잔여 후방 패턴에서의 뇌 연결성 특징 정제
New AI model RP-LGN captures subtle connectivity changes for better disease diagnosis, outperforming others with improved accuracy & noise handling.
배경 및 학문적 계보
인간 뇌의 진정한 본질을 이해하기 위해서는 고립된 영역을 넘어 그들의 소통 방식을 연구해야 한다. 역사적으로 신경과학자들은 뇌 활동을 포착하기 위해 기능적 자기공명영상(fMRI)을 사용해왔다. 계산 신경과학 분야가 발전함에 따라 연구자들은 뇌를 복잡한 네트워크, 즉 뇌 영역이 노드(node)이고 소통 경로는 엣지(edge)인 "그래프(graph)"로 표현하기 시작했다. 이는 자연스럽게 기능적 연결 패턴을 분석하여 자폐 스펙트럼 장애(ASD) 및 ADHD와 같은 신경정신 질환을 진단하기 위해 그래프 신경망(GNN)을 채택하는 결과로 이어졌다.
그러나 결정적인 병목 현상이 발생했다. 이러한 특정 작업에 대한 전통적인 GNN 접근 방식은 근본적으로 결함이 있었는데, 이는 실제 연결 경로(엣지)보다는 뇌 영역 자체(노드)에 주로 초점을 맞추었기 때문이다. 신경정신 질환에서 질병은 종종 물리적인 영역보다는 연결의 변화로 나타난다. 더욱이, 이전 모델들은 막대한 계산상의 난관에 직면했다. 만약 완전 연결된 뇌 그래프에서 모든 개별 연결을 주요 특징으로 취급하려고 한다면, 수학적으로 감당할 수 없게 된다. 일반적인 뇌 아틀라스는 수십억 개의 파라미터(parameter)를 가진 행렬을 생성할 수 있으며, 이는 계산적으로 처리하는 것을 불가능하게 만든다. 이 외에도 의료 데이터셋은 악명 높게 작고 노이즈가 많아 전통적인 모델이 과적합(overfitting)되는 문제를 야기한다. 이는 훈련 데이터를 암기하지만 실제 임상 적용에서는 완전히 실패하는 것을 의미한다.
이러한 격차를 해소하기 위해 저자들은 Residual-Posterior Line Graph Network (RP-LGN)을 소개했다. 그들이 사용한 고도로 전문화된 개념들을 직관적인 아이디어로 분해해보자.
전문 용어 해체
- 기능적 자기공명영상(fMRI) & BOLD 신호: 본 논문에서 이는 뇌의 혈류 변화를 측정하는 원시 데이터이다.
- 일상적 비유: 밤에 도시의 교통 체증을 헤드라이트 밀도를 보고 추적하는 위성을 상상해보라. fMRI는 혈류를 이용해 이와 유사한 작업을 수행한다. 즉, "교통량"(산소 공급 혈액)이 어디로 이동하는지를 추적하여 현재 활성화되어 서로 소통하고 있는 "교차로"(뇌 영역)를 파악한다.
- Line Graph Transformation: 엣지를 노드로 변환하는 수학적 기법이다.
- 일상적 비유: 전 세계 항공 네트워크를 연구한다고 가정해보자. 일반적으로 도시(노드)를 연구하고 항공 노선(엣지)에 선을 그린다. Line graph transformation은 이를 뒤집는다. 즉, 항공 노선을 연구의 주요 주제(새로운 노드)로 만들고, 도시들은 단순히 종착점이 된다. 이를 통해 AI는 실제 연결을 직접 연구할 수 있다.
- GNN에서의 Oversmoothing: 노드 간 메시지를 너무 많이 전달하면 모든 노드가 동일하게 보이게 되는 현상이다.
- 일상적 비유: 물감 섞기를 상상해보라. 빨간색과 파란색을 부드럽게 휘저으면 아름다운 대리석 무늬(유용한 정보)가 나온다. 하지만 끊임없이 휘저으면 평범하고 탁한 보라색만 남게 된다. Oversmoothing은 AI가 데이터를 너무 많이 휘저어 뇌의 모든 고유하고 구별되는 특징을 잃어버리는 경우이다.
- Bayesian Variational Posterior: 예측 불확실성을 정량화하기 위해 모델의 마지막 계층에 사용되는 통계적 방법이다.
- 일상적 비유: 날씨 앱이 "내일 비가 올 것이다"라고 단정적으로 말하는 대신(데이터에 노이즈가 많으면 틀릴 수 있음), 베이지안 접근 방식은 "비가 올 확률이 85%이며, 오차 범위는 5%이다"라고 말한다. 이는 오차 범위를 계산하여 환자의 스캔에 많은 배경 노이즈가 있더라도 AI의 의학적 진단을 훨씬 더 강력하고 신뢰할 수 있게 만든다.
수학적 청사진
저자들이 이를 수학적으로 어떻게 해석했는지 이해하기 위해서는 그들의 우주를 정의하는 변수들을 살펴볼 필요가 있다. 그들은 파라미터 폭발을 방지하기 위해 $K$-Nearest Neighbors (KNN) 접근 방식을 사용하여 초기 연결을 희소화(sparsify)한 다음, 그래프를 Line Graph $\tilde{G}$로 매핑한다. 마지막으로, Evidence Lower Bound (ELBO), 즉 $\mathcal{L}_{VB}$를 최대화함으로써 모델을 최적화한다.
| Notation | Description |
|---|---|
| $V$ | 뇌의 관심 영역(ROIs)을 나타내는 노드 집합. |
| $E$ | ROIs 간의 기능적 연결을 나타내는 엣지 집합. |
| $G = (\mathbf{A}, \mathbf{X})$ | fMRI 데이터로부터 구성된 원본 뇌 그래프. |
| $\mathbf{A} \in \mathbb{R}^{|V| \times |V|}$ | 뇌 영역 간의 부분 상관 계수를 정의하는 인접 행렬. |
| $\mathbf{X} \in \mathbb{R}^{|V| \times |F|}$ | 쌍별 BOLD 신호의 피어슨 상관 관계를 기반으로 한 노드 특징 행렬. |
| $n$ | 총 ROI 수, 여기서 $|V| = n$. |
| $\mathcal{N}_i$ | 그래프를 희소화하는 데 사용되는 노드 $i$의 $K$개 최근접 이웃 노드 집합. |
| $\tilde{G} = \{\tilde{\mathbf{A}}, \tilde{\mathbf{X}}\}$ | 원본 엣지가 이제 노드로 취급되는 구성된 Line Graph. |
| $\tilde{\mathbf{x}}_i$ | 새로 구성된 Line Graph의 $i$-번째 노드의 특징 벡터. |
| $\tilde{\mathbf{Z}}^{(l)}$ | $l$-번째 SAGEConv (GraphSAGE convolution) 계층의 출력 특징 행렬. |
| $W$ | 최종 선형 분류 계층의 가중치 행렬. |
| $\Sigma$ | 불확실성을 모델링하는 데 사용되는 변이 후의 공분산 행렬. |
| $\mathcal{L}_{VB}(\theta, \eta, \Sigma)$ | 모델을 최적화하기 위한 목적 함수로 사용되는 변이 하한(ELBO). |
이러한 요소들을 결합함으로써 저자들은 뇌 네트워크 분석 접근 방식에 혁신을 가져왔다. 그들은 AI의 주의를 뇌 영역에서 실제 연결로 성공적으로 전환하고, 계산 비용을 낮게 유지했으며, 작고 노이즈가 많은 의료 데이터셋의 불확실성을 처리하기 위한 수학적 "안전망"을 구축했다.
문제 정의 및 제약 조건
이 논문을 이해하기 위해서는 먼저 과학자들이 뇌를 어떻게 바라보는지 이해할 필요가 있다. 인간의 뇌를 광대한 국가로 상상해보자. 각기 다른 뇌 영역은 "도시"이며, 이들 간에 소통하는 신경 경로는 "고속도로"이다.
의사들이 기능적 자기공명영상(fMRI)을 사용할 때, 본질적으로 이 도시들 간의 교통량(혈류 및 산소)을 시간에 따라 추적하는 것이다. 임의의 두 도시 간 교통량의 동기화 정도를 계산함으로써 과학자들은 "기능적 연결성"(FC) 행렬을 생성한다. 수학적으로 이는 그래프 $G = (\mathbf{A}, \mathbf{X})$로 표현되며, 여기서 노드(도시)는 특징 $\mathbf{X}$를 가지며, 엣지(고속도로)는 영역 간 상관관계 강도를 나타내는 인접 행렬 $\mathbf{A}$로 표현된다.
시작점(Input)은 fMRI 데이터에서 파생된 이 원시적이고 환자별 뇌 그래프이다. 원하는 종착점(Output)은 매우 정확하고 해석 가능한 이진 분류, 특히 환자가 자폐 스펙트럼 장애(ASD) 또는 ADHD($y_D$)와 같은 신경정신과적 장애를 가지고 있는지, 아니면 건강한 대조군($y_{HC}$)인지 여부를 결정하는 것이다.
누락된 연결: 노드 대 엣지
이 논문이 연결하고자 하는 근본적인 간극이 바로 여기에 있다. 전통적인 그래프 신경망(GNN)은 매우 "노드 중심적"이다. 수학적 연산(메시지 전달이라고 함) 중에, 이들은 이웃 도시들의 데이터를 집계하여 도시(뇌 영역)의 정보를 끊임없이 업데이트한다. 고속도로(엣지)는 단순히 데이터가 흐르는 경로를 지정하는 멍청한 파이프로 취급될 뿐이다.
그러나 임상 신경과학에서 ADHD 및 ASD와 같은 질병은 고립된 뇌 영역을 단순히 변화시키는 것이 아니라, 연결성 자체를 근본적으로 교란한다. 정확한 수학적 간극은 전통적인 GNN이 이러한 연결성을 주요하고 학습 가능한 특징으로 취급하지 못한다는 것이다. 저자들은 엣지를 신경망에서 "일등 시민"으로 격상시켜야 할 필요성을 인식했다.
차원의 딜레마
이를 해결하기 위한 논리적인 단계는 "선 그래프" 변환을 사용하는 것이다. 그래프 이론에서 표준 그래프를 선 그래프로 변환하는 것은 원래의 모든 엣지를 새로운 노드로 바꾸는 것을 의미한다. 갑자기 고속도로가 도시가 되어 신경망이 연결성을 직접 분석할 수 있게 된다.
하지만 이것은 이전 연구자들을 가두었던 잔인하고 고통스러운 절충안을 도입한다: 표현 대 계산 폭발.
$n$개의 영역으로 구성된 뇌 아틀라스가 있다면, 완전 연결된 뇌 그래프는 대략 $n^2 / 2$개의 엣지를 가진다. 이를 선 그래프(여기서 각 엣지는 새로운 노드가 되고, 이 새로운 노드들 간의 엣지는 공유된 연결성을 나타냄)로 변환하면, 새로운 인접 행렬의 크기는 지수적으로 증가하여 다음과 같이 된다:
$$(n - 1)^2 \times n^2 / 4$$
뇌가 단 200개의 영역으로 나뉘어져 있다면, 이 선 그래프 변환은 수십억 개의 매개변수를 가진 행렬을 초래한다. 이는 계산상의 악몽이다. 뇌 연결성의 완벽한 표현을 얻지만, 현대 GPU의 하드웨어 메모리 한계를 완전히 무너뜨린다.
가혹한 벽과 제약
계산 폭발 외에도, 저자들은 이 문제를 극도로 어렵게 만드는 몇 가지 가혹하고 현실적인 벽에 부딪혔다:
- fMRI 데이터의 극심한 희소성과 노이즈: fMRI 스캔은 믿을 수 없을 정도로 노이즈가 많다. 환자의 움직임, 스캐너의 아티팩트, 그리고 혈류는 신경 활동의 간접적인 측정값이다. 더욱이, 의료 데이터셋은 방대한 특징 공간에 비해 악명 높게 작다(ABIDE 또는 ADHD-200 데이터셋과 같이 종종 수백 명의 환자에 불과함). 수십억 개의 매개변수를 가진 딥러닝 모델을 단 500명의 환자로 훈련하는 것은 치명적인 과적합을 보장한다.
- 과도한 평활화의 저주: GNN에서 복잡한 패턴을 학습하기 위해 너무 많은 레이어를 쌓으면, 모든 노드의 특징이 결국 균일한 죽처럼 섞이게 되는데, 이는 과도한 평활화 현상으로 알려져 있다. 모델이 과도하게 평활화되면, 특정 뇌 연결성에 숨겨진 고유한 질병 바이오마커가 씻겨 내려간다.
- 비방향성 그래프의 수학적 모호성: 비방향성 그래프에서의 표준 피어슨 상관관계는 양방향 및 단방향 신경 활성화 간의 구분을 모호하게 하여, 뇌 통신의 실제 흐름에 대해 모델을 혼란스럽게 한다.
저자들의 해결 방법
이러한 벽들을 부수기 위해, 저자들은 잔차-사후 선 그래프 신경망(Residual-Posterior Line Graph Network, RP-LGN)을 설계했다. 그들은 세 가지 훌륭한 단계를 통해 수학적으로 제약 조건을 우회했다:
1. K-최근접 이웃(KNN) 희소화
$O(n^4)$ 계산 폭발을 방지하기 위해, 그들은 완전 연결된 뇌에서 선 그래프를 구축하는 대신, 변환 전에 KNN 알고리즘을 사용하여 원래 그래프를 공격적으로 희소화했다. 노드 특징 간의 유클리드 거리를 계산하여:
$$d(v_i, v_j) = \|x_i - x_j\|_2$$
그들은 그래프를 $K=1$개의 가장 가까운 이웃으로만 제한했다. 이 집합 밖의 엣지는 0으로 강제되었다. 이는 그래프 크기를 극적으로 줄여, 선 그래프 $\tilde{G} = \{\tilde{\mathbf{A}}, \tilde{\mathbf{X}}\}$가 메모리에 들어갈 수 있도록 하면서 가장 중요한 신경 경로를 유지했다.
2. 잔차 GraphSAGE 아키텍처
과도한 평활화 저주에 맞서기 위해, 그들은 잔차 블록과 결합된 특정 유형의 그래프 컨볼루션(GraphSAGE)을 사용했다. 메시지 전달 중에 연결성 특징이 씻겨 내려가도록 하는 대신, 레이어의 원래 입력을 출력에 직접 더했다:
$$\tilde{\mathbf{X}}^{(l+1)} = \tilde{\mathbf{X}}^{(l)} + \tilde{\mathbf{Z}}^{(l)}$$
이 수학적 "스킵 연결"은 네트워크가 뇌 연결성의 원래 구조적 충실도를 기억하도록 강제한다.
3. 소규모 샘플 편향을 위한 베이즈 변분 추론
극심한 노이즈와 작은 샘플 크기를 극복하기 위해, 그들은 전통적인 결정론적 분류 계층을 폐기했다. 대신, 그들은 베이즈 변분 사후 분포를 도입했다. "이 연결 가중치는 정확히 0.8이다"라고 말하는 대신, 모델은 가중치 $W$와 공분산 $\Sigma$를 가우시안 분포를 가진 확률 변수로 취급한다:
$$q(\Sigma) = \prod_{k=1}^{C_y} \mathcal{N}(W_k \mid \mu_k, \Sigma_k)$$
이렇게 함으로써, 모델은 자체적인 불확실성을 정량화한다. fMRI 데이터의 일부가 노이즈가 많거나 이상하면, 모델은 노이즈에 과적합하는 대신 수학적으로 신뢰도를 낮춘다. 그들은 증거 하한(ELBO)을 최대화함으로써 이를 최적화한다:
$$S^{-1} \log p(Y \mid \mathbf{X}, \mathbf{A}, \theta) \geq \mathcal{L}_{VB}(\theta, \eta, \Sigma) - S^{-1}\text{KL}(q(W, \Sigma \mid \eta) \parallel p(W, \Sigma))$$
연결성을 목표로 하는 희소화된 선 그래프, 평활화를 방지하는 잔차 레이어, 그리고 노이즈가 많고 소규모 데이터에서 생존하기 위한 베이즈 확률을 결합함으로써, 저자들은 환자가 ADHD를 가지고 있는지 단순히 추측하는 것이 아니라, 이를 유발하는 정확한 결함 있는 신경 고속도로를 수학적으로 강조하는 모델을 성공적으로 만들었다.
이 접근 방식은 왜
Residual-Posterior Line Graph Network (RP-LGN)를 구축한 이유를 이해하기 위해서는 전통적인 Graph Neural Networks (GNNs)가 신경 영상 분야에서 한계에 부딪혔던 정확한 순간을 살펴볼 필요가 있다.
뇌 분석에 사용되는 표준 GNN에서 물리적인 뇌 영역은 "주인공"(노드)으로 취급되며, 이들 간의 기능적 연결은 단순히 배경 관계(엣지)로 취급된다. 그러나 저자들은 자폐증 및 ADHD와 같은 신경정신 질환에 대한 근본적인 진실을 깨달았다: 질병이 실제로 발현되는 곳은 바로 연결 자체라는 것이다. 전통적인 모델은 잘못된 주요 개체를 바라보고 있었다.
이를 해결하기 위해 저자들은 이러한 연결을 "일급 객체"로 격상시켜야 했다. 유일하게 실행 가능한 수학적 해결책은 엣지를 노드로 변환하는 것이었으며, 이는 "라인 그래프"로 알려진 것을 생성한다. 하지만 이는 치명적인 제약을 도입했다. $n$개의 영역을 가진 완전 연결된 초기 뇌 그래프는 대략 $n^2/2$개의 엣지를 가진다. 라인 그래프를 형성하기 위해 이러한 엣지를 노드로 변환하면, 새로운 인접 행렬은 $(n-1)^2 \times n^2/4$라는 엄청난 규모로 팽창한다. 수백 개의 영역을 가진 표준 뇌 지도서의 경우, 이는 수십억 개의 파라미터를 가진 행렬을 계산해야 함을 의미한다. 전통적인 SOTA 모델은 즉시 메모리 부족에 직면하여 순수 라인 그래프 접근 방식이 계산적으로 불가능하게 된다.
벤치마킹 로직 및 구조적 우수성
이러한 막대한 $O(N^4)$ 메모리 폭발을 극복하기 위해, 저자들은 단순히 더 많은 컴퓨팅 파워를 투입하는 대신 구조적으로 이를 우회했다. 그들은 라인 그래프 구성 전에 K-Nearest Neighbors (KNN) 희소화 단계를 도입했다. $K=1$로 설정함으로써 유클리드 거리를 사용하여 수학적으로 그래프를 가지치기했다:
$$ \mathcal{N}_i = \text{argmin}_j \{d(v_i, v_j) \mid j \neq i\}_{1 \leq j \leq K, i, j \in V} $$
이 뛰어난 제약은 밀집되고 불가능한 행렬을 매우 희소하고 관리 가능한 표현으로 줄여, 가장 중요한 기능적 연결만을 유지했다.
더욱이, 그들은 이 새로운 그래프를 처리할 올바른 백본을 선택해야 했다. 왜 Graph Attention Networks (GAT)와 같은 인기 있는 접근 방식을 사용하지 않았을까? 저자들의 ablation 연구는 GAT의 어텐션 메커니즘이 실제로 그들의 아키텍처와 충돌하여 역효과를 낳는 결과를 초래했음을 명확히 보여주었다. 대신, 그들은 residual GraphSAGE 백본을 선택했다. 이는 잔차 연결이 원래 그래프의 구조적 충실도를 완벽하게 보존하여, 메시지 전달 몇 계층 후 노드 특징이 구별할 수 없는 혼란으로 흐릿해지는 표준 GNN의 치명적인 결함인 "과도한 평활화(oversmoothing)"를 방지했기 때문에 질적으로 우수했다.
가혹한 제약과 베이지안 솔루션 간의 "결혼"
두 번째 거대한 장애물은 fMRI 데이터 자체의 특성이었다: 이는 엄청나게 노이즈가 많으며, 의료 데이터셋은 심각한 소표본 편향(small-sample bias)을 겪는다. 만약 저자들이 거의 모든 이전의 gold-standard 모델들이 그러했듯이 표준 완전 연결 계층을 분류기로 사용했다면, 네트워크는 소규모 데이터셋에 압도적으로 과적합(overfitted)되었을 것이다.
이를 해결하기 위해, 그들은 결정론적 분류기를 완전히 거부하고 베이지안 변분 사후 분포(Bayesian variational posterior)를 최종 계층으로 통합했다. 엄격하고 단일한 예측을 출력하는 대신, 베이지안 접근 방식은 최종 계층의 가중치 $W$와 공분산 행렬 $\Sigma$를 확률 변수로 모델링한다. 그들은 Evidence Lower Bound (ELBO)를 최대화함으로써 실제 사후 분포를 근사한다:
$$ S^{-1} \log p(Y | \mathbf{X}, \mathbf{A}, \theta) \geq \mathcal{L}_{VB}(\theta, \eta, \Sigma) - S^{-1}\text{KL}(q(W, \Sigma | \eta) \parallel p(W, \Sigma)) $$
이것이 바로 이 방법이 문제의 제약 조건과 완벽하게 일치하는 지점이다. 분류 가중치를 고정된 숫자가 아닌 분포로 취급함으로써, 모델은 본질적으로 불확실성을 정량화한다. 만약 fMRI 스캔이 비정상적인 데이터나 고차원 노이즈를 포함하고 있다면, 베이지안 계층은 그것에 속기보다는 그 불확실성을 흡수한다. 이 단일 통과, 저분산 확률적 추론은 RP-LGN을 전통적인 SOTA 모델을 파괴하는 소표본 과적합 함정에 대해 강건하게 만드는 것이며, 궁극적으로 뇌의 진정한, 숨겨진 연결 패턴을 발견할 수 있게 한다.
수학 및 논리 메커니즘
이 논문이 제시하는 심오한 전환을 이해하기 위해서는 먼저 인공지능이 인간의 뇌를 일반적으로 어떻게 바라보는지에 대한 배경을 확립해야 한다. 전통적으로 기능적 자기공명영상(fMRI) 데이터를 분석할 때, 그래프 신경망(GNN)은 물리적인 뇌 영역을 "노드(nodes)"로, 그들 간의 상관관계를 "엣지(edges)"로 취급한다. 그러나 ADHD 및 자폐증과 같은 신경정신과적 질환은 종종 의사소통 경로(pathways) 자체의 미묘한 저하로 나타난다. 본 논문의 동기는 이러한 경로, 즉 연결을 분석의 주요 대상으로 격상시키는 것이다.
이를 위해 저자들은 막대한 제약에 직면했다. 뇌 그래프를 수학적으로 역행하여 모든 연결을 새로운 노드로 만들면(이를 "라인 그래프(Line Graph)"라고 함), 파라미터 수가 수십억 개로 폭발하여 표준 모델이 즉시 충돌할 것이다. 또한, fMRI 데이터는 악명 높을 정도로 노이즈가 많고, 의료 데이터셋은 일반적으로 작다(종종 수백 명의 환자만). 이는 심각한 과적합(overfitting)으로 이어진다. 이러한 제약을 극복하기 위해 저자들은 K-최근접 이웃(K-Nearest Neighbors)을 사용하여 그래프를 희소화(sparsified)하고, 신호가 서로 흐릿해지는 것을 방지하기 위해 Residual GraphSAGE 백본을 구축했으며, 불확실성을 정량화하기 위해 베이지안 변분 사후 분포(Bayesian variational posterior)로 마무리했다.
이것이 어떻게 달성되었는지에 대한 수학적 부검은 다음과 같다.
핵심 방정식
Residual-Posterior Line Graph Network (RP-LGN)의 엔진은 두 개의 상호 연결된 수학적 시스템에 의해 구동된다.
첫째, 라인 그래프에서 구조적 특징을 추출하는 잔차 메시지 전달(Residual Message Passing) 메커니즘이다.
$$ \tilde{z}_i^{(l)} = \sigma\left(\theta_i^{(l)} \cdot \text{MEAN}\left(\{\tilde{x}_i^{(l)}\} \parallel \{\tilde{x}_j^{(l)}, \forall j \in \mathcal{N}_i\}\right)\right) $$
$$ \tilde{\mathbf{X}}^{(l+1)} = \tilde{\mathbf{X}}^{(l)} + \tilde{\mathbf{Z}}^{(l)} $$
둘째, 예측 정확도와 불확실성 간의 균형을 모델에 강요하는 궁극적인 손실 함수 역할을 하는 베이지안 변분 목적 함수(Bayesian Variational Objective)이다.
$$ \mathcal{L}_{VB}(\theta, \eta, \Sigma) = \frac{1}{S} \sum_{s=1}^S \left( y_s^\top W \phi_s - \log \sum_{k=1}^{C_y} \exp\left[w_k^\top \phi_s + \frac{1}{2}(\phi_s^\top \Sigma_k \phi_s + \sigma_k^2)\right] \right) $$
$$ \theta^*, \eta^*, \Sigma^* = \arg\max_{\eta, \Sigma} \left\{ \mathcal{L}_{VB}(\theta, \eta, \Sigma) + S^{-1}(\log p(\Sigma) - \text{KL}(q(W \mid \eta) \parallel p(W))) \right\} $$
방정식 해부
이 기계 장치의 모든 기어와 스프링을 분해해 보자.
- $\tilde{\mathbf{X}}^{(l)}$ 및 $\tilde{x}_i^{(l)}$: 레이어 $l$에서의 라인 그래프의 특징 행렬 및 개별 특징 벡터. 물리적으로, 이는 1급 노드로 승격된 실제 뇌 연결을 나타낸다.
- $\parallel$ (연결 연산자): 노드 자체의 특징과 이웃 노드들의 평균을 결합한다. 여기서 덧셈 대신 연결을 사용하는 이유는 무엇인가? 연결은 특정 뇌 연결의 고유하고 분리된 정체성을 유지하면서 이웃의 맥락을 추가한다. 덧셈은 이를 돌이킬 수 없이 뒤섞을 것이다.
- $\theta_i^{(l)}$: 학습 가능한 가중치 행렬. 이는 기하학적 조향 장치 역할을 하여, 특징 벡터를 질병이 있거나 건강한 패턴이 분리되는 고차원 공간으로 회전시킨다.
- $\sigma$: 활성화 함수. 이는 신경 연결 패턴 중 어떤 것이 앞으로 전달될 만큼 중요한지를 결정하는 생물학적 임계값 역할을 한다.
- $+$ (in $\tilde{\mathbf{X}}^{(l)} + \tilde{\mathbf{Z}}^{(l)}$): 잔차 연결. 곱셈 대신 덧셈을 사용하는 이유는 무엇인가? 덧셈은 안전한 우회 고속도로를 만든다. 그래프 컨볼루션이 불필요한 노이즈를 추출하는 경우, 네트워크는 가중치를 0으로 설정하고 원본 데이터를 그대로 전달할 수 있다. 곱셈은 전체 신호를 0으로 축소시켜 표현을 파괴할 위험이 있다.
- $\mathcal{L}_{VB}$: 변분 하한(Variational Lower Bound). 이는 모델의 분류 능력에 대한 주요 점수 지표이다.
- $S$: 피험자(환자) 수. 환자는 연속적인 스펙트럼이 아닌 이산적이고 셀 수 있는 개체이기 때문에 적분 대신 $S$에 대한 합계 $\sum$를 사용한다.
- $y_s^\top W \phi_s$: 올바른 진단에 대한 예상 로짓 점수. 여기서 $\phi_s$는 환자 $s$의 평탄화되고 완전히 처리된 뇌 지도이다.
- $\frac{1}{2}(\phi_s^\top \Sigma_k \phi_s + \sigma_k^2)$: 분산/불확실성 페널티. $\Sigma_k$는 공분산 행렬이다. 이 항은 계산된 양의 가우시안 노이즈를 예측에 직접 주입한다. 이는 fMRI 스캔의 고유한 노이즈에 대한 수학적 충격 흡수 장치 역할을 한다.
- $\text{KL}(q \parallel p)$: 쿨백-라이블러 발산(Kullback-Leibler divergence). 이는 학습된 사후 가중치 분포 $q$를 과적합을 방지하기 위해 안전하고 안정적인 사전 분포 $p$로 되돌리는 고무줄 역할을 한다.
단계별 흐름
단일 추상 데이터 포인트, 즉 전전두엽 피질과 기저핵 사이의 기능적 연결(150달러 fMRI 스캔에서 파생됨)을 상상해 보자.
먼저, 이 연결은 단순한 "엣지"에서 새로운 라인 그래프의 완전한 "노드"로 승격된다. 원래 뇌 영역의 상관관계 강도를 기반으로 특징 벡터가 할당된다. 다음으로, Residual GraphSAGE 조립 라인에 진입한다. 이웃 연결을 살펴보고, 그들의 정보를 평균화한 다음, 자신의 데이터와 결합한다.
이 결합된 패키지는 가중치 행렬 $\theta$와 곱해져 더 높은 수준의 위상 패턴을 추출하고, 활성화 함수 $\sigma$를 통과하여 음수 값을 잘라내고, 잔차 경로를 통해 원래 자신에게 추가된다. 이는 처리 중에 연결이 원래의 정체성을 잃지 않도록 보장한다.
여러 레이어를 통과한 후, 완전히 처리된 뇌 지도 $\phi_s$는 베이지안 분류기에 도달한다. 최종 답을 얻기 위해 엄격하고 결정론적인 가중치와 곱하는 대신, 분류기는 확률 분포에서 샘플링한다. 이는 진단(예: "ADHD")뿐만 아니라 원시 의료 데이터의 고유한 노이즈를 고려한 신뢰 수준도 출력한다.
최적화 역학
이 아키텍처는 실제로 어떻게 학습하고 수렴하는가? 모델은 악명 높은 어려운 손실 지형을 탐색하기 위해 확률적 변분 추론(Stochastic Variational Inference)에 의존한다.
전통적인 fMRI 분석에서 손실 지형은 데이터가 고차원이지만 표본 크기가 작기 때문에(소표본 편향, small-sample bias) 매우 들쭉날쭉하고 심각한 과적합에 취약하다. 베이지안 사후 분포($\Sigma$ 및 KL 발산 항)를 도입함으로써 손실 지형이 효과적으로 평활화된다. 모델은 데이터가 모호할 때 예측에 지나치게 확신하는 것에 대해 적극적으로 페널티를 받는다.
역전파(backpropagation) 중에 그래디언트는 ELBO 목적 함수에서 역방향으로 흐른다. 잔차 연결은 이러한 그래디언트가 첫 번째 레이어까지 완전히 역방향으로 이동할 수 있는 명확하고 방해받지 않는 고속도로를 갖도록 보장하여 소실 그래디언트 문제(vanishing gradient problem)를 완전히 우회한다. 반복적으로, 모델은 더 나은 구조적 특징을 추출하기 위해 $\theta$를 업데이트하는 동시에 불확실성을 보정하기 위해 $\eta$와 $\Sigma$를 업데이트한다. 이는 건강한 뇌와 질병이 있는 뇌를 정확하게 구별할 수 있는 강력한 상태로 수렴하며, 심지어 비정상적인 환자 데이터에 직면하더라도 그렇다.
결과, 한계점 및 결론
인간의 뇌를 광활하고 분주한 국가로 상상해 보자. 뇌 영역은 주요 도시이며, 그 사이의 신경 경로는 고속도로이다. 수년 동안 신경과학자와 AI 연구자들은 기능적 자기공명영상(fMRI)을 사용하여 이러한 도시들의 "교통량"(혈류)을 측정하여 자폐 스펙트럼 장애(ASD) 및 주의력 결핍 과잉 행동 장애(ADHD)와 같은 신경정신 질환을 진단해 왔다. 전통적인 그래프 신경망(GNN)은 뇌 영역을 노드(도시)로, 연결을 엣지(고속도로)로 취급하는 데 사용되어 왔다.
하지만 근본적인 결함이 있다. 질병이 도시를 파괴하는 것이 아니라 고속도로를 교란시킨다면 어떻게 될까? 전통적인 GNN은 노드의 특징 업데이트에 크게 집중하며, 연결을 단순한 이차적 속성으로 취급한다.
이 논문의 저자들은 이러한 맹점을 인식하고 잔차-사후선 그래프 신경망(Residual-Posterior Line Graph Network, RP-LGN)이라는 획기적인 패러다임 전환을 제안했다. 그들은 연결을 쇼의 주인공으로 만들기로 결정했다.
동기 및 수학적 제약
연결에 집중하기 위해 저자들은 그래프 이론의 "선 그래프(line graph)"라는 개념을 사용했다. 선 그래프에서 원래 그래프의 엣지는 새로운 그래프의 노드가 된다.
그러나 그들은 즉시 거대한 수학적 난관에 부딪혔다. 뇌 지도(atlas)가 뇌를 $n$개의 영역으로 나누면, 완전 연결 그래프는 $(n - 1) \times n / 2$개의 엣지를 갖는다. 이를 선 그래프로 변환하면, 새로운 인접 행렬은 $(n - 1)^2 \times n^2 / 4$의 규모로 폭발한다. 수백 개의 영역을 가진 뇌의 경우, 수십억 개의 파라미터를 다루게 된다. 이는 계산상의 악몽이다. 더욱이, fMRI 데이터는 악명 높을 정도로 노이즈가 많고, 의료 데이터셋은 일반적으로 표본 크기가 작아 거대한 모델은 과적합(overfitting)에 매우 취약하다.
해결 방법: RP-LGN 아키텍처
이러한 제약을 극복하기 위해 저자들은 네 단계의 파이프라인을 설계했다.
1. KNN을 통한 철저한 희소화(Sparsification)
선 그래프를 구축하기 전에 원래 그래프를 가지치기해야 했다. 그들은 K-최근접 이웃(KNN) 접근 방식을 사용했으며, 특히 $K=1$로 설정하여 유클리드 거리 기반으로 가장 중요한 연결만 유지했다.
$$d(v_i, v_j) = \|x_i - x_j\|_2$$
솔직히 말해서, 이 부분에 대해서도 완전히 확신할 수는 없다. 논문에서는 첫 번째 순서 이웃 엣지만 남기고 모두 버리는 것의 임상적 타당성을 깊이 정당화하지는 않지만, 계산 폭발을 확실히 해결한다.
2. 엣지-노드 변환(Edge-to-Node Transformation)
다음으로, 그들은 선 그래프를 구축했다. 새로운 노드(원래 고속도로를 나타냄)는 특징을 필요로 한다. 그들은 연결된 두 뇌 영역의 특징 합과 원래 엣지 가중치를 연결(concatenate)하여 이러한 특징을 독창적으로 구성했다.
$$\tilde{x}_i = \text{CONCATE}(\text{SUM}(x_i, x_j), a_{ij})$$
3. 메시지 전달을 위한 잔차 GraphSAGE(Residual GraphSAGE for Message Passing)
선 그래프는 자체적인 엣지 가중치를 가지고 있지 않기 때문에, 저자들은 GraphSAGE를 사용하여 이러한 새로운 연결 노드 간에 메시지를 전달했다. 반복적인 메시지 전달이 모든 특징을 일반적인 혼합물로 흐릿하게 만드는 일반적인 GNN 문제인 "과잉 평활화(oversmoothing)"를 방지하기 위해 잔차 연결을 추가했다.
$$\tilde{\mathbf{X}}^{(l+1)} = \tilde{\mathbf{X}}^{(l)} + \tilde{\mathbf{Z}}^{(l)}$$
4. 베이지안 변분 사후 분포(Bayesian Variational Posterior)
마지막으로, 노이즈와 작은 표본 과적합에 대처하기 위해 전통적인 결정론적 분류기를 폐기했다. 대신, 최종 계층의 가중치를 가우시안 분포를 갖는 확률 변수로 취급했다. 확률적 변분 추론을 사용하여 모델은 단순히 엄격한 추측을 하는 것이 아니라 자체 불확실성을 정량화한다. 이는 증거 하한(Evidence Lower Bound, ELBO)을 최대화함으로써 최적화되었다.
$$S^{-1} \log p(Y|\mathbf{X}, \mathbf{A}, \theta) \geq \mathcal{L}_{VB}(\theta, \eta, \Sigma) - S^{-1}\text{KL}(q(W, \Sigma|\eta) \parallel p(W, \Sigma))$$
실험 아키텍처 및 "희생자들"
저자들은 자신들의 수학이 작동한다고 주장하는 데 그치지 않고, 이를 증명하기 위해 가혹한 시험대를 설계했다. 그들은 엄격한 5-겹 교차 검증을 사용하여 ABIDE I (자폐증) 및 ADHD-200 데이터셋에서 RP-LGN을 테스트했다.
그들의 손에 떨어진 "희생자들"은 표준 및 최첨단 모델들의 총집합이었다. KAN과 같은 단일 분류기, 표준 GNN(GAT, GIN, GraphSAGE), 그리고 BrainNetCNN, BrainGNN, BrainGB, FBNETGEN, BrainNetworkTransformer와 같은 특화된 뇌 네트워크였다. RP-LGN은 이들 모두를 능가했다.
하지만 결정적이고 부인할 수 없는 증거는 단순히 높은 정확도 백분율이 아니었다. 그것은 두 가지 형태로 나타났다.
1. 제거 연구(Ablation Study): 그들은 체계적으로 잔차 연결과 베이지안 사후 분포를 제거했다. SAGE, GIN, GAT와 같은 기본 모델에 적용했을 때 성능이 눈에 띄게 하락했으며, 이는 이러한 특정 메커니즘이 모델의 우수성의 정확한 이유임을 입증했다.
- Grad-CAM을 통한 임상 검증: 그들은 기울기 기반 국소화(gradient-based localization)를 사용하여 모델이 ADHD 진단을 위해 어떤 "고속도로"에 의존하는지 시각적으로 매핑했다. 모델은 독립적으로 상두엽 소엽(Superior Parietal Lobule), 미상핵(Caudate Nucleus), 방추상회(Fusiform Gyrus) 간의 연결을 강조했다. 이것이 결정적인 증거이다. 이것들은 공간 주의력, 보상 처리, 충동 조절과 같은 ADHD의 핵심 결함과 임상 정신과 의사들이 오랫동안 연관시켜 온 정확한 뇌 영역이다. 수학은 생물학을 완벽하게 재발견했다.
미래 발전을 위한 논의 주제
이 훌륭한 기반을 바탕으로, 뇌 연결성에 대한 이러한 표현을 더욱 발전시킬 수 있는 몇 가지 다양한 관점은 다음과 같다.
- 희소화에서의 $K=1$ 딜레마: 저자들은 계산 오버헤드를 줄이기 위해 $K=1$을 사용했지만, 뇌는 고도로 통합된 다중 경로 시스템이다. 유클리드 최근접 이웃에 엄격하게 의존하는 대신 임상적으로 관련된 장거리 연결을 유지하는 주의 기반 가지치기(attention-based pruning)와 같은 동적 희소화 기법을 탐색할 수 있을까?
- 정적 스냅샷 대비 시간적 역학: RP-LGN은 fMRI 데이터를 부분 상관관계의 정적 그래프로 취급한다. 그러나 뇌 연결성은 매우 역동적이다. 고속도로는 인지 부하에 따라 열리고 닫힌다. 또 다른 파라미터 폭발을 일으키지 않고 선 그래프 프레임워크에 슬라이딩 윈도우 시간 역학을 통합할 수 있을까?
- 임상에서의 베이지안 불확실성 해석: 베이지안 사후 분포는 불확실성에 대한 수학적 정량화를 제공한다. 이러한 수학적 분산을 의사를 위한 실행 가능한 지표로 어떻게 번역할 수 있을까? 예를 들어, 모델이 높은 분산으로 진단을 출력하는 경우, 실제 임상 환경에서 특정 이차 검사 프로토콜을 트리거할 수 있을까?
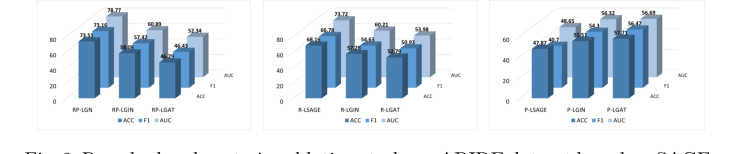 Figure 2. Resudual and posterior ablation study on ABIDE dataset based on SAGE, GIN and GAT. R: residual, P: posterior, L: line graph
Figure 2. Resudual and posterior ablation study on ABIDE dataset based on SAGE, GIN and GAT. R: residual, P: posterior, L: line graph