Уточнение признаков связности мозга на остаточных задних паттернах
Чтобы понять истинную природу человеческого мозга, необходимо выйти за рамки изучения отдельных областей и исследовать, как они взаимодействуют.
Предыстория и академическое происхождение
Чтобы понять истинную природу человеческого мозга, необходимо выйти за рамки изучения отдельных областей и исследовать, как они взаимодействуют. Исторически нейробиологи использовали функциональную магнитно-резонансную томографию (фМРТ) для регистрации активности мозга. По мере развития вычислительной нейронауки исследователи начали представлять мозг как сложную сеть, или "граф", где области мозга являются узлами, а пути их коммуникации — ребрами. Это естественным образом привело к применению графовых нейронных сетей (GNN) для диагностики нейропсихиатрических расстройств, таких как расстройства аутистического спектра (РАС) и СДВГ, путем анализа этих паттернов функциональной связности.
Однако возник критический "бутылочное горлышко". Традиционные подходы GNN оказались принципиально ошибочными для данной задачи, поскольку они фокусировались в первую очередь на самих областях мозга (узлах), а не на фактических путях коммуникации (ребрах). При нейропсихиатрических расстройствах заболевание часто проявляется в изменении связей, а не физических областей. Более того, предыдущие модели столкнулись с огромным вычислительным препятствием: если попытаться рассматривать каждое отдельное соединение как основную характеристику в полностью связанном графе мозга, математика "взорвется". Типичный атлас мозга может дать матрицу с миллиардами параметров, что делает ее вычислительно невозможной для обработки. Вдобавок к этому, медицинские наборы данных, как известно, малы и зашумлены, что приводит к переобучению традиционных моделей — то есть они запоминают обучающие данные, но полностью терпят неудачу в реальных клинических приложениях.
Чтобы преодолеть этот разрыв, авторы представили Residual-Posterior Line Graph Network (RP-LGN). Давайте разберем высокоспециализированные концепции, которые они использовали, на интуитивно понятные идеи:
Деконструкция жаргона
- Функциональная магнитно-резонансная томография (фМРТ) и BOLD-сигнал: В статье это сырые данные, измеряющие изменения кровотока в мозге.
- Бытовая аналогия: Представьте себе спутник, отслеживающий пробки в городе ночью, глядя на плотность фар. фМРТ делает это с кровотоком; он отслеживает, куда движется "трафик" (оксигенированная кровь), чтобы выяснить, какие "перекрестки" (области мозга) в данный момент активны и общаются друг с другом.
- Преобразование в линейный граф (Line Graph Transformation): Математический метод преобразования ребер в узлы.
- Бытовая аналогия: Предположим, вы изучаете глобальную авиационную сеть. Обычно вы изучаете города (узлы) и проводите линии для маршрутов полетов (ребер). Преобразование в линейный граф переворачивает это: вы делаете маршруты полетов основным предметом вашего исследования (новые узлы), а города становятся просто конечными точками. Это позволяет ИИ напрямую изучать фактические соединения.
- Пересглаживание (Oversmoothing) в GNN: Явление, при котором многократная передача сообщений между узлами приводит к тому, что все узлы выглядят идентично.
- Бытовая аналогия: Представьте смешивание красок. Если вы аккуратно смешаете красный и синий, вы получите красивый мраморный узор (полезная информация). Но если вы будете продолжать перемешивать без остановки, вы просто получите плоский, мутный фиолетовый цвет. Пересглаживание — это когда ИИ слишком сильно перемешивает данные, теряя все уникальные, отличительные черты мозга.
- Байесовское вариационное апостериорное распределение (Bayesian Variational Posterior): Статистический метод, используемый в последнем слое модели для количественной оценки неопределенности прогноза.
- Бытовая аналогия: Вместо того, чтобы приложение погоды безапелляционно заявляло: "Завтра будет дождь" (что может быть неверно, если данные зашумлены), байесовский подход говорит: "Я на 85% уверен, что будет дождь, с погрешностью 5%". Он рассчитывает погрешность, делая медицинский диагноз ИИ гораздо более надежным и заслуживающим доверия, даже когда на скане пациента много фонового шума.
Математический чертеж
Чтобы математически интерпретировать, как авторы решили эту проблему, нам нужно рассмотреть переменные, определяющие их вселенную. Они разреживают начальные соединения, используя подход $K$-ближайших соседей (KNN), чтобы предотвратить взрыв параметров, а затем отображают граф в линейный граф $\tilde{G}$. Наконец, они оптимизируют модель, максимизируя нижнюю границу свидетельства (ELBO), обозначаемую как $\mathcal{L}_{VB}$.
| Обозначение | Описание |
|---|---|
| $V$ | Множество узлов, представляющих области интереса (ROIs) в мозге. |
| $E$ | Множество ребер, представляющих функциональные связи между ROIs. |
| $G = (\mathbf{A}, \mathbf{X})$ | Исходный граф мозга, построенный на основе данных фМРТ. |
| $\mathbf{A} \in \mathbb{R}^{|V| \times |V|}$ | Матрица смежности, определяющая коэффициенты частичной корреляции между областями мозга. |
| $\mathbf{X} \in \mathbb{R}^{|V| \times |F|}$ | Матрица признаков узлов, основанная на корреляции Пирсона парных BOLD-сигналов. |
| $n$ | Общее количество ROIs, где $|V| = n$. |
| $\mathcal{N}_i$ | Множество $K$ ближайших соседей узла $i$, используемое для разреживания графа. |
| $\tilde{G} = \{\tilde{\mathbf{A}}, \tilde{\mathbf{X}}\}$ | Построенный линейный граф, где исходные ребра теперь рассматриваются как узлы. |
| $\tilde{\mathbf{x}}_i$ | Вектор признаков $i$-го узла в новом построенном линейном графе. |
| $\tilde{\mathbf{Z}}^{(l)}$ | Матрица выходных признаков $l$-го слоя свертки SAGE (GraphSAGE convolution). |
| $W$ | Матрица весов финального линейного слоя классификации. |
| $\Sigma$ | Ковариационная матрица вариационного апостериорного распределения, используемая для моделирования неопределенности. |
| $\mathcal{L}_{VB}(\theta, \eta, \Sigma)$ | Вариационная нижняя граница (ELBO), используемая в качестве целевой функции для оптимизации модели. |
Объединив эти элементы, авторы произвели революцию в подходе к анализу нейронных сетей мозга. Они успешно переключили внимание ИИ с областей мозга на фактические связи, сохранили низкие вычислительные затраты и встроили математическую "защитную сетку" для обработки неопределенности малых, зашумленных медицинских наборов данных.
Определение проблемы и ограничения
Чтобы понять эту статью, сначала необходимо разобраться, как ученые смотрят на мозг. Представьте человеческий мозг как огромную страну. Различные области мозга — это "города", а нейронные пути, связывающие их, — это "магистрали".
Когда врачи используют функциональную магнитно-резонансную томографию (фМРТ), они, по сути, отслеживают трафик (кровоток и кислород) между этими городами во времени. Вычисляя степень синхронизации трафика между любыми двумя городами, ученые создают матрицу "функциональной связности" (FC). В математическом смысле это граф $G = (\mathbf{A}, \mathbf{X})$, где узлы (города) имеют признаки $\mathbf{X}$, а ребра (магистрали) представлены матрицей смежности $\mathbf{A}$, показывающей силу корреляции между областями.
Исходной точкой (Input) является этот необработанный, специфичный для пациента граф мозга, полученный из данных фМРТ. Желаемой конечной точкой (Output) является высокоточная, интерпретируемая бинарная классификация — в частности, определение того, имеет ли пациент нейропсихиатрическое расстройство, такое как расстройство аутистического спектра (РАС) или СДВГ ($y_D$), или же он является здоровым контролем ($y_{HC}$).
Упущенное звено: узлы против ребер
Здесь кроется фундаментальный пробел, который данная статья пытается преодолеть. Традиционные графовые нейронные сети (GNN) в значительной степени "ориентированы на узлы". Во время своих математических операций (называемых передачей сообщений) они постоянно обновляют информацию о городах (областях мозга), агрегируя данные из соседних городов. Магистрали (ребра) рассматриваются лишь как пассивные каналы, определяющие направление потока данных.
Однако в клинической нейронауке такие заболевания, как СДВГ и РАС, не просто изменяют изолированные области мозга; они фундаментально нарушают сами соединения. Точный математический пробел заключается в том, что традиционные GNN не рассматривают эти соединения как первичные, обучаемые признаки. Авторы осознали, что им необходимо поднять ребра до статуса "граждан первого класса" в нейронной сети.
Дилемма размерности
Для решения этой проблемы логичным шагом является использование преобразования "линейного графа". В теории графов преобразование стандартного графа в линейный граф означает превращение каждого исходного ребра в новый узел. Внезапно магистрали становятся городами, что позволяет нейронной сети напрямую анализировать соединения.
Но это порождает жестокий, болезненный компромисс, который ставил в тупик предыдущих исследователей: представление против вычислительного взрыва.
Если у вас есть атлас мозга с $n$ областями, полностью связанный граф мозга имеет примерно $n^2 / 2$ ребер. Если преобразовать его в линейный граф (где каждое ребро становится узлом, а ребра между этими новыми узлами представляют общие соединения), размер вашей новой матрицы смежности экспоненциально увеличивается до:
$$(n - 1)^2 \times n^2 / 4$$
Если мозг разделен всего на 200 областей, такое преобразование в линейный граф приводит к матрицам с миллиардами параметров. Это вычислительный кошмар. Вы получаете идеальное представление связности мозга, но полностью нарушаете пределы памяти современного оборудования GPU.
Жесткие стены и ограничения
Помимо вычислительного взрыва, авторы столкнулись с несколькими суровыми, реалистичными проблемами, которые делают эту задачу невероятно сложной:
- Крайняя разреженность и шум данных фМРТ: Сканы фМРТ чрезвычайно зашумлены. Пациенты двигаются, сканеры имеют артефакты, а кровоток является косвенным показателем нейронной активности. Кроме того, медицинские наборы данных, как правило, очень малы (часто всего несколько сотен пациентов, как в наборах данных ABIDE или ADHD-200) по сравнению с огромным пространством признаков. Обучение модели глубокого обучения на миллиардах параметров при наличии всего 500 пациентов гарантирует катастрофический переобучение (overfitting).
- Проклятие чрезмерного сглаживания (oversmoothing): В GNN, если вы добавляете слишком много слоев для изучения сложных закономерностей, признаки всех узлов в конечном итоге сливаются в однородную массу — явление, известное как чрезмерное сглаживание. Если модель чрезмерно сглаживается, уникальные биомаркеры заболеваний, скрытые в специфических соединениях мозга, стираются.
- Математическая неоднозначность неориентированных графов: Стандартная корреляция Пирсона в неориентированных графах размывает различие между двунаправленной и однонаправленной нейронной активацией, сбивая модель с толку относительно фактического потока мозговой коммуникации.
Как авторы решили проблему
Чтобы разрушить эти стены, авторы разработали Residual-Posterior Line Graph Network (RP-LGN). Они математически обошли ограничения, используя три блестящих шага:
1. Сгущение на основе K-ближайших соседей (KNN)
Чтобы предотвратить вычислительный взрыв порядка $O(n^4)$, они не строили линейный граф из полностью связанного мозга. Вместо этого они агрессивно сгустили исходный граф, используя алгоритм KNN, перед преобразованием. Вычисляя евклидово расстояние между признаками узлов:
$$d(v_i, v_j) = \|x_i - x_j\|_2$$
Они ограничили граф только $K=1$ ближайшим соседом. Ребра вне этого множества были принудительно установлены в ноль. Это резко уменьшило размер графа, позволив линейному графу $\tilde{G} = \{\tilde{\mathbf{A}}, \tilde{\mathbf{X}}\}$ поместиться в память, сохранив при этом наиболее критичные нейронные пути.
2. Архитектура Residual GraphSAGE
Чтобы бороться с проклятием чрезмерного сглаживания, они использовали специфический тип графовой свертки (GraphSAGE) в сочетании с остаточными блоками (residual blocks). Вместо того чтобы позволять признакам соединений исчезать во время передачи сообщений, они добавляли исходный вход слоя непосредственно к выходу:
$$\tilde{\mathbf{X}}^{(l+1)} = \tilde{\mathbf{X}}^{(l)} + \tilde{\mathbf{Z}}^{(l)}$$
Это математическое "пропускающее соединение" (skip connection) заставляет сеть запоминать исходную структурную точность соединений мозга.
3. Байесовский вариационный вывод для смещения малых выборок
Чтобы преодолеть крайний шум и малые размеры выборок, они отказались от традиционного детерминированного классификационного слоя. Вместо этого они ввели байесовское вариационное апостериорное распределение. Вместо того чтобы говорить "этот вес соединения равен точно 0.8", модель рассматривает веса $W$ и ковариацию $\Sigma$ как случайные величины с нормальным распределением:
$$q(\Sigma) = \prod_{k=1}^{C_y} \mathcal{N}(W_k \mid \mu_k, \Sigma_k)$$
Таким образом, модель количественно оценивает собственную неопределенность. Если часть данных фМРТ зашумлена или аномальна, модель математически снижает свою уверенность, а не переобучается на шуме. Они оптимизируют это, максимизируя нижнюю границу свидетельства (Evidence Lower Bound, ELBO):
$$S^{-1} \log p(Y \mid \mathbf{X}, \mathbf{A}, \theta) \geq \mathcal{L}_{VB}(\theta, \eta, \Sigma) - S^{-1}\text{KL}(q(W, \Sigma \mid \eta) \parallel p(W, \Sigma))$$
Объединив сгущенные линейные графы для нацеливания на соединения, остаточные слои для предотвращения сглаживания и байесовскую вероятность для выживания в условиях зашумленных, маломасштабных данных, авторы успешно создали модель, которая не просто угадывает, есть ли у пациента СДВГ — она математически выделяет точные неисправные магистрали мозга, вызывающие его.
Почему этот подход
Чтобы понять, почему авторы разработали Residual-Posterior Line Graph Network (RP-LGN), необходимо обратиться к моменту, когда традиционные графовые нейронные сети (GNN) столкнулись с непреодолимым препятствием в нейровизуализации.
В стандартных GNN, используемых для анализа мозга, физические области мозга рассматриваются как "звезды шоу" (узлы), в то время как функциональные связи между ними являются лишь фоновыми отношениями (ребра). Однако авторы осознали фундаментальную истину о нейропсихиатрических расстройствах, таких как аутизм и СДВГ: именно сами связи являются местом проявления заболевания. Традиционные модели фокусировались не на тех первичных сущностях.
Чтобы исправить это, авторы решили поднять эти связи до уровня "объектов первого класса". Единственным жизнеспособным математическим решением была трансформация "ребро-в-узел", создающая так называемый "линейный граф". Но это ввело катастрофическое ограничение. Полностью связанный исходный граф мозга с $n$ областями имеет примерно $n^2/2$ ребер. Если преобразовать эти ребра в узлы для формирования линейного графа, новая матрица смежности увеличивается до ошеломляющих размеров $(n-1)^2 \times n^2/4$. Для стандартного атласа мозга с сотнями областей это означает вычисление матриц с миллиардами параметров. Традиционные SOTA модели мгновенно исчерпали бы память, делая чисто линейный подход вычислительно невозможным.
Логика бенчмаркинга и структурное превосходство
Чтобы преодолеть этот массивный взрыв памяти порядка $O(N^4)$, авторы не просто увеличили вычислительную мощность; они структурно обошли проблему. Они ввели шаг разреживания K-ближайших соседей (KNN) до построения линейного графа. Установив $K=1$, они математически обрезали граф, используя евклидово расстояние:
$$ \mathcal{N}_i = \text{argmin}_j \{d(v_i, v_j) \mid j \neq i\}_{1 \leq j \leq K, i, j \in V} $$
Это блестящее ограничение превратило плотную, невозможную матрицу в высоко разреженное, управляемое представление, сохранив только наиболее критические функциональные связи.
Кроме того, им пришлось выбрать подходящую основу для обработки этого нового графа. Почему бы не использовать популярные подходы, такие как Graph Attention Networks (GAT)? Исследования абляции авторов явно показали, что механизмы внимания GAT фактически конфликтовали с их архитектурой, приводя к контрпродуктивным результатам. Вместо этого они выбрали основу residual GraphSAGE. Это было качественно превосходящим решением, поскольку остаточные соединения идеально сохраняли структурную точность исходного графа, предотвращая "пересглаживание" — фатальный недостаток стандартных GNN, при котором признаки узлов сливаются в неразличимую массу после нескольких слоев передачи сообщений.
"Брак" жестких ограничений и байесовского решения
Вторым массивным препятствием была сама природа фМРТ-данных: они чрезвычайно зашумлены, а медицинские наборы данных страдают от сильной смещенности малых выборок. Если бы авторы использовали стандартные полносвязные слои в качестве классификаторов — как это делают почти все предыдущие эталонные модели — сеть бы подавляюще переобучилась на малом наборе данных.
Чтобы решить эту проблему, они полностью отказались от детерминированных классификаторов и интегрировали байесовское вариационное апостериорное распределение в качестве финального слоя. Вместо выдачи жесткого, единичного предсказания, байесовский подход моделирует веса финального слоя $W$ и ковариационную матрицу $\Sigma$ как случайные величины. Они аппроксимируют истинное апостериорное распределение путем максимизации нижней границы свидетельства (ELBO):
$$ S^{-1} \log p(Y | \mathbf{X}, \mathbf{A}, \theta) \geq \mathcal{L}_{VB}(\theta, \eta, \Sigma) - S^{-1}\text{KL}(q(W, \Sigma | \eta) \parallel p(W, \Sigma)) $$
Именно здесь метод идеально соответствует ограничениям задачи. Рассматривая веса классификации как распределение, а не фиксированные числа, модель по своей сути количественно оценивает неопределенность. Если фМРТ-скан содержит аномальные данные или высокоразмерный шум, байесовский слой поглощает эту неопределенность, а не обманывается ею. Этот однопроходный стохастический вывод с низкой дисперсией делает RP-LGN устойчивым к ловушке переобучения на малых выборках, которая разрушает традиционные SOTA модели, и в конечном итоге позволяет ему раскрыть истинные, скрытые паттерны связности мозга.
Математический и логический механизм
Чтобы понять глубокий сдвиг, представленный в данной статье, сначала необходимо установить контекст того, как ИИ обычно анализирует человеческий мозг. Традиционно при анализе данных функциональной магнитно-резонансной томографии (фМРТ) графовые нейронные сети (GNN) рассматривают физические области мозга как "узлы", а корреляции между ними — как "ребра". Однако нейропсихиатрические расстройства, такие как СДВГ и аутизм, часто проявляются как тонкие нарушения в самих путях коммуникации. Мотивация данной статьи заключается в том, чтобы вывести эти пути — связи — на первый план как основной объект анализа.
Для достижения этой цели авторы столкнулись с серьезными ограничениями. Если математически инвертировать граф мозга так, чтобы каждая связь стала новым узлом ("линейный граф"), количество параметров взлетит до миллиардов, что мгновенно приведет к сбою стандартной модели. Кроме того, данные фМРТ отличаются высокой зашумленностью, а медицинские наборы данных обычно малы (часто всего несколько сотен пациентов), что приводит к сильному переобучению (overfitting). Для преодоления этих ограничений авторы разрежили граф с помощью K-ближайших соседей (K-Nearest Neighbors), построили основу Residual GraphSAGE для предотвращения смешивания сигналов (oversmoothing) и завершили ее байесовским вариационным апостериори для количественной оценки неопределенности.
Ниже представлен математический анализ того, как им это удалось.
Основные уравнения
Движущей силой сети Residual-Posterior Line Graph Network (RP-LGN) являются две взаимосвязанные математические системы.
Во-первых, механизм Residual Message Passing, который извлекает структурные признаки из линейного графа:
$$ \tilde{z}_i^{(l)} = \sigma\left(\theta_i^{(l)} \cdot \text{MEAN}\left(\{\tilde{x}_i^{(l)}\} \parallel \{\tilde{x}_j^{(l)}, \forall j \in \mathcal{N}_i\}\right)\right) $$
$$ \tilde{\mathbf{X}}^{(l+1)} = \tilde{\mathbf{X}}^{(l)} + \tilde{\mathbf{Z}}^{(l)} $$
Во-вторых, Bayesian Variational Objective, который выступает в качестве конечной функции потерь, заставляя модель балансировать между точностью прогнозирования и неопределенностью:
$$ \mathcal{L}_{VB}(\theta, \eta, \Sigma) = \frac{1}{S} \sum_{s=1}^S \left( y_s^\top W \phi_s - \log \sum_{k=1}^{C_y} \exp\left[w_k^\top \phi_s + \frac{1}{2}(\phi_s^\top \Sigma_k \phi_s + \sigma_k^2)\right] \right) $$
$$ \theta^*, \eta^*, \Sigma^* = \arg\max_{\eta, \Sigma} \left\{ \mathcal{L}_{VB}(\theta, \eta, \Sigma) + S^{-1}(\log p(\Sigma) - \text{KL}(q(W \mid \eta) \parallel p(W))) \right\} $$
Разбор уравнений
Давайте разберем каждый механизм и элемент этой системы:
- $\tilde{\mathbf{X}}^{(l)}$ и $\tilde{x}_i^{(l)}$: Матрица признаков и индивидуальный вектор признаков линейного графа на слое $l$. Физически они представляют собой фактические связи мозга, которые были повышены до узлов первого класса.
- $\parallel$ (Оператор конкатенации): Этот оператор объединяет собственные признаки узла с усредненными признаками его соседей. Почему здесь используется конкатенация, а не сложение? Конкатенация сохраняет отдельную, изолированную идентичность конкретной связи мозга, добавляя контекст соседства. Сложение необратимо смешало бы их.
- $\theta_i^{(l)}$: Обучаемая матрица весов. Она действует как геометрический руль, вращая векторы признаков в многомерное пространство, где разделяются паттерны заболеваний и здоровых состояний.
- $\sigma$: Функция активации. Она действует как биологический порог, определяя, какие паттерны нейронных связей достаточно значимы, чтобы пройти дальше.
- $+$ (в $\tilde{\mathbf{X}}^{(l)} + \tilde{\mathbf{Z}}^{(l)}$): Остаточное соединение (residual connection). Почему сложение, а не умножение? Сложение создает безопасную обходную магистраль. Если свертка графа извлекает ненужный шум, сеть может обнулить веса и просто передать исходные данные вперед. Умножение рискует свести весь сигнал к нулю, разрушив представление.
- $\mathcal{L}_{VB}$: Вариационная нижняя граница (Variational Lower Bound). Это основной показатель оценки классификационной способности модели.
- $S$: Количество испытуемых (пациентов). Мы используем суммирование $\sum$ по $S$, а не интеграл, потому что пациенты являются дискретными, счетными сущностями, а не непрерывным спектром.
- $y_s^\top W \phi_s$: Ожидаемый логит-скор для правильного диагноза, где $\phi_s$ — это "сплющенная", полностью обработанная карта мозга пациента $s$.
- $\frac{1}{2}(\phi_s^\top \Sigma_k \phi_s + \sigma_k^2)$: Штраф за дисперсию/неопределенность. $\Sigma_k$ — ковариационная матрица. Этот член вводит рассчитанное количество гауссовского шума непосредственно в прогноз. Он действует как математический амортизатор против присущего шума фМРТ-сканов.
- $\text{KL}(q \parallel p)$: Дивергенция Кульбака-Лейблера. Она действует как резинка, притягивая выученное апостериорное распределение весов $q$ обратно к безопасному, стабильному априорному распределению $p$ для предотвращения переобучения.
Пошаговый процесс
Представим себе одну абстрактную точку данных — функциональную связь между префронтальной корой и базальными ганглиями, полученную в результате фМРТ-сканирования стоимостью 150 долларов.
Сначала эта связь извлекается из статуса простого "ребра" и повышается до полноценного "узла" в новом линейном графе. Ей присваивается вектор признаков на основе силы корреляции исходных областей мозга. Затем она поступает на сборочную линию Residual GraphSAGE. Она анализирует соседние связи, усредняет их информацию и объединяет ее с собственными данными.
Этот пакет объединяется с матрицей весов $\theta$ для извлечения топологических паттернов более высокого уровня, пропускается через функцию активации $\sigma$ для отсечения отрицательных значений, а затем прибавляется к исходному состоянию через остаточный путь. Это гарантирует, что связь не потеряет свою первоначальную идентичность в процессе обработки.
После прохождения через несколько слоев полностью обработанная карта мозга $\phi_s$ поступает в байесовский классификатор. Вместо умножения на жесткий, детерминированный вес для получения окончательного ответа, классификатор производит выборку из вероятностного распределения. Он выдает не просто диагноз (например, "СДВГ"), а уровень уверенности, учитывая присущий шум исходных медицинских данных.
Динамика оптимизации
Как эта архитектура фактически обучается и сходится? Модель полагается на стохастический вариационный вывод (Stochastic Variational Inference) для навигации по чрезвычайно сложному ландшафту потерь.
В традиционном анализе фМРТ ландшафт потерь сильно изрезан и подвержен сильному переобучению, поскольку данные имеют высокую размерность, но малый объем выборки (small-sample bias). Вводя байесовское апостериорное распределение (члены $\Sigma$ и KL-дивергенция), ландшафт потерь эффективно сглаживается. Модель активно штрафуется за чрезмерную уверенность в своих прогнозах, когда данные неоднозначны.
Во время обратного распространения ошибки (backpropagation) градиенты распространяются назад от целевой функции ELBO. Остаточные соединения гарантируют, что эти градиенты имеют четкую, беспрепятственную магистраль для прохождения до самого первого слоя, полностью минуя проблему исчезающих градиентов. Итеративно модель обновляет $\theta$ для извлечения лучших структурных признаков, одновременно обновляя $\eta$ и $\Sigma$ для калибровки своей неопределенности. Она сходится к устойчивому состоянию, где может точно различать здоровый и больной мозг, даже сталкиваясь с аномальными данными пациента.
Результаты, ограничения и заключение
Представьте человеческий мозг как обширную, оживленную страну. Области мозга — это крупные города, а нейронные пути между ними — магистрали. На протяжении многих лет нейробиологи и исследователи в области искусственного интеллекта использовали функциональную магнитно-резонансную томографию (фМРТ) для измерения «трафика» (кровотока) в этих городах с целью диагностики нейропсихиатрических расстройств, таких как расстройства аутистического спектра (РАС) и синдром дефицита внимания и гиперактивности (СДВГ). Традиционные графовые нейронные сети (GNN) были основным инструментом для этого, рассматривая области мозга как узлы (города), а соединения — как ребра (магистрали).
Но вот фундаментальный недостаток: что, если болезнь не разрушает город, а скорее нарушает работу магистрали? Традиционные GNN в значительной степени фокусируются на обновлении признаков узлов, рассматривая соединения как простые вторичные атрибуты.
Авторы данной статьи осознали этот пробел и предложили блестящую смену парадигмы: Residual-Posterior Line Graph Network (RP-LGN). Они решили сделать соединения главными действующими лицами.
Мотивация и математические ограничения
Чтобы сосредоточиться на соединениях, авторы использовали концепцию из теории графов, называемую «линейным графом». В линейном графе ребра исходного графа становятся узлами нового графа.
Однако они немедленно столкнулись с огромной математической стеной. Если атлас мозга делит мозг на $n$ областей, то полный граф имеет $(n - 1) \times n / 2$ ребер. Если преобразовать это в линейный граф, новая матрица смежности разрастается до масштаба $(n - 1)^2 \times n^2 / 4$. Для мозга с сотнями областей внезапно приходится иметь дело с миллиардами параметров. Это вычислительный кошмар. Кроме того, данные фМРТ заведомо зашумлены, а медицинские наборы данных обычно имеют небольшой размер выборки, что делает массивные модели очень склонными к переобучению (overfitting).
Как они решили проблему: архитектура RP-LGN
Чтобы преодолеть эти ограничения, авторы разработали четырехэтапный конвейер:
1. Жесткая разреженность с помощью KNN
Перед построением линейного графа им пришлось обрезать исходный граф. Они использовали подход K-ближайших соседей (KNN), в частности, установив $K=1$, чтобы сохранить только наиболее критические соединения на основе евклидова расстояния:
$$d(v_i, v_j) = \|x_i - x_j\|_2$$
Честно говоря, я тоже не до конца уверен в этой части — в статье не приводится глубокого обоснования клинической валидности отбрасывания всех ребер, кроме ребер первого порядка, хотя это, несомненно, решает проблему вычислительного взрыва.
2. Преобразование «ребро-узел»
Далее они построили линейный граф. Новые узлы (представляющие исходные магистрали) нуждаются в признаках. Они изобретательно сконструировали эти признаки, конкатенируя сумму признаков двух связанных областей мозга с исходным весом ребра:
$$\tilde{x}_i = \text{CONCATE}(\text{SUM}(x_i, x_j), a_{ij})$$
3. Residual GraphSAGE для передачи сообщений
Поскольку линейные графы не имеют собственных весов ребер, авторы использовали GraphSAGE для передачи сообщений между этими новыми узлами-соединениями. Чтобы предотвратить «пересглаживание» (oversmoothing) — распространенную проблему GNN, при которой многократная передача сообщений размывает все признаки в общий «кашеобразный» вид — они добавили остаточные соединения (residual connections):
$$\tilde{\mathbf{X}}^{(l+1)} = \tilde{\mathbf{X}}^{(l)} + \tilde{\mathbf{Z}}^{(l)}$$
4. Байесовское вариационное апостериорное распределение
Наконец, чтобы бороться с шумом и переобучением на малых выборках, они отказались от традиционного детерминированного классификатора. Вместо этого они рассматривали веса последнего слоя как случайные переменные с Гауссовым распределением (Gaussian distribution). Используя стохастическое вариационное выведение (stochastic variational inference), модель не просто делает жесткое предположение; она количественно оценивает собственную неопределенность. Они оптимизировали это, максимизируя нижнюю границу доказательства (Evidence Lower Bound, ELBO):
$$S^{-1} \log p(Y|\mathbf{X}, \mathbf{A}, \theta) \geq \mathcal{L}_{VB}(\theta, \eta, \Sigma) - S^{-1}\text{KL}(q(W, \Sigma|\eta) \parallel p(W, \Sigma))$$
Экспериментальная архитектура и «жертвы»
Авторы не просто заявили, что их математика работает; они разработали безжалостный испытательный полигон, чтобы доказать это. Они протестировали RP-LGN на наборах данных ABIDE I (Аутизм) и ADHD-200, используя строгую 5-кратную кросс-валидацию.
«Жертвами», оставшимися позади, были все ведущие стандартные и передовые модели: одиночные классификаторы, такие как KAN, стандартные GNN (GAT, GIN, GraphSAGE) и специализированные нейронные сети для мозга, такие как BrainNetCNN, BrainGNN, BrainGB, FBNETGEN и BrainNetworkTransformer. RP-LGN превзошел их всех.
Но окончательное, неоспоримое доказательство заключалось не просто в более высоком проценте точности. Оно было представлено в двух формах:
1. Абляционное исследование (Ablation Study): Они систематически удаляли остаточные соединения и байесовское апостериорное распределение. При применении к базовым моделям, таким как SAGE, GIN и GAT, производительность заметно падала, доказывая, что именно эти конкретные механизмы были причиной превосходства модели.
- Клиническая валидация с помощью Grad-CAM: Они использовали градиентную локализацию для визуального отображения того, на какие «магистрали» модель опиралась при диагностике СДВГ. Модель независимо выделяла соединения между верхней теменной долей (Superior Parietal Lobule), хвостатым ядром (Caudate Nucleus) и веретенообразной извилиной (Fusiform Gyrus). Это «дымящийся пистолет»: это именно те области мозга, которые клинические психиатры давно связывают с пространственным вниманием, обработкой вознаграждения и контролем импульсов — основными дефицитами при СДВГ. Математика идеально воссоздала биологию.
Темы для обсуждения для дальнейшего развития
Основываясь на этом блестящем фундаменте, вот несколько разнообразных перспектив того, как мы можем продвинуть это представление о связности мозга еще дальше:
- Дилемма $K=1$ при разрежении: Авторы использовали $K=1$ для экономии вычислительных ресурсов, но мозг — это высокоинтегрированная система с множеством путей. Можем ли мы исследовать динамические методы разрежения, такие как отсечение на основе внимания (attention-based pruning), которые сохраняют клинически значимые дальние соединения, вместо того чтобы строго полагаться на ближайших евклидовых соседей?
- Временная динамика против статических снимков: RP-LGN рассматривает данные фМРТ как статический граф частичных корреляций. Однако связность мозга очень динамична; магистрали открываются и закрываются в зависимости от когнитивной нагрузки. Как мы могли бы интегрировать динамику временных окон (sliding-window temporal dynamics) в структуру линейного графа, не вызывая нового взрыва параметров?
- Интерпретация байесовской неопределенности в клинике: Байесовское апостериорное распределение обеспечивает математическую количественную оценку неопределенности. Как мы можем перевести эту математическую дисперсию в действенный показатель для врача? Например, если модель выдает диагноз с высокой дисперсией, может ли это инициировать определенный протокол вторичного скрининга в реальной клинической практике?
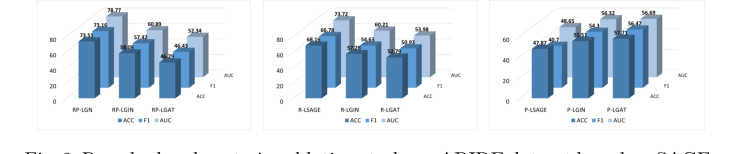 Figure 2. Resudual and posterior ablation study on ABIDE dataset based on SAGE, GIN and GAT. R: residual, P: posterior, L: line graph
Figure 2. Resudual and posterior ablation study on ABIDE dataset based on SAGE, GIN and GAT. R: residual, P: posterior, L: line graph