残差後部パターンにおける脳接続性特徴の洗練
New AI model RP-LGN captures subtle connectivity changes for better disease diagnosis, outperforming others with improved accuracy & noise handling.
背景と学術的系譜
人間の脳の真の性質を理解するためには、孤立した領域を超えて、それらがどのようにコミュニケーションするかを研究する必要がある。歴史的に、神経科学者は機能的磁気共鳴画像法(fMRI)を用いて脳活動を捉えてきた。計算神経科学の分野が進化するにつれて、研究者たちは脳を複雑なネットワーク、すなわち「グラフ」として表現するようになり、脳領域はノード、それらのコミュニケーション経路はエッジとして扱われるようになった。これは、自閉スペクトラム症(ASD)やADHDのような神経精神疾患を、これらの機能的結合パターンを分析することによって診断するために、グラフニューラルネットワーク(GNN)を採用することに自然につながった。
しかし、重要なボトルネックが出現した。従来のGNNアプローチは、この特定のタスクに対して根本的に欠陥があった。なぜなら、それらは実際のコミュニケーション経路(エッジ)ではなく、主に脳領域自体(ノード)に焦点を当てていたからである。神経精神疾患では、疾患はしばしば物理的な領域ではなく、結合の変化として現れる。さらに、以前のモデルは大規模な計算上のハードルに直面していた。もし、完全に接続された脳グラフにおいて、すべての単一の接続を主要な特徴として扱おうとすると、計算量が爆発してしまう。典型的な脳アトラスは、数十億のパラメータを持つ行列を生成する可能性があり、処理が計算上不可能になる。これに加えて、医療データセットは著しく小さくノイズが多いことが知られており、従来のモデルが過学習する原因となっている。これは、トレーニングデータを記憶するが、実際の臨床応用では完全に失敗することを意味する。
このギャップを埋めるために、著者らはResidual-Posterior Line Graph Network(RP-LGN)を導入した。彼らが使用した高度に専門化された概念を、直感的なアイデアに分解してみよう。
専門用語の解体
- 機能的磁気共鳴画像法(fMRI)とBOLD信号: この論文では、脳内の血流変化を測定する生データである。
- 日常的な例え: 夜の都市の交通渋滞を、ヘッドライトの密度を見て追跡する衛星を想像してほしい。fMRIはこれを血流で行う。それは「交通」(酸素化された血液)がどこに移動しているかを追跡し、どの「交差点」(脳領域)が現在活動しており、互いに通信しているかを把握する。
- Line Graph Transformation: エッジをノードに変換する数学的手法である。
- 日常的な例え: 世界的な航空ネットワークを研究しているとしよう。通常、都市(ノード)を研究し、フライトルート(エッジ)に線を描く。Line Graph Transformationはこれを反転させる。つまり、フライトルートを研究の主な対象(新しいノード)にし、都市は単に終点になる。これにより、AIは実際の接続を直接研究できるようになる。
- GNNにおけるOversmoothing: ノード間でメッセージを何度もやり取りすると、すべてのノードが同一に見えてしまう現象である。
- 日常的な例え: 絵の具を混ぜることを想像してほしい。赤と青を軽く混ぜると、美しい大理石模様(有用な情報)が得られる。しかし、執拗に混ぜ続けると、平坦で泥のような紫色になるだけだ。Oversmoothingは、AIがデータを過剰に混ぜ合わせ、脳のユニークで識別可能な特徴をすべて失ってしまう状態である。
- Bayesian Variational Posterior: モデルの最終層で使用される統計的手法で、予測の不確実性を定量化する。
- 日常的な例え: 天気予報アプリが「明日は雨が降る」と断定的に述べる(データがノイズが多い場合、これは間違っている可能性がある)のではなく、Bayesianアプローチは「雨が降る確率は85%で、誤差は5%程度です」と言う。これは誤差範囲を計算し、患者のスキャンに多くのバックグラウンドノイズがある場合でも、AIの医療診断をより堅牢で信頼性の高いものにする。
数学的青写真
著者らがこれをどのように数学的に解釈したかを見るためには、彼らの宇宙を定義する変数を調べる必要がある。彼らはパラメータ爆発を防ぐために、$K$-Nearest Neighbors(KNN)アプローチを用いて初期接続をスパース化し、その後グラフをLine Graph $\tilde{G}$ にマッピングする。最後に、Evidence Lower Bound(ELBO)、すなわち $\mathcal{L}_{VB}$ を最大化することによってモデルを最適化する。
| Notation | Description |
|---|---|
| $V$ | 脳内の関心領域(ROIs)を表すノードの集合。 |
| $E$ | ROIs間の機能的接続を表すエッジの集合。 |
| $G = (\mathbf{A}, \mathbf{X})$ | fMRIデータから構築された元の脳グラフ。 |
| $\mathbf{A} \in \mathbb{R}^{|V| \times |V|}$ | 脳領域間の部分相関係数を定義する隣接行列。 |
| $\mathbf{X} \in \mathbb{R}^{|V| \times |F|}$ | Pairwise BOLD信号のピアソン相関に基づくノード特徴行列。 |
| $n$ | ROIsの総数、ここで $|V| = n$。 |
| $\mathcal{N}_i$ | ノード $i$ の $K$ 個の最近傍ノード集合。グラフのスパース化に使用される。 |
| $\tilde{G} = \{\tilde{\mathbf{A}}, \tilde{\mathbf{X}}\}$ | 元のエッジがノードとして扱われる、構築されたLine Graph。 |
| $\tilde{\mathbf{x}}_i$ | 新しく構築されたLine Graphにおける $i$ 番目のノードの特徴ベクトル。 |
| $\tilde{\mathbf{Z}}^{(l)}$ | $l$ 番目のSAGEConv(GraphSAGE畳み込み)層の出力特徴行列。 |
| $W$ | 最終的な線形分類層の重み行列。 |
| $\Sigma$ | 不確実性をモデル化するために使用される、変分後方分布の共分散行列。 |
| $\mathcal{L}_{VB}(\theta, \eta, \Sigma)$ | モデルの最適化に使用される目的関数である変分下限(ELBO)。 |
これらの要素を組み合わせることで、著者らは脳ネットワーク分析のアプローチに革命をもたらした。彼らはAIの注意を脳領域から実際の接続へと首尾よくシフトさせ、計算コストを低く抑え、小さくノイズの多い医療データセットの不確実性を処理するための数学的な「安全ネット」を組み込んだ。
問題定義と制約
この論文を理解するためには、まず科学者が脳をどのように見ているかを理解する必要がある。人間の脳を広大な国家と想像してみよう。個々の脳領域は「都市」であり、それらの間で通信する神経経路は「高速道路」である。
医師が機能的磁気共鳴画像法(fMRI)を使用する際、彼らは本質的にこれらの都市間の交通(血流と酸素)を経時的に追跡している。任意の2つの都市間の交通の同期度を計算することにより、科学者は「機能的結合性」(FC)行列を作成する。数学的には、これはノード(都市)が特徴 $\mathbf{X}$ を持ち、エッジ(高速道路)が領域間の相関強度を示す隣接行列 $\mathbf{A}$ によって表されるグラフ $G = (\mathbf{A}, \mathbf{X})$ である。
出発点(入力)は、fMRIデータから派生した、患者固有の生の脳グラフである。望ましい終点(出力)は、高精度で解釈可能な二値分類、具体的には、患者が自閉スペクトラム障害(ASD)やADHD($y_D$)のような神経精神疾患を持っているか、あるいは健常対照($y_{HC}$)であるかを決定することである。
欠けているリンク:ノード対エッジ
ここに、この論文が橋渡ししようとしている根本的なギャップがある。従来のグラフニューラルネットワーク(GNN)は、「ノード中心」に大きく偏っている。それらの数学的演算(メッセージパッシングと呼ばれる)の間、それらは隣接都市からのデータを集約することにより、常に都市(脳領域)の情報を更新する。高速道路(エッジ)は、データの流れを指示するだけの「ダムパイプ」として扱われるに過ぎない。
しかし、臨床神経科学では、ADHDやASDのような疾患は、孤立した脳領域を変化させるだけでなく、接続自体を根本的に破壊する。正確な数学的ギャップは、従来のGNNがこれらの接続を主要な、学習可能な特徴として扱えていないことである。著者らは、エッジをニューラルネットワークにおける「ファーストクラス市民」に格上げする必要があることに気づいた。
次元性のジレンマ
これを解決するために、論理的なステップは「ライングラフ」変換を使用することである。グラフ理論では、標準グラフをライングラフに変換することは、各元のエッジを新しいノードに変換することを意味する。突然、高速道路が都市になり、ニューラルネットワークが接続を直接分析できるようになる。
しかし、これは過去の研究者を閉じ込めてきた、残酷で痛みを伴うトレードオフをもたらす:表現力対計算爆発。
脳アトラスに $n$ 個の領域があるとすると、完全接続された脳グラフは約 $n^2 / 2$ 個のエッジを持つ。これをライングラフ(各エッジが新しいノードになり、これらの新しいノード間のエッジが共有接続を表す)に変換すると、新しい隣接行列のサイズは指数関数的に増加して次のようになる:
$$(n - 1)^2 \times n^2 / 4$$
脳がわずか200個の領域に分割されている場合、このライングラフ変換は数十億のパラメータを持つ行列をもたらす。これは計算上の悪夢である。脳接続性の完璧な表現力を得るが、最新GPUのハードウェアメモリ制限を完全に破ってしまう。
厳しい壁と制約
計算爆発を超えて、著者らはこの問題を非常に困難にする、いくつかの厳しい現実的な壁に直面した:
- fMRIデータの極端な疎性とノイズ: fMRIスキャンは信じられないほどノイズが多い。患者は動き、スキャナーにはアーティファクトがあり、血流は神経活動の間接的な測定値である。さらに、医療データセットは、巨大な特徴空間と比較して、悪名高いほど小さい(ABIDEやADHD-200データセットのように、しばしば数百人の患者のみ)。数十億のパラメータを持つディープラーニングモデルをわずか500人の患者でトレーニングすることは、壊滅的な過学習を保証する。
- 過平滑化の呪い: GNNでは、複雑なパターンを学習するために多くのレイヤーを積み重ねると、すべてのノードの特徴は最終的に均一なマッシュに混ざり合い、過平滑化として知られる現象になる。モデルが過平滑化すると、特定の脳接続に隠されたユニークな疾患バイオマーカーは洗い流されてしまう。
- 無向グラフの数学的曖昧さ: 無向グラフにおける標準的なピアソン相関は、双方向および単方向の神経活動の区別を曖昧にし、モデルを実際の脳通信の流れについて混乱させる。
著者らが解決した方法
これらの壁を打ち破るために、著者らはResidual-Posterior Line Graph Network (RP-LGN)を設計した。彼らは3つの見事なステップを使用して、数学的に制約を回避した:
1. K近傍法(KNN)による疎化
$O(n^4)$ の計算爆発を防ぐために、完全接続された脳からライングラフを構築するのではなく、変換前にKNNアルゴリズムを使用して元のグラフを積極的に疎化した。ノード特徴間のユークリッド距離を計算することにより:
$$d(v_i, v_j) = \|x_i - x_j\|_2$$
グラフを $K=1$ の最近傍のみに制限した。このセット外のエッジはゼロに強制された。これによりグラフサイズが劇的に減少し、ライングラフ $\tilde{G} = \{\tilde{\mathbf{A}}, \tilde{\mathbf{X}}\}$ がメモリに収まるようになり、最も重要な神経経路を維持できた。
2. Residual GraphSAGEアーキテクチャ
過平滑化の呪いと戦うために、彼らは残差ブロックと組み合わせた特定のタイプのグラフ畳み込み(GraphSAGE)を使用した。接続特徴がメッセージパッシング中に洗い流されるのを許す代わりに、レイヤーの元の入力を直接出力に追加した:
$$\tilde{\mathbf{X}}^{(l+1)} = \tilde{\mathbf{X}}^{(l)} + \tilde{\mathbf{Z}}^{(l)}$$
この数学的な「スキップ接続」は、ネットワークに脳接続の元の構造的忠実度を記憶させることを強制する。
3. 小サンプルバイアスに対するベイズ変分推論
極端なノイズと小規模なサンプルサイズを克服するために、彼らは従来の決定論的分類層を破棄した。代わりに、ベイズ変分事後分布を導入した。モデルは、「この接続重みは正確に0.8である」と言うのではなく、重み $W$ と共分散 $\Sigma$ をガウス分布を持つ確率変数として扱う:
$$q(\Sigma) = \prod_{k=1}^{C_y} \mathcal{N}(W_k \mid \mu_k, \Sigma_k)$$
これにより、モデルは自身の不確実性を定量化する。fMRIデータの一部がノイズが多いか異常である場合、モデルはノイズに過学習するのではなく、その信頼度を数学的に低下させる。彼らはエビデンス下限(ELBO)を最大化することによりこれを最適化する:
$$S^{-1} \log p(Y \mid \mathbf{X}, \mathbf{A}, \theta) \geq \mathcal{L}_{VB}(\theta, \eta, \Sigma) - S^{-1}\text{KL}(q(W, \Sigma \mid \eta) \parallel p(W, \Sigma))$$
接続をターゲットにするための疎化されたライングラフ、平滑化を防ぐための残差レイヤー、およびノイズの多い小規模データで生き残るためのベイズ確率を組み合わせることにより、著者らは患者がADHDを持っているかどうかを推測するだけでなく、それを引き起こす正確な欠陥のある神経高速道路を数学的に強調するモデルを成功裏に作成した。
このアプローチの理由
Residual-Posterior Line Graph Network (RP-LGN) を構築した理由を理解するには、従来の Graph Neural Networks (GNNs) が神経画像処理において行き詰まった正確な瞬間に立ち返る必要がある。
脳解析に用いられる標準的な GNN では、物理的な脳領域が「主役」(ノード)として扱われ、それらの間の機能的接続は単なる背景的な関係(エッジ)として扱われる。しかし、著者らは自閉症や ADHD のような神経精神疾患において、接続そのもの が疾患の真の現れであるという根本的な真実に気づいた。従来のモデルは、間違った主要なエンティティを見ていたのである。
これを修正するために、著者らはこれらの接続を「ファーストクラスオブジェクト」に格上げする必要があった。唯一の実行可能な数学的解決策は、エッジからノードへの変換であり、これは「ライングラフ」として知られるものを生成する。しかし、これには壊滅的な制約が導入された。$n$ 個の領域を持つ完全に接続された初期脳グラフは、約 $n^2/2$ 個のエッジを持つ。これらのエッジをノードに変換してライングラフを形成すると、新しい隣接行列は驚異的なスケールである $(n-1)^2 \times n^2/4$ にまで膨張する。数百の領域を持つ標準的な脳アトラスの場合、これは数十億のパラメータを持つ行列の計算を意味する。従来の SOTA モデルは即座にメモリ不足に陥り、純粋なライングラフアプローチは計算不可能になる。
ベンチマーキングの論理と構造的優位性
この大規模な $O(N^4)$ メモリ爆発を克服するために、著者らは単に計算能力を増強したのではなく、構造的にそれを回避した。彼らは、ライングラフ構築の前に K-Nearest Neighbors (KNN) スパース化ステップを導入した。$K=1$ を設定することで、ユークリッド距離を用いて数学的にグラフを枝刈りした:
$$ \mathcal{N}_i = \text{argmin}_j \{d(v_i, v_j) \mid j \neq i\}_{1 \leq j \leq K, i, j \in V} $$
この巧妙な制約により、密で不可能な行列は、最も重要な機能的接続のみを保持する、高度にスパースで管理可能な表現に削減された。
さらに、この新しいグラフを処理するための適切なバックボーンを選択する必要があった。Graph Attention Networks (GAT) のような一般的なアプローチを使用しなかったのはなぜか?著者らのアブレーションスタディは、GAT のアテンションメカニズムが彼らのアーキテクチャと実際に衝突し、逆効果的な結果を生み出すことを明確に示した。代わりに、彼らは残差 GraphSAGE バックボーンを選択した。これは、残差接続が元のグラフの構造的忠実度を完全に維持し、メッセージパッシングの数層の後でノード特徴が区別不能な混乱にぼやけてしまう標準的な GNN の致命的な欠陥である「過剰平滑化」を防ぐため、質的に優れていた。
厳しい制約とベイズ的解決策の「結婚」
2番目の大きなハードルは、fMRI データ自体の性質であった。それは信じられないほどノイズが多く、医療データセットは深刻な小標本バイアスに悩まされている。著者らが、ほとんどすべての以前のゴールドスタンダードモデルが行っているように、標準的な全結合層を分類器として使用した場合、ネットワークは小標本データセットに圧倒的に過学習するだろう。
これを解決するために、彼らは決定論的な分類器を完全に拒否し、ベイズ変分事後分布を最終層として統合した。厳密で単一の予測を出力する代わりに、ベイズ的アプローチは最終層の重み $W$ と共分散行列 $\Sigma$ を確率変数としてモデル化する。彼らは、Evidence Lower Bound (ELBO) を最大化することによって真の事後分布を近似する:
$$ S^{-1} \log p(Y | \mathbf{X}, \mathbf{A}, \theta) \geq \mathcal{L}_{VB}(\theta, \eta, \Sigma) - S^{-1}\text{KL}(q(W, \Sigma | \eta) \parallel p(W, \Sigma)) $$
ここで、この手法が問題の制約と完全に一致する。分類重みを固定された数値ではなく分布として扱うことにより、モデルは本質的に不確実性を定量化する。fMRI スキャンに異常なデータや高次元ノイズが含まれている場合、ベイズ層はそれに騙されるのではなく、その不確実性を吸収する。この単一パス、低分散の確率的推論が、RP-LGN を従来の SOTA モデルを破壊する小標本過学習の罠に対してロバストにし、最終的に脳の真の隠れた接続パターンを明らかにするものである。
数学的・論理的メカニズム
この論文が導入する根本的な変化を理解するためには、まずAIが人間の脳をどのように捉えるかの背景を確立する必要がある。従来、機能的磁気共鳴画像法(fMRI)データを分析する際、グラフニューラルネットワーク(GNN)は物理的な脳領域を「ノード」として扱い、それらの間の相関を「エッジ」として扱っていた。しかし、ADHDや自閉症のような神経精神疾患は、それ自体コミュニケーション「経路」における微妙な劣化として現れることが多い。本論文の動機は、これらの経路、すなわち接続を、分析の主要な対象へと昇格させることである。
これを達成するために、著者らは巨大な制約に直面した。脳グラフを数学的に反転させ、すべての接続を新しいノード(「ライングラフ」)にすると、パラメータ数は数十億に爆発し、標準的なモデルは即座にクラッシュするだろう。さらに、fMRIデータは悪名高いほどノイズが多く、医療データセットは通常小さい(患者数は数百人程度)ため、深刻な過学習につながる。これらの制約を克服するため、著者らはK近傍法を用いてグラフを疎化させ、信号が混ざり合う(過剰平滑化)のを防ぐためにResidual GraphSAGEバックボーンを構築し、不確実性を定量化するためにベイズ変分事後分布で締めくくった。
以下に、彼らがこれを達成した数学的解剖を示す。
マスター方程式
Residual-Posterior Line Graph Network(RP-LGN)のエンジンは、相互接続された2つの数学的システムによって駆動される。
第一に、ライングラフから構造的特徴を抽出するResidual Message Passingメカニズムである。
$$ \tilde{z}_i^{(l)} = \sigma\left(\theta_i^{(l)} \cdot \text{MEAN}\left(\{\tilde{x}_i^{(l)}\} \parallel \{\tilde{x}_j^{(l)}, \forall j \in \mathcal{N}_i\}\right)\right) $$
$$ \tilde{\mathbf{X}}^{(l+1)} = \tilde{\mathbf{X}}^{(l)} + \tilde{\mathbf{Z}}^{(l)} $$
第二に、モデルに予測精度と不確実性のバランスを取らせる究極の損失関数として機能するBayesian Variational Objectiveである。
$$ \mathcal{L}_{VB}(\theta, \eta, \Sigma) = \frac{1}{S} \sum_{s=1}^S \left( y_s^\top W \phi_s - \log \sum_{k=1}^{C_y} \exp\left[w_k^\top \phi_s + \frac{1}{2}(\phi_s^\top \Sigma_k \phi_s + \sigma_k^2)\right] \right) $$
$$ \theta^*, \eta^*, \Sigma^* = \arg\max_{\eta, \Sigma} \left\{ \mathcal{L}_{VB}(\theta, \eta, \Sigma) + S^{-1}(\log p(\Sigma) - \text{KL}(q(W \mid \eta) \parallel p(W))) \right\} $$
方程式の分解
この機械仕掛けの各歯車とバネを分解してみよう。
- $\tilde{\mathbf{X}}^{(l)}$ および $\tilde{x}_i^{(l)}$: レイヤー$l$におけるライングラフの特徴行列および個々の特徴ベクトル。物理的には、これらは第一級ノードに昇格された実際の脳接続を表す。
- $\parallel$ (連結演算子): これは、ノード自身の特徴と、その近傍の平均を結合する。なぜここで加算ではなく連結なのか?連結は、特定の脳接続の明確で孤立したアイデンティティを保持しつつ、近傍のコンテキストを付加する。加算はそれらを不可逆的に混ぜ合わせるだろう。
- $\theta_i^{(l)}$: 学習可能な重み行列。これは幾何学的なステアリングホイールとして機能し、特徴ベクトルを高次元空間に回転させ、そこで疾患のあるパターンと健康なパターンが分離される。
- $\sigma$: 活性化関数。これは生物学的な閾値として機能し、どのニューラル接続パターンが順方向に通過するのに十分重要かを決定する。
- $+$ ( $\tilde{\mathbf{X}}^{(l)} + \tilde{\mathbf{Z}}^{(l)}$ における): 残差接続。なぜ乗算ではなく加算なのか?加算は安全なバイパスハイウェイを作成する。グラフ畳み込みが不要なノイズを抽出した場合、ネットワークは重みをゼロに押し込み、元のデータをそのまま転送することができる。乗算は、信号全体をゼロに収縮させ、表現を破壊するリスクがある。
- $\mathcal{L}_{VB}$: 変分下界。これは、モデルの分類能力のための主要なスコアリングメトリックである。
- $S$: 被験者(患者)の数。患者は連続スペクトルではなく、離散的で数えられるエンティティであるため、積分ではなく$S$に対する和$\sum$を使用する。
- $y_s^\top W \phi_s$: 正しい診断のための期待ロジットスコア。ここで、$\phi_s$は患者$s$の平坦化された、完全に処理された脳マップである。
- $\frac{1}{2}(\phi_s^\top \Sigma_k \phi_s + \sigma_k^2)$: 分散/不確実性ペナルティ。$\Sigma_k$は共分散行列である。この項は、計算された量のガウスノイズを予測に直接注入する。これは、fMRIスキャンの固有のノイズに対する数学的なショックアブソーバーとして機能する。
- $\text{KL}(q \parallel p)$: クルバック・ライブラーダイバージェンス。これはゴムバンドのように機能し、学習された事後重み分布$q$を安全で安定した事前分布$p$に引き戻し、過学習を防ぐ。
ステップ・バイ・ステップの流れ
抽象的な単一データポイント、すなわち前頭前野と基底核間の機能的接続(150ドルのfMRIスキャンから得られたもの)を想像してみよう。
まず、この接続は単なる「エッジ」であることから引き剥がされ、新しいライングラフの完全な「ノード」に昇格される。元の脳領域の相関強度に基づいて特徴ベクトルが割り当てられる。次に、Residual GraphSAGEのアセンブリラインに入る。近傍の接続を調べ、それらの情報を平均化し、自身のデータとバンドルする。
このバンドルされたパッケージは重み行列$\theta$で乗算されて高レベルのトポロジカルパターンが抽出され、活性化関数$\sigma$を通過して負の値がクリップされ、その後、残差経路を介して元の自身に加算される。これにより、処理中に接続が元のアイデンティティを失わないことが保証される。
複数のレイヤーを通過した後、完全に処理された脳マップ$\phi_s$がベイズ分類器に到達する。最終的な答えを得るために厳密で決定論的な重みで乗算する代わりに、分類器は確率分布からサンプリングする。それは単なる診断(例:「ADHD」)だけでなく、生の医療データの固有のノイズを考慮した信頼度レベルを出力する。
最適化ダイナミクス
このアーキテクチャは実際にどのように学習し、収束するのか?モデルは、非常に困難な損失ランドスケープをナビゲートするために、確率的変分推論に依存している。
従来のfMRI分析では、データは高次元であるがサンプルサイズは小さい(小標本バイアス)ため、損失ランドスケープは非常にギザギザしており、深刻な過学習を起こしやすい。ベイズ事後分布($\Sigma$およびKLダイバージェンス項)を導入することにより、損失ランドスケープは効果的に平滑化される。データが曖昧な場合に予測に過度に自信を持つことに対して、モデルは積極的にペナルティを受ける。
バックプロパゲーション中、勾配はELBO目的関数から逆方向に流れる。残差接続は、これらの勾配が最初のレイヤーまで完全にバイパスして、明確で妨げのないハイウェイを移動できるようにし、勾配消失問題を完全に回避する。反復的に、モデルはより良い構造的特徴を抽出するために$\theta$を更新し、同時に不確実性を調整するために$\eta$と$\Sigma$を更新する。それは、異常な患者データに直面しても、健康な脳と疾患のある脳を正確に区別できる堅牢な状態に収束する。
結果、限界および結論
人間の脳を広大で活気のある国と想像してみよう。脳の領域は主要な都市であり、それらを結ぶ神経経路は高速道路である。長年にわたり、神経科学者やAI研究者は機能的磁気共鳴画像法(fMRI)を用いて、これらの都市における「交通量」(血流)を測定し、自閉スペクトラム症(ASD)や注意欠陥・多動性障害(ADHD)のような神経精神疾患の診断を行ってきた。従来のグラフニューラルネットワーク(GNN)は、脳領域をノード(都市)とし、接続をエッジ(高速道路)として扱うための標準的なツールであった。
しかし、ここに根本的な欠陥がある。病気が都市を破壊するのではなく、高速道路を混乱させるとしたらどうだろうか?従来のGNNは、ノードの特徴量の更新に重点を置き、接続を単なる二次的な属性として扱っていた。
本論文の著者らはこの盲点に気づき、画期的なパラダイムシフトを提案した。すなわち、Residual-Posterior Line Graph Network (RP-LGN) である。彼らは接続を主役に据えることを決定した。
動機と数学的制約
接続に焦点を当てるため、著者らはグラフ理論の「線グラフ」という概念を用いた。線グラフでは、元のグラフのエッジが新しいグラフのノードとなる。
しかし、彼らはすぐに巨大な数学的壁に直面した。脳アトラスが脳を$n$個の領域に分割する場合、完全接続グラフは $(n - 1) \times n / 2$ のエッジを持つ。これを線グラフに変換すると、新しい隣接行列は $(n - 1)^2 \times n^2 / 4$ の規模に爆発する。数百の領域を持つ脳の場合、突然数十億のパラメータを扱うことになる。これは計算上の悪夢である。さらに、fMRIデータは非常にノイズが多く、医療データセットは通常サンプルサイズが小さいため、巨大なモデルは過学習(overfitting)を起こしやすい。
解決策:RP-LGNアーキテクチャ
これらの制約を克服するため、著者らは4段階のパイプラインを考案した。
1. KNNによる厳密なスパース化
線グラフを構築する前に、元のグラフを刈り込む必要があった。彼らはK-Nearest Neighbors (KNN) アプローチを使用し、特に$K=1$を設定して、ユークリッド距離に基づいて最も重要な接続のみを保持した。
$$d(v_i, v_j) = \|x_i - x_j\|_2$$
正直なところ、この部分についても完全には確信が持てない。論文では、最初の近傍エッジ以外をすべて破棄することの臨床的妥当性について深く正当化されていないが、計算爆発を解消する効果は疑いようがない。
2. エッジからノードへの変換
次に、線グラフを構築した。新しいノード(元の高速道路を表す)には特徴量が必要である。著者らは、接続されている2つの脳領域の特徴量の合計と元のエッジ重みを連結することで、これらの特徴量を巧妙に構築した。
$$\tilde{x}_i = \text{CONCATE}(\text{SUM}(x_i, x_j), a_{ij})$$
3. メッセージパッシングのためのResidual GraphSAGE
線グラフには独自の(エッジ)重みがないため、著者らはこれらの新しい接続ノード間でメッセージを伝達するためにGraphSAGEを使用した。繰り返しのメッセージパッシングによってすべての特徴量が一般的な混合物にぼやけてしまう一般的なGNNの問題である「過度の平滑化(oversmoothing)」を防ぐため、残差接続(residual connections)を追加した。
$$\tilde{\mathbf{X}}^{(l+1)} = \tilde{\mathbf{X}}^{(l)} + \tilde{\mathbf{Z}}^{(l)}$$
4. ベイズ変分事後分布
最後に、ノイズと小サンプル過学習に対抗するため、従来の決定論的分類器を破棄した。代わりに、最終層の重みをガウス分布を持つ確率変数として扱った。確率的変分推論を用いることで、モデルは単なる硬直した推測を行うのではなく、自身の不確実性を定量化する。これは、Evidence Lower Bound (ELBO) を最大化することによって最適化された。
$$S^{-1} \log p(Y|\mathbf{X}, \mathbf{A}, \theta) \geq \mathcal{L}_{VB}(\theta, \eta, \Sigma) - S^{-1}\text{KL}(q(W, \Sigma|\eta) \parallel p(W, \Sigma))$$
実験アーキテクチャと「犠牲者」
著者らは、自身の数学が機能することを主張するだけでなく、それを証明するために徹底的な試練を設計した。彼らは、厳密な5分割交差検証を用いて、ABIDE I(自閉症)およびADHD-200データセットでRP-LGNをテストした。
彼らの手にかかった「犠牲者」は、標準的なモデルや最先端のモデルの顔ぶれであった。KANのような単一分類器、標準的なGNN(GAT、GIN、GraphSAGE)、そしてBrainNetCNN、BrainGNN、BrainGB、FBNETGEN、BrainNetworkTransformerのような脳に特化したネットワークである。RP-LGNはそれらすべてを上回った。
しかし、決定的で否定できない証拠は、単なる高い精度率ではなかった。それは2つの形で現れた。
1. アブレーションスタディ(Ablation Study):残差接続とベイズ事後分布を体系的に取り除いた。SAGE、GIN、GATのようなベースモデルに適用すると、パフォーマンスは著しく低下し、これらの特定のメカニズムがモデルの優位性の正確な理由であることを証明した。
- Grad-CAMによる臨床的検証:勾配ベースの局在化を用いて、ADHD診断のためにモデルがどの「高速道路」に依存していたかを視覚的にマッピングした。モデルは、上頭頂小葉、尾状核、紡錘状回間の接続を独立して強調した。これは決定的な証拠である。これらは、臨床精神科医が空間的注意、報酬処理、衝動制御といったADHDの中心的欠陥と長年関連付けてきたまさにその脳領域である。数学は生物学を完璧に再発見した。
将来の進化に向けた議論トピック
この脳接続性の見事な基盤に基づき、この脳接続性の表現をさらに推し進めるための、多様な視点をいくつか挙げる。
- スパース化における$K=1$のジレンマ:著者らは計算オーバーヘッドを削減するために$K=1$を使用した。しかし、脳は高度に統合された多経路システムである。ユークリッド最近傍に厳密に依存するのではなく、臨床的に関連性の高い長距離接続を維持するような、注意機構ベースのプルーニングのような動的なスパース化技術を探求できるだろうか?
- 時間的ダイナミクス vs. 静的スナップショット:RP-LGNはfMRIデータを部分相関の静的なグラフとして扱う。しかし、脳接続性は非常に動的であり、認知負荷に応じて高速道路が開閉する。パラメータ爆発を再び引き起こすことなく、線グラフフレームワークにスライディングウィンドウの時間的ダイナミクスを統合するにはどうすればよいだろうか?
- 臨床におけるベイズ不確実性の解釈:ベイズ事後分布は、不確実性の数学的な定量化を提供する。この数学的な分散を、医師にとって実行可能な指標にどのように変換できるだろうか?例えば、モデルが高い分散で診断を出力した場合、実際の臨床現場で特定の二次スクリーニングプロトコルをトリガーできるだろうか?
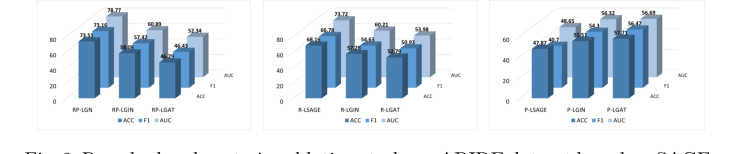 Figure 2. Resudual and posterior ablation study on ABIDE dataset based on SAGE, GIN and GAT. R: residual, P: posterior, L: line graph
Figure 2. Resudual and posterior ablation study on ABIDE dataset based on SAGE, GIN and GAT. R: residual, P: posterior, L: line graph