Адаптация в тестовое время для одного изображения посредством совместного обучения с несколькими представлениями
В области медицинских изображений с использованием ИИ долгое время существовала фрустрирующая реальность: модель глубокого обучения, обученная для обнаружения опухолей в Больнице А, часто не справляется при...
Предыстория и академическое происхождение
В области медицинских изображений с использованием ИИ долгое время существовала фрустрирующая реальность: модель глубокого обучения, обученная для обнаружения опухолей в Больнице А, часто не справляется при развертывании в Больнице Б. Это происходит потому, что разные больницы используют разные МРТ-сканеры (например, GE против Siemens), различные напряженности магнитного поля и отличающиеся программные протоколы. В академической области компьютерного зрения и анализа медицинских изображений это расхождение известно как "сдвиг домена" (domain shift).
Исторически исследователи пытались решить эту проблему, собирая огромные наборы данных из новой больницы для переобучения или дообучения (fine-tuning) модели. Однако в реальных клинических условиях врачам требуется немедленный анализ в режиме реального времени для одного пациента, который только что поступил в клинику. Нельзя попросить пациента ждать недели, пока больница соберет еще тысячу снимков для обновления своего программного обеспечения. Эта насущная потребность породила подполе адаптации во время тестирования (Test-Time Adaptation, TTA), где модель пытается адаптироваться к новым данным в момент инференса.
Несмотря на перспективность TTA, предыдущие подходы страдали от серьезных фундаментальных ограничений. Во-первых, большинство существующих методов TTA требуют большого "батча" (batch) входящих изображений для расчета статистических корректировок (в частности, статистики пакетной нормализации, Batch Normalization). Если больнице нужно просканировать только одного пациента, эти методы, зависящие от батча, полностью терпят неудачу. Во-вторых, предыдущие модели часто требовали существенных архитектурных модификаций или полагались на жесткие априорные сведения о форме, которые не выдерживают высокой анатомической вариабельности реальных опухолей. Наконец, большинство современных методов обрабатывают медицинские снимки как плоские 2D-срезы, полностью игнорируя богатый 3D-объемный контекст данных. Обработка 3D-медицинских объемов высокого разрешения требует огромной памяти GPU, что делает пакетную обработку не только математически некорректной для отдельных пациентов, но и вычислительно слишком дорогой — сродни тому, как заставлять клинику покупать массивный серверный кластер, когда они запланировали только стандартное обновление оборудования стоимостью 150 долларов США. Авторы были вынуждены написать эту статью, потому что ни один существующий метод не мог адаптировать модель, используя всего одно 3D-изображение в реальном времени без катастрофических затрат памяти или падения производительности.
Чтобы помочь вам понять, как авторы решили эту проблему, давайте разберем несколько узкоспециализированных терминов предметной области на интуитивно понятные концепции:
- Сдвиг домена (Domain Shift): Деградация производительности ИИ, когда данные, которые он видит в реальном мире, отличаются от данных, на которых он был обучен.
- Аналогия: Представьте, что вы учитесь водить машину в тихом, солнечном и предсказуемом пригороде (обучающие данные). Если вас внезапно поместят в хаотичный, заснеженный центр города в час пик (тестовые данные), ваши навыки вождения резко ухудшатся. Это изменение обстановки и есть сдвиг домена.
- Адаптация во время тестирования (Test-Time Adaptation, TTA): Способность модели ИИ обновляться и улучшаться на лету во время активного использования, вместо того чтобы требовать офлайн-переобучения.
- Аналогия: Представьте себе музыканта, выступающего вживую, который понимает, что акустика концертного зала немного не соответствует. Вместо того чтобы останавливать шоу, чтобы вернуться в репетиционную студию, он незаметно настраивает свой инструмент прямо на сцене между нотами.
- Псевдомаркировка (Pseudolabeling): Техника, при которой ИИ делает наилучшее предположение для неаннотированных данных, а затем рассматривает это предположение как "абсолютную истину" для дальнейшего обучения.
- Аналогия: Представьте студента, проходящего пробный тест без ключа с ответами. Он отвечает на вопросы, в которых уверен, предполагает, что эти ответы верны, и использует их для выявления закономерностей в более сложных вопросах.
- Совместное обучение по нескольким видам (Multi-View Co-Training): Обучение ИИ для обеспечения согласованности его предсказаний независимо от угла или перспективы, с которой он рассматривает 3D-данные (например, вид сверху, спереди или сбоку).
- Аналогия: Если вы осматриваете таинственный объект в темной комнате, вы не будете смотреть на него только спереди. Вы обойдете его и посмотрите сверху и сбоку. Если ваш мозг заключает, что это стул спереди, но стол сбоку, значит, что-то не так. Совместное обучение по нескольким видам заставляет выводы ИИ совпадать под всеми углами.
Чтобы математически интерпретировать, какую именно проблему решили авторы и как они структурировали свою адаптацию к одному изображению, мы должны определить основные переменные и параметры, которые они использовали. Ниже приведена таблица обозначений, которая представляет основу их фреймворка многовидовой согласованности.
| Обозначение | Описание |
|---|---|
| $M(\theta_s)$ | Предварительно обученная нейронная сеть, параметризованная весами $\theta_s$, полученными из исходного домена. |
| $X_s, Y_s$ | 3D-тензор изображения исходного домена и соответствующая ему маска истинных данных (ground truth mask) с плотной разметкой по вокселям. |
| $X_t, Y_t$ | 3D-тензор изображения целевого домена и его маска истинных данных (которая недоступна во время адаптации во время тестирования). |
| $x_t$ | Одиночное 3D-изображение целевого домена, встреченное во время тестирования, к которому модель должна адаптироваться. |
| $\mu_s, \sigma_s$ | Исходные средние и дисперсионные статистики, полученные во время фазы предварительного обучения модели. |
| $\gamma, \beta$ | Обучаемые параметры аффинного преобразования, используемые для модуляции сети во время тестирования без необходимости полного батча новых изображений. |
| $x_{t_{p_i}}$ | $i$-й перекрывающийся 3D-патч, извлеченный из одиночного целевого тестового изображения $x_t$. |
| $\pi_1, \pi_2$ | Функции перестановки, специфичные для вида, используемые для вращения или преобразования патча в альтернативные анатомические виды (например, из аксиального в сагиттальный или корональный). |
| $v$ | Набор видов, представляющий исходный патч и его преобразованные версии, определенный как $v \in \{x_{t_{p_i}}, x'_{t_{p_i}}, x''_{t_{p_i}}\}$. |
| $H(z)$ | Попиксельная энтропия, рассчитанная из предсказанной моделью вероятности $z$. Она измеряет неопределенность модели. |
| $\tau$ | Эмпирически установленный порог энтропии. Предсказания с неопределенностью ниже этого порога принимаются как уверенные. |
| $\hat{y}_{t_{p_i}}$ | Псевдометка, основанная на энтропии, сгенерированная для конкретного патча, используемая в качестве временной истинной разметки для самообучения. |
| $\mathcal{L}_{sl}$ | Функция потерь самообучения, объединяющая Dice Loss и Cross-Entropy Loss для обучения модели на ее собственных псевдометках. |
| $\mathcal{L}_{consistency}$ | Функция потерь согласованности, которая заставляет модель выдавать одинаковую сегментацию независимо от того, какой вид ($x'_{t_{p_i}}$ или $x''_{t_{p_i}}$) она обрабатывает. |
| $\mathcal{L}_{cosine}$ | Функция потерь косинусного сходства, которая гарантирует, что вложения глубоких признаков различных видов остаются выровненными, независимо от псевдометок. |
Замораживая исторические пакетные статистики ($\mu_s, \sigma_s$) и обновляя только легковесные параметры ($\gamma, \beta$) с использованием комбинированной функции потерь $$\mathcal{L}_{total} = \lambda_1\mathcal{L}_{sl} + \lambda_2\mathcal{L}_{consistency} + \lambda_3\mathcal{L}_{cosine}$$, авторы успешно создали метод, который адаптируется к МРТ-сканеру совершенно новой больницы, используя всего одно изображение, полностью обходя узкие места в данных и памяти, которые парализовали предыдущие подходы.
Определение проблемы и ограничения
Стартовая точка, цель и клиническая ловушка
Чтобы по-настоящему оценить масштаб прорыва, представленного в данной статье, нам сначала необходимо понять точную математическую и практическую отправную точку, желаемую конечную цель и суровую реальность внедрения искусственного интеллекта в больничной среде.
Стартовая точка (входное состояние):
Мы начинаем с модели глубокого обучения, обозначенной как $M(\theta_s)$, которая была предварительно обучена на исходном наборе данных для изучения функции отображения $f: X_s \rightarrow Y_s$. Здесь $X_s$ представляет собой 3D-тензоры медицинских изображений (например, МРТ молочной железы) из конкретной больницы, а $Y_s$ представляет собой плотно размеченные повоксельные 3D-маски сегментации (точные границы опухоли).
Во время тестирования модель развертывается в новой больнице. Ей передается единственный неразмеченный 3D-тензор изображения $x_t \in X_t$ из целевой области $t$. Это новое изображение может иметь отличающийся контраст, разрешение или профили шума, поскольку оно было получено на другом МРТ-сканере. У нас абсолютно нет доступа к исходным данным $s$, равно как и к эталонной метке для этого нового пациента.
Целевое состояние (выход):
Задача состоит в том, чтобы мгновенно адаптировать параметры модели $\theta_s$ к новой целевой области, изучив новую функцию $k: X_t \rightarrow Y_t$, которая точно выводит 3D-маску сегментации $Y_t$ для данного конкретного пациента. Важно отметить, что модель должна делать это "на лету", используя только предоставленное единственное изображение $x_t$.
Математический разрыв:
Отсутствующим звеном является мост неконтролируемой оптимизации. Как рассчитать градиент функции потерь для обновления $\theta_s$, когда у вас нет целевого значения $Y_t$ для сравнения, и у вас недостаточно точек данных в целевой области $X_t$ для оценки нового статистического распределения?
Болезненная дилемма: статистическая стабильность против клинической реальности
В области адаптации во время тестирования (Test-Time Adaptation, TTA) исследователи оказались в ловушке порочного компромисса между статистической стабильностью и клинической задержкой.
Большинство существующих методов TTA в значительной степени полагаются на обновление слоев пакетной нормализации (Batch Normalization, BN). Для адаптации модели к новой области эти методы пересчитывают среднее значение $\mu$ и дисперсию $\sigma^2$ нового целевого распределения. Однако для получения стабильной математической оценки распределения требуется большая выборка данных.
Вот дилемма: если вы ждете, чтобы собрать большую выборку снимков пациентов для стабилизации статистики BN, вы разрушаете природу клинической помощи в реальном времени и по запросу. Врач не может ждать, пока будут сделаны снимки еще 30 пациентов, прежде чем ИИ сможет диагностировать пациента, находящегося перед ним. И наоборот, если вы попытаетесь адаптировать статистику BN, используя размер пакета ровно один (один пациент), статистические оценки будут сильно колебаться, что приведет к коллапсу предсказаний модели. Вы вынуждены выбирать между нарушением точности модели и нарушением рабочего процесса больницы.
Суровые стены адаптации медицинских изображений
Авторы столкнулись с несколькими жестокими, реалистичными ограничениями, которые делают эту конкретную проблему чрезвычайно трудной для решения:
- Крайняя разреженность данных (стена одного изображения):
Модель должна адаптироваться, используя $N=1$ выборку. Во время тестирования нет набора данных для обучения, только один экземпляр. Опора на традиционные методы неконтролируемой доменной адаптации математически невозможна, поскольку невозможно отобразить распределение из одной точки. - Ограничение памяти оборудования (стена VRAM):
В отличие от 2D-фотографий, медицинская визуализация полагается на высокоразрешающие 3D-объемные данные. Обработка 3D-тензора требует огромного объема памяти GPU (VRAM). Даже если бы клиника захотела использовать большой размер пакета для стабилизации своих алгоритмов, стандартное больничное оборудование физически не может одновременно хранить в памяти большой пакет 3D-МРТ. - Ограничение отсутствия исходных данных (стена конфиденциальности):
Из-за строгих законов о конфиденциальности пациентов и огромных требований к хранению исходные обучающие данные $X_s$ не могут быть переданы вместе с моделью. Адаптация должна быть полностью "без исходных данных", что означает, что модель не может обращаться к старым данным, чтобы вспомнить, как должна выглядеть опухоль, во время адаптации к новому сканеру. - Движущаяся цель многосканерных установок:
Даже если бы больница решила отложить вывод и дождаться поступления пакета пациентов, нет гарантии, что эти пациенты имеют одно и то же целевое распределение. В многосканерной больнице пациент А может быть обследован на аппарате GE, а пациент Б — на аппарате Siemens. Группировка их в пакет для расчета общего целевого распределения математически ошибочна, что делает традиционные методы адаптации на основе пакетов совершенно неэффективными.
Почему этот подход
Чтобы понять гениальность данной работы, сначала необходимо осознать суровую реальность внедрения искусственного интеллекта в больницах. Представьте себе модель глубокого обучения, обученную детектировать опухоли молочной железы по МРТ-снимкам из Больницы А. Там она работает идеально. Но когда вы развертываете ее в Больнице Б, использующей другие МРТ-сканеры, другую напряженность магнитного поля и другие протоколы визуализации, модель внезапно перестает работать. Это называется "сдвигом домена" (domain shift).
Традиционно инженеры решают эту проблему, собирая тысячи изображений из Больницы Б и переобучая модель. Но в реальной клинической среде врачам необходимо анализировать снимки пациента немедленно. Они не могут ждать месяцы, чтобы собрать массивный набор данных. Модель должна адаптироваться "на лету", используя только снимок данного конкретного пациента. Это фундаментальная проблема адаптации в тестовом режиме по одному изображению (Single Image Test-Time Adaptation, TTA).
Момент "Эврика!": Почему SOTA-методы потерпели неудачу
Авторы пришли к критическому осознанию: современные передовые (State-of-the-Art, SOTA) методы компьютерного зрения принципиально несовместимы с физическими и клиническими ограничениями 3D-медицинской визуализации.
Рассматривая популярные методы TTA (такие как Tent, PTN или BNAdapt), авторы заметили фатальный недостаток. Эти методы сильно полагаются на пакетную нормализацию (Batch Normalization, BN). Для адаптации к новому домену они вычисляют статистическое среднее и дисперсию большого пакета поступающих тестовых изображений для обновления сети. Но в больнице вы оцениваете одного пациента за раз. Более того, медицинские изображения — это не плоские 2D-картинки; это массивные 3D-объемы высокого разрешения. Обработка большого пакета 3D-МРТ требует огромной памяти GPU (VRAM), что делает ее вычислительно невозможной для стандартного больничного оборудования.
Если вы попытаетесь вычислить статистику BN только по одному изображению, математика "рухнет", и производительность модели фактически ухудшится. Авторы поняли, что стандартные методы адаптации CNN и даже современные пакетные методы на основе трансформеров совершенно недостаточны для этой конкретной проблемы.
Честно говоря, я не до конца уверен, тестировали ли авторы явно тяжелые генеративные модели, такие как GAN или диффузионные модели, для этой точной конфигурации с одним изображением, но работа убедительно подразумевает, почему они потерпели бы неудачу: эти модели требуют массивных целевых наборов данных и длительного времени переобучения, что полностью нарушает ограничение "в реальном времени, на пациента", требуемое в клинических условиях. Кроме того, авторы явно отвергли методы адаптации "на основе прототипов" (Prototype-based). Почему? Потому что методы на основе прототипов полагаются на согласованные формы (shape priors), а опухоли молочной железы обладают чрезвычайно высокой анатомической вариабельностью. Они не следуют предсказуемой форме.
Логика бенчмаркинга: Структурное превосходство
Поскольку традиционные методы потерпели неудачу, авторам пришлось изобрести качественно превосходящий подход: Patch-Based Multi-View Co-Training (MuVi) (Ко-обучение на основе патчей с несколькими видами).
Вместо того чтобы полагаться на большие пакеты данных от разных пациентов для определения нового домена, MuVi извлекает перекрывающиеся 3D-патчи из МРТ одного пациента и рассматривает их под тремя различными ортогональными углами (аксиальные, сагиттальные и корональные виды).
Это дает огромное структурное преимущество. Принуждая модель смотреть на одну и ту же 3D-ткань с разных точек зрения, они искусственно создают достаточно "разнообразных" данных из одного изображения для адаптации сети. Это полностью обходит необходимость в большом размере пакета, эффективно сокращая потребность в памяти и данных с $N$ пациентов до $1$.
Математически они решили кризис пакетной нормализации, разделив процесс нормализации. Вместо замены исходных статистик они замораживают исходное среднее $\mu_s$ и дисперсию $\sigma_s$, полученные во время обучения, вычисляя нормализованный вход как:
$$ \hat{x} = \frac{x - \mu_s}{\sqrt{\sigma_s^2 + \epsilon}} $$
Затем они позволяют сети обновлять только легкие параметры аффинного преобразования ($\gamma$ и $\beta$) посредством градиентного спуска:
$$ y = \gamma \hat{x} + \beta $$
Это предотвращает "коллапс" модели при столкновении с высокоразмерным шумом одного изображения, в то же время позволяя ей адаптироваться к контрасту и интенсивности нового сканера.
Идеальное сочетание ограничений и решения
Истинная элегантность этой работы заключается в том, насколько идеально математическое решение согласуется с суровыми клиническими ограничениями.
Поскольку у них нет истинных меток (ground-truth labels) для нового пациента, модель должна учиться сама (self-training). Однако самообучение печально известно своей чувствительностью к шуму в метках; если модель ошибается, она будет учиться на своих ошибках и выйдет из-под контроля.
Чтобы преодолеть это, авторы ввели Entropy-guided Self-Training (самообучение с управлением энтропией). Они вычисляют энтропию Шеннона для каждого пикселя, чтобы измерить, насколько "неуверенна" модель в своем предсказании:
$$ H(z) = -z \log_2(z) - (1-z) \log_2(1-z) $$
где $z \in [0, 1]$ — предсказанная вероятность опухоли. Модель принимает только те предсказания, энтропия которых ниже строгого порога $\tau$ (что означает высокую уверенность модели).
Затем они объединяют эти предсказания с высокой степенью уверенности из трех различных видов для создания надежной "псевдометки" (pseudolabel). Наконец, они обновляют сеть, используя комбинированную функцию потерь, которая обеспечивает согласованность между всеми видами:
$$ \mathcal{L}_{total} = \lambda_1 \mathcal{L}_{sl} + \lambda_2 \mathcal{L}_{consistency} + \lambda_3 \mathcal{L}_{cosine} $$
Это идеальное сочетание:
1. Ограничение: Доступно только одно изображение. Решение: Генерация нескольких видов из этого единственного 3D-объема.
2. Ограничение: Нет доступных меток. Решение: Использование математики энтропии для фильтрации шума и генерации псевдометок с высокой степенью уверенности.
3. Ограничение: Ограниченная память GPU. Решение: Замораживание тяжелых пакетных статистик и обновление только легких параметров на небольших 3D-патчах.
Согласовав эти уникальные свойства, авторам удалось добиться улучшения показателя Dice Similarity Coefficient на 5,57% по сравнению с базовым уровнем, превзойдя все существующие SOTA-методы без необходимости в одном дополнительном снимке пациента.
Математический и логический механизм
Представьте, что вы обучили блестящего врача распознавать опухоли молочной железы на тысячах МРТ-снимков из Больницы А. Если вы внезапно переведете этого врача в Больницу Б, он может столкнуться с трудностями. Больница Б использует другие МРТ-аппараты с разной силой магнитного поля, контрастными веществами и профилями шума. В мире искусственного интеллекта мы называем это "сдвигом домена" (domain shift).
Обычно, чтобы исправить это, специалисты по данным собирают тысячи новых изображений из Больницы Б и переобучают ИИ. Но в реальных клинических условиях это невозможно. Врачу нужна точная сегментация для одного конкретного пациента, который находится перед ним прямо сейчас. Он не может ждать, пока будет собран огромный набор данных. Более того, медицинские изображения представляют собой богатые, трехмерные объемные данные, но большинство существующих методов адаптации рассматривают их как плоские двумерные фотографии, игнорируя пространственную глубину.
Авторы данной статьи решили высокоограниченную задачу: как заставить предварительно обученный 3D-медицинский ИИ адаптироваться к совершенно новой, невиданной среде, используя только одно изображение, в режиме реального времени, никогда больше не обращаясь к исходным обучающим данным?
Для достижения этой цели они создали движок Multi-View Co-Training. Давайте разберем математику, которая делает это возможным.
Основной математический движок
Система работает на основе двухфазного механизма: сначала генерируется "поддельная истинная метка" (псевдометка) с высокой степенью уверенности из одного изображения. Затем сеть принудительно обновляется путем минимизации составной функции потерь по различным 3D-геометрическим видам.
Вот основные уравнения, управляющие этой адаптацией:
1. Генерация псевдометки (Entropy-Guided Union):
$$ \hat{y} = \bigcup_{v \in \{x_t, x'_t, x''_t\}} \{j \mid H(\sigma(f(v(j)))) < \tau_v\} $$
2. Цель самообучения:
$$ \mathcal{L}_{sl} = \sum_{v \in \{x_{t_{p_i}}, x'_{t_{p_i}}, x''_{t_{p_i}}\}} \left[ \mathcal{L}_{DICE}(f(v), \hat{y}_{t_{p_i}}) + \mathcal{L}_{CE}(f(v), \hat{y}_{t_{p_i}}) \right] $$
3. Цель согласованности признаков:
$$ \mathcal{L}_{cosine} = 1 - \cos(g(x_{t_{p_i}}), g(x'_{t_{p_i}})) + 1 - \cos(g(x_{t_{p_i}}), g(x''_{t_{p_i}})) $$
4. Общий ландшафт оптимизации:
$$ \mathcal{L}_{total} = \lambda_1 \mathcal{L}_{sl} + \lambda_2 \mathcal{L}_{consistency} + \lambda_3 \mathcal{L}_{cosine} $$
Разбираем уравнения
Давайте разберем каждый винтик и пружинку в этом математическом механизме.
В уравнении псевдометки ($\hat{y}$):
* $\hat{y}$: Мастер-псевдометка. Это наилучшее, наиболее уверенное предположение модели о местоположении опухоли, которое будет служить "истинной меткой" для предстоящей фазы обучения.
* $v \in \{x_t, x'_t, x''_t\}$: Три различных 3D-вида целевого изображения (аксиальная, корональная и сагиттальная плоскости).
* $j$: Конкретный воксель (3D-пиксель) в МРТ-снимке.
* $f(v(j))$: Сырое предсказание нейронной сети для данного вокселя.
* $\sigma(\cdot)$: Сигмоидная функция активации. Она сжимает сырое предсказание в вероятность от 0 до 1.
* $H(\cdot)$: Функция Шенноновской энтропии, определяемая как $H(z) = -z \log_2(z) - (1-z) \log_2(1-z)$. Логически, она действует как строгий вышибала. Если модель не уверена (например, предсказывает 50% вероятность опухоли), энтропия высока. Если она очень уверена (например, 99% или 1%), энтропия низка.
* $\tau_v$: Порог уверенности. Если энтропия ниже этого числа, предсказание принимается.
* $\bigcup$: Оператор объединения. Почему используется объединение, а не пересечение? Потому что разные 3D-виды захватывают различные анатомические границы. Пересечение сохранило бы только те воксели, по которым согласны все три вида, что привело бы к сильно уменьшенной, консервативной маске опухоли. Объединение агрегирует высокоуверенные находки из всех перспектив, создавая комплексную 3D-карту.
В уравнении самообучения ($\mathcal{L}_{sl}$):
* $\sum$: Суммирование по трем видам. Почему сложение, а не умножение? Мы хотим, чтобы общая штрафная функция была накопленной ошибкой со всех точек зрения. Если бы мы их перемножили, почти нулевая ошибка в одном виде могла бы компенсировать огромные ошибки в другом, что опасно в медицинской визуализации.
* $\mathcal{L}_{DICE}$: Функция потерь Dice. Она измеряет пространственное перекрытие между предсказанием и псевдометкой. Она действует как резинка, подтягивая глобальную форму предсказанной опухоли к псевдометке, что критически важно для сильно несбалансированных медицинских изображений, где опухоль мала по сравнению с фоном.
* $\mathcal{L}_{CE}$: Функция потерь перекрестной энтропии. Она оценивает точность классификации по каждому вокселю. Почему DICE и CE складываются? DICE отлично подходит для глобальной формы, но может быть математически нестабильной при градиентном спуске. CE очень стабильна, но игнорирует глобальную структуру. Их сложение обеспечивает идеально сбалансированный, стабильный градиент.
В уравнении согласованности признаков ($\mathcal{L}_{cosine}$):
* $g(\cdot)$: Экстрактор признаков (глубокие внутренние слои нейронной сети, до финальной классификации).
* $\cos(\cdot, \cdot)$: Косинусное сходство.
* $1 - \cos(\cdot, \cdot)$: Косинусное расстояние. Почему используется косинусное расстояние вместо стандартного L2 (Евклидова) расстояния? В глубоких, высокоразмерных нейронных сетях направление вектора признаков несет семантическое значение (например, "эта текстура — опухоль"), в то время как величина просто отражает интенсивность этого признака. Косинусное расстояние строго измеряет угол между векторами, заставляя сеть выравнивать семантическое значение опухоли независимо от угла обзора.
В общей функции потерь ($\mathcal{L}_{total}$):
* $\lambda_1, \lambda_2, \lambda_3$: Скалярные веса, которые калибруют важность самообучения, согласованности предсказаний и согласованности признаков. Авторы установили их равными для балансировки сил.
Пошаговый поток: сборочная линия
Давайте проследим один абстрактный набор данных — 3D МРТ-снимок пациента — через этот движок.
- Разделение на виды: 3D-снимок $x_t$ поступает в систему и немедленно переупорядочивается в три различных геометрических ориентации: аксиальную, корональную и сагиттальную.
- Фильтр уверенности: Замороженная модель рассматривает все три вида и генерирует предварительные маски опухолей. Функция энтропии $H$ сканирует каждый воксель. Если модель колеблется или выдает слабую вероятность, этот воксель мгновенно отбрасывается.
- Создание мастер-ключа: Выжившие, высокоуверенные воксели из всех трех видов объединяются оператором $\bigcup$ для создания золотой псевдометки $\hat{y}$.
- Извлечение патчей: Поскольку 3D-медицинские изображения очень велики и могли бы вызвать сбой в памяти GPU, изображение разбивается на меньшие 3D-блоки (патчи) $x_{t_{p_i}}$.
- Цикл двойной коррекции: Каждый патч проходит через сеть. Финальный выход сети сравнивается с золотой псевдометкой с использованием функции потерь DICE + CE. Одновременно извлекается глубокое внутреннее представление патча $g(x)$. Функция потерь Cosine берет векторы признаков из разных видов и физически вращает их в высокоразмерном пространстве до тех пор, пока они не будут указывать в одном и том же направлении.
Динамика оптимизации: как это на самом деле обучается
Вот где авторы применяют блестящую стратегию оптимизации. Как обучить модель на одном изображении, не допустив мгновенного переобучения и коллапса?
Модель обновляется за одну эпоху. Более того, авторы не обновляют всю сеть. Они замораживают почти все и позволяют градиентам обновлять только аффинные параметры ($\gamma$ и $\beta$) слоев нормализации.
Почему? В стандартной пакетной нормализации (Batch Normalization) сеть полагается на среднее ($\mu$) и дисперсию ($\sigma$) большого пакета изображений. Но здесь у нас только одно изображение. Одно изображение не обладает достаточной статистической мощностью для переопределения распределения всего набора данных. Поэтому авторы фиксируют $\mu$ и $\sigma$ исходного домена.
По мере того как градиенты проходят обратно от $\mathcal{L}_{total}$, они лишь корректируют $\gamma$ (масштаб) и $\beta$ (сдвиг). Это действует как легкий калибровочный регулятор. Он сдвигает и масштабирует карты признаков ровно настолько, чтобы адаптироваться к контрасту и яркости МРТ нового госпиталя, не разрушая фундаментальную логику обнаружения опухолей, которую модель изучила изначально.
Ландшафт потерь здесь сильно ограничен согласованностью по нескольким видам. Заставляя модель согласовываться с самой собой при различных геометрических преобразованиях, члены $\mathcal{L}_{cosine}$ и $\mathcal{L}_{consistency}$ действуют как массивные регуляризаторы. Они прокладывают крутой, узкий путь к сходимости, предотвращая галлюцинации модели на основе одного зашумленного изображения. Сеть быстро сходится к локальному минимуму, который идеально соединяет разрыв между старыми обучающими данными и новым, невиданным пациентом.
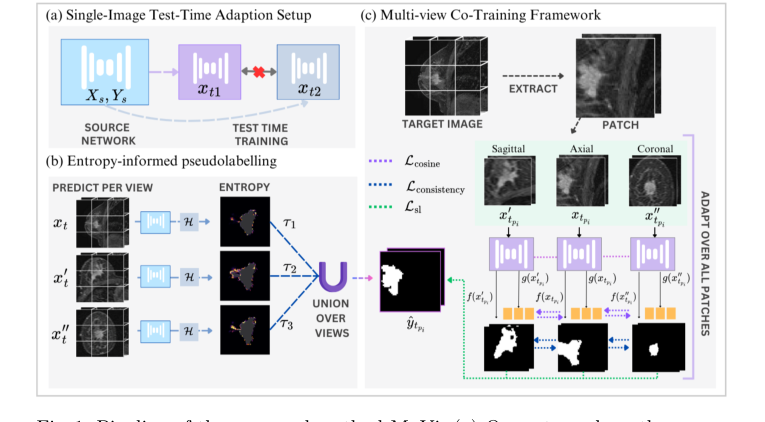 Figure 1. Pipeline of the proposed method MuVi. (a) Our setup where the source network is adapted independently for each target sample xt, (b) computing pseu- dolabel through entropy-threshold union of prediction from each view, (c) Adap- tation via patch-based training through our multi-view consistency framework
Figure 1. Pipeline of the proposed method MuVi. (a) Our setup where the source network is adapted independently for each target sample xt, (b) computing pseu- dolabel through entropy-threshold union of prediction from each view, (c) Adap- tation via patch-based training through our multi-view consistency framework
Результаты, ограничения и заключение
Представьте, что вы учитесь водить машину в тихом, солнечном пригороде. Вы осваиваете дороги, знаки и поток движения. Теперь вас внезапно бросают в центр хаотичного, заснеженного мегаполиса и говорят вести машину. Ваши фундаментальные навыки вождения остаются нетронутыми, но область изменилась настолько кардинально, что вы неизбежно совершите ошибки.
В мире медицинской визуализации модели глубокого обучения сталкиваются именно с таким кошмаром. Модель, обученная на изображениях с МРТ-сканера одной больницы, часто катастрофически выходит из строя при анализе изображений с МРТ-сканера другой больницы. Сила магнитного поля, программное обеспечение для реконструкции и протоколы получения изображений создают "сдвиг домена".
Для решения этой проблемы исследователи используют адаптацию в тестовое время (Test-Time Adaptation, TTA). Вместо того чтобы переобучать всю модель с нуля — что так же дорого, как покупать новое медицинское устройство стоимостью 150 000 долларов каждый раз при смене больницы — TTA немного корректирует модель именно в тот момент, когда она делает предсказание. Однако существующие методы TTA имеют фатальный недостаток: они требуют большого пакета изображений для понимания новой среды. В реальной клинической практике врачи не имеют пакетов; у них есть один 3D-скан одного пациента, ожидающего диагноза. Более того, существующие методы часто рассматривают 3D-медицинские изображения как стопку плоских 2D-фотографий, полностью игнорируя богатую, объемную реальность человеческой анатомии.
В данной статье представлено блестящее решение без использования исходных данных: Patch-Based Multi-View Co-Training (MuVi). Давайте разберем, как именно они решили проблему адаптации 3D-изображений на основе одного изображения.
Математическое ядро проблемы и решения
Проблема:
Нам дана модель $M(\theta_s)$ с параметрами $\theta_s$, которая уже изучила функцию отображения $f: X_s \rightarrow Y_s$ на исходном наборе данных $s$. Наша цель — адаптировать эту модель к новому целевому домену $t$ для изучения новой функции $k: X_t \rightarrow Y_t$. Основным ограничением здесь является то, что у нас нет доступа к исходным данным, нет доступа к истинным меткам целевых данных, и мы должны сделать это, используя только одно целевое изображение $x_t \in X_t$.
Решение:
Авторы решают эту задачу путем комбинации умного сохранения статистических данных и геометрической согласованности.
-
Сохранение исходной статистики:
Стандартная пакетная нормализация (Batch Normalization, BN) полагается на среднее значение $\mu$ и дисперсию $\sigma$ пакета данных. Если попытаться вычислить $\mu$ и $\sigma$ по одному изображению, математика распадается на шумный хаос. Поэтому авторы замораживают исходные статистические данные $\mu_s$ и $\sigma_s$. Они позволяют сети обновлять только обучаемые параметры аффинного преобразования $\gamma$ и $\beta$ во время тестирования, где нормализованный выход равен $y = \gamma \hat{x} + \beta$. -
Многовидовое совместное обучение и самообучение с управлением энтропией:
Поскольку у них есть только одно 3D-изображение, они извлекают перекрывающиеся 3D-патчи $\{x_{t_{p_1}}, x_{t_{p_2}}, \dots, x_{t_{p_n}}\}$. Для каждого патча они математически переставляют оси, чтобы рассматривать его с трех разных анатомических плоскостей: аксиальной, сагиттальной и корональной. Определим эти три вида как $v \in \{x_{t_{p_i}}, x'_{t_{p_i}}, x''_{t_{p_i}}\}$.Для обучения модели без человеческих меток они заставляют модель генерировать собственные "псевдометки". Они вычисляют попиксельную энтропию Шеннона для измерения неопределенности модели:
$$H(z) = -z \log_2(z) - (1-z) \log_2(1-z)$$
где $z \in [0, 1]$ — предсказанная вероятность опухоли. Они принимают только те предсказания, для которых энтропия $H(z)$ ниже строгого порога $\tau$. Окончательная псевдометка $\hat{y}$ является объединением уверенных предсказаний по всем трем видам. -
Цель оптимизации:
Затем модель адаптируется всего за одну эпоху путем минимизации трехкомпонентной функции потерь:
$$\mathcal{L}_{total} = \lambda_1 \mathcal{L}_{sl} + \lambda_2 \mathcal{L}_{consistency} + \lambda_3 \mathcal{L}_{cosine}$$
Здесь $\mathcal{L}_{sl}$ заставляет предсказания модели соответствовать псевдометкам с высокой степенью уверенности, используя потери Dice и Cross-Entropy. $\mathcal{L}_{consistency}$ заставляет предсказания трех разных видов согласовываться друг с другом. Наконец, $\mathcal{L}_{cosine}$ действует глубоко внутри нейронной сети, заставляя экстрактор признаков $g(\cdot)$ выравнивать глубокие вложения различных видов с использованием косинусного сходства:
$$\mathcal{L}_{cosine} = 1 - \cos(g(x_{t_{p_i}}), g(x'_{t_{p_i}})) + 1 - \cos(g(x_{t_{p_i}}), g(x''_{t_{p_i}}))$$
Экспериментальная архитектура и "жертвы"
Авторы не просто заявили, что их математика работает; они разработали безжалостную экспериментальную архитектуру, чтобы доказать это. Они обучили базовую 3D UNet на огромном наборе данных (Duke-Breast-Cancer-MRI), а затем подвергли ее атаке двумя совершенно незнакомыми наборами данных (TCGA-BRCA и ISPY1) с использованием различных сканеров (GE, Siemens, Philips) и различных плоскостей получения изображений.
"Жертвами" в этом эксперименте стали передовые методы TTA: PTN, Tent, BNAdapt, InTent и MEMO.
Окончательное доказательство превосходства MuVi было поразительным. Такие методы, как Tent и PTN, которые пытаются обновить пакетную статистику на основе одного изображения, фактически ухудшили производительность базовой модели. Они попали в ловушку статистического шума одного изображения. MEMO, который использует аугментации, едва сдвинул показатели. MuVi, однако, добился огромного скачка, улучшив коэффициент сходства Дайса (Dice Similarity Coefficient) на целых 5,57% по сравнению с базовой моделью.
Неоспоримым доказательством послужило их исследование аблирования. Когда они удалили ограничение многовидовой согласованности или когда они отказались от исходной статистики BN, производительность модели резко упала. Это неоспоримо доказало, что их конкретный механизм — принуждение 3D-модели к согласованию самой с собой по разным анатомическим плоскостям, опираясь на исходную статистику — был именно той причиной, по которой она добилась успеха на практике. Интересно, что при замене пакетной нормализации на инстанс-нормализацию (Instance Normalization) их неконтролируемый метод достиг метрик ошибки расстояния даже ниже, чем у модели, полностью контролируемой на целевых данных. Честно говоря, я не до конца понимаю, как неконтролируемая адаптация превосходит контролируемый верхний предел по этой конкретной метрике, но это убедительно свидетельствует о том, что инстанс-нормализация значительно лучше справляется с вариациями в стиле одного пациента.
Темы для обсуждения для будущего развития
Основываясь на этих блестящих выводах, вот несколько направлений для будущих исследований, стимулирующих критическое мышление:
- Пределы адаптации к одному экземпляру: Хотя адаптация к одному изображению является клинически идеальной, не жертвует ли она по своей сути "мудростью толпы"? Если модель гипер-адаптируется к уникальной анатомии одного пациента, не рискует ли она принять доброкачественные аномалии за галлюцинаторные опухоли, которые были бы проигнорированы при статистическом взгляде на уровне популяции? Как можно сбалансировать персонализацию для одного пациента с глобальными анатомическими априорными знаниями?
- За пределами энтропии для количественной оценки неопределенности: Авторы используют энтропию Шеннона как прокси для уверенности модели. Однако глубокие нейронные сети печально известны своей чрезмерной уверенностью, часто давая низкую энтропию, даже когда они совершенно неправы. Можно ли интегрировать байесовские нейронные сети или доказательное глубокое обучение для генерации математически строгих границ неопределенности, тем самым создавая гораздо более безопасные и точные псевдометки?
- Геометрическая согласованность между модальностями: Эта статья доказывает, что многовидовая согласованность работает при переключении между различными МРТ-сканерами. Но что, если сдвиг домена происходит между совершенно разными физическими модальностями, такими как адаптация модели, обученной на МРТ, к КТ-сканированию? Основная 3D-геометрия органов остается прежней, но физика интенсивности пикселей совершенно иная. Можно ли развить $\mathcal{L}_{cosine}$ для выравнивания структурных признаков между модальностями без опоры на попиксельное сходство?
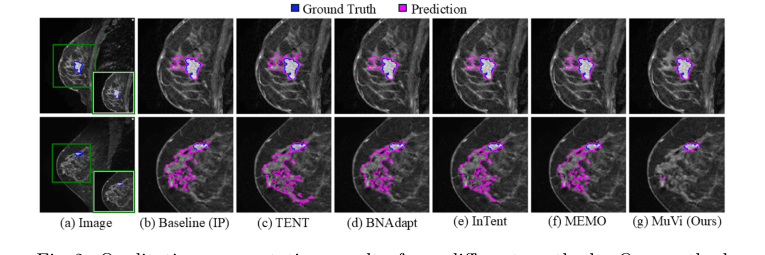 Figure 2. Qualitative segmentation results from different methods. Our method localizes the tumor precisely while removing the misidentified breast tissue
Figure 2. Qualitative segmentation results from different methods. Our method localizes the tumor precisely while removing the misidentified breast tissue