रैखिक प्रोग्रामिंग के लिए लघु-आकार ग्राफ़ न्यूरल नेटवर्क की शक्ति पर
रैखिक प्रोग्रामिंग के लिए लघु-आकार ग्राफ़ न्यूरल नेटवर्क की शक्ति पर
पृष्ठभूमि और अकादमिक वंश
उत्पत्ति और अकादमिक वंश
इस पत्र में संबोधित समस्या लर्निंग टू ऑप्टिमाइज़ (L2O) के बढ़ते क्षेत्र से उत्पन्न होती है, जो मशीन लर्निंग तकनीकों को एकीकृत करके पारंपरिक अनुकूलन प्रक्रियाओं की दक्षता को बढ़ाने का प्रयास करती है। L2O के भीतर, ग्राफ़ न्यूरल नेटवर्क (GNNs) ने हाल ही में जटिल अनुकूलन समस्याओं, विशेष रूप से रैखिक प्रोग्रामिंग (LP) और मिश्रित पूर्णांक रैखिक प्रोग्रामिंग (MILP) से निपटने की अपनी क्षमता के लिए महत्वपूर्ण कर्षण प्राप्त किया है।
ऐतिहासिक रूप से, GNNs को सैद्धांतिक रूप से LPs के लिए समाधान मैपिंग फ़ंक्शन को सार्वभौमिक रूप से अनुमानित दिखाने के लिए दिखाया गया है। हालांकि, ये मूलभूत सैद्धांतिक परिणाम, विशेष रूप से चेन एट अल. [8] और कियान एट अल. [29] से, आम तौर पर यह मानते हैं कि GNNs को मनमानी सटीकता प्राप्त करने के लिए समस्या आयाम के सापेक्ष बड़ी संख्या में पैरामीटर या बहुपद गहराई की आवश्यकता होती है। यह सैद्धांतिक आवश्यकता मल्टी-लेयर परसेप्ट्रॉन (MLPs) के लिए सार्वभौमिक सन्निकटन प्रमेय जैसी अवधारणाओं पर उनकी निर्भरता से उत्पन्न होती है।
इन पिछले दृष्टिकोणों की मूलभूत सीमा, या "दर्द बिंदु," सैद्धांतिक भविष्यवाणियों और अनुभवजन्य अवलोकनों के बीच तीव्र विसंगति है। व्यवहार में, शोधकर्ताओं ने पाया है कि अपेक्षाकृत छोटे GNNs—अक्सर मामूली चौड़ाई और दस से कम परतों के साथ—सैकड़ों नोड्स और बाधाओं वाले LPs को प्रभावी ढंग से हल कर सकते हैं, जो उनके सीमित आकार के बावजूद अच्छा प्रदर्शन प्राप्त करते हैं। बड़े, जटिल GNNs की सैद्धांतिक मांग के विपरीत यह व्यावहारिक सफलता, एक महत्वपूर्ण अंतर पैदा करती है। लेखकों ने विशेष रूप से इस अंतर को पाटने के लिए यह पत्र लिखा है, यह समझाने के लिए एक सैद्धांतिक आधार प्रदान करने की मांग की है कि क्यों और कब छोटे-आकार के GNNs प्रभावी ढंग से LPs, विशेष रूप से पैकिंग और कवरिंग LPs को हल कर सकते हैं।
सहज डोमेन शब्द
- रैखिक प्रोग्रामिंग (LP): कल्पना कीजिए कि आपके पास कुकीज़ बेक करने के लिए एक नुस्खा है, लेकिन आपके पास केवल सीमित मात्रा में आटा, चीनी और मक्खन है। आप जितनी संभव हो उतनी कुकीज़ बेक करना चाहते हैं (या यदि आप उन्हें बेचते हैं तो अपने लाभ को अधिकतम करना चाहते हैं) अपनी सामग्री की सीमाओं के भीतर रहते हुए। रैखिक प्रोग्रामिंग एक गणितीय उपकरण है जो आपको अपने लक्ष्य को प्राप्त करने के लिए कुकीज़ के सर्वोत्तम संयोजन का पता लगाने में मदद करता है, इन सरल, सीधी-रेखा बाधाओं को देखते हुए।
- ग्राफ़ न्यूरल नेटवर्क (GNNs): लोगों को नोड्स और दोस्ती को कनेक्शन के रूप में मानने वाले एक सामाजिक नेटवर्क के बारे में सोचें। एक GNN एक स्मार्ट जासूस की तरह है जो प्रत्येक व्यक्ति के बारे में उनसे और उनके दोस्तों से बात करके सीखता है, फिर पूरे नेटवर्क को समझने के लिए उस सामूहिक जानकारी का उपयोग करता है। अनुकूलन में, यह किसी समस्या में चर और बाधाओं के बीच संबंधों से सीखता है।
- पैकिंग LPs: एक ट्रक में यथासंभव विभिन्न आकार के बक्सों को फिट करने की कोशिश करने की कल्पना करें, बिना उसके वजन या मात्रा की क्षमता से अधिक हुए। एक पैकिंग LP एक अनुकूलन समस्या है जो आपको सीमित स्थान या बजट में चीजों (जैसे संसाधन या आइटम) को "पैक" करने का सबसे अच्छा तरीका खोजने में मदद करती है, यह सुनिश्चित करते हुए कि आप किसी भी सीमा को पार न करें।
- कवरिंग LPs: कल्पना कीजिए कि आपको एक इमारत के सभी प्रवेश द्वारों को कवर करने के लिए सुरक्षा कैमरे लगाने की आवश्यकता है, और प्रत्येक कैमरा कुछ विशिष्ट प्रवेश द्वारों को कवर करता है। एक कवरिंग LP आपको सभी प्रवेश द्वारों को "कवर" करने के लिए आवश्यक कैमरों की न्यूनतम संख्या खोजने में मदद करता है, यह सुनिश्चित करता है कि प्रत्येक प्रवेश द्वार की निगरानी की जाए।
- पॉलीलॉगरिदमिक-डेप्थ, कॉन्स्टेंट-विड्थ GNNs: यह एक GNN का वर्णन करता है जो "उथला" है (पॉलीलॉगरिदमिक गहराई का मतलब है कि इसकी परतें समस्या के आकार के साथ बहुत धीरे-धीरे बढ़ती हैं, जैसे $\log(\text{size})$ या $\log^2(\text{size})$) और "पतला" है (कॉन्स्टेंट चौड़ाई का मतलब है कि प्रत्येक परत में आंतरिक प्रसंस्करण इकाइयों की एक निश्चित, छोटी संख्या होती है, भले ही समस्या कितनी भी बड़ी हो जाए)। यह एक बहुत ही कुशल, कॉम्पैक्ट कम्प्यूटेशनल मशीन की तरह है जो अभी भी बड़ी समस्याओं को हल कर सकती है।
संकेतन तालिका
| संकेतन | विवरण |
|---|---|
| $A$ | LP का बाधा मैट्रिक्स ($n \times m$) |
| $x$ | प्रिमल चर वेक्टर ($m \times 1$) |
| $y$ | डुअल चर वेक्टर ($n \times 1$) |
| $X^k$ | पुनरावृति $k$ पर प्रिमल चर मैट्रिक्स ($m \times d$) |
| $Y^k$ | पुनरावृति $k$ पर डुअल चर मैट्रिक्स ($n \times d$) |
| $d$ | विस्तारित चर के लिए चैनल आयाम |
| $n$ | बाधाओं की संख्या ($A$ में पंक्तियाँ) |
| $m$ | प्रिमल चर की संख्या ($A$ में कॉलम) |
| $K$ | GNN परतों की कुल संख्या (पुनरावृति) |
| $\mu$ | ELU इनपुट के लिए स्केलिंग पैरामीटर |
| $\epsilon$ | सन्निकटन परिशुद्धता पैरामीटर |
| $\text{ELU}(\cdot)$ | एक्सपोनेंशियल लीनियर यूनिट सक्रियण फ़ंक्शन |
| $\text{ReLU}(\cdot)$ | रेक्टिफाइड लीनियर यूनिट सक्रियण फ़ंक्शन |
| $f_{\theta^k}(\cdot)$ | प्रिमल चर अपडेट के लिए सीखने योग्य फ़ंक्शन (गुणात्मक) |
| $g_{\theta^k}(\cdot)$ | प्रिमल चर अपडेट के लिए सीखने योग्य फ़ंक्शन (योगात्मक) |
| $W^k$ | चैनल मिश्रण के लिए सीखने योग्य भार मैट्रिक्स ($d \times d$) |
| $\odot$ | हैडामार्ड उत्पाद (तत्व-वार गुणन) |
| $1_{p \times q}$ | सभी-एक मैट्रिक्स आयाम $p \times q$ का |
| $\Theta$ | GD-Net में सभी सीखने योग्य मापदंडों का सेट |
| $obj_i$ | उदाहरण $i$ के लिए अनुमानित उद्देश्य मान |
| $obj^*_i$ | उदाहरण $i$ के लिए इष्टतम उद्देश्य मान |
| R. Gap | सापेक्ष गैप: $|obj_i - obj^*_i| / obj^*_i$ |
| A. Gap | निरपेक्ष गैप: $|obj_i - obj^*_i|$ |
समस्या परिभाषा और बाधाएँ
मुख्य समस्या सूत्रीकरण और दुविधा
यह पत्र रैखिक प्रोग्रामिंग (LP) समस्याओं के लिए ग्राफ़ न्यूरल नेटवर्क (GNNs) के संबंध में सैद्धांतिक समझ और अनुभवजन्य अवलोकनों के बीच एक महत्वपूर्ण अंतर को संबोधित करता है।
इनपुट/वर्तमान स्थिति:
शुरुआती बिंदु यह स्थापित सैद्धांतिक परिणाम है कि GNNs LP समस्याओं के समाधान मैपिंग फ़ंक्शन को सार्वभौमिक रूप से अनुमानित कर सकते हैं। हालांकि, इन सैद्धांतिक प्रमाणों में आम तौर पर समस्या आयाम में बहुपद पैरामीटर या बहुपद गहराई वाले GNNs की आवश्यकता होती है। साथ ही, अनुभवजन्य साक्ष्य लगातार प्रदर्शित करते हैं कि अपेक्षाकृत छोटे GNNs (जैसे, मामूली चौड़ाई और दस से कम परतों के साथ) प्रभावी ढंग से LPs को हल कर सकते हैं, व्यवहार में अच्छा प्रदर्शन प्राप्त कर सकते हैं।
वांछित अंतिम बिंदु/लक्ष्य स्थिति:
प्राथमिक लक्ष्य एक मजबूत सैद्धांतिक आधार प्रदान करना है जो बताता है कि क्यों और कब छोटे-आकार के GNNs LPs को हल करने के लिए प्रभावी हैं। विशेष रूप से, पत्र का उद्देश्य यह साबित करना है कि पॉलीलॉगरिदमिक गहराई और स्थिर चौड़ाई वाले GNNs, मनमानी परिशुद्धता के साथ LPs के एक व्यापक वर्ग, अर्थात् पैकिंग और कवरिंग LPs के समाधान मैपिंग का अनुमान लगाने के लिए पर्याप्त हैं। छोटे, अधिक कुशल GNNs के लिए यह सैद्धांतिक सत्यापन तब लर्निंग टू ऑप्टिमाइज़ (L2O) के लिए पैरामीटर-कुशल मॉडल के विकास का मार्गदर्शन करेगा और संभावित रूप से पारंपरिक LP और मिश्रित पूर्णांक रैखिक प्रोग्रामिंग (MILP) सॉल्वर को तेज करेगा।
लुप्त कड़ी/गणितीय अंतर:
सटीक लुप्त कड़ी छोटे-आकार के GNNs की अनुभवजन्य सफलता का सैद्धांतिक औचित्य है। LPs के लिए GNNs की सार्वभौमिक सन्निकटन क्षमताओं पर पिछला सैद्धांतिक कार्य बड़े मॉडल आकारों (जैसे, बड़े पैरामीटर गणना या बहुपद गहराई) की मान्यताओं पर निर्भर करता था, जिससे देखी गई व्यावहारिक दक्षता के साथ एक डिस्कनेक्ट बनता था। यह पत्र गणितीय रूप से यह प्रदर्शित करके इस अंतर को पाटने का प्रयास करता है कि GNNs सावधानीपूर्वक चयनित संभावित फ़ंक्शन पर ग्रेडिएंट डिसेंट एल्गोरिदम के एक प्रकार का अनुकरण कर सकते हैं, जिससे काफी छोटे आर्किटेक्चर (पॉलीलॉगरिदमिक गहराई और स्थिर चौड़ाई) के साथ मजबूत सन्निकटन गारंटी प्राप्त होती है।
दर्दनाक ट्रेड-ऑफ और दुविधा:
मुख्य दुविधा "सैद्धांतिक भविष्यवाणियों और व्यावहारिक अवलोकनों के बीच महत्वपूर्ण विसंगति" (सार, पी.1) है। शोधकर्ता एक ट्रेड-ऑफ द्वारा "फंसे" हुए हैं जहां LP हल करने में GNNs के लिए मजबूत सैद्धांतिक गारंटी प्राप्त करने के लिए पारंपरिक रूप से बड़े, कम्प्यूटेशनल रूप से गहन मॉडल की आवश्यकता होती है, जबकि व्यावहारिक कार्यान्वयन में अक्सर छोटे, अधिक कुशल मॉडल आश्चर्यजनक रूप से प्रभावी पाए जाते हैं। यह सैद्धांतिक कठोरता (उच्च कम्प्यूटेशनल लागत और व्यापक प्रशिक्षण डेटा के साथ बड़े मॉडल की मांग) और व्यावहारिक दक्षता (छोटे मॉडल द्वारा प्राप्त की गई जिनकी सफलता को औपचारिक रूप से समझाया नहीं गया था) के बीच एक दर्दनाक विकल्प बनाता है। पत्र स्पष्ट रूप से इसे एक "रोचक खुला प्रश्न: कब और क्यों छोटे-आकार के GNNs प्रभावी ढंग से LPs को हल कर सकते हैं?" (परिचय, पी.2) के रूप में फ्रेम करता है, जो इस सैद्धांतिक-अनुभवजन्य विभाजन को सुलझाने की आवश्यकता पर प्रकाश डालता है।
बाधाएँ और विफलता मोड
कुशल और सैद्धांतिक रूप से ग्राउंडेड GNNs को LP हल करने के लिए विकसित करने की समस्या कई कठोर, यथार्थवादी दीवारों द्वारा बाधित है:
- कम्प्यूटेशनल संसाधन सीमाएँ: बड़े GNNs स्वाभाविक रूप से "अधिक प्रशिक्षण उदाहरण और उच्च कम्प्यूटेशनल संसाधनों" (परिचय, पी.2) की मांग करते हैं। यह एक व्यावहारिक बाधा है जो GNNs की मापनीयता और प्रयोज्यता को सीमित करती है यदि सैद्धांतिक गारंटी हमेशा बड़े मॉडल की आवश्यकता होती है। "पैरामीटर-कुशल मॉडल" (परिचय, पी.2) की ड्राइव सीधे इस संबोधित करती है।
- समस्या जटिलता और पैमाना: LPs, विशेष रूप से पैकिंग और कवरिंग LPs, में सैकड़ों नोड्स और बाधाएं शामिल हो सकती हैं (परिचय, पी.2)। स्वीकार्य समय-सीमा के भीतर इन बड़े पैमाने की समस्याओं को कुशलतापूर्वक हल करना एक महत्वपूर्ण चुनौती है।
- मॉडल आकार पर सैद्धांतिक सीमाएँ: सामान्य LPs के लिए पूर्व सैद्धांतिक परिणामों में GNNs को "बड़े पैरामीटर आकार" या "समस्या आयाम के बहुपद में गहराई" (परिचय, पी.2) की आवश्यकता होती है। इस सैद्धांतिक बाधा ने छोटे GNNs की प्रभावशीलता को साबित करना मुश्किल बना दिया, भले ही उनका अनुभवजन्य सफलता हो।
- सन्निकटन परिशुद्धता आवश्यकताएँ: लक्ष्य एक $(1+\epsilon)$-अनुमानित समाधान प्राप्त करना है (धारा 1.1, पी.2)। इसका मतलब है कि GNN को न केवल कुशल होना चाहिए बल्कि समाधान की गुणवत्ता का उच्च स्तर भी बनाए रखना चाहिए, जो मॉडल आकार को कम करते समय एक गैर-तुच्छ कार्य है।
- समाधान व्यवहार्यता: अनुकूलन सॉल्वर पर आधारित मशीन लर्निंग के लिए एक सामान्य विफलता मोड अव्यवहार्य समाधान उत्पन्न करना है। GD-Net द्वारा आउटपुट
x_finalयाy_finalसभी LP बाधाओं (जैसे, $x \ge 0$, $Ax \le 1$) को संतुष्ट नहीं कर सकता है। पत्र इसे "व्यवहार्यता पुनर्संस्थापन" पोस्ट-प्रोसेसिंग प्रक्रिया (पी.7, पी.8) के साथ संबोधित करता है, जो इसे दूर करने के लिए एक महत्वपूर्ण बाधा के रूप में इंगित करता है। - गैर-विभेदक संचालन: अंतर्निहित ग्रेडिएंट डिसेंट एल्गोरिदम (एल्गोरिदम 1 और 2) में सशर्त अपडेट (यदि-अन्यथा कथन) और
maxसंचालन शामिल हैं, जो गैर-विभेदक हैं। इन्हें सीधे तंत्रिका नेटवर्क में अनुवाद करना समस्याग्रस्त है। लेखक हेविसाइड स्टेप फ़ंक्शन को सीखने योग्य सिग्मॉइड फ़ंक्शन (समीकरण 4, 5, 6, पी.6) के साथ अनुमानित करके और गैर-नकारात्मकता के लिए ReLU का उपयोग करके इसे दरकिनार करते हैं, प्रभावी रूप से गैर-विभेदक तर्क को विभेदक तंत्रिका नेटवर्क आर्किटेक्चर में परिवर्तित करते हैं। पुनरावृत्ति एल्गोरिदम को अनरोल करने में यह एक प्रमुख तकनीकी बाधा है। - हार्डवेयर मेमोरी सीमाएँ: हालांकि एक हार्ड सीमा के रूप में स्पष्ट रूप से हिट नहीं किया गया है, प्रयोगात्मक सेटअप "2.95 टीबी रैम" (धारा ई, पी.16) का उल्लेख करता है, जिसका अर्थ है कि बड़े LP उदाहरणों के लिए मेमोरी एक महत्वपूर्ण बाधा हो सकती है, और छोटे GNNs स्वाभाविक रूप से इस दबाव को कम करते हैं।
- अभिसरण गति: पुनरावृत्ति एल्गोरिदम को उचित संख्या में चरणों के भीतर अभिसरण करने की आवश्यकता है। पत्र Awerbuch-Khandekar एल्गोरिदम के "पॉलीलॉगरिदमिक अभिसरण" (पी.4) को नोट करता है, और GNN को इस कुशल अभिसरण का अनुकरण करने के लिए डिज़ाइन किया जाना चाहिए।
यह दृष्टिकोण क्यों
चुनाव की अनिवार्यता
GD-Net आर्किटेक्चर को अपनाना, जो Awerbuch-Khandekar ग्रेडिएंट डिसेंट एल्गोरिथम के एक प्रकार को अनरोल करता है, केवल एक डिजाइन विकल्प नहीं था, बल्कि ग्राफ़ न्यूरल नेटवर्क (GNNs फॉर लीनियर प्रोग्रामिंग (LP) के क्षेत्र में मौजूदा सैद्धांतिक समझ और अनुभवजन्य अवलोकनों के बीच एक महत्वपूर्ण अंतर से प्रेरित एक आवश्यकता थी। पारंपरिक सैद्धांतिक परिणाम, अक्सर सार्वभौमिक सन्निकटन प्रमेय पर निर्भर करते थे, सुझाव देते थे कि LPs को मनमानी परिशुद्धता के साथ प्रभावी ढंग से हल करने के लिए GNNs को बड़े पैरामीटर आकार या समस्या आयाम में बहुपद गहराई की आवश्यकता होगी (सार, पी.1; पी.2)। हालांकि, व्यावहारिक प्रयोगों ने लगातार दिखाया कि अपेक्षाकृत छोटे GNNs अच्छा प्रदर्शन प्राप्त कर सकते हैं, जिससे एक पेचीदा विसंगति पैदा होती है।
लेखकों ने महसूस किया कि मानक GNNs, जैसे कि पारंपरिक ग्राफ़ कन्वेन्शनल नेटवर्क (GCNs), इस अंतर को पाटने के लिए अपर्याप्त थे क्योंकि, जबकि वे पॉलीलॉगरिदमिक गहराई प्राप्त कर सकते थे, वे स्थिर चौड़ाई की गारंटी नहीं दे सकते थे (टिप्पणी 1, पी.7)। इसका मतलब यह था कि सामान्य-उद्देश्य वाले GNNs को अभी भी ELU जैसे फ़ंक्शन को मनमानी परिशुद्धता के साथ अनुकरण करने के लिए "पर्याप्त रूप से चौड़े परसेप्ट्रॉन" की आवश्यकता होगी, इस प्रकार "छोटे-आकार" की आवश्यकता को पूरा करने में विफल रहे (पी.7)। Awerbuch-Khandekar ग्रेडिएंट डिसेंट एल्गोरिथम का विशिष्ट प्रकार, हालांकि, एक अद्वितीय लाभ प्रदान करता है: इसे "GNNs द्वारा अधिक स्वाभाविक रूप से अनुकरण किया जा सकता है" जहां "एल्गोरिथम का एक पुनरावृति स्थिर चौड़ाई के एक GNN परत द्वारा अनुकरण किया जा सकता है" (पी.4)। एक पुनरावृत्ति अनुकूलन एल्गोरिथम से स्थिर चौड़ाई और पॉलीलॉगरिदमिक गहराई (प्रमेय 3 और 5, पी.7-8) वाले GNN संरचना तक यह सीधा मानचित्रण, पैकिंग और कवरिंग LPs के लिए छोटे-आकार के GNNs की अनुभवजन्य सफलता को सैद्धांतिक रूप से समझाने के लिए एकमात्र व्यवहार्य मार्ग प्रदान करता है।
तुलनात्मक श्रेष्ठता
GD-Net दृष्टिकोण सरल प्रदर्शन मेट्रिक्स से परे, मुख्य रूप से इसकी संरचनात्मक डिजाइन और अंतर्निहित पैरामीटर मितव्ययिता के कारण, पिछले तरीकों पर गुणात्मक श्रेष्ठता प्रदर्शित करता है।
सबसे पहले, GD-Net का आर्किटेक्चर मौलिक रूप से अंतर्निहित अनुकूलन समस्या के साथ संरेखित है। पैकिंग और कवरिंग LPs के लिए एक सैद्धांतिक रूप से ग्राउंडेड ग्रेडिएंट डिसेंट एल्गोरिथम को अनरोल करके, यह इन समस्याओं की अंतर्निहित संरचना का लाभ उठाता है। यह अधिक सामान्य GNN आर्किटेक्चर जैसे GCNs के विपरीत है, जो शक्तिशाली होने के बावजूद, विशेष रूप से ऐसे पुनरावृत्ति अनुकूलन प्रक्रियाओं का अनुकरण करने के लिए तैयार नहीं हैं। यह संरचनात्मक लाभ GD-Net को "समस्या की संरचनात्मक बारीकियों को बेहतर ढंग से पकड़ने" (पी.9) की अनुमति देता है।
दूसरे, GD-Net पैरामीटर दक्षता में भारी श्रेष्ठता प्रदर्शित करता है। प्रयोगों से पता चलता है कि GD-Net "GCN की तुलना में एक परिमाण कम पैरामीटर" (पी.3) के साथ बेहतर समाधान प्राप्त करता है। उदाहरण के लिए, 64 छिपे हुए इकाइयों के साथ एक चार-परत GD-Net केवल 1,656 पैरामीटर का उपयोग करता है, जबकि एक तुलनीय GCN को 34,306 पैरामीटर की आवश्यकता होती है (पी.9)। पैरामीटर में यह भारी कमी कम मेमोरी जटिलता और कम्प्यूटेशनल ओवरहेड में तब्दील होती है, जिससे मॉडल अधिक व्यावहारिक और स्केलेबल बनते हैं।
तीसरे, विधि समाधान की गुणवत्ता और गति के मामले में बेहतर प्रदर्शन प्रदर्शित करती है। तालिका 1 (पी.9) दर्शाती है कि GD-Net विभिन्न LP प्रकारों (IS, पैकिंग, ECP, SC) और समस्या आकारों में लगातार GCNs की तुलना में संकीर्ण सापेक्ष और निरपेक्ष अंतराल प्राप्त करता है। उन मामलों में भी जहां GD-Net की परीक्षण त्रुटि मामूली रूप से अधिक हो सकती है, इसका सापेक्ष अंतराल बेहतर बना रहता है, जो इष्टतम समाधान का गुणात्मक रूप से बेहतर सन्निकटन इंगित करता है। इसके अलावा, जब पारंपरिक सॉल्वर जैसे PDLP और Gurobi के खिलाफ बेंचमार्क किया जाता है, तो GD-Net लगातार तुलनीय परिशुद्धता स्तर प्राप्त करता है, जो काफी कम समय में होता है। उदाहरण के लिए, Gurobi की सिम्प्लेक्स विधि को GD-Net (पी.10) के समान गुणवत्ता के समाधान को अभिसरण करने के लिए 300 गुना अधिक समय की आवश्यकता थी। यह उच्च-गुणवत्ता वाले समाधानों को कुशलतापूर्वक उत्पन्न करने की GD-Net की क्षमता को उजागर करता है, जो वास्तविक दुनिया के अनुप्रयोगों के लिए महत्वपूर्ण है।
अंत में, GD-Net मजबूत सामान्यीकरण क्षमताओं और मापनीयता दिखाता है। यह "छोटे डेटासेट पर प्रशिक्षित होने पर केवल न्यूनतम प्रदर्शन गिरावट" के साथ बड़े समस्या उदाहरणों को सामान्यीकृत कर सकता है (पी.9, तालिका 2)। इसके अनुमान समय "समस्या के आकार बढ़ने पर भी तुलनीय रूप से स्वीकार्य बने रहते हैं," GCNs के विपरीत, जिन्हें "बड़े समस्या उदाहरणों को संसाधित करने और भविष्यवाणी करने के लिए काफी अधिक समय की आवश्यकता होती है" (पी.18)।
बाधाओं के साथ संरेखण
चुनी गई GD-Net विधि समस्या की अंतर्निहित बाधाओं के साथ पूरी तरह से संरेखित होती है, विशेष रूप से छोटे-आकार GNNs और एक मजबूत सैद्धांतिक आधार का उपयोग करके प्रभावी समाधानों की आवश्यकता। मुख्य समस्या कथन LP हल करने के लिए आवश्यक GNNs के आकार के संबंध में "सैद्धांतिक भविष्यवाणियों और व्यावहारिक अवलोकनों के बीच महत्वपूर्ण विसंगति" (सार, पी.1) को पाटने के इर्द-गिर्द घूमता है।
GD-Net का डिजाइन, जो Awerbuch-Khandekar ग्रेडिएंट डिसेंट एल्गोरिथम के एक प्रकार को अनरोल करता है, सीधे इस समस्या को यह साबित करके संबोधित करता है कि "पॉलीलॉगरिदमिक-डेप्थ, कॉन्स्टेंट-विड्थ GNNs पैकिंग और कवरिंग LPs को हल करने के लिए पर्याप्त हैं" (सार, पी.1; प्रमेय 3 और 5, पी.7-8)। यह सैद्धांतिक परिणाम छोटे GNNs की प्रभावशीलता के लिए आवश्यक आधार प्रदान करता है, सीधे सीमित मॉडल जटिलता के साथ उच्च प्रदर्शन प्राप्त करने की बाधा को पूरा करता है। समस्या की कठोर आवश्यकताओं (छोटे, कुशल मॉडल) और समाधान के अद्वितीय गुणों (स्थिर-चौड़ाई, पॉलीलॉगरिदमिक-गहराई GNNs जो एक ज्ञात पुनरावृत्ति एल्गोरिथम का अनुकरण करते हैं) के "विवाह" इस सैद्धांतिक गारंटी में स्पष्ट है।
इसके अलावा, स्थिर चौड़ाई की एक GNN परत के साथ ग्रेडिएंट डिसेंट एल्गोरिथम के एक पुनरावृति का अनुकरण करने की विधि की क्षमता यह सुनिश्चित करती है कि नेटवर्क की संरचना स्वाभाविक रूप से कुशल और स्केलेबल है। एल्गोरिथम चरणों और नेटवर्क परतों के बीच यह सीधा पत्राचार स्वाभाविक रूप से मॉडल की चौड़ाई को सीमित करता है, जो "छोटे-आकार" बाधा के साथ संरेखित होता है, जबकि एक स्पष्ट, व्याख्यात्मक तंत्र बनाए रखता है।
विकल्पों का अस्वीकरण
यह पत्र स्पष्ट रूप से और स्पष्ट रूप से विभिन्न वैकल्पिक दृष्टिकोणों को उनके सैद्धांतिक सीमाओं, अनुभवजन्य प्रदर्शन और पैकिंग और कवरिंग LPs को छोटे-आकार के GNNs के साथ हल करने की विशिष्ट समस्या के लिए कम्प्यूटेशनल अक्षमता के आधार पर अस्वीकार करता है।
सामान्य-उद्देश्य वाले GNNs (जैसे, GCNs): छोटे-आकार समाधान प्राप्त करने के लिए माना जाने वाला और अस्वीकृत प्राथमिक विकल्प GCNs जैसे सामान्य-उद्देश्य वाले GNNs हैं। जबकि ये मॉडल पॉलीलॉगरिदमिक गहराई भी प्राप्त कर सकते हैं, लेखकों ने स्पष्ट रूप से कहा है कि "स्थिर चौड़ाई की गारंटी नहीं है" ऐसे आर्किटेक्चर के लिए (टिप्पणी 1, पी.7)। इसका मतलब है कि मनमानी परिशुद्धता प्राप्त करने के लिए, GCNs को "पर्याप्त रूप से चौड़े परसेप्ट्रॉन" की आवश्यकता होगी, जिससे एक गैर-स्थिर चौड़ाई होगी और इस प्रकार GD-Net सफलतापूर्वक संबोधित करता है (पी.7) जो "छोटे-आकार" बाधा को पूरा करने में विफल रहेगा। अनुभवजन्य रूप से, GCNs ने लगातार सापेक्ष और निरपेक्ष अंतराल के मामले में निम्न प्रदर्शन दिखाया, और अक्सर उच्च सत्यापन/परीक्षण त्रुटियां, भले ही GD-Net "एक परिमाण कम पैरामीटर" (पी.3, तालिका 1, पी.9) का उपयोग करता हो। इसके अलावा, GCNs ने खराब मापनीयता प्रदर्शित की, "बड़े समस्या उदाहरणों को संसाधित करने और भविष्यवाणी करने के लिए काफी अधिक समय की आवश्यकता होती है" GD-Net की तुलना में (पी.18)।
पारंपरिक LP सॉल्वर (PDLP, Gurobi): पत्र स्थापित, सैद्धांतिक रूप से ग्राउंडेड LP सॉल्वर जैसे PDLP (एक प्रथम-क्रम विधि) और वाणिज्यिक सॉल्वर Gurobi (प्रिमल सिम्प्लेक्स विधि का उपयोग करके) के खिलाफ GD-Net का बेंचमार्क भी करता है। जबकि ये सॉल्वर मजबूत हैं, उन्हें उन परिदृश्यों के लिए प्राथमिक समाधान के रूप में अस्वीकार कर दिया जाता है जहां गति और दक्षता सर्वोपरि है। PDLP "कम समय में GD-Net के तुलनीय गुणवत्ता के समाधान का उत्पादन करने में असमर्थ" था (पी.10)। Gurobi, अपनी परिशुद्धता के बावजूद, "GD-Net के समान गुणवत्ता के समाधान को अभिसरण करने के लिए 300x अधिक समय की आवश्यकता थी" (पी.10)। इसका श्रेय सिम्प्लेक्स विधि के कम्प्यूटेशनल रूप से महंगे मैट्रिक्स गुणनखंडन (पी.10) को दिया जाता है। इस प्रकार, जबकि शुद्धता के मामले में "विफलता" नहीं है, उनकी कम्प्यूटेशनल लागत उन्हें तेज, उच्च-गुणवत्ता वाले अनुमानित समाधानों या गर्म-शुरुआत के लिए कम उपयुक्त बनाती है, जो GD-Net कुशलतापूर्वक प्रदान करता है।
पत्र अन्य मशीन लर्निंग प्रतिमानों जैसे जनरेटिव एडवरसैरियल नेटवर्क (GANs) या डिफ्यूजन मॉडल पर चर्चा नहीं करता है, क्योंकि वे रैखिक प्रोग्रामिंग समस्याओं को हल करने की समस्या पर सीधे लागू नहीं होते हैं। ध्यान GNNs और शास्त्रीय अनुकूलन एल्गोरिदम के साथ उनके संबंध पर बना हुआ है।
गणितीय और तार्किक तंत्र
मास्टर समीकरण
इस पत्र के तंत्र का मूल इसके ग्राफ़ न्यूरल नेटवर्क (GNN) आर्किटेक्चर, GD-Net में निहित है, जिसे रैखिक प्रोग्रामिंग (LP) समस्याओं को हल करने के लिए Awerbuch-Khandekar ग्रेडिएंट डिसेंट एल्गोरिथम के एक प्रकार का अनुकरण करने के लिए डिज़ाइन किया गया है। विशेष रूप से, पैकिंग LPs के लिए, एल्गोरिथम का एक पुनरावृति, जो एक एकल GNN परत के अनुरूप है, दो प्राथमिक अद्यतन समीकरणों द्वारा शासित होता है। ये समीकरण बताते हैं कि डुअल चर (बाधाओं का प्रतिनिधित्व करते हैं) और प्रिमल चर (आइटम का प्रतिनिधित्व करते हैं) को पुनरावृत्ति रूप से कैसे अपडेट किया जाता है।
पुनरावृति $k$ पर डुअल चर $Y^k$ के लिए अद्यतन दिया गया है:
$$Y^k := \text{ELU}[\mu(A X^k - 1_{n \times d})] + 1_{n \times d}$$
और अगली पुनरावृति $k+1$ के लिए प्रिमल चर $X^{k+1}$ का अद्यतन है:
$$X^{k+1} = \text{ReLU} (\{X^k + f_{\theta^k}(A^T Y^k - 1_{m \times d}) \odot X^k + g_{\theta^k}(A^T Y^k - 1_{m \times d})\} \cdot W^k)$$
कवरिंग LPs के लिए समीकरणों का एक समान सेट मौजूद है, जो इन समस्याओं की द्वैत प्रकृति को दर्शाता है।
पद-दर-पद विच्छेदन
आइए प्रत्येक घटक की भूमिका को समझने के लिए इन समीकरणों का विश्लेषण करें:
समीकरण 1: $Y^k := \text{ELU}[\mu(A X^k - 1_{n \times d})] + 1_{n \times d}$
- $Y^k$: यह पुनरावृति $k$ पर डुअल चर (या बाधा मूल्य) की वर्तमान स्थिति का प्रतिनिधित्व करने वाला एक $n \times d$ मैट्रिक्स है। प्रत्येक पंक्ति एक बाधा से मेल खाती है, और प्रत्येक कॉलम चैनल विस्तार से एक सुविधा आयाम है। इसकी भौतिक भूमिका प्रत्येक बाधा की "तंगी" या "उल्लंघन" को मापना है।
- $\text{ELU}[\cdot]$: एक्सपोनेंशियल लीनियर यूनिट सक्रियण फ़ंक्शन, तत्व-वार लागू किया जाता है। इसकी गणितीय परिभाषा $\text{ELU}(t) = t$ है जब $t > 0$ और $\text{ELU}(t) = \alpha(\exp(t) - 1)$ जब $t \le 0$ हो। इस पत्र में, $\alpha$ को 1 पर तय किया गया है। लेखक ELU का उपयोग मूल एल्गोरिथम 1 के एक्सपोनेंशियल फ़ंक्शन अपडेट $y_i := \exp[\mu(A_i x^k - 1)]$ को सटीक रूप से दोहराने के लिए करते हैं, यह देखते हुए कि ELU का इनपुट, $\mu(A_i x^k - 1)$, निष्पादन के दौरान हमेशा गैर-सकारात्मक होता है। यह गैर-रैखिकता GNN के लिए जटिल मैपिंग सीखने के लिए महत्वपूर्ण है।
- $\mu$: एक स्केलर पैरामीटर, जिसे $1/\ln(mA_{\max})$ के रूप में तय किया गया है। गणितीय रूप से, यह ELU फ़ंक्शन के इनपुट को स्केल करता है। इसकी भौतिक/तार्किक भूमिका डुअल चर अपडेट की बाधा उल्लंघनों के प्रति संवेदनशीलता को नियंत्रित करना है। एक छोटा $\mu$ (बड़े $m$ या $A_{\max}$ के कारण) कम आक्रामक अपडेट का मतलब है।
- $A$: यह रैखिक प्रोग्राम का $n \times m$ बाधा मैट्रिक्स है। प्रत्येक तत्व $A_{ij}$ या तो शून्य है या 1 से बड़ा है। इसकी भूमिका प्रिमल चर और बाधाओं के बीच संबंधों को परिभाषित करना है।
- $X^k$: पुनरावृति $k$ पर प्रिमल चर (या आइटम मात्रा) की वर्तमान स्थिति का प्रतिनिधित्व करने वाला एक $m \times d$ मैट्रिक्स। प्रत्येक पंक्ति एक प्रिमल चर से मेल खाती है, और प्रत्येक कॉलम एक सुविधा आयाम है। इसकी भौतिक भूमिका LP के प्रस्तावित वर्तमान समाधान का प्रतिनिधित्व करना है।
- $1_{n \times d}$: एक $n \times d$ मैट्रिक्स जहां सभी तत्व 1 हैं। यह तत्व-वार संचालन के लिए उपयोग किया जाता है।
- $A X^k$: यह एक मैट्रिक्स गुणन है, जिसके परिणामस्वरूप एक $n \times d$ मैट्रिक्स होता है। प्रत्येक तत्व $(A X^k)_{id}$ बाधा $i$ और सुविधा आयाम $d$ के लिए बाधा गुणांकों द्वारा भारित प्रिमल चर का योग दर्शाता है। इसकी भौतिक भूमिका पैकिंग LP बाधाओं के बाएं हाथ की ओर, $Ax \le 1$ की गणना करना है।
- $A X^k - 1_{n \times d}$: एक तत्व-वार घटाव। यह प्रत्येक सुविधा आयाम $d$ में प्रत्येक बाधा $i$ के लिए उल्लंघन या स्लैक को मापता है। यदि $(A X^k)_{id} - 1_{id} > 0$, तो बाधा का उल्लंघन होता है।
- $+ 1_{n \times d}$: एक मैट्रिक्स के एक तत्व-वार जोड़। यह शब्द, ELU फ़ंक्शन के साथ मिलकर, यह सुनिश्चित करता है कि $y$-अपडेट मूल Awerbuch-Khandekar एल्गोरिथम के एक्सपोनेंशियल अपडेट से बिल्कुल मेल खाता है। वांछित एक्सपोनेंशियल व्यवहार से मेल खाने के लिए ELU आउटपुट को शिफ्ट करने के लिए जोड़ का उपयोग किया जाता है।
समीकरण 2: $X^{k+1} = \text{ReLU} (\{X^k + f_{\theta^k}(A^T Y^k - 1_{m \times d}) \odot X^k + g_{\theta^k}(A^T Y^k - 1_{m \times d})\} \cdot W^k)$
- $X^{k+1}$: अगली पुनरावृति के लिए अद्यतन प्रिमल चर का प्रतिनिधित्व करने वाला $m \times d$ मैट्रिक्स।
- $\text{ReLU}(\cdot)$: रेक्टिफाइड लीनियर यूनिट सक्रियण फ़ंक्शन, तत्व-वार लागू किया जाता है। गणितीय रूप से, $\text{ReLU}(t) = \max(0, t)$। इसकी भौतिक/तार्किक भूमिका प्रिमल चर पर गैर-नकारात्मकता बाधा ($x \ge 0$) को लागू करना है, जो LPs के लिए मौलिक है।
- $X^k$: प्रिमल चर की वर्तमान स्थिति, जैसा कि ऊपर परिभाषित किया गया है।
- $f_{\theta^k}(\cdot)$ और $g_{\theta^k}(\cdot)$: ये सीखने योग्य फ़ंक्शन हैं, जिन्हें सिग्मॉइड फ़ंक्शन के योग के रूप में परिभाषित किया गया है (समीकरण 5 और 6)। वे इनपुट मैट्रिक्स पर तत्व-वार लागू होते हैं। उनकी गणितीय भूमिका मूल Awerbuch-Khandekar एल्गोरिथम के सशर्त अपडेट में उपयोग किए जाने वाले हेविसाइड स्टेप फ़ंक्शन $f(t)$ और $g(t)$ (समीकरण 4) का अनुमान लगाना है। उनकी भौतिक/तार्किक भूमिका एकत्रित डुअल जानकारी के आधार पर प्रत्येक प्रिमल चर पर लागू समायोजन की मात्रा और प्रकार निर्धारित करना है। लेखकों ने इन फ़ंक्शनों का निर्माण करने के लिए योग (सिग्मॉइड के योग के रूप में $f_{\theta^k}$ और $g_{\theta^k}$ की परिभाषा में स्पष्ट रूप से) का उपयोग किया है, जिससे मूल स्टेप-वार अपडेट का एक चिकना, विभेदक सन्निकटन संभव हो सके।
- $A^T$: बाधा मैट्रिक्स $A$ का ट्रांसपोज़।
- $A^T Y^k$: एक मैट्रिक्स गुणन, जिसके परिणामस्वरूप एक $m \times d$ मैट्रिक्स होता है। यह शब्द डुअल चर जानकारी ($Y^k$) को प्रिमल चर में वापस एकत्रित करता है, प्रभावी रूप से प्रत्येक प्रिमल चर के लिए एक "ग्रेडिएंट-जैसी" सिग्नल की गणना करता है। संभावित फ़ंक्शन $\Phi_p(x)$ के संदर्भ में, $\nabla \Phi_p(x) = A^T y$।
- $A^T Y^k - 1_{m \times d}$: एक तत्व-वार घटाव। यह प्रत्येक प्रिमल चर के लिए "ग्रेडिएंट" या "अपडेट की दिशा" का प्रतिनिधित्व करता है, यह दर्शाता है कि इसे कितना समायोजित किया जाना चाहिए।
- $\odot$: हैडामार्ड उत्पाद (तत्व-वार गुणन)। इस ऑपरेटर का उपयोग $f_{\theta^k}$ से स्केलिंग कारक को तत्व-वार $X^k$ पर लागू करने के लिए किया जाता है, जो मूल एल्गोरिथम में गुणक अपडेट $(1+\beta)$ या $(1-\beta)$ की नकल करता है।
- $W^k$: एक $d \times d$ सीखने योग्य भार मैट्रिक्स। यह तंत्रिका नेटवर्क में एक मानक रैखिक परिवर्तन है। इसकी भूमिका विस्तारित चर के $d$ सुविधा आयामों (चैनलों) में जानकारी को मिश्रित करना है, जिससे मॉडल की अभिव्यक्ति शक्ति बढ़ती है। यहां गुणन एक मैट्रिक्स गुणन है, जो फीचर वैक्टर को बदलता है।
- घुंघराले ब्रेसिज़ $\{\dots\}$ वर्तमान प्रिमल चर और दो अद्यतन शब्दों के योग को घेरते हैं। यह मुख्य ग्रेडिएंट डिसेंट चरण का प्रतिनिधित्व करता है, जहां वर्तमान समाधान की गणना ग्रेडिएंट और सीखने योग्य फ़ंक्शन के आधार पर समायोजित की जाती है। जोड़ की गणना किए गए अपडेट के साथ वर्तमान स्थिति को संयोजित करने के लिए उपयोग किया जाता है।
चरण-दर-चरण प्रवाह
एक एकल अमूर्त डेटा बिंदु की कल्पना करें, जो पैकिंग GD-Net की एक परत (पुनरावृति $k$) से गुजरने वाले एक प्रिमल चर $x_j$ का प्रतिनिधित्व करता है:
- आरंभीकरण: प्रक्रिया की शुरुआत में ($k=0$), सभी प्रिमल चर $X^0$ को $0_{m \times d}$ पर इनिशियलाइज़ किया जाता है। डुअल चर $Y^0$ भी प्रभावी रूप से इनिशियलाइज़ या $X^0$ से प्राप्त होते हैं।
- प्रिमल से डुअल संदेश पासिंग (Y-अपडेट):
- बाधा मूल्यांकन: प्रत्येक बाधा $i$ के लिए, वर्तमान प्रिमल चर $X^k$ इसे "संदेश भेजते हैं"। इसमें भारित योग $A_i X^k$ (A $X^k$ की $i$-वीं पंक्ति) की गणना शामिल है। यह योग दर्शाता है कि चुने गए प्रिमल चर द्वारा वर्तमान में $i$-वें संसाधन का कितना उपयोग किया जा रहा है।
- उल्लंघन गणना: गणना किए गए योग $A_i X^k$ की तुलना बाधा सीमा (सामान्य रूप LPs के लिए 1) से की जाती है, जिससे $A_i X^k - 1_{n \times d}$ प्राप्त होता है। यह मान इंगित करता है कि बाधा $i$ का उल्लंघन हुआ है (सकारात्मक) या संतुष्ट है (नकारात्मक/शून्य)।
- डुअल चर अद्यतन: इस "उल्लंघन संकेत" को $\mu$ से स्केल किया जाता है और ELU सक्रियण फ़ंक्शन के माध्यम से पारित किया जाता है, फिर $1_{n \times d}$ जोड़कर शिफ्ट किया जाता है। यह परिवर्तन अद्यतन डुअल चर $Y^k$ उत्पन्न करता है। वैचारिक रूप से, भारी उल्लंघन वाली बाधाओं के अनुरूप डुअल चर अधिक बढ़ेंगे, जिससे उनके उल्लंघन के लिए उच्च "लागत" का संकेत मिलेगा।
- डुअल से प्रिमल संदेश पासिंग (X-अपडेट):
- ग्रेडिएंट एकत्रीकरण: अब, अद्यतन डुअल चर $Y^k$ प्रिमल चर को वापस "संदेश भेजते हैं"। प्रत्येक प्रिमल चर $x_j$ के लिए, शब्द $A_j^T Y^k$ ($A^T Y^k$ की $j$-वीं पंक्ति) उन सभी बाधाओं के प्रभाव को एकत्रित करता है जिनमें $x_j$ भाग लेता है। यह एकत्रित संकेत एक "ग्रेडिएंट" के रूप में कार्य करता है, जो दर्शाता है कि $x_j$ को समायोजित करने से समग्र उद्देश्य और बाधा संतुष्टि कैसे प्रभावित होगी।
- सशर्त समायोजन: यह ग्रेडिएंट संकेत $A^T Y^k - 1_{m \times d}$ सीखने योग्य फ़ंक्शन $f_{\theta^k}$ और $g_{\theta^k}$ में फीड किया जाता है। ये फ़ंक्शन, एक परिष्कृत निर्णय लेने वाली इकाई की तरह काम करते हुए, यह निर्धारित करते हैं कि वर्तमान $X^k$ को कितना स्केल करना है ($f_{\theta^k} \odot X^k$ के माध्यम से) और कितना जोड़ना है ($g_{\theta^k}$ के माध्यम से)। यह चरण मूल एल्गोरिथम के सशर्त तर्क की नकल करता है: यदि किसी चर का ग्रेडिएंट एक सीमा से नीचे है, तो इसे बढ़ाएं; यदि ऊपर है, तो इसे घटाएं।
- फ़ीचर परिवर्तन: संयुक्त अद्यतन को फिर सीखने योग्य भार मैट्रिक्स $W^k$ से गुणा किया जाता है। यह चरण प्रत्येक प्रिमल चर के $d$ फ़ीचर आयामों में जानकारी को मिश्रित और बदलने की अनुमति देता है, इसके प्रतिनिधित्व को समृद्ध करता है।
- गैर-नकारात्मकता प्रवर्तन: अंत में, ReLU सक्रियण फ़ंक्शन परिणाम पर तत्व-वार लागू किया जाता है। यह सुनिश्चित करता है कि अद्यतन प्रिमल चर $X^{k+1}$ के सभी घटक गैर-नकारात्मक रहें, एक मौलिक LP बाधा का पालन करते हुए।
यह पूरी अनुक्रम GD-Net की एक परत का गठन करता है। आउटपुट $X^{k+1}$ तब अगली परत के लिए इनपुट $X^k$ बन जाता है, और प्रक्रिया $K$ परतों के लिए दोहराई जाती है, पुनरावृत्ति रूप से समाधान को परिष्कृत करती है।
अनुकूलन गतिशीलता
GD-Net की सीखने और अभिसरण गतिशीलता को सावधानीपूर्वक चयनित संभावित फ़ंक्शन पर ग्रेडिएंट डिसेंट के एक अनरोल्ड संस्करण के रूप में इसके डिजाइन में निहित है, जिसमें सीखने योग्य घटक हैं।
- सीखने की विधि: GD-Net अपने सीखने योग्य मापदंडों $\Theta = \{\theta^k, W^k\}_{k=0}^{K-1} \cup \{w^K\}$ के सेट को अनुकूलित करके सीखता है। इन मापदंडों में सिग्मॉइड-आधारित फ़ंक्शन $f_{\theta^k}$ और $g_{\theta^k}$ के आंतरिक गुणांक और चैनल मिश्रण मैट्रिक्स $W^k$ शामिल हैं। सीखने का उद्देश्य किसी दिए गए LP उदाहरण $A$ के लिए नेटवर्क के अंतिम आउटपुट $x^{\text{final}}(\Theta, A)$ और वास्तविक इष्टतम समाधान $x^*$ के बीच माध्य वर्ग त्रुटि (MSE) को कम करना है। यह एक पर्यवेक्षित शिक्षण कार्य है, जहां नेटवर्क को LP उदाहरणों और उनके ज्ञात इष्टतम समाधानों के डेटासेट पर प्रशिक्षित किया जाता है।
- पैरामीटर अद्यतन: पैरामीटर $\Theta$ को मानक ग्रेडिएंट-आधारित अनुकूलन एल्गोरिदम (जैसे, एडम, एसजीडी) का उपयोग करके अपडेट किया जाता है। प्रशिक्षण के दौरान, हानि फ़ंक्शन $L_p(\mathcal{I}; \Theta)$ की गणना की जाती है, और $\Theta$ के संबंध में इसके ग्रेडिएंट को पूरी $K$-परत नेटवर्क के माध्यम से बैकप्रॉपैगेशन द्वारा गणना की जाती है। ये ग्रेडिएंट इंगित करते हैं कि भविष्यवाणी त्रुटि को कम करने के लिए प्रत्येक पैरामीटर को कैसे समायोजित किया जाना चाहिए।
- हानि परिदृश्य और अभिसरण: पत्र इस बात पर प्रकाश डालता है कि मूल Awerbuch-Khandekar एल्गोरिथम एक सावधानीपूर्वक चयनित संभावित फ़ंक्शन $\Phi_p(x)$ (या $\Phi_c(y)$) पर संचालित होता है जो विभेदक और उत्तल है। इसका मतलब है कि ग्रेडिएंट डिसेंट के लिए अंतर्निहित अनुकूलन समस्या में एक अच्छी तरह से व्यवहार किया जाने वाला, एकल-न्यूनतम हानि परिदृश्य है। इस एल्गोरिथम को अनरोल करके और इसके सशर्त अपडेट को सीखने योग्य, विभेदक फ़ंक्शन ($f_{\theta^k}, g_{\theta^k}$ सिग्मॉइड से बने) और रैखिक परिवर्तनों ($W^k$) से बदलकर, GD-Net इस अभिसरण का अनुकरण और तेजी लाने का लक्ष्य रखता है।
- ELU और ReLU सक्रियण गैर-रैखिकताएं पेश करते हैं, जो GNN की अभिव्यक्ति शक्ति के लिए आवश्यक हैं। जबकि समग्र तंत्रिका नेटवर्क का प्रशिक्षण के लिए हानि परिदृश्य गैर-उत्तल हो सकता है, डिजाइन यह सुनिश्चित करता है कि प्रत्येक परत का अद्यतन चरण एक उत्तल फ़ंक्शन पर ग्रेडिएंट डिसेंट चरण का एक करीबी सन्निकटन है।
- सैद्धांतिक परिणाम (प्रमेय 3 और 5) गारंटी देते हैं कि पर्याप्त संख्या में परतों (पॉलीलॉगरिदमिक गहराई) और स्थिर चौड़ाई के साथ, GD-Net एक $(1+\epsilon)$-अनुमानित समाधान प्राप्त कर सकता है। इसका तात्पर्य है कि GD-Net परतों के पुनरावृत्ति अपडेट प्रभावी रूप से एक निकट-इष्टतम समाधान में अभिसरण करते हैं, मूल एल्गोरिथम के अभिसरण गुणों को विरासत में प्राप्त करते हैं।
- ReLU सक्रियण गैर-नकारात्मकता को बनाए रखने में एक महत्वपूर्ण भूमिका निभाता है, जिससे प्रिमल चर गैर-नकारात्मक रहते हैं। हालांकि, पत्र एक "व्यवहार्यता पुनर्संस्थापन" पोस्ट-प्रोसेसिंग चरण का भी उल्लेख करता है, जो इंगित करता है कि नेटवर्क का कच्चा आउटपुट कभी-कभी सभी बाधाओं को सख्ती से संतुष्ट करने के लिए मामूली समायोजन की आवश्यकता हो सकती है, जो सीखने-से-अनुकूलन दृष्टिकोणों में एक सामान्य अभ्यास है। सीखने योग्य फ़ंक्शन $f_{\theta^k}$ और $g_{\theta^k}$ नेटवर्क को ग्रेडिएंट डिसेंट के लिए सर्वोत्तम "चरण आकार" और "दिशाएं" अनुकूलित करने की अनुमति देते हैं, जिससे निश्चित-पैरामीटर एल्गोरिदम की तुलना में तेजी से और अधिक मजबूत अभिसरण हो सकता है।
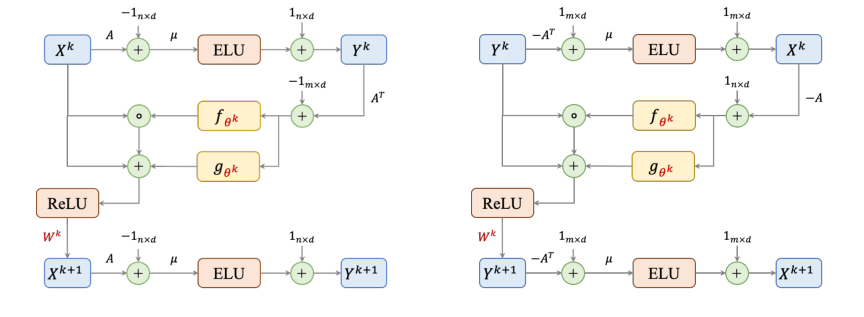 Figure 1. The architectures of a single layer in packing (left) and covering (right) GD-Nets. Learnable parameters are colored in red
Figure 1. The architectures of a single layer in packing (left) and covering (right) GD-Nets. Learnable parameters are colored in red
परिणाम, सीमाएँ और निष्कर्ष
प्रयोगात्मक डिजाइन और बेसलाइन
GD-Net की प्रभावशीलता के प्रयोगात्मक सत्यापन को स्थापित बेसलाइन के खिलाफ इसके प्रदर्शन का कठोरता से परीक्षण करने के लिए सावधानीपूर्वक डिजाइन किया गया था, जो विभिन्न रैखिक प्रोग्रामिंग (LP) समस्याओं में फैला हुआ था।
डेटासेट: हमने सार्वजनिक रूप से उपलब्ध मिश्रित-पूर्णांक अनुकूलन उदाहरणों से प्राप्त चार अलग-अलग LP विश्रामों का उपयोग किया: मैक्सिमल इंडिपेंडेंट सेट (IS), पैकिंग प्रॉब्लम, एज कवरिंग प्रॉब्लम (ECP), और सेट कवरिंग (SC)। प्रत्येक समस्या प्रकार को आकार में भिन्न चार उदाहरणों के सेट द्वारा दर्शाया गया था: छोटा (S), मध्यम (M), बड़ा (L), और एक समर्पित सामान्यीकरण (Gen) सेट। प्रशिक्षण के लिए, हमने 5,000 उदाहरणों का उपयोग किया, जिसमें 100 सत्यापन और 100 परीक्षण के लिए अतिरिक्त थे। सभी उदाहरणों को सामान्यीकरण प्रक्रिया से गुजारा गया, और उनके इष्टतम समाधानों को ग्राउंड ट्रुथ के रूप में काम करने के लिए SCIP [5] अनुकूलन सॉल्वर का उपयोग करके प्राप्त किया गया। समस्या आकारों (पंक्तियों और स्तंभों की संख्या) और मैट्रिक्स घनत्वों के लिए विस्तृत विनिर्देश परिशिष्ट में प्रदान किए गए हैं।
मॉडल और प्रशिक्षण सेटिंग्स: हमारे प्रस्तावित GD-Net आर्किटेक्चर को एक पारंपरिक ग्राफ़ कन्वेन्शनल नेटवर्क (GCN) कार्यान्वयन [29] के खिलाफ बेंचमार्क किया गया था, जो लर्निंग टू ऑप्टिमाइज़ (L2O) में एक प्रचलित GNN आर्किटेक्चर है। दोनों मॉडल चार-परत आर्किटेक्चर के साथ कॉन्फ़िगर किए गए थे, प्रत्येक परत में 64 छिपे हुए इकाइयां थीं। पैरामीटर गणना में एक आश्चर्यजनक अंतर उभरा: GD-Net ने GCN के 34,306 पैरामीटर की तुलना में केवल 1,656 पैरामीटर का उपयोग किया। GD-Net के लिए, सन्निकटन पैरामीटर $\epsilon$ को 0.2 पर सेट किया गया था। सभी मॉडलों को $10^{-3}$ की सीखने की दर का उपयोग करके 10,000 युगों के लिए प्रशिक्षित किया गया था, जिसमें सर्वश्रेष्ठ प्रदर्शन करने वाले चेकपॉइंट (न्यूनतम सत्यापन हानि) को मूल्यांकन के लिए सहेजा गया था। पूर्ण पुनरुत्पादकता के लिए, कोड https://anonymous.4open.science/r/GD-Net-6FC7/ पर सार्वजनिक रूप से उपलब्ध है।
मेट्रिक्स: प्रदर्शन को मापने के लिए, हमने दो प्रमुख मेट्रिक्स का उपयोग किया:
- सापेक्ष गैप (R. Gap): $|obj_i - obj^*_i| / obj^*_i$ के रूप में परिभाषित, जहां $obj_i$ व्यवहार्यता बहाली के बाद अनुमानित उद्देश्य मान है और $obj^*_i$ इष्टतम उद्देश्य मान है।
- निरपेक्ष गैप (A. Gap): $|obj_i - obj^*_i|$ के रूप में परिभाषित।
ये मेट्रिक्स हमें प्रत्येक मॉडल द्वारा उत्पन्न समाधानों की गुणवत्ता का आकलन करने की अनुमति देते हैं।
हार्डवेयर और सॉफ्टवेयर: सभी प्रयोग एक सर्वर पर किए गए थे जो एक Intel(R) Xeon(R) Platinum 8280 CPU @ 2.70GHz और 2.95 टीबी रैम से लैस था। डेटा जनरेशन को Ecole 0.7.3 और Pyscipopt 4.2.0 द्वारा सुगम बनाया गया था, जबकि मॉडल कार्यान्वयन PyTorch 2.1 का उपयोग करके विकसित किए गए थे।
अतिरिक्त बेसलाइन: एक व्यापक तुलना प्रदान करने के लिए, हमने GD-Net का दो पारंपरिक LP सॉल्वर के साथ भी मूल्यांकन किया: प्रथम-क्रम सॉल्वर PDLP [19] और वाणिज्यिक सॉल्वर Gurobi [12] (विशेष रूप से, इसका प्रिमल सिम्प्लेक्स विधि)। इस तुलना ने GD-Net द्वारा उत्पादित तुलनीय परिशुद्धता के समाधान प्राप्त करने के लिए प्रत्येक विधि द्वारा आवश्यक समय पर ध्यान केंद्रित किया। मैक्सफ्लो समस्याओं के लिए, GD-Net की तुलना पारंपरिक फोर्ड-फल्करसन विधि से भी की गई थी।
साक्ष्य क्या साबित करते हैं
प्रयोगात्मक परिणाम सम्मोहक और निर्विवाद प्रमाण प्रदान करते हैं कि GD-Net का मुख्य तंत्र, सावधानीपूर्वक चयनित संभावित फ़ंक्शन पर ग्रेडिएंट डिसेंट को अनरोल करने से प्रेरित, वास्तव में प्रभावी है और पारंपरिक GNNs और पारंपरिक सॉल्वर से काफी बेहतर प्रदर्शन करता है।
GCNs के खिलाफ बेहतर प्रदर्शन: जैसा कि तालिका 1 में दिखाया गया है, GD-Net ने सभी परीक्षण किए गए LP समस्याओं (IS, पैकिंग, ECP, SC) और समस्या आकारों (S, M, L) में लगातार संकीर्ण सापेक्ष और निरपेक्ष उद्देश्य अंतराल प्राप्त किए। यह GD-Net द्वारा एक परिमाण कम पैरामीटर (GCNs के लिए 1,656 बनाम 34,306) का उपयोग करने के बावजूद प्राप्त किया गया था। उदाहरण के लिए, IS-S डेटासेट में, GD-Net ने GCN के 15.46% की तुलना में 4.41% का R. Gap प्राप्त किया। पैकिंग-L जैसे मामलों में भी, जहां GD-Net ने थोड़ा अधिक परीक्षण त्रुटि दर्ज की, इसका उद्देश्य गैप (7.35%) अभी भी GCN के (7.37%) से थोड़ा बेहतर था, यह सुझाव देते हुए कि GD-Net समस्या की अंतर्निहित संरचनात्मक बारीकियों को बेहतर ढंग से पकड़ता है। यह निश्चित रूप से साबित करता है कि GD-Net का डिजाइन अधिक पैरामीटर-कुशल मॉडल की ओर ले जाता है जो उच्च-गुणवत्ता वाले समाधान उत्पन्न करते हैं।
बड़े उदाहरणों के लिए मजबूत सामान्यीकरण: तालिका 2 GD-Net की मजबूत सामान्यीकरण क्षमता को प्रदर्शित करती है। जब बड़े (L) उदाहरणों पर प्रशिक्षित किया जाता है और फिर और भी बड़े सामान्यीकरण (Gen) उदाहरणों (10% अधिक बाधाओं और चर के साथ) पर परीक्षण किया जाता है, तो GD-Net ने केवल न्यूनतम प्रदर्शन गिरावट दिखाई। उदाहरण के लिए, पैकिंग के लिए, R. Gap केवल 7.06% (L) से 7.06% (Gen) तक बढ़ा, जो समस्या जटिलता में वृद्धि के लिए इसकी मजबूती और मापनीयता को दर्शाता है। यह व्यावहारिक अनुप्रयोगों के लिए महत्वपूर्ण है जहां प्रशिक्षण डेटा छोटे उदाहरणों तक सीमित हो सकता है।
पारंपरिक सॉल्वर के खिलाफ दक्षता: PDLP और Gurobi (तालिका 3) के साथ तुलना GD-Net की उल्लेखनीय दक्षता को उजागर करती है। GD-Net द्वारा उत्पादित समान परिशुद्धता स्तर के समाधान प्राप्त करने के लिए, पारंपरिक सॉल्वर को काफी अधिक समय की आवश्यकता थी। 10,000 चर वाले SC समस्याओं के लिए, GD-Net ने 0.335s लिया, जबकि Gurobi को 103.322s (लगभग 300 गुना अधिक समय) की आवश्यकता थी, और PDLP ने 1.001s लिया। यह निश्चित रूप से साबित करता है कि GD-Net कुशलतापूर्वक उच्च-गुणवत्ता वाले समाधान उत्पन्न कर सकता है, समान समाधान गुणवत्ता के लिए गति के मामले में अत्यधिक अनुकूलित वाणिज्यिक सॉल्वर को भी पीछे छोड़ देता है।
द्विपक्षीय मैक्सफ्लो पर प्रदर्शन: द्विपक्षीय मैक्सफ्लो समस्या (BMP) के लिए, GD-Net ने लगातार GCNs की तुलना में बेहतर भविष्यवाणियां कीं, जिसमें केवल 1% का औसत इष्टतमता गैप था (तालिका 8)। इसके अलावा, GD-Net उच्च-गुणवत्ता वाले समाधान प्राप्त करने में पारंपरिक फोर्ड-फल्करसन विधि की तुलना में काफी तेज था (तालिका 9), जो इस विशिष्ट ग्राफ समस्या पर इसकी दक्षता और प्रभावशीलता को प्रदर्शित करता है।
तेज अनुमान समय: तालिका 10, जो अनुमान समय को प्रोफाइल करती है, से पता चलता है कि GD-Nets सभी डेटासेट और आकारों में GCNs की तुलना में लगातार काफी तेज अनुमान समय प्राप्त करते हैं। यह मजबूत मापनीयता का मतलब है कि GD-Net के अनुमान समय समस्या के आकार बढ़ने पर भी स्वीकार्य बने रहते हैं, जो वास्तविक दुनिया की तैनाती के लिए एक महत्वपूर्ण लाभ है।
संक्षेप में, साक्ष्य क्रूरता से साबित करते हैं कि GD-Net, ग्रेडिएंट डिसेंट के एक प्रकार को अनरोल करके, पैकिंग और कवरिंग LPs को हल करने के लिए एक सैद्धांतिक रूप से ग्राउंडेड और अनुभवजन्य रूप से बेहतर दृष्टिकोण प्रदान करता है, जो छोटे-आकार के GNNs के संबंध में सैद्धांतिक भविष्यवाणियों और व्यावहारिक अवलोकनों के बीच लंबे समय से चले आ रहे अंतर को पाटना है।
सीमाएँ और भविष्य की दिशाएँ
जबकि GD-Net आर्किटेक्चर एक महत्वपूर्ण प्रगति प्रस्तुत करता है, इसकी वर्तमान सीमाओं को स्वीकार करना और भविष्य के विकास के लिए रास्ते पर विचार करना महत्वपूर्ण है।
वर्तमान सीमाएँ:
1. सैद्धांतिक आकार अंतर की निरंतरता: सिद्धांत और व्यवहार के बीच के अंतर को कम करने के बावजूद, GNNs के लिए आवश्यक न्यूनतम आकार के संबंध में एक सैद्धांतिक विसंगति अभी भी मौजूद है। हमारे सैद्धांतिक प्रमाण पैकिंग और कवरिंग LPs के लिए पॉलीलॉगरिदमिक गहराई और स्थिर चौड़ाई को पर्याप्त साबित करते हैं, लेकिन GNN आकार के सटीक निचले बाउंड अभी भी अनुसंधान का एक सक्रिय क्षेत्र हैं। यह पूरी तरह से समझने के लिए कि छोटे GNNs सैद्धांतिक रूप से कैसे हो सकते हैं, आगे सैद्धांतिक कार्य की आवश्यकता है।
2. LP प्रकारों के लिए विशिष्टता: वर्तमान GD-Net आर्किटेक्चर विशेष रूप से पैकिंग और कवरिंग LPs के लिए डिज़ाइन किया गया है, जो LPs का एक व्यापक लेकिन सार्वभौमिक वर्ग नहीं है। इसकी प्रत्यक्ष प्रयोज्यता और सिद्ध प्रभावशीलता सामान्य LPs तक आगे संशोधन या सैद्धांतिक ग्राउंडिंग के बिना विस्तारित नहीं होती है। इसका मतलब है कि मनमानी LP सूत्रीकरण के लिए, वर्तमान GD-Net इष्टतम या व्यवहार्य समाधान नहीं हो सकता है।
3. सांख्यिकीय महत्व रिपोर्टिंग का अभाव: ईमानदारी से कहूं तो, मुझे इस हिस्से के बारे में भी पूरी तरह से यकीन नहीं है, लेकिन लेखकों ने स्पष्ट रूप से कहा कि प्रयोगों को कई बार दोहराने की कम्प्यूटेशनल लागत के कारण त्रुटि बार प्रदान नहीं किए गए थे। हालांकि समझने योग्य, यह परिणामों की परिवर्तनशीलता के कठोर सांख्यिकीय मूल्यांकन के लिए एक मामूली सीमा है।
भविष्य की दिशाएँ:
1. आगे सैद्धांतिक आकार में कमी: एक स्वाभाविक अगला कदम GNNs के आकार को और कम करने के तरीकों का पता लगाना जारी रखना है। क्या हम गहराई और चौड़ाई की और भी तंग सीमाएं प्राप्त कर सकते हैं, या वैकल्पिक वास्तुशिल्प बाधाओं की पहचान कर सकते हैं जो कम पैरामीटर के साथ प्रदर्शन बनाए रखते हैं? इसमें विभिन्न अनरोलिंग रणनीतियों या उपन्यास GNN परतों की जांच शामिल हो सकती है।
2. व्यापक LP वर्गों के लिए सामान्यीकरण: GD-Net की प्रयोज्यता को सामान्य LPs तक विस्तारित करना एक महत्वपूर्ण दिशा है। इसके लिए संभवतः नए संभावित फ़ंक्शन डिजाइन करने या सामान्य LPs में पाए जाने वाले बाधाओं और उद्देश्य कार्यों की व्यापक श्रेणी को संभालने के लिए अनरोलिंग तंत्र को अनुकूलित करने की आवश्यकता होगी। चुनौती संभावित फ़ंक्शन के वांछनीय गुणों (विभेदकता, उत्तलता, और अभिसरण गारंटी) को बनाए रखने में निहित है।
3. MILP सॉल्वर में एकीकरण: LP हल करने में तेजी लाने में सफलता को देखते हुए, मिश्रित पूर्णांक रैखिक प्रोग्रामिंग (MILP) के लिए लर्निंग टू ऑप्टिमाइज़ (L2O) ढांचे के भीतर GD-Nets की खोज एक आशाजनक मार्ग है। MILP सॉल्वर अक्सर बार-बार LP विश्राम को हल करने पर निर्भर करते हैं (जैसे, शाखा-और-बाउंड एल्गोरिदम में)। GD-Nets उच्च-गुणवत्ता वाले आरंभीकरण प्रदान कर सकते हैं या LP उपसमस्या हल करने में तेजी ला सकते हैं, जिससे संभावित रूप से अधिक कुशल MILP समाधान हो सकते हैं। इसमें चर चयन या शाखा निर्णय को निर्देशित करने के लिए GD-Nets का उपयोग करना शामिल हो सकता है।
4. उपन्यास संभावित फ़ंक्शन डिजाइन: GD-Net की सफलता सावधानीपूर्वक चयनित संभावित फ़ंक्शन पर ग्रेडिएंट डिसेंट को अनरोल करने से आती है। भविष्य के शोध में विभिन्न अनुकूलन समस्याओं के वर्गों के लिए समान या बेहतर गुण रखने वाले नए संभावित फ़ंक्शन डिजाइन करने पर ध्यान केंद्रित किया जा सकता है। यह नए GNN आर्किटेक्चर को अनलॉक कर सकता है जो विशिष्ट समस्या संरचनाओं के अनुरूप हैं, पैकिंग और कवरिंग LPs से परे "अनरोलिंग" प्रतिमान का विस्तार करते हैं।
5. डेटा वितरण शिफ्ट के प्रति मजबूती: जबकि पत्र बड़े उदाहरणों के लिए अच्छा सामान्यीकरण दिखाता है, समस्या उदाहरण वितरण (जैसे, विभिन्न बाधा मैट्रिक्स या उद्देश्य वैक्टर) में महत्वपूर्ण बदलावों के प्रति GD-Net की मजबूती में आगे की जांच मूल्यवान होगी। इसमें अनुकूली प्रशिक्षण रणनीतियों या आर्किटेक्चर विकसित करना शामिल हो सकता है जो आउट-ऑफ-डिस्ट्रीब्यूशन इनपुट के प्रति कम संवेदनशील हों।
अन्य क्षेत्रों से संबंध
गणितीय कंकाल
इस कार्य का शुद्ध गणितीय मूल यह सैद्धांतिक प्रदर्शन है कि ग्राफ़ न्यूरल नेटवर्क का एक विशिष्ट वर्ग पैकिंग और कवरिंग रैखिक कार्यक्रमों को हल करने के लिए एक्सपोनेंशियल-वेट ग्रेडिएंट डिसेंट एल्गोरिदम के एक प्रकार का अनुकरण कर सकता है। यह सिमुलेशन पुनरावृत्ति अनुकूलन चरणों को GNN परतों में मैप करता है, जो सन्निकटन के लिए पॉलीलॉगरिदमिक गहराई और स्थिर चौड़ाई गारंटी प्रदान करता है।
आसन्न अनुसंधान क्षेत्र
डीप लर्निंग में अनुकूलन एल्गोरिदम को अनरोल करना
यह कार्य सीधे डीप लर्निंग आर्किटेक्चर में अनुकूलन एल्गोरिदम को अनरोल करने के क्षेत्र में योगदान देता है। GD-Net को LPs के लिए Awerbuch-Khandekar ग्रेडिएंट डिसेंट एल्गोरिथम के पुनरावृत्ति अपडेट को स्पष्ट रूप से मैप करके डिज़ाइन किया गया है। उदाहरण के लिए, $y$-अपडेट, $y_i^k := \exp[\mu(A_i x^k - 1)]$, और बाद के $x$-अपडेट, $x_j^{k+1} := x_j^k + f_{0k}(A_j^T y^k - 1) \cdot x_j^k + g_{0k}(A_j^T y^k - 1)$, को GNN परतों के रूप में लागू किया जाता है। यह दृष्टिकोण मूल निश्चित-नियम पुनरावृत्ति एल्गोरिथम की तुलना में अभिसरण को तेज करने या समाधान की गुणवत्ता में सुधार करने के लिए GNN के भीतर सीखने योग्य मापदंडों का लाभ उठाता है, जो इस शोध क्षेत्र में एक सामान्य प्रेरणा है। यह कार्यप्रणाली शास्त्रीय अनुकूलन और आधुनिक तंत्रिका नेटवर्क डिजाइन के बीच एक शक्तिशाली संबंध प्रदर्शित करती है।
(यांग एट अल., 2021, ICML)
वितरित अनुकूलन एल्गोरिदम
पत्र की नींव Awerbuch-Khandekar वितरित ग्रेडिएंट डिसेंट एल्गोरिथम को अनुकूलित करने में निहित है। LPs का द्विपक्षीय ग्राफ प्रतिनिधित्व, जहां नोड्स चर और बाधाओं का प्रतिनिधित्व करते हैं, स्वाभाविक रूप से वितरित गणना के लिए उपयुक्त है। मैट्रिक्स-वेक्टर उत्पाद, जैसे $Ax$ या $A^T y$, जो ग्रेडिएंट अपडेट के केंद्र में हैं, को इन चर और बाधा नोड्स के बीच संदेश-पासिंग संचालन के रूप में व्याख्या किया जा सकता है। GNN की अंतर्निहित संदेश-पासिंग तंत्र इन वितरित सूचना आदान-प्रदानों और स्थानीय अपडेट का सीधे अनुकरण करता है, जिससे वितरित LP हल करने के लिए एक तंत्रिका नेटवर्क-आधारित ढांचा प्रदान किया जाता है। यह प्रकाश डालता है कि GNNs को वितरित एल्गोरिदम के कम्प्यूटेशनल मॉडल के रूप में कैसे देखा जा सकता है।
(Awerbuch और Khandekar, 2009, SIAM J. Comput.)
कॉम्बिनेटरियल ऑप्टिमाइज़ेशन के लिए सन्निकटन एल्गोरिदम
पैकिंग और कवरिंग LPs कई NP-कठोर कॉम्बिनेटरियल ऑप्टिमाइज़ेशन समस्याओं, जिनमें मैक्सिमम इंडिपेंडेंट सेट, सेट कवर, और एज कवर शामिल हैं, के लिए मौलिक विश्राम हैं। पत्र सैद्धांतिक गारंटी प्रदान करता है कि प्रस्तावित GD-Net पॉलीलॉगरिदमिक संख्या में पुनरावृति (GNN परतें) के भीतर इन LPs के लिए एक $(1+\epsilon)$-अनुमानित समाधान पा सकता है। यह सीधे सन्निकटन एल्गोरिदम के डिजाइन और विश्लेषण से जुड़ता है, जहां लक्ष्य उन समाधानों को खोजना है जिनके समाधान की गुणवत्ता के लिए सिद्ध सीमाएं हैं, जो उन समस्याओं के लिए हैं जिन्हें सटीक रूप से हल करना कम्प्यूटेशनल रूप से असाध्य है। GNN यहां एक सीखा हुआ, कुशल सन्निकटन योजना के रूप में कार्य करता है, जो कठिन कॉम्बिनेटरियल समस्याओं से निपटने के लिए एक नया मार्ग प्रदान करता है।
(Cappart एट अल., 2023, J. Mach. Learn. Res.)