PhoCoLens: 렌즈리스 이미징에서 사실적이고 일관된 복원
New AI reconstructs stunning images from simple sensors, overcoming past limitations.
배경 및 학술적 계보
기원 및 학술적 계보
렌즈리스 이미징 복원 문제는 초소형, 경량 및 비용 효율적인 카메라를 만들고자 하는 열망에서 정확하게 비롯되었습니다. 기존의 렌즈 기반 시스템은 부피가 크고 비싸서 의료 내시경이나 웨어러블 기술과 같이 소형화가 요구되는 분야에서의 응용을 제한합니다. 역사적 맥락을 보면, 연구자들은 센서 가까이에 진폭 또는 위상 마스크를 배치하여 들어오는 빛을 변조함으로써 기존 렌즈를 대체하기 시작했고, 이는 카메라 크기와 무게를 크게 줄였습니다. 이 혁신은 유망했지만 새로운 과제를 안겨주었습니다. 초점 렌즈가 없으면 원시 센서 측정값은 일반적으로 흐릿하고 인식할 수 없습니다. 카메라는 장면을 직접 기록하는 것이 아니라 복잡한 회절 패턴으로 인코딩하며, 이를 통해 고품질의 원본 장면 이미지를 복구하기 위한 정교한 계산 알고리즘이 필요합니다.
저자들이 이 논문을 작성하게 된 이전 접근 방식의 근본적인 한계 또는 "고충점"은 재구성된 이미지에서 사실성과 일관성을 모두 달성하는 것과 이미징 프로세스를 정확하게 모델링하는 것의 두 가지 주요 문제에서 비롯됩니다. 현재 알고리즘은 종종 부정확한 순방향 이미징 모델과 고품질 이미지를 복원하기 위한 불충분한 사전 지식으로 어려움을 겪습니다. 구체적으로:
- 낮은 시각적 품질 및 누락된 세부 정보: WienerDeconv와 같은 전통적인 방법은 ground truth와 일관된 이미지를 복원할 수 있지만 시각적 품질이 크게 저하되고 종종 풍부한 세부 정보가 부족하다는 문제가 있습니다. FlatNet-gen과 같은 학습 기반 접근 방식은 시각적 품질을 향상시키려고 시도하지만 고주파 세부 정보를 복구하는 데 자주 실패합니다.
- 생성적 사전 지식과의 일관성 부족: 생성적 복원 알고리즘(예: DiffBIR)은 풍부한 세부 정보를 주입하고 사실성을 향상시킬 수 있지만 종종 일관성을 희생합니다. 이러한 방법은 이미지 내용을 변경하거나 존재하지 않는 객체를 삽입하여 원본 장면과 다른 재구성을 초래할 수 있습니다(예: 잘못된 모양의 새 부리 또는 가짜처럼 보이는 잎).
- 부정확한 이미징 모델 (공간적으로 변하는 PSF): 대부분의 기존 복원 알고리즘은 이동 불변(shift-invariant) PSF(Point Spread Function)를 가정하여 렌즈리스 이미징 프로세스를 단순화합니다. 그러나 실제로는 특히 입사각이 증가하는 시야(FoV)의 주변부에서 PSF가 공간적으로 변합니다. 가정된 이미징 모델과 실제 이미징 모델 간의 이러한 불일치는 부정확성과 원본 장면에 대한 재구성된 유사성의 눈에 띄는 감소로 이어지며, 특히 주변 영역에서 그렇습니다. 이는 렌즈리스 마스크와 센서 간의 거리가 매우 작을 때(예: 일반적인 렌즈리스 카메라에서 2mm) 종종 발생하는 프레넬 근사(Fresnel approximation)가 이동 불변 컨볼루션으로의 빛 전파 모델을 단순화하기 때문에 발생합니다. 이 중요한 한계는 단일 디컨볼루션 커널이 이미지 전체에 걸쳐 블러링을 정확하게 되돌릴 수 없음을 의미합니다.
직관적인 도메인 용어
- 렌즈리스 이미징: 전통적인 유리 렌즈가 없는 카메라로 사진을 찍으려고 상상해 보세요. 센서 앞에 작은 패턴 창("마스크")만 있습니다. 빛은 이 창을 통과하면서 독특한 방식으로 섞입니다. 렌즈리스 이미징은 영리한 컴퓨터 프로그램을 사용하여 그 빛을 "섞어" 초점을 맞추는 렌즈가 사용되지 않았음에도 불구하고 선명한 사진을 복원하는 것입니다.
- 점 확산 함수 (PSF): 장면에 있는 단일의 작은 점의 빛을 생각해보세요. 이 점의 빛이 렌즈리스 카메라의 마스크를 통과하여 센서에 도달하면 완벽한 점으로 유지되지 않고 특정, 종종 흐릿한 패턴으로 퍼집니다. PSF는 카메라 시스템에 의해 단일 점의 빛이 어떻게 흐릿해지거나 인코딩되는지에 대한 고유한 "지문"과 같습니다. 각 점의 빛이 센서에 "퍼지는" 방식을 정확하게 알려줍니다.
- 공간적으로 변하는 디컨볼루션: "블러링 지문"(PSF)이 장면의 빛이 오는 위치에 따라 달라진다면(예: 장면 중앙에서 오는 빛은 가장자리에서 오는 빛과 다르게 흐릿해짐), 단순한 "블러 제거" 도구는 모든 곳에서 완벽하게 작동하지 않습니다. 공간적으로 변하는 디컨볼루션은 이미지의 다른 부분에 대해 자동으로 기술을 조정하여 전체 보기에서 더 선명하고 정확한 사진을 얻기 위해 각 특정 영역에 올바른 "블러 제거" 방법을 적용하는 스마트한 "블러 제거" 프로세스를 갖는 것과 같습니다.
- 범위-영공간 분해 (Range-Null Space Decomposition): 매우 흐릿한 사진을 상상해보세요. 이 수학적 트릭은 흐릿한 사진을 두 부분으로 분리하는 데 도움이 됩니다. "범위 공간" 부분에는 카메라가 흐릿하더라도 안정적으로 포착할 수 있었던 모든 기본, 저해상도 정보(일반적인 모양과 색상 등)가 포함됩니다. "영공간" 부분은 블러링 중에 완전히 손실되어 흐릿한 측정값에서 직접 복구할 수 없는 모든 미세한 세부 정보와 질감을 나타냅니다. 과제는 첫 번째 부분을 정확하게 복원한 다음 두 번째 부분을 아무것도 만들어내지 않고 사실적인 세부 정보로 지능적으로 "채우는" 것입니다.
- 생성적 사전 지식 (확산 모델에서): 거친 스케치에서 사실적인 이미지를 만드는 데 매우 능숙한 예술가를 상상해보세요. 확산 모델의 "생성적 사전 지식"은 그 예술가와 같습니다. 기본, 저해상도 정보(범위 공간 내용)가 주어지면 누락된 고주파, 사실적인 세부 정보(영공간 내용)를 실제 이미지처럼 자연스럽고 일관되게 보이도록 "상상하고" 다시 추가할 수 있어 최종 이미지가 훨씬 더 시각적으로 매력적입니다.
표기법 표
| 표기법 | 설명 |
|---|---|
| $\hat{y}$ | 렌즈리스 카메라로 캡처한 원시, 다중화된 측정값. |
| $x$ | 알고리즘이 복원을 목표로 하는 원본 장면 이미지. |
| $A$ | 순방향 이미징 모델을 나타내는 렌즈리스 이미징 시스템의 전달 행렬. |
| $n$ | 센서 노이즈. |
| $A^\dagger$ | 전달 행렬 $A$의 유사 역행렬. |
| $A^\dagger A x$ | 이미지 $x$의 범위 공간 구성 요소, 측정값에서 직접 복구 가능한 정보(저주파 콘텐츠)를 나타냄. |
| $(I - A^\dagger A)x$ | 이미지 $x$의 영공간 구성 요소, 이미징 중에 손실된 정보(고주파 세부 정보)를 나타냄. |
| $I$ | 항등 행렬. |
| $h$ | 렌즈리스 시스템의 점 확산 함수(PSF). |
| $*$ | 컨볼루션 연산자. |
| $p^{(i)}$ | SVDeconv 네트워크의 $i$번째 학습 가능한 점 확산 함수(PSF) 커널. |
| $\mathcal{F}$ | 이산 푸리에 변환(DFT). |
| $\mathcal{F}^{-1}$ | 역 이산 푸리에 변환(IDFT). |
| $\odot$ | 하다마드 곱(요소별 곱셈). |
| $x^{(i)}_e$ | 다중 커널 디컨볼루션에서 $i$번째 중간 디컨볼루션된 이미지. |
| $X_{int}$ | 중간 디컨볼루션된 이미지에서 공간적으로 보간된 이미지. |
| $w_i(u, v)$ | 역 유클리드 거리를 기반으로 한 $i$번째 디컨볼루션된 이미지에 대한 픽셀 $(u, v)$에서의 가중치. |
| $\mathbf{c}$ | 범위 공간 콘텐츠, 첫 번째 SVDeconv 단계의 출력으로 확산 모델의 조건으로 사용됨. |
| $\mathbf{x}_t$ | 확산 프로세스의 타임스텝 $t$에서의 노이즈 이미지. |
| $\mathbf{\epsilon}$ | 표준 정규 분포에서 샘플링된 실제 노이즈 벡터. |
| $\mathbf{\epsilon}_\theta(\mathbf{x}_t, t, \mathbf{c})$ | 조건부 확산 모델의 노이즈 예측 네트워크(매개변수 $\theta$). |
| $\theta$ | 노이즈 예측 네트워크의 학습 가능한 매개변수. |
| $\mathcal{L}_{null}$ | 영공간 복원 단계의 손실 함수, 측정 공간에서 일관성 강제. |
| $\mathbb{E}$ | 기대값 연산자. |
| $t$ | 확산 프로세스의 타임스텝. |
| $\mathcal{N}(0,1)$ | 표준 정규 분포. |
| $\| \cdot \|^2$ | 제곱 L2 노름. |
| $\mathcal{L}_{MSE}$ | 평균 제곱 오차 손실. |
| $\mathcal{L}_{LPIPS}$ | 학습된 지각 이미지 패치 유사도 손실. |
문제 정의 및 제약 조건
핵심 문제 공식화 및 딜레마
이 논문에서 다루는 근본적인 문제는 렌즈리스 카메라 측정값으로부터 사실적이고 일관된 이미지를 복원하는 것입니다.
입력/현재 상태:
시작점은 렌즈리스 카메라로 캡처한 원시, 다중화된 측정값 $\hat{y} \in \mathbb{R}^{N^2}$입니다. 이 측정값은 일반적으로 흐릿하고 인식할 수 없으며 고주파 세부 정보가 부족합니다. 수학적으로 렌즈리스 이미징 프로세스는 센서 노이즈 $n$이 추가된 원본 장면 $x \in \mathbb{R}^{M^2}$의 선형 변환으로 공식화될 수 있습니다.
$$ \hat{y} = Ax + n $$
여기서 $A \in \mathbb{R}^{N^2 \times M^2}$는 렌즈리스 이미징 시스템의 전달 행렬로, 장면의 각 지점에서 오는 빛이 각 센서 픽셀에 어떻게 기여하는지를 인코딩합니다. 이전 방법들은 종종 이 복잡한 프로세스를 단일 이동 불변 PSF(Point Spread Function)와의 컨볼루션으로 단순화합니다. 즉, $y = h * x$입니다.
원하는 최종 상태 (출력/목표 상태):
원하는 최종 상태는 사실적이고 원본 장면과 일관된 재구성된 이미지 $x$입니다.
* 사실성은 풍부하고 자연스러운 세부 정보를 갖춘 고품질 이미지를 의미하며, 렌즈리스 캡처 중에 손실된 고주파 콘텐츠를 효과적으로 복구합니다.
* 일관성은 재구성된 이미지의 내용이 원본 장면과 정확하게 일치해야 함을 의미하며, $Ax = y$ (여기서 $y$는 노이즈가 없는 측정값) 조건을 만족합니다.
누락된 연결 또는 수학적 격차:
정확히 누락된 연결은 렌즈리스 이미징 프로세스(A로 표시됨)의 복잡하고 공간적으로 변하는 특성을 정확하게 모델링하고 저주파(일관성 중요) 및 고주파(사실성 중요) 구성 요소를 저하된 측정값에서 효과적으로 복구하는 능력입니다. 이 논문은 이 격차를 해소하기 위해 범위-영공간 분해를 활용합니다. 모든 장면 $x$는 두 개의 직교 구성 요소로 분해될 수 있습니다.
$$ x = A^\dagger Ax + (I - A^\dagger A)x $$
여기서 $A^\dagger Ax$는 범위 공간 구성 요소(측정값에서 직접 복구 가능한 저주파 콘텐츠, 일관성 보장)이고 $(I - A^\dagger A)x$는 영공간 구성 요소(이미징 중에 손실된 고주파 세부 정보, 사실성에 중요)입니다. 이 논문은 먼저 범위 공간 콘텐츠를 정확하게 복원한 다음, 일관성을 유지하면서 생성적 사전 지식을 사용하여 영공간 콘텐츠를 풍부하게 하는 것을 목표로 합니다.
딜레마 (고통스러운 절충):
이전 연구자들을 가두었던 핵심 딜레마는 높은 시각적 품질(사실성) 달성과 데이터 일관성(원본 장면에 대한 충실도) 유지 사이의 고통스러운 절충입니다.
* 전통적인 복원 알고리즘(예: WienerDeconv)은 데이터 일관성을 우선시하여 ground truth와 일치하는 이미지를 생성하지만 종종 흐릿하고 시각적 품질이 크게 저하되며 미세한 세부 정보가 부족합니다. 이들은 고주파 정보를 복구하지 못합니다.
* 생성적 복원 알고리즘(예: 확산 모델을 사용하는 DiffBIR)은 풍부하고 사실적인 세부 정보를 주입하고 시각적 품질을 크게 향상시킬 수 있습니다. 그러나 이들은 종종 "이미지 내용을 변경하거나 존재하지 않는 객체를 삽입"하여 실제 장면과의 일관성을 깨뜨립니다. 예를 들어, 잘못된 모양이나 가짜 질감을 생성할 수 있으며, 이는 그림 1d에 표시됩니다.
이 딜레마는 한 측면(예: 사실성)을 개선하면 일반적으로 다른 측면(일관성)이 손상된다는 것을 의미하며, 기존 방법으로는 둘을 동시에 달성하기가 매우 어렵습니다.
제약 조건 및 실패 모드
사실적이고 일관된 렌즈리스 이미지 복원 문제는 몇 가지 가혹하고 현실적인 제약 조건과 이전 접근 방식의 일반적인 실패 모드로 인해 매우 어렵습니다.
-
공간적으로 변하는 점 확산 함수 (PSF):
- 물리적 제약: 전통적인 렌즈 기반 카메라와 달리 렌즈리스 시스템은 전체 시야(FoV)에 걸쳐 고정된 이동 불변 PSF를 갖지 않습니다. PSF는 입사광의 각도에 따라 크게 변하며, 특히 주변부에서 그렇습니다.
- 계산적 제약: 대부분의 기존 복원 알고리즘은 이동 불변 PSF를 가정하여 이미징 프로세스를 단순화하는데, 이는 부정확합니다. 실제 공간적으로 변하는 PSF를 모델링하는 것은 전체 전달 행렬 $A$가 실제 시스템에 대해 직접 "계산하기에 너무 크기" 때문에 계산 집약적입니다. 이 단순화는 특히 경계 영역에서 재구성된 이미지에 눈에 띄는 저하와 아티팩트를 초래하며, 이는 그림 4d에 표시됩니다.
-
고주파 정보 손실:
- 물리적 제약: 빛이 마스크에 의해 변조되는 렌즈리스 인코딩 프로세스는 저역 통과 필터 역할을 합니다. 이는 본질적으로 장면에서 고주파 세부 정보를 크게 손실시켜 원시 측정값을 흐릿하고 모호하게 만듭니다.
- 데이터 기반 제약: 이러한 손실된 고주파 세부 정보( "영공간" 콘텐츠)를 복구하려면 강력한 사전 지식이 필요합니다. 충분하고 정확한 사전 지식 없이는 알고리즘이 사실적인 이미지를 복원하는 데 어려움을 겪으며, 종종 시각적으로 저하된 출력을 초래하거나, 생성 모델이 무분별하게 사용되는 경우 충실도를 깨뜨리는 존재하지 않는 세부 정보를 환각합니다.
-
공간적으로 변하는 디컨볼루션의 계산 복잡성:
- 계산적 제약: 공간적으로 변하는 디컨볼루션이 정확한 복원에 필요하지만, 이 분야의 이전 방법들은 "종종 느리고 계산 집약적이며, 특히 복잡한 시스템에서 낮은 이미지 품질을 초래합니다."
- 보정 부담: 많은 다중 커널 디컨볼루션 접근 방식은 "지루한 다중 위치 PSF 보정"을 요구하며, 이는 시간이 많이 걸리고 노동 집약적인 프로세스이므로 광범위한 사용에 비실용적입니다. 이 논문은 단일 초기 PSF에서 변형을 자동으로 학습하여 이를 극복하는 것을 목표로 합니다.
-
생성적 사전 지식으로 데이터 충실도 유지:
- 논리적 제약: 생성 모델은 세부 정보를 환각하는 데 강력하지만 본질적으로 새로운 정보를 생성하는 방식으로 작동합니다. 주요 실패 모드는 "이미지 내용을 변경하거나 존재하지 않는 객체를 삽입"하여 재구성된 이미지가 실제 측정값과 일치해야 한다는 근본적인 일관성 요구 사항을 위반하는 경향이 있다는 것입니다. 과제는 이러한 생성 모델을 안내하여 기본 데이터와 일관된 사실적인 세부 정보를 생성하도록 하는 것입니다.
-
실시간 지연 (향후 제약):
- 계산적 제약: 이 논문에서 직접 해결된 제약 조건은 아니지만, 저자들은 "PhoCoLens의 2단계 특성과 확산 모델의 샘플링 시간이 실시간 적용 가능성을 방해한다"는 점을 인정합니다. 이는 실시간 비디오 또는 임상 이미징과 같이 즉각적인 피드백이 필요한 응용 프로그램의 경우 제안된 방법의 현재 계산 오버헤드가 상당한 장애물을 제시한다는 것을 의미합니다.
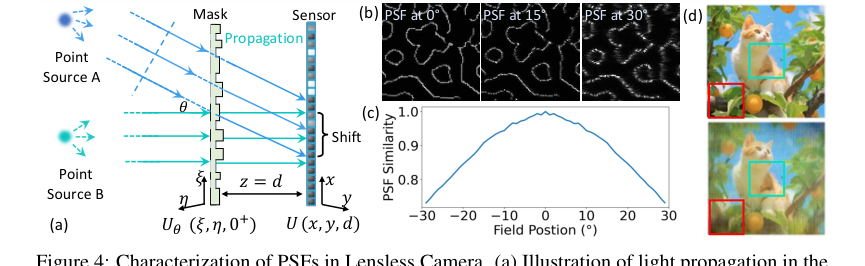 Figure 4. Characterization of PSFs in Lensless Camera. (a) Illustration of light propagation in the lensless camera: two point sources A and B at infinity emitting parallel light beams. Source A emits at angle θ relative to the optical axis, causing a PSF shift on the sensor plane This PSF shift depends on both the incident angle θ and the distance d between the sensor and the mask. (b) Simulated PSFs for light sources at angles of 0°, 15°, and 30°. (c) Inner product similarity between the on-axis PSF and off-axis PSFs at different field positions. (d) Reconstruction using PSF at 0°, degradation is more significant at the periphery (red box) than the center (green box)
Figure 4. Characterization of PSFs in Lensless Camera. (a) Illustration of light propagation in the lensless camera: two point sources A and B at infinity emitting parallel light beams. Source A emits at angle θ relative to the optical axis, causing a PSF shift on the sensor plane This PSF shift depends on both the incident angle θ and the distance d between the sensor and the mask. (b) Simulated PSFs for light sources at angles of 0°, 15°, and 30°. (c) Inner product similarity between the on-axis PSF and off-axis PSFs at different field positions. (d) Reconstruction using PSF at 0°, degradation is more significant at the periphery (red box) than the center (green box)
왜 이 접근 방식인가
선택의 불가피성
PhoCoLens의 저자들은 렌즈리스 이미징에서 근본적인 딜레마에 직면했습니다. 즉, 높은 시각적 품질(사실성)과 원본 장면에 대한 충실한 표현(일관성)을 모두 달성하는 방법입니다. 전통적인 최첨단(SOTA) 방법, 예를 들어 WienerDeconv와 같은 표준 디컨볼루션 기술은 사실성에 필요한 풍부한 세부 정보가 부족하여 시각적 품질이 크게 저하된 이미지를 생성했기 때문에 불충분하다고 판단되었습니다(그림 1b). FlatNet-gen과 같은 학습 기반 접근 방식은 시각적 품질을 향상시켰지만, 여전히 중요한 고주파 세부 정보를 복구하는 데 어려움을 겪어 덜 선명하고 덜 사실적인 이미지를 초래했습니다(그림 1c).
전통적인 방법이 불충분하다는 결정적인 깨달음은 DiffBIR와 같은 고급 생성 모델조차도 사실적인 세부 정보를 주입하는 데 탁월하지만 종종 일관성을 희생한다는 점을 저자들이 관찰했을 때 나왔습니다. 이러한 모델은 종종 잘못된 모양의 부리나 가짜처럼 보이는 잎과 같은 이미지 내용을 변경하거나 존재하지 않는 객체를 도입하여(그림 1d) ground truth에 대한 충실도를 깨뜨렸습니다. 이는 순전히 생성적인 접근 방식이 시각적으로 매력적이지만 정확성이 중요한 응용 프로그램의 경우 실행 가능한 유일한 솔루션이 아니라는 것을 나타냅니다.
더욱이, 기존 복원 알고리즘에서 확인된 중요한 한계는 렌즈리스 이미징 프로세스의 단순화였습니다. 대부분의 방법은 이동 불변 PSF를 가정하여 이미징을 단순한 컨볼루션으로 취급했습니다. 그러나 저자들은 실제 렌즈리스 시스템에서 PSF가 본질적으로 공간적으로 변하며, 특히 다른 입사각에서 그렇다는 것을 인식했습니다(그림 4a, 4b, 4c). 가정된 이동 불변 PSF와 실제 공간적으로 변하는 PSF 간의 이러한 불일치는 상당한 부정확성을 초래했으며, 특히 주변 시야에서 재구성된 유사성이 눈에 띄게 감소하여(그림 4d) 재구성된 유사성이 원래 장면에 떨어졌습니다. 이 근본적인 물리적 현실은 전통적인 컨볼루션 모델이 전체 시야에 걸쳐 정확한 렌즈리스 복원에 본질적으로 부적합하게 만들었습니다.
비교 우위
PhoCoLens는 렌즈리스 이미징의 핵심 과제를 구조적으로 해결하는 독창적인 2단계 아키텍처를 통해 질적 및 양적 우수성을 달성합니다. 핵심 구조적 이점은 범위-영공간 분해 프레임워크에 있습니다. 이 이론적 기반을 통해 방법은 문제를 두 개의 직교 구성 요소로 분리할 수 있습니다. 하나는 데이터 일관성(범위 공간)에 초점을 맞추고 다른 하나는 사실성(영공간)에 초점을 맞춥니다. 이는 둘 다 동시에 해결하려고 시도하여 종종 절충을 초래했던 이전 방법들에 비해 심오한 이점입니다.
- 범위 공간을 위한 공간적으로 변하는 디컨볼루션 (SVDeconv): 단일 이동 불변 PSF를 가정하는 이전 방법과 달리 SVDeconv는 데이터 기반 방식으로 카메라 시야에 걸쳐 PSF의 공간적 변화에 적응하도록 학습합니다. 이는 복잡한 순방향 이미징 프로세스를 더 정확하게 모델링하기 때문에 중요한 구조적 개선입니다. 이는 특히 다른 방법이 실패하는 이미지 주변부에서 구조적 무결성과 저주파 세부 정보의 우수한 복원을 초래합니다(그림 2, 그림 4d). 표 2는 SVDeconv가 다른 디컨볼루션 방법에 비해 범위 공간 복원에서 우수한 성능을 정량적으로 보여줍니다.
- 사실성을 위한 조건부 영공간 확산: 두 번째 단계는 사전 훈련된 확산 모델을 활용하지만, 결정적으로 이 생성 프로세스를 첫 번째 단계에서 복원된 저주파 콘텐츠에 조건화합니다. 이를 통해 고주파 세부 정보가 사실성을 향상시키더라도 범위 공간 복원에서 확립된 기본 구조와 일관성을 유지합니다. 이 접근 방식은 그림 1d에 표시된 것처럼 아티팩트를 도입하거나 콘텐츠를 변경하는 순수 생성 모델(DiffBIR와 같은)의 함정을 피합니다. 조건화 메커니즘은 시각적 품질을 향상시키면서 충실도를 유지하는 구조적 안전 장치입니다.
정량적으로 PhoCoLens는 압도적인 우수성을 보여줍니다. 표 1에 표시된 것처럼 PhlatCam 및 DiffuserCam 데이터셋 모두에서 충실도 메트릭(PSNR, SSIM, LPIPS)과 시각적 품질 메트릭(ManIQA, ClipIQA, MUSIQ) 간의 최상의 균형을 일관되게 달성합니다. 예를 들어, PhlatCam에서 PhoCoLens는 MUSIQ 점수 62.20을 달성하여 FlatNet+DiffBIR의 57.13보다 훨씬 높으며, LPIPS(0.215 대 0.391)도 더 좋습니다. 이는 단순히 약간 더 나은 것이 아니라 내재된 한계를 해결하여 이전의 금본위제를 능가하도록 구조적으로 설계된 방법임을 나타냅니다.
제약 조건과의 정렬
PhoCoLens의 선택된 2단계 접근 방식은 렌즈리스 이미징에서 사실성과 일관성을 모두 달성하고 기본 물리적 문제를 해결하는 이중 제약 조건과 완벽하게 일치합니다.
- 일관성을 위한 공간적으로 변하는 PSF 처리: 렌즈리스 PSF의 공간적으로 변하는 특성에도 불구하고 전체 시야에 걸쳐 정확한 복원을 요구하는 이 문제의 가혹한 요구 사항은 첫 번째 단계의 SVDeconv에 의해 직접 충족됩니다. 이러한 공간적 변화를 학습하고 적응함으로써 SVDeconv는 저주파 콘텐츠(범위 공간)가 높은 충실도와 구조적 무결성으로 복원되도록 보장하여 최종 이미지에 대한 일관된 기반을 마련합니다. 이것은 문제의 물리적 현실과 해결책의 적응형 디컨볼루션 속성 간의 직접적인 "결합"입니다.
- 사실성을 위한 생성적 사전 지식 활용 및 일관성 유지: 렌즈리스 캡처에서 종종 손실되는 풍부한 고주파 세부 정보를 요구하는 사실성 요구 사항은 두 번째 단계의 영공간 확산 모델에 의해 해결됩니다. 그러나 여기서 중요한 정렬은 생성 능력이 어떻게 활용되는가입니다. 단순히 세부 정보를 생성하는 대신, 확산 모델은 첫 번째 단계에서 복원된 저주파 출력에 조건화됩니다. 이를 통해 추가된 고주파 세부 정보(영공간에서 오는)가 일관성을 위반하지 않고 사실성을 향상시킵니다. 범위-영공간 분해의 수학적 프레임워크는 명시적으로 영공간 구성 요소가 추가될 때 측정값 $y$를 변경하지 않음을 보장하여 일관성을 보존합니다($A(x - A^\dagger Ax) = 0$). 이것은 생성 능력이 일관성 요구 사항에 의해 제약되는 완벽한 정렬입니다.
- 불충분한 사전 지식 극복: 전통적인 방법에서 시각적 품질 저하를 초래했던 불충분한 사전 지식 문제는 강력한 사전 훈련된 확산 모델을 통합하여 극복됩니다. 이 모델은 사실적인 이미지 질감에 대한 강력한 생성적 사전 지식을 제공하지만, 영공간 프레임워크 내에서의 적용은 임의적인 환각을 피하면서 실제 장면 데이터에 의해 안내되도록 보장합니다.
대안의 거부
이 논문은 이중 목표인 사실성과 일관성을 충족하는 데 있어 내재된 한계를 기반으로 여러 대안 접근 방식을 명시적으로 또는 암묵적으로 거부합니다.
- 전통적인 디컨볼루션 (예: WienerDeconv): 이러한 방법은 주로 사실적인 결과를 생성하지 못했기 때문에 거부되었습니다. 일부 데이터 일관성을 유지하지만 시각적 품질이 "크게 저하되어"(섹션 1, 그림 1b) 고품질 이미지 복원에는 부적합합니다.
- 학습 기반 디컨볼루션 (예: FlatNet-gen): 전통적인 방법보다 개선되었지만, 이러한 접근 방식은 "종종 고주파 세부 정보를 복구하는 데 실패하는 것"(섹션 1, 그림 1c)으로 밝혀졌습니다. 이 한계는 원하는 수준의 사실성을 달성할 수 없음을 의미하여 선명도와 미세 질감의 부족으로 이어졌습니다.
- 직접 사전 지식을 갖춘 생성 모델 (예: DiffBIR): 이러한 방법은 풍부한 세부 정보를 주입하고 시각적 품질을 향상시키는 데 탁월하지만, "이미지 내용을 변경하거나 존재하지 않는 객체를 삽입하여 일관성을 깰 수 있기 때문에"(섹션 1, 그림 1d) 거부되었습니다. 저자들은 왜곡된 객체(예: 잘못된 모양의 부리)와 가짜 질감의 명확한 예를 제공하여 사실성이 충실도에 대한 용납할 수 없는 비용으로 온다는 것을 보여줍니다.
- 이동 불변 PSF를 가정하는 방법: 주요 암묵적 거부는 이동 불변 PSF를 가정하여 렌즈리스 이미징 프로세스를 단순화하는 모든 방법에 대한 것입니다. 섹션 3.2에 자세히 설명되어 있고 그림 4d에 설명된 바와 같이 이 가정은 "부정확성"과 "주변 시야에서 원래 장면과의 재구성된 유사성의 눈에 띄는 감소"로 이어집니다. PhoCoLens의 SVDeconv 단계는 이 근본적인 결함을 극복하기 위해 특별히 설계되었으므로 실제 렌즈리스 시스템에 대해 이동 불변 접근 방식을 본질적으로 열등하게 만듭니다.
- 제로샷 확산 모델 (예: DDNM+): 확산 모델을 사용한 역 이미징의 범주로 언급되지만, 이 논문의 접근 방식은 "범위-영공간 분해에 기반한 이론적 프레임워크와 함께 지도 미세 조정을 통합합니다"(섹션 2). 이는 이 특정 문제에 대한 제로샷 방법이 분해 프레임워크 내에서의 지도 학습이 제공하는 세밀한 제어 또는 일관성 보장을 제공하지 못할 수 있기 때문에 순수 제로샷 방법을 거부함을 시사합니다. 표 3은 DDNM+가 영공간 복원에서 충실도 및 시각적 품질 메트릭 모두에서 PhoCoLens보다 훨씬 낮은 성능을 보여줍니다.
 Figure 1. We introduce PhoCoLens, a lensless reconstruction algorithm that achieves both better visual quality and consistency to the ground truth than existing methods. Our method recovers more details compared to traditional reconstruction algorithms (b) and (c), and also maintains better fidelity to the ground truth compared to the generative approach (d)
Figure 1. We introduce PhoCoLens, a lensless reconstruction algorithm that achieves both better visual quality and consistency to the ground truth than existing methods. Our method recovers more details compared to traditional reconstruction algorithms (b) and (c), and also maintains better fidelity to the ground truth compared to the generative approach (d)
수학적 및 논리적 메커니즘
마스터 방정식
이 논문을 구동하는 핵심 수학적 엔진, 특히 두 번째 단계에서 사실성과 일관성을 달성하기 위한 것은 영공간 확산 모델의 최적화 목표입니다. 이 방정식은 확산 모델이 생성한 고주파 세부 정보가 렌즈리스 이미징 시스템의 기본 물리학과 일관되도록 보장합니다. 공식적으로 다음과 같이 표현됩니다.
$$ \min_\theta \mathcal{L}_{null} = \min_\theta \mathbb{E}_{\mathbf{x},t,\mathbf{c},\mathbf{\epsilon} \sim \mathcal{N}(0,1)} \left[ \left\| A(\mathbf{\epsilon}_\theta(\mathbf{x}_t, t, \mathbf{c}) - \mathbf{\epsilon}) \right\|^2 \right] $$
이 방정식은 모든 이미지 $\mathbf{x}$가 범위 공간 구성 요소 $A^\dagger A \mathbf{x}$(카메라로 직접 관찰 가능한 정보를 나타냄)와 영공간 구성 요소 $(I - A^\dagger A) \mathbf{x}$(이미징 중에 손실되었지만 사실성에 중요한 세부 정보를 나타냄)로 분해될 수 있다고 가정하는 범위-영공간 분해의 기본 원리에서 파생됩니다. 여기서 목표는 생성 모델이 추가한 잔여 콘텐츠가 이상적으로 영공간에 속하더라도 순방향 이미징 모델과의 일관성을 위반하지 않도록 보장하는 것입니다.
용어별 분석
이 방정식을 조각별로 분석하여 그 역할과 중요성을 이해해 보겠습니다.
- $\min_\theta$: 이것은 표준 최소화 연산자로, 목표는 신경망에 대한 최적의 매개변수 세트 $\theta$를 찾는 것임을 나타냅니다.
- $\theta$: 이것은 노이즈 예측 네트워크 $\mathbf{\epsilon}_\theta$의 학습 가능한 매개변수입니다. 이 네트워크는 일반적으로 U-Net인 딥러닝 모델로, 노이즈 이미지를 예측하는 방법을 학습합니다.
- $\mathcal{L}_{null}$: 이 기호는 영공간 복원 단계를 위해 특별히 설계된 손실 함수를 나타냅니다. 이를 최소화하면 확산 모델이 일관되고 사실적인 세부 정보를 생성하도록 안내됩니다.
- $\mathbb{E}_{\mathbf{x},t,\mathbf{c},\mathbf{\epsilon} \sim \mathcal{N}(0,1)}$: 이것은 기대값 연산자를 의미하며, 여러 무작위 샘플에 대한 손실을 평균화한다는 것을 의미합니다.
- $\mathbf{x}$: 모델이 복원을 목표로 하는 ground truth, 깨끗한 이미지입니다. 이상적인 대상입니다.
- $t$: 이것은 순방향 확산 프로세스의 타임스텝을 나타내며, 이미지에 얼마나 많은 노이즈가 추가되었는지를 나타냅니다. 확산 모델은 점진적으로 노이즈를 추가한 다음 이 프로세스를 되돌리는 방법을 학습하는 방식으로 작동합니다.
- $\mathbf{c}$: 이것은 확산 모델의 조건으로, 특히 첫 번째 단계에서 복원된 범위 공간 콘텐츠 $A^\dagger A \mathbf{x}$입니다. 생성 모델이 준수해야 하는 저주파, 일관된 정보를 제공합니다.
- $\mathbf{\epsilon} \sim \mathcal{N}(0,1)$: 이것은 표준 정규 분포에서 샘플링된 실제 노이즈 벡터로, 깨끗한 이미지 $\mathbf{x}$에 추가되어 노이즈 이미지 $\mathbf{x}_t$를 생성합니다.
- $\| \cdot \|^2$: 이것은 회귀 작업에서 손실 함수로 일반적으로 선택되는 제곱 L2 노름입니다. 두 벡터 간의 제곱 유클리드 거리를 측정하며, 더 큰 오류에 더 큰 페널티를 부과합니다. 저자들은 이것이 예측된 노이즈와 실제 노이즈 간의 차이를 정량화하는 간단하고 효과적인 방법이기 때문에 이를 선택했습니다.
- $A$: 이것은 렌즈리스 이미징 시스템의 전달 행렬입니다. 장면 $\mathbf{x}$가 카메라에 의해 측정값 $\mathbf{y}$로 어떻게 변환되는지(즉, $\mathbf{y} = A\mathbf{x}$) 수학적으로 설명합니다. 여기서의 역할은 중요합니다. 노이즈 예측 오류를 측정 공간으로 투영합니다.
- $\mathbf{\epsilon}_\theta(\mathbf{x}_t, t, \mathbf{c})$: 이것은 $\theta$로 매개변수화된 신경망의 출력입니다. 노이즈 이미지 $\mathbf{x}_t$, 현재 타임스텝 $t$, 범위 공간 조건 $\mathbf{c}$가 주어지면 이 네트워크는 원본 이미지에 추가된 노이즈 구성 요소 $\mathbf{\epsilon}$을 예측합니다.
- $(\mathbf{\epsilon}_\theta(\mathbf{x}_t, t, \mathbf{c}) - \mathbf{\epsilon})$: 이 항은 노이즈 예측의 오류를 나타냅니다. 네트워크는 예측 $\mathbf{\epsilon}_\theta$를 실제 노이즈 $\mathbf{\epsilon}$에 최대한 가깝게 만들려고 합니다.
- $A(\mathbf{\epsilon}_\theta(\mathbf{x}_t, t, \mathbf{c}) - \mathbf{\epsilon})$: 이것은 손실의 가장 중요한 부분입니다. 예측된 노이즈와 실제 노이즈 간의 차이를 단순히 최소화하는 대신, 저자들은 전달 행렬 $A$를 이 차이에 적용합니다. 이를 통해 노이즈 예측 오류의 효과가 측정 공간으로 투영될 때 최소화되도록 보장합니다. 본질적으로, 이는 생성 모델이 예측하는 노이즈가 렌즈리스 카메라로 "이미징"될 때 측정 오류가 0이 되도록 강제합니다. 이는 생성된 세부 정보(영공간에서 오는)가 범위 공간 콘텐츠에서 얻을 수 있는 측정값을 변경해서는 안 된다는 일관성 요구 사항을 직접적으로 강제합니다. 여기서 $A$를 곱하는 사용은, 예를 들어 덧셈 대신, 측정 도메인으로 오류를 투영하는 데 기본이며 물리적 순방향 모델과 일치합니다.
단계별 흐름
PhoCoLens 방법은 각 단계가 특정 목표를 가지고 이미지 복원을 정교하게 개선하는 정교한 조립 라인과 유사한 영리한 2단계 파이프라인에서 작동합니다.
1단계: 공간적으로 변하는 디컨볼루션(SVDeconv)을 사용한 범위 공간 복원
- 초기 측정 입력: 프로세스는 원시, 흐릿하고 노이즈가 많은 렌즈리스 측정값 $\hat{y}$으로 시작됩니다. 이것은 센서에 의해 캡처된 복잡한 회절 패턴인 초기 추상 데이터 포인트입니다.
- 다중 커널 디컨볼루션: 이 측정값 $\hat{y}$는 SVDeconv 네트워크로 들어갑니다. 여기서 단일 디컨볼루션이 아니라 여러 번 수행됩니다. 네트워크는 이미지의 다른 공간 영역에 특화된 $K \times K$개의 학습 가능한 점 확산 함수(PSF) 커널 $p^{(i)}$ 세트를 유지합니다.
- 측정값 $\hat{y}$와 각 커널 $p^{(i)}$는 먼저 이산 푸리에 변환($\mathcal{F}$)을 사용하여 주파수 도메인으로 변환됩니다.
- 주파수 도메인에서 각 변환된 커널에 대해 변환된 측정값과 요소별 곱셈(하다마드 곱 $\odot$)이 수행됩니다. 이것은 해당 영역에 대한 렌즈리스 시스템에 의한 블러링을 "되돌리는" 주파수 도메인에 해당하는 디컨볼루션입니다.
- 각 결과는 역 이산 푸리에 변환($\mathcal{F}^{-1}$)을 사용하여 공간 도메인으로 다시 변환되어 $K \times K$개의 중간 디컨볼루션된 이미지 $x^{(i)}_e$를 생성합니다. 각 $x^{(i)}_e$는 특정 필드 지점에 최적화된 예비 복원입니다.
- 공간적으로 변하는 보간: 이 $K \times K$개의 중간 이미지는 비어 있지 않게 결합됩니다. 최종 출력의 각 픽셀 $(u, v)$에 대해 모든 $x^{(i)}_e$ 이미지의 해당 픽셀에 대한 가중치 합이 계산됩니다. 가중치 $w_i(u, v)$는 픽셀 $(u, v)$와 $i$번째 PSF 커널의 중심 사이의 역 유클리드 거리에 의해 결정됩니다. 이는 픽셀의 값이 공간적으로 가장 가까운 디컨볼루션 커널의 디컨볼루션에 주로 영향을 받는다는 것을 의미하며, PSF의 공간적으로 변하는 특성에 적응하는 통합 이미지를 생성합니다.
- 정제 U-Net: 보간된 이미지 $X_{int}$는 U-Net을 통과합니다. 이 신경망은 나머지 노이즈와 아티팩트를 제거하고 이미지를 추가로 정제하여 범위 공간 콘텐츠 $\mathbf{c}$를 생성하는 최종 정리 작업 역할을 합니다. 이 $\mathbf{c}$는 장면의 일관되고 저주파 표현으로, 다음 단계를 위한 준비가 되었습니다.
2단계: 조건부 확산을 사용한 영공간 콘텐츠 복구
- 노이즈 이미지 생성 및 조건화: 1단계의 범위 공간 콘텐츠 $\mathbf{c}$가 이제 조건으로 사용됩니다. 동시에 ground truth 이미지 $\mathbf{x}$는 여러 타임스텝 $t$에 걸쳐 무작위 노이즈 $\mathbf{\epsilon}$을 추가하여 점진적으로 손상되어 노이즈 이미지 $\mathbf{x}_t$를 생성합니다.
- 조건부 노이즈 예측: 노이즈 이미지 $\mathbf{x}_t$, 현재 타임스텝 $t$, 범위 공간 조건 $\mathbf{c}$는 조건부 확산 모델의 노이즈 예측 네트워크 $\mathbf{\epsilon}_\theta$에 공급됩니다.
- 조건 $\mathbf{c}$는 단순히 연결되는 것이 아니라 깊숙이 통합됩니다. 조건부 인코더는 $\mathbf{c}$에서 다중 스케일 특징을 추출하고, 이는 $\mathbf{\epsilon}_\theta$ 네트워크의 잔여 블록 내의 중간 특징 맵을 변조합니다. 이를 통해 생성 프로세스가 일관된 저주파 정보에 의해 엄격하게 안내됩니다.
- 네트워크 $\mathbf{\epsilon}_\theta$는 이러한 입력을 처리하고 $\mathbf{x}_t$를 생성하기 위해 원래 추가된 노이즈 $\mathbf{\epsilon}$에 대한 최상의 추측을 출력합니다.
- 일관성 강제 (손실 계산): 예측된 노이즈 $\mathbf{\epsilon}_\theta$는 실제 노이즈 $\mathbf{\epsilon}$과 비교됩니다. 중요한 단계는 차이에 전달 행렬 $A$를 적용하는 것입니다. $A(\mathbf{\epsilon}_\theta - \mathbf{\epsilon})$의 결과의 제곱 L2 노름이 $\mathcal{L}_{null}$ 손실을 형성합니다. 이를 통해 생성된 고주파 세부 정보가 렌즈리스 카메라의 순방향 모델을 통해 볼 때 측정 오류가 0이 되도록 보장합니다. 이는 본질적으로 생성 모델이 영공간에 속해야 하는 세부 정보를 예측하도록 하여, 범위 공간 콘텐츠에서 얻을 수 있는 측정값을 변경하지 않도록 하여 일관성 요구 사항을 보장합니다.
- 반복적 노이즈 제거 (추론): 추론 중에 확산 모델은 순전히 무작위 노이즈 이미지로 시작합니다. 여러 타임스텝에 걸쳐 학습된 $\mathbf{\epsilon}_\theta$ 네트워크를 사용하여 반복적으로 노이즈를 예측하고 제거하여 무작위 노이즈를 점진적으로 사실적인 이미지로 변환합니다. 각 단계에서 범위 공간 콘텐츠 $\mathbf{c}$는 생성을 지속적으로 안내하여 추가된 고주파 세부 정보가 저주파 구조와 일관되도록 보장하여 궁극적으로 최종 고품질 재구성 이미지를 생성합니다.
최적화 역학
PhoCoLens 시스템은 각각 해당 단계에 맞춰진 2개의 최적화 전략을 통해 학습하고 수렴합니다.
1단계: SVDeconv 최적화
첫 번째 단계인 SVDeconv는 범위 공간 콘텐츠 $A^\dagger A \mathbf{x}$를 복원하도록 훈련됩니다. 최적화에는 다중 커널 디컨볼루션 및 정제 U-Net의 매개변수 학습이 포함됩니다.
- 손실 함수: SVDeconv의 훈련 목표는 평균 제곱 오차(MSE) 손실과 LPIPS(Learned Perceptual Image Patch Similarity) 손실의 조합입니다.
- MSE 손실: 이것은 픽셀 단위 충실도 손실로, 재구성된 범위 공간 콘텐츠와 ground truth 범위 공간 콘텐츠 간의 제곱 차이를 최소화하는 것을 목표로 합니다. 이는 저주파 정보를 정확하게 복구하도록 보장합니다.
- LPIPS 손실: 이것은 사전 훈련된 딥 신경망에 의해 학습된 특징 공간에서 이미지 간의 유사성을 측정하는 지각 손실입니다. 픽셀 값이 완벽하게 일치하지 않더라도 재구성된 이미지가 인간 관찰자에게 시각적으로 매력적이고 사실적으로 보이도록 하는 데 중요합니다.
- 기울기 동작: MSE 및 LPIPS 손실 모두에서 기울기가 정제 U-Net과 중요하게도 미분 가능한 다중 커널 디컨볼루션 레이어를 통해 역전파됩니다. 이를 통해 네트워크는 렌즈리스 이미징 시스템의 공간적 변화에 가장 잘 적응하는 최적의 PSF 커널 $p^{(i)}$를 학습할 수 있습니다. 기울기는 커널이 공간적으로 변하는 블러를 효과적으로 "되돌리도록" 안내합니다.
- 상태 업데이트: Adam 옵티마이저를 사용하여 학습 가능한 PSF 커널과 U-Net 매개변수를 반복적으로 업데이트합니다. 학습률은 안정적이고 효과적인 수렴을 보장하기 위해 신중하게 선택됩니다(예: PhlatCam 디컨볼루션 커널의 경우 4e-9, U-Net의 경우 3e-5). 모델은 지루한 다중 위치 PSF 보정의 필요성을 제거하고 데이터 기반 방식으로 공간적 PSF 변화에 자동으로 적응하도록 학습합니다.
2단계: 영공간 확산 최적화
두 번째 단계인 조건부 확산 모델은 영공간 콘텐츠를 복구하여 일관성을 유지하면서 사실적인 고주파 세부 정보를 추가하도록 최적화됩니다.
- 손실 함수: 이 단계의 주요 손실은 마스터 방정식에 정의된 $\mathcal{L}_{null}$입니다. 이 손실은 전달 행렬 $A$를 노이즈 예측 오류에 적용하기 때문에 고유합니다.
- 손실 지형 형성: 오류 항 $A(\mathbf{\epsilon}_\theta - \mathbf{\epsilon})$에 $A$를 적용하는 것은 손실 지형을 심오하게 형성합니다. 이는 최소값이 생성된 고주파 세부 정보(예측된 노이즈에서 파생됨)가 렌즈리스 카메라의 순방향 모델에 "보이지 않는" 상태에 해당하는 지형을 만듭니다. 즉, 확산 모델이 추가한 모든 세부 정보는 $A$를 통해 투영될 때 측정값 $\mathbf{y}$를 변경하지 않는 영공간에 속해야 합니다. 이는 생성 모델이 물리적 측정값과 모순되는 세부 정보를 환각하는 것을 방지하여 데이터 일관성을 강제합니다.
- 기울기 동작: 기울기는 $A$ 연산자를 포함한 전체 표현을 통해 계산되고 노이즈 예측 네트워크 $\mathbf{\epsilon}_\theta$를 통해 역전파됩니다. 이러한 기울기는 예측된 노이즈가 결과 재구성 이미지가 순방향 이미징 모델 $A$를 통과할 때 저주파 범위 공간 콘텐츠 $\mathbf{c}$와 일관되도록 노이즈를 예측하도록 $\mathbf{\epsilon}_\theta$를 안내합니다. 이것은 생성 모델의 출력이 렌즈리스 시스템의 물리적 제약 조건과 일치하도록 보장하는 정교한 방법입니다.
- 상태 업데이트: 확산 모델은 상당한 에포크 수(예: 200 에포크) 동안 훈련됩니다. 이 논문은 사전 훈련된 확산 모델(Stable Diffusion과 같은)을 가중치를 고정하여 사용하고 보조 조건화 모듈만 훈련하는 데 중점을 둔다고 언급합니다. 이 전략을 통해 모델은 강력한 사전 훈련된 모델의 강력한 생성 기능을 활용하면서 렌즈리스 이미징의 특정 작업 및 일관성 요구 사항에 맞게 미세 조정할 수 있습니다. $\mathbf{c}$를 기반으로 내부 특징 맵을 변조하는 조건화 메커니즘은 생성된 고주파 콘텐츠가 첫 번째 단계에서 제공된 저주파 구조와 일관되도록 반복적으로 업데이트됩니다. 조건화의 이러한 반복적 개선은 최종 출력이 사실적이고 일관되도록 보장합니다.
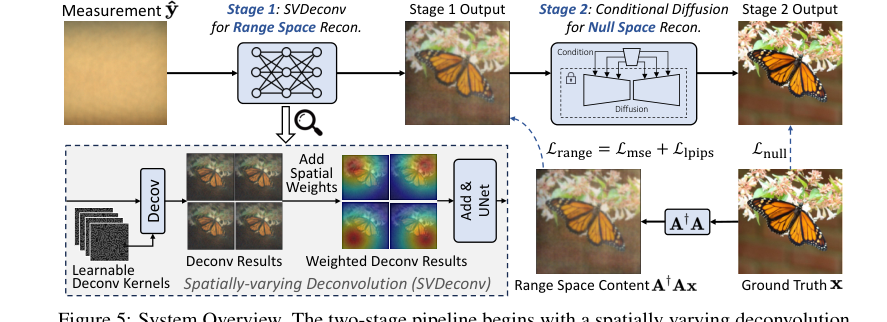 Figure 5. System Overview. The two-stage pipeline begins with a spatially varying deconvolution network mapping lensless measurements to range space. Then a conditional diffusion model for null space recovery refines details using the first stage output, achieving the final reconstruction
Figure 5. System Overview. The two-stage pipeline begins with a spatially varying deconvolution network mapping lensless measurements to range space. Then a conditional diffusion model for null space recovery refines details using the first stage output, achieving the final reconstruction
결과, 한계 및 결론
실험 설계 및 기준선
PhoCoLens를 엄격하게 검증하기 위해 저자들은 두 개의 서로 다른 실제 렌즈리스 이미징 데이터셋에서 새로운 2단계 접근 방식을 다양한 "피해자" 기준선 모델과 비교하는 포괄적인 실험 설계를 구성했습니다.
실험은 두 가지 인기 있는 렌즈리스 카메라 시스템을 활용했습니다.
- PhlatCam 데이터셋 [17]: 1,000개 클래스에 걸쳐 10,000개의 이미지를 포함하며, 384x384 픽셀로 크기가 조정되고 원시 캡처는 1280x1480 픽셀입니다. 훈련을 위해 990개 클래스, 테스트를 위해 10개 클래스의 분할이 사용되었습니다.
- DiffuserCam 데이터셋 [27]: 동시에 캡처된 25,000개의 쌍 이미지(렌즈리스 측정값 + ground truth)로 구성됩니다. 원래 1080x1920 픽셀이었던 이 이미지들은 270x480으로 다운샘플링된 후 최종 해상도 210x380 픽셀로 잘렸습니다. 데이터셋은 훈련용 24,000개, 테스트용 1,000개로 분할되었습니다.
수학적 주장을 확실하게 증명하기 위해 평가는 일관성(충실도)과 사실성(시각적 품질)을 모두 평가하는 두 가지 메트릭 세트를 사용했습니다.
- 일관성을 위한 전체 참조 메트릭: 피크 신호 대 잡음비(PSNR), 구조적 유사성 지수 측정(SSIM) [42], 학습된 지각 이미지 패치 유사도(LPIPS) [51]. 낮은 LPIPS 값은 더 나은 충실도를 나타냅니다.
- 사실성을 위한 비 참조 메트릭: 다차원 주의 네트워크를 사용한 비참조 이미지 품질 평가(ManIQA) [45], CLIP 기반 이미지 품질 평가(ClipIQA) [39], 다중 스케일 이미지 품질 트랜스포머(MUSIQ) [16]. 이러한 메트릭의 높은 값은 일반적으로 더 나은 시각적 품질을 나타냅니다.
구현 세부 사항은 재현성을 보장하기 위해 세심하게 설명되었습니다. SVDeconv 네트워크는 3x3 PSF 커널을 사용하고 단일 보정된 PSF로 초기화되었으며, U-Net은 기존 아키텍처(DiffuserCam의 경우 Le-ADMM-U, PhlatCam의 경우 FlatNet-gen)에서 조정되었습니다. 훈련은 배치 크기 5, Adam 옵티마이저 [18]를 사용하여 100 에포크 동안 진행되었습니다. U-Net 및 디컨볼루션 커널에 대한 특정 학습률과 MSE 및 LPIPS 손실 가중치(각각 1 및 0.05)가 설정되었습니다. 영공간 확산 단계의 경우 SVDeconv 출력이 조건으로 사용되었으며, 모델은 사전 훈련된 Stable Diffusion [32] 모델을 가중치를 고정하여 사용하고 보조 조건화 모듈만 훈련하는 데 중점을 두어 200 에포크 동안 훈련되었습니다.
비교 대상("피해자") 기준선 모델은 다음과 같습니다.
- 전통적인 방법: WienerDeconv [44] (티호노프 정규화 복원) 및 ADMM [7] (총 변동 정규화).
- 학습 기반 방법: Le-ADMM-U [27] (딥 언롤링 네트워크), MMCN [49], UPDN [19] (언롤링된 원시-쌍대 네트워크), FlatNet-gen [17] (순방향 디컨볼루션).
- 확산 기반 방법: DDNM+ [41] (사전 훈련된 Stable Diffusion을 사용한 제로샷 역 이미징) 및 FlatNet+DiffBIR [23] (사전 훈련된 블라인드 이미지 복원 확산 모델로 향상된 FlatNet-gen 출력).
또한 저자들은 각 핵심 구성 요소의 기여를 무자비하게 증명하기 위해 표적 축소 연구를 수행했습니다.
- 공간적으로 변하는 디컨볼루션 (SVDeconv): 범위 공간 및 원본 콘텐츠 복원을 위해 Le-ADMM-U, SingleDeconv(단일 커널 사용), MultiWienerNet [48]과 비교되었습니다.
- 영공간 확산: DiffBIR [23] 및 StableSR [39]와 같은 조건부 확산 모델 및 제로샷 역 이미징 방법인 DDNM+ [41]와 비교되었습니다.
- 범위 콘텐츠 조건: 첫 번째 단계에서 복원된 범위 콘텐츠를 확산 모델의 조건으로 대체한 축소 연구로, WienerDeconv, FlatNet-gen 및 SVD-OC(원본 콘텐츠로 훈련된 SVDeconv)의 출력을 사용했습니다.
증거가 증명하는 것
이 논문에서 제시된 증거는 PhoCoLens가 렌즈리스 이미징 복원에서 사실성과 일관성의 우수한 균형을 달성하여 모든 기준선을 능가한다는 결정적이고 부인할 수 없는 증거를 제공합니다.
전반적인 우수성:
표 1은 PhoCoLens의 지배력을 명확하게 보여줍니다. PhlatCam 및 DiffuserCam 데이터셋 모두에서 당사 방법은 거의 모든 전체 참조 메트릭(PSNR, SSIM, LPIPS↓)의 일관성과 비 참조 메트릭(ManIQA, ClipIQA, MUSIQ)의 시각적 품질에서 일관되게 최고의 성능을 달성합니다. 예를 들어, PhlatCam에서 PhoCoLens는 PSNR 22.07, SSIM 0.601, LPIPS 0.215를 달성하여 FlatNet-gen(PSNR 20.53, SSIM 0.549, LPIPS 0.375) 및 FlatNet+DiffBIR(PSNR 19.96, SSIM 0.544, LPIPS 0.391)과 같은 다음으로 좋은 방법들을 훨씬 능가합니다. 이 정량적 증거는 그림 1, 6, 7의 질적 비교를 통해 더욱 강화되며, PhoCoLens의 재구성은 시각적으로 ground truth에 가장 가깝고 선명한 세부 정보와 정확한 콘텐츠를 모두 보여줍니다.
공간적으로 변하는 디컨볼루션(SVDeconv)의 효율성:
이 논문의 공간적으로 변하는 디컨볼루션의 중요성에 대한 핵심 주장은 표 2와 그림 2, 8, A3에 의해 무자비하게 증명됩니다. 표 2는 SVDeconv(당사)가 범위 공간 및 원본 콘텐츠 복원에서 다른 디컨볼루션 방법(Le-ADMM-U, SingleDeconv, MultiWienerNet)보다 일관되게 우수함을 보여줍니다. 예를 들어, PhlatCam에서 SVDeconv는 범위 공간 PSNR 26.97을 달성하여 SingleDeconv의 25.61보다 훨씬 높습니다. 이는 실제 렌즈리스 시스템에서 이동 불변 PSF를 가정하는 SingleDeconv와 같은 전통적인 방법이 부정확하기 때문에 중요합니다. 그림 2와 8은 이를 시각적으로 강조하며, SVDeconv(오른쪽)가 단일 커널을 사용하는 방법(왼쪽)보다 특히 주변부에서 미세한 세부 정보를 훨씬 더 정확하게 복원함을 보여줍니다. 그림 4d의 빨간색 상자와 그림 8의 흰색 점선 상자는 당사의 SVDeconv 메커니즘이 PSF 변화가 가장 두드러지는 주변 영역에서 아티팩트를 효과적으로 완화하고 세부 정보를 보존하는 방법을 명확하게 보여줍니다. 그림 A3는 SVDeconv의 출력이 FlatNet과 달리 부정확한 고주파 세부 정보를 도입하는 것과 달리 ground truth의 저주파 구조와 높은 시각적 일관성을 유지함을 보여줌으로써 이를 더욱 공고히 합니다.
영공간 확산에 대한 결정적 증거:
일관성을 유지하면서 사실성을 위한 당사의 영공간 확산의 효율성은 표 3과 그림 9에서 부인할 수 없이 입증됩니다. 당사 방법은 PhlatCam에서 영공간 복원을 위해 가장 높은 PSNR(22.07), SSIM(0.601), 가장 낮은 LPIPS(0.215)를 달성하여 DiffBIR(PSNR 16.21, SSIM 0.432, LPIPS 0.502) 및 StableSR(PSNR 14.93, SSIM 0.446, LPIPS 0.624)과 같은 다른 확산 기반 접근 방식을 훨씬 능가합니다. 질적으로, 그림 9는 당사 방법이 시각적으로 매력적이고 원본 장면에 충실한 이미지를 생성하는 반면, DiffBIR와 같은 경쟁자는 아티팩트를 도입하거나 콘텐츠를 왜곡할 수 있음을(예: 그림 1d의 "잘못된 모양" 부리 또는 그림 7의 옷에 전이된 사람 손) 보여줍니다. 이는 첫 번째 단계의 저주파 콘텐츠에 대한 확산 모델의 조건화가 충실도를 희생하지 않고 사실적인 고주파 세부 정보를 복구하도록 효과적으로 안내한다는 것을 증명합니다.
범위 콘텐츠 조건의 영향:
범위 콘텐츠 조건에 대한 축소 연구(표 4 및 그림 10 요약)는 조건으로 당사의 첫 번째 단계 복원 출력을 사용하는 것의 중요성에 대한 설득력 있는 증거를 제공합니다. 당사 복원 범위 콘텐츠가 확산 모델을 조건화하는 데 사용될 때, WienerDeconv 또는 FlatNet-gen과 같은 기준선의 출력을 사용하는 것보다 일관된 재구성(더 높은 PSNR, SSIM, 낮은 LPIPS)에 대해 일관되게 더 나은 결과를 가져옵니다. 이는 이러한 대안적 조건이 두 번째 단계가 원본 이미지를 정확하게 복구하는 능력을 방해하는 아티팩트를 도입하기 때문입니다. 그림 10의 시각적 개선은 당사의 2단계 파이프라인이 신중하게 선택된 조건화와 함께 관찰된 우수한 성능을 달성하는 데 중요함을 더욱 강조합니다.
한계 및 향후 방향
PhoCoLens는 렌즈리스 이미징에서 상당한 발전을 이루었지만, 현재의 한계를 인정하고 향후 개발을 위한 경로를 고려하는 것이 중요합니다.
당사 접근 방식의 주요 한계 중 하나는 실시간 적용 가능성입니다. 2단계 아키텍처, 특히 두 번째 단계의 확산 모델 샘플링 프로세스는 현재 실시간 사진 및 비디오 캡처 시나리오에 대한 사용을 방해하는 계산 오버헤드를 도입합니다. 이것은 고품질 생성 모델의 일반적인 과제이며, 이를 해결하면 렌즈리스 카메라의 훨씬 더 넓은 범위의 응용 프로그램을 잠금 해제할 수 있습니다.
또한, 우수한 충실도를 달성했음에도 불구하고, 확산 모델은 본질적으로 생성적이기 때문에, 특히 본질적으로 부드럽거나 복잡한 질감이 부족한 영역에서 원본 장면에서 약간 벗어난 고주파 세부 정보를 여전히 도입할 수 있습니다. 이것은 향상된 사실성을 위한 절충이지만, 생성적 창의성과 엄격한 데이터 충실도 간의 균형을 개선할 여지가 있음을 시사합니다.
앞으로 몇 가지 흥미로운 방향은 이러한 발견을 더욱 발전시킬 수 있습니다.
- 확산 모델 샘플링 가속화: 중요한 미래 방향은 확산 모델 샘플링 프로세스를 크게 가속화하기 위한 기술을 연구하고 구현하는 것입니다. 여기에는 더 빠른 샘플링 알고리즘, 증류 기술 또는 하드웨어 인식 최적화를 탐색하는 것이 포함될 수 있습니다. 실시간 성능을 달성하면 렌즈리스 카메라를 동적 장면에 대한 실행 가능한 솔루션으로 변환하여 자율 내비게이션, 감시 및 대화형 이미징과 같은 응용 프로그램을 가능하게 할 것입니다.
- 3D 공간적으로 변하는 PSF 효과 탐색: 현재 작업은 주로 2D 이미지 복원에 중점을 둡니다. 그러나 렌즈리스 카메라는 복잡한 회절 패턴 내에 인코딩된 3D 장면 정보를 본질적으로 캡처합니다. 향후 작업은 2D 사실적인 이미지뿐만 아니라 깊이 맵 또는 전체 3D 장면 표현을 복원하기 위해 3D 공간적으로 변하는 점 확산 함수(PSF)를 모델링하고 활용하는 것을 탐구할 수 있습니다. 이는 초소형 장치를 사용한 체적 현미경 또는 증강 현실과 같은 새로운 3D 이미징 응용 프로그램을 열 것입니다.
- 적응형 일관성-사실성 절충: 현재 방법은 일관성과 사실성 사이에 고정된 균형을 맞춥니다. 향후 연구는 이러한 절충을 조정하기 위한 동적 또는 사용자 제어 메커니즘을 탐색할 수 있습니다. 예를 들어, 의료 영상에서는 엄격한 일관성이 가장 중요할 수 있지만, 예술적 응용 프로그램에서는 더 큰 사실성(약간의 편차가 있더라도)이 선호될 수 있습니다. 충실도와 생성적 사전 지식의 적응형 가중치를 허용하는 프레임워크를 개발하면 더 넓은 범위의 사용자 요구 사항과 응용 도메인을 충족할 수 있습니다.
- 다양한 이미징 조건에 대한 견고성: 두 가지 인기 있는 렌즈리스 시스템에 대해 테스트되었지만, 극단적이거나 새로운 이미징 조건(예: 매우 낮은 조명, 매우 동적인 장면, 다른 마스크 설계)에서의 성능을 추가로 조사할 수 있습니다. 모델의 견고성과 더 넓은 범위의 렌즈리스 카메라 설계 및 환경 요인에 대한 일반화 능력을 향상시키는 것은 가치 있는 기여가 될 것입니다.
- 윤리적 고려 사항 및 개인 정보 보호 강화 설계: 광범위한 영향 섹션에서 강조된 바와 같이, 작고 눈에 띄지 않는 렌즈리스 카메라의 확산은 상당한 개인 정보 보호 문제를 제기합니다. 향후 연구는 기술적 개선에 초점을 맞출 뿐만 아니라 개인 정보 보호 강화 메커니즘을 이미징 및 복원 파이프라인에 직접 통합하는 데 초점을 맞춰야 합니다. 여기에는 데이터 전송을 최소화하기 위한 온디바이스 처리, 차등 개인 정보 보호 기술을 탐색하거나 개인 정보 보호 권리를 보호하기 위해 캡처된 정보의 범위를 본질적으로 제한하는 렌즈리스 시스템을 설계하는 것이 포함될 수 있습니다. 엔지니어, 윤리학자 및 정책 입안자를 포함하는 이 학제 간 노력은 책임감 있는 기술 발전을 보장하는 데 필수적입니다.
 Table 2. Comparison of deconvolution methods for range space reconstruction and original content reconstruction
Table 2. Comparison of deconvolution methods for range space reconstruction and original content reconstruction
 Table 4. Comparison of different diffusion conditions
Table 4. Comparison of different diffusion conditions
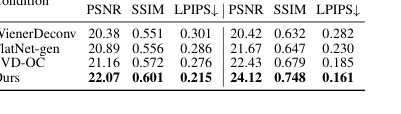 Table 3. Comparison of null space recovery methods
Table 3. Comparison of null space recovery methods