Генерация продольных данных с помощью геометрических скрытых вложений, управляемая временным атласом
Для понимания истоков данного исследования необходимо обратиться к исторической эволюции медицинской визуализации.
Предыстория и академическое происхождение
Для понимания истоков данного исследования необходимо обратиться к исторической эволюции медицинской визуализации. Десятилетия назад медицинские снимки, такие как КТ или МРТ, рассматривались как статичные фотографии — единичный снимок внутренней анатомии пациента в конкретный момент времени. Однако врачи и исследователи быстро осознали, что человеческая анатомия не статична; это высокодинамичный процесс, обусловленный генетикой, питанием и заболеваниями. Для точной диагностики таких состояний, как болезнь Альцгеймера, или отслеживания нормального развития скелетной структуры ребенка, медицинская область должна была перейти от трехмерных (3D) статичных изображений к четырехмерному (4D) статистическому анализу формы. Это означало добавление "времени" как четвертого измерения. Клиническая потребность наблюдать "фильм" анатомии пациента, а не просто "фотографию", породила спрос на продольные (longitudinal) данные визуализации.
Однако фундаментальное ограничение, побудившее авторов к написанию данной статьи, заключается в серьезном "узком месте" данных. Получение истинных продольных данных требует многократного сканирования одного и того же пациента в течение месяцев или лет. Это чрезвычайно дорого (часто стоит тысячи долларов, например, \$1,000+ за сканирование), трудоемко и логистически сложно, что приводит к острому дефициту таких данных. Предыдущие модели искусственного интеллекта (AI) пытались генерировать синтетические продольные данные, но они страдали от фатального недостатка: для обучения алгоритмов им требовались огромные наборы существующих продольных данных. Между тем, больницы располагают горами "поперечных" (cross-sectional) данных (единичные снимки множества разных людей). Предыдущие методы не могли эффективно использовать эти обильные поперечные данные для прогнозирования индивидуальных, специфичных для субъекта изменений во времени.
Для преодоления этого разрыва авторы вводят несколько узкоспециализированных концепций. Вот их значение в повседневных терминах:
- Продольные данные (Longitudinal Data): Представьте себе видео с ускоренной съемкой одного растения, растущего от ростка до цветущего растения. Оно отслеживает один и тот же объект во времени, демонстрируя причинно-следственные связи в его росте.
- Поперечные данные (Cross-sectional Data): Представьте, что вы сделали одну групповую фотографию детского сада, средней школы и старшей школы. Вы можете увидеть, как выглядит "средний" 5-летний или 15-летний ребенок, но вы понятия не имеете, как конкретный ребенок из детского сада будет выглядеть, когда достигнет старшей школы.
- Построение атласа (Atlas Building): Думайте об этом как о создании "композитного эскиза". Если взять тысячи фотографий бедер разных 10-летних детей и математически объединить их, вы получите стандартный, усредненный шаблон (атлас), представляющий типичное бедро 10-летнего ребенка.
- Диффеоморфизм (Diffeomorphism): Представьте, что вы напечатали медицинское изображение на листе очень эластичной, волшебной резины. Вы можете растягивать, деформировать и скручивать эту резину, чтобы одна форма стала похожа на другую, но вам никогда не разрешается рвать резину или складывать ее на себя. Поскольку она никогда не рвется, вы всегда можете идеально обратить растяжение, чтобы вернуться к исходной форме.
- Латентные эмбеддинги (Latent Embeddings): Представьте, что вы пытаетесь описать сложный 3D-автомобиль другу по телефону. Вместо того чтобы описывать каждый болт, вы просто даете ему несколько ключевых чисел: длину, вес и объем двигателя. Латентное представление — это способ AI сжать сложное 3D-медицинское изображение в короткий список основных математических признаков.
Математически авторы решили проблему генерации специфичных для субъекта продольных данных, используя преимущественно поперечные данные. Они сделали это, заставив две отдельные задачи AI работать совместно: построение усредненного атласа для каждой возрастной группы и обучение тому, как деформировать формы между разными возрастами.
Сначала они определяют задачу построения атласа путем минимизации энергетической функции:
$$E(I, v_0^n) = \sum_{n=1}^N \frac{1}{\sigma^2} \text{Dist}[I \circ \phi_1^{-1}(v_0^n), I_n] + \text{Reg}(v_0^n)$$
Простыми словами, это уравнение пытается найти идеальное среднее изображение ($I$), измеряя расстояние ($\text{Dist}$) между деформированным средним изображением и фактическими изображениями пациента ($I_n$). Член $\text{Reg}$ является правилом, которое гарантирует, что "растяжение резины" остается гладким и реалистичным.
Для достижения своей конечной цели авторы разработали унифицированную нейронную сеть, которая минимизирует комбинированную общую функцию потерь:
$$\ell = \mathcal{L}_{\text{tempo-atlas}}(\Theta) + \mathcal{L}_{\text{longitudinal}}(\Psi) + \gamma \mathcal{L}_{\text{latent}}(\mathbf{Z})$$
Здесь модель получает штраф, если она одновременно не справляется с тремя задачами:
1. $\mathcal{L}_{\text{tempo-atlas}}$: Она должна строить точные усредненные атласы для каждой конкретной возрастной группы.
2. $\mathcal{L}_{\text{longitudinal}}$: Она должна точно определять, как деформировать атлас от одного возраста (например, 10 лет) к следующему (например, 12 лет).
3. $\mathcal{L}_{\text{latent}}$: Она должна гарантировать, что сжатые математические сводки (эмбеддинги) этих форм логически кластеризуются, то есть формы, которые выглядят биологически схожими, остаются близко друг к другу в "мозгу" AI.
Решая это совместное уравнение, AI изучает общие закономерности старения на основе популяции (атласы) и применяет эти закономерности к одному снимку нового пациента, успешно прогнозируя, как анатомия этого конкретного пациента будет развиваться со временем.
| Обозначение | Описание |
|---|---|
| $I_n$ | $n$-е входное изображение в наборе данных (например, КТ-скан конкретного пациента). |
| $I$ | Среднее или шаблонное изображение, представляющее "среднюю" анатомию (Атлас). |
| $\phi$ | Математическое преобразование (функция "деформации"), применяемое к изображению. |
| $v_0$ | Начальное поле скоростей, которое определяет, как форма начнет деформироваться. |
| $\sigma^2$ | Дисперсия шума в изображениях, используемая для взвешивания измерения расстояния. |
| $A_q$ | Конкретный анатомический атлас, построенный для заданного возраста/времени $q$. |
| $\Theta$ | Обучаемые параметры нейронной сети, ответственной за построение временных атласов. |
| $\Psi$ | Обучаемые параметры нейронной сети, ответственной за регистрацию между возрастами (продольную). |
| $\mathbf{z}_q^i$ | Латентный эмбеддинг (сжатое математическое представление) изображения в возрасте $q$. |
| $\gamma$ | Параметр настройки, контролирующий, насколько сильно модель применяет правила латентных эмбеддингов. |
Определение проблемы и ограничения
Представьте, что вам поручено создать видео с ускоренной съемкой роста конкретного ребенка. Однако вместо непрерывного видео этого одного ребенка вам вручают огромный фотоальбом с фотографиями разных детей разного возраста. Вы легко можете понять, как выглядит средний 5-летний или средний 10-летний ребенок. Но предсказать, как именно конкретный 5-летний ребенок будет выглядеть в 10 лет, невероятно сложно, поскольку нам не хватает анатомической истории этого конкретного ребенка.
Это именно та ситуация, с которой сталкиваются медицинские исследователи, пытаясь моделировать развитие человеческих органов и костей с течением времени.
Отправная точка и целевое состояние
Входные данные (текущее состояние): Медицинская область богата 3D поперечными данными визуализации. Это одномоментные снимки (например, КТ или МРТ), полученные от множества разных индивидуумов. Несмотря на изобилие, эти наборы данных представляют собой лишь снимок во времени, не давая никакой информации о биологических изменениях, связанных с причиной и следствием.
Выходные данные (целевое состояние): Клиницистам отчаянно нужны 4D продольные данные. Это означает наличие структурных изменений одного и того же пациента с течением времени, специфичных для субъекта и меняющихся во времени. Если врач вводит 3D-скан тазобедренного сустава 8-летнего пациента, целью является получение биологически точного, высоко персонализированного 3D-скана того, как тазобедренный сустав этого конкретного пациента будет выглядеть в возрасте 10 или 15 лет.
Математический пробел: Отсутствующее звено — это непрерывное, обратимое поле преобразований, которое может развивать конкретную анатомическую структуру вперед во времени без опоры на парные продольные обучающие данные. Нам нужен математический мост, соединяющий популяционный средний показатель ( "атлас") с траекторией времени, специфичной для субъекта.
Мучительная дилемма
Для генерации реалистичных продольных данных модели глубокого обучения (такие как диффузионные модели, учитывающие последовательности) обычно требуют огромного количества продольных данных ground truth для обучения. Здесь кроется ловушка:
Вы не можете обучить хорошую продольную модель без продольных данных, но продольные данные стоят чрезвычайно дорого (часто более 1000 долларов за снимок пациента), требуют много времени и их невероятно сложно собрать. Если исследователи пытаются обойти это, обучая модели исключительно на обильных поперечных данных, генерируемые будущие изображения теряют свою специфичность для субъекта. Модель в конечном итоге предсказывает усредненного "типичного" человека, а не сохраняет уникальную скелетную геометрию исходного пациента. Предыдущие исследователи оказались в ловушке этого мучительного компромисса между доступностью данных и временной точностью.
Жесткие стены и ограничения
Чтобы решить эту проблему, авторы столкнулись с несколькими суровыми ограничениями:
- Крайняя разреженность данных: Сбор реальных продольных данных занимает годы. Пациенты выбывают из исследований, меняется оборудование для визуализации, а совмещение снимков, сделанных с разницей в годы, вносит огромную вариативность.
- Физика биологической деформации: Рост костей и тканей — это не просто простое смещение пикселей; он включает в себя сложные, нелинейные биологические изменения. Для моделирования этого авторам пришлось использовать Large Deformation Diffeomorphic Metric Mapping (LDDMM). Это гарантирует, что преобразования являются гладкими и обратимыми (диффеоморфными), то есть ткани не рвутся, не пересекаются и не складываются сами в себя. Однако для расчета этого требуется интегрирование полей скоростей вперед во времени с использованием уравнения Эйлера-Пуанкаре (EPDiff):
$$ \frac{\partial v_t}{\partial t} = -K \left[ (D v_t)^T \cdot m_t + D m_t \cdot v_t + m_t \cdot \text{div} \, v_t \right] $$
Решение этого уравнения для поиска оптимальных полей скоростей ($v_t$) и векторов импульса ($m_t$) представляет собой огромную вычислительную нагрузку. - Стена размытых артефактов: Когда предыдущие передовые модели (такие как VoxelMorph или B-сплайны) пытались трансформировать анатомии при больших возрастных разрывах, они вносили серьезные искажения и размытые границы. Сохранение мелких анатомических деталей, таких как трирадиатные хрящи в развивающемся бедре, чрезвычайно сложно, когда модель вынуждена угадывать, как структура расширяется в течение лет.
Как они решили проблему: Единая математическая основа
Авторы поняли, что для выхода из дилеммы им нужно было не просто построить генератор, а одновременно построить карту. Они разработали новую основу глубокого обучения, которая совместно выполняет две задачи: Построение временного атласа (поиск среднего значения популяции в заданном возрасте) и Регистрация изображений между возрастами (согласование этого среднего значения с конкретными целями для моделирования роста).
Сначала они определяют функцию потерь для построения последовательности атласов, специфичных для возраста ($A_q$), минимизируя расстояние между атласом и поперечными изображениями ($I_i^q$), с регуляризацией по полю скоростей ($v_i^q$):
$$ \mathcal{L}_{\text{tempo-atlas}}(\Theta) = \sum_{q=1}^{Q} \sum_{i=1}^{N_q} \text{Dist}\left[ \phi_{q \to i}^{-1}(\Theta) \circ A_q, I_i^q \right] + \text{Reg}(v_i^q) $$
Затем они моделируют продольные изменения, согласовывая исходный атлас с целевыми возрастами ($q'$):
$$ \mathcal{L}_{\text{longitudinal}}(\Psi) = \sum_{m=1}^{M} \text{Dist}\left[ \phi_{q \to q'}^{-1}(\Psi) \circ A_q, I_{q'}^m \right] + \text{Reg}(v_{m}^{q'}) $$
Прорыв: Истинный гений этой статьи заключается в том, как они связали эти два пространства с помощью различительных латентных вложений. Они заставляют нейронную сеть изучать латентное пространство $\mathbf{Z}$, где анатомически схожие структуры плотно группируются, а расстояние между этими вложениями строго коррелирует с физической деформацией (полями скоростей), необходимой для преобразования между ними.
Они обеспечивают это с помощью специализированной функции потерь:
$$ \mathcal{L}_{\text{latent}}(\mathbf{Z}) = \mathbb{E} \left[ -\log(\sigma(\text{sim}(\mathbf{z}_q^i, \mathbf{z}_{q'}^m))) \right] + \lambda \mathbb{E} \left[ \text{Corr}\left( \|\mathbf{z}_q^i - \mathbf{z}_{q'}^m\|^2, \|v_q^i - v_{q'}^m\|^2 \right) \right] $$
Первый член использует косинусное сходство для группировки связанных форм. Второй член — это главный ход: он вычисляет корреляцию между евклидовым расстоянием латентных вложений ($\|\mathbf{z}_q^i - \mathbf{z}_{q'}^m\|^2$) и физической энергией деформации ($\|v_q^i - v_{q'}^m\|^2$).
Математически связывая абстрактное латентное пространство с физическими законами диффеоморфной деформации, модель может взглянуть на один поперечный снимок, сопоставить его с временным атласом и точно спроецировать, как эта конкретная геометрия будет развиваться с течением времени, полностью обходя необходимость в массивных продольных обучающих наборах данных.
Почему этот подход
Чтобы понять, почему авторы выбрали этот узкоспециализированный, математически насыщенный подход, сначала необходимо рассмотреть тот момент, когда традиционные передовые (SOTA) методы уперлись в стену.
В последние годы сообщество глубокого обучения было одержимо генеративными моделями. Если вам нужно сгенерировать последовательность изображений, показывающих, как растет тазобедренная кость ребенка с течением времени, первой мыслью может быть использование диффузионной модели или трансформера. Фактически, авторы явно указывают, что предыдущие исследователи пытались именно это: Yoon et al. использовали диффузионные модели, учитывающие последовательность, а Puglisi et al. использовали латентные диффузионные модели для моделирования структурных изменений с течением времени.
Но вот в чем фатальный недостаток, который заставил авторов отказаться от этих популярных подходов: стандартные генеративные модели чрезвычайно требовательны к данным. Им требуются массивные, парные продольные наборы данных, что означает, что вам нужны тысячи 3D-сканов одних и тех же пациентов, сделанных год за годом. В реальной клинической среде такие данные непомерно дороги, трудоемки и практически отсутствуют. Подавляющее большинство доступных медицинских данных являются поперечными (снимки разных людей в отдельные, изолированные моменты времени). Диффузионные модели и GANs просто не могут изучить специфическую для субъекта временную динамику, не видя фактической временной последовательности во время обучения. Они потерпят неудачу здесь, потому что не могут сгенерировать биологически точные траектории роста из несвязанных снимков.
Столкнувшись с этим жестким ограничением, авторы поняли, что единственным жизнеспособным решением было встроить строгие законы физики и геометрии в процесс обучения. Они обратились к методу крупномасштабного деформационного диффеоморфического метрического отображения (LDDMM).
Почему это математически превосходит? Диффеоморфическое преобразование гарантирует, что отображение между двумя анатомическими формами является гладким, непрерывным и строго обратимым. В биологии ткани растягиваются и растут, но они не рвутся случайным образом, не складываются сами на себя и не телепортируются. Формулируя проблему через дифференциальное уравнение Эйлера-Пуанкаре (EPDiff), авторы гарантируют, что геодезический путь анатомического роста однозначно определяется путем интегрирования начального поля скоростей $v_0$ вперед во времени:
$$ \frac{\partial v_t}{\partial t} = -K \left[ (D v_t)^T \cdot m_t + D m_t \cdot v_t + m_t \cdot \text{div} \, v_t \right] $$
Это создает идеальный "союз" между жесткими ограничениями задачи (отсутствие продольных данных) и уникальными свойствами решения. Вместо того чтобы пытаться вслепую угадать, как растет кость, модель совместно выполняет две задачи: она строит "атлас" (среднюю форму популяции в определенном возрасте, скажем, 8 лет) и затем изучает диффеоморфические поля скоростей, которые деформируют 8-летний атлас в 10-летний атлас. Затем она применяет эти изученные, биологически правдоподобные поля скоростей к базовому скану конкретного пациента для генерации высоконадежных прогнозов его будущей анатомии.
Структурное преимущество этого метода перед предыдущими золотыми стандартами, такими как VoxelMorph (VM) или B-сплайновая регистрация, является глубоким. Традиционные методы регистрации просто пытаются минимизировать попиксельные различия между Изображением A и Изображением B. Как показано в сравнительном анализе статьи, это часто приводит к размытым границам и серьезным артефактам (таким как искажения вокруг подвздошного гребня в базовой модели VoxelMorph).
Чтобы преодолеть это, авторы ввели блестящую функцию потерь "Distinctive Latent Embedding". Они не просто выравнивают изображения; они заставляют латентное пространство нейронной сети идеально отражать пространство физической деформации. Функция потерь включает член, который измеряет корреляцию между расстоянием латентных вложений $\mathbf{z}$ и физическим расстоянием полей скоростей $v$:
$$ \mathcal{L}_{\text{latent}}(\mathbf{Z}) = \dots + \lambda \mathbb{E}_{(\mathbf{z}_q^i, \mathbf{z}_{q'}^m)} \left[ \text{Corr} \left( \|\mathbf{z}_q^i - \mathbf{z}_{q'}^m\|^2, \|v_q^i - v_{q'}^m\|^2 \right) \right] $$
Это математически заставляет латентное пространство сохранять геометрические и временные отношения, определяемые полями скоростей. Это разделяет прогрессивные вариации формы во времени, позволяя модели генерировать сверхчеткие, свободные от артефактов границы вокруг сложных центров роста, таких как трирадиарные хрящи.
Честно говоря, я не до конца уверен, уменьшает ли эта конкретная архитектура сложность вычислительной памяти с $O(N^2)$ до $O(N)$, поскольку авторы явно не предоставляют разбивки алгоритма по Big-O в тексте. Однако подавляюще очевидной является ее эффективность в отношении данных. Используя геометрические латентные пространства диффеоморфизмов, эта структура достигает того, чего не могут SOTA диффузионные модели: она синтезирует высокоточные, специфичные для субъекта 4D продольные данные, используя только разреженные, поперечные 3D входные данные.
Математический и логический механизм
Чтобы понять значимость данной статьи, необходимо сначала разобраться в фундаментальной проблеме обработки данных в медицинской визуализации. Представьте, что вы пытаетесь понять, как растет ребенок, просматривая фотоальбом. Если у вас есть "продольный" альбом — фотографии одного и того же ребенка, сделанные каждый год — вы можете легко увидеть точную траекторию его роста. Однако в медицинской сфере получение продольных 3D-сканов (таких как КТ или МРТ) одного и того же пациента на протяжении многих лет невероятно дорого, трудоемко и редко. Вместо этого в больницах хранятся горы "поперечных" данных: отдельные снимки разных людей разного возраста.
Авторы данной статьи создали блестящий математический механизм, который берет эти разрозненные снимки разных людей и изучает лежащие в их основе "правила роста". Затем он использует эти правила для генерации высокоточного, персонализированного 3D-таймлапса (продольных данных) для совершенно нового пациента, точно предсказывая, как его анатомия будет меняться со временем.
Вот точный математический аппарат, который делает это возможным.
Основные уравнения
Основной механизм данной статьи приводится в действие унифицированной целевой функцией, которая одновременно балансирует три масштабные задачи: построение "среднего" шаблона (атласа), прогнозирование роста в зависимости от возраста и принуждение модели к пониманию физической реальности этих изменений.
Общая функция потерь, которая питает всю сеть, имеет вид:
$$ \ell = \mathcal{L}_{\text{tempo-atlas}}(\Theta) + \mathcal{L}_{\text{longitudinal}}(\Psi) + \gamma \mathcal{L}_{\text{latent}}(\mathbf{Z}) $$
Но настоящий секретный ингредиент — самая инновационная часть этой статьи — это функция потерь Distinctive Latent Embedding, которая действует как мозг операции:
$$ \mathcal{L}_{\text{latent}}(\mathbf{Z}) = \mathbb{E}_{(\mathbf{z}_q^i, \mathbf{z}_{q'}^m)} \big[ -\log(\sigma(\text{sim}(\mathbf{z}_q^i, \mathbf{z}_{q'}^m))) \big] + \lambda \, \mathbb{E}_{(\mathbf{z}_q^i, \mathbf{z}_{q'}^m)} \big[ \text{Corr} \big( \|\mathbf{z}_q^i - \mathbf{z}_{q'}^m\|^2, \; \|v_q^i - v_{q'}^m\|^2 \big) \big] $$
Разбираем уравнения
Давайте разберем каждый винтик и пружинку этого механизма.
Из общей потери ($\ell$):
* $\ell$: Общая потеря. Это конечная "оценка ошибки", которую машина пытается минимизировать до нуля.
* $\mathcal{L}_{\text{tempo-atlas}}(\Theta)$: Потеря построения временного атласа. Этот член измеряет, насколько хорошо сеть (с параметрами $\Theta$) может создать "средний" анатомический шаблон для определенного возраста. Он действует как базовая точка отсчета.
* $\mathcal{L}_{\text{longitudinal}}(\Psi)$: Потеря регистрации между возрастами. Этот член измеряет, насколько хорошо сеть (с параметрами $\Psi$) может деформировать изображение одного возраста, чтобы соответствовать анатомии более старшего возраста. Это компонент "машины времени".
* $\gamma$: Скалярный вес (регулятор баланса). Он определяет, какое внимание модель должна уделять латентным представлениям по сравнению с генерацией изображений.
* Почему сложение, а не умножение? Авторы используют сложение для создания многозадачной весовой шкалы. Если бы они умножили эти члены, почти нулевая оценка в потере атласа полностью обнулила бы градиенты (сигналы обучения) для продольной потери, полностью остановив процесс обучения. Сложение гарантирует, что даже если одна задача выполняется идеально, модель все равно чувствует давление на улучшение других.
Из потери латентного представления ($\mathcal{L}_{\text{latent}}(\mathbf{Z})$):
* $\mathbf{Z}$: Матрица всех латентных представлений. Представление (embedding) — это сильно сжатое, абстрактное математическое резюме 3D-медицинского изображения.
* $\mathbb{E}_{(\mathbf{z}_q^i, \mathbf{z}_{q'}^m)}$: Математическое ожидание (среднее) по парам этих сжатых представлений. $\mathbf{z}_q^i$ — это представление пациента $i$ в возрасте $q$, а $\mathbf{z}_{q'}^m$ — пациента $m$ в возрасте $q'$.
* Почему ожидание, а не точная сумма ($\sum$)? В глубоком обучении вычисление точной суммы всех возможных пар изображений по огромному набору данных является вычислительно взрывным. Использование ожидания позволяет модели стохастически выбирать случайные пары во время обучения, аппроксимируя истинное среднее и экономя огромное количество памяти.
* $-\log(\sigma(\dots))$: Отрицательный логарифм сигмоидной функции. Это классический механизм штрафа. Сигмоида ($\sigma$) сжимает значения между 0 и 1 (подобно вероятности). Отрицательный логарифм сильно штрафует модель, если это значение приближается к 0.
* $\text{sim}(\mathbf{z}_q^i, \mathbf{z}_{q'}^m)$: Косинусное сходство между двумя представлениями. Оно измеряет угол между двумя векторами.
* Логическая роль: Весь этот первый член действует как гравитационное притяжение. Если две анатомические формы связаны, это заставляет их абстрактные математические векторы указывать в одном и том же направлении в латентном пространстве.
* $\lambda$: Еще один регулятор баланса, специально контролирующий силу физического ограничения.
* $\text{Corr}(\dots)$: Коэффициент корреляции Пирсона. Он измеряет, насколько линейно связаны две переменные.
* $\|\mathbf{z}_q^i - \mathbf{z}_{q'}^m\|^2$: Квадрат евклидова расстояния между двумя абстрактными представлениями. Представьте это как "концептуальное расстояние" между бедром 8-летнего и бедром 10-летнего ребенка.
* $\|v_q^i - v_{q'}^m\|^2$: Квадрат расстояния их соответствующих полей скоростей ($v$). Поле скоростей — это 3D-карта стрелок, точно определяющая, как пиксели должны физически перемещаться и растягиваться, чтобы трансформировать одну форму в другую.
* Логическая роль: Этот член корреляции — чистое гениальность. Он действует как строгий инспектор физики. Он заставляет абстрактное "концептуальное расстояние" представлений идеально коррелировать с фактической "энергией физического растяжения", необходимой для деформации ткани. Это предотвращает "обман" нейронной сети путем произвольного размещения изображений в латентном пространстве.
Пошаговый поток
Проследим за одной абстрактной точкой данных — 3D-сканом КТ бедра 8-летнего пациента — как она проходит через эту математическую сборочную линию.
- Сжатие: Сырые 3D-пиксели бедра 8-летнего ребенка поступают в сеть и немедленно сжимаются в плотный, абстрактный вектор $\mathbf{z}_q^i$.
- Привязка: Система сравнивает этот вектор с "средним шаблоном бедра 8-летнего ребенка", который она построила. Она вычисляет, насколько конкретный пациент отклоняется от нормы.
- Путешествие во времени: Пользователь запрашивает прогноз того, как это бедро будет выглядеть в 12 лет. Сеть обращается к "среднему шаблону 12-летнего ребенка". Она генерирует поле скоростей $v$ — карту стрелок, подобную потоку жидкости, которая определяет, как кость 8-летнего ребенка должна растягиваться, расти и изгибаться, чтобы достичь состояния 12-летнего.
- Контроль качества: Вступает в силу потеря $\mathcal{L}_{\text{latent}}$. Она проверяет абстрактное расстояние между вектором 8-летнего и вектором 12-летнего. Она строго проверяет, соответствует ли это абстрактное расстояние физической энергии поля скоростей $v$. Если математика не согласуется с физикой, модель штрафуется.
- Генерация: Наконец, поле скоростей применяется к исходному 3D-скану, плавно деформируя пиксели, подобно куску цифровой глины, чтобы получить биологически точный, синтетический скан бедра 12-летнего ребенка.
Динамика оптимизации
Как эта сложная архитектура на самом деле учится и сходится?
Модель оптимизирует свои параметры с помощью градиентного спуска (в частности, оптимизатора Adam). Изначально ландшафт потерь крайне хаотичен. Сеть пытается найти короткие пути, возможно, просто размывая изображение 8-летнего ребенка, чтобы оно отдаленно напоминало изображение 12-летнего, чтобы быстро уменьшить потерю расстояния между изображениями.
Однако модель ограничена диффеоморфной математикой (в частности, дифференциальными уравнениями Эйлера-Пуанкаре, упомянутыми в предыстории статьи). Это означает, что преобразования должны быть гладкими, непрерывными и обратимыми — как складывание резинового листа без его разрыва или пропускания его через себя.
Благодаря этому строгому физическому ограничению, ландшафт потерь приобретает форму крутой, гладкой воронки. По мере того как градиенты проходят обратно через сеть, представления $\mathbf{Z}$ вынуждены красиво организоваться. Снимки схожих возрастов плотно группируются, в то время как снимки разных возрастов располагаются на расстоянии, точно пропорциональном физическому росту, необходимому для перехода между ними. За 1000 эпох система достигает равновесия: сгенерированные атласы становятся предельно четкими, а прогнозируемые траектории роста — анатомически безупречными, что позволяет модели "галлюцинировать" будущее анатомии пациента с невероятной точностью.
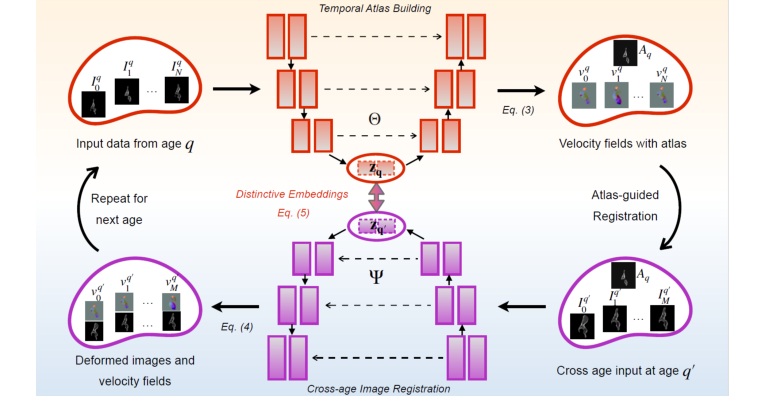 Figure 1. Overview of our model. Training: Our network constructs a sequence of tempo- ral atlases, starting at age q and modeling deformations across target ages. A geometric embedding loss in the latent space enforces structured, biologically meaningful anatom- ical evolution. Iterative refinement enhances the interplay between cross-sectional and longitudinal dynamics, generating anatomically coherent cross-age data. Inference: For each subject, we first align their baseline images to the corresponding age-specific atlas. The trained model Ψ operates as a longitudinal data generator, synthesizing anatomically plausible trajectories for unseen subjects by extracting geometric fea- tures through the atlas. It uses generated velocity fields from cross-age registration between age-specific atlases to deform subject-specific structures over time, ensuring a smooth and temporally consistent evolution
Figure 1. Overview of our model. Training: Our network constructs a sequence of tempo- ral atlases, starting at age q and modeling deformations across target ages. A geometric embedding loss in the latent space enforces structured, biologically meaningful anatom- ical evolution. Iterative refinement enhances the interplay between cross-sectional and longitudinal dynamics, generating anatomically coherent cross-age data. Inference: For each subject, we first align their baseline images to the corresponding age-specific atlas. The trained model Ψ operates as a longitudinal data generator, synthesizing anatomically plausible trajectories for unseen subjects by extracting geometric fea- tures through the atlas. It uses generated velocity fields from cross-age registration between age-specific atlases to deform subject-specific structures over time, ensuring a smooth and temporally consistent evolution
Результаты, ограничения и заключение
Основная проблема: Как избежать ловушки "снимка"
Чтобы понять значимость данной работы, необходимо прежде всего разобраться в фундаментальном различии между двумя типами медицинских данных: поперечными (cross-sectional) и продольными (longitudinal).
Представьте, что вы хотите понять, как стареют человеческие лица. Если вы сделаете фотографию 100 разных людей, каждый в возрасте от 5 до 50 лет, вы получите поперечные данные. Вы можете предположить общую тенденцию старения, но вы не знаете точно, как будет выглядеть 5-летний ребенок в 50 лет. Теперь представьте, что вы делаете фотографию одного и того же человека каждый год с 5 до 50 лет. Это продольные данные. Они фиксируют истинную, специфичную для субъекта пространственно-временную динамику изменений.
В медицинской визуализации продольные 3D-данные (делающие их 4D-данными во времени) являются Святым Граалем для отслеживания развития анатомических структур или прогрессирования заболеваний. Однако сбор таких данных представляет собой логистический кошмар. Это невероятно дорого — часто стоимость сканирования и административных расходов на одного пациента за десятилетие превышает 10 000 долларов США, — и крайне подвержено отсеву пациентов. Следовательно, подавляющее большинство медицинских баз данных являются поперечными.
Авторы данной статьи столкнулись с серьезным ограничением: Как точно предсказать будущую 3D-анатомическую форму конкретного пациента, когда наши обучающие данные в основном состоят из несвязанных "снимков" разных людей?
Математический двигатель: Диффеоморфизмы и латентное путешествие во времени
Чтобы решить эту проблему, авторы не просто обучили стандартную нейронную сеть угадывать следующий кадр. Они построили фреймворк, который совместно выполняет две задачи: построение атласа (Atlas Building) (поиск "средней" формы популяции в определенном возрасте) и генерация продольных данных (Longitudinal Data Generation) (предсказание того, как форма конкретного субъекта эволюционирует с возрастом).
Свое решение они обосновали на математике отображений метрики больших деформаций (Large Deformation Diffeomorphic Metric Mapping, LDDMM). Проще говоря, диффеоморфизм — это гладкое, непрерывное и обратимое преобразование. Представьте себе трансформацию глиняной скульптуры бедренной кости 5-летнего ребенка в бедренную кость 10-летнего ребенка, никогда не разрывая глину и не складывая ее на себя.
Базовая функция энергии для построения атласа (эталонного изображения $I$) из набора $N$ изображений определяется как:
$$E(I, v_0^n) = \sum_{n=1}^N \frac{1}{\sigma^2} \text{Dist}[I \circ \phi_1^{-1}(v_0^n), I_n] + \text{Reg}(v_0^n)$$
Здесь $v_0^n$ представляет собой начальное векторное поле скоростей — "толчок", необходимый для начала трансформации эталона в целевое изображение $I_n$. Путь преобразования управляется дифференциальным уравнением Эйлера-Пуанкаре (EPDiff), которое определяет, как эта скорость течет вперед во времени:
$$\frac{\partial v_t}{\partial t} = -K \left[ (D v_t)^T \cdot m_t + D m_t \cdot v_t + m_t \cdot \text{div} \, v_t \right]$$
Честно говоря, в статье не детализируется точный вычислительный объем памяти, необходимый для решения этой интеграции во время обучения глубокой нейронной сети, но, учитывая 3D-природу данных, можно предположить, что требуется значительная вычислительная мощность GPU (которую они обеспечили с помощью RTX A6000).
Истинный гений их архитектуры заключается в различительных латентных представлениях (Distinctive Latent Embeddings). Они заставляют нейронную сеть изучать латентное пространство $\mathbf{Z}$, где математическое расстояние между двумя представлениями идеально коррелирует с физической деформацией, необходимой для перехода между ними. Их функция потерь для латентного пространства:
$$\mathcal{L}_{\text{latent}}(\mathbf{Z}) = \mathbb{E}_{(\mathbf{z}_q^i, \mathbf{z}_{q'}^m)} \left[ -\log(\sigma(\text{sim}(\mathbf{z}_q^i, \mathbf{z}_{q'}^m))) \right] + \lambda \, \mathbb{E}_{(\mathbf{z}_q^i, \mathbf{z}_{q'}^m)} \left[ \text{Corr} \left( \|\mathbf{z}_q^i - \mathbf{z}_{q'}^m\|^2, \, \|v_q^i - v_{q'}^m\|^2 \right) \right]$$
Первый член заставляет связанные формы группироваться вместе с использованием косинусной схожести. Второй член является главным достижением: он гарантирует, что квадрат евклидова расстояния между двумя латентными векторами $\|\mathbf{z}_q^i - \mathbf{z}_{q'}^m\|^2$ коррелирует с физическим "усилием" (расстоянием векторного поля скоростей $\|v_q^i - v_{q'}^m\|^2$), необходимым для деформации одной формы в другую.
Итоговая целевая функция элегантно балансирует временное построение атласа, регистрацию между возрастами и это латентное представление:
$$\ell = \mathcal{L}_{\text{tempo-atlas}}(\Theta) + \mathcal{L}_{\text{longitudinal}}(\Psi) + \gamma \mathcal{L}_{\text{latent}}(\mathbf{Z})$$
Эксперимент: Жестокая валидация на реальности
Авторы не просто бросили метрики на стену; они разработали высокострогий эксперимент. Они обучили свою модель на поперечном наборе данных нормальных мужских тазобедренных суставов (возраст 4-18 лет). Но чтобы доказать, что их модель действительно работает, они протестировали ее на скрытом, высокоценном наборе данных истинных продольных КТ-сканов (12 пациентов, которые действительно имели несколько сканов с разницей в годы).
Жертвы (базовые модели):
Для построения атласа они полностью разобрали установленные модели, такие как B-spline, Multi-contrast registration (M-c. reg.) и VoxelMorph (VM). Для генерации продольных данных они победили NAHA (Nearest-Age Hip Approximation) и ABAA (Age-Based Atlas Approximation).
Окончательные доказательства:
Доказательство было не только в показателе Dice score (хотя они достигли доминирующего 0.88). Неоспоримым доказательством были визуальные и геометрические результаты. Они взяли реальный КТ-скан тазобедренного сустава 12-летнего пациента, подали его в свою модель и попросили "галлюцинировать" 15-летнюю версию того же самого пациента.
Когда они наложили свой синтетический 15-летний тазобедренный сустав на фактический 15-летний скан этого пациента, границы совпали превосходно. Базовые модели потерпели полное фиаско здесь — VoxelMorph создал сильные артефактные искажения вокруг заднего гребня подвздошной кости, а другие методы дали размытые, анатомически невозможные края костей. Модель авторов сохранила четкие, тонкие анатомические детали вокруг трирадиальных хрящей, доказав, что их латентное пространство успешно усвоило биологические правила роста костей, а не просто слепо интерполировало пиксели.
Будущие траектории и темы для обсуждения
Исходя из глубоких последствий данного фреймворка, можно выделить несколько критически важных направлений для будущих исследований:
-
Интеграция априорных биомеханических физических принципов:
В настоящее время модель изучает правила роста исключительно на основе геометрических преобразований (диффеоморфизмов). Однако развитие костей сильно зависит от физических сил (Закон Вольфа — кости адаптируются к нагрузкам, которым они подвергаются). Как можно внедрить тензоры биомеханических напряжений в уравнение EPDiff? Если у ребенка аномальная походка, можно ли обусловить латентное пространство для предсказания того, как это специфическое механическое напряжение изменит его будущую форму кости? -
Разветвленные патологические латентные пространства:
Данная статья была сосредоточена на нормальных мужских тазобедренных суставах для установления базового уровня. Но болезнь редко является линейным процессом. Если мы введем патологические данные (например, дисплазию тазобедренного сустава), как структурировать латентное пространство так, чтобы один поперечный скан мог предсказывать несколько возможных будущих? Нам нужно обсудить, как преобразовать эту детерминированную модель в вероятностную, возможно, используя диффузионные модели в латентном пространстве для генерации "конуса неопределенности" для будущей прогрессии заболевания. -
Кросс-модальное временное выравнивание:
Авторы использовали КТ-сканы, которые обеспечивают превосходный контраст костей, но подвергают детей ионизирующему излучению. Будущее детской визуализации — это МРТ или УЗИ. Однако эти модальности имеют совершенно разные профили шума и особенности артефактов. Интересным пунктом для обсуждения является то, могут ли геометрические латентные представления, полученные из данных КТ, быть перенесены на данные МРТ. Могут ли "векторные поля" роста быть отделены от интенсивности пикселей самой модальности визуализации?
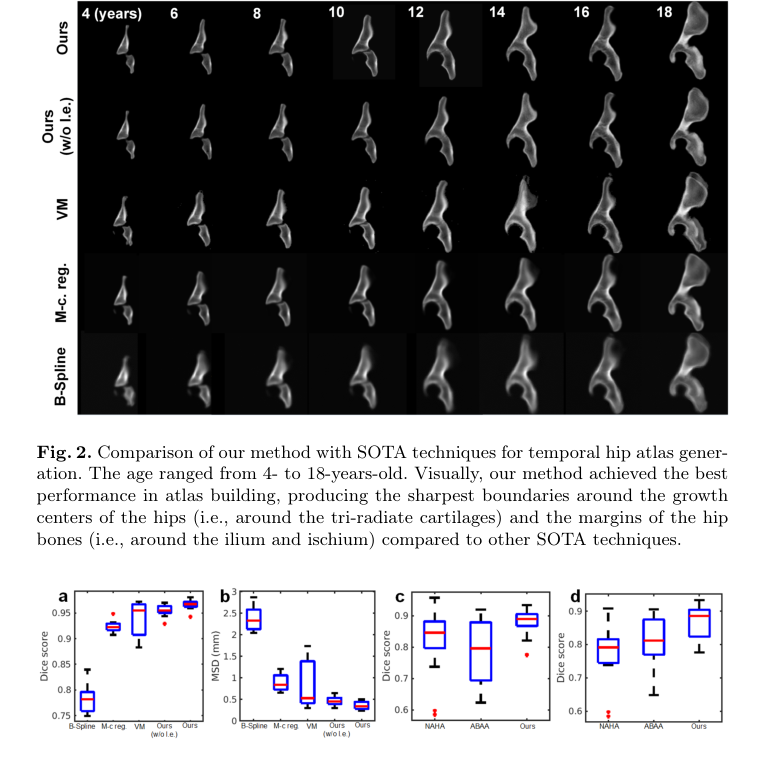 Figure 3. Boxplots of the atlas-to-patient (within-age) registration results based on the mean Dice score (a) and the MSD (b). Boxplots of the longitudinal data generation results for all testing cases (c) and for the cases when the age gap is >1 year (d) based on mean Dice score. The ages of the subjects in these experiments ranged from 4 to 18 years. Our method achieved superior performance compared to others
Figure 3. Boxplots of the atlas-to-patient (within-age) registration results based on the mean Dice score (a) and the MSD (b). Boxplots of the longitudinal data generation results for all testing cases (c) and for the cases when the age gap is >1 year (d) based on mean Dice score. The ages of the subjects in these experiments ranged from 4 to 18 years. Our method achieved superior performance compared to others
 Figure 2. Comparison of our method with SOTA techniques for temporal hip atlas gener- ation. The age ranged from 4- to 18-years-old. Visually, our method achieved the best performance in atlas building, producing the sharpest boundaries around the growth centers of the hips (i.e., around the tri-radiate cartilages) and the margins of the hip bones (i.e., around the ilium and ischium) compared to other SOTA techniques
Figure 2. Comparison of our method with SOTA techniques for temporal hip atlas gener- ation. The age ranged from 4- to 18-years-old. Visually, our method achieved the best performance in atlas building, producing the sharpest boundaries around the growth centers of the hips (i.e., around the tri-radiate cartilages) and the margins of the hip bones (i.e., around the ilium and ischium) compared to other SOTA techniques
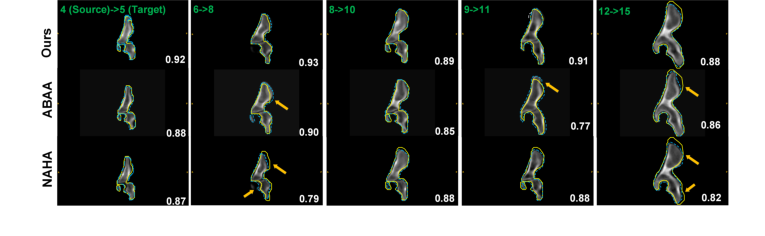 Figure 4. Comparison of various methods for the longitudinal data generation task based on a real longitudinal dataset. For example, in the first column, given an input hip dataset from a 4-year-old subject (source), the longitudinal data generator predicted the 3D synthetic longitudinal CT hip shape of the same subject at the age of 5. The source and target ages are denoted in green text in the left upper corner of each frame. The segmentation contour (blue dashed line) produced by our method aligns better with the ground truth contour (yellow line) than other techniques, as indicated by the higher Dice scores (white text). Arrows highlight regions with large alignment errors
Figure 4. Comparison of various methods for the longitudinal data generation task based on a real longitudinal dataset. For example, in the first column, given an input hip dataset from a 4-year-old subject (source), the longitudinal data generator predicted the 3D synthetic longitudinal CT hip shape of the same subject at the age of 5. The source and target ages are denoted in green text in the left upper corner of each frame. The segmentation contour (blue dashed line) produced by our method aligns better with the ground truth contour (yellow line) than other techniques, as indicated by the higher Dice scores (white text). Arrows highlight regions with large alignment errors
Изоморфизмы с другими полями
Механизм, который конструирует непрерывную, обратимую эволюционную траекторию между дискретными, статическими пространственными распределениями путем совместной оптимизации внутригруппового выравнивания и межгрупповых временных преобразований в геометрически ограниченном латентном пространстве.
Астрофизика и эволюция галактик
Астрономы сталкиваются с огромным наблюдательным препятствием: из-за скорости света и огромных размеров космоса они могут получать только статичные снимки галактик в определенные моменты времени (поперечные данные). Они не могут наблюдать эволюцию одной галактики на протяжении миллиардов лет (продольные данные). Основная логика данной работы — построение атласов "в пределах возраста" для управления диффеоморфными преобразованиями "между возрастами" — является идеальным отражением проблемы галактической морфологии. Подобно тому, как авторы картируют структурные изменения развивающейся бедренной кости по редким снимкам пациентов, астрофизикам необходимо картировать структурную эволюцию галактик (например, от спиральных к эллиптическим) с использованием редких снимков различных галактик при различных красных смещениях.
Количественные финансы и микроструктура рынка
В финансовой инженерии аналитики часто располагают огромными объемами поперечных данных по различным активам в один момент времени, но испытывают трудности с прогнозированием непрерывной, специфичной для объекта траектории одного актива в условиях меняющихся макроэкономических режимов. Концепция работы по использованию поля скоростей для обеспечения геометрической согласованности во времени отражает сложность моделирования деформации поверхностей волатильности или кривых доходности. Например, картирование того, как профиль риска конкретного актива деформируется при изменении его базовой цены со 100 до 150 долларов, требует точного такого же математического разделения "тенденций рынка на уровне популяции" (временной атлас) и "траекторий цен, специфичных для актива" (продольная генерация).
Сценарий "Что если"
Что, если бы теоретический астрофизик завтра украл точное уравнение суммарных потерь из этой статьи?
$$ \ell = \mathcal{L}_{\text{tempo-atlas}}(\Theta) + \mathcal{L}_{\text{longitudinal}}(\Psi) + \gamma \mathcal{L}_{\text{latent}}(\mathbf{Z}) $$
Подавая миллионы статичных изображений с космического телескопа Джеймса Уэбба в эту структуру, они могли бы рассматривать различные эпохи красного смещения как "возрасты", а отдельные формы галактик — как "поперечные входные данные". Член $\mathcal{L}_{\text{latent}}(\mathbf{Z})$ заставил бы латентное пространство сохранять геометрические отношения галактических структур. Прорыв был бы беспрецедентным: алгоритм синтезировал бы математически строгий 4D продольный фильм эволюции одной галактики на протяжении 10 миллиардов лет, эффективно решая проблему "утерянного звена" формирования галактик без необходимости ждать миллиард лет для получения данных.
Доказывая, что изолированные, статичные снимки могут быть математически сплетены в плавные, высокоперсонализированные истории, данная работа добавляет жизненно важный план в Универсальную библиотеку структур, демонстрируя, что биологический рост человеческой кости и космическое старение далекой галактики в конечном итоге управляются абсолютно одной и той же геометрической хореографией.