線形計画問題に対する小規模グラフニューラルネットワークの能力について
Graph neural networks (GNNs) have recently emerged as powerful tools for addressing complex optimization problems.
背景と学術的系譜
起源と学術的系譜
本論文で取り扱う問題は、従来の最適化プロセスを機械学習技術を統合することで効率化しようとする、成長著しい「学習による最適化(Learning to Optimize: L2O)」の分野に端を発する。L2Oの分野において、グラフニューラルネットワーク(GNN)は、特に線形計画問題(LP)や混合整数線形計画問題(MILP)のような複雑な最適化問題に取り組む能力から、近年大きな注目を集めている。
歴史的に、GNNはLPの解写像関数を普遍的に近似できることが理論的に示されてきた。しかし、Chenら[8]やQianら[29]によるこれらの基礎的な理論結果は、通常、任意の精度を達成するためには、問題次元に対して相当数のパラメータまたは多項式的な深さをGNNが要求すると仮定している。この理論的な要件は、多層パーセプトロン(MLP)に対する普遍近似定理のような概念への依存に由来する。
これらの従来のアプローチにおける根本的な限界、すなわち「ペインポイント」は、理論的な予測と経験的な観察との間の著しい乖離である。実際には、研究者たちは、比較的少数(通常は控えめな幅と10層未満)のGNNが、数百のノードと制約を持つLPを効果的に解決でき、その限定的なサイズにもかかわらず良好な性能を達成できることを見出している。大規模で複雑なGNNを要求する理論的な要件と対比されるこの実用的な成功は、大きなギャップを生み出した。著者らは、特にパッキングLPとカバリングLPにおいて、小規模GNNがLPを効果的に解決できる「理由」と「時期」についての理論的基盤を提供することを目指し、このギャップを埋めるためにまさにこの論文を書いた。
直感的なドメイン用語
- 線形計画問題(LP): クッキーを焼くためのレシピがあると想像してください。しかし、小麦粉、砂糖、バターの量は限られています。材料の制限内で、できるだけ多くのクッキーを焼きたい(または販売するなら利益を最大化したい)と考えています。線形計画問題は、これらの単純な直線的な制約の下で、目標を達成するために最適なクッキーの組み合わせを計算するのに役立つ数学的ツールです。
- グラフニューラルネットワーク(GNN): 人々がノード、友情が接続であるソーシャルネットワークを考えてみてください。GNNは、各個人とその友人から情報を得ることで、ネットワーク全体を理解するためにその集合情報を使用する、スマートな探偵のようなものです。最適化においては、問題内の変数と制約の関係から学習します。
- パッキングLP: 様々なサイズの箱を、トラックの重量や容積容量を超えずに、できるだけ多くトラックに詰め込もうとしている状況を想像してください。パッキングLPは、限られたスペースや予算に「詰め込む」(リソースやアイテムなど)最適な方法を見つけるのに役立つ最適化問題であり、いかなる制限も超えないことを保証します。
- カバリングLP: 建物のすべての入り口をカバーするために監視カメラを設置する必要があり、各カメラはいくつかの特定の入り口をカバーするとします。カバリングLPは、すべての入り口を「カバー」するために必要な最小限のカメラ数を特定するのに役立ち、すべての入り口が監視されていることを保証します。
- ポリ対数深さ、定数幅GNN: これは、「浅い」(ポリ対数深さとは、層の数が問題サイズに対して非常にゆっくりと増加することを意味し、$\log(\text{size})$または$\log^2(\text{size})$のようなもの)かつ「細い」(定数幅とは、各層が問題のサイズに関係なく固定された少数の内部処理ユニットを持つことを意味する)GNNを記述します。これは、大きな問題も解決できる、非常に効率的でコンパクトな計算機械のようなものです。
記法表
| 記法 | 説明 |
|---|---|
| $A$ | LPの制約行列 ($n \times m$) |
| $x$ | 主変数ベクトル ($m \times 1$) |
| $y$ | 双対変数ベクトル ($n \times 1$) |
| $X^k$ | $k$回目の反復における主変数行列 ($m \times d$) |
| $Y^k$ | $k$回目の反復における双対変数行列 ($n \times d$) |
| $d$ | 拡張変数のチャネル次元 |
| $n$ | 制約の数 ($A$の行数) |
| $m$ | 主変数の数 ($A$の列数) |
| $K$ | GNN層の総数(反復回数) |
| $\mu$ | ELU入力のスケーリングパラメータ |
| $\epsilon$ | 近似精度パラメータ |
| $\text{ELU}(\cdot)$ | 指数線形ユニット活性化関数 |
| $\text{ReLU}(\cdot)$ | 整流線形ユニット活性化関数 |
| $f_{\theta^k}(\cdot)$ | 主変数更新のための学習可能な関数(乗法的) |
| $g_{\theta^k}(\cdot)$ | 主変数更新のための学習可能な関数(加法的) |
| $W^k$ | チャネル混合のための学習可能な重み行列 ($d \times d$) |
| $\odot$ | アダマール積(要素ごとの乗算) |
| $1_{p \times q}$ | 全要素が1の行列、次元 $p \times q$ |
| $\Theta$ | GD-Net内の全ての学習可能パラメータの集合 |
| $obj_i$ | インスタンス $i$ の予測目的値 |
| $obj^*_i$ | インスタンス $i$ の最適目的値 |
| R. Gap | 相対ギャップ: $|obj_i - obj^*_i| / obj^*_i$ |
| A. Gap | 絶対ギャップ: $|obj_i - obj^*_i|$ |
問題定義と制約
中核的な問題定式化とジレンマ
本論文は、線形計画問題(LP)に対するグラフニューラルネットワーク(GNN)に関する理論的理解と経験的観察との間の大きなギャップに対処する。
入力/現在の状態:
出発点は、GNNがLP問題の解写像関数を普遍的に近似できるという確立された理論的結果である。しかし、これらの理論的証明は通常、問題次元に対して多数のパラメータまたは多項式的な深さを持つGNNを必要とする。同時に、経験的な証拠は、比較的(例えば、控えめな幅と10層未満の)小規模なGNNが効果的にLPを解決し、実際には良好な性能を達成できることを一貫して示している。
望ましい終点/目標状態:
主な目標は、小規模GNNがLPを効果的に解決できる「理由」と「時期」を説明する堅牢な理論的基盤を提供することである。具体的には、本論文は、ポリ対数深さと定数幅を持つGNNが、広範なLPクラス、すなわちパッキングLPとカバリングLPの解写像を任意の精度で近似するのに十分であることを証明することを目指している。これにより、より小さく、より効率的なGNNに対する理論的な検証は、学習による最適化(L2O)のためのパラメータ効率の良いモデルの開発を導き、潜在的に従来のLPおよび混合整数線形計画法(MILP)ソルバーを加速させるだろう。
欠落しているリンク/数学的ギャップ:
正確な欠落しているリンクは、小規模GNNの経験的な成功に対する理論的な正当化である。LPに対するGNNの普遍近似能力に関する以前の理論的研究は、大規模なモデルサイズ(例えば、多数のパラメータ数または多項式的な深さ)の仮定に依存しており、観察された実用的な効率との乖離を生み出していた。本論文は、GNNが注意深く選択されたポテンシャル関数に対する勾配降下アルゴリズムの変種をシミュレートできることを数学的に実証することにより、このギャップを埋めようと試み、大幅に小さいアーキテクチャ(ポリ対数深さと定数幅)で強力な近似保証を達成する。
痛みを伴うトレードオフとジレンマ:
中核的なジレンマは、「理論的な予測と経験的な観察との間の著しい乖離」(Abstract, p.1)である。研究者たちは、LP解決におけるGNNの強力な理論的保証を達成するためには伝統的に大規模で計算集約的なモデルが必要であったが、実際の実装ではしばしば小さく、より効率的なモデルが驚くほど効果的であることが判明したというトレードオフに「閉じ込められて」きた。これは、理論的な厳密さ(高い計算コストと広範な訓練データを持つ大規模モデルを要求する)と実用的な効率性(正式な説明を欠く成功を達成した小規模モデルによって達成される)との間の痛みを伴う選択を生み出す。本論文はこれを明確に「興味深い未解決の問題:いつ、なぜ小規模GNNがLPを効果的に解決できるのか?」(Introduction, p.2)として提示し、この理論的・経験的な分割を調和させる必要性を強調している。
制約と失敗モード
効率的で理論的に根拠のあるGNNをLP解決のために開発するという問題は、いくつかの厳しい現実的な壁によって制約されている。
- 計算リソースの限界: より大規模なGNNは本質的に「より多くの訓練例とより高い計算リソース」を必要とする(Introduction, p.2)。これは、理論的保証が常に大規模モデルを必要とする場合、GNNのスケーラビリティと適用可能性を制限する実用的な制約である。「パラメータ効率の良いモデル」への推進(Introduction, p.2)は、これを直接的にアドレスしている。
- 問題の複雑さと規模: LP、特にパッキングLPとカバリングLPは、数百のノードと制約を含む可能性がある(Introduction, p.2)。これらの大規模な問題を許容可能な時間枠内で効率的に解決することは、重大な課題である。
- モデルサイズに対する理論的上限: 一般的なLPに対する以前の理論的結果は、GNNが「大規模なパラメータサイズ」または「問題次元の多項式的な深さ」を持つことを要求した(Introduction, p.2)。この理論的な障壁は、経験的な成功にもかかわらず、小規模GNNの効果を証明することを困難にした。
- 近似精度要件: 目標は $(1+\epsilon)$-近似解を達成することである(Section 1.1, p.2)。これは、GNNが効率的であるだけでなく、高いレベルの解の質を維持する必要があることを意味し、モデルサイズを縮小する際には簡単なタスクではない。
- 解の実行可能性: 最適化ソルバーに基づく機械学習の一般的な失敗モードは、実行不可能な解を生成することである。GD-Netによって出力される
x_finalまたはy_finalは、すべてのLP制約(例えば、$x \ge 0$、$Ax \le 1$)を満たさない可能性がある。本論文は、「実行可能性回復」の後処理手順(p.7, p.8)でこれを対処しており、克服すべき重要な制約として示している。 - 非微分可能な操作: 基盤となる勾配降下アルゴリズム(Algorithms 1 and 2)は、条件付き更新(if-else文)と
max操作を含み、これらは非微分可能である。これらをニューラルネットワークに直接変換することは問題がある。著者らは、Heavisideステップ関数を学習可能なシグモイド関数で近似すること(Equations 4, 5, 6, p.6)と、非負性をReLUで処理することにより、非微分可能なロジックを微分可能なニューラルネットワークアーキテクチャに変換することで、これを回避している。これは、反復アルゴリズムをアンロールする際の重要な技術的制約である。 - ハードウェアメモリの制限: ハードな制限として明示的に言及されていないが、実験設定では「2.95 TB RAM」(Section E, p.16)が言及されており、これは大規模LPインスタンスにとってメモリが重大な制約となり得ることを示唆しており、小規模GNNは本質的にこの圧力を軽減する。
- 収束速度: 反復アルゴリズムは、合理的なステップ数で収束する必要がある。本論文は、Awerbuch-Khandekarアルゴリズムの「ポリ対数収束」(p.4)に言及しており、GNNは、この効率的な収束をシミュレートするように設計されなければならない。
なぜこのアプローチなのか
選択の必然性
Awerbuch-Khandekar勾配降下アルゴリズムの変種をアンロールするGD-Netアーキテクチャの採用は、単なる設計上の選択ではなく、グラフニューラルネットワーク(GNN)と線形計画問題(LP)の分野における既存の理論的理解と経験的観察との間の大きなギャップによって駆動された必然性であった。従来の理論的結果は、普遍近似定理に依存することが多く、GNNが任意の精度でLPを効果的に解決するためには、大規模なパラメータサイズまたは問題次元に対する多項式的な深さを必要とすると示唆していた(Abstract, p.1; p.2)。しかし、実際の結果は一貫して、比較的少数なGNNが良好な性能を達成できることを示しており、不可解な乖離を生み出していた。
著者らは、従来のGNN、例えば標準的なグラフ畳み込みネットワーク(GCN)が、このギャップを埋めるには不十分であると認識した。なぜなら、GCNはポリ対数深さを達成できる一方で、定数幅を保証できなかったからである(Remark 1, p.7)。これは、一般的なGNNがELUのような関数を任意の精度でシミュレートするために「十分に広いパーセプトロン」を依然として必要とし、それゆえ「小規模」要件を満たせないことを意味する(p.7)。しかし、Awerbuch-Khandekar勾配降下アルゴリズムの特定の変種は、ユニークな利点を提供した。それは、「GNNによってより自然にシミュレートできる」ことであり、「アルゴリズムの1回の反復は、定数幅の1つのGNN層によってシミュレートできる」(p.4)のである。この反復最適化アルゴリズムから定数幅とポリ対数深さを持つGNN構造への直接的なマッピング(Theorem 3 and 5, p.7-8)は、パッキングLPとカバリングLPに対する小規模GNNの経験的な成功を理論的に説明するための唯一実行可能な道を提供した。
比較優位性
GD-Netアプローチは、主にその構造設計と固有のパラメータ節約により、単純な性能指標を超えて、以前の方法に対して質的な優位性を示している。
第一に、GD-Netのアーキテクチャは、基盤となる最適化問題と根本的に整合している。パッキングLPとカバリングLPのための理論的に根拠のある勾配降下アルゴリズムをアンロールすることにより、これらの問題の固有の構造を活用している。これは、強力ではあるが、このような反復最適化プロセスをシミュレートするために特別に調整されていない、より一般的なGNNアーキテクチャであるGCNとは対照的である。この構造的な利点により、GD-Netは「問題の構造的なニュアンスをより良く捉える」(p.9)ことができる。
第二に、GD-Netはパラメータ効率において圧倒的な優位性を示している。実験によると、GD-Netは「GCNよりも桁違いに少ないパラメータ」でより良い解を達成している(p.3)。例えば、隠れユニット64の4層GD-Netはわずか1,656パラメータしか使用しないが、同等のGCNは34,306パラメータを必要とする(p.9)。このパラメータの大幅な削減は、メモリ複雑性と計算オーバーヘッドの低下につながり、モデルをより実用的でスケーラブルにする。
第三に、この方法は、解の質と速度の点で優れた性能を示している。Table 1(p.9)は、GD-NetがLPのタイプ(IS、Packing、ECP、SC)と問題サイズ全体で、GCNと比較して一貫して狭い相対ギャップと絶対ギャップを達成していることを示している。GD-Netのテスト誤差がわずかに高い場合でも、その相対ギャップは依然として優れており、最適解の質的な良い近似を示している。さらに、PDLPやGurobiのような従来のソルバーと比較ベンチマークされた場合、GD-Netは一貫して同等の精度レベルを大幅に短い時間で達成している。例えば、Gurobiのシンプレックス法は、GD-Netと同等の品質の解に収束するために最大300倍の時間を要した(p.10)。これは、GD-Netが高品質な解を効率的に生成する能力を強調しており、実世界のアプリケーションにとって重要である。
最後に、GD-Netは強力な汎化能力とスケーラビリティを示している。小さいデータセットで訓練された場合、「パフォーマンスの低下は最小限」で、より大きな問題インスタンスに汎化できる(p.9, Table 2)。問題サイズが増加しても、推論時間は「比較的に許容範囲内」に留まる一方、GCNは「より大きな問題インスタンスの処理と予測に大幅に多くの時間を必要とする」(p.18)。
制約への整合性
選択されたGD-Net方法は、特に小規模GNNを使用した効果的なソリューションと堅牢な理論的基盤の必要性という、問題の暗黙的な制約に完全に整合している。中核的な問題ステートメントは、LP解決に必要なGNNのサイズに関する「理論的な予測と経験的な観察との間の著しい乖離」(Abstract, p.1)を埋めることに関わっている。
Awerbuch-Khandekar勾配降下アルゴリズムの変種をアンロールするGD-Netのデザインは、「ポリ対数深さ、定数幅GNNがパッキングLPとカバリングLPを解決するのに十分である」(Abstract, p.1; Theorem 3 and 5, p.7-8)ことを証明することにより、これを直接的にアドレスしている。この理論的な結果は、小規模GNNの効果に対する長らく求められていた基盤を提供し、モデルの複雑性が限定された状態での高いパフォーマンス達成という制約を直接的に満たしている。問題の厳しい要件(小規模で効率的なモデル)とソリューションのユニークな特性(定数幅、ポリ対数深さGNNが既知の反復アルゴリズムをシミュレートする)の「結婚」は、この理論的な保証に明らかである。
さらに、1回の勾配降下アルゴリズムの反復を定数幅の単一GNN層でシミュレートする(p.4)この方法の能力は、ネットワークの構造が本質的に効率的でスケーラブルであることを保証する。アルゴリズムステップとネットワーク層とのこの直接的な対応は、モデルの幅を自然に制限し、「小規模」制約に整合しながら、明確で解釈可能なメカニズムを維持している。
代替案の却下
本論文は、パッキングLPとカバリングLPを小規模GNNで解決するという特定の問題に対して、理論的な限界、経験的な性能、および計算上の非効率性に基づいて、いくつかの代替アプローチを暗黙的かつ明示的に却下している。
汎用GNN(例:GCN): 小規模ソリューションを達成するための主要な代替案として検討され、却下されたのはGCNのような汎用GNNである。これらのモデルもポリ対数深さを達成できるが、著者らは「定数幅はもはや保証されない」(Remark 1, p.7)と明確に述べている。これは、任意の精度を達成するためには、GCNは「十分に広いパーセプトロン」を必要とし、GD-Netが成功裏に対処する「小規模」制約を満たさない非定数幅につながることを意味する(p.7)。経験的には、GD-Netが「桁違いに少ないパラメータ」を使用しているにもかかわらず、GCNは相対ギャップと絶対ギャップにおいて一貫して劣った性能を示し、しばしば高い検証/テスト誤差を示した(p.3, Table 1, p.9)。さらに、GCNは、GD-Netと比較して「より大きな問題インスタンスの処理と予測に大幅に多くの時間を必要とする」(p.18)など、スケーラビリティが悪かった。
従来のLPソルバー(PDLP、Gurobi): 本論文はまた、確立された理論的に根拠のあるLPソルバーであるPDLP(一次法)および商用ソルバーGurobi(主シンプレックス法を使用)ともGD-Netをベンチマークしている。これらのソルバーは堅牢であるが、速度と効率が最優先されるシナリオでは主要なソリューションとして却下されている。PDLPは「より短い時間でGD-Netと同等の品質の解を生成できなかった」(p.10)。Gurobiは、その精度にもかかわらず、「GD-Netと同等の品質の解に収束するために最大300倍の時間を要した」(p.10)。これは、シンプレックス法の計算コストの高い行列分解に起因すると考えられる(p.10)。したがって、正しさの点では「失敗」ではないが、それらの計算コストは、GD-Netが効率的に提供する、より高速で高品質な近似解またはウォームスタートの恩恵を受けるアプリケーションには不向きである。
生成敵対ネットワーク(GAN)や拡散モデルのような他の機械学習パラダイムについては、線形計画問題の解決という問題に直接適用できないため、議論されていない。焦点はGNNとその古典的な最適化アルゴリズムとの関係に留まる。
数学的・論理的メカニズム
マスター方程式
本論文のメカニズムの中核は、線形計画問題(LP)を解決するためのAwerbuch-Khandekar勾配降下アルゴリズムの変種をシミュレートするように設計されたグラフニューラルネットワーク(GNN)アーキテクチャ、GD-Netにある。具体的には、パッキングLPの場合、アルゴリズムの1回の反復は、1つのGNN層に対応し、2つの主要な更新方程式によって支配される。これらの方程式は、双対変数(制約を表す)と主変数(項目を表す)がどのように反復的に更新されるかを記述している。
$k$回目の反復における双対変数 $Y^k$ の更新は、次のように与えられる:
$$Y^k := \text{ELU}[\mu(A X^k - 1_{n \times d})] + 1_{n \times d}$$
そして、次の反復 $k+1$ のための主変数 $X^{k+1}$ の更新は、次のようになる:
$$X^{k+1} = \text{ReLU} (\{X^k + f_{\theta^k}(A^T Y^k - 1_{m \times d}) \odot X^k + g_{\theta^k}(A^T Y^k - 1_{m \times d})\} \cdot W^k)$$
カバリングLPのための同様の方程式のセットが存在し、これらの問題の双対的な性質を反映している。
項ごとの解剖
これらの式を分解して、各コンポーネントの役割を理解しよう。
式1: $Y^k := \text{ELU}[\mu(A X^k - 1_{n \times d})] + 1_{n \times d}$
- $Y^k$: これは、反復 $k$ における双対変数(または制約価格)の現在の状態を表す $n \times d$ 行列である。各行は制約に対応し、各列はチャネル拡張からの特徴次元である。その物理的な役割は、各制約の「厳しさ」または「違反」を定量化することである。
- $\text{ELU}(\cdot)$: 指数線形ユニット活性化関数。要素ごとに適用される。その数学的定義は、$\text{ELU}(t) = t$ ($t > 0$の場合) および $\text{ELU}(t) = \alpha(\exp(t) - 1)$ ($t \le 0$の場合) である。本論文では、$\alpha$は1に固定されている。著者らは、ELUの入力 $\mu(A_i x^k - 1)$ が実行中に常に非正であるという事実を考慮して、元のAlgorithm 1の指数関数更新 $y_i := \exp[\mu(A_i x^k - 1)]$ を正確に再現するためにELUを使用している。この非線形性は、GNNが複雑な写像を学習するために不可欠である。
- $\mu$: スカラーパラメータで、$1/\ln(mA_{\max})$として固定されている。数学的には、ELU関数への入力をスケーリングする。その物理的/論理的な役割は、制約違反に対する双対変数更新の感度を制御することである。より小さい $\mu$($m$ または $A_{\max}$ が大きいため)は、より積極的でない更新を意味する。
- $A$: これは線形計画問題の $n \times m$ 制約行列である。各要素 $A_{ij}$ はゼロまたは1より大きい。その役割は、主変数と制約の関係を定義することである。
- $X^k$: 反復 $k$ における主変数(または項目数量)の現在の状態を表す $m \times d$ 行列である。各行は主変数に対応し、各列は特徴次元である。その物理的な役割は、LPの現在の提案解を表すことである。
- $1_{n \times d}$: 全要素が1の $n \times d$ 行列。要素ごとの操作に使用される。
- $A X^k$: これは行列乗算であり、$n \times d$ 行列が得られる。各要素 $(A X^k)_{id}$ は、制約 $i$ と特徴次元 $d$ のための制約係数で重み付けされた主変数の合計を表す。その物理的な役割は、パッキングLP制約の左辺、$Ax \le 1$ を計算することである。
- $A X^k - 1_{n \times d}$: 要素ごとの減算。これは、各特徴次元 $d$ にわたる各制約 $i$ の違反または余裕を定量化する。もし $(A X^k)_{id} - 1_{id} > 0$ ならば、制約は違反している。
- $+ 1_{n \times d}$: 1の行列の要素ごとの加算。この項は、ELU関数と組み合わせて、y更新が元のAwerbuch-Khandekarアルゴリズムの指数更新と正確に一致することを保証する。加算は、ELU出力のシフトに使用され、望ましい指数関数的挙動に一致させる。
式2: $X^{k+1} = \text{ReLU} (\{X^k + f_{\theta^k}(A^T Y^k - 1_{m \times d}) \odot X^k + g_{\theta^k}(A^T Y^k - 1_{m \times d})\} \cdot W^k)$
- $X^{k+1}$: 次の反復のための更新された主変数を表す $m \times d$ 行列。
- $\text{ReLU}(\cdot)$: 整流線形ユニット活性化関数。要素ごとに適用される。数学的には、$\text{ReLU}(t) = \max(0, t)$ である。その物理的/論理的な役割は、主変数に対する非負制約 ($x \ge 0$) を強制することであり、これはLPの基本である。
- $X^k$: 主変数の現在の状態。上記で定義されている。
- $f_{\theta^k}(\cdot)$ および $g_{\theta^k}(\cdot)$: これらは学習可能な関数であり、シグモイド関数の和として定義されている(Equations 5 and 6 in the paper)。これらは要素ごとに、入力行列に適用される。それらの数学的な役割は、元のAwerbuch-Khandekarアルゴリズムの条件付き更新で使用されるHeavisideステップ関数 $f(t)$ および $g(t)$(Equation 4)を近似することである。それらの物理的/論理的な役割は、集約された双対情報に基づいて、各主変数に適用される調整の量と種類を決定することである。著者らは、これらの関数を構築するために和(シグモイドの和としての$f_{\theta^k}$および$g_{\theta^k}$の定義における暗黙的なもの)を使用しており、元のステップごとの更新の滑らかで微分可能な近似を可能にしている。
- $A^T$: 制約行列 $A$ の転置。
- $A^T Y^k$: 行列乗算であり、$m \times d$ 行列が得られる。この項は、双対変数情報 ($Y^k$) を主変数に集約し、実質的に各主変数に対する「勾配のような」信号を計算する。ポテンシャル関数 $\Phi_p(x)$ の文脈では、$\nabla \Phi_p(x) = A^T y$ である。
- $A^T Y^k - 1_{m \times d}$: 要素ごとの減算。これは、各主変数に対する「勾配」または「更新方向」を表し、それがどれだけ調整されるべきかを示している。
- $\odot$: アダマール積(要素ごとの乗算)。この演算子は、$f_{\theta^k}$からのスケーリング係数を要素ごとに$X^k$に適用するために使用され、元のアルゴリズムにおける乗法的更新 $(1+\beta)$ または $(1-\beta)$ を模倣している。
- $W^k$: $d \times d$ の学習可能な重み行列。これはニューラルネットワークにおける標準的な線形変換である。その役割は、拡張変数の $d$ 特徴次元(チャネル)間で情報を混合し、モデルの表現力を高めることである。ここでの乗算は行列乗算であり、特徴ベクトルを変換する。
- 波括弧 $\{\dots\}$ は、現在の主変数と2つの更新項の和を囲む。これは、計算された勾配と学習可能な関数に基づいて現在の解が調整される、中核的な勾配降下ステップを表す。加算は、現在の状態と計算された更新を組み合わせるために使用される。
ステップごとのフロー
1つの主変数 $x_j$ の抽象的なデータポイントが、パッキングGD-Netの1つの層(反復 $k$)を通過する様子を想像してください。
- 初期化: プロセスの開始時 ($k=0$)、すべての主変数 $X^0$ は $0_{m \times d}$ に初期化される。双対変数 $Y^0$ も同様に初期化されるか、$X^0$ から導出される。
- 主変数から双対変数へのメッセージパッシング(Y更新):
- 制約評価: 各制約 $i$ について、現在の主変数 $X^k$ がそれに「メッセージを送信」する。これには、重み付き合計 $A_i X^k$($A X^k$ の $i$ 行目)の計算が含まれる。この合計は、選択された主変数によって現在どれだけのリソース $i$ が使用されているかを表す。
- 違反計算: 計算された合計 $A_i X^k$ は、制約限度(正規形LPでは1)と比較され、$A_i X^k - 1_{n \times d}$ が得られる。この値は、制約 $i$ が違反しているか(正)、満たされているか(負/ゼロ)を示す。
- 双対変数更新: この「違反信号」は $\mu$ でスケーリングされ、ELU活性化関数を通過し、その後 $1_{n \times d}$ を加算することでシフトされる。この変換により、更新された双対変数 $Y^k$ が生成される。概念的には、重度に違反している制約は、対応する双対変数がより増加し、それらを違反することへの「コスト」が高いことを示す。
- 双対変数から主変数へのメッセージパッシング(X更新):
- 勾配集約: 次に、更新された双対変数 $Y^k$ が主変数に「メッセージを送信」する。各主変数 $x_j$ について、項 $A_j^T Y^k$($A^T Y^k$ の $j$ 行目)は、 $x_j$ が関与するすべての制約の影響を集約する。この集約された信号は「勾配」として機能し、$x_j$ を調整することが全体的な目的と制約の充足にどのように影響するかを示す。
- 条件付き調整: この勾配信号 $A^T Y^k - 1_{m \times d}$ は、学習可能な関数 $f_{\theta^k}$ および $g_{\theta^k}$ に供給される。これらの関数は、洗練された意思決定ユニットのように機能し、現在の $X^k$ をどれだけスケーリングするか($f_{\theta^k} \odot X^k$ を介して)と、どれだけ追加するか($g_{\theta^k}$ を介して)を決定する。このステップは、元のアルゴリズムの条件付きロジックを模倣する:変数の勾配が閾値を下回る場合は増加させ、上回る場合は減少させる。
- 特徴変換: 結合された更新は、学習可能な重み行列 $W^k$ で乗算される。このステップにより、各主変数の $d$ 特徴次元間の情報が混合および変換され、その表現が豊かになる。
- 非負性強制: 最後に、ReLU活性化関数が結果に要素ごとに適用される。これにより、更新された主変数 $X^{k+1}$ のすべての成分が非負に保たれ、基本的なLP制約を遵守する。
このシーケンス全体が、GD-Netの1つの層を構成する。出力 $X^{k+1}$ は次の層の入力 $X^k$ となり、プロセスは $K$ 層で繰り返され、解が反復的に洗練される。
最適化ダイナミクス
GD-Netの学習と収束ダイナミクスは、学習可能なコンポーネントを持つアンロールされた勾配降下アルゴリズムとしての設計に根ざしている。
- 学習メカニズム: GD-Netは、学習可能なパラメータ $\Theta = \{\theta^k, W^k\}_{k=0}^{K-1} \cup \{w^K\}$ のセットを最適化することによって学習する。これらのパラメータには、 $f_{\theta^k}$ および $g_{\theta^k}$ のシグモイドベースの関数、およびチャネル混合行列 $W^k$ の内部係数が含まれる。学習目標は、与えられたLPインスタンス $A$ に対するネットワークの最終出力 $x^{\text{final}}(\Theta, A)$ と真の最適解 $x^*$ との間の平均二乗誤差(MSE)を最小化することである。これは教師あり学習タスクであり、ネットワークはLPインスタンスとその既知の最適解のデータセットで訓練される。
- パラメータ更新: パラメータ $\Theta$ は、標準的な勾配ベースの最適化アルゴリズム(例:Adam、SGD)を使用して更新される。訓練中、損失関数 $L_p(\mathcal{I}; \Theta)$ が計算され、 $\Theta$ に関するその勾配が、全体の $K$ 層ネットワークを通じたバックプロパゲーションによって計算される。これらの勾配は、予測誤差を減らすために各パラメータがどのように調整されるべきかを示す。
- 損失ランドスケープと収束: 本論文は、元のAwerbuch-Khandekarアルゴリズムが、微分可能で凸な注意深く選択されたポテンシャル関数 $\Phi_p(x)$(または $\Phi_c(y)$)上で動作することを強調している。これは、勾配降下に対する基盤となる最適化問題が、適切に振る舞う単一の最小値を持つ損失ランドスケープを持つことを意味する。このアルゴリズムをアンロールし、その条件付き更新を学習可能で微分可能な関数(シグモイドの組み合わせである $f_{\theta^k}, g_{\theta^k}$)と線形変換($W^k$)に置き換えることにより、GD-Netは、この収束をシミュレートし加速することを目指す。
- ELUおよびReLU活性化の使用は、GNNの表現力に不可欠な非線形性を導入する。ニューラルネットワーク全体の訓練用損失ランドスケープは非凸である可能性があるが、設計により、各層の更新ステップが凸関数上の勾配降下ステップの正確な近似となることが保証される。
- 理論的結果(Theorems 3 and 5)は、十分な数の層(ポリ対数深さ)と定数幅があれば、GD-Netは $(1+\epsilon)$-近似解を達成できることを保証している。これは、GD-Net層の反復更新が、元のアルゴリズムの収束特性を継承して、ほぼ最適解に効果的に収束することを意味する。
- ReLU活性化は、主変数が非負であり続けることを保証することにより、主変数の実行可能性を維持する上で重要な役割を果たす。しかし、本論文では「実行可能性回復」の後処理ステップについても言及しており、ネットワークの生の出力がすべての制約を厳密に満たすために時折微調整が必要になる場合があることを示唆している。これは、最適化学習アプローチにおいて一般的な実践である。学習可能な関数 $f_{\theta^k}$ および $g_{\theta^k}$ により、ネットワークは勾配降下の最適な「ステップサイズ」と「方向」を適応的に学習でき、固定ルールアルゴリズムと比較して、より高速で堅牢な収束につながる可能性がある。
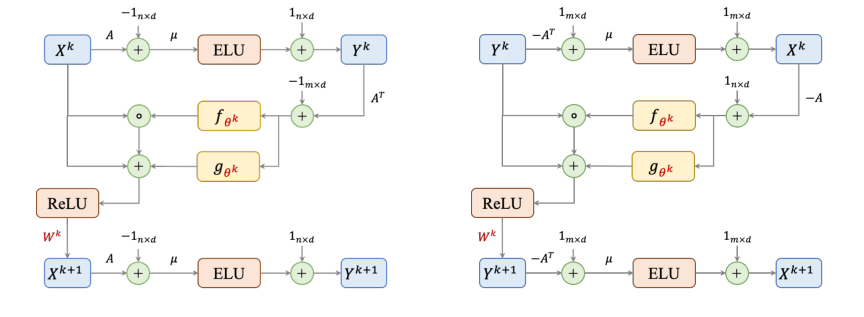 Figure 1. The architectures of a single layer in packing (left) and covering (right) GD-Nets. Learnable parameters are colored in red
Figure 1. The architectures of a single layer in packing (left) and covering (right) GD-Nets. Learnable parameters are colored in red
結果、限界、結論
実験設計とベースライン
GD-Netの有効性の実験的検証は、様々な線形計画問題(LP)にわたる確立されたベースラインに対してその性能を厳密にテストするために、細心の注意を払って設計された。
データセット: 我々は、公開されている混合整数最適化インスタンスから派生した4つの異なるLP緩和を使用しました:最大独立集合(IS)、パッキング問題、エッジカバリング問題(ECP)、およびセットカバリング(SC)。各問題タイプは、サイズが異なる4つのインスタンスセットで表されました:小(S)、中(M)、大(L)、および専用の汎化(Gen)セット。訓練のために、我々は5,000インスタンスを使用し、追加で100を検証用、100をテスト用としました。すべてのインスタンスは正規化手順を受け、その最適解はSCIP [5]最適化ソルバーを使用してグラウンドトゥルースとして取得されました。問題サイズ(行数と列数)と行列密度に関する詳細な仕様は、付録に記載されています。
モデルと訓練設定: 我々の提案するGD-Netアーキテクチャは、学習による最適化(L2O)において一般的なGNNアーキテクチャである[29]からの従来のグラフ畳み込みネットワーク(GCN)実装と比較ベンチマークされました。両モデルは4層アーキテクチャで構成され、各層は64の隠れユニットで構成されていました。パラメータ数には顕著な違いが現れました:GD-Netはわずか1,656パラメータしか使用しませんでしたが、GCNは34,306パラメータを使用しました。GD-Netの場合、近似パラメータ $\epsilon$ は0.2に設定されました。すべてのモデルは、学習率 $10^{-3}$ を使用して10,000エポック訓練され、最適なチェックポイント(最も低い検証損失)が評価用に保存されました。完全な再現性のために、コードは https://anonymous.4open.science/r/GD-Net-6FC7/ で公開されています。
メトリクス: パフォーマンスを定量化するために、我々は2つの主要なメトリクスを採用しました:
- 相対ギャップ(R. Gap): $|obj_i - obj^*_i| / obj^*_i$ と定義され、$obj_i$ は実行可能性回復後の予測目的値、$obj^*_i$ は最適目的値です。
- 絶対ギャップ(A. Gap): $|obj_i - obj^*_i|$ と定義されます。
これらのメトリクスにより、各モデルによって生成された解の質を評価することができました。
ハードウェアとソフトウェア: すべての実験は、Intel(R) Xeon(R) Platinum 8280 CPU @ 2.70GHz および 2.95 TB RAM を搭載したサーバーで実施されました。データ生成はEcole 0.7.3 および Pyscipopt 4.2.0 によって促進され、モデル実装は PyTorch 2.1 を使用して開発されました。
追加ベースライン: 包括的な比較を提供するために、我々はGD-Netを2つの従来のLPソルバー、すなわち一次法ソルバーPDLP [19] および商用ソルバーGurobi [12](特にその主シンプレックス法)とも評価しました。この比較は、各手法が同等の精度の解を達成するために要した時間に焦点を当てました。最大フロー問題については、GD-Netは従来のFord-Fulkerson法とも比較されました。
証拠が証明すること
実験結果は、ポテンシャル関数上の勾配降下をアンロールすることに触発されたGD-Netのコアメカニズムが、現実世界で効果的に機能し、従来のGNNおよび従来のソルバーを大幅に上回ることを、説得力があり否定できない証拠を提供しています。
GCNに対する優れたパフォーマンス: Table 1 に示されているように、GD-Netは、テストされたすべてのLP問題(IS、Packing、ECP、SC)および問題サイズ(S、M、L)全体で、一貫して狭い相対ギャップと絶対ギャップを達成しました。これは、GD-Netが桁違いに少ないパラメータ(GCNの1,656対34,306)を使用しているにもかかわらず達成されました。例えば、IS-Sデータセットでは、GD-NetはGCNの15.46%に対して4.41%のR. Gapを達成しました。Packing-LのようなGD-Netがわずかに高いテスト誤差を記録したケースでも、その目的ギャップ(7.35%)はGCNの(7.37%)よりもわずかに優れており、GD-Netが問題の根本的な構造的ニュアンスをより良く捉えていることを示唆しています。これは、GD-Netの設計が、より高品質な解をもたらす、よりパラメータ効率の良いモデルにつながることを決定的に証明しています。
より大きなインスタンスへの堅牢な汎化: Table 2 は、GD-Netの強力な汎化能力を示しています。大規模(L)インスタンスで訓練され、さらに大きな汎化(Gen)インスタンス(制約と変数が10%増加)でテストされた場合、GD-Netはパフォーマンスの低下が最小限に抑えられました。例えば、Packingの場合、R. Gapは7.06%(L)から7.06%(Gen)にしか増加せず、問題複雑性の増加に対するその堅牢性とスケーラビリティを示しています。これは、訓練データがより小さなインスタンスに限定される可能性がある実用的なアプリケーションにとって重要です。
従来のソルバーに対する効率性: PDLPおよびGurobi(Table 3)との比較は、GD-Netの顕著な効率性を強調しています。GD-Netと同等の精度レベルの解を達成するために、従来のソルバーは大幅に長い時間を必要としました。10,000個の変数を有するSC問題では、GD-Netは0.335秒を要しましたが、Gurobiは103.322秒(約300倍の時間)を要し、PDLPは1.001秒を要しました。これは、GD-Netが同等の解の質に対して、高度に最適化された商用ソルバーさえも凌駕し、高精度の解を効率的に生成できることを決定的に証明しています。
二部最大フロー問題におけるパフォーマンス: 二部最大フロー問題(BMP)では、GD-Netは一貫してGCNよりも優れた予測を達成し、平均最適性ギャップはわずか1%でした(Table 8)。さらに、GD-Netは高品質な解を達成する上で、従来のFord-Fulkerson法よりも大幅に高速でした(Table 9)。これは、この特定のグラフ問題に対するその効率性と有効性を示しています。
より高速な推論時間: 推論時間をプロファイリングするTable 10 は、GD-Netがすべてのデータセットとサイズ全体で、一貫してGCNよりも大幅に高速な推論時間を達成していることを示しています。この強力なスケーラビリティは、問題サイズが増加してもGD-Netの推論時間が許容範囲内に留まることを意味し、実世界での展開にとって重要な利点です。
要するに、証拠は、勾配降下アルゴリズムの変種をアンロールすることにより、GD-NetがパッキングLPとカバリングLPを解決するための理論的に根拠があり、経験的に優れたアプローチを提供し、小規模GNNに関する理論的予測と実用的観察との間の長年のギャップを埋めていることを厳しく証明しています。
限界と将来の方向性
GD-Netアーキテクチャは大きな進歩を示していますが、現在の限界を認識し、将来の開発の方向性を考慮することが重要です。
現在の限界:
1. 理論的ギャップの持続: 理論と実践の間のギャップを狭めたにもかかわらず、LPに必要なGNNの最小サイズに関する理論的な乖離は依然として存在します。我々の理論的証明は、パッキングLPとカバリングLPに対してポリ対数深さと定数幅が十分であることを確立していますが、GNNサイズの正確な下限は依然として活発な研究分野です。小規模GNNが理論的にどのように可能であるかを完全に理解するためには、さらなる理論的研究が必要です。
2. LPタイプへの特異性: 現在のGD-Netアーキテクチャは、パッキングLPとカバリングLPに特化して設計されています。これらは広範ではありますが、普遍的なLPクラスではありません。その直接的な適用可能性と証明された有効性は、さらなる変更または理論的根拠なしには、一般的なLPには拡張されません。これは、任意のLP定式化に対して、現在のGD-Netが最適または実行可能なソリューションではない可能性があることを意味します。
3. 統計的有意性の報告の欠如: 正直に言うと、この部分についても完全には確信が持てませんが、著者らは実験を複数回繰り返す計算コストのために誤差バーが提供されなかったと明示的に述べています。理解可能ではありますが、結果の変動性の厳密な統計的評価にとっては軽微な限界です。
将来の方向性:
1. さらなる理論的なサイズ削減: 自然な次のステップは、理論的にGNNのサイズをさらに削減する方法を引き続き探求することです。深さと幅のよりタイトな境界を達成できるか、またはより少ないパラメータでパフォーマンスを維持する代替アーキテクチャ制約を特定できるでしょうか?これには、異なるアンロール戦略や新しいGNN層の調査が含まれる可能性があります。
2. より広範なLPクラスへの汎化: GD-Netの適用範囲を一般的なLPに拡張することは、重要な方向性です。これには、新しいポテンシャル関数の設計や、一般的なLPに見られるより広範な制約と目的関数の範囲に対応するためのアンロールメカニズムの適応が必要になるでしょう。課題は、ポテンシャル関数の望ましい特性(微分可能性、凸性、収束保証)を維持することにあります。
3. MILPソルバーへの統合: LP解決の加速における成功を考慮すると、混合整数線形計画法(MILP)のための最適化学習(L2O)フレームワーク内でのGD-Netの探求は、有望な方向性です。MILPソルバーはしばしば、反復的にLP緩和を解決することに依存しています(例:分枝限定法アルゴリズム)。GD-Netは、高品質な初期化を提供したり、LPサブ問題の解決を加速したりすることで、より効率的なMILPソリューションにつながる可能性があります。これには、GD-Netを変数選択または分枝決定をガイドするために使用することが含まれるかもしれません。
4. 新しいポテンシャル関数の設計: GD-Netの成功は、注意深く選択されたポテンシャル関数上の勾配降下をアンロールすることに起因しています。将来の研究は、同様またはさらに優れた特性を持つ新しいポテンシャル関数を設計することに焦点を当てる可能性があります。これにより、パッキングLPとカバリングLPを超えて「アンロール」パラダイムを拡張する、特定の構造に合わせた新しいGNNアーキテクチャが可能になるかもしれません。
5. データ分布シフトに対する堅牢性: 本論文は、より大きなインスタンスへの良好な汎化を示していますが、問題インスタンス分布の大きなシフト(例:異なる制約行列または目的ベクトル)に対するGD-Netの堅牢性に関するさらなる調査は価値があるでしょう。これには、適応的な訓練戦略または分布外入力に対する感度が低いアーキテクチャの開発が含まれる可能性があります。
他分野との関連
数学的骨子
この研究の純粋な数学的核は、特定のクラスのグラフニューラルネットワークが、パッキングおよびカバリング線形計画問題を解決するための指数重み勾配降下アルゴリズムの変種をシミュレートできることを理論的に実証することである。このシミュレーションは、反復最適化ステップをGNN層にマッピングし、近似に対してポリ対数深さと定数幅の保証を提供する。
隣接研究分野
深層学習における最適化アルゴリズムのアンロール
この研究は、最適化アルゴリズムを深層学習アーキテクチャにアンロールする分野に直接貢献している。GD-Netは、LPのためのAwerbuch-Khandekar勾配降下アルゴリズムの反復更新をGNN層に明示的にマッピングすることによって設計されている。例えば、$y$更新、$y_i^k := \exp[\mu(A_i x^k - 1)]$、およびそれに続く$x$更新、$x_j^{k+1} := x_j^k + f_{0k}(A_j^T y^k - 1) \cdot x_j^k + g_{0k}(A_j^T y^k - 1)$ は、GNN層として実装されている。このアプローチは、GNN内の学習可能なパラメータを活用して、元の固定ルール反復アルゴリズムと比較して収束を加速したり、解の質を向上させたりする可能性がある。この方法論は、古典的な最適化と現代のニューラルネットワーク設計との間の強力なつながりを示している。
(Yang et al., 2021, ICML)
分散最適化アルゴリズム
本論文の基盤は、Awerbuch-Khandekar分散勾配降下アルゴリズムの適応にある。LPの二部グラフ表現、ここでノードは変数と制約を表す、は自然に分散計算に適している。勾配更新の中心となる行列ベクトル積、$Ax$ または $A^T y$ のようなものは、これらの変数と制約ノード間のメッセージパッシング操作として解釈できる。GNNの固有のメッセージパッシングメカニズムは、これらの分散情報交換とローカル更新を直接シミュレートし、分散LP解決のためのニューラルネットワークベースのフレームワークを提供する。これは、GNNが分散アルゴリズムの計算モデルとして見なされることができることを示している。
(Awerbuch and Khandekar, 2009, SIAM J. Comput.)
組み合わせ最適化のための近似アルゴリズム
パッキングLPとカバリングLPは、最大独立集合、セットカバー、エッジカバーを含む多数のNP困難な組み合わせ最適化問題の基本的な緩和である。本論文は、提案されたGD-Netが、ポリ対数反復回数(GNN層)内でこれらのLPの $(1+\epsilon)$-近似解を見つけることができるという理論的保証を提供している。これは、正確に解くことが計算上不可能である問題に対して、しばしば最適解に対する品質の証明可能な境界を持つ解を見つけることを目標とする、近似アルゴリズムの設計と分析に直接関連している。ここでのGNNは、学習された効率的な近似スキームとして機能し、困難な組み合わせ問題に取り組むための新しい道を提供する。
(Cappart et al., 2023, J. Mach. Learn. Res.)