時間的アトラス誘導による幾何学的潜在埋め込みを用いた縦断的データ生成
This paper introduces a new AI model that creates realistic "time-lapse" medical images from static scans, helping us understand how body parts grow and change.
背景と学術的系譜
この研究の根源を理解するためには、医用画像処理の歴史的進化を振り返る必要がある。数十年前、CTスキャンやMRIのような医用画像は、患者の特定の瞬間における内部解剖学の単一スナップショット、すなわち静的な写真として扱われていた。しかし、医師や研究者は、人間の解剖学が決して静的ではなく、遺伝、栄養、疾患によって駆動される非常に動的なプロセスであることをすぐに認識した。アルツハイマー病のような疾患を正確に診断したり、子供の骨格構造の正常な発達を追跡したりするためには、医用分野は3D静止画像から4D統計形状解析へと移行する必要があった。これは、「時間」を4番目の次元として追加することを意味する。患者の解剖学の「写真」だけでなく、「映画」を観察するという臨床的ニーズが、縦断的画像データの需要を生み出したのである。
しかし、著者らが本稿を執筆するに至った根本的な制約は、深刻なデータボトルネックである。真の縦断的データを取得するには、数ヶ月または数年にわたり、全く同じ患者を繰り返しスキャンする必要がある。これは非常に高価(スキャンあたり1,000ドル以上かかることも多い)であり、時間もかかり、物流的にも困難であるため、このデータの著しい不足を招いている。これまでのAIモデルは、合成縦断データを生成しようと試みたが、致命的な欠陥を抱えていた。それは、アルゴリズムを訓練するためだけに、既存の縦断データの膨大なデータセットを必要としたことである。一方、病院には「横断的」データ(多くの異なる人々からの単一スキャン)の山が眠っている。これまでの手法では、この豊富な横断的データを、個々の被験者固有の時間的変化を予測するために効果的に利用することができなかった。
このギャップを埋めるため、著者らはいくつかの高度に専門化された概念を導入する。それらを日常的な言葉で説明すると以下のようになる。
- 縦断的データ: 若芽から満開の花へと成長する単一の植物のタイムラプス映像を想像してほしい。これは、同じ被験者を時間とともに追跡し、その成長における原因と結果を示すものである。
- 横断的データ: 幼稚園、中学校、高校のクラスの集合写真を1枚撮ることを想像してほしい。これにより、「平均的な」5歳児や15歳児の外見を知ることはできるが、特定の幼稚園児が高校生になったときにどう見えるかについては全く分からない。
- アトラス構築: これは「似顔絵」を作成するようなものだと考えてほしい。異なる10歳児の股関節の写真を数千枚撮り、それらを数学的にブレンドすると、典型的な10歳児の股関節を表す標準的な平均テンプレート(アトラス)が得られる。
- 微分同相写像 (Diffeomorphism): 医療画像を非常に伸縮性のある魔法のゴムシートに印刷することを想像してほしい。このゴムを伸ばしたり、歪ませたり、ねじったりして、ある形状を別の形状に見せることができるが、ゴムを引き裂いたり、折りたたんだりすることは決して許されない。引き裂かれないため、常に完璧に伸ばし戻すことで元の形状に戻すことができる。
- 潜在埋め込み (Latent Embeddings): 電話で友人に複雑な3Dの車を説明しようとしていると想像してほしい。すべてのボルトを一つ一つ説明する代わりに、長さ、重量、エンジンサイズといったいくつかの重要な数値を伝えるだけである。潜在表現とは、AIが複雑な3D医療画像を、重要な数学的特徴の短いリストに圧縮する方法である。
数学的には、著者らは主に横断的データを用いて、被験者固有の縦断データを生成する問題を解決した。彼らは、2つの別々のAIタスクを協調させて実行させることでこれを達成した。すなわち、各年齢層の平均アトラスを構築することと、異なる年齢間での形状の歪みを学習することである。
まず、著者らはエネルギー関数を最小化することによってアトラス構築の問題を定義する。
$$E(I, v_0^n) = \sum_{n=1}^N \frac{1}{\sigma^2} \text{Dist}[I \circ \phi_1^{-1}(v_0^n), I_n] + \text{Reg}(v_0^n)$$
平易な言葉で言えば、この方程式は、歪んだ平均画像と実際の患者画像 ($I_n$) との距離 ($\text{Dist}$) を測定することによって、完璧な平均画像 ($I$) を見つけようとするものである。「ゴムの伸縮」が滑らかで現実的であることを保証する規則が $\text{Reg}$ 項である。
最終的な目標を達成するために、著者らは統合されたニューラルネットワークを設計し、結合された総損失関数を最小化する。
$$\ell = \mathcal{L}_{\text{tempo-atlas}}(\Theta) + \mathcal{L}_{\text{longitudinal}}(\Psi) + \gamma \mathcal{L}_{\text{latent}}(\mathbf{Z})$$
ここで、モデルは同時に3つのタスクで失敗した場合にペナルティを受ける。
1. $\mathcal{L}_{\text{tempo-atlas}}$: 各特定の年齢層に対して正確な平均アトラスを構築しなければならない。
2. $\mathcal{L}_{\text{longitudinal}}$: ある年齢(例:10歳)のアトラスを次の年齢(例:12歳)に歪ませる方法を正確に特定しなければならない。
3. $\mathcal{L}_{\text{latent}}$: これらの形状の圧縮された数学的要約(埋め込み)が論理的にクラスター化されることを保証しなければならない。つまり、生物学的に類似した形状は、AIの「脳」内で互いに近くに保持される。
この連立方程式を解くことで、AIは集団(アトラス)から老化の一般的な規則を学習し、その規則を新しい患者の単一のスナップショットに適用することで、その特定の患者の解剖学が時間とともにどのように成長するかを成功裏に予測する。
| 記号 | 説明 |
|---|---|
| $I_n$ | データセット内の $n$ 番目の入力画像(例:特定の患者のCTスキャン)。 |
| $I$ | 平均またはテンプレート画像、「平均的な」解剖学(アトラス)を表す。 |
| $\phi$ | 画像に適用される数学的変換(「歪み」関数)。 |
| $v_0$ | 初期速度場。形状がどのように変形し始めるかを決定する。 |
| $\sigma^2$ | 画像のノイズ分散。距離測定の重み付けに使用される。 |
| $A_q$ | 特定の年齢/時間 $q$ に対して構築された解剖学的アトラス。 |
| $\Theta$ | 時間的アトラスの構築を担当するニューラルネットワークの学習可能なパラメータ。 |
| $\Psi$ | 年齢間(縦断的)レジストレーションを担当するニューラルネットワークの学習可能なパラメータ。 |
| $\mathbf{z}_q^i$ | 年齢 $q$ における画像の潜在埋め込み(圧縮された数学的表現)。 |
| $\gamma$ | モデルが潜在埋め込み規則をどれだけ強く強制するかを制御するチューニングパラメータ。 |
問題定義と制約
特定の子供の成長を捉えたタイムラプス動画を作成するタスクを想像してみてください。しかし、その子供一人だけの連続した動画ではなく、様々な年齢の異なる子供たちの写真が収められた巨大なフォトアルバムが手元にあります。平均的な5歳児や10歳児がどのような見た目になるかは容易に理解できます。しかし、特定の5歳児が10歳になったときの正確な姿を予測することは、その子供の解剖学的な履歴が欠如しているため、信じられないほど困難です。
これは、医学研究者が人間の臓器や骨が時間とともにどのように発達するかをモデル化しようとする際に直面するまさにそのシナリオです。
開始点と目標状態
入力(現在の状態): 医学分野は、3Dの断層撮影画像データが豊富です。これらは、複数の異なる個人から取得された単一時点のスナップショット(CTスキャンやMRIスキャンなど)です。豊富に存在する一方で、これらのデータセットは時間のスナップショットを表すだけであり、原因と結果の関係にある生物学的な変化に関する情報は一切提供しません。
出力(目標状態): 臨床医は、4Dの縦断的データを切実に必要としています。これは、同じ患者の、時間とともに変化する構造的な変化を、患者固有に把握することを意味します。医師が8歳児の股関節の3Dスキャンを入力した場合、目標は、その患者の股関節が10歳または15歳になったときの、生物学的に正確で高度に個別化された3Dスキャンを出力することです。
数学的なギャップ: 欠けているのは、ペアになった縦断的トレーニングデータに依存することなく、特定の解剖学的構造を時間的に前進させることができる、連続的で可逆な変換フィールドです。集団レベルの平均(「アトラス」)と患者固有の時間的軌跡を結びつける数学的な架け橋が必要です。
苦痛なジレンマ
現実的な縦断的データを生成するために、ディープラーニングモデル(シーケンスを認識する拡散モデルなど)は、通常、トレーニングのために大量のグラウンドトゥルースの縦断的データを必要とします。ここに落とし穴があります。
縦断的データなしでは良好な縦断的モデルをトレーニングすることはできませんが、縦断的データは非常に高価(患者スキャンあたり1000ドル以上かかることも多い)であり、時間がかかり、収集が非常に困難です。研究者がこれを回避するために、豊富な断層撮影データのみでモデルをトレーニングしようとすると、生成される将来の画像は患者固有の忠実性を失います。モデルは、元の患者のユニークな骨格形状を維持するのではなく、一般的な「平均」人物を予測することになります。以前の研究者は、データの利用可能性と時間的精度の間のこの苦痛なトレードオフに囚われてきました。
過酷な壁と制約
これを解決するために、著者らはいくつかの厳しい制約に直面しました。
- 極端なデータの疎性: 真の縦断的データを収集するには何年もかかります。患者は研究から脱落し、画像ハードウェアは変更され、数年離れたスキャンのアライメントは大規模なばらつきをもたらします。
- 生物学的変形の物理学: 骨や組織の成長は単純なピクセルシフトではありません。複雑で非線形な生物学的変化を伴います。これをモデル化するために、著者らはLarge Deformation Diffeomorphic Metric Mapping (LDDMM) を使用する必要がありました。これにより、変換が滑らかで可逆的(微分同相)であることが保証されます。つまり、組織が魔法のように引き裂かれたり、交差したり、折りたたまれたりすることはありません。しかし、これを計算するには、Euler-Poincaré微分(EPDiff)方程式を使用して速度場を時間的に前進させる必要があります。
$$ \frac{\partial v_t}{\partial t} = -K \left[ (D v_t)^T \cdot m_t + D m_t \cdot v_t + m_t \cdot \text{div} \, v_t \right] $$
最適な速度場 ($v_t$) と運動量ベクトル ($m_t$) を見つけるためにこれを解くことは、膨大な計算負荷です。 - ぼやけたアーティファクトの壁: VoxelMorphやB-splineのような以前の最先端モデルが、大きな年齢差にわたる解剖学的構造の変形を試みた際、深刻な歪みとぼやけた境界線が生じました。モデルが構造が数年かけてどのように拡大するかを推測することを余儀なくされた場合、発達中の股関節の三放射軟骨のような細かい解剖学的詳細を維持することは非常に困難です。
彼らが解決した方法:統一された数学的フレームワーク
著者らは、ジレンマを打破するためには、ジェネレーターを構築するだけでなく、同時にマップを構築する必要があることに気づきました。彼らは、2つのタスクを同時に実行する新しいディープラーニングフレームワークを設計しました。時間的アトラス構築(指定された年齢での集団平均を見つけること)と年齢間画像レジストレーション(成長をモデル化するために平均を特定のターゲットにアライメントすること)です。
まず、アトラスと断層撮影画像 ($I_i^q$) との距離を、速度場 ($v_i^q$) によって正則化しながら最小化することにより、年齢別アトラスのシーケンス ($A_q$) を構築するための損失関数を定義します。
$$ \mathcal{L}_{\text{tempo-atlas}}(\Theta) = \sum_{q=1}^{Q} \sum_{i=1}^{N_q} \text{Dist}\left[ \phi_{q \to i}^{-1}(\Theta) \circ A_q, I_i^q \right] + \text{Reg}(v_i^q) $$
次に、ソースアトラスをターゲット年齢 ($q'$) にアライメントすることにより、縦断的変化をモデル化します。
$$ \mathcal{L}_{\text{longitudinal}}(\Psi) = \sum_{m=1}^{M} \text{Dist}\left[ \phi_{q \to q'}^{-1}(\Psi) \circ A_q, I_{q'}^m \right] + \text{Reg}(v_{m}^{q'}) $$
画期的な点: この論文の真の天才は、特徴的な潜在埋め込みを使用してこれらの2つの空間をどのように結びつけているかです。彼らは、解剖学的に類似した構造が密接にクラスター化する潜在空間 $\mathbf{Z}$ を学習するようにニューラルネットワークに強制し、これらの埋め込み間の距離がそれらの間の変形に必要な物理的変形(速度場)と厳密に相関するようにします。
彼らは、特殊な損失関数でこれを強制します。
$$ \mathcal{L}_{\text{latent}}(\mathbf{Z}) = \mathbb{E} \left[ -\log(\sigma(\text{sim}(\mathbf{z}_q^i, \mathbf{z}_{q'}^m))) \right] + \lambda \mathbb{E} \left[ \text{Corr}\left( \|\mathbf{z}_q^i - \mathbf{z}_{q'}^m\|^2, \|v_q^i - v_{q'}^m\|^2 \right) \right] $$
最初の項は、コサイン類似度を使用して関連する形状をグループ化します。2番目の項は、この論文のマスターストロークです。これは、潜在埋め込み間のユークリッド距離 ($\|\mathbf{z}_q^i - \mathbf{z}_{q'}^m\|^2$) と変形の物理的エネルギー ($\|v_q^i - v_{q'}^m\|^2$) の相関を計算します。
抽象的な潜在空間を微分同相変形の物理法則に数学的にロックすることにより、モデルは単一の断層撮影スキャンを見て、それを時間的アトラスにマッピングし、その特定の形状が時間とともにどのように進化するかを正確に予測できます。これにより、大規模な縦断的トレーニングデータセットの必要性が完全に回避されます。
このアプローチの理由
この著者らがこの極めて特異的で数学的に密度の高いアプローチを選択した理由を理解するためには、まず従来の最先端(SOTA)手法が壁に突き当たった正確な瞬間を振り返る必要がある。
近年、深層学習コミュニティは生成モデルに熱中している。子供の股関節が時間とともに成長する様子を示す一連の画像を生成したい場合、最初に思いつくのは拡散モデル(Diffusion model)やTransformerであろう。実際、著者らは先行研究者がまさにこれを試みたことを明確に指摘している。Yoonらは系列を認識する拡散モデルを、Puglisiらは潜在拡散モデル(latent diffusion models)を用いて経時的な構造変化をシミュレートした。
しかし、著者らがこれらの一般的なアプローチを断念せざるを得なかった致命的な欠陥がここにある。標準的な生成モデルは信じられないほどデータ飢餓である。それらは大規模でペアになった縦断的データセットを必要とする。これは、同じ患者の数千もの3Dスキャンを年ごとに取得する必要があることを意味する。現実の臨床環境では、この種のデータは法外に高価で、時間がかかり、実質的に存在しない。利用可能な医療データの大部分は横断的データ(cross-sectional data)(単一の孤立した時点における異なる人々のスナップショット)である。拡散モデルやGANは、学習中に実際の時間系列を見ることなしに、被験者固有の時間的ダイナミクスを学習することはできない。それらは、断片化されたスナップショットから生物学的に正確な成長軌跡を幻視できないため、ここで失敗するだろう。
この厳しい制約に直面し、著者らは学習プロセスに物理学と幾何学の厳密な法則を埋め込むことが唯一実行可能な解決策であると認識した。彼らはLarge Deformation Diffeomorphic Metric Mapping(LDDMM)に目を向けた。
なぜこれが数学的に優れているのか?微分同相写像(diffeomorphic transformation)は、2つの解剖学的形状間のマッピングが滑らかで、連続的で、厳密に可逆であることを保証する。生物学において、組織は伸び、成長するが、ランダムに引き裂かれたり、自分自身に折りたたまれたり、瞬間移動したりすることはない。著者らは、この問題をEuler-Poincaré微分(EPDiff)方程式を通して定式化することにより、解剖学的成長の測地線経路が初期速度場 $v_0$ を時間方向に積分することによって一意に決定されることを保証する。
$$ \frac{\partial v_t}{\partial t} = -K \left[ (D v_t)^T \cdot m_t + D m_t \cdot v_t + m_t \cdot \text{div} \, v_t \right] $$
これは、問題の厳しい制約(縦断的データの不足)と解のユニークな特性との間に完璧な「結婚」を生み出す。骨がどのように成長するかを盲目的に推測しようとする代わりに、モデルは2つのタスクを共同で実行する。それは「アトラス」(特定の年齢、例えば8歳における集団の平均形状)を構築し、次に8歳のアトラスを10歳のアトラスに歪める微分同相速度場を学習する。そして、これらの学習された生物学的に妥当な速度場を特定の患者のベースラインスキャンに適用して、将来の解剖学的構造の非常に信頼性の高い予測を生成する。
以前のゴールドスタンダード、例えばVoxelMorph(VM)やB-splineレジストレーションと比較した場合のこの手法の構造的利点は、甚大である。従来のレジストレーション手法は、画像Aと画像Bのピクセルごとの差を最小化しようとするだけである。論文のベンチマーキングで示されているように、これはしばしばぼやけた境界線と重度のアーティファクト(VoxelMorphベースラインで見られる腸骨稜の周りの歪みのような)をもたらす。
これを克服するために、著者らは見事な「Distinctive Latent Embedding」損失を導入した。彼らは画像を整列させるだけでなく、ニューラルネットワークの潜在空間に物理的変形空間を完全に反映させることを強制する。損失関数には、潜在埋め込み $\mathbf{z}$ の距離と速度場 $v$ の物理的距離との相関を測定する項が含まれる。
$$ \mathcal{L}_{\text{latent}}(\mathbf{Z}) = \dots + \lambda \mathbb{E}_{(\mathbf{z}_q^i, \mathbf{z}_{q'}^m)} \left[ \text{Corr} \left( \|\mathbf{z}_q^i - \mathbf{z}_{q'}^m\|^2, \|v_q^i - v_{q'}^m\|^2 \right) \right] $$
これは数学的に、潜在空間が速度場によって決定される幾何学的および時間的関係を保持することを強制する。それは時間を通じた段階的な形状変化を分離し、モデルが三放射軟骨のような複雑な成長中心の周りに、鋭くアーティファクトのない境界線を生成することを可能にする。
率直に言って、この特定のアーキテクチャが計算メモリ複雑性を $O(N^2)$ から $O(N)$ に削減するかどうかは完全には確信が持てない。なぜなら、著者らはテキスト内でBig-Oアルゴリズムの分解を明示的に提供していないからである。しかし、圧倒的に明確なのはそのデータ効率性である。微分同相写像の幾何学的潜在空間を活用することにより、このフレームワークはSOTA拡散モデルが達成できないことを達成する。それは、疎な横断的3D入力のみを使用して、極めて正確で被験者固有の4D縦断的データを合成する。
数学的・論理的メカニズム
この論文の重要性を理解するためには、まず医療画像における根本的なデータ問題を理解する必要がある。子供の成長を写真アルバムを見て理解しようとしていると想像してほしい。もし「縦断的」なアルバム――同じ子供の写真を毎年撮影したもの――があれば、その成長の正確な軌跡を容易に追うことができる。しかし、医療分野では、同じ患者の縦断的な3Dスキャン(CTやMRIなど)を長年にわたって取得することは、信じられないほど高価で、時間がかかり、稀である。その代わりに、病院には「横断的」なデータの山がある。これは、異なる年齢の異なる人々を単一のスナップショットで捉えたものである。
この論文の著者たちは、これらの断片的な異なる人々のスナップショットを取り込み、根底にある「成長の法則」を学習する、見事な数学的エンジンを構築した。そして、この法則を用いて、全く新しい患者に対して、その解剖学的構造が時間とともにどのように変化するかを正確に予測する、非常に精度の高い、パーソナライズされた3Dタイムラプス(縦断的データ)を生成する。
これが可能にする正確な数学的機構を以下に示す。
マスター方程式
この論文の中核となるエンジンは、3つの大規模なタスクを同時にバランスさせる、統一された目的関数によって駆動される。「平均」テンプレート(アトラス)の構築、年齢を超えた成長の予測、そしてモデルにこれらの変化の物理的現実を理解させることである。
ネットワーク全体を駆動する総損失関数は以下の通りである。
$$ \ell = \mathcal{L}_{\text{tempo-atlas}}(\Theta) + \mathcal{L}_{\text{longitudinal}}(\Psi) + \gamma \mathcal{L}_{\text{latent}}(\mathbf{Z}) $$
しかし、真の秘訣――この論文で最も革新的な部分――は、操作の脳として機能するDistinctive Latent Embedding lossである。
$$ \mathcal{L}_{\text{latent}}(\mathbf{Z}) = \mathbb{E}_{(\mathbf{z}_q^i, \mathbf{z}_{q'}^m)} \big[ -\log(\sigma(\text{sim}(\mathbf{z}_q^i, \mathbf{z}_{q'}^m))) \big] + \lambda \, \mathbb{E}_{(\mathbf{z}_q^i, \mathbf{z}_{q'}^m)} \big[ \text{Corr} \big( \|\mathbf{z}_q^i - \mathbf{z}_{q'}^m\|^2, \; \|v_q^i - v_{q'}^m\|^2 \big) \big] $$
方程式の分解
この機構のすべての歯車とバネを分解してみよう。
総損失 ($\ell$) から:
* $\ell$: 総損失。これは、機械がゼロに最小化しようとする究極の「誤差スコア」である。
* $\mathcal{L}_{\text{tempo-atlas}}(\Theta)$: Temporal Atlas Building loss。この項は、ネットワーク(パラメータ $\Theta$ を持つ)が特定の年齢の「平均」解剖学的テンプレートをどれだけうまく作成できるかを測定する。これはベースラインのアンカーとして機能する。
* $\mathcal{L}_{\text{longitudinal}}(\Psi)$: Cross-age Registration loss。これは、ネットワーク(パラメータ $\Psi$ を持つ)が、ある年齢の画像を、より年長の年齢の解剖学的構造に一致するようにどれだけうまくワープできるかを測定する。「タイムマシン」コンポーネントである。
* $\gamma$: スカラー重み(バランス調整ノブ)。これは、モデルが潜在埋め込みにどれだけ注意を払うべきかを、画像生成に対して指示する。
* なぜ乗算ではなく加算なのか? 著者たちは加算を使用してマルチタスクのバランススケールを作成している。これらの項を乗算した場合、アトラス損失のほぼゼロのスコアは、縦断的損失の勾配(学習信号)を完全に消去し、学習プロセスを完全に停止させるだろう。加算は、たとえ1つのタスクが完璧に実行されていても、モデルが他のタスクを改善する圧力を感じ続けることを保証する。
潜在埋め込み損失 ($\mathcal{L}_{\text{latent}}(\mathbf{Z})$) から:
* $\mathbf{Z}$: すべての潜在埋め込みの行列。埋め込みとは、3D医療画像の非常に圧縮された抽象的な数学的要約である。
* $\mathbb{E}_{(\mathbf{z}_q^i, \mathbf{z}_{q'}^m)}$: これらの圧縮された埋め込みのペアに対する期待値(平均)。$\mathbf{z}_q^i$ は年齢 $q$ における患者 $i$ の埋め込みであり、$\mathbf{z}_{q'}^m$ は年齢 $q'$ における患者 $m$ の埋め込みである。
* 厳密な総和 ($\sum$) の代わりに期待値を使用する理由とは? 深層学習では、巨大なデータセット全体にわたるすべての可能な画像のペアの正確な合計を計算することは、計算量が爆発的に増加する。期待値を使用することで、モデルはトレーニング中にランダムなペアを確率的にサンプリングし、真の平均を近似しながら、膨大なメモリを節約できる。
* $-\log(\sigma(\dots))$: シグモイド関数の負の対数。これは古典的なペナルティ機構である。シグモイド ($\sigma$) は値を0と1の間(確率のようなもの)に圧縮する。負の対数は、この値が0に近づいた場合にモデルに重くペナルティを与える。
* $\text{sim}(\mathbf{z}_q^i, \mathbf{z}_{q'}^m)$: 2つの埋め込み間のコサイン類似度。これは2つのベクトルの間の角度を測定する。
* 論理的役割: この最初の項全体は、重力のような引きとして機能する。2つの解剖学的形状が関連している場合、それらの抽象的な数学的ベクトルを潜在空間内で正確に同じ方向を指すように強制する。
* $\lambda$: 物理的制約の強さを特に制御する、もう1つのバランス調整ノブ。
* $\text{Corr}(\dots)$: ピアソン相関係数。これは2つの変数がどれだけ線形に関連しているかを測定する。
* $\|\mathbf{z}_q^i - \mathbf{z}_{q'}^m\|^2$: 2つの抽象的な埋め込み間のユークリッド距離の二乗。これは、8歳の股関節と10歳の股関節の間の「概念的な距離」として考えることができる。
* $\|v_q^i - v_{q'}^m\|^2$: 対応する速度場 ($v$) の二乗距離。速度場とは、ピクセルがどのように物理的に流れ、伸びて形状を変化させるかを正確に指示する3D矢印マップである。
* 論理的役割: この相関項は純粋に天才的である。これは厳格な物理検査官として機能する。埋め込みの抽象的な「概念的な距離」が、組織を変形させるために必要な実際の「物理的な伸張エネルギー」と完全に相関するように強制する。これにより、ニューラルネットワークが潜在空間に画像を任意に配置することによって不正を行うのを防ぐ。
ステップバイステップの流れ
8歳の患者の股関節の3D CTスキャンという、単一の抽象的なデータポイントが、この数学的な組み立てラインをどのように移動するかを追ってみよう。
- 圧縮: 8歳の股関節の生の3Dピクセルがネットワークに入力され、すぐに密な抽象ベクトル $\mathbf{z}_q^i$ に圧縮される。
- 固定: システムは、このベクトルを、構築された「平均的な8歳児の股関節」テンプレートと比較する。特定の患者が基準からどれだけ逸脱しているかを計算する。
- 時間旅行: ユーザーは、この股関節が12歳でどのように見えるかの予測を要求する。「平均的な12歳児」テンプレートを参照する。8歳の骨が12歳の状態に到達するために、どのように伸び、成長し、曲がるべきかを指示する流体のような矢印マップである速度場 $v$ を生成する。
- 品質管理: $\mathcal{L}_{\text{latent}}$ 損失が起動する。8歳ベクトルと12歳ベクトルの間の抽象的な距離をチェックする。この抽象的な距離が、速度場 $v$ の物理的なエネルギーと一致することを厳密に検証する。数学が物理学と一致しない場合、モデルはペナルティを受ける。
- 生成: 最後に、速度場が元の3Dスキャンに適用され、ピクセルがデジタル粘土のように滑らかに変形され、生物学的に正確な合成12歳児の股関節スキャンが出力される。
最適化ダイナミクス
この複雑なアーキテクチャは、実際にどのように学習し、収束するのだろうか?
モデルは勾配降下法(特にAdamオプティマイザ)を使用してパラメータを最適化する。当初、損失ランドスケープは非常に混沌としている。ネットワークはショートカットを取ろうとし、例えば、画像距離損失を迅速に減らすために、8歳の画像をぼかして12歳のように見えるようにするかもしれない。
しかし、モデルは微分同相数学(論文の背景で言及されているEuler-Poincaré微分方程式)によって制約される。これは、変換がゴムシートを破ることなく折りたたむような、滑らかで連続的で可逆的でなければならないことを意味する。
この厳格な物理的制約のため、損失ランドスケープは急で滑らかな漏斗のような形状になる。勾配がネットワークを逆方向に流れるにつれて、埋め込み $\mathbf{Z}$ は美しく整理されるように強制される。類似した年齢のスキャンは密接にクラスター化し、異なる年齢のスキャンは、それらの間の遷移に必要な物理的成長に正確な比例で配置される。1000エポックを超えると、システムは平衡状態に達する。生成されたアトラスは非常にシャープになり、予測された成長軌跡は解剖学的に完璧になり、モデルは患者の解剖学の未来を信じられないほどの精度で幻覚させることができるようになる。
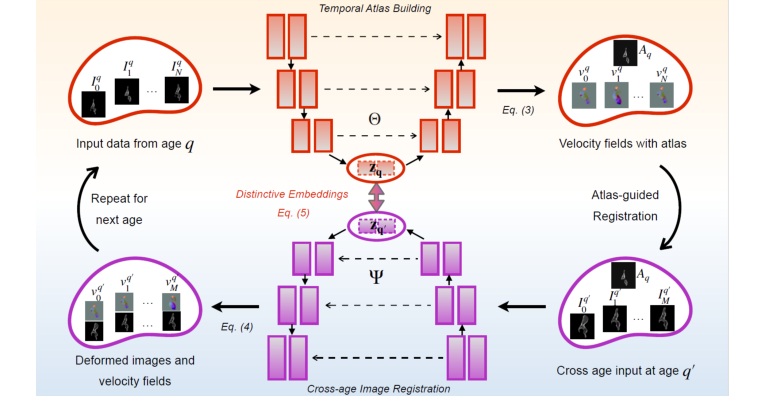 Figure 1. Overview of our model. Training: Our network constructs a sequence of tempo- ral atlases, starting at age q and modeling deformations across target ages. A geometric embedding loss in the latent space enforces structured, biologically meaningful anatom- ical evolution. Iterative refinement enhances the interplay between cross-sectional and longitudinal dynamics, generating anatomically coherent cross-age data. Inference: For each subject, we first align their baseline images to the corresponding age-specific atlas. The trained model Ψ operates as a longitudinal data generator, synthesizing anatomically plausible trajectories for unseen subjects by extracting geometric fea- tures through the atlas. It uses generated velocity fields from cross-age registration between age-specific atlases to deform subject-specific structures over time, ensuring a smooth and temporally consistent evolution
Figure 1. Overview of our model. Training: Our network constructs a sequence of tempo- ral atlases, starting at age q and modeling deformations across target ages. A geometric embedding loss in the latent space enforces structured, biologically meaningful anatom- ical evolution. Iterative refinement enhances the interplay between cross-sectional and longitudinal dynamics, generating anatomically coherent cross-age data. Inference: For each subject, we first align their baseline images to the corresponding age-specific atlas. The trained model Ψ operates as a longitudinal data generator, synthesizing anatomically plausible trajectories for unseen subjects by extracting geometric fea- tures through the atlas. It uses generated velocity fields from cross-age registration between age-specific atlases to deform subject-specific structures over time, ensuring a smooth and temporally consistent evolution
結果、限界、および結論
コア問題:スナップショットの罠からの脱却
本稿の重要性を理解するためには、まず2種類の医療データの根本的な違いを理解する必要がある:横断的データと縦断的データである。
人間の顔の老化を理解したいと想像してみよう。5歳から50歳までの異なる年齢の100人の人物の写真をそれぞれ撮影した場合、それは横断的データである。老化の一般的な傾向を推測することはできるが、5歳の子供が50歳になったときにどのように見えるかを正確に知ることはできない。次に、5歳から50歳まで、全く同じ人物の写真を毎年撮影することを想像してみよう。それが縦断的データである。これは、変化の真の、対象固有の時空間的ダイナミクスを捉える。
医用画像処理において、縦断的な3Dデータ(時間とともに4Dデータとなる)は、解剖学的構造の発達や疾患の進行を追跡するための聖杯である。しかし、このデータの収集はロジスティックな悪夢である。スキャン費用や10年間にわたる管理費を含め、患者一人あたり1万ドル以上かかることも珍しくなく、患者の脱落も非常に多い。その結果、医療データベースの大部分は横断的データである。
本稿の著者らは、次のような巨大な制約に直面した:訓練データが主に異なる人々の断片的なスナップショットで構成されている場合、特定の患者の将来の3D解剖学的形状をどのように正確に予測できるか?
数学的エンジン:微分同相写像と潜在的時間旅行
これを解決するために、著者らは単に標準的なニューラルネットワークを訓練して次のフレームを推測するのではなく、2つのタスクを共同で実行するフレームワークを構築した:アトラス構築(特定の年齢における集団の「平均」形状を見つけること)と縦断的データ生成(特定の対象の形状が年齢とともにどのように進化するかを予測すること)である。
彼らは、Large Deformation Diffeomorphic Metric Mapping (LDDMM) の数学に基づいた解決策を確立した。簡単に言えば、微分同相写像とは、滑らかで連続的かつ可逆な変換である。5歳児の股関節の粘土彫刻を、粘土を決して破ったり折りたたんだりすることなく、10歳児の股関節の粘土彫刻にモーフィングすることを想像してほしい。
$N$個の画像セットからアトラス(テンプレート画像 $I$)を構築するためのベースラインエネルギー関数は、次のように定義される:
$$E(I, v_0^n) = \sum_{n=1}^N \frac{1}{\sigma^2} \text{Dist}[I \circ \phi_1^{-1}(v_0^n), I_n] + \text{Reg}(v_0^n)$$
ここで、$v_0^n$は初期速度場を表す。これは、テンプレートをターゲット画像 $I_n$ へモーフィングを開始するために必要な「プッシュ」である。変換パスは、この速度が時間とともにどのように流れるかを指示するオイラー・ポアンカレ微分(EPDiff)方程式によって支配される:
$$\frac{\partial v_t}{\partial t} = -K \left[ (D v_t)^T \cdot m_t + D m_t \cdot v_t + m_t \cdot \text{div} \, v_t \right]$$
正直に言うと、本稿ではディープラーニングの訓練中にこの積分を解くために必要な正確な計算メモリフットプリントを明示的に詳述していないが、データの3D性質を考慮すると、ヘビーなGPU処理が必要であると推測できる(彼らはRTX A6000を使用してこれを処理した)。
彼らのアーキテクチャの真の巧妙さは、特徴的な潜在埋め込みにある。彼らは、2つの埋め込み間の数学的距離が、それらの間のモーフィングに必要な物理的変形と完全に相関するように、ニューラルネットワークに潜在空間 $\mathbf{Z}$ を学習させることを強制する。彼らの潜在損失関数は次の通りである:
$$\mathcal{L}_{\text{latent}}(\mathbf{Z}) = \mathbb{E}_{(\mathbf{z}_q^i, \mathbf{z}_{q'}^m)} \left[ -\log(\sigma(\text{sim}(\mathbf{z}_q^i, \mathbf{z}_{q'}^m))) \right] + \lambda \, \mathbb{E}_{(\mathbf{z}_q^i, \mathbf{z}_{q'}^m)} \left[ \text{Corr} \left( \|\mathbf{z}_q^i - \mathbf{z}_{q'}^m\|^2, \, \|v_q^i - v_{q'}^m\|^2 \right) \right]$$
最初の項は、コサイン類似度を使用して関連する形状をクラスター化するように強制する。2番目の項は、この研究の核心である:2つの潜在ベクトル間のユークリッド距離の二乗 $\|\mathbf{z}_q^i - \mathbf{z}_{q'}^m\|^2$ が、一方の形状を他方の形状に変形するために必要な物理的な「労力」(速度場距離 $\|v_q^i - v_{q'}^m\|^2$)と相関することを保証する。
最終的な目的関数は、時間的アトラス構築、年齢間レジストレーション、そしてこの潜在埋め込みをエレガントにバランスさせる:
$$\ell = \mathcal{L}_{\text{tempo-atlas}}(\Theta) + \mathcal{L}_{\text{longitudinal}}(\Psi) + \gamma \mathcal{L}_{\text{latent}}(\mathbf{Z})$$
実験:現実に対する徹底的な検証
著者らは単に指標を壁に投げつけたのではなく、非常に厳密な実験を設計した。彼らは、正常な男性の股関節(4〜18歳)の横断的データセットでモデルを訓練した。しかし、モデルが実際に機能したことを証明するために、彼らは真の縦断的CTスキャン(数年離れた複数のスキャンを受けた12人の患者)からなる隠された、非常に価値のあるデータセットでテストした。
犠牲者(ベースライン):
アトラス構築については、B-spline、Multi-contrast registration (M-c. reg.)、VoxelMorph (VM) のような確立されたモデルを完全に解体した。縦断的生成については、NAHA (Nearest-Age Hip Approximation) と ABAA (Age-Based Atlas Approximation) を打ち負かした。
決定的な証拠:
証明はダイススコア(彼らは支配的な0.88を達成したが)だけではなかった。否定できない証拠は視覚的かつ幾何学的であった。彼らは12歳患者の股関節の実際のCTスキャンを取得し、それをモデルに入力し、全く同じ患者の15歳バージョンを幻視するように求めた。
彼らの合成された15歳股関節を、その患者の実際の15歳スキャンに重ね合わせたとき、境界線は美しく一致した。ベースラインはここでひどく失敗した。VoxelMorphは後腸骨稜の周りに深刻なアーティファクト歪みを生成し、他の手法はぼやけた、解剖学的に不可能な骨縁を生成した。著者らのモデルは、三叉軟骨周辺のシャープで微細な解剖学的詳細を保持しており、彼らの潜在空間がピクセルを盲目的に補間するだけでなく、骨成長の生物学的規則をうまく学習したことを証明した。
将来の軌跡と議論のトピック
このフレームワークの深遠な意味合いに基づき、将来の探求のためのいくつかの重要な方向性を以下に示す:
-
生体力学的物理学の事前知識の統合:
現在、モデルは幾何学的変換(微分同相写像)からのみ成長の規則を学習している。しかし、骨の発達は物理的な力(ウォルフの法則—骨はそれに加えられた負荷に適応する)によって大きく影響される。EPDiff方程式に生体力学的応力テンソルを注入するにはどうすればよいか?子供が異常な歩行をしている場合、その特定の機械的ストレスが将来の骨形状をどのように変化させるかを予測するために、潜在空間を条件付けることができるか? -
分岐する病理学的潜在空間:
本稿では、ベースラインを確立するために正常な男性の股関節に焦点を当てた。しかし、疾患が線形的に進行することは稀である。病理学的データ(例:股関節形成不全)を導入した場合、単一の横断的スキャンが複数の可能な未来を予測できるように、潜在空間をどのように構造化するか?この決定論的モデルを確率論的なものに進化させる方法について議論する必要がある。おそらく、潜在空間で拡散モデルを使用して、将来の疾患進行のための「不確実性の円錐」を生成する。 -
クロスモダリティ時間アライメント:
著者らは、骨のコントラストに優れているが小児患者に電離放射線を被曝させるCTスキャンを使用した。小児画像処理の未来はMRIまたは超音波である。しかし、これらのモダリティはノイズプロファイルとアーティファクトの挙動が大きく異なる。CTデータから学習された幾何学的潜在埋め込みがMRIデータに転送できるかどうかは、興味深い議論点である。成長の「速度場」は、画像モダリティ自体のピクセル強度から分離できるか?
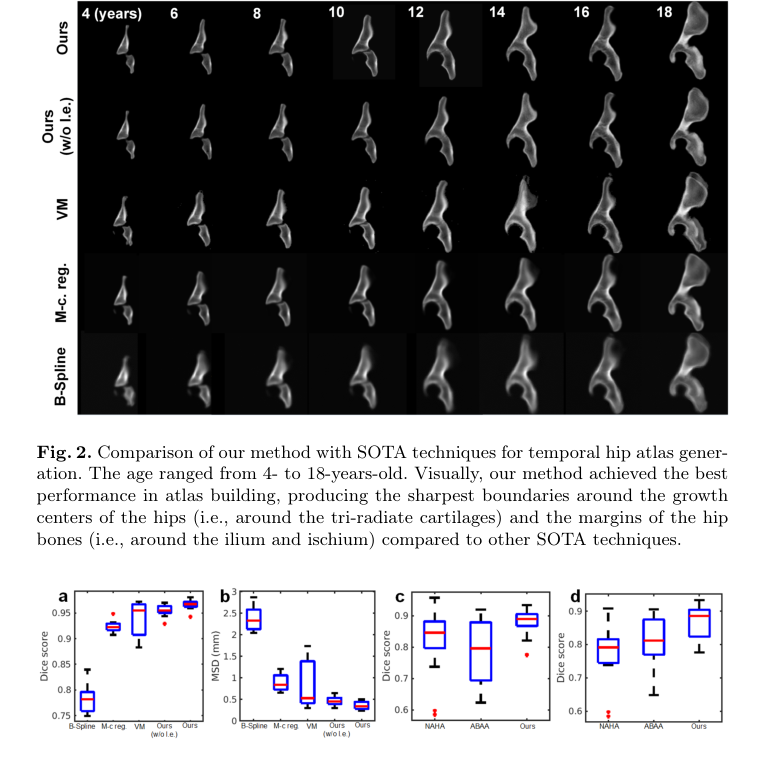 Figure 3. Boxplots of the atlas-to-patient (within-age) registration results based on the mean Dice score (a) and the MSD (b). Boxplots of the longitudinal data generation results for all testing cases (c) and for the cases when the age gap is >1 year (d) based on mean Dice score. The ages of the subjects in these experiments ranged from 4 to 18 years. Our method achieved superior performance compared to others
Figure 3. Boxplots of the atlas-to-patient (within-age) registration results based on the mean Dice score (a) and the MSD (b). Boxplots of the longitudinal data generation results for all testing cases (c) and for the cases when the age gap is >1 year (d) based on mean Dice score. The ages of the subjects in these experiments ranged from 4 to 18 years. Our method achieved superior performance compared to others
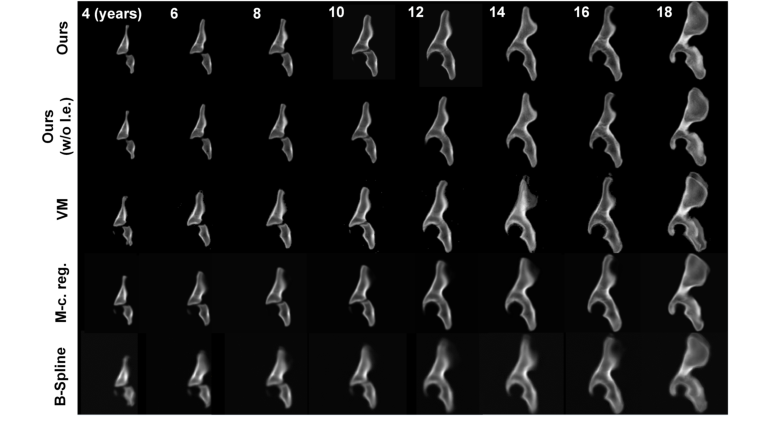 Figure 2. Comparison of our method with SOTA techniques for temporal hip atlas gener- ation. The age ranged from 4- to 18-years-old. Visually, our method achieved the best performance in atlas building, producing the sharpest boundaries around the growth centers of the hips (i.e., around the tri-radiate cartilages) and the margins of the hip bones (i.e., around the ilium and ischium) compared to other SOTA techniques
Figure 2. Comparison of our method with SOTA techniques for temporal hip atlas gener- ation. The age ranged from 4- to 18-years-old. Visually, our method achieved the best performance in atlas building, producing the sharpest boundaries around the growth centers of the hips (i.e., around the tri-radiate cartilages) and the margins of the hip bones (i.e., around the ilium and ischium) compared to other SOTA techniques
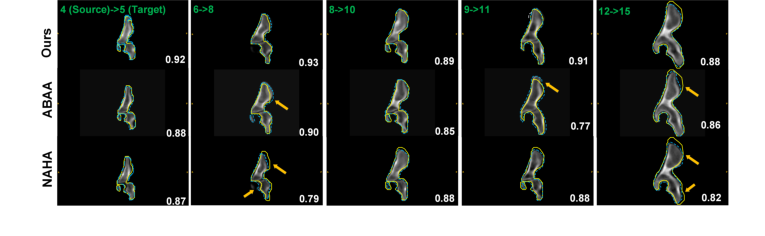 Figure 4. Comparison of various methods for the longitudinal data generation task based on a real longitudinal dataset. For example, in the first column, given an input hip dataset from a 4-year-old subject (source), the longitudinal data generator predicted the 3D synthetic longitudinal CT hip shape of the same subject at the age of 5. The source and target ages are denoted in green text in the left upper corner of each frame. The segmentation contour (blue dashed line) produced by our method aligns better with the ground truth contour (yellow line) than other techniques, as indicated by the higher Dice scores (white text). Arrows highlight regions with large alignment errors
Figure 4. Comparison of various methods for the longitudinal data generation task based on a real longitudinal dataset. For example, in the first column, given an input hip dataset from a 4-year-old subject (source), the longitudinal data generator predicted the 3D synthetic longitudinal CT hip shape of the same subject at the age of 5. The source and target ages are denoted in green text in the left upper corner of each frame. The segmentation contour (blue dashed line) produced by our method aligns better with the ground truth contour (yellow line) than other techniques, as indicated by the higher Dice scores (white text). Arrows highlight regions with large alignment errors
他の体との同型
離散的で静的な空間分布間に、幾何学的に制約された潜在空間内でのグループ内アライメントとグループ間時間変換を共同で最適化することにより、連続的で可逆的な進化軌道を構築するメカニズム。
天体物理学と銀河進化
天文学者は、光速と宇宙の広大さのために、特定の時点での銀河の静的なスナップショット(断面データ)しか取得できないという、膨大な観測上のハードルに直面している。単一の銀河が数十億年かけて進化する様子(縦断データ)を観察することはできない。本論文の核心的な論理、すなわち「年齢内」アトラスを構築して「年齢間」微分同相変換を導くことは、銀河の形態問題の完璧な鏡像である。著者らが、まばらな患者のスナップショットから発達中の股関節の構造的変化をマッピングするのと同様に、天体物理学者は、様々な赤方偏移における異なる銀河のまばらなスナップショットを使用して、銀河の構造的進化(例えば、渦巻銀河から楕円銀河へ)をマッピングする必要がある。
定量的金融と市場マイクロストラクチャ
金融工学において、アナリストはしばしば、単一時点における異なる資産間の膨大な断面データを保有しているが、マクロ経済体制の変化を通じて単一資産の連続的で対象固有の軌跡を予測することに苦労する。本論文の、時間経過に伴う幾何学的整合性を強制するために速度場を使用するという概念は、ボラティリティサーフェスやイールドカーブの変形をモデル化するという課題を反映している。例えば、特定の資産の価格が100ドルから150ドルに移行するにつれて、そのリスクプロファイルがどのように変形するかをマッピングするには、「集団レベルの市場トレンド」(時間的アトラス)と「資産固有の価格軌跡」(縦断的生成)の正確な数学的分離が必要となる。
「もしも」シナリオ
もし理論的な天体物理学者が、明日この論文の正確な総損失方程式を盗んだらどうなるだろうか?
$$ \ell = \mathcal{L}_{\text{tempo-atlas}}(\Theta) + \mathcal{L}_{\text{longitudinal}}(\Psi) + \gamma \mathcal{L}_{\text{latent}}(\mathbf{Z}) $$
このフレームワークにジェイムズ・ウェッブ宇宙望遠鏡の数百万枚の静的な画像を投入することで、異なる赤方偏移のエポックを「年齢」とし、個々の銀河の形状を「断面入力」として扱うことができるだろう。$\mathcal{L}_{\text{latent}}(\mathbf{Z})$ 項は、潜在空間に銀河構造の幾何学的関係を保持することを強制するだろう。このブレークスルーは前例のないものとなるだろう。このアルゴリズムは、単一の銀河が100億年かけて進化する、数学的に厳密な4次元の縦断的な映画を合成し、データの到着を10億年待つ必要なしに、銀河形成の「失われた環」問題を実質的に解決するだろう。
孤立した静的なスナップショットが、流動的で高度にパーソナライズされた履歴へと数学的に織り込むことができることを証明することにより、本論文は構造の普遍的ライブラリに不可欠な設計図を追加し、人間の骨の生物学的成長と遠方の銀河の宇宙的経年変化が、究極的には全く同じ幾何学的振り付けによって支配されていることを示している。