비평형 궤적을 따른 엔트로피 생성의 국소화
Entropy production is a universal measure of irreversibility and energy dissipation in physical, chemical, and biological systems operating far from equilibrium.
배경 및 학술적 계보
기원 및 학술적 계보
본 논문의 핵심 문제는 비평형 통계 물리학에서 근본적이고 오래된 과제에서 비롯된다. 즉, 실험적으로 관찰된 데이터로부터 복잡한 시스템 내의 비가역성과 에너지 소산을 정확하게 정량화하고 시공간적으로 국소화하는 방법이다. 엔트로피 생성 개념이 이러한 현상에 대한 보편적인 척도 역할을 하지만, 비평형 궤적을 따른 정확한 시공간적 국소화는 여전히 중요한 "미해결 과제"(Page 2)로 남아 있다.
역사적으로 학술적 계보는 확률론적 열역학[17-19]의 발전과 데이터 기반 접근 방식[11, 20-23]의 출현으로 거슬러 올라간다. 이 분야들은 비평형 과정의 개별 실현, 특히 열 요동이 두드러질 때[18, 26] 엔트로피 생산을 이해하기 위한 엄격한 틀을 제공했다. 그러나 주요 장애물이 지속되었다. 엔트로피 생산 또는 소산력 장을 측정하는 기존 방법은 일반적으로 Fokker-Planck 또는 Master 방정식과 같은 시스템의 근본적인 동역학 방정식에 대한 사전 지식에 의존했다. 많은 현실적인 실험 시나리오에서 이러한 방정식과 그 해는 알려져 있지 않아 전통적인 접근 방식을 비실용적으로 만든다(Page 2).
이전 연구는 주로 평균 엔트로피 생성 속도의 전역 추정치를 얻는 데 초점을 맞추었다. Harada-Sasa 등식[6], 정상 상태 전류 추정[5], 시간 비가역성 측정[26-31], 경로 확률 추정기[4, 32, 33]와 같은 방법은 귀중한 통찰력을 제공했지만, 일반적으로 상세하고 국소적인 소산 그림보다는 전반적인 척도를 제공했다. 엔트로피 생성을 국소화하려는 시도는 종종 제한적이었다. 예를 들어, 무차별 대입 통계 구간 분할[20]은 고차원 시스템에서 확장성이 떨어졌고, 일부 신경망 접근 방식은 궤적을 따른 엔트로피 생성을 학습했지만 근본적인 소산력 장의 구조를 완전히 명확히 밝히지 못했다[23]. 다른 방법들은 알려진 나머지 구성 요소를 가정하고 소산력 장의 일부만 추론할 수 있었다[11, 40]. 본 논문이 해결하고자 하는 근본적인 한계 또는 "고충점"은 복잡하고, 고차원이며, 시간에 따라 변하는 비평형 시스템에서, 통치 역학에 대한 명시적인 지식 없이도 실험 궤적 데이터로부터 직접 소산력 장과 요동치는 엔트로피 생성의 시공간적 구조를 추론하기 위한 강력하고 확장 가능하며 모델이 없는 방법의 부족이다. 이 중요한 격차는 열역학적 불확실성 관계(TUR)와 기계 학습을 활용하는 데이터 기반 접근 방식의 개발을 동기 부여했다.
직관적인 도메인 용어
- 엔트로피 생성 ($\sigma$): 완벽하게 정리된 방을 상상해 보라. 파티를 열면 방이 어질러진다. "엔트로피 생성"은 파티 중에 발생하는 비가역적인 어질러짐의 양과 같다. 값이 높을수록 더 큰 혼돈과 원래 상태로 쉽게 돌아갈 수 없는 능력이 더 커짐을 의미한다.
- 비평형 궤적: 붐비는 시장을 걸어가는 사람을 생각해 보라. 그들은 끊임없이 움직이고, 사람들과 부딪히고, 방향을 바꾸며, 균형 잡힌 상태에서 결코 진정으로 멈춰 서지 않는다. "비평형 궤적"은 그 사람이 취하는 특정하고 구불구불한 경로로, 항상 움직이며 주변 환경과 상호 작용한다.
- 열역학적 힘 장 ($F(\mathbf{x}, t)$): 이것은 복잡한 환경에서 물체를 특정하고 종종 소용돌이치는 방식으로 움직이게 하는 보이지 않는 "흐름" 또는 "바람"과 같다. 단순한 밀기뿐만 아니라 시스템을 차분하고 균형 잡힌 상태에서 멀리 몰아내고 에너지가 소산되도록 하는 동적이고 공간적으로 변하는 영향이다.
- 열역학적 불확실성 관계 (TUR): 줄타기 곡예사를 생각해 보라. "TUR"는 "로프를 더 빨리 건너려고 할수록(엔트로피 생성이 높을수록) 몸이 더 많이 흔들리고 흔들릴 것이다(움직임의 변동성이 커지는 것은 불가피하다)"라고 말하는 근본적인 규칙과 같다. 이는 비가역적인 작업을 얼마나 효율적으로 수행하는지와 경로가 얼마나 예측 가능할지 사이의 절충점을 설정한다.
- 과도 감쇠 확산 과정: 고요한 공기 속에서 천천히 아래로 떠내려가는 작은 깃털을 그려 보라. 그 낙하는 자체 운동량보다는 공기 저항과 무작위 공기 흐름에 의해 전적으로 결정된다. "과도 감쇠 확산 과정"은 관성이 무시할 수 있고 마찰과 환경으로부터의 무작위적인 밀기에 의해 운동이 지배되는 움직임을 설명한다.
표기법 표
| 표기법 | 설명 |
|---|---|
문제 정의 및 제약 조건
핵심 문제 공식화 및 딜레마
본 논문이 다루는 핵심 문제는 복잡한 비평형 시스템에서 엔트로피 생성과 근본적인 소산력 장을 실험적으로 측정된 궤적 데이터로부터 직접 파생시켜 정확하게 시공간적으로 국소화하는 것이다.
입력/현재 상태: 이 분석의 시작점은 열역학적 평형에서 멀리 떨어진 시스템의, 실험적으로 측정 가능한 원시 궤적 데이터 $\mathbf{x}(t)$이다. 중요한 측면은 시스템의 근본적인 동역학 방정식(예: Fokker-Planck 또는 Master 방정식)이나 그 해석적 해, 또는 특정 시스템 매개변수에 대한 사전 지식 없이 이 데이터에 접근할 수 있다고 가정한다는 것이다.
출력/목표 상태: 원하는 최종 목표는 시스템의 비가역성에 대한 상세하고 국소적인 이해이다. 여기에는 다음이 포함된다.
1. 비평형 동역학의 추진력인 소산(열역학적) 힘 장 $F(\mathbf{x},t)$
2. 개별 궤적을 따라 공간과 시간 모두에 국소화된 해당 요동치는 엔트로피 생성 $\sigma$ 이 출력은 연구자들이 시스템 내에서 에너지가 언제 어디서 소산되는지 정확히 파악할 수 있도록 한다.
누락된 연결 및 수학적 격차: 근본적인 격차는 원시 궤적 데이터를 이러한 국소화된 열역학적 양으로 효과적으로 변환하는 데 있다. 역사적으로 엔트로피 생성을 정량화하는 방법은 종종 시스템의 동역학 방정식에 대한 명시적인 지식에 의존해 왔는데, 이는 복잡하고, 고차원이며, 시간에 따라 변하는 시스템에 대해 일반적으로 알려져 있지 않거나 해석적으로 다루기 어렵다. 평균 엔트로피 생성 속도의 전역 추정치를 얻을 수 있지만, 요동치는 엔트로피 생성과 소산력 장의 시공간적 구조를 데이터만으로 추출하는 것은 중요한 과제로 남아 있다.
본 논문은 단기 열역학적 불확실성 관계(TUR)를 변분 원리로 구축한다. TUR는 엔트로피 생성 속도 $\sigma_{TUR}(t)$에 대한 공식을 제공하며, 이를 최대화하여 정확한 엔트로피 생성 속도 $\sigma(t)$를 얻을 수 있다. 결정적으로, 이 관계를 최대화하는 최적 계수 장 $d^*(\mathbf{x},t)$는 열역학적 힘 장 $F(\mathbf{x},t)$에 비례하는 것으로 알려져 있다. 따라서 수학적 격차는 이 복잡하고, 비선형적이며, 고차원적인 최적 계수 장 $d(\mathbf{x},t)$를 궤적 데이터로부터 직접 효과적으로 학습하는 방법이다. 본 논문은 딥 신경망을 사용하여 $d(\mathbf{x},t)$를 매개변수화하고 추론함으로써 이 격차를 해소하고, 따라서 소산력 장과 국소 엔트로피 생성 모두를 재구성한다.
딜레마: 역사적으로 연구자들을 가두었던 중심 딜레마는 엔트로피 생성에 대한 고해상도, 국소화된 정보에 대한 열망과 해석적 다루기 용이성 및 계산 확장성의 실질적인 한계 사이의 고통스러운 절충점이다. 이전 접근 방식은 다음 중 하나였다.
* 현실적인 복잡한 시스템에서는 거의 사용할 수 없는 시스템의 동역학에 대한 명시적인 지식이 필요했다.
* 전역적, 평균 엔트로피 생성 속도만 제공할 수 있어 모든 시공간적 세부 정보를 잃었다.
* 무차별 대입 통계 구간 분할과 같은 국소화 시도는 "고차원 시스템에 대한 확장성이 떨어진다"(Page 3)고 하여 많은 실제 시나리오에 비실용적이었다.
* 다른 데이터 기반 방법은 궤적을 따라 엔트로피 생성을 추론할 수 있지만 종종 "근본적인 소산력 장의 구조를 연구하지 않는다"(Page 3)는 점에서 동역학을 완전히 이해하는 데 필수적이다. 본 논문은 국소화된 엔트로피 생성과 힘 장 모두를 제공하는 데이터 기반, 모델이 없는 접근 방식을 제공함으로써 이를 극복하는 것을 목표로 한다.
제약 조건 및 실패 모드
실험 궤적에서 엔트로피 생성을 국소화하는 문제는 해결하기가 매우 어려운 몇 가지 가혹하고 현실적인 요인에 의해 제약된다.
- 계산 복잡성 및 고차원성: 생물학 또는 능동 물질과 같은 분야의 실제 비평형 시스템은 종종 수많은 상호 작용하는 구성 요소를 포함하여 고차원 위상 공간을 초래한다. 본 논문은 명시적으로 "고차원, 다체 상호 작용의 복잡성은 전통적인 최적화 방법에 상당한 어려움을 야기한다"(Page 5)고 언급한다. 이러한 광대한 공간에서 복잡한 비선형 힘 장을 추론하는 것은 계산 집약적이며 효율적으로 확장되지 않는 방법에 대해 빠르게 다루기 어려워질 수 있다.
- 사전 동역학 지식의 부재: 주요 장애물은 대부분의 실제 시스템[Page 2]에 대해 알려지지 않은 동역학 방정식(예: Fokker-Planck 또는 Master 방정식) 또는 그 해석적 해의 부재이다. 이는 본질적으로 사전 정의된 모델 내에서의 매개변수 추정보다 더 어려운 모델이 없는 추론 접근 방식을 필요로 한다.
- 시간 의존 동역학: 많은 비평형 과정은 명시적으로 시간에 따라 변하며, 이는 열역학적 힘 장과 엔트로피 생성 속도도 시간에 따라 변하는 양임을 의미한다. 이러한 시간 의존성은 "직접적인 이러한 양의 추정을 매우 어렵게 만드는 상당한 계산적 어려움을 야기한다"(Page 14). 이러한 동적 변화를 정확하게 포착하기 위해 모델을 훈련하려면 강력한 아키텍처와 충분한 데이터가 필요하다.
- 데이터 품질 및 신호 대 잡음비 (SNR): 실험 데이터는 본질적으로 노이즈가 많다. "약한 소산 영역"에서 "비가역적 서명이 요동에 비해 작다"(Page 10)는 점에서 중요한 제약이 발생한다. 이러한 저소산 영역에서 추론 모델을 훈련하기 위한 유효 SNR은 "크게 감소"하여 "엔트로피 생성 규모가 크게 다른 자유도에 걸쳐 균일하게 일반화하는 능력을 제한한다". 이는 그림 4(e)에 설명된 것처럼 이러한 영역에서 추론된 예측과 이론적 예측 간의 불일치를 초래할 수 있다.
- 실험 샘플링 제약: 실험 궤적의 샘플링 간격 $\Delta t$는 "종종 실질적인 제약에 의해 고정된다"(Page 5). 단기 TUR는 정확한 포화를 위해 이상적으로 $\Delta t \to 0$을 요구하지만, 실질적인 $\Delta t$ 값은 유한하다. 이 방법은 이러한 비이상적인 샘플링 속도를 처리할 만큼 강력해야 한다.
- 거칠게 보기 및 숨겨진 자유도: 실험 관찰은 종종 "근본적인 동역학의 축소된 설명"(Page 16)만을 제공한다. 이는 "숨겨진 자유도"(관찰되지 않은 변수) 또는 "유한한 시간 해상도"(하위 샘플링) 때문일 수 있다. 추론 방법은 관찰된 데이터가 거칠게 보더라도 의미 있는 결과를 제공할 수 있어야 하며, 이는 문제에 또 다른 복잡성 계층을 추가한다.
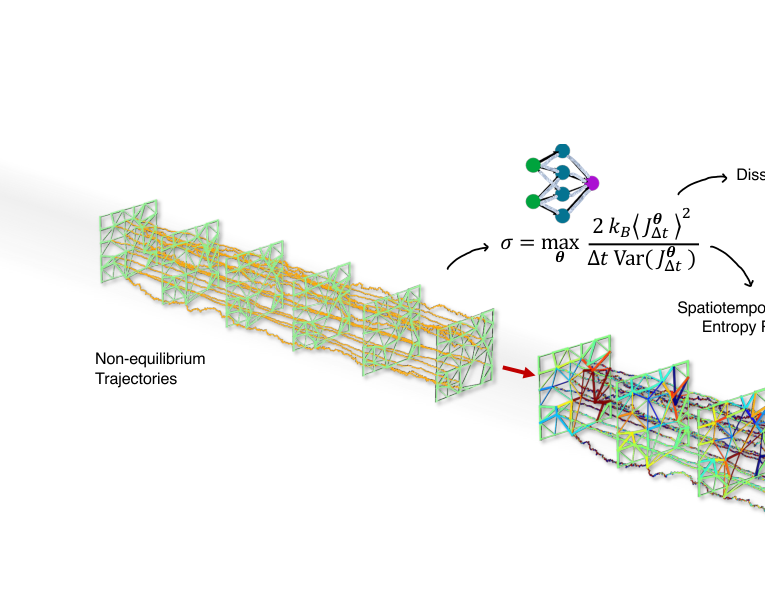 FIG. 1. Schematic of entropy production inference in an active biological network model. Input: The method processes experimentally measurable trajectory data without requiring prior knowledge of system parameters. Outputs: Using short-time Thermodynamic Uncertainty Relations and neural networks (schematically illustrated at the top with a cartoon), we simultaneously infer (i) the dissipative (thermodynamic) force field F (x, t) driving the nonequilibrium dynamics and (ii) the corresponding fluctuating entropy production (color scale: ±0.015kB/s), localized in both space and time. Here, σ denotes the local entropy production rate, and J∆t represents a generalized current in phase space
FIG. 1. Schematic of entropy production inference in an active biological network model. Input: The method processes experimentally measurable trajectory data without requiring prior knowledge of system parameters. Outputs: Using short-time Thermodynamic Uncertainty Relations and neural networks (schematically illustrated at the top with a cartoon), we simultaneously infer (i) the dissipative (thermodynamic) force field F (x, t) driving the nonequilibrium dynamics and (ii) the corresponding fluctuating entropy production (color scale: ±0.015kB/s), localized in both space and time. Here, σ denotes the local entropy production rate, and J∆t represents a generalized current in phase space
왜 이 접근 방식인가
선택의 불가피성
저자들이 단기 열역학적 불확실성 관계(TUR) 기반 추론 체계와 딥 신경망을 결합하기로 선택한 것은 기존 접근 방식의 내재된 한계에 의해 주도된 임의적인 선택이 아니라 필연적인 진화였다. 저자들이 전통적인 "SOTA" 방법이 이 특정 문제에 불충분하다는 것을 깨달은 순간은 실험 데이터에서 엔트로피 생성과 소산력 장을 직접 측정하는 어려움에 대해 논의할 때 명확하게 명시된다.
본 논문에서 언급하듯이 전통적인 접근 방식은 "종종 현실적인 설정에서 알려지지 않은 Fokker-Planck 및 Master 방정식과 같은 근본적인 동역학 방정식과 그 해에 의존한다"(Page 2). 사전 동역학 지식에 대한 이러한 근본적인 의존성은 그러한 방정식이 너무 복잡하여 파생되거나 단순히 사용할 수 없는 많은 실제 복잡한 시스템에 대해 비실용적으로 만든다. 또한, 일부 방법은 평균 엔트로피 생성의 전역 추정치를 제공할 수 있었지만, "복잡한 과정에서 실험 데이터로부터 직접 엔트로피 생성을 정량화하고 시공간적으로 국소화"(Page 2)해야 하는 중요한 필요성은 주요 미해결 과제로 남아 있었다. 무차별 대입 통계 구간 분할[20]과 같은 국소화 시도는 "고차원 시스템에 대한 확장성이 떨어진다"(Page 3)고 언급하며 확장성 부족을 나타낸다. [23]과 같은 다른 방법은 궤적을 따라 엔트로피 생성을 학습했지만, 동역학을 이해하는 데 중요한 근본적인 소산력 장을 밝히는 데 실패했다.
저자들은 특히 "고차원, 다체 상호 작용"(Page 5)의 복잡성이 "전통적인 최적화 방법에 상당한 어려움을 야기한다"(Page 5)는 것을 인식했다. 이것이 결정적인 깨달음이다. 기존 방법, 즉 분석적이든 더 간단한 통계 기법이든, 시스템의 지배 방정식에 대한 사전 지식 없이 데이터 기반, 확장 가능한 고차원 방식으로 국소 엔트로피 생성과 소산력 장을 동시에 추론할 수 없었다. 단기 TUR는 엔트로피 생성 속도에 대한 변분 표현을 제공하고 이를 소산력 장과 직접 연결한다(Eq. 9). 그러나 복잡하고 고차원적인 시스템에 대해 이 변분 문제를 실질적으로 해결하려면 강력한 함수 근사기가 필수적이었으며, 이는 딥 신경망의 채택으로 직접 이어졌다.
비교 우위
이 결합된 접근 방식은 단순한 성능 지표를 훨씬 뛰어넘는 압도적인 질적 우수성을 보여준다. 구조적 이점은 근본적인 동역학 방정식에 대한 명시적인 지식 없이 복잡하고, 고차원적이며, 잠재적으로 시간에 따라 변하는 소산력 장을 모델링할 수 있다는 능력에 있다.
- 모델 없는 추론: 명시적인 동역학 방정식(예: Fokker-Planck 또는 Master 방정식)을 요구하는 기존 방법과 달리, 이 프레임워크는 "과정의 명시적인 동역학적 설명에 대한 의존성을 제거한다"(Page 6). 이는 그러한 방정식이 종종 다루기 어렵거나 알려지지 않은 실험 데이터에 대한 심오한 이점이다.
- 고차원으로의 확장성: 엔트로피 생성을 국소화하려는 이전 시도, 예를 들어 무차별 대입 구간 분할[20]은 "고차원 시스템에 대한 확장성이 떨어진다"(Page 3). 딥 신경망은 "복잡하고, 고차원적인 함수를 근사하는 데 탁월하다"(Page 5)는 점을 활용하여 제안된 방법은 "서로 다른 엔트로피 생성 규모가 크게 분리된 시스템에서 엔트로피 생성을 분석하기 위한 확장 가능한 솔루션"(Page 6)을 제공한다. 이는 고차원 노이즈와 복잡한 상호 작용의 문제를 직접적으로 해결한다.
- 소산력의 시공간적 국소화: 이 방법은 전역 엔트로피 생성 속도를 추론할 뿐만 아니라, 결정적으로 "고차원적이며 잠재적으로 시간에 따라 변하는 소산력 장"을 재구성하고 "비평형 궤적을 따라 공간과 시간 모두에 요동치는 엔트로피 생성"을 국소화한다(Page 2). 이는 이전의 전역 추정 기법에서 대부분 누락되었던 소산의 미세하고 물리적으로 해석 가능한 이해를 제공한다.
- 시간적 부드러움 및 일반화 (시간 의존 시스템의 경우): 시간 의존 동역학의 경우, 신경망 아키텍처는 시간을 입력으로 포함하도록 확장된다. 이는 "공유 네트워크 매개변수를 통해 시간적 부드러움을 강제하고, 관찰되지 않은 시간에 대한 일반화를 가능하게 하며, 전체 시간 도메인에 걸쳐 데이터를 효율적으로 활용한다"(Page 6-7). 이는 각 이산 시간점에 대해 별도의 모델을 훈련하는 것보다 상당한 질적 개선이며, 이는 계산 비용이 많이 들고 과적합되기 쉽다.
- 강건성 및 광범위한 적용 가능성: 이 방법은 "광범위한 하이퍼파라미터 조정 없이 모든 예제에서 강력하게 작동하는 단일 신경망 아키텍처"(Page 4)에 의존하므로 실질적으로 광범위하게 적용 가능하며, 결과에서 입증된 바와 같이 다양한 시스템(정상 상태, 비정상 상태, 선형, 비선형, 저차원 및 고차원)을 처리할 수 있는 강력하고 일반화 가능한 프레임워크를 나타낸다.
제약 조건과의 일치
선택된 방법은 문제의 암묵적 및 명시적 제약 조건과 완벽하게 일치하며, "가혹한 요구 사항과 솔루션의 고유한 속성 간의 '결혼'을 형성한다."
- 데이터 기반 요구 사항: 주요 제약 조건은 "시스템 매개변수" 또는 "근본적인 동역학 방정식"에 대한 "사전 지식"을 요구하지 않고 "실험 데이터로부터 직접" 엔트로피를 추론하는 것이다(Page 2, Figure 1). 단기 TUR와 신경망의 결합은 본질적으로 데이터 기반이다. 이는 "실험적으로 측정 가능한 궤적 데이터"를 입력으로 받아 명시적인 모델 방정식의 필요성을 우회하여 이를 통해 힘 장과 엔트로피 생성을 학습한다.
- 시공간적 국소화: 핵심 문제는 "복잡한 과정에서 엔트로피 생성[을] 정량화하고 시공간적으로 국소화"(Page 2)하는 것이다. 이 방법은 "소산(열역학적) 힘 장 F(x,t)"와 "공간과 시간 모두에 국소화된 해당 요동치는 엔트로피 생성..."(Figure 1, Page 3)을 추론함으로써 이를 직접적으로 해결한다. TUR의 변분 원리는 신경망에 의해 최적화될 때 힘 장 $F(x,t)$를 제공하며, 이는 궤적 증분과 수축될 때 국소 엔트로피 생성 $dS(t) = F(x(t), t) \circ dx(t)$(Eq. 7)를 제공한다.
- 고차원성 및 복잡성 처리: 문제는 "복잡한 과정"과 "고차원, 다체 상호 작용"(Page 2, 5)을 포함한다. 딥 신경망은 "복잡하고, 고차원적인 함수를 근사하는 데 탁월하기"(Page 5) 때문에 특별히 선택되었으며, 이는 모델이 힘 장의 복잡하고 비선형적인 의존성을 고차원 위상 공간에서 포착할 수 있도록 하여, 전통적인 방법이 확장성 부족으로 실패했던 작업을 수행한다.
- 비평형 동역학 (정상 상태 및 시간 의존): 이 방법은 "평형에서 멀리 떨어진 시스템"(Page 2)을 위해 설계되었다. 단기 TUR는 정상 상태 및 시간에 따라 구동되는 경우 모두에 대해 유효한 것으로 입증되었다[21, 22]. 신경망 아키텍처는 비정상 상태 프로세스의 경우 시간 $t$를 추가 입력으로 포함하도록 조정되어 다양한 비평형 시나리오에 대한 적용 가능성을 보장한다.
- 실험 데이터로부터의 강건성: 이 프레임워크는 "실험적으로 다루기 쉬운 관찰"(Page 2)로부터의 강력한 추론을 목표로 한다. "광범위한 하이퍼파라미터 조정 없이"(Page 4) 단일의 강력한 신경망 아키텍처를 사용함으로써 실용적이고 광범위하게 적용 가능하며, 복잡한 모델과 관련된 취약성을 줄이고 실제 실험 노이즈에서도 신뢰할 수 있는 결과를 보장한다.
대안의 거부
본 논문은 문제의 맥락에서 그 한계를 강조함으로써 여러 대안적 접근 방식을 암묵적으로 그리고 명시적으로 거부한다.
- 전통적인 분석/방정식 기반 방법: "Fokker-Planck 및 Master 방정식과 같은 근본적인 동역학 방정식과 그 해에 의존하는"(Page 2) 방법이 가장 중요한 거부이다. 이러한 방법은 "현실적인 설정에서 종종 알려져 있지 않으며" "해석적으로 다루기 쉬운 제한된 수의 경우"(Page 2, 5)에만 사용할 수 있기 때문에 불충분하다고 간주된다. 제안된 데이터 기반, 모델이 없는 접근 방식은 이 근본적인 한계를 직접적으로 우회한다.
- 전역 엔트로피 생성 추정기: Harada-Sasa 등식[6], 정상 상태 전류/확률 분포 방법[5], 시간 비가역성 측정[26-31], 경로 확률 추정기[4, 32, 33], 분산 합 규칙(VSR)[13]을 포함한 많은 기존 방법은 주로 "평균 엔트로피 생성 속도의 전역 추정치를 얻는 데"(Page 3) 초점을 맞춘다. 유용하지만, 이러한 방법은 이 작업의 중심 목표인 엔트로피 생성과 근본적인 소산력 장의 "시공간적 국소화"를 제공하지 못한다.
- 무차별 대입 통계 구간 분할: 본 논문은 특히 열역학적 힘 장을 추정하기 위해 개발된 무차별 대입 통계 구간 분할 접근 방식[20]이 "고차원 시스템에 대한 확장성이 떨어진다"(Page 3)고 구체적으로 언급한다. 이는 저자들이 분석하고자 하는 복잡하고 고차원적인 시스템에 적합하지 않게 만드는 확장성 문제를 강조한다. 대조적으로 신경망 접근 방식은 이러한 복잡성을 효율적으로 처리하도록 설계되었다.
- 부분 추론 방법: 궤적을 따라 엔트로피 생성을 직접 학습하는 [23]과 같은 접근 방식은 "근본적인 소산력 장의 구조를 연구하지 않는다"(Page 3)는 점에서 주목된다. 마찬가지로 "나머지 구성 요소가 미리 알려져 있다고 가정하고"( [11, 40] ) 소산력 장의 일부만 추론하는 방법은 전체 힘 장에 대한 포괄적이고 모델이 없는 이해를 위해 불충분하다. 제안된 방법은 완전한 소산력 장 추론을 목표로 한다.
- 기타 기계 학습 모델 (암시적): GAN 또는 기본 Transformer와 같은 다른 ML 모델을 명시적으로 거부하지는 않지만, 딥 신경망 아키텍처, 특히 Deep-Ritz에서 영감을 받은 모델의 선택은 "복잡하고, 고차원적인 함수를 근사하는 데 탁월한 능력"과 "최적 제어 기술" 및 "희귀 사건을 효율적으로 샘플링하는 데"( [52, 53] ) 성공했기 때문에 동기 부여된다(Page 5). 이는 더 간단하거나 덜 전문화된 ML 아키텍처가 고차원 힘 장의 정확한 재구성이 필요한 점을 고려할 때 이 특정 변분 최적화 문제에 대한 동일한 수준의 유연성, 강건성 또는 효율성을 제공하지 못할 수 있음을 시사한다. 선택된 네트워크의 가법 구조 또한 "층 간의 정보를 보존하고 훈련을 안정화하는 데 도움이 된다"(Page 5)는 점에서 잠재적으로 덜 안정적인 대안에 대한 신중한 선택을 시사한다.
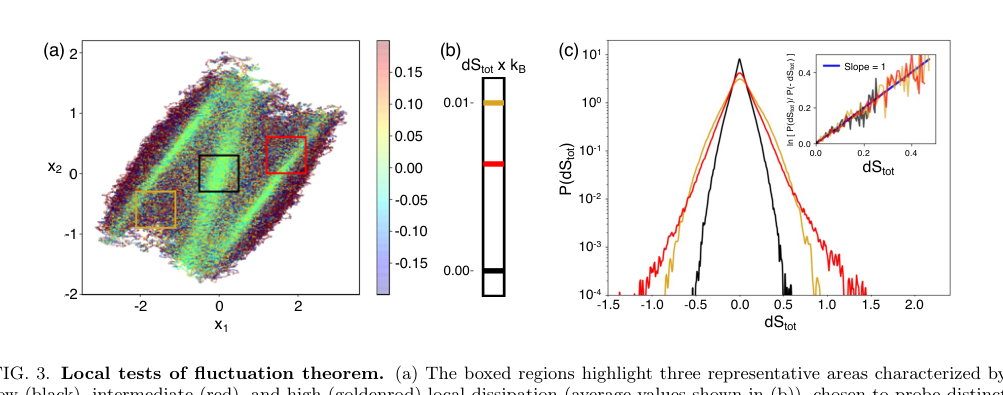 FIG. 3. Local tests of fluctuation theorem. (a) The boxed regions highlight three representative areas characterized by low (black), intermediate (red), and high (goldenrod) local dissipation (average values shown in (b)), chosen to probe distinct dynamical environments. (c) Probability distributions P(dStot) conditioned on these regions, illustrating pronounced region- dependent differences in the statistics of entropy production. The low-dissipation region exhibit narrow, nearly symmetric distributions, while higher-dissipation regions display broader, strongly skewed distributions with extended tails. The inset shows the corresponding fluctuation ratios ln[P(dStot)/P(−dStot)] as a function of dStot, demonstrating that each region independently satisfies a local fluctuation theorem with unit slope
FIG. 3. Local tests of fluctuation theorem. (a) The boxed regions highlight three representative areas characterized by low (black), intermediate (red), and high (goldenrod) local dissipation (average values shown in (b)), chosen to probe distinct dynamical environments. (c) Probability distributions P(dStot) conditioned on these regions, illustrating pronounced region- dependent differences in the statistics of entropy production. The low-dissipation region exhibit narrow, nearly symmetric distributions, while higher-dissipation regions display broader, strongly skewed distributions with extended tails. The inset shows the corresponding fluctuation ratios ln[P(dStot)/P(−dStot)] as a function of dStot, demonstrating that each region independently satisfies a local fluctuation theorem with unit slope
수학적 및 논리적 메커니즘
마스터 방정식
본 논문의 엔트로피 생성 국소화 접근 방식의 핵심 수학적 엔진은 단기 열역학적 불확실성 관계(TUR)에서 파생된 엔트로피 생성 속도의 변분 표현이다. 정상 비평형 과정의 경우, 모델이 훈련 중에 최대화하려는 목표 함수는 다음과 같다.
$$ f(\theta)_{\text{train}} = \frac{2k_B \langle J_{\Delta t}^\theta \rangle^2}{\Delta t \text{Var}(J_{\Delta t}^\theta)} $$
시간 의존 동역학의 경우, 이 목표는 미니 배치로 샘플링된 시간점 $\{t_k\}$에 대해 집계하도록 확장된다.
$$ f(\theta) = \sum_{k=1}^{\text{batch\_size}} \frac{2k_B \langle J_{\Delta t,k}^\theta \rangle^2}{\Delta t \text{Var}(J_{\Delta t,k}^\theta)} $$
이 방정식은 본질적으로 시스템의 비가역적 과정의 효율성을 정량화하며, "일반화된" 전류의 평균 흐름을 변동과 연관시킨다. 이 양의 최대화는 근본적인 소산력 장과 결과적으로 국소 엔트로피 생성을 추론할 수 있게 한다.
항별 분석
단기 TUR에서 파생된 정상 프로세스에 대한 주요 목표 함수 $f(\theta)_{\text{train}}$을 분해하여 각 구성 요소를 이해해 보자.
-
$f(\theta)_{\text{train}}$:
1) 수학적 정의: 이것은 학습 알고리즘이 훈련 단계 동안 최대화하려고 하는 목표 함수이다. 이는 추정된 엔트로피 생성 속도를 나타내는 스칼라 값이다.
2) 물리적/논리적 역할: 그 값은 주어진 모델 매개변수 $\theta$ 세트에 대한 추정된 엔트로피 생성 속도에 직접 해당한다. 최적화의 목표는 최대 가능한 값을 산출하는 $\theta$를 찾는 것이며, TUR에 따르면 이는 실제 엔트로피 생성 속도에 해당한다.
3) 이 형태인 이유: 이것은 엔트로피 생성을 추론하기 위해 최대화되는 단기 TUR에서 파생된 양이다. -
$k_B$:
1) 수학적 정의: 볼츠만 상수. 본 논문은 단순화를 위해 $k_B = 1$이라고 명시한다.
2) 물리적/논리적 역할: 열 요동의 자연 에너지 규모를 제공하고 온도를 에너지와 연결하는 근본적인 물리 상수이다. 이 맥락에서 엔트로피 생성의 단위가 일관되도록 보장한다(예: $k_B/s$ 단위). 이를 1로 설정하면 엔트로피가 $k_B$ 단위로 효과적으로 정규화된다.
3) 이 형태인 이유: 연산자가 아니라 상수 스케일링 인수이다. -
$\langle J_{\Delta t}^\theta \rangle$:
1) 수학적 정의: 이것은 일반화된 전류 $J_{\Delta t}^\theta$의 앙상블 평균(또는 기대값)을 나타낸다. 일반화된 전류 자체는 $J_{\Delta t}^\theta = d(x_{t+\Delta t/2}; \theta) \circ (x_{t+\Delta t} - x_t)$로 정의되며, 여기서 $d(x; \theta)$는 매개변수화된 소산력 장이고 $\circ$는 스트라토노비치 곱을 의미한다.
2) 물리적/논리적 역할: 이 항은 추정된 힘 장 $d(x; \theta)$에 의해 짧은 시간 간격 $\Delta t$ 동안 결정되는 위상 공간에서의 평균 "흐름" 또는 "드리프트"를 나타낸다. 0이 아닌 평균 전류는 열역학적 평형에서 벗어난 시스템 작동의 직접적인 지표이며 에너지 소산과 본질적으로 연결되어 있다.
3) 각괄호인 이유: 각괄호 $\langle \dots \rangle$는 앙상블 평균에 대한 표준 표기법으로, 확률에 의해 가중된 전류의 모든 가능한 실현에 대해 합산하거나 적분하는 것을 포함한다. 이는 통계적으로 강력한 평균값을 얻는 데 필수적이다. -
$(\dots)^2$:
1) 수학적 정의: 이 연산은 일반화된 전류의 앙상블 평균을 제곱한다.
2) 물리적/논리적 역할: 제곱은 평균 전류의 목표 함수에 대한 기여가 전류 방향에 관계없이 항상 양수가 되도록 한다. 더 중요하게는, 이는 평형에서 더 멀리 구동되어 더 많은 엔트로피를 생성하는 특성인 더 큰 평균 전류에 대한 제곱 강조를 제공한다.
3) 제곱인 이유: TUR의 수학적 형태는 분자에서 평균 전류의 제곱을 요구하며, 이는 평균 전류에 대한 제곱 의존성을 반영한다. -
$\Delta t$:
1) 수학적 정의: 이것은 시스템 궤적을 기록하는 데 사용되는 이산 샘플링 간격 또는 단계 크기이다.
2) 물리적/논리적 역할: 이것은 일반화된 전류가 계산되는 짧은 기간을 나타낸다. "단기" 한계는 TUR가 엔트로피 생성 속도의 정확한 추정치를 제공하는 데 중요하다. 분모에서 이는 $\Delta t$ 동안 누적된 총 전류를 시간당 속도로 변환하는 스케일링 인자 역할을 한다.
3) 나눗셈인 이유: $\Delta t$로 나누면 간격 동안 누적된 총 전류가 속도로 변환되어 엔트로피 생성 속도의 정의와 일치한다. -
$\text{Var}(J_{\Delta t}^\theta)$:
1) 수학적 정의: 이것은 일반화된 전류 $J_{\Delta t}^\theta$의 분산이며, $\text{Var}(X) = \langle X^2 \rangle - \langle X \rangle^2$로 정의된다.
2) 물리적/논리적 역할: 이 항은 일반화된 전류의 평균 주변의 변동 또는 불확실성을 정량화한다. TUR의 맥락에서 주어진 평균 전류에 대한 분산이 작을수록 "확실한" 또는 노이즈가 적은 프로세스를 의미하며, 이는 더 높은 추정 엔트로피 생성 속도로 이어진다. 이는 과도한 변동에 대한 페널티 역할을 하며, 높은 불확실성은 엔트로피 생성 추정치를 덜 신뢰할 수 있게 만든다.
3) 분모에 있는 이유: TUR는 엔트로피 생성과 전류의 상대적 변동 사이의 역관계를 설정한다. 분산이 분모에 배치되는 것은 이러한 근본적인 경계를 반영한다. -
$\max_{\theta}$:
1) 수학적 정의: 이것은 최대화 연산자로, 목표 함수 $f(\theta)_{\text{train}}$가 매개변수 $\theta$ 세트에 대해 최적화됨을 나타낸다.
2) 물리적/논리적 역할: 이것은 추론 체계의 핵심 메커니즘이다. 알고리즘은 목표 함수 $f(\theta)_{\text{train}}$를 최대화하는 $\theta$ 매개변수(소산력 장 $d(x;\theta)$를 정의하는)의 특정 세트를 적극적으로 검색한다. TUR에 뿌리를 둔 이 최대화 원리는 모델이 시스템의 비평형 동역학과 관련 엔트로피 생성을 가장 정확하게 설명하는 "최적" 힘 장을 식별할 수 있게 한다.
3) 최대화인 이유: TUR는 엔트로피 생성에 대한 하한을 제공한다. 이 특정 비율을 최대화함으로써, 방법은 이 경계를 포화하는 전류를 찾아 정확한 엔트로피 생성 속도를 산출하는 것을 목표로 한다.
단계별 흐름
하나의 추상적인 데이터 포인트, 즉 이 맥락에서 입자 궤적의 짧은 세그먼트가 수학적 엔진을 통과하는 것을 상상해 보라.
- 궤적 세그먼트 입력: 이 과정은 입력, 즉 비평형 궤적에서 샘플링된 입자의 두 연속적인 위치 $x_t$와 $x_{t+\Delta t}$로 시작된다. 이는 시간 $t$에서의 입자 상태와 그 직후 짧은 시간 $\Delta t$에서의 상태를 나타낸다.
- 중간점 계산: 먼저 시스템은 이 세그먼트의 중간점 $x_{\text{mid}} = (x_t + x_{t+\Delta t})/2$을 계산한다. 이 중간점은 해당 간격의 대표 위치 역할을 한다.
- 변위 계산: 동시에 이 세그먼트에 대한 변위 벡터 $\Delta x = x_{t+\Delta t} - x_t$가 계산된다. 이 벡터는 입자가 얼마나 이동했는지, 그리고 어떤 방향으로 이동했는지를 나타낸다.
- 힘 장 추론 (신경망 순방향 전달): 계산된 중간점 $x_{\text{mid}}$는 매개변수화된 소산력 장 $d(x; \theta)$를 나타내는 신경망에 공급된다. 현재 내부 가중치와 편향(매개변수 $\theta$)을 사용하여 네트워크는 순방향 전달을 수행하여 $x_{\text{mid}}$를 출력 벡터 $d(x_{\text{mid}}; \theta)$로 변환한다. 이 출력은 해당 위치와 시간에서 작용하는 열역학적 힘에 대한 모델의 현재 추정치이다.
- 일반화된 전류 계산: 추론된 힘 장 $d(x_{\text{mid}}; \theta)$는 스트라토노비치 곱(이 맥락에서는 점 곱과 효과적으로 동일)을 사용하여 변위 $\Delta x$와 결합되어 이 특정 세그먼트에 대한 일반화된 전류를 계산한다: $J_{\Delta t}^\theta = d(x_{\text{mid}}; \theta) \cdot \Delta x$. 이 값은 입자 경로를 따라 작용하는 추론된 힘에 의해 수행된 "일"을 정량화한다.
- 배치 누적: 이러한 모든 순서(단계 1-5)는 이러한 $J_{\Delta t}^\theta$ 값의 "배치"를 형성하는 많은 궤적 세그먼트에 대해 반복된다.
- 통계적 집계: $J_{\Delta t}^\theta$ 값의 배치로 축적되면 시스템은 앙상블 평균 $\langle J_{\Delta t}^\theta \rangle$와 분산 $\text{Var}(J_{\Delta t}^\theta)$을 계산한다. 이러한 통계적 측정은 배치 전체의 평균 흐름과 그 변동을 요약한다.
- 목표 함수 평가: 마지막으로, 이러한 계산된 평균 및 분산 값은 마스터 방정식(예: $f(\theta)_{\text{train}}$)에 플러그인되어 단일 스칼라 값을 계산한다. 이 값은 현재 힘 장 매개변수 $\theta$가 TUR에 따라 엔트로피 생성 속도를 추정하는 데 얼마나 잘 수행되는지를 나타낸다. 이것으로 평가를 위한 한 번의 전체 전달이 완료된다.
최적화 동역학
메커니즘은 목표 함수 $f(\theta)_{\text{train}}$ (또는 시간 의존의 경우 $f(\theta)$)를 최대화하기 위해 기울기 상승 과정을 통해 신경망의 내부 매개변수 $\theta$를 반복적으로 개선함으로써 학습하고 수렴한다.
-
손실 지형: 목표 함수 $f(\theta)$는 매개변수 $\theta$의 고차원 공간에서 복잡한 "손실 지형"을 정의한다. 손실 함수를 최소화하는 많은 기계 학습 작업과 달리, 여기서 목표는 이 지형의 최고점을 찾는 것이다. 왜냐하면 $f(\theta)$의 높은 값이 엔트로피 생성의 더 정확한 추론을 의미하기 때문이다. 딥 신경망의 비선형성과 통계적 연산(평균 및 분산)은 이 지형을 복잡하게 만든다.
-
기울기 상승: 훈련 과정의 각 단계에서 알고리즘은 $\theta$의 모든 매개변수에 대한 목표 함수의 기울기, 즉 $\nabla_\theta f(\theta)_{\text{train}}$을 계산한다. 이 기울기 벡터는 손실 지형에서 목표 함수의 가장 가파른 증가 방향을 가리킨다.
-
매개변수 업데이트: 그런 다음 매개변수 $\theta$는 이 양수 기울기 방향으로 단계를 밟아 업데이트된다. 이 단계의 크기는 "학습률" 하이퍼파라미터(lr)에 의해 제어된다. 업데이트 규칙은 일반적으로 다음과 같다.
$$ \theta_{\text{new}} = \theta_{\text{old}} + \text{lr} \cdot \nabla_\theta f(\theta)_{\text{train}} $$
이 반복적인 조정은 매개변수를 점진적으로 목표 함수를 최대화하는 구성으로 이동시켜, 실제 열역학적 힘 장의 근사를 개선한다. -
수렴 및 일반화:
- 수렴: 매개변수가 각 반복에서 업데이트되면서 훈련 루프가 계속된다. 매개변수 $\theta$가 개선됨에 따라 추론된 힘 장 $d(x;\theta)$는 실제 소산력 장 $F(x,t)$의 점점 더 나은 표현이 된다. 이는 목표 함수의 값 증가로 이어져 모델이 엔트로피 생성 속도의 더 정확한 추정치로 수렴하고 있음을 나타낸다.
- 과적합 관리: 최적화의 중요한 측면은 특히 데이터가 제한적일 때 과적합을 방지하는 것이다. 본 논문은 때때로 중간 매개변수 세트가 완전히 수렴된 최종 모델보다 보이지 않는 데이터에 대해 더 잘 수행될 수 있다고 언급한다. 이를 해결하기 위해 알고리즘은 훈련 중에 중간 매개변수 세트 $\{\theta_m\}$를 저장한다. 주요 훈련 루프가 완료된 후, 저장된 모든 모델은 별도의 보류된 검증 데이터 세트에서 평가된다. 최종 최적 매개변수 $\theta^*$는 이 검증 세트에서 목표 함수 값이 가장 높은 것을 산출하는 것으로 선택되어 모델이 훈련 데이터를 넘어 잘 일반화되도록 보장한다. 대규모 데이터 세트의 경우, 저자들은 과적합이 무시할 수 있게 되고 훈련 최적 모델도 검증 데이터에서 최적으로 수행된다고 관찰한다.
-
시간 의존 확장: 시간에 따라 변하는 동역학을 가진 시스템의 경우, 신경망은 시간 $t$를 추가 입력으로 받아들이도록 설계된다. 그런 다음 목표 함수(Eq. 17)는 샘플링된 시간점의 미니 배치에 대해 평균을 계산하여 계산된다. 이 공식은 신경망이 시간 의존 힘 장을 학습하는 동시에 공유 네트워크 매개변수를 통해 시간적 부드러움을 강제하여 관찰되지 않은 시간에 대한 일반화를 가능하게 하고 전체 시간 도메인에 걸쳐 데이터 활용을 효율적으로 한다. $\theta$를 업데이트하기 위한 기본 기울기 상승 메커니즘은 동일하게 유지되지만, 이제 이 시간 집계된 목표에 대해 작동한다. 이 반복적인 프로세스는 메커니즘이 엔트로피 생성이 발생하는 방식과 시스템의 상태가 시간에 따라 업데이트되는 방식을 효과적으로 학습하도록 보장한다.
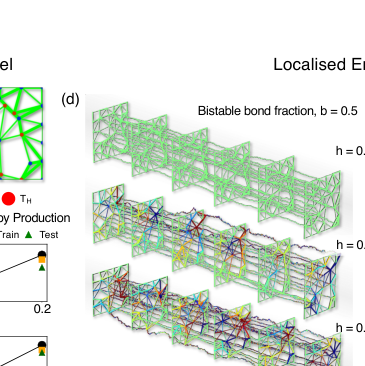 FIG. 5. Entropy production and finite-time fluctuations in active–bistable mechanical networks. (a) Example disordered two-dimensional spring network with a fraction of hot nodes (red, temperature Thot) and cold nodes (blue, Tcold). Thin green bonds denote linear springs, while thick green bonds indicate bistable springs. (b,c) Average entropy production rate as a function of the fraction of hot nodes h at fixed bistable bond fraction b = 0.5 (b), and as a function of the bistable bond fraction b at fixed h = 0.2 (c). Symbols show inferred values from training and test data, while solid lines indicate theoretical predictions for the total entropy production rate. (d) Spatial maps of the inferred local entropy production rate for increasing hot-node fraction h at fixed b = 0.5. (e) Spatial maps of the inferred local entropy production rate for increasing bistable bond fraction b at fixed h = 0.2. In (d) and (e), the network bonds are colored by the mean value of dissipation of the two nodes in the bond. Additionally, the time-series corresponds to 1000 consecutive steady state configurations. (f) Skewness of the time-integrated entropy production ∆Stot as a function of the integration time t for different bistable bond fractions b, showing a pronounced nonmonotonic dependence. (g) Fraction of time-integrated entropy production fluctuations lying above the mean, ⟨T+(t)⟩= P(∆Stot > ⟨∆Stot⟩), demonstrating a finite-time bias with ⟨T+(t)⟩< 1/2. (h) Characteristic integration time t∗at which the skewness is maximal, as a function of the bistable bond fraction b. Increasing the fraction of bistable bonds systematically amplifies finite-time asymmetries in cumulative entropy production and shifts the characteristic timescale to shorter values, demonstrating that mechanical nonlinearity enhances emergent non-Gaussian entropy production statistics at experimentally relevant finite times
FIG. 5. Entropy production and finite-time fluctuations in active–bistable mechanical networks. (a) Example disordered two-dimensional spring network with a fraction of hot nodes (red, temperature Thot) and cold nodes (blue, Tcold). Thin green bonds denote linear springs, while thick green bonds indicate bistable springs. (b,c) Average entropy production rate as a function of the fraction of hot nodes h at fixed bistable bond fraction b = 0.5 (b), and as a function of the bistable bond fraction b at fixed h = 0.2 (c). Symbols show inferred values from training and test data, while solid lines indicate theoretical predictions for the total entropy production rate. (d) Spatial maps of the inferred local entropy production rate for increasing hot-node fraction h at fixed b = 0.5. (e) Spatial maps of the inferred local entropy production rate for increasing bistable bond fraction b at fixed h = 0.2. In (d) and (e), the network bonds are colored by the mean value of dissipation of the two nodes in the bond. Additionally, the time-series corresponds to 1000 consecutive steady state configurations. (f) Skewness of the time-integrated entropy production ∆Stot as a function of the integration time t for different bistable bond fractions b, showing a pronounced nonmonotonic dependence. (g) Fraction of time-integrated entropy production fluctuations lying above the mean, ⟨T+(t)⟩= P(∆Stot > ⟨∆Stot⟩), demonstrating a finite-time bias with ⟨T+(t)⟩< 1/2. (h) Characteristic integration time t∗at which the skewness is maximal, as a function of the bistable bond fraction b. Increasing the fraction of bistable bonds systematically amplifies finite-time asymmetries in cumulative entropy production and shifts the characteristic timescale to shorter values, demonstrating that mechanical nonlinearity enhances emergent non-Gaussian entropy production statistics at experimentally relevant finite times
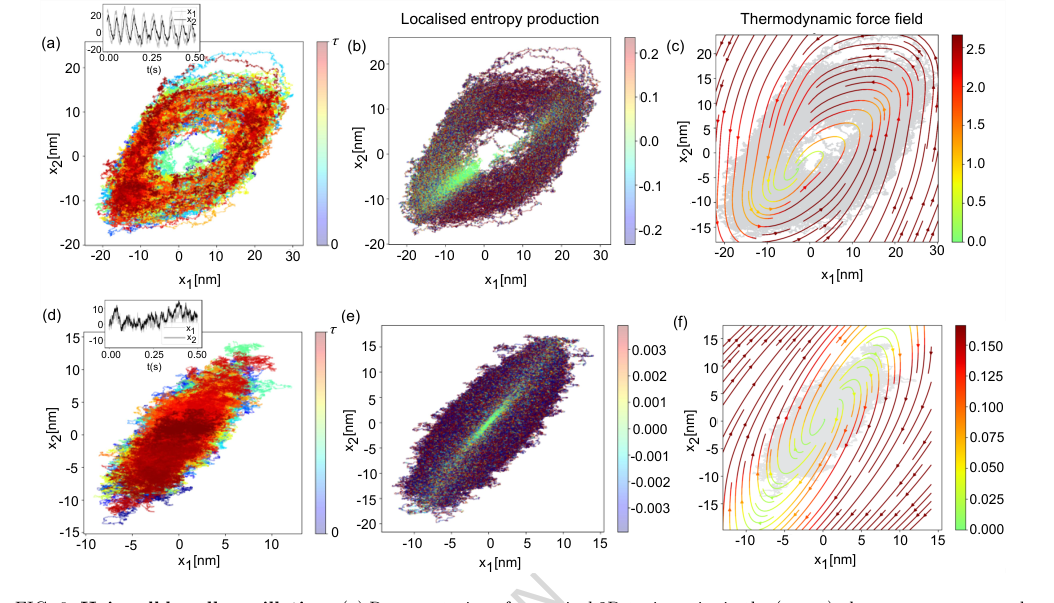 FIG. 6. Hair-cell bundle oscillation. (a) Representation of numerical 2D-trajectories in the (x1, x2) phase space correspond- ing to 5s simulation sampled at 100 kHz. The colorbar indicates progression along the trajectory. The inset plot indicates the oscillatory nature of dynamics for Fmax = 57.14 pN and S = 0.94. (b) The local entropy production rate (in units of kB/s) is computed using the neural network representation. It captures the active state of dynamics. The colours are for comparative visualisation and do not represent the true value. (c) Thermodynamic force field of the oscillatory state of the dynamics. (d) Representation of numerical 2D-trajectories in the (x1, x2) phase space corresponding to 5s simulation sampled at 100 kHz. The colorbar indicates progression along the trajectory. The inset plot indicates the quiescent (non-oscillatory) state of dynamics for Fmax = 40 pN and S = 1. (e) Entropy production rate (in units of kB/s) is locally computed along such trajectories. The colours are for comparative visualisation and do not represent the true value. (f) Thermodynamic force field of the oscillatory state of the dynamics. The colour scale of local entropy production is thresholded symmetrically between [−10× median, 10 × median] for the oscillatory case and [−500 × median, 500× median] for the quiescent case, while the colour scale for the force field of both cases is thresholded between [0, median]. The other system parameters remain the same as mentioned in Fig.(4) of Ref. [12]: γ1 = 2.8 µN s/m, γ2 = 10 µN s/m, kgs = 0.75 pN/nm, ksp = 0.6 pN/nm, D = 61 nm, N = 50, ∆G = 10kBT, kBT = 4.143 pNnm and Teff = 1.5T
FIG. 6. Hair-cell bundle oscillation. (a) Representation of numerical 2D-trajectories in the (x1, x2) phase space correspond- ing to 5s simulation sampled at 100 kHz. The colorbar indicates progression along the trajectory. The inset plot indicates the oscillatory nature of dynamics for Fmax = 57.14 pN and S = 0.94. (b) The local entropy production rate (in units of kB/s) is computed using the neural network representation. It captures the active state of dynamics. The colours are for comparative visualisation and do not represent the true value. (c) Thermodynamic force field of the oscillatory state of the dynamics. (d) Representation of numerical 2D-trajectories in the (x1, x2) phase space corresponding to 5s simulation sampled at 100 kHz. The colorbar indicates progression along the trajectory. The inset plot indicates the quiescent (non-oscillatory) state of dynamics for Fmax = 40 pN and S = 1. (e) Entropy production rate (in units of kB/s) is locally computed along such trajectories. The colours are for comparative visualisation and do not represent the true value. (f) Thermodynamic force field of the oscillatory state of the dynamics. The colour scale of local entropy production is thresholded symmetrically between [−10× median, 10 × median] for the oscillatory case and [−500 × median, 500× median] for the quiescent case, while the colour scale for the force field of both cases is thresholded between [0, median]. The other system parameters remain the same as mentioned in Fig.(4) of Ref. [12]: γ1 = 2.8 µN s/m, γ2 = 10 µN s/m, kgs = 0.75 pN/nm, ksp = 0.6 pN/nm, D = 61 nm, N = 50, ∆G = 10kBT, kBT = 4.143 pNnm and Teff = 1.5T
결과, 한계 및 결론
실험 설계 및 기준선
저자들의 수학적 주장을 철저히 증명하기 위한 접근 방식은 단기 열역학적 불확실성 관계(TUR) 추론 체계와 딥 신경망을 결합한 데이터 기반 프레임워크에 중점을 둔다. 핵심 실험 설계는 다음과 같다.
-
수학적 기초: 이 방법은 TUR에서 파생된 변분 목표 함수를 최대화함으로써 소산(열역학적) 힘 장 $F(x,t)$와 해당 요동치는 엔트로피 생성 $\sigma$를 추론하는 것을 목표로 한다. 구체적으로, 목표는 $\sigma_{TUR}(t) := \max_{d} \frac{1}{\Delta t} \frac{2 \langle J_{\Delta t}^d \rangle^2}{\text{Var}(J_{\Delta t}^d)}$를 최대화하는 것이며, 여기서 $J_{\Delta t}^d$는 일반화된 전류이다. 이 공식은 시스템의 근본적인 동역학 방정식에 대한 사전 지식 없이 추론을 가능하게 한다.
-
기계 학습 아키텍처: 다층 신경망은 열역학적 힘 장 $F(x,t)$에 비례하는 최적 계수 장 $d(x,t)$를 근사하는 데 사용된다. 시간 의존 프로세스의 경우, 네트워크는 시간 $t$를 추가 입력으로 포함하도록 확장되고, 훈련 목표는 시간적 부드러움을 강제하고 일반화를 가능하게 하기 위해 샘플링된 시간점의 미니 배치에 대해 집계된다.
-
데이터 생성 및 검증: 다양한 시스템에 대해 수치 궤적이 생성된다. 정상 상태 프로세스의 경우, 궤적은 훈련 및 검증 세트로 분할된다. 매개변수는 훈련 데이터에 대한 기울기 상승을 통해 최적화되고, 최종 모델은 과적합을 방지하기 위해 보류된 검증 데이터에 대한 성능을 기반으로 선택된다.
이 접근 방식이 패배하도록 설계되었고 그 성능이 평가된 "희생자"(기준선 모델 또는 어려운 시나리오)는 다음과 같다.
- 해석 가능한 시스템: 열역학적 힘 장과 엔트로피 생성이 해석적으로 알려진 시스템(예: 조화 브라운 회전 장치, N차원 선형 회전 장치, 거칠게 보기된 선형 회전 장치)의 경우, 추론된 결과는 이러한 이론적 벤치마크와 직접 비교된다. 이는 결정적인 정량적 검증을 제공한다.
- 복잡한 비선형 시스템: 해석적 해가 다루기 어렵거나 사전 예측하기 어려운 시스템(예: 비조화 브라운 회전 장치, 능동 이중 안정 기계 네트워크, 머리카락 세포 다발 진동)의 경우, 이 방법은 소산의 물리적으로 직관적이고 일관된 시공간 구조를 밝히는 능력을 보여준다. 이러한 시스템은 명시적인 동역학 방정식에 의존하는 전통적인 방법에 대한 과제를 나타낸다.
- 시간 의존 프로세스: 명시적으로 시간에 따라 변하는 비평형 프로세스인 비트 삭제 프로토콜은 시간에 따라 변하는 힘 장과 엔트로피 생성 속도를 처리하는 방법의 능력을 테스트하기 위한 테스트베드 역할을 하며, 이는 기존 접근 방식에 대해 계산적으로 어렵다.
- 축소된 관찰 접근: 3D 조화 회전 장치에 대한 거칠게 보기된 실험(차원 및 시간)은 부분적이거나 하위 샘플링된 궤적 데이터만 사용 가능한 경우 방법의 강건성을 테스트하며, 이는 숨겨진 자유도 또는 유한 샘플링 속도와 같은 현실적인 실험 제약을 모방한다.
증거가 증명하는 것
본 논문에서 제시된 증거는 단기 TUR와 딥 신경망을 결합한 핵심 메커니즘이 비평형 궤적을 따라 엔트로피 생성을 국소화하고 소산력 장을 재구성하는 데 성공했음을 결정적으로 증명한다.
-
정확한 힘 장 및 엔트로피 생성 추론:
-
브라운 회전 장치: 2D 회전 장치(그림 2)의 경우, 이 방법은 국소 엔트로피 생성 속도와 열역학적 힘 장을 모두 정확하게 추론한다. 조화의 경우, 추론된 힘 장의 크기는 잠재적 최소값 근처에서 최소이며, 이론적으로 예상되는 바와 같이 0에 가까운 엔트로피 생성과 상관관계가 있다. 비선형 비조화 및 4차 회전 장치의 경우, 이 방법은 4개의 소용돌이와 같은 매우 어렵고 비자명한 소산의 시공간 구조를 밝힌다(4차의 경우, 그림 2(i)). 이 데이터 기반 접근 방식 없이는 예측하기 어렵다.
-
N차원 회전 장치 (N=100): 추론된 국소 엔트로피 생성 속도는 해석적 추정치와 시각적으로 잘 일치한다(그림 4(b) 및 4(c)). 정량적으로, 추론된 총 엔트로피 생성과 해석적 총 엔트로피 생성을 비교하는 산점도는 $R^2$ 값이 0.7576(그림 4(d))으로, 특히 고소산 영역에서 강력한 선형 상관관계를 보여준다. 이것은 방법의 확장 및 고차원에서 정확하게 수행하는 능력에 대한 부인할 수 없는 증거이다.
-
능동 이중 안정 기계 네트워크: 추론된 평균 엔트로피 생성 속도(그림 5(b) 및 5(c)의 기호)는 뜨거운 노드 분율 및 이중 안정 결합 분율의 변화에 걸쳐 이론적 예측(실선)과 놀랍도록 잘 일치한다. 국소 엔트로피 생성의 공간적 지도(그림 5(d) 및 5(e))는 소산이 어떻게 이질적으로 구성되는지를 명확하게 보여주며, 복잡한 상호 작용 시스템에서 방법의 능력을 증명한다.
- 머리카락 세포 다발 진동: 이 방법은 진동 및 침묵 상태 모두에 대해 국소 엔트로피 생성 및 열역학적 힘 장을 성공적으로 계산한다(그림 6(b,c,e,f)). 이는 능동 동역학을 포착하고 다른 동역학적 영역을 구별한다. 예를 들어, 진동 상태의 강하게 순환하는 힘 장은 강한 비가역성의 명확한 서명이다.
- 비트 삭제 프로토콜: 시간에 따라 변하는 비트 삭제의 경우, 이 방법은 개별 궤적을 따라 국소 엔트로피 생성을 해결한다(그림 7(d) 및 7(f)). 이는 비가역적 동역학에 직접적으로 기인하는 급증 및 억제를 보여준다. 시간 평균 엔트로피 생성 속도(그림 8(a) 및 8(b))는 이러한 관찰을 뒷받침하며, 다른 삭제 경로에 대한 뚜렷한 특징을 강조한다.
-
-
근본적인 물리학과의 강건성 및 일관성:
- 국소 불확실성 정리: 중요한 증거는 추론된 국소 엔트로피 생성이 불확실성 정리를 만족한다는 시연이다. 국소 엔트로피 생성의 확률 분포의 지역별 차이가 상당함에도 불구하고, 그림 3(c)의 삽입은 불확실성 비율 $\ln[P(dS_{tot})/P(-dS_{tot})]$이 모든 샘플링된 영역에서 단위 기울기를 가진 $dS_{tot}$에 대한 선형 관계를 보여준다는 것을 보여준다. 이것은 추론된 양의 물리적 일관성에 대한 강력한 데이터 기반 검증이다.
- 거칠게 보기 강건성: 이 방법은 축소된 관찰 접근 하에서 강건함을 증명한다. 차원 및 시간적 거칠게 보기에 적용된 3D 회전 장치의 경우, 추론된 요동치는 엔트로피 생성 속도는 해석적 벤치마크와 잘 일치한다(그림 9(b) 및 9(d)). 산점도는 0.862 및 0.890($R^2$ 값, 그림 9(c) 및 9(e))의 강력한 선형 상관관계를 보여주며, 방법이 숨겨진 자유도 또는 하위 샘플링된 데이터로도 통계적으로 일관된 결과를 제공함을 확인한다.
요약하면, 본 논문은 핵심 메커니즘이 다음을 통해 실제로 작동한다는 결정적이고 부인할 수 없는 증거를 제공한다.
* 알려진 해석적 해와의 높은 정량적 일치 달성.
* 해석적 해가 없는 복잡한 비선형 시스템에서 물리적으로 일관되고 해석 가능한 시공간적 패턴을 밝힘.
* 국소 수준에서 불확실성 정리와 같은 근본적인 열역학 원리 준수 시연.
* 다양한 형태의 데이터 거칠게 보기에 대한 강건성 및 통계적 일관성 표시.
"희생자"는 실제로 패배했다. 왜냐하면 제안된 방법은 사전 동역학 지식을 요구하거나, 고차원성과 씨름하거나, 엔트로피 생성 및 소산력에 대한 국소화되고 궤적별 통찰력을 제공하지 못하는 전통적인 접근 방식의 한계를 극복하기 때문이다.
한계 및 향후 방향
제시된 프레임워크는 비평형 시스템을 이해하기 위한 강력한 새로운 렌즈를 제공하지만, 현재의 한계를 인정하고 미래 개발을 위한 흥미로운 방향을 고려하는 것이 중요하다.
한계:
- 저소산 영역에서의 성능: 본 논문은 고차원 시스템의 경우, 추론 정확도가 약한 소산 영역에서 감소할 수 있다고 언급한다(그림 4(e) 삽입). 이는 유효 신호 대 잡음비가 감소하기 때문이며, 신경망이 매우 다른 엔트로피 생성 규모에 걸쳐 균일하게 일반화하기 어렵게 만든다. 이러한 어려운 영역에서 강건성을 개선하는 것은 미해결 과제로 남아 있다.
- 계산 자원 및 데이터 요구 사항: 확장 가능하지만, 특히 고차원 및 시간 의존 시스템의 경우 딥 신경망을 훈련하는 것은 여전히 계산 집약적일 수 있으며 상당한 양의 궤적 데이터(예: 일부 모델의 경우 $2 \times 10^6$ 포인트)를 필요로 할 수 있다. 이는 데이터 가용성이 제한적인 실험에 실질적인 제약이 될 수 있다.
- 유한 시간 단계 효과: 이 방법은 TUR의 단기 한계에 의존한다. 실제 실험 데이터는 유한한 시간 간격 $\Delta t$로 샘플링된다. 본 논문은 $\Delta t/\tau_{min} \ll 1$이라는 기준을 제안하지만, 더 큰 $\Delta t$ 값이 추론된 양의 정확도와 해석에 미치는 영향, 특히 매우 동적인 시스템에 대한 포괄적인 분석은 유익할 수 있다.
- 거칠게 보기된 힘 장의 해석: 거칠게 보기를 적용할 때, 학습된 힘 장은 선택된 해상도에서의 유효 표현이다. 해석적 벤치마크가 없는 복잡한 비선형 시스템의 경우, 이러한 유효 힘 장의 정확한 물리적 해석은 추가적인 이론적 개발을 필요로 할 수 있다.
- 국소 엔트로피와 총 엔트로피 생성의 구별: 명시적으로 시간에 따라 변하는 프로세스의 경우, 이 방법으로 추론된 국소 엔트로피 생성 $dS(t)$는 확률 밀도의 명시적인 시간 의존성과 관련된 항으로 인해 총 확률론적 엔트로피 생성과 다르다. $dS(t)$는 평균 속도에 대한 비가역적 기여를 포착하지만, 2법칙 위반 사건의 완전한 특성화는 현재 추론에서 직접 제공되지 않는 이 추가 항을 고려해야 한다.
향후 방향:
본 논문의 결과는 수많은 미래 탐구를 위한 견고한 기반을 마련하며, 다양한 관점에서 비판적 사고를 자극한다.
-
다양한 실험 시스템으로 적용 확대:
- 생물학적 맥락: 이 방법을 실제 생물 시스템, 예를 들어 세포 신호 전달 네트워크, 대사 경로 또는 단일 분자 실험에서 분자 모터의 작동에서 에너지 소산을 정량화하고 시공간적으로 국소화하는 데 어떻게 적용할 수 있는가? 이는 살아있는 세포에서 새로운 에너지 변환 또는 조절 메커니즘을 밝힐 수 있는가?
- 능동 물질 물리학: 이 프레임워크를 자기 추진 콜로이드 또는 박테리아 군집과 같은 능동 물질 시스템에 적용하여 국소 에너지 소산이 집단 행동, 자기 조직화 및 위상 전환을 어떻게 구동하는지 이해할 수 있는가? 능동 난류 또는 패턴 형성에 대한 새로운 통찰력이 나올 수 있는가?
-
이론적 및 알고리즘적 기초 발전:
- 과도 감쇠 동역학 너머: 현재 작업은 과도 감쇠 확산 과정에 초점을 맞춘다. 관성 효과가 중요하거나 많은 복잡한 시스템에서 널리 퍼져 있는 비마르코프 동역학의 경우, 이 방법을 어떻게 확장하고 엄격하게 검증할 수 있는가?
- 저신호 대 잡음 비율에서의 강건성: 어떤 새로운 신경망 아키텍처, 정규화 기법 또는 물리학 기반 기계 학습 전략이 고차원, 약한 소산 영역에서 방법의 정확성과 일반화 능력을 향상시킬 수 있는가? 학습 목표에 더 명시적인 물리적 제약 조건을 통합하는 것이 도움이 될 수 있는가?
- 실시간 추론: 추론 알고리즘을 실험 데이터 스트림의 실시간 또는 거의 실시간 처리를 위해 최적화할 수 있는가? 이는 라이브 실험에서 적응형 샘플링 또는 피드백 제어 전략을 구현하는 데 중요할 것이다.
-
국소화된 엔트로피를 역설계 및 제어에 활용:
- 최적 제어 전략: 소산을 국소화할 수 있다는 점을 감안할 때, 이 정보를 사용하여 특정 작업(예: 비트 삭제, 분자 수송)에 대한 에너지 소산을 최소화하거나 원하는 비평형 상태를 달성하기 위한 최적 제어 프로토콜을 설계하는 방법은 무엇인가? 이는 더 에너지 효율적인 나노 기계로 이어질 수 있는가?
- 재료 및 시스템의 역설계: 이 방법은 맞춤형 시공간 소산 특성을 가진 능동 재료 또는 생물학적 네트워크의 역설계를 안내할 수 있는가? 예를 들어, 자기 조립 또는 표적 힘 생성을 위한 특정 국소 비평형 특성을 가진 콜로이드 격자를 설계한다.
- 적응형 샘플링: 추론된 국소 엔트로피 생성이 통계적 효율성을 개선하고 희귀 사건을 밝히기 위해 고소산 영역에 데이터 수집을 집중하는 적응형 샘플링 전략을 안내할 수 있는가?
-
정보 이론 및 열역학과의 연결 탐색:
- 정보-에너지 절충: 국소화된 엔트로피 생성은 복잡한 시스템, 특히 생물학적 맥락에서 정보 처리 및 저장과 어떻게 관련되는가? 이 프레임워크는 나노 규모에서의 계산 또는 감지의 근본적인 열역학적 비용에 대한 새로운 통찰력을 제공할 수 있는가?
- 복잡한 시스템에서의 불확실성 정리: 매우 비선형적이고, 시간에 따라 변하며, 거칠게 보기된 시스템에서의 국소 불확실성 정리에 대한 추가 탐구는 비평형 통계 역학에 대한 이해를 심화시킬 수 있다.
이러한 미래 방향은 복잡한 시스템에서의 에너지 소산 및 비가역성에 대한 미세한 이해로 나아가 기본 과학 및 엔지니어링에 대한 영향을 미치는 데이터 기반 접근 방식의 변혁적 잠재력을 강조한다.
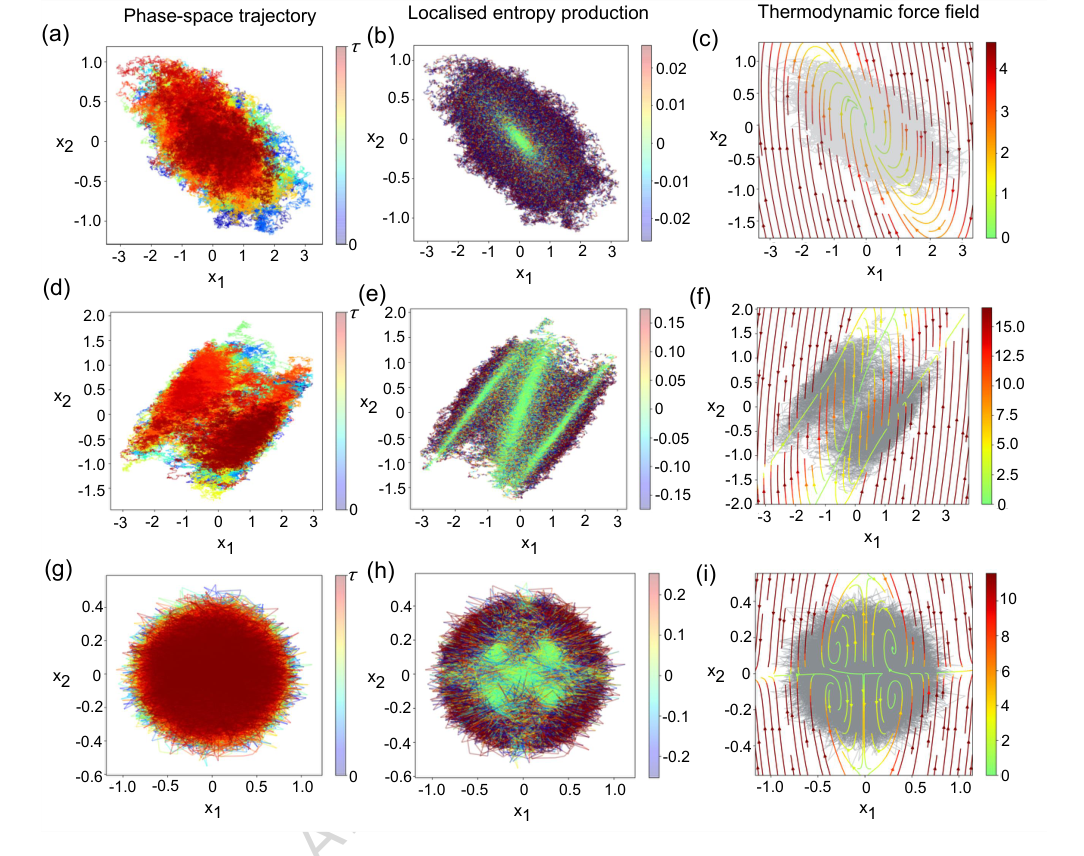 FIG. 2. Local entropy production in Brownian gyrator models. (a) 2D-dimensional trajectories of a Brownian gyrator system with harmonic confining potential. [Parameters: k1 = 1, k2 = 2, γ = 1, θ = π/4, D1 = 1, D2 = 0.1]. (b) local entropy production rate and (c) thermodynamic force field for the system with harmonic confinement - estimated using the neural network representation. (d) 2D-dimensional trajectories of a Brownian gyrator system with a bi-stable confining potential. [Parameters: k = 1, b = 1, γ = 1, θ = π/4, D1 = 1, D2 = 0.1] (e) local entropy production rate and (f) thermodynamic force field estimated using the neural network representation. (g) 2D-dimensional trajectories of a Brownian gyrator system with a quartic confining potential. [Parameters: k1 = k2 = 10, γ = 1, θ = π/4, D1 = 10, D2 = 1] (h) local entropy production rate and (i) thermodynamic force field estimated using the neural network representation. The colours corresponding to the local entropy production rate (in units of kB/s) of the gyrators are thresholded between [−α median, α median] , where α (typically 20 −50) multiplies the median of the corresponding local entropy production dataset. Values outside these ranges are clipped for visualisation purposes to prevent rare large fluctuations from dominating the colour mapping. Similarly, the thermodynamic force field values for the gyrators are thresholded within [0, median]. The numerical trajectories are usually generated for 2000s with a sampling rate of 1 kHz - from which trajectory traces of 500s are shown in the plots. The colorbars in panels (a), (d), and (e) indicate the progression along the trajectory
FIG. 2. Local entropy production in Brownian gyrator models. (a) 2D-dimensional trajectories of a Brownian gyrator system with harmonic confining potential. [Parameters: k1 = 1, k2 = 2, γ = 1, θ = π/4, D1 = 1, D2 = 0.1]. (b) local entropy production rate and (c) thermodynamic force field for the system with harmonic confinement - estimated using the neural network representation. (d) 2D-dimensional trajectories of a Brownian gyrator system with a bi-stable confining potential. [Parameters: k = 1, b = 1, γ = 1, θ = π/4, D1 = 1, D2 = 0.1] (e) local entropy production rate and (f) thermodynamic force field estimated using the neural network representation. (g) 2D-dimensional trajectories of a Brownian gyrator system with a quartic confining potential. [Parameters: k1 = k2 = 10, γ = 1, θ = π/4, D1 = 10, D2 = 1] (h) local entropy production rate and (i) thermodynamic force field estimated using the neural network representation. The colours corresponding to the local entropy production rate (in units of kB/s) of the gyrators are thresholded between [−α median, α median] , where α (typically 20 −50) multiplies the median of the corresponding local entropy production dataset. Values outside these ranges are clipped for visualisation purposes to prevent rare large fluctuations from dominating the colour mapping. Similarly, the thermodynamic force field values for the gyrators are thresholded within [0, median]. The numerical trajectories are usually generated for 2000s with a sampling rate of 1 kHz - from which trajectory traces of 500s are shown in the plots. The colorbars in panels (a), (d), and (e) indicate the progression along the trajectory
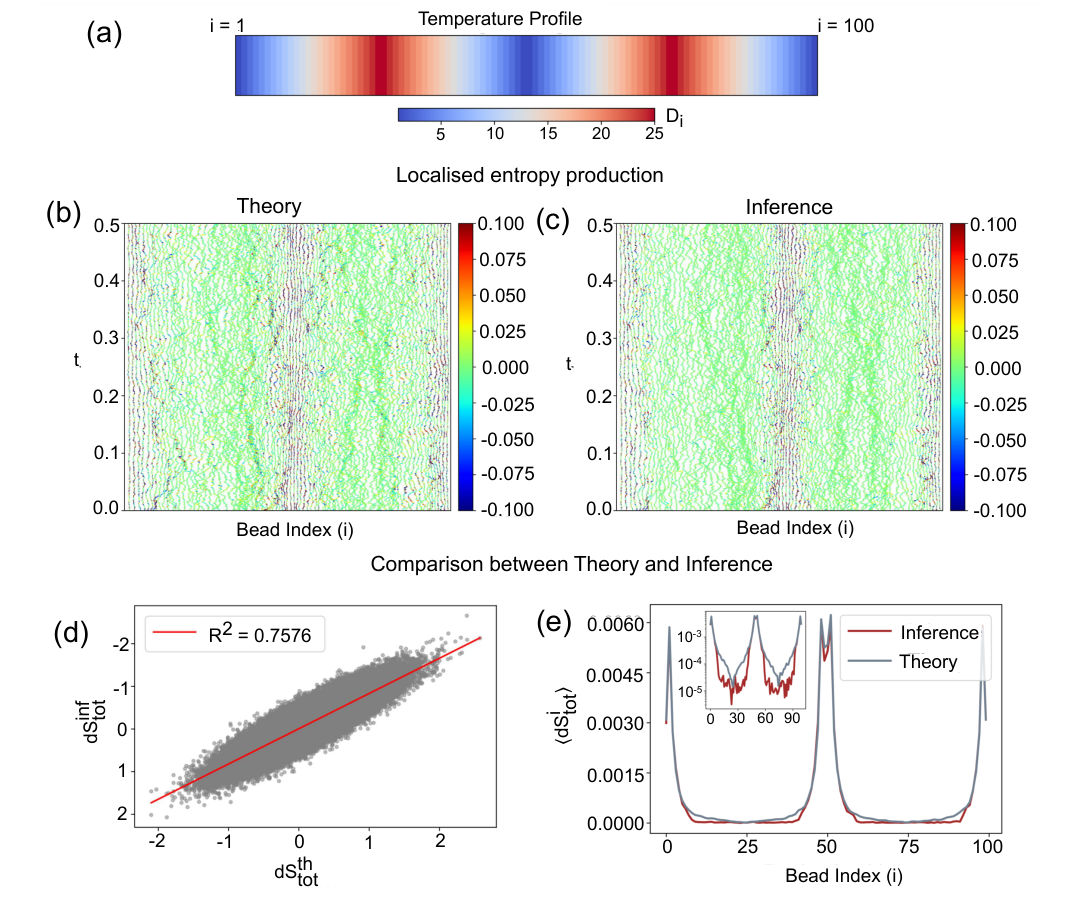 FIG. 4. Bead wise local entropy production for N-dimensional brownian gyrator model. (a) Temperature profile of the N-dimensional gyrator setup. Di denotes the diffusion coefficient of i-th bead as kB = γ = 1. (b) Analytically estimated local entropy production rate (in units of kB/s) of the system. (c) Local entropy production rate (in units of kB/s) inferred from the numerical trajectories using a neural network representation. The colors do not indicate the true values of the fluctuating entropy current, but they are thresholded for better visualisation. (d) Convergence test (R2 test) of the neural network–based estimation of the fluctuating entropy production rate for an N-dimensional Brownian gyrator with N = 100. The inferred and analytical local entropy production rates, averaged over all beads, exhibit a finite spread around the linear fit. (e) Comparison of the inferred average entropy production for each bead with the corresponding theoretical estimate. (Inset) The same data shown on a logarithmic (y-) scale reveals that dissipation of beads associated with low irreversible signature (entropy production) are challenging for the neural network to capture, resulting in a mismatch with the theoretical prediction
FIG. 4. Bead wise local entropy production for N-dimensional brownian gyrator model. (a) Temperature profile of the N-dimensional gyrator setup. Di denotes the diffusion coefficient of i-th bead as kB = γ = 1. (b) Analytically estimated local entropy production rate (in units of kB/s) of the system. (c) Local entropy production rate (in units of kB/s) inferred from the numerical trajectories using a neural network representation. The colors do not indicate the true values of the fluctuating entropy current, but they are thresholded for better visualisation. (d) Convergence test (R2 test) of the neural network–based estimation of the fluctuating entropy production rate for an N-dimensional Brownian gyrator with N = 100. The inferred and analytical local entropy production rates, averaged over all beads, exhibit a finite spread around the linear fit. (e) Comparison of the inferred average entropy production for each bead with the corresponding theoretical estimate. (Inset) The same data shown on a logarithmic (y-) scale reveals that dissipation of beads associated with low irreversible signature (entropy production) are challenging for the neural network to capture, resulting in a mismatch with the theoretical prediction
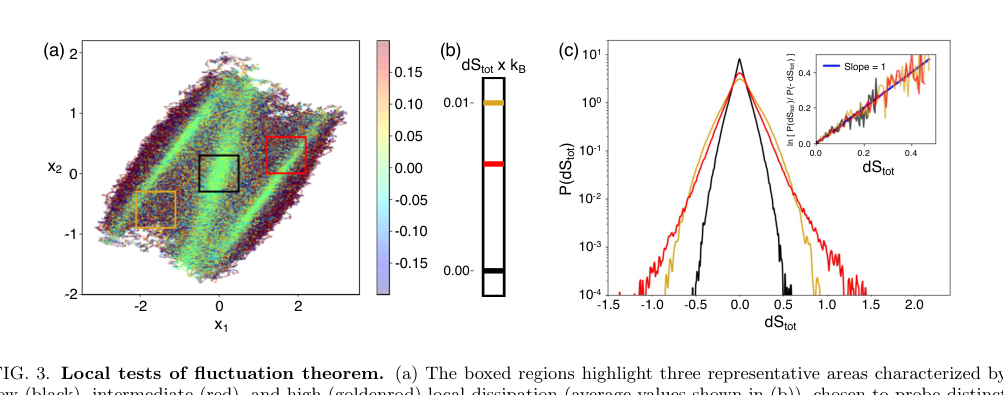 Figure 4. (b) depicts the local entropy production using the theoretically known form of F (x), while Figure 4(c) shows the same obtained from solving the inference algo- rithm. As we see, there is good visual agreement between the theory and the results obtained from the inference al- gorithm. To quantify the agreement between theory and infer- ence, Figure 4(d) shows a scatter plot comparing the analytically computed and learned entropy production, summed over all beads. The data follow a clear linear trend with an R2 value of 0.7576, with noticeably better agreement in the high-dissipation regime. To investigate the origin of the remaining spread, Figure 4(e) shows the time-averaged entropy production of each bead. This re- veals a separation of roughly two to three orders of mag- nitude between beads with high and low entropy produc- tion, and shows that the discrepancy between theory and inference is noticeably high at the low-dissipation beads
Figure 4. (b) depicts the local entropy production using the theoretically known form of F (x), while Figure 4(c) shows the same obtained from solving the inference algo- rithm. As we see, there is good visual agreement between the theory and the results obtained from the inference al- gorithm. To quantify the agreement between theory and infer- ence, Figure 4(d) shows a scatter plot comparing the analytically computed and learned entropy production, summed over all beads. The data follow a clear linear trend with an R2 value of 0.7576, with noticeably better agreement in the high-dissipation regime. To investigate the origin of the remaining spread, Figure 4(e) shows the time-averaged entropy production of each bead. This re- veals a separation of roughly two to three orders of mag- nitude between beads with high and low entropy produc- tion, and shows that the discrepancy between theory and inference is noticeably high at the low-dissipation beads
다른 분야와의 연결
수학적 골격
이 작업의 순수한 수학적 핵심은 노이즈가 있는 궤적 데이터에서 숨겨진 힘 장을 추론하기 위해 설계된 변분 최적화 프레임워크이다. 이는 일반화된 전류의 평균 대 분산이라는 특정 신호 대 잡음비(SNR)를 최대화함으로써 이를 달성하며, 여기서 알려지지 않은 힘 장은 딥 신경망에 의해 강력하게 매개변수화된다.
인접 연구 분야
최적 제어 이론
본 논문은 명시적으로 최적 제어 이론과의 연결을 끌어내며, 엔트로피 생성 속도의 변분 표현(Eq. (9))이 이 분야에서 잘 확립된 형태임을 언급한다. 최적 제어에서 목표는 종종 시스템 궤적 또는 통계적 평균에 의존할 수 있는 주어진 목표 함수를 최적화하는 제어 함수를 찾는 것이다. 여기서 열역학적 힘 장 $d(\mathbf{x},t)$는 이러한 함수 역할을 하며, 시스템 동역학에 영향을 미쳐 비율 $2 \langle J_{\Delta t}^d \rangle^2 / \text{Var}(J_{\Delta t}^d)$를 최대화한다. 이 힘 장을 매개변수화하기 위해 딥 신경망을 사용하고 그 최적화를 위해 기울기 기반 방법을 사용하는 것은 복잡한 데이터 기반 최적 제어 문제를 해결하는 현대적인 접근 방식이며, 특히 해석적 해가 드문 경우에 그렇다. 이 전략은 관찰된 시스템 동작에서 최적의 피드백 제어 법칙을 학습하는 것과 유사하다. 신경망과 최적 제어를 결합한 관련 접근 방식은 Yan, Touchette, and Rotskoff (2022, Physical Review E)를 참조하라.
확률 과정에 대한 통계적 추론
이 작업은 특히 비평형 시스템에서 확률 과정에 대한 통계적 추론에 상당한 기여를 한다. 과제는 근본적인 동역학 방정식에 대한 사전 지식 없이 실험 궤적 데이터로부터 직접 관찰되지 않은 매개변수 또는 힘 장을 추론하는 것이다. 제시된 방법은 단기 TUR의 단기 한계를 활용하여 소산력 장 및 국소 엔트로피 생성에 대한 모델이 없는 추론 체계를 제공한다. 이는 특정 모델 가정(예: Fokker-Planck 방정식)에 의존하거나 시스템을 교란해야 하는 전통적인 방법과 대조된다. 노이즈가 많은 고차원 데이터에서 열역학적 힘 장과 같은 물리적으로 의미 있는 양을 추출하는 능력은 이 분야의 핵심 문제이다. 이 영역의 관련 연구에는 Frishman 및 Ronceray (2020, Physical Review X) 및 Manikandan 등 (2020, Physical Review Letters)이 포함되며, 이들은 힘과 엔트로피 생성을 데이터 기반으로 추론하는 것을 탐구한다.
물리학 기반 기계 학습
명시적으로 레이블이 지정되지 않았지만, 방법론은 물리학 기반 기계 학습(PIML)의 원칙과 강력하게 일치한다. 신경망은 임의의 손실 함수에 대해 훈련되는 것이 아니라 TUR인 근본적인 물리 원리에서 파생된 목표 함수에 대해 훈련된다. Eq. (9)에 표현된 이 물리적 제약 조건은 학습 프로세스를 안내하여 추론된 소산력 장이 물리적으로 일관되고 의미 있도록 보장한다. 물리 법칙을 기계 학습 목표 함수에 통합하는 이러한 접근 방식은 특히 데이터가 제한적이거나 노이즈가 많은 시나리오에서 도메인별 지식을 학습 아키텍처에 내장함으로써 더 강력하고 해석 가능한 모델을 가능하게 한다. 이 접근 방식은 기계 학습 모델이 단순히 데이터 보간기가 아니라 근본적인 물리 법칙을 발견하는 도구인 과학적 발견의 강력한 패러다임을 나타낸다. PIML의 일반적인 개요는 Raissi, Perdikaris, and Karniadakis (2019, Journal of Computational Physics)에서 찾을 수 있다.