О мощности графовых нейронных сетей малого размера для линейного программирования
Проблема, рассматриваемая в данной статье, берет свое начало в бурно развивающейся области "Обучение оптимизации" (Learning to Optimize, L2O), которая стремится повысить эффективность традиционных процессов...
Предыстория и академическая родословная
Истоки и академическая родословная
Проблема, рассматриваемая в данной статье, берет свое начало в бурно развивающейся области "Обучение оптимизации" (Learning to Optimize, L2O), которая стремится повысить эффективность традиционных процессов оптимизации путем интеграции методов машинного обучения. В рамках L2O графовые нейронные сети (GNN) в последнее время приобрели значительную популярность благодаря своей способности решать сложные задачи оптимизации, в частности, линейное программирование (LP) и смешанное целочисленное линейное программирование (MILP).
Исторически сложилось так, что теоретически было показано, что GNN могут универсально аппроксимировать функции отображения решений для LP. Однако эти фундаментальные теоретические результаты, в частности, от Chen et al. [8] и Qian et al. [29], обычно предполагают, что GNN требуют существенного количества параметров или полиномиальной глубины относительно размерности задачи для достижения произвольной точности. Это теоретическое требование проистекает из их опоры на такие концепции, как теорема универсальной аппроксимации для многослойных перцептронов (MLP).
Фундаментальным ограничением, или "болевой точкой", этих предыдущих подходов является резкое расхождение между теоретическими предсказаниями и эмпирическими наблюдениями. На практике исследователи обнаружили, что относительно небольшие GNN — часто с умеренной шириной и менее чем десятью слоями — могут эффективно решать LP с сотнями узлов и ограничений, достигая хорошей производительности, несмотря на их ограниченный размер. Этот практический успех, контрастирующий с теоретическим требованием больших, сложных GNN, создал значительный разрыв. Авторы написали эту статью именно для того, чтобы преодолеть этот разрыв, стремясь предоставить теоретическую основу для того, почему и когда GNN малого размера могут эффективно решать LP, особенно задачи упаковки и покрытия.
Интуитивные термины предметной области
- Линейное программирование (LP): Представьте, что у вас есть рецепт выпечки печенья, но у вас есть только ограниченное количество муки, сахара и масла. Вы хотите испечь как можно больше печенья (или максимизировать свою прибыль, если вы его продаете), оставаясь в пределах лимитов ингредиентов. Линейное программирование — это математический инструмент, который помогает вам определить наилучшую комбинацию печенья для выпечки, чтобы достичь вашей цели, учитывая эти простые, прямолинейные ограничения.
- Графовые нейронные сети (GNN): Представьте себе социальную сеть, где люди — это узлы, а дружба — это связи. GNN — это как умный детектив, который узнает о каждом человеке, разговаривая с ним и его друзьями, а затем использует эту коллективную информацию для понимания всей сети. В оптимизации она учится на взаимосвязях между переменными и ограничениями в задаче.
- LP упаковки: Представьте, что вы пытаетесь уместить как можно больше коробок разного размера в грузовик, не превышая его грузоподъемность или объем. LP упаковки — это задача оптимизации, которая помогает вам найти наилучший способ "упаковать" вещи (например, ресурсы или предметы) в ограниченное пространство или бюджет, гарантируя, что вы не превысите никаких лимитов.
- LP покрытия: Представьте, что вам нужно разместить камеры наблюдения, чтобы охватить все входы в здание, и каждая камера охватывает несколько конкретных входов. LP покрытия помогает вам найти минимальное количество камер, необходимых для "покрытия" всех входов, гарантируя, что каждый вход будет под наблюдением.
- GNN с полилогарифмической глубиной и постоянной шириной: Это описывает GNN, которая "неглубокая" (полилогарифмическая глубина означает, что ее слои растут очень медленно с размером задачи, как $\log(\text{размер})$ или $\log^2(\text{размер})$) и "тонкая" (постоянная ширина означает, что каждый слой имеет фиксированное, небольшое количество внутренних вычислительных единиц, независимо от размера задачи). Это похоже на очень эффективную, компактную вычислительную машину, которая все еще может решать большие задачи.
Таблица обозначений
| Обозначение | Описание |
|---|---|
| $A$ | Матрица ограничений LP ($n \times m$) |
| $x$ | Вектор первичных переменных ($m \times 1$) |
| $y$ | Вектор вторичных переменных ($n \times 1$) |
| $X^k$ | Матрица первичных переменных на итерации $k$ ($m \times d$) |
| $Y^k$ | Матрица вторичных переменных на итерации $k$ ($n \times d$) |
| $d$ | Размерность канала для расширенных переменных |
| $n$ | Количество ограничений (строк в $A$) |
| $m$ | Количество первичных переменных (столбцов в $A$) |
| $K$ | Общее количество слоев GNN (итераций) |
| $\mu$ | Масштабирующий параметр для входа ELU |
| $\epsilon$ | Параметр точности аппроксимации |
| $\text{ELU}(\cdot)$ | Функция активации Exponential Linear Unit |
| $\text{ReLU}(\cdot)$ | Функция активации Rectified Linear Unit |
| $f_{\theta^k}(\cdot)$ | Обучаемая функция для обновления первичных переменных (мультипликативная) |
| $g_{\theta^k}(\cdot)$ | Обучаемая функция для обновления первичных переменных (аддитивная) |
| $W^k$ | Обучаемая матрица весов для смешивания каналов ($d \times d$) |
| $\odot$ | Побитовое произведение Адамара (поэлементное умножение) |
| $1_{p \times q}$ | Матрица из единиц размером $p \times q$ |
| $\Theta$ | Множество всех обучаемых параметров в GD-Net |
| $obj_i$ | Прогнозируемое значение целевой функции для экземпляра $i$ |
| $obj^*_i$ | Оптимальное значение целевой функции для экземпляра $i$ |
| R. Gap | Относительный разрыв: $|obj_i - obj^*_i| / obj^*_i$ |
| A. Gap | Абсолютный разрыв: $|obj_i - obj^*_i|$ |
Определение задачи и ограничения
Основная постановка задачи и дилемма
Статья посвящена значительному разрыву между теоретическим пониманием и практическими наблюдениями в отношении графовых нейронных сетей (GNN) для задач линейного программирования (LP).
Входное состояние/Текущее состояние:
Отправной точкой является установленный теоретический результат о том, что GNN могут универсально аппроксимировать функции отображения решений задач LP. Однако эти теоретические доказательства обычно требуют GNN с большим количеством параметров или глубиной, полиномиальной от размерности задачи. Одновременно эмпирические данные последовательно демонстрируют, что относительно небольшие GNN (например, с умеренной шириной и менее десяти слоев) могут эффективно решать LP, достигая хорошей производительности на практике.
Желаемая конечная точка/Целевое состояние:
Основная цель — предоставить надежную теоретическую основу, объясняющую, почему и когда GNN малого размера эффективны для решения LP. В частности, статья направлена на доказательство того, что GNN с полилогарифмической глубиной и постоянной шириной достаточны для аппроксимации отображения решений для широкого класса LP, а именно задач упаковки и покрытия, с произвольной точностью. Эта теоретическая валидация для меньших, более эффективных GNN затем будет направлять разработку параметрически эффективных моделей для "Обучения оптимизации" (L2O) и потенциально ускорит традиционные решатели LP и смешанного целочисленного линейного программирования (MILP).
Отсутствующее звено/Математический пробел:
Точным отсутствующим звеном является теоретическое обоснование эмпирического успеха GNN малого размера. Предыдущие теоретические работы по возможностям универсальной аппроксимации GNN для LP опирались на предположения о больших размерах моделей (например, большом количестве параметров или полиномиальной глубине), создавая разрыв с наблюдаемой практической эффективностью. Данная статья пытается преодолеть этот разрыв, математически демонстрируя, что GNN могут симулировать вариант алгоритмов градиентного спуска на тщательно отобранных потенциальных функциях, тем самым достигая сильных гарантий аппроксимации с существенно меньшими архитектурами (полилогарифмическая глубина и постоянная ширина).
Болезненный компромисс и дилемма:
Основная дилемма заключается в "значительном расхождении между теоретическими предсказаниями и практическими наблюдениями" (Abstract, p.1). Исследователи оказались "в ловушке" компромисса, когда достижение сильных теоретических гарантий для GNN в решении LP традиционно требовало больших, вычислительно затратных моделей, в то время как практические реализации часто находили, что меньшие, более эффективные модели удивительно эффективны. Это создает болезненный выбор между теоретической строгостью (требующей больших моделей с высокими вычислительными затратами и обширными обучающими данными) и практической эффективностью (достигаемой меньшими моделями, успех которых не имел формального объяснения). Статья явно формулирует это как "интригующий открытый вопрос: когда и почему GNN малого размера могут эффективно решать LP?" (Introduction, p.2), подчеркивая необходимость примирения этого теоретико-эмпирического разрыва.
Ограничения и режимы отказа
Проблема разработки эффективных и теоретически обоснованных GNN для решения LP ограничена несколькими суровыми, реалистичными стенами:
- Ограничения вычислительных ресурсов: Большие GNN по своей сути требуют "больше обучающих примеров и более высоких вычислительных ресурсов" (Introduction, p.2). Это практическое ограничение, которое ограничивает масштабируемость и применимость GNN, если теоретические гарантии всегда требуют массивных моделей. Стремление к "параметрически эффективным моделям" (Introduction, p.2) напрямую решает эту проблему.
- Сложность и масштаб задачи: LP, особенно задачи упаковки и покрытия, могут включать сотни узлов и ограничений (Introduction, p.2). Эффективное решение этих крупномасштабных задач в приемлемые сроки является серьезной проблемой.
- Теоретические границы размера модели: Предыдущие теоретические результаты для общих LP требовали, чтобы GNN имели "большие размеры параметров" или "глубину... полиномиальную от размерности задачи" (Introduction, p.2). Этот теоретический барьер затруднял доказательство эффективности меньших GNN, несмотря на их эмпирический успех.
- Требования к точности аппроксимации: Цель состоит в достижении $(1+\epsilon)$-приближенного решения (Section 1.1, p.2). Это означает, что GNN должна быть не только эффективной, но и поддерживать высокий уровень качества решения, что является нетривиальной задачей при уменьшении размера модели.
- Допустимость решения: Распространенным режимом отказа для решателей оптимизации на основе машинного обучения является получение недопустимых решений.
x_finalилиy_final, выводимые GD-Net, могут не удовлетворять всем ограничениям LP (например, $x \ge 0$, $Ax \le 1$). Статья решает эту проблему с помощью процедуры постобработки "Восстановление допустимости" (p.7, p.8), указывая на это как на критическое ограничение, которое необходимо преодолеть. - Недифференцируемые операции: Базовые алгоритмы градиентного спуска (Algorithms 1 и 2) включают условные обновления (операторы if-else) и операции
max, которые являются недифференцируемыми. Прямое преобразование этой логики в нейронные сети проблематично. Авторы обходят это, аппроксимируя ступенчатые функции Хевисайда обучаемыми сигмоидальными функциями (Equations 4, 5, 6, p.6) и используя ReLU для неотрицательности, эффективно преобразуя недифференцируемую логику в дифференцируемую архитектуру нейронной сети. Это ключевое техническое ограничение при развертывании итеративных алгоритмов. - Ограничения памяти оборудования: Хотя это явно не указано как достигнутый жесткий предел, экспериментальная установка упоминает "2.95 ТБ ОЗУ" (Section E, p.16), что подразумевает, что память может быть значительным ограничением для больших экземпляров LP, а меньшие GNN по своей сути снижают это давление.
- Скорость сходимости: Итеративные алгоритмы должны сходиться за разумное количество шагов. В статье отмечается "полилогарифмическая сходимость" алгоритмов Авербуха-Хандекара (p.4), и GNN должна быть спроектирована для симуляции этой эффективной сходимости.
Почему этот подход
Неизбежность выбора
Принятие архитектуры GD-Net, которая разворачивает вариант алгоритма градиентного спуска Авербуха-Хандекара, было не просто дизайнерским выбором, а необходимостью, обусловленной значительным разрывом между существующим теоретическим пониманием и эмпирическими наблюдениями в области графовых нейронных сетей (GNN для линейного программирования (LP)). Традиционные теоретические результаты, часто опирающиеся на теоремы универсальной аппроксимации, предполагали, что GNN потребуют больших размеров параметров или полиномиальной глубины относительно размерности задачи для эффективного решения LP с произвольной точностью (Abstract, p.1; p.2). Однако практические эксперименты последовательно показывали, что относительно небольшие GNN могут достигать хорошей производительности, создавая загадочное расхождение.
Авторы осознали, что стандартные GNN, такие как обычные графовые сверточные сети (GCN), недостаточны для преодоления этого разрыва, поскольку, хотя они и могут достигать полилогарифмической глубины, они не могут гарантировать постоянную ширину (Remark 1, p.7). Это означало, что общие GNN по-прежнему потребуют "достаточно широкого перцептрона" для симуляции таких функций, как ELU, с произвольной точностью, тем самым не удовлетворяя требованию "малого размера" (p.7). Однако конкретный вариант алгоритма градиентного спуска Авербуха-Хандекара предлагал уникальное преимущество: его "можно было более естественно симулировать с помощью GNN", где "одна итерация алгоритма может быть симулирована одним слоем GNN постоянной ширины" (p.4). Это прямое отображение итеративного алгоритма оптимизации на структуру GNN с постоянной шириной и полилогарифмической глубиной (Theorem 3 и 5, p.7-8) предоставило единственный жизнеспособный путь для теоретического объяснения эмпирического успеха GNN малого размера для задач упаковки и покрытия LP.
Сравнительное превосходство
Подход GD-Net демонстрирует качественное превосходство над предыдущими методами, выходящее за рамки простых метрик производительности, в первую очередь благодаря своей структурной конструкции и присущей ему экономии параметров.
Во-первых, архитектура GD-Net фундаментально соответствует лежащей в основе задаче оптимизации. Разворачивая теоретически обоснованный алгоритм градиентного спуска для LP упаковки и покрытия, он использует присущую этим задачам структуру. Это контрастирует с более общими архитектурами GNN, такими как GCN, которые, будучи мощными, не специально адаптированы для симуляции таких итеративных процессов оптимизации. Это структурное преимущество позволяет GD-Net "лучше улавливать структурные нюансы задачи" (p.9).
Во-вторых, GD-Net демонстрирует подавляющее превосходство в эффективности параметров. Эксперименты показывают, что GD-Net достигает лучших решений с "на порядок меньшим количеством параметров, чем GCN" (p.3). Например, четырехслойный GD-Net с 64 скрытыми единицами использует всего 1656 параметров, в то время как сопоставимый GCN требует 34306 параметров (p.9). Это резкое сокращение параметров приводит к снижению сложности памяти и вычислительных накладных расходов, делая модели более практичными и масштабируемыми.
В-третьих, метод демонстрирует превосходную производительность с точки зрения качества решения и скорости. Таблица 1 (p.9) иллюстрирует, что GD-Net последовательно достигает более узких относительных и абсолютных разрывов по сравнению с GCN для различных типов LP (IS, Packing, ECP, SC) и размеров задач. Даже в случаях, когда ошибка тестирования GD-Net может быть незначительно выше, его относительный разрыв остается превосходным, указывая на качественно лучшее приближение оптимального решения. Кроме того, при сравнении с традиционными решателями, такими как PDLP и Gurobi, GD-Net последовательно достигает сопоставимых уровней точности за значительно меньшее время. Например, симплекс-метод Gurobi потребовал до 300 раз больше времени для сходимости к решениям того же качества, что и GD-Net (p.10). Это подчеркивает способность GD-Net эффективно генерировать высококачественные решения, что крайне важно для реальных приложений.
Наконец, GD-Net демонстрирует сильные возможности обобщения и масштабируемости. Он может обобщаться на более крупные экземпляры задач с "лишь минимальным снижением производительности" при обучении на меньших наборах данных (p.9, Table 2). Его время вывода остается "сравнительно приемлемым даже при увеличении размеров задач", в отличие от GCN, которым требуется "существенно больше времени для обработки и прогнозирования для более крупных экземпляров задач" (p.18).
Соответствие ограничениям
Выбранный метод GD-Net идеально соответствует неявным ограничениям задачи, особенно необходимости эффективных решений с использованием GNN малого размера и надежной теоретической основы. Основная постановка задачи вращается вокруг преодоления "значительного расхождения между теоретическими предсказаниями и практическими наблюдениями" относительно размера GNN, необходимого для решения LP (Abstract, p.1).
Конструкция GD-Net, которая разворачивает вариант алгоритма градиентного спуска Авербуха-Хандекара, напрямую решает эту проблему, доказывая, что "GNN с полилогарифмической глубиной и постоянной шириной достаточны для решения LP упаковки и покрытия" (Abstract, p.1; Theorem 3 и 5, p.7-8). Этот теоретический результат предоставляет столь необходимую основу для эффективности меньших GNN, напрямую удовлетворяя ограничению достижения высокой производительности при ограниченной сложности модели. "Слияние" суровых требований задачи (малые, эффективные модели) и уникальных свойств решения (GNN с постоянной шириной и полилогарифмической глубиной, симулирующие известный итеративный алгоритм) очевидно в этой теоретической гарантии.
Более того, способность метода симулировать одну итерацию алгоритма градиентного спуска одним слоем GNN постоянной ширины (p.4) гарантирует, что структура сети изначально эффективна и масштабируема. Это прямое соответствие между шагами алгоритма и слоями сети естественным образом ограничивает ширину модели, соответствуя ограничению "малого размера" при сохранении четкого, интерпретируемого механизма.
Отклонение альтернатив
Статья неявно и явно отклоняет несколько альтернативных подходов на основе их теоретических ограничений, эмпирической производительности и вычислительной неэффективности для конкретной задачи решения LP упаковки и покрытия с помощью GNN малого размера.
Общие GNN (например, GCN): Основная альтернатива, рассматриваемая и отклоняемая для достижения решений малого размера, — это общие GNN, такие как GCN. Хотя эти модели также могут достигать полилогарифмической глубины, авторы явно заявляют, что "постоянная ширина больше не гарантируется" для таких архитектур (Remark 1, p.7). Это означает, что для достижения произвольной точности GCN потребуют "достаточно широких перцептронов", что приведет к непостоянной ширине и, следовательно, не удовлетворит ограничению "малого размера", которое успешно решает GD-Net (p.7). Эмпирически GCN последовательно показывали худшую производительность с точки зрения относительных и абсолютных разрывов, а также часто более высокие ошибки валидации/тестирования, несмотря на то, что GD-Net использовал "на порядок меньшее количество параметров" (p.3, Table 1, p.9). Кроме того, GCN продемонстрировали плохую масштабируемость, требуя "существенно больше времени для обработки и прогнозирования для более крупных экземпляров задач" по сравнению с GD-Net (p.18).
Традиционные решатели LP (PDLP, Gurobi): Статья также сравнивает GD-Net с установленными, теоретически обоснованными решателями LP, такими как PDLP (метод первого порядка) и коммерческий решатель Gurobi (использующий метод примитивного симплекса). Хотя эти решатели надежны, они отклоняются как основные решения для сценариев, где скорость и эффективность имеют первостепенное значение. PDLP "не смог произвести решения сопоставимого качества с решениями GD-Net за меньшее время" (p.10). Gurobi, несмотря на свою точность, "потребовал до 300 раз больше времени для сходимости к решению того же качества, что и GD-Net" (p.10). Это объясняется вычислительно затратным матричным разложением симплекс-метода (p.10). Таким образом, хотя это и не "провал" с точки зрения корректности, их вычислительная стоимость делает их менее подходящими для приложений, выигрывающих от более быстрых, высококачественных приближенных решений или "теплых стартов", которые GD-Net предоставляет эффективно.
Статья не обсуждает другие парадигмы машинного обучения, такие как генеративно-состязательные сети (GAN) или диффузионные модели, поскольку они напрямую не применимы к задаче решения задач линейного программирования. Основное внимание уделяется GNN и их связи с классическими алгоритмами оптимизации.
Математический и логический механизм
Мастер-уравнение
Суть механизма данной статьи заключается в архитектуре графовой нейронной сети (GNN) GD-Net, которая предназначена для симуляции варианта алгоритма градиентного спуска Авербуха-Хандекара для решения задач линейного программирования (LP). В частности, для LP упаковки одна итерация алгоритма, соответствующая одному слою GNN, управляется двумя основными уравнениями обновления. Эти уравнения описывают, как вторичные переменные (представляющие ограничения) и первичные переменные (представляющие элементы) итеративно обновляются.
Обновление вторичных переменных $Y^k$ на итерации $k$ дается выражением:
$$Y^k := \text{ELU}[\mu(A X^k - 1_{n \times d})] + 1_{n \times d}$$
И обновление первичных переменных $X^{k+1}$ для следующей итерации $k+1$ выглядит следующим образом:
$$X^{k+1} = \text{ReLU} (\{X^k + f_{\theta^k}(A^T Y^k - 1_{m \times d}) \odot X^k + g_{\theta^k}(A^T Y^k - 1_{m \times d})\} \cdot W^k)$$
Аналогичный набор уравнений существует для LP покрытия, отражая двойственную природу этих задач.
Поэлементный разбор
Давайте разберем эти уравнения, чтобы понять роль каждого компонента:
Уравнение 1: $Y^k := \text{ELU}[\mu(A X^k - 1_{n \times d})] + 1_{n \times d}$
- $Y^k$: Это матрица размером $n \times d$, представляющая текущее состояние вторичных переменных (или цен ограничений) на итерации $k$. Каждая строка соответствует ограничению, а каждый столбец — размерности признака из расширения канала. Ее физическая роль — количественно оценить "жесткость" или "нарушение" каждого ограничения.
- $\text{ELU}[\cdot]$: Функция активации Exponential Linear Unit, применяемая поэлементно. Ее математическое определение: $\text{ELU}(t) = t$ для $t > 0$ и $\text{ELU}(t) = \alpha(\exp(t) - 1)$ для $t \le 0$. В данной статье $\alpha$ фиксировано на 1. Авторы используют ELU для точного воспроизведения обновления экспоненциальной функцией $y_i := \exp[\mu(A_i x^k - 1)]$ из исходного Algorithm 1, учитывая, что вход в ELU, $\mu(A_i x^k - 1)$, всегда неположителен во время выполнения. Эта нелинейность имеет решающее значение для того, чтобы GNN могла изучать сложные отображения.
- $\mu$: Скалярный параметр, фиксированный как $1/\ln(mA_{\max})$. Математически он масштабирует вход в функцию ELU. Его физическая/логическая роль — контролировать чувствительность обновлений вторичных переменных к нарушениям ограничений. Меньшее $\mu$ (из-за большего $m$ или $A_{\max}$) означает менее агрессивные обновления.
- $A$: Это матрица ограничений LP размером $n \times m$. Каждый элемент $A_{ij}$ равен нулю или больше единицы. Ее роль — определять взаимосвязи между первичными переменными и ограничениями.
- $X^k$: Матрица размером $m \times d$, представляющая текущее состояние первичных переменных (или количеств элементов) на итерации $k$. Каждая строка соответствует первичной переменной, а каждый столбец — размерности признака. Ее физическая роль — представлять текущее предлагаемое решение LP.
- $1_{n \times d}$: Матрица размером $n \times d$, где все элементы равны 1. Она используется для поэлементных операций.
- $A X^k$: Это матричное умножение, дающее матрицу размером $n \times d$. Каждый элемент $(A X^k)_{id}$ представляет собой сумму первичных переменных, взвешенных коэффициентами ограничений для ограничения $i$ и размерности признака $d$. Ее физическая роль — вычислять левую часть ограничений LP упаковки, $Ax \le 1$.
- $A X^k - 1_{n \times d}$: Поэлементное вычитание. Этот член количественно определяет нарушение или запас для каждого ограничения $i$ по каждой размерности признака $d$. Если $(A X^k)_{id} - 1_{id} > 0$, ограничение нарушено.
- $+ 1_{n \times d}$: Поэлементное добавление матрицы единиц. Этот член, в сочетании с функцией ELU, гарантирует, что обновление $y$ точно соответствует экспоненциальному обновлению исходного алгоритма Авербуха-Хандекара. Добавление используется для сдвига выхода ELU, чтобы соответствовать желаемому экспоненциальному поведению.
Уравнение 2: $X^{k+1} = \text{ReLU} (\{X^k + f_{\theta^k}(A^T Y^k - 1_{m \times d}) \odot X^k + g_{\theta^k}(A^T Y^k - 1_{m \times d})\} \cdot W^k)$
- $X^{k+1}$: Матрица размером $m \times d$, представляющая обновленные первичные переменные для следующей итерации.
- $\text{ReLU}(\cdot)$: Функция активации Rectified Linear Unit, применяемая поэлементно. Математически $\text{ReLU}(t) = \max(0, t)$. Ее физическая/логическая роль — обеспечить соблюдение ограничения неотрицательности ($x \ge 0$) для первичных переменных, что является фундаментальным для LP.
- $X^k$: Текущее состояние первичных переменных, как определено выше.
- $f_{\theta^k}(\cdot)$ и $g_{\theta^k}(\cdot)$: Это обучаемые функции, определенные как суммы сигмоидальных функций (Equations 5 и 6 в статье). Они применяются поэлементно к входной матрице. Их математическая роль — аппроксимировать ступенчатые функции Хевисайда $f(t)$ и $g(t)$ (Equation 4), используемые в условных обновлениях исходного алгоритма Авербуха-Хандекара. Их физическая/логическая роль — определять величину и тип корректировки, применяемой к каждой первичной переменной на основе агрегированной информации вторичных переменных. Авторы используют суммирование (неявно в определении $f_{\theta^k}$ и $g_{\theta^k}$ как сумм сигмоид) для построения этих функций, что позволяет получить гладкую, дифференцируемую аппроксимацию исходных пошаговых обновлений.
- $A^T$: Транспонированная матрица ограничений $A$.
- $A^T Y^k$: Матричное умножение, дающее матрицу размером $m \times d$. Этот член агрегирует информацию вторичных переменных ($Y^k$) обратно к первичным переменным, эффективно вычисляя "градиентоподобный" сигнал для каждой первичной переменной. В контексте потенциальной функции $\Phi_p(x)$, $\nabla \Phi_p(x) = A^T y$.
- $A^T Y^k - 1_{m \times d}$: Поэлементное вычитание. Это представляет собой "градиент" или "направление обновления" для каждой первичной переменной, указывая, насколько ее следует скорректировать.
- $\odot$: Побитовое произведение Адамара (поэлементное умножение). Этот оператор используется для поэлементного применения масштабирующего множителя из $f_{\theta^k}$ к $X^k$, имитируя мультипликативные обновления $(1+\beta)$ или $(1-\beta)$ в исходном алгоритме.
- $W^k$: Обучаемая матрица весов размером $d \times d$. Это стандартное линейное преобразование в нейронных сетях. Ее роль — смешивать информацию между $d$ размерностями признаков (каналами) расширенных переменных, повышая выразительную способность модели. Здесь умножение является матричным умножением, преобразующим векторы признаков.
- Фигурные скобки $\{\dots\}$ заключают сумму текущих первичных переменных и двух членов обновления. Это представляет собой основной шаг градиентного спуска, где текущее решение корректируется на основе вычисленного градиента и обучаемых функций. Сложение используется для объединения текущего состояния с рассчитанными обновлениями.
Пошаговый поток
Представьте себе один абстрактный элемент данных, представляющий первичную переменную $x_j$, когда он проходит через один слой (итерацию $k$) LP GD-Net для упаковки:
- Инициализация: В начале процесса ($k=0$) все первичные переменные $X^0$ инициализируются как $0_{m \times d}$. Вторичные переменные $Y^0$ также эффективно инициализируются или выводятся из $X^0$.
- Передача сообщений от первичных к вторичным (обновление Y):
- Оценка ограничений: Для каждого ограничения $i$ текущие первичные переменные $X^k$ "передают сообщения" ему. Это включает вычисление взвешенной суммы $A_i X^k$ ( $i$-я строка $A X^k$). Эта сумма представляет собой количество ресурса $i$, которое в настоящее время используется выбранными первичными переменными.
- Расчет нарушения: Вычисленная сумма $A_i X^k$ затем сравнивается с пределом ограничения (который равен 1 для LP в нормальной форме), что дает $A_i X^k - 1_{n \times d}$. Это значение указывает, нарушено ли ограничение $i$ (положительное) или удовлетворено (отрицательное/нулевое).
- Обновление вторичных переменных: Этот "сигнал нарушения" масштабируется на $\mu$ и пропускается через функцию активации ELU, затем сдвигается добавлением $1_{n \times d}$. Это преобразование генерирует обновленную вторичную переменную $Y^k$. Концептуально, сильно нарушенные ограничения будут иметь соответствующие вторичные переменные, которые увеличиваются больше, сигнализируя о более высокой "стоимости" их нарушения.
- Передача сообщений от вторичных к первичным (обновление X):
- Агрегация градиента: Теперь обновленные вторичные переменные $Y^k$ "передают сообщения" обратно первичным переменным. Для каждой первичной переменной $x_j$ член $A_j^T Y^k$ ( $j$-я строка $A^T Y^k$) агрегирует влияние всех ограничений, в которых участвует $x_j$. Этот агрегированный сигнал действует как "градиент", указывая, как изменение $x_j$ повлияет на общую целевую функцию и удовлетворение ограничений.
- Условная корректировка: Этот сигнал градиента $A^T Y^k - 1_{m \times d}$ подается на вход обучаемым функциям $f_{\theta^k}$ и $g_{\theta^k}$. Эти функции, действуя как сложный блок принятия решений, определяют, насколько масштабировать текущий $X^k$ (через $f_{\theta^k} \odot X^k$) и насколько его добавить (через $g_{\theta^k}$). Этот шаг имитирует условную логику исходного алгоритма: если градиент переменной ниже порога, увеличить ее; если выше, уменьшить.
- Преобразование признаков: Комбинированное обновление затем умножается на обучаемую матрицу весов $W^k$. Этот шаг позволяет смешивать и преобразовывать информацию между $d$ размерностями признаков каждой первичной переменной, обогащая ее представление.
- Обеспечение неотрицательности: Наконец, функция активации ReLU применяется поэлементно к результату. Это гарантирует, что все компоненты обновленных первичных переменных $X^{k+1}$ остаются неотрицательными, соблюдая фундаментальное ограничение LP.
Эта вся последовательность составляет один слой GD-Net. Выход $X^{k+1}$ затем становится входом $X^k$ для следующего слоя, и процесс повторяется для $K$ слоев, итеративно уточняя решение.
Динамика оптимизации
Динамика обучения и сходимости GD-Net основана на его конструкции как развернутого алгоритма градиентного спуска с обучаемыми компонентами.
- Механизм обучения: GD-Net обучается путем оптимизации своего набора обучаемых параметров $\Theta = \{\theta^k, W^k\}_{k=0}^{K-1} \cup \{w^K\}$. Эти параметры включают внутренние коэффициенты функций $f_{\theta^k}$ и $g_{\theta^k}$, основанных на сигмоидах, и матрицы смешивания каналов $W^k$. Цель обучения — минимизировать среднеквадратичную ошибку (MSE) между конечным выходом сети $x^{\text{final}}(\Theta, A)$ и истинным оптимальным решением $x^*$ для данного экземпляра LP $A$. Это задача обучения с учителем, где сеть обучается на наборе экземпляров LP и их известных оптимальных решений.
- Обновления параметров: Параметры $\Theta$ обновляются с использованием стандартных алгоритмов оптимизации на основе градиента (например, Adam, SGD). Во время обучения вычисляется функция потерь $L_p(\mathcal{I}; \Theta)$, и ее градиенты по $\Theta$ рассчитываются с помощью обратного распространения ошибки через всю $K$-слойную сеть. Эти градиенты указывают, как каждый параметр должен быть скорректирован для уменьшения ошибки прогнозирования.
- Ландшафт потерь и сходимость: Статья подчеркивает, что исходный алгоритм Авербуха-Хандекара работает с тщательно выбранной потенциальной функцией $\Phi_p(x)$ (или $\Phi_c(y)$), которая является дифференцируемой и выпуклой. Это означает, что лежащая в основе задача оптимизации для градиентного спуска имеет хорошо себя ведущий, одноминимумный ландшафт потерь. Разворачивая этот алгоритм и заменяя его условные обновления обучаемыми, дифференцируемыми функциями ($f_{\theta^k}, g_{\theta^k}$, состоящими из сигмоид) и линейными преобразованиями ($W^k$), GD-Net стремится симулировать и ускорять эту сходимость.
- Использование активаций ELU и ReLU вводит нелинейности, которые необходимы для выразительной способности GNN. Хотя ландшафт потерь всей нейронной сети для обучения может быть невыпуклым, конструкция гарантирует, что шаг обновления каждого слоя является точной аппроксимацией шага градиентного спуска на выпуклой функции.
- Теоретические результаты (Theorems 3 и 5) гарантируют, что при достаточном количестве слоев (полилогарифмическая глубина) и постоянной ширине GD-Net может достичь $(1+\epsilon)$-приближенного решения. Это означает, что итеративные обновления слоев GD-Net эффективно сходятся к почти оптимальному решению, наследуя свойства сходимости исходного алгоритма.
- Активация ReLU играет решающую роль в поддержании допустимости первичных переменных, гарантируя, что они остаются неотрицательными. Однако в статье также упоминается шаг постобработки "восстановление допустимости", указывающий на то, что необработанный вывод сети иногда может потребовать незначительных корректировок для строгого удовлетворения всех ограничений, что является обычной практикой в подходах "обучение-оптимизации". Обучаемые функции $f_{\theta^k}$ и $g_{\theta^k}$ позволяют сети адаптивно изучать наилучшие "размеры шага" и "направления" для градиентного спуска, потенциально приводя к более быстрой и надежной сходимости по сравнению с алгоритмами с фиксированными параметрами.
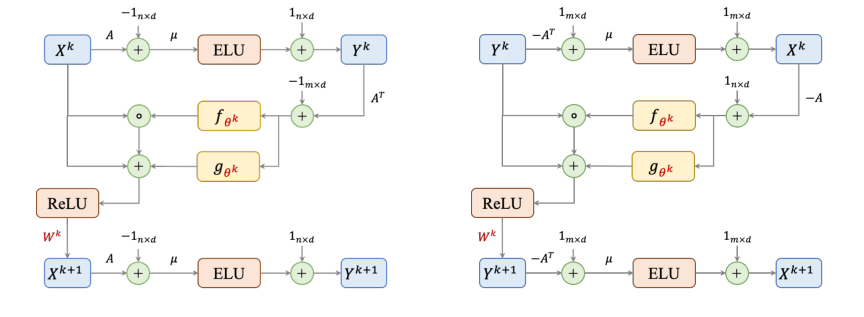 Figure 1. The architectures of a single layer in packing (left) and covering (right) GD-Nets. Learnable parameters are colored in red
Figure 1. The architectures of a single layer in packing (left) and covering (right) GD-Nets. Learnable parameters are colored in red
Результаты, ограничения и заключение
Экспериментальный дизайн и базовые линии
Экспериментальная проверка эффективности GD-Net была тщательно разработана для строгой проверки его производительности по сравнению с установленными базовыми линиями на различных задачах линейного программирования (LP).
Наборы данных: Мы использовали четыре различных релаксации LP, полученные из общедоступных экземпляров смешанного целочисленного программирования: максимальное независимое множество (IS), задача упаковки, задача покрытия ребер (ECP) и задача покрытия множеств (SC). Каждый тип задачи был представлен четырьмя наборами экземпляров, различающихся по размеру: малый (S), средний (M), большой (L) и выделенный набор для обобщения (Gen). Для обучения мы использовали 5000 экземпляров, с дополнительными 100 для валидации и 100 для тестирования. Все экземпляры прошли процедуру нормализации, и их оптимальные решения были получены с использованием решателя оптимизации SCIP [5] для служения в качестве истинных значений. Подробные спецификации размеров задач (количество строк и столбцов) и плотности матриц приведены в приложении.
Модели и настройки обучения: Наша предлагаемая архитектура GD-Net была сравнена с обычной графовой сверточной сетью (GCN) из [29], распространенной архитектурой GNN в области "Обучение оптимизации" (L2O). Обе модели были сконфигурированы с четырехслойной архитектурой, каждый слой состоял из 64 скрытых единиц. Поразительное различие проявилось в количестве параметров: GD-Net использовал всего 1656 параметров, что на порядок меньше, чем у GCN (34306 параметров). Для GD-Net параметр аппроксимации $\epsilon$ был установлен на 0.2. Все модели обучались в течение 10000 эпох с шагом обучения $10^{-3}$, сохраняя лучший чекпойнт (с наименьшей потерей на валидации) для оценки. Для полной воспроизводимости код общедоступен по адресу https://anonymous.4open.science/r/GD-Net-6FC7/.
Метрики: Для количественной оценки производительности мы использовали два ключевых показателя:
- Относительный разрыв (R. Gap): Определяется как $|obj_i - obj^*_i| / obj^*_i$, где $obj_i$ — прогнозируемое значение целевой функции после восстановления допустимости, а $obj^*_i$ — оптимальное значение целевой функции.
- Абсолютный разрыв (A. Gap): Определяется как $|obj_i - obj^*_i|$.
Эти метрики позволили нам оценить качество решений, генерируемых каждой моделью.
Оборудование и программное обеспечение: Все эксперименты проводились на сервере, оснащенном процессором Intel(R) Xeon(R) Platinum 8280 @ 2.70GHz и 2.95 ТБ ОЗУ. Генерация данных осуществлялась с помощью Ecole 0.7.3 и Pyscipopt 4.2.0, а реализации моделей разрабатывались с использованием PyTorch 2.1.
Дополнительные базовые линии: Для обеспечения всестороннего сравнения мы также оценили GD-Net против двух традиционных решателей LP: решателя первого порядка PDLP [19] и коммерческого решателя Gurobi [12] (в частности, его примитивного симплекс-метода). Это сравнение было сосредоточено на времени, необходимом каждому методу для достижения решений сопоставимой точности с теми, которые были получены GD-Net. Для задач Maxflow GD-Net также сравнивался с обычным методом Форда-Фалкерсона.
Что доказывают свидетельства
Экспериментальные результаты предоставляют убедительные и неоспоримые доказательства того, что основной механизм GD-Net, вдохновленный развертыванием градиентного спуска на тщательно отобранных потенциальных функциях, эффективно работает на практике и значительно превосходит традиционные GNN и традиционные решатели.
Превосходная производительность по сравнению с GCN: Как показано в Таблице 1, GD-Net последовательно достигал более узких относительных и абсолютных разрывов целевой функции для всех протестированных задач LP (IS, Packing, ECP, SC) и размеров задач (S, M, L). Это было достигнуто, несмотря на то, что GD-Net использовал на порядок меньше параметров (1656 против 34306 для GCN). Например, в наборе данных IS-S GD-Net достиг R. Gap 4.41% по сравнению с 15.46% у GCN. Даже в случаях, подобных Packing-L, где GD-Net показал немного более высокую ошибку тестирования, его разрыв целевой функции (7.35%) все же был незначительно лучше, чем у GCN (7.37%), предполагая, что GD-Net лучше улавливает лежащие в основе структурные нюансы задачи. Это окончательно доказывает, что конструкция GD-Net приводит к более параметрически эффективным моделям, которые дают решения более высокого качества.
Надежное обобщение на более крупные экземпляры: Таблица 2 демонстрирует сильную способность GD-Net к обобщению. При обучении на больших (L) экземплярах и последующем тестировании на еще более крупных обобщающих (Gen) экземплярах (с на 10% большим количеством ограничений и переменных) GD-Net показал лишь минимальное снижение производительности. Например, для Packing R. Gap увеличился всего с 7.06% (L) до 7.06% (Gen), демонстрируя его надежность и масштабируемость к увеличению сложности задачи. Это крайне важно для практических приложений, где обучающие данные могут быть ограничены меньшими экземплярами.
Эффективность по сравнению с традиционными решателями: Сравнение с PDLP и Gurobi (Таблица 3) подчеркивает замечательную эффективность GD-Net. Для достижения решений того же уровня точности, что и GD-Net, традиционные решатели требовали значительно больше времени. Для задач SC с 10000 переменными GD-Net занял 0.335 с, в то время как Gurobi потребовал 103.322 с (примерно в 300 раз дольше), а PDLP занял 1.001 с. Это окончательно доказывает, что GD-Net может эффективно генерировать высококачественные решения, превосходя даже высокооптимизированные коммерческие решатели по скорости для эквивалентного качества решения.
Производительность на двудольных максимальных потоках: Для задачи двудольного максимального потока (BMP) GD-Net последовательно достигал лучших прогнозов, чем GCN, с средним разрывом оптимальности всего 1% (Таблица 8). Кроме того, GD-Net был значительно быстрее обычного метода Форда-Фалкерсона в достижении высококачественных решений (Таблица 9), демонстрируя свою эффективность и результативность в этой конкретной графовой задаче.
Более быстрое время вывода: Таблица 10, которая профилирует время вывода, показывает, что GD-Net последовательно достигает существенно более быстрого времени вывода, чем GCN, для всех наборов данных и размеров. Эта сильная масштабируемость означает, что время вывода GD-Net остается приемлемым даже при увеличении размеров задач, что является критическим преимуществом для реального развертывания.
По сути, свидетельства безжалостно доказывают, что GD-Net, разворачивая вариант градиентного спуска, предоставляет теоретически обоснованный и эмпирически превосходящий подход к решению LP упаковки и покрытия, преодолевая давний разрыв между теоретическими предсказаниями и практическими наблюдениями относительно GNN малого размера.
Ограничения и будущие направления
Хотя архитектура GD-Net представляет собой значительный прогресс, важно признать ее текущие ограничения и рассмотреть направления для будущего развития.
Текущие ограничения:
1. Сохранение теоретического разрыва: Несмотря на сокращение разрыва между теорией и практикой, теоретическое расхождение все еще существует относительно минимального размера GNN, необходимого для достижения цели. Наши теоретические доказательства устанавливают полилогарифмическую глубину и постоянную ширину как достаточные для LP упаковки и покрытия, но точные нижние границы для размера GNN все еще являются активной областью исследований. Дальнейшая теоретическая работа необходима для полного понимания того, насколько малыми GNN могут быть теоретически.
2. Специфичность для типов LP: Текущая архитектура GD-Net специально разработана для LP упаковки и покрытия, которые являются широким, но не универсальным классом LP. Ее прямая применимость и доказанная эффективность не распространяются на общие LP без дальнейшей модификации или теоретического обоснования. Это означает, что для произвольных формулировок LP текущий GD-Net может быть не оптимальным или даже допустимым решением.
3. Отсутствие отчетности о статистической значимости: Честно говоря, я не совсем уверен в этой части, но авторы явно заявили, что доверительные интервалы не были предоставлены из-за вычислительной дороговизны многократного повторения экспериментов. Хотя это понятно, это незначительное ограничение для строгой статистической оценки вариабельности результатов.
Будущие направления:
1. Дальнейшее теоретическое сокращение размера: Естественным следующим шагом является дальнейшее изучение того, как теоретически уменьшить размер GNN еще больше. Можем ли мы достичь еще более жестких границ по глубине и ширине, или, возможно, выявить альтернативные архитектурные ограничения, которые сохраняют производительность при меньшем количестве параметров? Это может включать исследование различных стратегий развертывания или новых слоев GNN.
2. Обобщение на более широкие классы LP: Расширение применимости GD-Net на общие LP является критическим направлением. Это, вероятно, потребует разработки новых потенциальных функций или адаптации механизма развертывания для обработки более широкого спектра ограничений и целевых функций, найденных в общих LP. Задача заключается в поддержании желаемых свойств (дифференцируемость, выпуклость и гарантии сходимости) потенциальной функции.
3. Интеграция в решатели MILP: Учитывая успех в ускорении решения LP, изучение GD-Net в рамках "Обучение оптимизации" (L2O) для смешанного целочисленного линейного программирования (MILP) является перспективным направлением. Решатели MILP часто полагаются на многократное решение релаксаций LP (например, в алгоритмах ветвей и границ). GD-Net могут предоставлять высококачественные инициализации или ускорять решение подзадач LP, что потенциально приведет к более эффективным решениям MILP. Это может включать использование GD-Net для управления выбором переменных или решениями ветвления.
4. Разработка новых потенциальных функций: Успех GD-Net основан на развертывании градиентного спуска на тщательно отобранных потенциальных функциях. Будущие исследования могут сосредоточиться на разработке новых потенциальных функций, обладающих аналогичными или даже лучшими свойствами для различных классов задач оптимизации. Это может открыть новые архитектуры GNN, адаптированные к конкретным структурам задач, расширяя парадигму "развертывания" за пределы LP упаковки и покрытия.
5. Надежность к сдвигам в распределении данных: Хотя в статье показано хорошее обобщение на более крупные экземпляры, дальнейшее изучение надежности GD-Net к значительным сдвигам в распределениях экземпляров задач (например, различным матрицам ограничений или векторам целевых функций) было бы ценным. Это может включать разработку адаптивных стратегий обучения или архитектур, менее чувствительных к входным данным вне распределения.
Связи с другими областями
Математический каркас
Чистая математическая основа данной работы заключается в теоретической демонстрации того, что определенный класс графовых нейронных сетей может симулировать вариант алгоритмов градиентного спуска с экспоненциальным весом для решения задач линейного программирования упаковки и покрытия. Эта симуляция отображает итеративные шаги оптимизации на слои GNN, обеспечивая полилогарифмическую глубину и гарантии постоянной ширины для аппроксимации.
Смежные области исследований
Развертывание алгоритмов оптимизации в глубоком обучении
Данная работа напрямую вносит вклад в область развертывания алгоритмов оптимизации в архитектуры глубокого обучения. GD-Net разработан путем явного отображения итеративных обновлений алгоритма градиентного спуска Авербуха-Хандекара для LP на слои GNN. Например, обновление $y$, $y_i^k := \exp[\mu(A_i x^k - 1)]$, и последующее обновление $x$, $x_j^{k+1} := x_j^k + f_{0k}(A_j^T y^k - 1) \cdot x_j^k + g_{0k}(A_j^T y^k - 1)$, реализованы как слои GNN. Этот подход использует обучаемые параметры в GNN для потенциального ускорения сходимости или улучшения качества решения по сравнению с исходным итеративным алгоритмом с фиксированными правилами, что является распространенной мотивацией в этой исследовательской области. Эта методология демонстрирует мощную связь между классической оптимизацией и современным дизайном нейронных сетей.
(Yang et al., 2021, ICML)
Распределенные алгоритмы оптимизации
Основа данной работы лежит в адаптации распределенного алгоритма градиентного спуска Авербуха-Хандекара. Двудольное графовое представление LP, где узлы представляют переменные и ограничения, естественно подходит для распределенных вычислений. Матрично-векторные произведения, такие как $Ax$ или $A^T y$, которые являются центральными для градиентных обновлений, могут быть интерпретированы как операции передачи сообщений между этими узлами переменных и ограничений. Внутренний механизм передачи сообщений GNN напрямую симулирует эти распределенные обмены информацией и локальные обновления, предоставляя основу на основе нейронных сетей для распределенного решения LP. Это подчеркивает, как GNN могут рассматриваться как вычислительная модель для распределенных алгоритмов.
(Awerbuch and Khandekar, 2009, SIAM J. Comput.)
Алгоритмы аппроксимации для комбинаторной оптимизации
LP упаковки и покрытия являются фундаментальными релаксациями для многочисленных NP-трудных задач комбинаторной оптимизации, включая максимальное независимое множество, покрытие множеств и покрытие ребер. Данная работа предоставляет теоретические гарантии того, что предлагаемый GD-Net может найти $(1+\epsilon)$-приближенное решение для этих LP за полилогарифмическое количество итераций (слоев GNN). Это напрямую связано с разработкой и анализом алгоритмов аппроксимации, где цель состоит в поиске решений с доказуемыми границами их качества относительно оптимального решения, часто для задач, которые вычислительно неразрешимы для точного решения. GNN здесь действует как обученная, эффективная схема аппроксимации, предлагая новый путь для решения сложных комбинаторных задач.
(Cappart et al., 2023, J. Mach. Learn. Res.)