अवशिष्ट पश्च पैटर्न पर मस्तिष्क कनेक्टिविटी सुविधाओं का शोधन
मानव मस्तिष्क की वास्तविक प्रकृति को समझने के लिए, हमें अलग अलग क्षेत्रों से परे जाकर उनके संचार का अध्ययन करना चाहिए। ऐतिहासिक रूप से, तंत्रिका विज्ञानी मस्तिष्क की गतिविधि को पकड़ने के लिए फंक्शनल मैग्नेटिक रेजोनेंस...
पृष्ठभूमि और अकादमिक वंश
मानव मस्तिष्क की वास्तविक प्रकृति को समझने के लिए, हमें अलग-अलग क्षेत्रों से परे जाकर उनके संचार का अध्ययन करना चाहिए। ऐतिहासिक रूप से, तंत्रिका विज्ञानी मस्तिष्क की गतिविधि को पकड़ने के लिए फंक्शनल मैग्नेटिक रेजोनेंस इमेजिंग (fMRI) का उपयोग करते थे। कम्प्यूटेशनल न्यूरोसाइंस के क्षेत्र के विकसित होने के साथ, शोधकर्ताओं ने मस्तिष्क को एक जटिल नेटवर्क, या एक "ग्राफ" के रूप में प्रस्तुत करना शुरू किया, जहाँ मस्तिष्क के क्षेत्र नोड्स होते हैं और उनके संचार पथ किनारे होते हैं। इसने स्वाभाविक रूप से ऑटिज्म स्पेक्ट्रम डिसऑर्डर (ASD) और ADHD जैसे न्यूरोसाइकिएट्रिक विकारों का निदान करने के लिए इन फंक्शनल कनेक्टिविटी पैटर्न का विश्लेषण करके ग्राफ न्यूरल नेटवर्क (GNNs) को अपनाने की ओर अग्रसर किया।
हालांकि, एक महत्वपूर्ण बाधा उत्पन्न हुई। इस विशिष्ट कार्य के लिए पारंपरिक GNN दृष्टिकोण मौलिक रूप से त्रुटिपूर्ण थे क्योंकि वे मुख्य रूप से मस्तिष्क के क्षेत्रों (नोड्स) पर ही ध्यान केंद्रित कर रहे थे, न कि वास्तविक संचार पथों (किनारों) पर। न्यूरोसाइकिएट्रिक विकारों में, बीमारी अक्सर भौतिक क्षेत्रों के बजाय कनेक्शनों के परिवर्तन में प्रकट होती है। इसके अलावा, पिछले मॉडलों को एक बड़े कम्प्यूटेशनल बाधा का सामना करना पड़ा: यदि आप पूरी तरह से जुड़े मस्तिष्क ग्राफ में हर एकल कनेक्शन को एक प्राथमिक विशेषता के रूप में मानने का प्रयास करते हैं, तो गणित विस्फोट हो जाता है। एक विशिष्ट मस्तिष्क एटलस अरबों पैरामीटर के साथ एक मैट्रिक्स उत्पन्न कर सकता है, जिससे इसे संसाधित करना कम्प्यूटेशनल रूप से असंभव हो जाता है। इसके ऊपर, चिकित्सा डेटासेट कुख्यात रूप से छोटे और शोर वाले होते हैं, जिससे पारंपरिक मॉडल ओवरफिट हो जाते हैं - जिसका अर्थ है कि वे प्रशिक्षण डेटा को याद कर लेते हैं लेकिन वास्तविक दुनिया के नैदानिक अनुप्रयोगों में पूरी तरह से विफल हो जाते हैं।
इस अंतर को पाटने के लिए, लेखकों ने रेजिडुअल-पोस्टीरियर लाइन ग्राफ नेटवर्क (RP-LGN) पेश किया। आइए उनके द्वारा उपयोग की जाने वाली अत्यधिक विशिष्ट अवधारणाओं को सहज विचारों में तोड़ें:
शब्दावली का विच्छेदन
- फंक्शनल मैग्नेटिक रेजोनेंस इमेजिंग (fMRI) और BOLD सिग्नल: पेपर में, यह मस्तिष्क में रक्त प्रवाह परिवर्तन को मापने वाला कच्चा डेटा है।
- रोजमर्रा की सादृश्यता: कल्पना कीजिए कि एक उपग्रह रात में शहर में यातायात की भीड़ को हेडलाइट्स के घनत्व को देखकर ट्रैक कर रहा है। fMRI रक्त प्रवाह के साथ ऐसा करता है; यह ट्रैक करता है कि "यातायात" (ऑक्सीजन युक्त रक्त) कहाँ जा रहा है ताकि यह पता लगाया जा सके कि कौन से "चौराहे" (मस्तिष्क क्षेत्र) वर्तमान में सक्रिय हैं और एक-दूसरे से बात कर रहे हैं।
- लाइन ग्राफ ट्रांसफॉर्मेशन: किनारों को नोड्स में बदलने की एक गणितीय तकनीक।
- रोजमर्रा की सादृश्यता: मान लीजिए आप एक वैश्विक एयरलाइन नेटवर्क का अध्ययन कर रहे हैं। सामान्य तौर पर, आप शहरों (नोड्स) का अध्ययन करते हैं और उड़ान मार्गों (किनारों) के लिए रेखाएँ खींचते हैं। एक लाइन ग्राफ ट्रांसफॉर्मेशन इसे उलट देता है: आप उड़ान मार्गों को अपने अध्ययन का मुख्य विषय (नए नोड्स) बनाते हैं, और शहर केवल अंतिम बिंदु बन जाते हैं। यह AI को वास्तविक कनेक्शनों का सीधे अध्ययन करने की अनुमति देता है।
- GNNs में ओवरस्मूथिंग: एक घटना जहाँ नोड्स के बीच संदेशों को बहुत बार पास करने से सभी नोड्स समान दिखने लगते हैं।
- रोजमर्रा की सादृश्यता: पेंट मिलाने की कल्पना करें। यदि आप धीरे-धीरे लाल और नीले रंग को घुमाते हैं, तो आपको एक सुंदर संगमरमर का पैटर्न (उपयोगी जानकारी) मिलता है। लेकिन अगर आप लगातार हिलाते रहते हैं, तो आप केवल एक सपाट, गंदा बैंगनी रंग पाते हैं। ओवरस्मूथिंग तब होता है जब AI डेटा को बहुत अधिक हिलाता है, जिससे मस्तिष्क की सभी अनूठी, विशिष्ट विशेषताओं का नुकसान होता है।
- बायेसियन वेरिएशनल पोस्टीरियर: भविष्यवाणी की अनिश्चितता को मापने के लिए मॉडल की अंतिम परत में उपयोग की जाने वाली एक सांख्यिकीय विधि।
- रोजमर्रा की सादृश्यता: मौसम ऐप द्वारा "कल बारिश होगी" कहने के बजाय (जो शोर वाले डेटा के कारण गलत हो सकता है), एक बायेसियन दृष्टिकोण कहता है, "मुझे 85% विश्वास है कि बारिश होगी, 5% कम या ज्यादा।" यह त्रुटि मार्जिन की गणना करता है, जिससे AI का चिकित्सा निदान बहुत अधिक मजबूत और भरोसेमंद हो जाता है, भले ही रोगी के स्कैन में बहुत अधिक पृष्ठभूमि शोर हो।
गणितीय खाका
लेखकों ने इसे गणितीय रूप से कैसे हल किया, इसकी व्याख्या करने के लिए, हमें उन चर को देखना होगा जो उनके ब्रह्मांड को परिभाषित करते हैं। वे पैरामीटर विस्फोट को रोकने के लिए $K$-नियरेस्ट नेबर्स (KNN) दृष्टिकोण का उपयोग करके प्रारंभिक कनेक्शनों को स्पार्सिफाई करते हैं, और फिर ग्राफ को एक लाइन ग्राफ $\tilde{G}$ पर मैप करते हैं। अंत में, वे एविडेंस लोअर बाउंड (ELBO) को अधिकतम करके मॉडल को ऑप्टिमाइज़ करते हैं, जिसे $\mathcal{L}_{VB}$ के रूप में दर्शाया गया है।
| संकेतन | विवरण |
|---|---|
| $V$ | मस्तिष्क में रुचि के क्षेत्रों (ROIs) का प्रतिनिधित्व करने वाले नोड्स का सेट। |
| $E$ | ROIs के बीच फंक्शनल कनेक्शन का प्रतिनिधित्व करने वाले किनारों का सेट। |
| $G = (\mathbf{A}, \mathbf{X})$ | fMRI डेटा से निर्मित मूल मस्तिष्क ग्राफ। |
| $\mathbf{A} \in \mathbb{R}^{|V| \times |V|}$ | मस्तिष्क क्षेत्रों के बीच आंशिक सहसंबंध गुणांक को परिभाषित करने वाला आसन्नता मैट्रिक्स। |
| $\mathbf{X} \in \mathbb{R}^{|V| \times |F|}$ | जोड़ीदार BOLD संकेतों के पियर्सन सहसंबंध पर आधारित नोड फीचर मैट्रिक्स। |
| $n$ | ROIs की कुल संख्या, जहाँ $|V| = n$ है। |
| $\mathcal{N}_i$ | नोड $i$ का $K$ निकटतम पड़ोसी नोड्स सेट, जिसका उपयोग ग्राफ को स्पार्सिफाई करने के लिए किया जाता है। |
| $\tilde{G} = \{\tilde{\mathbf{A}}, \tilde{\mathbf{X}}\}$ | निर्मित लाइन ग्राफ जहाँ मूल किनारों को अब नोड्स के रूप में माना जाता है। |
| $\tilde{\mathbf{x}}_i$ | नव निर्मित लाइन ग्राफ में $i$-वें नोड का फीचर वेक्टर। |
| $\tilde{\mathbf{Z}}^{(l)}$ | $l$-वें SAGEConv (GraphSAGE कनवल्शन) परत का आउटपुट फीचर मैट्रिक्स। |
| $W$ | अंतिम रैखिक वर्गीकरण परत का भार मैट्रिक्स। |
| $\Sigma$ | वेरिएशनल पोस्टीरियर का सहप्रसरण मैट्रिक्स, जिसका उपयोग अनिश्चितता को मॉडल करने के लिए किया जाता है। |
| $\mathcal{L}_{VB}(\theta, \eta, \Sigma)$ | मॉडल को ऑप्टिमाइज़ करने के लिए उद्देश्य फ़ंक्शन के रूप में उपयोग किया जाने वाला वेरिएशनल लोअर बाउंड (ELBO)। |
इन तत्वों को मिलाकर, लेखकों ने मस्तिष्क नेटवर्क विश्लेषण के दृष्टिकोण में क्रांति ला दी। उन्होंने सफलतापूर्वक AI का ध्यान मस्तिष्क क्षेत्रों से वास्तविक कनेक्शनों की ओर स्थानांतरित किया, कम्प्यूटेशनल लागत को कम रखा, और छोटे, शोर वाले चिकित्सा डेटासेट की अनिश्चितता को संभालने के लिए एक गणितीय "सुरक्षा जाल" बनाया।
समस्या परिभाषा और बाधाएँ
इस पत्र को समझने के लिए, हमें पहले यह समझना होगा कि वैज्ञानिक मस्तिष्क को कैसे देखते हैं। मानव मस्तिष्क की कल्पना एक विशाल देश के रूप में करें। विशिष्ट मस्तिष्क क्षेत्र "शहर" हैं, और उनके बीच संवाद करने वाले तंत्रिका पथ "राजमार्ग" हैं।
जब डॉक्टर कार्यात्मक चुंबकीय अनुनाद इमेजिंग (fMRI) का उपयोग करते हैं, तो वे अनिवार्य रूप से समय के साथ इन शहरों के बीच यातायात (रक्त प्रवाह और ऑक्सीजन) को ट्रैक कर रहे होते हैं। किन्हीं दो शहरों के बीच यातायात कितना सिंक्रनाइज़ है, इसकी गणना करके, वैज्ञानिक एक "कार्यात्मक कनेक्टिविटी" (FC) मैट्रिक्स बनाते हैं। गणितीय शब्दों में, यह एक ग्राफ $G = (\mathbf{A}, \mathbf{X})$ है, जहाँ नोड्स (शहरों) में विशेषताएँ $\mathbf{X}$ होती हैं, और किनारे (राजमार्ग) एक आसन्नता मैट्रिक्स $\mathbf{A}$ द्वारा दर्शाए जाते हैं जो क्षेत्रों के बीच सहसंबंध की शक्ति को दर्शाता है।
प्रारंभिक बिंदु (इनपुट) fMRI डेटा से प्राप्त यह कच्चा, रोगी-विशिष्ट मस्तिष्क ग्राफ है। वांछित अंतिम बिंदु (आउटपुट) एक अत्यधिक सटीक, व्याख्या योग्य बाइनरी वर्गीकरण है—विशेष रूप से, यह निर्धारित करना कि क्या रोगी को ऑटिज्म स्पेक्ट्रम डिसऑर्डर (ASD) या ADHD ($y_D$) जैसी न्यूरोसाइकियाट्रिक डिसऑर्डर है, या यदि वे एक स्वस्थ नियंत्रण ($y_{HC}$) हैं।
लुप्त कड़ी: नोड्स बनाम किनारे
यहाँ वह मौलिक अंतर है जिसे यह पत्र पाटने का प्रयास करता है। पारंपरिक ग्राफ न्यूरल नेटवर्क (GNNs) अत्यधिक "नोड-केंद्रित" होते हैं। अपने गणितीय संचालन (जिन्हें संदेश पासिंग कहा जाता है) के दौरान, वे लगातार पड़ोसी शहरों से डेटा एकत्र करके शहरों (मस्तिष्क क्षेत्रों) की जानकारी को अपडेट करते हैं। राजमार्ग (किनारे) को केवल डमी पाइप के रूप में माना जाता है जो डेटा प्रवाह की दिशा तय करते हैं।
हालांकि, नैदानिक तंत्रिका विज्ञान में, ADHD और ASD जैसी बीमारियाँ केवल अलग-थलग मस्तिष्क क्षेत्रों को नहीं बदलती हैं; वे मौलिक रूप से कनेक्शनों को ही बाधित करती हैं। सटीक गणितीय अंतर यह है कि पारंपरिक GNNs इन कनेक्शनों को प्राथमिक, सीखने योग्य विशेषताओं के रूप में मानने में विफल रहते हैं। लेखकों ने महसूस किया कि उन्हें किनारों को न्यूरल नेटवर्क में "प्रथम श्रेणी के नागरिक" के रूप में ऊपर उठाने की आवश्यकता है।
आयामों की दुविधा
इसे हल करने के लिए, तार्किक कदम "लाइन ग्राफ" परिवर्तन का उपयोग करना है। ग्राफ सिद्धांत में, एक मानक ग्राफ को लाइन ग्राफ में परिवर्तित करने का अर्थ है प्रत्येक मूल किनारे को एक नए नोड में बदलना। अचानक, राजमार्ग शहर बन जाते हैं, जिससे न्यूरल नेटवर्क सीधे कनेक्शनों का विश्लेषण कर सकता है।
लेकिन यह एक क्रूर, दर्दनाक व्यापार-बंद पेश करता है जिसने पिछले शोधकर्ताओं को फंसाया है: प्रतिनिधित्व बनाम कम्प्यूटेशनल विस्फोट।
यदि आपके पास $n$ क्षेत्रों वाला एक मस्तिष्क एटलस है, तो एक पूरी तरह से जुड़ा हुआ मस्तिष्क ग्राफ में लगभग $n^2 / 2$ किनारे होते हैं। यदि आप इसे एक लाइन ग्राफ में बदलते हैं (जहाँ प्रत्येक किनारा एक नोड बन जाता है, और इन नए नोड्स के बीच के किनारे साझा कनेक्शनों का प्रतिनिधित्व करते हैं), तो आपके नए आसन्नता मैट्रिक्स का आकार घातीय रूप से बढ़ जाता है:
$$(n - 1)^2 \times n^2 / 4$$
यदि मस्तिष्क को केवल 200 क्षेत्रों में विभाजित किया गया है, तो यह लाइन ग्राफ परिवर्तन अरबों मापदंडों वाले मैट्रिक्स में परिणत होता है। यह एक कम्प्यूटेशनल दुःस्वप्न है। आपको मस्तिष्क कनेक्टिविटी का उत्तम प्रतिनिधित्व मिलता है, लेकिन आप आधुनिक GPU की हार्डवेयर मेमोरी सीमाओं को पूरी तरह से तोड़ देते हैं।
कठोर दीवारें और बाधाएँ
कम्प्यूटेशनल विस्फोट से परे, लेखकों को कई कठोर, यथार्थवादी बाधाओं का सामना करना पड़ा जो इस समस्या को अविश्वसनीय रूप से कठिन बनाती हैं:
- fMRI डेटा की अत्यधिक विरलता और शोर: fMRI स्कैन अविश्वसनीय रूप से शोर वाले होते हैं। रोगी हिलते हैं, स्कैनर में कलाकृतियाँ होती हैं, और रक्त प्रवाह तंत्रिका गतिविधि का एक अप्रत्यक्ष माप है। इसके अलावा, चिकित्सा डेटासेट कुख्यात रूप से छोटे होते हैं (अक्सर केवल कुछ सौ रोगी, जैसे ABIDE या ADHD-200 डेटासेट) विशाल फीचर स्पेस की तुलना में। केवल 500 रोगियों के साथ अरबों मापदंडों पर एक डीप लर्निंग मॉडल को प्रशिक्षित करना विनाशकारी ओवरफिटिंग की गारंटी देता है।
- ओवरस्मूथिंग का अभिशाप: GNNs में, यदि आप जटिल पैटर्न सीखने के लिए बहुत अधिक परतें लगाते हैं, तो सभी नोड्स की विशेषताएँ अंततः एक समान दलदल में मिल जाती हैं—एक घटना जिसे ओवरस्मूथिंग के रूप में जाना जाता है। यदि मॉडल ओवरस्मूथ हो जाता है, तो विशिष्ट मस्तिष्क कनेक्शनों में छिपे अद्वितीय रोग बायोमार्कर धुल जाते हैं।
- अनिर्देशित ग्राफ़ की गणितीय अस्पष्टता: अनिर्देशित ग्राफ़ में मानक पियर्सन सहसंबंध द्विदिश और एकदिश तंत्रिका सक्रियण के बीच अंतर को धुंधला करता है, जिससे मॉडल मस्तिष्क संचार के वास्तविक प्रवाह के बारे में भ्रमित हो जाता है।
लेखकों ने इसे कैसे हल किया
इन दीवारों को तोड़ने के लिए, लेखकों ने अवशिष्ट-पश्चात लाइन ग्राफ नेटवर्क (RP-LGN) को डिजाइन किया। उन्होंने तीन शानदार चरणों का उपयोग करके गणितीय रूप से बाधाओं को दूर किया:
1. K-निकटतम पड़ोसी (KNN) विरलीकरण
$O(n^4)$ कम्प्यूटेशनल विस्फोट को रोकने के लिए, उन्होंने पूरी तरह से जुड़े मस्तिष्क से लाइन ग्राफ नहीं बनाया। इसके बजाय, उन्होंने परिवर्तन से पहले KNN एल्गोरिथम का उपयोग करके मूल ग्राफ को आक्रामक रूप से विरल किया। नोड विशेषताओं के बीच यूक्लिडियन दूरी की गणना करके:
$$d(v_i, v_j) = \|x_i - x_j\|_2$$
उन्होंने ग्राफ को केवल $K=1$ निकटतम पड़ोसियों तक सीमित कर दिया। इस सेट के बाहर के किनारों को शून्य पर मजबूर किया गया। इसने ग्राफ के आकार को काफी कम कर दिया, जिससे लाइन ग्राफ $\tilde{G} = \{\tilde{\mathbf{A}}, \tilde{\mathbf{X}}\}$ मेमोरी में फिट हो गया, जबकि सबसे महत्वपूर्ण तंत्रिका पथों को बनाए रखा गया।
2. अवशिष्ट GraphSAGE वास्तुकला
ओवरस्मूथिंग अभिशाप से लड़ने के लिए, उन्होंने अवशिष्ट ब्लॉकों के साथ संयुक्त ग्राफ कनवल्शन (GraphSAGE) के एक विशिष्ट प्रकार का उपयोग किया। कनेक्शन विशेषताओं को संदेश पासिंग के दौरान धोने देने के बजाय, उन्होंने परत के मूल इनपुट को सीधे आउटपुट में जोड़ा:
$$\tilde{\mathbf{X}}^{(l+1)} = \tilde{\mathbf{X}}^{(l)} + \tilde{\mathbf{Z}}^{(l)}$$
यह गणितीय "स्किप कनेक्शन" नेटवर्क को मस्तिष्क कनेक्शनों की मूल संरचनात्मक निष्ठा को याद रखने के लिए मजबूर करता है।
3. लघु-नमूना पूर्वाग्रह के लिए बायेसियन भिन्नता अनुमान
अत्यधिक शोर और छोटे नमूना आकारों को दूर करने के लिए, उन्होंने पारंपरिक नियतात्मक वर्गीकरण परत को छोड़ दिया। इसके बजाय, उन्होंने एक बायेसियन भिन्नता पश्च प्रस्तुत किया। "यह कनेक्शन भार ठीक 0.8 है" कहने के बजाय, मॉडल भार $W$ और सहप्रसरण $\Sigma$ को गॉसियन वितरण के साथ यादृच्छिक चर के रूप में मानता है:
$$q(\Sigma) = \prod_{k=1}^{C_y} \mathcal{N}(W_k \mid \mu_k, \Sigma_k)$$
ऐसा करके, मॉडल अपनी अनिश्चितता को मापता है। यदि fMRI डेटा का एक टुकड़ा शोर वाला या विषम है, तो मॉडल शोर पर ओवरफिट होने के बजाय गणितीय रूप से अपने आत्मविश्वास को कम कर देता है। वे साक्ष्य निम्नतम बाउंड (ELBO) को अधिकतम करके इसे अनुकूलित करते हैं:
$$S^{-1} \log p(Y \mid \mathbf{X}, \mathbf{A}, \theta) \geq \mathcal{L}_{VB}(\theta, \eta, \Sigma) - S^{-1}\text{KL}(q(W, \Sigma \mid \eta) \parallel p(W, \Sigma))$$
कनेक्शनों को लक्षित करने के लिए विरल लाइन ग्राफ़, स्मूथिंग को रोकने के लिए अवशिष्ट परतों, और शोरगुल वाले, छोटे पैमाने के डेटा से बचने के लिए बायेसियन संभाव्यता को मिलाकर, लेखकों ने सफलतापूर्वक एक ऐसा मॉडल बनाया है जो केवल यह अनुमान नहीं लगाता है कि क्या रोगी को ADHD है—यह गणितीय रूप से उन सटीक दोषपूर्ण तंत्रिका राजमार्गों को उजागर करता है जो इसका कारण बन रहे हैं।
यह तरीका क्यों
Residual-Posterior Line Graph Network (RP-LGN) के निर्माण के कारणों को समझने के लिए, हमें उस सटीक क्षण पर विचार करना होगा जब पारंपरिक Graph Neural Networks (GNNs) न्यूरोइमेजिंग में एक बाधा से टकराए।
मस्तिष्क विश्लेषण में उपयोग किए जाने वाले मानक GNNs में, भौतिक मस्तिष्क क्षेत्रों को "शो के सितारे" (नोड्स) के रूप में माना जाता है, जबकि उनके बीच कार्यात्मक कनेक्शनों को केवल पृष्ठभूमि संबंधों (एज) के रूप में माना जाता है। हालांकि, लेखकों ने ऑटिज्म और ADHD जैसी न्यूरोसाइकियाट्रिक स्थितियों के बारे में एक मौलिक सत्य का एहसास किया: कनेक्शन स्वयं ही वह स्थान है जहाँ रोग वास्तव में प्रकट होता है। पारंपरिक मॉडल गलत प्राथमिक संस्थाओं को देख रहे थे।
इसे ठीक करने के लिए, लेखकों को इन कनेक्शनों को "प्रथम-श्रेणी की वस्तुएं" के रूप में उन्नत करने की आवश्यकता थी। एकमात्र व्यवहार्य गणितीय समाधान एक एज-टू-नोड परिवर्तन था, जिसने "लाइन ग्राफ" के रूप में जाना जाता है, उसका निर्माण किया। लेकिन इसने एक विनाशकारी बाधा पेश की। $n$ क्षेत्रों वाले एक पूरी तरह से जुड़े प्रारंभिक मस्तिष्क ग्राफ में लगभग $n^2/2$ एज होते हैं। यदि आप उन एज को लाइन ग्राफ बनाने के लिए नोड्स में परिवर्तित करते हैं, तो नया आसन्नता मैट्रिक्स $(n-1)^2 \times n^2/4$ के आश्चर्यजनक पैमाने तक बढ़ जाता है। सैकड़ों क्षेत्रों वाले एक मानक मस्तिष्क एटलस के लिए, इसका मतलब है कि अरबों मापदंडों वाले मैट्रिक्स की गणना करना। पारंपरिक SOTA मॉडल तुरंत मेमोरी से बाहर हो जाएंगे, जिससे शुद्ध लाइन-ग्राफ दृष्टिकोण कम्प्यूटेशनल रूप से असंभव हो जाएगा।
बेंचमार्किंग तर्क और संरचनात्मक श्रेष्ठता
इस विशाल $O(N^4)$ मेमोरी विस्फोट को दूर करने के लिए, लेखकों ने समस्या पर केवल अधिक कंप्यूटिंग शक्ति नहीं फेंकी; उन्होंने इसे संरचनात्मक रूप से बायपास किया। उन्होंने लाइन ग्राफ निर्माण से पहले K-Nearest Neighbors (KNN) स्पार्सिफिकेशन चरण पेश किया। $K=1$ सेट करके, उन्होंने यूक्लिडियन दूरी का उपयोग करके गणितीय रूप से ग्राफ को प्रून किया:
$$ \mathcal{N}_i = \text{argmin}_j \{d(v_i, v_j) \mid j \neq i\}_{1 \leq j \leq K, i, j \in V} $$
इस शानदार बाधा ने सघन, असंभव मैट्रिक्स को एक अत्यधिक स्पार्स, प्रबंधनीय प्रतिनिधित्व में कम कर दिया, जिसमें केवल सबसे महत्वपूर्ण कार्यात्मक कनेक्शन बनाए रखे गए।
इसके अलावा, उन्हें इस नए ग्राफ को संसाधित करने के लिए सही बैकबोन चुनना था। Graph Attention Networks (GAT) जैसे लोकप्रिय दृष्टिकोणों का उपयोग क्यों नहीं किया गया? लेखकों के एब्लेशन अध्ययनों ने स्पष्ट रूप से दिखाया कि GAT के ध्यान तंत्र वास्तव में उनके आर्किटेक्चर के साथ टकराते थे, जिससे प्रति-उत्पादक परिणाम उत्पन्न होते थे। इसके बजाय, उन्होंने एक अवशिष्ट GraphSAGE बैकबोन चुना। यह गुणात्मक रूप से श्रेष्ठ था क्योंकि अवशिष्ट कनेक्शन मूल ग्राफ की संरचनात्मक निष्ठा को पूरी तरह से संरक्षित करते थे, "ओवरस्मूथिंग" को रोकते थे - मानक GNNs में एक घातक दोष जहां नोड सुविधाएँ संदेश पासिंग की कुछ परतों के बाद एक अविभाज्य गड़बड़ी में धुंधली हो जाती हैं।
कठोर बाधाओं और बायेसियन समाधान के बीच "विवाह"
दूसरी विशाल बाधा fMRI डेटा की प्रकृति स्वयं थी: यह अविश्वसनीय रूप से शोरगुल वाला है, और चिकित्सा डेटासेट गंभीर छोटे-नमूना पूर्वाग्रह से ग्रस्त हैं। यदि लेखकों ने मानक पूरी तरह से जुड़े परतों को क्लासिफायर के रूप में उपयोग किया होता - जैसा कि लगभग सभी पिछले स्वर्ण-मानक मॉडल करते हैं - तो नेटवर्क छोटे डेटासेट के लिए अत्यधिक ओवरफिट हो जाता।
इसे हल करने के लिए, उन्होंने नियतात्मक क्लासिफायर को पूरी तरह से अस्वीकार कर दिया और अंतिम परत के रूप में एक बायेसियन वेरिएशननल पोस्टीरियर को एकीकृत किया। एक कठोर, एकल भविष्यवाणी आउटपुट करने के बजाय, बायेसियन दृष्टिकोण अंतिम परत $W$ और सहप्रसरण मैट्रिक्स $\Sigma$ के भार को यादृच्छिक चर के रूप में मॉडल करता है। वे एविडेंस लोअर बाउंड (ELBO) को अधिकतम करके वास्तविक पोस्टीरियर वितरण का अनुमान लगाते हैं:
$$ S^{-1} \log p(Y | \mathbf{X}, \mathbf{A}, \theta) \geq \mathcal{L}_{VB}(\theta, \eta, \Sigma) - S^{-1}\text{KL}(q(W, \Sigma | \eta) \parallel p(W, \Sigma)) $$
यहीं पर विधि समस्या की बाधाओं के साथ पूरी तरह से संरेखित होती है। वर्गीकरण भार को निश्चित संख्याओं के बजाय एक वितरण के रूप में मानकर, मॉडल स्वाभाविक रूप से अनिश्चितता को मापता है। यदि fMRI स्कैन में विषम डेटा या उच्च-आयामी शोर होता है, तो बायेसियन परत उस अनिश्चितता को अवशोषित कर लेती है बजाय इसके कि वह उससे धोखा खा जाए। यह एकल-पास, निम्न-विचरण स्टोकेस्टिक अनुमान ही RP-LGN को छोटे-नमूना ओवरफिटिंग जाल के खिलाफ मजबूत बनाता है जो पारंपरिक SOTA मॉडल को नष्ट कर देता है, अंततः इसे मस्तिष्क के वास्तविक, छिपे हुए कनेक्टिविटी पैटर्न को उजागर करने की अनुमति देता है।
गणितीय और तार्किक तंत्र
इस पत्र द्वारा प्रस्तुत गहन परिवर्तन को समझने के लिए, हमें पहले इस पृष्ठभूमि को स्थापित करने की आवश्यकता है कि कृत्रिम बुद्धिमत्ता (AI) सामान्यतः मानव मस्तिष्क को कैसे देखती है। पारंपरिक रूप से, कार्यात्मक चुंबकीय अनुनाद इमेजिंग (fMRI) डेटा का विश्लेषण करते समय, ग्राफ़ न्यूरल नेटवर्क (GNNs) भौतिक मस्तिष्क क्षेत्रों को "नोड्स" के रूप में और उनके बीच सहसंबंधों को "एज" के रूप में मानते हैं। हालाँकि, ADHD और ऑटिज़्म जैसे न्यूरोसाइकिएट्रिक विकार अक्सर स्वयं संचार पाथवे में सूक्ष्म गिरावट के रूप में प्रकट होते हैं। इस पत्र का उद्देश्य इन पाथवे—कनेक्शनों—को विश्लेषण के प्राथमिक विषय के रूप में ऊपर उठाना है।
ऐसा करने के लिए, लेखकों को भारी बाधाओं का सामना करना पड़ा। यदि आप किसी मस्तिष्क ग्राफ़ को गणितीय रूप से व्युत्क्रमित करते हैं ताकि प्रत्येक कनेक्शन एक नया नोड बन जाए ("लाइन ग्राफ़"), तो मापदंडों की संख्या अरबों में विस्फोट कर जाती है, जो तुरंत एक मानक मॉडल को क्रैश कर देगी। इसके अलावा, fMRI डेटा कुख्यात रूप से शोरगुल वाला होता है, और चिकित्सा डेटासेट आम तौर पर छोटे होते हैं (अक्सर केवल कुछ सौ रोगी), जिससे गंभीर ओवरफिटिंग होती है। इन बाधाओं को दूर करने के लिए, लेखकों ने K-निकटतम पड़ोसियों (K-Nearest Neighbors) का उपयोग करके ग्राफ़ को विरल (sparsified) किया, संकेतों को आपस में घुलने-मिलने से रोकने के लिए एक अवशिष्ट ग्राफ़सेज (Residual GraphSAGE) बैकबोन बनाया (ओवरस्मूथिंग), और अनिश्चितता को मापने के लिए इसे एक बायेसियन भिन्नता पश्च (Bayesian variational posterior) के साथ पूरा किया।
यहां इस बात का गणितीय विच्छेदन प्रस्तुत है कि उन्होंने यह कैसे प्राप्त किया।
मास्टर समीकरण
अवशिष्ट-पश्च रेखा ग्राफ़ नेटवर्क (RP-LGN) का इंजन दो परस्पर जुड़े गणितीय प्रणालियों द्वारा संचालित होता है।
पहला, अवशिष्ट संदेश पासिंग (Residual Message Passing) तंत्र जो रेखा ग्राफ़ से संरचनात्मक विशेषताओं को निकालता है:
$$ \tilde{z}_i^{(l)} = \sigma\left(\theta_i^{(l)} \cdot \text{MEAN}\left(\{\tilde{x}_i^{(l)}\} \parallel \{\tilde{x}_j^{(l)}, \forall j \in \mathcal{N}_i\}\right)\right) $$
$$ \tilde{\mathbf{X}}^{(l+1)} = \tilde{\mathbf{X}}^{(l)} + \tilde{\mathbf{Z}}^{(l)} $$
दूसरा, बायेसियन भिन्नता उद्देश्य (Bayesian Variational Objective) जो अंतिम हानि फलन (loss function) के रूप में कार्य करता है, मॉडल को भविष्य कहनेवाला सटीकता और अनिश्चितता के बीच संतुलन बनाने के लिए मजबूर करता है:
$$ \mathcal{L}_{VB}(\theta, \eta, \Sigma) = \frac{1}{S} \sum_{s=1}^S \left( y_s^\top W \phi_s - \log \sum_{k=1}^{C_y} \exp\left[w_k^\top \phi_s + \frac{1}{2}(\phi_s^\top \Sigma_k \phi_s + \sigma_k^2)\right] \right) $$
$$ \theta^*, \eta^*, \Sigma^* = \arg\max_{\eta, \Sigma} \left\{ \mathcal{L}_{VB}(\theta, \eta, \Sigma) + S^{-1}(\log p(\Sigma) - \text{KL}(q(W \mid \eta) \parallel p(W))) \right\} $$
समीकरणों का विच्छेदन
आइए इस मशीनरी के हर गियर और स्प्रिंग को अलग करें:
- $\tilde{\mathbf{X}}^{(l)}$ और $\tilde{x}_i^{(l)}$: परत $l$ पर रेखा ग्राफ़ का फीचर मैट्रिक्स और व्यक्तिगत फीचर वेक्टर। भौतिक रूप से, ये वास्तविक मस्तिष्क कनेक्शन का प्रतिनिधित्व करते हैं जिन्हें प्रथम श्रेणी के नोड्स के रूप में पदोन्नत किया गया है।
- $\parallel$ (संयोजन ऑपरेटर): यह एक नोड की अपनी विशेषताओं को उसके पड़ोसियों के औसत के साथ जोड़ता है। यहां जोड़ के बजाय संयोजन क्यों? संयोजन एक विशिष्ट मस्तिष्क कनेक्शन की विशिष्ट, अलग पहचान को बनाए रखता है जबकि पड़ोस के संदर्भ को जोड़ता है। जोड़ उन्हें अपरिवर्तनीय रूप से एक साथ मिला देगा।
- $\theta_i^{(l)}$: सीखने योग्य भार मैट्रिक्स। यह एक ज्यामितीय स्टीयरिंग व्हील के रूप में कार्य करता है, जो फीचर वैक्टर को एक उच्च-आयामी स्थान में घुमाता है जहां रोगग्रस्त और स्वस्थ पैटर्न अलग हो जाते हैं।
- $\sigma$: सक्रियण फलन (activation function)। यह एक जैविक सीमा के रूप में कार्य करता है, यह तय करता है कि कौन से तंत्रिका कनेक्शन पैटर्न आगे बढ़ने के लिए पर्याप्त महत्वपूर्ण हैं।
- $+$ ( $\tilde{\mathbf{X}}^{(l)} + \tilde{\mathbf{Z}}^{(l)}$ में): अवशिष्ट कनेक्शन। गुणा के बजाय जोड़ क्यों? जोड़ एक सुरक्षित बाईपास राजमार्ग बनाता है। यदि ग्राफ़ कनवल्शन अनावश्यक शोर निकालता है, तो नेटवर्क भार को शून्य तक धकेल सकता है और मूल डेटा को आगे बढ़ा सकता है। गुणा पूरे संकेत को शून्य तक ढहने का जोखिम उठाएगा, प्रतिनिधित्व को नष्ट कर देगा।
- $\mathcal{L}_{VB}$: भिन्नता निम्न सीमा (Variational Lower Bound)। यह मॉडल की वर्गीकरण शक्ति के लिए प्राथमिक स्कोरिंग मीट्रिक है।
- $S$: विषयों (रोगियों) की संख्या। हम एक सतत स्पेक्ट्रम के बजाय असतत, गणनीय संस्थाओं के रूप में रोगियों के कारण एक अभिन्न के बजाय $S$ पर एक योग $\sum$ का उपयोग करते हैं।
- $y_s^\top W \phi_s$: सही निदान के लिए अपेक्षित लॉजिट स्कोर, जहां $\phi_s$ रोगी $s$ के चपटा, पूरी तरह से संसाधित मस्तिष्क मानचित्र है।
- $\frac{1}{2}(\phi_s^\top \Sigma_k \phi_s + \sigma_k^2)$: विचरण/अनिश्चितता दंड। $\Sigma_k$ सहप्रसरण मैट्रिक्स है। यह पद सीधे भविष्यवाणी में गाऊसी शोर की एक परिकलित मात्रा को इंजेक्ट करता है। यह fMRI स्कैन के अंतर्निहित शोर के खिलाफ एक गणितीय शॉक एब्जॉर्बर के रूप में कार्य करता है।
- $\text{KL}(q \parallel p)$: कुल्बैक-लीब्लर विचलन (Kullback-Leibler divergence)। यह एक रबर बैंड के रूप में कार्य करता है, जो सीखे गए पश्च भार वितरण $q$ को एक सुरक्षित, स्थिर पूर्व वितरण $p$ की ओर वापस खींचता है ताकि ओवरफिटिंग को रोका जा सके।
चरण-दर-चरण प्रवाह
एकल अमूर्त डेटा बिंदु की कल्पना करें—प्रीफ्रंटल कॉर्टेक्स और बेसल गैन्ग्लिया के बीच एक कार्यात्मक कनेक्शन, जो \$150 fMRI स्कैन से प्राप्त हुआ है।
सबसे पहले, इस कनेक्शन को एक साधारण "एज" होने से छीन लिया जाता है और एक नए लाइन ग्राफ़ में एक पूर्ण "नोड" के रूप में पदोन्नत किया जाता है। इसे मूल मस्तिष्क क्षेत्रों की सहसंबंध शक्ति के आधार पर एक फीचर वेक्टर सौंपा गया है। अगला, यह अवशिष्ट ग्राफ़सेज असेंबली लाइन में प्रवेश करता है। यह अपने पड़ोसी कनेक्शनों को देखता है, उनकी जानकारी का औसत निकालता है, और इसे अपने स्वयं के डेटा के साथ बंडल करता है।
इस बंडल किए गए पैकेज को उच्च-स्तरीय टोपोलॉजिकल पैटर्न निकालने के लिए भार मैट्रिक्स $\theta$ से गुणा किया जाता है, नकारात्मक मानों को क्लिप करने के लिए सक्रियण फलन $\sigma$ से गुजारा जाता है, और फिर अवशिष्ट पथ के माध्यम से इसके मूल स्व में जोड़ा जाता है। यह सुनिश्चित करता है कि प्रसंस्करण के दौरान कनेक्शन अपनी मूल पहचान न खोए।
कई परतों से गुजरने के बाद, पूरी तरह से संसाधित मस्तिष्क मानचित्र $\phi_s$ बायेसियन क्लासिफायरियर तक पहुँचता है। अंतिम उत्तर प्राप्त करने के लिए एक कठोर, नियतात्मक भार से गुणा करने के बजाय, क्लासिफायरियर एक संभाव्यता वितरण से नमूना लेता है। यह न केवल एक निदान (जैसे, "ADHD") आउटपुट करता है, बल्कि एक आत्मविश्वास स्तर भी देता है, जो कच्चे चिकित्सा डेटा के अंतर्निहित शोर को ध्यान में रखता है।
अनुकूलन गतिशीलता
यह वास्तुकला वास्तव में कैसे सीखती है और अभिसरण करती है? मॉडल एक कुख्यात रूप से कठिन हानि परिदृश्य (loss landscape) को नेविगेट करने के लिए स्टोकेस्टिक भिन्नता अनुमान (Stochastic Variational Inference) पर निर्भर करता है।
पारंपरिक fMRI विश्लेषण में, डेटा उच्च-आयामी होने के बावजूद नमूना आकार छोटे (small-sample bias) होने के कारण हानि परिदृश्य अत्यधिक दांतेदार और गंभीर ओवरफिटिंग के लिए प्रवण होता है। बायेसियन पश्च ( $\Sigma$ और KL विचलन पद) को पेश करके, हानि परिदृश्य को प्रभावी ढंग से चिकना कर दिया जाता है। जब डेटा अस्पष्ट होता है तो मॉडल को अपनी भविष्यवाणियों में अत्यधिक आत्मविश्वास के लिए सक्रिय रूप से दंडित किया जाता है।
बैकप्रॉपैगेशन के दौरान, ग्रेडिएंट ELBO उद्देश्य से पीछे की ओर प्रवाहित होते हैं। अवशिष्ट कनेक्शन सुनिश्चित करते हैं कि इन ग्रेडिएंट्स के पास पहले परत तक पूरी तरह से बाईपास करते हुए, एक स्पष्ट, अबाधित राजमार्ग हो, जो लुप्तप्राय ग्रेडिएंट समस्या को पूरी तरह से बायपास करता है। पुनरावृत्त रूप से, मॉडल बेहतर संरचनात्मक विशेषताओं को निकालने के लिए $\theta$ को अपडेट करता है, साथ ही अपनी अनिश्चितता को कैलिब्रेट करने के लिए $\eta$ और $\Sigma$ को अपडेट करता है। यह एक मजबूत स्थिति में अभिसरण करता है जहां यह स्वस्थ और रोगग्रस्त मस्तिष्क के बीच सटीक रूप से अंतर कर सकता है, भले ही विषम रोगी डेटा का सामना करना पड़े।
परिणाम, सीमाएँ और निष्कर्ष
मानव मस्तिष्क को एक विशाल, हलचल भरे देश के रूप में कल्पना करें। मस्तिष्क के क्षेत्र प्रमुख शहर हैं, और उनके बीच तंत्रिका पथ राजमार्ग हैं। वर्षों से, तंत्रिका विज्ञानी और AI शोधकर्ता ऑटिज्म स्पेक्ट्रम डिसऑर्डर (ASD) और अटेंशन-डेफिसिट/हाइपरएक्टिविटी डिसऑर्डर (ADHD) जैसे न्यूरोसाइकिएट्रिक विकारों का निदान करने के लिए इन शहरों में "यातायात" (रक्त प्रवाह) को मापने के लिए फंक्शनल मैग्नेटिक रेजोनेंस इमेजिंग (fMRI) का उपयोग कर रहे हैं। पारंपरिक ग्राफ न्यूरल नेटवर्क्स (GNNs) इसके लिए पसंदीदा उपकरण रहे हैं, जो मस्तिष्क क्षेत्रों को नोड्स (शहरों) और कनेक्शन को किनारों (राजमार्गों) के रूप में मानते हैं।
लेकिन यहाँ मौलिक दोष है: क्या होगा यदि बीमारी शहर को नष्ट न करे, बल्कि राजमार्ग को बाधित कर दे? पारंपरिक GNNs नोड्स की विशेषताओं को अपडेट करने पर बहुत अधिक ध्यान केंद्रित करते हैं, कनेक्शन को केवल माध्यमिक विशेषताओं के रूप में मानते हैं।
इस पत्र के लेखकों ने इस अंध बिंदु को पहचाना और एक शानदार प्रतिमान बदलाव का प्रस्ताव दिया: रेसिडुअल-पोस्टीरियर लाइन ग्राफ नेटवर्क (RP-LGN)। उन्होंने कनेक्शन को शो का सितारा बनाने का फैसला किया।
प्रेरणा और गणितीय बाधाएँ
कनेक्शन पर ध्यान केंद्रित करने के लिए, लेखकों ने ग्राफ सिद्धांत से "लाइन ग्राफ" नामक एक अवधारणा का उपयोग किया। एक लाइन ग्राफ में, मूल ग्राफ के किनारे नए ग्राफ के नोड्स बन जाते हैं।
हालांकि, वे तुरंत एक विशाल गणितीय दीवार से टकरा गए। यदि एक मस्तिष्क एटलस मस्तिष्क को $n$ क्षेत्रों में विभाजित करता है, तो एक पूरी तरह से जुड़े ग्राफ में $(n - 1) \times n / 2$ किनारे होते हैं। यदि आप इसे लाइन ग्राफ में परिवर्तित करते हैं, तो नया आसन्नता मैट्रिक्स $(n - 1)^2 \times n^2 / 4$ के पैमाने पर फट जाता है। सैकड़ों क्षेत्रों वाले मस्तिष्क के लिए, आप अचानक अरबों मापदंडों से निपट रहे होते हैं। यह एक कम्प्यूटेशनल दुःस्वप्न है। इसके अलावा, fMRI डेटा कुख्यात रूप से शोरगुल वाला होता है, और चिकित्सा डेटासेट में आमतौर पर छोटे नमूना आकार होते हैं, जिससे बड़े मॉडल ओवरफिटिंग के अत्यधिक प्रवण होते हैं।
उन्होंने इसे कैसे हल किया: RP-LGN आर्किटेक्चर
इन बाधाओं को दूर करने के लिए, लेखकों ने एक चार-चरणीय पाइपलाइन तैयार की:
1. KNN के माध्यम से कठोर विरलता (Sparsification)
लाइन ग्राफ बनाने से पहले, उन्हें मूल ग्राफ को छांटना पड़ा। उन्होंने K-नियरेस्ट नेबर्स (KNN) दृष्टिकोण का उपयोग किया, विशेष रूप से $K=1$ सेट करके, केवल यूक्लिडियन दूरी के आधार पर सबसे महत्वपूर्ण कनेक्शन रखने के लिए:
$$d(v_i, v_j) = \|x_i - x_j\|_2$$
ईमानदारी से कहूं तो, मुझे इस हिस्से के बारे में भी पूरी तरह से यकीन नहीं है—पत्र पहले क्रम के पड़ोसी किनारों को छोड़कर सब कुछ फेंकने की नैदानिक वैधता को गहराई से उचित नहीं ठहराता है, हालांकि यह निर्विवाद रूप से कम्प्यूटेशनल विस्फोट को हल करता है।
2. एज-टू-नोड परिवर्तन (Edge-to-Node Transformation)
अगला, उन्होंने लाइन ग्राफ बनाया। नए नोड्स (जो मूल राजमार्गों का प्रतिनिधित्व करते हैं) को विशेषताओं की आवश्यकता होती है। उन्होंने दो जुड़े हुए मस्तिष्क क्षेत्रों की विशेषताओं के योग के साथ मूल किनारे के वजन को जोड़कर इन विशेषताओं का चतुराई से निर्माण किया:
$$\tilde{x}_i = \text{CONCATE}(\text{SUM}(x_i, x_j), a_{ij})$$
3. मैसेज पासिंग के लिए रेसिडुअल GraphSAGE
क्योंकि लाइन ग्राफ में अपने स्वयं के किनारे के वजन की कमी होती है, लेखकों ने इन नए कनेक्शन-नोड्स के बीच संदेश पास करने के लिए GraphSAGE का उपयोग किया। "ओवरस्मूथिंग"—एक सामान्य GNN समस्या जहां बार-बार संदेश पास करने से सभी विशेषताएं एक सामान्य दलदल में धुंधली हो जाती हैं—को रोकने के लिए, उन्होंने रेसिडुअल कनेक्शन जोड़े:
$$\tilde{\mathbf{X}}^{(l+1)} = \tilde{\mathbf{X}}^{(l)} + \tilde{\mathbf{Z}}^{(l)}$$
4. बायेसियन वेरिएशननल पोस्टीरियर (Bayesian Variational Posterior)
अंत में, शोर और छोटे-नमूने ओवरफिटिंग से निपटने के लिए, उन्होंने पारंपरिक नियतात्मक क्लासिफायरियर को छोड़ दिया। इसके बजाय, उन्होंने अंतिम परत के वजन को गाऊसी वितरण के साथ यादृच्छिक चर के रूप में माना। स्टोकेस्टिक वेरिएशननल अनुमान का उपयोग करके, मॉडल केवल एक कठोर अनुमान नहीं लगाता है; यह अपनी अनिश्चितता को मापता है। उन्होंने एविडेंस लोअर बाउंड (ELBO) को अधिकतम करके इसे अनुकूलित किया:
$$S^{-1} \log p(Y|\mathbf{X}, \mathbf{A}, \theta) \geq \mathcal{L}_{VB}(\theta, \eta, \Sigma) - S^{-1}\text{KL}(q(W, \Sigma|\eta) \parallel p(W, \Sigma))$$
प्रयोगात्मक वास्तुकला और "पीड़ित"
लेखकों ने केवल यह दावा नहीं किया कि उनका गणित काम करता है; उन्होंने इसे साबित करने के लिए एक कठोर परीक्षा का आयोजन किया। उन्होंने ABIDE I (ऑटिज्म) और ADHD-200 डेटासेट पर कठोर 5-फोल्ड क्रॉस-वैलिडेशन का उपयोग करके RP-LGN का परीक्षण किया।
उनके रास्ते में छोड़े गए "पीड़ित" मानक और अत्याधुनिक मॉडल का एक "who's who" थे: KAN जैसे एकल क्लासिफायरियर, मानक GNNs (GAT, GIN, GraphSAGE), और ब्रेननेटसीएनएन, ब्रेनजीएनएन, ब्रेनजीबी, एफबीनेटजेन, और ब्रेननेटवर्कट्रांसफार्मर जैसे विशेष मस्तिष्क नेटवर्क। RP-LGN ने उन सभी को बेहतर प्रदर्शन किया।
लेकिन निश्चित, निर्विवाद प्रमाण केवल एक उच्च सटीकता प्रतिशत नहीं था। यह दो रूपों में आया:
1. एब्लेशन स्टडी (Ablation Study): उन्होंने व्यवस्थित रूप से रेसिडुअल कनेक्शन और बायेसियन पोस्टीरियर को हटा दिया। जब SAGE, GIN, और GAT जैसे बेस मॉडल पर लागू किया गया, तो प्रदर्शन काफी गिर गया, यह साबित करते हुए कि ये विशिष्ट तंत्र मॉडल की श्रेष्ठता के सटीक कारण थे।
- Grad-CAM के माध्यम से नैदानिक सत्यापन: उन्होंने ADHD का निदान करने के लिए मॉडल द्वारा भरोसा किए गए "राजमार्गों" को नेत्रहीन रूप से मैप करने के लिए ग्रेडिएंट-आधारित स्थानीयकरण का उपयोग किया। मॉडल ने स्वतंत्र रूप से सुपीरियर पेरिएटल लोब्यूल, कॉडेट न्यूक्लियस और फ्यूसिफॉर्म गाइरस के बीच कनेक्शन को हाइलाइट किया। यह स्मोकिंग गन है: ये वही मस्तिष्क क्षेत्र हैं जिन्हें नैदानिक मनोचिकित्सकों ने लंबे समय से स्थानिक ध्यान, पुरस्कार प्रसंस्करण और आवेग नियंत्रण से जोड़ा है—ADHD में मुख्य कमी। गणित ने पूरी तरह से जीव विज्ञान को फिर से खोज लिया।
भविष्य के विकास के लिए चर्चा के विषय
इस शानदार नींव के आधार पर, यहां कुछ विविध दृष्टिकोण दिए गए हैं कि हम मस्तिष्क कनेक्टिविटी के इस प्रतिनिधित्व को और आगे कैसे बढ़ा सकते हैं:
- विरलता में $K=1$ दुविधा: लेखकों ने कम्प्यूटेशनल ओवरहेड को बचाने के लिए $K=1$ का उपयोग किया, लेकिन मस्तिष्क एक अत्यधिक एकीकृत, बहु-पथ प्रणाली है। क्या हम गतिशील विरलता तकनीकों का पता लगा सकते हैं, जैसे ध्यान-आधारित छंटाई, जो यूक्लिडियन निकटतम पड़ोसियों पर सख्ती से भरोसा करने के बजाय नैदानिक रूप से प्रासंगिक लंबी दूरी के कनेक्शन को बनाए रखती हैं?
- स्थैतिक स्नैपशॉट बनाम लौकिक गतिशीलता: RP-LGN आंशिक सहसंबंधों के एक स्थैतिक ग्राफ के रूप में fMRI डेटा का इलाज करता है। हालांकि, मस्तिष्क कनेक्टिविटी अत्यधिक गतिशील है; संज्ञानात्मक भार के आधार पर राजमार्ग खुलते और बंद होते हैं। हम पैरामीटर विस्फोट को फिर से ट्रिगर किए बिना लाइन-ग्राफ ढांचे में स्लाइडिंग-विंडो लौकिक गतिशीलता को कैसे एकीकृत कर सकते हैं?
- क्लिनिक में बायेसियन अनिश्चितता की व्याख्या: बायेसियन पोस्टीरियर अनिश्चितता का एक गणितीय मात्राकरण प्रदान करता है। हम इस गणितीय भिन्नता को एक डॉक्टर के लिए कार्रवाई योग्य मीट्रिक में कैसे अनुवाद कर सकते हैं? उदाहरण के लिए, यदि मॉडल उच्च भिन्नता के साथ निदान आउटपुट करता है, तो क्या यह वास्तविक दुनिया की नैदानिक सेटिंग में एक विशिष्ट माध्यमिक स्क्रीनिंग प्रोटोकॉल को ट्रिगर कर सकता है?
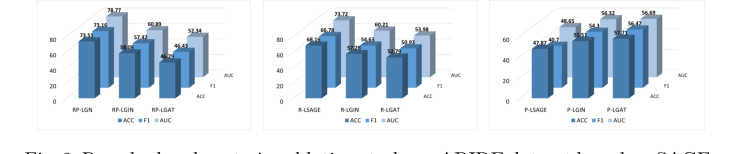 Figure 2. Resudual and posterior ablation study on ABIDE dataset based on SAGE, GIN and GAT. R: residual, P: posterior, L: line graph
Figure 2. Resudual and posterior ablation study on ABIDE dataset based on SAGE, GIN and GAT. R: residual, P: posterior, L: line graph