非平衡轨迹上的熵产生局部化
Entropy production is a universal measure of irreversibility and energy dissipation in physical, chemical, and biological systems operating far from equilibrium.
背景与学术渊源
起源与学术渊源
本文的核心问题源于非平衡统计物理学中一个根本性且长期存在的挑战:如何直接从实验观测数据中精确量化和时空局部化复杂系统内的不可逆性和能量耗散。尽管熵产生概念是这些现象的普适度量,但其在非平衡轨迹上的精确时空局部化仍然是一个重大的“开放性挑战”(第2页)。
历史上,学术渊源可追溯至随机热力学[17-19]的进展以及数据驱动方法[11, 20-23]的出现。这些领域为理解非平衡过程个体实现中的熵产生提供了严谨的框架,尤其是在热涨落显著时[18, 26]。然而,一个主要障碍依然存在:测量熵产生或耗散力场的常规方法通常依赖于对系统潜在动力学方程(如Fokker-Planck或主方程)的先验知识。在许多实际实验场景中,这些方程及其解是未知的,使得传统方法不切实际(第2页)。
以往的研究主要集中于获得平均熵产生率的全局估计。尽管Harada-Sasa等式[6]、稳态电流估计[5]、时间不可逆性度量[26-31]以及路径概率估计器[4, 32, 33]等方法提供了宝贵的见解,但它们通常提供的是整体度量,而非耗散的详细局部图景。尝试局部化熵产生的方法常常受限:例如,暴力统计分箱[20]在高维系统中的扩展性差,而某些神经网络方法虽然学习了轨迹上的熵产生,但未能完全阐明潜在耗散力场的结构[23]。其他方法只能推断耗散力场的部分,假设其余部分已知[11, 40]。本文旨在解决的基本限制或“痛点”是,缺乏一种稳健、可扩展且模型无关的方法,可以直接从实验轨迹数据中推断耗散力场和涨落熵产生的时空结构,尤其是在复杂、高维且随时间变化的非平衡系统中,而无需明确了解其控制动力学。这一关键差距促使了本文提出的数据驱动方法的开发,该方法利用了热力学不确定性关系(TUR)和机器学习。
直观领域术语
- 熵产生 ($\sigma$): 想象一个井井有条的房间。如果你举办派对,事情会变得混乱。 “熵产生”就像派对期间产生的不可逆混乱的量。值越高,意味着越混乱,越难将房间恢复到原始状态。
- 非平衡轨迹: 想象一个人穿过拥挤的市场。他们不断移动,与人碰撞,改变方向,从未真正处于平衡状态。 “非平衡轨迹”是那个人走的特定、蜿蜒的路径,始终处于运动中并与其周围环境互动。
- 热力学力场 ($F(\mathbf{x}, t)$): 这就像是推动和拉动物体在复杂环境中以特定、通常是旋转方式移动的无形“电流”或“风”。它不仅仅是一个简单的推力,而是一种动态的、空间变化的力,将系统推离平静、平衡的状态并导致能量耗散。
- 热力学不确定性关系 (TUR): 考虑一个走钢丝的人。“TUR”就像一条基本规则,说:“你试图过绳子的速度越快(熵产生越高),你的身体就会摇晃得越厉害(运动中的较大涨落是不可避免的)。”它建立了执行不可逆任务的效率与路径可预测性之间的权衡。
- 过阻尼扩散过程: 想象一根细小的羽毛在静止的空气中缓慢飘落。它的下落完全由空气阻力和随机气流决定,而不是由其自身动量决定。“过阻尼扩散过程”描述了惯性可忽略不计的运动,其运动主要受摩擦和环境的随机推力支配。
符号表
| 符号 | 描述 |
|---|---|
问题定义与约束
核心问题构建与困境
本文处理的核心问题是从复杂的非平衡系统的实验轨迹数据中,精确地时空局部化熵产生和潜在的耗散力场。
输入/当前状态: 分析的起点是系统在远离热力学平衡状态下运行的原始、实验可测量的轨迹数据 $\mathbf{x}(t)$。一个关键方面是,假设这些数据可在不预先了解系统潜在动力学方程(如Fokker-Planck或主方程)或其解析解,以及具体系统参数的情况下获得。
输出/目标状态: 期望的终点是对系统不可逆性的详细、局部化理解。这包括:
1. 耗散(热力学)力场 $F(\mathbf{x},t)$,这是非平衡动力学的驱动力。
2. 相应的涨落熵产生 $\sigma$,在单个轨迹上进行时空局部化。此输出允许研究人员精确确定系统内能量耗散发生何时和何地。
缺失环节与数学鸿沟: 基本鸿沟在于如何有效地将原始轨迹数据转化为这些局部化的热力学量。历史上,量化熵产生的方法通常依赖于对系统动力学方程的明确了解,而对于复杂、高维或随时间变化的系统,这些方程通常是未知的或解析上难以处理的。尽管可以获得平均熵产生率的全局估计,但从数据本身提取涨落熵产生和耗散力场的时空结构仍然是一个重大挑战。
本文基于短时热力学不确定性关系(TUR)作为一种变分原理。TUR提供了一个熵产生率 $\sigma_{TUR}(t)$ 的公式,可以通过最大化该公式来得到精确的熵产生率 $\sigma(t)$。至关重要的是,最大化该关系的优化系数场 $d^*(\mathbf{x},t)$ 被证明与热力学力场 $F(\mathbf{x},t)$ 成正比。因此,数学鸿沟在于如何直接从轨迹数据中有效地学习这个复杂、可能非线性且高维的优化系数场 $d(\mathbf{x},t)$。本文通过使用深度神经网络来参数化和推断 $d(\mathbf{x},t)$,从而重构耗散力场和局部熵产生,来弥合这一鸿沟。
困境: 长期以来困扰研究人员的核心困境在于,对熵产生的高分辨率、局部化信息的需求与解析可处理性和计算可扩展性的实际限制之间的痛苦权衡。先前的方法要么:
* 需要明确了解系统动力学,这对于现实的复杂系统很少可用。
* 只能提供全局、平均的熵产生率,从而丢失所有时空细节。
* 试图局部化量的方法,如暴力统计分箱,对“高维系统扩展性差”(第3页),使其在许多现实场景中不切实际。
* 其他数据驱动方法可能沿轨迹推断熵产生,但通常“不研究潜在耗散力场的结构”(第3页),而这对于完全理解驱动机制至关重要。本文旨在通过提供一种数据驱动、模型无关的方法来解决这一问题,该方法同时提供局部熵产生和力场。
约束与失效模式
从实验轨迹局部化熵产生的问题受到几个严酷、现实因素的约束,这些因素使得解决该问题异常困难:
- 计算复杂性与高维度: 现实世界的非平衡系统,尤其是在生物学或活性物质等领域,通常涉及大量相互作用的组分,导致高维相空间。本文明确指出,“高维、多体相互作用的复杂性给传统优化方法带来了重大挑战”(第5页)。在如此广阔的空间中推断复杂的非线性力场计算量巨大,对于不高效扩展的方法来说,会迅速变得难以处理。
- 缺乏先验动力学知识: 一个主要障碍是大多数现实系统缺乏已知的潜在动力学方程(例如,Fokker-Planck或主方程)或其解析解(第2页)。这需要一种模型无关的推断方法,这本身就比在预定义模型内进行参数估计更具挑战性。
- 时变动力学: 许多非平衡过程是显式随时间变化的,这意味着热力学力场和熵产生率也是随时间变化的量。这种时间依赖性“引入了重大的计算挑战,使得直接估计这些量变得非常不平凡”(第14页)。训练模型以准确捕捉这种动态变化需要强大的架构和足够的数据。
- 数据质量与信噪比 (SNR): 实验数据本质上是有噪声的。一个关键的约束出现在“弱耗散区域”,其中“不可逆信号相对于涨落很小”(第10页)。在这些低耗散状态下,推断模型的有效信噪比“大大降低”,这“限制了其在具有广泛分离的熵产生尺度上的自由度上均匀泛化的能力”。这可能导致在这些区域中推断值与理论预测值之间出现不匹配,如图4(e)所示。
- 实验采样限制: 实验轨迹的采样间隔 $\Delta t$ “通常由实际约束决定”(第5页)。尽管短时TUR理想情况下需要 $\Delta t \to 0$ 以实现精确饱和,但实际的 $\Delta t$ 值是有限的。该方法必须足够稳健,能够处理这些非理想的采样速率。
- 粗粒化与隐藏自由度: 实验观测通常只提供“对潜在动力学的简化描述”(第16页)。这可能是由于“隐藏的自由度”(未观测变量)或“有限的时间分辨率”(子采样)。推断方法必须能够在观测数据被粗粒化时也能提供有意义的结果,这为问题增加了另一层复杂性。
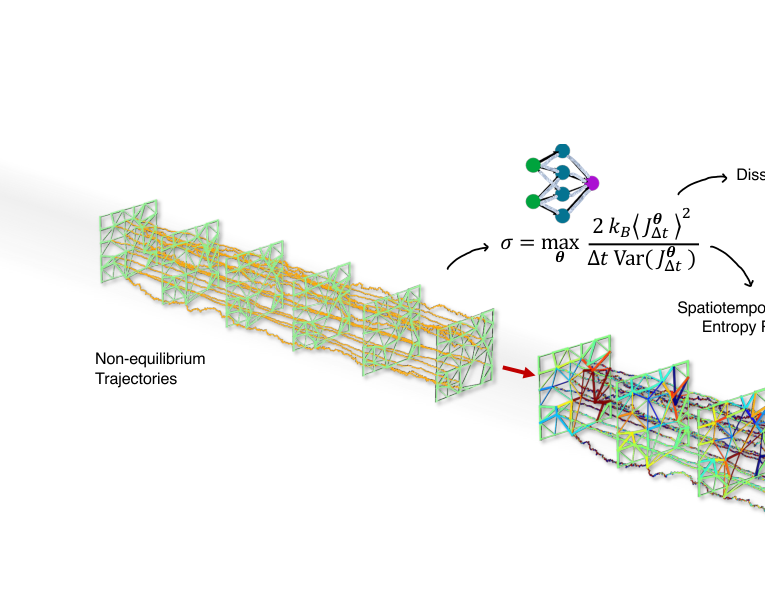 FIG. 1. Schematic of entropy production inference in an active biological network model. Input: The method processes experimentally measurable trajectory data without requiring prior knowledge of system parameters. Outputs: Using short-time Thermodynamic Uncertainty Relations and neural networks (schematically illustrated at the top with a cartoon), we simultaneously infer (i) the dissipative (thermodynamic) force field F (x, t) driving the nonequilibrium dynamics and (ii) the corresponding fluctuating entropy production (color scale: ±0.015kB/s), localized in both space and time. Here, σ denotes the local entropy production rate, and J∆t represents a generalized current in phase space
FIG. 1. Schematic of entropy production inference in an active biological network model. Input: The method processes experimentally measurable trajectory data without requiring prior knowledge of system parameters. Outputs: Using short-time Thermodynamic Uncertainty Relations and neural networks (schematically illustrated at the top with a cartoon), we simultaneously infer (i) the dissipative (thermodynamic) force field F (x, t) driving the nonequilibrium dynamics and (ii) the corresponding fluctuating entropy production (color scale: ±0.015kB/s), localized in both space and time. Here, σ denotes the local entropy production rate, and J∆t represents a generalized current in phase space
为什么选择这种方法
选择的必然性
作者选择将基于短时热力学不确定性关系(TUR)的推断方案与深度神经网络相结合,并非仅仅是任意选择,而是由传统方法固有的局限性驱动的必要演进。作者明确阐述了传统“SOTA”方法不足以解决此特定问题的确切时刻,当他们讨论直接从实验数据测量熵产生和耗散力场的挑战时。
正如论文所指出的,传统方法“依赖于对潜在动力学方程(如Fokker-Planck和主方程)及其解的了解,而这些在现实环境中通常是未知的”(第2页)。这种对系统动力学先验知识的基本依赖性使其对于许多现实世界的复杂系统不切实际,因为这些方程要么过于复杂而无法推导,要么根本不可用。此外,尽管一些方法可以提供平均熵产生率的全局估计,但“直接从实验数据中量化和时空局部化复杂过程中的熵产生”(第2页)的关键需求仍然是一个主要的开放性挑战。先前局部化的尝试,如暴力统计分箱方法[20],对“高维系统扩展性差”(第3页),表明缺乏可扩展性。其他方法,如[23],沿轨迹学习熵产生,但未能揭示潜在的耗散力场,而这对于理解动力学至关重要。
作者认识到,该问题的复杂性,尤其是在“高维、多体相互作用”方面,给“传统优化方法带来了重大挑战”(第5页)。这是关键的认识:现有方法,无论是解析的还是更简单的统计技术,都无法在没有系统控制方程先验知识的情况下,以数据驱动、可扩展且高维的方式同时推断局部熵产生和耗散力场。短时TUR提供熵产生率的变分表示,并将其直接与热力学力场联系起来(方程9),提供了理论基础。然而,为了在复杂、高维系统中实际解决这个变分问题,强大的函数逼近器是必不可少的,这直接导致了深度神经网络的应用。
相对优势
这种组合方法在定性上远远优于先前的黄金标准,其优势远超简单的性能指标。结构上的优势在于其能够在没有潜在动力学方程明确知识的情况下,对复杂、高维且可能随时间变化的耗散力场进行模型无关的推断。
- 模型无关推断: 与要求显式动力学方程(例如,Fokker-Planck或主方程)的传统方法不同,该框架“消除了对过程显式动力学描述的依赖”(第6页)。这对于系统动力学方程通常难以处理或未知的实验数据来说,是一个巨大的优势。
- 高维扩展性: 先前局部化熵产生的尝试,如暴力分箱[20],对“高维系统扩展性差”(第3页)。通过利用深度神经网络,“擅长逼近复杂、高维函数”(第5页),所提出的方法为“分析具有不同自由度之间非平凡相互作用的系统的熵产生提供了可扩展的解决方案”(第6页)。这直接解决了高维噪声和复杂相互作用的挑战。
- 耗散力场的时空局部化: 该方法不仅推断全局熵产生率,而且关键在于重构“高维、可能随时间变化的耗散力场”,并将“涨落熵产生在非平衡轨迹上的时空进行局部化”(第2页)。这提供了对不可逆性的精细、物理可解释的理解,这是先前全局估计技术所普遍缺乏的。
- 时间平滑性和泛化性(针对时变系统): 对于时变动力学,神经网络架构被扩展以将时间作为输入。这“通过共享网络参数强制执行时间平滑性,实现对未观测时间的泛化,并有效地利用整个时间域的数据”(第6-7页)。这比为每个离散时间点训练单独的模型有了显著的定性改进,后者计算成本高昂且容易过拟合。
- 稳健性和广泛适用性: 该方法依赖于“一个单一的神经网络架构,该架构在所有示例中都能稳健地运行,无需广泛的超参数调整,使其在实践中具有广泛的适用性”(第4页)。这表明了一个稳健且可泛化的框架,能够处理各种系统(稳态、非稳态、线性、非线性、低维和高维),如结果所示。
与约束的契合
所选方法完美契合问题的隐式和显式约束,形成了“严苛要求与解决方案独特属性的结合”。
- 数据驱动要求: 主要约束是从“实验数据中直接”推断熵产生,而无需“系统参数的先验知识”或“潜在动力学方程”(第2页,图1)。短时TUR结合神经网络本质上是数据驱动的。它以“实验可测量的轨迹数据”为输入,并从中学习力场和熵产生,绕过了显式模型方程的需要。
- 时空局部化: 核心问题是“在复杂过程中量化和时空局部化熵产生”(第2页)。该方法直接解决了这个问题,通过推断“耗散(热力学)力场 $F(\mathbf{x},t)$”和“相应的涨落熵产生……在时空上局部化”(图1,第3页)。TUR的变分原理,当由神经网络优化时,产生力场 $F(x,t)$,当与轨迹增量收缩时,得到局部熵产生 $dS(t) = F(x(t), t) \circ dx(t)$(方程7)。
- 处理高维性和复杂性: 问题涉及“复杂过程”和“高维、多体相互作用”(第2页,5页)。选择深度神经网络是因为它们“擅长逼近复杂、高维函数”(第5页),使模型能够捕捉力场在高维相空间中的复杂非线性依赖关系,这是传统方法因扩展性差而失败的任务。
- 非平衡动力学(稳态和时变): 该方法专为“远离平衡状态运行的系统”设计(第2页)。短时TUR已被证明对稳态和时变驱动情况都有效[21, 22]。神经网络架构被改编为将时间作为时变过程的附加输入,确保其在各种非平衡场景中的适用性。
- 来自实验数据的稳健性: 该框架旨在从“实验上可处理的观测”中进行稳健推断(第2页)。使用单一、稳健的神经网络架构“无需广泛的超参数调整”(第4页),使其具有实用性和广泛适用性,减少了复杂模型常有的脆弱性,并确保即使在真实世界实验噪声下也能获得可靠结果。
替代方案的排除
本文通过强调其局限性,在特定问题的背景下,隐式和显式地排除了几种替代方法。
- 传统解析/基于方程的方法: 最显著的排除是那些“依赖于对潜在动力学方程(如Fokker-Planck和主方程)及其解的了解”的方法(第2页)。这些方法被认为不足,因为这种知识“在现实环境中通常是未知的”,并且仅适用于“有限数量的解析可处理情况”(第2页,5页)。提出的数据驱动、模型无关的方法直接规避了这一基本限制。
- 全局熵产生估计器: 许多现有方法,包括Harada-Sasa等式[6]、稳态电流/概率分布方法[5]、时间不可逆性度量[26-31]、路径概率估计器[4, 32, 33]以及方差和规则(VSR)[13],主要侧重于“获得平均熵产生率的全局估计”(第3页)。尽管有价值,但这些方法未能提供所需的熵产生和潜在耗散力场的“时空局部化”,而这正是本工作的核心目标。
- 暴力统计分箱: 本文特别提到,为估计热力学力场而开发的暴力统计分箱方法[20]“对高维系统扩展性差”(第3页)。这突显了其可扩展性问题,使其不适用于作者旨在分析的复杂高维系统。相比之下,神经网络方法旨在高效处理这种复杂性。
- 部分推断方法: 如[23]等方法直接沿轨迹学习熵产生,但被指出“不研究潜在耗散力场的结构”(第3页)。同样,只推断“耗散力场的一部分……假设其余部分已知”[11, 40]的方法,不足以对整个力场进行全面的、模型无关的理解。本方法旨在对耗散力场进行完整推断。
- 其他机器学习模型(隐含): 虽然没有明确排除其他机器学习模型(如GANs或基本Transformers),但本文选择深度神经网络架构,特别是受Deep-Ritz启发的模型,是基于其在“逼近复杂、高维函数”方面的已证明能力,以及在“最优控制技术”和“高效采样稀有事件”[52, 53]方面的成功(第5页)。这暗示了更简单或不太专业的机器学习架构可能无法为这个特定的变分优化问题提供相同程度的灵活性、稳健性或效率,特别是考虑到需要准确重构高维力场。所选网络的加性结构还“有助于跨层保留信息并稳定训练”(第5页),表明其选择是经过深思熟虑的,优于可能不太稳定的替代方案。
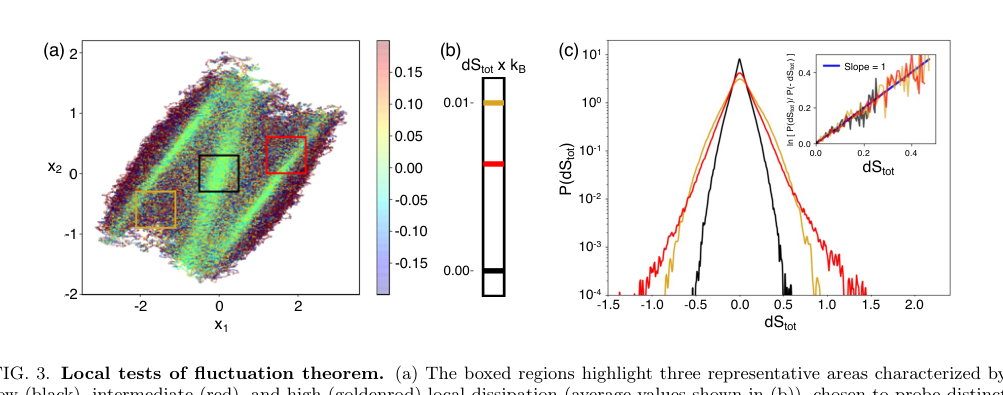 FIG. 3. Local tests of fluctuation theorem. (a) The boxed regions highlight three representative areas characterized by low (black), intermediate (red), and high (goldenrod) local dissipation (average values shown in (b)), chosen to probe distinct dynamical environments. (c) Probability distributions P(dStot) conditioned on these regions, illustrating pronounced region- dependent differences in the statistics of entropy production. The low-dissipation region exhibit narrow, nearly symmetric distributions, while higher-dissipation regions display broader, strongly skewed distributions with extended tails. The inset shows the corresponding fluctuation ratios ln[P(dStot)/P(−dStot)] as a function of dStot, demonstrating that each region independently satisfies a local fluctuation theorem with unit slope
FIG. 3. Local tests of fluctuation theorem. (a) The boxed regions highlight three representative areas characterized by low (black), intermediate (red), and high (goldenrod) local dissipation (average values shown in (b)), chosen to probe distinct dynamical environments. (c) Probability distributions P(dStot) conditioned on these regions, illustrating pronounced region- dependent differences in the statistics of entropy production. The low-dissipation region exhibit narrow, nearly symmetric distributions, while higher-dissipation regions display broader, strongly skewed distributions with extended tails. The inset shows the corresponding fluctuation ratios ln[P(dStot)/P(−dStot)] as a function of dStot, demonstrating that each region independently satisfies a local fluctuation theorem with unit slope
数学与逻辑机制
主方程
本文方法的核心数学引擎,用于局部化熵产生,是源自短时热力学不确定性关系(TUR)的熵产生率的变分表示。对于稳态非平衡过程,模型在训练期间寻求最大化的目标函数为:
$$ f(\theta)_{\text{train}} = \frac{2k_B \langle J_{\Delta t}^\theta \rangle^2}{\Delta t \text{Var}(J_{\Delta t}^\theta)} $$
对于时变动力学,该目标被扩展为对一批采样时间点 $\{t_k\}$ 进行聚合:
$$ f(\theta) = \sum_{k=1}^{\text{batch\_size}} \frac{2k_B \langle J_{\Delta t,k}^\theta \rangle^2}{\Delta t \text{Var}(J_{\Delta t,k}^\theta)} $$
该方程本质上通过将“广义”电流的平均流与其涨落联系起来,量化了系统不可逆过程的效率。最大化该量可以推断出潜在的耗散力场,进而推断出局部熵产生。
逐项解剖
让我们剖析稳态过程的主要目标函数 $f(\theta)_{\text{train}}$,以理解每个组成部分:
-
$f(\theta)_{\text{train}}$:
1) 数学定义: 这是学习算法在训练阶段旨在最大化的目标函数。它是一个标量值,代表估计的熵产生率。
2) 物理/逻辑作用: 其值直接对应于给定模型参数 $\theta$ 集合的推断熵产生率。优化目标是找到使熵产生率最大化的 $\theta$,根据TUR,这对应于真实的熵产生率。
3) 为何采用此形式: 这是从短时TUR推导出的量,通过最大化它来推断熵产生。 -
$k_B$:
1) 数学定义: 玻尔兹曼常数。本文明确指出为简化起见 $k_B = 1$。
2) 物理/逻辑作用: 一个基本物理常数,提供了热涨落的自然能量尺度,并将温度与能量联系起来。在此背景下,它确保了熵产生的单位一致性(例如,以 $k_B/s$ 为单位)。将其设为1有效地以 $k_B$ 为单位对熵进行归一化。
3) 为何采用此形式: 它是一个常数缩放因子,不是算子。 -
$\langle J_{\Delta t}^\theta \rangle$:
1) 数学定义: 这表示广义电流 $J_{\Delta t}^\theta$ 的系综平均(或期望值)。广义电流本身定义为 $J_{\Delta t}^\theta = d(x_{t+\Delta t/2}; \theta) \circ (x_{t+\Delta t} - x_t)$,其中 $d(x; \theta)$ 是参数化的耗散力场,$\circ$ 表示Stratonovich乘积。
2) 物理/逻辑作用: 该项代表由推断的力场 $d(x; \theta)$ 在短时间间隔 $\Delta t$ 内决定的相空间中的平均“流”或“漂移”。非零平均电流是系统运行在热力学平衡之外的直接指标,并与能量耗散内在相关。
3) 为何使用花括号: 花括号 $\langle \dots \rangle$ 是系综平均的标准符号,它涉及对所有可能的电流实现进行求和或积分,并按其概率加权。这对于获得统计上稳健的平均值至关重要。 -
$(\dots)^2$:
1) 数学定义: 此操作对广义电流的系综平均进行平方。
2) 物理/逻辑作用: 平方确保平均电流对目标函数的贡献始终为正,无论电流方向如何。更重要的是,它对较大的平均电流给予二次强调,这通常是远离平衡驱动的系统的特征,因此产生更多的熵。
3) 为何平方: TUR的数学形式要求在分子中出现平方平均电流,反映了对平均电流的二次依赖性。 -
$\Delta t$:
1) 数学定义: 这是记录系统轨迹所使用的离散采样间隔或步长。
2) 物理/逻辑作用: 它代表了在其中计算广义电流的短时间。 “短时”极限对于TUR提供熵产生率的精确估计至关重要。在分母中,它作为一个缩放因子,将间隔内的总电流量转换为每单位时间的速率,这与熵产生率的定义一致。
3) 为何除以: 除以 $\Delta t$ 将间隔内累积的总电流转换为速率,这与熵产生率的定义一致。 -
$\text{Var}(J_{\Delta t}^\theta)$:
1) 数学定义: 这是广义电流 $J_{\Delta t}^\theta$ 的方差,定义为 $\text{Var}(X) = \langle X^2 \rangle - \langle X \rangle^2$。
2) 物理/逻辑作用: 该项量化了广义电流平均值周围的涨落或不确定性。在TUR的背景下,给定平均电流的较小方差意味着一个更“确定”或噪声更小的过程,这会导致更高的推断熵产生率。它对过度的涨落起惩罚作用,因为高不确定性会使熵产生估计不太可靠。
3) 为何在分母中: TUR建立了熵产生与电流相对涨落之间的反比关系。将方差放在分母中反映了这种基本界限。 -
$\max_{\theta}$:
1) 数学定义: 这是最大化算子,表示目标函数 $f(\theta)_{\text{train}}$ 是相对于参数集 $\theta$ 进行优化的。
2) 物理/逻辑作用: 这是推断方案的核心机制。算法主动搜索一组特定的参数 $\theta$(定义了耗散力场 $d(x;\theta)$),以最大化平均电流与其方差的比率。这个基于TUR的优化原理使得模型能够识别出最能描述系统非平衡动力学及其相关熵产生的“最优”力场。
3) 为何最大化: TUR提供了一个熵产生的下界。通过最大化这个特定的比率,该方法旨在找到饱和该界限的电流,从而得到精确的熵产生率。
分步流程
想象一个单一的抽象数据点,在这种情况下,它是一段粒子轨迹的短片段,通过数学引擎:
- 轨迹片段输入: 过程始于输入:从长非平衡轨迹中采样的一对连续粒子位置 $x_t$ 和 $x_{t+\Delta t}$。这代表了粒子在时间 $t$ 和稍后 $\Delta t$ 时的状态。
- 中点计算: 首先,系统计算该片段的中点 $x_{\text{mid}} = (x_t + x_{t+\Delta t})/2$。该中点作为该时间间隔的代表性位置。
- 位移计算: 同时,计算该片段的位移向量:$\Delta x = x_{t+\Delta t} - x_t$。该向量指示了粒子移动了多少以及移动的方向。
- 力场推断(神经网络前向传播): 计算出的中点 $x_{\text{mid}}$ 然后被输入到神经网络中,该网络代表参数化的耗散力场 $d(x; \theta)$。利用其当前的内部权重和偏置(参数 $\theta$),网络执行前向传播,将 $x_{\text{mid}}$ 转换为输出向量 $d(x_{\text{mid}}; \theta)$。此输出是模型当前估计在该位置和时间作用的热力学力。
- 广义电流计算: 推断出的力场 $d(x_{\text{mid}}; \theta)$ 然后与位移 $\Delta x$ 使用Stratonovich乘积(在此上下文中有效为点积)结合,计算该特定片段的广义电流:$J_{\Delta t}^\theta = d(x_{\text{mid}}; \theta) \cdot \Delta x$。该值量化了沿粒子路径由推断力场完成的“功”。
- 批次累积: 这个整个序列(步骤1-5)对许多此类轨迹片段重复进行,形成一个 $J_{\Delta t}^\theta$ 值的“批次”。
- 统计聚合: 一旦累积了一批 $J_{\Delta t}^\theta$ 值,系统就计算它们的系综平均值 $\langle J_{\Delta t}^\theta \rangle$ 和方差 $\text{Var}(J_{\Delta t}^\theta)$。这些统计度量总结了批次中平均流及其涨落。
- 目标函数评估: 最后,将这些计算出的平均值和方差值代入主方程(例如,$f(\theta)_{\text{train}}$)以计算一个单一的标量值。该值指示了当前力场参数 $\theta$ 在根据TUR估计熵产生率方面的表现如何。这完成了评估目标的完整一次传递。
优化动力学
该机制通过梯度上升过程,迭代地优化神经网络的内部参数 $\theta$,以最大化目标函数 $f(\theta)_{\text{train}}$(或时变情况下的 $f(\theta)$),从而进行学习和收敛。
-
损失景观: 目标函数 $f(\theta)$ 在参数 $\theta$ 的高维空间中定义了一个复杂的“损失景观”。与许多最小化损失函数的机器学习任务不同,这里的目标是找到该景观的峰值,因为 $f(\theta)$ 值越高,表示对真实热力学力场推断得越准确。深度神经网络的非线性性质和统计运算(平均值和方差)使得该景观错综复杂。
-
梯度上升: 在训练过程的每个步骤中,算法计算目标函数相对于 $\theta$ 中每个参数的梯度,即 $\nabla_\theta f(\theta)_{\text{train}}$。该梯度向量指向损失景观上目标函数最陡峭的增加方向。
-
参数更新: 然后通过沿该正梯度方向迈出一步来更新参数 $\theta$。此步骤的大小由学习率(lr)超参数控制。更新规则通常为:
$$ \theta_{\text{new}} = \theta_{\text{old}} + \text{lr} \cdot \nabla_\theta f(\theta)_{\text{train}} $$
这种迭代调整逐渐将参数移动到最大化目标函数的配置,从而改进对真实热力学力场的逼近。 -
收敛与泛化:
- 收敛: 训练循环继续进行,参数在每次迭代中都被更新。随着参数 $\theta$ 的精炼,推断出的力场 $d(x;\theta)$ 成为实际耗散力场 $F(x,t)$ 的越来越好的表示。这导致目标函数值增加,表明模型正在收敛到熵产生率更精确的估计。
- 过拟合管理: 优化的一个关键方面是防止过拟合,尤其是在数据有限的情况下。本文指出,有时中间参数集在未见过的数据上的表现可能优于最终完全收敛的模型。为解决此问题,算法在整个训练过程中存储中间参数集 $\{\theta_m\}$。在主训练循环之后,所有这些存储的模型都在一个独立的、预留的验证数据集上进行评估。最终的最优参数 $\theta^*$ 被选为在验证集上产生最高目标函数值的参数,确保模型能够很好地泛化到训练数据之外。对于大型数据集,作者观察到过拟合可以忽略不计,并且训练最优模型在验证数据上也能获得最优性能。
-
时变扩展: 对于具有时变动力学的系统,神经网络被设计为接受时间 $t$ 作为附加输入。然后通过对采样时间点批次进行平均来计算目标函数(方程17)。这种公式化允许网络学习随时间变化的力场,同时通过共享网络参数强制执行时间平滑性,实现对未观测时间的泛化,并有效地利用整个时间域的数据。用于更新 $\theta$ 的底层梯度上升机制保持不变,但它现在作用于这个时间聚合的目标上。这种迭代过程确保了该机制有效地学习熵是如何产生的以及系统的状态是如何随时间更新的。
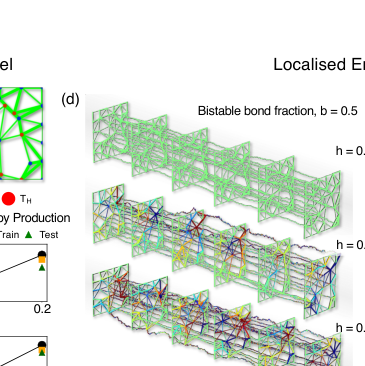 FIG. 5. Entropy production and finite-time fluctuations in active–bistable mechanical networks. (a) Example disordered two-dimensional spring network with a fraction of hot nodes (red, temperature Thot) and cold nodes (blue, Tcold). Thin green bonds denote linear springs, while thick green bonds indicate bistable springs. (b,c) Average entropy production rate as a function of the fraction of hot nodes h at fixed bistable bond fraction b = 0.5 (b), and as a function of the bistable bond fraction b at fixed h = 0.2 (c). Symbols show inferred values from training and test data, while solid lines indicate theoretical predictions for the total entropy production rate. (d) Spatial maps of the inferred local entropy production rate for increasing hot-node fraction h at fixed b = 0.5. (e) Spatial maps of the inferred local entropy production rate for increasing bistable bond fraction b at fixed h = 0.2. In (d) and (e), the network bonds are colored by the mean value of dissipation of the two nodes in the bond. Additionally, the time-series corresponds to 1000 consecutive steady state configurations. (f) Skewness of the time-integrated entropy production ∆Stot as a function of the integration time t for different bistable bond fractions b, showing a pronounced nonmonotonic dependence. (g) Fraction of time-integrated entropy production fluctuations lying above the mean, ⟨T+(t)⟩= P(∆Stot > ⟨∆Stot⟩), demonstrating a finite-time bias with ⟨T+(t)⟩< 1/2. (h) Characteristic integration time t∗at which the skewness is maximal, as a function of the bistable bond fraction b. Increasing the fraction of bistable bonds systematically amplifies finite-time asymmetries in cumulative entropy production and shifts the characteristic timescale to shorter values, demonstrating that mechanical nonlinearity enhances emergent non-Gaussian entropy production statistics at experimentally relevant finite times
FIG. 5. Entropy production and finite-time fluctuations in active–bistable mechanical networks. (a) Example disordered two-dimensional spring network with a fraction of hot nodes (red, temperature Thot) and cold nodes (blue, Tcold). Thin green bonds denote linear springs, while thick green bonds indicate bistable springs. (b,c) Average entropy production rate as a function of the fraction of hot nodes h at fixed bistable bond fraction b = 0.5 (b), and as a function of the bistable bond fraction b at fixed h = 0.2 (c). Symbols show inferred values from training and test data, while solid lines indicate theoretical predictions for the total entropy production rate. (d) Spatial maps of the inferred local entropy production rate for increasing hot-node fraction h at fixed b = 0.5. (e) Spatial maps of the inferred local entropy production rate for increasing bistable bond fraction b at fixed h = 0.2. In (d) and (e), the network bonds are colored by the mean value of dissipation of the two nodes in the bond. Additionally, the time-series corresponds to 1000 consecutive steady state configurations. (f) Skewness of the time-integrated entropy production ∆Stot as a function of the integration time t for different bistable bond fractions b, showing a pronounced nonmonotonic dependence. (g) Fraction of time-integrated entropy production fluctuations lying above the mean, ⟨T+(t)⟩= P(∆Stot > ⟨∆Stot⟩), demonstrating a finite-time bias with ⟨T+(t)⟩< 1/2. (h) Characteristic integration time t∗at which the skewness is maximal, as a function of the bistable bond fraction b. Increasing the fraction of bistable bonds systematically amplifies finite-time asymmetries in cumulative entropy production and shifts the characteristic timescale to shorter values, demonstrating that mechanical nonlinearity enhances emergent non-Gaussian entropy production statistics at experimentally relevant finite times
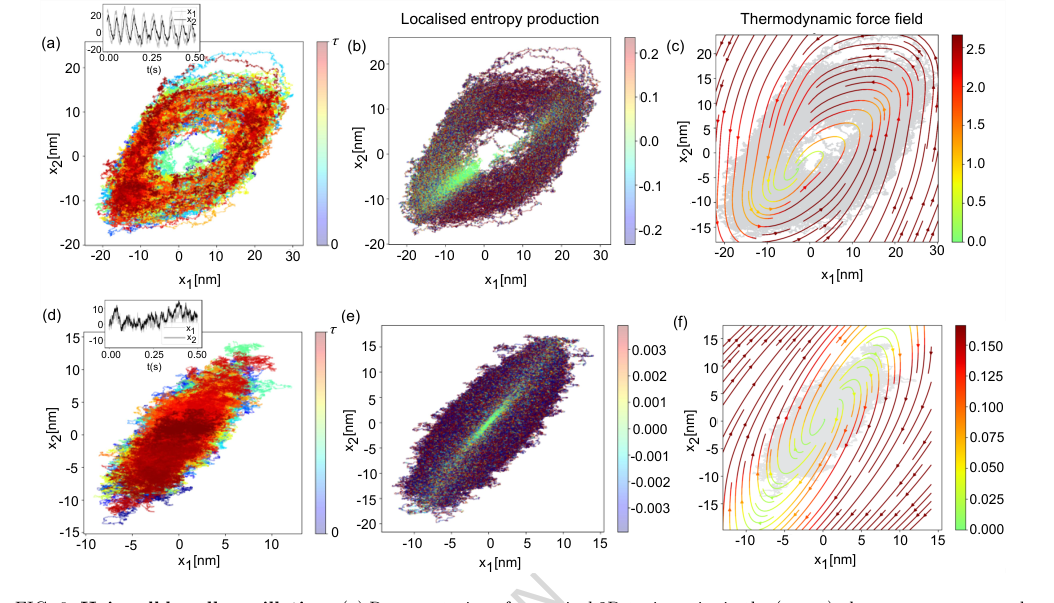 FIG. 6. Hair-cell bundle oscillation. (a) Representation of numerical 2D-trajectories in the (x1, x2) phase space correspond- ing to 5s simulation sampled at 100 kHz. The colorbar indicates progression along the trajectory. The inset plot indicates the oscillatory nature of dynamics for Fmax = 57.14 pN and S = 0.94. (b) The local entropy production rate (in units of kB/s) is computed using the neural network representation. It captures the active state of dynamics. The colours are for comparative visualisation and do not represent the true value. (c) Thermodynamic force field of the oscillatory state of the dynamics. (d) Representation of numerical 2D-trajectories in the (x1, x2) phase space corresponding to 5s simulation sampled at 100 kHz. The colorbar indicates progression along the trajectory. The inset plot indicates the quiescent (non-oscillatory) state of dynamics for Fmax = 40 pN and S = 1. (e) Entropy production rate (in units of kB/s) is locally computed along such trajectories. The colours are for comparative visualisation and do not represent the true value. (f) Thermodynamic force field of the oscillatory state of the dynamics. The colour scale of local entropy production is thresholded symmetrically between [−10× median, 10 × median] for the oscillatory case and [−500 × median, 500× median] for the quiescent case, while the colour scale for the force field of both cases is thresholded between [0, median]. The other system parameters remain the same as mentioned in Fig.(4) of Ref. [12]: γ1 = 2.8 µN s/m, γ2 = 10 µN s/m, kgs = 0.75 pN/nm, ksp = 0.6 pN/nm, D = 61 nm, N = 50, ∆G = 10kBT, kBT = 4.143 pNnm and Teff = 1.5T
FIG. 6. Hair-cell bundle oscillation. (a) Representation of numerical 2D-trajectories in the (x1, x2) phase space correspond- ing to 5s simulation sampled at 100 kHz. The colorbar indicates progression along the trajectory. The inset plot indicates the oscillatory nature of dynamics for Fmax = 57.14 pN and S = 0.94. (b) The local entropy production rate (in units of kB/s) is computed using the neural network representation. It captures the active state of dynamics. The colours are for comparative visualisation and do not represent the true value. (c) Thermodynamic force field of the oscillatory state of the dynamics. (d) Representation of numerical 2D-trajectories in the (x1, x2) phase space corresponding to 5s simulation sampled at 100 kHz. The colorbar indicates progression along the trajectory. The inset plot indicates the quiescent (non-oscillatory) state of dynamics for Fmax = 40 pN and S = 1. (e) Entropy production rate (in units of kB/s) is locally computed along such trajectories. The colours are for comparative visualisation and do not represent the true value. (f) Thermodynamic force field of the oscillatory state of the dynamics. The colour scale of local entropy production is thresholded symmetrically between [−10× median, 10 × median] for the oscillatory case and [−500 × median, 500× median] for the quiescent case, while the colour scale for the force field of both cases is thresholded between [0, median]. The other system parameters remain the same as mentioned in Fig.(4) of Ref. [12]: γ1 = 2.8 µN s/m, γ2 = 10 µN s/m, kgs = 0.75 pN/nm, ksp = 0.6 pN/nm, D = 61 nm, N = 50, ∆G = 10kBT, kBT = 4.143 pNnm and Teff = 1.5T
结果、局限性与结论
实验设计与基线
作者的方法旨在通过一个数据驱动的框架来无情地证明其数学主张,该框架结合了短时热力学不确定性关系(TUR)推断方案和深度神经网络。核心实验设计包括:
-
数学基础: 该方法旨在通过最大化源自TUR的变分目标函数来推断耗散(热力学)力场 $F(x,t)$ 和相应的涨落熵产生 $\sigma$。具体而言,目标是最大化 $\sigma_{TUR}(t) := \max_{d} \frac{1}{\Delta t} \frac{2 \langle J_{\Delta t}^d \rangle^2}{\text{Var}(J_{\Delta t}^d)}$,其中 $J_{\Delta t}^d$ 是一个广义电流。这种公式化允许在没有系统潜在动力学方程先验知识的情况下进行推断。
-
机器学习架构: 使用多层神经网络来逼近最优系数场 $d(x,t)$,该场与热力学力场 $F(x,t)$ 成正比。对于时变过程,网络被扩展以将时间 $t$ 作为附加输入,并且通过对采样时间点批次进行聚合来计算训练目标,以强制执行时间平滑性并实现泛化。
-
数据生成与验证: 为各种系统生成数值轨迹。对于稳态过程,将轨迹分为训练集和验证集。通过在训练数据上进行梯度上升来优化参数,并根据模型在保留的验证数据上的性能来选择最终模型,以防止过拟合。
该方法旨在击败(基线模型或挑战性场景)并对其性能进行评估的“受害者”包括:
- 解析可处理系统: 对于热力学力场和熵产生在解析上已知的系统(例如,谐振动布朗陀螺仪、N维线性陀螺仪、粗粒化线性陀螺仪),将推断结果与这些理论基准进行直接比较。这提供了明确的定量验证。
- 复杂非线性系统: 对于解析解难以处理或难以先验预测的系统(例如,非谐振动布朗陀螺仪、活性双稳态机械网络、毛细胞束振荡),展示了该方法揭示耗散和力场时空结构的物理直观且一致的能力。这些系统代表了依赖显式动力学方程的传统方法的挑战。
- 时变过程: 位能擦除协议,一个显式时变非平衡过程,作为该方法处理时变力场和熵产生率能力的测试平台,这对传统方法来说计算量很大。
- 有限观测能力: 对3D谐振动陀螺仪进行的粗粒化实验(维度和时间)测试了该方法在只有部分或子采样轨迹数据可用时的稳健性,模拟了隐藏自由度或有限采样率等实际实验约束。
证据证明了什么
本文提供的证据明确证明了核心机制——结合短时TUR和深度神经网络进行数据驱动推断——成功地在非平衡轨迹上局部化了熵产生并重构了耗散力场。
-
精确的力场和熵产生推断:
-
布朗陀螺仪: 对于2D陀螺仪(图2),该方法精确推断了局部熵产生率和热力学力场。对于谐振动情况,推断的力场幅度在势阱附近最小,与理论预期近乎零的熵产生相关。对于非线性非谐振动和四次陀螺仪,该方法揭示了耗散的复杂、非平凡的时空结构(例如,四次情况下的四个涡旋,图2(i)),如果没有这种数据驱动的方法,将极难预测。
-
N维陀螺仪 (N=100): 推断的局部熵产生率与解析估计(图4(b)和4(c))在视觉上高度一致。定量上,推断值与解析值总熵产生的散点图显示 $R^2$ 值为0.7576(图4(d)),表明存在强烈的线性相关,尤其是在高耗散区域。这是该方法能够扩展并准确处理更高维度的无可辩驳的证据。
-
活性双稳态机械网络: 推断的平均熵产生率(图5(b)和5(c)中的符号)与理论预测(实线)在不同热节点分数和双稳态键分数下惊人地吻合。局部熵产生的空间图(图5(d)和5(e))清楚地说明了耗散是如何异质分布的,证明了该方法在复杂相互作用系统中的能力。
- 毛细胞束振荡: 该方法成功地计算了振荡和静止状态下的局部熵产生和热力学力场(图6(b,c,e,f)),捕捉了活性动力学并区分了不同的动力学状态。例如,振荡状态下强烈的环流力场是强不可逆性的明确标志。
- 位能擦除协议: 对于时变位能擦除,该方法沿单个轨迹解析了局部熵产生(图7(d)和7(f)),显示了可归因于不可逆动力学的爆发和抑制。时间平均熵产生率(图8(a)和8(b))证实了这些观察结果,突出了不同擦除路径的独特特征。
-
-
稳健性与基本物理学的一致性:
- 局部涨落定理: 一个关键的证据是证明了推断的局部熵产生满足涨落定理。尽管在所有采样区域中局部熵产生的概率分布在区域之间存在显著差异,但图3(c)的插图显示,涨落比率 $\ln[P(dS_{tot})/P(-dS_{tot})]$ 与 $dS_{tot}$ 呈单位斜率的线性关系。这是对推断量物理一致性的强大、数据驱动的验证。
- 粗粒化稳健性: 该方法在有限观测能力下表现出稳健性。对于经过维度和时间粗粒化的3D陀螺仪,推断的涨落熵产生率与理论基准(图9(b)和9(d))非常吻合。散点图显示出与 $R^2$ 值分别为0.862和0.890的强线性相关性(图9(c)和9(e)),证实了即使在存在隐藏自由度或子采样数据的情况下,该方法也能提供统计上一致的结果。
总之,本文提供了确凿、无可辩驳的证据,证明其核心机制通过以下方式有效运行:
* 与已知的解析解实现高度定量一致。
* 在复杂非线性系统中揭示物理上一致且可解释的时空模式,这些系统缺乏解析解。
* 展示了在局部层面遵守基本热力学原理,如涨落定理。
* 在各种形式的数据粗粒化下显示出稳健性和统计一致性。
“受害者”确实被击败了,因为所提出的方法克服了传统方法的局限性,这些方法要么需要动力学的先验知识,要么难以处理高维度,要么无法提供熵产生和耗散力场的局部、轨迹解析的见解。
局限性与未来方向
尽管所提出的框架为理解非平衡系统提供了一个强大的新视角,但认识到其当前的局限性并考虑未来发展的激动人心的方向至关重要。
局限性:
- 低耗散区域的性能: 本文指出,对于高维系统,在弱耗散区域的推断精度可能会下降(图4(e)插图)。这归因于有效信噪比的降低,使得神经网络难以在截然不同的熵产生尺度之间均匀泛化。在这些具有挑战性的区域提高稳健性仍然是一个开放性问题。
- 计算资源和数据需求: 尽管具有可扩展性,但训练深度神经网络,特别是对于高维和时变系统,仍然可能计算量巨大,并且需要大量的轨迹数据(例如,某些模型的 $2 \times 10^6$ 个点)。这可能对数据可用性有限的实验构成实际限制。
- 有限时间步长效应: 该方法依赖于TUR的短时极限。实际上,实验数据是以有限时间间隔 $\Delta t$ 进行采样的。尽管本文提出了一个标准 $\Delta t/\tau_{min} \ll 1$,但对较大的 $\Delta t$ 值如何影响推断量的准确性和解释,特别是对于高度动态的系统,进行全面分析可能是有益的。
- 粗粒化力场的解释: 应用粗粒化时,学习到的力场是在选定分辨率下的有效表示。对于缺乏解析基准的复杂非线性系统,这些有效力场的精确物理解释可能需要进一步的理论发展。
- 局部熵与总熵产生的区别: 对于显式时变过程,方法推断的局部熵产生 $dS(t)$ 与总随机熵产生不同,相差一个与概率密度显式时间依赖性相关的项。尽管 $dS(t)$ 捕捉了平均速率的不可逆贡献,但对违反第二定律的事件进行全面描述需要考虑这个附加项,而当前推断并不直接提供。
未来方向:
本文的研究结果为许多未来的探索奠定了坚实的基础,激发了不同视角的批判性思考:
-
扩展到各种实验系统的适用性:
- 生物学背景: 如何将此方法应用于量化和时空局部化真实生物系统(如细胞信号网络、代谢途径或单分子实验中分子马达的运行)中的能量耗散?它能否揭示活细胞中能量转导或调控的新机制?
- 活性物质物理学: 该框架能否应用于活性物质系统,如自驱动胶体或细菌群落,以理解局部能量耗散如何驱动集体行为、自组织和相变?活性湍流或图案形成方面可能出现哪些新见解?
-
推进理论和算法基础:
- 超越过阻尼动力学: 当前工作侧重于过阻尼扩散过程。如何扩展并严格验证该方法以处理惯性效应显著的欠阻尼系统,或在许多复杂系统中普遍存在的非马尔可夫动力学?
- 低信噪比下的稳健性: 哪些新颖的神经网络架构、正则化技术或物理信息机器学习策略可以提高该方法在高维弱耗散区域的准确性和泛化能力?将更明确的物理约束纳入学习目标是否有帮助?
- 实时推断: 能否优化推断算法以实时或近实时处理实验数据流?这对于在现场实验中实现自适应采样或反馈控制策略至关重要。
-
利用局部熵进行逆设计和控制:
- 最优控制策略: 鉴于局部化耗散的能力,如何利用这些信息来设计最优控制方案,以最小化特定任务(例如,位能擦除、分子传输)的能量耗散,或实现期望的非平衡状态?这是否可能导致更节能的纳米机器?
- 材料和系统的逆设计: 该方法能否指导具有定制时空耗散特性的活性材料或生物网络的逆设计?例如,设计具有特定局部非平衡特性的胶体晶格,用于自组装或目标力生成。
- 自适应采样: 推断的局部熵产生能否指导实验中的自适应采样策略,将数据收集集中在高耗散区域,以提高统计效率并揭示稀有事件?
-
探索与信息论和热力学的联系:
- 信息-能量权衡: 局部熵产生与复杂系统中的信息处理和存储如何相关,尤其是在生物学背景下?该框架能否为纳米尺度计算或传感的基本热力学成本提供新见解?
- 复杂系统中的涨落定理: 在高度非线性、时变和粗粒化系统中进一步探索局部涨落定理,可以加深我们对非平衡统计力学的理解。
这些未来方向强调了这种数据驱动方法的变革潜力,它超越了全局平均值,实现了对复杂系统中能量耗散和不可逆性的精细理解,并对基础科学和工程学产生了影响。
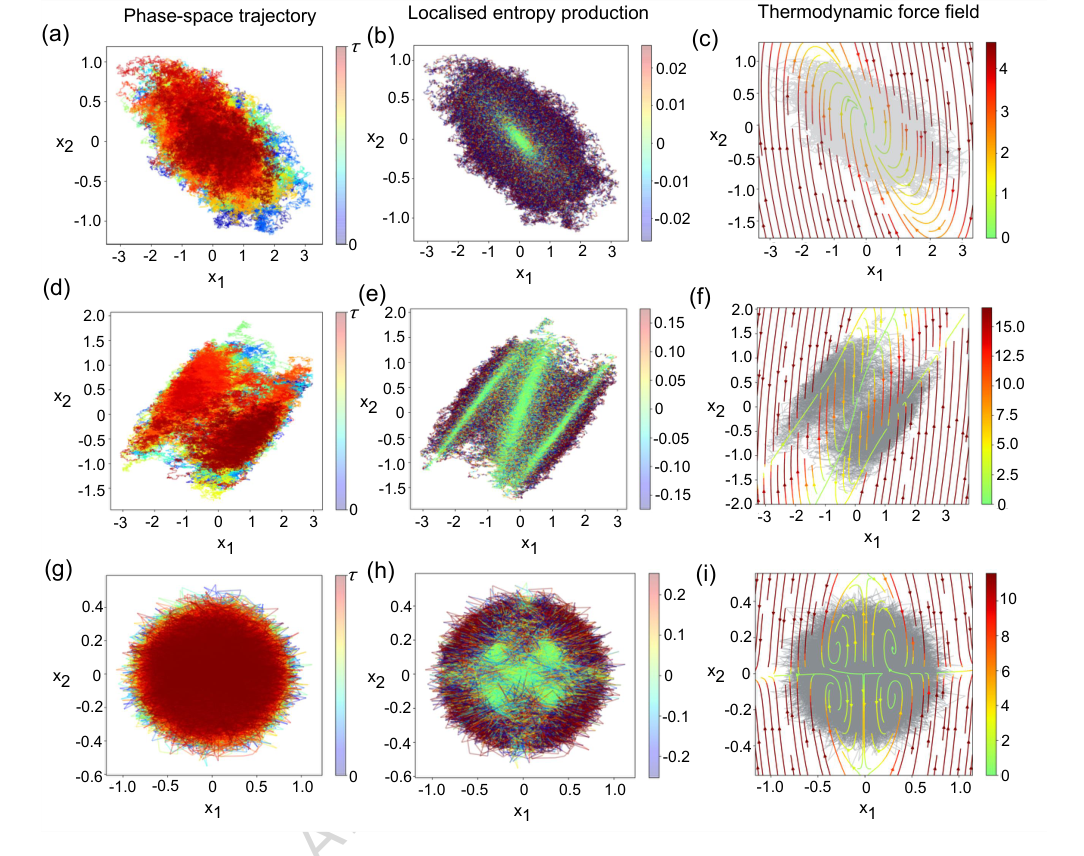 FIG. 2. Local entropy production in Brownian gyrator models. (a) 2D-dimensional trajectories of a Brownian gyrator system with harmonic confining potential. [Parameters: k1 = 1, k2 = 2, γ = 1, θ = π/4, D1 = 1, D2 = 0.1]. (b) local entropy production rate and (c) thermodynamic force field for the system with harmonic confinement - estimated using the neural network representation. (d) 2D-dimensional trajectories of a Brownian gyrator system with a bi-stable confining potential. [Parameters: k = 1, b = 1, γ = 1, θ = π/4, D1 = 1, D2 = 0.1] (e) local entropy production rate and (f) thermodynamic force field estimated using the neural network representation. (g) 2D-dimensional trajectories of a Brownian gyrator system with a quartic confining potential. [Parameters: k1 = k2 = 10, γ = 1, θ = π/4, D1 = 10, D2 = 1] (h) local entropy production rate and (i) thermodynamic force field estimated using the neural network representation. The colours corresponding to the local entropy production rate (in units of kB/s) of the gyrators are thresholded between [−α median, α median] , where α (typically 20 −50) multiplies the median of the corresponding local entropy production dataset. Values outside these ranges are clipped for visualisation purposes to prevent rare large fluctuations from dominating the colour mapping. Similarly, the thermodynamic force field values for the gyrators are thresholded within [0, median]. The numerical trajectories are usually generated for 2000s with a sampling rate of 1 kHz - from which trajectory traces of 500s are shown in the plots. The colorbars in panels (a), (d), and (e) indicate the progression along the trajectory
FIG. 2. Local entropy production in Brownian gyrator models. (a) 2D-dimensional trajectories of a Brownian gyrator system with harmonic confining potential. [Parameters: k1 = 1, k2 = 2, γ = 1, θ = π/4, D1 = 1, D2 = 0.1]. (b) local entropy production rate and (c) thermodynamic force field for the system with harmonic confinement - estimated using the neural network representation. (d) 2D-dimensional trajectories of a Brownian gyrator system with a bi-stable confining potential. [Parameters: k = 1, b = 1, γ = 1, θ = π/4, D1 = 1, D2 = 0.1] (e) local entropy production rate and (f) thermodynamic force field estimated using the neural network representation. (g) 2D-dimensional trajectories of a Brownian gyrator system with a quartic confining potential. [Parameters: k1 = k2 = 10, γ = 1, θ = π/4, D1 = 10, D2 = 1] (h) local entropy production rate and (i) thermodynamic force field estimated using the neural network representation. The colours corresponding to the local entropy production rate (in units of kB/s) of the gyrators are thresholded between [−α median, α median] , where α (typically 20 −50) multiplies the median of the corresponding local entropy production dataset. Values outside these ranges are clipped for visualisation purposes to prevent rare large fluctuations from dominating the colour mapping. Similarly, the thermodynamic force field values for the gyrators are thresholded within [0, median]. The numerical trajectories are usually generated for 2000s with a sampling rate of 1 kHz - from which trajectory traces of 500s are shown in the plots. The colorbars in panels (a), (d), and (e) indicate the progression along the trajectory
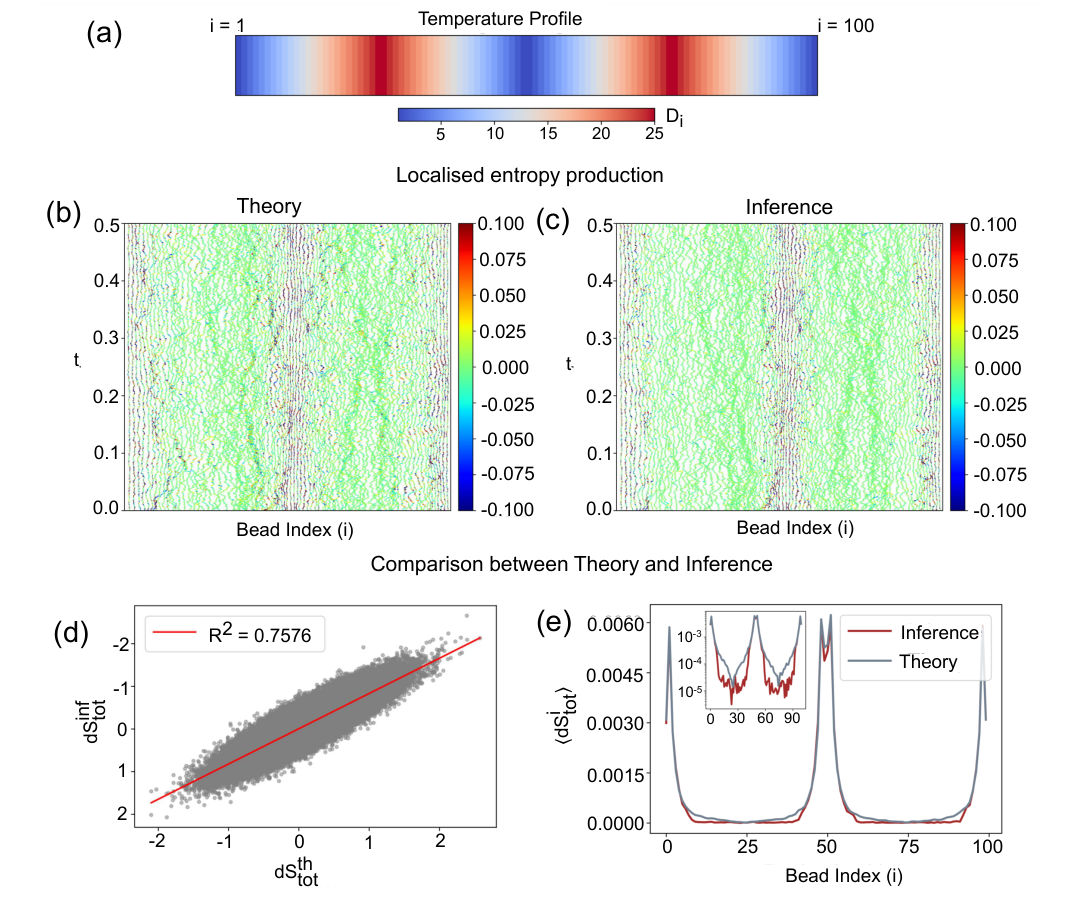 FIG. 4. Bead wise local entropy production for N-dimensional brownian gyrator model. (a) Temperature profile of the N-dimensional gyrator setup. Di denotes the diffusion coefficient of i-th bead as kB = γ = 1. (b) Analytically estimated local entropy production rate (in units of kB/s) of the system. (c) Local entropy production rate (in units of kB/s) inferred from the numerical trajectories using a neural network representation. The colors do not indicate the true values of the fluctuating entropy current, but they are thresholded for better visualisation. (d) Convergence test (R2 test) of the neural network–based estimation of the fluctuating entropy production rate for an N-dimensional Brownian gyrator with N = 100. The inferred and analytical local entropy production rates, averaged over all beads, exhibit a finite spread around the linear fit. (e) Comparison of the inferred average entropy production for each bead with the corresponding theoretical estimate. (Inset) The same data shown on a logarithmic (y-) scale reveals that dissipation of beads associated with low irreversible signature (entropy production) are challenging for the neural network to capture, resulting in a mismatch with the theoretical prediction
FIG. 4. Bead wise local entropy production for N-dimensional brownian gyrator model. (a) Temperature profile of the N-dimensional gyrator setup. Di denotes the diffusion coefficient of i-th bead as kB = γ = 1. (b) Analytically estimated local entropy production rate (in units of kB/s) of the system. (c) Local entropy production rate (in units of kB/s) inferred from the numerical trajectories using a neural network representation. The colors do not indicate the true values of the fluctuating entropy current, but they are thresholded for better visualisation. (d) Convergence test (R2 test) of the neural network–based estimation of the fluctuating entropy production rate for an N-dimensional Brownian gyrator with N = 100. The inferred and analytical local entropy production rates, averaged over all beads, exhibit a finite spread around the linear fit. (e) Comparison of the inferred average entropy production for each bead with the corresponding theoretical estimate. (Inset) The same data shown on a logarithmic (y-) scale reveals that dissipation of beads associated with low irreversible signature (entropy production) are challenging for the neural network to capture, resulting in a mismatch with the theoretical prediction
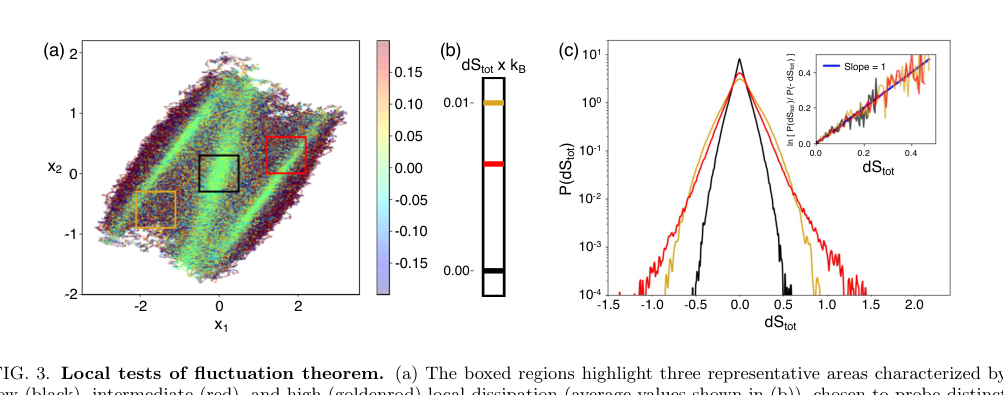 Figure 4. (b) depicts the local entropy production using the theoretically known form of F (x), while Figure 4(c) shows the same obtained from solving the inference algo- rithm. As we see, there is good visual agreement between the theory and the results obtained from the inference al- gorithm. To quantify the agreement between theory and infer- ence, Figure 4(d) shows a scatter plot comparing the analytically computed and learned entropy production, summed over all beads. The data follow a clear linear trend with an R2 value of 0.7576, with noticeably better agreement in the high-dissipation regime. To investigate the origin of the remaining spread, Figure 4(e) shows the time-averaged entropy production of each bead. This re- veals a separation of roughly two to three orders of mag- nitude between beads with high and low entropy produc- tion, and shows that the discrepancy between theory and inference is noticeably high at the low-dissipation beads
Figure 4. (b) depicts the local entropy production using the theoretically known form of F (x), while Figure 4(c) shows the same obtained from solving the inference algo- rithm. As we see, there is good visual agreement between the theory and the results obtained from the inference al- gorithm. To quantify the agreement between theory and infer- ence, Figure 4(d) shows a scatter plot comparing the analytically computed and learned entropy production, summed over all beads. The data follow a clear linear trend with an R2 value of 0.7576, with noticeably better agreement in the high-dissipation regime. To investigate the origin of the remaining spread, Figure 4(e) shows the time-averaged entropy production of each bead. This re- veals a separation of roughly two to three orders of mag- nitude between beads with high and low entropy produc- tion, and shows that the discrepancy between theory and inference is noticeably high at the low-dissipation beads
与其他领域的联系
数学骨架
这项工作的纯数学核心是一个变分优化框架,旨在从噪声轨迹数据中推断隐藏的力场。它通过最大化一个特定的信噪比——广义电流的平方平均值与其方差之比——来实现这一点,其中未知力场由深度神经网络稳健地参数化。
相邻研究领域
最优控制理论
本文明确地将工作与最优控制理论联系起来,指出熵产生率的变分表示(方程(9))在该领域是一个公认的形式。在最优控制中,目标通常是找到一个控制函数,该函数优化给定的目标泛函,该泛函可以依赖于系统轨迹或统计平均值。在这里,热力学力场 $d(\mathbf{x},t)$ 作为这样的函数,影响系统的动力学以最大化比率 $2 \langle J_{\Delta t}^d \rangle^2 / \text{Var}(J_{\Delta t}^d)$。使用深度神经网络来参数化该力场并通过基于梯度的优化方法进行优化,是解决复杂、数据驱动的最优控制问题的现代方法,特别是在解析解难以获得的情况下。这种策略类似于从观察到的系统行为中学习最优反馈控制律。有关结合最优控制和神经网络的相关方法,请参阅Yan、Touchette和Rotskoff(2022,Physical Review E)。
随机过程的统计推断
这项工作为随机过程的统计推断做出了重大贡献,特别是在非平衡系统中。挑战在于直接从实验轨迹数据中推断未观测到的参数或力场,而无需了解潜在动力学方程的先验知识。本文提出的方法利用了热力学不确定性关系(TUR)的短时极限,为耗散力场和局部熵产生提供了一种模型无关的推断方案。这与可能依赖特定模型假设(例如,Fokker-Planck方程)或需要扰动系统的传统方法形成对比。从嘈杂的高维数据中提取物理上有意义的量(如热力学力场)是该领域的一个关键问题。该领域的相关工作包括Frishman和Ronceray(2020,Physical Review X)以及Manikandan等人(2020,Physical Review Letters),他们探索了力场和熵产生的驱动数据推断。
物理信息机器学习
尽管没有明确标记,但该方法学与物理信息机器学习(PIML)的原理高度一致。神经网络不是基于任意损失函数进行训练,而是基于直接源自基本物理原理——热力学不确定性关系(TUR)——的目标函数进行训练。这种物理约束,如方程(9)所示,指导了学习过程,确保了推断出的耗散力场在物理上是一致且有意义的。这种将物理定律整合到机器学习目标函数中的方法,通过将领域特定的知识嵌入学习架构中,使得模型在数据有限或嘈杂的情况下更加稳健和可解释。这种方法代表了一种强大的科学发现范式,其中机器学习模型不仅仅是数据插值器,更是用于揭示潜在物理定律的工具。有关PIML的通用概述,请参阅Raissi、Perdikaris和Karniadakis(2019,Journal of Computational Physics)。