, MuVi)。让我们详细解析他们如何解决这个单图像 3D 自适应问题。
问题的数学核心与解决方案
问题:
我们有一个模型 $M(\theta_s)$,其参数为 $\theta_s$,该模型已经在源数据集 $s$ 上学习了一个映射函数 $f: X_s \rightarrow Y_s$。我们的目标是将此模型适应到新的目标域 $t$,以学习一个新的函数 $k: X_t \rightarrow Y_t$。这里的主要限制是,我们无法访问原始源数据,无法访问目标数据的真实标签,并且我们必须仅使用单个目标图像 $x_t \in X_t$ 来完成此任务。
解决方案:
作者们通过巧妙的统计量保持和几何一致性相结合的方式来解决这个问题。
-
保持源统计量:
标准的批量归一化(Batch Normalization, BN)依赖于数据批次的均值 $\mu$ 和方差 $\sigma$。如果你尝试从单个图像计算 $\mu$ 和 $\sigma$,数学会分解成嘈杂的混乱。因此,作者们冻结了原始源统计量 $\mu_s$ 和 $\sigma_s$。他们只允许网络在测试时更新可学习的仿射变换参数 $\gamma$ 和 $\beta$,其中归一化输出为 $y = \gamma \hat{x} + \beta$。 -
多视角协同训练与熵引导的自训练:
由于他们只有一个 3D 图像,他们提取了重叠的 3D 块 $\{x_{t_{p_1}}, x_{t_{p_2}}, \dots, x_{t_{p_n}}\}$。对于每个块,他们通过数学置换轴,从三个不同的解剖平面观察它:轴向(axial)、矢状(sagittal)和冠状(coronal)。我们将这三个视图定义为 $v \in \{x_{t_{p_i}}, x'_{t_{p_i}}, x''_{t_{p_i}}\}$。为了在没有人工标签的情况下训练模型,他们强迫模型生成自己的“伪标签”。他们计算像素级的香农熵来衡量模型的不确定性:
$$H(z) = -z \log_2(z) - (1-z) \log_2(1-z)$$
其中 $z \in [0, 1]$ 是肿瘤的预测概率。他们只接受熵 $H(z)$ 低于严格阈值 $\tau$ 的预测。最终的伪标签 $\hat{y}$ 是所有三个视图中置信度预测的并集。 -
优化目标:
然后,模型仅通过最小化三方损失函数进行一个 epoch 的自适应:
$$\mathcal{L}_{total} = \lambda_1 \mathcal{L}_{sl} + \lambda_2 \mathcal{L}_{consistency} + \lambda_3 \mathcal{L}_{cosine}$$
其中,$\mathcal{L}_{sl}$ 使用 Dice 和交叉熵损失,迫使模型的预测与高置信度伪标签匹配。$\mathcal{L}_{consistency}$ 迫使三个不同视图的预测彼此一致。最后,$\mathcal{L}_{cosine}$ 操作在神经网络深层,通过余弦相似度迫使特征提取器 $g(\cdot)$ 对齐不同视图的深度嵌入:
$$\mathcal{L}_{cosine} = 1 - \cos(g(x_{t_{p_i}}), g(x'_{t_{p_i}})) + 1 - \cos(g(x_{t_{p_i}}), g(x''_{t_{p_i}}))$$
实验架构与“牺牲品”
作者们不仅声称他们的数学有效,而且还设计了一个严酷的实验架构来证明它。他们在一个庞大的数据集(Duke-Breast-Cancer-MRI)上训练了一个基线 3D UNet,然后用两个完全未见过的数据集(TCGA-BRCA 和 ISPY1)对其进行“伏击”,这些数据集具有不同的扫描仪(GE、Siemens、Philips)和不同的采集平面。
实验中的“牺牲品”是 SOTA 的 TTA 方法:PTN、Tent、BNAdapt、InTent 和 MEMO。
MuVi 优越性的决定性证据非常显著。Tent 和 PTN 等方法试图基于单个图像更新批量统计量,实际上降低了基线模型的性能。它们陷入了单图像统计噪声的陷阱。MEMO 使用数据增强,几乎没有带来任何改变。然而,MuVi 实现了巨大的飞跃,将 Dice Similarity Coefficient 提高了高达 5.57%。
决定性的证据来自他们的消融研究。当他们移除多视角一致性约束,或者丢弃源 BN 统计量时,模型的性能会急剧下降。这无可辩驳地证明了他们特定的机制——迫使一个 3D 模型在不同解剖平面上与自身保持一致,同时以源统计量为锚点——是其在现实中成功的确切原因。有趣的是,当他们用实例归一化(Instance Normalization)替换批量归一化时,他们的无监督方法在距离误差指标上甚至低于在目标数据上完全监督的模型。老实说,我不太确定无监督自适应如何在特定指标上超越有监督的上限,但这强烈表明实例归一化在处理单患者风格变化方面具有压倒性优势。
未来演进的讨论话题
基于这些出色的发现,以下是几个未来探索的途径,以激发批判性思维:
- 单实例自适应的局限性: 虽然适应单个图像在临床上是理想的,但这是否会固有地牺牲“群体智慧”?如果一个模型过度适应某个患者独特的解剖结构,它是否会冒着将良性异常误判为肿瘤的风险,而这些异常在基于人群的统计视图中会被忽略?我们如何平衡单患者个性化与全局解剖学先验?
- 超越熵的置信度量化: 作者们使用香农熵作为模型置信度的代理。然而,深度神经网络以过度自信而闻名,即使完全错误,也常常产生低熵。我们能否集成贝叶斯神经网络或证据深度学习来生成数学上严谨的不确定性界限,从而创建更安全、更准确的伪标签?
- 跨模态几何一致性: 本文证明了在不同 MRI 扫描仪之间切换时,多视角一致性是有效的。但如果领域偏移跨越完全不同的物理模态,例如将 MRI 训练的模型适应到 CT 扫描?器官的底层 3D 几何结构保持不变,但像素强度物理学完全不同。$\mathcal{L}_{cosine}$ 能否演进为在不依赖像素级相似性的情况下,对跨模态的结构特征进行对齐?
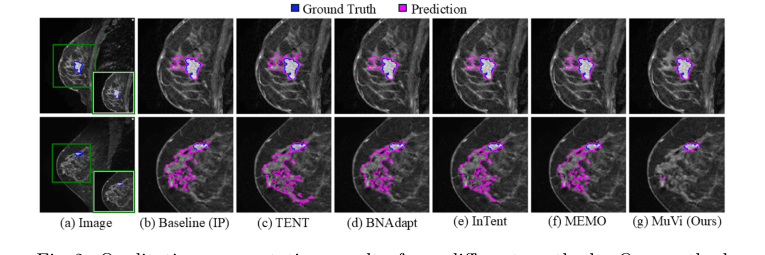 Figure 2. Qualitative segmentation results from different methods. Our method localizes the tumor precisely while removing the misidentified breast tissue
Figure 2. Qualitative segmentation results from different methods. Our method localizes the tumor precisely while removing the misidentified breast tissue