単一画像テスト時適応のためのマルチビュー共同訓練
Test-time adaptation enables a trained model to adjust to a new domain during inference, making it particularly valuable in clinical settings where such on-the-fly adaptation is required.
背景と学術的系譜
医療画像AIは、長らくフラストレーションの溜まる現実に直面してきた。すなわち、病院Aで腫瘍を検出するために訓練された深層学習モデルが、病院Bに展開されると頻繁に失敗するという問題である。これは、異なる病院が異なるMRIスキャナー(例:GE対Siemens)、異なる磁場強度、そして異なるソフトウェアプロトコルを使用するためである。コンピュータビジョンおよび医療画像解析の学術分野では、この不一致は「ドメインシフト」として知られている。
歴史的に、研究者たちは新しい病院から大規模なデータセットを収集し、モデルを再訓練またはファインチューニングすることでこの問題を解決しようとしてきた。しかし、現実の臨床環境では、医師はクリニックに現れた単一の患者に対して、即座にオンザフライでの解析を必要とする。患者に、ソフトウェアを更新するためにさらに1000枚のスキャンを収集するために数週間待つように言うことはできない。この緊急の必要性から、推論のまさにその瞬間にモデルが新しいデータに自身を調整しようとするTest-Time Adaptation (TTA)というサブ分野が誕生した。
TTAは有望であるにもかかわらず、以前のアプローチは深刻な根本的な限界に悩まされていた。第一に、既存のTTA手法のほとんどは、統計的調整(具体的にはBatch Normalization統計)を計算するために、大量の入力画像の「バッチ」を必要とする。病院が1人の患者のスキャンしか必要としない場合、これらのバッチ依存手法は完全に失敗する。第二に、以前のモデルはしばしば重いアーキテクチャの変更を必要としたり、実際の腫瘍の高い解剖学的変動性に対抗できない厳格な形状事前情報に依存したりしていた。最後に、現在の手法のほとんどは、医療スキャンを平坦な2Dスライスとして処理し、データの豊富な3Dボリュームコンテキストを完全に無視している。高解像度3D医療ボリュームの処理には膨大なGPUメモリが必要であり、大規模バッチ処理は単一患者に対して数学的に欠陥があるだけでなく、計算コストも高すぎる。これは、クリニックが標準的な150米ドルのハードウェアアップグレードしか予算に組んでいないのに、大規模なサーバーファームの購入を強制するようなものである。著者らは、既存の手法では、壊滅的なメモリコストやパフォーマンス低下なしに、単一の3D画像のみを使用してリアルタイムでモデルを適応させることができなかったため、この論文を書かざるを得なかった。
著者らがこれをどのように解決したかを理解するために、いくつかの高度に専門的なドメイン用語を直感的な概念に分解してみよう。
- ドメインシフト (Domain Shift): AIが現実世界で見られるデータが、訓練されたデータと異なる場合に、AIのパフォーマンスが低下すること。
- アナロジー: 静かで、晴れていて、予測可能な郊外で運転を学ぶことを想像してほしい(訓練データ)。もし突然、ラッシュアワー中の雪の都市中心部の混沌とした状況に放り込まれたら(テストデータ)、運転スキルは劇的に低下するだろう。その景色の変化がドメインシフトである。
- テスト時適応 (Test-Time Adaptation, TTA): AIモデルが、再訓練のためにオフラインにする必要なく、アクティブに使用されている間に、オンザフライで自身を更新および改善する能力。
- アナロジー: コンサートホールの音響が少しずれていることに気づいたライブステージのミュージシャンを考えてほしい。ショーを止めてリハーサルスタジオに戻るのではなく、音符の間にステージ上で微妙に楽器をチューニングする。
- 疑似ラベリング (Pseudolabeling): AIが注釈なしのデータに対して最良の推測を行い、その推測を「絶対的な真実」としてさらに訓練するために扱う技術。
- アナロジー: 学生が解答集なしで練習問題を解いているのを想像してほしい。自信のある問題に答え、それらの答えが正しいと仮定し、それらを使って難しい問題のパターンを解き明かす。
- マルチビュー共同訓練 (Multi-View Co-Training): AIが、3Dデータをどの角度または視点から見ても、その予測が一貫性を保つように訓練すること(例:上、前、または横から見る)。
- アナロジー: 暗い部屋で謎の物体を検査している場合、正面から見るだけではないだろう。周りを歩き回り、上や横から見るだろう。正面から見ると椅子だと結論付け、横から見るとテーブルだと結論付けた場合、何か問題がある。マルチビュー共同訓練は、AIの結論があらゆる角度から一致するように強制する。
著者らが解決した問題と、単一画像適応をどのように構造化したかを正確に数学的に解釈するには、彼らが使用したコア変数とパラメータを定義する必要がある。以下は、マルチビュー整合性フレームワークの基盤を表す表記法の表である。
| Notations | Description |
|---|---|
| $M(\theta_s)$ | ソースドメインから学習された重み $\theta_s$ でパラメータ化された、事前訓練済みニューラルネットワークモデル。 |
| $X_s, Y_s$ | ソースドメインの3D画像テンソルとその対応する密にラベル付けされたボクセルごとのグラウンドトゥルースマスク。 |
| $X_t, Y_t$ | ターゲットドメインの3D画像テンソルとそのグラウンドトゥルースマスク(テスト時適応中は利用不可)。 |
| $x_t$ | テスト時に遭遇する単一の3Dターゲット画像で、モデルはそれに適応する必要がある。 |
| $\mu_s, \sigma_s$ | モデルの事前訓練フェーズ中に取得された元の平均および分散統計。 |
| $\gamma, \beta$ | 新しい画像のフルバッチを必要とせずに、テスト時にネットワークをモジュレートするために使用される学習可能なアフィン変換パラメータ。 |
| $x_{t_{p_i}}$ | 単一ターゲットテスト画像 $x_t$ から抽出された $i$ 番目のオーバーラップする3Dパッチ。 |
| $\pi_1, \pi_2$ | パッチを別の解剖学的ビュー(例:軸方向から矢状方向または冠状方向)に回転または変換するために使用されるビュー固有の順列関数。 |
| $v$ | 元のパッチとその変換されたバージョンを表すビューのセットで、$v \in \{x_{t_{p_i}}, x'_{t_{p_i}}, x''_{t_{p_i}}\}$ と定義される。 |
| $H(z)$ | モデルの予測確率 $z$ から計算されるピクセルごとのエントロピー。モデルの不確実性を測定する。 |
| $\tau$ | 経験的に設定されたエントロピーしきい値。このしきい値以下の不確実性を持つ予測は、確信度が高いと受け入れられる。 |
| $\hat{y}_{t_{p_i}}$ | 特定のパッチに対して生成されるエントロピーベースの疑似ラベルで、自己訓練のための一時的なグラウンドトゥルースとして使用される。 |
| $\mathcal{L}_{sl}$ | モデル自身の疑似ラベルでモデルを訓練するために、Dice LossとCross-Entropy Lossを組み合わせた自己学習損失関数。 |
| $\mathcal{L}_{consistency}$ | どのビュー($x'_{t_{p_i}}$ または $x''_{t_{p_i}}$)を処理しているかに関わらず、モデルが同じセグメンテーションを出力するように強制する整合性損失関数。 |
| $\mathcal{L}_{cosine}$ | 疑似ラベルとは無関係に、異なるビューのディープ特徴埋め込みが整列したままであることを保証するコサイン類似度損失。 |
歴史的なバッチ統計 ($\mu_s, \sigma_s$) を凍結し、組み合わせた損失関数 $$\mathcal{L}_{total} = \lambda_1\mathcal{L}_{sl} + \lambda_2\mathcal{L}_{consistency} + \lambda_3\mathcal{L}_{cosine}$$ を使用して軽量パラメータ ($\gamma, \beta$) のみを更新することにより、著者らは、単一の画像のみを使用してブランドの新しい病院のMRIスキャナーに適応する手法を成功裏に作成し、以前のアプローチを crippled していた大規模なデータとメモリのボトルネックを完全に回避した。
問題定義と制約
開始点、ゴール、そして臨床現場の落とし穴
本論文におけるブレークスルーの大きさを真に理解するためには、まず、その厳密な数学的および実践的な出発点、望ましい終着点、そして病院環境における人工知能展開の過酷な現実を理解する必要がある。
出発点(入力状態):
我々は、ソースデータセット上で事前学習され、マッピング関数 $f: X_s \rightarrow Y_s$ を学習したディープラーニングモデル $M(\theta_s)$ から開始する。ここで、$X_s$ は特定の病院からの3D医用画像テンソル(乳房MRIなど)を表し、$Y_s$ は高密度にラベル付けされたボクセル単位の3Dセグメンテーションマスク(腫瘍の正確な境界)を表す。
テスト時には、モデルは新しい病院に展開される。ターゲットドメイン $t$ からの単一のラベルなし3D画像テンソル $x_t \in X_t$ が与えられる。この新しい画像は、異なるMRIスキャナーで撮影されたため、コントラスト、解像度、またはノイズプロファイルが異なる可能性がある。元のソースデータ $s$ へのアクセスは一切なく、この新しい患者のグラウンドトゥルースラベルも存在しない。
ゴール状態(出力):
目的は、モデルパラメータ $\theta_s$ を新しいターゲットドメインに即座に適応させ、この特定の患者に対して3Dセグメンテーションマスク $Y_t$ を正確に出力する新しい関数 $k: X_t \rightarrow Y_t$ を学習することである。極めて重要なのは、モデルは提供された単一画像 $x_t$ のみを使用して、オンザフライでこれを実行しなければならないという点である。
数学的なギャップ:
欠けているのは、教師なし最適化の橋渡しである。ターゲット $Y_t$ が比較対象として存在せず、新しい統計分布を推定するのに十分なターゲットドメイン $X_t$ のデータポイントがない場合、どのようにして損失勾配を計算して $\theta_s$ を更新するのか?
統計的安定性と臨床的現実の間の痛みを伴うジレンマ
Test-Time Adaptation (TTA) の分野において、研究者たちは統計的安定性と臨床的レイテンシの間の悪循環的なトレードオフに囚われてきた。
ほとんどの既存のTTA手法は、Batch Normalization (BN) 層の更新に大きく依存している。モデルを新しいドメインに適応させるために、これらの手法は新しいターゲット分布の平均 $\mu$ と分散 $\sigma^2$ を再計算する。しかし、分布の安定した数学的推定値を得るためには、大量のデータバッチが必要である。
ここにジレンマがある:BN統計を安定させるために大量の患者スキャンを収集するのを待つと、臨床ケアのリアルタイムかつオンデマンドな性質が破壊される。医師は、AIが目の前の患者を診断できるようになる前に、さらに30人の患者がスキャンされるのを待つことはできない。逆に、バッチサイズちょうど1(単一患者)を使用してBN統計を適応させようとすると、統計的推定値が激しく変動し、モデルの予測が崩壊する。モデルの精度を壊すか、病院のワークフローを壊すかの選択を迫られる。
医用画像適応における過酷な壁
著者らは、この特定の問題を解決することを極めて困難にしている、いくつかの過酷で現実的な制約に直面した。
- データの極端なスパース性(単一画像壁):
モデルは $N=1$ サンプルを使用して適応しなければならない。テスト時には学習するためのデータセットはなく、単一のインスタンスのみが存在する。単一の点から分布をマッピングすることはできないため、従来の教師なしドメイン適応技術に依存することは数学的に不可能である。 - ハードウェアメモリの制限(VRAM壁):
2D写真とは異なり、医用画像は高解像度の3Dボリュームデータに依存する。3Dテンソルを処理するには、大量のGPUメモリ(VRAM)が必要となる。クリニックが統計を安定させるために大きなバッチサイズを使用したいと考えていたとしても、標準的な病院のハードウェアでは、一度に大量の3D MRIをメモリに保持することは物理的に不可能である。 - ソースフリー制約(プライバシー壁):
厳格な患者プライバシー法と膨大なストレージ要件のため、元のソーストレーニングデータ $X_s$ をモデルと共に配布することはできない。適応は完全に「ソースフリー」でなければならず、これはモデルが新しいスキャナーに適応する際に、腫瘍がどのように見えるべきかを思い出すために古いデータを参照できないことを意味する。 - マルチスキャナー設定の動的なターゲット:
病院が推論を遅延させて患者のバッチを待つことを決定したとしても、それらの患者が単一のターゲット分布を共有するという保証はない。マルチスキャナー病院では、患者AはGE製マシンで、患者BはSiemens製マシンでスキャンされる可能性がある。共有ターゲット分布を計算するためにそれらをバッチにグループ化することは数学的に誤っており、従来のバッチベースの適応技術を完全に無効にする。
このアプローチの理由
この論文の画期的な点を理解するためには、まず病院における人工知能(AI)導入の厳しい現実を理解する必要がある。病院AのMRIスキャンから乳がん腫瘍を検出するために訓練された深層学習モデルを想像してみよう。そのモデルは病院Aでは完璧に機能する。しかし、異なるMRIスキャナー、異なる磁場強度、異なる画像撮影プロトコルを使用する病院Bに展開すると、モデルは突然失敗する。これは「ドメインシフト」と呼ばれる。
従来、エンジニアはこの問題を解決するために、病院Bから数千枚の画像を収集し、モデルを再訓練していた。しかし、実際の臨床環境では、医師は患者のスキャンを即座に分析する必要がある。彼らは数ヶ月かけて大規模なデータセットを収集するのを待つことはできない。モデルは、その単一の患者のスキャンのみを使用して、その場で適応する必要がある。これが、Single Image Test-Time Adaptation(TTA)の根本的な課題である。
「アハ!」の瞬間:なぜSOTA手法は失敗したのか
著者らは決定的な洞察を得た。現在のコンピュータビジョンの最先端(SOTA)手法は、3D医療画像の物理的および臨床的制約と根本的に互換性がないということである。
Tent、PTN、BNAdaptなどの一般的なTTA手法を見ると、著者らは致命的な欠陥に気づいた。これらの手法は、バッチ正規化(BN)に大きく依存している。新しいドメインに適応するために、それらはネットワークを更新するために多数のテスト画像の統計的な平均と分散を計算する。しかし、病院では一度に一人の患者を評価している。さらに、医療画像は平坦な2D画像ではなく、巨大で高解像度の3Dボリュームである。3D MRIの多数のバッチを処理するには、膨大なGPUメモリ(VRAM)が必要となり、標準的な病院のハードウェアでは計算上不可能である。
単一の画像でBN統計を計算しようとすると、計算が破綻し、モデルのパフォーマンスは実際には悪化する。著者らは、標準的なCNN適応技術、さらには最新のTransformerベースのバッチ手法さえも、この特定の問題には全く不十分であると認識した。
正直に言うと、著者らがこの正確な単一画像設定でGANや拡散モデルのような重い生成モデルを明示的にテストしたかどうかは完全にはわからないが、この論文はそれらがなぜ失敗するのかを強く示唆している。それらのモデルは、臨床現場で要求される「リアルタイム、患者ごと」の制約を完全に無視して、大規模なターゲットデータセットと広範な再訓練時間を必要とする。さらに、著者らは「プロトタイプベース」の適応手法を明確に却下した。なぜか?プロトタイプ手法は一貫した形状(形状事前情報)に依存するが、乳がん腫瘍は解剖学的なばらつきが極めて高い。それらは予測可能な形状に従わない。
ベンチマーキングの論理:構造的優位性
従来の СТАНДАРТНЫЕ методы が失敗したため、著者らは質的に優れたアプローチを考案する必要があった。それは Patch-Based Multi-View Co-Training (MuVi) である。
MuViは、異なる患者の多数のバッチに依存して新しいドメインを把握する代わりに、単一の患者のMRIから重複する3Dパッチを抽出し、それらを3つの異なる直交角度(軸方向、矢状面、冠状面)から観察する。
これにより、構造的な大きな利点が得られる。モデルに同じ3D組織を異なる視点から見させることで、単一の画像から適応に必要な「多様な」データを人工的に生成する。これにより、大規模なバッチサイズを必要とする必要がなくなり、メモリとデータの要件を$N$人の患者から$1$人に効果的に削減できる。
数学的には、正規化プロセスを分割することによってバッチ正規化の危機を解決した。ソース統計を置き換える代わりに、訓練中に学習された元の平均$\mu_s$と分散$\sigma_s$を固定し、正規化された入力を次のように計算する。
$$ \hat{x} = \frac{x - \mu_s}{\sqrt{\sigma_s^2 + \epsilon}} $$
次に、勾配降下法を通じて、軽量なアフィン変換パラメータ($\gamma$と$\beta$)のみを更新できるようにする。
$$ y = \gamma \hat{x} + \beta $$
これにより、単一画像の高次元ノイズに直面したときにモデルが破綻するのを防ぎつつ、新しいスキャナーのコントラストと強度に適応させることができる。
制約と解決策の完璧な融合
この論文の真の巧妙さは、数学的な解決策が厳しい臨床的制約といかに完璧に一致しているかにある。
新しい患者に対するグラウンドトゥルースラベルがないため、モデルは自己学習(セルフトレーニング)する必要がある。しかし、セルフトレーニングはラベルノイズに非常に敏感である。モデルが間違った予測をすると、自身の誤りから学習し、制御不能に陥る可能性がある。
これを克服するために、著者らはEntropy-guided Self-Trainingを導入した。ピクセルごとのシャノンエントロピーを計算して、モデルが予測に対してどれだけ「不確か」であるかを測定する。
$$ H(z) = -z \log_2(z) - (1-z) \log_2(1-z) $$
ここで、$z \in [0, 1]$は腫瘍の予測確率である。モデルは、エントロピーが厳密な閾値$\tau$を下回る(モデルが非常に確信していることを意味する)予測のみを受け入れる。
次に、これらの非常に確信度の高い予測を3つの異なるビューから組み合わせて、信頼性の高い「疑似ラベル」を作成する。最後に、すべてのビュー間で一貫性を強制する組み合わせ損失関数を使用してネットワークを更新する。
$$ \mathcal{L}_{total} = \lambda_1 \mathcal{L}_{sl} + \lambda_2 \mathcal{L}_{consistency} + \lambda_3 \mathcal{L}_{cosine} $$
これは完璧な融合である。
1. 制約: 画像は1枚のみ利用可能。解決策: その単一の3Dボリュームから複数のビューを生成する。
2. 制約: ラベルは利用不可。解決策: エントロピー数学を使用してノイズを除外し、非常に確信度の高い疑似ラベルを生成する。
3. 制約: GPUメモリが限られている。解決策: 重いバッチ統計を固定し、小さな3Dパッチ上の軽量パラメータのみを更新する。
これらのユニークな特性を整合させることにより、著者らはベースラインに対してDice Similarity Coefficientで5.57%の改善を達成し、追加の患者スキャンを一切必要とせずに、既存のすべてのSOTA手法を上回ることに成功した。
数学的・論理的メカニズム
病院Aの数千枚のMRIスキャンを用いて、乳がん腫瘍を特定するように訓練された優秀な医師を想像してほしい。もしその医師を突然病院Bに異動させたとすると、苦労するかもしれない。病院Bでは、磁場の強さ、造影剤、ノイズプロファイルが異なる、異なるMRI装置を使用しているからだ。人工知能の世界では、これを「ドメインシフト」と呼ぶ。
通常、これを修正するために、データサイエンティストは病院Bから数千枚の新しい画像を収集し、AIを再訓練する。しかし、実際の臨床現場では、これは不可能である。医師は、今まさに目の前にいる単一の患者に対して、正確なセグメンテーションを必要とする。大規模なデータセットがコンパイルされるのを待つことはできない。さらに、医療画像はリッチな3Dボリュームデータであるが、既存の適応手法の多くは、それらを平坦な2D写真のように扱い、空間的な奥行きを無視している。
本論文の著者らは、高度に制約された問題を解決した。それは、元の訓練データに一切触れることなく、単一の画像のみを使用して、リアルタイムで、完全に新しい未知の環境に事前訓練済みの3D医療AIを適応させるにはどうすればよいか、という問題である。
これを達成するために、彼らはMulti-View Co-Trainingエンジンを構築した。この数学がそれを可能にする仕組みを分解してみよう。
コアとなる数学エンジン
このシステムは2段階のメカニズムによって駆動される。まず、単一の画像から高い信頼度を持つ「偽のグラウンドトゥルース」(擬似ラベル)を生成する。次に、異なる3D幾何学的ビューにわたる複合損失関数を最小化することによって、ネットワーク自身を更新するように強制する。
この適応を駆動するマスター方程式を以下に示す。
1. 擬似ラベル生成(エントロピー誘導ユニオン):
$$ \hat{y} = \bigcup_{v \in \{x_t, x'_t, x''_t\}} \{j \mid H(\sigma(f(v(j)))) < \tau_v\} $$
2. 自己学習目的関数:
$$ \mathcal{L}_{sl} = \sum_{v \in \{x_{t_{p_i}}, x'_{t_{p_i}}, x''_{t_{p_i}}\}} \left[ \mathcal{L}_{DICE}(f(v), \hat{y}_{t_{p_i}}) + \mathcal{L}_{CE}(f(v), \hat{y}_{t_{p_i}}) \right] $$
3. 特徴整合性目的関数:
$$ \mathcal{L}_{cosine} = 1 - \cos(g(x_{t_{p_i}}), g(x'_{t_{p_i}})) + 1 - \cos(g(x_{t_{p_i}}), g(x''_{t_{p_i}})) $$
4. 総最適化ランドスケープ:
$$ \mathcal{L}_{total} = \lambda_1 \mathcal{L}_{sl} + \lambda_2 \mathcal{L}_{consistency} + \lambda_3 \mathcal{L}_{cosine} $$
方程式の分解
この数学的機構のすべての歯車とバネを分解してみよう。
擬似ラベル方程式 ($\hat{y}$) において:
* $\hat{y}$: マスター擬似ラベル。これは、腫瘍の位置に関するモデルの最も信頼できる推測であり、次の訓練フェーズの「グラウンドトゥルース」として機能する。
* $v \in \{x_t, x'_t, x''_t\}$: 対象画像の3つの異なる3Dビュー(軸断面、冠状断面、矢状断面)。
* $j$: MRIスキャン内の特定のボクセル(3Dピクセル)。
* $f(v(j))$: その特定のボクセルに対するニューラルネットワークの生の予測。
* $\sigma(\cdot)$: シグモイド活性化関数。生の予測を0から1の間の確率に圧縮する。
* $H(\cdot)$: シャノンエントロピー関数。定義は $H(z) = -z \log_2(z) - (1-z) \log_2(1-z)$。論理的には、これは厳格な門番として機能する。モデルが不確かな場合(例:腫瘍の確率が50%)、エントロピーは高くなる。非常に確信している場合(例:99%または1%)、エントロピーは低くなる。
* $\tau_v$: 信頼度閾値。エントロピーがこの数値を下回る場合、予測は受け入れられる。
* $\bigcup$: ユニオン演算子。なぜインターセクションではなくユニオンを使用するのか? 異なる3Dビューは異なる解剖学的境界を捉えるためである。インターセクションを使用すると、3つのビューすべてが合意したボクセルのみが保持され、腫瘍マスクは著しく縮小され、保守的になる。ユニオンは、すべての視点からの高い信頼度を持つ発見を集約し、包括的な3Dマップを構築する。
自己学習方程式 ($\mathcal{L}_{sl}$) において:
* $\sum$: 3つのビューにわたる合計。なぜ乗算ではなく加算なのか? すべての視点からの累積誤差を総ペナルティとしたいからである。もし乗算すると、1つのビューでのほぼゼロの誤差が別のビューでの巨大な誤差を相殺する可能性があり、これは医療画像では危険である。
* $\mathcal{L}_{DICE}$: ダイス損失。予測と擬似ラベル間の空間的重複を測定する。これはゴムバンドのように機能し、予測された腫瘍の全体的な形状を擬似ラベルに合わせるように引っ張る。これは、腫瘍が背景に比べて非常に小さい、高度に不均衡な医療画像において重要である。
* $\mathcal{L}_{CE}$: 交差エントロピー損失。ボクセルごとの分類精度を評価する。なぜDICEとCEを一緒に加算するのか? DICEは全体的な形状には優れているが、勾配降下中に数学的に不安定になることがある。CEは非常に安定しているが、全体的な構造を無視する。これらを加算することで、完全にバランスの取れた安定した勾配が得られる。
特徴整合性方程式 ($\mathcal{L}_{cosine}$) において:
* $g(\cdot)$: 特徴抽出器(ニューラルネットワークの深い内部層、最終分類の前)。
* $\cos(\cdot, \cdot)$: コサイン類似度。
* $1 - \cos(\cdot, \cdot)$: コサイン距離。なぜ標準的なL2(ユークリッド)距離ではなくコサイン距離を使用するのか? 深く高次元のニューラルネットワークでは、特徴ベクトルの方向が意味論的な意味(例:「このテクスチャは腫瘍である」)を持ち、その大きさは単にその特徴の強度を表すだけである。コサイン距離は厳密にベクトル間の角度を測定し、ビュー角に関係なく腫瘍の意味論的な意味を整列させるようにネットワークに強制する。
総損失 ($\mathcal{L}_{total}$) において:
* $\lambda_1, \lambda_2, \lambda_3$: 自己学習、予測整合性、特徴整合性の重要度を調整するスカラー重み。著者らは、バランスを取るためにこれらを等しく設定した。
ステップバイステップフロー:組み立てライン
抽象的なデータポイント、つまり患者の3D MRIスキャンを、このエンジンを通してトレースしてみよう。
- 視点のスライス: 3Dスキャン $x_t$ がシステムに入力され、軸断面、冠状断面、矢状断面の3つの異なる幾何学的配向に即座に置換される。
- 信頼度フィルター: フリーズされたモデルが3つのビューすべてを参照し、予備的な腫瘍マスクを生成する。エントロピー関数 $H$ がすべてのボクセルをスキャンする。モデルが躊躇したり、弱い確率を出力したりした場合、そのボクセルは即座に破棄される。
- マスターキーの鍛造: 3つのビューすべてから生き残った、高い信頼度を持つボクセルがユニオン演算子 $\bigcup$ を介して融合され、ゴールデン擬似ラベル $\hat{y}$ が作成される。
- パッチ抽出: 3D医療画像は巨大であり、GPUメモリをクラッシュさせる可能性があるため、画像はより小さな3Dブロック(パッチ) $x_{t_{p_i}}$ に分割される。
- デュアル補正ループ: 各パッチがネットワークを通過する。ネットワークの最終出力は、DICE + CE損失を使用してゴールデン擬似ラベルと比較される。同時に、パッチの深い内部表現 $g(x)$ が抽出される。コサイン損失は、異なるビューからの特徴ベクトルを取得し、それらがまったく同じ方向を指すまで、高次元空間で物理的に回転させる。
最適化ダイナミクス:実際の学習方法
ここで、著者らは見事な最適化戦略を実行する。単一の画像でモデルを訓練し、それが即座に過学習して崩壊しないようにするにはどうすればよいか?
モデルは単一エポックで更新される。さらに、著者らはネットワーク全体を更新しない。ほとんどすべてをフリーズし、勾配のみが正規化層のアフィンパラメータ ($\gamma$ および $\beta$) を更新できるようにする。
なぜか?標準的なバッチ正規化では、ネットワークは大量の画像の平均 ($\mu$) および分散 ($\sigma$) に依存する。しかし、ここでは画像は1つしかない。単一の画像では、データセット全体の分布を再定義するのに十分な統計的パワーがない。したがって、著者らは元のソースドメインの $\mu$ および $\sigma$ を固定する。
勾配が $\mathcal{L}_{total}$ から逆伝播するにつれて、$\gamma$(スケール)と $\beta$(シフト)のみが微調整される。これは軽量なキャリブレーションノブとして機能する。それは、モデルが元々学習した基本的な腫瘍検出ロジックを破壊することなく、新しい病院のMRIコントラストと明るさに適応するために、特徴マップをちょうど良い程度にシフトおよびスケールする。
ここでの損失ランドスケープは、マルチビュー整合性によって高度に制約される。モデルに異なる幾何学的変換間で合意するように強制することで、$\mathcal{L}_{cosine}$ および $\mathcal{L}_{consistency}$ 項は巨大な正則化器として機能する。それらは収束への急で狭いパスを刻み、モデルが単一のノイズの多い画像に基づいて誤った予測を幻覚するのを防ぐ。ネットワークは、古い訓練データと新しい未知の患者との間のギャップを完全に橋渡しする局所的最小値に急速に落ち着く。
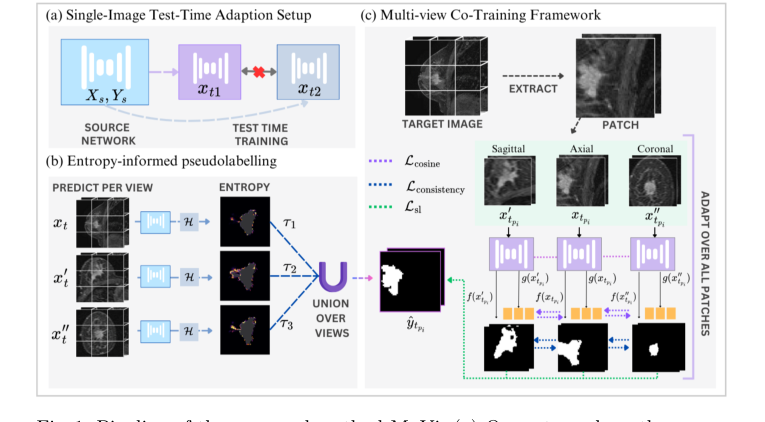 Figure 1. Pipeline of the proposed method MuVi. (a) Our setup where the source network is adapted independently for each target sample xt, (b) computing pseu- dolabel through entropy-threshold union of prediction from each view, (c) Adap- tation via patch-based training through our multi-view consistency framework
Figure 1. Pipeline of the proposed method MuVi. (a) Our setup where the source network is adapted independently for each target sample xt, (b) computing pseu- dolabel through entropy-threshold union of prediction from each view, (c) Adap- tation via patch-based training through our multi-view consistency framework
結果、限界、および結論
静かで日当たりの良い郊外の町で運転を学ぶと想像してほしい。あなたは道路、標識、交通の流れをマスターする。しかし、突然、あなたは混沌とした吹雪に見舞われた大都市の真ん中に放り込まれ、運転するように言われる。あなたの基本的な運転スキルはそのまま残っているが、ドメインが劇的に変化したため、間違いを犯すことは避けられない。
医療画像の世界では、深層学習モデルはまさにこの悪夢に直面している。ある病院のMRIスキャナーからの画像で学習したモデルは、別の病院のスキャナーからの画像を分析する際には、しばしば壊滅的に失敗する。磁場の強さ、再構成ソフトウェア、画像プロトコルが「ドメインシフト」を生み出す。
これを修正するために、研究者はテスト時適応(TTA)を使用する。モデル全体をゼロから再学習するのではなく――これは病院を切り替えるたびに15万ドルの新しい医療機器を購入するのと同じくらい高価である――TTAは予測を行うまさにその瞬間にモデルをわずかに調整する。しかし、既存のTTA手法には致命的な欠陥がある。それは、新しい環境を理解するために大量の画像バッチを必要とすることである。実際の臨床現場では、医師はバッチを持っておらず、診断を待っている単一の患者の単一の3Dスキャンを持っているだけである。さらに、既存の手法はしばしば3D医療画像を平坦な2D写真のスタックのように扱い、人間の解剖学の豊かで体積的な現実を完全に無視している。
本稿では、画期的なソースフリーソリューションであるPatch-Based Multi-View Co-Training (MuVi)を紹介する。この論文が、この単一画像3D適応問題をどのように解決したかを詳しく見ていこう。
問題と解決策の数学的核
問題:
ソースデータセット $s$ 上で既にマッピング関数 $f: X_s \rightarrow Y_s$ を学習したパラメータ $\theta_s$ を持つモデル $M(\theta_s)$ が与えられる。目標は、新しいターゲットドメイン $t$ にこのモデルを適応させ、新しい関数 $k: X_t \rightarrow Y_t$ を学習することである。ここでの大きな制約は、元のソースデータへのアクセスがないこと、ターゲットデータのグラウンドトゥルースラベルへのアクセスがないこと、そしてターゲット画像 $x_t \in X_t$ が1枚だけであることである。
解決策:
著者らは、巧妙な統計的保存と幾何学的整合性の組み合わせによって、この問題に取り組んでいる。
-
ソース統計の保存:
標準的なバッチ正規化(BN)は、データバッチの平均 $\mu$ と分散 $\sigma$ に依存する。単一の画像から $\mu$ と $\sigma$ を計算しようとすると、数学はノイズの多いカオスに陥る。したがって、著者らは元のソース統計 $\mu_s$ と $\sigma_s$ を固定する。テスト時には、正規化された出力が $y = \gamma \hat{x} + \beta$ となるように、学習可能なアフィン変換パラメータ $\gamma$ と $\beta$ のみを更新できるようにする。 -
マルチビュー共同学習とエントロピー誘導型自己学習:
単一の3D画像しか持たないため、重複する3Dパッチ $\{x_{t_{p_1}}, x_{t_{p_2}}, \dots, x_{t_{p_n}}\}$ を抽出する。各パッチについて、軸を数学的に並べ替えて、3つの異なる解剖学的平面、すなわち軸状断、矢状断、冠状断から見る。これらの3つのビューを $v \in \{x_{t_{p_i}}, x'_{t_{p_i}}, x''_{t_{p_i}}\}$ と定義しよう。人間のラベルなしでモデルをトレーニングするために、モデルに独自の「擬似ラベル」を生成させる。ピクセルごとのシャノンエントロピーを計算して、モデルの不確実性を測定する。
$$H(z) = -z \log_2(z) - (1-z) \log_2(1-z)$$
ここで、$z \in [0, 1]$ は腫瘍の予測確率である。エントロピー $H(z)$ が厳密な閾値 $\tau$ を下回る予測のみを受け入れる。最終的な擬似ラベル $\hat{y}$ は、3つのビューすべてにわたる確信度の高い予測の和集合である。 -
最適化目標:
モデルは、3つの損失関数を最小化することによって、わずか1エポックで適応される。
$$\mathcal{L}_{total} = \lambda_1 \mathcal{L}_{sl} + \lambda_2 \mathcal{L}_{consistency} + \lambda_3 \mathcal{L}_{cosine}$$
ここで、$\mathcal{L}_{sl}$ は、Dice損失と交差エントロピー損失を使用して、モデルの予測を確信度の高い擬似ラベルに一致させることを強制する。$\mathcal{L}_{consistency}$ は、3つの異なるビューからの予測が互いに一致することを強制する。最後に、$\mathcal{L}_{cosine}$ はニューラルネットワークの深層で動作し、コサイン類似度を使用して、特徴抽出器 $g(\cdot)$ が異なるビューの深い埋め込みを整列させることを強制する。
$$\mathcal{L}_{cosine} = 1 - \cos(g(x_{t_{p_i}}), g(x'_{t_{p_i}})) + 1 - \cos(g(x_{t_{p_i}}), g(x''_{t_{p_i}}))$$
実験アーキテクチャと「犠牲者」
著者らは、数学が機能すると主張するだけでなく、それを証明するために、過酷な実験アーキテクチャを考案した。彼らは、大規模なデータセット(Duke-Breast-Cancer-MRI)でベースライン3D UNetをトレーニングし、その後、異なるスキャナー(GE、Siemens、Philips)と異なる取得平面を持つ、完全に未知の2つのデータセット(TCGA-BRCAおよびISPY1)でそれを「襲撃」した。
この実験における「犠牲者」は、最先端のTTA手法であった。PTN、Tent、BNAdapt、InTent、MEMOである。
MuViの優位性の決定的な証拠は明白であった。単一画像に基づいてバッチ統計を更新しようとするTentやPTNのような手法は、実際にはベースラインモデルのパフォーマンスを低下させた。それらは単一画像統計ノイズの罠に陥った。Augmentationを使用するMEMOは、ほとんど効果がなかった。しかし、MuViは、Dice Similarity Coefficientをベースラインと比較して最大5.57%向上させるという、劇的な飛躍を達成した。
決定的な証拠は、それらのアブレーションスタディであった。マルチビュー整合性制約を削除した場合、またはソースBN統計を破棄した場合、モデルのパフォーマンスは崩壊した。これは、3Dモデルに異なる解剖学的平面間で自己整合性を強制し、ソース統計によって固定するという、彼らの特定のメカニズムが、現実世界で成功したまさにその理由であることを否定できないほど証明した。興味深いことに、バッチ正規化をインスタンス正規化に置き換えた場合、彼らの教師なし手法は、ターゲットデータで完全に教師あり学習されたモデルよりもさらに低い距離誤差メトリックを達成した。正直なところ、教師なし適応が特定のメトリックで教師あり上限をどのように上回るのか完全にはわからないが、インスタンス正規化が単一患者スタイルのバリエーションを処理する上で圧倒的に優れていることを強く示唆している。
将来の進化のための議論トピック
これらの画期的な発見に基づいて、批判的思考を刺激するための将来の探求のいくつかの方向性を以下に示す。
- 単一インスタンス適応の限界: 単一画像への適応は臨床的に理想的であるが、それは本質的に「群衆の知恵」を犠牲にするのだろうか?モデルが1人の患者のユニークな解剖学に過剰適応した場合、集団レベルの統計的視点があれば無視されたであろう良性の異常から腫瘍を幻覚するリスクがあるのだろうか?単一患者のパーソナライゼーションとグローバルな解剖学的事前知識をどのようにバランスさせることができるだろうか?
- 不確実性定量化のためのエントロピー以外の方法: 著者らは、モデルの信頼性の代理としてシャノンエントロピーを使用している。しかし、深層ニューラルネットワークは悪名高く過度に自信があり、完全に間違っている場合でも低いエントロピーを生成することが多い。ベイズ深層学習またはエビデンシャル深層学習を統合して、数学的に厳密な不確実性境界を生成し、それによって、はるかに安全で正確な擬似ラベルを作成できるだろうか?
- クロスモダリティ幾何学的整合性: 本稿は、マルチビュー整合性が異なるMRIスキャナー間でのシフトにおいて機能することを証明している。しかし、ドメインシフトが完全に異なる物理的モダリティ間である場合はどうだろうか?例えば、MRIでトレーニングされたモデルをCTスキャンに適合させる場合などである。臓器の基本的な3D幾何学は同じままであるが、ピクセル強度の物理学は完全に異なる。$\mathcal{L}_{cosine}$ を、ピクセルレベルの類似性に依存せずに、モダリティ間の構造的特徴を整列させるように進化させることができるだろうか?
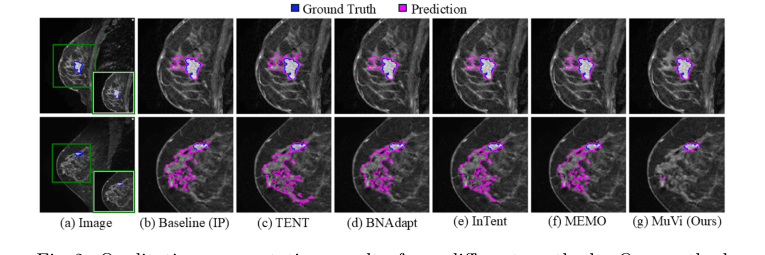 Figure 2. Qualitative segmentation results from different methods. Our method localizes the tumor precisely while removing the misidentified breast tissue
Figure 2. Qualitative segmentation results from different methods. Our method localizes the tumor precisely while removing the misidentified breast tissue