PhoCoLens: レンズレス撮像におけるフォトリアルかつ一貫性のある再構成
New AI reconstructs stunning images from simple sensors, overcoming past limitations.
背景と学術的系譜
起源と学術的系譜
レンズレス撮像再構成の問題は、超小型、軽量、低コストなカメラを実現したいという願望から正確に生まれました。従来のレンズベースのシステムはかさばり高価であり、医療内視鏡やウェアラブル技術のように小型化が求められる分野での応用を制限していました。歴史的な文脈から、研究者たちは従来のレンズをセンサーの近くに配置された振幅または位相マスクに置き換えることで、入射光を変調し、カメラのサイズと重量を大幅に削減し始めました。この革新は有望でしたが、新たな課題をもたらしました。焦点レンズがないため、生のセンサー測定値は通常ぼやけて認識できません。カメラはシーンを直接記録するのではなく、複雑な回折パターンにエンコードするため、高品質な元のシーン画像を復元するには洗練された計算アルゴリズムが必要となります。
著者らが本論文を執筆するに至った、従来のアプローチの根本的な限界または「ペインポイント」は、再構成された画像におけるフォトリアリズムと一貫性の両方を達成すること、および撮像プロセスを正確にモデル化するという2つの主要な問題に起因しています。現在のアルゴリズムは、不正確なフォワード撮像モデルと高品質画像を再構成するための不十分な事前知識に苦労することがよくあります。具体的には以下の通りです。
- 低い視覚品質と欠落した詳細: WienerDeconvのような従来のメソッドは、Ground Truthと一貫性のある画像を再構成できますが、視覚品質が著しく低下し、豊かな詳細が欠けていることがよくあります。FlatNet-genのような学習ベースのアプローチは視覚品質の向上を試みますが、高周波の詳細を回復できないことがよくあります。
- 生成モデルの事前知識との一貫性の欠如: 生成的復元アルゴリズム(例:DiffBIR)は豊かな詳細を注入し、フォトリアリズムを向上させることができますが、しばしば一貫性を犠牲にします。これらのメソッドは画像の内容を変更したり、存在しないオブジェクトを挿入したりする可能性があり、元のシーンから逸脱した再構成につながります(例:間違った形状の鳥のくちばしや偽物のように見える葉)。
- 不正確な撮像モデル(空間的に変動するPSF): ほとんどの既存の再構成アルゴリズムは、シフト不変の点広がり関数(PSF)を仮定することでレンズレス撮像プロセスを単純化します。しかし、実際には、特に視野(FoV)の周辺部では、入射角が増加するため、PSFは空間的に変動します。仮定された撮像モデルと実際の撮像モデルとの間のこの不一致は、特に周辺領域における再構成された類似性の不正確さと顕著な低下につながります。これは、シフト不変の畳み込みに光伝播モデルを単純化するフレネル近似が、レンズレスマスクとセンサー間の距離が非常に小さい場合(レンズレスカメラでは典型的には2mmなど)、しばしばそうであるため、壊れるためです。この重要な制限は、単一のデコンボリューションカーネルが画像全体にわたるぼけを正確に逆転できないことを意味します。
直感的なドメイン用語
- レンズレス撮像: 従来のガラスレンズなしで写真を撮ろうとしていると想像してください。センサーの前に小さな模様の付いた窓(「マスク」)があるだけです。光はこの窓を通過する際に独特の方法で混乱します。レンズレス撮像は、巧妙なコンピュータプログラムを使用してその光を「解きほぐし」、焦点合わせのためにレンズが使用されていないにもかかわらず、鮮明な画像を再構成することです。
- 点広がり関数 (PSF): シーン内の単一の小さな光の点を考えてみてください。この光の点がレンズレスカメラのマスクを通過してセンサーに当たると、完璧な点にとどまらず、特定の、しばしばぼやけたパターンに広がります。PSFは、単一の光の点がカメラシステムによってどのようにぼやけたりエンコードされたりするかのユニークな「指紋」のようなものです。各光の点がセンサー上にどのように「広がる」かを正確に伝えます。
- 空間的に変動するデコンボリューション: 「ぼけの指紋」(PSF)がシーン内の光の来る場所によって変化する場合(例:シーン中央からの光は端からの光とは異なるようにぼやける)、単純な「ぼけ解除」ツールはどこでも完璧に機能しません。空間的に変動するデコンボリューションは、画像の異なる部分に対して技術を自動的に調整し、ビュー全体でより鮮明で正確な画像を得るために各特定の領域に適切な「ぼけ解除」方法を適用するスマートな「ぼけ解除」プロセスのようなものです。
- レンジ・ヌル空間分解: 非常にぼやけた写真を想像してください。この数学的なトリックは、ぼやけた写真を2つの部分に分離するのに役立ちます。「レンジ空間」部分は、カメラがぼやけていても、カメラが確実にキャプチャできたすべての基本的な低詳細情報(一般的な形状や色など)を含みます。「ヌル空間」部分は、ぼけで完全に失われ、ぼやけた測定値から直接回復できないすべての細かい詳細とテクスチャを表します。課題は、最初の部分を正確に再構成し、次に何も作り出さずに現実的な詳細で2番目の部分をインテリジェントに「埋める」ことです。
- 生成モデルの事前知識(拡散モデルから): ラフスケッチから現実的な画像を生成するのに非常に熟練したアーティストを想像してください。「生成モデルの事前知識」は、そのアーティストのようなものです。基本的な低詳細情報(レンジ空間の内容)が与えられると、それは現実世界の画像が通常どのように見えるかに自然で一貫性のある方法で、失われた高周波でフォトリアルな詳細(ヌル空間の内容)を「想像して」追加することができます。これにより、最終的な画像ははるかに視覚的に魅力的になります。
表記表
| 表記 | 説明 |
|---|---|
| $\hat{y}$ | レンズレスカメラでキャプチャされた生の多重化測定値。 |
| $x$ | アルゴリズムが再構成を目指す元のシーン画像。 |
| $A$ | レンズレス撮像システムの転送行列。フォワード撮像モデルを表す。 |
| $n$ | センサーノイズ。 |
| $A^\dagger$ | 転送行列 $A$ の擬似逆行列。 |
| $A^\dagger A x$ | 画像 $x$ のレンジ空間成分。測定値から直接回復可能な情報(低周波成分)を表す。 |
| $(I - A^\dagger A)x$ | 画像 $x$ のヌル空間成分。撮像中に失われた情報(高周波詳細)を表す。 |
| $I$ | 単位行列。 |
| $h$ | レンズレスシステムの点広がり関数(PSF)。 |
| $*$ | 畳み込み演算子。 |
| $p^{(i)}$ | SVDeconvネットワークにおける $i$ 番目の学習可能な点広がり関数(PSF)カーネル。 |
| $\mathcal{F}$ | 離散フーリエ変換(DFT)。 |
| $\mathcal{F}^{-1}$ | 逆離散フーリエ変換(IDFT)。 |
| $\odot$ | アダマール積(要素ごとの乗算)。 |
| $x^{(i)}_e$ | マルチカーネルデコンボリューションからの $i$ 番目の途中デコンボリューション画像。 |
| $X_{int}$ | 中間デコンボリューション画像から空間的に補間された画像。 |
| $w_i(u, v)$ | ピクセル $(u, v)$ における $i$ 番目のデコンボリューション画像の重み。ユークリッド距離の逆数に基づく。 |
| $\mathbf{c}$ | レンジ空間コンテンツ。SVDeconvの最初のステージの出力であり、拡散モデルの条件として使用される。 |
| $\mathbf{x}_t$ | 拡散プロセスにおけるタイムステップ $t$ のノイズ画像。 |
| $\mathbf{\epsilon}$ | 標準正規分布からサンプリングされた真のノイズベクトル。 |
| $\mathbf{\epsilon}_\theta(\mathbf{x}_t, t, \mathbf{c})$ | 条件付き拡散モデルのノイズ予測ネットワーク($\theta$ によってパラメータ化される)。 |
| $\theta$ | ノイズ予測ネットワークの学習可能なパラメータ。 |
| $\mathcal{L}_{null}$ | ヌル空間回復ステージの損失関数。測定空間における一貫性を強制する。 |
| $\mathbb{E}$ | 期待値演算子。 |
| $t$ | 拡散プロセスにおけるタイムステップ。 |
| $\mathcal{N}(0,1)$ | 標準正規分布。 |
| $\| \cdot \|^2$ | 二乗L2ノルム。 |
| $\mathcal{L}_{MSE}$ | 平均二乗誤差損失。 |
| $\mathcal{L}_{LPIPS}$ | 学習済み知覚画像パッチ類似性損失。 |
問題定義と制約
コア問題の定式化とジレンマ
本論文で扱われる根本的な問題は、レンズレスカメラ測定値からフォトリアルかつ一貫性のある画像を再構成することです。
入力/現在の状態:
出発点は、レンズレスカメラでキャプチャされた生の多重化測定値 $\hat{y} \in \mathbb{R}^{N^2}$ です。この測定値は通常、ぼやけており、認識できず、高周波の詳細が欠けています。数学的には、レンズレス撮像プロセスは、センサーノイズ $n$ を加えた元のシーン $x \in \mathbb{R}^{M^2}$ の線形変換として定式化できます。
$$ \hat{y} = Ax + n $$
ここで、$A \in \mathbb{R}^{N^2 \times M^2}$ はレンズレス撮像システムの転送行列であり、シーンの各点からの光が各センサーピクセルにどのように寄与するかをエンコードします。従来の方法では、この複雑なプロセスを単一のシフト不変の点広がり関数(PSF)との畳み込みとして単純化することがよくあります。すなわち、$y = h * x$ です。
望ましい終点(出力/目標状態):
望ましい終点は、フォトリアルかつ元のシーンと一貫性のある再構成画像 $x$ です。
* フォトリアリズムとは、豊かな自然な見た目の詳細を持つ高品質な画像を意味し、レンズレスキャプチャ中に失われた高周波コンテンツを効果的に回復することです。
* 一貫性とは、再構成された画像のコンテンツが元のシーンと正確に一致し、$Ax = y$(ここで $y$ はノイズフリー測定値)の条件を満たすことを意味します。
欠落しているリンクまたは数学的なギャップ:
正確に欠落しているリンクは、レンズレス撮像プロセス($A$ で表される)の複雑で空間的に変動する性質を正確にモデル化し、劣化された測定値から低周波(一貫性重視)および高周波(フォトリアリズム重視)の両方のシーン成分を効果的に回復する能力です。本論文は、このギャップを埋めるためにレンジ・ヌル空間分解を活用しています。任意のシーン $x$ は、2つの直交成分に分解できます。
$$ x = A^\dagger Ax + (I - A^\dagger A)x $$
ここで、$A^\dagger Ax$ はレンジ空間成分(測定値から直接回復可能な低周波コンテンツ、一貫性を保証)であり、$(I - A^\dagger A)x$ はヌル空間成分(撮像中に失われた高周波詳細、フォトリアリズムに不可欠)です。本論文は、レンジ空間コンテンツを正確に再構成し、その後、生成モデルの事前知識を使用してヌル空間コンテンツを豊かにすることを目的としており、すべて一貫性を維持しながら行います。
ジレンマ(痛みを伴うトレードオフ):
過去の研究者を閉じ込めてきた中心的なジレンマは、高い視覚品質(フォトリアリズム)の達成とデータ一貫性(元のシーンへの忠実性)の維持との間の痛みを伴うトレードオフです。
* 従来の再構成アルゴリズム(例:WienerDeconv)はデータ一貫性を優先し、Ground Truthと一致する画像を生成しますが、しばしばぼやけており、視覚品質が著しく低下し、細かい詳細が欠けています。高周波情報を回復できません。
* 生成的復元アルゴリズム(例:拡散モデルを使用するもの、DiffBIRなど)は、豊かなフォトリアルな詳細を注入し、視覚品質を大幅に向上させることができます。しかし、それらはしばしば「画像の内容を変更したり、存在しないオブジェクトを挿入したりする」ため、実際のシーンとの一貫性が損なわれます。例えば、間違った形状や偽のテクスチャを生成する可能性があり、図1dに示すとおりです。
このジレンマは、一方の側面(例:フォトリアリズム)を改善すると通常は他方(一貫性)が損なわれることを意味し、既存の方法で両方を同時に達成することは非常に困難です。
制約と失敗モード
フォトリアルかつ一貫性のあるレンズレス画像再構成の問題は、いくつかの厳しい現実的な制約と従来のアプローチの一般的な失敗モードにより、非常に困難です。
-
空間的に変動する点広がり関数(PSF):
- 物理的制約: 従来のレンズベースのカメラとは異なり、レンズレスシステムは、視野全体にわたって固定されたシフト不変のPSFを持っていません。PSFは、特に周辺部では、入射光の角度によって大きく変動します。
- 計算的制約: ほとんどの既存の再構成アルゴリズムは、シフト不変のPSFを仮定することで撮像プロセスを単純化しますが、これは不正確です。真の空間的に変動するPSFをモデル化することは計算集約的です。なぜなら、完全な転送行列 $A$ は、実際のシステムでは直接「計算するには大きすぎる」からです。この単純化は、特に周辺領域で、再構成された画像の不正確さと顕著な劣化を引き起こし、元のシーンとの再構成された類似性が低下します(図4d)。
-
高周波情報の損失:
- 物理的制約: 光がマスクによって変調されるレンズレスエンコーディングプロセスは、ローパスフィルターのように機能します。これにより、シーンからの高周波詳細が大幅に失われ、生の測定値がぼやけて曖昧になります。
- データ駆動型制約: これらの失われた高周波詳細(「ヌル空間」コンテンツ)を回復するには、強力な事前知識が必要です。十分かつ正確な事前知識がない場合、アルゴリズムはフォトリアルな画像を再構成するのに苦労し、視覚的に劣化された出力を生成したり、生成モデルが単純に使用された場合は忠実性を損なう存在しない詳細を幻視したりすることがよくあります。
-
空間的に変動するデコンボリューションの計算複雑性:
- 計算的制約: 空間的に変動するデコンボリューションは正確な再構成に必要ですが、この分野の従来の方法は「しばしば遅く、計算集約的であり、特に複雑なシステムでは画質が低下する」という結果になります。
- キャリブレーションの負担: 多くのマルチカーネルデコンボリューションアプローチは、「手間のかかるマルチロケーションPSFキャリブレーション」を必要としますが、これは時間と労力がかかるプロセスであり、広範な使用には実用的ではありません。本論文は、単一の初期PSFから自動的にバリエーションを学習することでこれを克服することを目指しています。
-
生成モデルの事前知識を用いたデータ忠実性の維持:
- 論理的制約: 生成モデルは、詳細を幻視するのに強力ですが、本質的に新しい情報を作成することによって動作します。主要な失敗モードは、それらが「画像の内容を変更したり、存在しないオブジェクトを挿入したりする」傾向があるため、再構成された画像が実際の物理測定値と一致しなければならないという基本的な一貫性要件に違反することです。課題は、これらの生成モデルを、実際の画像データと一貫性のある現実的な詳細を生成するように誘導することです。
-
リアルタイム遅延(将来の制限):
- 計算的制約: 本論文で直接克服された制約ではありませんが、著者は「PhoCoLensの2段階性質と拡散モデルのサンプリング時間により、リアルタイムでの適用が妨げられる」ことを認めています。これは、リアルタイムビデオや臨床画像のように即時のフィードバックを必要とするアプリケーションでは、提案された方法の現在の計算オーバーヘッドが重大なハードルとなることを意味します。
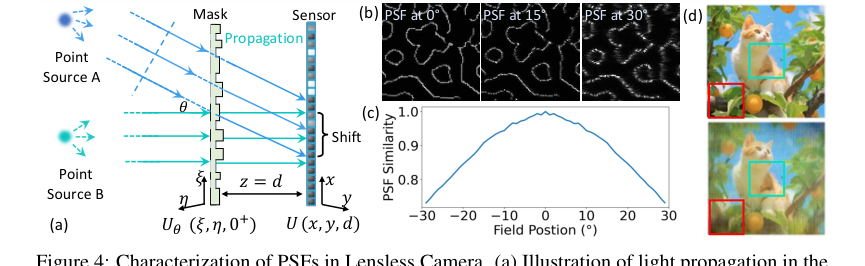 Figure 4. Characterization of PSFs in Lensless Camera. (a) Illustration of light propagation in the lensless camera: two point sources A and B at infinity emitting parallel light beams. Source A emits at angle θ relative to the optical axis, causing a PSF shift on the sensor plane This PSF shift depends on both the incident angle θ and the distance d between the sensor and the mask. (b) Simulated PSFs for light sources at angles of 0°, 15°, and 30°. (c) Inner product similarity between the on-axis PSF and off-axis PSFs at different field positions. (d) Reconstruction using PSF at 0°, degradation is more significant at the periphery (red box) than the center (green box)
Figure 4. Characterization of PSFs in Lensless Camera. (a) Illustration of light propagation in the lensless camera: two point sources A and B at infinity emitting parallel light beams. Source A emits at angle θ relative to the optical axis, causing a PSF shift on the sensor plane This PSF shift depends on both the incident angle θ and the distance d between the sensor and the mask. (b) Simulated PSFs for light sources at angles of 0°, 15°, and 30°. (c) Inner product similarity between the on-axis PSF and off-axis PSFs at different field positions. (d) Reconstruction using PSF at 0°, degradation is more significant at the periphery (red box) than the center (green box)
なぜこのアプローチなのか
選択の必然性
PhoCoLensの著者は、レンズレス撮像における根本的なジレンマに直面しました。すなわち、高い視覚品質(フォトリアリズム)と元のシーンの忠実な表現(一貫性)の両方をどのように達成するかということです。従来の最先端(SOTA)手法、例えばWienerDeconvのような標準的なデコンボリューション技術は、視覚品質が著しく低下し、フォトリアリズムに必要な豊かな詳細が欠けている画像を生成したため、不十分であることが判明しました(図1b)。FlatNet-genに代表される学習ベースのアプローチは視覚品質を向上させましたが、重要な高周波詳細を回復するのに依然として苦労し、シャープさやリアルさが低下した画像を生成しました(図1c)。
従来のメソッドが不十分であるという決定的な認識は、DiffBIRのような高度な生成モデルでさえ、フォトリアルな詳細を注入するのに優れているにもかかわらず、しばしば一貫性を犠牲にしていたことを著者が観察したときに起こりました。これらのモデルは頻繁に画像の内容を変更したり、間違った形状のくちばしや偽物のように見える葉(図1d)のような存在しないオブジェクトを挿入したりし、それによって真実への忠実性を損ないました。これは、視覚的に魅力的であっても、純粋に生成的なアプローチは、精度が最優先されるアプリケーションでは実行可能な唯一の解決策ではないことを示しました。
さらに、既存の再構成アルゴリズムで特定された重要な制限は、レンズレス撮像プロセスの単純化でした。ほとんどの方法は、シフト不変の点広がり関数(PSF)を仮定し、撮像を単なる畳み込みとして扱っていました。しかし、著者は、実際のレンズレスシステムでは、PSFは特に異なる入射角(図4a、4b、4c)で、本質的に空間的に変動することに気づきました。仮定されたシフト不変PSFと実際の空間的に変動するPSFとの間のこの不一致は、特に周辺視野において、再構成された類似性が著しく低下するという実質的な不正確さにつながりました(図4d)。この根本的な物理的現実は、従来の畳み込みモデルが、視野全体にわたる正確なレンズレス再構成には本質的に不十分であることを意味しました。
比較優位性
PhoCoLensは、レンズレス撮像のコアチャレンジに構造的に対処する独自の2段階アーキテクチャを通じて、質的および量的な優位性を達成します。主な構造的利点は、レンジ・ヌル空間分解フレームワークにあります。この理論的基盤により、メソッドは問題を2つの直交成分に分離できます。1つはデータ一貫性(レンジ空間)に焦点を当て、もう1つはフォトリアリズム(ヌル空間)に焦点を当てます。これは、両方を同時に解決しようとしてトレードオフにつながることが多かった以前の方法に対する大きな利点です。
- 空間的に変動するデコンボリューション(SVDeconv)によるレンジ空間: 以前の方法が単一のシフト不変PSFを仮定していたのに対し、SVDeconvはデータ駆動型の方法でカメラの視野全体にわたるPSFの空間的変動に適応することを学習します。これは、より複雑なフォワード撮像プロセスをより正確にモデル化するため、重要な構造的改善です。これにより、特に他の方法が失敗する画像周辺部において、構造的完全性と低周波詳細の再構成が向上します(図2、図4d)。表2は、他のデコンボリューションメソッドと比較して、レンジ空間再構成におけるSVDeconvの優れたパフォーマンスを定量的に示しています。
- フォトリアリズムのための条件付きヌル空間拡散: 2番目のステージは、事前学習済みの拡散モデルを活用しますが、決定的に、この生成プロセスを最初のステージから回復された低周波コンテンツに条件付けします。これにより、高周波詳細がフォトリアリズムを向上させるために追加されても、レンジ空間再構成によって確立された基盤構造と一貫性が保たれることが保証されます。このアプローチは、図1dに示すように、アーティファクトを導入したりコンテンツを変更したりする純粋な生成モデル(DiffBIRなど)の欠点を回避します。条件付けメカニズムは、視覚品質を向上させながら忠実性を維持するための構造的保護策です。
定量的に、PhoCoLensは圧倒的な優位性を示しています。表1に示すように、PhlatCamとDiffuserCamの両方のデータセットで、忠実度メトリック(PSNR、SSIM、LPIPS)と視覚品質メトリック(ManIQA、ClipIQA、MUSIQ)の間の最適なバランスを一貫して達成しています。例えば、PhlatCamでは、PhoCoLensは62.20のMUSIQスコアを達成しており、FlatNet+DiffBIRの57.13を大幅に上回っていますが、LPIPS(0.215対0.391)も改善しています。これは、単にわずかに優れているだけでなく、固有の制限に対処するために構造的に設計されたメソッドであることを示しています。
制約との整合性
PhoCoLensの選択された2段階アプローチは、レンズレス撮像におけるフォトリアリズムと一貫性の両方を達成するという二重の制約と、根本的な物理的課題に対処することに完全に整合しています。
- 一貫性のための空間的に変動するPSFへの対応: レンズレスPSFの空間的に変動する性質にもかかわらず、視野全体にわたる正確な再構成という問題の厳しい要件は、最初のステージのSVDeconvによって直接満たされます。これらの空間的変動を学習して適応させることにより、SVDeconvは、低周波コンテンツ(レンジ空間)が、最終的な画像の安定した基盤を築きながら、高い忠実度と構造的完全性で再構成されることを保証します。これは、問題の物理的現実とソリューションの適応的デコンボリューションプロパティとの直接的な「結婚」です。
- フォトリアリズムのための生成モデルの事前知識の活用と一貫性の維持: 高周波詳細の回復を必要とするフォトリアリズムの達成という制約は、2番目のステージのヌル空間拡散モデルによって対処されます。しかし、ここでの決定的な整合性は、この生成能力がどのように活用されるかです。盲目的に詳細を生成する代わりに、拡散モデルは最初のステージからの一貫した低周波出力に条件付けされます。これにより、追加された高周波詳細(ヌル空間から)が、以前に確立された一貫性を損なうことなくフォトリアリズムを向上させることが保証されます。レンジ・ヌル空間分解の数学的フレームワークは、明示的に、ヌル空間成分が追加されたときに測定値 $y$ を変更しないことを保証し、それによって一貫性を維持します($A(x - A^\dagger Ax) = 0$)。これは、生成能力が一貫性要件によって制約される場合の完璧な整合性です。
- 不十分な事前知識の克服: 視覚品質の低下につながった従来のメソッドにおける不十分な事前知識の問題は、強力な事前学習済み拡散モデルを統合することによって克服されます。このモデルは現実的な画像テクスチャのための強力な生成モデルの事前知識を提供しますが、ヌル空間フレームワーク内でのその適用は、実際のシーンデータによってガイドされることを保証し、任意の幻視を回避します。
代替案の却下
本論文は、フォトリアリズムと一貫性の両方の目標を達成する上での固有の制限に基づいて、いくつかの代替アプローチを明示的かつ暗黙的に却下しています。
- 従来のデコンボリューション(例:WienerDeconv): これらのメソッドは、主にフォトリアルな結果を生成できないために却下されました。データ一貫性をある程度維持しますが、視覚品質は「著しく低下」しており(セクション1、図1b)、高品質な画像再構成には不向きです。
- 学習ベースのデコンボリューション(例:FlatNet-gen): 従来のメソッドよりも改善されていますが、これらのアプローチは「高周波詳細を回復できないことがよくあります」(セクション1、図1c)。この制限は、望ましいレベルのフォトリアリズムを達成できないことを意味し、シャープさや細かいテクスチャの欠如につながりました。
- 直接的な事前知識を持つ生成モデル(例:DiffBIR): これらのメソッドは、豊かな詳細を注入し、視覚品質を向上させるのに優れていますが、「画像の内容を変更したり、存在しないオブジェクトを挿入したりして、一貫性を損なう可能性がある」ため却下されました(セクション1、図1d)。著者は、それらのフォトリアリズムが忠実性に対する許容できないコストで来ることを示し、歪んだオブジェクト(例:くちばしの「間違った形状」)や偽のテクスチャの明確な例を提供しています。
- シフト不変PSFを仮定するメソッド: 主要な暗黙的な却下は、シフト不変PSFを仮定することによってレンズレス撮像プロセスを単純化するあらゆるメソッドに対するものです。セクション3.2で詳述され、図4dで示されているように、この仮定は「不正確さ」と「特に周辺視野における元のシーンとの再構成された類似性の顕著な低下」につながります。PhoCoLensのSVDeconvステージは、この根本的な欠陥を克服するために特別に設計されており、現実世界のレンズレスシステムでは、シフト不変のアプローチは本質的に劣っています。
- ゼロショット拡散モデル(例:DDNM+): 拡散モデルを使用した逆撮像のカテゴリとして言及されていますが、本論文のアプローチは「レンジ・ヌル空間分解に基づく理論的フレームワークによる教師ありファインチューニング」を統合しています(セクション2)。これは、この特定のタスクに対する純粋なゼロショットメソッドを却下することを示唆しています。おそらく、分解フレームワーク内での教師ありトレーニングが提供するきめ細かな制御や一貫性保証が欠けているためです。表3は、DDNM+がヌル空間回復における忠実度と視覚品質の両方のメトリックでPhoCoLensよりも大幅にパフォーマンスが低いことを示しています。
 Figure 1. We introduce PhoCoLens, a lensless reconstruction algorithm that achieves both better visual quality and consistency to the ground truth than existing methods. Our method recovers more details compared to traditional reconstruction algorithms (b) and (c), and also maintains better fidelity to the ground truth compared to the generative approach (d)
Figure 1. We introduce PhoCoLens, a lensless reconstruction algorithm that achieves both better visual quality and consistency to the ground truth than existing methods. Our method recovers more details compared to traditional reconstruction algorithms (b) and (c), and also maintains better fidelity to the ground truth compared to the generative approach (d)
数学的および論理的メカニズム
マスター方程式
本論文、特に2番目のステージのフォトリアリズムと一貫性の達成を推進する中心的な数学的エンジンは、ヌル空間拡散モデルの最適化目的です。この方程式は、拡散モデルによって生成された高周波詳細がレンズレス撮像システムの物理学と一貫性を保つことを保証します。これは正式には次のように表されます。
$$ \min_\theta \mathcal{L}_{null} = \min_\theta \mathbb{E}_{\mathbf{x},t,\mathbf{c},\mathbf{\epsilon} \sim \mathcal{N}(0,1)} \left[ \left\| A(\mathbf{\epsilon}_\theta(\mathbf{x}_t, t, \mathbf{c}) - \mathbf{\epsilon}) \right\|^2 \right] $$
この方程式は、任意の画像 $\mathbf{x}$ がレンジ空間成分 $A^\dagger A \mathbf{x}$(カメラによって直接観測可能な情報)とヌル空間成分 $(I - A^\dagger A) \mathbf{x}$(撮像中に失われたがフォトリアリズムに不可欠な詳細)に分割できると仮定するレンジ・ヌル空間分解の基本原則から導き出されます。ここでの目的は、生成モデルによって追加された残差コンテンツが、理想的にはヌル空間に属するものであっても、フォワード撮像モデルとの一貫性を損なわないことを保証することです。
用語ごとの解剖
この方程式を部分ごとに分解して、その役割と重要性を理解しましょう。
- $\min_\theta$: これは標準的な最小化演算子であり、目標はニューラルネットワークの最適なパラメータセット $\theta$ を見つけることであることを示しています。
- $\theta$: これらはノイズ予測ネットワーク $\mathbf{\epsilon}_\theta$ の学習可能なパラメータです。このネットワークは通常、ノイズ画像内のノイズ成分を予測することを学習するU-Netのようなディープラーニングモデルです。
- $\mathcal{L}_{null}$: この記号は、ヌル空間回復ステージ専用に設計された損失関数を表します。その最小化は、拡散モデルが、一貫性がありフォトリアルな詳細を生成するように導きます。
- $\mathbb{E}_{\mathbf{x},t,\mathbf{c},\mathbf{\epsilon} \sim \mathcal{N}(0,1)}$: これは期待値演算子を意味し、損失を複数のランダムサンプルの平均を取ることを意味します。
- $\mathbf{x}$: これはモデルが再構成を目指すGround Truthのクリーンな画像です。理想的なターゲットです。
- $t$: これはフォワード拡散プロセスにおけるタイムステップを表し、画像にどれだけのノイズが追加されたかを示します。拡散モデルは、ノイズを段階的に追加し、その後このプロセスを逆転させることを学習することによって動作します。
- $\mathbf{c}$: これは拡散モデルの条件であり、具体的には最初のステージから再構成されたレンジ空間コンテンツ $A^\dagger A \mathbf{x}$ です。生成モデルが従わなければならない低周波で一貫性のある情報を提供します。
- $\mathbf{\epsilon} \sim \mathcal{N}(0,1)$: これは標準正規分布からサンプリングされた実際のノイズベクトルであり、クリーンな画像 $\mathbf{x}$ に追加されてノイズ画像 $\mathbf{x}_t$ を作成します。
- $\| \cdot \|^2$: これは二乗L2ノルムであり、回帰タスクにおける損失関数として一般的に選択されます。2つのベクトルの間の二乗ユークリッド距離を測定し、より大きな誤差をより大きく罰します。著者はこれを、予測されたノイズと実際のノイズの違いを定量化するための直接的で効果的な方法として選択しました。
- $A$: これはレンズレス撮像システムの転送行列です。シーン $\mathbf{x}$ がカメラによって測定値 $\mathbf{y}$ にどのように変換されるかを数学的に記述します(すなわち、$\mathbf{y} = A\mathbf{x}$)。ここでの役割は重要です。それはノイズ予測誤差を測定空間に投影します。
- $\mathbf{\epsilon}_\theta(\mathbf{x}_t, t, \mathbf{c})$: これは $\theta$ によってパラメータ化されたニューラルネットワークの出力です。ノイズ画像 $\mathbf{x}_t$、現在のタイムステップ $t$、およびレンジ空間条件 $\mathbf{c}$ が与えられると、このネットワークは元の画像に追加されたノイズ成分 $\mathbf{\epsilon}$ を予測します。
- $(\mathbf{\epsilon}_\theta(\mathbf{x}_t, t, \mathbf{c}) - \mathbf{\epsilon})$: この項はノイズ予測の誤差を表します。ネットワークは、その予測 $\mathbf{\epsilon}_\theta$ を実際のノイズ $\mathbf{\epsilon}$ にできるだけ近づけようとします。
- $A(\mathbf{\epsilon}_\theta(\mathbf{x}_t, t, \mathbf{c}) - \mathbf{\epsilon})$: これは損失の最も重要な部分です。予測されたノイズと実際のノイズの違いを単純に最小化するのではなく、著者はこの違いに転送行列 $A$ を適用します。これにより、ノイズ予測誤差の効果が測定空間に投影されたときに最小化されることが保証されます。本質的に、それは生成モデルが、レンズレスカメラによって「撮像」された場合に測定誤差ゼロにつながるようなノイズを予測するように強制します。これは、生成された詳細(ヌル空間から来る)がレンジ空間コンテンツから得られる測定値を変えないという一貫性要件を直接強制します。ここでの $A$ による乗算の使用は、例えば加算ではなく、誤差を測定ドメインに投影することにおいて基本的であり、フォワードモデルに整合しています。
ステップバイステップの流れ
PhoCoLensメソッドは、各ステージが画像再構成を特定の目的で洗練する、洗練された組み立てラインに似た、巧妙な2段階パイプラインで動作します。
ステージ1:空間的に変動するデコンボリューション(SVDeconv)によるレンジ空間再構成
- 初期測定入力: プロセスは、生の、ぼやけた、ノイズの多いレンズレス測定値 $\hat{y}$ から始まります。これは、センサーによってキャプチャされた複雑な回折パターンである、初期の抽象的なデータポイントです。
- マルチカーネルデコンボリューション: この測定値 $\hat{y}$ はSVDeconvネットワークに入力されます。ここでは、単一のデコンボリューションではなく、多数のデコンボリューションが行われます。ネットワークは、画像の異なる空間領域にそれぞれ特化した、学習可能な点広がり関数(PSF)カーネル $p^{(i)}$ の $K \times K$ セットを維持します。
- 測定値 $\hat{y}$ と各カーネル $p^{(i)}$ は、まず離散フーリエ変換($\mathcal{F}$)を使用して周波数領域に変換されます。
- 周波数領域では、変換された測定値と各変換されたカーネルとの間で要素ごとの乗算(アダマール積 $\odot$)が実行されます。これはデコンボリューションの周波数領域等価物であり、その特定の領域のレンズレスシステムによって引き起こされるぼけを効果的に「元に戻します」。
- 各結果は、逆離散フーリエ変換($\mathcal{F}^{-1}$)を使用して空間領域に戻され、$K \times K$ の中間デコンボリューション画像 $x^{(i)}_e$ が生成されます。各 $x^{(i)}_e$ は、特定の視野ポイントに対して最適化された予備的な再構成です。
- 空間的に変動する補間: これらの $K \times K$ の中間画像は、シームレスに結合されます。最終出力の各ピクセル $(u, v)$ について、すべての $x^{(i)}_e$ 画像の対応するピクセルの加重合計が計算されます。重み $w_i(u, v)$ は、ピクセル $(u, v)$ と $i$ 番目のPSFカーネルの中心との間のユークリッド距離の逆数に基づいて決定されます。これは、ピクセルの値が、それに最も近いPSFカーネルのデコンボリューションカーネルから主に影響を受けることを意味し、PSFの空間的変動に適合する統一された画像 $X_{int}$ を作成します。
- 洗練U-Net: 補間された画像 $X_{int}$ は、U-Netを通過します。このニューラルネットワークは、最終的なクリーンアップ担当者として機能し、残りのノイズやアーティファクトを除去し、画像をさらに洗練してレンジ空間コンテンツ $\mathbf{c}$ を生成します。この $\mathbf{c}$ は、次のステージの準備ができた、一貫性のある低周波のシーン表現です。
ステージ2:条件付き拡散によるヌル空間コンテンツ回復
- ノイズ画像生成と条件付け: ステージ1からのレンジ空間コンテンツ $\mathbf{c}$ が条件として使用されます。同時に、Ground Truth画像 $\mathbf{x}$ は、複数のタイムステップ $t$ にわたってランダムノイズ $\mathbf{\epsilon}$ を追加することによって段階的に破損され、ノイズ画像 $\mathbf{x}_t$ が生成されます。
- 条件付きノイズ予測: ノイズ画像 $\mathbf{x}_t$、現在のタイムステップ $t$、およびレンジ空間条件 $\mathbf{c}$ は、条件付き拡散モデルのノイズ予測ネットワーク $\mathbf{\epsilon}_\theta$ に供給されます。
- 条件 $\mathbf{c}$ は単に連結されるだけでなく、深く統合されます。条件付きエンコーダーは $\mathbf{c}$ からマルチスケール特徴を抽出し、それが $\mathbf{\epsilon}_\theta$ ネットワークの残差ブロック内の内部特徴マップを変調します。これにより、生成プロセスがレンジ空間の一貫した低周波情報によって厳密にガイドされることが保証されます。
- ネットワーク $\mathbf{\epsilon}_\theta$ はこれらの入力を処理し、$\mathbf{x}_t$ を作成するために元々追加されたノイズ $\mathbf{\epsilon}$ の最良の推定値を出力します。
- 一貫性強制(損失計算): 予測されたノイズ $\mathbf{\epsilon}_\theta$ は、実際のノイズ $\mathbf{\epsilon}$ と比較されます。重要なステップは、それらの差に転送行列 $A$ を適用することです。この結果の二乗L2ノルムが $\mathcal{L}_{null}$ 損失を形成します。これにより、予測されたノイズと実際のノイズの間のあらゆる不一致が、レンズレスカメラのフォワードモデルを通して見られたときに最小限に抑えられることが保証されます。これは、生成モデルが、レンジ空間コンテンツから得られる測定値を変えないようなノイズを予測するように学習させることを意味し、データ一貫性を強制します。
- 反復的ノイズ除去(推論): 推論中、拡散モデルは純粋なランダムノイズ画像から始まります。多数のタイムステップにわたって、学習された $\mathbf{\epsilon}_\theta$ ネットワークを繰り返し使用してノイズを予測および減算し、ランダムノイズを徐々にフォトリアルな画像に変換します。各ステップで、レンジ空間コンテンツ $\mathbf{c}$ は生成を継続的にガイドし、追加された高周波詳細が低周波構造と一貫していることを保証し、最終的に高品質な再構成画像をもたらします。
最適化ダイナミクス
PhoCoLensシステムは、それぞれがその対応するステージに合わせた2つの二重最適化戦略を通じて学習および収束します。
ステージ1:SVDeconvによるレンジ空間コンテンツの最適化
最初のステージであるSVDeconvは、レンジ空間コンテンツ $A^\dagger A \mathbf{x}$ を再構成するようにトレーニングされます。その最適化には、マルチカーネルデコンボリューションと洗練U-Netのパラメータ学習が含まれます。
- 損失関数: SVDeconvのトレーニング目的は、平均二乗誤差(MSE)損失とLPIPS(学習済み知覚画像パッチ類似性)損失の組み合わせです。
- MSE損失: これはピクセルごとの忠実度損失であり、再構成されたレンジ空間コンテンツとGround Truthのレンジ空間コンテンツとの間の二乗差を最小化することを目指します。低周波情報を正確に回復することを保証します。
- LPIPS損失: これは、事前学習済みのディープニューラルネットワークによって学習された特徴空間で画像の類似性を測定する知覚損失です。ピクセル値が完全に一致しなくても、再構成された画像が人間にとって視覚的に魅力的で現実的に見えることを保証するために不可欠です。
- 勾配挙動: MSEとLPIPS損失の両方からの勾配は、洗練U-Netを介して、そして特に微分可能なマルチカーネルデコンボリューションレイヤーを介してバックプロパゲートされます。これにより、ネットワークは、空間的に変動するレンズレス撮像システムに最もよく適応するPSFカーネル $p^{(i)}$ を学習できます。勾配は、カーネルが空間的に変動するぼけを効果的に「元に戻す」ように導きます。
- 状態更新: Adamオプティマイザを使用して、学習可能なPSFカーネルとU-Netパラメータを反復的に更新します。学習率は、安定した効果的な収束を保証するために慎重に選択されています(例:PhlatCamデコンボリューションカーネルには4e-9、U-Netには3e-5)。モデルは、手間のかかるマルチロケーションPSFキャリブレーションを必要とせずに、データ駆動型の方法で空間PSF変動に自動的に適応することを学習します。
ステージ2:条件付き拡散によるヌル空間コンテンツの最適化
2番目のステージである条件付き拡散モデルは、ヌル空間コンテンツを回復するように最適化され、一貫性を維持しながらフォトリアルな高周波詳細を追加します。
- 損失関数: このステージの主な損失は、マスター方程式で定義されている $\mathcal{L}_{null}$ です。この損失は、転送行列 $A$ をノイズ予測誤差に適用するため、ユニークです。
- 損失ランドスケープ形成: 誤差項 $A(\mathbf{\epsilon}_\theta - \mathbf{\epsilon})$ への $A$ の適用は、損失ランドスケープを劇的に形成します。これは、最小値が、生成された高周波詳細(予測されたノイズから派生)がレンズレスカメラのフォワードモデルに対して「見えない」状態に対応するランドスケープを作成します。言い換えれば、拡散モデルによって追加されたあらゆる詳細が $A$ を介して投影されたときに測定値を変更しないヌル空間に存在しなければなりません。これにより、生成モデルが、測定値と矛盾する詳細を幻視することを防ぎ、それによってデータ一貫性を強制します。
- 勾配挙動: 勾配は、 $A$ 演算子を含む式全体を通じて計算され、ノイズ予測ネットワーク $\mathbf{\epsilon}_\theta$ を介してバックプロパゲートされます。これらの勾配は、再構成された画像がフォワード撮像モデル $A$ を通過したときに、低周波レンジ空間コンテンツ $\mathbf{c}$ と一貫性を保つように、ノイズを予測するように $\mathbf{\epsilon}_\theta$ を導きます。これは、生成モデルの出力がレンズレスシステムの物理的制約に整合することを保証するための洗練された方法です。
- 状態更新: 拡散モデルは、多数のエポック(例:200エポック)でトレーニングされます。本論文では、事前学習済みの拡散モデル(Stable Diffusionなど)を重みを固定して利用し、主に補助的な条件付けモジュールのみをトレーニングすることに言及しています。この戦略により、モデルは大規模な事前学習済みモデルの強力な生成能力を活用しながら、レンズレス撮像の特定のタスクと一貫性要件に合わせてファインチューニングできます。 $\mathbf{c}$ に基づいて内部特徴マップを変調する条件付けメカニズムは、生成された高周波コンテンツが最初のステージによって提供された低周波構造と一貫していることを保証するために反復的に更新されます。この条件付けの反復的洗練により、最終出力がフォトリアルかつ一貫性のあるものになります。
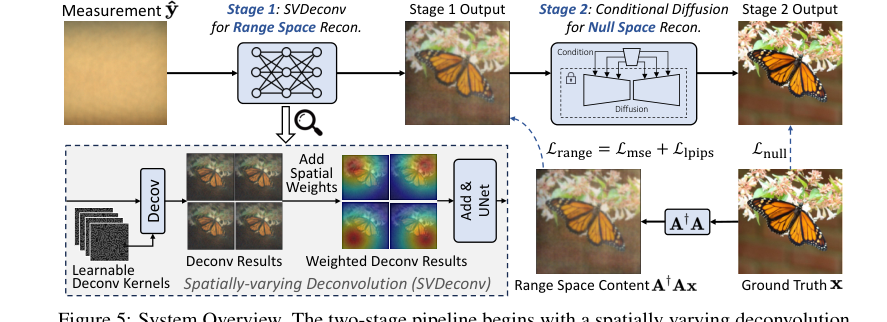 Figure 5. System Overview. The two-stage pipeline begins with a spatially varying deconvolution network mapping lensless measurements to range space. Then a conditional diffusion model for null space recovery refines details using the first stage output, achieving the final reconstruction
Figure 5. System Overview. The two-stage pipeline begins with a spatially varying deconvolution network mapping lensless measurements to range space. Then a conditional diffusion model for null space recovery refines details using the first stage output, achieving the final reconstruction
結果、限界、および結論
実験設計とベースライン
PhoCoLensの厳密な検証を確実にするために、著者は、2つの異なる実世界のレンズレス撮像データセット全体で、独自の2段階アプローチを多様な「犠牲」ベースラインモデルと比較する包括的な実験セットアップを考案しました。
実験では、2つの一般的なレンズレスカメラシステムが利用されました。
- PhlatCamデータセット [17]: 1,000クラスにわたる10,000枚の画像で構成され、384x384ピクセルにリサイズされ、生のキャプチャは1280x1480ピクセルです。トレーニング用に990クラス、テスト用に10クラスの分割が使用されました。
- DiffuserCamデータセット [27]: 同時にキャプチャされた25,000枚のペア画像(レンズレス測定値+Ground Truth)で構成されています。元々1080x1920ピクセルだったこれらの画像は、270x480にダウンサンプリングされ、その後210x380ピクセルにクロップされました。データセットは、トレーニング用に24,000、テスト用に1,000に分割されました。
数学的な主張を決定的に証明するために、評価では、一貫性(忠実性)とフォトリアリズム(視覚品質)の両方を評価する2つのメトリックセットが使用されました。
- 一貫性のためのフルリファレンスメトリック: ピーク信号対ノイズ比(PSNR)、構造類似性指数尺度(SSIM)[42]、および学習済み知覚画像パッチ類似性(LPIPS)[51]。低いLPIPS値は、より高い忠実度を示します。
- フォトリアリズムのためのノンリファレンスメトリック: 多次元注意ネットワークによるノンリファレンス画像品質評価(ManIQA)[45]、CLIPベースの画像品質評価(ClipIQA)[39]、およびマルチスケール画像品質トランスフォーマー(MUSIQ)[16]。これらのメトリックの値が高いほど、一般的に視覚品質が向上します。
実装の詳細は再現性を確保するために細心の注意を払って概説されました。SVDeconvネットワークは3x3 PSFカーネルを使用し、単一のキャリブレーション済みPSFで初期化され、U-Netは既存のアーキテクチャ(DiffuserCamの場合はLe-ADMM-U、PhlatCamの場合はFlatNet-gen)から適応されました。トレーニングはバッチサイズ5で100エポックにわたり行われ、Adamオプティマイザ[18]が使用されました。U-Netとデコンボリューションカーネルには特定の学習率が設定され、MSEとLPIPS損失の重み(それぞれ1と0.05)が設定されました。ヌル空間拡散ステージでは、SVDeconvの出力が条件として使用され、モデルは200エポックでトレーニングされ、重みを固定した事前学習済みのStable Diffusion [32] モデルを活用し、補助的な条件付けモジュールのトレーニングのみに焦点を当てました。
比較対象となった「犠牲」(ベースラインモデル)は次のとおりです。
- 従来のメソッド: WienerDeconv [44](チホノフ正則化再構成)およびADMM [7](全変動正則化)。
- 学習ベースのメソッド: Le-ADMM-U [27](ディープアンロールネットワーク)、MMCN [49]、UPDN [19](アンロールドプリマルデュアルネットワーク)、およびFlatNet-gen [17](フィードフォワードデコンボリューション)。
- 拡散ベースのメソッド: DDNM+ [41](事前学習済みStable Diffusionによるゼロショット逆撮像)およびFlatNet+DiffBIR [23](FlatNet-genの出力を事前学習済みブラインド画像復元拡散モデルで強化)。
さらに、著者は各コアコンポーネントの貢献を徹底的に証明するために、ターゲットを絞ったアブレーションスタディを実施しました。
- 空間的に変動するデコンボリューション(SVDeconv): レンジ空間と元のコンテンツの両方の再構成のために、Le-ADMM-U、SingleDeconv(単一カーネルを使用)、およびMultiWienerNet [48]と比較されました。
- ヌル空間拡散: DiffBIR [23] や StableSR [39] のような条件付き拡散モデル、およびゼロショット逆撮像メソッドである DDNM+ [41] と比較されました。
- レンジコンテンツ条件: 最初のステージの再構成されたレンジコンテンツを、WienerDeconv、FlatNet-gen、およびSVD-OC(元のコンテンツでトレーニングされたSVDeconv)の出力で置き換えたアブレーション。
証拠が証明すること
本論文で提示された証拠は、PhoCoLensがレンズレス撮像におけるフォトリアリズムと一貫性の優れたバランスを達成し、すべてのベースラインを上回っているという、決定的で否定できない証拠を提供します。
全体的な優位性:
表1は、PhoCoLensの優位性を明確に示しています。PhlatCamとDiffuserCamの両方のデータセットで、当社のメソッドは、一貫性のためのほとんどすべてのフルリファレンスメトリック(PSNR、SSIM、LPIPS↓)と視覚品質のためのノンリファレンスメトリック(ManIQA、ClipIQA、MUSIQ)で一貫して最高のパフォーマンスを達成しています。例えば、PhlatCamでは、PhoCoLensは22.07のPSNR、0.601のSSIM、および0.215のLPIPSを達成しており、次の最高のメソッドであるFlatNet-gen(PSNR 20.53、SSIM 0.549、LPIPS 0.375)やFlatNet+DiffBIR(PSNR 19.96、SSIM 0.544、LPIPS 0.391)を大幅に上回っています。この定量的な証拠は、PhoCoLensの再構成が視覚的にGround Truthに最も近く、シャープな詳細と正確なコンテンツの両方を備えている図1、6、および7の定性的な比較によってさらに強化されています。
空間的に変動するデコンボリューション(SVDeconv)の有効性:
空間的に変動するデコンボリューションの重要性に関する論文の核心的な主張は、表2と図2、8、およびA3によって徹底的に証明されています。表2は、SVDeconv(Ours)が、レンジ空間コンテンツと元のコンテンツの両方の再構成において、他のデコンボリューションメソッド(Le-ADMM-U、SingleDeconv、MultiWienerNet)を常に上回っていることを示しています。例えば、PhlatCamでは、SVDeconvは26.97のレンジ空間PSNRを達成しており、SingleDeconvの25.61を大幅に上回っています。これは、SingleDeconvのような従来のメソッドがシフト不変PSFを仮定しているため、実際のレンズレスシステムでは不正確であるため、非常に重要です。図2と図8はこれを視覚的に強調しており、SVDeconv(右)が、単一カーネルを使用するメソッド(左)よりも、特に周辺部で、はるかに正確に細かい詳細を再構成していることを示しています。図4dの赤いボックスと図8の白い破線ボックスは、当社のSVDeconvメカニズムがアーティファクトを効果的に軽減し、PSF変動が最も顕著な周辺領域の詳細をどのように維持しているかを明確に示しています。図A3は、SVDeconvの出力がGround Truthの低周波構造と高い視覚的整合性を維持していることを示しており、FlatNetとは異なり、不正確な高周波詳細を導入していることを示しています。
ヌル空間拡散の決定的な証拠:
一貫性を維持しながらフォトリアリズムを実現するためのヌル空間拡散の効果は、表3と図9で否定できないほど証明されています。当社のメソッドは、PhlatCamでのヌル空間回復において最高のPSNR(22.07)、SSIM(0.601)、および最低のLPIPS(0.215)を達成しており、DiffBIR(PSNR 16.21、SSIM 0.432、LPIPS 0.502)やStableSR(PSNR 14.93、SSIM 0.446、LPIPS 0.624)のような他の拡散ベースのアプローチを大幅に上回っています。定性的に、図9は、当社のメソッドが視覚的に魅力的で元のシーンに忠実な画像を生成しているのに対し、DiffBIRのような競合他社はアーティファクトを導入したりコンテンツを歪めたりする可能性があること(図1dの「間違った形状」のくちばし、または図7の服に転送された人間の手など)を示しています。これは、最初のステージからの低周波コンテンツに拡散モデルを条件付けることが、忠実性を犠牲にすることなく現実的な高周波詳細を回復するように効果的にガイドすることを示しています。
レンジコンテンツ条件の影響:
レンジコンテンツ条件に関するアブレーションスタディ(表4と図10に要約)は、最初のステージの出力を条件として使用することの重要性について説得力のある証拠を提供します。当社の再構成されたレンジコンテンツが拡散モデルを条件付けるために使用される場合、WienerDeconvやFlatNet-genのようなベースラインの出力を使用する場合と比較して、再構成の一貫性が一貫して向上します(より高いPSNR、SSIM、低いLPIPS)。これは、これらの代替条件が、2番目のステージが元の画像を正確に回復する能力を妨げるアーティファクトを導入するためです。図10の視覚的な改善は、当社の2段階パイプラインが、慎重に選択された条件付けにより、観察された優れたパフォーマンスを達成するために不可欠であることをさらに強調しています。
限界と将来の方向性
PhoCoLensはレンズレス撮像における大きな進歩を示していますが、現在の限界を認識し、将来の開発の方向性を検討することが重要です。
当社の主な限界の1つは、リアルタイム適用性です。2段階アーキテクチャ、特に2番目のステージの拡散モデルのサンプリングプロセスは、現在、リアルタイムの写真およびビデオキャプチャシナリオでの使用を妨げる計算オーバーヘッドを導入しています。これは、高品質な生成モデルによく見られる課題であり、これを解決することは、レンズレスカメラのより広範なアプリケーションを解き放つでしょう。
さらに、優れた忠実性を達成しているにもかかわらず、拡散モデルは、その生成的な性質により、特に本質的に滑らかであるか、複雑なテクスチャが欠けている領域では、元のシーンからわずかに逸脱する高周波詳細を依然として導入する可能性があります。これは視覚的なリアリズムを高めるためのトレードオフですが、生成的な創造性と厳密なデータ忠実性との間のバランスをさらに洗練させる余地があることを示唆しています。
将来に向けて、いくつかのエキサイティングな方向性がこれらの発見をさらに進化させる可能性があります。
- 拡散モデルサンプリングの高速化: 重要な将来の方向性は、拡散モデルのサンプリングプロセスを大幅に高速化する技術を研究および実装することです。これには、より高速なサンプリングアルゴリズム、蒸留技術、またはハードウェアを意識した最適化の探求が含まれる可能性があります。リアルタイムパフォーマンスの達成は、レンズレスカメラを動的なシーンに対応できるソリューションに変え、自律ナビゲーション、監視、およびインタラクティブ撮像の分野でのアプリケーションを可能にするでしょう。
- 3D空間的に変動するPSF効果の探求: 現在の研究は主に2D画像再構成に焦点を当てています。しかし、レンズレスカメラは、その複雑な回折パターンにエンコードされた3Dシーン情報を本質的にキャプチャします。将来の研究では、2Dフォトリアルな画像だけでなく、深度マップや完全な3Dシーン表現を再構成するために、3D空間的に変動する点広がり関数(PSF)のモデル化と活用を掘り下げることができます。これにより、体積顕微鏡や拡張現実のような超小型デバイスを使用した新しい3D撮像アプリケーションへの道が開かれるでしょう。
- 適応的な一貫性-フォトリアリズムトレードオフ: 現在の方法は、一貫性とフォトリアリズムの間に固定されたバランスを取っています。将来の研究では、このトレードオフを調整するための動的またはユーザー制御のメカニズムを探索できる可能性があります。例えば、医療画像では厳密な一貫性が最優先されるかもしれませんが、芸術的なアプリケーションでは、より大きなフォトリアリズム(わずかな逸脱があっても)が好まれるかもしれません。適応的な忠実度と生成モデルの事前知識の重み付けを可能にするフレームワークを開発することは、より幅広いユーザーのニーズとアプリケーションドメインに対応できるでしょう。
- 多様な撮像条件に対する堅牢性: 2つの一般的なレンズレスシステムでテストされましたが、極端または新しい撮像条件(例:非常に低い光、非常に動的なシーン、異なるマスク設計)でのパフォーマンスをさらに調査できます。モデルの堅牢性と、より広範なレンズレスカメラ設計と環境要因に対する汎化能力を向上させることは、価値のある貢献となるでしょう。
- 倫理的考慮事項とプライバシー保護設計: 広範な影響セクションで強調されているように、小型で目立たないレンズレスカメラの普及は、重大なプライバシー懸念を引き起こします。将来の研究は、技術的な改善に焦点を当てるだけでなく、プライバシー保護メカニズムを撮像および再構成パイプラインに直接統合することにも焦点を当てるべきです。これには、データ送信を最小限に抑えるためのオンデバイス処理、差分プライバシー技術の探求、または個人のプライバシー権を保護するためにキャプチャされた情報の範囲を本質的に制限するレンズレスシステムの設計が含まれる可能性があります。技術者、倫理学者、および政策立案者を含むこの学際的な努力は、責任ある技術的進歩を保証するために不可欠です。
 Table 2. Comparison of deconvolution methods for range space reconstruction and original content reconstruction
Table 2. Comparison of deconvolution methods for range space reconstruction and original content reconstruction
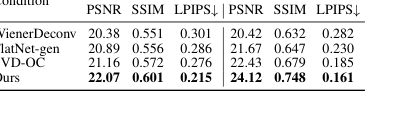 Table 4. Comparison of different diffusion conditions
Table 4. Comparison of different diffusion conditions
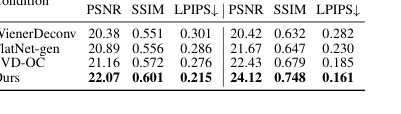 Table 3. Comparison of null space recovery methods
Table 3. Comparison of null space recovery methods