기하학적 잠재 임베딩을 통한 시계열 데이터의 템포럴 아틀라스 안내 생성
This paper introduces a new AI model that creates realistic "time-lapse" medical images from static scans, helping us understand how body parts grow and change.
배경 및 학문적 계보
이 연구의 근원을 이해하기 위해서는 의료 영상의 역사적 발전을 살펴볼 필요가 있다. 수십 년 전, CT나 MRI와 같은 의료 영상은 단일 순간의 환자 내부 해부학적 구조를 담은 정적인 사진으로 취급되었다. 그러나 의사와 연구자들은 인간의 해부학이 유전, 영양, 질병에 의해 주도되는 매우 역동적인 과정이라는 것을 빠르게 인지했다. 알츠하이머와 같은 질환을 정확하게 진단하거나 아동의 골격 구조의 정상적인 발달 과정을 추적하기 위해, 의료 분야는 3D 정적 이미지에서 4D 통계적 형태 분석으로 전환해야 했다. 이는 "시간"을 네 번째 차원으로 추가하는 것을 의미했다. 환자 해부학의 "사진"뿐만 아니라 "영화"를 관찰하고자 하는 임상적 필요성은 종단적(longitudinal) 영상 데이터에 대한 수요를 촉발시켰다.
그러나 저자들이 이 논문을 작성하게 된 근본적인 한계는 심각한 데이터 병목 현상이다. 진정한 종단적 데이터를 획득하려면 수개월 또는 수년에 걸쳐 동일한 환자를 반복적으로 스캔해야 한다. 이는 엄청나게 비싸고(종종 스캔당 수천 달러, 예: \$1,000 이상), 시간이 많이 소요되며, 물류적으로 어려워 이러한 데이터의 막대한 부족을 초래한다. 이전의 AI 모델들은 합성 종단적 데이터를 생성하려고 시도했지만, 치명적인 결함이 있었다. 즉, 알고리즘을 훈련하기 위해 기존 종단적 데이터의 방대한 데이터셋이 필요했다. 한편, 병원들은 산더미 같은 "횡단면적(cross-sectional)" 데이터(많은 다른 사람들의 단일 스캔)를 보유하고 있다. 이전 방법들은 이 풍부한 횡단면적 데이터를 효과적으로 사용하여 개인별, 대상별 시간 경과에 따른 변화를 예측할 수 없었다.
이러한 격차를 해소하기 위해, 저자들은 몇 가지 고도로 전문화된 개념을 소개한다. 일상적인 용어로 설명하면 다음과 같다.
- 종단적 데이터 (Longitudinal Data): 어린 싹에서 만개한 꽃으로 자라는 단일 식물의 타임랩스 비디오를 상상해 보라. 이는 동일한 대상을 시간에 따라 추적하며 성장 과정에서의 인과 관계를 보여준다.
- 횡단면적 데이터 (Cross-sectional Data): 유치원생 반, 중학생 반, 고등학생 반의 단체 사진을 찍는 것을 상상해 보라. "평균적인" 5세 또는 15세 아동의 모습을 볼 수 있지만, 특정 유치원생이 고등학생이 되었을 때 어떻게 보일지는 전혀 알 수 없다.
- 아틀라스 구축 (Atlas Building): 이를 "종합 스케치"를 만드는 것으로 생각하라. 서로 다른 10세 아동의 엉덩이 사진 수천 장을 찍어 수학적으로 혼합하면, 전형적인 10세 아동의 엉덩이를 나타내는 표준적인 평균 템플릿(아틀라스)을 얻게 된다.
- 미분동형사상 (Diffeomorphism): 의료 영상을 매우 신축성 있는 마법의 고무 시트에 인쇄하는 것을 상상해 보라. 이 고무를 늘리거나 왜곡하거나 비틀어 한 형태를 다른 형태처럼 보이게 할 수 있지만, 고무를 찢거나 접는 것은 절대 허용되지 않는다. 찢어지지 않기 때문에 항상 완벽하게 늘림을 되돌려 원래 형태로 돌아갈 수 있다.
- 잠재 임베딩 (Latent Embeddings): 전화로 친구에게 복잡한 3D 자동차를 설명하려고 한다고 상상해 보라. 모든 볼트를 하나하나 설명하는 대신, 길이, 무게, 엔진 크기와 같은 몇 가지 주요 숫자만 제공한다. 잠재적 표현은 AI가 복잡한 3D 의료 영상을 필수적인 수학적 특징의 짧은 목록으로 압축하는 방식이다.
수학적으로, 저자들은 주로 횡단면적 데이터를 사용하여 대상별 종단적 데이터를 생성하는 문제를 해결했다. 이는 두 개의 별도 AI 작업을 협력하도록 강제함으로써 이루어졌다. 즉, 각 연령 그룹에 대한 평균 아틀라스를 구축하고, 다른 연령에 걸쳐 형태를 왜곡하는 방법을 학습하는 것이다.
먼저, 에너지 함수를 최소화함으로써 아틀라스 구축 문제를 정의한다.
$$E(I, v_0^n) = \sum_{n=1}^N \frac{1}{\sigma^2} \text{Dist}[I \circ \phi_1^{-1}(v_0^n), I_n] + \text{Reg}(v_0^n)$$
이 방정식은 왜곡된 평균 이미지와 실제 환자 이미지($I_n$) 간의 거리($\text{Dist}$)를 측정하여 완벽한 평균 이미지($I$)를 찾는 것을 시도한다. $\text{Reg}$ 항은 "고무의 늘어남"이 부드럽고 현실적으로 유지되도록 보장하는 규칙이다.
궁극적인 목표를 달성하기 위해, 저자들은 결합된 총 손실 함수를 최소화하는 통합 신경망을 설계했다.
$$\ell = \mathcal{L}_{\text{tempo-atlas}}(\Theta) + \mathcal{L}_{\text{longitudinal}}(\Psi) + \gamma \mathcal{L}_{\text{latent}}(\mathbf{Z})$$
여기서 모델은 세 가지를 동시에 실패할 경우 페널티를 받는다.
1. $\mathcal{L}_{\text{tempo-atlas}}$: 각 특정 연령 그룹에 대한 정확한 평균 아틀라스를 구축해야 한다.
2. $\mathcal{L}_{\text{longitudinal}}$: 한 연령(예: 10세)의 아틀라스를 다음 연령(예: 12세)으로 왜곡하는 방법을 정확하게 파악해야 한다.
3. $\mathcal{L}_{\text{latent}}$: 이러한 형태의 압축된 수학적 요약(임베딩)이 논리적으로 클러스터링되도록 보장해야 한다. 즉, 생물학적으로 유사해 보이는 형태가 AI의 "뇌"에서 서로 가깝게 유지되어야 한다.
이 공동 방정식을 해결함으로써, AI는 모집단(아틀라스)으로부터 노화의 일반적인 규칙을 학습하고, 새로운 환자의 단일 스냅샷에 해당 규칙을 적용하여 해당 특정 환자의 해부학이 시간이 지남에 따라 어떻게 성장할지를 성공적으로 예측한다.
| 기호 | 설명 |
|---|---|
| $I_n$ | 데이터셋의 $n$번째 입력 이미지 (예: 특정 환자의 CT 스캔). |
| $I$ | 평균 또는 템플릿 이미지, "평균적인" 해부학(아틀라스)을 나타낸다. |
| $\phi$ | 이미지에 적용되는 수학적 변환("왜곡" 함수). |
| $v_0$ | 초기 속도 필드, 형태가 어떻게 변형되기 시작할지를 결정한다. |
| $\sigma^2$ | 이미지의 노이즈 분산, 거리 측정의 가중치로 사용된다. |
| $A_q$ | 주어진 연령/시간 $q$에 대해 구성된 특정 해부학적 아틀라스. |
| $\Theta$ | 시간적 아틀라스 구축을 담당하는 신경망의 학습 가능한 매개변수. |
| $\Psi$ | 연령 간(종단적) 등록을 담당하는 신경망의 학습 가능한 매개변수. |
| $\mathbf{z}_q^i$ | 연령 $q$에서의 이미지의 잠재 임베딩(압축된 수학적 표현). |
| $\gamma$ | 모델이 잠재 임베딩 규칙을 얼마나 강하게 강제하는지를 제어하는 튜닝 매개변수. |
문제 정의 및 제약 조건
특정 어린이가 성장하는 과정을 담은 타임랩스 비디오를 제작해야 한다고 가정해 보자. 그런데 해당 어린이의 연속적인 비디오 대신, 다양한 연령대의 서로 다른 어린이들의 사진이 담긴 방대한 사진첩이 주어졌다고 하자. 5살 어린이 또는 10살 어린이의 평균적인 모습을 쉽게 파악할 수 있다. 하지만 특정 5살 어린이가 10살이 되었을 때 정확히 어떻게 보일지 예측하는 것은 해당 어린이의 해부학적 이력을 알 수 없기 때문에 극도로 어렵다.
이것이 바로 의료 연구자들이 인간 장기와 뼈가 시간에 따라 어떻게 발달하는지 모델링하려고 할 때 직면하는 정확한 시나리오이다.
시작점과 목표 상태
입력 (현재 상태): 의료 분야는 3D 단면 영상 데이터가 풍부하다. 이는 여러 다른 개체로부터 얻은 단일 시점의 스냅샷(CT 또는 MRI 스캔 등)이다. 이러한 데이터셋은 풍부하지만, 시간의 스냅샷만을 나타낼 뿐 인과 관계를 가지는 생물학적 변화에 대한 정보는 전혀 제공하지 않는다.
출력 (목표 상태): 임상의들은 4D 종단 데이터를 절실히 필요로 한다. 이는 동일한 환자에 대해 시간에 따른 주관-특이적, 시간 변화 구조 변화를 의미한다. 만약 의사가 8살 환자의 엉덩이에 대한 3D 스캔을 입력하면, 목표는 해당 환자의 엉덩이가 10살 또는 15살이 되었을 때 어떻게 보일지에 대한 생물학적으로 정확하고 고도로 개인화된 3D 스캔을 출력하는 것이다.
수학적 간극: 누락된 연결고리는 쌍으로 된 종단 훈련 데이터에 의존하지 않고 특정 해부학적 구조를 시간적으로 발전시킬 수 있는 연속적이고 역변환 가능한 변환 필드이다. 우리는 집단 수준의 평균("아틀라스")을 주관-특이적 시간 궤적에 연결하는 수학적 다리가 필요하다.
고통스러운 딜레마
현실적인 종단 데이터를 생성하기 위해, 시퀀스 인식 확산 모델과 같은 딥러닝 모델은 일반적으로 훈련을 위해 방대한 양의 Ground Truth 종단 데이터를 필요로 한다. 여기서 함정이 발생한다:
종단 데이터 없이는 좋은 종단 모델을 훈련할 수 없지만, 종단 데이터는 악명 높게 비싸며(종종 환자 스캔당 1000달러 이상 소요), 시간이 많이 걸리고 수집하기가 극도로 어렵다. 연구자들이 풍부한 단면 데이터만으로 모델을 훈련하여 이를 우회하려고 시도하면, 생성된 미래 이미지는 주관-특이적 충실도를 잃게 된다. 모델은 결국 원래 환자의 고유한 골격 기하학을 보존하는 대신 일반적인 "평균" 사람을 예측하게 된다. 이전 연구자들은 데이터 가용성과 시간적 정확성 사이의 이 고통스러운 절충안에 갇혀 있었다.
가혹한 벽과 제약
이를 해결하기 위해, 저자들은 몇 가지 가혹한 제약에 직면했다:
- 극심한 데이터 희소성: 실제 종단 데이터는 수집하는 데 수년이 걸린다. 환자 탈락, 영상 하드웨어 변경, 수년 간격으로 촬영된 스캔의 정렬은 엄청난 변동성을 야기한다.
- 생물학적 변형의 물리: 뼈와 조직의 성장은 단순한 픽셀 이동이 아니다. 복잡하고 비선형적인 생물학적 변화를 포함한다. 이를 모델링하기 위해 저자들은 Large Deformation Diffeomorphic Metric Mapping (LDDMM)을 사용해야 했다. 이는 변환이 부드럽고 역변환 가능(diffeomorphic)함을 보장한다. 즉, 조직이 마법처럼 찢어지거나, 교차하거나, 스스로 접히지 않는다. 그러나 이를 계산하려면 오일러-푸앵카레 미분(EPDiff) 방정식을 사용하여 속도 필드를 시간적으로 적분해야 한다:
$$ \frac{\partial v_t}{\partial t} = -K \left[ (D v_t)^T \cdot m_t + D m_t \cdot v_t + m_t \cdot \text{div} \, v_t \right] $$
최적의 속도 필드($v_t$)와 운동량 벡터($m_t$)를 찾기 위해 이를 해결하는 것은 엄청난 계산 부담이다. - 흐릿한 아티팩트 벽: 이전의 SOTA 모델(예: VoxelMorph 또는 B-spline)이 큰 연령 간격에 걸쳐 해부학을 변형하려고 시도했을 때, 심각한 왜곡과 흐릿한 경계를 야기했다. 모델이 수년에 걸쳐 구조가 확장되는 방식을 추측하도록 강요받을 때, 발달 중인 엉덩이의 삼중 방사형 연골과 같은 미세 해부학적 세부 사항을 보존하는 것은 극도로 어렵다.
해결 방법: 통합된 수학적 프레임워크
저자들은 딜레마에서 벗어나기 위해 생성기만 구축하는 것이 아니라 동시에 맵을 구축해야 한다는 것을 깨달았다. 그들은 두 가지 작업을 동시에 수행하는 새로운 딥러닝 프레임워크를 설계했다: 시간적 아틀라스 구축 (주어진 연령에서의 집단 평균 찾기) 및 연령 간 이미지 등록 (성장을 모델링하기 위해 평균을 특정 대상에 정렬).
먼저, 그들은 아틀라스와 단면 이미지($I_i^q$) 간의 거리를 최소화하고 속도 필드($v_i^q$)로 정규화하여 연령별 아틀라스 시퀀스($A_q$)를 구성하기 위한 손실 함수를 정의한다:
$$ \mathcal{L}_{\text{tempo-atlas}}(\Theta) = \sum_{q=1}^{Q} \sum_{i=1}^{N_q} \text{Dist}\left[ \phi_{q \to i}^{-1}(\Theta) \circ A_q, I_i^q \right] + \text{Reg}(v_i^q) $$
다음으로, 그들은 소스 아틀라스를 대상 연령($q'$)에 정렬하여 종단 변화를 모델링한다:
$$ \mathcal{L}_{\text{longitudinal}}(\Psi) = \sum_{m=1}^{M} \text{Dist}\left[ \phi_{q \to q'}^{-1}(\Psi) \circ A_q, I_{q'}^m \right] + \text{Reg}(v_{m}^{q'}) $$
돌파구: 이 논문의 진정한 천재성은 고유한 잠재 임베딩을 사용하여 이 두 공간을 연결하는 방식에 있다. 그들은 신경망이 해부학적으로 유사한 구조가 빡빡하게 클러스터링되는 잠재 공간 $\mathbf{Z}$를 학습하도록 강제하며, 이러한 임베딩 간의 거리는 그것들 사이의 변형에 필요한 물리적 변형(속도 필드)과 엄격하게 상관관계를 가진다.
그들은 특수화된 손실 함수를 사용하여 이를 강제한다:
$$ \mathcal{L}_{\text{latent}}(\mathbf{Z}) = \mathbb{E} \left[ -\log(\sigma(\text{sim}(\mathbf{z}_q^i, \mathbf{z}_{q'}^m))) \right] + \lambda \mathbb{E} \left[ \text{Corr}\left( \|\mathbf{z}_q^i - \mathbf{z}_{q'}^m\|^2, \|v_q^i - v_{q'}^m\|^2 \right) \right] $$
첫 번째 항은 코사인 유사도를 사용하여 관련 모양을 그룹화한다. 두 번째 항은 핵심이다. 이는 잠재 임베딩의 유클리드 거리($\|\mathbf{z}_q^i - \mathbf{z}_{q'}^m\|^2$)와 변형의 물리적 에너지($\|v_q^i - v_{q'}^m\|^2$) 간의 상관관계를 계산한다.
추상적인 잠재 공간을 미분 변형의 물리 법칙에 수학적으로 고정함으로써, 모델은 단일 단면 스캔을 보고, 이를 시간적 아틀라스에 매핑하고, 해당 특정 기하학이 시간에 따라 어떻게 진화할지를 정확하게 투영할 수 있다. 이는 방대한 종단 훈련 데이터셋의 필요성을 완전히 우회한다.
이 접근 방식은 왜
저자들이 이처럼 고도로 특수하고 수학적으로 밀도 높은 접근 방식을 선택한 이유를 이해하기 위해서는 먼저 전통적인 최신 기술(SOTA) 방법론이 한계에 부딪힌 정확한 순간을 살펴볼 필요가 있다.
최근 몇 년간 딥러닝 커뮤니티는 생성 모델에 열광해 왔다. 만약 시간이 지남에 따라 아동의 고관절 골격이 성장하는 과정을 보여주는 일련의 이미지를 생성하고자 한다면, 가장 먼저 떠오르는 방법은 확산 모델(Diffusion model)이나 트랜스포머(Transformer)를 사용하는 것일 수 있다. 실제로 저자들은 이전 연구자들이 정확히 이 방법을 시도했음을 명시적으로 지적한다: Yoon 등은 시퀀스 인식 확산 모델을 사용했으며, Puglisi 등은 잠재 확산 모델(latent diffusion models)을 사용하여 시간 경과에 따른 구조적 변화를 시뮬레이션했다.
하지만 이것이 저자들이 이러한 인기 있는 접근 방식을 포기하도록 강요한 치명적인 결함이다: 표준 생성 모델은 엄청난 양의 데이터를 요구한다. 이들은 대규모의 쌍을 이루는 종단 데이터셋(longitudinal datasets)을 필요로 하는데, 이는 수년간 동일한 환자의 수천 개의 3D 스캔 데이터가 필요함을 의미한다. 실제 임상 환경에서 이러한 유형의 데이터는 비용이 엄청나게 많이 들고, 시간이 오래 걸리며, 사실상 존재하지 않는다. 이용 가능한 의료 데이터의 대다수는 단면 데이터(cross-sectional)이다 (단일, 고립된 시점에서 서로 다른 사람들의 스냅샷). 확산 모델과 GAN은 훈련 중에 실제 시간적 시퀀스를 보지 않고는 주체별 시간적 역학을 학습할 수 없다. 이들은 단절된 스냅샷으로부터 생물학적으로 정확한 성장 궤적을 환각(hallucinate)할 수 없기 때문에 여기서 실패할 것이다.
이러한 혹독한 제약에 직면하여, 저자들은 학습 과정에 물리 및 기하학의 엄격한 법칙을 내장하는 것이 유일하게 실행 가능한 해결책임을 깨달았다. 그들은 대변형 미분 동형 거리 매핑(Large Deformation Diffeomorphic Metric Mapping, LDDMM)으로 눈을 돌렸다.
이것이 수학적으로 우수한 이유는 무엇인가? 미분 동형 변환(diffeomorphic transformation)은 두 해부학적 형태 간의 매핑이 부드럽고, 연속적이며, 엄격하게 역변환 가능함을 보장한다. 생물학에서 조직은 늘어나고 성장하지만, 무작위로 찢어지거나, 스스로 접히거나, 순간 이동하지 않는다. 오일러-푸앵카레 미분 방정식(Euler-Poincaré differential, EPDiff)을 통해 문제를 구성함으로써, 저자들은 초기 속도 필드 $v_0$를 시간적으로 적분함으로써 해부학적 성장의 측지선 경로(geodesic path)가 고유하게 결정되도록 보장한다:
$$ \frac{\partial v_t}{\partial t} = -K \left[ (D v_t)^T \cdot m_t + D m_t \cdot v_t + m_t \cdot \text{div} \, v_t \right] $$
이는 문제의 혹독한 제약(종단 데이터 부족)과 해결책의 고유한 특성 사이에 완벽한 "결합"을 만들어낸다. 뼈가 어떻게 성장하는지 맹목적으로 추측하려 하는 대신, 모델은 두 가지 작업을 공동으로 수행한다: 특정 연령(예: 8세)에서의 모집단의 평균 형태인 "아틀라스(atlas)"를 구축하고, 그런 다음 8세 아틀라스를 10세 아틀라스로 왜곡하는 미분 동형 속도 필드(diffeomorphic velocity fields)를 학습한다. 그런 다음 이러한 학습된, 생물학적으로 타당한 속도 필드를 특정 환자의 기준 스캔에 적용하여 미래 해부학에 대한 매우 신뢰할 수 있는 예측을 생성한다.
이 방법이 이전의 골드 스탠다드(gold standards)인 VoxelMorph(VM) 또는 B-스플라인 등록(B-spline registration)과 같은 방법보다 구조적으로 우수한 점은 심오하다. 전통적인 등록 방법은 단순히 이미지 A와 이미지 B 간의 픽셀 단위 차이를 최소화하려고 시도한다. 논문의 벤치마킹에서 보여주듯이, 이는 종종 흐릿한 경계와 심각한 인공물(artifacts)을 초래한다 (VoxelMorph 기준선에서 장골능(iliac crest) 주변에서 보이는 왜곡과 같은).
이를 극복하기 위해, 저자들은 독창적인 "고유 잠재 임베딩(Distinctive Latent Embedding)" 손실을 도입했다. 그들은 단순히 이미지를 정렬하는 것이 아니라, 신경망의 잠재 공간(latent space)이 물리적 변형 공간을 완벽하게 반영하도록 강제한다. 손실 함수에는 잠재 임베딩 $\mathbf{z}$의 거리와 속도 필드 $v$의 물리적 거리 간의 상관관계를 측정하는 항이 포함된다:
$$ \mathcal{L}_{\text{latent}}(\mathbf{Z}) = \dots + \lambda \mathbb{E}_{(\mathbf{z}_q^i, \mathbf{z}_{q'}^m)} \left[ \text{Corr} \left( \|\mathbf{z}_q^i - \mathbf{z}_{q'}^m\|^2, \|v_q^i - v_{q'}^m\|^2 \right) \right] $$
이는 수학적으로 잠재 공간이 속도 필드에 의해 결정되는 기하학적 및 시간적 관계를 보존하도록 강제한다. 이는 시간 경과에 따른 점진적인 형태 변화를 분리하여, 모델이 삼중 방사 연골(tri-radiate cartilages)과 같은 복잡한 성장 중심 주변에 날카롭고 인공물이 없는 경계를 생성할 수 있도록 한다.
솔직히 말해서, 이 특정 아키텍처가 계산 메모리 복잡도를 $O(N^2)$에서 $O(N)$으로 줄이는지에 대해서는 완전히 확신할 수 없다. 저자들이 텍스트에서 Big-O 알고리즘 분석을 명시적으로 제공하지 않았기 때문이다. 그러나 압도적으로 명확한 것은 데이터 효율성이다. 미분 동형의 기하학적 잠재 공간을 활용함으로써, 이 프레임워크는 SOTA 확산 모델이 할 수 없는 것을 달성한다: 단지 희소한, 단면 3D 입력만을 사용하여 매우 정확하고 주체별인 4D 종단 데이터를 합성한다.
수학 및 논리 메커니즘
이 논문의 중요성을 이해하기 위해서는 먼저 의료 영상 분야의 근본적인 데이터 문제를 파악해야 한다. 아이가 성장하는 과정을 사진 앨범을 보며 이해한다고 상상해보자. 만약 당신에게 "종단적" 앨범, 즉 매년 같은 아이를 찍은 사진이 있다면, 아이의 성장 궤적을 정확하게 쉽게 볼 수 있다. 그러나 의료 분야에서는 동일한 환자의 종단적 3D 스캔(CT 또는 MRI와 같은)을 수년에 걸쳐 얻는 것이 엄청나게 비싸고 시간이 많이 소요되며 드물다. 대신 병원에는 "횡단면" 데이터가 산더미처럼 쌓여 있다: 서로 다른 나이의 다양한 사람들의 단일 스냅샷이다.
이 논문의 저자들은 이러한 단절된 다양한 사람들의 스냅샷을 받아들여 근본적인 "성장 규칙"을 학습하는 훌륭한 수학적 엔진을 구축했다. 그런 다음 이 규칙을 사용하여 완전히 새로운 환자에 대해 매우 정확하고 개인화된 3D 타임랩스(종단적 데이터)를 생성하여 해부학이 시간이 지남에 따라 어떻게 변할지 정확하게 예측한다.
이것을 가능하게 하는 정확한 수학적 메커니즘은 다음과 같다.
마스터 방정식
이 논문의 핵심 엔진은 세 가지 거대한 작업을 동시에 균형 있게 수행하는 통합 목적 함수에 의해 구동된다: "평균" 템플릿(아틀라스) 구축, 연령별 성장 예측, 그리고 모델이 이러한 변화의 물리적 현실을 이해하도록 강제하는 것이다.
전체 네트워크를 구동하는 총 손실 함수는 다음과 같다:
$$ \ell = \mathcal{L}_{\text{tempo-atlas}}(\Theta) + \mathcal{L}_{\text{longitudinal}}(\Psi) + \gamma \mathcal{L}_{\text{latent}}(\mathbf{Z}) $$
하지만 진정한 비법, 즉 이 논문에서 가장 혁신적인 부분은 Distinctive Latent Embedding loss로, 이것이 작업의 두뇌 역할을 한다:
$$ \mathcal{L}_{\text{latent}}(\mathbf{Z}) = \mathbb{E}_{(\mathbf{z}_q^i, \mathbf{z}_{q'}^m)} \big[ -\log(\sigma(\text{sim}(\mathbf{z}_q^i, \mathbf{z}_{q'}^m))) \big] + \lambda \, \mathbb{E}_{(\mathbf{z}_q^i, \mathbf{z}_{q'}^m)} \big[ \text{Corr} \big( \|\mathbf{z}_q^i - \mathbf{z}_{q'}^m\|^2, \; \|v_q^i - v_{q'}^m\|^2 \big) \big] $$
방정식 분해
이 메커니즘의 모든 기어와 스프링을 해부해보자.
총 손실 ($\ell$)에서:
* $\ell$: 총 손실. 이것은 기계가 0으로 최소화하려고 하는 궁극적인 "오류 점수"이다.
* $\mathcal{L}_{\text{tempo-atlas}}(\Theta)$: 시간적 아틀라스 구축 손실. 이 항은 네트워크(매개변수 $\Theta$ 포함)가 특정 연령에 대한 "평균" 해부학적 템플릿을 얼마나 잘 생성할 수 있는지 측정한다. 이것은 기준선 역할을 한다.
* $\mathcal{L}_{\text{longitudinal}}(\Psi)$: 연령 간 등록 손실. 이것은 네트워크(매개변수 $\Psi$ 포함)가 한 연령의 이미지를 더 나이 든 연령의 해부학에 맞게 얼마나 잘 왜곡할 수 있는지 측정한다. 이것은 "타임머신" 구성 요소이다.
* $\gamma$: 스칼라 가중치(균형 조절기). 이것은 잠재 임베딩과 이미지 생성에 얼마나 많은 주의를 기울여야 하는지를 결정한다.
* 곱셈 대신 덧셈을 사용하는 이유는? 저자들은 다중 작업 균형 저울을 만들기 위해 덧셈을 사용한다. 만약 이 항들을 곱했다면, 아틀라스 손실에서 거의 0에 가까운 점수가 종단적 손실에 대한 기울기(학습 신호)를 완전히 제거하여 학습 과정을 완전히 중단시켰을 것이다. 덧셈은 한 작업이 완벽하게 수행되더라도 모델이 다른 작업을 개선해야 하는 압력을 느끼도록 보장한다.
잠재 임베딩 손실 ($\mathcal{L}_{\text{latent}}(\mathbf{Z})$)에서:
* $\mathbf{Z}$: 모든 잠재 임베딩의 행렬. 임베딩은 3D 의료 영상의 매우 압축되고 추상적인 수학적 요약이다.
* $\mathbb{E}_{(\mathbf{z}_q^i, \mathbf{z}_{q'}^m)}$: 이러한 압축된 임베딩 쌍에 대한 기댓값(평균). $\mathbf{z}_q^i$는 연령 $q$에서의 환자 $i$의 임베딩이고, $\mathbf{z}_{q'}^m$는 연령 $q'$에서의 환자 $m$의 임베딩이다.
* 하드 합계($\sum$) 대신 기댓값을 사용하는 이유는? 딥러닝에서 방대한 데이터셋에 걸쳐 모든 가능한 이미지 쌍의 정확한 합계를 계산하는 것은 계산적으로 폭발적이다. 기댓값을 사용하면 모델이 훈련 중에 무작위 쌍을 확률적으로 샘플링하여 실제 평균을 근사하면서도 엄청난 양의 메모리를 절약할 수 있다.
* $-\log(\sigma(\dots))$: 시그모이드 함수의 음수 로그. 이것은 고전적인 페널티 메커니즘이다. 시그모이드($\sigma$)는 값을 0과 1 사이(확률과 같음)로 압축한다. 음수 로그는 이 값이 0에 가까워지면 모델에 크게 페널티를 부과한다.
* $\text{sim}(\mathbf{z}_q^i, \mathbf{z}_{q'}^m)$: 두 임베딩 간의 코사인 유사도. 두 벡터 간의 각도를 측정한다.
* 논리적 역할: 이 첫 번째 항 전체는 중력과 같은 역할을 한다. 두 해부학적 형태가 관련되어 있다면, 이는 수학적 벡터가 잠재 공간에서 정확히 같은 방향을 가리키도록 강제한다.
* $\lambda$: 또 다른 균형 조절기로, 특히 물리적 제약 조건의 강도를 제어한다.
* $\text{Corr}(\dots)$: 피어슨 상관 계수. 두 변수가 얼마나 선형적으로 관련되어 있는지 측정한다.
* $\|\mathbf{z}_q^i - \mathbf{z}_{q'}^m\|^2$: 두 추상 임베딩 간의 제곱 유클리드 거리. 이것을 8세 고관절과 10세 고관절 간의 "개념적 거리"로 생각할 수 있다.
* $\|v_q^i - v_{q'}^m\|^2$: 해당 속도 필드($v$)의 제곱 거리. 속도 필드는 픽셀이 어떻게 물리적으로 흐르고 늘어나야 한 형태를 다른 형태로 변형해야 하는지를 정확하게 지시하는 3D 화살표 지도이다.
* 논리적 역할: 이 상관 항은 순수한 천재성이다. 이것은 엄격한 물리 검사관 역할을 한다. 임베딩의 추상적인 "개념적 거리"가 조직을 변형하는 데 필요한 실제 "물리적 스트레칭 에너지"와 완벽하게 상관되도록 강제한다. 이것은 신경망이 잠재 공간에 이미지를 임의로 배치하여 속이는 것을 방지한다.
단계별 흐름
8세 환자의 고관절에 대한 단일 추상 데이터 포인트, 즉 3D CT 스캔이 이 수학적 조립 라인을 통과하는 과정을 추적해보자.
- 압축: 8세 고관절의 원시 3D 픽셀이 네트워크에 입력되고 즉시 조밀하고 추상적인 벡터 $\mathbf{z}_q^i$로 압축된다.
- 고정: 시스템은 이 벡터를 구축된 "평균 8세 고관절" 템플릿과 비교한다. 특정 환자가 표준에서 얼마나 벗어나는지 계산한다.
- 시간 여행: 사용자는 이 고관절이 12세에 어떻게 보일지에 대한 예측을 요청한다. 네트워크는 "평균 12세" 템플릿을 살펴본다. 8세 뼈가 12세 상태에 도달하기 위해 어떻게 늘어나고, 성장하고, 구부러져야 하는지를 지시하는 유체와 같은 화살표 지도인 속도 필드 $v$를 생성한다.
- 품질 관리: $\mathcal{L}_{\text{latent}}$ 손실이 작동한다. 8세 벡터와 12세 벡터 간의 추상적 거리를 확인한다. 이 추상적 거리가 속도 필드 $v$의 물리적 에너지와 일치하는지 엄격하게 검증한다. 수학이 물리학과 일치하지 않으면 모델에 페널티가 부과된다.
- 생성: 마지막으로 속도 필드가 원본 3D 스캔에 적용되어 픽셀을 디지털 점토 조각처럼 부드럽게 왜곡하여 생물학적으로 정확한 합성 12세 고관절 스캔을 출력한다.
최적화 역학
이 복잡한 아키텍처는 실제로 어떻게 학습하고 수렴하는가?
모델은 경사 하강법(특히 Adam 옵티마이저)을 사용하여 매개변수를 최적화한다. 초기에는 손실 지형이 매우 혼란스럽다. 네트워크는 지름길을 택하려고 할 수 있으며, 예를 들어 이미지 거리 손실을 빠르게 줄이기 위해 8세 이미지를 흐리게 하여 12세 이미지처럼 보이게 할 수 있다.
그러나 모델은 미분 동형 수학(논문의 배경에서 언급된 오일러-푸앵카레 미분 방정식)에 의해 제약된다. 이는 변환이 고무 시트를 찢지 않고 통과하지 않도록 접는 것처럼 부드럽고 연속적이며 역변환 가능해야 함을 의미한다.
이러한 엄격한 물리적 제약으로 인해 손실 지형은 가파르고 부드러운 깔때기 모양을 띤다. 기울기가 네트워크를 통해 역방향으로 흐르면서 임베딩 $\mathbf{Z}$는 아름답게 구성되도록 강제된다. 유사한 연령의 스캔은 촘촘하게 클러스터링되고, 다른 연령의 스캔은 그 사이를 전환하는 데 필요한 물리적 성장량에 정확히 비례하여 공간을 차지한다. 1000 에포크를 거치면서 시스템은 평형 상태에 도달한다: 생성된 아틀라스는 날카로워지고, 예측된 성장 궤적은 해부학적으로 완벽해져 모델이 환자 해부학의 미래를 놀라운 정밀도로 환각할 수 있게 된다.
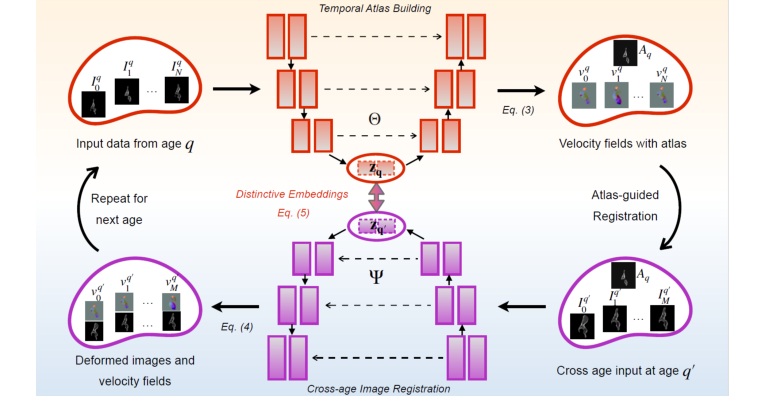 Figure 1. Overview of our model. Training: Our network constructs a sequence of tempo- ral atlases, starting at age q and modeling deformations across target ages. A geometric embedding loss in the latent space enforces structured, biologically meaningful anatom- ical evolution. Iterative refinement enhances the interplay between cross-sectional and longitudinal dynamics, generating anatomically coherent cross-age data. Inference: For each subject, we first align their baseline images to the corresponding age-specific atlas. The trained model Ψ operates as a longitudinal data generator, synthesizing anatomically plausible trajectories for unseen subjects by extracting geometric fea- tures through the atlas. It uses generated velocity fields from cross-age registration between age-specific atlases to deform subject-specific structures over time, ensuring a smooth and temporally consistent evolution
Figure 1. Overview of our model. Training: Our network constructs a sequence of tempo- ral atlases, starting at age q and modeling deformations across target ages. A geometric embedding loss in the latent space enforces structured, biologically meaningful anatom- ical evolution. Iterative refinement enhances the interplay between cross-sectional and longitudinal dynamics, generating anatomically coherent cross-age data. Inference: For each subject, we first align their baseline images to the corresponding age-specific atlas. The trained model Ψ operates as a longitudinal data generator, synthesizing anatomically plausible trajectories for unseen subjects by extracting geometric fea- tures through the atlas. It uses generated velocity fields from cross-age registration between age-specific atlases to deform subject-specific structures over time, ensuring a smooth and temporally consistent evolution
결과, 한계점 및 결론
핵심 문제: 스냅샷 함정 탈출
본 논문의 중요성을 이해하기 위해서는 먼저 두 가지 유형의 의료 데이터, 즉 단면(cross-sectional) 데이터와 종단(longitudinal) 데이터 간의 근본적인 차이를 이해해야 한다.
인간 얼굴의 노화 과정을 이해하고 싶다고 상상해보자. 5세부터 50세까지 각기 다른 연령대의 100명에게서 사진을 한 장씩 찍었다면, 이는 단면 데이터이다. 노화의 일반적인 추세를 추측할 수는 있지만, 5세 아이가 50세가 되었을 때 정확히 어떤 모습일지는 알 수 없다. 이제 5세부터 50세까지 정확히 동일한 사람에게서 매년 사진을 찍는다고 상상해보자. 이것이 바로 종단 데이터이다. 이는 변화의 진정한, 개체별 시공간적 역학을 포착한다.
의료 영상 분야에서 종단 3D 데이터(시간에 따라 4D 데이터가 됨)는 해부학적 구조가 발달하는 방식이나 질병이 진행되는 방식을 추적하는 데 있어 성배와 같다. 그러나 이러한 데이터를 수집하는 것은 물류상의 악몽이다. 10년 동안 스캔 비용과 행정 비용으로 환자당 1만 달러 이상이 소요될 정도로 엄청나게 비싸며, 환자 이탈률도 매우 높다. 결과적으로 대부분의 의료 데이터베이스는 단면 데이터이다.
본 논문의 저자들은 다음과 같은 거대한 제약에 직면했다: 서로 연결되지 않은 다양한 사람들의 스냅샷으로 주로 구성된 훈련 데이터를 사용하여 특정 환자의 미래 3D 해부학적 형태를 정확하게 예측하는 방법은 무엇인가?
수학적 엔진: 미분동형사상과 잠재 시간 여행
이를 해결하기 위해 저자들은 단순히 다음 프레임을 추측하도록 표준 신경망을 훈련시키지 않았다. 그들은 두 가지 작업을 공동으로 수행하는 프레임워크를 구축했다: 아틀라스 구축(특정 연령대의 "평균" 형태를 찾는 것)과 종단 데이터 생성(특정 개체의 형태가 연령에 따라 어떻게 진화하는지 예측하는 것).
그들은 Large Deformation Diffeomorphic Metric Mapping (LDDMM)의 수학에 기반을 두었다. 간단히 말해, 미분동형사상(diffeomorphism)은 부드럽고 연속적이며 역변환 가능한 변환이다. 5세 아이의 고관절 뼈의 점토 조각을 10세 아이의 고관절 뼈로, 점토가 찢어지거나 스스로 접히지 않도록 변형시키는 것을 상상해보라.
$N$개의 이미지 집합에서 아틀라스(템플릿 이미지 $I$)를 구축하기 위한 기본 에너지 함수는 다음과 같이 정의된다:
$$E(I, v_0^n) = \sum_{n=1}^N \frac{1}{\sigma^2} \text{Dist}[I \circ \phi_1^{-1}(v_0^n), I_n] + \text{Reg}(v_0^n)$$
여기서 $v_0^n$은 초기 속도 필드, 즉 템플릿을 대상 이미지 $I_n$으로 변형시키기 시작하는 데 필요한 "밀기"를 나타낸다. 변환 경로는 오일러-푸앵카레 미분 방정식(Euler-Poincaré differential (EPDiff) equation)에 의해 제어되며, 이 방정식은 이 속도가 시간에 따라 어떻게 흐르는지를 결정한다:
$$\frac{\partial v_t}{\partial t} = -K \left[ (D v_t)^T \cdot m_t + D m_t \cdot v_t + m_t \cdot \text{div} \, v_t \right]$$
솔직히 말해서, 본 논문은 딥러닝 훈련 중에 이 적분을 해결하는 데 필요한 정확한 계산 메모리 발자국을 명시적으로 자세히 설명하지는 않지만, 데이터의 3D 특성을 고려할 때, 이는 상당한 GPU 연산 능력을 요구한다고 추론할 수 있다(이는 RTX A6000을 사용하여 처리했다).
그들의 아키텍처의 진정한 천재성은 독특한 잠재 임베딩(Distinctive Latent Embeddings)에 있다. 그들은 신경망이 두 임베딩 간의 수학적 거리가 그것들 사이의 변형에 필요한 물리적 변형과 완벽하게 상관관계를 갖는 잠재 공간 $\mathbf{Z}$를 학습하도록 강제한다. 그들의 잠재 손실 함수는 다음과 같다:
$$\mathcal{L}_{\text{latent}}(\mathbf{Z}) = \mathbb{E}_{(\mathbf{z}_q^i, \mathbf{z}_{q'}^m)} \left[ -\log(\sigma(\text{sim}(\mathbf{z}_q^i, \mathbf{z}_{q'}^m))) \right] + \lambda \, \mathbb{E}_{(\mathbf{z}_q^i, \mathbf{z}_{q'}^m)} \left[ \text{Corr} \left( \|\mathbf{z}_q^i - \mathbf{z}_{q'}^m\|^2, \, \|v_q^i - v_{q'}^m\|^2 \right) \right]$$
첫 번째 항은 코사인 유사도(cosine similarity)를 사용하여 관련 형태가 함께 군집화되도록 강제한다. 두 번째 항은 핵심적인 부분이다: 이는 두 잠재 벡터 간의 제곱 유클리드 거리 $\|\mathbf{z}_q^i - \mathbf{z}_{q'}^m\|^2$이 한 형태를 다른 형태로 변형시키는 데 필요한 물리적 "노력"(속도 필드 거리 $\|v_q^i - v_{q'}^m\|^2$)과 상관관계를 갖도록 보장한다.
최종 목적 함수는 시간적 아틀라스 구축, 연령 간 등록, 그리고 이 잠재 임베딩을 우아하게 균형 잡는다:
$$\ell = \mathcal{L}_{\text{tempo-atlas}}(\Theta) + \mathcal{L}_{\text{longitudinal}}(\Psi) + \gamma \mathcal{L}_{\text{latent}}(\mathbf{Z})$$
실험: 현실에 대한 무자비한 검증
저자들은 단순히 메트릭을 벽에 던지지 않았다. 그들은 매우 엄격한 실험을 설계했다. 그들은 정상 남성 고관절(4-18세)의 단면 데이터셋으로 모델을 훈련시켰다. 그러나 모델이 실제로 작동했음을 증명하기 위해, 그들은 실제 종단 CT 스캔(수년 간격으로 여러 번의 스캔을 받은 12명의 환자)으로 구성된 숨겨진, 매우 가치 있는 데이터셋으로 모델을 테스트했다.
희생양 (베이스라인):
아틀라스 구축을 위해 B-spline, Multi-contrast registration (M-c. reg.), VoxelMorph (VM)과 같은 기존 모델들을 완전히 해체했다. 종단 생성을 위해 NAHA (Nearest-Age Hip Approximation)와 ABAA (Age-Based Atlas Approximation)를 능가했다.
결정적인 증거:
증거는 단순히 Dice score에만 있는 것이 아니었다(비록 그들이 압도적인 0.88을 달성했지만). 부인할 수 없는 증거는 시각적이고 기하학적이었다. 그들은 12세 환자의 고관절 CT 스캔을 가져와 모델에 입력하고, 정확히 동일한 환자의 15세 버전을 환각하도록 요청했다.
그들의 합성 15세 고관절을 해당 환자의 실제 15세 스캔과 겹쳤을 때, 경계가 아름답게 일치했다. 베이스라인 모델들은 여기서 끔찍하게 실패했다. VoxelMorph는 후장골능(posterior iliac crest) 주변에 심각한 인공물 왜곡을 생성했고, 다른 방법들은 흐릿하고 해부학적으로 불가능한 뼈의 윤곽을 생성했다. 저자들의 모델은 삼중방사 연골(tri-radiate cartilages) 주변의 날카롭고 미세한 해부학적 세부 사항을 보존하여, 그들의 잠재 공간이 단순히 픽셀을 맹목적으로 보간하는 것이 아니라 성공적으로 뼈 성장이라는 생물학적 규칙을 학습했음을 증명했다.
미래 궤적 및 논의 주제
이 프레임워크의 심오한 함의를 바탕으로, 미래 탐구를 위한 몇 가지 중요한 방향은 다음과 같다:
-
생체역학적 물리 법칙 사전 통합:
현재 모델은 기하학적 변환(미분동형사상)만을 통해 성장 규칙을 학습한다. 그러나 뼈 발달은 물리적 힘(볼프의 법칙—뼈는 가해지는 하중에 적응한다)에 의해 크게 영향을 받는다. EPDiff 방정식에 생체역학적 응력 텐서를 어떻게 주입할 수 있을까? 아이가 비정상적인 보행을 한다면, 특정 기계적 스트레스가 미래의 뼈 형태를 어떻게 변화시킬지 예측하도록 잠재 공간을 조건화할 수 있을까? -
분기하는 병리학적 잠재 공간:
본 논문은 기준선을 설정하기 위해 정상 남성 고관절에 초점을 맞췄다. 그러나 질병은 거의 선형적으로 진행되지 않는다. 병리학적 데이터(예: 고관절 이형성증)를 도입한다면, 단일 단면 스캔이 여러 가능한 미래를 예측하도록 잠재 공간을 어떻게 구조화해야 할까? 이 결정론적 모델을 확률론적 모델로 발전시키는 방법에 대해 논의해야 하며, 아마도 잠재 공간에서 확산 모델(diffusion models)을 사용하여 미래 질병 진행에 대한 "불확실성의 원뿔"을 생성해야 할 것이다. -
교차 양식 시간 정렬:
저자들은 뼈 대비가 뛰어나지만 소아 환자에게 이온화 방사선을 노출시키는 CT 스캔을 사용했다. 소아 영상의 미래는 MRI 또는 초음파이다. 그러나 이러한 양식들은 노이즈 프로파일과 아티팩트 동작이 크게 다르다. 흥미로운 논의점은 CT 데이터에서 학습된 기하학적 잠재 임베딩이 MRI 데이터로 전이될 수 있는지 여부이다. 성장의 "속도 필드"를 영상 양식 자체의 픽셀 강도에서 분리할 수 있을까?
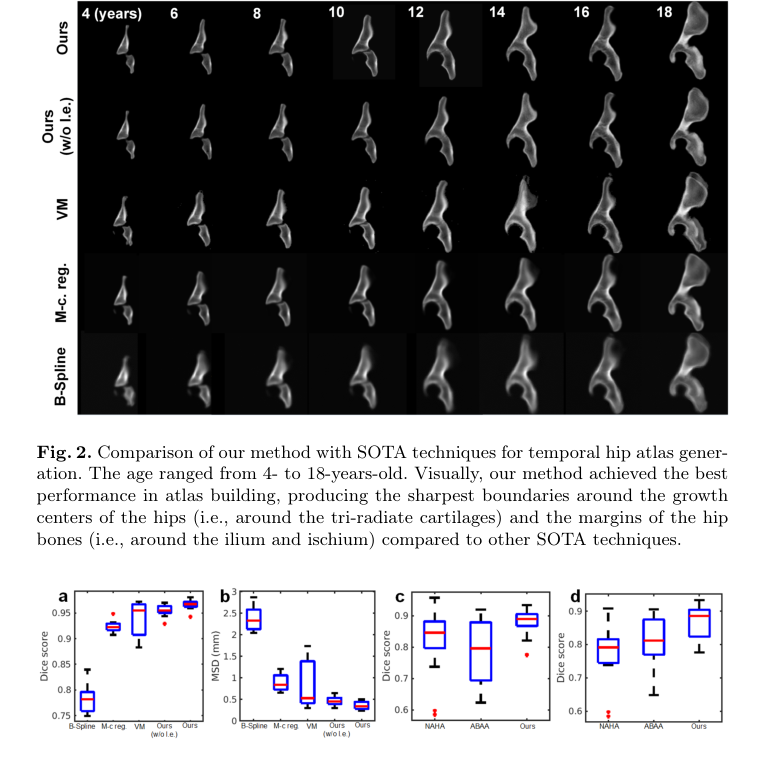 Figure 3. Boxplots of the atlas-to-patient (within-age) registration results based on the mean Dice score (a) and the MSD (b). Boxplots of the longitudinal data generation results for all testing cases (c) and for the cases when the age gap is >1 year (d) based on mean Dice score. The ages of the subjects in these experiments ranged from 4 to 18 years. Our method achieved superior performance compared to others
Figure 3. Boxplots of the atlas-to-patient (within-age) registration results based on the mean Dice score (a) and the MSD (b). Boxplots of the longitudinal data generation results for all testing cases (c) and for the cases when the age gap is >1 year (d) based on mean Dice score. The ages of the subjects in these experiments ranged from 4 to 18 years. Our method achieved superior performance compared to others
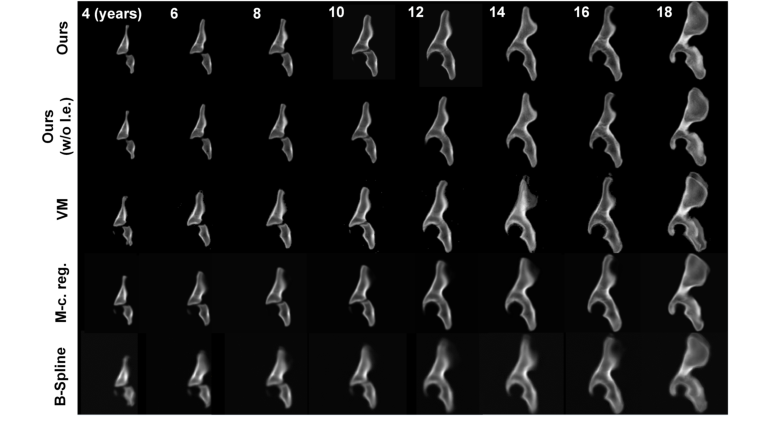 Figure 2. Comparison of our method with SOTA techniques for temporal hip atlas gener- ation. The age ranged from 4- to 18-years-old. Visually, our method achieved the best performance in atlas building, producing the sharpest boundaries around the growth centers of the hips (i.e., around the tri-radiate cartilages) and the margins of the hip bones (i.e., around the ilium and ischium) compared to other SOTA techniques
Figure 2. Comparison of our method with SOTA techniques for temporal hip atlas gener- ation. The age ranged from 4- to 18-years-old. Visually, our method achieved the best performance in atlas building, producing the sharpest boundaries around the growth centers of the hips (i.e., around the tri-radiate cartilages) and the margins of the hip bones (i.e., around the ilium and ischium) compared to other SOTA techniques
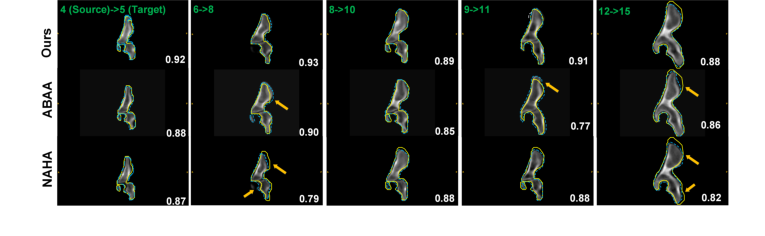 Figure 4. Comparison of various methods for the longitudinal data generation task based on a real longitudinal dataset. For example, in the first column, given an input hip dataset from a 4-year-old subject (source), the longitudinal data generator predicted the 3D synthetic longitudinal CT hip shape of the same subject at the age of 5. The source and target ages are denoted in green text in the left upper corner of each frame. The segmentation contour (blue dashed line) produced by our method aligns better with the ground truth contour (yellow line) than other techniques, as indicated by the higher Dice scores (white text). Arrows highlight regions with large alignment errors
Figure 4. Comparison of various methods for the longitudinal data generation task based on a real longitudinal dataset. For example, in the first column, given an input hip dataset from a 4-year-old subject (source), the longitudinal data generator predicted the 3D synthetic longitudinal CT hip shape of the same subject at the age of 5. The source and target ages are denoted in green text in the left upper corner of each frame. The segmentation contour (blue dashed line) produced by our method aligns better with the ground truth contour (yellow line) than other techniques, as indicated by the higher Dice scores (white text). Arrows highlight regions with large alignment errors
다른 필드와의 동형사상
이산적이고 정적인 공간 분포 사이에 연속적이고 역행 가능한 진화 궤적을 구축하는 메커니즘으로, 기하학적으로 제약된 잠재 공간 내에서 그룹 내 정렬과 그룹 간 시간 변환을 공동으로 최적화한다.
천체물리학 및 은하 진화
천문학자들은 막대한 관측상의 난관에 직면해 있다. 빛의 속도와 우주의 광대함 때문에 은하의 특정 시점에서의 정적인 스냅샷(횡단면 데이터)만을 포착할 수 있을 뿐, 단일 은하가 수십억 년에 걸쳐 진화하는 과정(종단면 데이터)을 직접 관찰할 수는 없다. 본 논문의 핵심 논리, 즉 "연령 내(within-age)" 아틀라스를 구축하여 "연령 간(cross-age)" 미분 변환을 안내하는 것은 은하 형태 문제의 완벽한 반영이다. 저자들이 희소한 환자 스냅샷으로부터 발달 중인 엉덩이뼈의 구조적 변화를 매핑하는 것처럼, 천체물리학자들은 다양한 적색편이에서 서로 다른 은하의 희소한 스냅샷을 사용하여 은하의 구조적 진화(예: 나선형에서 타원형으로)를 매핑해야 한다.
정량 금융 및 시장 미시구조
금융 공학에서 분석가들은 종종 단일 시점에서 다양한 자산에 걸친 방대한 양의 횡단면 데이터를 보유하지만, 거시경제 체제의 변화를 통해 단일 자산의 연속적이고 개체별 궤적을 예측하는 데 어려움을 겪는다. 시간 경과에 따른 기하학적 일관성을 강제하기 위해 속도장을 사용하는 본 논문의 개념은 변동성 표면 또는 수익률 곡선의 변형을 모델링하는 과제와 유사하다. 예를 들어, 특정 자산의 위험 프로필이 기초 가격이 \$100에서 \$150으로 이동함에 따라 어떻게 변형되는지를 매핑하려면 "개체군 수준의 시장 추세"(시간 아틀라스)와 "자산별 가격 궤적"(종단면 생성)의 정확히 동일한 수학적 분리가 필요하다.
"만약에" 시나리오
만약 이론 천체물리학자가 내일 이 논문의 정확한 총 손실 방정식을 훔친다면 어떻게 될까?
$$ \ell = \mathcal{L}_{\text{tempo-atlas}}(\Theta) + \mathcal{L}_{\text{longitudinal}}(\Psi) + \gamma \mathcal{L}_{\text{latent}}(\mathbf{Z}) $$
이 프레임워크에 수백만 장의 제임스 웹 우주 망원경 정적 이미지를 입력함으로써, 그들은 서로 다른 적색편이 시대를 "연령"으로, 개별 은하의 형태를 "횡단면 입력"으로 취급할 수 있을 것이다. $\mathcal{L}_{\text{latent}}(\mathbf{Z})$ 항은 잠재 공간이 은하 구조의 기하학적 관계를 보존하도록 강제할 것이다. 이 돌파구는 전례 없는 것이 될 것이다. 이 알고리즘은 단일 은하의 100억 년에 걸친 진화에 대한 수학적으로 엄밀하고 4차원적인 종단면 영화를 합성하여, 데이터 수집을 위해 10억 년을 기다릴 필요 없이 은하 형성의 "잃어버린 연결고리" 문제를 효과적으로 해결할 것이다.
고립되고 정적인 스냅샷이 유동적이고 고도로 개인화된 역사로 수학적으로 짜여질 수 있음을 증명함으로써, 본 논문은 보편적 구조 라이브러리에 중요한 청사진을 추가하며, 인간 뼈의 생물학적 성장과 멀리 떨어진 은하의 우주적 노화가 궁극적으로 정확히 동일한 기하학적 안무에 의해 지배된다는 것을 보여준다.