基于几何潜在嵌入的时间序列图引导纵向数据生成
This paper introduces a new AI model that creates realistic "time-lapse" medical images from static scans, helping us understand how body parts grow and change.
背景与学术传承
为了理解本研究的根源,我们必须回顾医学影像学的历史演变。数十年前,CT或MRI等医学扫描被视为静态照片——在某一特定时刻患者内部解剖结构的单一快照。然而,医生和研究人员很快意识到,人体解剖结构并非静态不变;它是一个由遗传、营养和疾病驱动的高度动态的过程。为了准确诊断阿尔茨海默病等疾病或追踪儿童骨骼结构的正常发育,医学领域需要从三维静态图像转向四维统计形状分析。这意味着将“时间”作为第四维度加入。观察患者解剖结构的“电影”而非仅仅“照片”的临床需求,催生了对纵向影像数据的需求。
然而,迫使作者撰写本文的根本性限制是严重的数据瓶颈。获取真实的纵向数据需要对同一患者在数月或数年内进行重复扫描。这极其昂贵(通常每扫描一次花费数千美元,例如1000美元以上)、耗时且在后勤上困难重重,导致此类数据严重短缺。以往的AI模型试图生成合成的纵向数据,但它们存在一个致命缺陷:它们需要海量的现有纵向数据才能训练算法。与此同时,医院堆积着大量的“横断面”数据(来自许多不同个体的单次扫描)。以往的方法无法有效利用这些丰富的横断面数据来预测个体、受试者随时间推移的特定变化。
为了弥合这一差距,作者引入了几个高度专业化的概念。以下是它们在日常语言中的含义:
- 纵向数据(Longitudinal Data): 想象一株植物从萌芽到盛开的延时视频。它追踪同一主体随时间的变化,展示其生长过程中的因果关系。
- 横断面数据(Cross-sectional Data): 想象拍摄一张幼儿园班级、一个中学班级和一个高中班级的集体照。你可以看到一个“平均”的5岁或15岁儿童的样子,但你不知道一个特定的幼儿园儿童长大后会是什么样子。
- 图谱构建(Atlas Building): 可以将其视为创建一张“合成素描”。如果你拍摄数千张不同10岁儿童臀部的照片,并将它们进行数学上的融合,你就会得到一个代表典型10岁儿童臀部的标准、平均模板(即图谱)。
- 微分同胚(Diffeomorphism): 想象将医学图像打印在一张高度可拉伸的魔法橡胶片上。你可以拉伸、扭曲和弯曲这张橡胶片,使一个形状看起来像另一个形状,但你绝不允许撕裂橡胶片或将其折叠。由于它从未被撕裂,你总是可以完美地反向拉伸以恢复原始形状。
- 潜在嵌入(Latent Embeddings): 想象试图通过电话向朋友描述一辆复杂的3D汽车。与其描述每一个螺栓,你只需给出几个关键数字:长度、重量和发动机尺寸。潜在表示是AI将复杂的3D医学图像压缩成一串关键数学特征的方式。
在数学上,作者通过强制两个独立的AI任务协同工作,解决了仅使用大部分横断面数据生成受试者特定纵向数据的问题:构建每个年龄段的平均图谱,以及学习如何在不同年龄段之间进行形状变形。
首先,他们通过最小化一个能量函数来定义图谱构建问题:
$$E(I, v_0^n) = \sum_{n=1}^N \frac{1}{\sigma^2} \text{Dist}[I \circ \phi_1^{-1}(v_0^n), I_n] + \text{Reg}(v_0^n)$$
用通俗的话来说,这个方程试图通过测量变形后的平均图像与实际患者图像之间的距离($\text{Dist}$)来找到一个完美的平均图像($I$)。$\text{Reg}$项是一个规则,确保“橡胶片的拉伸”保持平滑和逼真。
为了实现他们的最终目标,作者设计了一个统一的神经网络,该网络最小化一个组合的总损失函数:
$$\ell = \mathcal{L}_{\text{tempo-atlas}}(\Theta) + \mathcal{L}_{\text{longitudinal}}(\Psi) + \gamma \mathcal{L}_{\text{latent}}(\mathbf{Z})$$
在这里,如果模型在以下三项任务中同时失败,就会受到惩罚:
1. $\mathcal{L}_{\text{tempo-atlas}}$:它必须为每个特定年龄组构建准确的平均图谱。
2. $\mathcal{L}_{\text{longitudinal}}$:它必须准确地弄清楚如何将一个年龄(例如10岁)的图谱变形到下一个年龄(例如12岁)。
3. $\mathcal{L}_{\text{latent}}$:它必须确保这些形状的压缩数学摘要(嵌入)在逻辑上聚集在一起,这意味着生物学上相似的形状在AI的“大脑”中保持接近。
通过解决这个联合方程,AI从人群(图谱)中学习衰老的普遍规律,并将这些规律应用于新患者的单一快照,从而成功预测该特定患者的解剖结构将如何随时间生长。
| 符号 | 描述 |
|---|---|
| $I_n$ | 数据集中的第 $n$ 个输入图像(例如,特定患者的CT扫描)。 |
| $I$ | 平均图像或模板图像,代表“平均”解剖结构(图谱)。 |
| $\phi$ | 应用于图像的数学变换(“变形”函数)。 |
| $v_0$ | 初始速度场,它决定了形状将如何开始变形。 |
| $\sigma^2$ | 图像中的噪声方差,用于加权距离测量。 |
| $A_q$ | 为给定年龄/时间 $q$ 构建的特定解剖图谱。 |
| $\Theta$ | 负责构建时间图谱的神经网络的可学习参数。 |
| $\Psi$ | 负责跨年龄(纵向)配准的神经网络的可学习参数。 |
| $\mathbf{z}_q^i$ | 年龄为 $q$ 时图像的潜在嵌入(压缩数学表示)。 |
| $\gamma$ | 一个调优参数,控制模型强制执行潜在嵌入规则的强度。 |
问题定义与约束
想象一下,你的任务是创建一个特定儿童成长的延时视频。然而,你手里没有那个孩子的连续视频,而是拿到了一本包含不同儿童不同年龄照片的庞大相册。你可以轻易地看出一个平均5岁或平均10岁的孩子是什么样子。但要准确预测一个特定的5岁孩子在10岁时会是什么样子,却极其困难,因为我们缺乏那个特定孩子的解剖学历史。
这正是医学研究人员在试图模拟人体器官和骨骼随时间发育时所面临的精确情景。
起始点与目标状态
输入(当前状态): 医学领域拥有丰富的3D横断面成像数据。这些是来自多个不同个体的单时间点快照(如CT或MRI扫描)。尽管数据量丰富,但这些数据集仅代表时间上的一个瞬间,对因果生物学变化提供零信息。
输出(目标状态): 临床医生迫切需要4D纵向数据。这意味着需要同一患者随时间的、个体化的、随时间变化的结构变化。如果医生输入一个8岁患者髋部的3D扫描,目标是输出一个生物学上准确的、高度个性化的3D扫描,显示该患者在10岁或15岁时髋部将呈现的样子。
数学鸿沟: 缺失的环节是一个连续的、可逆的变换场,它可以在不依赖配对的纵向训练数据的情况下,将特定的解剖结构向前推进时间。我们需要一座数学桥梁,连接群体平均值(一个“图谱”)与个体化的时间轨迹。
痛苦的困境
为了生成逼真的纵向数据,深度学习模型(如序列感知扩散模型)通常需要海量的真实纵向数据进行训练。陷阱就在于此:
没有纵向数据就无法训练出好的纵向模型,而纵向数据则以昂贵(每位患者扫描费用常高达1000美元以上)、耗时且极其难以收集而闻名。如果研究人员试图绕过这一点,仅依靠丰富的横断面数据来训练模型,生成的未来图像就会失去个体特异性。模型最终会预测出一个通用的“平均”个体,而不是保留原始患者独特的骨骼几何形状。以往的研究人员一直被困在数据可用性与时间精度之间的这种痛苦权衡中。
严酷的壁垒与约束
为了解决这个问题,作者们面临着几个严峻的约束:
- 极端数据稀疏性: 真实的纵向数据需要数年时间收集。患者会退出研究,成像硬件会发生变化,而对相隔数年的扫描进行对齐会引入巨大的变异性。
- 生物形变物理学: 骨骼和组织的生长不仅仅是简单的像素移动;它涉及复杂的非线性生物学变化。为了模拟这一点,作者们不得不使用大形变微分同胚度量映射(LDDMM)。这确保了变换是平滑且可逆的(微分同胚的),意味着组织不会神奇地撕裂、交叉或折叠。然而,计算这个需要使用欧拉-庞加莱微分(EPDiff)方程将速度场向前积分:
$$ \frac{\partial v_t}{\partial t} = -K \left[ (D v_t)^T \cdot m_t + D m_t \cdot v_t + m_t \cdot \text{div} \, v_t \right] $$
求解这个方程以找到最优速度场 ($v_t$) 和动量向量 ($m_t$) 是一个巨大的计算负担。 - 模糊伪影壁垒: 当以往最先进的模型(如VoxelMorph或B-splines)尝试在大的年龄跨度之间变形解剖结构时,它们引入了严重的畸变和模糊的边界。当模型被迫猜测一个结构如何随年增长时,保留精细的解剖细节,如发育中的髋部三叉软骨,就变得异常困难。
他们如何解决:一个统一的数学框架
作者们意识到,要打破困境,他们不能仅仅构建一个生成器;他们必须同时构建一个映射。他们设计了一个新颖的深度学习框架,该框架同时执行两项任务:时间图谱构建(在给定年龄找到群体平均值)和跨年龄图像配准(将该平均值与特定目标对齐以模拟生长)。
首先,他们定义了一个损失函数,通过最小化图谱与横断面图像 ($I_i^q$) 之间的距离,并以速度场 ($v_i^q$) 进行正则化,来构建一系列特定年龄的图谱 ($A_q$):
$$ \mathcal{L}_{\text{tempo-atlas}}(\Theta) = \sum_{q=1}^{Q} \sum_{i=1}^{N_q} \text{Dist}\left[ \phi_{q \to i}^{-1}(\Theta) \circ A_q, I_i^q \right] + \text{Reg}(v_i^q) $$
接下来,他们通过将源图谱与目标年龄 ($q'$) 对齐来模拟纵向变化:
$$ \mathcal{L}_{\text{longitudinal}}(\Psi) = \sum_{m=1}^{M} \text{Dist}\left[ \phi_{q \to q'}^{-1}(\Psi) \circ A_q, I_{q'}^m \right] + \text{Reg}(v_{m}^{q'}) $$
突破点: 该论文真正的天才之处在于他们如何使用独特的潜在嵌入将这两个空间联系起来。他们迫使神经网络学习一个潜在空间 $\mathbf{Z}$,在这个空间中,解剖学上相似的结构紧密聚集,而这些嵌入之间的距离严格地与变形所需的物理形变(速度场)相关联。
他们通过一个专门的损失函数来强制执行这一点:
$$ \mathcal{L}_{\text{latent}}(\mathbf{Z}) = \mathbb{E} \left[ -\log(\sigma(\text{sim}(\mathbf{z}_q^i, \mathbf{z}_{q'}^m))) \right] + \lambda \mathbb{E} \left[ \text{Corr}\left( \|\mathbf{z}_q^i - \mathbf{z}_{q'}^m\|^2, \|v_q^i - v_{q'}^m\|^2 \right) \right] $$
第一项使用余弦相似度来对相关形状进行分组。第二项是关键的创新:它计算潜在嵌入的欧几里得距离 ($\|\mathbf{z}_q^i - \mathbf{z}_{q'}^m\|^2$) 与形变的物理能量 ($\|v_q^i - v_{q'}^m\|^2$) 之间的相关性。
通过将抽象的潜在空间与微分同胚形变的物理定律在数学上锁定,模型可以查看单个横断面扫描,将其映射到时间图谱,并准确地预测该特定几何形状将如何随时间演变——完全绕过了对海量纵向训练数据集的需求。
为何采用此方法
为了理解作者为何选择这种高度特定且数学上复杂的处理方法,我们首先需要审视传统最先进(SOTA)方法遭遇瓶颈的确切时刻。
近年来,深度学习领域一直沉迷于生成模型。如果你想生成一系列图像来展示儿童髋骨随时间如何生长,你的第一反应可能是使用扩散模型(Diffusion model)或Transformer。事实上,作者明确指出,之前的研究者正是这样做的:Yoon等人使用了序列感知扩散模型,Puglisi等人使用了潜在扩散模型(latent diffusion models)来模拟结构随时间的变化。
但这里存在一个致命的缺陷,迫使作者放弃了这些流行的方法:标准的生成模型极其消耗数据。它们需要海量的、配对的纵向数据集——这意味着你需要对同一患者进行多年、数千次的3D扫描。在真实的临床环境中,这类数据的成本高昂得令人望而却步,耗时耗力,并且实际上并不存在。绝大多数可用的医疗数据是横断面的(cross-sectional)(即不同个体在单一、孤立时间点的快照)。扩散模型和GAN(生成对抗网络)在训练过程中如果没有看到实际的时间序列,就无法学习特定个体的时序动力学。它们在这里会失败,因为它们无法从不连续的快照中推断出生物学上准确的生长轨迹。
面对这一严峻的限制,作者意识到唯一可行的解决方案是将物理和几何学的严格定律嵌入到学习过程中。他们转向了大规模变形微分同胚度量映射(Large Deformation Diffeomorphic Metric Mapping, LDDMM)。
为什么这在数学上更优越?微分同胚变换保证了两个解剖形状之间的映射是光滑的、连续的且严格可逆的。在生物学中,组织会拉伸和生长,但它们不会随机撕裂、折叠自身或瞬移。通过将问题框架化在欧拉-庞加莱微分(Euler-Poincaré differential, EPDiff)方程中,作者确保了解剖学生长的测地线路径由初始速度场 $v_0$ 随时间积分唯一确定:
$$ \frac{\partial v_t}{\partial t} = -K \left[ (D v_t)^T \cdot m_t + D m_t \cdot v_t + m_t \cdot \text{div} \, v_t \right] $$
这在问题的严峻约束(缺乏纵向数据)和解决方案的独特属性之间建立了完美的“结合”。模型不再试图盲目猜测骨骼如何生长,而是联合执行两项任务:它构建一个“图谱”(atlas)(例如,8岁人群的平均形状),然后学习将8岁图谱扭曲成10岁图谱的微分同胚速度场。接着,它将这些学习到的、具有生物学合理性的速度场应用于特定患者的基线扫描,以生成对其未来解剖结构的极其可靠的预测。
与之前的金标准——如VoxelMorph(VM)或B样条配准(B-spline registration)——相比,该方法在结构上的优势是深远的。传统的配准方法只是试图最小化图像A和图像B之间的像素级差异。正如论文的基准测试所示,这通常会导致模糊的边界和严重的伪影(例如,在VoxelMorph基线中看到的髂骨周围的扭曲)。
为了克服这一点,作者引入了一个巧妙的“区分性潜在嵌入”(Distinctive Latent Embedding)损失。他们不仅仅是匹配图像;他们强制神经网络的潜在空间完美地镜像物理变形空间。损失函数包含一个项,用于衡量潜在嵌入 $\mathbf{z}$ 的距离与速度场 $v$ 的物理距离之间的相关性:
$$ \mathcal{L}_{\text{latent}}(\mathbf{Z}) = \dots + \lambda \mathbb{E}_{(\mathbf{z}_q^i, \mathbf{z}_{q'}^m)} \left[ \text{Corr} \left( \|\mathbf{z}_q^i - \mathbf{z}_{q'}^m\|^2, \|v_q^i - v_{q'}^m\|^2 \right) \right] $$
这在数学上迫使潜在空间保留由速度场决定的几何和时间关系。它解耦了随时间变化的渐进形状,使得模型能够生成清晰锐利、无伪影的边界,尤其是在三叉软骨(tri-radiate cartilages)等复杂生长中心周围。
坦白说,我并不完全确定该特定架构是否将计算内存复杂度从 $O(N^2)$ 降低到 $O(N)$,因为作者在文本中并未明确提供大O(Big-O)算法分析。然而,压倒性清晰的是其数据效率。通过利用微分同胚的几何潜在空间,该框架实现了SOTA扩散模型无法实现的目标:它仅使用稀疏的、横断面的3D输入,即可合成高度准确的、特定于个体的4D纵向数据。
数学与逻辑机制
为了理解本文的深远意义,我们首先需要理解医学影像领域的基本数据问题。想象一下,试图通过翻阅一本相册来了解一个孩子的成长过程。如果你有一本“纵向”相册——包含同一孩子每年拍摄的照片——你就能轻松地看到他们成长的确切轨迹。但在医学领域,获取同一患者多年来的纵向三维扫描(如 CT 或 MRI)极其昂贵、耗时且罕见。取而代之的是,医院拥有海量的“横断面”数据:不同年龄段不同个体的单一快照。
本文的作者构建了一个精妙的数学引擎,它能够处理这些来自不同个体的、不相关的快照,并学习潜在的“生长规律”。然后,它利用这些规律,为一名全新的患者生成高度精确、个性化的三维延时摄影(纵向数据),精确预测其解剖结构将如何随时间变化。
以下是实现这一目标的确切数学机制。
主方程
本文的核心引擎由一个统一的目标函数驱动,该函数同时平衡三个庞大的任务:构建一个“平均”模板(图谱),预测不同年龄段的生长,以及迫使模型理解这些变化的物理现实。
驱动整个网络的总损失函数为:
$$ \ell = \mathcal{L}_{\text{tempo-atlas}}(\Theta) + \mathcal{L}_{\text{longitudinal}}(\Psi) + \gamma \mathcal{L}_{\text{latent}}(\mathbf{Z}) $$
但真正的“秘方”——本文最具创新性的部分——是区分性潜在嵌入损失,它充当了操作的大脑:
$$ \mathcal{L}_{\text{latent}}(\mathbf{Z}) = \mathbb{E}_{(\mathbf{z}_q^i, \mathbf{z}_{q'}^m)} \big[ -\log(\sigma(\text{sim}(\mathbf{z}_q^i, \mathbf{z}_{q'}^m))) \big] + \lambda \, \mathbb{E}_{(\mathbf{z}_q^i, \mathbf{z}_{q'}^m)} \big[ \text{Corr} \big( \|\mathbf{z}_q^i - \mathbf{z}_{q'}^m\|^2, \; \|v_q^i - v_{q'}^m\|^2 \big) \big] $$
解析方程
让我们来剖析这个机制中的每一个齿轮和弹簧。
来自总损失 ($\ell$):
* $\ell$:总损失。这是机器试图最小化至零的最终“误差分数”。
* $\mathcal{L}_{\text{tempo-atlas}}(\Theta)$:时间图谱构建损失。此项衡量网络(参数为 $\Theta$)在特定年龄段创建“平均”解剖模板的能力。它充当基线锚点。
* $\mathcal{L}_{\text{longitudinal}}(\Psi)$:跨年龄配准损失。此项衡量网络(参数为 $\Psi$)将一个年龄段的图像变形以匹配更年长年龄段解剖结构的能力。它是“时间机器”组件。
* $\gamma$:标量权重(一个平衡旋钮)。它决定了模型应将多少注意力放在潜在嵌入上,而不是图像生成上。
* 为何使用加法而非乘法? 作者使用加法来创建一个多任务平衡秤。如果他们将这些项相乘,图谱损失中的一个接近零的分数将完全抹去纵向损失的梯度(学习信号),从而完全停止学习过程。加法确保即使一项任务表现完美,模型仍然感受到改进其他任务的压力。
来自潜在嵌入损失 ($\mathcal{L}_{\text{latent}}(\mathbf{Z})$):
* $\mathbf{Z}$:所有潜在嵌入的矩阵。嵌入是对三维医学图像的高度压缩、抽象的数学摘要。
* $\mathbb{E}_{(\mathbf{z}_q^i, \mathbf{z}_{q'}^m)}$:这些压缩嵌入对的期望值(平均值)。$\mathbf{z}_q^i$ 是患者 $i$ 在年龄 $q$ 时的嵌入,$\mathbf{z}_{q'}^m$ 是患者 $m$ 在年龄 $q'$ 时的嵌入。
* 为何使用期望值而非硬求和($\sum$)? 在深度学习中,计算海量数据集上所有可能图像对的确切总和在计算上是爆炸性的。使用期望值允许模型在训练过程中随机抽样成对图像,从而近似真实平均值,同时节省大量内存。
* $-\log(\sigma(\dots))$:Sigmoid 函数的负对数。这是一个经典的惩罚机制。Sigmoid ($\sigma$) 将值压缩到 0 和 1 之间(类似于概率)。如果此值接近 0,负对数将对模型进行严厉惩罚。
* $\text{sim}(\mathbf{z}_q^i, \mathbf{z}_{q'}^m)$:两个嵌入之间的余弦相似度。它衡量两个向量之间的角度。
* 逻辑作用: 整个第一项充当引力。如果两个解剖形状相关,它就会迫使它们的抽象数学向量在潜在空间中指向完全相同的方向。
* $\lambda$:另一个平衡旋钮,专门控制物理约束的强度。
* $\text{Corr}(\dots)$:皮尔逊相关系数。它衡量两个变量之间的线性相关程度。
* $\|\mathbf{z}_q^i - \mathbf{z}_{q'}^m\|^2$:两个抽象嵌入之间的平方欧几里得距离。将其视为 8 岁髋关节和 10 岁髋关节之间的“概念距离”。
* $\|v_q^i - v_{q'}^m\|^2$:其关联速度场($v$)的平方距离。速度场是一个三维箭头图,精确指示像素如何物理流动和拉伸以变形一个形状到另一个形状。
* 逻辑作用: 这个相关项是纯粹的创新。它充当严格的物理检查员。它迫使嵌入的抽象“概念距离”与变形组织所需的实际“物理拉伸能量”完美相关。它阻止神经网络通过任意地将图像放置在潜在空间中来作弊。
逐步流程
让我们追踪一个抽象数据点——一名 8 岁患者髋部的三维 CT 扫描——在数学流水线中的移动过程。
- 压缩: 8 岁髋部的原始三维像素进入网络,并立即被压缩成一个密集、抽象的向量 $\mathbf{z}_q^i$。
- 锚定: 系统将此向量与已构建的“平均 8 岁髋部”模板进行比较。它计算特定患者偏离正常值的程度。
- 时间旅行: 用户请求预测该髋部在 12 岁时会是什么样子。网络查看“平均 12 岁”模板。它生成一个速度场 $v$——一个流体状的箭头图,指示 8 岁骨骼必须如何拉伸、生长和弯曲才能达到 12 岁状态。
- 质量控制: $\mathcal{L}_{\text{latent}}$ 损失开始发挥作用。它检查 8 岁向量和 12 岁向量之间的抽象距离。它严格验证此抽象距离是否与速度场 $v$ 的物理能量相匹配。如果数学与物理不符,模型将受到惩罚。
- 生成: 最后,速度场被应用于原始三维扫描,像数字粘土一样平滑地变形像素,输出生物学上准确的、合成的 12 岁髋部扫描。
优化动力学
这个复杂的架构实际上是如何学习和收敛的?
模型使用梯度下降(特别是 Adam 优化器)来优化其参数。最初,损失景观非常混乱。网络试图走捷径,也许只是模糊 8 岁的图像,使其看起来大致像 12 岁的图像,以快速减小图像距离损失。
然而,模型受到微分同胚数学的约束(特别是论文背景中提到的欧拉-庞加莱微分方程)。这意味着变换必须是平滑的、连续的和可逆的——就像折叠一张橡皮纸而不撕裂它或让它穿过自身一样。
由于这种严格的物理约束,损失景观呈陡峭、平滑的漏斗状。当梯度通过网络反向流动时,嵌入 $\mathbf{Z}$ 被迫进行精美的组织。相似年龄的扫描紧密聚集在一起,而不同年龄的扫描则以与它们之间过渡所需的物理生长精确成比例的方式分开。经过 1000 个 epoch 的训练,系统达到平衡:生成的图谱变得锐利无比,预测的生长轨迹变得解剖学上完美,使模型能够以惊人的精度“幻觉”出患者解剖结构的未来。
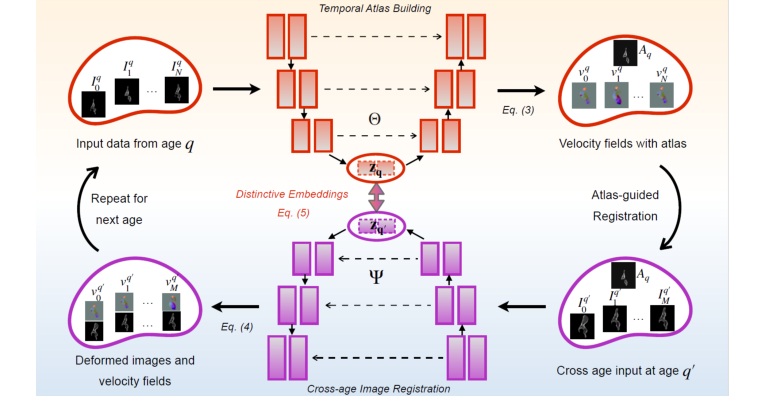 Figure 1. Overview of our model. Training: Our network constructs a sequence of tempo- ral atlases, starting at age q and modeling deformations across target ages. A geometric embedding loss in the latent space enforces structured, biologically meaningful anatom- ical evolution. Iterative refinement enhances the interplay between cross-sectional and longitudinal dynamics, generating anatomically coherent cross-age data. Inference: For each subject, we first align their baseline images to the corresponding age-specific atlas. The trained model Ψ operates as a longitudinal data generator, synthesizing anatomically plausible trajectories for unseen subjects by extracting geometric fea- tures through the atlas. It uses generated velocity fields from cross-age registration between age-specific atlases to deform subject-specific structures over time, ensuring a smooth and temporally consistent evolution
Figure 1. Overview of our model. Training: Our network constructs a sequence of tempo- ral atlases, starting at age q and modeling deformations across target ages. A geometric embedding loss in the latent space enforces structured, biologically meaningful anatom- ical evolution. Iterative refinement enhances the interplay between cross-sectional and longitudinal dynamics, generating anatomically coherent cross-age data. Inference: For each subject, we first align their baseline images to the corresponding age-specific atlas. The trained model Ψ operates as a longitudinal data generator, synthesizing anatomically plausible trajectories for unseen subjects by extracting geometric fea- tures through the atlas. It uses generated velocity fields from cross-age registration between age-specific atlases to deform subject-specific structures over time, ensuring a smooth and temporally consistent evolution
结果、局限性与结论
核心问题:摆脱快照陷阱
要理解本文的意义,我们首先需要理解两种医学数据之间的根本区别:横断面 (cross-sectional) 和 纵向 (longitudinal)。
想象一下,你想了解人类面部是如何衰老的。如果你拍摄 100 个不同年龄(从 5 岁到 50 岁)的人的照片,你就获得了横断面数据。你可以推测出衰老的总体趋势,但你无法确切知道 5 岁的孩子 50 岁时会长成什么样子。现在,想象一下拍摄完全相同的人从 5 岁到 50 岁每年一次的照片。这就是纵向数据。它捕捉了变化真正、个体特异性的时空动力学。
在医学影像学中,纵向 3D 数据(随时间推移成为 4D 数据)是追踪解剖结构如何发育或疾病如何进展的“圣杯”。然而,收集这些数据是一场后勤噩梦。它极其昂贵——在十年内,扫描费用和行政开销往往每位患者高达 10,000 美元以上——并且患者极易流失。因此,绝大多数医学数据库都是横断面的。
本文的作者面临一个巨大的限制:当我们训练数据主要由不同个体的断开的快照组成时,如何准确预测特定患者未来的 3D 解剖形状?
数学引擎:微分同胚与潜在时间旅行
为了解决这个问题,作者们并没有仅仅训练一个标准的神经网络来猜测下一帧。他们构建了一个框架,同时执行两项任务:图谱构建 (Atlas Building)(找到特定年龄人群的“平均”形状)和 纵向数据生成 (Longitudinal Data Generation)(预测特定个体的形状如何随年龄演变)。
他们将解决方案建立在大型变形微分同胚度量映射 (Large Deformation Diffeomorphic Metric Mapping, LDDMM) 的数学基础上。简单来说,微分同胚是一种光滑、连续且可逆的变换。想象一下将一个 5 岁儿童髋骨的粘土雕塑变形为一个 10 岁儿童的髋骨,而粘土从未破裂或自身折叠。
从一组 $N$ 张图像构建图谱(模板图像 $I$)的基线能量函数定义为:
$$E(I, v_0^n) = \sum_{n=1}^N \frac{1}{\sigma^2} \text{Dist}[I \circ \phi_1^{-1}(v_0^n), I_n] + \text{Reg}(v_0^n)$$
这里,$v_0^n$ 代表初始速度场——这是将模板变形为目标图像 $I_n$ 所需的“推动力”。变换路径由欧拉-庞加莱微分 (Euler-Poincaré differential, EPDiff) 方程控制,该方程决定了速度如何随时间向前流动:
$$\frac{\partial v_t}{\partial t} = -K \left[ (D v_t)^T \cdot m_t + D m_t \cdot v_t + m_t \cdot \text{div} \, v_t \right]$$
坦白说,本文并未明确详细说明在深度学习训练过程中求解此积分所需的具体计算内存占用,但考虑到数据的 3D 特性,我们可以推断它需要强大的 GPU 支持(他们使用了 RTX A6000 来处理)。
他们架构的真正天才在于独特的潜在嵌入 (Distinctive Latent Embeddings)。他们迫使神经网络学习一个潜在空间 $\mathbf{Z}$,在这个空间中,两个嵌入之间的数学距离与将它们变形所需的物理变形完美相关。他们的潜在损失函数是:
$$\mathcal{L}_{\text{latent}}(\mathbf{Z}) = \mathbb{E}_{(\mathbf{z}_q^i, \mathbf{z}_{q'}^m)} \left[ -\log(\sigma(\text{sim}(\mathbf{z}_q^i, \mathbf{z}_{q'}^m))) \right] + \lambda \, \mathbb{E}_{(\mathbf{z}_q^i, \mathbf{z}_{q'}^m)} \left[ \text{Corr} \left( \|\mathbf{z}_q^i - \mathbf{z}_{q'}^m\|^2, \, \|v_q^i - v_{q'}^m\|^2 \right) \right]$$
第一项使用余弦相似度迫使相关的形状聚集在一起。第二项是点睛之笔:它确保两个潜在向量之间的平方欧几里得距离 $\|\mathbf{z}_q^i - \mathbf{z}_{q'}^m\|^2$ 与将一种形状变形为另一种形状所需的物理“努力”(速度场距离 $\|v_q^i - v_{q'}^m\|^2$)相关。
最终的目标函数优雅地平衡了时间图谱构建、跨年龄配准以及这种潜在嵌入:
$$\ell = \mathcal{L}_{\text{tempo-atlas}}(\Theta) + \mathcal{L}_{\text{longitudinal}}(\Psi) + \gamma \mathcal{L}_{\text{latent}}(\mathbf{Z})$$
实验:严酷的现实验证
作者们并没有随意地套用指标,而是设计了一个高度严谨的实验。他们在正常男性髋部的横断面数据集(年龄 4-18 岁)上进行了训练。但为了证明他们的模型确实有效,他们在一个隐藏的、极具价值的真实纵向 CT 扫描数据集(12 名患者,多年后进行了多次扫描)上进行了测试。
受害者(基线):
对于图谱构建,他们彻底拆解了 B-spline、多对比度配准 (Multi-contrast registration, M-c. reg.) 和 VoxelMorph (VM) 等成熟模型。对于纵向生成,他们击败了 NAHA (Nearest-Age Hip Approximation) 和 ABAA (Age-Based Atlas Approximation)。
决定性证据:
证据不仅仅在于 Dice 分数(尽管他们取得了主导性的 0.88)。无可辩驳的证据是视觉和几何上的。他们取了一个 12 岁患者真实髋部的 CT 扫描,将其输入模型,并要求模型“幻觉”出同一患者的 15 岁版本。
当他们将合成的 15 岁髋部叠加到该患者实际的 15 岁扫描上时,边界完美匹配。基线模型在此处惨败——VoxelMorph 在后髂嵴周围产生了严重的伪影失真,而其他方法则产生了模糊、解剖上不可能的骨骼边缘。作者的模型保留了三叉软骨周围清晰、精细的解剖细节,证明了他们的潜在空间成功地学习了骨骼生长的生物学规律,而不仅仅是盲目地插值像素。
未来轨迹与讨论话题
基于该框架的深远影响,以下是几个关键的未来探索方向:
-
生物力学物理先验的整合:
目前,该模型仅从几何变换(微分同胚)中学习生长规律。然而,骨骼发育受到物理力(沃尔夫定律——骨骼适应所承受的载荷)的强烈影响。我们如何将生物力学应力张量注入 EPDiff 方程?如果一个孩子有异常步态,我们能否将潜在空间条件化,以预测该特定机械应力将如何改变他们未来的骨骼形状? -
分支病理性潜在空间:
本文侧重于正常男性髋部以建立基线。但疾病很少是线性进展的。如果我们引入病理性数据(例如,髋关节发育不良),我们如何构建潜在空间,使得单个横断面扫描可以预测多种可能的未来?我们需要讨论如何将这种确定性模型演变为概率性模型,也许可以使用潜在空间中的扩散模型来生成未来疾病进展的“不确定性锥”。 -
跨模态时间对齐:
作者使用了 CT 扫描,它提供了出色的骨骼对比度,但会使儿科患者暴露于电离辐射。儿科影像学的未来是 MRI 或超声。然而,这些模态具有截然不同的噪声特性和伪影行为。一个有趣的讨论点是,从 CT 数据中学习到的几何潜在嵌入是否可以转移到 MRI 数据上。生长的“速度场”是否可以与成像模态本身的像素强度解耦?
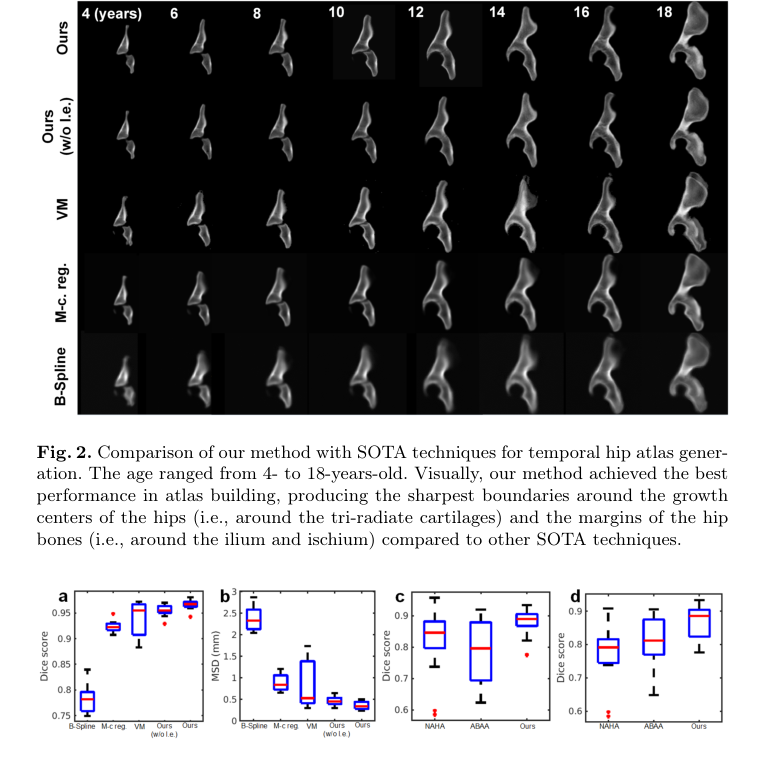 Figure 3. Boxplots of the atlas-to-patient (within-age) registration results based on the mean Dice score (a) and the MSD (b). Boxplots of the longitudinal data generation results for all testing cases (c) and for the cases when the age gap is >1 year (d) based on mean Dice score. The ages of the subjects in these experiments ranged from 4 to 18 years. Our method achieved superior performance compared to others
Figure 3. Boxplots of the atlas-to-patient (within-age) registration results based on the mean Dice score (a) and the MSD (b). Boxplots of the longitudinal data generation results for all testing cases (c) and for the cases when the age gap is >1 year (d) based on mean Dice score. The ages of the subjects in these experiments ranged from 4 to 18 years. Our method achieved superior performance compared to others
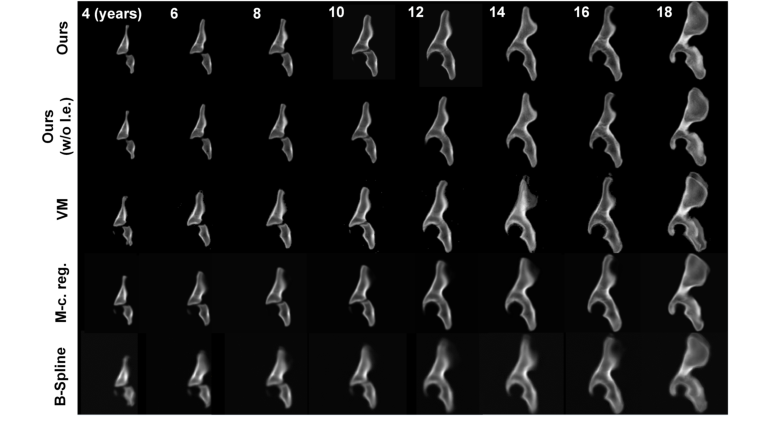 Figure 2. Comparison of our method with SOTA techniques for temporal hip atlas gener- ation. The age ranged from 4- to 18-years-old. Visually, our method achieved the best performance in atlas building, producing the sharpest boundaries around the growth centers of the hips (i.e., around the tri-radiate cartilages) and the margins of the hip bones (i.e., around the ilium and ischium) compared to other SOTA techniques
Figure 2. Comparison of our method with SOTA techniques for temporal hip atlas gener- ation. The age ranged from 4- to 18-years-old. Visually, our method achieved the best performance in atlas building, producing the sharpest boundaries around the growth centers of the hips (i.e., around the tri-radiate cartilages) and the margins of the hip bones (i.e., around the ilium and ischium) compared to other SOTA techniques
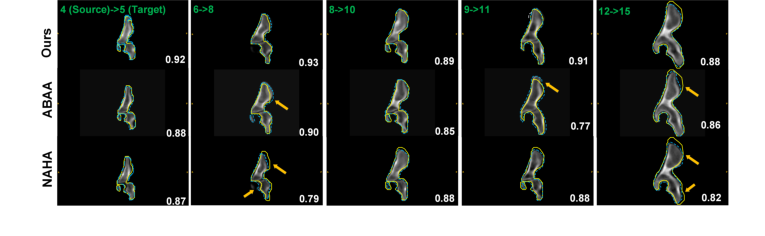 Figure 4. Comparison of various methods for the longitudinal data generation task based on a real longitudinal dataset. For example, in the first column, given an input hip dataset from a 4-year-old subject (source), the longitudinal data generator predicted the 3D synthetic longitudinal CT hip shape of the same subject at the age of 5. The source and target ages are denoted in green text in the left upper corner of each frame. The segmentation contour (blue dashed line) produced by our method aligns better with the ground truth contour (yellow line) than other techniques, as indicated by the higher Dice scores (white text). Arrows highlight regions with large alignment errors
Figure 4. Comparison of various methods for the longitudinal data generation task based on a real longitudinal dataset. For example, in the first column, given an input hip dataset from a 4-year-old subject (source), the longitudinal data generator predicted the 3D synthetic longitudinal CT hip shape of the same subject at the age of 5. The source and target ages are denoted in green text in the left upper corner of each frame. The segmentation contour (blue dashed line) produced by our method aligns better with the ground truth contour (yellow line) than other techniques, as indicated by the higher Dice scores (white text). Arrows highlight regions with large alignment errors
与其他域的同构
一种在几何约束的潜在空间内,通过联合优化组内对齐和组间时间变换,来构建离散、静态空间分布之间连续、可逆演化轨迹的机制。
天体物理学与星系演化
天文学家面临着巨大的观测障碍:由于光速和宇宙的浩瀚,他们只能在特定时间点捕捉到星系的静态快照(横截面数据),而无法观察单个星系数十亿年的演化过程(纵向数据)。本文的核心逻辑——构建“年龄内”图谱以指导“年龄间”的微分同胚变换——与星系形态学问题完美对应。正如作者从稀疏的患者快照中描绘发育中的髋骨的结构变化一样,天体物理学家需要利用不同红移下不同星系的稀疏快照来描绘星系的结构演化(例如,从旋涡状到椭圆形)。
量化金融与市场微观结构
在金融工程领域,分析师通常拥有同一时间点跨不同资产的大量横截面数据,但却难以预测单个资产在宏观经济环境变化下的连续、个体化轨迹。本文利用速度场来强制执行时间上的几何一致性的概念,与模拟波动率曲面或收益率曲线变形的挑战相呼应。例如,要描绘特定资产的风险剖面如何随着其基础价格从100美元涨到150美元而变形,就需要将“群体层面市场趋势”(时间图谱)和“资产特定价格轨迹”(纵向生成)进行精确的数学分离。
“如果”场景
如果一位理论天体物理学家明天窃取了本文的精确总损失方程,会发生什么?
$$ \ell = \mathcal{L}_{\text{tempo-atlas}}(\Theta) + \mathcal{L}_{\text{longitudinal}}(\Psi) + \gamma \mathcal{L}_{\text{latent}}(\mathbf{Z}) $$
通过将数百万张詹姆斯·韦伯太空望远镜的静态图像输入该框架,他们可以将不同的红移时期视为“年龄”,将单个星系的形状视为“横截面输入”。$\mathcal{L}_{\text{latent}}(\mathbf{Z})$ 项将强制潜在空间保持星系结构的几何关系。这将是一项前所未有的突破:该算法将合成一个数学上严谨的、为期100亿年的单个星系演化的4D纵向电影,从而有效解决了星系形成中的“缺失环节”问题,而无需等待数十亿年才能获得数据。
通过证明孤立的静态快照可以被数学地编织成流畅的、高度个性化的历史,本文为“结构通用图书馆”增添了一份重要的蓝图,表明人类骨骼的生物生长和遥远星系的宇宙衰老,最终都遵循着完全相同的几何编排。