PhoCoLens: Фотореалистичная и согласованная реконструкция в безлинзовой визуализации
Проблема реконструкции изображений в безлинзовой визуализации возникла из желания создать сверхкомпактные, легкие и экономичные камеры.
Предыстория и академическая родословная
Истоки и академическая родословная
Проблема реконструкции изображений в безлинзовой визуализации возникла из желания создать сверхкомпактные, легкие и экономичные камеры. Традиционные системы с линзами громоздки и дороги, что ограничивает их применение в областях, требующих миниатюризации, таких как медицинская эндоскопия или носимые технологии. Исторический контекст показывает, что исследователи начали заменять традиционные линзы масками амплитуды или фазы, расположенными близко к датчику, для модуляции падающего света, что значительно уменьшает размер и вес камеры. Это инновационное решение, хотя и многообещающее, породило новую проблему: без фокусирующей линзы необработанные измерения датчика обычно размыты и неузнаваемы. Камера не записывает сцену напрямую, а кодирует ее в сложный дифракционный узор, что требует сложных вычислительных алгоритмов для восстановления высококачественного изображения исходной сцены.
Фундаментальное ограничение или "болевая точка" предыдущих подходов, побудившая авторов написать эту статью, проистекает из двух основных проблем: достижения как фотореализма, так и согласованности реконструированных изображений, а также точного моделирования процесса визуализации. Современные алгоритмы часто испытывают трудности с неточными моделями прямого формирования изображения и недостаточными априорными знаниями для реконструкции высококачественных изображений. В частности:
- Низкое визуальное качество и недостающие детали: Традиционные методы, такие как WienerDeconv, могут реконструировать изображения, соответствующие истинным данным (ground truth), но страдают от значительно ухудшенного визуального качества, часто лишенного богатых деталей. Обучаемые подходы, такие как FlatNet-gen, пытаются улучшить визуальное качество, но часто не могут восстановить высокочастотные детали.
- Отсутствие согласованности с генеративными априорными данными: В то время как алгоритмы генеративной реставрации (например, DiffBIR) могут вводить богатые детали и улучшать фотореализм, они часто делают это ценой согласованности. Эти методы могут изменять содержимое изображения или вставлять несуществующие объекты, что приводит к реконструкциям, отклоняющимся от исходной сцены (например, клюв птицы неправильной формы или ненастоящие листья).
- Неточная модель формирования изображения (пространственно-изменяющаяся PSF): Большинство существующих алгоритмов реконструкции упрощают процесс безлинзовой визуализации, предполагая инвариантную к сдвигу функцию рассеяния точки (PSF). Однако на практике PSF пространственно-изменяется, особенно на периферии поля зрения (FoV), где угол падения увеличивается. Это несоответствие между предполагаемой и фактической моделью формирования изображения приводит к неточностям и заметному снижению сходства реконструированного изображения с исходной сценой, особенно в периферийных областях. Это происходит потому, что приближение Френеля, которое упрощает модель распространения света до свертки, инвариантной к сдвигу, нарушается, когда расстояние между безлинзовой маской и датчиком очень мало (например, 2 мм в типичных безлинзовых камерах), что часто имеет место. Это критическое ограничение означает, что один деконволюционный фильтр не может точно обратить размытие по всему изображению.
Интуитивные термины предметной области
- Безлинзовая визуализация: Представьте, что вы пытаетесь сделать снимок камерой без традиционной стеклянной линзы, просто с крошечным узорчатым окном ("маской") перед датчиком. Свет уникальным образом искажается, проходя через это окно. Безлинзовая визуализация заключается в использовании умных компьютерных программ для "распутывания" этого света и реконструкции четкого изображения, даже если для фокусировки не использовалась линза.
- Функция рассеяния точки (PSF): Представьте себе одну крошечную точку света в сцене. Когда эта точка света проходит через маску безлинзовой камеры и попадает на датчик, она не остается идеальной точкой; она рассеивается в определенный, часто размытый, узор. PSF подобна уникальному "отпечатку пальца" того, как одна точка света размывается или кодируется системой камеры. Она точно показывает, как каждая точка света "рассеивается" на датчике.
- Пространственно-изменяющаяся деконволюция: Если "отпечаток размытия" (PSF) меняется в зависимости от того, откуда исходит свет в сцене (например, свет из центра сцены размывается иначе, чем свет с краев), простой инструмент "анти-размытия" не будет работать идеально везде. Пространственно-изменяющаяся деконволюция подобна умному процессу "анти-размытия", который автоматически настраивает свою технику для разных частей изображения, применяя правильный метод "анти-размытия" для каждой конкретной области, чтобы получить более четкое и точное изображение по всему полю зрения.
- Разложение на пространство образов и нулевое пространство: Представьте себе очень размытую фотографию. Этот математический трюк помогает нам разделить размытую фотографию на две части. Часть "пространства образов" содержит всю базовую информацию с низким уровнем детализации (например, общие формы и цвета), которую камера могла надежно захватить, даже если она размыта. Часть "нулевого пространства" представляет собой все мелкие детали и текстуры, которые были полностью потеряны в размытии и не могут быть напрямую восстановлены из размытого измерения. Задача состоит в том, чтобы точно реконструировать первую часть, а затем интеллектуально "заполнить" вторую часть реалистичными деталями, ничего не выдумывая.
- Генеративный априорный источник (из диффузионных моделей): Представьте себе художника, который невероятно искусно создает реалистичные изображения по наброску. "Генеративный априорный источник" из диффузионной модели подобен этому художнику. Получив базовую информацию с низким уровнем детализации (содержимое пространства образов), он может "вообразить" и восстановить недостающие высокочастотные, фотореалистичные детали (содержимое нулевого пространства) таким образом, чтобы это выглядело естественно и соответствовало тому, как обычно выглядят изображения реального мира, делая финальное изображение гораздо более визуально привлекательным.
Таблица обозначений
| Обозначение | Описание |
|---|---|
| $\hat{y}$ | Необработанное, мультиплексированное измерение, полученное безлинзовой камерой. |
| $x$ | Исходное изображение сцены, которое алгоритм стремится реконструировать. |
| $A$ | Матрица преобразования безлинзовой системы визуализации, представляющая модель прямого формирования изображения. |
| $n$ | Шум датчика. |
| $A^\dagger$ | Псевдообратная матрица $A$. |
| $A^\dagger A x$ | Компонента пространства образов изображения $x$, представляющая информацию, непосредственно восстанавливаемую из измерений (низкочастотное содержимое). |
| $(I - A^\dagger A)x$ | Компонента нулевого пространства изображения $x$, представляющая информацию, потерянную при формировании изображения (высокочастотные детали). |
| $I$ | Единичная матрица. |
| $h$ | Функция рассеяния точки (PSF) безлинзовой системы. |
| $*$ | Оператор свертки. |
| $p^{(i)}$ | $i$-е обучаемое ядро функции рассеяния точки (PSF) в сети SVDeconv. |
| $\mathcal{F}$ | Дискретное преобразование Фурье (DFT). |
| $\mathcal{F}^{-1}$ | Обратное дискретное преобразование Фурье (IDFT). |
| $\odot$ | Произведение Адамара (поэлементное умножение). |
| $x^{(i)}_e$ | $i$-е промежуточное деконволюционное изображение из многофильтровой деконволюции. |
| $X_{int}$ | Пространственно интерполированное изображение из промежуточных деконволюционных изображений. |
| $w_i(u, v)$ | Вес для $i$-го деконволюционного изображения в пикселе $(u, v)$, основанный на обратном евклидовом расстоянии. |
| $\mathbf{c}$ | Содержимое пространства образов, выход первого этапа SVDeconv, используемый в качестве условия для диффузионной модели. |
| $\mathbf{x}_t$ | Зашумленное изображение во временном шаге $t$ в диффузионном процессе. |
| $\mathbf{\epsilon}$ | Вектор истинного шума, выборка из стандартного нормального распределения. |
| $\mathbf{\epsilon}_\theta(\mathbf{x}_t, t, \mathbf{c})$ | Сеть предсказания шума (параметризованная $\theta$) условной диффузионной модели. |
| $\theta$ | Обучаемые параметры сети предсказания шума. |
| $\mathcal{L}_{null}$ | Функция потерь для этапа восстановления нулевого пространства, обеспечивающая согласованность в пространстве измерений. |
| $\mathbb{E}$ | Оператор математического ожидания. |
| $t$ | Временной шаг в диффузионном процессе. |
| $\mathcal{N}(0,1)$ | Стандартное нормальное распределение. |
| $\| \cdot \|^2$ | Квадрат L2-нормы. |
| $\mathcal{L}_{MSE}$ | Среднеквадратичная ошибка (MSE). |
| $\mathcal{L}_{LPIPS}$ | Потери сходства патчей изображений, полученные с помощью LPIPS. |
Определение проблемы и ограничения
Формулировка основной проблемы и дилемма
Основная проблема, рассматриваемая в данной статье, заключается в реконструкции фотореалистичных и согласованных изображений из измерений безлинзовой камеры.
Вход/Текущее состояние:
Отправной точкой является необработанное, мультиплексированное измерение $\hat{y} \in \mathbb{R}^{N^2}$, полученное безлинзовой камерой. Это измерение обычно размыто, неузнаваемо и лишено высокочастотных деталей. Математически процесс безлинзовой визуализации может быть сформулирован как линейное преобразование исходной сцены $x \in \mathbb{R}^{M^2}$ с добавлением шума датчика $n$:
$$ \hat{y} = Ax + n $$
Здесь $A \in \mathbb{R}^{N^2 \times M^2}$ — матрица преобразования безлинзовой системы визуализации, которая кодирует, как свет из каждой точки сцены вносит вклад в каждый пиксель датчика. Предыдущие методы часто упрощают этот сложный процесс как свертку с одной, инвариантной к сдвигу функцией рассеяния точки (PSF), т.е. $y = h * x$.
Желаемый конечный результат (целевое состояние):
Желаемым конечным результатом является реконструированное изображение $x$, которое является одновременно фотореалистичным и согласованным с исходной сценой.
* Фотореализм подразумевает высококачественное изображение с богатыми, естественно выглядящими деталями, эффективно восстанавливающее высокочастотное содержимое, потерянное во время безлинзовой съемки.
* Согласованность означает, что содержимое реконструированного изображения должно точно соответствовать исходной сцене, удовлетворяя условию $Ax = y$ (где $y$ — измерение без шума).
Утерянное звено или математический пробел:
Точным утерянным звеном является способность точно моделировать сложную, пространственно-изменяющуюся природу безлинзового процесса визуализации (представленного $A$) и эффективно восстанавливать как низкочастотные (критичные для согласованности), так и высокочастотные (критичные для фотореализма) компоненты сцены из деградировавшего измерения. Статья использует разложение на пространство образов и нулевое пространство для преодоления этого пробела. Любое изображение $x$ может быть разложено на две ортогональные компоненты:
$$ x = A^\dagger Ax + (I - A^\dagger A)x $$
где $A^\dagger Ax$ — компонента пространства образов (низкочастотное содержимое, непосредственно восстанавливаемое из измерений, обеспечивающее согласованность), а $(I - A^\dagger A)x$ — компонента нулевого пространства (высокочастотные детали, потерянные в процессе визуализации, критичные для фотореализма). Цель состоит в том, чтобы сначала точно реконструировать содержимое пространства образов, а затем обогатить его содержимым нулевого пространства с использованием генеративных априорных данных, сохраняя при этом согласованность.
Дилемма (болезненный компромисс):
Основная дилемма, которая поставила в тупик предыдущих исследователей, — это болезненный компромисс между достижением высокого визуального качества (фотореализма) и поддержанием согласованности данных (точности исходной сцены).
* Традиционные алгоритмы реконструкции (например, WienerDeconv) отдают приоритет согласованности данных, производя изображения, которые соответствуют истинным данным, но часто размыты и значительно деградированы по визуальному качеству, лишены мелких деталей. Они не могут восстановить высокочастотную информацию.
* Алгоритмы генеративной реставрации (например, использующие диффузионные модели, такие как DiffBIR) могут вводить богатые, фотореалистичные детали и значительно улучшать визуальное качество. Однако они часто "изменяют содержимое изображения или вставляют несуществующие объекты", тем самым нарушая согласованность с фактической сценой. Например, они могут генерировать неправильные формы или поддельные текстуры, как показано на рисунке 1d.
Эта дилемма означает, что улучшение одного аспекта (например, фотореализма) обычно ухудшает другой (согласованность), что делает чрезвычайно трудным одновременное достижение обоих с помощью существующих методов.
Ограничения и режимы отказа
Проблема фотореалистичной и согласованной реконструкции безлинзовых изображений чрезвычайно сложна из-за нескольких жестких, реалистичных ограничений и распространенных режимов отказа предыдущих подходов:
-
Пространственно-изменяющаяся функция рассеяния точки (PSF):
- Физическое ограничение: В отличие от традиционных камер с линзами, безлинзовые системы не имеют фиксированной, инвариантной к сдвигу PSF по всему полю зрения (FoV). PSF значительно меняется в зависимости от угла падающего света, особенно на периферии.
- Вычислительное ограничение: Большинство существующих алгоритмов реконструкции упрощают процесс формирования изображения, предполагая инвариантную к сдвигу PSF, что неточно. Моделирование истинной пространственно-изменяющейся PSF является вычислительно затратным, поскольку полная матрица преобразования $A$ "слишком велика для вычисления" напрямую для реальных систем. Это упрощение приводит к заметной деградации и артефактам в реконструированных изображениях, особенно на границах, как показано на рисунке 4d.
-
Потеря высокочастотной информации:
- Физическое ограничение: Процесс безлинзового кодирования, при котором свет модулируется маской, действует как фильтр нижних частот. Это неизбежно приводит к значительной потере высокочастотных деталей из сцены, делая необработанные измерения размытыми и неоднозначными.
- Ограничение на основе данных: Восстановление этих потерянных высокочастотных деталей (содержимого "нулевого пространства") требует сильных априорных данных. Без достаточных и точных априорных данных алгоритмы испытывают трудности с реконструкцией фотореалистичных изображений, часто приводя к визуально деградированным результатам или, при наивном использовании генеративных моделей, к галлюцинации несуществующих деталей, нарушающих точность.
-
Вычислительная сложность пространственно-изменяющейся деконволюции:
- Вычислительное ограничение: Хотя пространственно-изменяющаяся деконволюция необходима для точной реконструкции, предыдущие методы в этой области "часто медленны, вычислительно затратны и приводят к низкому качеству изображения, особенно в сложных системах".
- Нагрузка калибровки: Многие подходы к многофильтровой деконволюции требуют "тщательной калибровки PSF в нескольких точках", что является трудоемким и трудоемким процессом, делающим их непрактичными для широкого использования. Статья направлена на преодоление этого путем автоматического обучения вариаций на основе одной начальной PSF.
-
Поддержание точности данных с помощью генеративных априорных данных:
- Логическое ограничение: Генеративные модели, хотя и мощны для галлюцинации деталей, по своей сути работают, создавая новую информацию. Основной режим отказа заключается в том, что они склонны "изменять содержимое изображения или вставлять несуществующие объекты", тем самым нарушая фундаментальное требование согласованности, согласно которому реконструированное изображение должно соответствовать фактическим измерениям. Задача состоит в том, чтобы направлять эти генеративные модели для создания реалистичных деталей, которые согласованы с лежащими в основе данными.
-
Задержка в реальном времени (будущее ограничение):
- Вычислительное ограничение: Хотя это и не является прямым ограничением, преодоленным в данной статье, авторы признают, что "двухэтапный характер PhoCoLens и время выборки диффузионной модели препятствуют его применимости в реальном времени". Это подразумевает, что для приложений, требующих немедленной обратной связи, таких как видео в реальном времени или клиническая визуализация, текущие вычислительные накладные расходы предлагаемого метода представляют собой значительное препятствие.
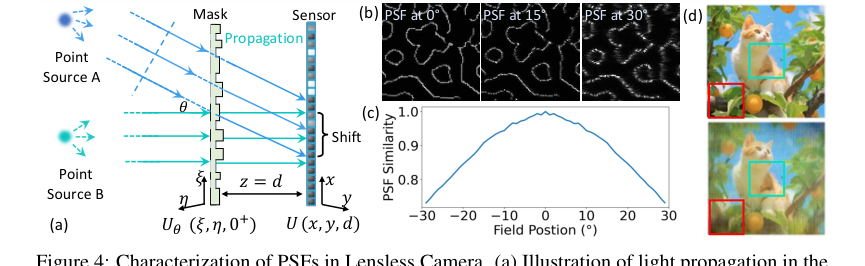 Figure 4. Characterization of PSFs in Lensless Camera. (a) Illustration of light propagation in the lensless camera: two point sources A and B at infinity emitting parallel light beams. Source A emits at angle θ relative to the optical axis, causing a PSF shift on the sensor plane This PSF shift depends on both the incident angle θ and the distance d between the sensor and the mask. (b) Simulated PSFs for light sources at angles of 0°, 15°, and 30°. (c) Inner product similarity between the on-axis PSF and off-axis PSFs at different field positions. (d) Reconstruction using PSF at 0°, degradation is more significant at the periphery (red box) than the center (green box)
Figure 4. Characterization of PSFs in Lensless Camera. (a) Illustration of light propagation in the lensless camera: two point sources A and B at infinity emitting parallel light beams. Source A emits at angle θ relative to the optical axis, causing a PSF shift on the sensor plane This PSF shift depends on both the incident angle θ and the distance d between the sensor and the mask. (b) Simulated PSFs for light sources at angles of 0°, 15°, and 30°. (c) Inner product similarity between the on-axis PSF and off-axis PSFs at different field positions. (d) Reconstruction using PSF at 0°, degradation is more significant at the periphery (red box) than the center (green box)
Почему такой подход
Неизбежность выбора
Авторы PhoCoLens столкнулись с фундаментальной дилеммой в безлинзовой визуализации: как достичь как высокого визуального качества (фотореализма), так и точного представления исходной сцены (согласованности). Традиционные передовые (SOTA) методы, такие как стандартные методы деконволюции, например WienerDeconv, оказались недостаточными, поскольку они производили изображения со значительно деградировавшим визуальным качеством, лишенные богатых деталей, необходимых для фотореализма (рис. 1b). В то время как обучаемые подходы, представленные FlatNet-gen, улучшали визуальное качество, они все еще испытывали трудности с восстановлением критически важных высокочастотных деталей, что приводило к менее резким и менее реалистичным изображениям (рис. 1c).
Критическим осознанием того, что традиционные методы недостаточны, стало наблюдение авторов, что даже передовые генеративные модели, такие как DiffBIR, которые отлично справляются с введением фотореалистичных деталей, часто делали это ценой согласованности. Эти модели часто изменяли содержимое изображения или вводили несуществующие объекты, такие как клюв неправильной формы или ненастоящие листья (рис. 1d), тем самым нарушая точность исходных данных. Это указывало на то, что чисто генеративный подход, хотя и визуально привлекательный, не являлся жизнеспособным единственным решением для приложений, где точность исходной сцены имеет первостепенное значение.
Более того, значительным ограничением, выявленным в существующих алгоритмах реконструкции, было их упрощение процесса безлинзовой визуализации. Большинство методов предполагали инвариантную к сдвигу функцию рассеяния точки (PSF), рассматривая визуализацию как простую свертку. Однако авторы признали, что в реальных безлинзовых системах PSF по своей природе пространственно-изменяются, особенно под разными углами падения (рис. 4a, 4b, 4c). Это несоответствие между предполагаемой инвариантной к сдвигу PSF и фактической пространственно-изменяющейся PSF приводило к существенным неточностям, особенно на периферии поля зрения, где сходство реконструированного изображения с исходной сценой заметно снижалось. Эта фундаментальная физическая реальность делала традиционные сверточные модели по своей сути непригодными для точной безлинзовой реконструкции по всему полю зрения.
Сравнительное превосходство
PhoCoLens достигает качественного и количественного превосходства благодаря своей новой двухэтапной архитектуре, которая структурно решает основные проблемы безлинзовой визуализации. Ключевое структурное преимущество заключается в его фреймворке разложения на пространство образов и нулевое пространство. Эта теоретическая основа позволяет методу разделить проблему на две ортогональные компоненты: одна сосредоточена на согласованности данных (пространство образов), а другая — на фотореализме (нулевое пространство). Это является значительным преимуществом по сравнению с предыдущими методами, которые пытались решить обе задачи одновременно, часто приводя к компромиссам.
- Пространственно-изменяющаяся деконволюция (SVDeconv) для пространства образов: В отличие от предыдущих методов, которые предполагают одну, инвариантную к сдвигу PSF, SVDeconv учится адаптироваться к пространственным вариациям PSF по полю зрения камеры в режиме, управляемом данными. Это значительное структурное улучшение, поскольку оно более точно моделирует сложный процесс прямого формирования изображения. Это приводит к превосходной реконструкции структурной целостности и низкочастотных деталей, особенно на периферии изображения, где другие методы терпят неудачу (рис. 2, рис. 4d). Таблица 2 количественно демонстрирует превосходную производительность SVDeconv в реконструкции пространства образов по сравнению с другими методами деконволюции.
- Условная диффузия нулевого пространства для фотореализма: Второй этап использует предварительно обученную диффузионную модель, но критически важно, что он обуславливает этот генеративный процесс низкочастотным содержимым, полученным на первом этапе. Это гарантирует, что, хотя высокочастотные детали добавляются для фотореализма, они остаются согласованными с лежащей в основе структурой, установленной реконструкцией пространства образов. Этот подход позволяет избежать подводных камней чисто генеративных моделей (таких как DiffBIR), которые вводят артефакты или изменяют содержимое, как показано на рисунке 1d. Механизм обусловливания является структурной защитой, которая поддерживает точность при улучшении визуального качества.
Количественно PhoCoLens демонстрирует подавляющее превосходство. Как показано в Таблице 1, он последовательно достигает наилучшего баланса между метриками точности (PSNR, SSIM, LPIPS) и метриками визуального качества (ManIQA, ClipIQA, MUSIQ) на наборах данных PhlatCam и DiffuserCam. Например, на PhlatCam PhoCoLens достигает показателя MUSIQ 62.20, что значительно выше, чем у FlatNet+DiffBIR (57.13), при этом сохраняя лучший LPIPS (0.215 против 0.391). Это указывает на метод, который не просто немного лучше, а структурно разработан для превосходства над предыдущими золотыми стандартами, решая их присущие ограничения.
Соответствие ограничениям
Выбранный двухэтапный подход PhoCoLens идеально соответствует двойным ограничениям достижения как фотореализма, так и согласованности в безлинзовой визуализации, одновременно решая лежащие в основе физические проблемы.
- Решение проблемы пространственно-изменяющихся PSF для согласованности: Жесткое требование точной реконструкции по всему полю зрения, несмотря на пространственно-изменяющийся характер безлинзовых PSF, напрямую удовлетворяется SVDeconv на первом этапе. Обучаясь и адаптируясь к этим пространственным вариациям, SVDeconv гарантирует, что низкочастотное содержимое (пространство образов) реконструируется с высокой точностью и структурной целостностью, закладывая согласованную основу для финального изображения. Это идеальное "слияние" физической реальности проблемы и адаптивного деконволюционного свойства решения.
- Использование генеративных априорных данных для фотореализма при сохранении согласованности: Ограничение достижения фотореализма, которое требует богатых высокочастотных деталей, часто теряемых при безлинзовой съемке, решается диффузионной моделью нулевого пространства на втором этапе. Однако критическое соответствие здесь заключается в том, как эта генеративная мощность используется. Вместо слепой генерации деталей, диффузионная модель обусловливается согласованным низкочастотным выходом с первого этапа. Это гарантирует, что добавленные высокочастотные детали (из нулевого пространства) улучшают фотореализм, не нарушая установленную ранее согласованность. Математическая структура разложения на пространство образов и нулевое пространство явно гарантирует, что компонента нулевого пространства, при добавлении, не изменяет измерение $y$, тем самым сохраняя согласованность ($A(x - A^\dagger Ax) = 0$). Это идеальное соответствие, когда генеративная способность ограничивается требованием согласованности.
- Преодоление недостаточных априорных данных: Проблема недостаточных априорных данных в традиционных методах, которая приводила к деградировавшему визуальному качеству, решается интеграцией мощной предварительно обученной диффузионной модели. Эта модель предоставляет сильный генеративный априорный источник для реалистичных текстур изображений, но ее применение в рамках фреймворка нулевого пространства гарантирует, что она руководствуется фактическими данными сцены, избегая произвольной галлюцинации.
Отклонение альтернатив
Статья явно и неявно отклоняет несколько альтернативных подходов на основе их присущих ограничений в достижении двойных целей фотореализма и согласованности:
- Традиционная деконволюция (например, WienerDeconv): Эти методы были отклонены в первую очередь из-за их неспособности производить фотореалистичные результаты. Хотя они поддерживают некоторую согласованность данных, их визуальное качество "значительно деградировано" (Раздел 1, Рисунок 1b), что делает их непригодными для высококачественной реконструкции изображений.
- Обучаемая деконволюция (например, FlatNet-gen): Хотя и являются улучшением по сравнению с традиционными методами, эти подходы, как было установлено, "часто не могут восстановить высокочастотные детали" (Раздел 1, Рисунок 1c). Это ограничение означало, что они не могли достичь желаемого уровня фотореализма, что приводило к отсутствию резкости и мелких текстур.
- Генеративные модели с прямыми априорными данными (например, DiffBIR): Эти методы, хотя и отлично справляются с введением богатых деталей и улучшением визуального качества, были отклонены, поскольку они "могут также изменять содержимое изображения или вставлять несуществующие объекты, нарушая согласованность" (Раздел 1, Рисунок 1d). Авторы предоставляют четкие примеры искаженных объектов (например, неправильной формы клюва) и поддельных текстур, демонстрируя, что их фотореализм достигается за неприемлемую цену точности.
- Методы, предполагающие инвариантные к сдвигу PSF: Основным неявным отклонением является любой метод, который упрощает процесс безлинзовой визуализации, предполагая инвариантную к сдвигу PSF. Как подробно описано в Разделе 3.2 и проиллюстрировано на Рисунке 4d, это предположение приводит к "неточностям" и "заметному снижению реконструированного сходства с исходной сценой, особенно на периферии поля зрения". Этап SVDeconv PhoCoLens был специально разработан для преодоления этого фундаментального недостатка, делая любой инвариантный к сдвигу подход по своей сути уступающим для реальных безлинзовых систем.
- Диффузионные модели без обучения (например, DDNM+): Хотя и упомянуты как категория обратной визуализации с диффузионными моделями, статья интегрирует "обучение с учителем с теоретическим фреймворком, основанным на разложении на пространство образов и нулевое пространство" (Раздел 2). Это подразумевает отклонение чисто без обучения методов для данной конкретной проблемы, вероятно, потому, что им может не хватать тонкой настройки или гарантий согласованности, которые обеспечивает обучение с учителем в рамках разложения. Таблица 3 показывает, что DDNM+ значительно уступает PhoCoLens как по метрикам точности, так и по визуальному качеству для восстановления нулевого пространства.
 Figure 1. We introduce PhoCoLens, a lensless reconstruction algorithm that achieves both better visual quality and consistency to the ground truth than existing methods. Our method recovers more details compared to traditional reconstruction algorithms (b) and (c), and also maintains better fidelity to the ground truth compared to the generative approach (d)
Figure 1. We introduce PhoCoLens, a lensless reconstruction algorithm that achieves both better visual quality and consistency to the ground truth than existing methods. Our method recovers more details compared to traditional reconstruction algorithms (b) and (c), and also maintains better fidelity to the ground truth compared to the generative approach (d)
Математический и логический механизм
Мастер-уравнение
Основной математический механизм, лежащий в основе данной статьи, особенно для достижения фотореализма и согласованности на втором этапе реконструкции, — это оптимизационная цель для диффузионной модели нулевого пространства. Это уравнение гарантирует, что высокочастотные детали, генерируемые диффузионной моделью, остаются согласованными с лежащей в основе физикой безлинзовой системы визуализации. Оно формально выражается как:
$$ \min_\theta \mathcal{L}_{null} = \min_\theta \mathbb{E}_{\mathbf{x},t,\mathbf{c},\mathbf{\epsilon} \sim \mathcal{N}(0,1)} \left[ \left\| A(\mathbf{\epsilon}_\theta(\mathbf{x}_t, t, \mathbf{c}) - \mathbf{\epsilon}) \right\|^2 \right] $$
Это уравнение выведено из фундаментального принципа разложения на пространство образов и нулевое пространство, который утверждает, что любое изображение $\mathbf{x}$ может быть разделено на компоненту пространства образов $A^\dagger A \mathbf{x}$ (представляющую информацию, непосредственно наблюдаемую камерой) и компоненту нулевого пространства $(I - A^\dagger A) \mathbf{x}$ (представляющую детали, потерянные в процессе визуализации, но критичные для фотореализма). Цель здесь состоит в том, чтобы гарантировать, что остаточное содержимое, добавляемое генеративной моделью, которое в идеале должно находиться в нулевом пространстве, не нарушает согласованность с прямой моделью формирования изображения.
Поэлементный анализ
Давайте разберем это уравнение по частям, чтобы понять его роль и значение:
- $\min_\theta$: Это стандартный оператор минимизации, указывающий на то, что цель состоит в нахождении оптимального набора параметров $\theta$ для нейронной сети.
- $\theta$: Это обучаемые параметры сети предсказания шума $\mathbf{\epsilon}_\theta$. Эта сеть является моделью глубокого обучения, обычно U-Net, которая учится предсказывать шумовую компоненту в зашумленном изображении.
- $\mathcal{L}_{null}$: Этот символ представляет функцию потерь, специально разработанную для этапа восстановления нулевого пространства. Ее минимизация направляет диффузионную модель на генерацию согласованных и фотореалистичных деталей.
- $\mathbb{E}_{\mathbf{x},t,\mathbf{c},\mathbf{\epsilon} \sim \mathcal{N}(0,1)}$: Это обозначает оператор математического ожидания, что означает, что мы усредняем потери по нескольким случайным выборкам.
- $\mathbf{x}$: Это истинное, чистое изображение, которое модель стремится реконструировать. Это идеальная цель.
- $t$: Это представляет временной шаг в прямой диффузионной модели, указывающий, сколько шума было добавлено к изображению. Диффузионные модели работают путем постепенного добавления шума, а затем обучения обращению этого процесса.
- $\mathbf{c}$: Это условие для диффузионной модели, в частности, содержимое пространства образов $A^\dagger A \mathbf{x}$, реконструированное на первом этапе. Оно предоставляет низкочастотную, согласованную информацию, которой должна придерживаться генеративная модель.
- $\mathbf{\epsilon} \sim \mathcal{N}(0,1)$: Это фактический вектор шума, выборка из стандартного нормального распределения, который добавляется к чистому изображению $\mathbf{x}$ для создания зашумленного изображения $\mathbf{x}_t$.
- $\| \cdot \|^2$: Это квадрат L2-нормы, распространенный выбор для функций потерь в задачах регрессии. Он измеряет квадрат евклидова расстояния между двумя векторами, наказывая большие ошибки более значительно. Авторы выбрали его, потому что это простой и эффективный способ количественно оценить разницу между предсказанным шумом и фактическим шумом.
- $A$: Это матрица преобразования безлинзовой системы визуализации. Она математически описывает, как сцена $\mathbf{x}$ преобразуется в измерение $\mathbf{y}$ камерой (т.е. $\mathbf{y} = A\mathbf{x}$). Ее роль здесь критична: она проецирует ошибку предсказания шума в пространство измерений.
- $\mathbf{\epsilon}_\theta(\mathbf{x}_t, t, \mathbf{c})$: Это выход нейронной сети, параметризованной $\theta$. Получив зашумленное изображение $\mathbf{x}_t$, текущий временной шаг $t$ и условие пространства образов $\mathbf{c}$, эта сеть предсказывает шумовую компоненту $\mathbf{\epsilon}$, которая была добавлена к исходному изображению.
- $(\mathbf{\epsilon}_\theta(\mathbf{x}_t, t, \mathbf{c}) - \mathbf{\epsilon})$: Этот член представляет собой ошибку в предсказании шума. Сеть пытается сделать свой прогноз $\mathbf{\epsilon}_\theta$ как можно ближе к истинному шуму $\mathbf{\epsilon}$.
- $A(\mathbf{\epsilon}_\theta(\mathbf{x}_t, t, \mathbf{c}) - \mathbf{\epsilon})$: Это самая важная часть потерь. Вместо простого минимизации разницы между предсказанным и фактическим шумом, авторы применяют матрицу преобразования $A$ к этой разнице. Это гарантирует, что эффект ошибки предсказания шума, при проецировании в пространство измерений, минимизируется. По сути, это заставляет генеративную модель предсказывать шум, который, если бы он был "сфотографирован" безлинзовой камерой, привел бы к нулевой ошибке измерения. Это напрямую обеспечивает требование согласованности, согласно которому любые сгенерированные детали (которые исходят из нулевого пространства) не должны изменять измерение, которое было бы получено из содержимого пространства образов. Использование умножения на $A$ здесь, а не, скажем, сложения, является фундаментальным для проецирования ошибки в домен измерений, в соответствии с физической прямой моделью.
Пошаговый поток
Метод PhoCoLens работает в хитроумном двухэтапном конвейере, подобном сложному сборочному конвейеру, где каждый этап уточняет реконструкцию изображения с конкретными целями.
Этап 1: Реконструкция пространства образов с пространственно-изменяющейся деконволюцией (SVDeconv)
- Входное необработанное измерение: Процесс начинается с необработанного, размытого и зашумленного безлинзового измерения $\hat{y}$. Это начальная абстрактная точка данных, сложный дифракционный узор, захваченный датчиком.
- Многофильтровая деконволюция: Это измерение $\hat{y}$ поступает в сеть SVDeconv. Здесь это не просто одна деконволюция, а множество. Сеть поддерживает набор обучаемых ядер функции рассеяния точки (PSF) $K \times K$, $p^{(i)}$, каждое из которых специализировано для определенной пространственной области изображения.
- Измерение $\hat{y}$ и каждое ядро $p^{(i)}$ сначала преобразуются в частотную область с помощью дискретного преобразования Фурье ($\mathcal{F}$).
- В частотной области выполняется поэлементное умножение (произведение Адамара $\odot$) между преобразованным измерением и каждым преобразованным ядром. Это эквивалент деконволюции в частотной области, эффективно "отменяющий" размытие, вызванное безлинзовой системой для данной конкретной области.
- Затем каждый результат преобразуется обратно в пространственную область с помощью обратного дискретного преобразования Фурье ($\mathcal{F}^{-1}$), давая $K \times K$ промежуточных деконволюционных изображений $x^{(i)}_e$. Каждое $x^{(i)}_e$ является предварительной реконструкцией, оптимизированной для определенной точки поля.
- Пространственно-изменяющаяся интерполяция: Эти $K \times K$ промежуточных изображений затем бесшовно сшиваются. Для каждого пикселя $(u, v)$ в конечном выводе вычисляется взвешенная сумма соответствующих пикселей из всех изображений $x^{(i)}_e$. Веса $w_i(u, v)$ определяются обратным евклидовым расстоянием от пикселя $(u, v)$ до центра $i$-го ядра PSF. Это означает, что значение пикселя преимущественно зависит от деконволюционного фильтра, который пространственно ближе всего к нему, создавая единое изображение $X_{int}$, которое адаптируется к пространственно-изменяющейся природе PSF.
- Уточняющая U-Net: Интерполированное изображение $X_{int}$ затем проходит через U-Net. Эта нейронная сеть действует как финальная команда по очистке, удаляя любые оставшиеся шумы и артефакты, и далее уточняя изображение для получения содержимого пространства образов $\mathbf{c}$. Это $\mathbf{c}$ — согласованное, низкочастотное представление сцены, готовое для следующего этапа.
Этап 2: Восстановление содержимого нулевого пространства с помощью условной диффузии
- Генерация зашумленного изображения и обусловливание: Содержимое пространства образов $\mathbf{c}$ с Этапа 1 теперь используется в качестве условия. Одновременно истинное изображение $\mathbf{x}$ постепенно искажается путем добавления случайного шума $\mathbf{\epsilon}$ в течение нескольких временных шагов $t$, в результате чего получается зашумленное изображение $\mathbf{x}_t$.
- Условное предсказание шума: Зашумленное изображение $\mathbf{x}_t$, текущий временной шаг $t$ и условие пространства образов $\mathbf{c}$ подаются в сеть предсказания шума условной диффузионной модели $\mathbf{\epsilon}_\theta$.
- Условие $\mathbf{c}$ не просто конкатенируется; оно глубоко интегрируется. Условный энкодер извлекает многомасштабные признаки из $\mathbf{c}$, которые затем модулируют промежуточные карты признаков внутри остаточных блоков сети $\mathbf{\epsilon}_\theta$. Это гарантирует, что генеративный процесс тесно руководствуется согласованной низкочастотной информацией.
- Сеть $\mathbf{\epsilon}_\theta$ обрабатывает эти входные данные и выдает свою лучшую догадку относительно шумовой компоненты $\mathbf{\epsilon}$, которая была изначально добавлена для создания $\mathbf{x}_t$.
- Обеспечение согласованности (расчет потерь): Предсказанный шум $\mathbf{\epsilon}_\theta$ сравнивается с фактическим шумом $\mathbf{\epsilon}$. Ключевым шагом является применение матрицы преобразования $A$ к их разнице, $A(\mathbf{\epsilon}_\theta - \mathbf{\epsilon})$. Квадрат L2-нормы этого результата формирует потери $\mathcal{L}_{null}$. Это гарантирует, что любые расхождения между предсказанным и фактическим шумом, при рассмотрении через прямую модель безлинзовой камеры, минимизируются. По сути, это заставляет генеративную модель предсказывать шум, который, будучи "сфотографированным" безлинзовой камерой, приведет к нулевой ошибке измерения. Это напрямую обеспечивает требование согласованности, согласно которому любые сгенерированные детали (которые исходят из нулевого пространства) не должны изменять измерение, которое было бы получено из содержимого пространства образов.
- Итеративное шумоподавление (инференс): Во время инференса диффузионная модель начинает со случайного шумового изображения. За множество временных шагов она итеративно использует обученную сеть $\mathbf{\epsilon}_\theta$ для предсказания и вычитания шума, постепенно преобразуя случайный шум в фотореалистичное изображение. На каждом шаге содержимое пространства образов $\mathbf{c}$ непрерывно направляет генерацию, гарантируя, что добавленные высокочастотные детали согласованы с низкочастотной структурой, в конечном итоге давая финальное, высококачественное реконструированное изображение.
Динамика оптимизации
Система PhoCoLens обучается и сходится посредством двухсторонней стратегии оптимизации, каждая из которых настроена на соответствующий этап.
Этап 1: Оптимизация SVDeconv
Первый этап, SVDeconv, обучается для реконструкции содержимого пространства образов $A^\dagger A \mathbf{x}$. Его оптимизация включает обучение параметров многофильтровой деконволюции и уточняющей U-Net.
- Функция потерь: Цель обучения для SVDeconv — это комбинация потерь среднеквадратичной ошибки (MSE) и потерь сходства патчей изображений, полученных с помощью LPIPS (Learned Perceptual Image Patch Similarity).
- Потери MSE: Это пиксельная потеря точности, направленная на минимизацию квадратичной разницы между реконструированным содержимым пространства образов и истинным содержимым пространства образов. Это гарантирует, что модель точно восстанавливает низкочастотную информацию.
- Потери LPIPS: Это перцептивная потеря, которая измеряет сходство между изображениями в пространстве признаков, изученном предварительно обученной глубокой нейронной сетью. Это критически важно для обеспечения того, чтобы реконструированные изображения выглядели визуально приятными и реалистичными для человеческих наблюдателей, даже если значения пикселей не совпадают идеально.
- Поведение градиента: Градиенты как от потерь MSE, так и от LPIPS обратно распространяются через уточняющую U-Net и, что важно, через дифференцируемый слой многофильтровой деконволюции. Это позволяет сети изучать оптимальные ядра PSF $p^{(i)}$, которые лучше всего адаптируются к пространственным вариациям в безлинзовой системе визуализации. Градиенты направляют ядра для эффективного "отмены" пространственно-изменяющегося размытия.
- Обновления состояния: Оптимизатор Adam используется для итеративного обновления обучаемых ядер PSF и параметров U-Net. Скорости обучения тщательно выбираются (например, 4e-9 для ядер деконволюции PhlatCam, 3e-5 для U-Net) для обеспечения стабильной и эффективной сходимости. Модель учится автоматически адаптироваться к пространственным вариациям PSF в режиме, управляемом данными, устраняя необходимость в утомительной калибровке PSF в нескольких точках.
Этап 2: Оптимизация диффузионной модели нулевого пространства
Второй этап, условная диффузионная модель, оптимизируется для восстановления содержимого нулевого пространства, добавляя фотореалистичные высокочастотные детали при сохранении согласованности.
- Функция потерь: Основная потеря для этого этапа — $\mathcal{L}_{null}$, как определено мастер-уравнением. Эта потеря уникальна, поскольку она применяет матрицу преобразования $A$ к ошибке предсказания шума.
- Формирование ландшафта потерь: Применение $A$ к члену ошибки $A(\mathbf{\epsilon}_\theta - \mathbf{\epsilon})$ глубоко формирует ландшафт потерь. Оно создает ландшафт, где минимум соответствует состоянию, в котором сгенерированные высокочастотные детали (полученные из предсказанного шума) "невидимы" для прямой модели безлинзовой камеры. Другими словами, любые детали, добавленные диффузионной моделью, должны находиться в нулевом пространстве $A$, что означает, что они не изменяют измерение $\mathbf{y}$ при проецировании через $A$. Это предотвращает галлюцинацию генеративной моделью деталей, которые противоречат физическим измерениям, тем самым обеспечивая согласованность данных.
- Поведение градиента: Градиенты вычисляются через все выражение, включая оператор $A$, и обратно распространяются через сеть предсказания шума $\mathbf{\epsilon}_\theta$. Эти градиенты направляют $\mathbf{\epsilon}_\theta$ на обучение предсказанию шума таким образом, чтобы результирующее реконструированное изображение, пропущенное через прямую модель формирования изображения $A$, оставалось согласованным с низкочастотным содержимым пространства образов $\mathbf{c}$. Это сложный способ гарантировать, что выход генеративной модели соответствует физическим ограничениям безлинзовой системы.
- Обновления состояния: Диффузионная модель обучается в течение значительного количества эпох (например, 200 эпох). В статье упоминается использование предварительно обученной диффузионной модели (например, Stable Diffusion) с замороженными весами и обучение в основном дополнительных модулей обусловливания. Эта стратегия позволяет модели использовать мощные генеративные возможности больших предварительно обученных моделей, одновременно донастраивая их для конкретной задачи и требований согласованности безлинзовой визуализации. Механизм обусловливания, который модулирует внутренние карты признаков на основе $\mathbf{c}$, итеративно обновляется для обеспечения того, чтобы сгенерированное высокочастотное содержимое было согласовано с низкочастотной структурой, предоставленной первым этапом. Эта итеративная доработка обусловливания гарантирует, что финальный результат будет как фотореалистичным, так и согласованным.
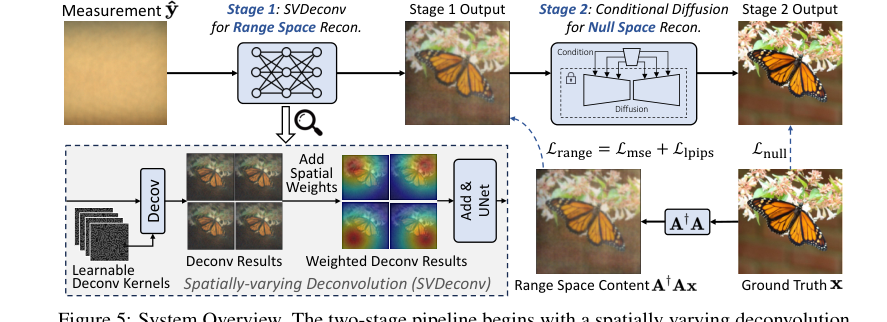 Figure 5. System Overview. The two-stage pipeline begins with a spatially varying deconvolution network mapping lensless measurements to range space. Then a conditional diffusion model for null space recovery refines details using the first stage output, achieving the final reconstruction
Figure 5. System Overview. The two-stage pipeline begins with a spatially varying deconvolution network mapping lensless measurements to range space. Then a conditional diffusion model for null space recovery refines details using the first stage output, achieving the final reconstruction
Результаты, ограничения и заключение
Экспериментальный дизайн и базовые модели
Для строгого подтверждения PhoCoLens авторы разработали комплексную экспериментальную установку, противопоставив свой новый двухэтапный подход разнообразному набору "жертвенных" базовых моделей на двух различных наборах данных реальной безлинзовой визуализации.
Эксперименты использовали две популярные системы безлинзовых камер:
- Набор данных PhlatCam [17]: Состоящий из 10 000 изображений по 1000 классам, измененных до размера 384x384 пикселей, с необработанными снимками размером 1280x1480 пикселей. Для обучения использовалось разделение на 990 классов, а для тестирования — на 10.
- Набор данных DiffuserCam [27]: Состоящий из 25 000 пар изображений (безлинзовое измерение + истинные данные), снятых одновременно. Эти изображения, изначально размером 1080x1920 пикселей, были уменьшены до 270x480, а затем обрезаны до конечного разрешения 210x380 пикселей. Набор данных был разделен: 24 000 для обучения и 1000 для тестирования.
Чтобы окончательно доказать свои математические утверждения, оценка использовала двойной набор метрик, оценивающих как согласованность (точность), так и фотореализм (визуальное качество):
- Метрики полного сравнения для согласованности: Пиковое отношение сигнал/шум (PSNR), Индекс структурного сходства (SSIM) [42] и Потери сходства патчей изображений, полученные с помощью LPIPS (Learned Perceptual Image Patch Similarity) [51]. Более низкие значения LPIPS указывают на лучшую точность.
- Метрики без сравнения для фотореализма: Многомерная сеть внимания для оценки качества изображений без сравнения (ManIQA) [45], Оценка качества изображений на основе CLIP (ClipIQA) [39] и Многомасштабный трансформер качества изображений (MUSIQ) [16]. Более высокие значения этих метрик обычно указывают на лучшее визуальное качество.
Детали реализации были тщательно изложены для обеспечения воспроизводимости. Сеть SVDeconv использовала ядра PSF 3x3, инициализированные одной калиброванной PSF, и U-Net, адаптированную из существующих архитектур (Le-ADMM-U для DiffuserCam, FlatNet-gen для PhlatCam). Обучение охватывало 100 эпох с размером пакета 5, используя оптимизатор Adam [18]. Были установлены конкретные скорости обучения для U-Net и ядер деконволюции, а также веса потерь MSE и LPIPS (1 и 0.05 соответственно). Для этапа диффузии нулевого пространства выход SVDeconv служил входными условиями, и модель обучалась в течение 200 эпох, используя предварительно обученную модель Stable Diffusion [32] с замороженными весами, фокусируясь только на обучении дополнительных модулей обусловливания.
"Жертвы" (базовые модели), с которыми сравнивался PhoCoLens, включали:
- Традиционные методы: WienerDeconv [44] (реконструкция с регуляризацией Тихонова) и ADMM [7] (регуляризация полного вариации).
- Обучаемые методы: Le-ADMM-U [27] (глубокая развернутая сеть), MMCN [49], UPDN [19] (развернутые примально-дуальные сети) и FlatNet-gen [17] (прямая деконволюция).
- Диффузионные методы: DDNM+ [41] (без обучения обратная визуализация с предварительно обученной Stable Diffusion) и FlatNet+DiffBIR [23] (выходы FlatNet-gen, улучшенные предварительно обученной диффузионной моделью слепой реставрации изображений).
Кроме того, авторы провели целенаправленные абляционные исследования, чтобы безжалостно доказать вклад каждого основного компонента:
- Пространственно-изменяющаяся деконволюция (SVDeconv): Сравнение с Le-ADMM-U, SingleDeconv (используя одно ядро) и MultiWienerNet [48] для реконструкции как пространства образов, так и исходного содержимого.
- Диффузия нулевого пространства: Сравнение с условными диффузионными моделями, такими как DiffBIR [23] и StableSR [39], а также с методом обратной визуализации без обучения DDNM+ [41].
- Условия содержимого пространства образов: Абляция, в которой реконструированное содержимое пространства образов первого этапа было заменено выходами WienerDeconv, FlatNet-gen и SVD-OC (SVDeconv, обученный с исходным содержимым) для обусловливания диффузии второго этапа.
Что доказывают доказательства
Представленные в статье доказательства предоставляют окончательные, неоспоримые подтверждения того, что PhoCoLens достигает превосходного баланса фотореализма и согласованности в безлинзовой визуализации, превосходя все базовые модели.
Общее превосходство:
Таблица 1 недвусмысленно демонстрирует доминирование PhoCoLens. На обоих наборах данных PhlatCam и DiffuserCam наш метод последовательно достигает наилучшей производительности почти по всем метрикам полного сравнения (PSNR, SSIM, LPIPS↓) для согласованности и метрикам без сравнения (ManIQA, ClipIQA, MUSIQ) для визуального качества. Например, на PhlatCam PhoCoLens достигает PSNR 22.07, SSIM 0.601 и LPIPS 0.215, значительно превосходя ближайшие лучшие методы, такие как FlatNet-gen (PSNR 20.53, SSIM 0.549, LPIPS 0.375) и FlatNet+DiffBIR (PSNR 19.96, SSIM 0.544, LPIPS 0.391). Эти количественные данные дополнительно подкрепляются качественными сравнениями на рисунках 1, 6 и 7, где реконструкции PhoCoLens визуально наиболее близки к истинным данным, демонстрируя как резкие детали, так и точное содержимое.
Эффективность пространственно-изменяющейся деконволюции (SVDeconv):
Основное утверждение статьи о важности пространственно-изменяющейся деконволюции безжалостно доказано в Таблице 2 и на рисунках 2, 8 и A3. Таблица 2 показывает, что SVDeconv (Наш) последовательно превосходит другие методы деконволюции (Le-ADMM-U, SingleDeconv, MultiWienerNet) в реконструкции как содержимого пространства образов, так и исходного содержимого. Например, на PhlatCam SVDeconv достигает PSNR пространства образов 26.97, что значительно выше, чем у SingleDeconv (25.61). Это важно, поскольку традиционные методы, такие как SingleDeconv, предполагают инвариантную к сдвигу PSF, что неточно в реальных безлинзовых системах. Рисунки 2 и 8 наглядно иллюстрируют это, показывая, что SVDeconv (справа) реконструирует мелкие детали, особенно на периферии, с гораздо большей точностью, чем методы, использующие одно ядро (слева). Красные поля на Рисунке 4d и белые пунктирные поля на Рисунке 8 наглядно демонстрируют, как наш механизм SVDeconv эффективно смягчает артефакты и сохраняет детали в периферийных областях, где вариации PSF наиболее выражены. Рисунок A3 далее укрепляет это, показывая, что выходы SVDeconv сохраняют высокое визуальное соответствие низкочастотной структуре истинных данных, в отличие от FlatNet, который вводит некорректные высокочастотные детали.
Окончательные доказательства диффузии нулевого пространства:
Эффективность нашей диффузии нулевого пространства для фотореализма при сохранении согласованности неоспоримо продемонстрирована в Таблице 3 и на Рисунке 9. Наш метод достигает наивысшего PSNR (22.07), SSIM (0.601) и самого низкого LPIPS (0.215) на PhlatCam для восстановления нулевого пространства, значительно превосходя другие диффузионные подходы, такие как DiffBIR (PSNR 16.21, SSIM 0.432, LPIPS 0.502) и StableSR (PSNR 14.93, SSIM 0.446, LPIPS 0.624). Качественно, Рисунок 9 показывает, что наш метод производит изображения, которые являются как визуально привлекательными, так и точными к исходной сцене, в то время как конкуренты, такие как DiffBIR, могут вводить артефакты или искажать содержимое (например, клюв "неправильной формы" на Рисунке 1d или человеческая рука, перенесенная на одежду на Рисунке 7). Это доказывает, что обусловливание диффузионной модели низкочастотным содержимым с первого этапа эффективно направляет ее на восстановление реалистичных высокочастотных деталей без ущерба для точности.
Влияние условий содержимого пространства образов:
Абляционное исследование условий содержимого пространства образов, обобщенное в Таблице 4 и на Рисунке 10, предоставляет убедительные доказательства важности использования нашего вывода первого этапа в качестве условия. Когда наше реконструированное содержимое пространства образов используется для обусловливания диффузионной модели, это последовательно приводит к лучшей согласованности реконструкции (более высокие PSNR, SSIM, более низкий LPIPS) по сравнению с использованием выходов базовых моделей, таких как WienerDeconv или FlatNet-gen. Это связано с тем, что эти альтернативные условия вводят артефакты, которые препятствуют способности второго этапа точно восстановить исходное изображение. Визуальные улучшения на Рисунке 10 далее подчеркивают, что наш двухэтапный конвейер с тщательно выбранным обусловливанием имеет решающее значение для достижения наблюдаемого превосходного результата.
Ограничения и будущие направления
Хотя PhoCoLens знаменует собой значительный прогресс в безлинзовой визуализации, важно признать его текущие ограничения и рассмотреть направления для будущего развития.
Одним из основных ограничений нашего подхода является его применимость в реальном времени. Двухэтапная архитектура, особенно процесс выборки диффузионной модели на втором этапе, вносит вычислительные накладные расходы, которые в настоящее время препятствуют его использованию в сценариях фото- и видеосъемки в реальном времени. Это распространенная проблема для высококачественных генеративных моделей, и ее решение откроет гораздо более широкий спектр применений для безлинзовых камер.
Кроме того, несмотря на достижение превосходной точности, диффузионная модель, по своей генеративной природе, может по-прежнему вводить высокочастотные детали, которые незначительно отклоняются от исходной сцены, особенно в областях, которые по своей сути гладкие или лишены сложных текстур. Хотя это компромисс ради улучшенного фотореализма, это предполагает, что еще есть возможности для уточнения баланса между генеративной креативностью и строгой точностью данных.
Заглядывая вперед, несколько захватывающих направлений могут далее развить эти выводы:
- Ускорение выборки диффузионной модели: Важным будущим направлением является исследование и внедрение методов для значительного ускорения процесса выборки диффузионной модели. Это может включать изучение более быстрых алгоритмов выборки, методов дистилляции или оптимизаций, учитывающих аппаратное обеспечение. Достижение производительности в реальном времени превратит безлинзовые камеры в жизнеспособные решения для динамических сцен, открывая возможности в таких областях, как автономная навигация, наблюдение и интерактивная визуализация.
- Исследование 3D пространственно-изменяющихся эффектов PSF: Текущая работа в основном сосредоточена на 2D реконструкции изображений. Однако безлинзовые камеры по своей сути захватывают 3D информацию о сцене, закодированную в их сложных дифракционных узорах. Будущие работы могли бы углубиться в моделирование и использование 3D пространственно-изменяющихся функций рассеяния точки (PSF) для реконструкции не только фотореалистичных 2D изображений, но и карт глубины или полных 3D представлений сцены. Это открыло бы двери для новых 3D приложений визуализации с использованием сверхкомпактных устройств, таких как объемная микроскопия или дополненная реальность.
- Адаптивный компромисс между согласованностью и фотореализмом: Текущий метод устанавливает фиксированный баланс между согласованностью и фотореализмом. Будущие исследования могли бы изучить динамические или управляемые пользователем механизмы для регулировки этого компромисса. Например, в медицинской визуализации строгая согласованность может быть первостепенной, в то время как для художественных приложений может быть предпочтительнее больший фотореализм (даже с незначительными отклонениями). Разработка фреймворка, который позволяет динамически взвешивать точность и генеративные априорные данные, могла бы удовлетворить более широкий спектр потребностей пользователей и областей применения.
- Устойчивость к разнообразным условиям визуализации: Хотя тестирование проводилось на двух популярных безлинзовых системах, производительность в экстремальных или новых условиях визуализации (например, очень слабое освещение, высокодинамичные сцены, различные конструкции масок) может быть дополнительно исследована. Повышение устойчивости модели и ее обобщающих способностей к более широкому спектру конструкций безлинзовых камер и факторов окружающей среды было бы ценным вкладом.
- Этические соображения и дизайн, сохраняющий конфиденциальность: Как подчеркивается в разделе о более широком влиянии, распространение небольших, незаметных безлинзовых камер вызывает серьезные опасения по поводу конфиденциальности. Будущие исследования должны быть сосредоточены не только на технических улучшениях, но и на интеграции механизмов сохранения конфиденциальности непосредственно в конвейер визуализации и реконструкции. Это может включать изучение обработки на устройстве для минимизации передачи данных, методов дифференциальной конфиденциальности или разработку безлинзовых систем, которые по своей сути ограничивают объем захватываемой информации для защиты прав конфиденциальности отдельных лиц. Это междисциплинарное усилие, включающее инженеров, этиков и политиков, необходимо для обеспечения ответственного технологического прогресса.
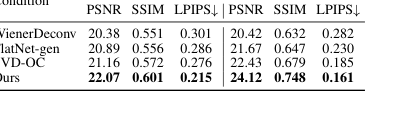 Table 2. Comparison of deconvolution methods for range space reconstruction and original content reconstruction
Table 2. Comparison of deconvolution methods for range space reconstruction and original content reconstruction
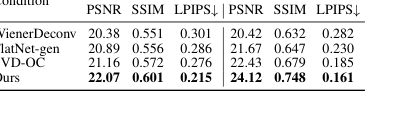 Table 4. Comparison of different diffusion conditions
Table 4. Comparison of different diffusion conditions
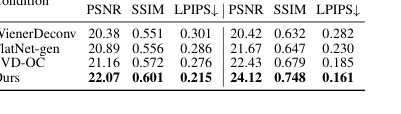 Table 3. Comparison of null space recovery methods
Table 3. Comparison of null space recovery methods