ज्यामितीय गुप्त एम्बेडिंग के माध्यम से अनुदैर्ध्य डेटा का टेम्पोरल एटलस-निर्देशित उत्पादन
इस शोध की जड़ों को समझने के लिए, हमें चिकित्सा इमेजिंग के ऐतिहासिक विकास को देखना होगा। दशकों पहले, सीटी या एमआरआई जैसे चिकित्सा स्कैन को स्थिर तस्वीरों के रूप में माना जाता था—एक विशिष्ट क्षण में रोगी की आंतरिक...
पृष्ठभूमि और अकादमिक वंश
इस शोध की जड़ों को समझने के लिए, हमें चिकित्सा इमेजिंग के ऐतिहासिक विकास को देखना होगा। दशकों पहले, सीटी या एमआरआई जैसे चिकित्सा स्कैन को स्थिर तस्वीरों के रूप में माना जाता था—एक विशिष्ट क्षण में रोगी की आंतरिक शारीरिक रचना का एक एकल स्नैपशॉट। हालाँकि, डॉक्टरों और शोधकर्ताओं ने जल्दी ही महसूस किया कि मानव शारीरिक रचना स्थिर नहीं है; यह आनुवंशिकी, पोषण और बीमारी से प्रेरित एक अत्यधिक गतिशील प्रक्रिया है। अल्जाइमर जैसी स्थितियों का सटीक निदान करने या बच्चे की कंकाल संरचना के सामान्य विकास को ट्रैक करने के लिए, चिकित्सा क्षेत्र को 3डी स्थिर छवियों से 4डी सांख्यिकीय आकार विश्लेषण की ओर बढ़ने की आवश्यकता थी। इसका मतलब "समय" को चौथे आयाम के रूप में जोड़ना था। रोगी की शारीरिक रचना की "तस्वीर" के बजाय "फिल्म" का निरीक्षण करने की नैदानिक आवश्यकता ने अनुदैर्ध्य इमेजिंग डेटा की मांग को जन्म दिया।
हालाँकि, मौलिक सीमा जिसने लेखकों को यह पत्र लिखने के लिए मजबूर किया, वह एक गंभीर डेटा बाधा है। वास्तविक अनुदैर्ध्य डेटा को कैप्चर करने के लिए महीनों या वर्षों में ठीक उसी रोगी को बार-बार स्कैन करने की आवश्यकता होती है। यह अविश्वसनीय रूप से महंगा (अक्सर प्रति स्कैन हजारों डॉलर, जैसे \$1,000+), समय लेने वाला और तार्किक रूप से कठिन है, जिससे इस डेटा की भारी कमी हो जाती है। पिछले एआई मॉडल ने सिंथेटिक अनुदैर्ध्य डेटा उत्पन्न करने का प्रयास किया, लेकिन वे एक घातक दोष से ग्रस्त थे: उन्हें एल्गोरिदम को प्रशिक्षित करने के लिए मौजूदा अनुदैर्ध्य डेटा के विशाल डेटासेट की आवश्यकता थी। इस बीच, अस्पताल "क्रॉस-सेक्शनल" डेटा (कई अलग-अलग लोगों से एकल स्कैन) के पहाड़ों पर बैठे हैं। पिछले तरीके इस प्रचुर मात्रा में क्रॉस-सेक्शनल डेटा का उपयोग समय के साथ व्यक्तिगत, विषय-विशिष्ट परिवर्तनों की भविष्यवाणी करने के लिए प्रभावी ढंग से नहीं कर सके।
इस अंतर को पाटने के लिए, लेखकों ने कुछ अत्यधिक विशिष्ट अवधारणाओं का परिचय दिया है। यहाँ उनका सामान्य शब्दों में अर्थ है:
- अनुदैर्ध्य डेटा (Longitudinal Data): एक एकल पौधे के अंकुर से खिले हुए फूल तक बढ़ने की टाइम-लैप्स वीडियो की कल्पना करें। यह समय के साथ ठीक उसी विषय को ट्रैक करता है, जो इसके विकास में कारण-और-प्रभाव को दर्शाता है।
- क्रॉस-सेक्शनल डेटा (Cross-sectional Data): एक किंडरगार्टन कक्षा, एक मध्य विद्यालय कक्षा और एक हाई स्कूल कक्षा की एक एकल समूह तस्वीर लेने की कल्पना करें। आप देख सकते हैं कि एक "औसत" 5-वर्षीय या 15-वर्षीय कैसा दिखता है, लेकिन आपको इस बात का कोई अंदाज़ा नहीं है कि एक विशिष्ट किंडरगार्टनर हाई स्कूल पहुँचने पर कैसा दिखेगा।
- एटलस निर्माण (Atlas Building): इसे "कम्पोजिट स्केच" बनाने के रूप में सोचें। यदि आप विभिन्न 10-वर्षीय कूल्हों की हजारों तस्वीरें लेते हैं और उन्हें गणितीय रूप से एक साथ मिश्रित करते हैं, तो आपको एक मानक, औसत टेम्पलेट (एटलस) मिलता है जो एक विशिष्ट 10-वर्षीय कूल्हे का प्रतिनिधित्व करता है।
- डिफ़ेओमोर्फिज्म (Diffeomorphism): एक चिकित्सा छवि को अत्यधिक खिंचाव योग्य, जादुई रबर की शीट पर प्रिंट करने की कल्पना करें। आप इस रबर को खींच, विकृत और मोड़ सकते हैं ताकि एक आकार दूसरे जैसा दिखे, लेकिन आपको कभी भी रबर को फाड़ने या उसे स्वयं पर मोड़ने की अनुमति नहीं है। क्योंकि यह कभी फटा नहीं है, आप मूल आकार पर वापस जाने के लिए हमेशा खिंचाव को पूरी तरह से उलट सकते हैं।
- लेटेंट एम्बेडिंग (Latent Embeddings): फोन पर किसी मित्र को एक जटिल 3डी कार का वर्णन करने का प्रयास करने की कल्पना करें। हर एक बोल्ट का वर्णन करने के बजाय, आप उन्हें कुछ प्रमुख संख्याएँ देते हैं: लंबाई, वजन और इंजन का आकार। लेटेंट प्रतिनिधित्व एआई का एक जटिल 3डी चिकित्सा छवि को आवश्यक गणितीय विशेषताओं की एक छोटी सूची में संपीड़ित करने का तरीका है।
गणितीय रूप से, लेखकों ने ज्यादातर क्रॉस-सेक्शनल डेटा का उपयोग करके विषय-विशिष्ट अनुदैर्ध्य डेटा उत्पन्न करने की समस्या को हल किया। उन्होंने ऐसा दो अलग-अलग एआई कार्यों को एक साथ काम करने के लिए मजबूर करके किया: प्रत्येक आयु वर्ग के लिए एक औसत एटलस का निर्माण, और विभिन्न आयु समूहों में आकृतियों को विकृत करने का तरीका सीखना।
सबसे पहले, वे एक ऊर्जा फ़ंक्शन को कम करके एटलस बनाने की समस्या को परिभाषित करते हैं:
$$E(I, v_0^n) = \sum_{n=1}^N \frac{1}{\sigma^2} \text{Dist}[I \circ \phi_1^{-1}(v_0^n), I_n] + \text{Reg}(v_0^n)$$
सरल शब्दों में, यह समीकरण वास्तविक रोगी छवियों ($I_n$) और विकृत औसत छवि के बीच की दूरी ($\text{Dist}$) को मापकर एक आदर्श औसत छवि ($I$) खोजने का प्रयास करता है। $\text{Reg}$ शब्द एक नियम है जो सुनिश्चित करता है कि "रबर का खिंचाव" चिकना और यथार्थवादी बना रहे।
अपने अंतिम लक्ष्य को प्राप्त करने के लिए, लेखकों ने एक एकीकृत तंत्रिका नेटवर्क डिज़ाइन किया जो एक संयुक्त कुल हानि फ़ंक्शन को कम करता है:
$$\ell = \mathcal{L}_{\text{tempo-atlas}}(\Theta) + \mathcal{L}_{\text{longitudinal}}(\Psi) + \gamma \mathcal{L}_{\text{latent}}(\mathbf{Z})$$
यहां, मॉडल को तीन चीजों में एक साथ विफल होने पर दंडित किया जाता है:
1. $\mathcal{L}_{\text{tempo-atlas}}$: इसे प्रत्येक विशिष्ट आयु वर्ग के लिए सटीक औसत एटलस का निर्माण करना चाहिए।
2. $\mathcal{L}_{\text{longitudinal}}$: इसे एक आयु (जैसे, आयु 10) से अगली आयु (जैसे, आयु 12) तक एक एटलस को विकृत करने का तरीका सटीक रूप से पता लगाना चाहिए।
3. $\mathcal{L}_{\text{latent}}$: इसे यह सुनिश्चित करना चाहिए कि इन आकृतियों के संपीड़ित गणितीय सारांश (एम्बेडिंग) तार्किक रूप से एक साथ क्लस्टर हों, जिसका अर्थ है कि जैविक रूप से समान दिखने वाली आकृतियों को एआई के "मस्तिष्क" में एक साथ रखा जाता है।
इस संयुक्त समीकरण को हल करके, एआई जनसंख्या (एटलस) से उम्र बढ़ने के सामान्य नियमों को सीखता है और उन नियमों को एक नए रोगी के एकल स्नैपशॉट पर लागू करता है, जिससे उस विशिष्ट रोगी की शारीरिक रचना समय के साथ कैसे बढ़ेगी, इसकी सफलतापूर्वक भविष्यवाणी की जाती है।
| संकेतन | विवरण |
|---|---|
| $I_n$ | डेटासेट में $n$-वीं इनपुट छवि (जैसे, एक विशिष्ट रोगी का सीटी स्कैन)। |
| $I$ | माध्य या टेम्पलेट छवि, जो "औसत" शारीरिक रचना (एटलस) का प्रतिनिधित्व करती है। |
| $\phi$ | छवि पर लागू गणितीय परिवर्तन ( "विकृत" फ़ंक्शन)। |
| $v_0$ | प्रारंभिक वेग क्षेत्र, जो यह निर्धारित करता है कि आकार कैसे विकृत होना शुरू होगा। |
| $\sigma^2$ | छवियों में शोर विचरण, जिसका उपयोग दूरी माप को भारित करने के लिए किया जाता है। |
| $A_q$ | किसी दिए गए आयु/समय $q$ के लिए निर्मित विशिष्ट शारीरिक एटलस। |
| $\Theta$ | अस्थायी एटलस के निर्माण के लिए जिम्मेदार तंत्रिका नेटवर्क के सीखने योग्य पैरामीटर। |
| $\Psi$ | क्रॉस-एज (अनुदैर्ध्य) पंजीकरण के लिए जिम्मेदार तंत्रिका नेटवर्क के सीखने योग्य पैरामीटर। |
| $\mathbf{z}_q^i$ | आयु $q$ पर एक छवि का लेटेंट एम्बेडिंग (संपीड़ित गणितीय प्रतिनिधित्व)। |
| $\gamma$ | एक ट्यूनिंग पैरामीटर जो नियंत्रित करता है कि मॉडल लेटेंट एम्बेडिंग नियमों को कितनी मजबूती से लागू करता है। |
समस्या परिभाषा और बाधाएँ
कल्पना कीजिए कि आपको किसी विशिष्ट बच्चे के बड़े होने का टाइम-लैप्स वीडियो बनाने का काम सौंपा गया है। हालाँकि, उस एक बच्चे का निरंतर वीडियो होने के बजाय, आपको विभिन्न आयुओं में अलग-अलग बच्चों की तस्वीरों वाला एक विशाल फोटो एल्बम दिया जाता है। आप आसानी से यह पता लगा सकते हैं कि औसतन 5 साल का बच्चा या औसतन 10 साल का बच्चा कैसा दिखता है। लेकिन यह अनुमान लगाना अविश्वसनीय रूप से कठिन है कि कोई विशिष्ट 5 साल का बच्चा 10 साल की उम्र में कैसा दिखेगा क्योंकि हमारे पास उस विशिष्ट बच्चे का शारीरिक इतिहास नहीं है।
यह ठीक वही परिदृश्य है जिसका सामना चिकित्सा शोधकर्ता मानव अंगों और हड्डियों के समय के साथ विकसित होने के तरीके को मॉडल करने का प्रयास करते समय करते हैं।
प्रारंभिक बिंदु और लक्ष्य अवस्था
इनपुट (वर्तमान अवस्था): चिकित्सा क्षेत्र 3D क्रॉस-सेक्शनल इमेजिंग डेटा से समृद्ध है। ये एकल-समय बिंदु स्नैपशॉट (जैसे सीटी या एमआरआई स्कैन) हैं जो कई अलग-अलग व्यक्तियों से लिए गए हैं। प्रचुर मात्रा में होने के बावजूद, ये डेटासेट केवल समय में एक स्नैपशॉट का प्रतिनिधित्व करते हैं, जो कारण-और-प्रभाव जैविक परिवर्तनों के बारे में शून्य जानकारी प्रदान करते हैं।
आउटपुट (लक्ष्य अवस्था): चिकित्सकों को 4D लॉन्गिट्यूडिनल डेटा की सख्त आवश्यकता है। इसका मतलब है कि समय के साथ एक ही रोगी के व्यक्ति-विशिष्ट, समय-भिन्न संरचनात्मक परिवर्तन होते हैं। यदि कोई डॉक्टर 8 साल के रोगी के कूल्हे का 3D स्कैन इनपुट करता है, तो लक्ष्य यह है कि वह जैविक रूप से सटीक, अत्यधिक व्यक्तिगत 3D स्कैन आउटपुट करे कि उस विशिष्ट रोगी का कूल्हा 10 या 15 साल की उम्र में कैसा दिखेगा।
गणितीय अंतर: लुप्त कड़ी एक निरंतर, व्युत्क्रमणीय परिवर्तन क्षेत्र है जो युग्मित लॉन्गिट्यूडिनल प्रशिक्षण डेटा पर निर्भर हुए बिना किसी विशिष्ट शारीरिक संरचना को समय के साथ आगे बढ़ा सकता है। हमें एक गणितीय पुल की आवश्यकता है जो जनसंख्या-स्तरीय औसत ("एटलस") को व्यक्ति-विशिष्ट लौकिक प्रक्षेपवक्र से जोड़ता है।
दर्दनाक दुविधा
यथार्थवादी लॉन्गिट्यूडिनल डेटा उत्पन्न करने के लिए, डीप लर्निंग मॉडल (जैसे अनुक्रम-जागरूक प्रसार मॉडल) को आम तौर पर प्रशिक्षित करने के लिए ग्राउंड-ट्रुथ लॉन्गिट्यूडिनल डेटा की भारी मात्रा की आवश्यकता होती है। यहीं पर जाल निहित है:
आप लॉन्गिट्यूडिनल डेटा के बिना एक अच्छा लॉन्गिट्यूडिनल मॉडल प्रशिक्षित नहीं कर सकते हैं, लेकिन लॉन्गिट्यूडिनल डेटा कुख्यात रूप से महंगा है (अक्सर प्रति रोगी स्कैन \$1000 से अधिक की लागत आती है), समय लेने वाला है, और एकत्र करना अविश्वसनीय रूप से कठिन है। यदि शोधकर्ता प्रचुर मात्रा में क्रॉस-सेक्शनल डेटा पर विशेष रूप से मॉडल को प्रशिक्षित करके इसे बायपास करने का प्रयास करते हैं, तो उत्पन्न भविष्य की छवियां अपनी व्यक्ति-विशिष्ट निष्ठा खो देती हैं। मॉडल मूल रोगी की अद्वितीय कंकाल ज्यामिति को बनाए रखने के बजाय एक सामान्य "औसत" व्यक्ति की भविष्यवाणी करता है। पिछले शोधकर्ता डेटा उपलब्धता और लौकिक सटीकता के बीच इस दर्दनाक ट्रेड-ऑफ में फंस गए हैं।
कठोर दीवारें और बाधाएँ
इसे हल करने के लिए, लेखकों ने कई क्रूर बाधाओं का सामना किया:
- चरम डेटा विरलता: वास्तविक लॉन्गिट्यूडिनल डेटा एकत्र करने में वर्षों लगते हैं। रोगी अध्ययनों से बाहर हो जाते हैं, इमेजिंग हार्डवेयर बदल जाता है, और वर्षों के अंतराल पर लिए गए स्कैन को संरेखित करने से भारी परिवर्तनशीलता उत्पन्न होती है।
- जैविक विरूपण का भौतिकी: हड्डी और ऊतक का विकास केवल एक साधारण पिक्सेल शिफ्ट नहीं है; इसमें जटिल, गैर-रैखिक जैविक परिवर्तन शामिल हैं। इसे मॉडल करने के लिए, लेखकों को लार्ज डिफॉर्मेशन डिफिओमॉर्फिक मेट्रिक मैपिंग (LDDMM) का उपयोग करना पड़ा। यह सुनिश्चित करता है कि परिवर्तन चिकने और व्युत्क्रमणीय (डिफिओमॉर्फिक) हों - जिसका अर्थ है कि ऊतक जादुई रूप से फटते नहीं हैं, एक-दूसरे को पार नहीं करते हैं, या खुद में मुड़ते नहीं हैं। हालाँकि, इसकी गणना के लिए यूलर-पोइंकेयर डिफरेंशियल (EPDiff) समीकरण का उपयोग करके वेग क्षेत्रों को समय के साथ आगे एकीकृत करने की आवश्यकता होती है:
$$ \frac{\partial v_t}{\partial t} = -K \left[ (D v_t)^T \cdot m_t + D m_t \cdot v_t + m_t \cdot \text{div} \, v_t \right] $$
इष्टतम वेग क्षेत्रों ($v_t$) और संवेग वैक्टर ($m_t$) को खोजने के लिए इसे हल करना एक विशाल कम्प्यूटेशनल बोझ है। - धुंधला कलाकृति दीवार: जब पिछले अत्याधुनिक मॉडल (जैसे VoxelMorph या B-splines) ने बड़े आयु अंतराल में एनाटॉमी को मोर्फ करने का प्रयास किया, तो उन्होंने गंभीर विकृतियाँ और धुंधली सीमाएँ पेश कीं। महीन शारीरिक विवरणों को बनाए रखना, जैसे कि विकसित हो रहे कूल्हे में ट्राई-रेडिएट कार्टिलेज, तब असाधारण रूप से कठिन होता है जब मॉडल को यह अनुमान लगाने के लिए मजबूर किया जाता है कि कोई संरचना वर्षों में कैसे फैलती है।
उन्होंने इसे कैसे हल किया: एक एकीकृत गणितीय ढाँचा
लेखकों ने महसूस किया कि दुविधा से बाहर निकलने के लिए, वे केवल एक जनरेटर नहीं बना सकते थे; उन्हें एक साथ एक मानचित्र बनाना पड़ा। उन्होंने एक उपन्यास डीप लर्निंग फ्रेमवर्क डिजाइन किया जो संयुक्त रूप से दो कार्य करता है: टेम्पोरल एटलस बिल्डिंग (किसी दिए गए आयु में जनसंख्या औसत खोजना) और क्रॉस-एज इमेज रजिस्ट्रेशन (विकास को मॉडल करने के लिए इसे विशिष्ट लक्ष्यों के साथ संरेखित करना)।
सबसे पहले, वे एटलस और क्रॉस-सेक्शनल छवियों ($I_i^q$) के बीच की दूरी को कम करके आयु-विशिष्ट एटलस ($A_q$) के अनुक्रम का निर्माण करने के लिए एक हानि फ़ंक्शन को परिभाषित करते हैं, जिसे वेग क्षेत्र ($v_i^q$) द्वारा नियमित किया जाता है:
$$ \mathcal{L}_{\text{tempo-atlas}}(\Theta) = \sum_{q=1}^{Q} \sum_{i=1}^{N_q} \text{Dist}\left[ \phi_{q \to i}^{-1}(\Theta) \circ A_q, I_i^q \right] + \text{Reg}(v_i^q) $$
इसके बाद, वे स्रोत एटलस को लक्ष्य आयुओं ($q'$) के साथ संरेखित करके लॉन्गिट्यूडिनल परिवर्तनों को मॉडल करते हैं:
$$ \mathcal{L}_{\text{longitudinal}}(\Psi) = \sum_{m=1}^{M} \text{Dist}\left[ \phi_{q \to q'}^{-1}(\Psi) \circ A_q, I_{q'}^m \right] + \text{Reg}(v_{m}^{q'}) $$
सफलता: पेपर की असली प्रतिभा यह है कि उन्होंने इन दो स्थानों को विशिष्ट लेटेंट एम्बेडिंग का उपयोग करके कैसे जोड़ा है। वे तंत्रिका नेटवर्क को एक लेटेंट स्पेस $\mathbf{Z}$ सीखने के लिए मजबूर करते हैं जहाँ शारीरिक रूप से समान संरचनाएँ कसकर क्लस्टर होती हैं, जबकि इन एम्बेडिंग के बीच की दूरी भौतिक विरूपण (वेग क्षेत्रों) के साथ सख्ती से सहसंबद्ध होती है जो उनके बीच मोर्फ करने के लिए आवश्यक है।
वे इसे एक विशेष हानि फ़ंक्शन के साथ लागू करते हैं:
$$ \mathcal{L}_{\text{latent}}(\mathbf{Z}) = \mathbb{E} \left[ -\log(\sigma(\text{sim}(\mathbf{z}_q^i, \mathbf{z}_{q'}^m))) \right] + \lambda \mathbb{E} \left[ \text{Corr}\left( \|\mathbf{z}_q^i - \mathbf{z}_{q'}^m\|^2, \|v_q^i - v_{q'}^m\|^2 \right) \right] $$
पहला पद संबंधित आकृतियों को समूहित करने के लिए कोसाइन समानता का उपयोग करता है। दूसरा पद मास्टरस्ट्रोक है: यह लेटेंट एम्बेडिंग की यूक्लिडियन दूरी ($\|\mathbf{z}_q^i - \mathbf{z}_{q'}^m\|^2$) और विरूपण की भौतिक ऊर्जा ($\|v_q^i - v_{q'}^m\|^2$) के बीच सहसंबंध की गणना करता है।
अमूर्त लेटेंट स्पेस को डिफिओमॉर्फिक विरूपण के भौतिक नियमों से गणितीय रूप से लॉक करके, मॉडल एकल क्रॉस-सेक्शनल स्कैन को देख सकता है, इसे लौकिक एटलस पर मैप कर सकता है, और सटीक रूप से अनुमान लगा सकता है कि वह विशिष्ट ज्यामिति समय के साथ कैसे विकसित होगी - बड़े पैमाने पर लॉन्गिट्यूडिनल प्रशिक्षण डेटासेट की आवश्यकता को पूरी तरह से बायपास करते हुए।
यह तरीका क्यों
यह समझने के लिए कि लेखकों ने इस अत्यधिक विशिष्ट, गणितीय रूप से सघन दृष्टिकोण को क्यों चुना, हमें पहले उस सटीक क्षण को देखना होगा जब पारंपरिक अत्याधुनिक (SOTA) विधियाँ एक बाधा से टकराईं।
हाल के वर्षों में, डीप लर्निंग समुदाय जनरेटिव मॉडल के प्रति जुनूनी रहा है। यदि आप किसी बच्चे की कूल्हे की हड्डी के समय के साथ बढ़ने को दर्शाने वाली छवियों का एक क्रम उत्पन्न करना चाहते हैं, तो आपकी पहली प्रवृत्ति डिफ्यूजन मॉडल या ट्रांसफार्मर का उपयोग करने की हो सकती है। वास्तव में, लेखक स्पष्ट रूप से बताते हैं कि पिछले शोधकर्ताओं ने ठीक यही कोशिश की है: यून एट अल. ने अनुक्रम-जागरूक डिफ्यूजन मॉडल का उपयोग किया, और पुग्लिसी एट अल. ने समय के साथ संरचनात्मक परिवर्तनों का अनुकरण करने के लिए लेटेंट डिफ्यूजन मॉडल का उपयोग किया।
लेकिन यहाँ घातक दोष है जिसने लेखकों को इन लोकप्रिय दृष्टिकोणों को छोड़ने के लिए मजबूर किया: मानक जनरेटिव मॉडल अविश्वसनीय रूप से डेटा-भूखे होते हैं। उन्हें बड़े, युग्मित अनुदैर्ध्य डेटासेट की आवश्यकता होती है—जिसका अर्थ है कि आपको एक ही रोगियों के हजारों 3D स्कैन की आवश्यकता होती है जो साल दर साल लिए गए हों। वास्तविक दुनिया के नैदानिक वातावरण में, इस प्रकार का डेटा निषेधात्मक रूप से महंगा, समय लेने वाला और व्यावहारिक रूप से अस्तित्वहीन है। उपलब्ध अधिकांश चिकित्सा डेटा क्रॉस-सेक्शनल (एकल, अलग-अलग क्षणों में विभिन्न लोगों के स्नैपशॉट) होता है। डिफ्यूजन मॉडल और GANs प्रशिक्षण के दौरान वास्तविक लौकिक अनुक्रम देखे बिना विषय-विशिष्ट लौकिक गतिकी को नहीं सीख सकते। वे यहाँ विफल हो जाएंगे क्योंकि वे असंबद्ध स्नैपशॉट से जैविक रूप से सटीक विकास पथ का अनुमान नहीं लगा सकते।
इस कठोर बाधा का सामना करते हुए, लेखकों ने महसूस किया कि एकमात्र व्यवहार्य समाधान सीखने की प्रक्रिया में भौतिकी और ज्यामिति के सख्त नियमों को एम्बेड करना था। उन्होंने लार्ज डिफॉर्मेशन डिफिओमॉर्फिक मेट्रिक मैपिंग (LDDMM) की ओर रुख किया।
यह गणितीय रूप से बेहतर क्यों है? एक डिफिओमॉर्फिक परिवर्तन गारंटी देता है कि दो शारीरिक आकृतियों के बीच मैपिंग चिकनी, निरंतर और सख्ती से व्युत्क्रमणीय है। जीव विज्ञान में, ऊतक खिंचते और बढ़ते हैं, लेकिन वे बेतरतीब ढंग से फटते नहीं हैं, खुद पर मुड़ते नहीं हैं, या टेलीपोर्ट नहीं करते हैं। यूलर-पोइंकेयर डिफरेंशियल (EPDiff) समीकरण के माध्यम से समस्या को फ्रेम करके, लेखक यह सुनिश्चित करते हैं कि शारीरिक विकास का जियोडेसिक पथ एक प्रारंभिक वेग क्षेत्र $v_0$ को समय में आगे एकीकृत करके विशिष्ट रूप से निर्धारित किया जाता है:
$$ \frac{\partial v_t}{\partial t} = -K \left[ (D v_t)^T \cdot m_t + D m_t \cdot v_t + m_t \cdot \text{div} \, v_t \right] $$
यह समस्या की कठोर बाधाओं (अनुदैर्ध्य डेटा की कमी) और समाधान के अद्वितीय गुणों के बीच एक आदर्श "विवाह" बनाता है। यह अनुमान लगाने की कोशिश करने के बजाय कि हड्डी कैसे बढ़ती है, मॉडल संयुक्त रूप से दो कार्य करता है: यह एक "एटलस" बनाता है (एक विशिष्ट आयु, जैसे, 8 वर्ष की आयु में एक जनसंख्या का औसत आकार) और फिर डिफिओमॉर्फिक वेग क्षेत्रों को सीखता है जो 8-वर्षीय एटलस को 10-वर्षीय एटलस में विकृत करते हैं। फिर यह इन सीखे हुए, जैविक रूप से प्रशंसनीय वेग क्षेत्रों को एक विशिष्ट रोगी के बेसलाइन स्कैन पर लागू करता है ताकि उनके भविष्य के शरीर रचना विज्ञान की अत्यधिक विश्वसनीय भविष्यवाणियां उत्पन्न की जा सकें।
पिछले स्वर्ण मानकों—जैसे VoxelMorph (VM) या B-spline पंजीकरण—पर इस विधि का संरचनात्मक लाभ गहरा है। पारंपरिक पंजीकरण विधियाँ केवल छवि A और छवि B के बीच पिक्सेल-वार अंतर को कम करने का प्रयास करती हैं। जैसा कि पेपर की बेंचमार्किंग में दिखाया गया है, यह अक्सर धुंधली सीमाओं और गंभीर कलाकृतियों (जैसे VoxelMorph बेसलाइन में इलियाक क्रेस्ट के आसपास देखे गए विकृतियों) में परिणत होता है।
इसे दूर करने के लिए, लेखकों ने एक शानदार "विशिष्ट लेटेंट एम्बेडिंग" हानि पेश की। वे केवल छवियों को संरेखित नहीं करते हैं; वे तंत्रिका नेटवर्क के लेटेंट स्पेस को शारीरिक विरूपण स्थान को पूरी तरह से प्रतिबिंबित करने के लिए मजबूर करते हैं। हानि फ़ंक्शन में एक पद शामिल है जो लेटेंट एम्बेडिंग $\mathbf{z}$ की दूरी और वेग क्षेत्रों $v$ की भौतिक दूरी के बीच सहसंबंध को मापता है:
$$ \mathcal{L}_{\text{latent}}(\mathbf{Z}) = \dots + \lambda \mathbb{E}_{(\mathbf{z}_q^i, \mathbf{z}_{q'}^m)} \left[ \text{Corr} \left( \|\mathbf{z}_q^i - \mathbf{z}_{q'}^m\|^2, \|v_q^i - v_{q'}^m\|^2 \right) \right] $$
यह गणितीय रूप से लेटेंट स्पेस को वेग क्षेत्रों द्वारा निर्देशित ज्यामितीय और लौकिक संबंधों को बनाए रखने के लिए मजबूर करता है। यह समय के साथ प्रगतिशील आकार भिन्नताओं को अलग करता है, जिससे मॉडल ट्राई-रेडिएट कार्टिलेज जैसे जटिल विकास केंद्रों के चारों ओर तेज, कलाकृति-मुक्त सीमाएँ उत्पन्न कर पाता है।
ईमानदारी से कहूं तो, मुझे पूरी तरह से यकीन नहीं है कि यह विशिष्ट वास्तुकला कम्प्यूटेशनल मेमोरी जटिलता को $O(N^2)$ से $O(N)$ तक कम करती है, क्योंकि लेखक पाठ में स्पष्ट रूप से बिग-ओ एल्गोरिथम ब्रेकडाउन प्रदान नहीं करते हैं। हालांकि, जो अत्यधिक स्पष्ट है वह इसकी डेटा दक्षता है। डिफिओमॉर्फिज्म के ज्यामितीय लेटेंट स्पेस का लाभ उठाकर, यह ढांचा वह प्राप्त करता है जो SOTA डिफ्यूजन मॉडल नहीं कर सकते: यह केवल विरल, क्रॉस-सेक्शनल 3D इनपुट का उपयोग करके अत्यधिक सटीक, विषय-विशिष्ट 4D अनुदैर्ध्य डेटा को संश्लेषित करता है।
गणितीय और तार्किक तंत्र
इस पत्र की गंभीरता को समझने के लिए, हमें पहले चिकित्सा इमेजिंग में मौलिक डेटा समस्या को समझना होगा। कल्पना कीजिए कि आप एक फोटो एल्बम देखकर बच्चे के विकास को समझने की कोशिश कर रहे हैं। यदि आपके पास एक "लॉन्जिट्यूडिनल" एल्बम है - एक ही बच्चे की हर साल ली गई तस्वीरें - तो आप उसके विकास की सटीक गति को आसानी से देख सकते हैं। लेकिन चिकित्सा क्षेत्र में, एक ही रोगी के कई वर्षों तक लॉनिट्यूडिनल 3D स्कैन (जैसे सीटी या एमआरआई) प्राप्त करना अविश्वसनीय रूप से महंगा, समय लेने वाला और दुर्लभ है। इसके बजाय, अस्पतालों में "क्रॉस-सेक्शनल" डेटा का पहाड़ होता है: विभिन्न उम्र के विभिन्न लोगों के एकल स्नैपशॉट।
इस पत्र के लेखकों ने एक शानदार गणितीय इंजन बनाया है जो विभिन्न लोगों के इन असंबद्ध स्नैपशॉट को लेता है और विकास के अंतर्निहित "नियमों" को सीखता है। फिर यह इन नियमों का उपयोग एक नए रोगी के लिए एक अत्यधिक सटीक, व्यक्तिगत 3D टाइम-लैप्स (लॉन्जिट्यूडिनल डेटा) उत्पन्न करने के लिए करता है, जो भविष्यवाणी करता है कि समय के साथ उनकी शारीरिक रचना कैसे बदलेगी।
यहाँ वह सटीक गणितीय मशीनरी है जो इसे संभव बनाती है।
मास्टर समीकरण
इस पत्र का मुख्य इंजन एक एकीकृत उद्देश्य फ़ंक्शन द्वारा संचालित होता है जो तीन विशाल कार्यों को एक साथ संतुलित करता है: एक "औसत" टेम्पलेट (एटलस) का निर्माण, उम्र भर विकास की भविष्यवाणी, और मॉडल को इन परिवर्तनों की भौतिक वास्तविकता को समझने के लिए मजबूर करना।
पूरे नेटवर्क को शक्ति प्रदान करने वाला कुल हानि फ़ंक्शन है:
$$ \ell = \mathcal{L}_{\text{tempo-atlas}}(\Theta) + \mathcal{L}_{\text{longitudinal}}(\Psi) + \gamma \mathcal{L}_{\text{latent}}(\mathbf{Z}) $$
लेकिन असली गुप्त सॉस - इस पत्र का सबसे नवीन हिस्सा - विशिष्ट अव्यक्त एम्बेडिंग हानि है, जो संचालन के मस्तिष्क के रूप में कार्य करता है:
$$ \mathcal{L}_{\text{latent}}(\mathbf{Z}) = \mathbb{E}_{(\mathbf{z}_q^i, \mathbf{z}_{q'}^m)} \big[ -\log(\sigma(\text{sim}(\mathbf{z}_q^i, \mathbf{z}_{q'}^m))) \big] + \lambda \, \mathbb{E}_{(\mathbf{z}_q^i, \mathbf{z}_{q'}^m)} \big[ \text{Corr} \big( \|\mathbf{z}_q^i - \mathbf{z}_{q'}^m\|^2, \; \|v_q^i - v_{q'}^m\|^2 \big) \big] $$
समीकरणों को अलग करना
आइए इस तंत्र में हर एक गियर और स्प्रिंग को अलग करें।
कुल हानि ($\ell$) से:
* $\ell$: कुल हानि। यह अंतिम "त्रुटि स्कोर" है जिसे मशीन शून्य तक कम करने का प्रयास करती है।
* $\mathcal{L}_{\text{tempo-atlas}}(\Theta)$: टेम्पोरल एटलस बिल्डिंग हानि। यह पद मापता है कि नेटवर्क (पैरामीटर $\Theta$ के साथ) किसी विशिष्ट आयु के लिए "औसत" शारीरिक टेम्पलेट बनाने में कितना अच्छा है। यह आधार रेखा के रूप में कार्य करता है।
* $\mathcal{L}_{\text{longitudinal}}(\Psi)$: क्रॉस-एज पंजीकरण हानि। यह मापता है कि नेटवर्क (पैरामीटर $\Psi$ के साथ) एक उम्र की छवि को दूसरी उम्र की शारीरिक रचना से मिलान करने के लिए कितनी अच्छी तरह से विकृत कर सकता है। यह "टाइम मशीन" घटक है।
* $\gamma$: एक स्केलर भार (एक संतुलन घुंडी)। यह निर्धारित करता है कि मॉडल को अव्यक्त एम्बेडिंग पर छवि निर्माण की तुलना में कितना ध्यान देना चाहिए।
* गुणा के बजाय जोड़ क्यों? लेखक एक बहु-कार्य संतुलन पैमाने बनाने के लिए जोड़ का उपयोग करते हैं। यदि वे इन पदों को गुणा करते, तो एटलस हानि में एक शून्य के करीब स्कोर लॉनिट्यूडिनल हानि के लिए ग्रेडिएंट्स (सीखने के संकेतों) को पूरी तरह से मिटा देता, जिससे सीखने की प्रक्रिया पूरी तरह से रुक जाती। जोड़ यह सुनिश्चित करता है कि भले ही एक कार्य पूरी तरह से प्रदर्शन कर रहा हो, फिर भी मॉडल दूसरों को बेहतर बनाने के दबाव को महसूस करता है।
अव्यक्त एम्बेडिंग हानि ($\mathcal{L}_{\text{latent}}(\mathbf{Z})$) से:
* $\mathbf{Z}$: सभी अव्यक्त एम्बेडिंग का मैट्रिक्स। एक एम्बेडिंग 3D चिकित्सा छवि का एक अत्यधिक संपीड़ित, अमूर्त गणितीय सारांश है।
* $\mathbb{E}_{(\mathbf{z}_q^i, \mathbf{z}_{q'}^m)}$: इन संपीड़ित एम्बेडिंग के जोड़े पर अपेक्षित मान (औसत)। $\mathbf{z}_q^i$ रोगी $i$ का आयु $q$ पर एम्बेडिंग है, और $\mathbf{z}_{q'}^m$ रोगी $m$ का आयु $q'$ पर एम्बेडिंग है।
* कठोर योग ($\sum$) के बजाय अपेक्षा क्यों? डीप लर्निंग में, एक बड़े डेटासेट में छवियों के हर संभव जोड़े के सटीक योग की गणना करना कम्प्यूटेशनल रूप से विस्फोटक है। अपेक्षा का उपयोग मॉडल को प्रशिक्षण के दौरान यादृच्छिक जोड़े को स्टोकेस्टिक रूप से नमूना करने की अनुमति देता है, जो वास्तविक औसत का अनुमान लगाता है जबकि भारी मात्रा में मेमोरी बचाता है।
* $-\log(\sigma(\dots))$: सिग्मॉइड फ़ंक्शन का ऋणात्मक लॉग। यह एक क्लासिक दंड तंत्र है। सिग्मॉइड ($\sigma$) मानों को 0 और 1 के बीच स्क्वैश करता है (एक संभावना की तरह)। ऋणात्मक लॉग मॉडल को भारी दंडित करता है यदि यह मान 0 के करीब गिर जाता है।
* $\text{sim}(\mathbf{z}_q^i, \mathbf{z}_{q'}^m)$: दो एम्बेडिंग के बीच कोसाइन समानता। यह दो वैक्टर के बीच के कोण को मापता है।
* तार्किक भूमिका: यह पूरा पहला पद एक गुरुत्वाकर्षण खिंचाव के रूप में कार्य करता है। यदि दो शारीरिक आकार संबंधित हैं, तो यह उनके अमूर्त गणितीय वैक्टर को अव्यक्त स्थान में ठीक उसी दिशा में इंगित करने के लिए मजबूर करता है।
* $\lambda$: एक और संतुलन घुंडी, विशेष रूप से भौतिकी बाधा की ताकत को नियंत्रित करती है।
* $\text{Corr}(\dots)$: पियर्सन सहसंबंध गुणांक। यह मापता है कि दो चर कितने रैखिक रूप से संबंधित हैं।
* $\|\mathbf{z}_q^i - \mathbf{z}_{q'}^m\|^2$: दो अमूर्त एम्बेडिंग के बीच वर्गाकार यूक्लिडियन दूरी। इसे 8-वर्षीय कूल्हे और 10-वर्षीय कूल्हे के बीच "वैचारिक दूरी" के रूप में सोचें।
* $\|v_q^i - v_{q'}^m\|^2$: उनके संबंधित वेग क्षेत्रों ($v$) की दूरी का वर्ग। वेग क्षेत्र तीरों का एक 3D मानचित्र है जो ठीक से बताता है कि एक आकार को दूसरे में बदलने के लिए पिक्सेल को भौतिक रूप से कैसे प्रवाहित और खिंचाव करना चाहिए।
* तार्किक भूमिका: यह सहसंबंध पद शुद्ध प्रतिभा है। यह एक सख्त भौतिकी निरीक्षक के रूप में कार्य करता है। यह एम्बेडिंग की अमूर्त "वैचारिक दूरी" को ऊतक को विकृत करने के लिए आवश्यक वास्तविक "भौतिक खिंचाव ऊर्जा" के साथ पूरी तरह से सहसंबंधित होने के लिए मजबूर करता है। यह तंत्रिका नेटवर्क को अव्यक्त स्थान में छवियों को मनमाने ढंग से रखकर धोखा देने से रोकता है।
चरण-दर-चरण प्रवाह
आइए एक एकल अमूर्त डेटा बिंदु - एक 8-वर्षीय रोगी के कूल्हे का 3D सीटी स्कैन - को इस गणितीय असेंबली लाइन से गुजरते हुए ट्रेस करें।
- संपीड़न: 8-वर्षीय कूल्हे के कच्चे 3D पिक्सेल नेटवर्क में प्रवेश करते हैं और तुरंत एक सघन, अमूर्त वेक्टर $\mathbf{z}_q^i$ में संपीड़ित हो जाते हैं।
- एंकरिंग: सिस्टम इस वेक्टर की तुलना "औसत 8-वर्षीय कूल्हे" टेम्पलेट से करता है जिसे उसने बनाया है। यह गणना करता है कि विशिष्ट रोगी सामान्य से कितना विचलित होता है।
- समय यात्रा: उपयोगकर्ता एक भविष्यवाणी का अनुरोध करता है कि यह कूल्हा 12 साल की उम्र में कैसा दिखेगा। नेटवर्क "औसत 12-वर्षीय" टेम्पलेट को देखता है। यह एक वेग क्षेत्र $v$ उत्पन्न करता है - तीरों का एक द्रव-जैसा मानचित्र जो यह निर्धारित करता है कि 8-वर्षीय हड्डी को 12-वर्षीय स्थिति तक पहुंचने के लिए कैसे खिंचाव, बढ़ना और झुकना चाहिए।
- गुणवत्ता नियंत्रण: $\mathcal{L}_{\text{latent}}$ हानि सक्रिय होती है। यह 8-वर्षीय वेक्टर और 12-वर्षीय वेक्टर के बीच अमूर्त दूरी की जांच करती है। यह सख्ती से सत्यापित करता है कि यह अमूर्त दूरी वेग क्षेत्र $v$ की भौतिक ऊर्जा से मेल खाती है। यदि गणित भौतिकी के साथ संरेखित नहीं होता है, तो मॉडल को दंडित किया जाता है।
- उत्पन्न करना: अंत में, वेग क्षेत्र को मूल 3D स्कैन पर लागू किया जाता है, पिक्सेल को डिजिटल मिट्टी के एक टुकड़े की तरह सुचारू रूप से विकृत करता है ताकि जैविक रूप से सटीक, सिंथेटिक 12-वर्षीय कूल्हे स्कैन आउटपुट हो सके।
अनुकूलन गतिशीलता
यह जटिल वास्तुकला वास्तव में कैसे सीखती है और अभिसरण करती है?
मॉडल ग्रेडिएंट डिसेंट (विशेष रूप से एडम ऑप्टिमाइज़र) का उपयोग करके अपने मापदंडों को अनुकूलित करता है। प्रारंभ में, हानि परिदृश्य अत्यधिक अराजक होता है। नेटवर्क शॉर्टकट लेने की कोशिश करता है, शायद छवि दूरी हानि को जल्दी से कम करने के लिए 8-वर्षीय छवि को धुंधला करके इसे किसी तरह 12-वर्षीय छवि जैसा दिखाने की कोशिश करता है।
हालांकि, मॉडल को डिफियोमोर्फिक गणित (विशेष रूप से पेपर की पृष्ठभूमि में उल्लिखित यूलर-पोइंकेयर डिफरेंशियल समीकरणों) द्वारा बाधित किया जाता है। इसका मतलब है कि परिवर्तन चिकने, निरंतर और व्युत्क्रमणीय होने चाहिए - जैसे रबर की चादर को बिना फाड़े या खुद से गुजरने दिए मोड़ना।
इस सख्त भौतिक बाधा के कारण, हानि परिदृश्य एक खड़ी, चिकनी कीप की तरह आकार लेता है। जैसे-जैसे ग्रेडिएंट नेटवर्क के माध्यम से पीछे की ओर प्रवाहित होते हैं, एम्बेडिंग $\mathbf{Z}$ खुद को खूबसूरती से व्यवस्थित करने के लिए मजबूर होते हैं। समान उम्र के स्कैन कसकर क्लस्टर होते हैं, जबकि विभिन्न उम्र के स्कैन उनके बीच संक्रमण के लिए आवश्यक भौतिक विकास के सटीक अनुपात में खुद को अलग करते हैं। 1000 युगों से अधिक समय तक, सिस्टम संतुलन तक पहुँचता है: उत्पन्न एटलस तेज हो जाते हैं, और अनुमानित विकास प्रक्षेपवक्र शारीरिक रूप से त्रुटिहीन हो जाते हैं, जिससे मॉडल रोगी की शारीरिक रचना के भविष्य को अविश्वसनीय सटीकता के साथ मतिभ्रम कर सकता है।
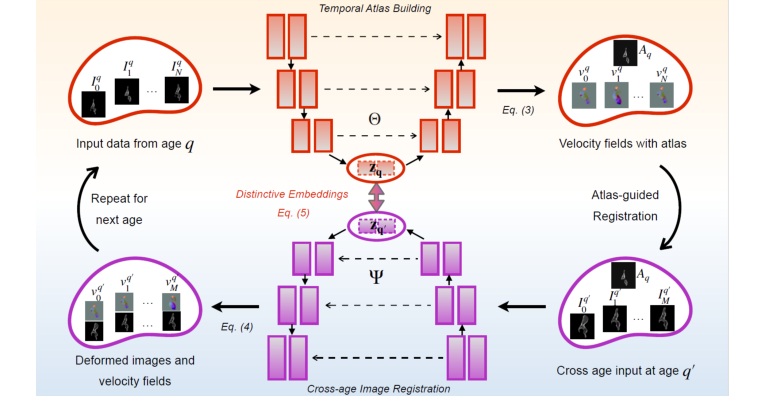 Figure 1. Overview of our model. Training: Our network constructs a sequence of tempo- ral atlases, starting at age q and modeling deformations across target ages. A geometric embedding loss in the latent space enforces structured, biologically meaningful anatom- ical evolution. Iterative refinement enhances the interplay between cross-sectional and longitudinal dynamics, generating anatomically coherent cross-age data. Inference: For each subject, we first align their baseline images to the corresponding age-specific atlas. The trained model Ψ operates as a longitudinal data generator, synthesizing anatomically plausible trajectories for unseen subjects by extracting geometric fea- tures through the atlas. It uses generated velocity fields from cross-age registration between age-specific atlases to deform subject-specific structures over time, ensuring a smooth and temporally consistent evolution
Figure 1. Overview of our model. Training: Our network constructs a sequence of tempo- ral atlases, starting at age q and modeling deformations across target ages. A geometric embedding loss in the latent space enforces structured, biologically meaningful anatom- ical evolution. Iterative refinement enhances the interplay between cross-sectional and longitudinal dynamics, generating anatomically coherent cross-age data. Inference: For each subject, we first align their baseline images to the corresponding age-specific atlas. The trained model Ψ operates as a longitudinal data generator, synthesizing anatomically plausible trajectories for unseen subjects by extracting geometric fea- tures through the atlas. It uses generated velocity fields from cross-age registration between age-specific atlases to deform subject-specific structures over time, ensuring a smooth and temporally consistent evolution
परिणाम, सीमाएँ और निष्कर्ष
मुख्य समस्या: स्नैपशॉट जाल से बचना
इस पत्र के महत्व को समझने के लिए, हमें पहले दो प्रकार के चिकित्सा डेटा के बीच मौलिक अंतर को समझना होगा: क्रॉस-सेक्शनल और लॉन्जिट्यूडिनल।
कल्पना कीजिए कि आप मानव चेहरे की उम्र बढ़ने को समझना चाहते हैं। यदि आप 5 से 50 वर्ष की आयु के 100 विभिन्न लोगों की एक-एक तस्वीर लेते हैं, तो आपके पास क्रॉस-सेक्शनल डेटा होता है। आप उम्र बढ़ने के सामान्य रुझान का अनुमान लगा सकते हैं, लेकिन आपको ठीक से पता नहीं है कि 5 साल का बच्चा 50 साल का होने पर कैसा दिखेगा। अब, कल्पना कीजिए कि आप 5 से 50 वर्ष की आयु तक ठीक उसी व्यक्ति की हर साल एक तस्वीर लेते हैं। यह लॉन्जिट्यूडिनल डेटा है। यह परिवर्तन की वास्तविक, विषय-विशिष्ट स्थानिक-कालिक गतिशीलता को पकड़ता है।
चिकित्सा इमेजिंग में, लॉन्जिट्यूडिनल 3डी डेटा (समय के साथ इसे 4डी डेटा बनाना) यह ट्रैक करने के लिए एक पवित्र लक्ष्य है कि शारीरिक संरचनाएं कैसे विकसित होती हैं या बीमारियां कैसे बढ़ती हैं। हालांकि, इस डेटा को इकट्ठा करना एक लॉजिस्टिक दुःस्वप्न है। यह अविश्वसनीय रूप से महंगा है - अक्सर एक दशक में स्कैन शुल्क और प्रशासनिक ओवरहेड में प्रति रोगी \$10,000 से अधिक का खर्च आता है - और रोगी के छोड़ने की संभावना बहुत अधिक होती है। नतीजतन, अधिकांश चिकित्सा डेटाबेस क्रॉस-सेक्शनल होते हैं।
इस पत्र के लेखकों को एक बड़ी बाधा का सामना करना पड़ा: जब हमारे प्रशिक्षण डेटा में ज्यादातर अलग-अलग लोगों के असंबद्ध स्नैपशॉट होते हैं, तो हम किसी विशिष्ट रोगी के भविष्य के 3डी शारीरिक आकार की सटीक भविष्यवाणी कैसे कर सकते हैं?
गणितीय इंजन: डिफियोमोर्फिज्म और अव्यक्त समय-यात्रा
इसे हल करने के लिए, लेखकों ने केवल अगले फ्रेम का अनुमान लगाने के लिए एक मानक तंत्रिका नेटवर्क को प्रशिक्षित नहीं किया। उन्होंने एक ऐसा ढांचा बनाया जो संयुक्त रूप से दो कार्य करता है: एटलस निर्माण (एक विशिष्ट आयु में एक जनसंख्या के "औसत" आकार का पता लगाना) और लॉन्जिट्यूडिनल डेटा जनरेशन (यह भविष्यवाणी करना कि किसी विशिष्ट विषय का आकार उम्र के साथ कैसे विकसित होता है)।
उन्होंने अपने समाधान को बड़े विरूपण डिफियोमोर्फिक मीट्रिक मैपिंग (LDDMM) के गणित में आधारित किया। सरल शब्दों में, एक डिफियोमोर्फिज्म एक चिकना, निरंतर और व्युत्क्रमणीय परिवर्तन है। 5 साल के बच्चे के कूल्हे की हड्डी की मिट्टी की मूर्ति को 10 साल के बच्चे की कूल्हे की हड्डी में बिना मिट्टी को फाड़े या खुद पर मोड़े हुए मोड़ने की कल्पना करें।
$N$ छवियों के एक सेट से एक एटलस (एक टेम्पलेट छवि $I$) बनाने के लिए आधारभूत ऊर्जा फ़ंक्शन को इस प्रकार परिभाषित किया गया है:
$$E(I, v_0^n) = \sum_{n=1}^N \frac{1}{\sigma^2} \text{Dist}[I \circ \phi_1^{-1}(v_0^n), I_n] + \text{Reg}(v_0^n)$$
यहां, $v_0^n$ प्रारंभिक वेग क्षेत्र का प्रतिनिधित्व करता है - टेम्पलेट को लक्ष्य छवि $I_n$ में मोड़ने के लिए आवश्यक "धक्का"। परिवर्तन पथ यूलर-पोइंकेयर डिफरेंशियल (EPDiff) समीकरण द्वारा शासित होता है, जो यह निर्धारित करता है कि यह वेग समय के साथ कैसे प्रवाहित होता है:
$$\frac{\partial v_t}{\partial t} = -K \left[ (D v_t)^T \cdot m_t + D m_t \cdot v_t + m_t \cdot \text{div} \, v_t \right]$$
ईमानदारी से कहें तो, पत्र में डीप लर्निंग प्रशिक्षण के दौरान इस एकीकरण को हल करने के लिए आवश्यक सटीक कम्प्यूटेशनल मेमोरी फुटप्रिंट का स्पष्ट रूप से विवरण नहीं दिया गया है, लेकिन डेटा की 3डी प्रकृति को देखते हुए, हम अनुमान लगा सकते हैं कि इसके लिए भारी जीपीयू लिफ्टिंग की आवश्यकता होती है (जिसे उन्होंने RTX A6000 का उपयोग करके संभाला)।
उनके आर्किटेक्चर की असली प्रतिभा विशिष्ट अव्यक्त एम्बेडिंग में निहित है। वे तंत्रिका नेटवर्क को एक अव्यक्त स्थान $\mathbf{Z}$ सीखने के लिए मजबूर करते हैं जहां दो एम्बेडिंग के बीच गणितीय दूरी उन्हें मोड़ने के लिए आवश्यक भौतिक विरूपण के साथ पूरी तरह से सहसंबद्ध होती है। उनका अव्यक्त हानि फ़ंक्शन है:
$$\mathcal{L}_{\text{latent}}(\mathbf{Z}) = \mathbb{E}_{(\mathbf{z}_q^i, \mathbf{z}_{q'}^m)} \left[ -\log(\sigma(\text{sim}(\mathbf{z}_q^i, \mathbf{z}_{q'}^m))) \right] + \lambda \, \mathbb{E}_{(\mathbf{z}_q^i, \mathbf{z}_{q'}^m)} \left[ \text{Corr} \left( \|\mathbf{z}_q^i - \mathbf{z}_{q'}^m\|^2, \, \|v_q^i - v_{q'}^m\|^2 \right) \right]$$
पहला पद कोसाइन समानता का उपयोग करके संबंधित आकृतियों को एक साथ क्लस्टर करने के लिए मजबूर करता है। दूसरा पद मास्टरस्ट्रोक है: यह सुनिश्चित करता है कि दो अव्यक्त वैक्टर $\|\mathbf{z}_q^i - \mathbf{z}_{q'}^m\|^2$ के बीच वर्ग यूक्लिडियन दूरी भौतिक "प्रयास" (वेग क्षेत्र दूरी $\|v_q^i - v_{q'}^m\|^2$) के साथ सहसंबद्ध हो, जो एक आकार को दूसरे में विकृत करने के लिए आवश्यक है।
अंतिम उद्देश्य फ़ंक्शन सुरुचिपूर्ण ढंग से अस्थायी एटलस निर्माण, क्रॉस-आयु पंजीकरण और इस अव्यक्त एम्बेडिंग को संतुलित करता है:
$$\ell = \mathcal{L}_{\text{tempo-atlas}}(\Theta) + \mathcal{L}_{\text{longitudinal}}(\Psi) + \gamma \mathcal{L}_{\text{latent}}(\mathbf{Z})$$
प्रयोग: वास्तविकता के विरुद्ध निर्मम सत्यापन
लेखकों ने केवल मेट्रिक्स को दीवार पर नहीं फेंका; उन्होंने एक अत्यधिक कठोर प्रयोग की वास्तुकला बनाई। उन्होंने सामान्य पुरुष कूल्हों (आयु 4-18) के क्रॉस-सेक्शनल डेटासेट पर अपने मॉडल को प्रशिक्षित किया। लेकिन यह साबित करने के लिए कि उनका मॉडल वास्तव में काम करता है, उन्होंने इसे वास्तविक लॉन्जिट्यूडिनल सीटी स्कैन के एक छिपे हुए, अत्यधिक मूल्यवान डेटासेट पर परीक्षण किया (12 रोगी जिनके पास वास्तव में वर्षों के अंतराल पर कई स्कैन थे)।
पीड़ित (बेसलाइन):
एटलस निर्माण के लिए, उन्होंने बी-स्प्लाइन, मल्टी-कंट्रास्ट पंजीकरण (एम-सी. रेज।), और वोक्सेलमोर्फ (वीएम) जैसे स्थापित मॉडलों को पूरी तरह से ध्वस्त कर दिया। लॉन्जिट्यूडिनल जनरेशन के लिए, उन्होंने एनएएचए (निकटतम-आयु कूल्हे सन्निकटन) और एबीआईए (आयु-आधारित एटलस सन्निकटन) को हराया।
निर्णायक साक्ष्य:
सबूत केवल डाइस स्कोर में नहीं था (हालांकि उन्होंने एक प्रमुख 0.88 हासिल किया)। निर्विवाद प्रमाण दृश्य और ज्यामितीय था। उन्होंने 12 वर्षीय रोगी के कूल्हे का एक वास्तविक सीटी स्कैन लिया, इसे अपने मॉडल में फीड किया, और उससे ठीक उसी रोगी का 15 वर्षीय संस्करण बनाने के लिए कहा।
जब उन्होंने अपने सिंथेटिक 15 वर्षीय कूल्हे को उस रोगी के वास्तविक 15 वर्षीय स्कैन के साथ ओवरले किया, तो सीमाएं खूबसूरती से मेल खा गईं। बेसलाइन यहां बुरी तरह विफल रहीं - वोक्सेलमोर्फ ने पश्च इलियाक क्रेस्ट के आसपास गंभीर कलाकृति विकृतियां पैदा कीं, और अन्य विधियों ने धुंधले, शारीरिक रूप से असंभव हड्डी मार्जिन का उत्पादन किया। लेखकों के मॉडल ने ट्राई-रेडिएट कार्टिलेज के आसपास तेज, महीन शारीरिक विवरणों को संरक्षित किया, यह साबित करते हुए कि उनके अव्यक्त स्थान ने केवल पिक्सेल को अंधाधुंध इंटरपोलेट करने के बजाय, हड्डी के विकास के जैविक नियमों को सफलतापूर्वक सीखा था।
भविष्य की प्रक्षेपवक्र और चर्चा के विषय
इस ढांचे के गहन निहितार्थों के आधार पर, भविष्य के अन्वेषण के लिए कई महत्वपूर्ण रास्ते यहां दिए गए हैं:
-
बायोमैकेनिकल भौतिकी पूर्वजों का एकीकरण:
वर्तमान में, मॉडल केवल ज्यामितीय परिवर्तनों (डिफियोमोर्फिज्म) से विकास के नियमों को सीखता है। हालांकि, हड्डी का विकास भौतिक बलों (वोल्फ का नियम - हड्डियां उन पर पड़ने वाले भार के अनुकूल होती हैं) से बहुत प्रभावित होता है। हम EPDiff समीकरण में बायोमैकेनिकल तनाव टेंसर कैसे इंजेक्ट कर सकते हैं? यदि किसी बच्चे का चाल असामान्य है, तो क्या हम अव्यक्त स्थान को इस बात की भविष्यवाणी करने के लिए कंडीशन कर सकते हैं कि वह विशिष्ट यांत्रिक तनाव उनके भविष्य के हड्डी के आकार को कैसे बदलेगा? -
शाखाओं वाले पैथोलॉजिकल अव्यक्त स्थान:
इस पत्र ने एक आधार रेखा स्थापित करने के लिए सामान्य पुरुष कूल्हों पर ध्यान केंद्रित किया। लेकिन बीमारी शायद ही कभी एक रैखिक प्रगति होती है। यदि हम पैथोलॉजिकल डेटा (जैसे, कूल्हे की डिसप्लेसिया) पेश करते हैं, तो हम अव्यक्त स्थान को कैसे संरचित करते हैं ताकि एक एकल क्रॉस-सेक्शनल स्कैन कई संभावित भविष्यवाणियों की भविष्यवाणी कर सके? हमें इस नियतात्मक मॉडल को संभाव्य मॉडल में विकसित करने के तरीके पर चर्चा करने की आवश्यकता है, शायद भविष्य की रोग प्रगति के लिए "अनिश्चितता का शंकु" उत्पन्न करने के लिए अव्यक्त स्थान में प्रसार मॉडल का उपयोग करके। -
क्रॉस-मोडेलिटी टेम्पोरल अलाइनमेंट:
लेखकों ने सीटी स्कैन का इस्तेमाल किया, जो उत्कृष्ट हड्डी कंट्रास्ट प्रदान करते हैं लेकिन बाल रोगियों को आयनकारी विकिरण के संपर्क में लाते हैं। बाल चिकित्सा इमेजिंग का भविष्य एमआरआई या अल्ट्रासाउंड है। हालांकि, इन तौर-तरीकों में काफी अलग शोर प्रोफाइल और कलाकृति व्यवहार होते हैं। एक आकर्षक चर्चा बिंदु यह है कि क्या सीटी डेटा से सीखे गए ज्यामितीय अव्यक्त एम्बेडिंग को एमआरआई डेटा में स्थानांतरित किया जा सकता है। क्या विकास के "वेग क्षेत्र" को इमेजिंग तौर-तरीके के पिक्सेल तीव्रता से अलग किया जा सकता है?
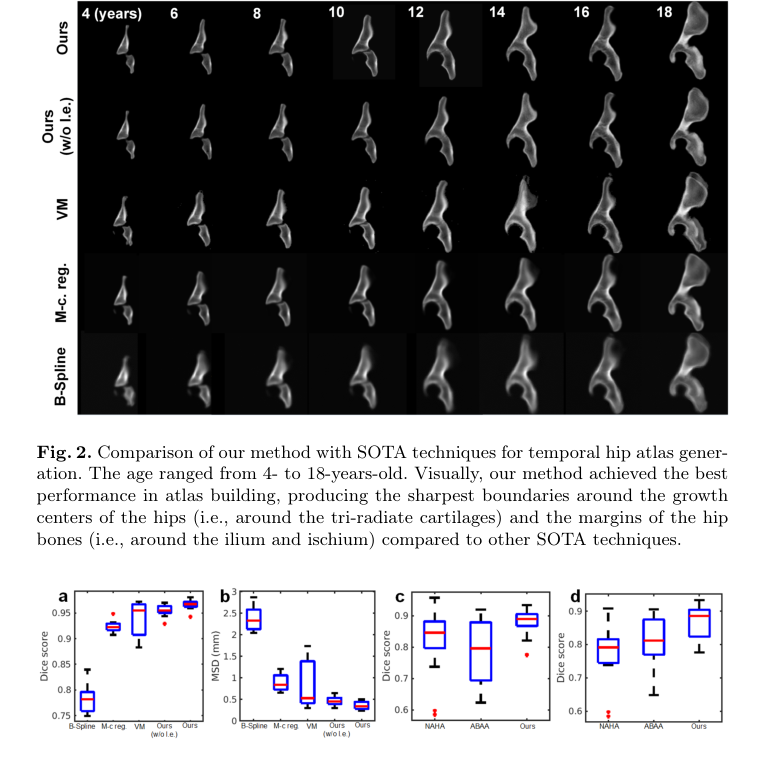 Figure 3. Boxplots of the atlas-to-patient (within-age) registration results based on the mean Dice score (a) and the MSD (b). Boxplots of the longitudinal data generation results for all testing cases (c) and for the cases when the age gap is >1 year (d) based on mean Dice score. The ages of the subjects in these experiments ranged from 4 to 18 years. Our method achieved superior performance compared to others
Figure 3. Boxplots of the atlas-to-patient (within-age) registration results based on the mean Dice score (a) and the MSD (b). Boxplots of the longitudinal data generation results for all testing cases (c) and for the cases when the age gap is >1 year (d) based on mean Dice score. The ages of the subjects in these experiments ranged from 4 to 18 years. Our method achieved superior performance compared to others
 Figure 2. Comparison of our method with SOTA techniques for temporal hip atlas gener- ation. The age ranged from 4- to 18-years-old. Visually, our method achieved the best performance in atlas building, producing the sharpest boundaries around the growth centers of the hips (i.e., around the tri-radiate cartilages) and the margins of the hip bones (i.e., around the ilium and ischium) compared to other SOTA techniques
Figure 2. Comparison of our method with SOTA techniques for temporal hip atlas gener- ation. The age ranged from 4- to 18-years-old. Visually, our method achieved the best performance in atlas building, producing the sharpest boundaries around the growth centers of the hips (i.e., around the tri-radiate cartilages) and the margins of the hip bones (i.e., around the ilium and ischium) compared to other SOTA techniques
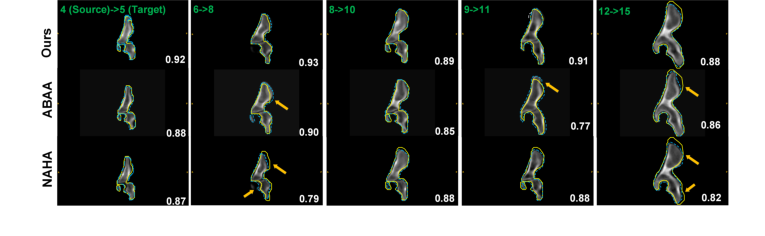 Figure 4. Comparison of various methods for the longitudinal data generation task based on a real longitudinal dataset. For example, in the first column, given an input hip dataset from a 4-year-old subject (source), the longitudinal data generator predicted the 3D synthetic longitudinal CT hip shape of the same subject at the age of 5. The source and target ages are denoted in green text in the left upper corner of each frame. The segmentation contour (blue dashed line) produced by our method aligns better with the ground truth contour (yellow line) than other techniques, as indicated by the higher Dice scores (white text). Arrows highlight regions with large alignment errors
Figure 4. Comparison of various methods for the longitudinal data generation task based on a real longitudinal dataset. For example, in the first column, given an input hip dataset from a 4-year-old subject (source), the longitudinal data generator predicted the 3D synthetic longitudinal CT hip shape of the same subject at the age of 5. The source and target ages are denoted in green text in the left upper corner of each frame. The segmentation contour (blue dashed line) produced by our method aligns better with the ground truth contour (yellow line) than other techniques, as indicated by the higher Dice scores (white text). Arrows highlight regions with large alignment errors