PhoCoLens: लेंसलेस इमेजिंग में फोटोरियलिस्टिक और सुसंगत पुनर्निर्माण
लेंसलेस इमेजिंग पुनर्निर्माण की समस्या विशेष रूप से अल्ट्रा कॉम्पैक्ट, हल्के और लागत प्रभावी कैमरे बनाने की इच्छा से उत्पन्न हुई। पारंपरिक लेंस आधारित सिस्टम भारी और महंगे होते हैं, जो चिकित्सा एंडोस्कोपी या पहनने...
पृष्ठभूमि और अकादमिक वंश
उत्पत्ति और अकादमिक वंश
लेंसलेस इमेजिंग पुनर्निर्माण की समस्या विशेष रूप से अल्ट्रा-कॉम्पैक्ट, हल्के और लागत प्रभावी कैमरे बनाने की इच्छा से उत्पन्न हुई। पारंपरिक लेंस-आधारित सिस्टम भारी और महंगे होते हैं, जो चिकित्सा एंडोस्कोपी या पहनने योग्य प्रौद्योगिकियों जैसे क्षेत्रों में उनके अनुप्रयोग को सीमित करते हैं, जहां लघुकरण की आवश्यकता होती है। ऐतिहासिक संदर्भ से पता चलता है कि शोधकर्ताओं ने सेंसर के पास रखे गए आयाम या चरण मास्क के साथ पारंपरिक लेंसों को बदलना शुरू कर दिया, ताकि आने वाले प्रकाश को संशोधित किया जा सके, जिससे कैमरे का आकार और वजन काफी कम हो गया। यह नवाचार, जबकि आशाजनक है, एक नई चुनौती पेश करता है: फोकसिंग लेंस के बिना, कच्चे सेंसर माप आमतौर पर धुंधले और अपरिचित होते हैं। कैमरा सीधे दृश्य को रिकॉर्ड नहीं करता है, बल्कि इसे एक जटिल विवर्तन पैटर्न में एन्कोड करता है, जिसके लिए मूल दृश्य की उच्च-गुणवत्ता वाली छवि को पुनर्प्राप्त करने के लिए परिष्कृत कम्प्यूटेशनल एल्गोरिदम की आवश्यकता होती है।
पिछले दृष्टिकोणों की मौलिक सीमा या "दर्द बिंदु" जिसने लेखकों को यह पेपर लिखने के लिए मजबूर किया, वह दो मुख्य मुद्दों से उत्पन्न होता है: पुनर्निर्मित छवियों में फोटोरियलिज्म और संगति दोनों प्राप्त करना, और इमेजिंग प्रक्रिया का सटीक मॉडलिंग करना। वर्तमान एल्गोरिदम अक्सर गलत फॉरवर्ड इमेजिंग मॉडल और उच्च-गुणवत्ता वाली छवियों को पुनर्निर्मित करने के लिए अपर्याप्त पूर्व ज्ञान के साथ संघर्ष करते हैं। विशेष रूप से:
- खराब दृश्य गुणवत्ता और छूटे हुए विवरण: पारंपरिक विधियाँ, जैसे WienerDeconv, ऐसी छवियां पुनर्निर्मित कर सकती हैं जो ग्राउंड ट्रुथ के अनुरूप हैं, लेकिन काफी खराब दृश्य गुणवत्ता से ग्रस्त हैं, अक्सर समृद्ध विवरणों की कमी होती है। सीखने-आधारित दृष्टिकोण, जैसे FlatNet-gen, दृश्य गुणवत्ता बढ़ाने का प्रयास करते हैं, लेकिन अक्सर उच्च-आवृत्ति विवरणों को पुनर्प्राप्त करने में विफल रहते हैं।
- जनरेटिव प्रायर के साथ संगति की कमी: जबकि जनरेटिव पुनर्स्थापन एल्गोरिदम (जैसे, DiffBIR) समृद्ध विवरण इंजेक्ट कर सकते हैं और फोटोरियलिज्म में सुधार कर सकते हैं, वे अक्सर संगति की कीमत पर ऐसा करते हैं। ये विधियाँ छवि सामग्री को बदल सकती हैं या गैर-मौजूद वस्तुओं को सम्मिलित कर सकती हैं, जिससे पुनर्निर्माण मूल दृश्य से विचलित हो जाते हैं (जैसे, गलत आकार की पक्षी की चोंच या नकली दिखने वाली पत्तियां)।
- गलत इमेजिंग मॉडल (स्थानिक रूप से भिन्न PSF): अधिकांश मौजूदा पुनर्निर्माण एल्गोरिदम पॉइंट स्प्रेड फ़ंक्शन (PSF) को शिफ्ट-इनवेरिएंट मानकर लेंसलेस इमेजिंग प्रक्रिया को सरल बनाते हैं। हालांकि, व्यवहार में, PSF स्थानिक रूप से भिन्न होता है, विशेष रूप से दृश्य के क्षेत्र (FoV) के परिधि पर जहां घटना का कोण बढ़ता है। माने गए और वास्तविक इमेजिंग मॉडल के बीच यह बेमेल सटीकता की ओर ले जाता है और मूल दृश्य के साथ पुनर्निर्मित समानता में एक ध्यान देने योग्य गिरावट आती है, विशेष रूप से परिधीय क्षेत्रों में। ऐसा इसलिए होता है क्योंकि फ्रेस्नेल सन्निकटन, जो प्रकाश प्रसार मॉडल को एक शिफ्ट-इनवेरिएंट कनवल्शन तक सरल बनाता है, तब टूट जाता है जब लेंसलेस मास्क और सेंसर के बीच की दूरी बहुत कम होती है (जैसे, विशिष्ट लेंसलेस कैमरों में 2 मिमी), जो अक्सर मामला होता है। यह महत्वपूर्ण सीमा का मतलब है कि एक एकल डीकनवल्शन कर्नेल पूरी छवि में धुंधलापन को सटीक रूप से उलट नहीं सकता है।
सहज डोमेन शब्द
- लेंसलेस इमेजिंग: एक ऐसे कैमरे से तस्वीर लेने की कोशिश करने की कल्पना करें जिसमें कोई पारंपरिक कांच का लेंस न हो, बस सेंसर के सामने एक छोटा, पैटर्न वाला खिड़की (एक "मास्क") हो। इस खिड़की से गुजरने पर प्रकाश एक अनूठे तरीके से उलझ जाता है। लेंसलेस इमेजिंग में चालाक कंप्यूटर प्रोग्राम का उपयोग करके उस प्रकाश को "अनस्क्रैम्बल" करना और एक स्पष्ट तस्वीर पुनर्निर्मित करना शामिल है, भले ही इसे फोकस करने के लिए किसी लेंस का उपयोग न किया गया हो।
- पॉइंट स्प्रेड फ़ंक्शन (PSF): दृश्य में प्रकाश के एक एकल, छोटे बिंदु के बारे में सोचें। जब प्रकाश का यह बिंदु लेंसलेस कैमरे के मास्क से गुजरता है और सेंसर से टकराता है, तो यह एक पूर्ण बिंदु के रूप में नहीं रहता है; यह एक विशिष्ट, अक्सर धुंधले पैटर्न में फैल जाता है। PSF लेंसलेस कैमरा सिस्टम द्वारा प्रकाश के एक बिंदु को कैसे धुंधला या एन्कोड किया जाता है, उसके अद्वितीय "फिंगरप्रिंट" की तरह है। यह आपको ठीक-ठीक बताता है कि प्रकाश का प्रत्येक बिंदु सेंसर पर कैसे "फैलता है"।
- स्थानिक रूप से भिन्न डीकनवल्शन: यदि "धुंधला फिंगरप्रिंट" (PSF) इस बात पर निर्भर करता है कि दृश्य में प्रकाश कहाँ से आ रहा है (जैसे, दृश्य के केंद्र से प्रकाश किनारों से प्रकाश की तुलना में अलग तरह से धुंधला होता है), तो एक साधारण "अन-ब्लरिंग" टूल हर जगह पूरी तरह से काम नहीं करेगा। स्थानिक रूप से भिन्न डीकनवल्शन एक स्मार्ट "अन-ब्लरिंग" प्रक्रिया की तरह है जो स्वचालित रूप से छवि के विभिन्न हिस्सों के लिए अपनी तकनीक को समायोजित करती है, एक स्पष्ट, अधिक सटीक तस्वीर प्राप्त करने के लिए प्रत्येक विशिष्ट क्षेत्र के लिए सही "अन-ब्लरिंग" विधि लागू करती है।
- रेंज-नल स्पेस डीकंपोज़िशन: एक बहुत धुंधली तस्वीर की कल्पना करें। यह गणितीय चाल हमें धुंधली तस्वीर को दो भागों में अलग करने में मदद करती है। "रेंज स्पेस" भाग में सभी बुनियादी, कम-विवरण वाली जानकारी (जैसे सामान्य आकार और रंग) होती है जिसे कैमरा मज़बूती से कैप्चर कर सकता था, भले ही वह धुंधला हो। "नल स्पेस" भाग उन सभी महीन विवरणों और बनावटों का प्रतिनिधित्व करता है जो धुंधलापन में पूरी तरह से खो गए थे और धुंधले माप से सीधे पुनर्प्राप्त नहीं किए जा सकते हैं। चुनौती पहले भाग को सटीक रूप से पुनर्निर्मित करना है और फिर दूसरे भाग को यथार्थवादी विवरणों के साथ बुद्धिमानी से "भरना" है, बिना कुछ भी मनगढ़ंत किए।
- जनरेटिव प्रायर (डिफ्यूजन मॉडल से): एक ऐसे कलाकार की कल्पना करें जो केवल एक मोटे स्केच से यथार्थवादी छवियां बनाने में अविश्वसनीय रूप से कुशल है। डिफ्यूजन मॉडल से "जनरेटिव प्रायर" उस कलाकार की तरह है। बुनियादी, कम-विवरण वाली जानकारी (रेंज स्पेस सामग्री) को देखते हुए, यह लापता उच्च-आवृत्ति, फोटोरियलिस्टिक विवरण (नल स्पेस सामग्री) को इस तरह से "कल्पना" और वापस जोड़ सकता है जो प्राकृतिक दिखता है और वास्तविक दुनिया की छवियों के सामान्य रूप से दिखने के तरीके के अनुरूप है, जिससे अंतिम छवि बहुत अधिक आकर्षक बन जाती है।
संकेतन तालिका
| संकेतन | विवरण |
|---|---|
| $\hat{y}$ | लेंसलेस कैमरे द्वारा कैप्चर किया गया कच्चा, मल्टीप्लेक्स माप। |
| $x$ | मूल दृश्य छवि जिसे एल्गोरिथम पुनर्निर्मित करने का लक्ष्य रखता है। |
| $A$ | लेंसलेस इमेजिंग सिस्टम का ट्रांसफर मैट्रिक्स, जो फॉरवर्ड इमेजिंग मॉडल का प्रतिनिधित्व करता है। |
| $n$ | सेंसर शोर। |
| $A^\dagger$ | ट्रांसफर मैट्रिक्स $A$ का स्यूडो-इनवर्स। |
| $A^\dagger A x$ | छवि $x$ का रेंज स्पेस घटक, माप से सीधे पुनर्प्राप्त करने योग्य जानकारी (कम-आवृत्ति सामग्री) का प्रतिनिधित्व करता है। |
| $(I - A^\dagger A)x$ | छवि $x$ का नल स्पेस घटक, इमेजिंग के दौरान खोई हुई जानकारी (उच्च-आवृत्ति विवरण) का प्रतिनिधित्व करता है। |
| $I$ | पहचान मैट्रिक्स। |
| $h$ | लेंसलेस सिस्टम का पॉइंट स्प्रेड फ़ंक्शन (PSF)। |
| $*$ | कनवल्शन ऑपरेटर। |
| $p^{(i)}$ | SVDeconv नेटवर्क में $i$-वां सीखने योग्य पॉइंट स्प्रेड फ़ंक्शन (PSF) कर्नेल। |
| $\mathcal{F}$ | असतत फूरियर ट्रांसफॉर्म (DFT)। |
| $\mathcal{F}^{-1}$ | व्युत्क्रम असतत फूरियर ट्रांसफॉर्म (IDFT)। |
| $\odot$ | हैडामार्ड उत्पाद (तत्व-वार गुणन)। |
| $x^{(i)}_e$ | मल्टी-कर्नेल डीकनवल्शन से $i$-वां मध्यवर्ती डीकनवॉल्व्ड छवि। |
| $X_{int}$ | मध्यवर्ती डीकनवॉल्व्ड छवियों से स्थानिक रूप से इंटरपोलेटेड छवि। |
| $w_i(u, v)$ | पिक्सेल $(u, v)$ पर $i$-वें डीकनवॉल्व्ड छवि के लिए वजन, व्युत्क्रम यूक्लिडियन दूरी पर आधारित। |
| $\mathbf{c}$ | रेंज स्पेस सामग्री, पहले SVDeconv चरण का आउटपुट, डिफ्यूजन मॉडल के लिए एक शर्त के रूप में उपयोग किया जाता है। |
| $\mathbf{x}_t$ | डिफ्यूजन प्रक्रिया में टाइमस्टेप $t$ पर शोर वाली छवि। |
| $\mathbf{\epsilon}$ | एक मानक सामान्य वितरण से नमूना लिया गया वास्तविक शोर वेक्टर। |
| $\mathbf{\epsilon}_\theta(\mathbf{x}_t, t, \mathbf{c})$ | सशर्त डिफ्यूजन मॉडल का शोर भविष्यवाणी नेटवर्क (पैरामीट्रिज्ड बाय $\theta$)। |
| $\theta$ | शोर भविष्यवाणी नेटवर्क के सीखने योग्य पैरामीटर। |
| $\mathcal{L}_{null}$ | नल स्पेस रिकवरी चरण के लिए लॉस फ़ंक्शन, माप स्थान में संगति को लागू करता है। |
| $\mathbb{E}$ | अपेक्षा ऑपरेटर। |
| $t$ | डिफ्यूजन प्रक्रिया में टाइमस्टेप। |
| $\mathcal{N}(0,1)$ | मानक सामान्य वितरण। |
| $\| \cdot \|^2$ | वर्गित L2 मानदंड। |
| $\mathcal{L}_{MSE}$ | माध्य वर्ग त्रुटि हानि। |
| $\mathcal{L}_{LPIPS}$ | सीखा हुआ अवधारणात्मक छवि पैच समानता हानि। |
समस्या परिभाषा और बाधाएँ
मुख्य समस्या सूत्रीकरण और दुविधा
इस पेपर द्वारा संबोधित मौलिक समस्या लेंसलेस कैमरा मापों से फोटोरियलिस्टिक और सुसंगत छवियों का पुनर्निर्माण है।
इनपुट/वर्तमान स्थिति:
प्रारंभिक बिंदु एक लेंसलेस कैमरे द्वारा कैप्चर किया गया एक कच्चा, मल्टीप्लेक्स माप $\hat{y} \in \mathbb{R}^{N^2}$ है। यह माप आमतौर पर धुंधला, अपरिचित और उच्च-आवृत्ति विवरणों से रहित होता है। गणितीय रूप से, लेंसलेस इमेजिंग प्रक्रिया को मूल दृश्य $x \in \mathbb{R}^{M^2}$ के रैखिक परिवर्तन के रूप में अतिरिक्त सेंसर शोर $n$ के साथ तैयार किया जा सकता है:
$$ \hat{y} = Ax + n $$
यहां, $A \in \mathbb{R}^{N^2 \times M^2}$ लेंसलेस इमेजिंग सिस्टम का ट्रांसफर मैट्रिक्स है, जो एन्कोड करता है कि दृश्य में प्रत्येक बिंदु से प्रकाश प्रत्येक सेंसर पिक्सेल में कैसे योगदान देता है। पिछले तरीके अक्सर इस जटिल प्रक्रिया को एक एकल, शिफ्ट-इनवेरिएंट पॉइंट स्प्रेड फ़ंक्शन (PSF) के साथ कनवल्शन के रूप में सरल बनाते हैं, अर्थात, $y = h * x$।
वांछित अंतिम बिंदु (आउटपुट/लक्ष्य स्थिति):
वांछित अंतिम बिंदु एक पुनर्निर्मित छवि $x$ है जो फोटोरियलिस्टिक और मूल दृश्य के सुसंगत दोनों है।
* फोटोरियलिज्म का तात्पर्य एक उच्च-गुणवत्ता वाली छवि से है जिसमें समृद्ध, प्राकृतिक दिखने वाले विवरण हों, जो लेंसलेस कैप्चर के दौरान खोई हुई उच्च-आवृत्ति सामग्री को प्रभावी ढंग से पुनर्प्राप्त करता है।
* संगति का अर्थ है कि पुनर्निर्मित छवि की सामग्री को मूल दृश्य के साथ सटीक रूप से संरेखित करना चाहिए, $Ax = y$ (जहां $y$ शोर-मुक्त माप है) की शर्त को संतुष्ट करना चाहिए।
लुप्त कड़ी या गणितीय अंतर:
सटीक लुप्त कड़ी लेंसलेस इमेजिंग प्रक्रिया (जो $A$ द्वारा दर्शाई गई है) की जटिल, स्थानिक रूप से भिन्न प्रकृति को सटीक रूप से मॉडल करने की क्षमता है और खराब माप से दृश्य के निम्न-आवृत्ति (संगति-महत्वपूर्ण) और उच्च-आवृत्ति (फोटोरियलिज्म-महत्वपूर्ण) दोनों घटकों को प्रभावी ढंग से पुनर्प्राप्त करना है। पेपर इस अंतर को पाटने के लिए रेंज-नल स्पेस डीकंपोज़िशन का लाभ उठाता है। किसी भी दृश्य $x$ को दो ऑर्थोगोनल घटकों में विघटित किया जा सकता है:
$$ x = A^\dagger Ax + (I - A^\dagger A)x $$
जहां $A^\dagger Ax$ रेंज स्पेस घटक (कम-आवृत्ति सामग्री सीधे मापों से पुनर्प्राप्त करने योग्य, संगति सुनिश्चित करना) है और $(I - A^\dagger A)x$ नल स्पेस घटक (इमेजिंग के दौरान खोई हुई उच्च-आवृत्ति विवरण, फोटोरियलिज्म के लिए महत्वपूर्ण) है। पेपर का लक्ष्य पहले रेंज स्पेस सामग्री को सटीक रूप से पुनर्निर्मित करना है, और फिर जनरेटिव प्रायर का उपयोग करके इसे नल स्पेस सामग्री के साथ समृद्ध करना है, जबकि सभी संगति बनाए रखना है।
दुविधा (दर्दनाक समझौता):
मुख्य दुविधा जिसने पिछले शोधकर्ताओं को फंसाया है, वह उच्च दृश्य गुणवत्ता (फोटोरियलिज्म) प्राप्त करने और डेटा संगति (मूल दृश्य के प्रति निष्ठा) बनाए रखने के बीच दर्दनाक समझौता है।
* पारंपरिक पुनर्निर्माण एल्गोरिदम (जैसे, WienerDeconv) डेटा संगति को प्राथमिकता देते हैं, ऐसी छवियां उत्पन्न करते हैं जो ग्राउंड ट्रुथ के साथ संरेखित होती हैं लेकिन अक्सर धुंधली और दृश्य गुणवत्ता में काफी खराब होती हैं, जिनमें महीन विवरणों की कमी होती है। वे उच्च-आवृत्ति जानकारी को पुनर्प्राप्त करने में विफल रहते हैं।
* जनरेटिव पुनर्स्थापन एल्गोरिदम (जैसे, डिफ्यूजन मॉडल जैसे DiffBIR का उपयोग करने वाले) समृद्ध, फोटोरियलिस्टिक विवरण इंजेक्ट कर सकते हैं और दृश्य गुणवत्ता में काफी सुधार कर सकते हैं। हालांकि, वे अक्सर "छवि सामग्री को बदलते हैं या गैर-मौजूद वस्तुओं को सम्मिलित करते हैं," जिससे वास्तविक दृश्य के साथ संगति टूट जाती है। उदाहरण के लिए, वे गलत आकार या नकली दिखने वाले बनावट उत्पन्न कर सकते हैं, जैसा कि चित्र 1d में दिखाया गया है।
यह दुविधा का मतलब है कि एक पहलू (जैसे, फोटोरियलिज्म) में सुधार आमतौर पर दूसरे (संगति) से समझौता करता है, जिससे मौजूदा तरीकों से दोनों को एक साथ प्राप्त करना अविश्वसनीय रूप से कठिन हो जाता है।
बाधाएँ और विफलता मोड
फोटोरियलिस्टिक और सुसंगत लेंसलेस छवि पुनर्निर्माण की समस्या कई कठोर, यथार्थवादी बाधाओं और पूर्व दृष्टिकोणों के सामान्य विफलता मोड के कारण अविश्वसनीय रूप से कठिन है:
-
स्थानिक रूप से भिन्न पॉइंट स्प्रेड फ़ंक्शन (PSF):
- भौतिक बाधा: पारंपरिक लेंस-आधारित कैमरों के विपरीत, लेंसलेस सिस्टम में पूरे दृश्य के क्षेत्र (FoV) में एक निश्चित, शिफ्ट-इनवेरिएंट PSF नहीं होता है। PSF आपतित प्रकाश के कोण के साथ महत्वपूर्ण रूप से भिन्न होता है, विशेष रूप से परिधि पर।
- कम्प्यूटेशनल बाधा: अधिकांश मौजूदा पुनर्निर्माण एल्गोरिदम इमेजिंग प्रक्रिया को शिफ्ट-इनवेरिएंट PSF मानने की धारणा के साथ सरल बनाते हैं, जो गलत है। वास्तविक स्थानिक रूप से भिन्न PSF को मॉडल करना कम्प्यूटेशनल रूप से गहन है, क्योंकि पूर्ण ट्रांसफर मैट्रिक्स $A$ वास्तविक दुनिया की प्रणालियों के लिए सीधे "गणना करने के लिए बहुत बड़ा" है। यह सरलीकरण पुनर्निर्मित छवियों में, विशेष रूप से सीमाओं पर, ध्यान देने योग्य गिरावट और कलाकृतियों की ओर ले जाता है, जैसा कि चित्र 4d में दिखाया गया है।
-
उच्च-आवृत्ति जानकारी का नुकसान:
- भौतिक बाधा: लेंसलेस एन्कोडिंग प्रक्रिया, जहां प्रकाश को एक मास्क द्वारा संशोधित किया जाता है, एक लो-पास फिल्टर की तरह काम करती है। यह स्वाभाविक रूप से दृश्य से उच्च-आवृत्ति विवरणों का महत्वपूर्ण नुकसान का कारण बनता है, जिससे कच्चे माप धुंधले और अस्पष्ट हो जाते हैं।
- डेटा-संचालित बाधा: इन खोए हुए उच्च-आवृत्ति विवरणों (नल स्पेस सामग्री) को पुनर्प्राप्त करने के लिए मजबूत प्रायर की आवश्यकता होती है। पर्याप्त और सटीक प्रायर के बिना, एल्गोरिदम फोटोरियलिस्टिक छवियों को पुनर्निर्मित करने के लिए संघर्ष करते हैं, जिसके परिणामस्वरूप अक्सर दृश्य रूप से खराब आउटपुट होते हैं या, यदि जनरेटिव मॉडल का लापरवाही से उपयोग किया जाता है, तो गैर-मौजूद विवरणों का मतिभ्रम होता है जो निष्ठा को तोड़ते हैं।
-
स्थानिक रूप से भिन्न डीकनवल्शन की कम्प्यूटेशनल जटिलता:
- कम्प्यूटेशनल बाधा: जबकि सटीक पुनर्निर्माण के लिए स्थानिक रूप से भिन्न डीकनवल्शन आवश्यक है, इस क्षेत्र में पिछले तरीके "अक्सर धीमे, कम्प्यूटेशनल रूप से गहन होते हैं, और विशेष रूप से जटिल प्रणालियों में खराब छवि गुणवत्ता का परिणाम देते हैं।"
- कैलिब्रेशन बोझ: कई मल्टी-कर्नेल डीकनवल्शन दृष्टिकोणों के लिए "थकाऊ मल्टी-लोकेशन PSF कैलिब्रेशन" की आवश्यकता होती है, जो एक समय लेने वाली और श्रम-गहन प्रक्रिया है, जिससे वे व्यापक उपयोग के लिए अव्यावहारिक हो जाते हैं। पेपर का लक्ष्य एक एकल प्रारंभिक PSF से स्वचालित रूप से भिन्नताओं को सीखकर इसे दूर करना है।
-
जनरेटिव प्रायर के साथ डेटा निष्ठा बनाए रखना:
- तार्किक बाधा: जनरेटिव मॉडल, जबकि विवरणों का मतिभ्रम करने के लिए शक्तिशाली होते हैं, स्वाभाविक रूप से नई जानकारी बनाने के द्वारा संचालित होते हैं। एक प्रमुख विफलता मोड यह है कि वे "छवि सामग्री को बदलते हैं या गैर-मौजूद वस्तुओं को सम्मिलित करते हैं," जिससे यह मौलिक संगति आवश्यकता का उल्लंघन होता है कि पुनर्निर्मित छवि को वास्तविक भौतिक मापों के साथ संरेखित होना चाहिए। चुनौती इन जनरेटिव मॉडलों को ऐसे यथार्थवादी विवरण उत्पन्न करने के लिए निर्देशित करना है जो अंतर्निहित डेटा के सुसंगत हों।
-
वास्तविक समय विलंबता (भविष्य की सीमा):
- कम्प्यूटेशनल बाधा: हालांकि इस पेपर में सीधे तौर पर दूर नहीं किया गया है, लेखकों ने स्वीकार किया है कि "PhoCoLens की दो-चरणीय प्रकृति और डिफ्यूजन मॉडल का नमूना समय वास्तविक समय प्रयोज्यता में बाधा डालता है।" इसका तात्पर्य है कि तत्काल प्रतिक्रिया की आवश्यकता वाले अनुप्रयोगों के लिए, जैसे कि वास्तविक समय वीडियो या नैदानिक इमेजिंग, प्रस्तावित विधि की वर्तमान कम्प्यूटेशनल ओवरहेड एक महत्वपूर्ण बाधा प्रस्तुत करती है।
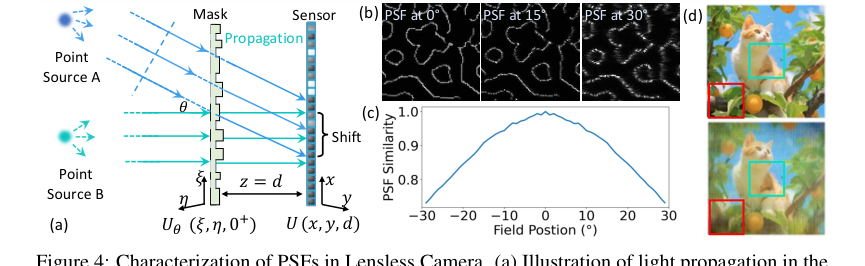 Figure 4. Characterization of PSFs in Lensless Camera. (a) Illustration of light propagation in the lensless camera: two point sources A and B at infinity emitting parallel light beams. Source A emits at angle θ relative to the optical axis, causing a PSF shift on the sensor plane This PSF shift depends on both the incident angle θ and the distance d between the sensor and the mask. (b) Simulated PSFs for light sources at angles of 0°, 15°, and 30°. (c) Inner product similarity between the on-axis PSF and off-axis PSFs at different field positions. (d) Reconstruction using PSF at 0°, degradation is more significant at the periphery (red box) than the center (green box)
Figure 4. Characterization of PSFs in Lensless Camera. (a) Illustration of light propagation in the lensless camera: two point sources A and B at infinity emitting parallel light beams. Source A emits at angle θ relative to the optical axis, causing a PSF shift on the sensor plane This PSF shift depends on both the incident angle θ and the distance d between the sensor and the mask. (b) Simulated PSFs for light sources at angles of 0°, 15°, and 30°. (c) Inner product similarity between the on-axis PSF and off-axis PSFs at different field positions. (d) Reconstruction using PSF at 0°, degradation is more significant at the periphery (red box) than the center (green box)
यह दृष्टिकोण क्यों
पसंद की अनिवार्यता
PhoCoLens के लेखकों को लेंसलेस इमेजिंग में एक मौलिक दुविधा का सामना करना पड़ा: उच्च दृश्य गुणवत्ता (फोटोरियलिज्म) और मूल दृश्य के वफादार प्रतिनिधित्व (संगति) दोनों को कैसे प्राप्त किया जाए। पारंपरिक अत्याधुनिक (SOTA) विधियाँ, जैसे कि WienerDeconv जैसी मानक डीकनवल्शन तकनीकें, अपर्याप्त पाई गईं क्योंकि वे काफी खराब दृश्य गुणवत्ता वाली छवियां उत्पन्न करती थीं, जिनमें फोटोरियलिज्म के लिए आवश्यक समृद्ध विवरणों की कमी थी (चित्र 1b)। जबकि सीखने-आधारित दृष्टिकोण, जैसे FlatNet-gen द्वारा उदाहरणित, ने दृश्य गुणवत्ता में सुधार किया, वे अभी भी महत्वपूर्ण उच्च-आवृत्ति विवरणों को पुनर्प्राप्त करने के लिए संघर्ष करते थे, जिसके परिणामस्वरूप कम तेज और कम यथार्थवादी छवियां होती थीं (चित्र 1c)।
यह महत्वपूर्ण अहसास कि पारंपरिक विधियाँ अपर्याप्त थीं, तब हुआ जब लेखकों ने देखा कि डिफ्यूजन मॉडल, जैसे DiffBIR, जो फोटोरियलिस्टिक विवरण इंजेक्ट करने में उत्कृष्ट हैं, अक्सर संगति की कीमत पर ऐसा करते हैं। ये मॉडल अक्सर छवि सामग्री को बदलते थे या गैर-मौजूद वस्तुओं को पेश करते थे, जैसे कि गलत आकार की चोंच या नकली दिखने वाली पत्तियां (चित्र 1d), जिससे ग्राउंड ट्रुथ के साथ निष्ठा टूट जाती थी। इसने संकेत दिया कि विशुद्ध रूप से जनरेटिव दृष्टिकोण, जबकि दृश्य रूप से आकर्षक है, उन अनुप्रयोगों के लिए एक व्यवहार्य एकमात्र समाधान नहीं था जहां मूल दृश्य के प्रति सटीकता सर्वोपरि है।
इसके अलावा, मौजूदा पुनर्निर्माण एल्गोरिदम में पहचानी गई एक महत्वपूर्ण सीमा इमेजिंग प्रक्रिया का उनका सरलीकरण था। अधिकांश विधियों ने एक शिफ्ट-इनवेरिएंट पॉइंट स्प्रेड फ़ंक्शन (PSF) को माना, इमेजिंग को एक साधारण कनवल्शन के रूप में माना। हालांकि, लेखकों ने महसूस किया कि वास्तविक दुनिया के लेंसलेस सिस्टम में, PSF स्वाभाविक रूप से स्थानिक रूप से भिन्न होते हैं, विशेष रूप से विभिन्न घटना कोणों पर (चित्र 4a, 4b, 4c)। माने गए शिफ्ट-इनवेरिएंट PSF और वास्तविक स्थानिक रूप से भिन्न PSF के बीच यह बेमेल, विशेष रूप से दृश्य के परिधीय में, जहां पुनर्निर्मित समानता मूल दृश्य के साथ काफी कम हो गई थी (चित्र 4d), के साथ महत्वपूर्ण अशुद्धियों का कारण बना। यह मौलिक भौतिक वास्तविकता ने पारंपरिक कनवल्शनल मॉडल को पूरे दृश्य के क्षेत्र में सटीक लेंसलेस पुनर्निर्माण के लिए स्वाभाविक रूप से अपर्याप्त बना दिया।
तुलनात्मक श्रेष्ठता
PhoCoLens अपनी नवीन दो-चरणीय वास्तुकला के माध्यम से गुणात्मक और मात्रात्मक श्रेष्ठता प्राप्त करता है, जो लेंसलेस इमेजिंग की मुख्य चुनौतियों को संरचनात्मक रूप से संबोधित करता है। मुख्य संरचनात्मक लाभ इसके रेंज-नल स्पेस डीकंपोज़िशन फ्रेमवर्क में निहित है। यह सैद्धांतिक आधार विधि को समस्या को दो ऑर्थोगोनल घटकों में अलग करने की अनुमति देता है: एक डेटा संगति (रेंज स्पेस) पर केंद्रित है और दूसरा फोटोरियलिज्म (नल स्पेस) पर। यह पिछले तरीकों पर एक गहरा लाभ है जो दोनों को एक साथ हल करने का प्रयास करते थे, अक्सर व्यापार-बंद की ओर ले जाते थे।
- रेंज स्पेस के लिए स्थानिक रूप से भिन्न डीकनवल्शन (SVDeconv): पिछले तरीकों के विपरीत जो एक एकल, शिफ्ट-इनवेरिएंट PSF को मानते हैं, SVDeconv डेटा-संचालित तरीके से कैमरे के दृश्य के क्षेत्र में PSF में स्थानिक विविधताओं के अनुकूल होना सीखता है। यह एक महत्वपूर्ण संरचनात्मक सुधार है, क्योंकि यह जटिल फॉरवर्ड इमेजिंग प्रक्रिया को अधिक सटीक रूप से मॉडल करता है। यह संरचनात्मक अखंडता और कम-आवृत्ति विवरणों के बेहतर पुनर्निर्माण की ओर ले जाता है, विशेष रूप से छवि परिधि में, जहां अन्य तरीके विफल हो जाते हैं (चित्र 2, चित्र 4d)। तालिका 2 मात्रात्मक रूप से अन्य डीकनवल्शन विधियों की तुलना में रेंज स्पेस पुनर्निर्माण में SVDeconv के बेहतर प्रदर्शन को प्रदर्शित करती है।
- फोटोरियलिज्म के लिए सशर्त नल-स्पेस डिफ्यूजन: दूसरा चरण एक पूर्व-प्रशिक्षित डिफ्यूजन मॉडल का लाभ उठाता है, लेकिन महत्वपूर्ण रूप से, यह इस जनरेटिव प्रक्रिया को पहले चरण से पुनर्प्राप्त कम-आवृत्ति सामग्री पर सशर्त करता है। यह सुनिश्चित करता है कि जबकि उच्च-आवृत्ति विवरण फोटोरियलिज्म के लिए जोड़े जाते हैं, वे रेंज स्पेस पुनर्निर्माण द्वारा स्थापित अंतर्निहित संरचना के अनुरूप बने रहते हैं। यह दृष्टिकोण शुद्ध जनरेटिव मॉडल (जैसे DiffBIR) की कमियों से बचता है जो कलाकृतियों को पेश करते हैं या सामग्री को बदलते हैं, जैसा कि चित्र 1d में दिखाया गया है। कंडीशनिंग तंत्र एक संरचनात्मक सुरक्षा उपाय है जो दृश्य गुणवत्ता को बढ़ाते हुए निष्ठा बनाए रखता है।
मात्रात्मक रूप से, PhoCoLens जबरदस्त श्रेष्ठता प्रदर्शित करता है। जैसा कि तालिका 1 में दिखाया गया है, यह PhlatCam और DiffuserCam दोनों डेटासेट पर निष्ठा मेट्रिक्स (PSNR, SSIM, LPIPS) और दृश्य गुणवत्ता मेट्रिक्स (ManIQA, ClipIQA, MUSIQ) के बीच लगातार सबसे अच्छा संतुलन प्राप्त करता है। उदाहरण के लिए, PhlatCam पर, PhoCoLens 62.20 का MUSIQ स्कोर प्राप्त करता है, जो FlatNet+DiffBIR के 57.13 से काफी अधिक है, जबकि बेहतर LPIPS (0.215 बनाम 0.391) भी बनाए रखता है। यह इंगित करता है कि एक विधि जो केवल थोड़ी बेहतर नहीं है, बल्कि संरचनात्मक रूप से पिछले स्वर्ण मानकों को उनके अंतर्निहित सीमाओं को संबोधित करके बेहतर प्रदर्शन करने के लिए डिज़ाइन की गई है।
बाधाओं के साथ संरेखण
PhoCoLens के चुने हुए दो-चरणीय दृष्टिकोण लेंसलेस इमेजिंग में फोटोरियलिज्म और संगति दोनों प्राप्त करने की दोहरी बाधाओं के साथ पूरी तरह से संरेखित होते हैं, साथ ही अंतर्निहित भौतिक चुनौतियों का भी समाधान करते हैं।
- संगति के लिए स्थानिक रूप से भिन्न PSFs को संबोधित करना: पूरे दृश्य के क्षेत्र में सटीक पुनर्निर्माण प्राप्त करने की समस्या की कठोर आवश्यकता, लेंसलेस PSFs की स्थानिक रूप से भिन्न प्रकृति के बावजूद, सीधे पहले चरण में SVDeconv द्वारा पूरी की जाती है। इन स्थानिक विविधताओं को सीखकर और अनुकूलित करके, SVDeconv सुनिश्चित करता है कि कम-आवृत्ति सामग्री (रेंज स्पेस) को उच्च निष्ठा और संरचनात्मक अखंडता के साथ पुनर्निर्मित किया जाए, अंतिम छवि के लिए एक सुसंगत नींव रखी जाए। यह समस्या की भौतिक वास्तविकता और समाधान के अनुकूली डीकनवल्शन गुण के बीच एक सीधा "विवाह" है।
- फोटोरियलिज्म के लिए जनरेटिव प्रायर का लाभ उठाना जबकि संगति बनाए रखना: फोटोरियलिज्म प्राप्त करने की बाधा, जिसके लिए उच्च-आवृत्ति विवरणों की आवश्यकता होती है जो अक्सर लेंसलेस कैप्चर में खो जाते हैं, दूसरे चरण में नल-स्पेस डिफ्यूजन मॉडल द्वारा संबोधित की जाती है। हालांकि, यहां महत्वपूर्ण संरेखण यह है कि इस जनरेटिव शक्ति का उपयोग कैसे किया जाता है। अंधाधुंध विवरण उत्पन्न करने के बजाय, डिफ्यूजन मॉडल को पहले चरण से प्राप्त सुसंगत कम-आवृत्ति आउटपुट पर सशर्त किया जाता है। यह सुनिश्चित करता है कि जोड़ी गई उच्च-आवृत्ति विवरण (नल स्पेस से) पहले स्थापित संगति का उल्लंघन किए बिना फोटोरियलिज्म को बढ़ाते हैं। रेंज-नल स्पेस डीकंपोज़िशन का गणितीय ढांचा स्पष्ट रूप से सुनिश्चित करता है कि नल स्पेस घटक, जब जोड़ा जाता है, तो माप $y$ को नहीं बदलता है, इस प्रकार संगति को बनाए रखता है ($A(x - A^\dagger Ax) = 0$)। यह एक आदर्श संरेखण है जहां जनरेटिव क्षमता को संगति आवश्यकता द्वारा बाधित किया जाता है।
- अपर्याप्त प्रायर पर काबू पाना: पारंपरिक तरीकों में अपर्याप्त प्रायर की समस्या, जिसके परिणामस्वरूप खराब दृश्य गुणवत्ता हुई, एक शक्तिशाली पूर्व-प्रशिक्षित डिफ्यूजन मॉडल को एकीकृत करके दूर की जाती है। यह मॉडल यथार्थवादी छवि बनावट के लिए एक मजबूत जनरेटिव प्रायर प्रदान करता है, लेकिन नल-स्पेस ढांचे के भीतर इसका अनुप्रयोग सुनिश्चित करता है कि यह वास्तविक दृश्य डेटा द्वारा निर्देशित है, मनमाने मतिभ्रम से बचता है।
विकल्पों का अस्वीकरण
पेपर स्पष्ट रूप से और अप्रत्यक्ष रूप से फोटोरियलिज्म और संगति दोनों के दोहरे लक्ष्यों को पूरा करने में उनकी अंतर्निहित सीमाओं के आधार पर कई वैकल्पिक दृष्टिकोणों को अस्वीकार करता है:
- पारंपरिक डीकनवल्शन (जैसे, WienerDeconv): इन विधियों को मुख्य रूप से फोटोरियलिस्टिक परिणाम उत्पन्न करने में उनकी असमर्थता के कारण अस्वीकार कर दिया गया था। जबकि वे कुछ डेटा संगति बनाए रखते हैं, उनकी दृश्य गुणवत्ता "काफी खराब" है (धारा 1, चित्र 1b), जिससे वे उच्च-गुणवत्ता वाले छवि पुनर्निर्माण के लिए अनुपयुक्त हैं।
- लर्निंग-आधारित डीकनवल्शन (जैसे, FlatNet-gen): पारंपरिक विधियों से एक सुधार होने के बावजूद, इन दृष्टिकोणों को "अक्सर उच्च-आवृत्ति विवरणों को पुनर्प्राप्त करने में विफल" पाया गया (धारा 1, चित्र 1c)। इस सीमा का मतलब था कि वे वांछित स्तर के फोटोरियलिज्म को प्राप्त नहीं कर सके, जिसके परिणामस्वरूप तेज और महीन बनावट की कमी हुई।
- प्रत्यक्ष प्रायर के साथ जनरेटिव मॉडल (जैसे, DiffBIR): ये विधियाँ, जबकि समृद्ध विवरण इंजेक्ट करने और दृश्य गुणवत्ता बढ़ाने में उत्कृष्ट हैं, उन्हें इसलिए अस्वीकार कर दिया गया क्योंकि वे "छवि सामग्री को बदल सकते हैं या गैर-मौजूद वस्तुओं को पेश कर सकते हैं, जिससे संगति टूट जाती है" (धारा 1, चित्र 1d)। लेखकों ने विकृत वस्तुओं (जैसे, चोंच का "गलत आकार") और नकली बनावट के स्पष्ट उदाहरण प्रदान किए हैं, यह प्रदर्शित करते हुए कि उनका फोटोरियलिज्म निष्ठा की अस्वीकार्य लागत पर आता है।
- शिफ्ट-इनवेरिएंट PSFs मानने वाले तरीके: एक प्रमुख अप्रत्यक्ष अस्वीकरण किसी भी विधि का है जो लेंसलेस इमेजिंग प्रक्रिया को शिफ्ट-इनवेरिएंट PSF मानने की धारणा के साथ सरल बनाता है। जैसा कि धारा 3.2 में विस्तृत है और चित्र 4d में दर्शाया गया है, यह धारणा "अशुद्धियों" और "मूल दृश्य के साथ पुनर्निर्मित समानता में एक ध्यान देने योग्य गिरावट" की ओर ले जाती है, विशेष रूप से परिधीय दृश्य क्षेत्र में। PhoCoLens के SVDeconv चरण को विशेष रूप से इस मौलिक दोष को दूर करने के लिए डिज़ाइन किया गया था, जिससे वास्तविक दुनिया के लेंसलेस सिस्टम के लिए किसी भी शिफ्ट-इनवेरिएंट दृष्टिकोण को स्वाभाविक रूप से निम्नतर बना दिया गया।
- जीरो-शॉट डिफ्यूजन मॉडल (जैसे, DDNM+): जबकि डिफ्यूजन मॉडल के साथ व्युत्क्रम इमेजिंग की एक श्रेणी के रूप में उल्लेख किया गया है, पेपर का दृष्टिकोण "रेंज-नल स्पेस डीकंपोज़िशन पर आधारित एक सैद्धांतिक ढांचे के साथ पर्यवेक्षित फाइन-ट्यूनिंग" को एकीकृत करता है (धारा 2)। यह इस विशिष्ट समस्या के लिए विशुद्ध रूप से जीरो-शॉट विधियों के अस्वीकरण का अर्थ है, संभवतः क्योंकि वे डीकंपोज़िशन ढांचे के भीतर पर्यवेक्षित प्रशिक्षण द्वारा प्रदान किए जाने वाले ठीक-ठाक नियंत्रण या संगति गारंटी की कमी हो सकती है। तालिका 3 से पता चलता है कि DDNM+ नल स्पेस रिकवरी के लिए निष्ठा और दृश्य गुणवत्ता मेट्रिक्स दोनों में PhoCoLens से काफी खराब प्रदर्शन करता है।
 Figure 1. We introduce PhoCoLens, a lensless reconstruction algorithm that achieves both better visual quality and consistency to the ground truth than existing methods. Our method recovers more details compared to traditional reconstruction algorithms (b) and (c), and also maintains better fidelity to the ground truth compared to the generative approach (d)
Figure 1. We introduce PhoCoLens, a lensless reconstruction algorithm that achieves both better visual quality and consistency to the ground truth than existing methods. Our method recovers more details compared to traditional reconstruction algorithms (b) and (c), and also maintains better fidelity to the ground truth compared to the generative approach (d)
गणितीय और तार्किक तंत्र
मास्टर समीकरण
इस पेपर को चलाने वाला मुख्य गणितीय इंजन, विशेष रूप से पुनर्निर्माण के दूसरे चरण में फोटोरियलिज्म और संगति प्राप्त करने के लिए, नल स्पेस डिफ्यूजन मॉडल के लिए अनुकूलन उद्देश्य है। यह समीकरण सुनिश्चित करता है कि डिफ्यूजन मॉडल द्वारा उत्पन्न उच्च-आवृत्ति विवरण लेंसलेस इमेजिंग सिस्टम की अंतर्निहित भौतिकी के अनुरूप बने रहें। इसे औपचारिक रूप से व्यक्त किया गया है:
$$ \min_\theta \mathcal{L}_{null} = \min_\theta \mathbb{E}_{\mathbf{x},t,\mathbf{c},\mathbf{\epsilon} \sim \mathcal{N}(0,1)} \left[ \left\| A(\mathbf{\epsilon}_\theta(\mathbf{x}_t, t, \mathbf{c}) - \mathbf{\epsilon}) \right\|^2 \right] $$
यह समीकरण रेंज-नल स्पेस डीकंपोज़िशन के मौलिक सिद्धांत से लिया गया है, जो मानता है कि किसी भी छवि $\mathbf{x}$ को एक रेंज स्पेस घटक $A^\dagger A \mathbf{x}$ (जो कैमरा द्वारा सीधे अवलोकन योग्य जानकारी का प्रतिनिधित्व करता है) और एक नल स्पेस घटक $(I - A^\dagger A) \mathbf{x}$ (जो इमेजिंग के दौरान खोई हुई जानकारी का प्रतिनिधित्व करता है लेकिन फोटोरियलिज्म के लिए महत्वपूर्ण है) में विभाजित किया जा सकता है। यहां उद्देश्य यह सुनिश्चित करना है कि जनरेटिव मॉडल द्वारा जोड़ी गई अवशिष्ट सामग्री, जो आदर्श रूप से नल स्पेस में स्थित होनी चाहिए, फॉरवर्ड इमेजिंग मॉडल के साथ संगति का उल्लंघन न करे।
पद-दर-पद विच्छेदन
आइए इसके अर्थ और महत्व को समझने के लिए इस समीकरण को टुकड़ों में तोड़ें:
- $\min_\theta$: यह मानक न्यूनतम ऑपरेटर है, जो इंगित करता है कि लक्ष्य तंत्रिका नेटवर्क के लिए $\theta$ मापदंडों का इष्टतम सेट खोजना है।
- $\theta$: ये शोर भविष्यवाणी नेटवर्क, $\mathbf{\epsilon}_\theta$ के सीखने योग्य पैरामीटर हैं। यह नेटवर्क एक डीप लर्निंग मॉडल है, आमतौर पर एक U-Net, जो एक शोर वाली छवि में शोर घटक की भविष्यवाणी करना सीखता है।
- $\mathcal{L}_{null}$: यह प्रतीक विशेष रूप से नल स्पेस रिकवरी चरण के लिए डिज़ाइन किए गए लॉस फ़ंक्शन का प्रतिनिधित्व करता है। इसका न्यूनतमकरण डिफ्यूजन मॉडल को सुसंगत और फोटोरियलिस्टिक विवरण उत्पन्न करने के लिए निर्देशित करता है।
- $\mathbb{E}_{\mathbf{x},t,\mathbf{c},\mathbf{\epsilon} \sim \mathcal{N}(0,1)}$: यह अपेक्षा ऑपरेटर को दर्शाता है, जिसका अर्थ है कि हम कई यादृच्छिक नमूनों पर हानि का औसत निकाल रहे हैं।
- $\mathbf{x}$: यह ग्राउंड ट्रुथ, साफ छवि है जिसे मॉडल पुनर्निर्मित करने का लक्ष्य रखता है। यह आदर्श लक्ष्य है।
- $t$: यह फॉरवर्ड डिफ्यूजन प्रक्रिया में एक टाइमस्टेप का प्रतिनिधित्व करता है, जो इंगित करता है कि मूल छवि में कितना शोर जोड़ा गया है। डिफ्यूजन मॉडल शोर को उत्तरोत्तर जोड़कर और फिर इस प्रक्रिया को उलटने के लिए सीखकर काम करते हैं।
- $\mathbf{c}$: यह डिफ्यूजन मॉडल के लिए शर्त है, विशेष रूप से पहले चरण से पुनर्निर्मित रेंज स्पेस सामग्री $A^\dagger A \mathbf{x}$। यह कम-आवृत्ति, सुसंगत जानकारी प्रदान करता है जिसका जनरेटिव मॉडल को पालन करना चाहिए।
- $\mathbf{\epsilon} \sim \mathcal{N}(0,1)$: यह मानक सामान्य वितरण से नमूना लिया गया वास्तविक शोर वेक्टर है, जिसे $\mathbf{x}_t$ शोर वाली छवि बनाने के लिए साफ छवि $\mathbf{x}$ में जोड़ा जाता है।
- $\| \cdot \|^2$: यह वर्गित L2 मानदंड है, जो प्रतिगमन कार्यों में हानि कार्यों के लिए एक सामान्य विकल्प है। यह दो वैक्टर के बीच वर्गित यूक्लिडियन दूरी को मापता है, बड़े त्रुटियों को अधिक महत्वपूर्ण रूप से दंडित करता है। लेखकों ने इसे चुना क्योंकि यह अनुमानित शोर और वास्तविक शोर के बीच के अंतर को मापने का एक सीधा और प्रभावी तरीका है।
- $A$: यह लेंसलेस इमेजिंग सिस्टम का ट्रांसफर मैट्रिक्स है। यह गणितीय रूप से बताता है कि एक दृश्य $\mathbf{x}$ कैमरे द्वारा एक माप $\mathbf{y}$ में कैसे परिवर्तित होता है (अर्थात, $\mathbf{y} = A\mathbf{x}$)। यहां इसकी भूमिका महत्वपूर्ण है: यह शोर भविष्यवाणी त्रुटि को माप स्थान में प्रोजेक्ट करता है।
- $\mathbf{\epsilon}_\theta(\mathbf{x}_t, t, \mathbf{c})$: यह तंत्रिका नेटवर्क का आउटपुट है, जो $\theta$ द्वारा पैरामीट्रिज्ड है। एक शोर वाली छवि $\mathbf{x}_t$, वर्तमान टाइमस्टेप $t$, और रेंज स्पेस कंडीशन $\mathbf{c}$ को देखते हुए, यह नेटवर्क शोर घटक $\mathbf{\epsilon}$ की भविष्यवाणी करता है जिसे मूल छवि में जोड़ा गया था।
- $(\mathbf{\epsilon}_\theta(\mathbf{x}_t, t, \mathbf{c}) - \mathbf{\epsilon})$: यह पद शोर भविष्यवाणी में त्रुटि का प्रतिनिधित्व करता है। नेटवर्क अपनी भविष्यवाणी $\mathbf{\epsilon}_\theta$ को वास्तविक शोर $\mathbf{\epsilon}$ के जितना संभव हो उतना करीब बनाने की कोशिश कर रहा है।
- $A(\mathbf{\epsilon}_\theta(\mathbf{x}_t, t, \mathbf{c}) - \mathbf{\epsilon})$: यह हानि का सबसे महत्वपूर्ण हिस्सा है। अनुमानित और वास्तविक शोर के बीच अंतर को केवल कम करने के बजाय, लेखकों ने इस अंतर पर ट्रांसफर मैट्रिक्स $A$ लागू किया। यह सुनिश्चित करता है कि शोर भविष्यवाणी त्रुटि का प्रभाव, जब लेंसलेस कैमरे के फॉरवर्ड मॉडल के माध्यम से प्रोजेक्ट किया जाता है, तो कम से कम हो। अनिवार्य रूप से, यह जनरेटिव मॉडल को ऐसे शोर की भविष्यवाणी करने के लिए मजबूर करता है, यदि लेंसलेस कैमरे द्वारा "इमेज" किया गया हो, तो शून्य माप त्रुटि का परिणाम होगा। यह सीधे उस संगति आवश्यकता को लागू करता है कि उत्पन्न कोई भी विवरण (जो नल स्पेस से आते हैं) उस माप को नहीं बदलना चाहिए जो रेंज स्पेस सामग्री से प्राप्त होगा। यहां $A$ द्वारा गुणन का उपयोग, बजाय, उदाहरण के लिए, जोड़ के, त्रुटि को माप डोमेन में प्रोजेक्ट करने के लिए मौलिक है, जो भौतिक फॉरवर्ड मॉडल के साथ संरेखित होता है।
चरण-दर-चरण प्रवाह
PhoCoLens विधि एक चतुर दो-चरणीय पाइपलाइन में संचालित होती है, जो एक परिष्कृत असेंबली लाइन की तरह है, जहां प्रत्येक चरण विशिष्ट उद्देश्यों के साथ छवि पुनर्निर्माण को परिष्कृत करता है।
चरण 1: स्थानिक रूप से भिन्न डीकनवल्शन (SVDeconv) के साथ रेंज स्पेस पुनर्निर्माण
- प्रारंभिक माप इनपुट: प्रक्रिया एक कच्चे, धुंधले और शोर वाले लेंसलेस माप $\hat{y}$ के साथ शुरू होती है। यह प्रारंभिक अमूर्त डेटा बिंदु है, जो सेंसर द्वारा कैप्चर किया गया एक जटिल विवर्तन पैटर्न है।
- मल्टी-कर्नेल डीकनवल्शन: यह माप $\hat{y}$ SVDeconv नेटवर्क में प्रवेश करता है। यहां, यह सिर्फ एक डीकनवल्शन नहीं है, बल्कि कई हैं। नेटवर्क $K \times K$ सीखने योग्य पॉइंट स्प्रेड फ़ंक्शन (PSF) कर्नेल, $p^{(i)}$ का एक सेट बनाए रखता है, प्रत्येक छवि के एक अलग स्थानिक क्षेत्र के लिए विशेष है।
- माप $\hat{y}$ और प्रत्येक कर्नेल $p^{(i)}$ को पहले असतत फूरियर ट्रांसफॉर्म ($\mathcal{F}$) का उपयोग करके आवृत्ति डोमेन में परिवर्तित किया जाता है।
- आवृत्ति डोमेन में, परिवर्तित माप और प्रत्येक परिवर्तित कर्नेल के बीच एक तत्व-वार गुणन (हैडामार्ड उत्पाद $\odot$) किया जाता है। यह डीकनवल्शन का आवृत्ति-डोमेन समकक्ष है, जो प्रभावी रूप से उस विशेष क्षेत्र के लिए लेंसलेस सिस्टम के कारण होने वाले धुंधलापन को "पूर्ववत" करता है।
- प्रत्येक परिणाम को व्युत्क्रम असतत फूरियर ट्रांसफॉर्म ($\mathcal{F}^{-1}$) का उपयोग करके स्थानिक डोमेन में वापस परिवर्तित किया जाता है, जिससे $K \times K$ मध्यवर्ती डीकनवॉल्व्ड छवियां, $x^{(i)}_e$ प्राप्त होती हैं। प्रत्येक $x^{(i)}_e$ एक प्रारंभिक पुनर्निर्माण है, जो एक विशेष क्षेत्र बिंदु के लिए अनुकूलित है।
- स्थानिक रूप से भिन्न इंटरपोलेशन: इन $K \times K$ मध्यवर्ती छवियों को फिर सहज रूप से एक साथ जोड़ा जाता है। अंतिम आउटपुट में प्रत्येक पिक्सेल $(u, v)$ के लिए, सभी $x^{(i)}_e$ छवियों से संबंधित पिक्सेल का भारित योग गणना की जाती है। वजन $w_i(u, v)$ पिक्सेल $(u, v)$ से $i$-वें PSF कर्नेल के केंद्र तक व्युत्क्रम यूक्लिडियन दूरी से निर्धारित होते हैं। इसका मतलब है कि एक पिक्सेल का मान मुख्य रूप से उस डीकनवल्शन कर्नेल से प्रभावित होता है जो स्थानिक रूप से उसके सबसे करीब होता है, जिससे एक एकीकृत छवि $X_{int}$ बनती है जो PSF की स्थानिक रूप से भिन्न प्रकृति के अनुकूल होती है।
- रिफाइनमेंट U-Net: इंटरपोलेटेड छवि $X_{int}$ फिर एक U-Net से गुजरती है। यह तंत्रिका नेटवर्क किसी भी शेष शोर और कलाकृतियों को हटाने के लिए एक अंतिम सफाई दल के रूप में कार्य करता है, और छवि को रेंज स्पेस सामग्री, $\mathbf{c}$ का उत्पादन करने के लिए और परिष्कृत करता है। यह $\mathbf{c}$ दृश्य का एक सुसंगत, कम-आवृत्ति प्रतिनिधित्व है, जो अगले चरण के लिए तैयार है।
चरण 2: सशर्त डिफ्यूजन के साथ नल स्पेस सामग्री पुनर्प्राप्ति
- शोर वाली छवि निर्माण और कंडीशनिंग: चरण 1 से रेंज स्पेस सामग्री $\mathbf{c}$ का अब एक शर्त के रूप में उपयोग किया जाता है। साथ ही, एक ग्राउंड ट्रुथ छवि $\mathbf{x}$ को कई टाइमस्टेप $t$ पर यादृच्छिक शोर $\mathbf{\epsilon}$ जोड़कर उत्तरोत्तर दूषित किया जाता है, जिससे एक शोर वाली छवि $\mathbf{x}_t$ प्राप्त होती है।
- सशर्त शोर भविष्यवाणी: शोर वाली छवि $\mathbf{x}_t$, वर्तमान टाइमस्टेप $t$, और रेंज स्पेस कंडीशन $\mathbf{c}$ को एक सशर्त डिफ्यूजन मॉडल के शोर भविष्यवाणी नेटवर्क, $\mathbf{\epsilon}_\theta$ में फीड किया जाता है।
- शर्त $\mathbf{c}$ को केवल जोड़ा नहीं जाता है; इसे गहराई से एकीकृत किया जाता है। एक सशर्त एन्कोडर $\mathbf{c}$ से मल्टी-स्केल फीचर्स निकालता है, जो फिर $\mathbf{\epsilon}_\theta$ नेटवर्क के अवशिष्ट ब्लॉक के भीतर मध्यवर्ती फीचर मैप्स को संशोधित करता है। यह सुनिश्चित करता है कि जनरेटिव प्रक्रिया को कम-आवृत्ति जानकारी की सुसंगत जानकारी द्वारा कसकर निर्देशित किया जाए।
- नेटवर्क $\mathbf{\epsilon}_\theta$ इन इनपुट को संसाधित करता है और शोर $\mathbf{\epsilon}$ का अपना सबसे अच्छा अनुमान आउटपुट करता है जिसे $\mathbf{x}_t$ बनाने के लिए मूल रूप से जोड़ा गया था।
- संगति प्रवर्तन (हानि गणना): अनुमानित शोर $\mathbf{\epsilon}_\theta$ की तुलना वास्तविक शोर $\mathbf{\epsilon}$ से की जाती है। महत्वपूर्ण कदम उनके अंतर पर ट्रांसफर मैट्रिक्स $A$ लागू करना है, $A(\mathbf{\epsilon}_\theta - \mathbf{\epsilon})$। इसके परिणाम का वर्गित L2 मानदंड $\mathcal{L}_{null}$ हानि बनाता है। यह सुनिश्चित करता है कि अनुमानित और वास्तविक शोर के बीच कोई भी विसंगतियां, लेंसलेस कैमरे के फॉरवर्ड मॉडल के माध्यम से देखे जाने पर, कम से कम हों। संक्षेप में, यह जनरेटिव मॉडल को ऐसे शोर की भविष्यवाणी करने के लिए मजबूर करता है, यदि वे "इमेज" किए गए हों, तो शून्य माप त्रुटि का परिणाम होगा। यह सीधे उस संगति आवश्यकता को लागू करता है कि उत्पन्न विवरण (जो नल स्पेस से आते हैं) को माप को नहीं बदलना चाहिए जो रेंज स्पेस सामग्री से प्राप्त होगा।
- पुनरावृत्त डीनोइजिंग (अनुमान): अनुमान के दौरान, डिफ्यूजन मॉडल एक विशुद्ध रूप से यादृच्छिक शोर छवि के साथ शुरू होता है। कई टाइमस्टेप्स पर, यह उत्तरोत्तर शोर की भविष्यवाणी और घटाव करने के लिए सीखे गए $\mathbf{\epsilon}_\theta$ नेटवर्क का उपयोग करता है, धीरे-धीरे यादृच्छिक शोर को एक फोटोरियलिस्टिक छवि में बदलता है। प्रत्येक चरण में, रेंज स्पेस सामग्री $\mathbf{c}$ लगातार पीढ़ी का मार्गदर्शन करती है, यह सुनिश्चित करती है कि जोड़ी गई उच्च-आवृत्ति विवरण कम-आवृत्ति संरचना के अनुरूप हों, अंततः अंतिम, उच्च-गुणवत्ता वाली पुनर्निर्मित छवि का उत्पादन करती है।
अनुकूलन गतिशीलता
PhoCoLens प्रणाली दो-तरफा अनुकूलन रणनीति के माध्यम से सीखती है और अभिसरण करती है, प्रत्येक अपने संबंधित चरण के लिए तैयार की जाती है।
चरण 1: SVDeconv अनुकूलन
पहला चरण, SVDeconv, रेंज स्पेस सामग्री $A^\dagger A \mathbf{x}$ को पुनर्निर्मित करने के लिए प्रशिक्षित किया जाता है। इसके अनुकूलन में मल्टी-कर्नेल डीकनवल्शन और रिफाइनमेंट U-Net के मापदंडों को सीखना शामिल है।
- हानि फ़ंक्शन: SVDeconv के लिए प्रशिक्षण उद्देश्य माध्य वर्ग त्रुटि (MSE) हानि और LPIPS (सीखा हुआ अवधारणात्मक छवि पैच समानता) हानि का एक संयोजन है।
- MSE हानि: यह एक पिक्सेल-वार निष्ठा हानि है, जिसका लक्ष्य पुनर्निर्मित रेंज स्पेस सामग्री और ग्राउंड ट्रुथ रेंज स्पेस सामग्री के बीच वर्ग अंतर को कम करना है। यह सुनिश्चित करता है कि मॉडल कम-आवृत्ति जानकारी को सटीक रूप से पुनर्प्राप्त करता है।
- LPIPS हानि: यह एक अवधारणात्मक हानि है जो एक पूर्व-प्रशिक्षित डीप न्यूरल नेटवर्क द्वारा सीखी गई फीचर स्पेस में छवियों के बीच समानता को मापती है। यह सुनिश्चित करने के लिए महत्वपूर्ण है कि पुनर्निर्मित छवियां मानव पर्यवेक्षकों के लिए दृश्य रूप से मनभावन और यथार्थवादी दिखें, भले ही पिक्सेल मान पूरी तरह से मेल न खाते हों।
- ग्रेडिएंट व्यवहार: MSE और LPIPS दोनों हानियों से ग्रेडिएंट को रिफाइनमेंट U-Net और, महत्वपूर्ण रूप से, डिफरेंशिएबल मल्टी-कर्नेल डीकनवल्शन लेयर के माध्यम से बैकप्रोपैगेट किया जाता है। यह नेटवर्क को इष्टतम PSF कर्नेल $p^{(i)}$ सीखने की अनुमति देता है जो लेंसलेस इमेजिंग सिस्टम में स्थानिक विविधताओं के अनुकूल होते हैं। ग्रेडिएंट कर्नेल को स्थानिक रूप से भिन्न धुंधलापन को प्रभावी ढंग से "पूर्ववत" करने के लिए निर्देशित करते हैं।
- स्थिति अद्यतन: एडम ऑप्टिमाइज़र का उपयोग पुनरावृत्ति से PSF कर्नेल और U-Net मापदंडों को अद्यतन करने के लिए किया जाता है। सीखने की दरें (जैसे, PhlatCam डीकनवल्शन कर्नेल के लिए 4e-9, U-Net के लिए 3e-5) स्थिर और प्रभावी अभिसरण सुनिश्चित करने के लिए सावधानीपूर्वक चुनी जाती हैं। मॉडल डेटा-संचालित तरीके से स्थानिक PSF विविधताओं के अनुकूल होना सीखता है, जिससे थकाऊ मल्टी-लोकेशन PSF कैलिब्रेशन की आवश्यकता समाप्त हो जाती है।
चरण 2: नल स्पेस डिफ्यूजन अनुकूलन
दूसरा चरण, सशर्त डिफ्यूजन मॉडल, नल स्पेस सामग्री को पुनर्प्राप्त करने के लिए अनुकूलित किया जाता है, संगति बनाए रखते हुए फोटोरियलिस्टिक उच्च-आवृत्ति विवरण जोड़ता है।
- हानि फ़ंक्शन: इस चरण के लिए प्राथमिक हानि $\mathcal{L}_{null}$ है, जैसा कि मास्टर समीकरण द्वारा परिभाषित किया गया है। यह हानि अद्वितीय है क्योंकि यह शोर भविष्यवाणी त्रुटि पर ट्रांसफर मैट्रिक्स $A$ लागू करती है।
- हानि परिदृश्य आकार: त्रुटि पद $A(\mathbf{\epsilon}_\theta - \mathbf{\epsilon})$ पर $A$ के अनुप्रयोग से हानि परिदृश्य गहराई से आकार लेता है। यह एक ऐसा परिदृश्य बनाता है जहां न्यूनतम एक ऐसी स्थिति के अनुरूप होता है जहां उत्पन्न उच्च-आवृत्ति विवरण (अनुमानित शोर से प्राप्त) लेंसलेस कैमरे के फॉरवर्ड मॉडल के लिए "अदृश्य" होते हैं। दूसरे शब्दों में, डिफ्यूजन मॉडल द्वारा जोड़े गए किसी भी विवरण को नल स्पेस में स्थित होना चाहिए, जिसका अर्थ है कि वे माप $\mathbf{y}$ को $A$ के माध्यम से प्रोजेक्ट करने पर नहीं बदलते हैं। यह जनरेटिव मॉडल को ऐसे विवरणों का मतिभ्रम करने से रोकता है जो भौतिक बाधाओं का खंडन करते हैं, इस प्रकार डेटा संगति को लागू करता है।
- ग्रेडिएंट व्यवहार: ग्रेडिएंट की गणना $A$ ऑपरेटर सहित पूरे व्यंजक के माध्यम से की जाती है, और शोर भविष्यवाणी नेटवर्क $\mathbf{\epsilon}_\theta$ के माध्यम से बैकप्रोपैगेट की जाती है। ये ग्रेडिएंट $\mathbf{\epsilon}_\theta$ को ऐसे शोर की भविष्यवाणी करना सीखने के लिए निर्देशित करते हैं कि परिणामी पुनर्निर्मित छवि, फॉरवर्ड इमेजिंग मॉडल $A$ के माध्यम से पारित होने पर, कम-आवृत्ति रेंज स्पेस सामग्री $\mathbf{c}$ के अनुरूप बनी रहे। यह सुनिश्चित करने का एक परिष्कृत तरीका है कि जनरेटिव मॉडल का आउटपुट लेंसलेस सिस्टम की भौतिक बाधाओं के साथ संरेखित हो।
- स्थिति अद्यतन: डिफ्यूजन मॉडल को बड़ी संख्या में युगों (जैसे, 200 युगों) के लिए प्रशिक्षित किया जाता है। पेपर एक पूर्व-प्रशिक्षित डिफ्यूजन मॉडल (जैसे स्टेबल डिफ्यूजन) का लाभ उठाने का उल्लेख करता है जिसमें जमे हुए वजन होते हैं, और मुख्य रूप से पूरक कंडीशनिंग मॉड्यूल को प्रशिक्षित करता है। यह रणनीति मॉडल को बड़े पूर्व-प्रशिक्षित मॉडलों की शक्तिशाली जनरेटिव क्षमताओं का लाभ उठाने की अनुमति देती है, जबकि उन्हें लेंसलेस इमेजिंग के विशिष्ट कार्य और संगति आवश्यकताओं के अनुरूप ठीक-ठाक करती है। कंडीशनिंग तंत्र, जो $\mathbf{c}$ के आधार पर मध्यवर्ती फीचर मैप्स को संशोधित करता है, यह सुनिश्चित करने के लिए पुनरावृत्ति से अद्यतन किया जाता है कि उत्पन्न उच्च-आवृत्ति सामग्री पहले चरण द्वारा प्रदान की गई कम-आवृत्ति संरचना के सुसंगत हो। यह कंडीशनिंग का पुनरावृत्त शोधन सुनिश्चित करता है कि अंतिम आउटपुट फोटोरियलिस्टिक और सुसंगत दोनों हो।
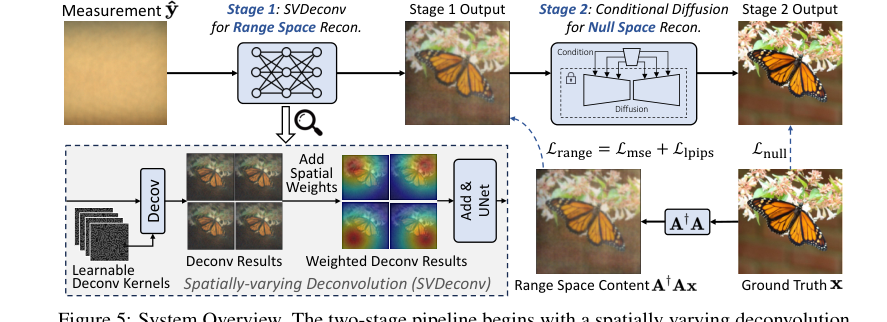 Figure 5. System Overview. The two-stage pipeline begins with a spatially varying deconvolution network mapping lensless measurements to range space. Then a conditional diffusion model for null space recovery refines details using the first stage output, achieving the final reconstruction
Figure 5. System Overview. The two-stage pipeline begins with a spatially varying deconvolution network mapping lensless measurements to range space. Then a conditional diffusion model for null space recovery refines details using the first stage output, achieving the final reconstruction
परिणाम, सीमाएँ और निष्कर्ष
प्रयोगात्मक डिजाइन और बेसलाइन
PhoCoLens को कठोरता से मान्य करने के लिए, लेखकों ने दो अलग-अलग वास्तविक दुनिया के लेंसलेस इमेजिंग डेटासेट पर अपने नवीन दो-चरणीय दृष्टिकोण को विभिन्न प्रकार के "पीड़ित" बेसलाइन मॉडल के खिलाफ खड़ा करते हुए एक व्यापक प्रयोगात्मक सेटअप तैयार किया।
प्रयोगों ने दो लोकप्रिय लेंसलेस कैमरा सिस्टम का लाभ उठाया:
- PhlatCam डेटासेट [17]: 1,000 वर्गों में 10,000 छवियों का संकलन, 384x384 पिक्सेल तक आकार बदला गया, 1280x1480 पिक्सेल पर कच्चे कैप्चर के साथ। प्रशिक्षण के लिए 990 वर्गों और परीक्षण के लिए 10 का विभाजन उपयोग किया गया था।
- DiffuserCam डेटासेट [27]: एक साथ कैप्चर की गई 25,000 युग्मित छवियों (लेंसलेस माप + ग्राउंड ट्रुथ) का संकलन। ये छवियां, मूल रूप से 1080x1920 पिक्सेल, को 270x480 तक डाउनसैंपल किया गया और फिर अंतिम रिज़ॉल्यूशन 210x380 पिक्सेल तक क्रॉप किया गया। डेटासेट को प्रशिक्षण के लिए 24,000 और परीक्षण के लिए 1,000 में विभाजित किया गया था।
अपने गणितीय दावों को निश्चित रूप से साबित करने के लिए, मूल्यांकन ने मेट्रिक्स के दोहरे सेट का उपयोग किया, जो संगति (निष्ठा) और फोटोरियलिज्म (दृश्य गुणवत्ता) दोनों का आकलन करते हैं:
- संगति के लिए पूर्ण-संदर्भ मेट्रिक्स: पीक सिग्नल-टू-नॉइज़ रेशियो (PSNR), स्ट्रक्चरल सिमिलैरिटी इंडेक्स मेजर (SSIM) [42], और लर्नड पर्सेप्चुअल इमेज पैच सिमिलैरिटी (LPIPS) [51]। कम LPIPS मान बेहतर निष्ठा का संकेत देते हैं।
- फोटोरियलिज्म के लिए गैर-संदर्भ मेट्रिक्स: मल्टी-डायमेंशन अटेंशन नेटवर्क फॉर नो-रेफरेंस इमेज क्वालिटी असेसमेंट (ManIQA) [45], क्लिप-आधारित इमेज क्वालिटी असेसमेंट (ClipIQA) [39], और मल्टी-स्केल इमेज क्वालिटी ट्रांसफार्मर (MUSIQ) [16]। इन मेट्रिक्स के लिए उच्च मान आम तौर पर बेहतर दृश्य गुणवत्ता का संकेत देते हैं।
पुनरुत्पादकता सुनिश्चित करने के लिए कार्यान्वयन विवरणों को सावधानीपूर्वक रेखांकित किया गया था। SVDeconv नेटवर्क ने 3x3 PSF कर्नेल का उपयोग किया, जिसे एक एकल कैलिब्रेटेड PSF के साथ इनिशियलाइज़ किया गया था, और एक U-Net को मौजूदा आर्किटेक्चर (DiffuserCam के लिए Le-ADMM-U, PhlatCam के लिए FlatNet-gen) से अनुकूलित किया गया था। प्रशिक्षण 100 युगों तक 5 के बैच आकार के साथ, एडम ऑप्टिमाइज़र [18] का उपयोग करके चला। U-Net और डीकनवल्शन कर्नेल के लिए विशिष्ट सीखने की दरें, साथ ही MSE और LPIPS हानि भार (क्रमशः 1 और 0.05) निर्धारित की गईं। नल-स्पेस डिफ्यूजन चरण के लिए, SVDeconv आउटपुट को इनपुट शर्तों के रूप में उपयोग किया गया था, और मॉडल को 200 युगों के लिए प्रशिक्षित किया गया था, एक पूर्व-प्रशिक्षित स्टेबल डिफ्यूजन [32] मॉडल का लाभ उठाते हुए जमे हुए वजन के साथ, केवल पूरक कंडीशनिंग मॉड्यूल को प्रशिक्षित करने पर ध्यान केंद्रित किया गया था।
जिन "पीड़ितों" (बेसलाइन मॉडल) की तुलना PhoCoLens से की गई थी, उनमें शामिल थे:
- पारंपरिक विधियाँ: WienerDeconv [44] (टिखोनोव नियमित पुनर्निर्माण) और ADMM [7] (कुल भिन्नता नियमितीकरण)।
- लर्निंग-आधारित विधियाँ: Le-ADMM-U [27] (डीप अनरोल्ड नेटवर्क), MMCN [49], UPDN [19] (अनरोल्ड प्राइमल-डुअल नेटवर्क), और FlatNet-gen [17] (फीडफॉरवर्ड डीकनवल्शन)।
- डिफ्यूजन-आधारित विधियाँ: DDNM+ [41] (पूर्व-प्रशिक्षित स्टेबल डिफ्यूजन के साथ जीरो-शॉट व्युत्क्रम इमेजिंग) और FlatNet+DiffBIR [23] (FlatNet-gen आउटपुट को पूर्व-प्रशिक्षित ब्लाइंड इमेज रेस्टोरेशन डिफ्यूजन मॉडल द्वारा बढ़ाया गया)।
इसके अलावा, लेखकों ने प्रत्येक मुख्य घटक के योगदान को क्रूरतापूर्वक साबित करने के लिए लक्षित एब्लेशन अध्ययन किए:
- स्थानिक रूप से भिन्न डीकनवल्शन (SVDeconv): रेंज स्पेस और मूल सामग्री पुनर्निर्माण दोनों के लिए Le-ADMM-U, SingleDeconv (एकल कर्नेल का उपयोग करके), और MultiWienerNet [48] की तुलना में।
- नल-स्पेस डिफ्यूजन: DiffBIR [23] और StableSR [39] जैसे सशर्त डिफ्यूजन मॉडल, और जीरो-शॉट व्युत्क्रम इमेजिंग विधि DDNM+ [41] की तुलना में।
- रेंज सामग्री की शर्तें: एक एब्लेशन जहां पहले चरण से पुनर्निर्मित रेंज सामग्री को दूसरे चरण के डिफ्यूजन को सशर्त करने के लिए WienerDeconv, FlatNet-gen, और SVD-OC (मूल सामग्री के साथ प्रशिक्षित SVDeconv) के आउटपुट से बदल दिया गया था।
साक्ष्य क्या साबित करते हैं
पेपर में प्रस्तुत साक्ष्य लेंसलेस इमेजिंग में फोटोरियलिज्म और संगति के बेहतर संतुलन को प्राप्त करने में PhoCoLens की श्रेष्ठता के निश्चित, निर्विवाद प्रमाण प्रदान करते हैं, जो सभी बेसलाइन से बेहतर प्रदर्शन करते हैं।
समग्र श्रेष्ठता:
तालिका 1 निर्विवाद रूप से PhoCoLens के प्रभुत्व को प्रदर्शित करती है। PhlatCam और DiffuserCam दोनों डेटासेट पर, हमारी विधि लगातार संगति के लिए लगभग सभी पूर्ण-संदर्भ मेट्रिक्स (PSNR, SSIM, LPIPS↓) और दृश्य गुणवत्ता के लिए गैर-संदर्भ मेट्रिक्स (ManIQA, ClipIQA, MUSIQ) में सर्वश्रेष्ठ प्रदर्शन प्राप्त करती है। उदाहरण के लिए, PhlatCam पर, PhoCoLens 22.07 का PSNR, 0.601 का SSIM, और 0.215 का LPIPS प्राप्त करता है, जो FlatNet-gen (PSNR 20.53, SSIM 0.549, LPIPS 0.375) और FlatNet+DiffBIR (PSNR 19.96, SSIM 0.544, LPIPS 0.391) जैसे अगले सर्वश्रेष्ठ तरीकों से काफी बेहतर है। यह मात्रात्मक साक्ष्य चित्र 1, 6 और 7 में गुणात्मक तुलनाओं द्वारा और मजबूत होता है, जहां PhoCoLens के पुनर्निर्माण दृश्य रूप से ग्राउंड ट्रुथ के सबसे करीब होते हैं, जिनमें तेज विवरण और सटीक सामग्री दोनों प्रदर्शित होती है।
स्थानिक रूप से भिन्न डीकनवल्शन (SVDeconv) की प्रभावकारिता:
पेपर के स्थानिक रूप से भिन्न डीकनवल्शन के महत्व के बारे में मुख्य दावे को तालिका 2 और चित्र 2, 8 और A3 द्वारा क्रूरतापूर्वक साबित किया गया है। तालिका 2 से पता चलता है कि SVDeconv (हमारा) लगातार अन्य डीकनवल्शन विधियों (Le-ADMM-U, SingleDeconv, MultiWienerNet) को रेंज स्पेस सामग्री और मूल सामग्री दोनों के पुनर्निर्माण में बेहतर प्रदर्शन करता है। उदाहरण के लिए, PhlatCam पर, SVDeconv 26.97 का रेंज स्पेस PSNR प्राप्त करता है, जो SingleDeconv के 25.61 से काफी अधिक है। यह महत्वपूर्ण है क्योंकि पारंपरिक विधियाँ, जैसे SingleDeconv, एक शिफ्ट-इनवेरिएंट PSF को मानती हैं, जो वास्तविक दुनिया के लेंसलेस सिस्टम में गलत है। चित्र 2 और 8 इसे दृश्य रूप से उजागर करते हैं, यह दिखाते हुए कि SVDeconv (दाएं) उन विधियों की तुलना में कहीं अधिक सटीकता के साथ महीन विवरणों को पुनर्निर्मित करता है जो एकल कर्नेल (बाएं) का उपयोग करते हैं। चित्र 4d में लाल बक्से और चित्र 8 में सफेद धराशायी बक्से स्पष्ट रूप से दर्शाते हैं कि हमारा SVDeconv तंत्र कलाकृतियों को प्रभावी ढंग से कैसे कम करता है और परिधीय क्षेत्रों में विवरणों को संरक्षित करता है, जहां PSF भिन्नताएं सबसे अधिक स्पष्ट होती हैं। चित्र A3 आगे इस बात को पुष्ट करता है कि SVDeconv के आउटपुट ग्राउंड ट्रुथ की कम-आवृत्ति संरचना के साथ उच्च दृश्य संगति बनाए रखते हैं, इसके विपरीत फ्लैटनेट, जो गलत उच्च-आवृत्ति विवरण पेश करता है।
नल-स्पेस डिफ्यूजन के लिए निश्चित प्रमाण:
संगति बनाए रखते हुए फोटोरियलिज्म के लिए हमारे नल-स्पेस डिफ्यूजन की प्रभावशीलता निर्विवाद रूप से तालिका 3 और चित्र 9 में प्रदर्शित की गई है। हमारी विधि PhlatCam पर नल स्पेस रिकवरी के लिए उच्चतम PSNR (22.07), SSIM (0.601), और सबसे कम LPIPS (0.215) प्राप्त करती है, जो अन्य डिफ्यूजन-आधारित दृष्टिकोणों जैसे DiffBIR (PSNR 16.21, SSIM 0.432, LPIPS 0.502) और StableSR (PSNR 14.93, SSIM 0.446, LPIPS 0.624) से काफी बेहतर है। गुणात्मक रूप से, चित्र 9 दिखाता है कि हमारी विधि ऐसी छवियां उत्पन्न करती है जो मूल दृश्य के प्रति यथार्थवादी और वफादार दोनों हैं, जबकि प्रतिस्पर्धी जैसे DiffBIR कलाकृतियों को पेश कर सकते हैं या सामग्री को विकृत कर सकते हैं (जैसे, चित्र 1d में "गलत आकार" की चोंच, या चित्र 7 में कपड़ों में स्थानांतरित मानव हाथ)। यह साबित करता है कि पहले चरण से कम-आवृत्ति सामग्री पर डिफ्यूजन मॉडल को सशर्त करना, निष्ठा का त्याग किए बिना यथार्थवादी उच्च-आवृत्ति विवरण पुनर्निर्मित करने के लिए इसे प्रभावी ढंग से निर्देशित करता है।
रेंज सामग्री की शर्तों का प्रभाव:
रेंज सामग्री की शर्तों पर एब्लेशन अध्ययन, तालिका 4 और चित्र 10 में संक्षेपित, हमारे पहले चरण के आउटपुट को एक शर्त के रूप में उपयोग करने के महत्व के लिए सम्मोहक साक्ष्य प्रदान करता है। जब हमारे पुनर्निर्मित रेंज सामग्री का उपयोग डिफ्यूजन मॉडल को सशर्त करने के लिए किया जाता है, तो यह लगातार बेसलाइन जैसे WienerDeconv या FlatNet-gen से आउटपुट का उपयोग करने की तुलना में बेहतर पुनर्निर्माण संगति (उच्च PSNR, SSIM, कम LPIPS) की ओर ले जाता है। ऐसा इसलिए है क्योंकि ये वैकल्पिक शर्तें कलाकृतियों को पेश करती हैं जो दूसरे चरण की मूल छवि को सटीक रूप से पुनर्प्राप्त करने की क्षमता में बाधा डालती हैं। चित्र 10 में दृश्य सुधार इस बात पर जोर देते हैं कि हमारे दो-चरणीय पाइपलाइन, इसके सावधानीपूर्वक चुने गए कंडीशनिंग के साथ, देखे गए बेहतर प्रदर्शन को प्राप्त करने के लिए महत्वपूर्ण है।
सीमाएँ और भविष्य की दिशाएँ
जबकि PhoCoLens लेंसलेस इमेजिंग में एक महत्वपूर्ण प्रगति का प्रतीक है, इसकी वर्तमान सीमाओं को स्वीकार करना और भविष्य के विकास के लिए भविष्य के रास्तों पर विचार करना महत्वपूर्ण है।
हमारे दृष्टिकोण की एक प्राथमिक सीमा इसकी वास्तविक समय प्रयोज्यता है। दो-चरणीय वास्तुकला, विशेष रूप से दूसरे चरण में डिफ्यूजन मॉडल की नमूना प्रक्रिया, एक कम्प्यूटेशनल ओवरहेड पेश करती है जो वर्तमान में इसे वास्तविक समय फोटो और वीडियो कैप्चर परिदृश्यों में उपयोग करने में बाधा डालती है। यह उच्च-गुणवत्ता वाले जनरेटिव मॉडल के साथ एक सामान्य चुनौती है, और इसे संबोधित करने से लेंसलेस कैमरों के लिए बहुत व्यापक अनुप्रयोगों को अनलॉक किया जाएगा।
इसके अतिरिक्त, बेहतर निष्ठा प्राप्त करने के बावजूद, डिफ्यूजन मॉडल, अपनी जनरेटिव प्रकृति के कारण, अभी भी उच्च-आवृत्ति विवरण पेश कर सकता है जो मूल दृश्य से थोड़ा विचलित होते हैं, विशेष रूप से उन क्षेत्रों में जो स्वाभाविक रूप से चिकने होते हैं या जिनमें जटिल बनावट की कमी होती है। जबकि यह दृश्य गुणवत्ता में वृद्धि के लिए फोटोरियलिज्म के बीच एक व्यापार-बंद है, यह बताता है कि जनरेटिव रचनात्मकता और सख्त डेटा निष्ठा के बीच संतुलन को परिष्कृत करने के लिए अभी भी जगह है।
आगे देखते हुए, कई रोमांचक दिशाएँ इन निष्कर्षों को और विकसित कर सकती हैं:
- डिफ्यूजन मॉडल नमूनाकरण में तेजी लाना: एक महत्वपूर्ण भविष्य की दिशा डिफ्यूजन मॉडल के नमूनाकरण प्रक्रिया को महत्वपूर्ण रूप से तेज करने के लिए तकनीकों पर शोध और कार्यान्वयन करना है। इसमें तेज नमूनाकरण एल्गोरिदम, आसवन तकनीकों, या हार्डवेयर-जागरूक अनुकूलन की खोज शामिल हो सकती है। वास्तविक समय प्रदर्शन प्राप्त करने से लेंसलेस कैमरों को गतिशील दृश्यों के लिए व्यवहार्य समाधानों में बदल दिया जाएगा, जिससे स्वायत्त नेविगेशन, निगरानी और इंटरैक्टिव इमेजिंग जैसे क्षेत्रों में अनुप्रयोग सक्षम होंगे।
- 3D स्थानिक रूप से भिन्न PSF प्रभावों की खोज: वर्तमान कार्य मुख्य रूप से 2D छवि पुनर्निर्माण पर केंद्रित है। हालांकि, लेंसलेस कैमरे स्वाभाविक रूप से अपने जटिल विवर्तन पैटर्न के भीतर एन्कोड की गई 3D दृश्य जानकारी कैप्चर करते हैं। भविष्य का काम 2D फोटोरियलिस्टिक छवियों के साथ-साथ गहराई मानचित्र या पूर्ण 3D दृश्य अभ्यावेदन के पुनर्निर्माण के लिए 3D स्थानिक रूप से भिन्न पॉइंट स्प्रेड फ़ंक्शन (PSFs) को मॉडल करने और उनका लाभ उठाने में तल्लीन हो सकता है। यह अल्ट्रा-कॉम्पैक्ट उपकरणों के साथ उपन्यास 3D इमेजिंग अनुप्रयोगों के द्वार खोलेगा, जैसे कि वॉल्यूमेट्रिक माइक्रोस्कोपी या संवर्धित वास्तविकता।
- अनुकूली संगति-फोटोरियलिज्म व्यापार-बंद: वर्तमान विधि संगति और फोटोरियलिज्म के बीच एक निश्चित संतुलन बनाती है। भविष्य का शोध गतिशील या उपयोगकर्ता-नियंत्रित तंत्रों का पता लगा सकता है ताकि इस व्यापार-बंद को समायोजित किया जा सके। उदाहरण के लिए, चिकित्सा इमेजिंग में, सख्त संगति सर्वोपरि हो सकती है, जबकि कलात्मक अनुप्रयोगों के लिए, अधिक फोटोरियलिज्म (यहां तक कि मामूली विचलन के साथ) को प्राथमिकता दी जा सकती है। एक ऐसे ढांचे का विकास जो अनुकूली भार को निष्ठा और जनरेटिव प्रायर में समायोजित करने की अनुमति देता है, उपयोगकर्ता की जरूरतों और अनुप्रयोग डोमेन की एक विस्तृत श्रृंखला को पूरा कर सकता है।
- विविध इमेजिंग स्थितियों के प्रति मजबूती: दो लोकप्रिय लेंसलेस सिस्टम पर परीक्षण किए जाने के बावजूद, चरम या उपन्यास इमेजिंग स्थितियों (जैसे, बहुत कम रोशनी, अत्यधिक गतिशील दृश्य, विभिन्न मास्क डिजाइन) के तहत प्रदर्शन की आगे जांच की जा सकती है। मॉडल की मजबूती और सामान्यीकरण क्षमताओं को लेंसलेस कैमरा डिजाइनों और पर्यावरणीय कारकों के व्यापक स्पेक्ट्रम तक बढ़ाना एक मूल्यवान योगदान होगा।
- नैतिक विचार और गोपनीयता-संरक्षण डिजाइन: जैसा कि व्यापक प्रभावों वाले अनुभाग में उजागर किया गया है, छोटे, विवेकपूर्ण लेंसलेस कैमरों के प्रसार से महत्वपूर्ण गोपनीयता चिंताएं पैदा होती हैं। भविष्य के शोध में न केवल तकनीकी सुधारों पर ध्यान केंद्रित करना चाहिए, बल्कि इमेजिंग और पुनर्निर्माण पाइपलाइन में सीधे गोपनीयता-संरक्षण तंत्र को एकीकृत करना भी शामिल होना चाहिए। इसमें ऑन-डिवाइस प्रोसेसिंग की खोज शामिल हो सकती है ताकि डेटा ट्रांसमिशन को कम किया जा सके, विभेदक गोपनीयता तकनीकों, या लेंसलेस सिस्टम को डिजाइन करना जो स्वाभाविक रूप से व्यक्तिगत गोपनीयता अधिकारों की रक्षा के लिए कैप्चर की गई जानकारी के दायरे को सीमित करते हैं। यह क्रॉस-अनुशासनात्मक प्रयास, जिसमें इंजीनियर, नैतिकतावादी और नीति निर्माता शामिल हैं, जिम्मेदार तकनीकी प्रगति सुनिश्चित करने के लिए आवश्यक है।
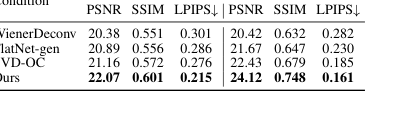 Table 2. Comparison of deconvolution methods for range space reconstruction and original content reconstruction
Table 2. Comparison of deconvolution methods for range space reconstruction and original content reconstruction
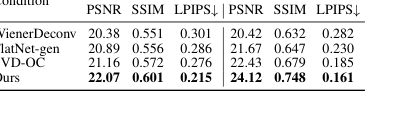 Table 4. Comparison of different diffusion conditions
Table 4. Comparison of different diffusion conditions
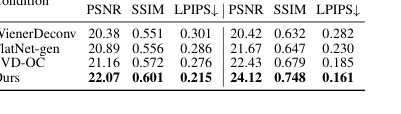 Table 3. Comparison of null space recovery methods
Table 3. Comparison of null space recovery methods