PhoCoLens:无透镜成像中的照片级真实感与一致性重建
New AI reconstructs stunning images from simple sensors, overcoming past limitations.
背景与学术渊源
起源与学术渊源
无透镜成像重建问题的出现,源于创造超紧凑、轻量化且成本效益高的相机的愿望。传统的基于透镜的系统体积庞大且昂贵,限制了其在需要小型化的领域的应用,例如医疗内窥镜或可穿戴技术。历史背景表明,研究人员开始用放置在传感器附近的振幅或相位掩模来调制入射光,以取代传统的透镜,从而显著减小了相机的尺寸和重量。这项创新虽然前景广阔,但也引入了一个新的挑战:没有聚焦透镜,原始传感器测量通常是模糊不清且无法识别的。相机并不直接记录场景,而是将其编码为复杂的衍射图案,这需要复杂的计算算法来恢复原始场景的高质量图像。
迫使作者撰写本文的先前方法的根本限制或“痛点”源于两个主要问题:实现重建图像的照片级真实感和一致性,以及准确建模成像过程。当前算法常常在不准确的前向成像模型和不足的先验知识方面遇到困难,无法重建高质量图像。具体而言:
- 视觉质量差和细节丢失:传统方法,如 WienerDeconv,可以重建与真实情况一致的图像,但视觉质量会显著下降,常常缺乏丰富的细节。基于学习的方法,如 FlatNet-gen,试图提高视觉质量,但经常无法恢复高频细节。
- 与生成先验缺乏一致性:虽然生成恢复算法(例如 DiffBIR)可以注入丰富的细节并提高照片级真实感,但它们常常以牺牲一致性为代价。这些方法可能会改变图像内容或插入不存在的对象,导致重建结果偏离原始场景(例如,鸟嘴形状错误或叶子看起来是假的)。
- 成像模型不准确(空间变化的 PSF):大多数现有的重建算法通过假设一个移不变的点扩展函数(PSF)来简化无透镜成像过程。然而,在实践中,PSF 是空间变化的,尤其是在视场(FoV)的周边区域,入射角会增加。假设的成像模型与实际成像模型之间的不匹配会导致不准确,并导致重建图像与原始场景的相似性明显下降,尤其是在周边区域。这是因为当无透镜掩模和传感器之间的距离非常小时(例如,典型无透镜相机中的 2mm),这通常是这种情况,菲涅尔近似(将光传播模型简化为移不变卷积)会失效。这种关键限制意味着单个反卷积核无法准确地逆转整个图像的模糊。
直观的领域术语
- 无透镜成像:想象一下,用一个没有传统玻璃透镜的相机拍照,只有一个微小的、有图案的窗口(“掩模”)在传感器前面。光线穿过这个窗口时会以独特的方式被扰乱。无透镜成像就是利用巧妙的计算机程序来“解扰”这些光线并重建清晰的图像,即使没有使用透镜来聚焦它。
- 点扩展函数(PSF):想象场景中一个微小的光点。当这个光点穿过无透镜相机的掩模并照射到传感器上时,它不会保持为一个完美的光点;它会扩散成一个特定的、通常是模糊的图案。PSF 就像相机系统如何模糊或编码单个光点的独特“指纹”。它精确地告诉你每个光点如何在传感器上“扩散”。
- 空间变化的去卷积:如果“模糊指纹”(PSF)根据场景中光线的来源而变化(例如,来自场景中心的点与来自边缘的点模糊方式不同),那么一个简单的“去模糊”工具在所有地方都无法完美工作。空间变化的去卷积就像一个智能的“去模糊”过程,可以自动调整其技术以适应图像的不同部分,为每个特定区域应用正确的“去模糊”方法,以获得整个视图中更清晰、更准确的图像。
- 值域-零空间分解:想象一张非常模糊的照片。这个数学技巧可以帮助我们将模糊的照片分成两部分。“值域空间”部分包含相机能够可靠捕获的所有基本、低细节信息(如一般形状和颜色),即使它是模糊的。“零空间”部分代表所有在模糊中完全丢失且无法直接从模糊测量中恢复的精细细节和纹理。挑战在于准确地重建第一部分,然后用逼真的细节智能地“填充”第二部分,而不会凭空捏造。
- 生成先验(来自扩散模型):想象一位艺术家,他非常擅长根据粗略的草图创作逼真的图像。“扩散模型”的“生成先验”就像那位艺术家一样。给定基本、低细节信息(值域空间内容),它可以“想象”并添加回丢失的高频、照片级真实感细节(零空间内容),使其看起来自然且与真实世界图像的通常外观一致,从而使最终图像更具视觉吸引力。
符号表
| 符号 | 描述 |
|---|---|
| $\hat{y}$ | 由无透镜相机捕获的原始、多路复用的测量值。 |
| $x$ | 算法旨在重建的原始场景图像。 |
| $A$ | 无透镜成像系统的传递矩阵,代表前向成像模型。 |
| $n$ | 传感器噪声。 |
| $A^\dagger$ | 传递矩阵 $A$ 的伪逆。 |
| $A^\dagger A x$ | 图像 $x$ 的值域空间分量,代表可直接从测量值恢复的信息(低频内容)。 |
| $(I - A^\dagger A)x$ | 图像 $x$ 的零空间分量,代表成像过程中丢失的信息(高频细节)。 |
| $I$ | 单位矩阵。 |
| $h$ | 无透镜系统的点扩展函数(PSF)。 |
| $*$ | 卷积算子。 |
| $p^{(i)}$ | SVDeconv 网络中第 $i$ 个可学习的点扩展函数(PSF)核。 |
| $\mathcal{F}$ | 离散傅里叶变换(DFT)。 |
| $\mathcal{F}^{-1}$ | 逆离散傅里叶变换(IDFT)。 |
| $\odot$ | Hadamard 积(逐元素乘法)。 |
| $x^{(i)}_e$ | 多核反卷积的第 $i$ 个中间反卷积图像。 |
| $X_{int}$ | 中间反卷积图像的空间插值图像。 |
| $w_i(u, v)$ | 第 $i$ 个反卷积图像在像素 $(u, v)$ 处的权重,基于反向欧氏距离。 |
| $\mathbf{c}$ | 值域空间内容,第一个 SVDeconv 阶段的输出,用作扩散模型的条件。 |
| $\mathbf{x}_t$ | 扩散过程中时间步 $t$ 处的噪声图像。 |
| $\mathbf{\epsilon}$ | 从标准正态分布采样的真实噪声向量。 |
| $\mathbf{\epsilon}_\theta(\mathbf{x}_t, t, \mathbf{c})$ | 条件扩散模型的噪声预测网络(由 $\theta$ 参数化)。 |
| $\theta$ | 噪声预测网络的可学习参数。 |
| $\mathcal{L}_{null}$ | 零空间恢复阶段的损失函数,强制在测量空间中保持一致性。 |
| $\mathbb{E}$ | 期望算子。 |
| $t$ | 扩散过程中的时间步。 |
| $\mathcal{N}(0,1)$ | 标准正态分布。 |
| $\| \cdot \|^2$ | 平方 L2 范数。 |
| $\mathcal{L}_{MSE}$ | 均方误差损失。 |
| $\mathcal{L}_{LPIPS}$ | 学习感知图像块相似度损失。 |
问题定义与约束
核心问题表述与困境
本文解决的核心问题是从无透镜相机测量中重建照片级真实感且一致的图像。
输入/当前状态:
起点是由无透镜相机捕获的原始、多路复用的测量值 $\hat{y} \in \mathbb{R}^{N^2}$。该测量值通常是模糊不清、无法识别且缺乏高频细节的。在数学上,无透镜成像过程可以表述为原始场景 $x \in \mathbb{R}^{M^2}$ 的线性变换,并加上传感器噪声 $n$:
$$ \hat{y} = Ax + n $$
其中,$A \in \mathbb{R}^{N^2 \times M^2}$ 是无透镜成像系统的传递矩阵,它编码了来自场景中每个点如何贡献到每个传感器像素。先前的方法通常将这个复杂的过程简化为与单个、移不变点扩展函数(PSF)的卷积,即 $y = h * x$。
期望终点(输出/目标状态):
期望的终点是重建的图像 $x$,它既是照片级真实感的,又是与原始场景一致的。
* 照片级真实感意味着高质量的图像,具有丰富、自然的细节,有效地恢复了在无透镜捕获过程中丢失的高频内容。
* 一致性意味着重建图像的内容必须准确地与原始场景对齐,满足条件 $Ax = y$(其中 $y$ 是无噪声测量值)。
缺失环节或数学鸿沟:
确切的缺失环节是能够准确建模无透镜成像过程(由 $A$ 表示)的复杂、空间变化的性质,并有效地从退化的测量值中恢复场景的低频(一致性关键)和高频(照片级真实感关键)分量。本文利用值域-零空间分解来弥合这一鸿沟。任何场景 $x$ 都可以分解为两个正交分量:
$$ x = A^\dagger Ax + (I - A^\dagger A)x $$
其中 $A^\dagger Ax$ 是值域空间分量(可直接从测量值恢复的低频内容,确保一致性),而 $(I - A^\dagger A)x$ 是零空间分量(成像过程中丢失的高频细节,对照片级真实感至关重要)。本文旨在首先准确地重建值域空间内容,然后使用生成先验来丰富它,同时保持一致性。
困境(痛苦的权衡):
困扰先前研究人员的核心困境是在实现高视觉质量(照片级真实感)和保持数据一致性(与原始场景的保真度)之间的痛苦权衡。
* 传统重建算法(例如,WienerDeconv)优先考虑数据一致性,生成与真实情况对齐的图像,但这些图像通常是模糊的,视觉质量显著下降,缺乏照片级真实感所需的精细细节。它们无法恢复高频信息。
* 生成恢复算法(例如,使用扩散模型如 DiffBIR 的算法)可以注入丰富的照片级真实感细节并显著提高视觉质量。然而,它们经常“改变图像内容或插入不存在的对象”,从而破坏了与实际场景的一致性。例如,它们可能会生成不正确的形状或伪造的纹理,如图 1d 所示。
这种困境意味着提高一个方面(例如,照片级真实感)通常会损害另一个方面(一致性),使得在现有方法中同时实现两者变得极其困难。
约束与失败模式
由于几个严酷的、现实的约束和先前方法的常见失败模式,照片级真实感且一致的无透镜图像重建问题异常困难:
-
空间变化的点扩展函数(PSF):
- 物理约束:与传统的基于透镜的相机不同,无透镜系统在整个视场(FoV)中没有固定的、移不变的 PSF。PSF 随入射光的角度显著变化,尤其是在周边区域。
- 计算约束:大多数现有的重建算法通过假设一个移不变的 PSF 来简化成像过程,这是不准确的。建模真实的空间变化的 PSF 计算量很大,因为完整的传递矩阵 $A$ 对于真实系统来说“太大而无法计算”。这种简化会导致重建图像中出现明显的不准确和伪影,尤其是在边界处,如图 4d 所示。
-
高频信息丢失:
- 物理约束:无透镜编码过程,其中光线由掩模调制,起着低通滤波器的作用。这固有地导致场景高频细节的显著丢失,使得原始测量值模糊且模棱两可。
- 数据驱动约束:恢复这些丢失的高频细节(“零空间”内容)需要强大的先验。没有足够且准确的先验,算法就难以重建照片级真实感的图像,通常会导致视觉退化的输出,或者,如果天真地使用生成模型,则会产生不存在的细节,从而破坏保真度。
-
空间变化的去卷积的计算复杂性:
- 计算约束:虽然空间变化的去卷积对于准确重建是必需的,但该领域先前的方法“通常速度慢、计算量大,并且图像质量差,尤其是在复杂系统中。”
- 校准负担:许多多核去卷积方法需要“繁琐的多位置 PSF 校准”,这是一个耗时且劳动密集的过程,使其不适合广泛使用。本文旨在通过从单个初始 PSF 中自动学习变化来克服这一点。
-
使用生成先验保持数据保真度:
- 逻辑约束:生成模型虽然在生成细节方面功能强大,但本质上是通过创建新信息来运行的。一个主要的失败模式是它们倾向于“改变图像内容或插入不存在的对象”,从而违反了重建图像必须与实际测量值对齐的基本一致性要求。挑战在于指导这些生成模型生成与底层数据一致的逼真细节。
-
实时延迟(未来限制):
- 计算约束:尽管不是本文直接克服的约束,但作者承认“PhoCoLens 的两阶段性质和扩散模型的采样时间阻碍了其实时适用性。” 这意味着对于需要即时反馈的应用,例如实时视频或临床成像,所提出方法的当前计算开销是一个重大障碍。
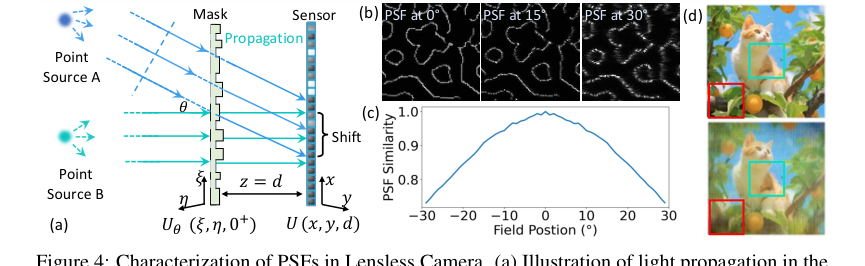 Figure 4. Characterization of PSFs in Lensless Camera. (a) Illustration of light propagation in the lensless camera: two point sources A and B at infinity emitting parallel light beams. Source A emits at angle θ relative to the optical axis, causing a PSF shift on the sensor plane This PSF shift depends on both the incident angle θ and the distance d between the sensor and the mask. (b) Simulated PSFs for light sources at angles of 0°, 15°, and 30°. (c) Inner product similarity between the on-axis PSF and off-axis PSFs at different field positions. (d) Reconstruction using PSF at 0°, degradation is more significant at the periphery (red box) than the center (green box)
Figure 4. Characterization of PSFs in Lensless Camera. (a) Illustration of light propagation in the lensless camera: two point sources A and B at infinity emitting parallel light beams. Source A emits at angle θ relative to the optical axis, causing a PSF shift on the sensor plane This PSF shift depends on both the incident angle θ and the distance d between the sensor and the mask. (b) Simulated PSFs for light sources at angles of 0°, 15°, and 30°. (c) Inner product similarity between the on-axis PSF and off-axis PSFs at different field positions. (d) Reconstruction using PSF at 0°, degradation is more significant at the periphery (red box) than the center (green box)
为什么选择这种方法
选择的必然性
PhoCoLens 的作者在无透镜成像中面临一个根本性的困境:如何实现高视觉质量(照片级真实感)和原始场景的忠实表示(一致性)。发现传统的最新技术(SOTA)方法,例如标准的去卷积技术(如 WienerDeconv),是不足的,因为它们产生的图像视觉质量显著下降,缺乏照片级真实感所需的丰富细节(图 1b)。虽然基于学习的方法(以 FlatNet-gen 为例)提高了视觉质量,但它们仍然难以恢复关键的高频细节,导致图像不够清晰,不够逼真(图 1c)。
当作者观察到即使是先进的生成模型(如 DiffBIR)在注入照片级真实感细节方面表现出色,但它们经常以牺牲一致性为代价时,他们意识到传统方法不足。这些模型经常改变图像内容或引入不存在的对象,例如形状错误的鸟嘴或看起来是假的叶子(图 1d),从而破坏了与真实情况的保真度。这表明,纯粹的生成方法虽然在视觉上吸引人,但对于保真度至关重要的应用来说,并不是一个可行的唯一解决方案。
此外,现有重建算法中发现的一个重大限制是它们对无透镜成像过程的简化。大多数方法假设一个移不变的点扩展函数(PSF),将成像视为简单的卷积。然而,作者认识到,在现实世界的无透镜系统中,PSF 在整个视场中本质上是空间变化的,尤其是在不同的入射角下(图 4a、4b、4c)。这种假设的移不变 PSF 与实际的空间变化的 PSF 之间的不匹配导致了实质性的不准确,尤其是在外围视场中,重建图像与原始场景的相似性明显下降(图 4d)。这种基本的物理现实使得传统的卷积模型在整个视场中进行准确的无透镜重建时,本质上是不够的。
比较优势
PhoCoLens 通过其新颖的两阶段架构,在结构上解决了无透镜成像的核心挑战,从而实现了定性和定量的优越性。关键的结构优势在于其值域-零空间分解框架。这个理论基础允许该方法将问题分解为两个正交分量:一个专注于数据一致性(值域空间),另一个专注于照片级真实感(零空间)。这比以前试图同时解决这两个问题的现有方法具有显著优势,后者常常导致权衡。
- 空间变化的去卷积(SVDeconv)用于值域空间:与假设单个移不变 PSF 的先前方法不同,SVDeconv 以数据驱动的方式学习适应相机视场中 PSF 的空间变化。这是一个重大的结构改进,因为它更准确地建模了复杂的前向成像过程。这导致了结构完整性和低频细节的卓越重建,尤其是在其他方法失败的外围区域(图 2、图 4d)。表 2 定量地证明了 SVDeconv 在值域空间重建方面优于其他去卷积方法。
- 条件零空间扩散用于照片级真实感:第二阶段利用预训练的扩散模型,但关键在于它以第一阶段恢复的低频内容为条件。这确保了在添加高频细节以实现照片级真实感的同时,它们与值域空间重建建立的底层结构保持一致。这种方法避免了纯生成模型(如 DiffBIR)引入伪影或改变内容的陷阱,如图 1d 所示。条件机制是一个结构性保障,可在提高视觉质量的同时保持保真度。
定量而言,PhoCoLens 展现了压倒性的优势。如表 1 所示,它在 PhlatCam 和 DiffuserCam 数据集上始终在保真度指标(PSNR、SSIM、LPIPS)和视觉质量指标(ManIQA、ClipIQA、MUSIQ)之间实现了最佳平衡。例如,在 PhlatCam 上,PhoCoLens 实现了 62.20 的 MUSIQ 分数,显著高于 FlatNet+DiffBIR 的 57.13,同时还保持了更好的 LPIPS(0.215 对 0.391)。这表明该方法不仅略有改进,而且在结构上旨在通过解决现有方法的固有局限性来超越以前的黄金标准。
与约束的对齐
PhoCoLens 选择的两阶段方法完美地符合实现无透镜成像中照片级真实感和一致性的双重约束,同时解决了潜在的物理挑战。
- 解决空间变化的 PSF 以实现一致性:尽管无透镜 PSF 具有空间变化的性质,但该问题对整个视场进行准确重建的严苛要求,通过第一阶段的 SVDeconv 直接得到满足。通过学习和适应这些空间变化,SVDeconv 确保了低频内容(值域空间)以高保真度和结构完整性进行重建,为最终图像奠定了一致的基础。这是问题物理现实与解决方案自适应去卷积属性的直接“结合”。
- 利用生成先验实现照片级真实感,同时保持一致性:照片级真实感的要求,即需要无透镜捕获中经常丢失的丰富高频细节,通过第二阶段的零空间扩散模型得到满足。然而,关键的对齐在于如何利用这种生成能力。扩散模型不是盲目地生成细节,而是以第一阶段的低频输出为条件。这确保了添加的高频细节(来自零空间)在不违反先前建立的一致性的情况下增强了照片级真实感。值域-零空间分解的数学框架明确确保了添加的零空间分量不会改变测量值 $y$,从而保持一致性 ($A(x - A^\dagger Ax) = 0$)。这是一种完美的对齐,其中生成能力受到一致性要求的约束。
- 克服不足的先验:传统方法中不足的先验导致视觉质量下降的问题,通过集成强大的预训练扩散模型得到解决。该模型为逼真的图像纹理提供了强大的生成先验,但其在零空间框架内的应用确保了它由实际场景数据指导,避免了任意的幻觉。
替代方案的拒绝
该论文基于其在满足照片级真实感和一致性这两个目标方面的固有局限性,明确和隐含地拒绝了几种替代方法:
- 传统去卷积(例如,WienerDeconv):这些方法被拒绝主要是因为它们无法产生照片级真实感的结果。虽然它们保持了一定的数据一致性,但它们的视觉质量“显著下降”(第 1 节,图 1b),使其不适合高质量图像重建。
- 基于学习的去卷积(例如,FlatNet-gen):虽然比传统方法有所改进,但发现这些方法“经常无法恢复高频细节”(第 1 节,图 1c)。这种限制意味着它们无法达到所需的照片级真实感水平,导致缺乏清晰度和精细纹理。
- 具有直接先验的生成模型(例如,DiffBIR):这些方法在注入丰富细节和提高视觉质量方面表现出色,但被拒绝是因为它们“也可能改变图像内容或插入不存在的对象,破坏一致性”(第 1 节,图 1d)。作者提供了扭曲对象(例如,鸟嘴形状)和伪造纹理的清晰示例,表明它们的照片级真实感是以牺牲保真度为不可接受的代价换取的。
- 假设移不变 PSF 的方法:一项主要的隐含拒绝是任何通过假设移不变 PSF 来简化无透镜成像过程的方法。如第 3.2 节所述,并如图 4d 所示,这种假设会导致“不准确”和“重建图像与原始场景的相似性明显下降,尤其是在外围视场中”。PhoCoLens 的 SVDeconv 阶段专门设计用于克服这一根本性缺陷,使得任何移不变方法对于真实世界的无透镜系统都明显劣于。
- 零样本扩散模型(例如,DDNM+):虽然被提及为具有扩散模型的逆成像类别,但本文的方法整合了“基于值域-零空间分解的理论框架的监督微调”(第 2 节)。这暗示拒绝纯零样本方法用于此特定问题,可能是因为它们可能缺乏分解框架内监督训练提供的细粒度控制或一致性保证。表 3 显示 DDNM+ 在零空间恢复的保真度和视觉质量指标方面均显著差于 PhoCoLens。
 Figure 1. We introduce PhoCoLens, a lensless reconstruction algorithm that achieves both better visual quality and consistency to the ground truth than existing methods. Our method recovers more details compared to traditional reconstruction algorithms (b) and (c), and also maintains better fidelity to the ground truth compared to the generative approach (d)
Figure 1. We introduce PhoCoLens, a lensless reconstruction algorithm that achieves both better visual quality and consistency to the ground truth than existing methods. Our method recovers more details compared to traditional reconstruction algorithms (b) and (c), and also maintains better fidelity to the ground truth compared to the generative approach (d)
数学与逻辑机制
主方程
驱动本文的核心数学引擎,尤其是在重建的第二阶段实现照片级真实感和一致性方面,是零空间扩散模型的优化目标。该方程确保了扩散模型生成的细节保持与无透镜成像系统的物理学一致。它正式表述为:
$$ \min_\theta \mathcal{L}_{null} = \min_\theta \mathbb{E}_{\mathbf{x},t,\mathbf{c},\mathbf{\epsilon} \sim \mathcal{N}(0,1)} \left[ \left\| A(\mathbf{\epsilon}_\theta(\mathbf{x}_t, t, \mathbf{c}) - \mathbf{\epsilon}) \right\|^2 \right] $$
该方程源于值域-零空间分解的基本原理,该原理认为任何图像 $\mathbf{x}$ 都可以分解为值域空间分量 $A^\dagger A \mathbf{x}$(代表相机可直接观察到的信息)和零空间分量 $(I - A^\dagger A) \mathbf{x}$(代表成像过程中丢失但对照片级真实感至关重要的细节)。这里的目标是确保生成模型添加的残差内容,理想情况下应位于零空间,不会违反与前向成像模型的一致性。
逐项剖析
让我们逐项剖析这个方程,以理解其作用和意义:
- $\min_\theta$:这是标准的最小化算子,表示目标是找到神经网络的最佳参数集 $\theta$。
- $\theta$:这些是噪声预测网络 $\mathbf{\epsilon}_\theta$ 的可学习参数。该网络通常是一个 U-Net,它学习预测噪声分量在有噪声图像中的位置。
- $\mathcal{L}_{null}$:该符号代表专门为零空间恢复阶段设计的损失函数。其最小化指导扩散模型生成一致且照片级真实感的细节。
- $\mathbb{E}_{\mathbf{x},t,\mathbf{c},\mathbf{\epsilon} \sim \mathcal{N}(0,1)}$:这表示期望算子,意味着我们正在对多个随机样本的损失进行平均。
- $\mathbf{x}$:这是模型旨在重建的真实、干净的图像。它是理想的目标。
- $t$:这代表了前向扩散过程中的一个时间步,表明图像添加了多少噪声。扩散模型通过逐步添加噪声,然后学习逆转此过程来工作。
- $\mathbf{c}$:这是扩散模型的条件,特别是从第一阶段恢复的值域空间内容 $A^\dagger A \mathbf{x}$。它提供了生成模型必须遵守的低频、一致的信息。
- $\mathbf{\epsilon} \sim \mathcal{N}(0,1)$:这是从标准正态分布采样的真实噪声向量,它被添加到原始图像 $\mathbf{x}$ 中以创建有噪声图像 $\mathbf{x}_t$。
- $\| \cdot \|^2$:这是平方 L2 范数,是回归任务中损失函数的常见选择。它测量两个向量之间的平方欧氏距离,对较大的误差给予更大的惩罚。作者选择此项是因为它是一种简单有效的方法来量化预测噪声与实际噪声之间的差异。
- $A$:这是无透镜成像系统的传递矩阵。它在数学上描述了场景 $\mathbf{x}$ 如何通过相机转换为测量值 $\mathbf{y}$(即 $\mathbf{y} = A\mathbf{x}$)。它在这里的作用至关重要:它将噪声预测误差投影到测量空间。
- $\mathbf{\epsilon}_\theta(\mathbf{x}_t, t, \mathbf{c})$:这是由 $\theta$ 参数化的神经网络的输出。给定有噪声图像 $\mathbf{x}_t$、当前时间步 $t$ 和值域空间条件 $\mathbf{c}$,该网络预测了添加到原始图像中的噪声分量 $\mathbf{\epsilon}$。
- $(\mathbf{\epsilon}_\theta(\mathbf{x}_t, t, \mathbf{c}) - \mathbf{\epsilon})$:这一项代表噪声预测中的误差。网络试图使其预测 $\mathbf{\epsilon}_\theta$ 尽可能接近真实噪声 $\mathbf{\epsilon}$。
- $A(\mathbf{\epsilon}_\theta(\mathbf{x}_t, t, \mathbf{c}) - \mathbf{\epsilon})$:这是损失中最关键的部分。作者没有简单地最小化预测噪声与实际噪声之间的差异,而是将传递矩阵 $A$ 应用于此差异。这确保了噪声预测误差的效应,当通过无透镜相机的前向模型投影时,最小化了测量误差。本质上,它迫使生成模型预测的噪声,如果被无透镜相机“成像”,将导致零测量误差。这直接强制执行了任何生成细节(来自零空间)不应改变从值域空间内容获得的测量的这个一致性要求。此处使用乘以 $A$ 而不是,例如,加法,是投影误差到测量域的基础,与物理前向模型一致。
分步流程
PhoCoLens 方法在一个巧妙的两阶段流水线中运行,类似于一个复杂的装配线,每个阶段都以特定的目标来优化图像重建。
第一阶段:具有空间变化的去卷积(SVDeconv)的值域空间重建
- 初始测量输入:过程以原始、模糊且有噪声的无透镜测量值 $\hat{y}$ 开始。这是初始的抽象数据点,是传感器捕获的复杂衍射图案。
- 多核去卷积:该测量值 $\hat{y}$ 进入 SVDeconv 网络。这里,它不仅仅是一个去卷积,而是许多个。网络维护一组 $K \times K$ 个可学习的点扩展函数(PSF)核 $p^{(i)}$,每个核都专门用于图像的不同空间区域。
- 首先使用离散傅里叶变换($\mathcal{F}$)将测量值 $\hat{y}$ 和每个核 $p^{(i)}$ 转换到频域。
- 在频域中,对变换后的测量值和每个变换后的核执行逐元素乘法(Hadamard 积 $\odot$)。这是频域中的去卷积等效操作,有效地“撤销”了该特定区域无透镜系统引起的模糊。
- 然后使用逆离散傅里叶变换($\mathcal{F}^{-1}$)将每个结果转换回空间域,得到 $K \times K$ 个中间反卷积图像 $x^{(i)}_e$。每个 $x^{(i)}_e$ 都是初步重建,针对特定视场点进行了优化。
- 空间变化的插值:然后将这 $K \times K$ 个中间图像无缝地拼接在一起。对于最终输出中的每个像素 $(u, v)$,计算所有 $x^{(i)}_e$ 图像中相应像素的加权和。权重 $w_i(u, v)$ 由像素 $(u, v)$ 到第 $i$ 个 PSF 核中心的欧氏距离的倒数确定。这意味着像素的值主要受空间上最接近其的去卷积核的影响,从而创建了一个统一的图像 $X_{int}$,该图像适应 PSF 的空间变化特性。
- 精炼 U-Net:插值图像 $X_{int}$ 然后通过一个 U-Net。该神经网络充当最终的清理团队,去除任何残留的噪声和伪影,并进一步精炼图像以生成值域空间内容 $\mathbf{c}$。这个 $\mathbf{c}$ 是场景的一致的、低频表示,已准备好进入下一阶段。
第二阶段:具有条件扩散的零空间内容恢复
- 有噪声图像生成与条件化:来自第一阶段的值域空间内容 $\mathbf{c}$ 现在用作条件。同时,通过在多个时间步 $t$ 上逐步添加随机噪声 $\mathbf{\epsilon}$ 来对真实图像 $\mathbf{x}$ 进行损坏,从而得到有噪声图像 $\mathbf{x}_t$。
- 条件噪声预测:有噪声图像 $\mathbf{x}_t$、当前时间步 $t$ 和值域空间条件 $\mathbf{c}$ 被馈送到条件扩散模型的噪声预测网络 $\mathbf{\epsilon}_\theta$。
- 条件 $\mathbf{c}$ 不仅仅是拼接;它被深度集成。条件编码器从 $\mathbf{c}$ 中提取多尺度特征,然后调制 $\mathbf{\epsilon}_\theta$ 网络残差块中的中间特征图。这确保了生成过程受到一致的低频信息的严格指导。
- 网络 $\mathbf{\epsilon}_\theta$ 处理这些输入并输出其对创建 $\mathbf{x}_t$ 时添加的噪声 $\mathbf{\epsilon}$ 的最佳猜测。
- 一致性强制执行(损失计算):将预测的噪声 $\mathbf{\epsilon}_\theta$ 与实际噪声 $\mathbf{\epsilon}$ 进行比较。关键步骤是将传递矩阵 $A$ 应用于它们的差值 $A(\mathbf{\epsilon}_\theta - \mathbf{\epsilon})$。该结果的平方 L2 范数构成了 $\mathcal{L}_{null}$ 损失。这确保了预测与实际噪声之间的任何差异,当通过无透镜相机的前向模型进行观察时,都会被最小化。这本质上是强制生成模型预测的噪声,如果被无透镜相机“成像”,将导致零测量误差。这直接强制执行了任何生成细节(它们来自零空间)不应改变从值域空间内容获得的测量的这个一致性要求。
- 迭代去噪(推理):在推理过程中,扩散模型从一个纯粹的随机噪声图像开始。经过许多时间步,它会迭代地使用学习到的 $\mathbf{\epsilon}_\theta$ 网络来预测和减去噪声,逐渐将随机噪声转换为照片级真实感的图像。在每一步,值域空间内容 $\mathbf{c}$ 会持续指导生成,确保添加的高频细节与低频结构一致,最终产生高质量的重建图像。
优化动力学
PhoCoLens 系统通过一个双管齐下的优化策略进行学习和收敛,每个策略都针对其各自的阶段进行了定制。
第一阶段:SVDeconv 优化
第一阶段 SVDeconv 经过训练,用于重建值域空间内容 $A^\dagger A \mathbf{x}$。其优化涉及学习多核去卷积和精炼 U-Net 的参数。
- 损失函数:SVDeconv 的训练目标是均方误差(MSE)损失和 LPIPS(学习感知图像块相似度)损失的组合。
- MSE 损失:这是一种逐像素保真度损失,旨在最小化重建值域空间内容与真实值域空间内容之间的平方差。它确保模型准确地恢复低频信息。
- LPIPS 损失:这是一种感知损失,它在一个预训练的深度神经网络学习到的特征空间中测量图像之间的相似度。它对于确保重建的图像看起来视觉上令人愉悦且逼真至关重要,即使像素值不完全匹配。
- 梯度行为:来自 MSE 和 LPIPS 损失的梯度通过精炼 U-Net 和重要的多核去卷积层进行反向传播。这使得网络能够学习最佳的 PSF 核 $p^{(i)}$,以适应无透镜成像系统的空间变化。梯度指导核有效地“撤销”空间变化的模糊。
- 状态更新:使用 Adam 优化器迭代更新可学习的 PSF 核和 U-Net 参数。学习率经过精心选择(例如,PhlatCam 去卷积核为 4e-9,U-Net 为 3e-5),以确保稳定有效的收敛。该模型学会以数据驱动的方式自动适应空间 PSF 变化,消除了繁琐的多位置 PSF 校准的需要。
第二阶段:零空间扩散优化
第二阶段,条件扩散模型,经过优化,用于恢复零空间内容,在保持一致性的同时添加照片级真实感的高频细节。
- 损失函数:此阶段的主要损失是 $\mathcal{L}_{null}$,如主方程所定义。该损失是独特的,因为它将传递矩阵 $A$ 应用于噪声预测误差。
- 损失景观塑造:将 $A$ 应用于误差项 $A(\mathbf{\epsilon}_\theta - \mathbf{\epsilon})$ 深刻地塑造了损失景观。它创建了一个景观,其最小值对应于一个状态,即生成的高频细节(来自预测噪声)对无透镜相机的正向模型“不可见”。换句话说,扩散模型添加的任何细节都必须位于 $A$ 的零空间中,这意味着它们在通过 $A$ 投影时不会改变测量值 $\mathbf{y}$。这可以防止生成模型产生与物理约束相矛盾的细节,从而强制执行数据一致性。
- 梯度行为:梯度通过整个表达式计算,包括 $A$ 算子,并通过噪声预测网络 $\mathbf{\epsilon}_\theta$ 反向传播。这些梯度指导 $\mathbf{\epsilon}_\theta$ 学习预测噪声,使得重建的图像通过前向成像模型 $A$ 时,与第一阶段提供的值域空间低频内容保持一致。这是一种复杂的方式,可以确保生成模型的输出与无透镜系统的物理约束相符。
- 状态更新:扩散模型经过多个 epoch(例如,200 个 epoch)的训练。本文提到利用预训练的扩散模型(如 Stable Diffusion)并冻结权重,主要训练补充的条件模块。这种策略允许模型利用大型预训练模型的强大生成能力,同时对其进行微调以适应无透镜成像的特定任务和一致性要求。条件机制通过 $\mathbf{c}$ 调制内部特征图,会迭代更新,以确保生成的细节内容与第一阶段提供的高频结构相连贯。这种对条件的迭代细化确保了最终输出既照片级真实感又一致。
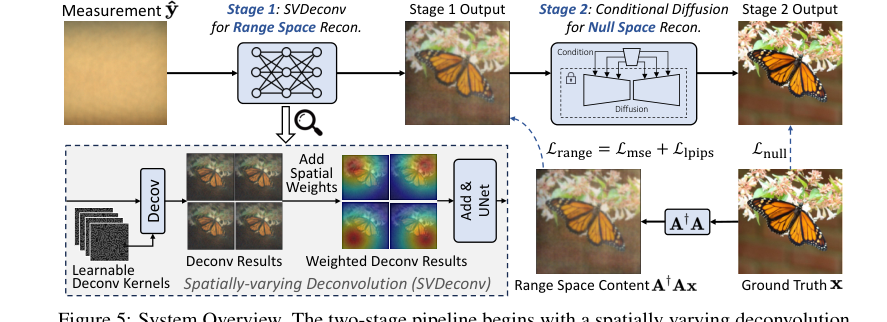 Figure 5. System Overview. The two-stage pipeline begins with a spatially varying deconvolution network mapping lensless measurements to range space. Then a conditional diffusion model for null space recovery refines details using the first stage output, achieving the final reconstruction
Figure 5. System Overview. The two-stage pipeline begins with a spatially varying deconvolution network mapping lensless measurements to range space. Then a conditional diffusion model for null space recovery refines details using the first stage output, achieving the final reconstruction
结果、局限性与结论
实验设计与基线
为了严格验证 PhoCoLens,作者设计了一个全面的实验设置,在两个不同的真实世界无透镜成像数据集上,将其新颖的两阶段方法与各种“受害者”基线模型进行了比较。
实验利用了两个流行的无透镜相机系统:
- PhlatCam 数据集 [17]:包含 10,000 张图像,跨越 1,000 个类别,调整为 384x384 像素,原始捕获为 1280x1480 像素。使用了 990 个类别的训练集和 10 个类别的测试集。
- DiffuserCam 数据集 [27]:包含 25,000 对图像(无透镜测量值 + 真实情况),同时捕获。这些图像最初为 1080x1920 像素,被下采样到 270x480,然后裁剪为最终分辨率 210x380 像素。数据集分为 24,000 个用于训练,1,000 个用于测试。
为了明确证明他们的数学声明,评估采用了双重指标集,分别评估一致性(保真度)和照片级真实感(视觉质量):
- 用于一致性的全参考指标:峰值信噪比(PSNR)、结构相似性指数度量(SSIM)[42] 和学习感知图像块相似度(LPIPS)[51]。较低的 LPIPS 值表示更好的保真度。
- 用于照片级真实感的无参考指标:多维度注意力网络无参考图像质量评估(ManIQA)[45]、基于 CLIP 的图像质量评估(ClipIQA)[39] 和多尺度图像质量 Transformer(MUSIQ)[16]。这些指标的较高值通常表示更好的视觉质量。
详细列出了实现细节以确保可复现性。SVDeconv 网络使用了 3x3 PSF 核,并用单个校准的 PSF 初始化,以及一个从现有架构改编的 U-Net(DiffuserCam 的 Le-ADMM-U,PhlatCam 的 FlatNet-gen)。训练跨越 100 个 epoch,批次大小为 5,使用 Adam 优化器 [18]。为 U-Net 和去卷积核设置了特定的学习率,以及 MSE 和 LPIPS 损失权重(分别为 1 和 0.05)。对于零空间扩散阶段,SVDeconv 输出作为输入条件,模型训练了 200 个 epoch,利用预训练的 Stable Diffusion [32] 模型并冻结权重,仅专注于训练补充的条件模块。
与 PhoCoLens 比较的“受害者”(基线模型)包括:
- 传统方法:WienerDeconv [44](Tikhonov 正则化重建)和 ADMM [7](全变分正则化)。
- 基于学习的方法:Le-ADMM-U [27](深度展开网络)、MMCN [49]、UPDN [19](展开的原始-对偶网络)和 FlatNet-gen [17](前馈去卷积)。
- 基于扩散的方法:DDNM+ [41](使用预训练 Stable Diffusion 的零样本逆成像)和 FlatNet+DiffBIR [23](FlatNet-gen 输出由预训练的盲图像恢复扩散模型增强)。
此外,作者进行了有针对性的消融研究,以无情地证明每个核心组件的贡献:
- 空间变化的去卷积(SVDeconv):与 Le-ADMM-U、SingleDeconv(使用单个核)和 MultiWienerNet [48] 进行了比较,用于值域空间和原始内容重建。
- 零空间扩散:与条件扩散模型如 DiffBIR [23] 和 StableSR [39],以及零样本逆成像方法 DDNM+ [41] 进行了比较。
- 值域内容条件:一项消融研究,其中第一阶段重建的值域内容被替换为来自 WienerDeconv、FlatNet-gen 和 SVD-OC(使用原始内容训练的 SVDeconv)的输出,以条件化第二阶段扩散。
证据证明的内容
本文提供的证据提供了确凿、不可否认的证据,证明 PhoCoLens 在无透镜成像中实现了照片级真实感和一致性的卓越平衡,超越了所有基线。
总体优势:
表 1 明确展示了 PhoCoLens 的主导地位。在 PhlatCam 和 DiffuserCam 数据集上,我们的方法在几乎所有用于一致性的全参考指标(PSNR、SSIM、LPIPS↓)和用于视觉质量的无参考指标(ManIQA、ClipIQA、MUSIQ)方面始终实现了最佳性能。例如,在 PhlatCam 上,PhoCoLens 实现了 22.07 的 PSNR、0.601 的 SSIM 和 0.215 的 LPIPS,显著优于次优方法,如 FlatNet-gen(PSNR 20.53、SSIM 0.549、LPIPS 0.375)和 FlatNet+DiffBIR(PSNR 19.96、SSIM 0.544、LPIPS 0.391)。这些定量证据得到了图 1、6 和 7 中定性比较的进一步加强,其中 PhoCoLens 的重建在视觉上最接近真实情况,展现了清晰的细节和准确的内容。
空间变化的去卷积(SVDeconv)的有效性:
本文关于空间变化的去卷积重要性的核心论点,通过表 2 和图 2、8 和 A3 得到了无情的证明。表 2 显示 SVDeconv(Ours)在重建值域空间内容和原始内容方面始终优于其他去卷积方法(Le-ADMM-U、SingleDeconv、MultiWienerNet)。例如,在 PhlatCam 上,SVDeconv 实现了 26.97 的值域空间 PSNR,显著高于 SingleDeconv 的 25.61。这至关重要,因为传统方法(如 SingleDeconv)假设移不变 PSF,这在真实世界的无透镜系统中是不准确的。图 2 和图 8 直观地突出了这一点,显示 SVDeconv(右)比使用单个核的方法(左)在重建精细细节方面具有更高的准确性,尤其是在外围区域。图 4d 中的红色框和图 8 中的白色虚线框清楚地说明了我们的 SVDeconv 机制如何有效地减轻伪影并保留外围区域的细节,而 PSF 变化在那里最为明显。图 A3 进一步巩固了这一点,显示 SVDeconv 的输出在低频结构上与真实情况保持了高视觉一致性,而 FlatNet 则引入了不正确的高频细节。
零空间扩散的确定性证据:
我们的零空间扩散在保持一致性的同时实现照片级真实感的有效性,通过表 3 和图 9 得到了无可辩驳的证明。我们的方法在 PhlatCam 上实现了最高的 PSNR(22.07)、SSIM(0.601)和最低的 LPIPS(0.215)用于零空间恢复,显著优于其他基于扩散的方法,如 DiffBIR(PSNR 16.21、SSIM 0.432、LPIPS 0.502)和 StableSR(PSNR 14.93、SSIM 0.446、LPIPS 0.624)。在定性上,图 9 显示我们的方法生成的图像既具有视觉吸引力又忠实于原始场景,而像 DiffBIR 这样的竞争对手可能会引入伪影或扭曲内容(例如,图 1d 中的“形状错误”的鸟嘴,或图 7 中转移到衣服上的人手)。这证明了以第一阶段的值域内容为条件来条件化扩散模型,有效地指导它在不牺牲保真度的情况下生成逼真的高频细节。
值域内容条件的影响:
关于值域内容条件的消融研究,总结在表 4 和图 10 中,为使用我们第一阶段的输出作为条件的重要性提供了令人信服的证据。当使用我们重建的值域内容来条件化扩散模型时,与使用 WienerDeconv 或 FlatNet-gen 等基线的输出相比,它始终能带来更好的重建一致性(更高的 PSNR、SSIM、更低的 LPIPS)。这是因为这些替代条件引入了伪影,阻碍了第二阶段准确恢复原始图像的能力。图 10 中的视觉改进进一步强调了我们精心选择条件的两阶段流程对于实现观察到的卓越性能至关重要。
局限性与未来方向
尽管 PhoCoLens 在无透镜成像领域取得了重大进展,但承认其当前局限性并考虑未来发展方向至关重要。
我们方法的一个主要局限性是其实时适用性。两阶段架构,特别是第二阶段的扩散模型采样过程,引入了计算开销,目前阻碍了其在实时照片和视频捕获场景中的使用。这是高质量生成模型面临的常见挑战,解决它将为无透镜相机解锁更广泛的应用。
此外,尽管实现了卓越的保真度,但扩散模型由于其生成性质,仍可能引入与原始场景略有偏差的高频细节,尤其是在本质上平滑或缺乏复杂纹理的区域。虽然这是为了增强照片级真实感而进行的权衡,但它表明在平衡生成创造力和严格的数据保真度方面仍有改进空间。
展望未来,几个令人兴奋的方向可以进一步发展这些发现:
- 加速扩散模型采样:一个关键的未来方向是研究和实施显著加速扩散模型采样过程的技术。这可能包括探索更快的采样算法、蒸馏技术或硬件感知优化。实现实时性能将使无透镜相机成为动态场景的可行解决方案,从而在自主导航、监控和交互式成像等领域实现应用。
- 探索 3D 空间变化的 PSF 效应:当前工作主要集中在 2D 图像重建上。然而,无透镜相机本质上捕获编码在其复杂衍射图案中的 3D 场景信息。未来的工作可以深入研究建模和利用 3D 空间变化的点扩展函数(PSF)来重建不仅是 2D 照片级真实感图像,还有深度图或完整的 3D 场景表示。这将为具有超紧凑设备的全新 3D 成像应用打开大门,例如体积显微镜或增强现实。
- 自适应一致性-照片级真实感权衡:当前方法在一致性和照片级真实感之间取得了固定的平衡。未来的研究可以探索动态或用户控制的机制来调整这种权衡。例如,在医学成像中,严格的一致性可能至关重要,而对于艺术应用,更大的照片级真实感(即使有轻微偏差)可能更受青睐。开发一种允许保真度和生成先验自适应加权的框架可以满足更广泛的用户需求和应用领域。
- 对各种成像条件的鲁棒性:尽管在两个流行的无透镜系统上进行了测试,但仍可以进一步研究在极端或新颖成像条件下的性能(例如,极低光照、高度动态场景、不同的掩模设计)。增强模型在更广泛的无透镜相机设计和环境因素下的鲁棒性和泛化能力将是一项有价值的贡献。
- 伦理考量和隐私保护设计:正如在更广泛的影响部分所强调的,小型、隐蔽的无透镜相机的普及引发了重大的隐私担忧。未来的研究不仅应侧重于技术改进,还应侧重于将隐私保护机制直接集成到成像和重建流程中。这可能包括探索设备上的处理以最小化数据传输、差分隐私技术,或设计本质上限制捕获信息范围以保护个人隐私权的无透镜系统。这种跨学科的努力,涉及工程师、伦理学家和政策制定者,对于确保负责任的技术进步至关重要。
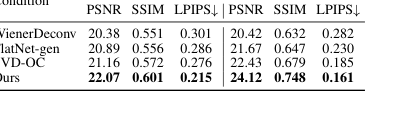 Table 2. Comparison of deconvolution methods for range space reconstruction and original content reconstruction
Table 2. Comparison of deconvolution methods for range space reconstruction and original content reconstruction
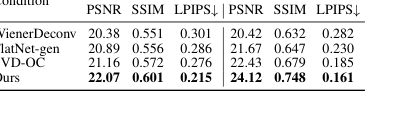 Table 4. Comparison of different diffusion conditions
Table 4. Comparison of different diffusion conditions
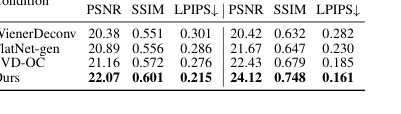 Table 3. Comparison of null space recovery methods
Table 3. Comparison of null space recovery methods
与其他领域的同构性
结构骨架
一种机制,将一个病态逆问题分解为两个正交分量——一个用于一致的低频重建,另一个用于照片级真实感的高频细节生成,并按顺序求解。