선형 계획법을 위한 소형 그래프 신경망의 성능에 관하여
Graph neural networks (GNNs) have recently emerged as powerful tools for addressing complex optimization problems.
배경 및 학술적 계보
기원 및 학술적 계보
본 논문에서 다루는 문제는 전통적인 최적화 과정의 효율성을 향상시키기 위해 머신러닝 기법을 통합하려는 학습 기반 최적화(Learning to Optimize, L2O) 분야에서 비롯되었다. L2O 내에서 그래프 신경망(Graph Neural Networks, GNNs)은 복잡한 최적화 문제, 특히 선형 계획법(Linear Programming, LP) 및 혼합 정수 선형 계획법(Mixed Integer Linear Programming, MILP)을 해결하는 능력으로 인해 최근 상당한 주목을 받고 있다.
역사적으로 GNN은 LP의 해 매핑 함수를 보편적으로 근사할 수 있다는 이론적 증명을 보여왔다. 그러나 Chen 등[8] 및 Qian 등[29]의 이러한 기초 이론적 결과는 일반적으로 임의의 정밀도를 달성하기 위해 문제 차원에 대해 상당한 수의 매개변수 또는 다항식 깊이를 요구한다고 가정한다. 이러한 이론적 요구 사항은 다층 퍼셉트론(MLP)에 대한 보편적 근사 정리와 같은 개념에 의존하는 데서 비롯된다.
이러한 이전 접근 방식의 근본적인 한계점, 즉 "고충점(pain point)"은 이론적 예측과 경험적 관찰 사이의 극명한 불일치이다. 실제 연구자들은 수백 개의 노드와 제약 조건을 가진 LP를 효과적으로 해결할 수 있는, 종종 적당한 너비와 10개 미만의 레이어를 가진 비교적 작은 GNN을 발견했으며, 제한된 크기에도 불구하고 좋은 성능을 달성했다. 대규모의 복잡한 GNN에 대한 이론적 요구와 이러한 실질적인 성공의 대조는 상당한 격차를 만들었다. 저자들은 특히 패킹 및 커버링 LP에 대해 소형 GNN이 효과적으로 LP를 해결할 수 있는 이유와 시기에 대한 이론적 기반을 제공하고자 이 논문을 작성하여 이 격차를 해소하고자 했다.
직관적인 도메인 용어
- 선형 계획법 (Linear Programming, LP): 쿠키를 굽는 레시피가 있지만 밀가루, 설탕, 버터가 제한되어 있다고 상상해 보라. 재료 한도를 초과하지 않으면서 가능한 한 많은 쿠키를 굽고 싶다(또는 판매한다면 이익을 극대화하고 싶다). 선형 계획법은 이러한 간단하고 직선적인 제약 조건 하에서 목표를 달성하기 위한 최적의 쿠키 조합을 파악하는 데 도움이 되는 수학적 도구이다.
- 그래프 신경망 (Graph Neural Networks, GNNs): 사람들을 노드로, 우정을 연결로 하는 소셜 네트워크를 생각해 보라. GNN은 각 사람과 그들의 친구들과 대화하여 각 사람에 대해 배우고, 그 집합 정보를 사용하여 전체 네트워크를 이해하는 똑똑한 탐정과 같다. 최적화에서 GNN은 문제의 변수와 제약 조건 간의 관계로부터 학습한다.
- 패킹 LP (Packing LPs): 트럭의 무게 또는 부피 용량을 초과하지 않으면서 가능한 한 많은 다양한 크기의 상자를 트럭에 싣는 것을 상상해 보라. 패킹 LP는 제한된 공간이나 예산에 물건(자원 또는 품목 등)을 "패킹"하는 최적의 방법을 찾는 데 도움이 되는 최적화 문제로, 어떤 한도도 초과하지 않도록 보장한다.
- 커버링 LP (Covering LPs): 건물 입구를 모두 커버하기 위해 보안 카메라를 배치해야 하고 각 카메라는 몇 개의 특정 입구를 커버한다고 상상해 보라. 커버링 LP는 모든 입구를 "커버"하는 데 필요한 최소 카메라 수를 찾는 데 도움이 되며, 모든 입구가 모니터링되도록 보장한다.
- 폴리로그 깊이, 상수 너비 GNN (Polylogarithmic-depth, Constant-width GNNs): 이는 "얕은"(폴리로그 깊이는 레이어 수가 문제 크기에 따라 매우 느리게 증가하는 것을 의미하며, $\log(\text{size})$ 또는 $\log^2(\text{size})$와 같음) 그리고 "좁은"(상수 너비는 각 레이어가 문제 크기에 관계없이 고정되고 작은 수의 내부 처리 단위를 갖는 것을 의미함) GNN을 설명한다. 이는 큰 문제도 해결할 수 있는 매우 효율적이고 컴팩트한 계산 기계와 같다.
표기법 표
| 표기법 | 설명 |
|---|---|
| $A$ | LP의 제약 행렬 ($n \times m$) |
| $x$ | 원시 변수 벡터 ($m \times 1$) |
| $y$ | 쌍대 변수 벡터 ($n \times 1$) |
| $X^k$ | 반복 $k$에서의 원시 변수 행렬 ($m \times d$) |
| $Y^k$ | 반복 $k$에서의 쌍대 변수 행렬 ($n \times d$) |
| $d$ | 확장된 변수의 채널 차원 |
| $n$ | 제약 조건 수 ($A$의 행 수) |
| $m$ | 원시 변수 수 ($A$의 열 수) |
| $K$ | 총 GNN 레이어 수 (반복 횟수) |
| $\mu$ | ELU 입력의 스케일링 매개변수 |
| $\epsilon$ | 근사 정밀도 매개변수 |
| $\text{ELU}(\cdot)$ | 지수 선형 유닛 활성화 함수 |
| $\text{ReLU}(\cdot)$ | 정류 선형 유닛 활성화 함수 |
| $f_{\theta^k}(\cdot)$ | 원시 변수 업데이트를 위한 학습 가능한 함수 (곱셈적) |
| $g_{\theta^k}(\cdot)$ | 원시 변수 업데이트를 위한 학습 가능한 함수 (덧셈적) |
| $W^k$ | 채널 혼합을 위한 학습 가능한 가중치 행렬 ($d \times d$) |
| $\odot$ | Hadamard 곱 (요소별 곱셈) |
| $1_{p \times q}$ | 모든 요소가 1인 $p \times q$ 차원의 행렬 |
| $\Theta$ | GD-Net의 모든 학습 가능한 매개변수 집합 |
| $obj_i$ | 인스턴스 $i$에 대한 예측 목표값 |
| $obj^*_i$ | 인스턴스 $i$에 대한 최적 목표값 |
| R. Gap | 상대적 오차: $|obj_i - obj^*_i| / obj^*_i$ |
| A. Gap | 절대적 오차: $|obj_i - obj^*_i|$ |
문제 정의 및 제약 조건
핵심 문제 공식화 및 딜레마
본 논문은 선형 계획법(LP) 문제에 대한 그래프 신경망(GNN)과 관련하여 이론적 이해와 경험적 관찰 사이의 중요한 격차를 다룬다.
입력/현재 상태:
시작점은 GNN이 LP 문제의 해 매핑 함수를 보편적으로 근사할 수 있다는 확립된 이론적 결과이다. 그러나 이러한 이론적 증명은 일반적으로 문제 차원에 대해 큰 수의 매개변수 또는 다항식 깊이를 가진 GNN을 필요로 한다. 동시에 경험적 증거는 비교적 작은 GNN(예: 적당한 너비와 10개 미만의 레이어)이 실제로 LP를 효과적으로 해결하고 좋은 성능을 달성할 수 있음을 일관되게 보여준다.
원하는 최종 상태/목표 상태:
주요 목표는 소형 GNN이 LP를 효과적으로 해결하는 데 왜 그리고 언제 효과적인지를 설명하는 강력한 이론적 기반을 제공하는 것이다. 구체적으로, 본 논문은 폴리로그 깊이와 상수 너비를 가진 GNN이 광범위한 LP 클래스, 즉 패킹 및 커버링 LP에 대해 임의의 정밀도로 해 매핑을 근사하는 데 충분함을 증명하는 것을 목표로 한다. 따라서 더 작고 효율적인 GNN에 대한 이러한 이론적 검증은 학습 기반 최적화(L2O)를 위한 매개변수 효율적인 모델 개발을 안내하고 잠재적으로 전통적인 LP 및 혼합 정수 선형 계획법(MILP) 솔버를 가속화할 것이다.
누락된 연결/수학적 격차:
정확한 누락된 연결은 소형 GNN의 경험적 성공에 대한 이론적 정당성이다. LP에 대한 GNN의 보편적 근사 능력에 대한 이전 이론적 작업은 대규모 모델 크기(예: 큰 매개변수 수 또는 다항식 깊이)의 가정에 의존하여 관찰된 실질적인 효율성과 단절을 야기했다. 본 논문은 GNN이 신중하게 선택된 잠재 함수에 대한 경사 하강법 변형을 시뮬레이션할 수 있음을 수학적으로 입증함으로써 이 격차를 해소하고자 하며, 이를 통해 훨씬 더 작은 아키텍처(폴리로그 깊이 및 상수 너비)로 강력한 근사 보증을 달성한다.
고통스러운 절충안 및 딜레마:
핵심 딜레마는 "이론적 예측과 경험적 관찰 사이의 상당한 불일치"(초록, 1쪽)이다. 연구자들은 LP 해결을 위한 GNN에 대한 강력한 이론적 보증을 달성하기 위해 전통적으로 대규모의 계산 집약적인 모델이 필요했지만, 실제 구현에서는 종종 더 작고 효율적인 모델이 놀랍도록 효과적이라는 것을 발견했다는 절충안에 "갇혀" 있었다. 이는 이론적 엄격성(높은 계산 비용과 광범위한 훈련 데이터가 필요한 대규모 모델 요구)과 실질적인 효율성(공식적인 설명이 부족한 성공을 달성한 더 작은 모델로 달성됨) 사이의 고통스러운 선택을 야기한다. 본 논문은 이를 명시적으로 "흥미로운 열린 질문: 소형 GNN이 언제 그리고 왜 효과적으로 LP를 해결할 수 있는가?"(서론, 2쪽)로 프레임화하여 이러한 이론-경험적 격차를 조화시킬 필요성을 강조한다.
제약 조건 및 실패 모드
효율적이고 이론적으로 근거 있는 GNN을 LP 해결을 위해 개발하는 문제는 여러 가지 가혹하고 현실적인 장벽에 의해 제약된다.
- 계산 자원 한계: 더 큰 GNN은 본질적으로 "더 많은 훈련 예제와 더 높은 계산 자원"(서론, 2쪽)을 요구한다. 이는 이론적 보증이 항상 대규모 모델을 요구하는 경우 GNN의 확장성과 적용 가능성을 제한하는 실질적인 제약이다. "매개변수 효율적인 모델"(서론, 2쪽)에 대한 추진은 직접적으로 이를 해결한다.
- 문제 복잡성 및 규모: LP, 특히 패킹 및 커버링 LP는 수백 개의 노드와 제약 조건을 포함할 수 있다(서론, 2쪽). 이러한 대규모 문제를 허용 가능한 시간 내에 효율적으로 해결하는 것은 상당한 과제이다.
- 모델 크기에 대한 이론적 한계: 일반 LP에 대한 이전 이론적 결과는 GNN이 "큰 매개변수 크기" 또는 "문제 차원에 다항식인 깊이"(서론, 2쪽)를 갖도록 요구했다. 이러한 이론적 장벽은 경험적 성공에도 불구하고 더 작은 GNN의 효과를 증명하는 것을 어렵게 만들었다.
- 근사 정밀도 요구 사항: 목표는 $(1+\epsilon)$-근사 해를 달성하는 것이다(1.1절, 2쪽). 이는 GNN이 효율적일 뿐만 아니라 높은 수준의 해 품질을 유지해야 함을 의미하며, 이는 모델 크기를 줄일 때 사소하지 않은 작업이다.
- 해의 타당성: 머신러닝 기반 최적화 솔버의 일반적인 실패 모드는 타당하지 않은 해를 생성하는 것이다. GD-Net에서 출력되는
x_final또는y_final은 LP 제약 조건(예: $x \ge 0$, $Ax \le 1$)을 모두 만족하지 못할 수 있다. 본 논문은 "타당성 복원"(post-processing) 절차(7쪽, 8쪽)를 통해 이를 해결하며, 이는 극복해야 할 중요한 제약 조건임을 나타낸다. - 미분 불가능한 연산: 기본 경사 하강법 알고리즘(알고리즘 1 및 2)은 조건부 업데이트(if-else 문)와
max연산을 포함하며, 이는 미분 불가능하다. 이를 신경망으로 직접 변환하는 것은 문제가 된다. 저자들은 헤비사이드 계단 함수를 학습 가능한 시그모이드 함수로 근사하고(4, 5, 6번 식, 6쪽) ReLU를 비음수성을 위해 사용하여 미분 불가능한 논리를 미분 가능한 신경망 아키텍처로 효과적으로 변환함으로써 이를 우회한다. 이는 반복 알고리즘을 언롤링하는 데 있어 핵심적인 기술적 제약이다. - 하드웨어 메모리 한계: 명시적으로 하드 한계로 명시되지는 않았지만, 실험 설정에서 "2.95 TB RAM"(E절, 16쪽)을 언급하며, 이는 대규모 LP 인스턴스의 경우 메모리가 상당한 제약이 될 수 있으며, 더 작은 GNN은 본질적으로 이 압력을 완화한다는 것을 암시한다.
- 수렴 속도: 반복 알고리즘은 합리적인 단계 수 내에서 수렴해야 한다. 본 논문은 Awerbuch-Khandekar 알고리즘의 "폴리로그 수렴"(4쪽)을 언급하며, GNN은 이러한 효율적인 수렴을 시뮬레이션하도록 설계되어야 한다.
왜 이 접근 방식인가
선택의 불가피성
Awerbuch-Khandekar 경사 하강법 변형을 언롤링하는 GD-Net 아키텍처의 채택은 선형 계획법(LP)에 대한 그래프 신경망(GNN) 분야의 기존 이론적 이해와 경험적 관찰 사이의 상당한 격차에 의해 주도된 설계 선택이 아니라 필수였다. 일반적인 이론적 결과는 종종 보편적 근사 정리에 의존하여 GNN이 임의의 정밀도로 LP를 효과적으로 해결하기 위해 큰 매개변수 크기 또는 문제 차원에 대한 다항식 깊이를 요구할 것이라고 제안했다(초록, 1쪽; 2쪽). 그러나 실제 실험에서는 비교적 작은 GNN이 좋은 성능을 달성할 수 있음을 일관되게 보여주어 혼란스러운 불일치를 만들었다.
저자들은 GCN과 같은 표준 GNN이 이러한 격차를 해소하는 데 불충분하다는 것을 깨달았다. 왜냐하면 GCN은 폴리로그 깊이를 달성할 수 있지만 상수 너비를 보장할 수 없기 때문이다(비고 1, 7쪽). 이는 일반 GNN이 ELU와 같은 함수를 임의의 정밀도로 시뮬레이션하기 위해 "충분히 넓은 퍼셉트론"을 여전히 필요로 할 것이며, 따라서 "소형" 제약 조건을 충족하지 못한다는 것을 의미한다(7쪽). 그러나 Awerbuch-Khandekar 경사 하강법 알고리즘의 특정 변형은 고유한 이점을 제공했다. 즉, "상수 너비의 GNN 레이어 하나로 알고리즘의 한 반복을 시뮬레이션할 수 있는" GNN으로 "더 자연스럽게 시뮬레이션될 수 있다"(4쪽). 반복 최적화 알고리즘에서 GNN 구조로의 이러한 직접적인 매핑은 상수 너비와 폴리로그 깊이를 가진 GNN(정리 3 및 5, 7-8쪽)은 패킹 및 커버링 LP에 대한 소형 GNN의 경험적 성공을 이론적으로 설명하는 유일하게 실행 가능한 경로를 제공했다.
비교 우위
GD-Net 접근 방식은 주로 구조 설계와 고유한 매개변수 절약으로 인해 단순한 성능 지표를 넘어 질적인 우수성을 보여준다.
첫째, GD-Net의 아키텍처는 근본적으로 기본 최적화 문제와 일치한다. 패킹 및 커버링 LP에 대한 이론적으로 근거 있는 경사 하강법 알고리즘을 언롤링함으로써 문제의 고유한 구조를 활용한다. 이는 강력하지만 반복적인 최적화 프로세스를 시뮬레이션하는 데 특별히 맞춰지지 않은 GCN과 같은 보다 일반적인 GNN 아키텍처와 대조된다. 이러한 구조적 이점을 통해 GD-Net은 "문제의 구조적 뉘앙스를 더 잘 포착할 수 있다"(9쪽).
둘째, GD-Net은 매개변수 효율성에서 압도적인 우수성을 보여준다. 실험에 따르면 GD-Net은 "GCN보다 한 자릿수 적은 매개변수"(3쪽)로 더 나은 솔루션을 달성한다. 예를 들어, 64개의 은닉 유닛을 가진 4레이어 GD-Net은 1,656개의 매개변수만 사용하는 반면, 비교 가능한 GCN은 34,306개의 매개변수를 필요로 한다(9쪽). 이러한 매개변수의 급격한 감소는 더 낮은 메모리 복잡성과 계산 오버헤드로 이어져 모델을 더 실용적이고 확장 가능하게 만든다.
셋째, 이 방법은 솔루션 품질과 속도 측면에서 우수한 성능을 보여준다. 표 1(9쪽)은 GD-Net이 다양한 LP 유형(IS, 패킹, ECP, SC) 및 문제 크기에 걸쳐 GCN보다 일관되게 더 좁은 상대 및 절대 오차를 달성함을 보여준다. GD-Net의 테스트 오류가 약간 더 높을 수 있는 경우에도 상대적 오차는 여전히 우수하여 최적 솔루션에 대한 질적으로 더 나은 근사를 나타낸다. 또한, PDLP 및 Gurobi와 같은 전통적인 솔버와 벤치마킹했을 때 GD-Net은 일관되게 유사한 정밀도 수준을 훨씬 적은 시간 내에 달성한다. 예를 들어, Gurobi의 심플렉스 방법은 GD-Net과 동일한 품질의 솔루션으로 수렴하는 데 최대 300배 더 많은 시간이 걸렸다(10쪽). 이는 GD-Net이 고품질 솔루션을 효율적으로 생성할 수 있는 능력을 강조하며, 이는 실제 응용 프로그램에 매우 중요하다.
마지막으로, GD-Net은 강력한 일반화 능력과 확장성을 보여준다. "작은 데이터셋으로 훈련되었을 때 최소한의 성능 저하"(9쪽, 표 2)로 더 큰 문제 인스턴스로 일반화될 수 있다. 추론 시간은 "문제 크기가 증가하더라도 비교적 허용 가능한 상태로 유지된다" 반면 GCN은 "더 큰 문제 인스턴스를 처리하고 예측하는 데 훨씬 더 많은 시간이 필요하다"(18쪽).
제약 조건과의 일치
선택된 GD-Net 방법은 특히 소형 GNN을 사용한 효과적인 솔루션과 강력한 이론적 기반에 대한 필요성과 같은 문제의 암묵적 제약 조건과 완벽하게 일치한다. 핵심 문제 설명은 LP 해결을 위해 필요한 GNN 크기에 관한 "이론적 예측과 경험적 관찰 사이의 상당한 불일치"(초록, 1쪽)를 해소하는 데 중점을 둔다.
Awerbuch-Khandekar 경사 하강법 알고리즘 변형을 언롤링하는 GD-Net의 설계는 "폴리로그 깊이, 상수 너비 GNN이 패킹 및 커버링 LP를 해결하는 데 충분하다"(초록, 1쪽; 정리 3 및 5, 7-8쪽)고 증명함으로써 직접적으로 이를 해결한다. 이 이론적 결과는 더 작은 GNN의 효과에 대한 필요한 기반을 제공하며, 제한된 모델 복잡성으로 높은 성능을 달성한다는 제약 조건을 직접적으로 충족한다. 문제의 가혹한 요구 사항(작고 효율적인 모델)과 솔루션의 고유한 속성(상수 너비, 폴리로그 깊이 GNN이 알려진 반복 알고리즘 시뮬레이션) 간의 "결합"은 이러한 이론적 보증에서 분명하다.
또한, 알고리즘 단계와 네트워크 레이어 간의 직접적인 대응은 모델의 너비를 본질적으로 제한하여 "소형" 제약 조건과 일치하면서도 명확하고 해석 가능한 메커니즘을 유지한다.
대안의 기각
본 논문은 소형 GNN을 사용하여 패킹 및 커버링 LP를 해결하는 특정 문제에 대해 이론적 한계, 경험적 성능 및 계산 비효율성을 기반으로 여러 대안 접근 방식을 암묵적으로 그리고 명시적으로 기각한다.
일반 GNN (예: GCN): 소형 솔루션을 달성하기 위해 고려되고 기각된 주요 대안은 GCN과 같은 일반 GNN이다. 이러한 모델도 폴리로그 깊이를 달성할 수 있지만, 저자들은 "상수 너비가 더 이상 보장되지 않는다"(비고 1, 7쪽)고 명시적으로 언급한다. 이는 임의의 정밀도를 달성하기 위해 GCN은 "충분히 넓은 퍼셉트론"을 필요로 할 것이며, 이는 비상수 너비로 이어져 GD-Net이 성공적으로 해결하는 "소형" 제약 조건을 충족하지 못하게 된다(7쪽). 경험적으로 GCN은 GD-Net이 "한 자릿수 적은 매개변수"(3쪽, 표 1, 9쪽)를 사용했음에도 불구하고 상대 및 절대 오차 측면에서 일관되게 열등한 성능을 보였으며, 종종 더 높은 검증/테스트 오류를 보였다. 또한 GCN은 "더 큰 문제 인스턴스를 처리하고 예측하는 데 훨씬 더 많은 시간이 필요하다"(18쪽)는 점에서 확장성이 좋지 않았다.
전통적인 LP 솔버 (PDLP, Gurobi): 본 논문은 또한 PDLP(1차 방법) 및 상용 솔버 Gurobi(프라이멀 심플렉스 방법 사용)와 같은 확립된 이론적으로 근거 있는 LP 솔버와 GD-Net을 벤치마킹한다. 이러한 솔버는 강력하지만, 속도와 효율성이 가장 중요한 시나리오에서는 주요 솔루션으로 간주되지 않는다. PDLP는 "GD-Net과 유사한 품질의 솔루션을 더 짧은 시간 내에 생성하지 못했다"(10쪽). Gurobi는 정밀도에도 불구하고 "GD-Net과 동일한 품질의 솔루션으로 수렴하는 데 최대 300배 더 많은 시간이 걸렸다"(10쪽). 이는 심플렉스 방법의 계산적으로 비싼 행렬 분해(10쪽)에 기인한다. 따라서 정확성 측면에서 "실패"는 아니지만, 계산 비용으로 인해 빠른 고품질 근사 솔루션 또는 따뜻한 시작이 필요한 응용 프로그램에는 덜 적합하며, GD-Net은 이를 효율적으로 제공한다.
본 논문은 생성적 적대 신경망(GAN) 또는 확산 모델과 같은 다른 머신러닝 패러다임을 논의하지 않는다. 왜냐하면 이러한 모델은 선형 계획법 문제를 해결하는 문제에 직접적으로 적용되지 않기 때문이다. 초점은 GNN과 고전적인 최적화 알고리즘과의 관계에 남아 있다.
수학적 및 논리적 메커니즘
마스터 방정식
본 논문의 메커니즘의 핵심은 선형 계획법(LP) 문제를 해결하기 위한 Awerbuch-Khandekar 경사 하강법 알고리즘 변형을 시뮬레이션하도록 설계된 그래프 신경망(GNN) 아키텍처인 GD-Net에 있다. 구체적으로, 패킹 LP의 경우, 알고리즘의 한 반복(단일 GNN 레이어에 해당)은 두 가지 주요 업데이트 방정식에 의해 제어된다. 이러한 방정식은 쌍대 변수(제약 조건을 나타냄)와 원시 변수(항목을 나타냄)가 반복적으로 업데이트되는 방법을 설명한다.
반복 $k$에서의 쌍대 변수 $Y^k$에 대한 업데이트는 다음과 같이 주어진다.
$$Y^k := \text{ELU}[\mu(A X^k - 1_{n \times d})] + 1_{n \times d}$$
그리고 다음 반복 $k+1$에 대한 원시 변수 $X^{k+1}$의 업데이트는 다음과 같다.
$$X^{k+1} = \text{ReLU} (\{X^k + f_{\theta^k}(A^T Y^k - 1_{m \times d}) \odot X^k + g_{\theta^k}(A^T Y^k - 1_{m \times d})\} \cdot W^k)$$
커버링 LP에 대한 유사한 방정식 세트가 존재하며, 이는 이러한 문제의 쌍대적 특성을 반영한다.
용어별 분석
이러한 방정식을 해부하여 각 구성 요소의 역할을 이해해 보자.
방정식 1: $Y^k := \text{ELU}[\mu(A X^k - 1_{n \times d})] + 1_{n \times d}$
- $Y^k$: 이는 반복 $k$에서의 쌍대 변수(또는 제약 가격)의 현재 상태를 나타내는 $n \times d$ 행렬이다. 각 행은 제약 조건을 나타내고 각 열은 채널 확장의 특징 차원이다. 물리적 역할은 각 제약 조건의 "단단함" 또는 "위반"을 정량화하는 것이다.
- $\text{ELU}[\cdot]$: 요소별로 적용되는 지수 선형 유닛 활성화 함수이다. 수학적 정의는 $t > 0$일 때 $\text{ELU}(t) = t$이고 $t \le 0$일 때 $\text{ELU}(t) = \alpha(\exp(t) - 1)$이다. 본 논문에서는 $\alpha$가 1로 고정된다. 저자들은 ELU의 입력 $\mu(A_i x^k - 1)$이 실행 중에 항상 음수가 아니므로 원래 알고리즘 1의 지수 함수 업데이트 $y_i := \exp[\mu(A_i x^k - 1)]$를 정확하게 복제하기 위해 ELU를 사용한다. 이러한 비선형성은 GNN이 복잡한 매핑을 학습하는 데 중요하다.
- $\mu$: 스칼라 매개변수로, $1/\ln(mA_{\max})$로 고정된다. 수학적으로 ELU 함수의 입력에 대한 민감도를 조절한다. 더 작은 $\mu$(더 큰 $m$ 또는 $A_{\max}$로 인해)는 덜 공격적인 업데이트를 의미한다.
- $A$: 이는 선형 계획법의 $n \times m$ 제약 행렬이다. 각 요소 $A_{ij}$는 0이거나 1보다 크다. 물리적 역할은 원시 변수와 제약 조건 간의 관계를 정의하는 것이다.
- $X^k$: 반복 $k$에서의 원시 변수의 현재 상태를 나타내는 $m \times d$ 행렬이다. 각 행은 원시 변수를 나타내고 각 열은 특징 차원이다. 물리적 역할은 LP에 대한 현재 제안된 솔루션을 나타내는 것이다.
- $1_{n \times d}$: 모든 요소가 1인 $n \times d$ 행렬이다. 이는 요소별 연산에 사용된다.
- $A X^k$: 이는 행렬 곱셈으로, $n \times d$ 행렬을 생성한다. 각 요소 $(A X^k)_{id}$는 제약 조건 $i$ 및 특징 차원 $d$에 대한 제약 조건 계수로 가중치가 부여된 원시 변수의 합을 나타낸다. 물리적 역할은 패킹 LP 제약 조건 $Ax \le 1$의 좌변을 계산하는 것이다.
- $A X^k - 1_{n \times d}$: 요소별 뺄셈이다. 이 항은 각 특징 차원 $d$에 걸쳐 각 제약 조건 $i$의 위반 또는 여유를 정량화한다. $(A X^k)_{id} - 1_{id} > 0$이면 제약 조건이 위반된 것이다.
- $+ 1_{n \times d}$: 1로 채워진 행렬의 요소별 덧셈이다. 이 항은 ELU 함수와 함께 $y$-업데이트가 원래 Awerbuch-Khandekar 알고리즘의 지수 업데이트와 정확히 일치하도록 보장한다. 덧셈은 ELU 출력의 이동에 사용되어 원하는 지수 동작과 일치시킨다.
방정식 2: $X^{k+1} = \text{ReLU} (\{X^k + f_{\theta^k}(A^T Y^k - 1_{m \times d}) \odot X^k + g_{\theta^k}(A^T Y^k - 1_{m \times d})\} \cdot W^k)$
- $X^{k+1}$: 다음 반복에 대한 업데이트된 원시 변수를 나타내는 $m \times d$ 행렬이다.
- $\text{ReLU}(\cdot)$: 요소별로 적용되는 정류 선형 유닛 활성화 함수이다. 수학적으로 $\text{ReLU}(t) = \max(0, t)$이다. 물리적/논리적 역할은 원시 변수에 대한 비음수 제약 조건($x \ge 0$)을 강제하는 것으로, LP의 기본이다.
- $X^k$: 위에서 정의한 원시 변수의 현재 상태이다.
- $f_{\theta^k}(\cdot)$ 및 $g_{\theta^k}(\cdot)$: 이들은 시그모이드 함수의 합으로 정의된 학습 가능한 함수이다(논문의 5번 및 6번 식). 이들은 입력 행렬에 요소별로 적용된다. 수학적 역할은 원래 Awerbuch-Khandekar 알고리즘의 조건부 업데이트에 사용된 헤비사이드 계단 함수 $f(t)$ 및 $g(t)$를 근사하는 것이다(4번 식). 물리적/논리적 역할은 집계된 쌍대 정보를 기반으로 각 원시 변수에 적용할 조정의 크기와 유형을 결정하는 것이다. 저자들은 이러한 함수를 구성하기 위해 합계(시그모이드의 합으로 $f_{\theta^k}$ 및 $g_{\theta^k}$의 정의에 암묵적으로 포함됨)를 사용하여 원래 계단식 업데이트의 부드럽고 미분 가능한 근사를 가능하게 한다.
- $A^T$: 제약 행렬 $A$의 전치 행렬이다.
- $A^T Y^k$: 행렬 곱셈으로, $m \times d$ 행렬을 생성한다. 이 항은 쌍대 변수 정보($Y^k$)를 원시 변수로 다시 집계하여 각 원시 변수에 대한 "기울기 유사" 신호를 효과적으로 계산한다. 잠재 함수 $\Phi_p(x)$의 맥락에서 $\nabla \Phi_p(x) = A^T y$이다.
- $A^T Y^k - 1_{m \times d}$: 요소별 뺄셈이다. 이는 각 원시 변수에 대한 "기울기" 또는 "업데이트 방향"을 나타내며, 조정해야 하는 정도를 나타낸다.
- $\odot$: Hadamard 곱(요소별 곱셈)이다. 이 연산자는 $f_{\theta^k}$의 스케일링 인자를 $X^k$에 요소별로 적용하는 데 사용되며, 원래 알고리즘의 곱셈 업데이트 $(1+\beta)$ 또는 $(1-\beta)$를 모방한다.
- $W^k$: $d \times d$ 학습 가능한 가중치 행렬이다. 이는 신경망의 표준 선형 변환이다. 물리적 역할은 확장된 변수의 $d$ 특징 차원(채널) 간의 정보를 혼합하여 모델의 표현력을 향상시키는 것이다. 여기서의 곱셈은 행렬 곱셈으로, 특징 벡터를 변환한다.
- 중괄호 $\{\dots\}$는 현재 원시 변수와 두 업데이트 항의 합을 포함한다. 이는 현재 솔루션이 계산된 기울기와 학습 가능한 함수에 따라 조정되는 핵심 경사 하강법 단계를 나타낸다. 덧셈은 현재 상태와 계산된 업데이트를 결합하는 데 사용된다.
단계별 흐름
패킹 GD-Net의 한 레이어(반복 $k$)를 통과하는 단일 추상 데이터 포인트, 즉 원시 변수 $x_j$를 상상해 보라.
- 초기화: 프로세스 시작 시($k=0$), 모든 원시 변수 $X^0$는 $0_{m \times d}$로 초기화된다. 쌍대 변수 $Y^0$도 효과적으로 초기화되거나 $X^0$에서 파생된다.
- 원시에서 쌍대로 메시지 전달 (Y-업데이트):
- 제약 조건 평가: 각 제약 조건 $i$에 대해 현재 원시 변수 $X^k$는 이를 향해 "메시지를 보낸다". 여기에는 가중 합 $A_i X^k$( $A X^k$의 $i$-번째 행)을 계산하는 것이 포함된다. 이 합은 선택된 원시 변수에 의해 현재 사용되는 리소스의 양을 나타낸다.
- 위반 계산: 계산된 합 $A_i X^k$는 제약 조건 한도(정규 형식 LP의 경우 1)와 비교되어 $A_i X^k - 1_{n \times d}$를 생성한다. 이 값은 제약 조건 $i$가 위반되었는지(양수) 또는 만족되었는지(음수/0)를 나타낸다.
- 쌍대 변수 업데이트: 이 "위반 신호"는 $\mu$로 스케일링되고 ELU 활성화 함수를 통과한 다음 $1_{n \times d}$를 더하여 이동된다. 이 변환은 업데이트된 쌍대 변수 $Y^k$를 생성한다. 개념적으로, 심하게 위반된 제약 조건은 해당 쌍대 변수가 더 많이 증가하여 위반에 대한 "비용"이 더 높음을 신호한다.
- 쌍대에서 원시로 메시지 전달 (X-업데이트):
- 기울기 집계: 이제 업데이트된 쌍대 변수 $Y^k$는 원시 변수로 "메시지를 다시 보낸다". 각 원시 변수 $x_j$에 대해 항 $A_j^T Y^k$($A^T Y^k$의 $j$-번째 행)는 $x_j$가 참여하는 모든 제약 조건의 영향을 집계한다. 이 집계된 신호는 "기울기" 역할을 하며, $x_j$를 조정하면 전체 목표 및 제약 조건 만족에 어떤 영향을 미칠지 나타낸다.
- 조건부 조정: 이 기울기 신호 $A^T Y^k - 1_{m \times d}$는 학습 가능한 함수 $f_{\theta^k}$ 및 $g_{\theta^k}$에 공급된다. 시그모이드 기반 함수로 구성된 이러한 함수는 원래 알고리즘의 조건부 논리를 모방하여 각 원시 변수에 적용할 조정의 양과 유형을 결정한다.
- 특징 변환: 결합된 업데이트는 학습 가능한 가중치 행렬 $W^k$와 곱해진다. 이 단계는 각 원시 변수의 $d$ 특징 차원에 걸친 정보를 혼합하고 변환할 수 있도록 하여 표현력을 풍부하게 한다.
- 비음수성 강제: 마지막으로 ReLU 활성화 함수가 결과에 요소별로 적용된다. 이는 업데이트된 원시 변수 $X^{k+1}$의 모든 구성 요소가 비음수 상태를 유지하도록 보장하며, 이는 LP의 기본 제약 조건을 준수한다.
이 전체 시퀀스는 GD-Net의 한 레이어를 구성한다. 출력 $X^{k+1}$은 다음 레이어의 입력 $X^k$가 되고, 프로세스는 $K$ 레이어 동안 반복되어 솔루션을 반복적으로 개선한다.
최적화 역학
GD-Net의 학습 및 수렴 역학은 학습 가능한 구성 요소가 있는 언롤링된 경사 하강법 알고리즘으로 설계된 것에 뿌리를 두고 있다.
- 학습 메커니즘: GD-Net은 학습 가능한 매개변수 집합 $\Theta = \{\theta^k, W^k\}_{k=0}^{K-1} \cup \{w^K\}$를 최적화하여 학습한다. 이러한 매개변수에는 $f_{\theta^k}$ 및 $g_{\theta^k}$의 시그모이드 기반 함수의 내부 계수와 채널 혼합 행렬 $W^k$가 포함된다. 학습 목표는 주어진 LP 인스턴스 $A$에 대해 네트워크의 최종 출력 $x^{\text{final}}(\Theta, A)$와 실제 최적 솔루션 $x^*$ 간의 평균 제곱 오차(MSE)를 최소화하는 것이다. 이는 지도 학습 작업으로, 네트워크는 LP 인스턴스 및 알려진 최적 솔루션 데이터셋으로 훈련된다.
- 매개변수 업데이트: 매개변수 $\Theta$는 표준 경사 기반 최적화 알고리즘(예: Adam, SGD)을 사용하여 업데이트된다. 훈련 중에는 손실 함수 $L_p(\mathcal{I}; \Theta)$가 계산되고, $\Theta$에 대한 해당 기울기는 전체 $K$-레이어 네트워크를 통한 역전파를 통해 계산된다. 이러한 기울기는 예측 오류를 줄이기 위해 각 매개변수가 어떻게 조정되어야 하는지를 나타낸다.
- 손실 지형 및 수렴: 본 논문은 원래 Awerbuch-Khandekar 알고리즘이 신중하게 선택된 잠재 함수 $\Phi_p(x)$(또는 $\Phi_c(y)$)에서 작동하며, 이는 미분 가능하고 볼록하다는 점을 강조한다. 이는 경사 하강법에 대한 기본 최적화 문제가 잘 정의된 단일 최소값 손실 지형을 갖는다는 것을 의미한다. 이 알고리즘을 언롤링하고 조건부 업데이트를 학습 가능한 미분 가능한 함수($f_{\theta^k}, g_{\theta^k}$는 시그모이드로 구성됨) 및 선형 변환($W^k$)으로 대체함으로써 GD-Net은 이러한 수렴을 시뮬레이션하고 가속화하는 것을 목표로 한다.
- ELU 및 ReLU 활성화의 사용은 GNN의 표현력에 필수적인 비선형성을 도입한다. 신경망의 전체 훈련 손실 지형은 비볼록할 수 있지만, 설계는 각 레이어의 업데이트 단계가 볼록 함수에 대한 경사 하강법 단계의 근접한 근사임을 보장한다.
- 이론적 결과(정리 3 및 5)는 충분한 수의 레이어(폴리로그 깊이)와 상수 너비를 가진 GD-Net이 $(1+\epsilon)$-근사 솔루션을 달성할 수 있음을 보장한다. 이는 GD-Net 레이어의 반복 업데이트가 원래 알고리즘의 수렴 속성을 상속하여 거의 최적의 솔루션으로 효과적으로 수렴함을 의미한다.
- ReLU 활성화는 원시 변수가 음수가 되지 않도록 하여 원시 변수의 타당성을 유지하는 데 중요한 역할을 한다. 그러나 본 논문은 "타당성 복원" 후처리 단계를 언급하며, 이는 네트워크의 원시 출력이 때때로 모든 제약 조건을 엄격하게 만족시키기 위해 약간의 조정이 필요할 수 있음을 나타낸다. 이는 학습 기반 최적화 접근 방식에서 일반적인 관행이다. 학습 가능한 함수 $f_{\theta^k}$ 및 $g_{\theta^k}$는 네트워크가 경사 하강법에 대한 최적의 "단계 크기" 및 "방향"을 적응적으로 학습할 수 있도록 하여, 고정 매개변수 알고리즘에 비해 더 빠르고 강력한 수렴을 가능하게 한다.
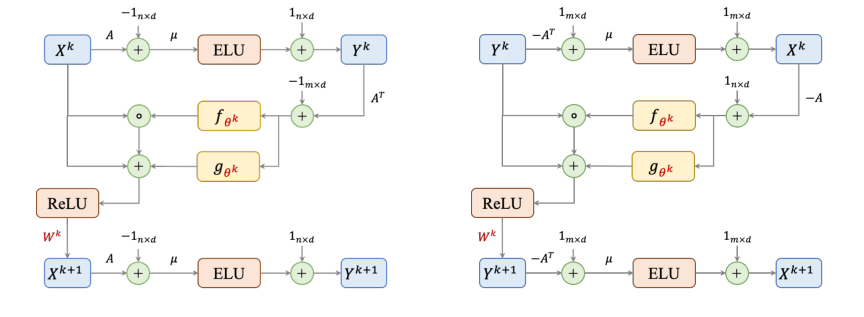 Figure 1. The architectures of a single layer in packing (left) and covering (right) GD-Nets. Learnable parameters are colored in red
Figure 1. The architectures of a single layer in packing (left) and covering (right) GD-Nets. Learnable parameters are colored in red
결과, 한계 및 결론
실험 설계 및 기준선
GD-Net의 효능에 대한 실험적 검증은 다양한 선형 계획법(LP) 문제에 걸쳐 확립된 기준선에 대해 엄격하게 테스트하도록 세심하게 설계되었다.
데이터셋: 우리는 공개적으로 이용 가능한 혼합 정수 최적화 인스턴스에서 파생된 네 가지 구별되는 LP 완화 집합을 사용했다: 최대 독립 집합(IS), 패킹 문제, 에지 커버링 문제(ECP), 집합 커버(SC). 각 문제 유형은 크기가 다른 네 세트의 인스턴스로 표현되었다: 작음(S), 중간(M), 큼(L), 그리고 전용 일반화(Gen) 세트. 훈련을 위해 5,000개의 인스턴스를 사용했으며, 추가로 100개는 검증용, 100개는 테스트용으로 사용했다. 모든 인스턴스는 정규화 절차를 거쳤으며, SCIP [5] 최적화 솔버를 사용하여 최적 솔루션을 얻어 실제 정답으로 사용했다. 문제 크기(행 및 열 수) 및 행렬 밀도에 대한 자세한 사양은 부록에 제공된다.
모델 및 훈련 설정: 제안된 GD-Net 아키텍처는 학습 기반 최적화(L2O)에서 널리 사용되는 GNN 아키텍처인 [29]의 기존 그래프 컨볼루션 네트워크(GCN) 구현과 비교 벤치마킹되었다. 두 모델 모두 4레이어 아키텍처로 구성되었으며, 각 레이어는 64개의 은닉 유닛을 포함했다. 매개변수 수에서 눈에 띄는 차이가 나타났다. GD-Net은 GCN의 34,306개 매개변수보다 한 자릿수 적은 1,656개의 매개변수만 사용했다. GD-Net의 경우 근사 매개변수 $\epsilon$은 0.2로 설정되었다. 모든 모델은 학습률 $10^{-3}$을 사용하여 10,000 에포크 동안 훈련되었으며, 최상의 성능을 보인 체크포인트(가장 낮은 검증 손실)를 평가용으로 저장했다. 완전한 재현성을 위해 코드는 https://anonymous.4open.science/r/GD-Net-6FC7/에서 공개적으로 이용 가능하다.
지표: 성능을 정량화하기 위해 두 가지 주요 지표를 사용했다.
- 상대적 오차 (R. Gap): 타당성 복원 후 예측된 목표값 $obj_i$와 최적 목표값 $obj^*_i$를 사용하여 $|obj_i - obj^*_i| / obj^*_i$로 정의된다.
- 절대적 오차 (A. Gap): $|obj_i - obj^*_i|$로 정의된다.
이러한 지표를 통해 각 모델이 생성한 솔루션의 품질을 평가할 수 있었다.
하드웨어 및 소프트웨어: 모든 실험은 Intel(R) Xeon(R) Platinum 8280 CPU @ 2.70GHz 및 2.95 TB RAM이 장착된 서버에서 수행되었다. 데이터 생성은 Ecole 0.7.3 및 Pyscipopt 4.2.0을 통해 용이하게 이루어졌으며, 모델 구현은 PyTorch 2.1을 사용하여 개발되었다.
추가 기준선: 포괄적인 비교를 제공하기 위해 두 가지 전통적인 LP 솔버, 즉 1차 솔버 PDLP [19] 및 상용 솔버 Gurobi 12와 GD-Net을 평가했다. 이 비교는 각 방법이 GD-Net이 생성한 비슷한 정밀도의 솔루션을 달성하는 데 걸리는 시간에 중점을 두었다. 최대 흐름 문제의 경우 GD-Net은 전통적인 Ford-Fulkerson 방법과도 비교되었다.
증거가 증명하는 것
실험 결과는 경사 하강법 변형을 언롤링하는 것에 영감을 받은 GD-Net의 핵심 메커니즘이 실제로 효과적이며 기존 GNN 및 전통적인 솔버보다 훨씬 뛰어나다는 것을 설득력 있고 부인할 수 없는 증거를 제공한다.
GCN 대비 우수한 성능: 표 1에서 볼 수 있듯이 GD-Net은 테스트된 모든 LP 문제(IS, 패킹, ECP, SC) 및 문제 크기(S, M, L)에 걸쳐 일관되게 더 좁은 상대 및 절대 목표 오차를 달성했다. 이는 GD-Net이 한 자릿수 적은 매개변수(GCN의 1,656개 대비 34,306개)를 사용했음에도 불구하고 달성되었다. 예를 들어, IS-S 데이터셋에서 GD-Net은 GCN의 15.46%에 비해 4.41%의 R. Gap을 달성했다. GD-Net이 테스트 오류가 약간 더 높게 기록된 Packing-L과 같은 경우에도 목표 오차(7.35%)는 GCN의 (7.37%)보다 여전히 약간 더 나았으며, 이는 GD-Net이 문제의 기본 구조적 뉘앙스를 더 잘 포착함을 시사한다. 이는 GD-Net의 설계가 더 매개변수 효율적인 모델로 이어져 더 높은 품질의 솔루션을 제공함을 명확히 증명한다.
더 큰 인스턴스로의 강력한 일반화: 표 2는 GD-Net의 강력한 일반화 능력을 보여준다. 대규모(L) 인스턴스로 훈련된 후 더 큰 일반화(Gen) 인스턴스(제약 조건 및 변수가 10% 더 많음)로 테스트되었을 때 GD-Net은 성능 저하가 최소화되었다. 예를 들어, 패킹의 경우 R. Gap은 7.06%(L)에서 7.06%(Gen)로만 증가했으며, 이는 복잡성 증가에 대한 견고성과 확장성을 보여준다. 이는 훈련 데이터가 더 작은 인스턴스로 제한될 수 있는 실제 응용 프로그램에 매우 중요하다.
전통적인 솔버 대비 효율성: PDLP 및 Gurobi(표 3)와의 비교는 GD-Net의 놀라운 효율성을 강조한다. GD-Net과 동일한 정밀도 수준의 솔루션을 달성하기 위해 전통적인 솔버는 훨씬 더 많은 시간이 필요했다. 10,000개의 변수를 가진 SC 문제의 경우 GD-Net은 0.335초가 걸렸고, Gurobi는 103.322초(약 300배 더 오래 걸림)가 걸렸고, PDLP는 1.001초가 걸렸다. 이는 GD-Net이 고품질 솔루션을 효율적으로 생성할 수 있음을 명확히 증명하며, 동일한 솔루션 품질에 대해 최적화된 상용 솔버보다 속도 측면에서 우수하다.
이분 최대 흐름 문제에서의 성능: 이분 최대 흐름 문제(BMP)의 경우 GD-Net은 GCN보다 일관되게 더 나은 예측을 달성했으며, 평균 최적성 오차는 1%에 불과했다(표 8). 또한 GD-Net은 고품질 솔루션을 달성하는 데 있어 전통적인 Ford-Fulkerson 방법보다 훨씬 빨랐으며(표 9), 이 특정 그래프 문제에 대한 효율성과 효과성을 입증했다.
더 빠른 추론 시간: 추론 시간을 프로파일링하는 표 10은 GD-Net이 모든 데이터셋과 크기에 걸쳐 GCN보다 일관되게 훨씬 더 빠른 추론 시간을 달성함을 보여준다. 이러한 강력한 확장성은 GD-Net의 추론 시간이 문제 크기가 증가하더라도 허용 가능한 상태로 유지됨을 의미하며, 이는 실제 배포에 중요한 이점이다.
본질적으로, 증거는 경사 하강법 변형을 언롤링함으로써 GD-Net이 패킹 및 커버링 LP를 해결하기 위한 이론적으로 근거 있고 경험적으로 우수한 접근 방식을 제공하며, 소형 GNN에 관한 오랜 이론적 예측과 실제 관찰 사이의 격차를 해소한다고 강력하게 증명한다.
한계 및 향후 방향
GD-Net 아키텍처는 상당한 발전을 보여주지만, 현재의 한계를 인식하고 향후 개발을 고려하는 것이 중요하다.
현재 한계:
1. 이론적 크기 격차 지속: 이론과 실제 사이의 격차를 좁혔음에도 불구하고, LP 해결에 필요한 GNN의 최소 크기에 관한 이론적 불일치가 여전히 존재한다. 우리의 이론적 증명은 패킹 및 커버링 LP에 대해 폴리로그 깊이와 상수 너비가 충분함을 확립하지만, GNN 크기에 대한 정확한 하한은 여전히 활발한 연구 분야이다. 더 작은 GNN이 이론적으로 어떻게 될 수 있는지 완전히 이해하기 위해서는 추가적인 이론적 작업이 필요하다.
2. LP 유형에 대한 특수성: 현재 GD-Net 아키텍처는 패킹 및 커버링 LP에 대해 특별히 설계되었으며, 이는 광범위하지만 보편적이지 않은 LP 클래스이다. 직접적인 적용 가능성과 입증된 효과는 추가 수정 또는 이론적 근거 없이는 일반 LP로 확장되지 않는다. 이는 임의의 LP 공식화의 경우 현재 GD-Net이 최적이거나 심지어 실행 가능한 솔루션이 아닐 수 있음을 의미한다.
3. 통계적 유의성 보고 부족: 솔직히 말해서, 이 부분에 대해서도 완전히 확신할 수는 없지만, 저자들은 실험을 여러 번 반복하는 데 드는 계산 비용 때문에 오차 막대가 제공되지 않았다고 명시적으로 언급했다. 이해할 만하지만, 결과의 변동성에 대한 엄격한 통계적 평가에는 사소한 한계이다.
향후 방향:
1. 이론적 크기 추가 감소: 자연스러운 다음 단계는 GNN 크기를 이론적으로 더 줄이는 방법을 계속 탐색하는 것이다. 성능을 유지하면서 깊이와 너비에 대한 더 엄격한 경계를 달성하거나, 더 적은 매개변수로 성능을 유지하는 다른 아키텍처 제약 조건을 식별할 수 있을까? 이는 다른 언롤링 전략이나 새로운 GNN 레이어를 조사하는 것을 포함할 수 있다.
2. 더 넓은 LP 클래스로의 일반화: GD-Net의 적용 범위를 일반 LP로 확장하는 것은 중요한 방향이다. 이는 새로운 잠재 함수를 설계하거나 일반 LP에서 발견되는 더 넓은 범위의 제약 조건 및 목표 함수를 처리하기 위해 언롤링 메커니즘을 조정해야 할 가능성이 높다. 과제는 잠재 함수의 바람직한 속성(미분 가능성, 볼록성 및 수렴 보증)을 유지하는 데 있다.
3. MILP 솔버로의 통합: LP 해결 가속화에서의 성공을 고려할 때, 혼합 정수 선형 계획법(MILP)을 위한 학습 기반 최적화(L2O) 프레임워크 내에서 GD-Net을 탐색하는 것은 유망한 방향이다. MILP 솔버는 종종 반복적으로 LP 완화(예: 분기 및 한계 알고리즘)를 해결하는 데 의존한다. GD-Net은 고품질 초기화를 제공하거나 LP 하위 문제 해결을 가속화하여 더 효율적인 MILP 솔루션으로 이어질 수 있다. 이는 GD-Net을 사용하여 변수 선택 또는 분기 결정을 안내하는 것을 포함할 수 있다.
4. 새로운 잠재 함수 설계: GD-Net의 성공은 신중하게 선택된 잠재 함수에 대한 경사 하강법을 언롤링하는 데서 비롯된다. 향후 연구는 다른 최적화 문제 클래스에 대해 유사하거나 더 나은 속성을 가진 새로운 잠재 함수를 설계하는 데 초점을 맞출 수 있다. 이는 패킹 및 커버링 LP를 넘어 "언롤링" 패러다임을 확장하는 특정 문제 구조에 맞춰진 새로운 GNN 아키텍처를 잠금 해제할 수 있다.
5. 데이터 분포 변화에 대한 견고성: 본 논문은 더 큰 인스턴스로의 일반화가 좋다는 것을 보여주지만, 문제 인스턴스 분포의 상당한 변화(예: 다른 제약 행렬 또는 목표 벡터)에 대한 GD-Net의 견고성에 대한 추가 조사가 가치가 있을 것이다. 이는 분포 외 입력에 덜 민감한 적응형 훈련 전략 또는 아키텍처를 개발하는 것을 포함할 수 있다.
다른 분야와의 연결
수학적 골격
이 연구의 순수한 수학적 핵심은 특정 클래스의 그래프 신경망이 패킹 및 커버링 선형 프로그램을 해결하기 위한 지수 가중치 경사 하강법 알고리즘 변형을 시뮬레이션할 수 있음을 이론적으로 입증하는 것이다. 이 시뮬레이션은 반복 최적화 단계를 GNN 레이어로 매핑하여 근사에 대해 폴리로그 깊이 및 상수 너비 보증을 제공한다.
인접 연구 영역
딥러닝에서 최적화 알고리즘 언롤링
이 연구는 최적화 알고리즘을 딥러닝 아키텍처로 언롤링하는 분야에 직접적으로 기여한다. GD-Net은 LP에 대한 Awerbuch-Khandekar 경사 하강법 알고리즘의 반복 업데이트를 GNN 레이어로 명시적으로 매핑함으로써 설계되었다. 예를 들어, $y$-업데이트 $y_i^k := \exp[\mu(A_i x^k - 1)]$ 및 후속 $x$-업데이트 $x_j^{k+1} := x_j^k + f_{0k}(A_j^T y^k - 1) \cdot x_j^k + g_{0k}(A_j^T y^k - 1)$는 GNN 레이어로 구현된다. 이 방법론은 GNN 내의 학습 가능한 매개변수를 활용하여 원래의 고정 규칙 반복 알고리즘에 비해 수렴을 가속화하거나 솔루션 품질을 개선할 수 있다. 이는 고전적인 최적화와 현대 신경망 설계 간의 강력한 연결을 보여준다.
(Yang et al., 2021, ICML)
분산 최적화 알고리즘
본 논문의 기초는 Awerbuch-Khandekar 분산 경사 하강법 알고리즘을 적용하는 데 있다. 변수와 제약 조건을 나타내는 LP의 이분 그래프 표현은 분산 계산에 자연스럽게 적합하다. 경사 업데이트의 중심인 $Ax$ 또는 $A^T y$와 같은 행렬-벡터 곱셈은 이러한 변수 및 제약 노드 간의 메시지 전달 연산으로 해석될 수 있다. GNN의 고유한 메시지 전달 메커니즘은 이러한 분산 정보 교환 및 로컬 업데이트를 직접 시뮬레이션하여 분산 LP 해결을 위한 신경망 기반 프레임워크를 제공한다. 이는 GNN이 분산 알고리즘의 계산 모델로 볼 수 있음을 강조한다.
(Awerbuch and Khandekar, 2009, SIAM J. Comput.)
조합 최적화에 대한 근사 알고리즘
패킹 및 커버링 LP는 최대 독립 집합, 집합 커버, 에지 커버를 포함한 수많은 NP-난해 조합 최적화 문제에 대한 기본적인 완화이다. 본 논문은 제안된 GD-Net이 이러한 LP에 대해 폴리로그 수의 반복(GNN 레이어) 내에서 $(1+\epsilon)$-근사 솔루션을 찾을 수 있다는 이론적 보증을 제공한다. 이는 계산적으로 정확하게 해결하기 어려운 문제에 대해 종종 최적 솔루션에 비해 품질에 대한 증명 가능한 경계를 가진 솔루션을 찾는 것을 목표로 하는 근사 알고리즘의 설계 및 분석에 직접적으로 연결된다. 여기서 GNN은 학습된 효율적인 근사 스킴 역할을 하여 어려운 조합 문제를 해결하는 새로운 길을 제공한다.
(Cappart et al., 2023, J. Mach. Learn. Res.)